I2AM:通过归因图解释图像到图像的潜在扩散模型
抽象的
大规模扩散模型在图像生成领域取得了重大进展,特别是在使用交叉注意力机制方面,该机制基于文本描述引导图像形成。 尽管近年来对扩散模型中文本引导的交叉注意力的分析已得到广泛研究,但其在图像到图像扩散模型中的应用仍未得到充分探索。 本文介绍了图像到图像归因图 () 方法,该方法聚合了补丁级别的交叉注意力得分,以增强跨时间步、头部和注意力层的潜在扩散模型的可解释性。 便于详细的图像到图像归因分析,能够观察扩散模型在从参考图像生成图像的过程中如何随时间和头部优先考虑关键特征。 通过大量实验,我们首先可视化了生成图像和参考图像的归因图,验证了参考图像中的关键信息已有效地整合到生成图像中,反之亦然。 为了进一步评估我们的理解,我们引入了一个新的评估指标,专门针对基于参考的图像修复任务。 该指标衡量了生成图像和参考图像的归因图之间的一致性,与用于修复任务的已建立性能指标显示出强烈的相关性,验证了 在未来研究工作中的潜在用途。
1简介
潜在扩散模型 (LDM) 的最新进展彻底改变了图像生成和编辑领域。 值得注意的发展,如谷歌的 Imagen Saharia et al. (2022b)、OpenAI 的 DALL-E 2 Ramesh et al. (2022) 和 Stability AI 的 Stable Diffusion Rombach et al. (2022) 为逼真的图像生成开辟了新的视野。 虽然这些模型通过基于不同输入生成复杂视觉效果在各种应用中显示出前景,但了解其决策过程仍然很困难。 这一挑战强调了可解释人工智能 (XAI) 的重要性,它提供了用于解释这些模型行动的工具,增强了它们的可靠性和用户洞察力。
近年来,使用交叉注意力模块分析文本到图像 LDM 并理解生成过程取得了进展 Hertz 等人 (2022);Tang 等人 (2022)。 这使得能够更精确地处理模型的输出,例如关注理想的特征或管理生成过程中的特定步骤。 甚至可以检查生成过程以确定特定文本如何影响最终图像。 通过调试模型,这些技术产生的结果反映了更具体的标准,从而显着提高了模型在各个行业的应用范围。
虽然已经提出了大量针对文本到图像 LDM 分析和应用的解决方案,但目前关于图像到图像 LDM 的研究却很缺乏。 图像到图像模型使用输入图像(我们称之为 参考图像)作为条件来生成图像,被称为 生成图像。 文本条件模型生成视觉上解释提供的文本描述的图像,而图像条件模型将参考图像转换为图像的不同视觉形式,但与参考图像在语境上相关。 将文本到图像解释方法 Tang 等人 (2022) 应用于图像到图像生成具有潜力,因为参考图像被划分为类似于文本符元的补丁。 但是,由于参考图像和生成图像之间的空间和语境连续性,在文本中进行的符元级解释在实践中不太可行,这带来了困难。 此外,缺乏空间信息将解释限制在文本到图像生成中的一个方向。
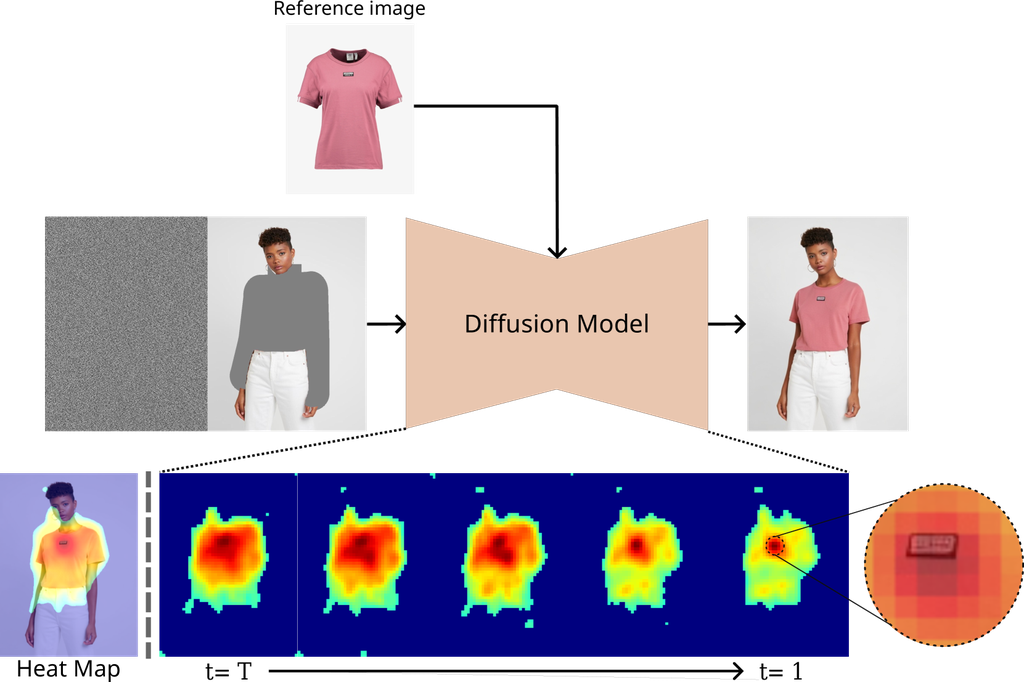
我们的目标是了解图像到图像 LDM 并分析执行修复任务的三个模型。 与文本到图像模型不同,图像到图像处理看起来更直观,因为它是在同一个域中运行。 尽管如此,我们研究的潜在扩散模型并不是在像素空间中工作,而是在潜在空间中工作,这使得直观的映射变得困难。 我们的第一个研究问题是,“生成图像的哪些部分受参考图像的影响?” 解决这个问题有助于确定模型是否在正确区域使用来自参考图像的信息。 尽管如此,它并不能最终确定模型是否从参考图像中提取了有用的信息。 因此,我们的第二个研究问题是,“生成图像参考了参考图像的哪些部分?” 为了回答这些问题,我们建议将交叉注意力图合并以创建归因图。 随着时间的推移,我们观察到模型逐渐形成了物体的形状,并专注于关键特征(例如,印刷图案和徽标),如图 1 所示。 此过程类似于勾勒总体结构并填充细节,类似于人类绘画的方式。 此外,该模型始终优先考虑增强所有归因图中图像质量的关键特征。 我们还建议可视化参考图像的关键区域,以验证内容是否被适当地提取。
