tcolorbox backgroundcolor=shadecolor,linecolor=darkgray,linewidth=1.5pt,roundcorner=5pt,nobreak=true,innerleftmargin=15pt,innerrightmargin=15pt,innertopmargin=10pt,innerbottommargin=10pt,skipabove=10pt,skipbelow=10pt,
超越欧几里得:
具有几何、拓扑和代数结构的现代机器学习图解指南
摘要
欧几里德几何的持久遗产支撑着经典机器学习,几十年来,经典机器学习主要是针对欧几里德空间中的数据开发的。 然而,现代机器学习越来越多地遇到本质上非欧几里得的丰富结构化数据。 这些数据可以表现出复杂的几何、拓扑和代数结构:从时空曲率的几何形状,到大脑中神经元之间拓扑复杂的相互作用,再到描述物理系统对称性的代数变换。 从此类非欧几里得数据中提取知识需要更广泛的数学视角。 与 19 世纪引发非欧几里得几何学的革命相呼应,一条新兴的研究路线正在用非欧几里得结构重新定义现代机器学习。 其目标:将经典方法推广到几何、拓扑和代数的非常规数据类型。 在这篇评论中,我们为这个快速发展的领域提供了一个可访问的门户,并提出了一种图形分类法,将最新的进展集成到一个直观的统一框架中。 随后,我们深入了解当前的挑战,并强调该领域未来发展的令人兴奋的机遇。
索引术语:
几何深度学习、几何、拓扑、代数、机器学习我简介
近两千年来,欧几里得的几何原理构成了我们理解空间和形状的支柱。 这种以平面和直线为特征的“欧几里得”几何观直到 19 世纪才受到质疑。 直到那时,数学家才敢于“超越”,发展弯曲空间上的非欧几里得几何原理。 他们的开创性工作揭示了不存在单一的、真正的几何形状。 相反,欧几里得几何只是数学几何宇宙中的一种,每一种几何都可以用来阐明自然界中的不同结构——从拥抱时空曲率的天体力学到自然界中神经元的拓扑和代数复杂的电模式。和人工神经网络。
这场非欧几里得革命是 19 世纪和 20 世纪数学普遍化和抽象化大趋势的一部分。 除了扩展几何领域之外,数学家还开始定义更多抽象的空间概念,摆脱距离和角度等严格的几何概念。 这催生了拓扑学领域,它研究在拉伸和弯曲等连续变换下保留的空间属性。 通过抽象出几何结构的刚性,拓扑强调更一般的空间属性,例如连续性和连通性。 事实上,从几何角度看起来非常不同的两种结构可以被认为在拓扑上是等效的。 著名的例子是甜甜圈和咖啡杯,它们在拓扑上是等效的,因为一个可以连续变形为另一个。 摘要等价的这一概念得到了同时发展的摘要代数领域的支持,该领域检查对象的对称性——保持其基本结构不变的变换。 这些数学思想很快在自然科学中找到了应用,并彻底改变了我们模拟世界的方式。
一场类似的革命正在机器学习领域展开。 在过去的二十年中,新兴的研究机构拓展了机器学习的视野,超越了传统上用于数据分析的平面欧几里得空间,拥抱非欧几何、拓扑和抽象代数提供的丰富多样的结构。 。 这一运动包括在几何统计(Pennec,2006;Guigui et al、2023)以及 几何、(Bronstein 等,2021)、拓扑 (Hajij 等,2023a, Bodnar, 2021)等领域的深度学习模型、2023a,Bodnar,2023),以及 等式 (Cohen 等人,2021) 深度学习。 20 世纪,非欧几里得几何从根本上改变了我们用笔和纸模拟世界的方式。 在 21 世纪,它有望彻底改变我们用机器建模世界的方式。
这篇评论文章对这一运动的核心概念进行了简单易懂的介绍。 我们将文献中的模型组织成由数据和机器学习模型的数学结构定义的连贯分类法。 在此过程中,我们澄清了方法之间的区别,并强调了尚未探索的挑战和高潜力研究领域。 我们首先在第II节中介绍基本的数学背景,并在第III节中分析数据中的数学结构,然后介绍机器学习和深度学习方法的本体论在第 IV 和 V 节中。我们在第 VI 节中探讨开源软件库的相关前景,并在第 VII 因此,这篇评论文章揭示了这个新的机器学习框架——诞生于几何、拓扑和代数的优雅数学——是如何开发、实施和调整的,以针对现实世界的挑战提出变革性的解决方案。
拓扑特性
连通性 连续性 关系 几何特性
距离 角 测量 代数特性
对称性 不变性 Transformer
II 非欧几何元素
我们首先对基本数学概念进行简单易懂的介绍。 为了便于阅读,我们在这里主要从语言学角度定义概念,并请读者参考作品Guigui 等人 (2023)、Bronstein 等人 (2021)、Hajij 等人 (2023a)、Cohen 等人 (2021) 的精确数学定义。
拓扑学、几何和代数是研究抽象空间性质的数学分支。 在机器学习中,数据可以拥有明确的空间结构,例如大脑扫描的图像或蛋白质表面的渲染。 即使数据不是明显的空间数据,数据集也可以自然地被概念化为从嵌入高维空间中的摘要表面提取的一组样本。 了解数据的“形状”(即该数据所属空间的形状)可以对赋予数据意义的关系模式提供重要的见解。
拓扑、几何和代数各自提供了不同的视角和工具集来研究数据空间的属性及其“形状”,如下面的文本框所示。 拓扑提供了最抽象、灵活的视角,并将空间视为弹性结构,只要保持连通性和连续性,就可以不断变形。 因此,拓扑学研究点之间的关系。 几何允许我们量化熟悉的属性,例如距离和角度,换句话说:对点执行测量。 代数提供了研究对象对称性的工具——可以在保持其基本结构不变的情况下应用的变换。
II-A 拓扑:关系
拓扑空间是一组点,配备了称为拓扑的结构,该结构确定集合中哪些点彼此“接近”。 拓扑为原本非结构化的集合提供了空间结构。 正式地,拓扑被定义为开集的集合。 开集是空间区域中不包括边界上的点的点的集合。 通过将点分组为开放集,我们可以讨论点的“邻域”和点之间的“路径”,这为我们提供了一种将连续性等概念形式化的方法(你可以在不传送的情况下从一个位置移动到另一个位置吗?) 和连通性(两个地点是否位于同一社区或地区?)。
鉴于拓扑结构的普遍性,拓扑空间可能非常奇特。 在本文中,我们不考虑连续的拓扑空间,并且明确将术语拓扑限制为离散拓扑结构,例如图、元胞复合体和超图。 我们认为这些空间是离散欧几里得空间的推广。 事实上,欧几里得空间离散成规则网格,而图、元胞复合体和超图放松了规则性假设,并允许点与更复杂的关系连接起来,如图所示



II-B 几何:测量
流形是一个连续空间,在每个点的邻域中局部“类似于”(同胚)欧几里得空间。 换句话说,它是局部线性的,并且不与自身相交。 虽然局部它类似于平坦的空间,但它的整体形状可能表现出曲率。 在没有额外结构的情况下,歧管可以被视为柔软且有弹性的表面。 为了给它更严格、更明确的形式,流形可以配备点之间的距离的概念,它冻结每个点彼此之间的距离,从而冻结流形的整体形状。
有两种主要方法来定义流形上的距离,将其转换为 (i) 度量空间,其中外在距离可以独立于流形的属性进行选择,或转换为 (ii) 长度空间(也称为路径) -度量空间),其中流形上两点之间的距离本质上由连接点的曲线长度的下确界定义。 在本文中,我们关注长度空间。 为这种方法建立距离概念的一个有效方法是考虑黎曼流形,即:一个光滑流形,在流形上每个点的切空间上配备有正定内积。 该内积系列定义了黎曼度量,它定义了流形上给定点处的切向量的长度以及它们之间的角度。 最终,黎曼度量通过对其切向量的积分得出沿流形曲线的距离。 测地线将欧几里得的“直线”概念推广到弯曲流形。 黎曼测地线是追踪两点之间局部最短路径的曲线。
存在不同风格的黎曼流形,例如球体、双曲空间和环面。 我们认为这些空间是连续欧几里得空间的推广。 事实上,欧几里得空间总体上是平坦的,而球体、双曲空间和环面可以表现出曲率 - 如图 2 所示。 文献中最常研究的流形——欧几里得空间、超球面和双曲空间——是常曲率的三个流形,这并非巧合。 欧几里得空间的曲率为 0,球体(和超球面)的曲率为 1,而双曲空间的曲率为 -1。 它们曲率的均匀性使得它们比更一般的任意流形更容易建模。
II-C 代数:变换
group 是一组可以组合的变换,例如 3D 旋转。 组可以是离散的或连续的。 李群是一个连续群,定义为配备有兼容群结构的光滑流形,使得流形上元素的组合遵循群公理。 李群的一个示例是矩阵乘法下 中的特殊正交矩阵集合,它定义了 3 维旋转群 。 每个矩阵都是该群的一个元素,并定义一定角度的旋转。 李群在物理学中被广泛使用,它们描述物理系统中的对称性。
一组变换,例如 (3D 旋转组)可以作用于另一个流形以变换其元素。 组动作将流形中的元素映射到新位置,该位置由转换它们的组元素确定。 例如,欧几里得空间上的群动作可以平移、旋转和反映其元素,如图3所示。 在本文中,我们使用术语代数来表示我们为空间配备群动作。
III 数据结构
拓扑、几何和代数的数学提供了一个概念框架来对机器学习中发现的数据的性质进行分类。 我们通常会遇到两种类型的数据:一种是 空间中的坐标数据--例如,物体在二维空间中的位置坐标;另一种是 空间上的信号数据--例如,图像是定义在二维空间上的三维(RGB)信号。 在每种情况下,空间可以是欧几里得空间,也可以配备拓扑、几何和代数结构,例如II节中介绍的结构。
了解该空间的结构可以提供对数据本质的重要见解。 反过来,这些见解对于选择最适合从这些数据中提取知识的机器学习模型至关重要。 在本节中,我们提供了一个图形分类法,如图 4 所示,根据拓扑、几何和代数数学对数据结构进行分类。
III-A 数据作为空间坐标
我们首先对数据的数学结构进行分类,其中数据点是空间坐标——如图4的前两行所示,并在下面详细描述。 我们用 表示数据集 中的数据点,并删除其下标 以简化符号。
-
卡C1:
欧几里得空间中的点:此类数据点构成了传统机器学习和深度学习方法的基础。 图 4 中的卡片 C1(白色)显示了欧几里得空间 中的点的示例,它表示 Iris 数据集 中花朵的尺寸(Fisher,1936 ),其中 表示研究的特征数量。
-
卡C2:
流形中的点:向坐标空间添加非欧几里得几何图形,卡片 C2(橙色)说明了流形 上的数据点,其中流形是球体。 例如,该数据点可以表示风暴事件的地理坐标,即其在地球表面上以球体表示的位置。
-
卡C3:
拓扑空间中的点:卡 C3(紫色)考虑驻留在拓扑空间 中的数据点,此处对应于图中的节点。 此类别的一个示例是代表社交网络图中的人的数据点,其中边代表社交关系。
接下来的三个数据类别向上述数据空间添加了组操作。
-
卡C4:
欧几里得空间中的点配备群动作:卡片C4(蓝色)显示欧几里德空间中已配备群动作的数据点。 群体行动使我们能够建模并保持数据的对称性。 例如,对花朵尺寸的集体操作可以是单位的变化,从厘米到毫米。 在这种情况下,感兴趣的组是缩放组。 该组的行为不会改变数据中包含的信息(花在现实世界中仍然具有相同的大小),它只会改变我们编码该信息的方式。
-
卡C5:
流形中的点 配备集体行动:卡片 C5 将群体行动的概念添加到流形中。 这种集体行动的一个例子是改变球体上的坐标系,改变经度的原点。 在这种情况下,感兴趣的组将是 3D 旋转组 。 同样,该群体的行为代表了数据的对称性:信息内容不变(现实世界中同一地理位置仍会发生风暴),但我们编码信息的方式已经改变。
-
卡C6:
拓扑空间中的点 配备集体行动:卡 C6 为拓扑空间配备了群作用的概念。 一个例子是配备了可以更改数据集索引完成方式的操作的人员图。 我们为人们建立索引的顺序不会改变他们的社会关系,只会改变我们在计算机中表示这些数据的方式。 本例中感兴趣的组位于排列组中。
这些类别描述了机器学习中遇到的数据空间的数学结构。 然而,即使数据点属于具有拓扑、几何或代数结构的空间,它们的计算表示通常采用数组的形式。 因此,这些数据点可能在计算机内存中显示为向量,但这只是为了方便处理和存储。 通过对这些向量的值施加约束来保留基础数学结构。
例如,位于球体上的数据点可以表示为 3D 坐标向量,但对该向量的范数的约束编码了定义数学空间的属性。 我们注意到数据点可以由不同大小的数组表示。 例如,球体上的数据点可以用大小为 3 的向量(其值编码其笛卡尔坐标)来表示,或者用大小为 2 的向量(其值表示其纬度和经度)来表示。 在这两种情况下,数据点的数学性质都没有改变:它仍然代表流形上的一个点,独立于计算机中用于处理它的数组。

III-B 数据作为信号
在许多应用中,数据点不是空间中的坐标,而是在空间上定义的函数,通常将中的向量分配给空间中的每个点。 形式上,我们可以编写这样一个函数 ,其中输入空间(此处为 )称为域,输出空间(此处为 )称为共域。 我们将这种类型的数据称为信号。 共域的元素称为信号的值。
彩色图像提供了一个明显的例子。 域是 的有界区域:例如,限制在水平轴上的范围 和垂直轴上的 范围,使得该域表示像素位置。 每个像素位置都在共域 中分配一个向量,该向量指定每个 RGB 颜色通道的强度。
图4介绍了几种类型的数据点作为从域到共域的函数,以及现实世界的数据示例。 以这种方式形式化信号使我们能够灵活地使用非欧几里得结构来表示更一般的信号类别。 域或余域(或两者)可以是上一节中介绍的任何一个非欧几里得空间。 我们在图 4 的底部四行中展示了不同的选项,并在下面详细说明。
-
卡S1:
欧几里德域上的欧几里德信号:这代表经典深度学习中最常见的数据类型之一,功能为,来自域中的点到 codomain 中的功能。 灰度图像提供了一个明显的例子。 该域是表示像素位置的 有界区域。 每个像素位置都在共域中分配一个向量,该向量指定灰度强度。
-
卡S2:
欧几里得域上的流形值信号:这表示可以形式化为函数的信号,该函数分配流形 到欧几里得域 中的每个点。 这方面的一个例子发生在扩散张量成像中,其中拍摄了大脑的 3D 图像。 域 中的每个体素位置附加一个 协方差矩阵,用于描述水分子如何在大脑中扩散,即来自对称正定矩阵流形 (Pennec等人,2006)。
-
卡S3:
流形域上的流形值信号:在该类别中,域和余域都是流形和,分别是,。 空中交通协方差数据是一个用例,其中域是球体 (地球表面),值为 SPD 矩阵,即流形余域 这些矩阵可以对代表不同级别局部复杂性的协方差矩阵进行编码(Le Brigant 和 Puechmorel,2018)。
-
卡S4:
多值信号 在拓扑域上:这里,信号输入位于拓扑域 中,信号值位于流形 中,例如 。 此设置的代表性示例是人体姿势。 身体中的每个关节都由其 3D 方向表示,即由 3D 旋转的特殊正交组 上的旋转矩阵表示。 代表身体关节索引的域可以被编码为无向图。
-
卡S5:
