揭示超大核卷积网络鲁棒性的黑暗秘密
摘要
在实际部署深度学习模型时,鲁棒性是需要考虑的一个重要方面。 大量研究致力于研究视觉变换器 (ViT) 的鲁棒性,自 2020 年代初以来,ViT 一直作为视觉任务的主流骨干选择占据主导地位。 最近,一些大型内核卷积网络以令人印象深刻的性能和效率卷土重来。 然而,目前仍不清楚大型内核网络是否具有鲁棒性以及其鲁棒性的归属。 在本文中,我们首先在六个不同的鲁棒性基准数据集上对大型内核卷积网络的鲁棒性及其与典型小内核对应物和 ViT 的差异进行了全面评估。 然后,为了分析其强大鲁棒性背后的潜在因素,我们从定量和定性的角度设计实验,以揭示大核卷积网络与典型卷积网络完全不同的有趣特性。 我们的实验首次证明纯 CNN 可以实现与 ViT 相当甚至优于 ViT 的卓越鲁棒性。 我们对遮挡不变性、内核注意力模式和频率特征的分析为鲁棒性的来源提供了新的见解。 代码位于:https://github.com/Lauch1ng/LKRobust。
[table]capposition=顶部 capbtabboxtable[][]
1简介
过去十年来,深度学习的发展与卷积神经网络(CNN)紧密相连(LeCun 等人,1998;Krizhevsky 等人,2012;Simonyan & Zisserman,2014;He 等人,2016),为推动人工智能的进步发挥了至关重要的作用。 尽管如此,随着 2020 年代的到来,视觉变形金刚(ViTs)的出现(Dosovitskiy 等人,2020;Liu 等人,2021;Touvron 等人,2021;Wang 等人,2021)深刻动摇了CNN的霸主地位。 在自注意力机制的推动下,ViT 在图像分类等各种视觉任务中表现出了最先进的性能(Dosovitskiy 等人,2020;Liu 等人,2021),物体检测(Carion等人,2020;戴等人,2021;朱等人,2020;孟等人,2021),语义分割(程等人,2021,2022) 和自监督学习(Bao 等人,2021;He 等人,2022;Chen 等人,2024b),展示了它们作为基础模型选择的特殊属性。
作为一种通用且广泛使用的骨干网,ViT 的一个关键属性是其强大的鲁棒性。 在野外部署深度学习模型时,鲁棒性是需要考虑的一个重要方面(Paul & Chen,2022)。 具体来说,对于自动驾驶汽车、机器人和医疗保健等安全关键应用,学习到的表示必须具有鲁棒性,如果没有很强的鲁棒性,模型就无法实际实现(Naseer等人,2021)。 许多研究致力于评估 ViT 的稳健性(Mahmood 等人,2021;Naseer 等人,2021;Paul & Chen,2022;Shao 等人,2021;Bhojanapalli 等人,2021). 他们证明了 ViT 具有通用且强大的鲁棒性,在各种鲁棒数据集上表现出色(Hendrycks 等人,2021b;Hendrycks & Dietterich,2019;Hendrycks 等人,2021a;Xiao 等人,2020) 并展示在处理特定干扰(例如图像遮挡和对抗性攻击)方面比典型的 CNN 具有明显的优势(Naseer 等人,2021)。 强大的鲁棒性为ViT在各种现实场景中的广泛应用铺平了道路。
另一方面,各方共同努力致力于 CNN 的复兴。 值得注意的是,在重新审视大型内核设计方面的最新进展(Liu 等人,2022b;Ding 等人,2022;Liu 等人,2022a;Ding 等人,2023;Chen 等人,2024a)表明:当配备大内核(例如 )时,纯 CNN 架构的性能可以与最先进的 ViT 相当甚至更好。 大核卷积可以大幅增加模型的有效感受野(Ding等人,2022),使得大核卷积网络在各种视觉任务中都具有出色的性能(Liu等人,2022b; Woo等人, 2023; 刘等人, 2022a; 卢等人, 2023; 黄等人, 2023),例如分类、分割和检测等。 然而,目前仍不清楚大型内核网络是否具有鲁棒性以及其鲁棒性的归属,这至关重要,可能会对其实际应用和发展产生重大影响。 人们很自然地会问: 大型内核网络本质上是鲁棒的吗? 它们在鲁棒性方面与典型的 CNN 和 ViT 有何不同? 如果它们足够强大, 是什么有助于它们的稳健性? 在本文中,我们深入研究了上述问题,为推理大型内核卷积网络的鲁棒性提供了经验证据和新颖的见解。
为了回答前两个问题,我们对六个不同且广泛使用的稳健性基准数据集进行了彻底的实验。 这些数据集从自然对抗性(Hendrycks等人, 2021b)、常见损坏(Hendrycks & Dietterich, 2019)、语义转变( Hendrycks 等人, 2021a)、域外分布(Hendrycks 等人, 2021b)、常见扰动(Hendrycks & Dietterich, 2019)和背景依赖(Xiao 等人, 2020)。 与传统 CNN 形成鲜明对比的是,大型内核网络表现出异常强大的鲁棒性,可与 ViT 相媲美甚至优于 ViT。
为了理解大型内核网络卓越鲁棒性的根本因素,我们系统地设计了九个实验,从定量和定性的角度深入了解其鲁棒性。 这些实验和可视化揭示了大型内核卷积网络的有趣特性,例如遮挡不变性、内核注意力模式和频率特征,这有助于理解其鲁棒性背后的原因。 我们的贡献可总结如下:
-
我们在六个 ImageNet 数据集上探讨了大型内核网络的鲁棒性,涉及不同类型的鲁棒性评估,并与典型的 CNN 和 ViT 进行了全面比较。 我们证明了大内核卷积网络的鲁棒性与典型的 CNN 显着不同,并且与 ViT 相当甚至优于 ViT。
-
我们设计了九个实验,从定量和定性的角度研究大型内核卷积网络的鲁棒性、传播遮挡不变性、对抗性攻击、模型扰动、频率特征和内核注意模式等。
-
我们的分析提供了对大型内核卷积网络的鲁棒性的见解,促进了它们的应用和更广泛的发展。 此外,我们的研究首次揭示纯 CNN 可以实现与 ViT 相当甚至更高的鲁棒性,这表明自注意力并不是实现强鲁棒性的唯一途径,为 CNN 的复兴又迈出了一步。
2相关工作
2.1 大型内核卷积网络
大核卷积网络可以追溯到深度学习早期阶段的一些传统模型(Krizhevsky等人,2012;Szegedy等人,2015,2016)。 然而,以 VGG-Net (Simonyan & Zisserman,2014) 和 ResNet (He 等人,2016)为代表的小型卷积网络的兴起,促进了CNN 的成功。 从那时起,一堆小内核(例如 或 )成为卷积网络设计的主流选择。 大核卷积很少受到关注,甚至被发现对 Imagenet 性能不利(Peng 等人,2017)。 最近,以ConvNeXt (Liu 等人,2022b)和RepLKNet (Ding 等人,2022)为代表的工作引发了大核卷积网络的复兴(Trockman & Kolter, 2022; 刘等人, 2022b; 丁等人, 2022; 刘等人, 2024a)。 他们证明,大内核可以有效增强模型性能,尤其是在下游任务中(Ding等人,2022)。 大核设计也被引入到其他领域,例如3D主干(Chen等人,2023;Lu等人,2023)、连续卷积(Romero等人,2021b,a) 、知识蒸馏(黄等人,2023)和多模态学习(丁等人,2023)。 尽管取得了这些进展,但它们的稳健性评估和归因在很大程度上仍未得到探索,这可能会对其实际应用和开发产生重大影响。 与以往的工作不同,本文研究了大核网络的鲁棒性,设计实验从多个角度分析其有趣的特性,为大核的复兴又迈出了一步。
2.2 ViT 的稳健性
作为多才多艺的骨干网,ViT(Dosovitskiy 等人,2020;Liu 等人,2021)在各种视觉任务中表现出了令人印象深刻的性能(Dosovitskiy 等人,2020;Liu 等人, 2021;戴等人,2021;朱等人,2020;程等人,2021,2022)。 ViT 相对于 CNN 的一个关键优势是其强大的鲁棒性,这为 ViT 在各种现实场景中的广泛应用铺平了道路。 许多作品试图从不同的角度研究 ViT 的鲁棒性。 与 ResNet (He 等人, 2016)、Bhojanapalli et al 相比。 (Bhojanapalli 等人,2021) 研究了在对抗性和自然对抗性示例上进行评估时 ViT 鲁棒性的提高。 邵等人。 (Shao等人,2021)揭示了ViT比CNN具有更好的对抗鲁棒性,这很大程度上归因于它们学习高度泛化的高频特征的能力,而卷积层似乎会阻碍这一点。 保罗等人。 (Paul & Chen,2022)进一步整合并扩展稳健性分析的范围,以阐明 Vits 卓越稳健性背后的潜在因素。 Raghu 等人。 (Raghu等人,2021)从不同角度对ViT和CNN的差异进行了详细分析,深入了解了它们的鲁棒性差异。 通过与规范CNN的比较,这些研究表明ViT通常更加鲁棒,同时也启发了进一步提高ViT鲁棒性的工作(毛等人,2022;周等人,2022;郭等人,2023)。 与之前的 ViT 鲁棒性分析工作不同,这项工作重点关注大型内核网络(Trockman & Kolter, 2022; Liu 等人, 2022b; Woo 等人, 2023; Ding 等人, 2022; Liu 等人,2022a),在主流任务上展示了与 ViT 竞争的性能,并且最近引起了相当大的兴趣。 我们设计系统实验来评估其稳健性,并提供分析潜在因素的见解。
3大型内核卷积网络是否稳健?
