检索增强型机器学习:综合和机遇
摘要。
在语言建模领域,使用检索组件增强的模型已成为解决自然语言处理 (NLP) 领域面临的若干挑战的有前景的解决方案,包括知识基础、可解释性和可扩展性。 尽管主要关注 NLP,但我们认为检索增强的范式可以扩展到更广泛的机器学习 (ML) 领域,例如计算机视觉、时间序列预测和计算生物学。 因此,这项工作通过综合 ML 各个领域的文献以及当前文献中缺少的一致符号,引入了该范式的正式框架,即检索增强机器学习 (REML)。 此外,我们发现,虽然许多研究采用检索组件来增强其模型,但缺乏与基础信息检索 (IR) 研究的集成。 我们通过研究组成 REML 框架的每个组成部分,弥合了开创性 IR 研究和当代 REML 研究之间的差距。 最终,这项工作的目标是为各个学科的研究人员提供一个全面的、正式结构化的检索增强模型框架,从而促进跨学科的未来研究。
1. 介绍
1.1. 背景
近年来,围绕大语言模型(大语言模型)的研究领域出现了大幅增长,这些模型在各种自然语言处理(NLP)任务中具有巨大的潜力。 推动这一领域向前发展的重大进步之一是大语言模型参数数量的扩展,这使得能够训练具有前所未有的规模和复杂性的模型(Zhao等人,2023) 。 我们在与机器学习相关的其他领域也看到了类似的趋势,例如用于表示图像和视频的大型视觉基础模型(Dosovitskiy 等人,2021;Arnab 等人,2021)。 与此同时,上下文学习(ICL)的概念(董等人,2023)已经成为一种变革能力,允许大语言模型在推理过程中动态适应和融入新信息。 与此同时,信息检索 (IR) 界一直在积极探索旨在提高从大规模馆藏中访问信息的效率、有效性和稳健性的技术。
这两个领域的融合引发了研究的新趋势,模型配备了检索功能,可以在训练和推理阶段访问外部知识(Mialon 等人, 2023; Zamani 等人, 2022). 将检索机制集成到预测管道中开始获得重大关注,因为它允许模型将其预测建立在外部知识的基础上,而无需增加模型容量。 Hashemi 等人 (2020) 和 Lewis 等人 (2020b) 提出的方法是该领域最早的工作之一;前者侧重于通过扩展 Transformer 网络来进行检索增强表示学习,而后者则研究知识密集型语言任务的检索增强生成(RAG)范式。 也就是说,使用检索结果来改进机器学习系统并不是什么新鲜事。 伪相关反馈方法(使用检索最多的文档表示搜索查询的方法)可能是此类中的第一组方法(Attar 和 Fraenkel,1977;Croft 和 Harper,1979)。 大语言模型固有的 ICL 能力在促进这些检索增强方法的传播和采用方面发挥了关键作用。 通过将检索到的文档集成到大语言模型的提示中,研究人员能够利用外部知识源,而无需从根本上改变底层模型架构。
1.2. 动机
由于通过增加参数数量来提高模型性能是不可持续的,基于检索的模型的一个动机源于这样的发现:虽然大型模型倾向于记住训练数据(Carlini等人,2021),结合基于检索的方法可以有效地将记忆负担转移到外部存储系统(Borgeaud 等人,2022)。 我们主张总体上增强机器学习 (ML) 模型(即超越生成),使其能够通过信息检索技术利用存储的信息。 IR 已经显示出其在帮助人类与庞大文本数据库进行交互方面的优点。 我们认为,IR 的效用可以扩大,使机器不仅可以访问广泛的文本数据库,还可以访问以更多抽象形式表示的知识。 通过将 ML 架构与直接访问 IR 系统集成,我们的目标是将推理和记忆过程分开。 Zamani 等人 (2022) 将这种方法称为检索增强机器学习 (REML),作为扩展 ML 的更广泛概念。 扩展他们的工作,我们进一步调查了 REML 在 ML 领域(包括 NLP)的最新进展,并具有一致的数学符号。 通过这样做,我们的目标是为研究人员提供 REML 方法的全面、结构化的概述,使他们能够迅速开展该领域的研究。
1.3. REML的应用
REML 范式涵盖了一系列不同的子领域,每个子领域都有其独特的挑战和应用。 其中包括语言建模方面的开创性工作(Guu 等人,2020;Lewis 等人,2020b;Borgeaud 等人,2022;Izacard 等人,2021b;Zhong 等人,2022;Izacard 等人,2024;Ram 等人, 2023; 石等人, 2024; Khandelwal 等人, 2020; Lyu 等人, 2023), 机器翻译 (Khandelwal 等人, 2021) ,问答(Yu 等人, 2022a; Chen 等人, 2017a; Lee 等人, 2019; Nakano 等人, 2022; Lazaridou 等人, 2022; Wu 等人, 2022d; Chen 等人,2023c,d;Zhang 等人,2024),事实验证(Lewis 等人,2020b;Petroni 等人,2023;Chen 等人,2023b),开放域 (Shuster 等人, 2022b, a; Komeili 等人, 2022; Thoppilan 等人, 2022) 和任务导向(Thulke 等人, 2021; Cai 等人, 2023; Eric 等人, 2017 ; Raghu 等人,2021;Nekvinda 和 Dušek,2022) 对话系统,槽填充(Glass 等人,2021),状态跟踪(King 和 Flanigan,2023)、多模态对话(Fan 等人, 2021)、强化学习(Fernández 和 Veloso, 2006; Goyal 等人, 2022; Humphreys 等人, 2022),计算机视觉 (Chen 等人, 2023a;安永等人,2023;拉莫斯等人,2023; Shrestha 等人, 2024)0>、常识推理 (Yu 等人, 2022c)1>、证据归属 (Gao 等人, 2023b; Aksitov 等人, 2023; Menick 等人, 2022;Huo 等人,2023;Gao 等人,2023a)2>,知识图增强 (Sen 等人,2023;Kang 等人,2023;Baek 等人,2023;Ju 等人,2022 ; 胡等人, 2023; 张等人, 2022b; 于等人, 2022a)3>, 排名(Hui 等人, 2022a)4>, 个性化(Salemi 等人, 2024b) , a)5>、数学问题解决(Yang 等人, 2024b)6>、代码生成(Zhang 等人, 2023; Zhou 等人, 2023; Wang 等人, 2024a )7>、音频和语音的表示学习(Sanabria 等人, 2023; Lin 等人, 2024)8>、时间序列预测(Jing 等人, 2022; Yang 等人, 2022)9>,以及蛋白质结构预测(Cramer,2021)0>。 行业和开源社区迅速接受了基于检索的模型的采用,认识到它们加速适应和性能增强的潜力。 LangChain等框架111https://www.langchain.com LlamaIndex,222https://www.llamaindex.ai 和 DSPy (Khattab 等人, 2024)2> 的出现,简化了基于检索的模型的实现过程。 这一广泛的领域(并非详尽的列表)强调了 REML 范例在不同应用程序中的多功能性和影响力。
1.4. 这项工作的主要贡献
尽管当前许多应用程序都以自然语言处理为中心,但我们相信利用检索组件的 ML 模型不仅仅局限于语言模型,而是可以扩展到任何 ML 模型。 为了解决这种更广泛的适用性,我们将框架形式化为检索增强机器学习(REML),并用当前文献中缺乏的一致的数学符号综合现有研究。 此外,尽管 REML 模型取得了进步,但信息检索研究中丰富而广泛的工作仍然没有得到充分利用,这些研究可以提供大量的方法和见解,从而使 REML 模型受益匪浅。 这项工作旨在通过将 IR 研究整合到 REML 模型的设计中来弥补这一差距。 最终,我们希望这项工作能让各个领域的研究人员利用 ML 轻松理解 REML 的框架及其可扩展性。
2. 检索增强型机器学习
Notation Description input instance input space output target output space L labeled data (i.e., ) U unlabeled data (i.e., ) The downstream loss function a predictive machine learning model parameterized by a retrieval model parameterized by a tuple of predictive and retrieval model retrieval item retrieval space retrieval key space C stored retrievable items query query space retrieval results retrieval result space model feedback model feedback space evaluation metric
为了开始深入探索检索增强机器学习(REML),我们首先重申 Zamani 等人(2022) 所设置的任务的广义形式定义。 与所有预测机器学习框架(随后称为 ML 模型)一样,REML 的任务是学习将输入空间 映射到输出空间 的函数关系。 与其他 ML 模型不同,REML 通过与一个或多个信息访问模型的交互来预测结果,每个模型都促进对数据库或知识存储库的访问。 因此,REML 正式表达为 ,其中 和 分别表示输入实例和目标输出, 表示 ML 参数化的模型,表示参数化的信息访问模型。 这里,表示可以参考的信息访问模型的总数。 每个 都与一个集合、存储库或内存 相关联,它们可能由自然语言文本或替代索引表示形式组成。 因此,集合充当可用的通用参数数组,可以临时使用,就像许多非参数和惰性学习技术。 Zamani 等人 (2022) 概述了 REML 模型的三个必要(Reqs)和可选(Opts)要求。
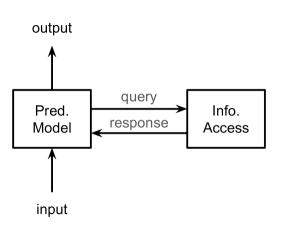