拓扑域上的欧几里德信号:这表示具有拓扑域和欧几里德空间中的值的信号,即是:。 重用编码人体姿势的示例,每个身体关节可以用其在空间中的 3D 位置来表示,即使用在非有向图域 上定义的 中的值来表示。
-
卡S6:
流形域上的欧几里得信号:表示流形 上的信号输入和欧几里得空间 中的信号值,即 。 一个例子是代表给定时间地球快照的数据点,显示全球温度的分布:地球表面温度位置位于球体流形 上,温度本身位于 (图像和数据集来源:Atmo, Inc.)。
数据结构的下一个类别在给定信号的域或共域(或两者)中添加组动作。
-
卡S7:
拓扑域上的欧氏信号配备域动作:这里的信号是,其中 配备集体行动。 这里的一个应用示例是人体的姿势,其中域是表示身体关节的无向图,域上的组动作是排列组。 排列可以通过改变表示关节的图的节点的索引来重新索引身体关节的顺序。
-
卡S8:
流形域 配备域作用上的欧几里得信号:这里,信号为,其中流形域配备集体行动。 使用卡 S6 中的地球表面温度示例,我们可以通过更改球坐标的原点来在域上应用旋转。 在这种情况下,操作组是作用于 的旋转 组。
-
卡S9:
欧几里德域上的欧几里德信号配备域和共域操作:这表示诸如之类的信号,其中域和codomain 配备了组操作。 卡片中的插图显示了域 中的向量场,其值为 中的向量。 在此示例中,域和余域上的操作均来自旋转组 ,该组将相同的旋转应用于域中的每个点以及矢量场中的每个独立矢量。
-
卡S10:
拓扑域上的欧几里得信号配备域和共域动作:这里,函数是,其中和配备了团体动作。 置换组通过改变图中的关节索引 作用于域,3D 旋转组 作用于表示每个关节处的速度矢量的值。
-
卡S11:
流形域上的欧几里得信号配备域和共域操作:这里,其中 和 配备了群组操作。 我们提供了一个在球体 上定义的矢量场示例,矢量值在 中。 在此示例中,应用 3D 旋转操作会旋转矢量的球坐标及其实际矢量方向。 这对于坐标的更改很有用。
与上一小节一样,我们强调数据的数学表示与数据的计算表示之间的区别。 到目前为止,我们将数据描述为信号,表示为域上的函数。 然而,大多数时候,函数在计算机中是离散的。 例如,将 2D 彩色图像表示为信号 的函数域被离散化为具有 像素的网格,其中每个像素都有一个 因此,数据点 在计算机中由长度为 的数组表示。
最近的一项研究——算子和神经算子文献(Kovachki等人,2023)——提供了一种不同的方法,将每个数据点视为连续函数而不离散化。
备注:机会
表中不包括流形域上的流形值信号、拓扑域上的拓扑值信号或流形域上的拓扑值信号的情况,因为它们很少在机器学习和深度学习文献中被考虑。 这些课程代表了未来研究的有趣途径。
备注:数据为空格
除了作为坐标的数据和作为信号的数据之外,还可以考虑第三类数据类型:作为空间的数据。 在此类中,数据点可能代表整个空间:数据点本身就是流形或拓扑空间。 例如,考虑分子数据集。 每个分子 可以表示为捕获分子结构的不同图,其中节点代表原子,边缘代表键。 数据集由一组不同的图表组成。 或者,数据集可以由人体的 3D 表面扫描组成,例如心脏表面的数据集 - 每个数据点 是一个不同的流形。 然而,大多数时候,每个数据点都有附加信息,因此不仅仅是一个空格。
例如,分子不仅可以用其原子之间的关系来描述,还可以用其原子的位置或两个原子之间的距离来描述。 换句话说,每个原子都会有一个关联的特征,代表该原子的 3D 位置。 因此,事实上,分子将被表示为从图形 到 的信号,而不仅仅是图形:它将属于卡 S5 描述的类别。
同样,处理心脏表面等器官形状需要了解心脏表面上每个点的 3D 坐标。 事实上,每颗心都被表示为从流形 到 的信号,而不仅仅是流形。 因此,这些示例属于信号数据的类别。
在本次综述中,我们将使用两类主要的数据表示形式(作为坐标和作为信号)来表征机器学习和深度学习模型中的非欧几里得结构。
IV 调查:非欧几里得机器学习
我们现在回顾大量不同的文献,这些文献是针对欧几里德空间中的数据经典定义的算法的非欧几里德概括。 机器学习方法对非欧几里德数据的推广依赖于其数学基础(概率和统计)对非欧几里德空间的推广。 在大多数情况下,这需要不平凡的算法创新。 这些概括构成了这里回顾的大部分工作。
然而,我们注意到有两种“简单”的方法可以推广欧几里得模型,不需要显着的算法创新。 它们并不适用于所有算法,并且有局限性。 然而,如果可能的话,它们具有实施简单的优点。 我们在此简要描述此类方法的两类 - 我们称之为“插件”方法和切线空间方法。
非欧几里得概率与统计。 在非欧几里得空间中,必须修改许多基本数学概念以尊重空间的固有结构。 例如,考虑一个由位于球体表面的点组成的数据集,例如全球不同城市的坐标。 这些点的欧几里得平均值是一个偏离流形的值,即位于球体“内部”某处但不在球体上的点。 为了找到流形上这些点的质心,我们必须使用Fréchet平均值,它被定义为最小化到所有其他测地距离平方和的点数据集中的点。 通过使用测地线,Fréchet 均值被限制为流形,并导致均值概念自然推广到非欧几里得空间。 几何统计领域定义了这种非欧几里得概括。 我们建议读者参考 Pennec (2006) 了解流形的理论基础,参考 Guigui 等人 (2023) 来全面介绍这些基础,参考 Pennec 等人 (2019) 用于实际应用。
“插件”方法
将机器学习方法推广到非欧几里德空间的最直接方法是简单地将欧几里德方法中使用的加法、减法、距离和均值的定义替换为非欧几里德方法中的定义。 例如,通过用测地线替换欧几里德距离,可以自然地为任意非欧几里德流形定义 k 最近邻算法。 类似地,k 均值可以使用测地距离和 Fréchet 均值进行推广。 任何在核函数中使用测地距离的核方法也属于此类。 许多流行的机器学习算法实现(例如在 scikit-learn 包中)允许用户指定距离函数,从而有助于轻松推广到非欧几里得空间。
切空间方法
另一种方法对于流形的非欧几里得空间特别方便。 我们称之为切空间法。 它包括使用所谓的指数图将流形上的数据投影到流形上特定点的切线空间中。 重要的是,切线空间可以看作是欧几里得空间。 一旦数据映射到欧几里德空间,就可以应用传统的欧几里德机器学习。 这种方法通常比直接将欧几里德方法应用于原始非欧几里德数据获得更好的结果。 然而,在许多情况下,特别是对于具有较大曲率的流形,由于流形的局部欧几里德近似中的错误,它会导致结果出现偏差。 尽管如此,该方法相对简单,并且对于位于相对平坦的流形上或在数据传播尺度上平坦的流形上的数据来说是值得的。
插件法和切空间法都具有实现简单的优点。 然而,许多机器学习算法需要的不仅仅是距离和均值的规范,这限制了插件方法的适用性。 此外,在许多情况下,切线空间投影引起的偏差对于应用程序来说是无法容忍的,这限制了其范围。 因此,在许多情况下,有必要将算法的各个方面显式约束到感兴趣的流形。 这包含了我们在本节中介绍的非欧几里得机器学习的大部分工作。 我们首先介绍回归方法,然后介绍降维方法。 在下一节中,我们将介绍非欧几里得深度学习方法,这些方法可用于回归、降维或分类。
我们注意到,本文回顾的非欧几里得机器学习方法假设某些拓扑、代数或几何结构先验已知存在于数据或学习问题中。 因此,这些方法需要预先指定这些结构。 然而,有时底层结构是未知的。 一类方法旨在发现并表征数据中未知的非欧几里得结构。 此类包括拓扑数据分析、学习潜在流形参数的某些流形学习方法(例如度量学习)以及用于发现潜在群结构的代数方法(也称为作为小组学习。 此类方法可用于识别数据中存在的非欧几里德结构,以便可以指定和应用适当的非欧几里德机器学习方法。 这些方法超出了本次审查的范围,因为它们是在非欧几里得机器学习“之前”使用的。
IV-A 回归
本小节回顾流形的回归。 我们首先介绍由数据空间和回归模型的数学结构定义的分类法。 然后,我们回顾图5中关于该主题的文献,并在文本中提供详细信息。
分类
在机器学习中,回归问题可以定义为学习从输入空间到输出空间的函数。 图5将回归模型组织成一个分类法,该分类法首先基于输入和输出空间的几何属性 - 请参见图5中的前两列。 在这里,我们将传统的欧几里德空间与更复杂的流形空间区分开来,为详细探索五个关键配置奠定了基础:欧几里德到欧几里德、一维欧几里德到流形、欧几里德到流形、流形到欧几里德和流形到流形。
然后,每个配置都通过其回归模型进行区分 - 请参见图 5 中的第三列。 线性方法假设输入变量和输出变量之间的关系可以用线性函数表示为,其中 是系数矩阵, 是常量向量 - 因此限制 属于由参数表征的线性空间。 我们注意到线性回归不适用于流形,因为加法运算(一种线性运算)在流形(非线性空间)上没有明确定义。 因此,线性方法成为图 5 第 2 行和第 3 行流形上的测地线方法,其中 和 之间的关系> 可以用测地线来表示,该测地线的特征是类似于上面的的一组参数。 接下来,非线性参数化和非测地线参数化方法涉及由一组固定参数但以更复杂的形式描述的关系,例如多项式或其他非线性方程,其中代表参数。 另一方面,非参数方法不会为和之间的关系假设参数形式,从而为建模关系提供了灵活性直接从数据中得出。 非参数一词并不一定意味着此类模型完全缺乏参数,而是与参数方法相反,参数的数量和性质是灵活的并且不是预先固定的。
此外,这些方法被分类为贝叶斯或非贝叶斯——由图5中的模糊线或直线表示。 贝叶斯方法将先验概率分布与观测数据相结合,促进根据新证据更新有关参数的知识。 这种方法与非贝叶斯方法形成鲜明对比,非贝叶斯方法完全依赖于观测数据,通常采用所谓的频率统计原理,而不结合参数的先验分布。
接下来,我们将根据这种几何分类法逐行回顾图 5 中的回归模型。 对于每一类回归模型,我们都展示了一篇标志性的、类别定义的论文,它反映了从传统欧几里得分析到流形范式的转变。 我们认为以下论文超出了范围:1) 概括流形上的一类曲线(例如样条曲线)的论文,但不利用这种概括来执行回归,2) 执行回归的论文流形上的插值,但不是回归,3) 其回归方法仅针对一种类型的流形(例如,仅针对球体)开发的论文。 此外,本节中回顾的方法专门适用于第 III 节中介绍的数据类型之一:回归输入 和输出 是坐标数据在一个空间中,该空间要么是欧几里得空间,要么是流形。
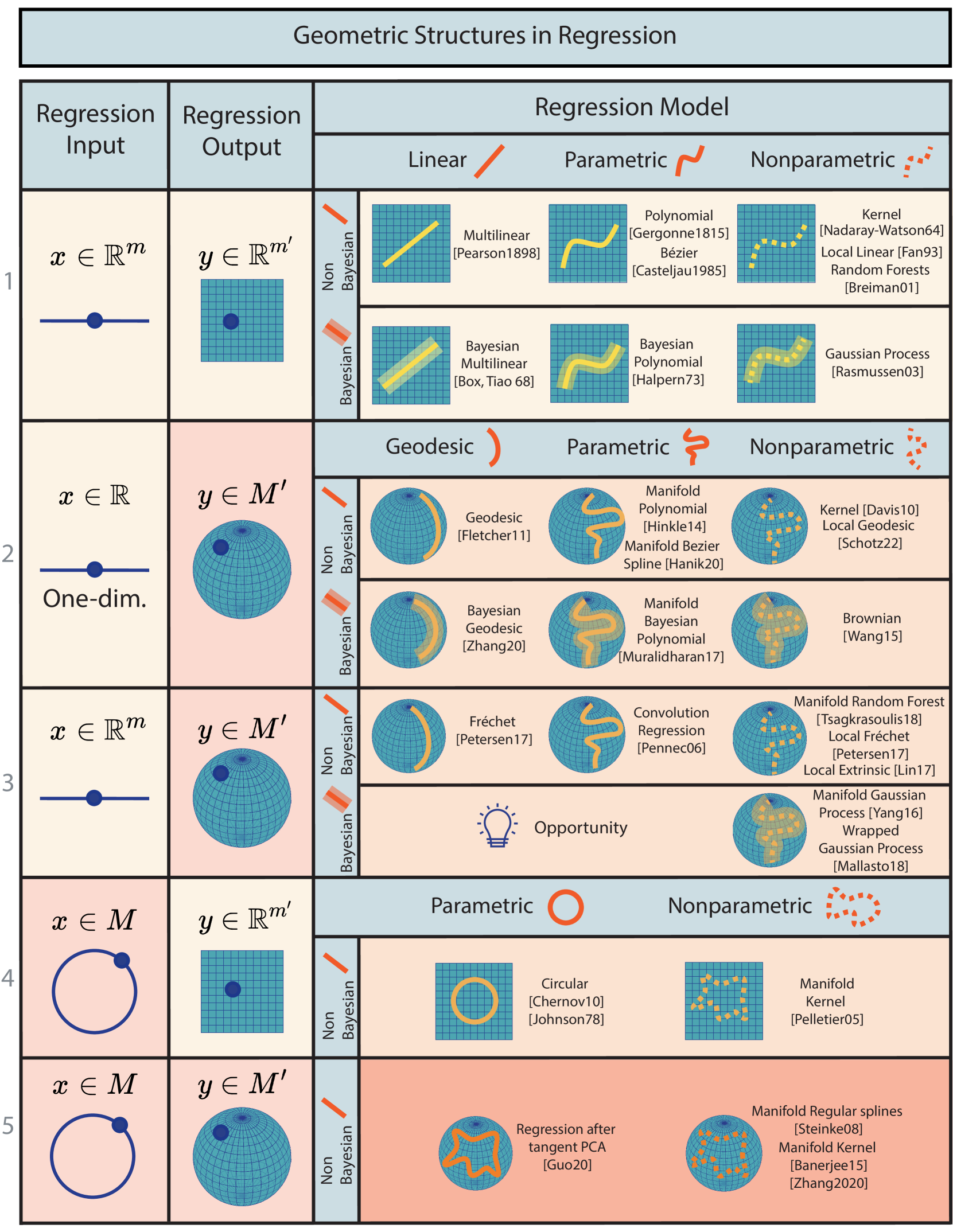
-
1.
欧几里德输入,欧几里德输出: 我们回顾了图 5 第一行中已推广到流形的经典回归模型。 该类别由 Legendre 和 Gauss (Legendre,1805) 发起线性回归,现已扩展到包括非线性参数模型,特别是 Gergonne (Gergonne,1815) 引入的多项式模型。 非参数方法的纳入以 Nadaraya-Watson 核方法(Nadaraya,1964)、进一步的局部线性模型(Fan,1993)以及 Breiman 的发展为标志。随机森林(Breiman,2001)。 在贝叶斯分析中,线性和多项式方法分别以贝叶斯多重线性(Box and Tiao,1968)和多项式贝叶斯模型(Halpern,1973)为代表,并采用高斯过程(Williams 和 Rasmussen,1995) 说明非参数贝叶斯观点。
-
2.
一维欧几里德输入, 歧管输出: 早期将经典回归模型推广到流形涉及输出空间的推广。 其中许多模型都考虑一维输入,如图5的第二行所示。 测地线回归将线性模型从一维欧几里得输入扩展到流形(Fletcher,2011)。 我们注意到线性回归的建立与其对应的几何回归之间相差 206 年。 流形上的多项式回归(Hinkle等人,2012a)和流形上的贝塞尔样条拟合(Hanik等人,2020)将它们的欧几里得对应项推广到输出空间中的流形,分别是197年和35年后。 流形上输出值的非参数方法包括 Fréchet-casted Nadaraya-Watson 核回归(Davis 等人,2010),以及局部测地线回归(Schötz,2022)—后者是流形局部线性回归的对应部分。 贝叶斯方法方面,(张等人,2020)中的测地回归模型变为贝叶斯模型,Muralidharan等人(2017)中的流形多项式回归变为贝叶斯模型。 最后,一种非测地线、非参数贝叶斯模型属于这一类:Devito 和 Wang 的布朗运动模型的核回归(Wang,2015),它概括了 51 年后 Nadaraya-Watson 的方法。
-
3.
欧几里得输入, 歧管输出: 接下来,我们回顾图5第三行中输出为流形的回归模型,其输入不限于一维。 Fréchet 回归(Petersen 和 Muller,2016) 将测地线回归推广到更高维的欧几里得输入。 我们还发现了几种非测地线参数回归模型。 该类别最早的著作之一涉及正则化流形值函数的参数回归(Pennec 等人,2006)。 一个关键思想是将卷积重新表述为流形变量的加权 Fréchet 均值,这些变量成为隐函数的参数。 同样在非测地线参数回归类别中,我们发现了(石等人,2009)的半参数内在回归模型,或Kühnel和Sommer(2017)的随机发展回归 t1>. 具有流形值输出的非参数方法包括流形随机森林(Tsagkrasoulis 和 Montana,2018),它概括了 15 年后的欧几里得对应物,局部 Fréchet 回归(Petersen 和 Muller,2016) ),局部线性回归的另一种多维推广,以及(Lin等人,2017)的局部外在回归。 就贝叶斯方法而言,我们观察到测地线和非测地线参数模型中缺乏方法。 然而,我们发现贝叶斯非参数方法,例如流形高斯过程(Yang和Dunson,2016)和Mallasto的包裹高斯过程(Mallasto和Feragen,2018),它们概括了9 年后和 13 年后,Williams 和 Rasmussen 的高斯过程。
-
4.
歧管输入,欧几里得输出: 现在,我们回顾一下较少受到关注的欧几里得回归模型的几何推广:回归输入空间是流形的模型。 我们从输出空间是欧几里德空间的方法开始,如图 5 的第四行。 Johnson 和 Wehrly 使用欧几里得标量(一维)输出变量(Johnson 和 Wehrly,1978) 定义了角度(一维)变量的回归模型。 切尔诺夫的循环回归输出到更高维的欧几里得空间,通常是二维或三维(Chernov,2010)。 Pelletier 的非参数回归方法在估计从流形输入到欧几里得输出的函数方面表现出色(Pelletier,2006)。 两种方法都是非贝叶斯方法。 在贝叶斯方法方面,我们发现了贝叶斯循环线性回归方法(Gill and Hangartner,2010),但没有发现贝叶斯非参数方法——这表明有进一步探索的机会。
-
5.