在本节中,我们深入研究前两个问题:大型内核卷积网络是否是鲁棒学习器,以及它们在鲁棒性方面与典型的 CNN 和 ViT 有何不同。 具体来说,我们在六个广泛接受的鲁棒性数据集上进行了一项实证研究,将大内核卷积网络与其典型的小内核对应物和 ViT 进行比较。 3.1节详细介绍了模型的配置,而3.2节则介绍并讨论了数据集和相应的结果。
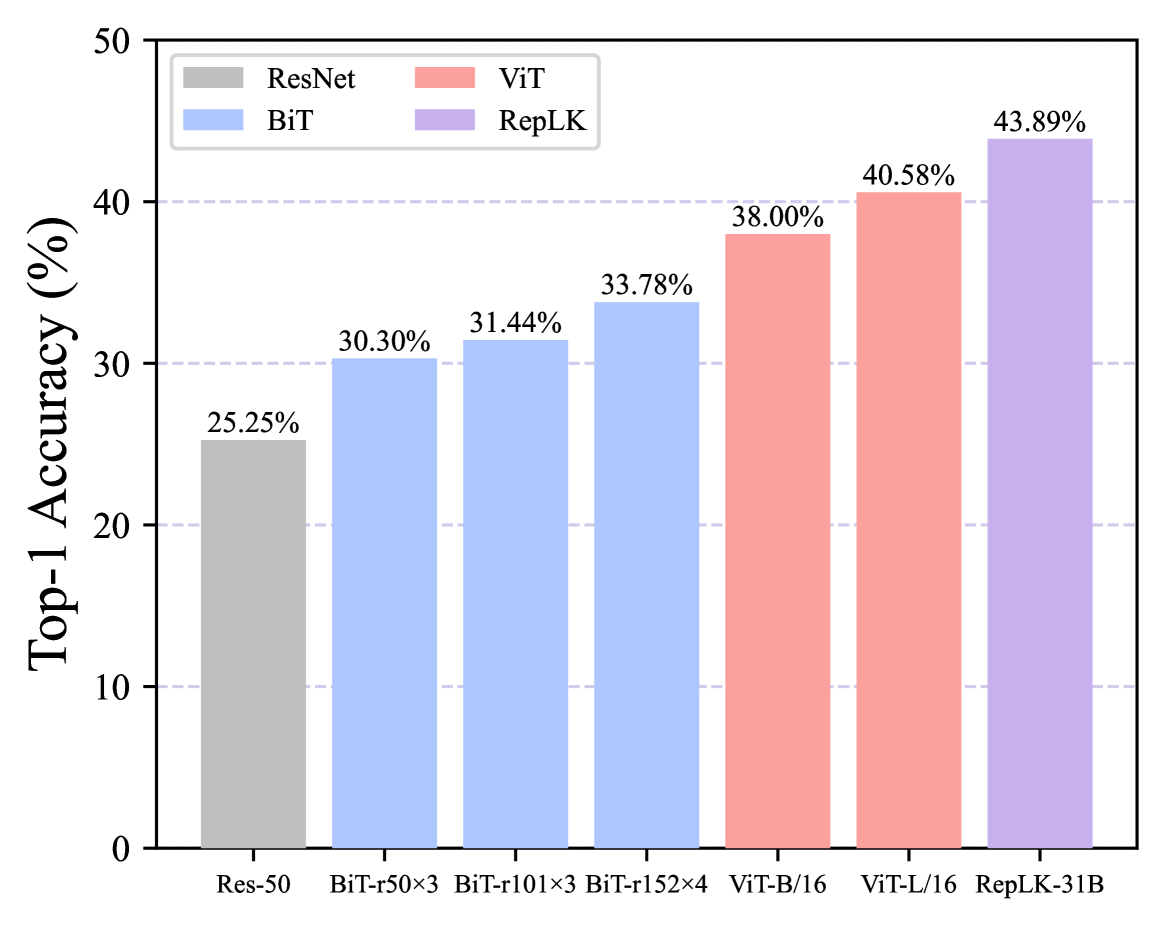
3.1模型配置
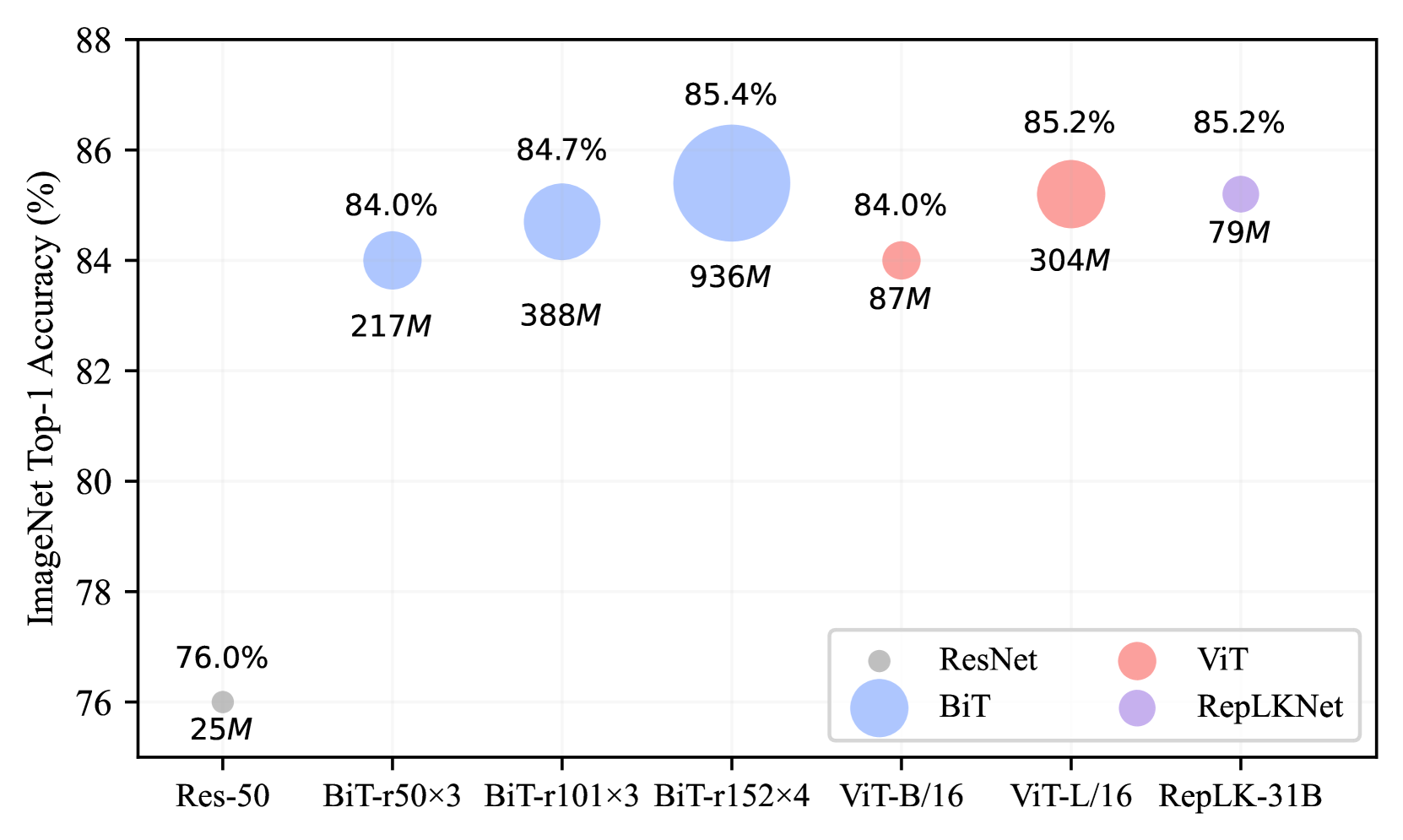
我们选择大型内核卷积网络的代表作品 RepLKNet (Ding 等人, 2022) 作为我们实验的主要模型。 RepLKNet 是第一个将内核尺寸扩展到极大(即 )的工作,并已应用于各种视觉任务(Liu 等人,2022a;Chen 等人,2023;Lu 等人,2023;黄等人,2023)。 为了进行比较,我们选择 ViT (Dosovitskiy 等人, 2020) 作为强基线。 ViT 已被大量研究证明具有显着的鲁棒性(Naseer 等人, 2021; Paul & Chen, 2022; Shao 等人, 2021; Bhojanapalli 等人, 2021),与传统方法相比具有明显的优势卷积网络。 为了与典型的卷积网络进行比较,我们选择 Big Transfer (BiT) (Kolesnikov 等人, 2020),它不仅在 ImageNet 上而且在各种迁移学习场景上都具有出色的性能(Lin 等人,2014;翟等人,2019)。 由于 RepLKNet、BiT 和 ViT 共享相似的预训练策略(例如使用更大的数据集,如 ImageNet-21K (Deng 等人, 2009)、扩展的预训练计划等),因此它们服务作为我们比较目的的优秀候选者。 此外,我们添加 ResNet-50 (He 等人, 2016) 作为基本基线。 我们选择具有相似精度和参数数量的模型(除了 resnet-50 作为基线)。 不同模型在ImageNet-1K上的参数数量和top-1准确率如图1所示。 请注意,所有报告的变体最初都是在 ImageNet-21K 上进行预训练,然后在 ImageNet-1K 上进行微调。
3.2不同数据集的鲁棒性评估
接下来,我们在六个稳健性基准数据集上评估上述模型变体的性能。 这些数据集从多个维度评估模型的稳健性,包括:i)自然对抗; ii) 常见腐败; iii) 域外分发; iv) 常见扰动; v) 语义转变; vi) 后台依赖。 附录A总结了他们的具体目标和地点。
ImageNet-A (Hendrycks 等人, 2021b) 是真实世界的对抗性过滤图像的数据集,可以欺骗当前的 ImageNet 分类器。 在图2(a)中,我们报告了ResNet、BiT、ViT和RepLKNet在ImageNet-A数据集上的top-1准确率。 与典型的卷积网络相比,RepLKNet 的性能大幅优于 ResNet 和 BiT。 例如,RepLKNet-31B 的 top-1 精度高于 BiT-m r1013。 它甚至略微超过了模型尺寸更大的 ViT-L,这表明大内核卷积网络对自然对抗性挑战具有很强的鲁棒性。
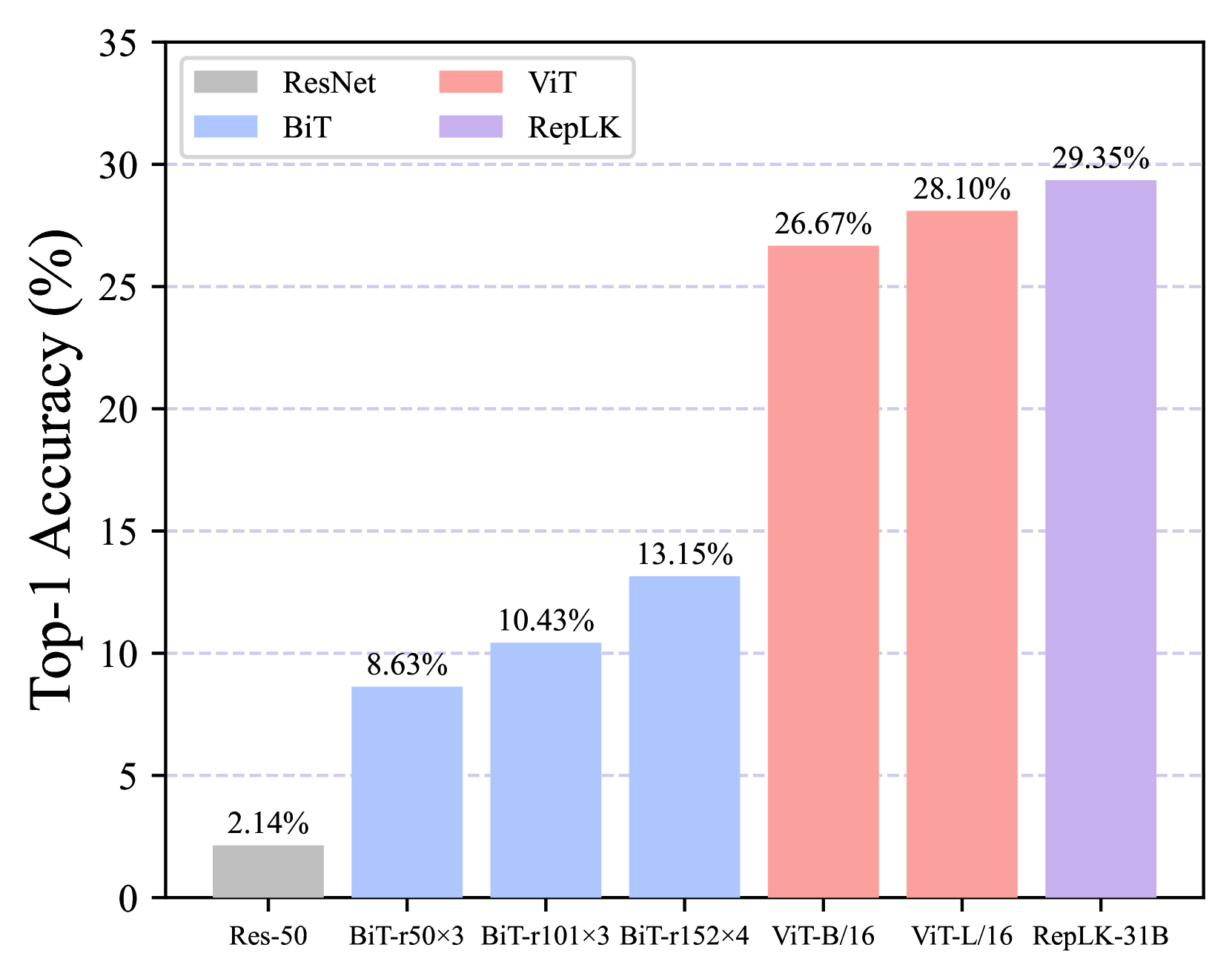
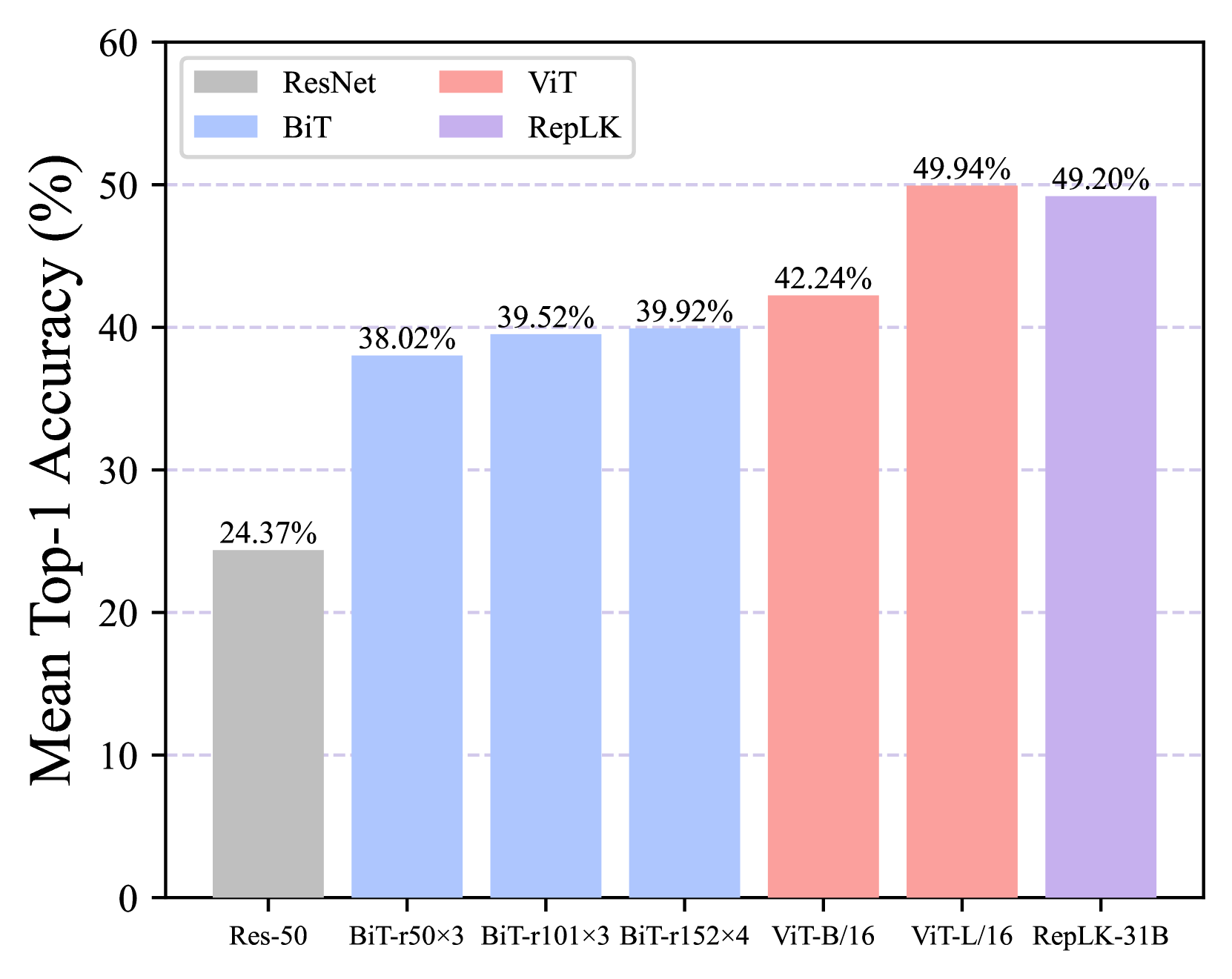
ImageNet-C (Hendrycks & Dietterich,2019) 包含 15 类算法生成的损坏和另外四种一般损坏类型,总共有 19 种损坏类别。 每种腐败类型都有五个严重级别,从可忽略到极严重。 我们评估了所有 19 个损坏的最高严重级别 (5),并在图 2(b) 中描绘了平均 top-1 准确度。 我们观察到 RepLKNet 的性能与 ViT-L 相当,并超越所有典型的卷积网络和 ViT-B/16。 考虑到 ViT-L 的参数数量明显高于 RepLKNet,这进一步验证了大型内核卷积网络的鲁棒性。
| Model / Method | mCE |
|---|---|
| ResNet-50 | 76.7 |