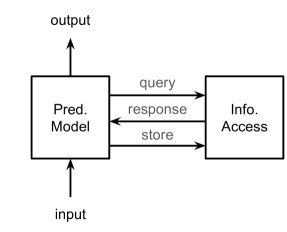
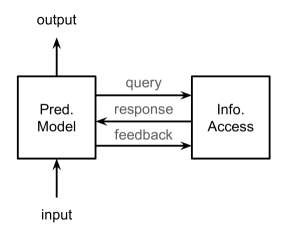
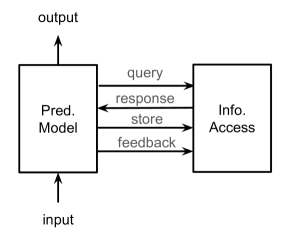
REML 模型的最简单形式如图 1(a) 所示,仅关注基本标准。 第二类,如图1(b)所示,通过将信息存储在存储器中以供后续检索来利用第一个可选属性。 第三类如图1(c)所示,采用第二个可选属性,为信息访问模型提供反馈。 最后一个类别包含所有可选属性,如图 1(d) 中详述。
根据需求,Zamani等人(2022)提出了REML的综合框架,如图2所示。 该框架围绕两个主要组件构建:预测模型和信息检索模型。对于任何给定的输入,预测模型可以灵活地发起多个检索操作。 这可能涉及调度多个查询、参与大量数据存储库、向信息检索组件提供反馈或采用这些策略的组合。 值得注意的是,对于某些输入,检索过程的数量可能为零,从而允许 REML 扩展传统的预测模型。
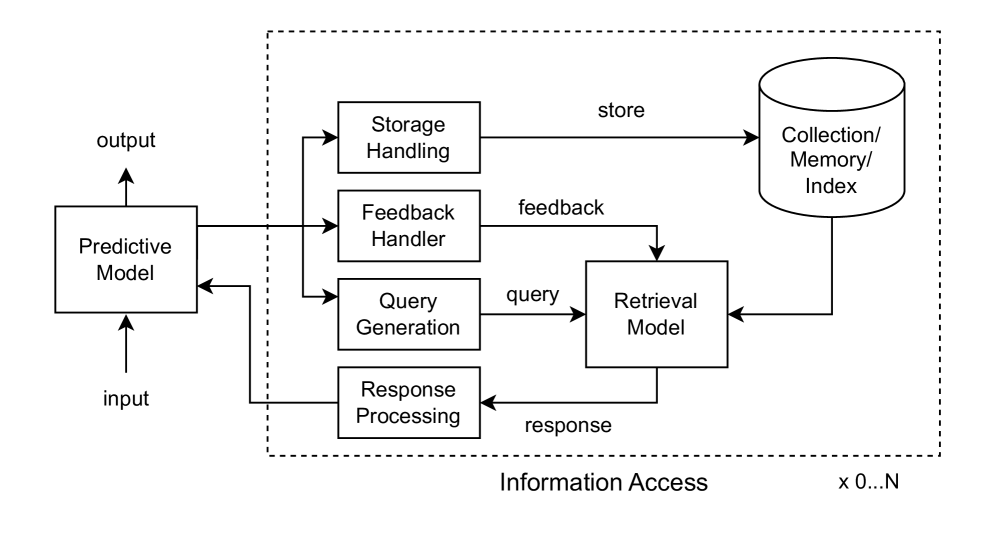
3. 查询
在 REML 中,获取信息的过程取决于查询知识或信息存储库的行为。 因此,从输入中制定查询,无论是非结构化还是结构化,都是 REML 框架内预测模型和检索模型之间相互作用的关键起始点。 以下部分介绍用于根据任务输入生成查询的常见操作。
3.1. 决定在哪里查询
在将查询发送到信息访问系统之前,REML 系统可以决定其查询应发送到哪里。 请记住,每个 都与 相关联(图 2 中描述的信息访问过程的乘法性质),查询生成模块首先决定哪个元组 和 的 (s) 应根据与 Pan 等人 (2023)< 描述的专家混合解释相一致的上下文来选择/t6> 333在 KiC (Pan 等人, 2023) 中,路由器选择具有特定知识源的专家预测模型(而不是检索器)。 但是,我们认为这有助于理解查询生成模块的第一步。. 这个查询决策问题可以通过以下子问题来理解。 1)语料库选择:决定需要搜索哪些语料库(不需要检索时可以为空),2)检索器选择:决定应该使用哪种检索模型用于搜索所选语料库。
3.1.1. 语料库选择
选择不仅是决定向提供什么样的外部信息(Pan 等人, 2023),也包含了这个问题何时查询(当没有检索对有利时,不选择语料库)。 这可能是一个关键问题,因为检索增强可能会损害某些输入类型的性能(Maekawa 等人,2024;Mallen 等人,2023;Asai 等人,2024)。 它还可以通过减少搜索次数来节省计算资源(Labruna等人,2024)。 关于外部信息是否对预测模型有益可以有几个标准。 它可以基于术语流行度 (Mallen 等人, 2023)、输入复杂度 (Jeong 等人, 2024) 或训练模型 (Asai 等人) ,2024)。
3.1.2. 猎犬选择
一旦选择了一个或多个 ,REML 系统就可以通过选择专门搜索所选语料库的最佳检索器来进一步使自己受益。 这是一项相对具有挑战性的新任务,我们建议读者参考Khramtsova 等人(2023, 2024)以进行更深入的理解。
3.2. 重新制定输入
在许多情况下,原始用户输入不能直接用作对检索模型的查询,这强调了将输入重新表述为不同表示的迫切需要。 这种重新表述是通过一个过程进行的,其中根据系统的特定要求使用单独的组件或相同的预测模型来转换输入。 变换的一般方程是
| (1) |
其中 是应应用转换的输入(即任务的原始输入、先前的搜索查询、另一个转换的输出等)和 是该函数在执行转换时可以使用的辅助信息。 例如, 的用例之一可以是用户配置文件,它可以帮助为用户 个性化此转换(Salemi 等人,2024b)。 将输入转换为替代格式的常见动机包括一系列因素,包括但不限于截断、扩展和转换。
3.2.1. 压缩
在某些情况下,并非输入的所有单词或组件都证明与搜索目标相关。 因此,在许多先前的研究中已经采用了省略输入的特定部分的常见做法。 在大多数情况下,序列到序列模型经过训练来识别和标记需要减少的片段(Ni等人,2019;Musa等人,2019;Yadegari等人,2022;Khashabi等人,2017 )。 有时,一种简单的方法(例如将输入分段为不同的块并将这些分段用作查询)可能非常有效(Borgeaud 等人,2022)。 在多模态搜索场景中,从输入中省略特定模态并从不同模态跨语料库进行搜索已被证明是有价值的(Gui 等人,2022)。
3.2.2. 扩张
在某些情况下,单独的输入可能缺乏搜索系统产生所需结果所需的基本信息。 在这种情况下,可以使用额外的相关数据来增强输入。 这一扩展过程拓宽了上下文并增强了搜索系统检索相关且有意义的结果的能力,从而提高了整体系统性能。 通常,扩展是通过将输入与之前检索到的结果 (Zhu 等人, 2021; Xiong 等人, 2021) 或以输入 (Wang 等人, 2023d;毛等人,2021;刘等人,2022;庄等人,2023)。
3.2.3. 转换
对于某些情况,根据其固有结构将输入重塑为新查询,而不是仅仅扩展,被证明是有利的。 在为数据库 (Arcadinho 等人,2022;Dou 等人,2023) 和 API 访问(Schick 等人,2023;Qin 等人,2023;Qin 等人,2023;欧阳等人,2022;金等人,2024)。
转换操作可以导致输入空间到查询空间的转换。因此,必须注意 和 不一定等效,这意味着与原始输入相比,转换后的查询可能在不同的空间中运行。 在复杂的多模式搜索场景中,直接使用输入可能不可行。 因此,将输入转换为不同的模态形式变得势在必行,确保预测模型和搜索系统之间无缝高效的通信(Gao等人,2022;Lin和Byrne,2022;Wu和Mooney,2022;Lin等人,2023;萨莱米等人,2023a)。
此外,将输入从原始输入空间转换到语言模型的潜在空间,并从模型先前与数据的交互中检索信息,就像 kNN-LM (Khandelwal 等人, 2020) 中发生的情况一样,表示改变查询空间的附加转换(Chen 等人,2022;Yogatama 等人,2021;He 等人,2021;Khandelwal 等人,2021;Kassner 和 Schütze,2020)。 事实上,神经图灵机(Graves等人,2014;Gulcehre等人,2017;Rae等人,2016)和记忆 Transformer (Zhong等人,2022;Wu等人,2022a; Wan 等人,2022) 采用类似的转换过程将输入转换为潜在变量。 这种转换对于从这些模型的内存/存储组件中进行有效检索至关重要。
3.3. 分解输入
此类别涉及将复杂的输入分解为更简单的部分,通常是为了更好地理解内容并检索更准确的结果。 这种技术在处理涵盖多个主题或概念的长而复杂的输入时特别有用(Min 等人,2019;Perez 等人,2020;Zhou 等人,2022)。 分解的一般方程是
| (2) |
其中 是应该分解的输入(即任务的原始输入、转换的输出等), 是该函数可以使用的辅助信息在执行分解时,是分解查询的集合。 请注意,与仅返回单个查询的转换操作相比,分解返回一组查询。
3.4. 查询生成的统一方程
因此,查询生成的统一方程是
| (3) |
这些函数中的任何一个都可以替换为恒等函数(Izacard and Grave, 2021b; Karpukhin 等人, 2020; Asai 等人, 2022; Yamada 等人, 2021; Lewis 等人, 2020b, b; Thorne 等人, 2018; Guu 等人, 2020) 不考虑模态(Salemi 等人, 2023b; Qu 等人, 2021)。 此外,可以想象多次并以不同的顺序应用这些功能。 特别是在多跳问答和事实验证领域,先前的研究广泛采用多种转换和分解来完成任务要求(Qi等人,2019;Trivedi等人,2023;Yadav等人,2020;Das等人,2019;江等人,2023)。 鉴于这些任务的复杂性,利用各种转换和分解的组合变得至关重要。
4. 搜寻中
根据文档、查询和任务的性质,需要和期望不同的搜索功能。 例如,在一些面向任务的对话系统中,(对话代理)需要访问关系数据库。 因此,在这种场景下,需要使用SQL等结构化查询来进行搜索。 话虽如此,大多数应用中的检索项都是半结构化或非结构化文本的形式,或者涉及多模式方面。 下面,我们回顾一下针对不同情况的不同检索模型。
4.1. 具有稀疏表示的检索模型
许多基于文本的检索模型使用稀疏表示来表示查询和文档。 例如,术语匹配(词汇)检索模型,例如 TF-IDF (Salton 和 Buckley,1988)、BM25 (Robertson 等人,1995) 和查询可能性(Ponte and Croft,1998),使用维稀疏向量表示每个查询和文档,其中表示词汇量大小。 在这些模型中,与给定文本中出现的术语相关的维度带有非零值,其余为零。 大多数这些模型都基于术语独立或词袋假设。 尽管如此,考虑术语位置和顺序的模型是存在的,例如高阶语言模型(Song and Croft,1999)、位置语言模型(Lv and Zhai,2009) t1> 和顺序依赖模型(Metzler 和 Croft,2005)。
这些检索模型中数据的稀疏性使它们能够使用倒排索引数据结构来进行可扩展且高效的检索。 请注意,这些模型经常遇到词汇不匹配问题,这意味着使用不同的词汇来表示查询和文档中的相同概念不会对估计的相关性得分产生影响。 这会显着影响 的性能,尤其是从召回的角度来看。 查询扩展和文档扩展方法可以解决词汇不匹配问题,包括伪相关反馈模型(Lavrenko 和 Croft,2001;Zhai 和 Lafferty,2001;Rocchio,1971)。 用于扩展文档的神经网络解决方案,例如 SPLADE (Formal 等人, 2021),在足够大规模的数据可用时已显示出有希望的结果。
词汇表示的替代方法是使用潜在向量。 例如,SNRM (Zamani 等人, 2018) 学习深度学习模型生成的高维稀疏潜在向量,用于表示查询和文档。
4.2. 具有密集表示的检索模型
