1603 研究应用 Y.Ye 和 W. Zeng 分别来自香港科技大学(广州)和香港科技大学。 邮箱:yyebd@connect.ust.hk; weizeng@hkust-gz.edu.cn S. Shaw 和 X. Zeng 来自香港科技大学(广州)。 邮箱:sxiao713@connect.hkust-gz.edu.cn; xzeng159@connect.hkust-gz.edu.cn。 曾伟为通讯作者。
ModalChorus:通过模态融合图进行多模态嵌入的视觉探测和对齐
摘要
多模态嵌入构成了视觉语言模型的基础,例如 CLIP 嵌入,这是使用最广泛的文本图像嵌入。 然而,这些嵌入很容易受到跨模式特征的细微错位的影响,从而导致模型性能下降和泛化能力减弱。 为了解决这个问题,我们设计了ModalChorus,一个用于视觉探测和多模态嵌入对齐的交互式系统。 ModalChorus主要提供两个阶段的过程:1)使用模态融合图(MFM)进行嵌入探测,这是一种新颖的参数降维方法,集成了度量和非度量目标以增强模态融合; 2)嵌入对齐,允许用户交互式地表达点集对齐和集集对齐的意图。 CLIP 嵌入与现有降维(t-SNE 和 MDS)和数据融合(数据上下文图)方法的定量和定性比较证明了 MFM 在展示跨模态特征方面优于共同视觉-语言数据集。 案例研究表明,ModalChorus可以在从零样本分类到跨模态检索和生成的场景中促进错位的直观发现和高效的重新对齐。
关键词:
多模态嵌入、降维、数据融合、交互式对齐![[Uncaptioned image]](x1.png)
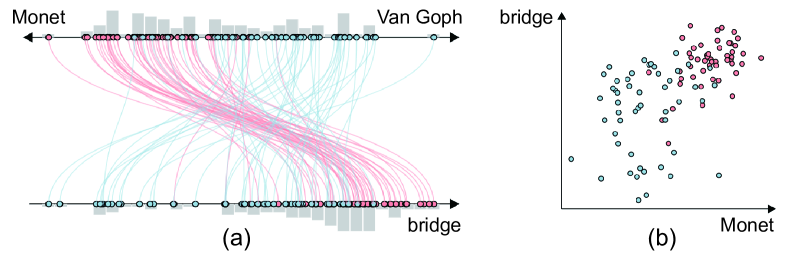
用于文本到图像生成的多模式 CLIP 嵌入的视觉探测。 (a) 对于“莫奈的睡莲池”的提示,用户首先发现预训练模型的错位,表现为“莫奈”和“桥”之间概念纠缠的形式> 使用我们的模态融合图投影和概念轴视图。 (b)可以执行基于加权嵌入生成的数据增强以提供额外的对齐参考集。 (c) 执行集合-集合对齐交互,将初始生成的“莫奈的睡莲池”图像与反映用户意图的增强图像对齐。 (d) 对齐后模型可以通过解开“Monet”和“bridge”来生成一组更具多样性的图像。
1简介
神经嵌入是从自监督预训练中捕获的知识的高维潜在表示,例如词嵌入和图像嵌入。 最近,多模态(文本和图像)嵌入在推进多模态人工智能模型方面发挥着关键作用。 这种类型的嵌入学习一个联合表示空间,该空间编码不同的模态及其关系,形成跨模态任务的基础,例如文本到图像检索和生成[3, 49, 66]。 多模态嵌入模型的性能在很大程度上依赖于多模态对齐的质量,多模态对齐旨在将嵌入空间内不同模态的数据与相应的语义相匹配[48,22,23]。 然而,由于不同模态的概念之间复杂的多对多映射,多模态嵌入中的错位很常见。 例如,文本到图像的嵌入很容易遇到概念纠缠的错位问题。 如图ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map(a)所示,'Monet的睡莲池<的文本提示/t3>' 与图像模态中的 'bridge' 概念纠缠在一起,降低了生成图像的多样性。
识别多模态嵌入中的错位对于提高模型性能至关重要。 评估错位的现有方法通常依赖于基于参考的评估(CIDEr [57] 和 SPICE [2]),这需要大量的人工标记参考或无参考来自保留的多模态模型的指标(CLIPScore [28])。 尽管不依赖于参考,但无参考指标依赖于预先训练的模型,这使得全自动方法在不同和上下文相关的场景中检测错位变得具有挑战性。 例如,文本提示“莫奈的睡莲池”的CLIPScore未能反映概念纠缠的问题,因为CLIP模型本身偏向“桥”图像形态中的概念。 因此,现有的用于改善对齐的微调技术在许多情况下常常达不到预期。 需要一种交互式可视化工具来帮助用户直观地调查和解决错位问题。
然而,多模态嵌入中固有的复杂数据结构和特征特征给视觉探测和交互式对齐带来了特殊的挑战。 一个关键的挑战来自模态间隙,其中来自不同模态的嵌入向量在联合嵌入空间[39]中本质上是不相交的。 为了实现多模态嵌入的凝聚可视化,必须解决模态间隙问题并在单个显示空间内统一不同模态的呈现。 以前的神经嵌入可视化主要集中在单模态嵌入,例如单词或图像嵌入[41,42,26]。 值得注意的是,这些作品通常采用经典的降维(DR)方法,例如 t-SNE [56] 和 MDS[5],这些方法仅限于单独显示多模态嵌入在不同的空间中。 基于融合的 DR 方法([13, 10])提供了一种潜在的解决方案,可以联合投影不同模式的嵌入。 然而,这些方法通常平等地对待模内和模间距离,而没有特别考虑跨模态关系。 例如,数据上下文映射 (DCM) [10] 仅依赖于基于度量的目标,而这些目标很难捕获模间距离的相对排序。 如图4(左)所示,DCM 在文本概念周围投影图像嵌入点的分布相当均匀,使得观察分布模式的差异变得更加困难。
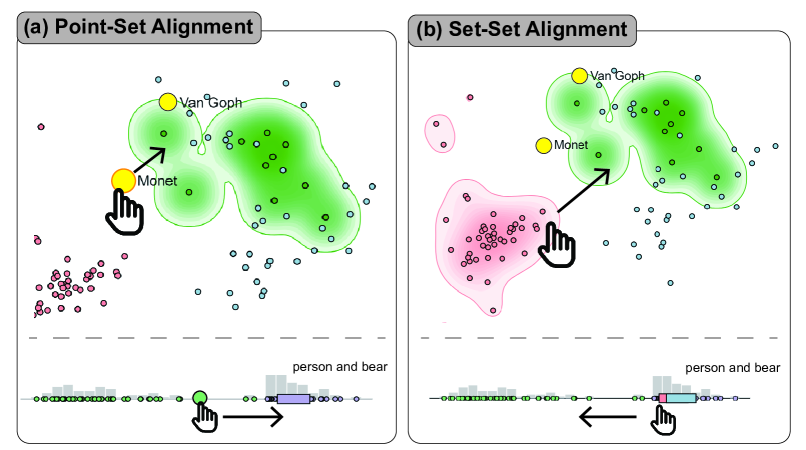
此外,实现多模式嵌入的交互式对齐提出了另一个挑战,主要有两个原因。 首先,用户意图的对齐策略包含不同的操作。 例如,在图 ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map,当识别出文本模态中的"莫奈"和图像模态中的"桥"之间存在概念纠缠时,用户可能会倾向于将"桥"点拖到较远的位置,或将整组"莫奈"图像重新定位。 然而,现有的研究通常关注基于点的操作[16, 62],而其他研究仅支持基于集合的交互[19]。 其次,用户将利用交互式对齐来细化底层模型,并确保细化后的模型按预期执行,如图4(d)所示对齐后生成的解开图像所示。 现有的 DR 细化研究主要集中在调整投影布局[16,62,58,19],而忽视了模型细化。
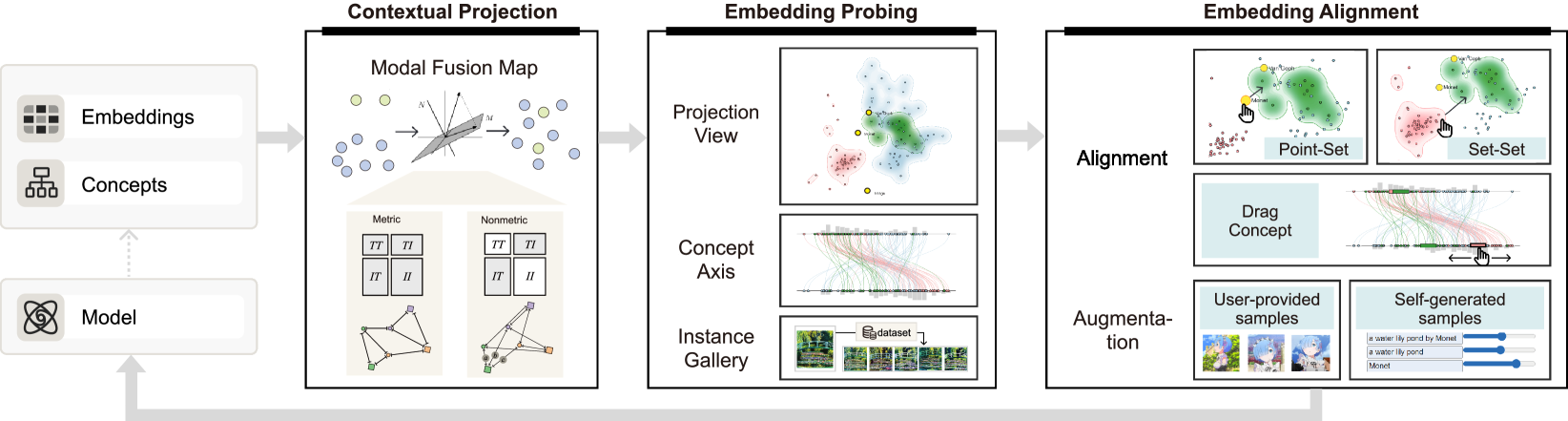
为了填补这一空白,我们提出了 ModalChorus,这是一个支持视觉探测和多模态嵌入对齐的交互式系统。 ModalChorus主要包括两阶段探索。 首先,在嵌入探测阶段,我们提出了模态融合图 (MFM),这是一种新颖的参数 DR 方法,集成了度量和非度量目标,用于增强模态融合。 通过利用基于度量的目标在保留模态内距离和非基于度量的目标在捕获模态间距离排序 [5, 13] 方面的优势,MFM 有效地解决了模态差距多模态嵌入引发的挑战。 与传统的单模态和基于融合的DR方法相比,MFM在模态间关系方面实现了更高的可信度和连续性(见表1),并且可以更好地直观地反映模态内和模间上下文分布(见图3和4)。 接下来,在嵌入对齐阶段,为了适应不同的对齐场景,我们设计了一种对齐交互方案,允许在包括点、子集和集合在内的多个级别上进行对齐。 交互方案与包含点集和集集对齐的 MFM 集成。 此外,还开发了概念轴视图,以实现多模态嵌入的探测和对齐的线性视觉表示。