| BiT m-r101×3 | 58.3 |
| DeepAugment + AugMix | 53.6 |
| ViT-L/16 | 45.5 |
| RepLKNet-31B | 36.5 |
| Model / Method | mFR | mT5D |
|---|---|---|
| ResNet-50 | 58.0 | 82.0 |
| BiT m-r101×3 | 50.0 | 76.7 |
| AugMix | 37.4 | N/A |
| ViT-L/16 | 33.1 | 50.2 |
| RepLKNet-31B | 29.2 | 49.8 |
| Model | Origin | Mixed-Same | Mixed-Rand | BG-Gap |
|---|---|---|---|---|
| BiT m-r101×3 | 94.3 | 81.2 | 76.6 | 4.6 |
| ResNet-50 | 95.6 | 86.2 | 78.9 | 7.3 |
| ViT-L/16 | 96.7 | 88.5 | 81.7 | 6.8 |
| RepLKNet-31B | 97.3 | 92.3 | 88.2 | 4.1 |
此外,(Hendrycks & Dietterich,2019)提出平均损坏误差(mCE)来量化 ImageNet-C 上模型的鲁棒性因素。我们遵循相同的评估方法并在表 3 中报告 mCE 比较。 我们还添加了 DeepAugment (Hendrycks 等人, 2021a) 和 AugMix (Hendrycks 等人, 2020),它们专门旨在增强模型针对 ImageNet 中观察到的损坏的鲁棒性 - C。 令人惊讶的是,RepLKNet 的性能优于其他方法,并且有明显的差距。
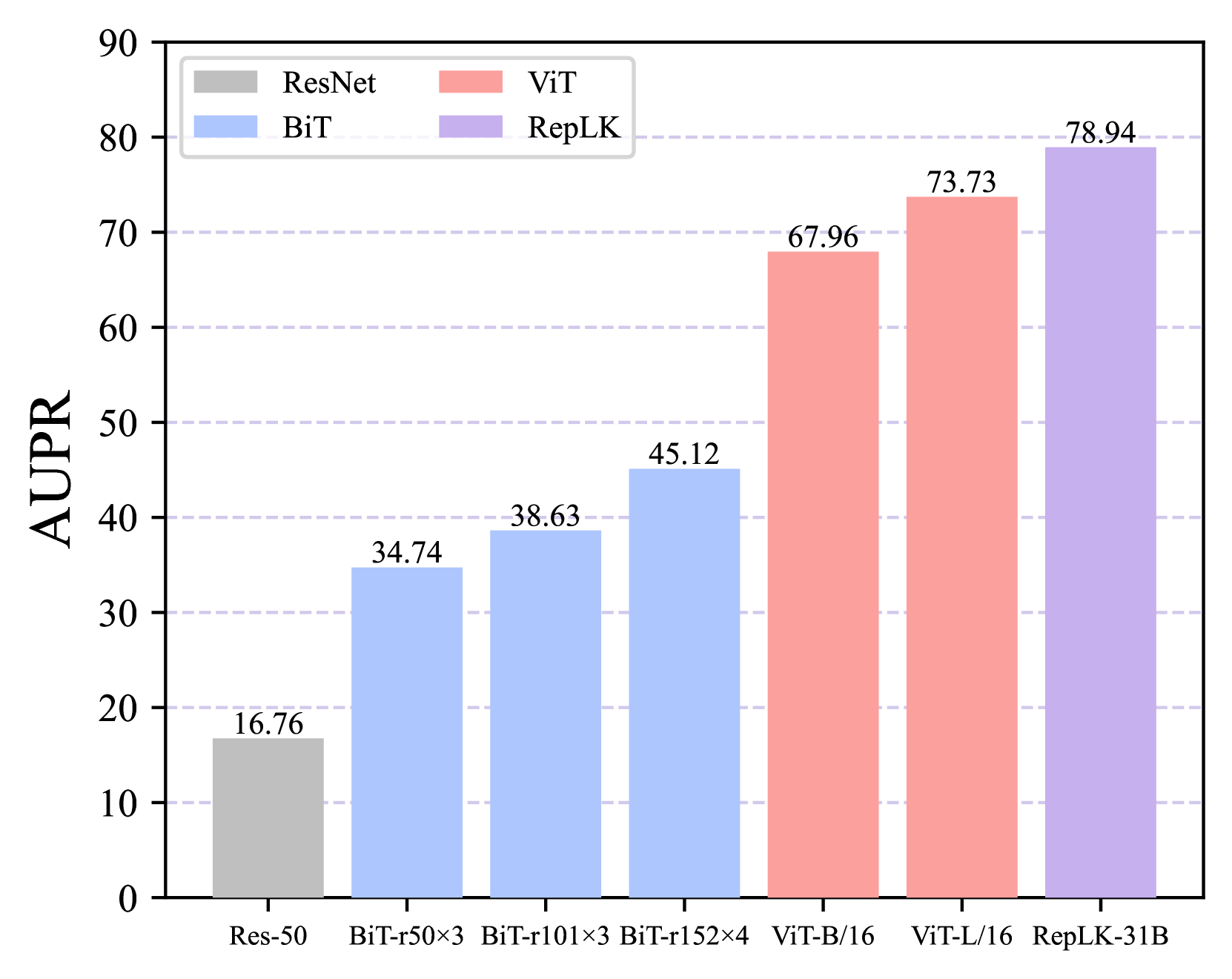
ImageNet-O (Hendrycks 等人, 2021b) 是 ImageNet 分布外检测器的对抗性过滤示例的数据集。 继(Hendrycks等人, 2021b)之后,我们使用精确召回曲线下面积(AUPR)作为ImageNet-O的评估指标。 如图2(c)所示,RepLKNet 明显优于所有其他模型变体,展示了大内核卷积网络在异常检测方面的卓越鲁棒性。
ImageNet-P (Hendrycks & Dietterich,2019) 由 10 种常见扰动组成。 ImageNet-P 与 ImageNet-C 的不同之处在于它从每个 ImageNet 验证图像生成扰动序列。 这些扰动是微妙的,影响图像中较少数量的像素。 我们按照(Hendrycks & Dietterich,2019)使用平均翻转率(mFR)和平均top-5距离(mT5D)作为评估模型稳健性的标准指标。 为了简洁起见,我们在这里省略了 mFR 和 mT5D 的详细公式。 如表3所示,RepLKNet的鲁棒性再次被证实优于BiT、ViT和AugMix。
ImageNet-R (Hendrycks 等人, 2021a) 包含 ImageNet-1K 数据集中 200 个类别的各种艺术表现形式。 我们在图 3 中报告了 ImageNet-R 上的 top-1 精度比较,表明 RepLKNet 对域适应的鲁棒性优于 BiT 和 ViT。
ImageNet-9 (Xiao 等人, 2020) 有助于理清前景和背景信号对分类的影响。 它衡量模型对背景变化的鲁棒性。 如表3所示,我们报告了四个指标来评估模型对背景变化的稳健性。 Origin指的是不修改背景的原始精度。 混合相同涉及用相同类中的随机背景替换原始背景。 Mixed-Rand 表示用随机类中的随机背景替换原始背景。 BG-Gap = Mixed-Same - Mixed-Rand,用于衡量存在正确标记的前景时背景相关性的影响程度。 结果表明,RepLKNet 在前三个指标上始终超过 BiT 和 ViT。 此外,RepLKNet 的 BG-Gap 要小得多,这表明大内核卷积网络对背景修改不太敏感,表现出更强的背景鲁棒性。
4 为什么大型内核卷积网络具有鲁棒性?