查询和文档可以使用低维(与词汇大小相比)密集向量来表示。 这种密集向量通常是使用预先训练的语言模型获得的,例如 BERT (Devlin 等人, 2019),这些模型针对检索任务进行了微调(Karpukhin 等人, 2020). 密集检索模型通常基于双编码器架构——一个编码器用于表示查询,另一个编码器用于表示文档。 这些编码器可以共享参数。 一些稠密检索方法,例如 DPR (Karpukhin 等人, 2020),用单个稠密向量表示每个查询或文档。 而其他算法,例如 ColBERT (Khattab 和 Zaharia,2020),每个词符使用一个向量,从而为每个查询和文档生成多个向量。 近似最近邻 (ANN) 算法,例如 HNSW (Malkov 和 Yashunin,2020),用于在处理密集表示时进行高效检索。 密集检索方法也常用于处理多媒体和多模态数据(Qu等人,2021;Salemi等人,2023a)。
4.3. 重新排序模型
现代搜索引擎主要是基于多级级联架构设计的——一堆排名模型,其中第一个模型有效地检索文档列表,随后的模型对前一阶段的结果进行重新排名。 常见的场景是一个两阶段过程:检索和重新排名。 重新排序模型通常使用显式或隐式相关标签进行优化。 这些模型称为学习排序模型。 早期的学习排序模型依赖于手动提取和设计的特征集,而最新的模型则依赖于深度学习模型进行表示学习和重新排序。 使用深度学习模型进行重新排名的常见策略称为交叉编码(Nogueira 和 Cho,2019),这意味着将查询和候选文档连接起来并馈送到像 BERT (Devlin等人,2019),经过训练(或微调)以产生相关性分数。 学习排序模型可以使用逐点、成对或列表损失函数进行优化。 如需了解更多信息,请参阅 Liu (2009) 的学习排名调查以及 Mitra 和 Craswell (2018) 以及 Guo 的神经排名模型调查等人(2020a)。
4.4. 生成检索模型
生成检索模型或可微分搜索索引采用编码器-解码器或仅解码器神经网络架构,其目标是根据给定的查询生成文档标识符。 尽管早期开发这些模型的尝试(Tay 等人,2022)未能大规模有效地执行(Pradeep 等人,2023),Zeng 最近的研究等人 (2024) 开发了面向前缀的优化方法,使生成检索模型能够有效地扩展到大型集合。 这些模型通常为集合中的每个文档分配语义文档标识符,并进行优化以使用顺序解码算法(例如波束搜索)生成相关文档的标识符。
4.5. 统一搜索方程
当前的搜索文献可以通过借用神经图灵机(NTM)范式的寻址和读取方程来概括(Graves等人, 2014, 2016) ;雷等人,2016)。 在读取集合之前,模型应该通过寻址来决定它应该关注集合的哪一部分。 可以通过将查询(来自3)与集合中的键进行比较和/或通过查找集合中的位置来完成寻址。 构造集合时也会使用寻址,这将在第 6 节中讨论。
4.5.1. 基于内容的寻址
在第 次迭代中,稍微滥用了符号(将 简化为 ),给定查询 ,集合 ,基于内容的寻址可以定义为:
| (4) |
其中k是根据查询要选择的相关地址的数量,score是评分函数,例如BM25(Robertson等人,1995) 或余弦相似度 (Guu 等人, 2020; Majumder 等人, 2024)。 基于内容的地址向量 可以通过查询和集合 的所有元素的成对比较来详尽计算(Graves 等人, 2014, 2016; Weston 等人, 2015; Santoro 等人, 2016;Chen 等人,2018;Sukhbaatar 等人,2015),加速(Lample 等人,2019;Weston 等人,2015),或通过 ANN 近似,选择顶部 项 ,产生 和 个非零元素 (Rae 等人, 2016; Kumar 等人, 2016;Khandelwal 等人,2022;Alon 等人,2024)。 当集合中的内容无法随时与 进行比较时,可能需要使用函数 ,例如,映射到特征空间 (Weston 等人,2015 年;Shi 等人,2024 年;Guu 等人,2020 年;Borgeaud 等人,2022 年) 和词法转换 (Madaan 等人,2022 年)。 当不需要变换时,该函数可以是恒等函数(Grave等人,2017)。
4.5.2. 基于位置的寻址
基于位置的寻址允许搜索系统纯粹通过存储位置(例如索引)访问语料库,而无需在查询和语料库之间进行任何词汇或上下文比较。 因此,这通常用于存储(第 6 节)或基于新近度的检索。 因此,
| (5) |
其中 context 是此函数在生成基于位置的地址时可以使用的辅助信息(例如,此函数之前生成的地址)。 对于某些应用,基于内容的寻址和基于位置的寻址可以一起使用。 为此,最终地址可以定义为:
| (6) |
其中 combine 是一个根据基于位置和基于内容的地址生成地址的函数。 尽管之前的大部分工作使用纯基于内容的寻址(Santoro 等人, 2016; Guu 等人, 2020; Khandelwal 等人, 2020; Rae 等人, 2016) 或纯基于位置的寻址寻址(Weston等人,2015;Shinn等人,2023),一些工作同时采用基于内容和基于位置的寻址(Graves等人,2014,2016)。
4.5.3. 统一搜索方程
有了最终的地址向量,的检索结果可以定义为
| (7) |
其中 read 只是从位置 的语料库中选择由 转换的内容。
5. 展示与消费
在本节中,我们将介绍 REML 的两个关键部分。 表示不仅涉及我们如何定义结果空间,还涉及如何为下一步的消费准备检索结果。 根据应用程序,呈现阶段的范围可以从简单的结果复制到具有中间预处理和基于模型的转换的更复杂的管道。 消耗是预测模型()合并检索到的信息的过程。 在设计有效的呈现和消费方法时需要考虑很多因素。 人们通常希望合并尽可能多的信息,同时平衡效率和准确性之间的权衡。
5.1. 推介会
当向人类读者呈现搜索结果时,界面旨在使搜索结果易于使用,例如通过按相关性对项目进行排序或突出显示显着片段(White等人,2003)。 在 REML 中,我们遵循类似的原则,只不过检索数据的目标消费者是一台机器,它具有不同的限制和功能。 表2总结了与演示相关的研究。
5.1.1. 转换数据
根据任务和数据源,结果数据在使用之前将是不完整的。 数据转换是一个通用且强大的过程,根据系统的需要通过单独的模型转换数据。 需要进一步数据转换的常见原因包括去上下文化、翻译和摘要等,因此 可以通过以下等式进行转换:
| (8) |
去情境化
当检索到的项目只是更大文档的几个句子时,可能需要去上下文化来解决照应或先前定义的缩写(Newman等人,2023)。
翻译
搜索可能在跨语言表示空间中进行,并且检索到的项目与所需的输出语言之间可能存在语言不匹配(Lavrenko等人,2002)。 多语言语言模型可能对检索上下文中的代码切换具有鲁棒性,但在处理任何检索到的文档进行预测之前对其进行翻译可能会更可靠(Parton等人,2008;Jiang等人,2024). 翻译可以应用于其他模式,例如重新生成图像以匹配预期的风格。
总结
由于预测模型可能存在上下文限制,因此需要压缩文档数据,以便更多文档可以适应上下文。 这可以通过自动摘要来实现,通过提取或抽象过程将原始数据转换为缩短的形式(高等人,2023b;李等人,2023)。 此外,可以在输入的上下文中总结数据,提供清晰度并解释文档为何相关。
5.1.2. 合并结果项
为了进一步优化结果项的大小或清晰度的呈现,可以组合多个项,例如,共同总结所有项(Wu等人,2021;Sarthi等人,2024)。 并非所有 REML 系统都会组合项目,因为对单个项目的操作可以高效且有效。 此外,组合项目可能会导致复杂化,例如单个分数与组合结果分数之间的校准错误,这由 compose 表示:
| (9) |
5.1.3. 截断结果列表
如果并非所有文档都适合消费上下文,我们会根据这些限制丢弃或截断文档,优化长度和潜在的其他属性,例如多样性 (Hofstätter 等人,2023;Bahri 等人,2020;Meng 等人, 2024),用truncate表示:
| (10) |
5.1.4. 用于演示的统一方程
完整的演示方程:
| (11) |
其中任何一个函数都可以替换为简单的形式,例如恒等函数 (Lewis 等人,2020a;Izacard 和 Grave,2021b,a)。 此外,我们可以想象这些函数以任意顺序多次应用。 考虑到上下文长度限制,我们将这种排序视为最自然的排序。 用于单个项目, 与 类似,但用于项目组。 未显示检索到的项目的加载。 与数据通常仅用于训练的传统 ML 系统不同,REML 系统具有与数据加载相关的独特要求。 由于输入所需的外部数据量是动态且巨大的(Borgeaud 等人,2022),因此数据的高效加载和管理至关重要(Douze 等人,2024;Guo 等人,2020b)。 我们假设加载是由检索模块隐式处理的。
Transform (§5.1.1) ALCE (Gao et al., 2023b) Explores both summarization and extractive snippets to compress retrieved items. Teach LLMs to Personalize (Li et al., 2023) Context independent and dependent summarization to emphasize key retrieved aspects. QADecontext (Newman et al., 2023) An example application where decontextualization is done as the downstream task when presenting passages from scientific documents. Compose (§5.1.2) Fixed Chunking (Wu et al., 2021) Recursively summarizes adjacent chunks in books. RAPTOR (Sarthi et al., 2024) First clusters then summarizes related chunks of text. Truncate (§5.1.3) FiD-Light (Hofstätter et al., 2023) Extracts subset lists of vectors in an FiD-like model to speed up attention-related performance bottleneck during decoding. Choppy (Bahri et al., 2020) A supervised approach to ranked list truncation.