歧管输入、歧管输出: 图5 的第五行从几何角度呈现了最一般的回归情况。 在这些模型中,回归输入和输出空间都是流形的。 该类别包括首先将输入和输出数据从流形转换到欧几里德空间,然后在欧几里德空间上应用辅助经典回归模型(郭等人,2019)的方法。 在非参数方法中,我们发现Steinke的正则样条方法(Steinke等人,2008)和Banerjee的流形核回归(Banerjee等人,2015)在2015年推广了经典的1964 年的核回归及其从 2010 年到流形输出空间的推广。 在审查时,该类别中没有采用贝叶斯观点的方法。
IV-B 降维
本小节回顾了降维方法,其中包括:流形学习方法,其中在高维欧几里得空间内学习低维流形;子流形学习方法,在高维流形内学习低维子流形;和编码方法,其中高维欧几里得或流形中的数据通过编码器映射到低维欧几里得或流形。 我们首先介绍由空间和降维模型的数学结构定义的分类法。 然后,我们回顾图6中关于该主题的文献,并在文本中提供详细信息。
分类
我们将降维问题定义为将高维数据从数据空间 转换为较低维度的潜在空间 ,即 。 图6首先根据数据和潜在空间的几何属性将降维方法组织成分类法 - 请参阅前两列。 它区分了传统的欧几里德空间和更复杂的流形空间,为以下四个关键配置奠定了基础:欧几里德数据到欧几里德潜伏,流形数据到一维欧几里德潜伏,流形数据到欧几里德潜伏,欧几里德数据到流形潜伏,和流形数据到流形潜伏。 对于每种配置,低维潜在空间 示意性地表示为 1 维空间:欧几里得空间为直线,流形为圆。 高维数据空间示意性地表示为2维空间:欧几里得空间为平面,流形为球体。 然而,我们强调我们在这里回顾了所有的降维方法;不仅仅是从 2 维到 1 维的方法。
然后通过降维方法来区分每种配置 - 请参阅图 6 中的第三列。 首先,降维方法的组织取决于它们是否利用解码器,如果是的话,是哪种类型:线性(或线性)。 测地线),非线性(分别) 非测地线)参数化、非参数化——用图6象形图中的实线、实曲线和虚曲线表示。 虽然每种降维方法都会将高维数据转换为低维潜在数据,但只有某些方法引入了解码器 将低维潜在数据 转换回高维数据 的:。 当解码器存在时,潜在空间可以通过嵌入到数据空间中。 象形图中的黄色和橙色曲线代表该嵌入。 我们进一步区分两种子情况:嵌入空间 是线性的(测地线,在流形情况下)还是非线性的(或非测地线)。 解码器的存在由黑色箭头和图例 表示;如果解码器是非参数的,则黑色箭头是虚线箭头。 图6底部独立审查了不利用任何解码器的降维方法。 此外,如果假设数据来自生成模型,我们会在象形图中突出显示。 生成模型解释了如何使用概率分布从潜在变量生成数据点。 当生成模型用于给定的降维方法时,它由黄色或橙色阴影点表示。 当没有生成模型时,我们只使用非阴影的黄色或橙色点。 例如,主成分分析(PCA)有解码器,但没有生成模型;而概率 PCA 使用具有生成模型的解码器。
其次,方法的组织取决于它们是否利用编码器 ,其中 是将数据 映射到潜在变量 的函数> 的:。 事实上,虽然每种降维方法都会将高维数据转换为低维潜在数据,但只有某些方法通过显式编码器函数 来实现这一点。其他人可能仅通过优化结果 计算与数据点 相对应的潜在 。 编码器的存在由黑色箭头和图例表示,并且箭头是虚线箭头表示编码器是非参数的。 优化的使用由表示 并且没有黑色箭头。
第三,根据是否计算与数据点 相关的潜在变量 的不确定性来组织方法。 潜在的不确定性由后验分布 表示。 如果该方法提供后验分布(或至少是其近似值),我们将使用蓝色阴影点。 如果没有,我们使用无阴影的蓝点。 不带后验和带后验的两种情况形成表中给定配置的子行。 我们用 标记后验分布 不是通过分析计算而是通过采样方法提供的情况。
第四,方法根据如何计算解码器参数的不确定性(即它们是否是贝叶斯)进行分类。 例如,传统 PCA 不包含不确定性,但贝叶斯 PCA 包含不确定性。 这种区别代表每个配置的最后一个子行,由橙色阴影线表示。
我们现在在图6中逐行调查降维的各种类别。
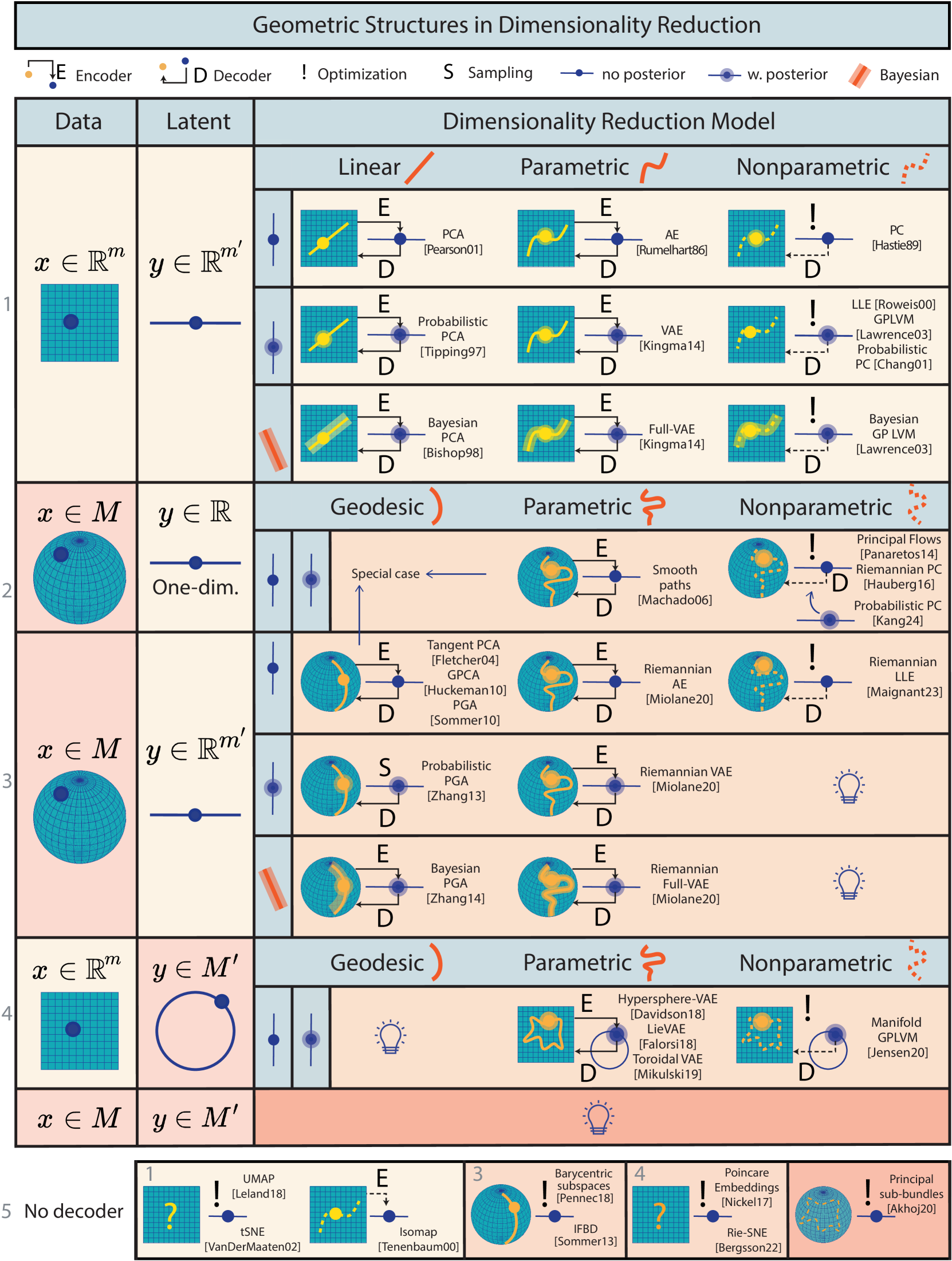
-
1.
欧几里德数据、欧几里德潜伏: 我们逐个子列描述此配置子列中的方法。 主成分分析 (PCA) (Pearson,1901) 学习线性子空间,而概率 PCA (PPCA) (Tipping 和 Bishop,1999) 在概率内实现相同的目标该框架依赖于潜在变量生成模型,该模型提供了潜在变量的后验分布。 贝叶斯 PCA (Bishop,1998) 另外学习模型参数的概率分布,表示线性子空间的参数(例如斜率和截距)。 这些方法受到可拟合数据的子空间类型的限制:仅限线性子空间。 为了解除这个限制,我们还找到了许多从欧几里得数据中学习非线性流形的方法。 在这种情况下,整个流形学习领域都可以细分为更多的子类别,具体取决于学习到的流形是如何表示的:非线性参数解码器、非参数解码器,或者根本不需要任何解码器。 在这里,我们只为我们考虑的每个子类别介绍一种类别定义方法。
在非线性参数解码器类别中,我们引入自动编码器。 自动编码器 (AE) (Rumelhart 等人, 1986) 学习欧几里德空间的非线性子空间,而变分自动编码器 (VAES) (Kingma 和 Welling, 2014) 实现相同的效果具有依赖于潜变量生成模型的概率框架的目标。 (Kingma and Welling,2014)中提出的Full-VAE模型还学习了模型参数的后验,即解码器的参数。 这些类别中的方法都利用编码器。 在非参数解码器类别中,我们引入了主曲线(Hastie and Stuetzle,1989),它将非线性流形拟合到数据,但不利用潜在的后验。 在同一类别中,我们还介绍了局部线性嵌入 (LLE) (Roweis 和 Saul,2000) 和高斯过程潜变量模型 (GP LVM) (Lawrence,2003) ,它们都提供了潜在的后验。 Chang 和 Ghosh (2001) 开发的主曲线概率方法 (PPS) 也属于此类。 最后,我们介绍贝叶斯 GP LVM,它还提供了模型参数的后验。 我们注意到,此类方法不利用任何编码器,而是通过解决优化问题来计算与给定数据点相关的潜在值。
这些技术基于向量空间运算,这使得它们不适合流形上的数据。 因此,研究人员开发了流形数据的方法,其中考虑了几何结构;请参阅表中的下一行,在下一段中进行描述。
-
2.
流形数据,一维欧几里得潜函数: 在许多领域中,已经使用最小二乘法或其他似然标准将测地线拟合到流形数据点,特别是作为将 PCA 扩展到流形的第一步(参见下一段)。 在非测地线参数解码器类别中,一维潜伏的自然扩展是使用高阶多项式定义近似样条线,然后将其拟合到黎曼流形上的一组点(Machado and Leite, 2006, Machado 等人, 2010) 或李群(Gay-Balmaz 等人, 2012)。 在非测地线、非参数解码器类别中,主流(Panaretos等人,2014)和黎曼主曲线(Hauberg,2016)将传统欧几里得主曲线推广到黎曼流形,25多年后。 概率黎曼主曲线(Kang and Oh,2024)进一步引入了依赖于潜变量生成模型的概率框架,从而在23年后推广了欧几里得概率主曲线。
-
3.
流形数据,欧几里德潜伏: 我们逐个子列描述方法。 我们注意到,这种配置的方法可以应用于之前的配置,即也可以应用于一维潜在空间。 在测地线解码类中,主测地线分析(PGA)(Fletcher等人,2004,Sommer等人,2014),切线PGA(tPGA)(Fletcher等人,2004) t1> 和测地线主成分分析 (GPCA) (Huckemann 等人, 2010)。 学习测地线子空间的变体,将线性子空间的概念推广到流形。 因此,这些方法代表了 PCA 对流形的不同推广。 概率 PGA (Zhang 和 Fletcher,2013) 实现了相同的目标,同时添加了一个在流形上生成数据的潜变量模型,从而在 16 年后推广了概率 PCA。 类似地,贝叶斯 PGA (Zhang 和 Fletcher,2013) 通过包含定义子流形的参数的后验分布(即定义主(测地线)分量的基点和切向量)来推广贝叶斯 PCA。 然而,这些方法受到可以拟合数据的子流形类型的限制,即:一点的测地线子空间。
基于测地线对全局定义子空间的限制既可以被视为优点,也可以被视为缺点。 虽然它可以防止过于灵活的子流形的过度拟合问题,但它也可以防止该方法捕获可能的非线性效应。 随着当前数据集大小的爆炸式增长(即使在历史上较小的生物医学成像数据集中),对灵活子流形学习技术的研究可能变得越来越重要。
在非测地参数解码器类别中,我们考虑流形上的自动编码器方法。 变分自编码器已被推广到(Miolane 和 Holmes,2020) 中的流形数据,这种方法可应用于流形上的 AE 和 Full-VAE。 这是学习用潜变量模型参数化的多维非测地线子流形的唯一方法。 最后,我们提出了一种利用非参数解码器的方法:黎曼 LLE (Maignant 等人, 2023),它在 23 年后推广了其欧几里得对应物 LLE。 我们注意到在生成模型或贝叶斯框架中都没有通过非参数解码器执行降维的工作。 这代表了一种可能的研究途径。
-
4.
欧几里得数据, 流形潜伏。 我们逐个子列描述此配置子列中的方法。 我们首先找到属于 VAE 框架的方法,其中潜在空间是流形,即使数据属于欧几里德空间。 例如,Davidson 等人 (2018) 的超球面 VAE 提出了超球面潜在空间,Falorsi 等人 (2018) 提出了李群潜在空间, Mikulski 和 Duda (2019) 提出了环形潜在空间。 所有这些方法都提供了潜在变量的(近似、摊销)后验,表示为感兴趣流形上的概率分布。 从某种意义上说,这些方法代表了 Miolane 和 Holmes (2020) 的对应方法,它考虑了流形数据空间和欧几里德潜在空间。 接下来,我们找到非参数解码器方法,例如流形高斯过程潜变量模型(GPLVM)(Jensen等人,2020),它从欧几里得案例(Lawrence,2003)推广了GPLVM 。
-
5.
无解码器。 很少有降维模型会避免使用解码器。 因此,我们简要调查了所有几何数据和潜在结构的这些模型。 在具有欧几里德潜在情况的欧几里德数据中(对应于第 1 行),我们发现 t 分布随机邻域嵌入 (tSNE) (van der Maaten and Hinton, 2008)、统一流形逼近和投影 (UMAP) ) (McInnes 等人, 2018) 和 Isomap (Tenenbaum 等人, 2000)。 这些方法学习数据的低维表示,但不提供潜在变量生成模型,也不提供恢复子空间的参数化。 在具有欧几里得潜在情况的流形数据中(对应于第 3 行),线性子空间到流形的灵活推广由重心子空间 (Pennec,2018) 给出,其中子流形通过测地线隐式定义为几个参考点。 在这方面的工作中,一种令人感兴趣的方法是提供维度递增的嵌套空间的序列,以更好地逼近数据,这是概念化的概念(Damon 和 Marron,2013) 具有可能非测地线子空间的嵌套关系序列。 迭代框架束开发 (IFBD) (Sommer,2013) 是另一种沿新方向迭代构建主坐标的优化方法。 在具有流形潜在情况的欧几里得数据中(对应于第 4 行),我们首先找到庞加莱嵌入 Nickel 和 Kiela (2017),它将 中的数据点嵌入到双曲潜在中space ,对于表示具有层次结构的数据很有用。 我们注意到,这种方法没有利用任何编码器函数 ,而是解决优化问题以找到与每个数据点 对应的潜在变量 ,在图6上用象形图“!”表示。 其次,黎曼 SNE (Bergsson 和 Hauberg,2022) 概括了传统的欧几里得 SNE (van der Maaten 和 Hinton,2008),但晚了 14 年。 最后,最后一个无解码器模型,称为主子束(Akhøj等人,2023),是唯一为流形数据和流形潜伏设计的降维模型。 事实上,我们注意到,对于这种情况,没有基于解码器的降维方法。 主要子束方法不利用编码器或解码器,而是解决优化问题以找到与每个数据点 关联的低维潜在变量 。 作者还提出了一种解码方法,该方法使用优化而不是显式解码器来查找解码给定潜在变量 的数据点 。 总体而言,无解码器降维模型的稀疏性为几何数据/潜在变量的许多选择留下了开放的机会。
我们对回归和降维机器学习方法的非欧几里得概括的回顾和分类到此结束。 虽然一些深度神经网络模型(例如变分自动编码器)出现在我们的降维分类中,但我们为下一节保留了更完整的深度学习处理。 深度神经网络从更传统的机器学习方法中脱颖而出,因为它们是灵活的函数组合,可以在空间之间逐步转换数据。 在考虑降维方法时,我们从各个神经网络层执行的转换中抽象出来,只考虑输入和潜在空间的结构(模型中可能有很多层)。 在下一节中,我们明确考虑各个神经网络层的输入输出结构,以及将拓扑、几何和代数合并到这些层中的方式。
V 调查:非欧几里得深度学习
我们现在回顾深度学习中的非欧几里得结构,特别关注几何、拓扑和代数如何丰富深度神经网络中给定层的结构。 神经网络层是一个函数,因此可以根据输入空间和输出空间的数学结构来分析和分类。 我们首先介绍没有注意力机制的神经网络层,然后是具有注意力的层。 然后,我们编制了文献中使用的数据集和基准列表,以将深度学习方法与几何、拓扑或代数属性进行比较。
V-A 没有注意的神经网络层
我们根据神经网络的数学结构对层进行分类。 如果本文介绍了几个新颖的层,则给定的论文可以在本小节(以及下一节)中出现多次。 使用注意力机制的神经网络超出了本小节的范围,将在下一小节中介绍。
分类
图7根据神经网络层输入和输出的数学属性(前两列)以及层模型的属性(第三列)将深度学习方法组织成分类法。 这些行显示了文献中已发表的不同类型的图层,通过使用几何、代数(群作用)和拓扑来组织它们。 该图以图形方式展示了现有方法并确定了潜在的创新领域。 我们在图7中逐行调查了该字段。
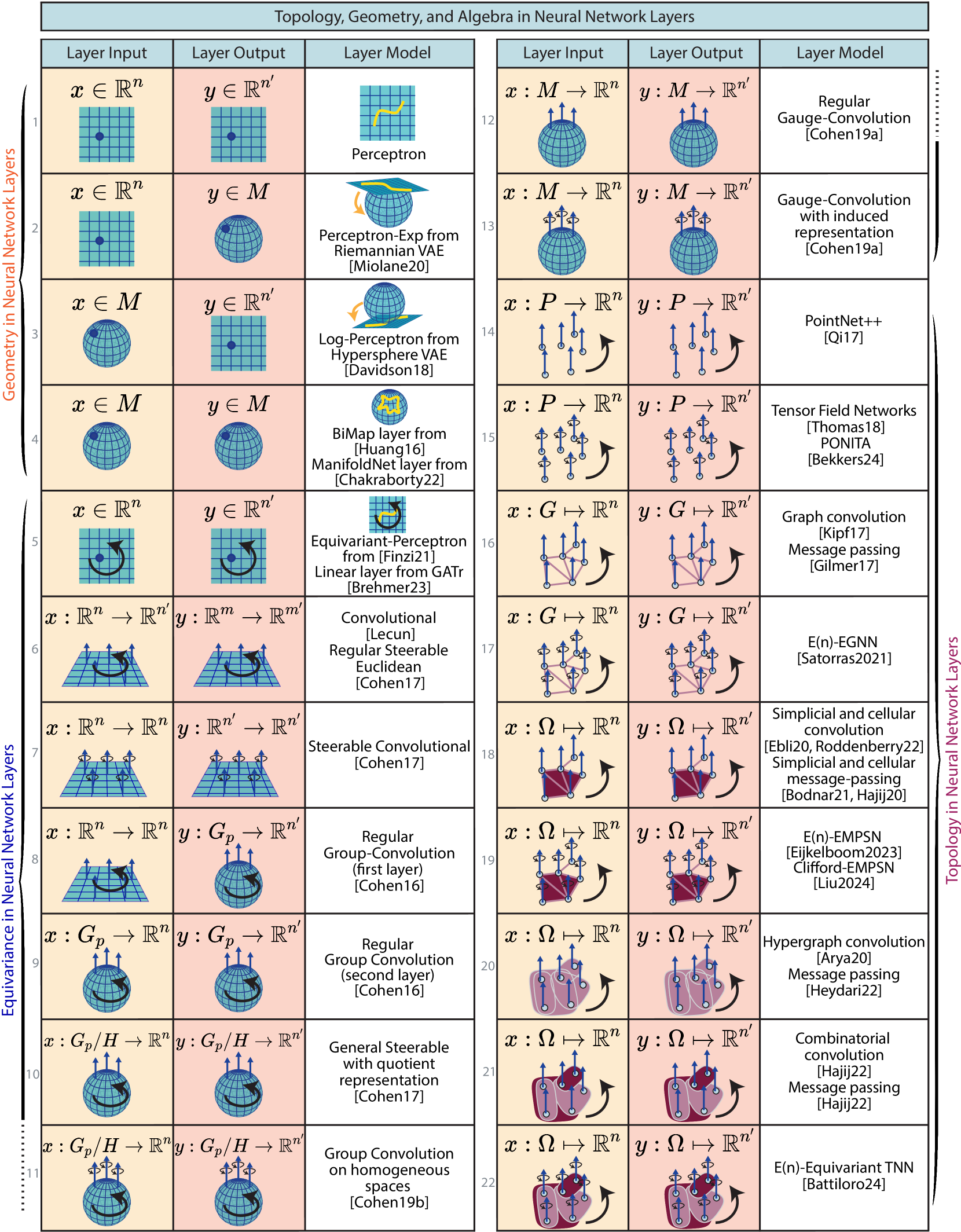
神经网络层中的几何
在这里,我们对神经网络层进行分类,将其输入和输出视为空间中的坐标,其中空间可以配备几何结构。
-
1.
欧几里德输入,欧几里德输出:此配置的类别定义层是感知器层(Rosenblatt,1958),通常用作深度神经网络中的组件,其中包括几个相同的层:著名的多层感知器(MLP)。
-
2.
欧几里得输入,流形输出:Miolane 和 Holmes (2020) 的 Perceptron-Exp 层将感知器层推广到流形上的层输出。 这里,Exp 表示黎曼指数图,它应用于感知器的结果。 事实上,Exp 是将切向量映射到流形上的点的运算,即将欧几里得空间中的输入映射到流形上的输出。 只有该层的感知器组件具有可学习的权重;为了指定和实现适当的指数映射,需要先验地知道流形。 另外,一般来说,Exp图没有解析表达式,需要进行数值计算。 为了避免这种计算成本,该层最好针对 Exp 具有解析表达式的流形实现。
-
3.
流形输入,欧几里德输出:来自(Davidson等人,2018)的Log-Perceptron层将感知器层推广到流形上的层输入。 这里,Log 表示黎曼对数映射,它在感知器之前应用。 事实上,Log 是将流形上的点映射到切向量的运算;也就是说,它是 Exp 的倒数。 该层将流形上的输入映射到欧几里得空间中的输出,其中可以应用具有可学习权重的感知器。 因此,该层可以被认为是 Miolane 和 Holmes (2020) 中 Perceptron-Exp 层的逆。 就像 Perceptron-Exp 一样,需要知道流形才能实现该层,并且优先考虑 Log 具有解析表达式的流形。
-
4.