在本节中,我们从定量和定性的角度全面研究大型内核卷积网络的鲁棒性。 具体来说,我们系统地设计了九个独特的实验,对其遮挡不变性和内核注意力模式等关键特性进行全面深入的分析,为其强大的鲁棒性提供了多维度的见解。
4.1 遮挡不变性
遮挡不变性在科学和深度学习中很重要(Kosmann-Schwarzbach 等人,2011;Kong & Zhu,2023)。 它对人类视觉的鲁棒性起着至关重要的作用:例如,即使大部分物体不可见,我们也可以根据纹理或形状想象被遮挡的部分,在高遮挡率下保持一致的判断。 为此,我们深入研究了大型内核网络在某些或大部分图像内容丢失的各种场景下的遮挡不变性。

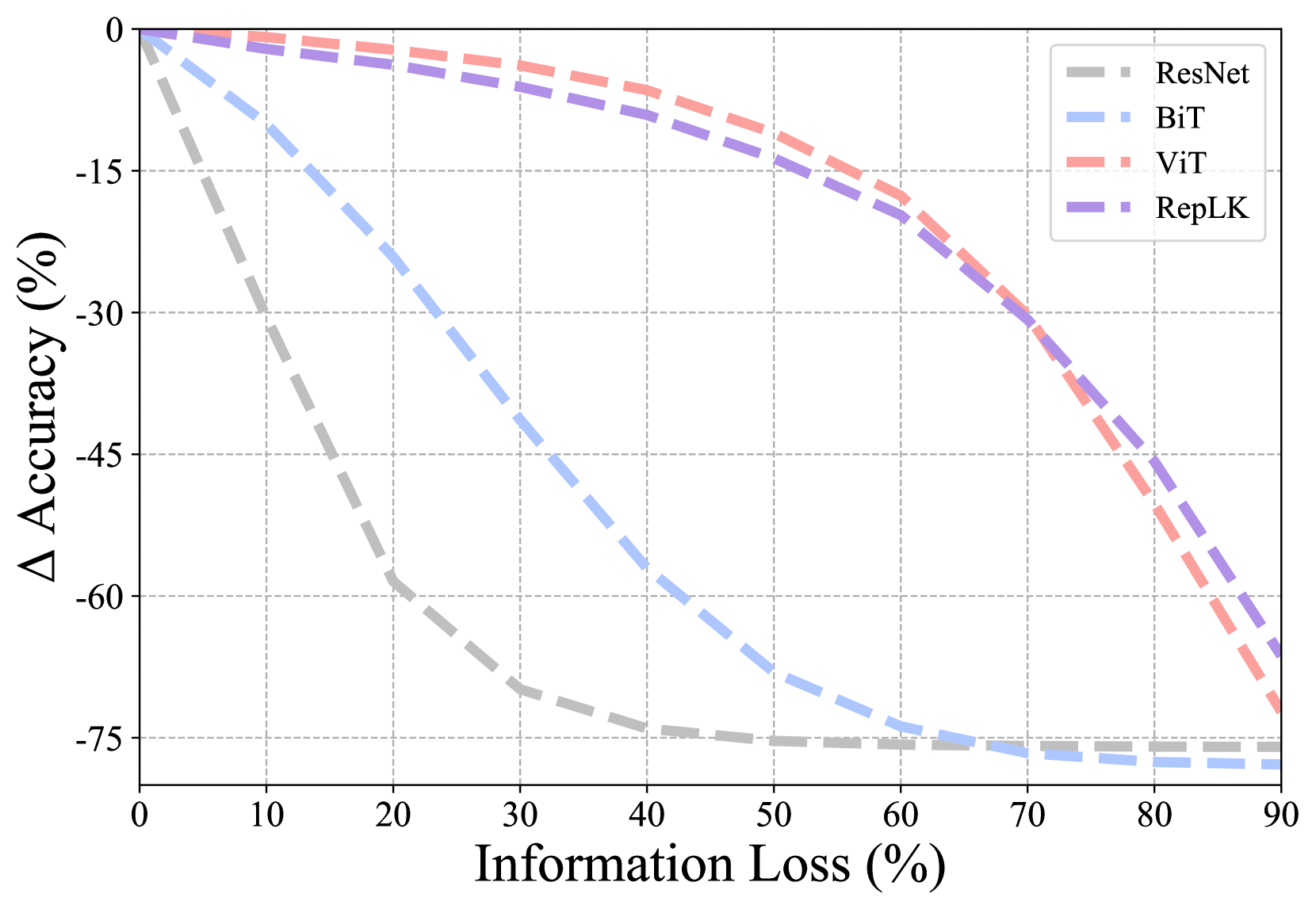
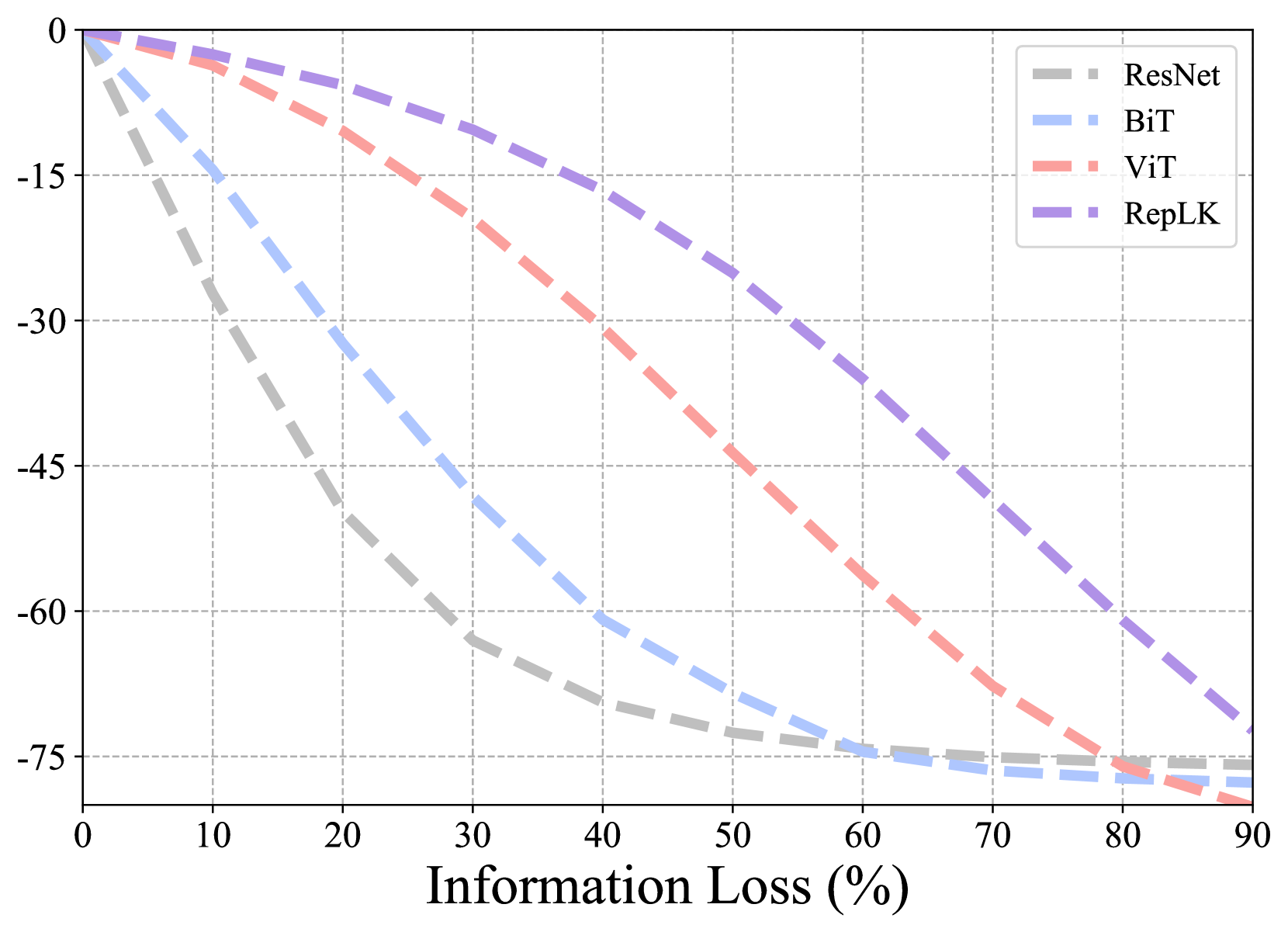
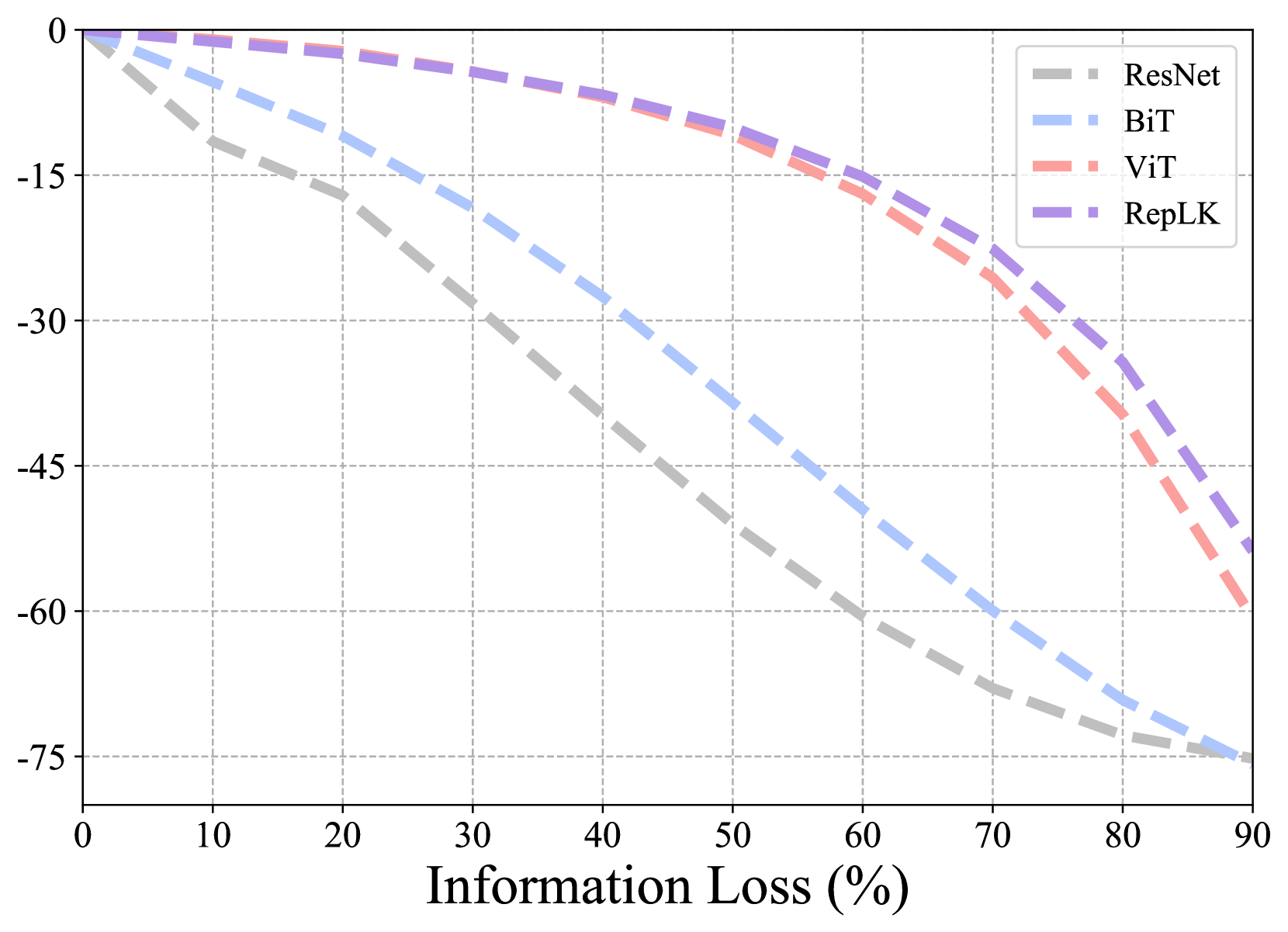
遮挡建模。 形式上,我们以补丁方式定义遮挡:首先将输入图像 划分为不重叠的扁平补丁 ,其中 根据补丁size , 是补丁的数量。 我们选择总图像块的子集,并将这些块的像素值设置为零以生成遮挡图像,表示为。 我们将 输入到不同的模型中,并通过 上的 top-1 精度来测量它们的遮挡不变性。 我们使用三种遮挡类型进行实验:i)随机下降; ii) 显着(前景)下降; 3)非显着(背景)下降。 图5提供了说明。
随机掉落。 遵循 ViT (Dosovitskiy 等人, 2020),我们将图像划分为 个 patch,那么对于分辨率为 的典型图像,将有 196 个 patch 。 这种设计在不改变ViT输入格式的情况下,与ViT进行了方便、公平的比较。 我们随机屏蔽图像的不同比例,范围从 10% 到 90%。 如图4(a)所示,当遮挡率达到50%时,典型的卷积网络会遭受灾难性的退化,而RepLKNet和ViT则表现出明显的优势。 此外,随着遮挡率变得极高,RepLKNet 逐渐优于 ViT,这表明大内核卷积网络对极端遮挡场景更加鲁棒。
显着(前景)下降。 前景物体在视觉识别中起着决定性作用,因此研究针对前景遮挡的鲁棒性至关重要。 首先,我们使用预训练的 DINO (Caron 等人, 2021) 来检测物体并识别显着区域。 然后,我们屏蔽包含前 K% 前景信息的补丁子集。 需要注意的是,这个 K% 并不总是等于像素百分比。 例如,图像 70% 的前景数据可能仅包含在 20% 的像素中。 如图4(b)所示,RepLKNet对显着遮挡表现出显着的鲁棒性,甚至明显超过了ViT。 我们认为这是它在背景依赖数据集(即 ImageNet-9)上相对 ViT 具有巨大优势的关键原因。
非显着(背景)下降。 与上述显着设置相反,我们进一步选择包含最低 K% 的前景信息的补丁并屏蔽它们。 图4(c)显示RepLKNet对于非显着遮挡也具有优异的鲁棒性。
4.2 对抗性攻击的鲁棒性
先前的研究表明,即使是很小的对抗性扰动也可以极大地改变神经网络的决策边界(Ortiz-Jimenez 等人,2020),并且研究对抗性攻击对于增强模型的鲁棒性起着至关重要的作用 (Madry等人,2017a)。 因此,在本小节中,我们将进一步研究大型内核卷积网络对抗对抗性攻击的性能。
我们使用单步和多步样本特定攻击,快速梯度符号方法(FGSM)(Goodfellow等人,2014)和投影梯度攻击(PGD)(Madry等人, 2017b) 分别。 请注意,在本实验中,我们仅将 RepLKNet 与 ResNet 和 ViT 进行比较,并在此处省略 BiT,因为它继续表现出 ResNet 和 ViT 之间的性能,类似于前几节的观察结果。
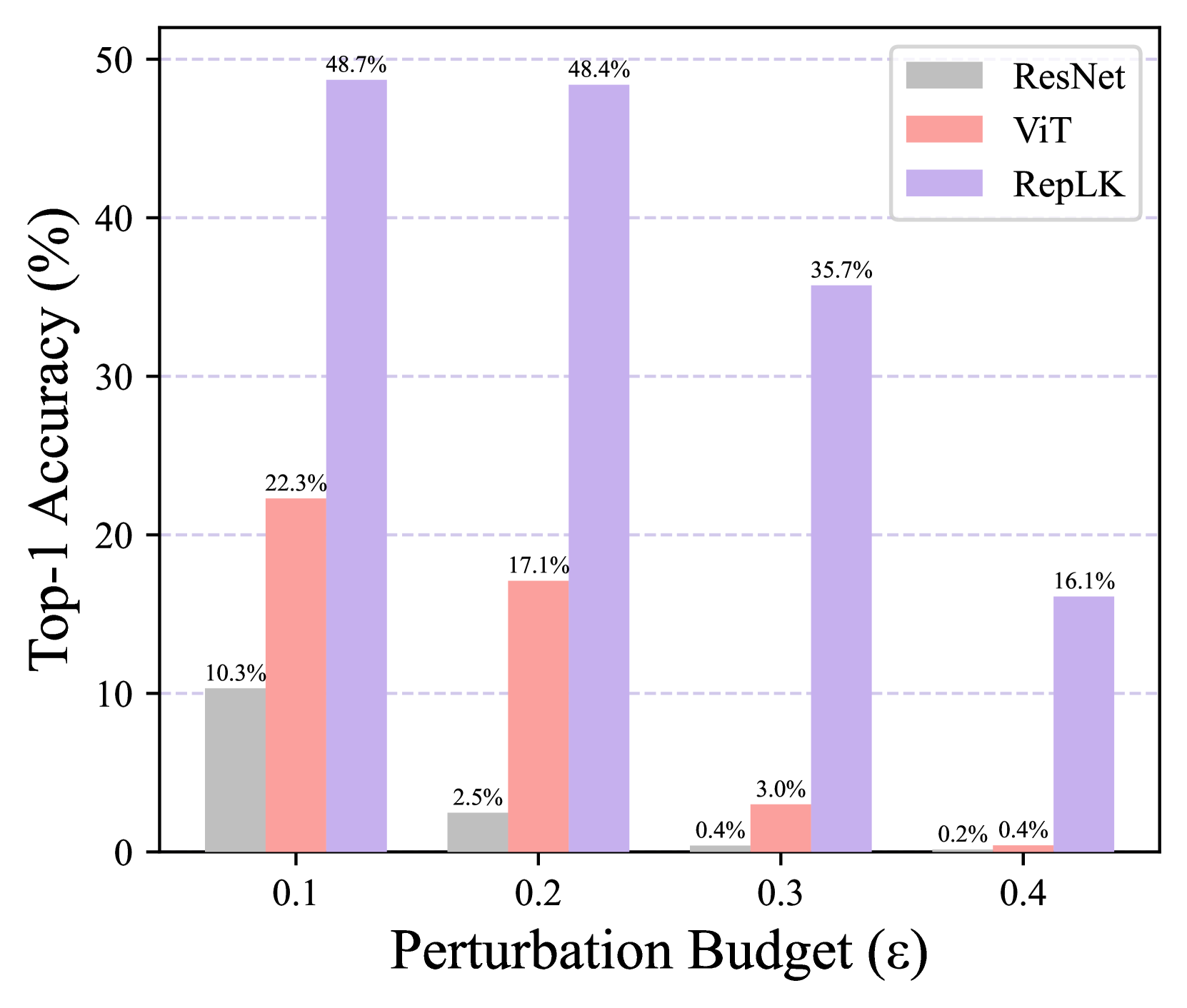
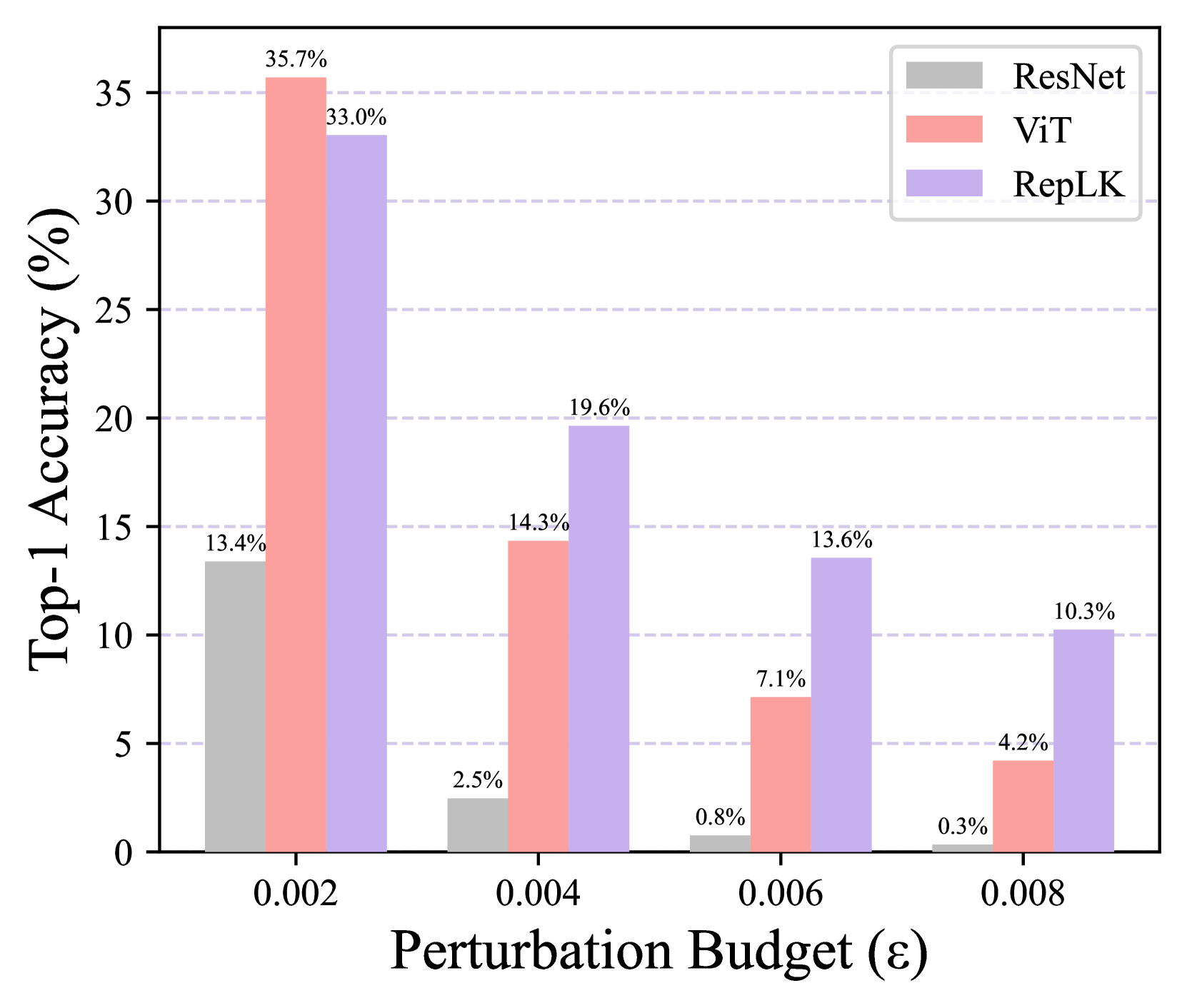
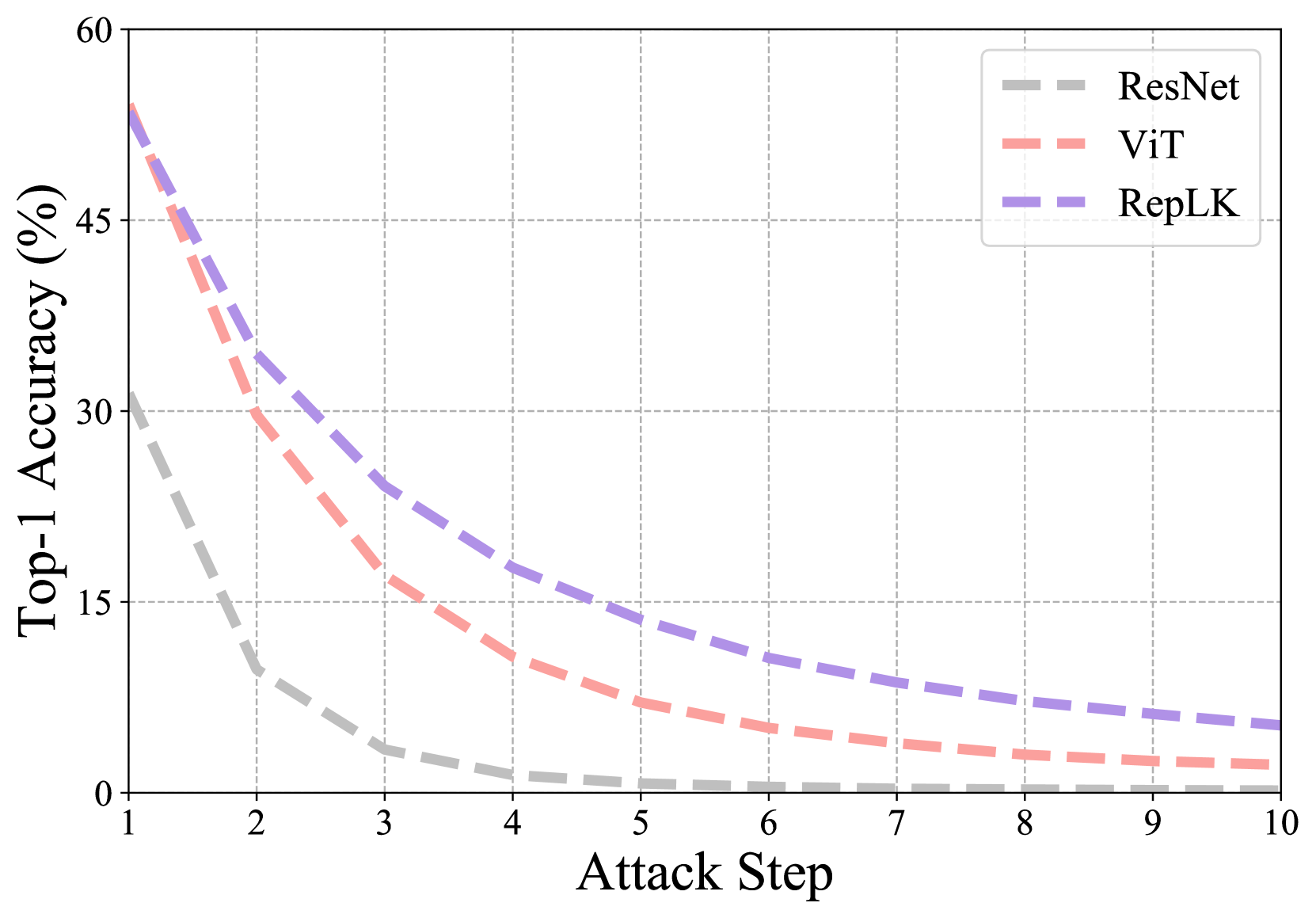