总而言之,我们做出以下贡献:
-
•
我们提出了模态融合图(MFM),这是一种专为多模态嵌入的融合投影而设计的新颖的降维方法。 MFM 的有效性通过定量和定性评估来证明。
-
•
我们开发了ModalChorus,这是一个交互式系统,支持对多模态嵌入进行视觉探测以发现错位,以及支持对底层多模态嵌入模型进行交互式微调的交互方案。
-
•
我们通过对三个基于嵌入的跨模态任务的案例研究(从零样本分类到跨模态检索和生成)展示了我们系统的有效性。
2相关工作
神经嵌入可视化。 深度学习依赖于通常根据大量数据进行预训练的神经网络。 神经嵌入是神经网络编码的原始数据的基础高维特征表示,例如像 word2vec [45] 和 BERT [15] 这样的文本嵌入以及像SimCLR [9]。 可视化研究人员付出了巨大的努力来增强对神经嵌入的理解。 之前的研究主要集中在单峰嵌入,包括单词嵌入[41,26,27]和图像嵌入[42]。 其中许多研究将投影方法与基于轴的[41,26,42]或基于集合的[27]探索技术相结合。 例如,Liu等人[41]在t-SNE投影的词嵌入中识别了具有相同语义转换的多对词之间的类比轴。 潜在空间制图[42]将语义轴的概念扩展到用户定义的自定义轴,可应用于单峰词嵌入和图像嵌入的探索。 EmbComp [27] 将 t-SNE 投影与邻域集重叠可视化相结合,以比较不同的词嵌入模型。
最近,CLIP [48] 和 ALIGN [33] 等多模态嵌入推动了文本到图像生成等多模态 AI 的进步。 这些嵌入可以在联合空间中对来自不同模态的数据进行编码,有助于各种应用,例如跨模态图像检索[4]和生成[49]。 然而,这种集成还引入了模态间隙[39],它表示不同模态嵌入之间的差异,使多模态嵌入的理解变得复杂。 缺乏适合该任务的可视化工具。 具体来说,该任务需要一种有效的可视化方法来探测多模态嵌入,以及一种交互式方案来改进多模态嵌入的对齐。 为了实现这一目标,我们提出了模态融合图,它可以更好地保留多模态嵌入的上下文信息,以及交互式对齐方案,为模态对齐提供视觉引导。
上下文降维。 与 t-SNE [56]、PCA [59] 和 MDS [5 等传统 DR 方法相比,多模态数据的降维一直是一个具有挑战性的问题由于模态间隙[39,71,46],]无法解释跨模态关系。 上下文可视化是一种DR方法,旨在投影与属性点[10,69,44]相关的数据点,可应用于多模态数据投影。 现有的上下文可视化可以分为两种类型:基于锚的投影和基于融合的方法。 基于锚的方法采用两阶段方法,首先确定一种模态中点的布局,然后计算另一种模态中点的位置。 例如,RadViz 方法 [29, 11, 65] 首先将属性点布置在圆上,然后根据数据点的多维属性值投影数据点。 然而,由于最佳布局锚点的挑战,嵌入空间的结构可能会显着扭曲。
一类融合方法,称为共同嵌入方法[64, 12],引入了自己的多模态数据的高维表示或修改某些数据点的嵌入以实现所需的视觉效果布局。 然而,这些方法偏离了我们的目标,因为它们用自定义模型改变了原始嵌入,这无法帮助用户理解人工智能任务中常用的多模态嵌入。 可视化研究人员开发了更通用的融合方法[10, 69]。 特别是,数据上下文映射(DCM)[10]定义了属性的距离矩阵,并在使用MDS联合投影属性点和数据点之前将其与数据距离矩阵合并。 然而,在 DCM 中,模态内和模态间距离在基于度量的优化中受到同等对待,这限制了其充分捕获多模态嵌入的跨模态非度量序数结构的能力。 在我们的研究中,我们引入了模态融合图,它使用一种新颖的参数 DR 方法将度量和非度量目标集成到模态融合中,以有效保留多模态嵌入的模态内和模态间距离的关系。
模态对齐的视觉转向。 多模态基础嵌入模型的预训练依赖于通过对比学习等方法进行对齐,例如 ViLBERT [43] 和 CLIP [48]。 例如,CLIP 嵌入 [48] 是通过在具有对比多类 N 对损失的联合表示空间中匹配图像和文本标题来在大规模图像文本对语料库上进行预训练的。 预训练方法通常旨在建立基础模型,但预训练数据的质量参差不齐,在特定情况下往往会留下一些偏差,这需要进行诸如少样本微调之类的调整[31,20,46] 来细化对齐。 未对准情况可能需要人类知识才能发现,并且微调过程通常还涉及用户对对准数据和方向的选择,这需要一个交互式系统来支持人在环工作流程。 这种场景与预训练模型的交互式提示工程不同[61,55,18],因为提示工程仅寻求改变输入而不细化模型,这不足以引导复杂的多模型。具有未对准的模态模型。
之前的一些视觉分析系统支持通过标签校正或数据增强来交互式改进人工智能模型[7,24,25]。 例如,VATLD [24] 利用解缠结表示学习对与可解释数据维度相关的交通灯检测结果进行语义探索。 然而,这些研究只关注特定于任务的模型,而没有关注基础嵌入。 许多研究还依赖于真实标签来进行洞察发现,这可能无法在预训练模型的实时探测中使用。 此外,这些研究缺乏对直接在可视化空间中的视觉转向交互的支持,这对于我们研究目标的对齐操作来说更加直观。
一些可视化研究人员研究了降维结果的交互式视觉引导[16,62,58,19]。 例如,Xia 等人 [62]提出了一种对比学习驱动的参数降维方法,支持点级交互,增强视觉聚类效果。 ULCA [19]支持集合级视觉引导交互进行比较分析。 DRAVA [58]在的基础上引入了一种在基于轴的可视化中调整小倍数位置的交互方法。 然而,这些交互仅侧重于为了视觉探索目的而细化投影布局,缺乏对齐底层模型或高维表示的能力。 此外,大多数先前研究的交互方案仅限于单一类型的交互,例如单个视图中基于点或基于集合的交互,无法覆盖多模态嵌入的多样化对齐场景。 在我们的研究中,我们开发了一种支持点集和集集对齐的交互方案,这使得底层基于嵌入的模型能够灵活对齐。
3概述
3.1 背景和领域问题
多模式嵌入。 多模态嵌入模型是用于表示多模态数据的预训练编码器模型。 例如,CLIP 模型是在大型图像文本对语料库上进行预训练的,使用 Transformer 和 Vision Transformer 首先将文本和图像分别编码为高维向量。 然后,通过线性变换,文本嵌入和图像嵌入向量在具有对比损失的共享嵌入空间中对齐。 多模态嵌入是许多人工智能任务的基础编码器,这些任务在输入和/或输出中涉及多模态数据。 常见任务包括基于语义的图像分类 [48]、跨模态检索 [23] 和文本到图像生成 [50, 8].
对齐。 在多模态模型中,对齐意味着数据表示与来自不同模态的相应语义的匹配。 例如,在 CLIP 的预训练阶段,对齐是通过更新图像及其相应文本标题的嵌入来实现的,以便它们比高维表示空间中的错误对更接近。 然而,由于预训练数据质量参差不齐、数据量大以及训练算法的不完善,预训练模型可能会出现错位,需要进一步调整以增强对齐[31,20,46].