最后,我们建议使用归因图作为 XAI 模型,为图像到图像 LDM 在修复任务中的评估指标。 虽然此指标不确定下游任务的性能,但它评估了模型的可解释性性能,并证明了与下游任务性能的一致性。 我们展示了两个现有基于扩散的模型和一个我们训练的模型的结果。 我们的贡献总结如下:
-
1.
我们提出了对图像到图像潜在扩散模型的分析和可视化方法,这些方法以前没有积极尝试过。
-
2.
通过分析每个时间步长和注意力头的归因图,我们深入了解了扩散模型的生成过程。
-
3.
我们使用图像到图像潜在扩散模型的特征,展示了生成的图像和参考图像的归因图。 这些地图可以明确地用于模型的训练过程。
-
4.
我们提出了一个评估指标,用于执行修复任务的图像到图像潜在扩散模型作为 XAI 模型。
2 相关工作
使用归因图解释模型。 传统上,神经网络的内部运作一直不透明,通常被描述为黑盒子。 早期的努力 Zhou 等人 (2016);Wang 等人 (2020);Selvaraju 等人 (2016);Chattopadhay 等人 (2018);Jiang 等人 (2021),例如类激活图及其变体,利用基于 CNN 的图像分类器来突出显示图像中目标的兴趣区域,识别与特定类别相关的特征。 最近,Transformer 的出现将重点转移到使用 注意力或归因图 来辨别符元之间的相对重要性,从而增强我们对模型决策的理解,尤其是在文本到图像应用中。 一些新颖的方法,例如 Prompt-to-prompt Hertz 等人 (2022) 和 DAAM Tang 等人 (2022),已将技术应用于可视化 U-Net 中的交叉注意力图,以观察更复杂的视觉交互,例如文本引导的图像编辑。 具体而言,DAAM 评估了句法关系如何转化为视觉交互,揭示了同义词中的混淆以及对形容词的过度关注。 但是,图像到图像模型中的直接应用受到限制,并且还没有研究专注于可视化或分析模型在图像到图像生成中将注意力集中在何处。
基于图像到图像扩散的图像修复。 与文本到图像扩散模型相比,执行图像修复的图像到图像扩散模型应用较少。 值得注意的例子包括 Palette Saharia 等人 (2022a) 和 Paint-by-Example (PBE) Yang 等人 (2023),它们处理修复任务。 Palette 是一个通用的图像到图像转换框架,它在图像修复和各种其他任务中产生真实的结果。 然而,由于它接收以连接形式的图像,因此无法使用本研究中提出的方法对其进行可视化。 为了减轻通过复制参考图像来生成图像中的自引用现象,PBE 提供了强大的增强功能,并且只有 CLIP 图像编码器 Radford 等人 (2021) 的 CLS 符元来理解参考图像中的对象并忽略背景中的噪声。 由于 PBE 提供具有交叉注意力的图像嵌入,因此本研究中提出的方法可以应用。 此外,StableVITON Kim 等人 (2023) 和 DCI-VTON Gou 等人 (2023) 通过结合额外的 ControlNet Zhang 等人 (2023) 结构和变形网络 Ge 等人 (2021),在虚拟穿衣这一专门的修复任务中表现出色,它们是基于 PBE 的模型。 这些模型也可以应用我们的方法。 因此,本研究介绍了针对这三个模型的方法。
3 预备知识
扩散模型。 扩散模型 Ho 等人 (2020); Sohl-Dickstein 等人 (2015); Song 等人 (2022) 是一种概率生成模型,通过逐渐对初始高斯噪声进行去噪来学习数据分布。 给定一个来自未知分布 的样本 ,扩散模型的目标是学习一个参数模型 来近似 。 这些模型可以解释为一系列等权重的去噪自动编码器 ,这些编码器经过训练可以预测其输入 在每个时间点 的去噪变体,其中 是输入 的噪声版本。 对应的目标可以简化为
| (1) |
其中 是时间步长, 是高斯噪声。