5.2. 消耗
在 REML 中,预测模型通过一个或多个文档来呈现。 的有效性受到所提供文档的消耗的影响。 理想情况下,会同时消耗所有文档,但我们的系统在计算上受到限制;因此,消费的粒度通常仅限于所提供文档的子集。 根据任务的不同,不同的消耗算法的效用可能会有所不同——一些算法用于提取,另一些算法用于预测模型参数的动态更新。 相比之下,解码算法,例如波束搜索(Freitag and Al-Onaizan,2017)或核采样(Holtzman等人,2020) ,提供解码给定文档的有效输出的方法,并且可以合并验证以提高有效性。 消费过程中还存在其他问题,例如效率(De Jong 等人, 2023; Hofstätter 等人, 2023)和归因(Gao 等人, 2023b; Schuster 等人, 2024; Asai等人,2024;Menick 等人,2022),提供进一步的实用性。
5.2.1. 检索项不同粒度的消费
通常,检索多个项目,并且单独或一起处理检索到的项目是设计选择。 以下是使用检索项的主要范例:
-
•
单个:预测中仅包含单个项目。 这对于简单查询来说可能足够了,但通常需要跨多个检索到的项目组合信息。
-
•
集成:以单一方式对多个检索项进行预测,然后聚合(Khandelwal等人,2020;Shi等人,2024)。
-
•
联合:当预测具有足够灵活的上下文表示时,可以在单个推理过程中同时传递多个检索项(Izacard 和 Grave,2021b;Lewis 等人,2020a)。 这可能比集成方法更丰富,因为每个检索到的项目都知道其他项目。 由于计算限制,只有少数检索项能够以这种方式处理,并且集成方法相对更具可扩展性。
-
•
多轮:一种混合方法,一次处理检索到的项目的子集,下一个子集包含有关迄今为止处理的检索到的项目的信息(Jiang 等人,2023)。 虽然比联合方法更具可扩展性,但这可能会更慢。 话虽这么说,一些应用程序(例如对话)自然符合多轮框架。
这些范例是原子函数,可以组合起来形成更复杂的操作。 例如,给定检索项目的列表,表示为,具有不同粒度的原子函数可以组成如下等式:
| (12) |
5.2.2. 消费算法
与粒度的选择无关,存在适用于消费的算法。 一般来说,它们分为以下几类:
-
•
提取:预测模型仅限于从检索到的项目中提取准确的信息,例如,从检索段落中提取一段文本来回答问题(Khandelwal等人,2020;Lan等人,2023) 。 这可以通过指针网络(Vinyals等人,2015)、约束解码(Hokamp和Liu,2017;Hu等人,2019;Post和Vilar,2018)来实现,以及其他类似的技术。
-
•
类比:通过示例学习、基于案例的推理以及检索和编辑方法都属于类比推理的范畴。 每一种都涉及不同的底层机制,但本质上,预测模型将从一个或多个示范性示例中进行推断来进行预测,而不一定从检索到的项目中提取事实知识(Das等人,2020) 。
-
•
上下文:预测模型将检索到的项目合并到其上下文中,但输出的解码不受任何方式的约束(Shi等人,2024)。
-
•
潜在:一种混合方法,其中检索到的项目不会直接合并到上下文中,而是以其他方式合并,例如通过合并隐藏状态(Yogatama等人,2021)。 与上下文方法类似,解码不受限制。
5.2.3. 解码算法
独立于消费算法,可以使用不同的解码算法来预测 REML 中的高质量输出。 一般来说,迄今为止探索的解码算法分为以下几类:
-
•
仅输出:波束搜索等搜索算法(Freitag 和 Al-Onaizan,2017) 在对候选预测进行评分时仅考虑模型输出(Khandelwal 等人,2020)。
-
•
检索增强:束搜索等搜索算法在对候选预测进行评分时会同时考虑模型输出和检索到的项目(Lewis 等人,2020a;Asai 等人,2024)。 这应该惩罚查询和检索到的项目之间的虚假关联。
-
•
基于验证:预测模型的初始输出将由验证模块仔细检查,如果满足条件,则可能会被拒绝,例如,输出不包含检索到的项目(Jiang等人,2023).
5.2.4. 消费效率
可以在演示中采取步骤来加速推理,例如通过摘要压缩段落或截断检索到的项目列表(De Jong 等人, 2023; Hofstätter 等人, 2023). 还有其他与消耗更紧密结合的提高效率的方法,例如部分预计算通道嵌入。
5.2.5. 归因和其他扩展
REML 的高级应用将扩大预测模型输出空间,以纳入 REML 特定信息。 最常见的例子可能是支持归因,以便输出的每个部分都可以追溯到相关的检索项 (Gao 等人, 2023b; Schuster 等人, 2024; Asai 等人, 2024;梅尼克等人,2022)。 其他情况涉及内联验证或调用外部工具,如果不合并适当的检索项(Asai 等人,2024),这些是不可能轻易实现的。
Consumption Granularities (§5.2.1) NN-LM (Khandelwal et al., 2020) Single + Ensemble Probabilities are computed for each retrieved item independently then combined. RePLUG (Shi et al., 2024) Single + Ensemble Probabilities are computed for each retrieved item independently then combined. RAG (Lewis et al., 2020a) Joint Retrieved items are concatenated before consumption. FiD (Izacard and Grave, 2021b) Joint Retrieved items are concatenated in the decoder during consumption. FLARE (Jiang et al., 2023) Multi-round Potentially retrieves new items as generation progresses. Consumption Algorithms (§5.2.2) kNN-LM (Khandelwal et al., 2020) Extractive A single word is selected from the retrieved context. CoG (Lan et al., 2023) Extractive An extension of kNN-LM that can output both words and phrases. CBR (Das et al., 2020) Analogical Incorporate knowledge graphs into neural models in spirt of case based reasoning. Dynamic L2M (Drozdov et al., 2023) Analogical Retrieves demonstrations for few-shot prompting. RePLUG (Shi et al., 2024) Contextual Uses retrieved items in the context. SPALM (Yogatama et al., 2021) Latent Incorporates retrieved items into the hidden state. Decoding Algorithms (§5.2.3) kNN-LM (Khandelwal et al., 2020) Text-only Retrieval probability is ignored for next word prediction. RAG (Lewis et al., 2020a) Retrieval-enhanced Retrieval probability is incorporated in beam search. Self-RAG (Asai et al., 2024) Retrieval-enhanced Critic probability is incorporated in beam search. FLARE (Jiang et al., 2023) Verification-based Discards low confidence continuations, triggering retrieval. Consumption Efficiency (§5.2.4) LUMEN (De Jong et al., 2023) Precompute Partially computes passage representations offline. Attribution and Extensions (§5.2.5) ALCE (Gao et al., 2023b) Attribution End of sentence. Multi-source. SemQA (Schuster et al., 2024) Attribution Mid-sentence. Multi-source. Self-RAG (Asai et al., 2024) Attribution End of sentence. Single source. Verification Outputs a special token indicating whether to use document.