多级对齐。 主要有点、子集、集合三个层面的对齐,需要两种对齐方式:点集对齐和集集对齐。 具体来说,用户可能会发现单个点(错误分类的图像点或误解的文本点)、子集(整个文本到图像检索结果集中不正确样本的子集)和集合(有偏差的点)的未对准。或文本到图像模型的纠缠生成结果),需要不同的对齐操作。为了澄清,我们将系统提取的关键字或用户输入的关键字称为概念,这是我们在本研究中重点关注的主要文本嵌入,用于嵌入的上下文探索,而特定的图像点被称为作为实例。
问题:嵌入可视化。 许多可视化研究将嵌入方法视为处理数据的工具,目的是优化原始输入数据的视觉显示。 也就是说,这些可视化将嵌入视为一种投影方法。 相反,在人工智能领域,单模态和多模态嵌入的表示学习一直在各种下游任务中发挥着关键作用[51, 37]。 高维嵌入本身是从原始文本或像素中提取的数据的关键中间表示,而不仅仅是用于视觉显示的表示。 为了深入了解大型 AI 模型,特别是对齐问题,高维可视化方法应优先考虑捕获基础嵌入本身的特征 (G1)。 例如,假设两类图像在嵌入空间中确实很接近,这意味着嵌入中存在未对准的风险。 在这种情况下,我们不希望仅仅为了视觉显示而最大化投影空间中的类分离,因为它可能会误导用户。 再比如,如果生成模型中提示的文本嵌入与生成的图像不接近,我们应该谨慎地将文本直接放在生成图像集的质心处,这可能会导致用户认为生成完全对齐。
总而言之,以前的研究重点是可视化的嵌入,而我们的工作旨在嵌入的可视化。 此外,此场景中交互的目标是改进基础高维嵌入(G2),而不是像之前的研究那样改进数据的视觉显示[62, 19]。
3.2挑战和设计要求
实现这两个目标对于现有的可视化方法来说是一项挑战,特别是因为:
-
C1
模态差距。 联合嵌入空间中不同模态的异构分布导致模态间隙[39, 71],使得现有的DR方法难以同时捕获模内和跨模态特征。
-
C2
多样化的对齐意图。 不同跨模式任务中的不同对齐场景对设计集成到可视化中的综合交互方案提出了挑战。
为了应对这些挑战,我们总结了ModalChorus的设计要求,它应该支持灵活有效的R1)视觉探测多模态嵌入以满足G1。
-
R1.1
准确保留模式间和模式内的距离。 需要一种有效的基于融合的 DR 方法来弥合模态差距,同时最大限度地保留模态间和模内关系。
-
R1.2
有效的视觉呈现有助于识别错位。 除了投影之外,还需要有效的图形增强来帮助发现错位问题,例如错误分类或纠缠。
其次,ModalChorus 应促进多模态嵌入的 R2) 交互式对齐,以支持 G2:
-
R2.1
支持点和集级别上的对齐。 用户可能会发现在单个数据点或整组点上嵌入未对齐,从而需要不同类型的对齐交互,包括点集对齐和集集对齐。
-
R2.2
支持基于轴的对齐。 先前的嵌入可视化研究已将语义轴确定为整体投影的有效补充,以实现更集中的概念相关探索[41,26,42]。 除了直接操作嵌入的投影之外,用户还需要执行基于轴的对齐,因为轴可以更清楚地显示相对于特定语义概念的对齐方向。
-
R2.3
支持数据增强。 当用户发现未对准但无法找到正确的参考数据时,他们希望提供额外的数据并对其进行处理以帮助对准。
3.3 ModalChorus 概述
我们的系统概述如图1所示,主要包含两个阶段:1)嵌入探测和2)嵌入对齐。 在第一阶段,从特定的数据集和任务开始,以及用户提供的输入或自动提取的概念,我们支持使用采样数据对嵌入进行视觉探测,以解释嵌入并发现错位。 特别是,我们开发了模态融合图,这是一种新颖的参数融合方法,它集成了多模态嵌入投影的度量和非度量目标。 我们还结合了概念轴视图,允许用户探索图像嵌入与概念文本嵌入的相关性。 附加实例库显示与嵌入空间中所选图像点相似的图像,以进行邻域探索。
在第二阶段,一旦发现未对准,我们使用户能够选择特定的点、子集或集合,并在投影视图或概念轴视图中执行点集对齐或集集对齐。 在某些情况下,当需要新数据来增强对齐时,我们允许用户上传收集的数据以进行少样本对齐或使用我们系统的加权嵌入生成功能来生成候选增强数据。 最后,将视觉对齐操作映射到后端微调。
4 多模态上下文可视化
在本节中,我们将描述模态融合图,这是我们提出的一种新颖的 DR 方法,用于解决多模态嵌入的R1 视觉探测。
4.1问题识别
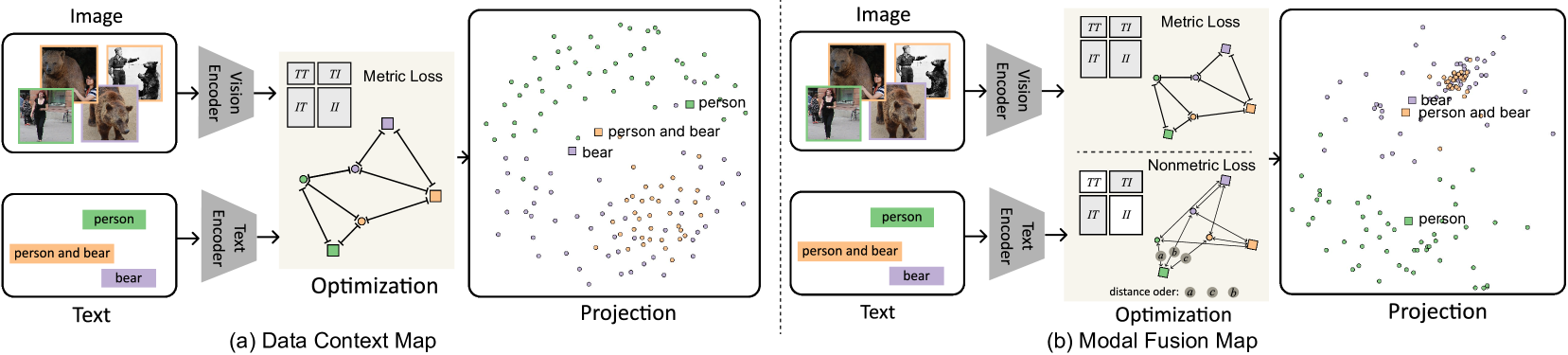
为了解决多模态嵌入可视化中的模态间隙问题,数据矩阵融合方法[13, 10]是一个有前途的解决方案。 数据上下文映射(DCM)[10]等矩阵融合方法源自用于基于距离的融合的MDS方法。 最初的Data Context Map是针对多维数据的属性和数据空间而设计的。 具体来说,为了对齐来自不同模态的数据点,它构造了一个包含所有数据点和属性点之间的成对距离的大距离矩阵,其中模内距离是原始高维距离,例如欧氏距离或余弦距离,而模态距离是原始高维距离,例如欧氏距离或余弦距离。跨模态距离需要根据数据属性来定义。 例如,DCM将属性点和数据点之间的距离定义为,其中是该属性维度中数据点的值。
首先,为了考虑高维潜在空间,我们可以自然地将 DCM 中的属性数据距离更改为文本嵌入和图像嵌入之间的余弦距离。 然而,这种修改可能不足以满足多模态嵌入的复杂性。 具体来说,为了增强模态融合效果,灵活调整模态内和模态间距离的权重非常重要。 如[13]中提到的直接缩放子矩阵可能存在显着扭曲嵌入空间或加剧模态差距的风险。 更重要的是,当像 CLIP 这样的多模态嵌入用于文本到图像检索等跨模态任务时,文本和图像嵌入之间的绝对距离不如距离值的相对顺序重要。 在多模态嵌入的可视化中,还应该考虑这些特征。 这意味着我们应该开发一种更好的融合方法,同时考虑度量和非度量目标[30,47,17]。
4.2 模态融合图
降维。 受最近参数降维工作[62,63,67]的启发,为了满足上述投影要求,我们提出了模态融合图(MFM),它可以灵活地组合不同的目标进行联合多模态嵌入投影。 假设在高维嵌入空间中,文本嵌入集和图像嵌入集之间存在子空间或流形表面,例如两种模态的嵌入在该表面上的投影 () 可以产生优化的二维参数表示 。 具体来说,与其他基于矩阵的方法一样,我们首先计算合并距离矩阵:
| (1) |
其中是图像距离子矩阵,是文本距离子矩阵,是跨模态距离子矩阵,均使用余弦距离。 每个子矩阵均按其平均值进行归一化。
接下来,我们没有像 DCM 那样直接将传统的 MDS 方法应用于合并矩阵,而是使用三层前馈神经网络将投影参数化,将 512 或 1024 维 CLIP 嵌入映射到二维投影空间。 有关更多详细信息,请参阅补充材料。 然后,为了实现 MDS 目标,我们利用高维合并距离矩阵和投影距离矩阵之间的皮尔逊相关性构建了一个损失函数,以进行无标度优化。
| (2) |
其中代表投影点的距离矩阵。
通过这种方式,我们可以轻松地定义模态内和模态间子矩阵的损失项,分别表示为、和。 因此,度量 MDS 的损失函数是加权和。 在我们的例子中,我们只考虑整体术语和跨模式术语:,其中我们设置。