我们实现的扩散模型是潜在扩散模型 (LDM),它在特征空间而不是图像空间中执行去噪操作。 具体来说,LDM 的编码器 将输入图像 转换为潜在代码 ,该代码经过训练可以对具有可变噪声的潜在代码 进行去噪,训练目标如下:
| (2) |
其中 是图像 的条件向量,该向量由图像编码器 获得。 在训练过程中, 和 共同优化以最小化 LDM 损失 (2)。
无分类器引导。 无分类器引导 Ho 和 Salimans (2022) (CFG) 是一种权衡扩散模型生成样本的质量和多样性的方法。 它通常用于文本、类别和图像条件下的图像生成,以提高生成图像的视觉质量,并创建更符合条件的采样图像。 CFG 有效地将概率转移到对条件 具有高似然的实现数据。 无条件去噪的训练包括定期将条件设置为空值。 在推理时,引导尺度 设置为 ,将修改后的分数估计 外推到条件输出 ,同时远离无条件输出 方向。
| (3) |
图像修复。 此任务涉及使用语义掩码控制图像编辑。 虽然传统的图像修复 Lugmayr 等人 (2022) 仅专注于填充遮罩区域,但最近的方法,例如多模态图像修复 Xie 等人 (2023); Nichol 等人 (2021); Avrahami 等人 (2022); Couairon 等人 (2022); Yu 等人 (2023),使用文本或分割图等指导来填充遮罩区域。 本文的重点是 VITON,一种在人身上虚拟穿衣的图像修复类型。 其独特之处在于,在保持人物姿势、体型和身份的同时,服装产品必须无缝变形到所需的服装区域。 此外,保留服装产品的细节也是一项要求。
4 方法:
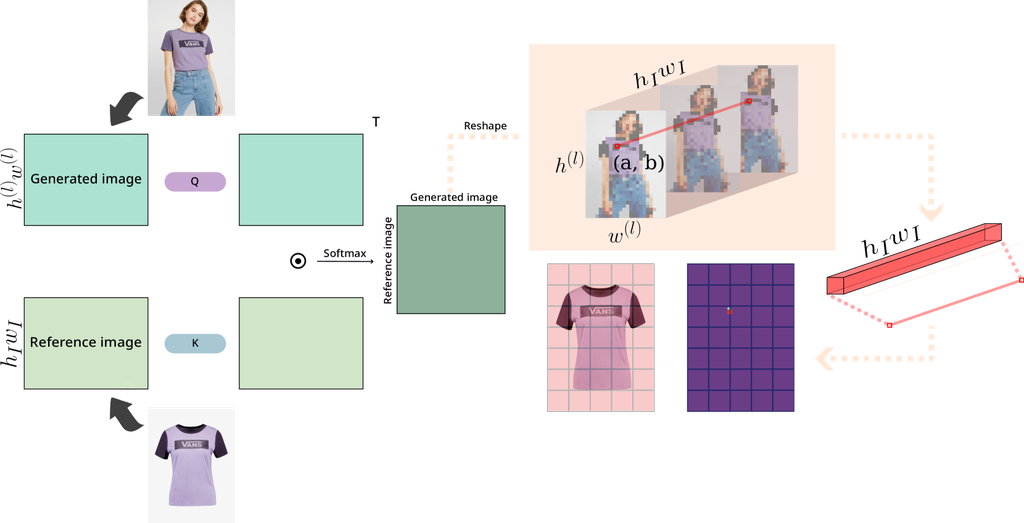
我们利用交叉注意力图来阐释图像不同部分之间的空间关系,从而分析图像到图像的潜在扩散模型。 属性映射是通过测量图像或文本不同部分(例如,补丁或符元)的重要性来分析模型预测的强大方法。 为此,我们首先获得参考图像和生成图像的补丁嵌入,它们充当交叉注意力的查询、键和值。 我们注意到,在图像到图像生成中,与文本到图像不同,这种交叉注意力方法允许双向分析,便于可视化两种不同的属性映射。 这种双重视角不仅能识别 (i) 生成图像中的哪些区域受到参考图像的影响,而且还能突出显示 (ii) 参考图像中的哪些区域对塑造生成图像最具影响力。 这种我们称为 的图像到图像属性映射方法,还使我们能够确定对应于生成图像中特定补丁的参考图像的特定部分,从而增强我们对模型功能和准确性的理解。 在本节中,我们将详细阐述通过将图像分割成更小的补丁并分析它们在各种扩散时间步长、注意力头和层之间的交互作用来可视化双向属性映射的过程。
| Symbol | Description | Dimensions |
| Input image | ||
| Reference image | ||
| Latent code | ||
| Embeddings of reference image | ||
| Number of cross-attention layers | – | |
| Index of cross-attention layer | – | |
| Number of attention heads | – | |
| Index of attention heads | – | |
| g | Generated image | – |
| r | Reference image | – |
| Time step | – | |
| Coordinate of | – | |
| Coordinate of | – | |
| Attention score for of the head and layer at time | ||
| Attention map for generated image g | ||
| Attention map for reference image r | ||