我们用三种变体进行了这个实验。 i) 对于 FGSM 攻击,我们应用 增加预算 的扰动,范围从 0.1 到 0.4。 如图6(a)所示,当预算增长到0.3时,ViT和ResNet被彻底摧毁,而RepLKNet仍然保持着35.7%的top-1准确率; ii)对于PGD攻击,我们首先将攻击步长固定为5,将扰动预算从0.002更改为0.008。 图6(b)中的结果表明,当对抗性攻击较强时,RepLKNet 明显优于 ViT; iii)然后对于PGD攻击,我们将扰动预算固定为0.006,并逐渐增加步长,观察图6(c)。 同样,RepLKNet 始终超过 ViT 和 ResNet。 请注意,对于所有实验,我们使用默认的 ImageNet 均值和标准差对像素值进行归一化。 上述三种设置的实验都得出了相同的结论:大型内核网络具有更广泛和更强的对抗鲁棒性,这可能解释为什么 RepLKNet 在自然对抗数据集(即 ImageNet-A)上表现更好。
| Model | |||
|---|---|---|---|
| ResNet-50 | 47.7 | 65.2 | 67.9 |
| BiT-r1524 | 44.6 | 60.2 | 63.1 |
| ViT-B | 62.3 | 73.3 | 75.6 |
| ViT-L | 54.9 | 67.9 | 69.8 |
| RepLKNet-31B | 39.2 | 56.1 | 59.3 |
除了经典的对抗性攻击 FGSM 和 PGD 之外,我们还进一步使用现代强对抗性攻击 TAIG 进行评估(Huang & Kong, 2022)。 具体来说,对于卷积网络(即ResNet、BiT、RepLKNet),选择ViT-B作为代理模型来生成对抗性示例,对于ViT,选择RepLKNet-31B作为代理模型。 我们将 从 0.03 增加到 0.1,以逐渐增加攻击预算。 我们报告攻击成功率(越低越好)。 如表4所示,大型内核网络的表现仍然优于典型的小型内核卷积网络和ViT,显示出其针对对抗性攻击的固有鲁棒性。
4.3模型扰动的稳健性
之前的研究(Greff 等人,2016;Veit 等人,2016;Bhojanapalli 等人,2021)表明残差网络中的层表现出大量冗余,并且几乎任何单个层都可以训练后移除,不会影响表现。 另一方面,据观察,身份快捷方式至关重要,特别是对于具有非常大内核的网络(Ding等人,2022)。 为了理解大型内核卷积网络中的信息流,我们进行了一项损伤研究,在推理过程中从已经训练的网络中删除了几个块,以便信息必须流经跳跃连接。
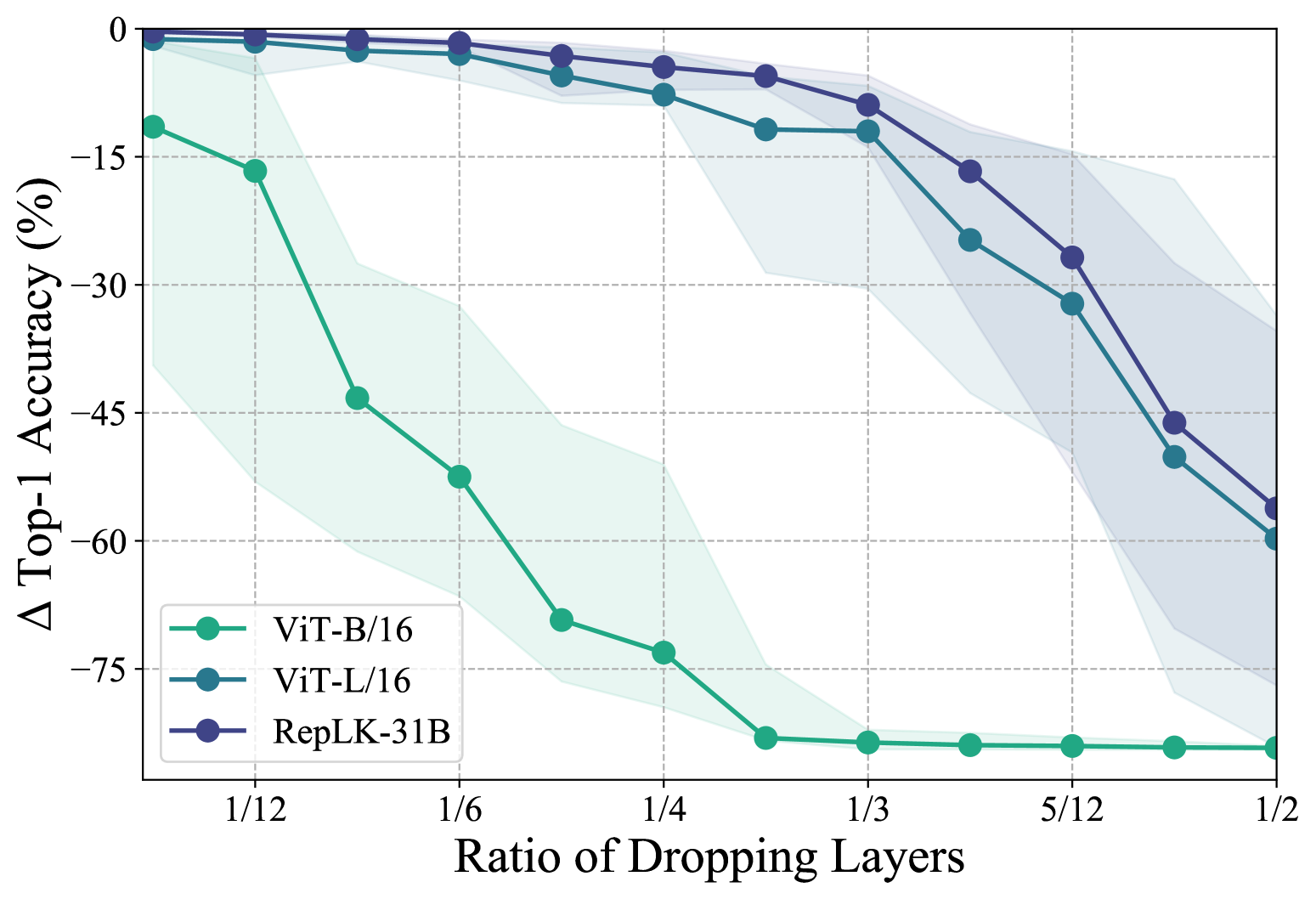
具体来说,我们随机删除 块并报告 top-1 准确率的变化。 对于每个 ,结果来自 块的 10 个独立样本,我们显示样本之间的平均精度(线)和最小/最大(阴影区域)。 鉴于ViT-B中的块数量仅为RepLKNet和ViT-L中的一半,我们使用丢弃块的比例作为图7中的x轴。 我们在这里省略 ResNet,因为它比 ViT-B 脆弱得多。
我们观察到 ViT-B 对层移除高度敏感,仅移除 块后模型的精度接近于零。 相比之下,RepLKNet 和 ViT-L 在该下降率下仍然可以保持 左右的精度。 此外,我们注意到,尽管容量较小,但在相同的块丢弃率下,RepLKNet 在准确性方面始终优于 ViT-L。 这表明大型内核网络对模型扰动更加鲁棒,这可以解释它们对常见扰动的鲁棒性(即 ImageNet-P)。
| Model | ImageNet-A | ImageNet-C | ImageNet-R | ImageNet-O | Salient-Drop-50% | Noise- |
|---|---|---|---|---|---|---|
| RepLKNet-31B | 29.4 (+2.7) | 49.2 (+7.0) | 43.9 (+5.9) | 78.9 (+10.9) | -25.1 (+19.3) | -5.0 (+1.6) |
| ViT-B | 26.7 (– –) | 42.2 (– –) | 38.0 (– –) | 68.0 (– –) | -44.4 (– –) | -6.6 (– –) |
| RepLKNet-3B | 14.6 (-12.1) | 39.1 (-3.1) | 32.9 (-5.1) | 51.6 (-16.4) | -61.8 (-17.4) | -10.6 (-4.0) |
4.4对噪声频率的鲁棒性
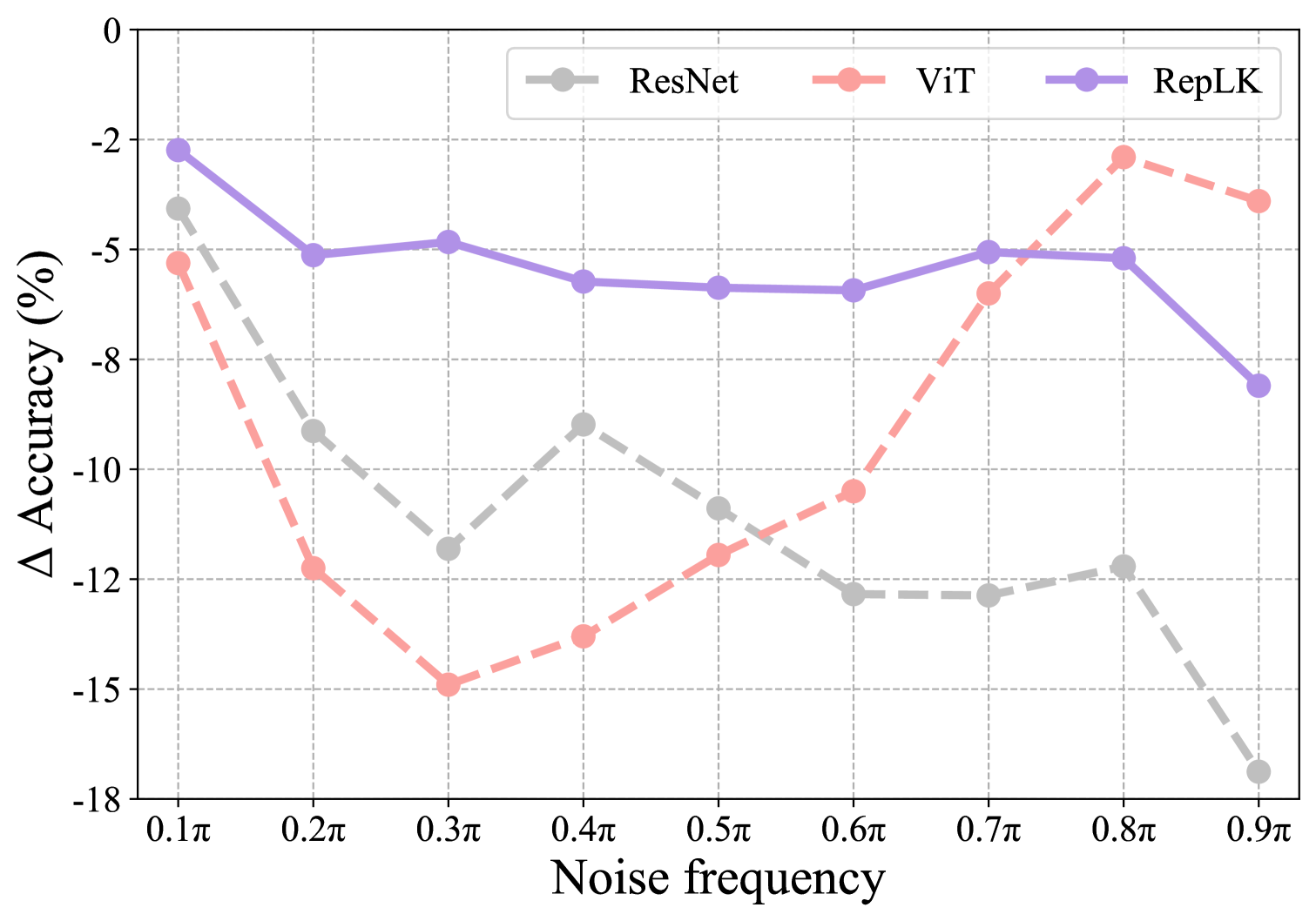