流形输入,流形输出:此配置首先使用(Huang and Van Gool,2016)中的 Bimap 和 SPDNet 层进行说明,其中 SPD 指对称正定矩阵。 该层确实仅限于 SPD 矩阵的流形。 更一般地说,ManifoldNet (Chakraborty 等人, 2022) 基于将卷积重新表述为 Pennec 等人 (2006) 的加权 Fréchet 均值来提出一个其输入和输出的层都是流形上的坐标。 在这一层中,计算输入的加权平均值,其中权重是通过经典反向传播学习的。 由于卷积相当于计算加权和,因此该层也被称为流形数据卷积。 我们注意到,一般来说,加权Fréchet均值没有解析表达式,需要通过优化来获得。 为了避免这种计算成本,还考虑使用正切均值的近似。
神经网络层中的代数
在这里,我们考虑属于等变深度学习类别的神经网络层,它利用对称性和群体行为的概念。 我们建议读者参考 Cohen 等人 (2021) 和 Weiler 等人 (2024) 来广泛讨论该领域的基础知识。 这一工作的核心思想是将数据域自然的对称性(例如用于对象分类的平移和旋转对称性)构建到模型的结构中。 这有利于不同变换之间的权重共享,以便可以使用相同的卷积滤波器来检测图像中的给定特征,例如在所有方向上。 为了实现这一点,这些层的输入和输出空间配备了组动作,并且定义层的方程被编写为与这些动作兼容。 直观地说,如果一个层与一个组动作等变,这意味着,如果该层为给定的输入生成输出,那么它还应该为任何转换后的 生成转换后的 - 其中转换在这里意味着“由同一组元素执行”。在这里,我们重点介绍属于我们分类法每个类别的不同等变层的关键示例。
-
5.
输入和输出:欧几里德 通过集体行动。 (Finzi 等人, 2021) 中的等变感知器层和几何代数变换器 (GATr) (Brehmer 等人, 2023) 中的线性层说明了这种配置。 它们代表唯一处理空间坐标输入和输出的等变层,而不是空间上的信号。 (Finzi 等人, 2021) 的工作允许我们在给定输入和输出空间上的任何矩阵组作用的情况下构建等变感知器层。
-
6.
输入和输出:欧几里德域上的欧几里德信号 通过集体行动。 前一行将数据视为空间坐标,而这一行将数据视为信号。 事实上,输入和输出都是由函数 和 定义的。 例如,输入和输出可以是分别在域 和 上定义的图像或特征图。 经典的卷积层(LeCun等人,1998)是一个具有平移等方差的层:输入图像的平移产生平移的特征图作为输出。 常规可操纵卷积层(Cohen 和 Welling,2017) 使用翻译组之外的组将这种方法推广到更复杂的等方差情况。 在这一行中,群作用仅在输入和输出信号的域上:这就是规则可操纵卷积中形容词“规则”的含义。
-
7.
输入和输出:欧几里德域上的欧几里德信号具有群作用 通过集体行动。 与上一行类似,输入和输出都是空格上的信号:。 然而,与前一行相比,每个信号的域和共域都配备了群动作。 Steerable Convolutional 层(Cohen 和 Welling,2017) 说明了这种配置。 与上述同一篇论文中的其他层相比,群体行为可以同时影响域和共域。
-
8.
输入:欧几里德域上的欧几里德信号具有群作用;输出:流形上的欧几里德信号 通过集体行动。 该行呈现的层的输入可以描述为信号 (通常是图像),其输出是形式为 的更复杂的信号,即在李群上定义——我们记得李群是一个流形,也是一个群。 (Cohen 和 Welling,2016) 的组卷积网络的第一层说明了这种配置。 在该网络中,第二层必须输入第一层的输出,即输入在李群上定义的信号。 因此,该神经网络的第二层(及后续层)出现在下一行中。
-
9.
输入和输出:流形上的欧几里德信号 通过集体行动。 这里输入和输出信号的流形域都配备了群动作。 (Cohen 和 Welling,2016) 的群卷积网络的第二层展示了这个例子,其中流形实际上是一个李群,群动作是群的组成。
-
10.
输入和输出:齐次流形 具有群作用上的欧几里德信号。 该行显示了处理表示为 形式的信号的输入和输出的层。 这里,域定义了所谓的齐次流形,即:具有群作用的流形,对于流形上的每一对点,都存在一个群元素,该群元素可以通过动作将一个点转换到另一点。 具有所谓商表示的通用可操纵卷积层(Cohen 和 Welling,2017) 就属于这一类。
-
11.
输入和输出:齐次流形 具有群作用上的欧几里德信号具有群作用。 与前一行类似,信号由函数 表示,即具有具有群作用的齐次流形域。 然而,与前一行相比,输入和输出信号的欧几里德余域上也存在群作用。 (Cohen 等人, 2019b) 的同质空间组卷积层就属于这一类,还有 General Steerable 层。
-
12.
输入和输出:流形上的欧几里德信号。 在这一行中,输入和输出信号具有流形域和欧几里得共域。 因此信号被表示为。 (Cohen 等人, 2019a) 的通道式规范卷积层处理此类信号。 这里,规范等方差的概念取代了群等方差。 规范等方差描述了与感兴趣的流形上局部坐标系的方向无关的想法。
-
13.
输入和输出:流形上的欧几里德信号具有群体作用。 此行概括了前一行,其中操作可以转换信号 的共域元素。 这一类的一个例子是具有诱导表示的通用规范卷积层(Cohen等人,2019a)。
神经网络层的拓扑
在这里,我们对神经网络层进行分类,将其输入和输出视为拓扑域上的信号。 我们建议读者参阅 Papillon 等人 (2023) 的调查,以全面概述此类别的神经网络层,并且我们仅关注选定的说明性示例。 这些层都等效于其拓扑域元素的排列:集合中的点的排列、图中的节点的排列等。因此,所有这些层至少都配备了对他们的域名。
-
14.
输入和输出:集合上的欧几里德信号, 与域组操作。 PointNet++ (Qi 等人, 2017) 中的层处理点云,点云具有 形式的信号,其中 是一个集合。 在这项工作中,共域仅限于 2D 或 3D 欧几里得空间 、,因为它旨在处理 2D 或 3D 点云。 由于其域组操作,该模型与 中的排列等价。然而,PointNet++ 对于在余域 中操作的 3D 旋转和平移仅具有近似不变性。 也就是说,它利用预处理步骤,首先在位置和方向上对齐点云。
-
15.
输入和输出:集合上的欧几里德信号, 具有域和共域组操作。 这里,输入和输出信号是点云,就像上面的行一样。 张量场网络 (TFN) (Thomas 等人,2018) 和 PONITA (Bekkers 等人,2024) 中的层处理此类别的信号。 与 PointNet++ 一样,TFN 和 PONITA 处理 2D 和 3D 点云,并且与它们在 中的点的排列等价。 TFN 和 PONITA 还与 中的 3D 旋转和平移等价。
-
16.
输入和输出:图上的欧几里德信号, 与域组操作。 该行中的层处理 形式的信号,即在图形 上定义的信号。此类别的例子是图卷积层(Kipf和Welling,2017)和消息传递层(Gilmer等人,2017)。
-
17.
输入和输出:图上的欧几里德信号, 具有域和共域组操作。 此行中的层与前一行中的层类似,只是它们在信号的共域上添加了组操作。 例如,我们发现了 (Satorras 等人,2021) 的 -等变图神经网络 (EGNN)。
-
18.
输入和输出:细胞复合物上的欧几里德信号, 与域组操作。 该行考虑在细胞复合体 上定义的信号,即 形式的函数。 示例包括单纯卷积 (Ebli 等人, 2020)、细胞卷积 (Roddenberry 等人, 2022)、单纯消息传递 (Bodnar 等人, 2021) 和蜂窝消息传递(Hajij 等人, 2020) 层。
-
19.
输入和输出:细胞复合体上的欧几里德信号, 具有域和共域组操作。 此行中的层与前一行中的层类似,只是它们在信号的共域上添加了组操作。 例如,我们发现-等效消息传递简单网络(EMPSN)(Eijkelboom等人,2023)和Clifford组等效消息传递简单网络(EMPSN)(Liu 等人, 2024) 两者都在共域上引入了组操作,但是针对不同的组。
-
20.
输入和输出:超图上的欧几里德信号, 与域组操作。 该行变为信号 ,其中 现在表示超图,这是另一种类型的拓扑空间。 这种配置的例子是超图卷积层(Arya等人,2020)和超图消息传递层(Heydari和Livi,2022)。
-
21.
输入和输出:组合复形上的欧几里德信号, 与域组操作。 该行考虑具有最一般类型的拓扑域的信号,即组合复数 ,即 形式的信号。 处理此类信号的神经网络层的示例包括组合卷积(Hajij等人,2023b)和组合消息传递(Hajij等人,2023b)。
-
22.
输入和输出:组合复形上的欧几里德信号, 具有域和共域组操作。 与前一行类似,最后一个配置过程信号在具有欧几里德余域的组合复数域 上定义。 然而,与前一行相比,欧几里得共域配备了群作用。 (Battiloro 等人, 2024) 中的 等变拓扑神经网络就是这种配置的一个示例。 该网络的各层可以处理共域中的几何特征,例如与拓扑域的元素相关联的速度或位置。
V-B 具有注意力的神经网络层
我们现在回顾利用注意力机制的神经网络层中的数学结构。 我们特别关注几何、拓扑和代数如何丰富注意力系数和注意力层的结构。
分类
图8根据输入和输出的数学属性将注意力系数和层组织成分类法。 首先,注意力系数 是根据查询 和键 计算的。因此,我们检查键 和查询 输入的结构,表示为域上的信号。 例如,传统的 Transformer 将键和查询视为表示时间的一维域 上的函数。 输出注意力系数 表示为乘积域上的信号:在 Transformer 示例中,它是乘积域 上的函数。 其次,注意力层通过注意力系数将输入值转换为输出值。 因此,我们研究 和 的数学属性,它们都表示为域上的信号。 在经典 Transformer 中,它们是时域上的信号。
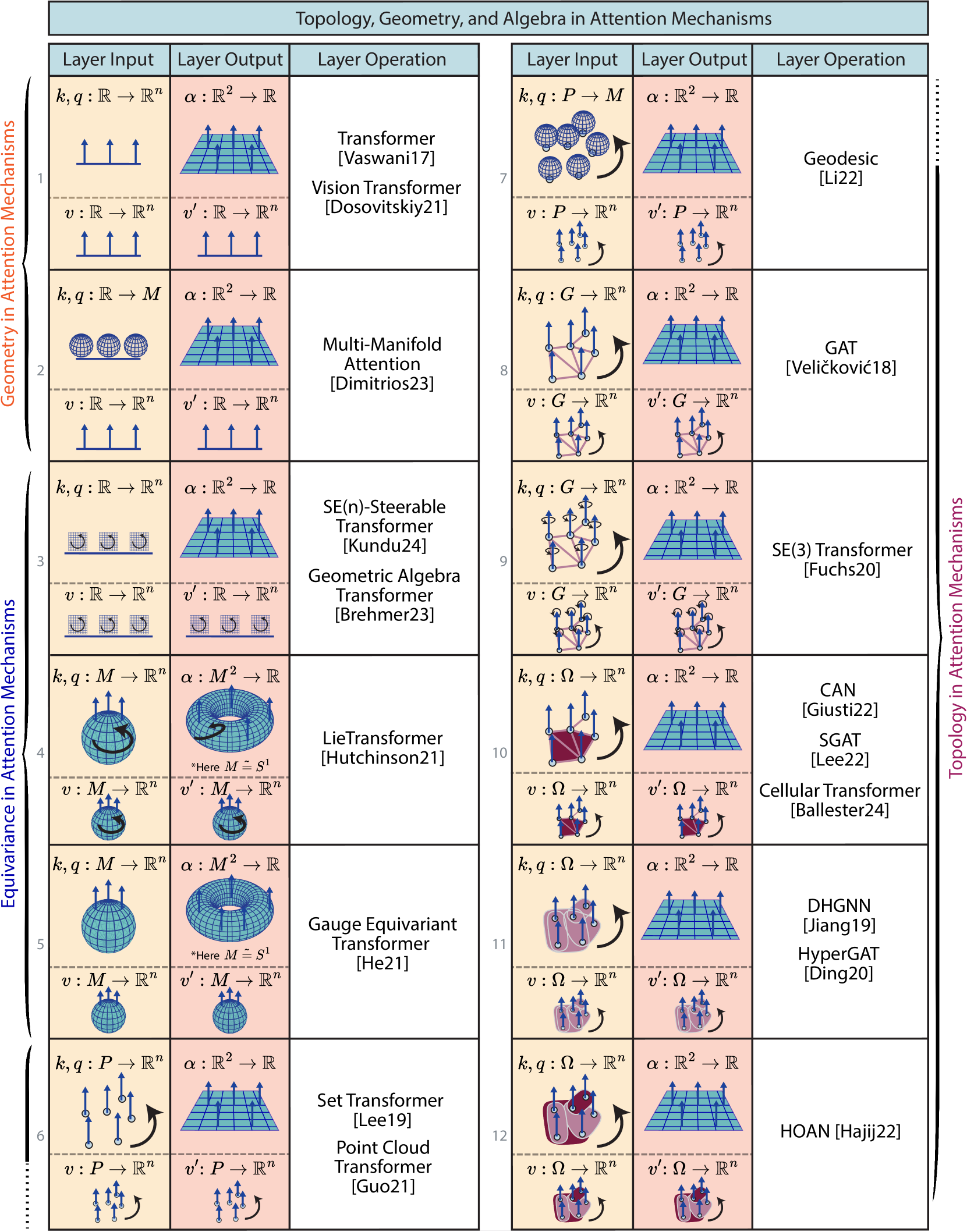
注意机制中的几何。
-
1.
欧几里德域上的欧几里德信号。 这一行展示了经典的 Transformer (Vaswani 等人,2017),其中键、查询和输入值表示为信号 。 注意力系数为,而层输出值为。 该行还说明了视觉变换器 (Dosovitskiy 等人, 2021) 的设置,它将图像划分为一系列图像块:因此, 中的块位于 。 我们强调这些信号的数学表示与其在 Transformer 的实际实现过程中的计算表示之间的差异。 在数学上,我们将信号域表示为连续实线。然而,在计算上,这条实线被离散化为 步骤和关联的 离散标记(对于单词或图像块)。 然而,作为实线的表示对于将原始 Transformer 与接下来介绍的更复杂的层统一起来很有用。
-
2.
欧几里得域上的流形信号用于键和查询。 与上一行的经典 Transformer 相比,这一行在键和查询信号的共域中引入了几何图形,即 。 同时,注意力系数、输入和输出值与经典Transformer具有相同的结构。 (Konstantinidis 等人, 2023) 的多流形注意力机制说明了这种配置。 具体来说,这项工作将经典的注意力系数 视为键和查询之间的欧几里德距离的计算。 因此,他们提出的几何注意系数用密钥和查询之间的黎曼测地距离代替了欧几里得距离,这些距离被解释为流形的元素:SPD(对称正定)矩阵的流形、格拉斯曼流形或两者 - 因此术语“多”流形。 我们注意到,这个 Transformer 架构的输入数据仍然是欧几里得的,因为这种注意力机制是针对视觉 Transformer 中的图像提出的。 然而,Transformer 内部层处理这些数据的方式是非欧几里得的。
注意机制的等效性。
-
3.
欧几里德域上的欧几里德信号用于键、查询和值,在共域上进行组操作。 这一行说明了一种注意力机制,其中包括键、查询、输入和输出值中的附加代数结构。 几何代数转换器代表了这种配置 Brehmer 等人 (2023)。 它的层旨在处理定义为标量、向量、直线、平面、对象及其在 3D 空间中的变换(例如旋转)的“几何数据”。 此类几何数据被编码为多向量,它们是射影几何代数(也称为 Clifford 代数)的元素。 为了简单起见,我们将该空间视为具有代数结构的欧几里得空间。 对于 3D 空间中平移、旋转和反射的欧几里得群 ,注意力系数是群不变的,而注意力层是群等变的。 这种配置还可以通过可操纵 Transformer (Kundu 和 Kondor,2024) 来说明,它处理与特殊欧几里得群 等变的欧几里得共域 ,应用到图像处理和机器学习任务。
-
4.
所有输入/输出的流形域上的欧几里得信号,具有域组操作。 与上一行类似,这一行也在键、查询、值中引入了几何结构。 然而,与前一行相反,该层将几何图形带入信号域:,而上一层将几何图形带入其共域。 因此,对于这一行,注意力系数具有乘积流形作为它们的domain=。 这种配置在李变换器 (Hutchinson 等人,2020) 中进行了说明,其中感兴趣的流形是李群及其子群。 我们注意到,该架构处理的数据不必属于李群;只能由李群采取行动。 引入提升层将原始数据转换为李群元素,然后由李变换器处理。 那么注意力层是等变的。
-
5.
所有输入/输出的流形域上的欧几里德信号。 这一行与前一行类似,使用流形域作为键、查询、值和注意力系数。 与上一行相比,群等方差被规范等方差和不变性的概念所取代。 He等人(2021)中的规范不变Transformer提出了这样的配置:注意力系数是规范不变的,注意力层是规范等变的。 这项工作专门关注嵌入 3D 欧几里德空间中的二维流形 。
注意力机制中的拓扑。
-
6.
设置域上的欧几里得信号,具有域组操作:此行介绍了信号域上的拓扑结构,通过点集。集变换器 (ST) (Lee 等人, 2019) 和点云变换器 (PCT) (Guo 等人, 2021) 是这种配置的两个示例。 它们与排列组具有等变性,排列组通过排列集合中(分别是点云中)点的索引来起作用。
-
7.
流形信号 在设置域上,使用域组操作. 该行包括前一行拓扑结构之上的几何结构,使用流形余域作为键 、查询 以及使用欧几里德信号作为 和 ,全部在设定域上。 geodesic Transformer (Li 等人, 2022b) 提供了处理此配置的架构。 与第 2 行的多流形注意力类似,测地线 Transformer 的注意力系数是使用键和查询之间的测地距离来计算的:基于图的测地距离,或所谓的倾斜流形上的黎曼测地距离。
-
8.
图域上的欧几里得信号,具有域组操作。 此行与前一行类似,但没有对信号共域进行组操作。 这在图注意力变换器(GAT)(Veličković 等人,2018)中进行了说明。
-
9.
图域上的欧几里得信号,具有域和共域组操作。 该行还使用图形域,使得。 此配置的一个示例是 -Transformer,其中这些信号的共域还被限制为 ,配备了 3D 中平移和旋转组的动作 (Fuchs 等人,2020)。 该 Transformer 被提出来处理 3D 点云,并提供 - 不变注意系数和 - 等变注意层。
-
10.