| Inpainting/Reference mask |
4.1 时间和头部集成归因图
首先,我们在所有扩散时间步骤和注意力头上计算归因图,反映了扩散模型的特征,如 DAAM 中所述 唐等(2022)。 从现在开始,生成的图像的归因图将用下标 g 表示,而参考图像将用下标 r 表示。 直到 4.2 部分都是基于生成的图像的归因图的可视化。 我们从生成的图像的角度考察生成的图像和参考图像之间的相关性是否被正确地分配。 如果没有实现适当的分配,则表明参考图像的信息在生成过程中丢失了。 具体来说,给定输入图像 、潜在代码 和图像嵌入 ,在时间步长 时,U-Net 内块的前注意力输出向量 被获取,其中 表示交叉注意力层的数量。 我们使用一个总共 个头的多头交叉注意力机制来将这些表示条件化为图像嵌入。 因此,每个时间步长 和层 处生成的图像的注意力得分 通过使用 Softmax 计算如下:
| (4) |
其中 和 是投影矩阵,分别具有 个键和查询的潜在投影维度。 通过这样做,可以通过在第一个轴中选择相应的行来获得每个头的得分 ,此外,在时间步长 上的聚合会导致值以增强特定位置的信息:
| (5) |
对于每个头部和层的注意力得分 ,执行平均以组合信息,通过整合各种见解来实现全面理解。 我们将每个层的 的维度调整为潜在代码 的维度,因为它们可能在层之间有所不同。
| (6) |
其中 。 最后,由于我们将获得生成的图像的注意力图,我们需要对 和 进行平均,如下所示:
| (7) |
其中 被归一化为 。 和 分别是 和 坐标。 对于像素级可视化,只需调整大小以匹配输入图像大小,并在最后叠加即可。 此外,使用阈值移除小值,以获得更清晰可辨的视觉效果。 我们将阈值设置为 ,总体计算如下:
| (8) | ||||
| (9) |
其中 是一个指示函数。
4.2 头/时间集成归因图
虽然时间步长和注意力头在上一节中被组合在一起,但我们现在将在本节中探讨它们的独立分析。 扩散模型通过在每个时间步长上的迭代去噪过程生成图像。 自然地,为了分析生成过程,我们需要分别考虑时间步长,并考虑到注意力模块的注意力头。
头集成归因图。 首先,我们更新了可视化生成过程随时间变化的方法。 公式 (5) 已被修改,其余公式可以像以前一样直接应用于分组注意力分数。 给定总时间步数 ,时间组数 和组大小 ,每组 的注意力分数计算为 (10)。 通过观察模型随时间的生成过程,我们了解了模型如何逐步合成图像。
| (10) |
时间集成归因图。 可视化每个注意力头的生成过程,以观察它们对生成的图像的不同部分的贡献。 如果头部的分布存在多样性,则表明每个注意力头都很好地检测并强调了多个特征。 物体的核心元素在时间积分归因图中始终保持高分。 为了计算每个注意力头的注意力图 ,我们需要修改公式 (6)。 具体来说,如下所示:
| (11) |
4.3 参考归因图
在本节中,我们介绍了一种用于参考图像的可视化方法。 文本到图像的潜在扩散模型难以可视化文本如何影响图像(文本是抽象的)。 相反,参考图像保留空间信息,便于清晰地可视化所用信息及其在条件中的范围。
4.4 修复掩码注意力一致性得分
在本节中,我们介绍了 修复掩码注意力一致性得分 (IMACS),这是一种用于图像修复的新型评估指标。 我们提出的双向注意力可视化适用于所有图像到图像的潜在扩散模型。 它对于基于掩码的任务(例如基于参考的图像修复)特别有用,其中双向注意力被大量使用。 因此,我们专注于具有修复和参考掩码数据的任务 ( 和 )。 IMACS 使用交叉注意力模块来评估生成图像和参考图像的注意力图 ( 和 ) 与各自掩码(修复和参考掩码)之间的对齐。 这种一致性测量指标表明模型从参考图像中提取显著信息并将其应用于生成图像的适当区域的程度,是评估 XAI 模型性能的关键指标。