为了加深对大核卷积网络强大鲁棒性的理解,我们进一步分析其在频域的鲁棒性。 特别是,我们使模型受到不同频率的随机噪声攻击并评估准确性下降。 我们将频率标准化为 (中心)和 (边界)之间。 我们对基于频率的噪声使用频率窗口大小 。
如图8所示,ResNet对高频噪声非常敏感,而ViT对低频噪声的表现较差。 这一现象与之前的研究(Park & Kim,2022)非常吻合。 相比之下,RepLKNet 在所有频段上始终表现出对噪声的鲁棒性。 例如,对于 到 频率范围内的噪声,RepLKNet 始终将精度损失保持在 6% 以内,始终优于 ResNet 和 ViT。
4.5 大内核是关键
由于 RepLKNet、BiT 和 ViT 具有相似的预训练策略,因此它们之间的主要区别在于大核卷积的使用。 因此,我们继续探讨内核大小对鲁棒性的影响。 具体来说,我们将 RepLKNet-31B 中的所有大内核卷积替换为 3x3 小内核卷积(与 BiT 和 ResNet 中使用的内核大小相同),同时保持相同的数据增强和训练计划。 我们训练修改后的模型 RepLKNet-3B,并评估其在多个上述任务中的稳健性。 如表5所示,将内核大小从 31 减少到 3 会显着降低 RepLKNet 在各种指标上的鲁棒性,导致性能低于 ViT-B。 这一发现凸显了大核卷积在增强模型鲁棒性方面的关键作用。
4.6 本地和全局内核注意力
然后我们深入研究内核注意力模式来探索大内核的属性。 在自注意力机制的推动下,ViT 可以通过所有 Token 之间的全局交互来聚合全局信息。 然而,全局注意力并不总是最佳的。 Raghu 等人 (Raghu 等人, 2021) 揭示了强大的 ViT 会同时考虑浅层的局部信息和全局信息,主要关注更深层次的全局信息。 这与典型的 CNN (Simonyan & Zisserman,2014;He 等人,2016)形成对比,后者被硬编码为仅在所有层中进行本地参与。 由于大核卷积网络具有与 ViT 相当的大感受野(Ding 等人, 2022; Liu 等人, 2022a),我们推测它们可能表现出与 ViT 类似的注意力模式,同时关注局部和全局浅层信息主要是全局信息,而深层信息主要是全局信息。
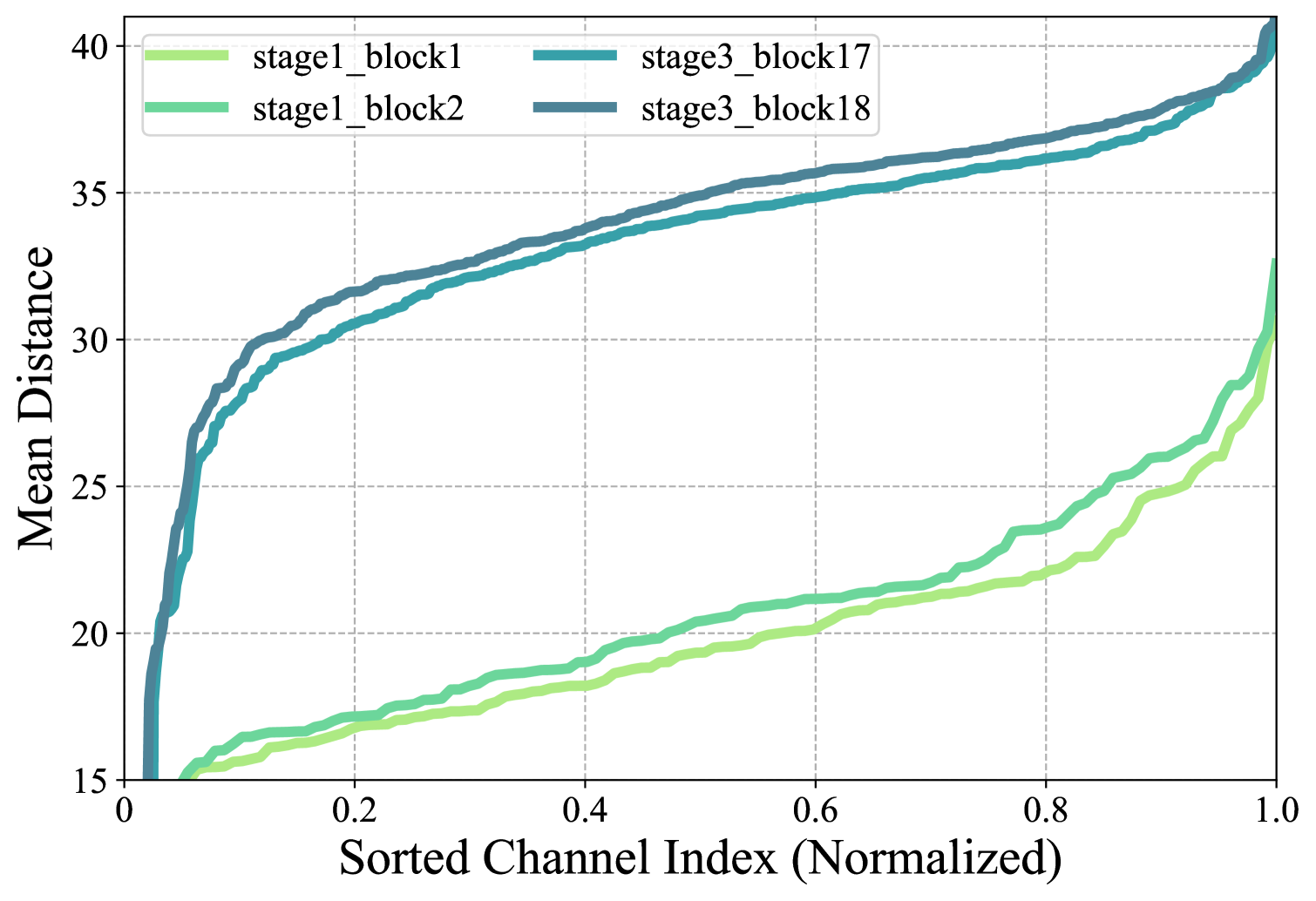
为了验证,我们计算了 RepLKNet 中不同层的平均内核注意力距离。 具体来说,对于每个核,我们测量每个核位置到核中心的欧氏距离,我们用相应参数的绝对值对这个距离进行加权,然后对所有参数的总和进行归一化以获得这个核的注意力距离。 由于每个内核都有多个通道,因此我们按内核注意距离对它们进行排序。
我们在图9中描绘了stage1的前两层和stage3的最后两层的内核注意距离,由于它们具有不同的通道尺寸,因此我们对通道索引进行归一化以便更好的比较。 有趣的是,RepLKNet 还倾向于在浅层聚合局部和全局信息,同时更多地关注更深层的全局信息。 这本质上表明,同时聚合局部和全局信息可以更有效地捕获图像中不同级别的信息,从而产生更强大和鲁棒的性能。
4.7 稳定的特征图方差
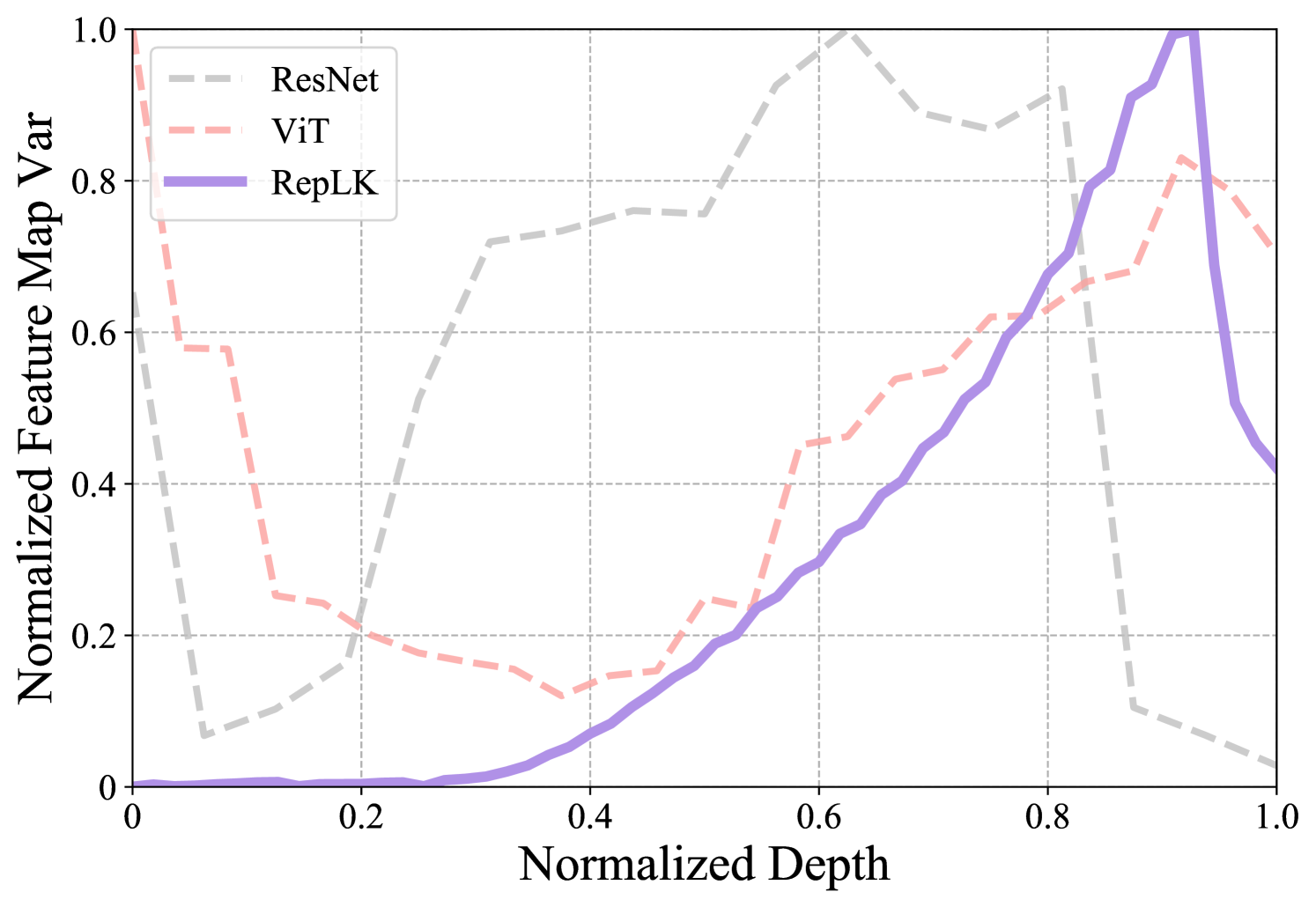
此外,我们研究了大型内核网络特征图的稳定性。 具体来说,我们将一批 ImageNet 验证图像输入到不同的网络中,批量大小设置为 64,并且我们使用常规验证增强(仅中心裁剪和归一化)。 然后我们逐层计算归一化特征图方差。
| Model | Kernel Size | ImageNet | ImageNet-A | ImageNet-R | ImageNet-C* |
|---|---|---|---|---|---|
| BiT-r1524 | 85.4 | 13.2 | 33.8 | 39.9 | |
| ViT-B | N/A | 84.0 | 26.7 | 38.0 | 42.2 |
| ViT-L | N/A | 85.2 | 28.1 | 40.6 | 49.9 |
| ConvNeXt-B | 85.8 | 33.9 | 45.5 | 53.2 | |
| ConvNeXt-L | 86.6 | 38.7 | 47.6 | 56.5 | |
| RepLKNet-31B | 85.2 | 29.4 | 43.9 | 49.2 | |
| RepLKNet-31L | 86.6 | 39.6 | 49.1 | 52.6 |