6. 储存
存储是 REML 模型的可选但重要的属性之一,指的是可检索项目的保存、表示和索引方式。 存储组件可以分为耦合存储和解耦存储。 如果至少一个外部存储器与预测模型联合优化,我们称该架构具有耦合存储。 在耦合存储架构中,内容可以在线填充到存储中,并与预测模型一起更新,例如神经图灵机(NTM)(Graves等人,2014,2016) 和 REALM (Guu 等人, 2020)。 另一方面,如果所有外部存储都来自现成的系统,并且内容离线填充,我们称该架构具有解耦存储,例如kNN -LM (Khandelwal 等人, 2020) 和 ED2LM (Hui 等人, 2022b)。
在最简单的形式中,REML 系统将使用解耦存储进行操作,其中检索模型的实现独立于预测模型。 由于存储中的条目是离线填充的,并且许多现成的检索模型很容易获得,因此构建解耦存储相对方便。 另一方面,许多先进的 REML 系统使用耦合存储进行操作,其中检索模型直接受到预测模型的影响。 在这里,存储中的条目在线填充并与预测模型一起更新。 在本节中,我们将描述与耦合和解耦存储相关的存储操作和挑战。
6.1. 主存储操作
一般来说,每个存储系统必须支持三种类型的操作才能在 REML 系统中有效利用:地址生成、读取和写入。 存储操作通常用于三种场景:1)需要在其预测中结合历史上下文,例如长上下文语言模型; 2)利用最近/过去的交互进行各种类型的在线学习,例如强化学习和语言代理中的经验回放; 3)是一个类似内存网络的架构(Weston等人,2015),其中检索是一个抽象过程,写入存储或从存储读取的所有内容都由网络是正在优化的目标的服务。
6.1.1. 地址生成
在 REML 系统中利用存储的一个重要方面是存储和检索特定信息的能力。 因此,存储系统必须能够生成用于读取或写入存储的特定地址。 存储位置可以分为抽象位置(存储空间中的插槽)和物理位置(存储在硬件中的位置)。 对于摘要位置,它归结为 的角色,如 4.5 节中介绍的。 在大多数情况下,它将是一个简单的旋转函数(Graves等人,2014,2016),它允许通过一系列槽进行迭代。 为了提高效率,该函数可以按内容(Weston等人,2015)或层(Lample等人,2019)将条目存储到集群中,从而减少搜索过程中的计算量。 对于物理位置,不需要位于 RAM 或 VRAM 中的条目可以通过内存映射移动到磁盘,而必须位于 RAM 中的条目(例如要搜索的嵌入索引)可以进行压缩,而不会导致性能明显下降(Izacard 等人,2024)。
6.1.2. 读
6.1.3. 写
在时间,获得地址向量后,可以通过更新数据存储的write函数来完成存储操作> 如下:
| (13) |
其中payload可以是向量或原始表示形式,在存储到存储之前可以通过一些函数进行预处理,类似于5节中定义的函数(Hui等人,2022b)。
从4.5节提到的寻址机制来看,可以理解,在写操作之前使用基于位置的寻址,遵循神经图灵机(NTM)的框架(Graves等)人,2014,2016)。 在大多数情况下,写操作将简单地将最新条目附加到存储的末尾(指向下一个可用槽的地址向量),在每个新输入之后按顺序执行,遵循神经缓存模型 的工作(坟墓等人,2017)。 另一方面,一些架构,例如记忆神经网络(MemNN)(Weston等人,2015)或大型记忆层(Lample等人,2019)的操作方式不同,并将生成一个地址,指定在内存中写入新条目的位置,可能会覆盖之前存在的任何条目。 正则化可以应用于内存网络,以确保使用大部分内存。 这些决策可以通过与存储管理组件的协同努力来做出。
6.2. 存储操作的阶段
在 REML 系统中,存储通过两个不同的阶段进行操作。 初始阶段称为存储构建,涉及系统使用必要的信息设置存储基础设施以促进其操作。 完成此设置后,系统将过渡到存储管理阶段,在此阶段确定存储信息的适当策略,包括选择要保留的数据、最佳存储位置以及组织数据的方法。供将来检索的信息。
6.2.1. 仓储建设
在大多数情况下,REML 系统将通过处理整个检索语料库来初始化其存储。 这可以根据需要在训练之前、训练之后、推理之前以及整个过程中离线完成。 存储构造已得到充分记录和研究,初始存储构造本质上是一系列写入和地址生成操作。 存储可以构建为键值结构,其中检索空间 可以定义为:
| (14) |
其中 是一个键表示函数,可以获取语料库中的每个条目或输入实例 。 类似地,是一个值表示函数,它可以采用语料库中的每个条目或输入实例在存储中生成一个值。 需要注意的是, 和 函数可以只是恒等函数,这意味着它根本不会更改键和值。 表4描述了每篇论文如何构建其离线和/或在线存储。 例如,在 EMAT (Wu 等人, 2022d) 中,集合是问题和答案对, 函数仅利用每对中的问题来生成密钥表示, 函数仅使用每对的答案来生成值表示。
6.2.2. 存储管理
一旦存储初始化,为了最佳的任务完成和效率,需要对存储操作进行调度,我们将这个阶段称为存储管理。 存储的有效使用可以从空间和速度的角度来理解,这归结为确定三个决策:存储时间、存储内容和存储方式。
何时储存
大多数场景下,会根据的需要,从初始阶段构建的存储中拉取信息。 但是,当 与 顺序或联合训练期间 发生变化时,此设置可能会引入存储陈旧问题。 由于(C中key的检索空间)是在训练过程中由构建的,因此需要将存储刷新为 已更新; MemNN (Weston 等人, 2015) 甚至提到了这一点。 这归结为提出两个问题:1) 更新频率,以及 2) 更新存储的哪一部分。 对于第一个问题,可以同步(每个训练步骤)或异步(每个 训练步骤)更新存储(Asai 等人, 2023a)。 对于第二个问题,可以选择更新整个存储、存储的子集,或者根本不更新存储。
储存什么
从何时存储继续,如果存储定期更新,则有选择地存储可能是有益的。 对于同步更新,由于计算开销较大,优选通过批量近似或重新排序来更新存储子集,而异步更新时通常会执行完整存储更新(Izacard 等人, 2024; Asai 等人,2023a;钟等人,2022;顾等人,2020)。 另一种选择性存储的方法是随着存储空间变满而定期更新,擦除过去存储的一些条目。 一种简单的方法是设置存储的窗口大小并像队列一样管理它(Shinn 等人, 2023; Wu 等人, 2022b; Dai 等人, 2019; Rae 等人, 2020) ,类似于丢弃存储中最旧的条目(Grave等人,2017)。 Weston 等人 (2015) 设计了一个单独的擦除模块,对每个条目的效用进行评分,以丢弃最不有用的条目。
如何储存
这包括条目表示,例如索引压缩(Wu等人,2022b;Rae等人,2020;Martins等人,2022)和量化(Izacard等人,2024) 以及存储的架构选择,例如键值结构(Grave 等人, 2017; Khandelwal 等人, 2020; Wu 等人, 2022c; Zhu 等人, 2022; Min 等人, 2023; Borgeaud 等人, 2022; Yogatama 等人, 2021; Alon 等人, 2022; Hui 等人, 2022b),其中压缩和表示计算可以批量进行(Zamani 等人, 2022).