计算参考归因图得分时,使用对应于修复掩码区域的参考图像归因图。 如果修复掩码的大小很小,背景将占更大的比例,参考归因图得分可能会被错误地测量。 因此,为了只考虑与修复掩模区域相对应的参考属性图的分数,在从 (14) 获得的 和调整大小的修复掩模 之间额外执行逐元素乘法。
| (17) | ||||
| (18) |
其中 表示修复/参考掩模(VITON 数据集中的无差别映射/服装掩模)。 生成的图像的注意力图的分数表示为 ,而对于参考图像,则表示为 。 我们将两幅图像的注意力图的组合表示为 IMACS。 惩罚因子,用 表示,默认值为 。 在这种情况下, 范围为 ,较高的值表示作为可解释人工智能 (XAI) 指标的性能更优越。 增加该值会对偏离修复目的的注意力施加更强的惩罚。
5 实验
数据集。 按示例绘制 (PBE) 在 OpenImages Kuznetsova 等人 (2020) 上进行训练。 它包含 百万个边界框,用于跨 百万张图像的 个对象类别。 StableVITON 和 DCI-VTON 在 VITON-HD Choi 等人 (2021) 上进行训练。 它是一个用于高分辨率(即 )服装项目虚拟试穿的数据集。 特别是,它包含 张正面女性和上衣图像对,进一步分为 个训练/测试对
评估。 我们使用 IMACS 评估了 DCI-VTON、StableVITON 和自定义模型。 为了证明 IMACS 与下游任务的一致性,我们还采用了来自 VITON 任务的评估指标:FID、KID、SSIM 和 LPIPS。 具体而言,我们使用配对设置,其中有穿着参考服装的人员图像,以及非配对设置,其中没有穿着参考服装的人员图像。 在配对设置中,我们应用 SSIM 和 LPIPS 来衡量两幅图像之间的相似度,而在非配对设置中,我们使用 FID 和 KID 来衡量真实图像和生成图像之间的统计相似度。 FID、KID 和 LPIPS 的得分越低,SSIM 和 IMACS 的得分越高,表示性能越好。 我们对大小为 的图像进行所有评估,所有图像是使用第 4 节中介绍的 可视化的。
5.1 模型
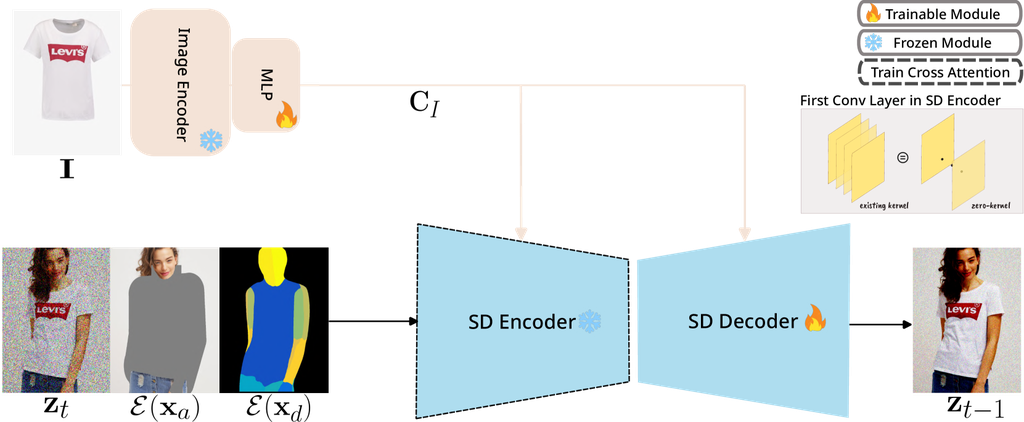
我们可视化了三种执行修复任务的现有模型(PBE、StableVITON、DCI-VTON)Yang et al. (2023); Kim et al. (2023); Gou et al. (2023) 的归因图。 如第 4.3 节所述,所有补丁嵌入必须提供给跨注意力模块才能可视化参考归因图。 但是,与接收来自参考图像的所有补丁嵌入的 StableVITON 不同,PBE 和 DCI-VTON 只使用 CLS 符元。 结果,有限的样本用于测量模型的 ,这使得难以证明 与下游任务性能的一致性。 因此,我们构建了一个自定义模型,它利用所有参考图像的所有补丁嵌入。 构建自定义模型的另一个原因是展示利用其他图像到图像潜在扩散模型的可能性,这些模型提供所有参考图像的补丁嵌入,而不仅仅是 StableVITON。
基于 Stable Diffusion v1.5 的自定义模型在 VITON-HD 数据集上进行了微调,使用大型图像编码器(使用所有补丁嵌入)而不是 CLIP 文本编码器。 给定人物图像 ,与服装无关的人物表示 ,密集姿态 和服装图像 ,模型用服装图像(参考图像) 填充无关映射 。 作为 U-Net 的输入,我们将 U-Net 的初始卷积层扩展到 (即 )通道,并使用权重初始化为零的卷积层。 除 和 之外的所有组件都通过编码器 。 自定义模型概述如图 3 所示。
实现细节。 我们使用 的批次大小训练自定义模型 个纪元。 其他模型利用其 GitHub 存储库中提供的预训练模型,其中 DDIM Song et al. (2022) 作为采样器, 设置为 步, 设置为 。 CFG 比例 对于 PBE、StableVITON 和自定义模型为 ,而对于 DCI-VTON 为 。
5.2 时间和头部集成属性图