此外,为了使非度量损失保持跨模态距离顺序,我们进一步引入另一个损失项:
| (3) |
其中。 当所有跨模态距离顺序都保留在投影中时,该损失项将为零。 最终的损失。 、、 是根据经验选择的。
基于轮廓的图形增强。 受最近工作[69]的启发,我们以密度等值线的形式提供了图形增强功能。 如图4所示,密度图可以显示数据点分布的默认KDE密度估计。 KDE 轮廓可以作为投影视图中集合的图形表示,这可以促进后续的对齐交互,如下所述。 或者,当用户提供为数据点定义的自定义指标(例如生成样本的 CLIP-Score)时,密度图可以显示指标值分布的核估计。
| Inter-modal | Intra-modal | |||
| T(30) | C(30) | T(30) | C(30) | |
| PCA | 0.9177 | 0.9301 | 0.7297 | 0.8183 |
| MDS | 0.9274 | 0.9336 | 0.8039 | 0.8537 |
| Isomap | 0.9307 | 0.9281 | 0.7706 | 0.8637 |
| t-SNE | 0.9290 | 0.9296 | 0.9098 | 0.9010 |
| NDCM | 0.9223 | 0.9225 | 0.5304 | 0.5309 |
| DCM | 0.9385 | 0.9434 | 0.8481 | 0.8941 |
| MFM | 0.9589 | 0.9645 | 0.8764 | 0.9117 |
4.3评估
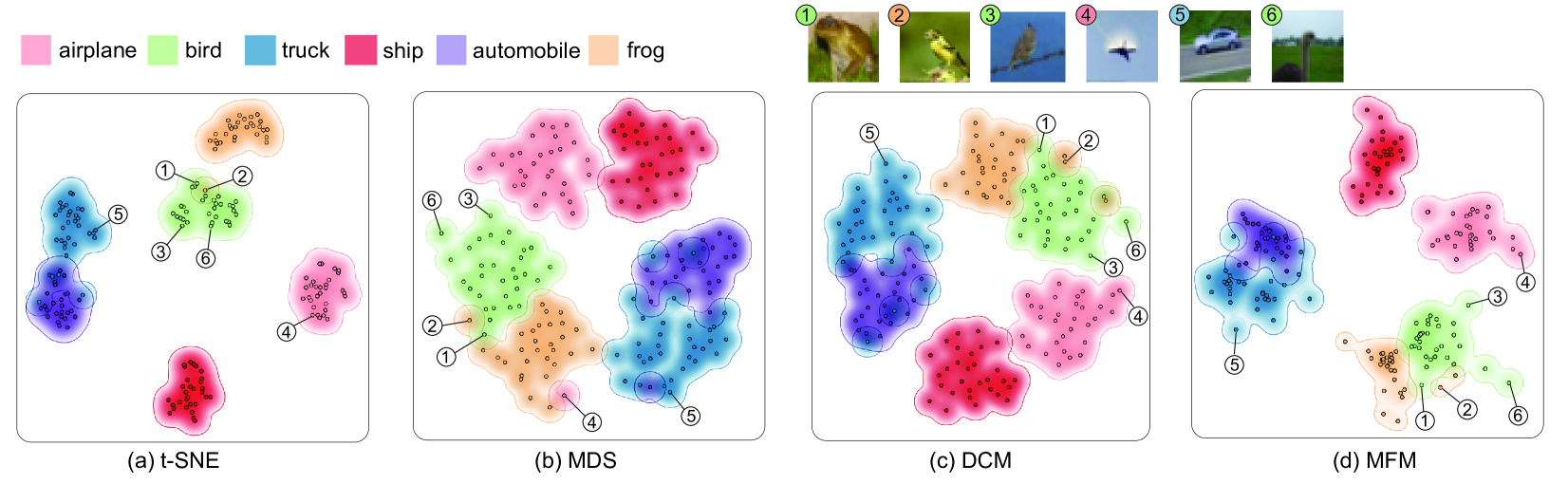
定性比较。 如图3和图4所示,与DCM方法和传统投影方法(如MDS 和 t-SNE。 具体来说,图 3 显示了 CIFAR-10 数据集中 6 类样本的 CLIP 图像嵌入投影的模内情况。 颜色代表基于 CLIP 的零样本分类结果。 结果中,我们可以看到t-SNE取得了最好的分离效果。 然而,t-SNE 在理解嵌入和识别错位方面也存在明显的缺点,因为它没有考虑跨模态特征。 首先,t-SNE 在显示上下文信息方面较弱,例如不同集合之间的关系。 例如,我们可以在图3中发现,由于颜色或背景相似,青蛙集(绿点1)可能与鸟集(黄点2)混淆,但t-SNE与 MFM 相比,投影并没有清楚地显示这种关系。 此外,我们的联合投影还显示出比 t-SNE 更好的组内分布。 例如,通过 MFM,我们可以清楚地看到集合内的离群值 或边界点(蓝色点 5 和绿色点 6)。 点5对应于在高速公路上行驶的汽车的图像,而大多数其他汽车图像是停放的汽车的静态场景。 点6是一种长颈鸵鸟,它的外貌与其他鸟类有很大不同。 然而,这些点在 t-SNE 投影中很难识别。 图3(b)中的MDS结果比t-SNE更能有效地显示点关系,但聚类效果明显弱于t-SNE和MFM。 此外,MDS 倾向于在投影空间中相当均匀地分布点,这会影响组内分布和异常值的显示。 DCM 方法显示的上下文集合关系比 t-SNE 更好,并且显示集合离群值 仅 略好于 MDS, 因为对于图像模态,DCM 和 MDS 都使用度量损失 ,但MFM在这两方面都取得了更好的效果。 此外,我们计算数据点的 Z 分数,以帮助验证视觉异常值或边界点是否确实在原始高维空间中(详细信息请参阅补充)。 我们发现图 3 (d) 中最明显的异常点 6 确实具有最高的 Z 得分 1.2379。
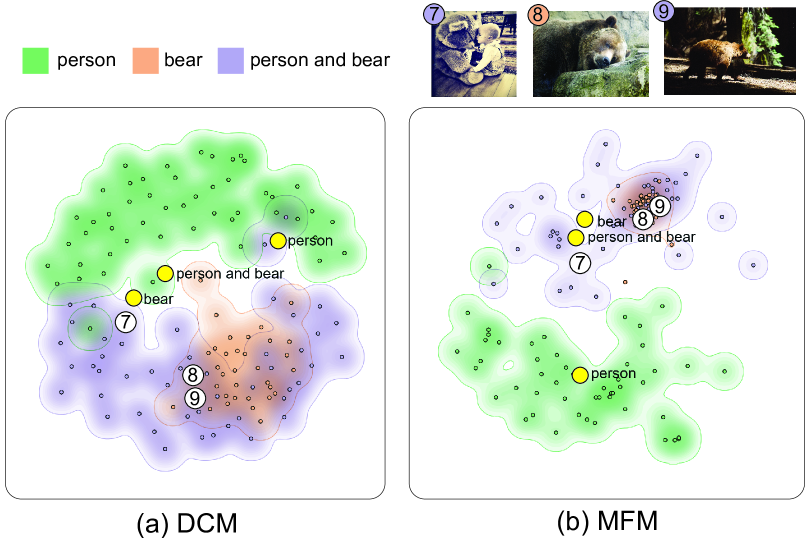
图4显示了跨模态情况,其中三个文本查询的CLIP文本嵌入与查询结果的图像嵌入一起投影。 关于 DCM 结果(图 4 (a)),它确实成功地合并了模态。 然而,正如这两种情况所示,DCM 有一个显着的弱点,即它将图像嵌入点相当均匀地分散在空间中,使得用户很难发现不同区域之间的分布差异。 相比之下,例如,在图4(b)中,我们可以在MFM结果中发现明显的密集簇,其中包含许多类似的野生熊图像,但这种模式在DCM中不太明显结果。 此外,MFM也比DCM更清楚地展示了概念之间的关系,我们可以发现bear和person and bear的查询结果有明显的重叠 DCM 和 MFM 结果均一致,表明这两个文本概念之间的关系更密切,但 MFM 中文本嵌入的相对位置比 DCM 更符合这种关系。
定量评估。 为了展示 MFM 优势的一些定量证据,我们使用可信度度量和连续性度量 [34, 62] 在 COCO 数据集上评估该方法,其中前者计算投影 kNN 反映真实情况的真实程度kNN 在嵌入空间中,后者计算原始高维 kNN 在投影中的保留程度。 特别是,我们计算 k=30 时的模态间和模态内 kNN。 然而,在我们的场景中,模态间度量更为重要,因为它衡量方法保留多模态嵌入结构的能力。 对于评估过程,我们执行多轮 () 评估,每轮我们从 COCO 中随机采样 500 张图像,并将它们与 COCO 对象标签中的 80 个类别文本嵌入一起投影。 最终的指标是所有轮次结果的平均值。 如表1所示,实验结果表明,MFM方法在模间真实性和连续性方面始终优于所有其他方法,比最强基线DCM高出2%以上。 此外,MFM 在模态内指标方面也取得了良好的表现,仅次于 t-SNE。 NDCM [13] 是另一种使用完全非度量目标的融合方法。 我们可以看到,在三种融合方法(MFM、DCM 和 NDCM)中,我们的 MFM 在模态间和模态内度量上始终表现得更好,而完全非度量融合方法在保持模态内特征方面具有显着劣势。 我们还需要注意的是,t-SNE和MDS等非融合传统方法的模态间度量不能完全反映它们在模态间场景中的弱点,因为模态间隙会导致投影中图像嵌入和文本嵌入之间的距离过大空间,使得很难感知模态间距离之间的差异[39,71,46]。
5 ModalChorus系统
5.1可视化界面
设置面板。 设置面板(图5(a))允许用户为他们的探索指定一些基本设置,包括任务和输入。 用户还可以在输入中选择特定概念,以在投影视图中生成上下文可视化。 ModalChorus 不是仅仅依赖于从现有文本标签或提示中显式提取的文本概念,而是从图像中提取隐式概念以提供概念的全面显示。 为了实现这一目标,我们首先利用 BLIP-2 [38],这是一种多模态语言模型,能够接收图像作为输入并生成这些图像的文本描述。 然后,我们采用 TopicRank [6] 算法根据 BLIP-2 生成的文本提取候选视觉概念。
投影视图。 投影视图(图5(b))是系统的主视图,利用我们提出的模态融合图来帮助用户探测不同任务和数据的嵌入。 用户可以选择打开或关闭轮廓来分别强调集合关系或方便实例探索。 投影视图还包括下面的实例检索子视图(图5(c))。 用户可以将鼠标悬停在嵌入点上以查看图库中相应的图像。 他们还可以单击该点来检索与所选图像相似的图像。 此外,用户还可以通过套索或按住Ctrl键单击来选择点的子集,如第1节中的案例2和图9所示。 6.