6.3. 存储类型
Coupled Storage (§6.3.1) Key Value NTM (Graves et al., 2014, 2016) transformed output of (the same as the Key) MemNN (Weston et al., 2015) & MemN2N (Sukhbaatar et al., 2015) input feature embedding (the same as the Key) Dynamic Memory Network (Kumar et al., 2016) input feature embedding (the same as the Key) Neural Cache Model (Grave et al., 2017) hidden representation of RNN next word RUM (Chen et al., 2018) user-item embedding (the same as the Key) Transformer-XL (Dai et al., 2019) hidden representation of Transformer (the same as the Key) LongMem (Wang et al., 2023a) attention-key attention-value Memorizing Transformer (Wu et al., 2022c) attention-key attention-value MemTransformer (Burtsev et al., 2021) sequence of tokens tokens RPT (Rubin and Berant, 2023) token chunk embedding (the same as the Key) Unlimiformer (Bertsch et al., 2023) token chunk embedding (the same as the Key) MeMViT (Wu et al., 2022b) image frame embedding (the same as the Key) PFMN (Lee et al., 2018) image frame embedding (the same as the Key) REALM (Guu et al., 2020) document embedding (the same as the Key) REPLUG LSR (Shi et al., 2024) document embedding (the same as the Key) ATLAS (Izacard et al., 2024) document embedding (the same as the Key) EMAT (Wu et al., 2022d) question embedding answer embedding QAMAT (Chen et al., 2023c) question embedding question-answer embedding TRIME (Zhong et al., 2022) context (sequence of tokens) next token NPM (Min et al., 2023) token embedding token Reflexion (Shinn et al., 2023) NL self-reflection in NL (the same as the Key) CLIN (Majumder et al., 2024) self-reflection in NL (the same as the Key) ExpeL (Zhao et al., 2024) self-reflection in NL (the same as the Key) Generative Agent (Park et al., 2023) stream of experience in NL (the same as the Key) Voyager (Wang et al., 2023c) program description embedding program code MemPrompt (Madaan et al., 2022) NL question NL human feedback Decoupled Storage (§6.3.2) kNN-LM (Khandelwal et al., 2020) context embedding next token SPALM (Yogatama et al., 2021) context embedding next token RAG (Lewis et al., 2020b) document embedding (the same as the Key) RETOMATON (Alon et al., 2022) context embedding next token, pointer KIF (Fan et al., 2021) evidence embedding (multimodal) (the same as the Key) RETRO (Borgeaud et al., 2022) token chunk embedding token chunk ED2LM (Hui et al., 2022b) document embedding document REPLUG (Shi et al., 2024) document embedding (the same as the Key)
在文献中,REML 系统中确定了两种类型的存储架构:耦合存储和解耦存储。 以下各节将详细介绍这些架构,并介绍与每种存储类型相关的特征。
6.3.1. 耦合存储
耦合存储被定义为可以在预测模型的训练和推理过程中在线更新并可以联合优化的存储。 耦合存储增强的最初开发主要由神经图灵机 (NTM) (Graves 等人, 2014, 2016) 和内存网络 (MemNN) (Weston 等人, 2015). 他们通过利用外部可寻址存储向语言推理任务展示了摘要操作,例如复制、召回和排序,其中这些架构存储中的内容是可以被 轻松使用的密集向量。 我们建议读者参考这两个模型的原始论文,以更深入地了解具有耦合存储的 REML 模型的主要形状。 具有耦合内存的 REML 系统有一些显着的特征,包括但不限于:
耦合存储的陈旧性
耦合存储的主要问题之一是在训练 时出现,导致存储过时。 这仍然是社区中持续存在的挑战,但正如 6.2 节中提到的,已经设计了几种技术来通过回答更新频率(同步或异步)以及要更新存储的哪一部分(全部或部分)。 因此,有五种不同的策略,包括避免更新。 同步完整更新是通过在每个训练步骤更新存储来解决陈旧问题的简单方法。 它在一些研究中进行了尝试(Rubin和Berant,2023;Bertsch等人,2023),但其巨大的计算开销使其无法在实际环境中使用(Izacard等人, 2024)。 同步部分更新可以通过选择一批条目进行更新(Izacard等人,2024)来完成。 根据应用的不同,可以有多种批量选择策略,例如词汇相似度(Zhong等人,2022)或文档内采样(Min等人,2023) 。 异步完整更新是通过每训练步更新完整存储(Guu 等人, 2020; Izacard 等人, 2024; Shi 等人, 2024; Wu等人,2022d)。 这使得索引在再次更新之前就已经过时。 例如,Wu 等人 (2022d) 在每个训练 epoch 开始时冻结存储,仅在每个 epoch 结束时更新。 据我们所知,很少有人尝试异步部分更新,因为它可能会大幅降低训练性能。 另外,由于索引重新创建的成本非常高,因此可以忽略陈旧性并避免使用适当的策略重新建立索引,而不会大幅影响性能(Rae等人,2016;Lewis等人,2020b;Izacard 等人,2024;Guu 等人,2023a;Wu 等人,2022c)。
耦合存储中的冷启动问题
配备耦合存储的模型的另一个特点是它们可能存在冷启动问题,即在存储填满足够的信息之前 的性能不是最佳的。 大多数以空存储开始的架构,例如语言代理(LA)或在多个训练步骤中处理长文档的长上下文语言模型都有这个问题(Park 等人,2023;Majumder 等人,2024 ; Shinn 等人, 2023; 王等人, 2023c; 钟等人, 2022)。 然而,当模型可以适应新任务并且之前任务中建立的存储/经验可以转移到新任务时,冷启动问题可以得到缓解(Majumder等人,2024)。
耦合存储的多功能性
尽管有其缺点,耦合存储在理论上和各种应用中都取得了显着的发展。 它包括使具有端到端可训练耦合存储的 REML 系统(Sukhbaatar 等人,2015),使用情景存储捕获语言的位置和时间性(Kumar 等人,2016),并通过稀疏访问(Rae等人,2016;Zaremba和Sutskever,2016)和战略存储管理(Lample等人,2019;Grave等人,2017)来扩展存储)。 这些导致了在各个领域的应用,例如元学习(Santoro等人,2016)、顺序推荐(Chen等人,2018)、视频摘要和识别(Lee等人,2018;Wu等人,2022b)。 在长上下文语言模型(Bertsch等人,2023;Zhong等人,2022)中,已经有通过注意力循环来解决任务的方法(Dai等人,2019;Yogatama等人) , 2021; Wu 等人, 2022c; Wang 等人, 2023a) 和隐藏状态压缩(Rae 等人, 2020; Martins 等人, 2022; Wu 等人, 2022b) 。 近年来,语言智能体的研究重点关注智能体在与外部环境交互时使用语言模型进行感知、推理、规划和管理记忆的能力(Sumers等人,2024)。 这些智能体根据观察结果独立学习并调整知识,配备了用于长期记忆的外部存储,使它们能够存储过去的推理(Majumder 等人,2024;Wang 等人,2023c;Zhao 等人,2024;Park 等人,2023;Shinn 等人,2023)或用户反馈(Madaan 等人,2022)以供将来使用和自我反思(Madaan 等人) ,2024)。
6.3.2. 解耦存储
解耦存储被定义为 REML 系统中的一种存储方法,其中 独立于 运行。 与耦合存储相反,耦合存储中的条目动态在线更新通常受到 和 联合优化的影响,解耦存储涉及条目的离线填充,即存储变为读取-仅限在线阶段。 具有解耦内存的 REML 系统有一些显着的特征,包括但不限于:
易于实施。