细胞复合域上的欧几里德信号,具有域组作用。 从这一行开始,在信号的域上引入了更复杂的拓扑结构。 我们建议读者参阅调查(Papillon 等人,2023),以详细阐述使用拓扑的注意机制。 该行呈现专门使用元胞复形或单纯复形作为域的体系结构。 细胞注意力网络(CAN)(Giusti 等人,2023)和简单图注意力网络(SGAT)(Lee 等人,2022)说明了这种类型的注意力机制,而Cellular Transformer (Ballester 等人, 2024) 另外包括位置编码。
-
11.
超图域上的欧几里得信号,具有域组操作。 与前一行类似,此配置在信号域上使用拓扑结构:此处利用超图。 这种配置的示例包括动态超图神经网络(DHGNN)(Jiang 等人,2019)和超图注意力网络(Hyper GAT)(Ding 等人,2020)。
-
12.
组合复杂域上的欧几里得信号,具有域组操作。 最后一行使用组合复数域来定义注意力系数和注意力层的输入信号。 高阶注意力网络 (HOAN) 架构是最后一类的最新示例(Hajij 等人,2023b)。
V-C 基准测试
现在,我们简要回顾一下非欧几里得深度学习文献中考虑的基准,并从表I中编译了具有拓扑、几何和代数层的广泛神经网络样本的结果,并强调文献中使用的任务和数据集的多样性。
任务和数据集
我们首先观察到文献中使用了各种各样的任务和基准数据集,模型之间几乎没有重叠。 换句话说,很少有两个不同的模型在同一数据集上进行基准测试。 这并不奇怪,因为不同的模型使用不同的几何、拓扑和代数结构,并且不同的结构非常适合不同的任务。
然而,跨模型出现了几个基准:用于图像分类的 MNIST 和 CIFAR,以及用于图分类的 Cora、Citeseer 和 Pubmed。 许多几何模型都是通过检查它们模拟动力或物理系统的效果来进行测试的。 这些结果不容易在模型之间进行比较,因为任务通常是针对每篇论文定制的。
我们根据是否使用注意力及其几何、拓扑和代数结构来组织模型,缩写为:M:流形,:组,:集合,:图,:拓扑域,:代数。 模型还根据其执行的任务以及基准数据集进行组织。 我们包括两个或多个模型使用的基准的精度,在需要时将测试误差转换为精度,并在报告时将标准误差转换为标准误差。 如果论文报道了模型参数,则会列出它们。 N.R. 表示未报告。
| Model | Structure | Task | Benchmark datasets | # Params | |
|---|---|---|---|---|---|
| Without Attention | Riemannian VAE ite]cite.Miolane2019UnsupervisedNetworksMiolane19 | M | Dimension Reduction | Human Connectome Project (HCP) | N.R. |
| S-VAE/VGAE ite]cite.Davidson2018HypersphericalAuto-encodersDavidson18 | M | Latent representation for image classification and link prediction | MNIST (93.4 0.2*), Cora (94.10.3), Citeseer (95.20.2), Pubmed (96.00.1) | N.R. | |
| SPDNet ite]cite.Huang2016ALearningHuang,VanGool16 | M | Visual classification (emotion, action, face) | AFEW, HDM05 and PaSC | N.R. | |
| EMLP ite]cite.finzi2021Finzi21 | Dynamical modeling | Double pendulum | N.R. | ||
| LeNet-5 ite]cite.LeCun1998Gradient-BasedRecognitionLeCun98 | Image classification | MNIST (99.20.1) | N.R. | ||
| Steerable CNN ite]cite.cohen2017steerableCohen,Welling17 | Image classification | CIFAR (10: 76.3; 10+: 96.4; 100+: 81.2) |
4.4M
9.1M |
||
| G-CNN ite]cite.cohen16Cohen,Welling16 | Image classification | Rotated MNIST, CIFAR (10: 93.5; 10+: 95.1) | 2.6M | ||
| G-CNN ite]cite.cohen2019gaugeCohen19a | Climate, pointcloud segmentation | Climate Segmentation, Stanford 2D-3D-S | N.R. | ||
| E(n)-EGNN ite]cite.satorras2021nSatorras2021 | Molecular property prediction, dynamical modeling | QM9, N-body, Graph autoencoder | N.R. | ||
| PONITA ite]cite.bekkers2024fastBekkers2024 | Molecular property prediction and generation, dynamical modeling | rMD17, QM9, N-body | N.R. | ||
| PointNet++ ite]cite.qi2017pointnetppQi17 | S | Image, 3D, scene classification | MNIST (99.49), ModelNet40 (91.9), SHREC15, ScanNet | 1.7M | |
| Tensor field network ite]cite.Thomas2018TensorCloudsThomas18 | S | 3D-point-cloud prediction | QM9 | N.R. | |
| GCN ite]cite.kipf2017semisupervisedKipf,Welling17 | G | Link prediction | Cora, Citeseer, Pubmed, NELL | N.R. | |
| enn-s2s ite]cite.gilmer17messagepassingGilmer17 | G | Molecular property prediction | QM9 | N.R. | |
| SNN ite]cite.ebli2020simplicialEbli20 | Coauthorship prediction | Semantic Scholar Open Research Corpus | N.R. | ||
| MPSN ite]cite.bodnar2021mpsnBodnar21 | Trajectory, graph classification | TUDataset | N.R. | ||
| CXN ite]cite.hajij2020cellHajij20 | - | - | N.R. | ||
| HMPNN ite]cite.heydari22Heydari22 | Citation node classification | Cora (92.2) | N.R. | ||
| CCNN ite]cite.hajij2023topologicalHajij23 | Image segmentation, image, mesh, graph classification | Human Body, COSEG, SHREC11 | N.R. | ||
| E(n)-EMPSN ite]cite.eijkelboom2023nEijkelboom2023 | Molecular property prediction, dynamical modeling | QM9, N-body | 200K | ||
| Clifford-EMPSN ite]cite.liu2024cliffordLiu2024 | Pose estimation, dynamical modeling | CMU MoCap, MD17 | 200K | ||
| E(n) Equivariant TNN ite]cite.battiloro2024nBattiloro2024 | Molecular property, air pollution prediction | QM9, Air Pollution Downscaling | 1.5M | ||
| With Attention | Transformer ite]cite.vaswani2017transformerVaswani17 | - | Machine translation | WMT 2014 | N.R. |
| MMA ViT ite]cite.konstantinidis2023Konstantinidis23 | M | Image classification, segmentation | CIFAR (10: 94.7, 100+: 77.5), T-ImageNet, ImageNet, ADE20K | 3.9M | |
| GATr ite]cite.brehmer2023geometricBrehmer23 | A | Dynamical modeling | N-body, artery stress, diffusion robotics | 4.0M | |
| Steerable Transformer ite]cite.kundu2024steerableKundu2024 | Point-cloud, Image classification | Rotated MNIST (99.03), ModelNet10 (90.4) | 0.9M | ||
| Lie Transformer ite]cite.hutchinson2020lietransformerHutchinson20 | Regression, dynamics | QM9, ODE spring simulation | 0.9M | ||
| GET ite]cite.he2021gaugeinvariantHe21 | M | Shape classification, segmentation | SHREC07, Human Body Segmentation | 0.15M | |
| Set Transformer ite]cite.lee2019stLee19 | S | Max value regression, clustering | Omniglot, CIFAR (100: 0.920.01 | N.R. | |
| PCT ite]cite.guo2021pctGuo21 | S | Point-cloud classification, regression, segmentation | ModelNet40 (93.2), ShapeNet (86.4), S3DIS | 1.4M | |
| GSA ite]cite.li2022geodesictransformerLi22 | S | Object classification, segmentation | ModelNet40 (93.3), ScanObjectNN, ShapeNet (85.9) | 18.5M | |
| SE(3)-Transformer ite]cite.fuchs2020se3Fuchs20 | G | Dynamics, classification, regression | N-body, ScanObjectNN, QM9 | N.R. | |
| GAT ite]cite.velickovic2018graphVeličković18 | G | Link prediction | Cora, Citeseer, Pubmed, PPI | N.R. | |
| CAN ite]cite.giusti2023Giusti23 | Graph classification | TUDataset | N.R. | ||
| Cellular Transformer ite]cite.ballester2024attendingBallester24 | Graph classifical, Graph regression | GCB, Zinc, Ogbg Molhiv | N.R. | ||
| SGAT ite]cite.lee2022sgatLee22 | Node classification | DBLP2, ACM, IMDB | N.R. | ||
| DHGNN ite]cite.jiang2019dhgnnJiang19 | Link, sentiment prediction | Cora (82.5), Microblog | 0.13M | ||
| HyperGAT ite]cite.ding2020hypergatDing20 | Text classification | 20NG, R8, R52, Ohsumed, MR | N.R. |
参数数量
将数学结构构建到神经网络中的一个主要好处是它限制了假设搜索空间。 如果结构与问题匹配得很好,模型应该需要更少的参数和更少的计算。 许多论文都提到了这一点,但只有少数报告了参数的数量(参见表I的右列)。 由于参数和数据效率经常被认为是在神经网络模型中构建结构的优势,因此我们鼓励作者更定期地在论文中报告参数计数和计算成本以及性能指标。
V-D 概括
我们对深度神经网络层中非欧几里得的回顾到此结束。 虽然已经提出了多种多样的结构、层类型和机制,但我们希望我们的图示分类法可以帮助研究人员理解它们的差异和相似之处,并确定创新和应用的机会。 现在,我们简要总结在线提供的现有非欧几里德机器学习软件库,最后概述非欧几里德机器学习方法的应用领域。
VI 非欧几里得软件
在本节中,我们重点介绍公开可用的软件库,这些软件库使该领域的方法可通过计算进行访问,如表II所示。 在这里,我们将讨论仅限于那些提交历史表明持续开发并且拥有至少 50 个 Github Stars 的追随者的库。
表II突出显示了该领域的核心库。 从星星数量和积极开发的存储库来看,拓扑方法包的开发最为完善,包括 CUDA 和 C++ 加速网络原语等重要的工程基础,以及继续维护的大量模型实现。 几何学习方法的库生态系统正在迅速引起人们的兴趣和贡献者的增长,将包从特定流形的优化器扩展到更通用的微分几何工具。 虽然机器学习中的代数包是最新的,但随着对更专业应用程序的需求的出现,在过去几年中,在制作更专业的包来加速群卷积和其他代数运算方面出现了令人兴奋的新发展。
VII 非欧几何的应用
科学和工程中的许多问题本质上都是非欧几里德的,因此为非欧几里德机器学习方法的应用提供了令人兴奋的机会。 在这里,我们简要强调选定应用领域的关键进展。 我们建议读者参考 Wu 等人 (2021)、Bronstein 等人 (2021)、Gaudelet 等人 (2021)、Rajpurkar 等人 (2022)、Li 等人 (2022a)、Wu 等人 (2022)、 Wang 等人 (2023) 以获取更全面的应用讨论。
化学与药物开发
在计算化学中,分子分析和设计传统上是漫长且昂贵的过程,有时需要数十年的开发时间以及数十亿美元的投资和基础设施。 分子数据本质上具有几何和图形结构,非常适合非欧几里得方法(Atz等人,2021)。
图神经网络已成为分子分析的主力,将分子视为以原子为节点、键为边的图(Gilmer 等人,2017,Bronstein 等人,2021)。 该领域的进展主要涉及构建具有有利特性的消息传递神经网络,例如不断增长的群变换家族的等方差、新颖的权重共享形式、更具表现力的原语以及更有效的参数化和计算公式(Schütt 等人, 2017, Thomas 等人, 2018, Batzner 等人, 2022, Satorras 等人, 2022, Bekkers 等人, 2024)。 具有几何结构的深层网络也已直接用于药物筛选,以发现新的抗生素(Stokes等人,2020)。
最近,深度等变生成模型已成为分子合成的强大框架。 (Gebauer 等人, 2020, Simonovsky and Komodakis, 2018, Simm 等人, 2020) 之前的工作确立了利用几何特性合成分子的重要性。 (Hoogeboom 等人, 2022) 通过直接生成 3D 原子坐标引入用于分子生成的等变去噪扩散模型,证明了质量和效率的提高。 最近,(Xu 等人,2023)对此进行了扩展,以在分子潜在空间上执行等变扩散,并且 (Vignac 等人,2023) 实现了更高的稳定性用于在 GEOM-DRUGS 数据集上生成的分子。 另一项工作是生成角度和距离等分子不变量,然后将其用于生成坐标(Luo 和 Ji,2022)。 最近的工作还证明了等变性和不变性对于分子构象异构体生成的重要性(Xu等人,2022,Reidenbach和Krishnapriyan,2023)。
| Geometry | |||
| Packages | Domains | Core Features | Stars |
| GeomStats 2019 | Manifolds, Lie Groups, Fiber Bundles, Shape Spaces, Information Manifolds, Graphs | Manifold operations, Algorithms, Statistics, Optimizers | 1.2k |
| GeoOpt 2020 | Manifolds | Layers, Manifold operations, Stochastic optimizers for deep learning | 812 |
| PyManOpt 2016 | Manifolds, Lie Groups | Manifold operations, Optimizers | 734 |
| PyRiemann 2023 | SPD Matricies | Machine Learning, Data Analysis for biosignals | 606 |
| Topology | |||
| Packages | Domains | Core Features | Stars |
| PytorchGeometric 2019 | Graphs | Baseline Models, Layers, Fast Basic Graph Operations, Datasets, Dataloaders | 20.6k |
| NetworkX Hagberg et al. (2008) | Graphs, Digraphs, Multigraphs | Data structures, Graph generators, Graph Algorithms, Network Analysis Measures | 14.5k |
| DGL 2019 | Graphs | Baseline Models, Layers, Fast Basic Graph Operations, Datasets, Dataloaders, Framework-agnostic (PyTorch, Tensorflow, etc. are swappable) | 13.2k |
| DIG 2021 | Graphs | Baseline models, Datasets, Evaluation Metrics | 1.8k |
| AutoGL 2021 | Graphs | Neural Architecture Search, Hyper-Parameter Tuning, Ensembles | 1.1k |
| HyperNetX 2023 | Hypergraphs | Machine Learning Algorithms, Analysis, Visualization | 502 |
| DHG 2022 | Graphs, hypergraphs, bipartite graphs, hypergraphs, directed hypergraphs, … | Models, Basic Operations, Dataloaders, Visualization, Auto ML, Metrics, Graph generators | 566 |
| TopoModelX 2024 | Graphs, colored hypergraphs, complexes | Baseline Models, Layers, Higher-order message passing | 205 |
| TopoNetX 2024 | Graphs, colored hypergraphs, complexes | Topography Generators, Computing topological properties, Arbitrary cell attributes | 168 |
| TopoEmbedX 2024 | Graphs, colored hypergraphs, complexes | Representation learning, embeddings | 72 |
| TopoBenchmarkX 2024 | Graphs, hypergraphs, complexes | Benchmarks, lifting, dataloaders, losses, training framework | 54 |
| XGI 2023 | Hypergraphs, directed hypergraphs, symplical complexes | Graph generators, metrics, algorithms, dataloaders, visualization | 172 |
| Algebra | |||
| Packages | Domains | Core Features | Stars |
| E3NN 2022 | E(3) Equivariant Feature Fields | Group Convolutions, Steerable Group Convolutions | 891 |
| ESCNN & E2CNN 2022 | E(n) Equivariant Feature Fields, Graphs | Group Convolutions, Steerable Group Convolutions | 584 111Stars inherited from e2cnn, which this extends. |
| NequIP 2022 | E(3) Equivariance on Graphs | Group Convolutions, Steerable Group Convolutions | 538 |
| EMLP 2021 | Matrix Groups, Tensors, Irreducible Representations, Induced Representations | Programmatic generation of equivariant MLPs for arbitrary matrix groups in JAX | 249 |
| PyQuaternion | Quaternions | Quaternion operations, rotation representation conversions, differentiation, integration | 336 |
结构生物学和蛋白质工程
蛋白质是折叠成 3D 结构的 1D 氨基酸序列。 蛋白质的功能由其结构定义,因此从原始一维序列预测蛋白质结构对于分析其用途以及与其他生物分子的相互作用至关重要。 AlphaFold 2 结合了图结构主干、等变注意力和许多关于分子的几何先验(Jumper 等人,2021),已成为预测蛋白质结构的里程碑式论文。 这种蛋白质结构预测通常用于生物学和医学领域(Yang 等人,2023)。 预测蛋白质与其他分子的相互作用也是一个具有挑战性的问题,可以通过图表和等变方法很好地体现(Ingraham等人,2019,Anand和Achim,2022,Ingraham等人,2023)。
计算机视觉
计算机视觉需要从图像或其他测量(例如激光雷达)推断视觉世界的属性。 计算机视觉中有许多子任务,例如目标识别、语义分割、图像和视频生成、深度估计等。 从历史上看,捕获图像的拓扑结构和对称性的网络原语一直主导着视觉基准,包括 CNN、GCNN 和 Vision Transformer (LeCun 等人,1998,Krizhevsky 等人,2012,Cohen 和 Welling,2016,Dosovitskiy 等)人,2021)。
最近,非欧几里得深度学习最成功的应用之一是图神经网络,它在原生或提升到点云的数据上实现。 Pointnet++ 和 PointTransformer 等开创性工作引入了图结构深度网络,作为全房间尺度 3D 语义分割和对象检测的突破性方法(Qi 等人,2017,Engel 等人,2020)。 另一个有前途的计算原语 Slot Attention 引入了一种新颖的消息传递策略,使用排列不变槽来执行无监督对象发现,该策略使用以槽为中心的参考框架 合并空间对称性(Locatello 等人,2020,Biza 等人,2023 )。
生物医学成像
生物医学成像涉及通过测量生物组织的物理特性(通常以电磁场、声波和其他物理现象的形式)来推断生物组织的结构。 感兴趣的量包括形状、成分或内部状态。 因此,几何和拓扑结构在它们的分析中起着重要作用。
医学成像中的许多机器学习问题需要对 3D 结构进行推理,包括它们的形状、它们在人群中的变化以及随时间的变化。 由于组织状态是非欧几里德的,它们的统计和演化需要进行几何处理(Pennec等人,2019)。 器官形状的变化取决于低维流形,几何感知的降维方法,例如切线 PCA (Boisvert 等人,2008) 或原理测地线分析 (PGA) 可以为下游任务提供有意义的表示(Fletcher 等人,2004,Fletcher 和 Joshi,2007,Hinkle 等人,2012a)。 几何方法已应用于通过 MRI 扫描分析衰老对胼胝体的影响(Hinkle 等人,2012b),以及扩散张量成像中的脑连接组学数据(Pennec 等人, 2006),以及侧脑室、肾实质和骨盆以及海马的 CT 和 MRI 扫描的 3D 解剖结构分割(Pizer 等人,2003)。
医学图像配准历史上引导了李群统计发展的需求,从有限维群 (Pennec 和 Thirion,1997,Pennec,2006) 到无限维群微分同胚的维群(Trouvé,1998,Younes,2010)。 不幸的是,任何依赖黎曼几何结构对李群进行机器学习的尝试通常都是不适定的。 具体来说,李群上的经典黎曼度量(称为左不变或右不变)通常无法在所有群运算(特别是反演)中保持不变。 这引发了对替代几何结构的搜索(Pennec 和 Arsigny,2012,Miolane 和 Pennec,2015) 以及用规范双不变对称嘉当取代(非双不变)黎曼度量。申天连接Pennec 和 Lorenzi (2020)。 在无限维度中,这为稳态速度场 (SVF) 流的微分同胚参数化奠定了基础。 这种基于李群的几何统计框架现已用于许多非线性医学图像配准算法(Arsigny等人,2006年,Lorenzi和Pennec,2013)并用于建模形状演化,例如大脑变化阿尔茨海默病(Lorenzi 等人, 2015, Hadj-Hamou 等人, 2016, Sivera 等人, 2019)。
在医学图像分割中,几个像素数量级的估计误差可能会导致严重的误解。 该领域最近看到了添加拓扑结构带来的好处。 提高一致性和准确性的拓扑约束示例包括保留细胞图像的膜连接性以及纳入解剖学上正确的器官相对位置(Hu 等人, 2019, 2021, Clough 等人, 2022, Gupta 等人, 2022).