概念轴视图。 如图5(d)和图6(a)所示,概念轴视图支持与文本嵌入相关的基于轴的图像嵌入探索 对于用户从设置面板选择的概念。 用户可以用单一概念(桥)定义一端轴,也可以用他们想要对比的相反概念(莫奈和梵高)定义两端轴。对于一端轴,图像嵌入点的位置为:
| (4) |
其中表示嵌入空间中概念的和文本嵌入之间的余弦相似度, 是轴的长度。 对于两端轴,的位置计算为。 当用户定义多个轴时,我们使用连接两个轴上同一实例的曲线来显示相关性。 直方图还用于帮助用户查看整体分布。 除了显示图像嵌入的实例之外,概念轴还可以将整个集合或子集表示为所有集合内点的平均位置处的小框,向用户显示集合的平均值并支持进一步的基于集合的对齐交互如图7和Sect.中所述。 5.2. 我们还允许用户切换到散点图可视化(图 6 (b))。

增强面板。 数据增强面板(图5(e))支持对齐数据的交互式增强。 在某些对齐场景中,用户无法从原始数据集中找到合适的对齐数据(例如,用户可能找不到预训练生成模型生成的任何令人满意的结果)。 对于这样的问题,增强面板首先允许用户上传样本子集来补充比对数据。 对于上传的未标记原始图像数据,该面板还集成了基于CLIP-interrogator[1]的自动标记功能,可以生成与图像相关的标记以增强对齐性能。 其次,在用户甚至发现很难收集自己的数据的情况下,增强面板还包含一个生成功能,使用户能够利用现有文本嵌入 [14, 60] 的加权和。预训练的生成模型可以合成更多符合意图的样本候选。
5.2 交互式对齐
对齐交互设计。 我们设计了一系列视觉对齐交互,让用户可以通过视觉隐喻直观地表达不同的对齐意图,并触发后端微调,而无需编写复杂的训练代码。 如图7所示,我们的交互方案支持集合和点级别的对齐意图。 首先,常见的对齐类型主要涉及数据点或点的子集,我们将其分为两类:点集对齐和集集对齐,如图7所示。 首先,点集对齐包含将集合与数据点对齐的各种场景,反之亦然。 例如,当用户想要将检索结果的子集与查询文本嵌入对齐时,或者当用户想要将提示嵌入与自己提供的错误样本对齐时。 如图7(a)所示,点集对齐既可以在投影视图上进行,也可以在概念轴上进行。 形式上,点集对齐的高级思想可以总结如下:假设我们有一个基于 CLIP 的模型 ,它可以将输入文本或图像映射到不同的集合 在采样数据中。 例如,在分类中,对应于预测类的嵌入集合;在检索和生成中,对应于单个查询或提示结果的嵌入集。 给定用户选择的未对齐图像或文本点 ,点集对齐的目标是调整 的权重,使 更接近嵌入空间中正确的集合。 虽然不同任务的具体实现可能有所不同,但就合并距离矩阵而言,其效果相当于实现以下对比目标:
| (5) |
其中 和 之间的估计距离应小于任何其他集合 。 其次,集合-集合对齐涉及在概念轴或投影视图中将点的两个子集移动得更近或更远。 这种对齐的目的是缩小嵌入空间中两个集合或分布之间的差距,或者对比两个集合以更好地区分它们,这对于在检索或生成中合并或解开概念等情况非常有用。 如图7(b)所示,在投影视图中,他们可以将一组轮廓拖向另一组轮廓,而在轴视图中,他们可以将一个组框拖近或远离另一个组框。 从形式上讲,集合对齐的高层次思想是:假设用户识别出一个不对齐的嵌入集或子集 ,其中 与输入 不对齐。接下来,用户可以通过对其他投影数据点的可视化探索或数据增强来找到另一个正确的集合 。 集合-集合对齐的目标可以表述为:
| (6) |
对齐微调实现。 我们的系统提供了一个通用框架,将图 7 中所示的用户视觉交互映射到后端微调操作,从而在嵌入空间中对齐模型的输出。 由于视觉表示与实际后端实现分离,我们的框架可以结合任何类型的特定微调方法。 出于演示目的,我们的研究采用了两种方法。 首先,对于分类和检索案例,我们实现基于三元组损失[54]的对齐。 其次,对于生成情况,我们实现了低秩自适应方法[31]。 补充材料中提供了更多详细信息。
6案例研究
在本节中,我们进行了三个案例研究来演示 Modal Fusion Map 和 ModalChorus 系统的有用性,它们涵盖了基于多模态嵌入的三个不同任务,包括零样本分类、文本到图像检索和生成。 特别是,我们展示了我们的视觉探测如何与交互式少样本对齐集成并增强[21, 32]。
6.1案例1:零样本分类
在本例中,我们演示了如何使用我们的系统基于多模态嵌入聚类来可视化零样本分类[48],并帮助通过一次性点交互式地细化嵌入设置对齐方式。 具体来说,我们使用 CIFAR-10 图像分类数据集 [36] 来展示示例。 这里我们假设没有可用的真实标签。 这是为了模拟对未知数据进行基于零样本嵌入的分类的实时分析,其中人工干预的交互式视觉分析是最有帮助的。
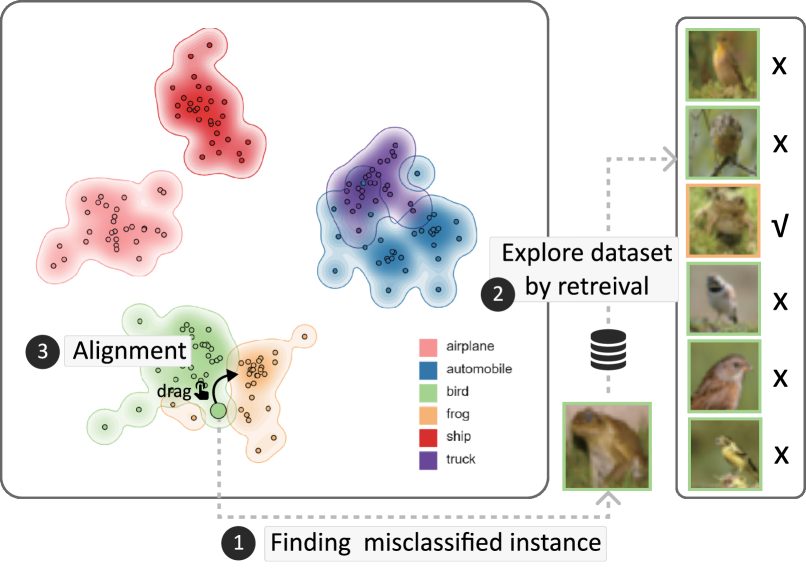
用户首先选择分类任务和数据集。 然后,用户主观地选择一些他们怀疑可能会使 CLIP 混淆的类别,包括小型野生动物类别和车辆类别。 具体来说,他们选择了想要探索的 6 个类别概念,包括 airplane、automobile、truck、ship、鸟和青蛙。 然后,系统根据图像嵌入和类别文本嵌入之间的跨模态接近度来预测每个图像的类别。 系统对数据进行采样以进行视觉探测。 具体来说,它根据 CLIP 嵌入检索与每个类文本最接近的 50 个图像。 他们可以看到bird和frog集群的CLIP嵌入集确实非常接近,并且他们可以发现与概念中选择的数据项对应的突出显示点view 位于 bird 集群的边界。 事实上,当用户看到该图像时,他们发现该项目实际上是青蛙,但被错误分类为鸟。 通过在实例检索视图中检索相似的图像,用户可以进一步了解这是因为有一些鸟类和青蛙具有相似的颜色和轮廓。 随后,用户通过将该点拖动到更接近正确的frog簇来执行点集对齐,如图8所示。
在后端,我们使用基本事实来验证我们的视觉对齐确实有帮助。 具体来说,在对齐之前,总体精度为。 其中,准确率最低的类别是frog,只有。 在这种情况下,仅对一个数据点进行视觉对齐后,在 CIFAR-10 第 1 批的 10,000 张图像中,frog 类别的准确度上升到 。 同时,整体准确率也提升至。
6.2 案例2:实例检索和组合逻辑
在本例中,我们展示了如何使用我们的系统来可视化和细化实例检索中的组合逻辑。 具体来说,我们在 COCO 2017 数据集 [40] 上测试跨模态检索。 COCO 数据集的训练集由超过 110,000 张图像组成,其中包含来自 80 个类别的图像中的标题和对象的注释。
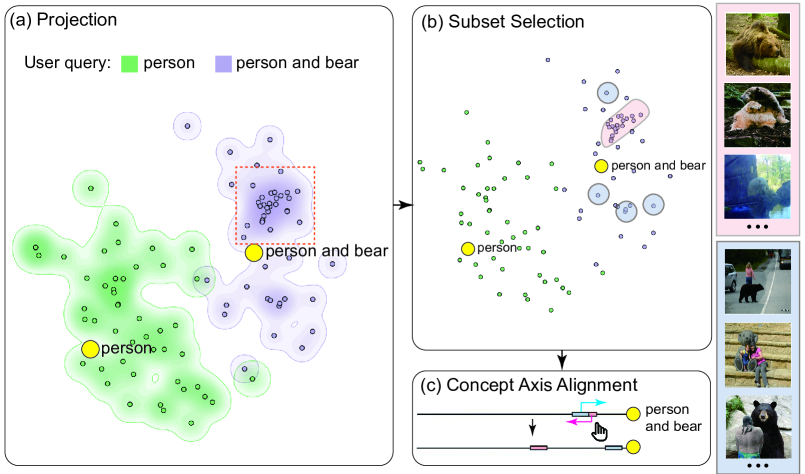
为了进行检索,用户输入两个查询:第一个是简单的关键字:“人”,第二个是使用自然语言逻辑表达的两个元素组成:“人与熊” 。 用户首先利用我们的 MFM 方法来投影与 CLIP 嵌入中的关键字文本相关的两个查询各自的前 50 个图像结果。 在图9(a)所示的上下文投影中,用户可以看到在组合查询“person and bear”的文本嵌入附近有一个明显的密集簇。 相比之下,在简单查询 "人"的文本嵌入附近,图像嵌入的分布相当稀疏。 当用户将鼠标悬停在某些数据点上探索特定实例时,他们发现“人”的检索结果比“人和熊”的检索结果更加多样化。 更重要的是,他们甚至发现该集群实际上包含许多类似的错误结果,只包含野外的熊,而没有任何人,这表明 CLIP 嵌入没有充分理解“人与熊”中的逻辑。 用户可以通过添加另一个关键字查询“bear”来进一步验证这一发现,并将结果一起可视化,如图4(b)所示。
在识别出组合查询的错位问题后,用户可以继续在系统的对齐模式下以交互方式对齐 CLIP 嵌入。 具体来说,在投影视图中,他们首先套索选择错误簇的样本,将其添加到由粉红色表示的第一个对齐子集中。 接下来,他们还发现了文本嵌入附近包含人和熊的正确图像的一些单独样本,这些样本被添加到以蓝色表示的第二个对齐子集中。 随后,用户可以看到错误子集和正确样本非常接近且难以分离。 最后,用户可以通过将不正确的子集拖得更远来执行集合对齐,从而触发后端的微调。
对齐后,用户可以利用新的 CLIP 嵌入对之前的前 500 个结果进行重新排名。 我们实施重新排名,而不是完全索引数据集中的所有数据点,以加快系统反应。 连同少量样本对齐,这只需要几秒钟。 为了定量验证这种对齐确实有帮助,在后端,我们计算新结果与之前结果相比的前 k 个准确度,如表所示。