由于检索器完全独立于预测模型,因此与耦合存储相比,REML系统的实现变得容易得多(Borgeaud等人, 2022; Hui等人, 2022b; Yogatama等人, 2021; Khandelwal等人,2020;阿隆等人,2022)。 在训练 REML 系统时,在解耦存储架构中,可以单独训练检索器,也可以使用已经公开可用的现成检索器(Shi 等人,2024)。 这也意味着只需更换 REML 系统的组件即可轻松编辑 REML 系统。 因此,与耦合存储架构不同,这种设计可以保证摆脱存储陈旧和冷启动问题。 当系统需要整合多模式或多源的多个存储时,实施的简便性就显得尤为突出(Fan 等人,2021;Yang 等人,2024a;Yu 等人,2022b),使用耦合内存架构来实现可能会很棘手。
性能次优。
一般来说,众所周知,在具有多个组件的 REML 系统中,与单独训练每个组件相比,端到端训练会产生更好的性能(Sachan 等人,2021;Wang 等人,2024b;Zamani 和 Bendersky,2024 )。 然而,在具有解耦存储的 REML 系统中,存储组件和预测模型是分开训练的。 此配置可能会导致系统下游任务的性能不佳。 换句话说,尽管很方便,但在解耦存储系统中,在预测模型训练期间存储的固定性质(反之亦然)阻碍了它们适应彼此的需求。
7. 优化
如图2所示,REML系统由多个相互交互的组件组成。 优化可以进行端到端(即,为了共同目标同时优化所有模型参数)。 或者,可以对模型参数的子集进行优化,例如 REML 中每个组件的独立优化。 例如,为了优化查询生成组件,需要真实查询来独立优化该组件。 对于某些组件来说,获得此类数据是困难的。 远程或弱监督是解决这个问题的一个潜在解决方案。 在本节的其余部分中,我们主要关注 REML 系统的两个主要组成部分——检索模型和预测模型的优化。
7.1. 检索模型优化
7.1.1. 无 REML 优化
在广泛的研究中,检索模型并未优化。 在其中许多中,查询和文档都是非结构化文本的形式。 在这种情况下,查询和文档表示通常是根据术语统计数据计算的,例如文档中的术语频率或文档集合中的文档频率。 使用检索模型,例如 TF-IDF (Salton 和 Buckley,1988)、BM25 (Robertson 等人,1995) 和查询似然 (Ponte 和 Croft, 1998),带有默认参数,就属于这一类。 例如。 Dr.QA 模型(Chen 等人,2017a) 使用 TF-IDF 的 ElasticSearch 实现从 Wikipedia 进行文档检索,以进行事实问答。 SelfMem 模型(Cheng 等人,2024) 使用 BM25 进行文档检索,用于许多检索增强的文本生成任务,例如翻译和对话。
预训练的语言模型(例如编码器表示)也可用于生成查询和文档的潜在表示,其中简单的相似性函数(例如点积或余弦相似性)用于计算查询-文档对的相关性分数。 尽管这些语言模型经历了昂贵的优化过程,但它们的优化并不是特定于 REML 的。 请注意,使用未经优化的语言模型表示进行检索通常效果不佳。 例如,Lien 等人 (2024) 证明,使用简单的 BERT 或 RoBERTa 表示进行零样本检索比术语匹配模型(如 BM25)要差得多。
最近,人们发现大规模指令调整语言模型(例如 GPT-3.5)可以经过仔细指示,对给定查询的一些文档进行排名(Sun 等人,2023) 。 这些模型可以有效地执行,但不能应用于大型文档集合,只能用作重新排序模型。
通过结构化查询(例如 SQL)从数据库中检索也属于这一类。 各种面向任务的对话系统,例如旅行预订和餐厅预订的智能助手,需要访问数据库以获取最新的可用性(Chen 等人,2017b)。
7.1.2. 独立优化
REML 可以利用检索模型,其优化独立于预测模型的参数。 检索模型通常使用一组查询-文档-相关性三元组进行训练。 相关性信号可能来自(1)显式注释,例如来自专家评估员或众包人员,(2)隐式反馈(Joachims,2002;Joachims等人,2017) ,例如,用户点击、停留时间、鼠标移动等,或(3)自动生成的微弱信号(也称为远程监督信号),例如短语的出现,例如 QA 上下文中的回答,文档、另一个检索模型的检索分数(Dehghani 等人,2017)、大型语言模型生成的注释(Thomas 等人,2023)。 使用这些训练三元组,可以使用三种不同的方法来优化检索模型:(1) 逐点排序、(2) 成对排序和 (3) 列表排序。 有关各种排名损失函数的更多信息,请参阅Liu (2009)。
在 REML 的背景下,大量研究,例如 (Vu 等人, 2023; Hashemi 等人, 2021; Lyu 等人, 2023; Jiang 等人, 2023) 使用商业搜索引擎,例如 Bing 或 Google,作为它们的检索模型。 这些搜索引擎使用上述相关性信号的组合进行优化。 因此,它们被认为是独立的优化模型。 一组方法,例如(Izacard and Grave,2021b),在明确标记的集合上训练检索模型,例如MS MARCO (Campos等人,2016)或出处KILT 基准(Petroni 等人,2021) 中的标签,然后在经常超出域的 REML 场景中使用经过训练的模型。 (Qu 等人, 2021, 2020; Salemi 等人, 2023b) 中也使用弱监督或远程监督来进行开放域(视觉)问答,假设任何包含答案短语的文档是相关的。
7.1.3. 条件优化
在条件优化中,检索模型以预测模型 为条件进行优化。 一组条件优化方法使用知识蒸馏。 例如,Izacard 和 Grave (2021a) 使用融合解码器架构中交叉注意力权重的聚合作为检索模型的弱信号。 这里,提供权重的解码器扮演教师模型的角色,而密集段落检索模型扮演学生模型的角色。 或者,Yang 和 Seo (2020) 使用答案跨度选择模型(即读者)产生的相似性得分作为教师得分,并最小化它们与检索得分之间的 KL 散度。
正如 Izacard 和 Grave (2021a) 所示,从下游 ML 模型到检索模型的知识蒸馏可以迭代完成,如下所示:
| (15) |
其中迭代(或纪元)中的检索模型根据迭代时预测模型的参数进行优化,其中是下游损失函数。
7.2. 预测模型优化
7.2.1. 无 REML 优化
与检索模型类似,预测模型也可以用作“黑盒”系统,无需 REML 特定的训练。 例如,各种查询扩展方法,例如 Rocchio 算法(Rocchio,1971)、相关性模型(Lavrenko 和 Croft,2001) 以及散度最小化模型(Zhai 和 Lafferty,2001) 根据检索结果中术语和概念的出现来扩展查询。 在零样本环境中使用预先训练的大型语言模型是近年来受到广泛关注的另一个例子(Shi等人,2024;Salemi等人,2024b)。
7.2.2. 独立优化
REML 中的预测模型可以独立于检索模型的参数进行优化。 例如,我们可以通过假设检索模型是最优的(即检索真实相关文档)来优化预测模型。 此时,预测模型的优化可以建模为:
| (16) |
其中 是下游任务的损失函数。 例如,许多开放域 QA 模型经过优化,可以根据问题和黄金(基本事实)段落(Chen 等人,2017a)提取或生成答案。 有些可能会放宽检索模型的最优性假设,并将不相关的文档注入地面实况集。 这些文档可以随机采样,也可以从检索模型的输出中采样,但不能是 。
7.2.3. 条件优化
或者,可以根据检索模型的性能来训练预测模型。 在不失一般性的情况下,这可以被视为迭代过程,其中预测模型在一次迭代中被优化并且检索模型可选地在下一次迭代中被优化。 利用这个公式,可以得到迭代时预测模型的参数,如下所示:
| (17) |
7.3. 检索和预测模型的联合优化
7.3.1. 联合多任务优化
检索模型和预测模型可以联合训练。 联合优化可以端到端建模(本节稍后解释)或通过多任务学习建模。 在联合多任务优化中,对于任何训练实例,检索结果和预测模型参数都会更新。 例如,FiD-Light (Hofstätter 等人,2023) 除了用于检索增强文本生成任务的输出文本之外,还生成具有正来源分数的文档。 然后,生成的文档 ID 用于对结果列表重新排序。 因此,这可以看作是重排序和生成的联合优化。
7.3.2. 端到端优化
遵循风险最小化框架,REML 中的端到端优化可以建模如下:
| (18) |
其中两个参数集 和 通过优化下游机器学习任务的适当损失函数来同时更新。 然而,REML 的端到端优化可能具有挑战性。 这主要是由于 REML 中信息访问模型的顶级项选择过程导致端到端 REML 模型不可微。 现有的工作做了一些简化的假设,将优化转变为可微的过程。 例如,Lewis 等人 (2020b) 中的 RAG 模型将检索到的文档集边缘化为一组预先选择的文档。 后来 Sachan 等人 (2021) 使用类似的方法进行开放域问答。 除了边缘化之外,RetGen (Zhang 等人, 2022a) 和 EMDR2 (Singh 等人, 2021) 还做出了文档独立性假设,将损失函数计算为每个单独文档的总和。
8. 评估
我们评估的目标是了解对系统进行更改(包括完全替换)是否比保持现状更好。 例如,我们可能有兴趣了解更改搜索组件是否可以提高预测性能。 我们将此评估指标称为 ,其参数将很快解释。 我们计算关于某些总体的分布的预期度量值,理想情况下这与训练数据使用的分布相同。
我们将评估分类为外部(查看预测模型的最终性能)或内部(使用本地质量度量查看系统组件的性能)而不是预测模型性能(Sparck-Jones 和 Galliers,1996)。 模型的内在评估可以是外在评估的有效近似,或者可以测量一些独立值,例如资源消耗。
8.1. 外在评价
在所有情况下,我们最感兴趣的是系统指标的预期值。 也就是说,对于模型和评估数据,计算,
| (19) |
从外部评估系统时,我们可以通过多种方式提出有关系统相对性能的假设(Guu 等人,2020;Petroni 等人,2021;Lewis 等人,2020b)。 在非重叠系统比较中,给定两个模型元组和,判断是否。 在固定检索模型比较中,给定两个模型元组和,判断是否。 作为一种特殊情况,我们可以根据某些内在标准将 视为最佳排序器;这使我们能够检查系统是否可以有效地合并相关项目。 在固定预测模型比较中,给定两个模型元组和,判断是否。 在这种情况下,我们可以根据一些内在标准将视为最佳预测模型;这使我们能够检查系统是否可以有效地检索相关项目。
8.2. 内在评价
REML 系统由众多组件组成,每个组件都能够进行单独评估。 组件的内在评估涉及根据系统相对于该组件的孤立性能来比较系统。 然而,此类系统最重要的组成部分是检索和预测模型。
8.2.1. 检索的内在评价
检索模型的内在评估侧重于根据系统的孤立检索性能来比较系统。 在这种情况下,假设单轮检索,我们可以提出两种类型的假设。 在非重叠系统比较中,给定两个模型元组和,确定是否,其中,滥用表示法,和仅考虑和的查询处理。 在固定查询处理比较中,给定两个模型元组和,判断是否。 指标 的选择取决于任务,但应该是某种检索指标,除非检索结果不是排名。 此类指标需要对每个项目进行一些相关性估计。 对于 REML,这可能来自,
-
(1)