扩散模型依赖于无分类器引导 (CFG) 技术,如图 4 所示,描绘了基于 CFG 存在的时间和头部集成属性图。 CFG 为参考图像分配更高的可能性,从而相应地改变输出。 此偏移输出被反复用作模型的输入,导致属性图分布发生偏移。 通过应用 CFG,模型更好地反映了参考图像,便于在适当的区域合成图像。

5.3 头部/时间综合归因图
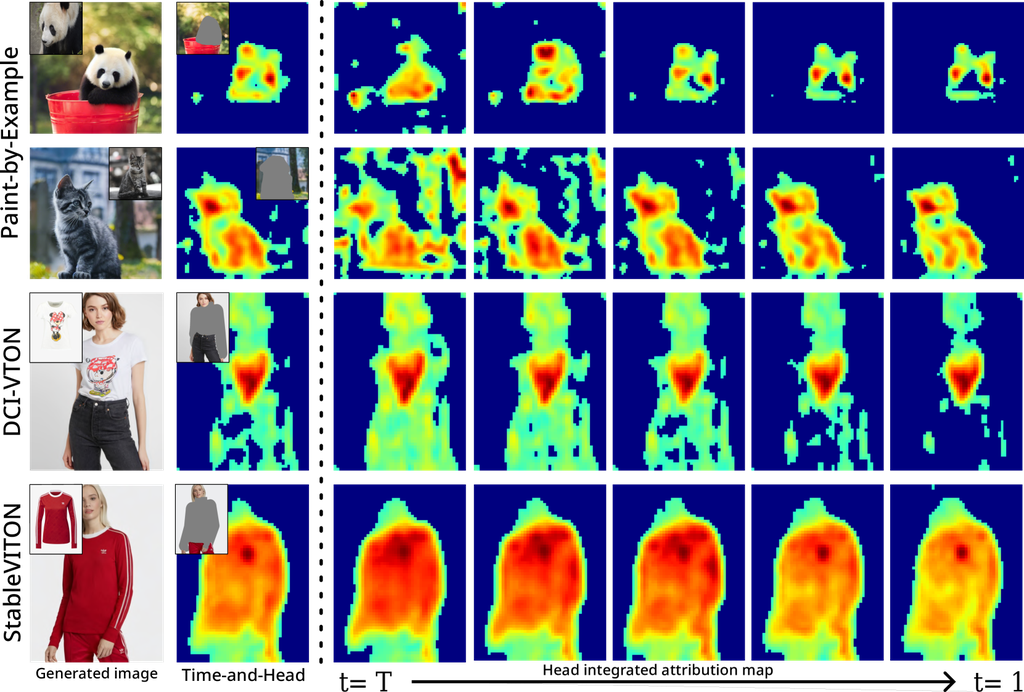

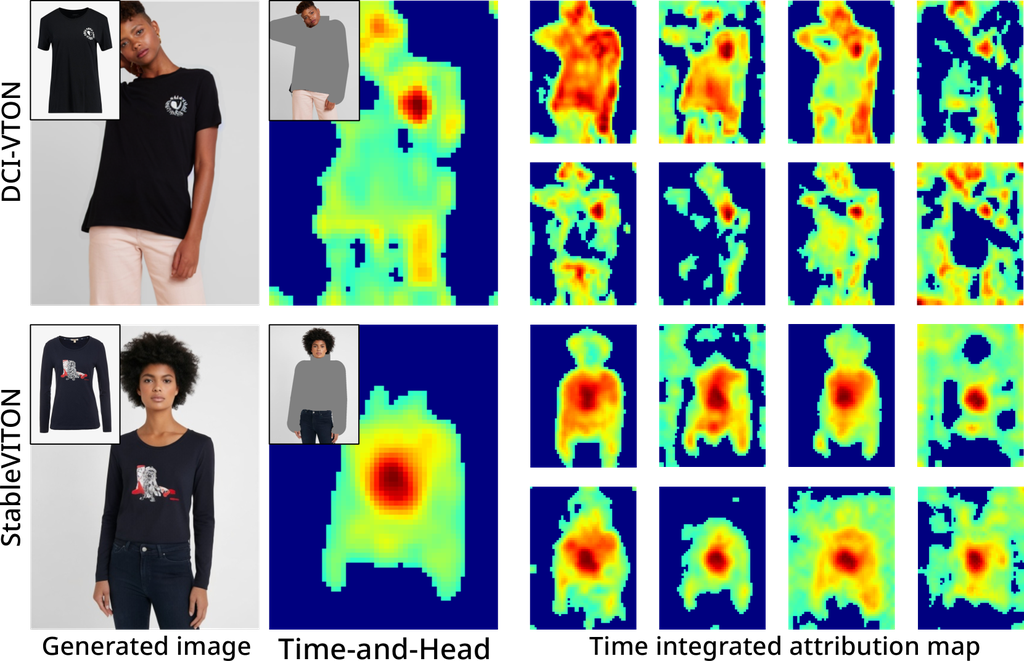
随着时间的推移观察图 5 表明,模型逐渐形成目标的结构,始终将高注意力分数分配给重要特征,例如面部细节或服装徽标。 这种模式意味着模型通过强调和理解其特征来学习准确识别和理解目标,因为它处理和分析输入数据。 此外,模型首先生成低频特征,然后继续生成高频特征。
5.4 参考归因图


为了确认是否从参考图像中提取了有意义的信息以进行图像合成,需要检查参考归因图。 在图 8 中,基于注意力头提取了参考图像的不同部分,但随着时间的推移变化很小:重要特征始终保持高分。 与生成的图像不同,参考图像没有噪声,因此提供一致的信息。 噪声的缺失使重要的特征可以清晰地辨别,从而使模型主要关注这些关键特征并保持对这些关键特征的高度关注。 值得注意的是,与生成的图像的归因图类似,无论处于哪个阶段,模型始终突出显示重要特征。 此外,我们通过特定参考属性图验证每个块之间的位置映射是否一致。 这使我们能够专门评估是否有用特征是从参考图像中提取的。 在图 9 中,与生成的块位置相对应的高分被准确地获得,保留了诸如服装颜色和图案位置等信息。
5.5 图像修复掩码注意力一致性得分
在评估每个模型的性能时,同时考虑分散程度和对齐程度至关重要。 到目前为止的分析揭示了不同模型之间时间和头部集成属性图分散度的差异。 在图像修复任务中,每个掩码的对齐在不同模型之间有所不同,其中 DCI-VTON 特别表现出分散的得分。 当对齐没有正确实现时,就会出现诸如颜色差异、参考图像信息丢失和不必要的图案等问题。 这些因素会降低生成图像的质量并降低与原始图像的一致性。 对齐程度更高的模型更有可能产生准确一致的结果。
在表 2 中,我们使用 IMACS 和几个指标评估了定制模型和现有模型。 StableVITON 在下游任务中表现出最佳性能,其次是定制模型和 DCI-VTON。 StableVITON 在衡量注意力图与图像修复/参考掩码之间的对齐程度方面也优于其他模型,正如 所量化的那样,其次是定制模型(阈值和 设置为 和 )。 这些结果表明,IMACS 表现出与实际性能相似的趋势。
| Method | FID | KID | LPIPS | SSIM | ||
|---|---|---|---|---|---|---|
| DCI-VTON | – | |||||
| StableVITON | 10.6755 | 0.0817 | 0.8634 | 0.3083 | 0.3388 | |
| Custom model | 0.0037 |
6 结论
我们提出 作为一种可视化方法来分析图像到图像的潜在扩散模型的生成过程。 通过按时间和头部对归因图进行分区,我们表明该模型识别了重要因素并始终如一地给出高注意力分数。 特别是,我们引入了特定的参考归因图来识别生成图像的特定块引用了来自参考图像的哪些信息。 双向归因图可视化超越了理解模型的操作;它还有助于检测模型错误,并且可以在训练和评估中使用。 本文介绍的 IMACS 和 StableVITON 的 Kim 等人 (2023) ATV 损失是示例。
致谢
这项工作得到了韩国 MSIT 在 ITRC(信息技术研究中心)(IITP-2023-2020-0-01789)和人工智能融合创新人力资源开发(IITP-2023-RS-2023-00254592)的支持,由 IITP(信息和通信技术规划和评估研究所)监督。
参考文献