冷冻电镜数据从不同角度提供 3D 生物分子的多个 2D 图像投影。 推断生物分子原始 3D 结构的任务极大受益于拓扑和几何结构的结合(Donnat 等人, 2022, Miolane 等人, 2020)。
组织学图像没有规范方向,这意味着特定细胞的每个方向出现的可能性相同。 最近的工作探索了等变和可操纵的 CNN,以利用数据中的这些对称性(Bekkers 等人,2018,Veeling 等人,2018,Graham 等人,2020,Lafarge 等人,2020,Adnan 等人,2020)
推荐系统和社交网络
推荐系统是图表示学习最早的成功应用之一,其中可以通过图卷积学习特定节点与其他节点的接近度来表示相似性。 这对于根据用户的数据和偏好推荐广告、产品、音乐和内容具有明显的经济效用。 Pinterest 的 PinSage 是最早在商业规模上展示其潜力的公司之一(Ying 等人,2018)。 有关推荐系统中图神经网络的全面综述,请参阅(Wu 等人,2022)。
物理
物理数据自然具有许多对称性,并且通常采用无序集合之间关系的形式,这是拓扑和等变方法的理想设置。 可以使用各种类型物理数据的学习图消息传递来有效计算网格中粒子或节点之间的动力学(Sanchez-Gonzalez 等人,2020,Pfaff 等人,2021)。 等变Transformer和图神经网络架构已成功应用于大型强子对撞机的数据分析以及n体问题的重力等其他模拟(Fuchs等人,2020,Brandstetter等人,2022)。 拓扑方法非常适合处理大型强子对撞机实验产生的数百 PB 高度相关的数据,并已证明其对于粒子物理学下一阶段基础发现的实用性(DeZoort 等人,2023). 最近的工作(Brehmer等人,2023)提出了一种将几何数据嵌入到几何代数表示中以由等变Transformer网络处理的架构,并展示了其在网格交互估计和n体模拟方面的功效。 天体物理学数据也非常适合等变网络的应用。 一些示例包括使用群等变 CNN 对射电星系进行分类(Scaife 和 Porter,2021)、使用等变归一化流进行最优宇宙学分析(Dai 和 Seljak,2022)、使用球形等变 CNN 进行宇宙微波背景辐射分析(McEwen 等人,2022)。
其他应用
非欧几里得方法在不完全属于这些类别的领域还有许多其他有趣的应用,例如用于到达时间预测的 GNN (Derrow-Pinion 等人,2021)、天气预报 (Keisler, 2022, Lam 等人, 2023)、材料科学(Reiser 等人, 2022)、患者电子健康记录(Li 等人, 2022a) t3> 等等。 作为一个新兴的新兴领域,非欧几里得机器学习在新领域的应用正在不断推进。 我们预计(并希望)此处介绍的亮点仅代表未来内容的一小部分。
八结论
随着丰富的结构化非欧几里得数据的可用性在应用领域不断增长,人们越来越需要能够充分利用底层几何、拓扑和对称性来提取见解的机器学习方法。 在这种需求的推动下,一种新的非欧几里得机器学习范式正在出现,它将经典技术推广到弯曲流形、拓扑空间和群结构数据。 这种范式转变与 19 世纪数学中的非欧几里得革命相呼应,这场革命从根本上扩展了我们的几何概念,并促进了自然科学的重大进步。
在这篇综述中,我们对这个新兴领域提供了一个易于理解的概述,将文献中不同的线索统一到一个共同的组织框架中。 我们的插图分类法对现有方法进行了背景分析、分类和区分,并阐明了提供创新机会的差距。 我们希望这能邀请理论家和实践者进一步探索非欧几何、拓扑和代数重塑现代机器学习的潜力,就像一个多世纪前它们重塑了我们对空间的基本理解一样。
通过为模型提供尊重数据底层结构的工具,非欧几里得机器学习极大地扩展了可以解决的学习问题类型的前沿。 随着理论理解的不断深入以及充分利用几何、拓扑和代数的数学形式主义的架构设计,非欧几里得方法在改变更广泛的机器学习领域及其在未来工程问题和自然科学中的应用方面具有巨大的潜力年。
参考
- Adnan et al. (2020) Mohammed Adnan, Shivam Kalra, and Hamid R. Tizhoosh. Representation learning of histopathology images using graph neural networks, 2020.
- Akhøj et al. (2023) Morten Akhøj, James Benn, Erlend Grong, Stefan Sommer, and Xavier Pennec. Principal subbundles for dimension reduction. working paper or preprint, July 2023. URL https://inria.hal.science/hal-04156036.
- Anand and Achim (2022) Namrata Anand and Tudor Achim. Protein structure and sequence generation with equivariant denoising diffusion probabilistic models, 2022.
- Arsigny et al. (2006) Vincent Arsigny, Olivier Commowick, Xavier Pennec, and Nicholas Ayache. A Log-Euclidean Framework for Statistics on Diffeomorphisms. In Proc. of the 9th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI’06), Part I, LNCS, pages 924–931, October 2006. doi: 10.1007/11866565˙113.
- Arya et al. (2020) Devanshu Arya, Richard Olij, Deepak K. Gupta, Ahmed El Gazzar, Guido van Wingen, Marcel Worring, and Rajat Mani Thomas. Fusing structural and functional mris using graph convolutional networks for autism classification. In Tal Arbel, Ismail Ben Ayed, Marleen de Bruijne, Maxime Descoteaux, Herve Lombaert, and Christopher Pal, editors, Proceedings of the Third Conference on Medical Imaging with Deep Learning, volume 121 of Proceedings of Machine Learning Research, pages 44–61. PMLR, 06–08 Jul 2020. URL https://proceedings.mlr.press/v121/arya20a.html.
- Atz et al. (2021) Kenneth Atz, Francesca Grisoni, and Gisbert Schneider. Geometric deep learning on molecular representations, 2021.
- Ballester et al. (2024) Rubén Ballester, Pablo Hernández-García, Mathilde Papillon, Claudio Battiloro, Nina Miolane, Tolga Birdal, Carles Casacuberta, Sergio Escalera, and Mustafa Hajij. Attending to topological spaces: The cellular transformer. arXiv preprint arXiv:2405.14094, 2024.
- Banerjee et al. (2015) Monami Banerjee, Rudrasis Chakraborty, Edward Ofori, David Vaillancourt, and Baba C. Vemuri. Nonlinear Regression on Riemannian Manifolds and Its Applications to Neuro-Image Analysis, page 719–727. Springer International Publishing, 2015. ISBN 9783319245539. doi: 10.1007/978-3-319-24553-9˙88. URL http://dx.doi.org/10.1007/978-3-319-24553-9_88.
- Barachant et al. (2023) Alexandre Barachant, Quentin Barthélemy, Jean-Rémi King, Alexandre Gramfort, Sylvain Chevallier, Pedro L. C. Rodrigues, Emanuele Olivetti, Vladislav Goncharenko, Gabriel Wagner vom Berg, Ghiles Reguig, Arthur Lebeurrier, Erik Bjäreholt, Maria Sayu Yamamoto, Pierre Clisson, and Marie-Constance Corsi. pyriemann/pyriemann: v0.5, 2023. URL https://doi.org/10.5281/zenodo.8059038.
- Battiloro et al. (2024) Claudio Battiloro, Ege Karaismailoğlu, Mauricio Tec, George Dasoulas, Michelle Audirac, and Francesca Dominici. E (n) equivariant topological neural networks. arXiv preprint arXiv:2405.15429, 2024.
- Batzner et al. (2022) Simon Batzner, Albert Musaelian, Lixin Sun, Mario Geiger, Jonathan P Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E Smidt, and Boris Kozinsky. E (3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials. Nature communications, 13(1):2453, 2022.
- Bekkers et al. (2018) Erik J Bekkers, Maxime W Lafarge, Mitko Veta, Koen AJ Eppenhof, Josien PW Pluim, and Remco Duits. Roto-translation covariant convolutional networks for medical image analysis, 2018.
- Bekkers et al. (2024) Erik J Bekkers, Sharvaree Vadgama, Rob D Hesselink, Putri A van der Linden, and David W Romero. Fast, expressive se equivariant networks through weight-sharing in position-orientation space, 2024.
- Bergsson and Hauberg (2022) Andri Bergsson and Søren Hauberg. Visualizing riemannian data with rie-sne. arXiv preprint arXiv:2203.09253, 2022.
- Bishop (1998) Charles M. Bishop. Bayesian pca. In Neural Information Processing Systems, 1998. URL https://api.semanticscholar.org/CorpusID:43329106.
- Biza et al. (2023) Ondrej Biza, Sjoerd van Steenkiste, Mehdi S. M. Sajjadi, Gamaleldin F. Elsayed, Aravindh Mahendran, and Thomas Kipf. Invariant slot attention: Object discovery with slot-centric reference frames, 2023.
- Bodnar (2023) Cristian Bodnar. Topological Deep Learning: Graphs, Complexes, Sheaves. PhD thesis, 2023.
- Bodnar et al. (2021) Cristian Bodnar, Fabrizio Frasca, Yuguang Wang, Nina Otter, Guido F Montufar, Pietro Lió, and Michael Bronstein. Weisfeiler and lehman go topological: Message passing simplicial networks. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 1026–1037. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/bodnar21a.html.
- Boisvert et al. (2008) Jonathan Boisvert, Farida Cheriet, Xavier Pennec, Hubert Labelle, and Nicholas Ayache. Geometric Variability of the Scoliotic Spine using Statistics on Articulated Shape Models. IEEE Transactions on Medical Imaging, 27(4):557–568, 2008. doi: 10.1109/TMI.2007.911474.
- Box and Tiao (1968) G. E. P. Box and G. C. Tiao. A bayesian approach to some outlier problems. Biometrika, 55(1):119–129, 1968. ISSN 1464-3510. doi: 10.1093/biomet/55.1.119. URL http://dx.doi.org/10.1093/biomet/55.1.119.
- Brandstetter et al. (2022) Johannes Brandstetter, Rob Hesselink, Elise van der Pol, Erik J Bekkers, and Max Welling. Geometric and physical quantities improve e(3) equivariant message passing, 2022.
- Brehmer et al. (2023) Johann Brehmer, Pim De Haan, Sönke Behrends, and Taco Cohen. Geometric algebra transformer. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=M7r2CO4tJC.
- Breiman (2001) Leo Breiman. Machine Learning, 45(1):5–32, 2001. ISSN 0885-6125. doi: 10.1023/a:1010933404324. URL http://dx.doi.org/10.1023/A:1010933404324.
- Bronstein et al. (2021) Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv:2104.13478, 2021.
- Cesa et al. (2022) Gabriele Cesa, Leon Lang, and Maurice Weiler. A program to build E(N)-equivariant steerable CNNs. In International Conference on Learning Representations (ICLR), 2022.
- Chakraborty et al. (2022) Rudrasis Chakraborty, Jose Bouza, Jonathan H. Manton, and Baba C. Vemuri. ManifoldNet: A Deep Neural Network for Manifold-Valued Data With Applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(2):799–810, February 2022. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2020.3003846. URL https://ieeexplore.ieee.org/document/9122448/.
- Chang and Ghosh (2001) Kui Yu Chang and Joydeep Ghosh. A unified model for probabilistic principal surfaces. IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(1):22–41, 2001. ISSN 01628828. doi: 10.1109/34.899944.
- Chernov (2010) Nikolai Chernov. Circular and Linear Regression: Fitting Circles and Lines by Least Squares. CRC Press, June 2010. ISBN 9780429151415. doi: 10.1201/ebk1439835906. URL http://dx.doi.org/10.1201/EBK1439835906.
- Clough et al. (2022) James R. Clough, Nicholas Byrne, Ilkay Oksuz, Veronika A. Zimmer, Julia A. Schnabel, and Andrew P. King. A topological loss function for deep-learning based image segmentation using persistent homology. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(12):8766–8778, December 2022. ISSN 1939-3539. doi: 10.1109/tpami.2020.3013679. URL http://dx.doi.org/10.1109/TPAMI.2020.3013679.
- Cohen and Welling (2016) Taco Cohen and Max Welling. Group equivariant convolutional networks. In Maria Florina Balcan and Kilian Q. Weinberger, editors, Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 2990–2999, New York, New York, USA, 20–22 Jun 2016. PMLR. URL https://proceedings.mlr.press/v48/cohenc16.html.
- Cohen et al. (2019a) Taco Cohen, Maurice Weiler, Berkay Kicanaoglu, and Max Welling. Gauge equivariant convolutional networks and the icosahedral cnn. In International conference on Machine learning, pages 1321–1330. PMLR, 2019a.
- Cohen et al. (2021) Taco Cohen et al. Equivariant convolutional networks. PhD thesis, Taco Cohen, 2021.
- Cohen and Welling (2017) Taco S. Cohen and Max Welling. Steerable CNNs. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=rJQKYt5ll.
- Cohen et al. (2019b) Taco S Cohen, Mario Geiger, and Maurice Weiler. A general theory of equivariant cnns on homogeneous spaces. Advances in neural information processing systems, 32, 2019b.
- Dai and Seljak (2022) Biwei Dai and Uroš Seljak. Translation and rotation equivariant normalizing flow (trenf) for optimal cosmological analysis. 2022. URL https://doi.org/10.1093/mnras/stac2010.
- Damon and Marron (2013) James Damon and J. S. Marron. Backwards Principal Component Analysis and Principal Nested Relations. Journal of Mathematical Imaging and Vision, 50(1-2):107–114, October 2013. ISSN 0924-9907, 1573-7683. doi: 10.1007/s10851-013-0463-2. URL http://link.springer.com/article/10.1007/s10851-013-0463-2.
- Davidson et al. (2018) Tim R. Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M. Tomczak. Hyperspherical variational auto-encoders. 34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, 2:856–865, 2018.
- Davis et al. (2010) Brad C. Davis, P. Thomas Fletcher, Elizabeth Bullitt, and Sarang Joshi. Population shape regression from random design data. International Journal of Computer Vision, 90(2):255–266, jul 2010. ISSN 1573-1405. doi: 10.1007/s11263-010-0367-1. URL http://dx.doi.org/10.1007/s11263-010-0367-1.
- Derrow-Pinion et al. (2021) Austin Derrow-Pinion, Jennifer She, David Wong, Oliver Lange, Todd Hester, Luis Perez, Marc Nunkesser, Seongjae Lee, Xueying Guo, Brett Wiltshire, Peter W. Battaglia, Vishal Gupta, Ang Li, Zhongwen Xu, Alvaro Sanchez-Gonzalez, Yujia Li, and Petar Velickovic. Eta prediction with graph neural networks in google maps. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, CIKM ’21. ACM, October 2021. doi: 10.1145/3459637.3481916. URL http://dx.doi.org/10.1145/3459637.3481916.
- DeZoort et al. (2023) Gage DeZoort, Peter W Battaglia, Catherine Biscarat, and Jean-Roch Vlimant. Graph neural networks at the large hadron collider. Nature Reviews Physics, 5(5):281–303, 2023.
- Ding et al. (2020) Kaize Ding, Jianling Wang, Jundong Li, Dingcheng Li, and Huan Liu. Be more with less: Hypergraph attention networks for inductive text classification. In Conference on Empirical Methods in Natural Language Processing, 2020. URL https://api.semanticscholar.org/CorpusID:226226607.
- Donnat et al. (2022) Claire Donnat, Axel Levy, Frederic Poitevin, Ellen Zhong, and Nina Miolane. Deep generative modeling for volume reconstruction in cryo-electron microscopy, 2022.
- Dosovitskiy et al. (2021) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021.
- Ebli et al. (2020) Stefania Ebli, Michaël Defferrard, and Gard Spreemann. Simplicial neural networks. In TDA & Beyond, 2020. URL https://openreview.net/forum?id=nPCt39DVIfk.
- Eijkelboom et al. (2023) Floor Eijkelboom, Rob Hesselink, and Erik J Bekkers. E equivariant message passing simplicial networks. In International Conference on Machine Learning, pages 9071–9081. PMLR, 2023.
- Engel et al. (2020) Nico Engel, Vasileios Belagiannis, and Klaus C. J. Dietmayer. Point transformer. IEEE Access, 9:134826–134840, 2020. URL https://api.semanticscholar.org/CorpusID:226227046.
- Falorsi et al. (2018) Luca Falorsi, Pim de Haan, Tim R. Davidson, Nicola De Cao, Maurice Weiler, Patrick Forré, and Taco S. Cohen. Explorations in Homeomorphic Variational Auto-Encoding. 2018. URL http://arxiv.org/abs/1807.04689.
- Fan (1993) Jianqing Fan. Local linear regression smoothers and their minimax efficiencies. The Annals of Statistics, 21(1), March 1993. ISSN 0090-5364. doi: 10.1214/aos/1176349022. URL http://dx.doi.org/10.1214/aos/1176349022.
- Fey and Lenssen (2019) Matthias Fey and Jan E. Lenssen. Fast graph representation learning with PyTorch Geometric. In ICLR Workshop on Representation Learning on Graphs and Manifolds, 2019.
- Finzi et al. (2021) Marc Finzi, Max Welling, and Andrew Gordon Gordon Wilson. A practical method for constructing equivariant multilayer perceptrons for arbitrary matrix groups. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 3318–3328. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/finzi21a.html.
- Fisher (1936) R. A. Fisher. The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(7):179–188, 1936.
- Fletcher and Joshi (2007) P. Thomas Fletcher and Sarang Joshi. Riemannian geometry for the statistical analysis of diffusion tensor data. Signal Processing, 87(2):250–262, 2007. ISSN 0165-1684. doi: https://doi.org/10.1016/j.sigpro.2005.12.018. URL https://www.sciencedirect.com/science/article/pii/S0165168406001691.
- Fletcher et al. (2004) P Thomas Fletcher, Conglin Lu, Stephen M Pizer, and Sarang Joshi. Principal geodesic analysis for the study of nonlinear statistics of shape. IEEE transactions on medical imaging, 23(8):995–1005, 2004.
- Fletcher (2011) Thomas Fletcher. Geodesic regression on riemannian manifolds. In Proceedings of the Third International Workshop on Mathematical Foundations of Computational Anatomy-Geometrical and Statistical Methods for Modelling Biological Shape Variability, pages 75–86, 2011.
- Fuchs et al. (2020) Fabian Fuchs, Daniel Worrall, Volker Fischer, and Max Welling. Se(3)-transformers: 3d roto-translation equivariant attention networks. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1970–1981. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/15231a7ce4ba789d13b722cc5c955834-Paper.pdf.