| top 5 | top 20 | top 30 | top 40 | top 50 | |
|---|---|---|---|---|---|
| Before | 60.00% | 50.00% | 43.33% | 40.00% | 40.00% |
| After | 80.00% | 60.00% | 53.33% | 52.50% | 52.00% |
6.3 案例3:跨模态生成中的概念注入和解开
在本例中,我们展示了如何使用我们的系统在跨模式生成中进行对齐,并举例说明对齐文本到图像稳定扩散模型。 特别是,与专门的 AIGC 微调工具(如 IntentTuner [68])相比,它只专注于数据增强和训练功能,如 LoRA [31] 和 DreamBooth [52],我们的视觉探测框架允许用户通过嵌入可视化来直观地检查和比较微调前后的生成结果、增强数据和提示关键字。 我们选择Stable Diffusion V1-4,它使用CLIP作为输入编码器。
第一个示例(图10)显示了概念注入对齐的情况,其中预训练的模型不理解概念,用户尝试将其注入模型的知识中。 例如,如图10所示,用户可能希望输入提示“Rem rezero”(动画角色的名称)来生成该角色的图像。 然而,在原始模型生成 50 个样本后,用户可以发现我们的系统检测到一些视觉关键字,例如“紫色头发”,这是意想不到的,因为所需的字符具有短蓝色的突出特征头发。 用户还输入另一个概念关键字“女仆”,它描述了预期角色的标志性着装风格。 然后,MFM产生关键词和生成图像的联合投影,如图10(a)所示。 用户可以在该投影视图中发现许多异常结果。 例如,如图10(a)(1)这样的异常值是真实照片的图像。 用户还可以确认一些接近“purple hair”文本嵌入的图像包含与预期的蓝色头发不同的紫色头发(图10 (a) (2)) 。
为了使模型与这个新概念保持一致,用户收集了 20 张正确的 Rem 样本图像并将其上传到系统。 新上传的样本被添加到投影中,如图10(b)所示。 我们可以看到投影视图清楚地显示了预生成结果(红色)和正确样本(蓝色)之间的差距,而提示关键字 “rem rezero” 位于两者之间的中间位置簇,表明与正确集的对齐不足。 观察后,用户可以直接将“rem rezero”的文本嵌入点拖向正确的样本集,如图10(c)所示。 此操作会触发后端对齐过程。 对齐完成后,系统使用新对齐的模型生成“rem rezero”的50个样本(绿色)(图10(d))。 我们可以看到,与红色集相比,绿色集更接近正确的样本簇,这意味着成功对齐到正确的概念。 用户进一步探索新生成的图像的细节,发现他们已经捕捉到了所需角色最重要的特征,包括标志性的蓝色短发和女仆装。
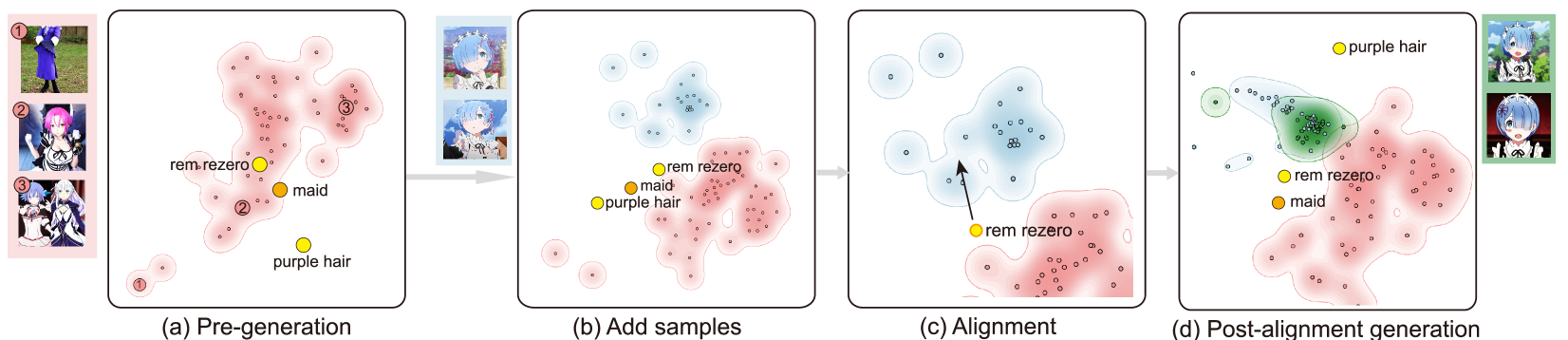
第二个示例(图ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map)展示了用于解开生成的对齐方式。 有时,跨模式生成模型中的错位会导致概念纠缠,从而导致意外且无法控制的生成。 例如,当用户想要生成山水画时,输入两个主题相同但艺术家姓名不同的提示:“梵高的睡莲池”和“莫奈的睡莲池”. 系统首先使用同一组随机种子为每个提示生成 50 个样本。 除了“Monet”和“Van Goph”等文本关键字之外,系统还检测到一个意想不到的视觉概念:“bridge”。 然后,通过探索如图ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map(a)所示的MFM投影视图,用户可以发现“莫奈的睡莲池”(红色)生成的点集中在靠近“bridge”文本嵌入的密集簇中,而“的结果Van Goph 的睡莲池” 在投影空间中分布更加稀疏。 检查数据点,用户可以发现莫奈结果具有高度相似的成分,几乎总是包含一座桥。 这种模式在图 ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map (a) 的概念轴中得到了更明显的体现,其中高值莫奈尺寸上的值与红色组的桥尺寸上的高值紧密相关。 相比之下,Van Goph 的结果因不同的成分而更加多样化。 这一观察表明,在莫奈提示中,艺术家的名字与桥梁的视觉概念高度纠缠,从而显着降低了生成的多样性。 为了调整模型以解开纠缠,用户首先需要一些微调数据,但可能会发现手动收集莫奈的睡莲池画作很困难。 为了解决这个问题,他们可以利用我们的增强面板提供的加权嵌入函数来生成更多解缠结的样本。 具体来说,用户可以通过嵌入向量的加权和来组合原始提示中不同关键字和短语的CLIP嵌入,以指导增强样本的生成。 用户可以从这些生成的增强图像中选择与提示“莫奈的睡莲池”匹配的满意样本。 然后,他们可以将样本添加到图 ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map (b) 中的投影(绿色集),其中用户可以发现预生成的莫奈集和增强集之间存在明显的距离。 接下来,如图ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map(c)所示,用户可以拖动预先生成的莫奈集轮廓朝向投影中的增强集或拖动概念轴中代表预生成的莫奈集的框,这会触发两个集的后端对齐过程。 最后,在图ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map(d)中,系统将通过原始红色集(“莫奈的睡莲池”)与对齐后模型的提示相同。 用户可以看到,与红色集相比,紫色集与绿色集更加一致,同时具有更多多样性(包含带桥和不带桥的图像)。
7讨论
速度限制. 我们的系统和方法在速度方面有两个限制。 首先,尽管参数方法可以以较短的渐近时间扩展到大型数据集(如补充材料所示),但对于较小的数据集,它不如一些传统方法(如 t-SNE)那么快。 其次,对齐微调的速度取决于不同任务的具体实现。 对于分类和检索任务,基于三元组损失的微调只需要几秒钟。 然而,对于生成任务,常用的LoRA微调可能需要几分钟的时间。 为了解决这个问题,我们可以利用 HyperDreamBooth [53] 等最新的加速微调方法。
可扩展到更多模式。 在本研究中,我们仅在两种模态的嵌入上测试我们的系统和方法。 然而,一些多模态嵌入涉及两种以上的模态。 例如,ImageBind [23] 嵌入模型包含六种模式,包括图像、文本、音频、深度、热和 IMU 数据。 对于这些数据,我们可以提取多模态语义特征作为概念,并扩展我们的概念可视化以涵盖更多模态。 对于难以视觉观察的模态,例如音频,我们可以使用文本或图像来表示其概念特征。 我们的 MFM 方法还可以改进以可视化不同的模态对,例如文本音频和图像音频。
像素级对齐。 尽管我们的研究实现了各种集合和点级别的对齐,但有时这些对齐对于细粒度的跨模式任务来说是不够的。 例如,基于嵌入的物体检测需要子实例像素级对齐[70]。 到目前为止,我们的研究尚未涉及这种类型的子实例对齐。 关于这个问题,在未来的工作中,我们的系统可以将交互式语义分割(例如Segment Anything Model [35])集成到对齐过程中,以允许用户强调他们希望模型理解的图像的某些部分。
8结论
在这项研究中,我们提出了一个视觉探测和对齐框架,用于探索和交互地细化多模态嵌入。 特别是,对于视觉探测,我们通过开发一种称为模态融合图(MFM)的降维方法来解决模态间隙问题,以优化模态间嵌入特征的显示。 为了促进交互式对齐,我们设计了一个支持各种对齐意图的交互方案,包括点集对齐和集集对齐。 正如我们的定量评估和案例研究所示,我们的框架可以帮助对不同任务进行直观的视觉探测和对齐。 这表明未来研究有机会增加对规模不断扩大但透明度不断下降的大型模型的人工审核。
致谢。
作者衷心感谢匿名审稿人提出的宝贵意见。 该工作得到国家自然科学基金(62172398)和广州市基础与应用基础研究基金(2024A04J6462、2023A03J0142)的部分支持。参考
- [1] CLIP-Interrogator. https://github.com/pharmapsychotic/clip-interrogator.