如图10所示,RepLKNet与其他两个网络有两个不同的地方:i)它在早期阶段非常稳定。 例如,当归一化深度小于0.4时,RepLKNet特征图的方差保持在很低的水平,而ViT和ResNet从一开始就往往有很大的方差; ii) 方差以简单且连贯的方式变化。 RepLKNet升降缓慢,整个过程变化简单稳定,而ResNet和ViT则波动剧烈。
4.8更多大型内核ConvNets的结果
为了进一步验证大核卷积对鲁棒性及其缩放特性的影响,我们添加了另一个现代强大核卷积网络ConvNeXt (Liu 等人, 2022b),并增加了RepLKNet的模型大小和 ConvNeXt 从基础到大进行比较。 如表6所示,ConvNeXt还表现出很强的鲁棒性,并且当模型尺寸增大时其鲁棒性进一步提高。 对于RepLKNet-31L,我们使用官方发布的预训练模型,它在ImageNet、ImageNet-A和ImageNet-R上实现了一致的改进。对于ImageNet-C,该数据集的图像都是,在此数据集上评估模型将导致输入分布不一致,因此对该数据集的改进不太显着。
4.9多大可以使鲁棒性强?
虽然 ConvNeXt 和 RepLKNet 具有不同的大内核大小(即 与 ),它们都表现出很强的鲁棒性。 人们很自然地会问: 多大的内核才能使鲁棒性强? 为了回答这个问题,我们通过逐渐增加内核大小来进行消融研究。
具体来说,我们在 ImageNet-1K 上以 120 epoch 的时间表训练具有不同内核大小的 ConvNext-Tiny(由于计算限制,我们无法在 ImageNet-21K 上进行这种消融)。 唯一的区别是内核大小。 如表7所示,有三个观察结果:i)扩大内核可以在ImageNet和鲁棒性基准上带来一致的改进; ii) 基本上,扩大到 可以带来良好的鲁棒性,但是继续扩大内核大小到 可以带来进一步的鲁棒性; iii) 虽然放大到极大不能给 ImageNet 带来显着的改进,但它可以在鲁棒性上带来更好的改进。
| Model | Kernel | ImgN | ImgN-A | ImgN-R |
|---|---|---|---|---|
| ConvNeXt-3 | 79.4 | 5.20 | 28.87 | |
| ConvNeXt-7 | 80.7 | 7.76 | 29.86 | |
| ConvNeXt-13 | 81.3 | 9.89 | 30.97 | |
| ConvNeXt-31 | 81.4 | 10.20 | 31.34 | |
| ConvNeXt-51 | 81.6 | 10.71 | 31.77 |
5限制
尽管我们从多个定量和定性的角度对大核卷积网络的强鲁棒性进行了全面而深入的实证分析,但考虑到深度学习的黑盒性质,我们很难提供直接的理论证明。 另一个限制是由于计算限制,我们在 ImageNet-1K 上进行内核大小消融,但不在 ImageNet-21K 上进行。
6结论
在这项研究中,我们深入研究了大型内核卷积网络的鲁棒性,在六个广泛使用的鲁棒性基准数据集上验证了其强大的鲁棒性。 然后,我们从定量和定性的角度全面分析其异常稳健的来源。 我们的研究和分析为鲁棒性的来源提供了新颖的见解,有可能促进大型内核卷积网络未来的应用和发展。
致谢
该工作得到了国家重点研发计划(批准号:2022ZD0116403)、国家自然科学基金(批准号:2022ZD0116403)的部分支持。 61721004)和中国科学院战略性先导研究计划(批准号:61721004) XDA27000000)。
影响报告
本文介绍的工作旨在推动机器学习领域的发展。 我们的工作有许多潜在的社会后果,我们认为没有必要在此特别强调。
参考
- Bao et al. (2021) Bao, H., Dong, L., Piao, S., and Wei, F. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
- Bhojanapalli et al. (2021) Bhojanapalli, S., Chakrabarti, A., Glasner, D., Li, D., Unterthiner, T., and Veit, A. Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 10231–10241, 2021.