- Gao et al. (2022) Yue Gao, Yifan Feng, Shuyi Ji, and Rongrong Ji. Hgnn: General hypergraph neural networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- Gaudelet et al. (2021) Thomas Gaudelet, Ben Day, Arian R Jamasb, Jyothish Soman, Cristian Regep, Gertrude Liu, Jeremy B R Hayter, Richard Vickers, Charles Roberts, Jian Tang, David Roblin, Tom L Blundell, Michael M Bronstein, and Jake P Taylor-King. Utilizing graph machine learning within drug discovery and development. 2021. URL https://doi.org/10.1093/bib/bbab159.
- Gay-Balmaz et al. (2012) F Gay-Balmaz, DD Holm, DM Meier, TS Ratiu, and F-X Vialard. Invariant Higher-Order Variational Problems. Communications in Mathematical Physics, 309:413–458, 2012. doi: 10.1007/s00220-011-1313-y. URL http://dx.doi.org/10.1007/s00220-011-1313-y.
- Gebauer et al. (2020) Niklas W. A. Gebauer, Michael Gastegger, and Kristof T. Schütt. Symmetry-adapted generation of 3d point sets for the targeted discovery of molecules, 2020.
- Geiger et al. (2022) Mario Geiger, Tess Smidt, Alby M., Benjamin Kurt Miller, Wouter Boomsma, Bradley Dice, Kostiantyn Lapchevskyi, Maurice Weiler, Michał Tyszkiewicz, Simon Batzner, Dylan Madisetti, Martin Uhrin, Jes Frellsen, Nuri Jung, Sophia Sanborn, Mingjian Wen, Josh Rackers, Marcel Rød, and Michael Bailey. Euclidean neural networks: e3nn, April 2022. URL https://doi.org/10.5281/zenodo.6459381.
- Gergonne (1815) J.D. Gergonne. Application de la méthode des moindres carrés à l’interpolation des suites. Annales des Mathématiques Pures et Appliquées, 6:242–252, 1815.
- Gill and Hangartner (2010) Jeff Gill and Dominik Hangartner. Circular data in political science and how to handle it. Political Analysis, 18(3):316–336, 2010. ISSN 1476-4989. doi: 10.1093/pan/mpq009. URL http://dx.doi.org/10.1093/pan/mpq009.
- Gilmer et al. (2017) Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1263–1272. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/gilmer17a.html.
- Giusti et al. (2023) Lorenzo Giusti, Claudio Battiloro, Lucia Testa, Paolo Di Lorenzo, Stefania Sardellitti, and Sergio Barbarossa. Cell attention networks. In 2023 International Joint Conference on Neural Networks (IJCNN). IEEE, June 2023. doi: 10.1109/ijcnn54540.2023.10191530. URL http://dx.doi.org/10.1109/IJCNN54540.2023.10191530.
- Graham et al. (2020) Simon Graham, David Epstein, and Nasir Rajpoot. Dense steerable filter cnns for exploiting rotational symmetry in histology images, 2020.
- Guan et al. (2021) Chaoyu Guan, Ziwei Zhang, Haoyang Li, Heng Chang, Zeyang Zhang, Yijian Qin, Jiyan Jiang, Xin Wang, and Wenwu Zhu. AutoGL: A library for automated graph learning. In ICLR 2021 Workshop on Geometrical and Topological Representation Learning, 2021. URL https://openreview.net/forum?id=0yHwpLeInDn.
- Guigui et al. (2023) Nicolas Guigui, Nina Miolane, Xavier Pennec, et al. Introduction to riemannian geometry and geometric statistics: from basic theory to implementation with geomstats. Foundations and Trends® in Machine Learning, 16(3):329–493, 2023.
- Guo et al. (2021) Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R. Martin, and Shi-Min Hu. Pct: Point cloud transformer. Computational Visual Media, 7(2):187–199, April 2021. ISSN 2096-0662. doi: 10.1007/s41095-021-0229-5. URL http://dx.doi.org/10.1007/s41095-021-0229-5.
- Guo et al. (2019) Mengmeng Guo, Jingyong Su, Li Sun, and Guofeng Cao. Statistical regression analysis of functional and shape data. Journal of Applied Statistics, 47(1):28–44, September 2019. ISSN 1360-0532. doi: 10.1080/02664763.2019.1669541. URL http://dx.doi.org/10.1080/02664763.2019.1669541.
- Gupta et al. (2022) Saumya Gupta, Xiaoling Hu, James Kaan, Michael Jin, Mutshipay Mpoy, Katherine Chung, Gagandeep Singh, Mary Saltz, Tahsin Kurc, Joel Saltz, Apostolos Tassiopoulos, Prateek Prasanna, and Chao Chen. Learning topological interactions for multi-class medical image segmentation, 2022.
- Hadj-Hamou et al. (2016) Mehdi Hadj-Hamou, Marco Lorenzi, Nicholas Ayache, and Xavier Pennec. Longitudinal Analysis of Image Time Series with Diffeomorphic Deformations: A Computational Framework Based on Stationary Velocity Fields. Frontiers in Neuroscience, 10, 2016. ISSN 1662-453X. doi: 10.3389/fnins.2016.00236. URL https://www.frontiersin.org/articles/10.3389/fnins.2016.00236/full.
- Hagberg et al. (2008) Aric Hagberg, Pieter J Swart, and Daniel A Schult. Exploring network structure, dynamics, and function using networkx. Technical report, Los Alamos National Laboratory (LANL), Los Alamos, NM (United States), 2008.
- Hajij et al. (2020) Mustafa Hajij, Kyle Istvan, and Ghada Zamzmi. Cell complex neural networks. In TDA & Beyond, 2020. URL https://openreview.net/forum?id=6Tq18ySFpGU.
- Hajij et al. (2023a) Mustafa Hajij, Ghada Zamzmi, Theodore Papamarkou, Nina Miolane, Aldo Guzmán-Sáenz, Karthikeyan Natesan Ramamurthy, Tolga Birdal, Tamal K Dey, Soham Mukherjee, Shreyas N Samaga, et al. Topological deep learning: Going beyond graph data. 2023a.
- Hajij et al. (2023b) Mustafa Hajij, Ghada Zamzmi, Theodore Papamarkou, Nina Miolane, Aldo Guzmán-Sáenz, Karthikeyan Natesan Ramamurthy, Tolga Birdal, Tamal K. Dey, Soham Mukherjee, Shreyas N. Samaga, Neal Livesay, Robin Walters, Paul Rosen, and Michael T. Schaub. Topological deep learning: Going beyond graph data, 2023b.
- Hajij et al. (2024) Mustafa Hajij, Mathilde Papillon, Florian Frantzen, Jens Agerberg, Ibrahem AlJabea, Ruben Ballester, Claudio Battiloro, Guillermo Bernárdez, Tolga Birdal, Aiden Brent, Peter Chin, Sergio Escalera, Simone Fiorellino, Odin Hoff Gardaa, Gurusankar Gopalakrishnan, Devendra Govil, Josef Hoppe, Maneel Reddy Karri, Jude Khouja, Manuel Lecha, Neal Livesay, Jan Meißner, Soham Mukherjee, Alexander Nikitin, Theodore Papamarkou, Jaro Prílepok, Karthikeyan Natesan Ramamurthy, Paul Rosen, Aldo Guzmán-Sáenz, Alessandro Salatiello, Shreyas N. Samaga, Simone Scardapane, Michael T. Schaub, Luca Scofano, Indro Spinelli, Lev Telyatnikov, Quang Truong, Robin Walters, Maosheng Yang, Olga Zaghen, Ghada Zamzmi, Ali Zia, and Nina Miolane. Topox: A suite of python packages for machine learning on topological domains, 2024. URL https://arxiv.org/abs/2402.02441.
- Halpern (1973) Elkan F. Halpern. Polynomial regression from a bayesian approach. Journal of the American Statistical Association, 68(341):137–143, March 1973. ISSN 1537-274X. doi: 10.1080/01621459.1973.10481352. URL http://dx.doi.org/10.1080/01621459.1973.10481352.
- Hanik et al. (2020) Martin Hanik, Hans-Christian Hege, Anja Hennemuth, and Christoph von Tycowicz. Nonlinear regression on manifolds for shape analysis using intrinsic bézier splines. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 2020. URL https://api.semanticscholar.org/CorpusID:220486926.
- Hastie and Stuetzle (1989) Trevor Hastie and Werner Stuetzle. Principal Curves. Journal of the American Statistical Association, 84(406):502–516, 1989.
- Hauberg (2016) Søren Hauberg. Principal Curves on Riemannian Manifolds. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(9):1915–1921, 2016. ISSN 01628828. doi: 10.1109/TPAMI.2015.2496166.
- He et al. (2021) Lingshen He, Yiming Dong, Yisen Wang, Dacheng Tao, and Zhouchen Lin. Gauge equivariant transformer. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 27331–27343. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/file/e57c6b956a6521b28495f2886ca0977a-Paper.pdf.
- Heydari and Livi (2022) Sajjad Heydari and Lorenzo Livi. Message passing neural networks for hypergraphs. In Elias Pimenidis, Plamen Angelov, Chrisina Jayne, Antonios Papaleonidas, and Mehmet Aydin, editors, Artificial Neural Networks and Machine Learning – ICANN 2022, pages 583–592, Cham, 2022. Springer Nature Switzerland.
- Hinkle et al. (2012a) Jacob Hinkle, Prasanna Muralidharan, P. Fletcher, and Sarang Joshi. Polynomial regression on riemannian manifolds. 7574, 10 2012a. doi: 10.1007/978-3-642-33712-3˙1.
- Hinkle et al. (2012b) Jacob Hinkle, Prasanna Muralidharan, P Thomas Fletcher, and Sarang Joshi. Polynomial regression on riemannian manifolds. In European conference on computer vision, pages 1–14. Springer, 2012b.
- Hoogeboom et al. (2022) Emiel Hoogeboom, Victor Garcia Satorras, Clément Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d, 2022.
- Hu et al. (2019) Xiaoling Hu, Li Fuxin, Dimitris Samaras, and Chao Chen. Topology-preserving deep image segmentation, 2019.
- Hu et al. (2021) Xiaoling Hu, Yusu Wang, Li Fuxin, Dimitris Samaras, and Chao Chen. Topology-aware segmentation using discrete morse theory, 2021.
- Huang and Van Gool (2016) Zhiwu Huang and Luc Van Gool. A Riemannian Network for SPD Matrix Learning. pages 2036–2042, 2016. URL http://arxiv.org/abs/1608.04233.
- Huckemann et al. (2010) Stephan Huckemann, Thomas Hotz, and Axel Munk. Intrinsic shape analysis: Geodesic PCA for riemannian manifolds modulo isometric lie group actions. Statistica Sinica, 20(1):1–58, 2010. ISSN 10170405.
- Hutchinson et al. (2020) Michael J. Hutchinson, Charline Le Lan, Sheheryar Zaidi, Emilien Dupont, Yee Whye Teh, and Hyunjik Kim. Lietransformer: Equivariant self-attention for lie groups. In International Conference on Machine Learning, 2020. URL https://api.semanticscholar.org/CorpusID:229340145.
- Ingraham et al. (2023) J.B. Ingraham, M. Baranov, and Z. et al. Costello. Illuminating protein space with a programmable generative model. 2023. URL https://doi.org/10.1038/s41586-023-06728-8.
- Ingraham et al. (2019) John Ingraham, Vikas Garg, Regina Barzilay, and Tommi Jaakkola. Generative models for graph-based protein design. 2019. URL https://papers.nips.cc/paper_files/paper/2019/hash/f3a4ff4839c56a5f460c88cce3666a2b-Abstract.html.
- Jensen et al. (2020) Kristopher T. Jensen, Ta-Chu Kao, Marco Tripodi, and Guillaume Hennequin. Manifold gplvms for discovering non-euclidean latent structure in neural data. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY, USA, 2020. Curran Associates Inc. ISBN 9781713829546.
- Jiang et al. (2019) Jianwen Jiang, Yuxuan Wei, Yifan Feng, Jingxuan Cao, and Yue Gao. Dynamic hypergraph neural networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-2019. International Joint Conferences on Artificial Intelligence Organization, August 2019. doi: 10.24963/ijcai.2019/366. URL http://dx.doi.org/10.24963/ijcai.2019/366.
- Johnson and Wehrly (1978) Richard A. Johnson and Thomas E. Wehrly. Some angular-linear distributions and related regression models. Journal of the American Statistical Association, 73:602–606, 1978. URL https://api.semanticscholar.org/CorpusID:122640093.
- Jumper et al. (2021) J. Jumper, R. Evans, and A. et al. Pritzel. Highly accurate protein structure prediction with alphafold. Nature, 2021. URL https://doi.org/10.1038/s41586-021-03819-2.
- Kang and Oh (2024) Seungwoo Kang and Hee-Seok Oh. Probabilistic Principal Curves on Riemannian Manifolds. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(7):4843–4849, July 2024. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2024.3357801. URL https://ieeexplore.ieee.org/document/10413614/.
- Keisler (2022) Ryan Keisler. Forecasting global weather with graph neural networks, 2022.
- Kingma and Welling (2014) Diederik P. Kingma and Max Welling. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations (ICLR), 2014.
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=SJU4ayYgl.
- Kochurov et al. (2020) Max Kochurov, Rasul Karimov, and Serge Kozlukov. Geoopt: Riemannian optimization in pytorch, 2020.
- Konstantinidis et al. (2023) Dimitrios Konstantinidis, Ilias Papastratis, Kosmas Dimitropoulos, and Petros Daras. Multi-manifold attention for vision transformers. IEEE Access, 11:123433–123444, 2023. ISSN 2169-3536. doi: 10.1109/access.2023.3329952. URL http://dx.doi.org/10.1109/ACCESS.2023.3329952.
- Kovachki et al. (2023) Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes. Journal of Machine Learning Research, 24(89):1–97, 2023.
- Krizhevsky et al. (2012) Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60:84 – 90, 2012. URL https://api.semanticscholar.org/CorpusID:195908774.
- Kühnel and Sommer (2017) Line Kühnel and Stefan Sommer. Stochastic development regression on non-linear manifolds. In Information Processing in Medical Imaging, 2017. URL https://api.semanticscholar.org/CorpusID:122942.
- Kundu and Kondor (2024) Soumyabrata Kundu and Risi Kondor. Steerable transformers. arXiv preprint arXiv:2405.15932, 2024.
- Lafarge et al. (2020) Maxime W. Lafarge, Erik J. Bekkers, Josien P. W. Pluim, Remco Duits, and Mitko Veta. Roto-translation equivariant convolutional networks: Application to histopathology image analysis, 2020.
- Lam et al. (2023) Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, Alexander Merose, Stephan Hoyer, George Holland, Oriol Vinyals, Jacklynn Stott, Alexander Pritzel, Shakir Mohamed, and Peter Battaglia. Graphcast: Learning skillful medium-range global weather forecasting, 2023.
- Landry et al. (2023) Nicholas W. Landry, Maxime Lucas, Iacopo Iacopini, Giovanni Petri, Alice Schwarze, Alice Patania, and Leo Torres. XGI: A Python package for higher-order interaction networks. Journal of Open Source Software, 8(85):5162, May 2023. doi: 10.21105/joss.05162. URL https://doi.org/10.21105/joss.05162.
- Lawrence (2003) Neil Lawrence. Gaussian process latent variable models for visualisation of high dimensional data. In S. Thrun, L. Saul, and B. Schölkopf, editors, Advances in Neural Information Processing Systems, volume 16. MIT Press, 2003. URL https://proceedings.neurips.cc/paper_files/paper/2003/file/9657c1fffd38824e5ab0472e022e577e-Paper.pdf.
- Le Brigant and Puechmorel (2018) Alice Le Brigant and Stéphane Puechmorel. Optimal Riemannian quantization with an application to air traffic analysis. arXiv preprint arXiv:1806.07605, 2018.
- LeCun et al. (1998) Yann LeCun, Leon Botton, Yoshua Bengio, and Patrick Haffner. Gradient-Based Learning Applied to Document Recognition. Proc. of the IEEE, 86(11):2278 – 2324, 1998.
- Lee et al. (2019) Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 3744–3753. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/lee19d.html.
- Lee et al. (2022) See Lee, Feng Ji, and Wee Peng Tay. Sgat: Simplicial graph attention network. pages 3167–3175, 07 2022. doi: 10.24963/ijcai.2022/440.
- Legendre (1805) Adrien-Marie Legendre. Nouvelles méthodes pour la détermination des orbites des comètes. 1805.
- Li et al. (2022a) M.M. Li, K. Huang, and M. Zitnik. Graph representation learning in biomedicine and healthcare. Nature Biomedicine, 2022a. URL https://doi.org/10.1038/s41551-022-00942-x.
- Li et al. (2022b) Zhengyu Li, XUAN TANG, Zihao Xu, Xihao Wang, Hui Yu, Mingsong Chen, and xian wei. Geodesic self-attention for 3d point clouds. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 6190–6203. Curran Associates, Inc., 2022b. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/28e4ee96c94e31b2d040b4521d2b299e-Paper-Conference.pdf.
- Lin et al. (2017) Lizhen Lin, Brian St. Thomas, Hongtu Zhu, and David B. Dunson. Extrinsic local regression on manifold-valued data. Journal of the American Statistical Association, 112(519):1261–1273, May 2017. ISSN 1537-274X. doi: 10.1080/01621459.2016.1208615. URL http://dx.doi.org/10.1080/01621459.2016.1208615.
- Liu et al. (2024) Cong Liu, David Ruhe, Floor Eijkelboom, and Patrick Forré. Clifford group equivariant simplicial message passing networks. arXiv preprint arXiv:2402.10011, 2024.
- Liu et al. (2021) Meng Liu, Youzhi Luo, Limei Wang, Yaochen Xie, Haonan Yuan, Shurui Gui, Zhao Xu, Haiyang Yu, Jingtun Zhang, Yi Liu, Keqiang Yan, Bora Oztekin, Haoran Liu, Xuan Zhang, Cong Fu, and Shuiwang Ji. Dig: A turnkey library for diving into graph deep learning research. ArXiv, abs/2103.12608, 2021. URL https://api.semanticscholar.org/CorpusID:232320529.
- Locatello et al. (2020) Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-centric learning with slot attention, 2020.
- Lorenzi and Pennec (2013) Marco Lorenzi and Xavier Pennec. Geodesics, Parallel Transport & One-parameter Subgroups for Diffeomorphic Image Registration. International Journal of Computer Vision, 105(2):111–127, November 2013. doi: 10.1007/s11263-012-0598-4. URL https://hal.inria.fr/hal-00813835. Publisher: Springer Verlag.
- Lorenzi et al. (2015) Marco Lorenzi, Xavier Pennec, Giovanni B. Frisoni, and Nicholas Ayache. Disentangling normal aging from Alzheimer’s disease in structural magnetic resonance images. Neurobiology of Aging, 36:S42–S52, January 2015. ISSN 01974580. doi: 10.1016/j.neurobiolaging.2014.07.046. URL https://linkinghub.elsevier.com/retrieve/pii/S0197458014005594.
- Luo and Ji (2022) Youzhi Luo and Shuiwang Ji. An autoregressive flow model for 3d molecular geometry generation from scratch. In International Conference on Learning Representations, 2022. URL https://api.semanticscholar.org/CorpusID:251647192.