- [2] P. Anderson, B. Fernando, M. Johnson, and S. Gould. SPICE: Semantic propositional image caption evaluation. pp. 382–398. Springer, 2016. doi: 10 . 1007/978-3-319-46454-1_24
- [3] A. Baldrati, M. Bertini, T. Uricchio, and A. Del Bimbo. Conditioned and composed image retrieval combining and partially fine-tuning CLIP-based features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 4959–4968, 2022. doi: 10 . 1109/CVPRW56347 . 2022 . 00543
- [4] A. Baldrati, M. Bertini, T. Uricchio, and A. Del Bimbo. Effective conditioned and composed image retrieval combining clip-based features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21466–21474, 2022. doi: 10 . 1109/CVPR52688 . 2022 . 02080
- [5] I. Borg and P. J. Groenen. Modern multidimensional scaling: Theory and applications. Springer Science & Business Media, 2005.
- [6] A. Bougouin, F. Boudin, and B. Daille. TopicRank: Graph-based topic ranking for keyphrase extraction. In International Joint Conference on Natural Language Processing (IJCNLP), pp. 543–551, 2013.
- [7] C. Chen, J. Wu, X. Wang, S. Xiang, S.-H. Zhang, Q. Tang, and S. Liu. Towards better caption supervision for object detection. IEEE Transactions on Visualization and Computer Graphics, 28(4):1941–1954, 2021. doi: 10 . 1109/TVCG . 2021 . 3138933
- [8] F.-L. Chen, D.-Z. Zhang, M.-L. Han, X.-Y. Chen, J. Shi, S. Xu, and B. Xu. Vlp: A survey on vision-language pre-training. Machine Intelligence Research, 20(1):38–56, 2023. doi: 10 . 1007/s11633-022-1369-5
- [9] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning, pp. 1597–1607. PMLR, 2020. doi: 10 . 48550/arXiv . 2002 . 05709
- [10] S. Cheng and K. Mueller. The data context map: Fusing data and attributes into a unified display. IEEE Transactions on Visualization and Computer Graphics, 22(1):121–130, 2015. doi: 10 . 1109/TVCG . 2015 . 2467552
- [11] S. Cheng, W. Xu, and K. Mueller. RadViz deluxe: An attribute-aware display for multivariate data. Processes, 5(4):75, 2017. doi: 10 . 3390/pr5040075
- [12] D. Choi, B. Drake, and H. Park. Co-embedding multi-type data for information fusion and visual analytics. In Proceedings of International Conference on Information Fusion (FUSION), pp. 1–8, 2023. doi: 10 . 23919/FUSION52260 . 2023 . 10224157
- [13] J. Choo, S. Bohn, G. C. Nakamura, A. M. White, and H. Park. Heterogeneous data fusion via space alignment using nonmetric multidimensional scaling. In Proceedings of the International Conference on Data Mining, pp. 177–188. SIAM, 2012. doi: 10 . 1137/1 . 9781611972825 . 16
- [14] J. J. Y. Chung and E. Adar. PromptPaint: Steering text-to-image generation through paint medium-like interactions. In Proceedings of the Annual ACM Symposium on User Interface Software and Technology, pp. 1–17, 2023. doi: 10 . 1145/3586183 . 3606777
- [15] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, 2019. doi: 10 . 18653/v1/N19-1423
- [16] A. Endert, C. Han, D. Maiti, L. House, and C. North. Observation-level interaction with statistical models for visual analytics. In IEEE Conference on Visual Analytics Science and Technology (VAST), pp. 121–130. IEEE, 2011. doi: 10 . 1109/VAST . 2011 . 6102449
- [17] D. P. Faith, P. R. Minchin, and L. Belbin. Compositional dissimilarity as a robust measure of ecological distance. Vegetatio, 69:57–68, 1987. doi: 10 . 1007/BF00038687
- [18] Y. Feng, X. Wang, K. K. Wong, S. Wang, Y. Lu, M. Zhu, B. Wang, and W. Chen. PromptMagician: Interactive prompt engineering for text-to-image creation. IEEE Transactions on Visualization and Computer Graphics, 30(1):295–305, 2024. doi: 10 . 1109/TVCG . 2023 . 3327168
- [19] T. Fujiwara, X. Wei, J. Zhao, and K.-L. Ma. Interactive dimensionality reduction for comparative analysis. IEEE Transactions on Visualization and Computer Graphics, 28(1):758–768, 2021. doi: 10 . 1109/TVCG . 2021 . 3114807
- [20] R. Gal, Y. Alaluf, Y. Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-or. An image is worth one word: Personalizing text-to-image generation using textual inversion. In Proceedings of International Conference on Learning Representations, 2022.
- [21] P. Gao, S. Geng, R. Zhang, T. Ma, R. Fang, Y. Zhang, H. Li, and Y. Qiao. Clip-Adapter: Better vision-language models with feature adapters. International Journal of Computer Vision, 132(2):581–595, 2024. doi: 10 . 1007/s11263-023-01891-x
- [22] Y. Gao, J. Liu, Z. Xu, T. Wu, E. Zhang, K. Li, J. Yang, W. Liu, and X. Sun. SoftCLIP: Softer cross-modal alignment makes clip stronger. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 1860–1868, 2024. doi: 10 . 1609/aaai . v38i3 . 27955
- [23] R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V. Alwala, A. Joulin, and I. Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15180–15190, 2023. doi: 10 . 1109/CVPR52729 . 2023 . 01457
- [24] L. Gou, L. Zou, N. Li, M. Hofmann, A. K. Shekar, A. Wendt, and L. Ren. VATLD: A visual analytics system to assess, understand and improve traffic light detection. IEEE Transactions on Visualization and Computer Graphics, 27(2):261–271, 2020. doi: 10 . 1109/TVCG . 2020 . 3030350
- [25] W. He, L. Zou, A. K. Shekar, L. Gou, and L. Ren. Where can we help? a visual analytics approach to diagnosing and improving semantic segmentation of movable objects. IEEE Transactions on Visualization and Computer Graphics, 28(1):1040–1050, 2021. doi: 10 . 1109/TVCG . 2021 . 3114855
- [26] F. Heimerl and M. Gleicher. Interactive analysis of word vector embeddings. Computer Graphics Forum, 37(3):253–265, 2018. doi: 10 . 1111/cgf . 13417
- [27] F. Heimerl, C. Kralj, T. Möller, and M. Gleicher. EmbComp: Visual interactive comparison of vector embeddings. IEEE Transactions on Visualization and Computer Graphics, 28(8):2953–2969, 2020. doi: 10 . 1109/TVCG . 2020 . 3045918
- [28] J. Hessel, A. Holtzman, M. Forbes, R. Le Bras, and Y. Choi. CLIPScore: A reference-free evaluation metric for image captioning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 7514–7528, 2021. doi: 10 . 18653/v1/2021 . emnlp-main . 595
- [29] P. Hoffman, G. Grinstein, K. Marx, I. Grosse, and E. Stanley. DNA visual and analytic data mining. In Proceedings of IEEE VIS, pp. 437–441, 1997. doi: 10 . 1109/VISUAL . 1997 . 663916
- [30] M. C. Hout, M. H. Papesh, and S. D. Goldinger. Multidimensional scaling. Wiley Interdisciplinary Reviews: Cognitive Science, 4(1):93–103, 2013. doi: 10 . 1002/wcs . 1203
- [31] E. J. Hu, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, et al. LoRA: Low-rank adaptation of large language models. In Proceedings of International Conference on Learning Representations, 2021.