- Carion et al. (2020) Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., and Zagoruyko, S. End-to-end object detection with transformers. In European conference on computer vision, pp. 213–229. Springer, 2020.
- Caron et al. (2021) Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., and Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 9650–9660, 2021.
- Chen et al. (2024a) Chen, H., Chu, X., Ren, Y., Zhao, X., and Huang, K. Pelk: Parameter-efficient large kernel convnets with peripheral convolution. arXiv preprint arXiv:2403.07589, 2024a.
- Chen et al. (2024b) Chen, H., Kong, X., Zhang, X., Zhao, X., and Huang, K. Ddae: Towards deep dynamic vision bert pretraining. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 1037–1045, 2024b.
- Chen et al. (2023) Chen, Y., Liu, J., Zhang, X., Qi, X., and Jia, J. Largekernel3d: Scaling up kernels in 3d sparse cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13488–13498, 2023.
- Cheng et al. (2021) Cheng, B., Schwing, A., and Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. Advances in Neural Information Processing Systems, 34:17864–17875, 2021.
- Cheng et al. (2022) Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., and Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1290–1299, 2022.
- Dai et al. (2021) Dai, X., Chen, Y., Yang, J., Zhang, P., Yuan, L., and Zhang, L. Dynamic detr: End-to-end object detection with dynamic attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2988–2997, 2021.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Ding et al. (2022) Ding, X., Zhang, X., Han, J., and Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11963–11975, 2022.
- Ding et al. (2023) Ding, X., Zhang, Y., Ge, Y., Zhao, S., Song, L., Yue, X., and Shan, Y. Unireplknet: A universal perception large-kernel convnet for audio, video, point cloud, time-series and image recognition. arXiv preprint arXiv:2311.15599, 2023.
- Dosovitskiy et al. (2020) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Goodfellow et al. (2014) Goodfellow, I. J., Shlens, J., and Szegedy, C. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Greff et al. (2016) Greff, K., Srivastava, R. K., and Schmidhuber, J. Highway and residual networks learn unrolled iterative estimation. arXiv preprint arXiv:1612.07771, 2016.
- Guo et al. (2023) Guo, Y., Stutz, D., and Schiele, B. Robustifying token attention for vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 17557–17568, 2023.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- He et al. (2022) He, K., Chen, X., Xie, S., Li, Y., Dollár, P., and Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000–16009, 2022.
- Hendrycks & Dietterich (2019) Hendrycks, D. and Dietterich, T. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261, 2019.
- Hendrycks et al. (2020) Hendrycks, D., Mu, N., Cubuk, E. D., Zoph, B., Gilmer, J., and Lakshminarayanan, B. Augmix: A simple method to improve robustness and uncertainty under data shift. In International conference on learning representations, volume 1, pp. 5, 2020.
- Hendrycks et al. (2021a) Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8340–8349, 2021a.
- Hendrycks et al. (2021b) Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., and Song, D. Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15262–15271, 2021b.
- Huang et al. (2023) Huang, T., Yin, L., Zhang, Z., Shen, L., Fang, M., Pechenizkiy, M., Wang, Z., and Liu, S. Are large kernels better teachers than transformers for convnets? arXiv preprint arXiv:2305.19412, 2023.
- Huang & Kong (2022) Huang, Y. and Kong, A. W.-K. Transferable adversarial attack based on integrated gradients. arXiv preprint arXiv:2205.13152, 2022.
- Kolesnikov et al. (2020) Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., and Houlsby, N. Big transfer (bit): General visual representation learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16, pp. 491–507. Springer, 2020.
- Kong & Zhang (2023) Kong, X. and Zhang, X. Understanding masked image modeling via learning occlusion invariant feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6241–6251, 2023.
- Kosmann-Schwarzbach et al. (2011) Kosmann-Schwarzbach, Y., Schwarzbach, B. E., and Kosmann-Schwarzbach, Y. The Noether Theorems. Springer, 2011.
- Krizhevsky et al. (2012) Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
- LeCun et al. (1998) LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, 2014.
- Liu et al. (2022a) Liu, S., Chen, T., Chen, X., Chen, X., Xiao, Q., Wu, B., Pechenizkiy, M., Mocanu, D., and Wang, Z. More convnets in the 2020s: Scaling up kernels beyond 51x51 using sparsity. arXiv preprint arXiv:2207.03620, 2022a.
- Liu et al. (2021) Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., and Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022, 2021.
- Liu et al. (2022b) Liu, Z., Mao, H., Wu, C.-Y., Feichtenhofer, C., Darrell, T., and Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11976–11986, 2022b.
- Lu et al. (2023) Lu, T., Ding, X., Liu, H., Wu, G., and Wang, L. Link: Linear kernel for lidar-based 3d perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1105–1115, 2023.
- Madry et al. (2017a) Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017a.
- Madry et al. (2017b) Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017b.
- Mahmood et al. (2021) Mahmood, K., Mahmood, R., and Van Dijk, M. On the robustness of vision transformers to adversarial examples. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7838–7847, 2021.
- Mao et al. (2022) Mao, X., Qi, G., Chen, Y., Li, X., Duan, R., Ye, S., He, Y., and Xue, H. Towards robust vision transformer. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pp. 12042–12051, 2022.
- Meng et al. (2021) Meng, D., Chen, X., Fan, Z., Zeng, G., Li, H., Yuan, Y., Sun, L., and Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3651–3660, 2021.
- Naseer et al. (2021) Naseer, M. M., Ranasinghe, K., Khan, S. H., Hayat, M., Shahbaz Khan, F., and Yang, M.-H. Intriguing properties of vision transformers. Advances in Neural Information Processing Systems, 34:23296–23308, 2021.
- Ortiz-Jimenez et al. (2020) Ortiz-Jimenez, G., Modas, A., Moosavi, S.-M., and Frossard, P. Hold me tight! influence of discriminative features on deep network boundaries. Advances in Neural Information Processing Systems, 33:2935–2946, 2020.
- Park & Kim (2022) Park, N. and Kim, S. How do vision transformers work? arXiv preprint arXiv:2202.06709, 2022.
- Paul & Chen (2022) Paul, S. and Chen, P.-Y. Vision transformers are robust learners. In Proceedings of the AAAI conference on Artificial Intelligence, volume 36, pp. 2071–2081, 2022.
- Peng et al. (2017) Peng, C., Zhang, X., Yu, G., Luo, G., and Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4353–4361, 2017.
- Raghu et al. (2021) Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C., and Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Advances in neural information processing systems, 34:12116–12128, 2021.
- Romero et al. (2021a) Romero, D. W., Bruintjes, R.-J., Tomczak, J. M., Bekkers, E. J., Hoogendoorn, M., and van Gemert, J. C. Flexconv: Continuous kernel convolutions with differentiable kernel sizes. arXiv preprint arXiv:2110.08059, 2021a.
- Romero et al. (2021b) Romero, D. W., Kuzina, A., Bekkers, E. J., Tomczak, J. M., and Hoogendoorn, M. Ckconv: Continuous kernel convolution for sequential data. arXiv preprint arXiv:2102.02611, 2021b.
- Shao et al. (2021) Shao, R., Shi, Z., Yi, J., Chen, P.-Y., and Hsieh, C.-J. On the adversarial robustness of vision transformers. arXiv preprint arXiv:2103.15670, 2021.
- Simonyan & Zisserman (2014) Simonyan, K. and Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- Szegedy et al. (2015) Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9, 2015.
- Szegedy et al. (2016) Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2818–2826, 2016.
- Touvron et al. (2021) Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., and Jégou, H. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pp. 10347–10357. PMLR, 2021.
- Trockman & Kolter (2022) Trockman, A. and Kolter, J. Z. Patches are all you need? arXiv preprint arXiv:2201.09792, 2022.
- Veit et al. (2016) Veit, A., Wilber, M. J., and Belongie, S. Residual networks behave like ensembles of relatively shallow networks. Advances in neural information processing systems, 29, 2016.
- Wang et al. (2021) Wang, W., Xie, E., Li, X., Fan, D.-P., Song, K., Liang, D., Lu, T., Luo, P., and Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 568–578, 2021.
- Woo et al. (2023) Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I. S., and Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16133–16142, 2023.
- Xiao et al. (2020) Xiao, K., Engstrom, L., Ilyas, A., and Madry, A. Noise or signal: The role of image backgrounds in object recognition. arXiv preprint arXiv:2006.09994, 2020.
- Zhai et al. (2019) Zhai, X., Puigcerver, J., Kolesnikov, A., Ruyssen, P., Riquelme, C., Lucic, M., Djolonga, J., Pinto, A. S., Neumann, M., Dosovitskiy, A., et al. A large-scale study of representation learning with the visual task adaptation benchmark. arXiv preprint arXiv:1910.04867, 2019.
- Zhou et al. (2022) Zhou, D., Yu, Z., Xie, E., Xiao, C., Anandkumar, A., Feng, J., and Alvarez, J. M. Understanding the robustness in vision transformers. In International Conference on Machine Learning, pp. 27378–27394. PMLR, 2022.
- Zhu et al. (2020) Zhu, X., Su, W., Lu, L., Li, B., Wang, X., and Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020.
附录A稳健性数据集详细信息
ImageNet-A (Hendrycks 等人, 2021b) 是真实世界的对抗性过滤图像的数据集,可以欺骗当前的 ImageNet 分类器。 具体来说,它包含 ImageNet-1K 1000 个类的 200 个类子集,涵盖了最广泛的类别。 这些本应正确分类的图像,却被 ResNet-50 以高置信度错误分类为不正确的类别。 由于场景配置的长尾中遇到的场景复杂性以及利用分类器盲点,它们会在各种模型中导致一致的分类错误。
ImageNet-C (Hendrycks & Dietterich,2019) 包含 15 类算法生成的损坏和另外四种一般损坏类型,总共有 19 种损坏类别。 每种腐败类型都有五个严重级别,从可忽略到极严重。 该范围允许基准对每种腐败类型进行全面评估。 这些损坏全部应用于 ImageNet 验证图像,因此 ImageNet-C 的总数据量为 图像。
ImageNet-O (Hendrycks 等人, 2021b) 是 ImageNet 分布外检测器的对抗性过滤示例的数据集。 它包含 ImageNet-22K 中未包含在 ImageNet-1K 中的 200 个类别。 它包含不可预见类别的异常,对于这些异常,稳健的模型预计会输出低置信度的预测。
ImageNet-P (Hendrycks & Dietterich,2019) 由 10 种常见扰动组成。 ImageNet-P 与 ImageNet-C 的不同之处在于它从每个 ImageNet 验证图像生成扰动序列。 这些扰动是微妙的,影响图像中较少数量的像素。 为了抵消每个包含超过 30 帧的序列导致的数据集大小和评估时间的增加,它仅包含 10 个常见扰动。
ImageNet-R (Hendrycks 等人, 2021a) 包含 ImageNet-1K 数据集中 200 个类别的各种艺术表现形式。 与最初的 ImageNet 不鼓励此类图像,因为注释者被指示收集“仅照片,没有绘画,没有图画等”相反,ImageNet-R 采用了相反的方法。 旨在验证不同领域下语义变化下视觉网络的鲁棒性。
ImageNet-9 (Xiao 等人, 2020) 有助于理清前景和背景信号对分类的影响。 人类视觉对背景变化表现出高度的鲁棒性,只要前景保持不变,就能保持一致的决策。 然而,对于大多数视觉模型来说,背景的改变会显着影响模型的输出和准确性。 因此,我们进一步深入研究对背景变化的稳健性。
| Dataset | Objective | Venue |
|---|---|---|
| ImageNet-A | natural adversarial | CVPR |
| ImageNet-C | common corruptions | ICLR |
| ImageNet-O | out-of-domain distribution | CVPR |
| ImageNet-P | common perturbations | ICLR |
| ImageNet-R | semantic shifts | ICCV |
| ImageNet-9 | background dependency | ICLR |