- Machado et al. (2010) L. Machado, F. Silva Leite, and K. Krakowski. Higher-order smoothing splines versus least squares problems on Riemannian manifolds. Journal of Dynamical and Control Systems, 16(1):121–148, January 2010. ISSN 1079-2724, 1573-8698. doi: 10.1007/s10883-010-9080-1. URL http://link.springer.com/10.1007/s10883-010-9080-1.
- Machado and Leite (2006) Luıs Machado and F Silva Leite. Fitting Smooth Paths on Riemannian Manifolds. nternational Journal of Applied Mathematics and Statistics, 4, 2006.
- Maignant et al. (2023) Elodie Maignant, Alain Trouvé, and Xavier Pennec. Riemannian Locally Linear Embedding with Application to Kendall Shape Spaces, page 12–20. Springer Nature Switzerland, 2023. ISBN 9783031382710. doi: 10.1007/978-3-031-38271-0˙2. URL http://dx.doi.org/10.1007/978-3-031-38271-0_2.
- Mallasto and Feragen (2018) Anton Mallasto and Aasa Feragen. Application de la methode des moindre quarres a l’interpolation des suites. In Annales des Math Pures, pages 5580–5588, 2018.
- McEwen et al. (2022) Jason D. McEwen, Christopher G. R. Wallis, and Augustine N. Mavor-Parker. Scattering networks on the sphere for scalable and rotationally equivariant spherical cnns, 2022.
- McInnes et al. (2018) Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. Umap: Uniform manifold approximation and projection. Journal of Open Source Software, 3(29):861, 2018. doi: 10.21105/joss.00861. URL https://doi.org/10.21105/joss.00861.
- Mikulski and Duda (2019) Maciej Mikulski and Jaroslaw Duda. Toroidal autoencoder, 2019.
- Miolane and Pennec (2015) N. Miolane and X. Pennec. Computing bi-invariant pseudo-metrics on lie groups for consistent statistics. Entropy, 17(4), 2015. ISSN 10994300. doi: 10.3390/e17041850.
- Miolane et al. (2019) N. Miolane, A. Le Brigant, B. Hou, C. Donnat, M. Jorda, J. Mathe, X. Pennec, and S. Holmes. Geomstats: a python module for computations and statistics on manifolds. Submitted to JMLR, 2019. URL https://github.com/geomstats/geomstats.
- Miolane and Holmes (2020) Nina Miolane and Susan Holmes. Learning weighted submanifolds with variational autoencoders and riemannian variational autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14503–14511, 2020.
- Miolane et al. (2020) Nina Miolane, Frederic Poitevin, Yee-Ting Li, and Susan Holmes. Estimation of orientation and camera parameters from cryo-electron microscopy images with variational autoencoders and generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2020.
- Muralidharan et al. (2017) Prasanna Muralidharan, Jacob Hinkle, and P. Fletcher. A map estimation algorithm for bayesian polynomial regression on riemannian manifolds. pages 215–219, 09 2017. doi: 10.1109/ICIP.2017.8296274.
- Nadaraya (1964) E. A. Nadaraya. On estimating regression. Theory of Probability and its Applications, 9:141–142, 1964.
- Nickel and Kiela (2017) Maximillian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical representations. Advances in neural information processing systems, 30, 2017.
- Panaretos et al. (2014) Victor M. Panaretos, Tung Pham, and Zhigang Yao. Principal flows. Journal of the American Statistical Association, 109(505):424–436, 2014. ISSN 1537274X. doi: 10.1080/01621459.2013.849199.
- Papillon et al. (2023) Mathilde Papillon, Sophia Sanborn, Mustafa Hajij, and Nina Miolane. Architectures of topological deep learning: A survey on topological neural networks. arXiv preprint arXiv:2304.10031, 2023.
- Pearson (1901) Karl Pearson. Liii. on lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin philosophical magazine and journal of science, 2(11):559–572, 1901.
- Pelletier (2006) Bruno Pelletier. Non-parametric regression estimation on closed riemannian manifolds. Journal of Nonparametric Statistics, 18:57 – 67, 2006. URL https://api.semanticscholar.org/CorpusID:17937994.
- Pennec et al. (2019) X. Pennec, S. Sommer, and T. Fletcher. Riemannian Geometric Statistics in Medical Image Analysis. Elsevier Science & Technology, 2019. ISBN 978-0-12-814725-2. URL https://books.google.com/books?id=k8qsDwAAQBAJ.
- Pennec (2006) Xavier Pennec. Intrinsic Statistics on Riemannian Manifolds: Basic Tools for Geometric Measurements. Journal of Mathematical Imaging and Vision, 25(1):127–154, 2006. ISSN 0924-9907.
- Pennec (2018) Xavier Pennec. Barycentric subspace analysis on manifolds. Annals of Statistics, 46(6A):2711–2746, 2018. ISSN 00905364. doi: 10.1214/17-AOS1636.
- Pennec and Arsigny (2012) Xavier Pennec and Vincent Arsigny. Exponential Barycenters of the Canonical Cartan Connection and Invariant Means on Lie Groups. In Frederic Barbaresco, Amit Mishra, and Frank Nielsen, editors, Matrix Information Geometry, pages 123–168. Springer, 5 2012. ISBN 978-3-642-30231-2 (Print) / 978-3-642-30232-9 (Online). doi: 10.1007/978-3-642-30232-9.
- Pennec and Lorenzi (2020) Xavier Pennec and Marco Lorenzi. 5 - Beyond Riemannian geometry: The affine connection setting for transformation groups. In Xavier Pennec, Stefan Sommer, and Tom Fletcher, editors, Riemannian Geometric Statistics in Medical Image Analysis, pages 169–229. Academic Press, January 2020. ISBN 978-0-12-814725-2. doi: 10.1016/B978-0-12-814725-2.00012-1. URL http://www.sciencedirect.com/science/article/pii/B9780128147252000121.
- Pennec and Thirion (1997) Xavier Pennec and Jean-Philippe Thirion. A Framework for Uncertainty and Validation of 3D Registration Methods based on Points and Frames. Int. Journal of Computer Vision, 25(3):203–229, December 1997. doi: 10.1023/A:1007976002485. URL http://www.springerlink.com/openurl.asp?genre=article&issn=0920-5691&volume=25&issue=3&spage=203.
- Pennec et al. (2006) Xavier Pennec, Pierre Fillard, and Nicholas Ayache. A Riemannian Framework for Tensor Computing. International Journal of Computer Vision, 66(1):41–66, 1 2006.
- Petersen and Muller (2016) Alexander Petersen and Hans-Georg Muller. Fréchet regression for random objects with euclidean predictors. The Annals of Statistics, 2016. URL https://api.semanticscholar.org/CorpusID:13666043.
- Pfaff et al. (2021) Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter W. Battaglia. Learning mesh-based simulation with graph networks, 2021.
- Pizer et al. (2003) Stephen M. Pizer, P. Thomas Fletcher, Sarang Joshi, Andrew Thall, Jiahui Z. Chen, Yael Fridman, Daniel S. Fritsch, Grant Gash, James M. Glotzer, Mark R. Jiroutek, Chiwu Lu, Keith E. Muller, George Tracton, Paul Yushkevich, and Edward L. Chaney. Deformable m-reps for 3d medical image segmentation. International Journal of Computer Vision, 55(2-3):85–106, November 2003. doi: 10.1023/a:1026313132218.
- Praggastis et al. (2023) Brenda Praggastis, Sinan G. Aksoy, Dustin Arendt, Mark Bonicillo, Cliff A Joslyn, Emilie Purvine, Madelyn R Shapiro, and Ji Young Yun. Hypernetx: A python package for modeling complex network data as hypergraphs. ArXiv, abs/2310.11626, 2023. URL https://api.semanticscholar.org/CorpusID:264288882.
- PyT-Team (2024) PyT-Team. Topobenchmarkx, 2024.
- Qi et al. (2017) Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/d8bf84be3800d12f74d8b05e9b89836f-Paper.pdf.
- Rajpurkar et al. (2022) P. Rajpurkar, E. Chen, and O. et al. Banerjee. Ai in health and medicine. Nature Medicine, 2022. URL https://doi.org/10.1038/s41591-021-01614-0.
- Reidenbach and Krishnapriyan (2023) Danny Reidenbach and Aditi S. Krishnapriyan. Coarsenconf: Equivariant coarsening with aggregated attention for molecular conformer generation, 2023.
- Reiser et al. (2022) P. Reiser, M. Neubert, and A. et al. Eberhard. Graph neural networks for materials science and chemistry. 2022. URL https://doi.org/10.1038/s43246-022-00315-6.
- Roddenberry et al. (2022) T. Mitchell Roddenberry, Michael T. Schaub, and Mustafa Hajij. Signal processing on cell complexes. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8852–8856, 2022. doi: 10.1109/ICASSP43922.2022.9747233.
- Rosenblatt (1958) Frank Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review, 65(6):386, 1958.
- Roweis and Saul (2000) Sam T. Roweis and Lawrence K. Saul. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science, 290(22):2323–2326, 2000. URL http://www.robots.ox.ac.uk/~az/lectures/ml/lle.pdf.
- Rumelhart et al. (1986) David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back-propagating errors. Nature, 323:533–536, 1986. URL https://api.semanticscholar.org/CorpusID:205001834.
- Sanchez-Gonzalez et al. (2020) Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter W. Battaglia. Learning to simulate complex physics with graph networks, 2020.
- Satorras et al. (2021) Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E (n) equivariant graph neural networks. In International conference on machine learning, pages 9323–9332. PMLR, 2021.
- Satorras et al. (2022) Victor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E(n) equivariant graph neural networks, 2022.
- Scaife and Porter (2021) Anna M M Scaife and Fiona Porter. Fanaroff–riley classification of radio galaxies using group-equivariant convolutional neural networks. Monthly Notices of the Royal Astronomical Society, 503(2):2369–2379, February 2021. ISSN 1365-2966. doi: 10.1093/mnras/stab530. URL http://dx.doi.org/10.1093/mnras/stab530.
- Schötz (2022) Christof Schötz. Nonparametric regression in nonstandard spaces. Electronic Journal of Statistics, 16(2):4679 – 4741, 2022. doi: 10.1214/22-EJS2056. URL https://doi.org/10.1214/22-EJS2056.
- Schütt et al. (2017) Kristof T. Schütt, Pieter-Jan Kindermans, Huziel E. Sauceda, Stefan Chmiela, Alexandre Tkatchenko, and Klaus-Robert Müller. Schnet: A continuous-filter convolutional neural network for modeling quantum interactions, 2017.
- Shi et al. (2009) Xiaoyan Shi, Martin Styner, Jeffrey Lieberman, Joseph G. Ibrahim, Weili Lin, and Hongtu Zhu. Intrinsic Regression Models for Manifold-Valued Data, page 192–199. Springer Berlin Heidelberg, 2009. ISBN 9783642042713. doi: 10.1007/978-3-642-04271-3˙24. URL http://dx.doi.org/10.1007/978-3-642-04271-3_24.
- Simm et al. (2020) Gregor N. C. Simm, Robert Pinsler, Gábor Csányi, and José Miguel Hernández-Lobato. Symmetry-aware actor-critic for 3d molecular design, 2020.
- Simonovsky and Komodakis (2018) Martin Simonovsky and Nikos Komodakis. Graphvae: Towards generation of small graphs using variational autoencoders, 2018.
- Sivera et al. (2019) Raphaël Sivera, Hervé Delingette, Marco Lorenzi, Xavier Pennec, and Nicholas Ayache. A model of brain morphological changes related to aging and Alzheimer’s disease from cross-sectional assessments. NeuroImage, 198:255–270, September 2019. ISSN 10538119. doi: 10.1016/j.neuroimage.2019.05.040. URL https://linkinghub.elsevier.com/retrieve/pii/S105381191930432X.
- Sommer (2013) Stefan Sommer. Horizontal Dimensionality Reduction and Iterated Frame Bundle Development. In Frank Nielsen and Frédéric Barbaresco, editors, Geometric Science of Information, pages 76–83. Springer Berlin Heidelberg, 2013. ISBN 978-3-642-40019-3 978-3-642-40020-9. URL http://link.springer.com/chapter/10.1007/978-3-642-40020-9_7.
- Sommer et al. (2014) Stefan Sommer, François Lauze, and Mads Nielsen. Optimization over geodesics for exact principal geodesic analysis. Advances in Computational Mathematics, 40(2):283–313, 2014.
- Steinke et al. (2008) Florian Steinke, Matthias Hein, Jan Peters, and Bernhard Schölkopf. Manifold-valued thin-plate splines with applications in computer graphics. Comput. Graph. Forum, 27:437–448, 04 2008. doi: 10.1111/j.1467-8659.2008.01141.x.
- Stokes et al. (2020) Jonathan M Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos-Ruiz, Nina M. Donghia, Craig R. MacNair, Shawn French, Lindsey A. Carfrae, Zohar Bloom-Ackermann, Victoria M. Tran, Anush Chiappino-Pepe, Ahmed H. Badran, Ian W. Andrews, Emma J. Chory, George Church, Eric D. Brown, T. Jaakkola, Regina Barzilay, and James J Collins. A deep learning approach to antibiotic discovery. Cell, 180:688–702.e13, 2020. URL https://api.semanticscholar.org/CorpusID:261621991.
- Tenenbaum et al. (2000) Joshua B. Tenenbaum, Vin de Silva, and John C. Langford. A Global Geometric Framework for Nonlinear Dimensionality Reduction. Science, 290(5500):2319, 2000.
- Thomas et al. (2018) Nathaniel Thomas, Tess Smidt, Steven Kearnes, Lusann Yang, Li Li, Kai Kohlhoff, and Patrick Riley. Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds. 2018. URL http://arxiv.org/abs/1802.08219.
- Tipping and Bishop (1999) Michael E Tipping and Christopher M Bishop. Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61(3):611–622, 1999.
- Townsend et al. (2016) James Townsend, Niklas Koep, and Sebastian Weichwald. Pymanopt: A python toolbox for optimization on manifolds using automatic differentiation. J. Mach. Learn. Res., 17:137:1–137:5, 2016. URL https://api.semanticscholar.org/CorpusID:29194288.
- Trouvé (1998) Alain Trouvé. Diffeomorphisms Groups and Pattern Matching in Image Analysis. International Journal of Computer Vision, 28(3):213–221, 1998. ISSN 1573-1405.
- Tsagkrasoulis and Montana (2018) Dimosthenis Tsagkrasoulis and Giovanni Montana. Random forest regression for manifold-valued responses. Pattern Recognition Letters, 101:6–13, January 2018. ISSN 0167-8655. doi: 10.1016/j.patrec.2017.11.008. URL http://dx.doi.org/10.1016/j.patrec.2017.11.008.
- van der Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. Visualizing Data using {t-SNE}. Journal of Machine Learning Research, 9:2579–2605, 2008.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Veeling et al. (2018) Bastiaan S. Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling. Rotation equivariant cnns for digital pathology, 2018.
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph Attention Networks. International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=rJXMpikCZ.
- Vignac et al. (2023) Clement Vignac, Nagham Osman, Laura Toni, and Pascal Frossard. Midi: Mixed graph and 3d denoising diffusion for molecule generation, 2023.
- Wang et al. (2023) Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, Anima Anandkumar, Karianne J. Bergen, Carla P. Gomes, Shirley Ho, Pushmeet Kohli, Joan Lasenby, Jure Leskovec, Tie-Yan Liu, Arjun K. Manrai, Debora S. Marks, Bharath Ramsundar, Le Song, Jimeng Sun, Jian Tang, Petar Velickovic, Max Welling, Linfeng Zhang, Connor W. Coley, Yoshua Bengio, and Marinka Zitnik. Scientific discovery in the age of artificial intelligence. Nature, 620:47–60, 2023. URL https://api.semanticscholar.org/CorpusID:260384616.
- Wang et al. (2019) Minjie Wang, Da Zheng, Zihao Ye, Quan Gan, Mufei Li, Xiang Song, Jinjing Zhou, Chao Ma, Lingfan Yu, Yu Gai, Tianjun Xiao, Tong He, George Karypis, Jinyang Li, and Zheng Zhang. Deep graph library: A graph-centric, highly-performant package for graph neural networks. arXiv preprint arXiv:1909.01315, 2019.
- Wang (2015) Minmin Wang. Height and diameter of brownian tree. Electronic Communications in Probability, 20(none), January 2015. ISSN 1083-589X. doi: 10.1214/ecp.v20-4193. URL http://dx.doi.org/10.1214/ECP.v20-4193.
- Weiler et al. (2024) Maurice Weiler et al. Equivariant and coordinate independent convolutional networks: A gauge field theory of neural networks. 2024.
- Williams and Rasmussen (1995) Christopher Williams and Carl Rasmussen. Gaussian processes for regression. In D. Touretzky, M.C. Mozer, and M. Hasselmo, editors, Advances in Neural Information Processing Systems, volume 8. MIT Press, 1995. URL https://proceedings.neurips.cc/paper_files/paper/1995/file/7cce53cf90577442771720a370c3c723-Paper.pdf.
- Wu et al. (2022) Shiwen Wu, Fei Sun, Wentao Zhang, Xu Xie, and Bin Cui. Graph neural networks in recommender systems: A survey. ACM Comput. Surv., 55(5), dec 2022. ISSN 0360-0300. doi: 10.1145/3535101. URL https://doi.org/10.1145/3535101.
- Wu et al. (2021) Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems, 32(1):4–24, 2021. doi: 10.1109/TNNLS.2020.2978386.
- Xu et al. (2022) Minkai Xu, Lantao Yu, Yang Song, Chence Shi, Stefano Ermon, and Jian Tang. Geodiff: a geometric diffusion model for molecular conformation generation, 2022.
- Xu et al. (2023) Minkai Xu, Alexander Powers, Ron Dror, Stefano Ermon, and Jure Leskovec. Geometric latent diffusion models for 3d molecule generation, 2023.
- Yang and Dunson (2016) Yun Yang and David B. Dunson. Bayesian manifold regression. The Annals of Statistics, 44(2):876 – 905, 2016. doi: 10.1214/15-AOS1390. URL https://doi.org/10.1214/15-AOS1390.
- Yang et al. (2023) Z. Yang, X. Zeng, and Y. et al. Zhao. Alphafold2 and its applications in the fields of biology and medicine. 2023. URL https://doi.org/10.1038/s41392-023-01381-z.
- Ying et al. (2018) Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L. Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18. ACM, July 2018. doi: 10.1145/3219819.3219890. URL http://dx.doi.org/10.1145/3219819.3219890.
- Younes (2010) Laurent Younes. Shapes and diffeomorphisms. Number v. 171 in Applied mathematical sciences. Springer, Heidelberg ; New York, 2010. ISBN 978-3-642-12054-1. OCLC: ocn632088149.
- Zhang et al. (2020) Liangliang Zhang, Yushu Shi, Robert R. Jenq, Kim‐Anh Do, and Christine B. Peterson. Bayesian compositional regression with structured priors for microbiome feature selection. Biometrics, 77(3):824–838, July 2020. ISSN 1541-0420. doi: 10.1111/biom.13335. URL http://dx.doi.org/10.1111/biom.13335.
- Zhang and Fletcher (2013) Miaomiao Zhang and P. Thomas Fletcher. Probabilistic principal geodesic analysis. Advances in Neural Information Processing Systems, pages 1–9, 2013. ISSN 10495258.