- Avrahami et al. [2022] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022.
- Chattopadhay et al. [2018] Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In 2018 IEEE winter conference on applications of computer vision (WACV), pages 839–847. IEEE, 2018.
- Choi et al. [2021] Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14131–14140, 2021.
- Couairon et al. [2022] Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance. arXiv preprint arXiv:2210.11427, 2022.
- Ge et al. [2021] Yuying Ge, Yibing Song, Ruimao Zhang, Chongjian Ge, Wei Liu, and Ping Luo. Parser-free virtual try-on via distilling appearance flows. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8485–8493, 2021.
- Gou et al. [2023] Junhong Gou, Siyu Sun, Jianfu Zhang, Jianlou Si, Chen Qian, and Liqing Zhang. Taming the power of diffusion models for high-quality virtual try-on with appearance flow. In Proceedings of the 31st ACM International Conference on Multimedia, pages 7599–7607, 2023.
- Hertz et al. [2022] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- Ho and Salimans [2022] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Jiang et al. [2021] Peng-Tao Jiang, Chang-Bin Zhang, Qibin Hou, Ming-Ming Cheng, and Yunchao Wei. Layercam: Exploring hierarchical class activation maps for localization. IEEE Transactions on Image Processing, 30:5875–5888, 2021.
- Kim et al. [2023] Jeongho Kim, Gyojung Gu, Minho Park, Sunghyun Park, and Jaegul Choo. Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on. arXiv preprint arXiv:2312.01725, 2023.
- Kuznetsova et al. [2020] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision, 128(7):1956–1981, 2020.
- Lugmayr et al. [2022] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022.
- Nichol et al. [2021] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arxiv 2022. arXiv preprint arXiv:2204.06125, 2022.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Saharia et al. [2022a] Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022.
- Saharia et al. [2022b] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- Selvaraju et al. [2016] Ramprasaath R Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra. Grad-cam: Why did you say that? arXiv preprint arXiv:1611.07450, 2016.
- Sohl-Dickstein et al. [2015] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics, 2015.
- Song et al. [2022] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022.
- Tang et al. [2022] Raphael Tang, Linqing Liu, Akshat Pandey, Zhiying Jiang, Gefei Yang, Karun Kumar, Pontus Stenetorp, Jimmy Lin, and Ferhan Ture. What the daam: Interpreting stable diffusion using cross attention. arXiv preprint arXiv:2210.04885, 2022.
- Wang et al. [2020] Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-cam: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 24–25, 2020.
- Xie et al. [2023] Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang. Smartbrush: Text and shape guided object inpainting with diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22428–22437, 2023.
- Yang et al. [2023] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18381–18391, 2023.
- Yu et al. [2023] Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting. arXiv preprint arXiv:2304.06790, 2023.
- Zhang et al. [2023] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.
- Zhou et al. [2016] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2921–2929, 2016.