- [32] Y. Huang, F. Shakeri, J. Dolz, M. Boudiaf, H. Bahig, and I. Ben Ayed. LP++: A surprisingly strong linear probe for few-shot clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 23773–23782, 2024. doi: 10 . 48550/arXiv . 2404 . 02285
- [33] C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. Le, Y.-H. Sung, Z. Li, and T. Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning, pp. 4904–4916. PMLR, 2021. doi: 10 . 48550/arXiv . 2102 . 05918
- [34] S. Kaski, J. Nikkilä, M. Oja, J. Venna, P. Törönen, and E. Castrén. Trustworthiness and metrics in visualizing similarity of gene expression. BMC Bioinformatics, 4(1):1–13, 2003. doi: 10 . 1186/1471-2105-4-48
- [35] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4015–4026, 2023. doi: 10 . 1109/ICCV51070 . 2023 . 00371
- [36] A. Krizhevsky, G. Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [37] P. H. Le-Khac, G. Healy, and A. F. Smeaton. Contrastive representation learning: A framework and review. IEEE Access, 8:193907–193934, 2020. doi: 10 . 1109/ACCESS . 2020 . 3031549
- [38] J. Li, D. Li, S. Savarese, and S. Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning, pp. 19730–19742. PMLR, 2023. doi: 10 . 5555/3618408 . 3619222
- [39] V. W. Liang, Y. Zhang, Y. Kwon, S. Yeung, and J. Y. Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Proceedings of the International Conference on Neural Information Processing Systems, 35:17612–17625, 2022. doi: 10 . 5555/3600270 . 3601550
- [40] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In Proceedings of European Conference on Computer Vision, pp. 740–755. Springer, 2014. doi: 10 . 1007/978-3-319-10602-1_48
- [41] S. Liu, P.-T. Bremer, J. J. Thiagarajan, V. Srikumar, B. Wang, Y. Livnat, and V. Pascucci. Visual exploration of semantic relationships in neural word embeddings. IEEE Transactions on Visualization and Computer Graphics, 24(1):553–562, 2017. doi: 10 . 1109/TVCG . 2017 . 2745141
- [42] Y. Liu, E. Jun, Q. Li, and J. Heer. Latent space cartography: Visual analysis of vector space embeddings. Computer Graphics Forum, 38(3):67–78, 2019. doi: 10 . 1111/cgf . 13672
- [43] J. Lu, D. Batra, D. Parikh, and S. Lee. VilBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Proceedings of the International Conference on Neural Information Processing Systems, 32, 2019. doi: 10 . 5555/3454287 . 3454289
- [44] M. Meyer, A. Barr, H. Lee, and M. Desbrun. Generalized barycentric coordinates on irregular polygons. Journal of Graphics Tools, 7(1):13–22, 2002. doi: 10 . 1080/10867651 . 2002 . 10487551
- [45] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. Proceedings of the International Conference on Neural Information Processing Systems, 26:1–9, 2013. doi: 10 . 5555/2999792 . 2999959
- [46] Y. Ouali, A. Bulat, B. Matinez, and G. Tzimiropoulos. Black box few-shot adaptation for vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 15534–15546, 2023. doi: 10 . 1109/ICCV51070 . 2023 . 01424
- [47] M. Quist and G. Yona. Distributional scaling: An algorithm for structure-preserving embedding of metric and nonmetric spaces. The Journal of Machine Learning Research, 5:399–420, 2004. doi: 10 . 5555/1005332 . 1005346
- [48] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, pp. 8748–8763, 2021. doi: 10 . 48550/arXiv . 2103 . 00020
- [49] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125, 2022. doi: 10 . 48550/arXiv . 2204 . 06125
- [50] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695, 2022. doi: 10 . 1109/CVPR52688 . 2022 . 01042
- [51] S. Ruder, I. Vulić, and A. Søgaard. A survey of cross-lingual word embedding models. Journal of Artificial Intelligence Research, 65:569–631, 2019. doi: 10 . 1613/jair . 1 . 11640
- [52] N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, and K. Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22500–22510, 2023. doi: 10 . 1109/CVPR52729 . 2023 . 02155
- [53] N. Ruiz, Y. Li, V. Jampani, W. Wei, T. Hou, Y. Pritch, N. Wadhwa, M. Rubinstein, and K. Aberman. Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6527–6536, 2024. doi: 10 . 48550/arXiv . 2307 . 06949
- [54] F. Schroff, D. Kalenichenko, and J. Philbin. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815–823, 2015. doi: 10 . 1109/CVPR . 2015 . 7298682
- [55] H. Strobelt, A. Webson, V. Sanh, B. Hoover, J. Beyer, H. Pfister, and A. M. Rush. Interactive and visual prompt engineering for ad-hoc task adaptation with large language models. IEEE Transactions on Visualization and Computer Graphics, 29(1):1146–1156, 2022. doi: 10 . 1109/TVCG . 2022 . 3209479
- [56] L. Van der Maaten and G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research, 9(11):2579–2605, 2008.
- [57] R. Vedantam, C. Lawrence Zitnick, and D. Parikh. CIDEr: Consensus-based image description evaluation. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4566–4575, 2015. doi: 10 . 1109/CVPR . 2015 . 7299087
- [58] Q. Wang, S. L’Yi, and N. Gehlenborg. DRAVA: Aligning human concepts with machine learning latent dimensions for the visual exploration of small multiples. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 1–15, 2023. doi: 10 . 1145/3544548 . 3581127
- [59] S. Wold, K. Esbensen, and P. Geladi. Principal component analysis. Chemometrics and Intelligent Laboratory Systems, 2(1-3):37–52, 1987. doi: 10 . 1016/0169-7439(87)80084-9
- [60] Q. Wu, Y. Liu, H. Zhao, A. Kale, T. Bui, T. Yu, Z. Lin, Y. Zhang, and S. Chang. Uncovering the disentanglement capability in text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1900–1910, 2023. doi: 10 . 1109/CVPR52729 . 2023 . 00189
- [61] T. Wu, E. Jiang, A. Donsbach, J. Gray, A. Molina, M. Terry, and C. J. Cai. PromptChainer: Chaining large language model prompts through visual programming. In CHI Conference on Human Factors in Computing Systems Extended Abstracts, pp. 1–10, 2022. doi: 10 . 1145/3491101 . 3519729
- [62] J. Xia, L. Huang, W. Lin, X. Zhao, J. Wu, Y. Chen, Y. Zhao, and W. Chen. Interactive visual cluster analysis by contrastive dimensionality reduction. IEEE Transactions on Visualization and Computer Graphics, 29(1):734–744, 2022. doi: 10 . 1109/TVCG . 2022 . 3209423
- [63] J. Xia, L. Huang, Y. Sun, Z. Deng, X. L. Zhang, and M. Zhu. A parallel framework for streaming dimensionality reduction. IEEE Transactions on Visualization and Computer Graphics, 30(1):142–152, 2023. doi: 10 . 1109/TVCG . 2023 . 3326515
- [64] X. Xie, X. Cai, J. Zhou, N. Cao, and Y. Wu. A semantic-based method for visualizing large image collections. IEEE Transactions on Visualization and Computer Graphics, 25(7):2362–2377, 2018. doi: 10 . 1109/TVCG . 2018 . 2835485
- [65] Y. Ye, R. Huang, and W. Zeng. VISAtlas: An image-based exploration and query system for large visualization collections via neural image embedding. IEEE Transactions on Visualization and Computer Graphics, 2022. doi: 10 . 1109/TVCG . 2022 . 3229023
- [66] Y. Ye, Q. Zhu, S. Xiao, K. Zhang, and W. Zeng. The contemporary art of image search: Iterative user intent expansion via vision-language model. Proc. ACM Hum.-Comput. Interact., 8(CSCW1):Article 180:1–31, 2024. doi: 10 . 1145/3641019
- [67] Z. Zang, S. Cheng, L. Lu, H. Xia, L. Li, Y. Sun, Y. Xu, L. Shang, B. Sun, and S. Z. Li. DMT-EV: An explainable deep network for dimension reduction. IEEE Transactions on Visualization and Computer Graphics, 30(3):1710–1727, 2022. doi: 10 . 1109/TVCG . 2022 . 3223399
- [68] X. Zeng, Z. Gao, Y. Ye, and W. Zeng. IntentTuner: An interactive framework for integrating human intents in fine-tuning text-to-image generative models. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pp. 182:1–18, 2024. doi: 10 . 1145/3613904 . 3642165
- [69] X. Zhang, S. Cheng, and K. Mueller. Graphical enhancements for effective exemplar identification in contextual data visualizations. IEEE Transactions on Visualization and Computer Graphics, 29(9):3775–3787, 2022. doi: 10 . 1109/TVCG . 2022 . 3170531
- [70] Y. Zhong, J. Yang, P. Zhang, C. Li, N. Codella, L. H. Li, L. Zhou, X. Dai, L. Yuan, Y. Li, et al. RegionCLIP: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16793–16803, 2022. doi: 10 . 1109/CVPR52688 . 2022 . 01629
- [71] C. Zhou, F. Zhong, and C. Öztireli. CLIP-PAE: Projection-augmentation embedding to extract relevant features for a disentangled, interpretable and controllable text-guided face manipulation. In ACM SIGGRAPH 2023 Conference Proceedings, pp. 1–9, 2023. doi: 10 . 1145/3588432 . 3591532