从人类评估者那里收集的明确标签。 这要求实例、目标和项目是可解释的。 KILT 基准中针对一些任务的“来源标签”,例如 Natural Questions (Kwiatkowski 等人, 2019) 和 ELI5 (Fan 等人, 2019) 可以被认为是这样的标签。
-
(2)
从目标推断标签。 例如,在 QA 中,我们可以计算检索到的项目与目标之间的相似度。 RAGAS (Es 等人, 2024) 和 ARES (Saad-Falcon 等人, 2024) 中的“上下文相关性”可以被认为是这种情况的变体。
-
(3)
来自模型预测的属性标签。 例如,在 QA 中,如果模型正确生成答案,我们可以尝试将答案的正确性归因于每个检索到的项目。 该方法受到 eRAG (Salemi 和 Zamani,2024a) 的启发,通过量化每个检索到的文档对获得正确答案的贡献来评估检索模型的性能。
8.2.2. 消费的内在评价
消费的内在评估侧重于根据系统将检索结果转化为有效预测的孤立能力来比较系统。 虽然外部评估一般衡量系统的有效性,但消费的内部评估侧重于预测是否可归因于检索结果(例如,与消费模型参数中已有的信息相比)。 在固定检索比较中,给定两个模型元组和,判断是否。 指标的选择取决于任务,但衡量预测是否与检索结果相关。 RAGAS (Es 等人, 2024) 和 ARES (Saad-Falcon 等人, 2024) 中的“忠诚”可以被认为是这种情况的变体。
8.3. 数据集
每个 REML 系统都经过定制,可以执行一系列特定的任务。 在文献中,各种基准和数据集用于从不同角度评估这些系统。 一般来说,数据集分为两类:1)专门考虑 REML 系统的外部评估,仅根据端到端性能对其进行评估。 2)那些提供检索相关性标签来评估除端到端性能之外的检索性能。 也就是说,表 5 说明了文献中最常用的数据集和基准。
End-to-End Evaluation (§8.3) Task Datasets Corpus Entity Related QA PopQA(Mallen et al., 2023), EntityQuestions(Sciavolino et al., 2021) Wikipedia Current Events Related QA RealtimeQA(Kasai et al., 2023) News Websites Science Related Multiple-choice QA ARC (Clark et al., 2018) Subset of Web Science Related QA Qasper(Dasigi et al., 2021) Scientific Articles Story Related Long-form QA NarrativeQA(Kočiský et al., 2018) A Long Story Query-based Summarization QMSum(Zhong et al., 2021) A Meeting Transcript Personalized Classification and Generation LaMP(Salemi et al., 2024b) A User Profile End-to-End & Retrieval Evaluation (§8.3) Open-domain Multi-Hop QA 2WikiMultiHopQA(Ho et al., 2020), HotpotQA(Yang et al., 2018; Petroni et al., 2021) Wikipedia Open-domain Short-form QA Natural Questions(Kwiatkowski et al., 2019; Petroni et al., 2021), TriviaQA(Joshi et al., 2017; Petroni et al., 2021), StrategyQA(Geva et al., 2021) Wikipedia Open-domain Long-form QA ELI5(Fan et al., 2019; Petroni et al., 2021), ASQA(Gao et al., 2023b) Wikipedia Dialogue Generation Wizard of Wikipedia(Dinan et al., 2019; Petroni et al., 2021) Wikipedia Slot Filling ZeroShot RE(Levy et al., 2017; Petroni et al., 2021), T-REx(Elsahar et al., 2018; Petroni et al., 2021) Wikipedia Entity Linking AIDA CoNLL-YAGO(Hoffart et al., 2011; Petroni et al., 2021), WNED-WIKI/CWEB (Alani et al., 2018; Petroni et al., 2021) Wikipedia Fact Verification FEVER(Thorne et al., 2018; Petroni et al., 2021) Wikipedia Open-domain Visual QA OK-VQA(Marino et al., 2019; Qu et al., 2021) Wikipedia Open-domain Visual QA FVQA(Wang et al., 2017) A Supporting Facts Set
9. 未来发展方向
考虑到迄今为止在设计 REML 系统方面所做的广泛努力,本节提出了旨在增强这些系统各个方面的未来工作的新想法。 具体来说,我们为前面讨论的每个部分提出了几个未来的方向。
9.1. 查询
9.1.1. 查询指令
大语言模型指令调优的最新进展表明下游任务的性能有了显着提高(Wei 等人,2022;Mishra 等人,2022;Wang 等人,2022)。 此外,最近关于利用指令进行检索的研究已经超越了竞争基线,在检索效率方面展示了卓越的性能(Asai等人,2023b)。 考虑到这一点,开发用于查询生成的转换函数,在查询的同时生成任务和特定于查询的指令,可以显着增强检索模型满足预测模型要求的能力。
9.1.2. 检索系统感知查询生成
大多数现有的查询生成转换和分解函数在运行时没有考虑检索模型的类型和配置。 但是,使用考虑检索模型规范的查询生成组件可以生成更有效的查询,以满足模型的特定要求。 例如,当使用强调术语匹配的BM25作为检索器模型时,与相关文档紧密对齐的术语的查询可以提高检索性能。 相反,在优先考虑查询和文档之间的语义相似性的密集检索模型中,生成与相关文档具有增强的语义对齐的查询将更有利。
9.1.3. 检索模型和预测模型之间分离的接口
大多数 REML 系统使用自然语言在预测模型和检索模型之间进行通信。 像 kNN-LM (Khandelwal 等人, 2020) 这样的模型,使用预测模型的隐藏表示作为查询和键,表示全部来自预测模型。 然而,仅仅依赖自然语言或一种模型的表示可能不是最佳的。 另一种方法是联合训练检索模型和预测模型,以学习共享的隐藏空间,从而实现更有效的沟通。 这种方法可以更有效地传达信息并增强模型之间的交互,从而带来更好的性能和协调。
9.2. 搜寻中
9.2.1. 预测模型感知检索系统
IR 中的个性化文献可以成为制作针对特定预测模型定制的检索模型的良好动机。 例如,可能存在这样的情况:多个预测模型由几个检索模型提供服务(Salemi 和 Zamani,2024b)。 在这种情况下,检索模型可以存储它们所服务的预测模型的元数据,从而为针对每个或一组预测模型定制检索结果提供了机会。
9.2.2. 重新定义相关性
与预测模型感知的 IR 系统相关,当前的 IR 模型是基于文档的相关性构建的。 这种相关性是通过该文档是否有助于满足用户的信息需求来定义的。 然而,在 REML 中,文档的使用者是预测模型,而不是人类用户(Salemi 和 Zamani,2024a)。 因此,应该重新定义相关性,以纳入文档在预测目标输出时的有用性。
9.3. 展示与消费
9.3.1. 任务专门的呈现和消耗
与特定于任务的检索有利于区分事实验证、实体链接、QA 等类似,使用特定于当前任务的文档表示可能会更好。 这可以具体化为带有特定于任务的指令、特定于任务的中间步骤(包括文档如何相关的解释)、甚至特定于任务的文档嵌入的提示。
9.3.2. 主动REML
在实践中,不仅回答查询提出的直接问题,而且解决潜在的后续问题(Samarinas 和 Zamani,2024;Liao 等人,2023)是有益的。 后续问题可以过渡到新主题(例如,预订航班后购买酒店),或者深入研究最初答案的一部分(例如,Dave Grohl 不仅组建了 Foo Fighters,而且之前还是 Nirvana 乐队的鼓手)。
9.4. 储存
9.4.1. 共享收藏
图2描述了单个与多个信息访问系统交互。 然而,也可以将多个映射到单个信息访问系统。 在这种特定情况下,多个预测模型共享单个集合,模型了解存储什么重要、什么不重要的能力变得至关重要,因为将不相关的内容推送到共享存储可能会导致其实用性下降并导致性能下降共享同一集合的其他。
9.4.2. 存储陈旧性
在训练 REML 模型时,更新的检索器通常会使之前构建的存储变得陈旧。 尽管已经有很多尝试绕开这个问题,但没有研究找到解决该问题的深刻方法。 这一持续存在的挑战需要进一步研究自适应存储机制,该机制可以动态地与检索器更新保持一致,确保数据完整性和模型效率。
9.5. 评估
9.5.1. 透明的内在评估
尽管对 REML 模型进行系统评估已有一些尝试(Saad-Falcon 等人, 2024; Es 等人, 2024; Salemi and Zamani, 2024a),但大多数都使用大语言模型来进行评估。 然而,这些指标缺乏透明度,因为它们没有给出以这种方式评估的有效理由。 也就是说,研究 REML 系统的透明评估是未来的一个重要方向。
9.5.2. 产出公平、可信、透明
尽管这些主题正在兴起,但它们主要在非 REML 设置上进行评估(例如,没有检索增强的文本生成)。 这些评估标准可以针对 REML 应用提出不同的研究方向。 识别不公平可能发生的位置(在检索和/或消费期间)并检查不公平是否传播到系统的最终输出可能是未来的研究方向。 在模型可信度和透明度研究中可以探索类似的方向。
9.6. 优化
9.6.1. 有效且高效的端到端优化
REML 中某些组件或其交互的不可微性质使得端到端优化 REML 系统具有挑战性。 现有的方法基于一些简化的假设,为端到端 REML 优化开发更准确和鲁棒的近似是一个重要的研究方向。 此外,基于人类和人工智能反馈的这些系统的基于奖励的优化还相对缺乏探索。 需要更好地理解信息访问系统提供的信息项的探索和利用。
9.6.2. 从在线和基于会话的反馈中学习
预测模型和信息访问模型之间的交互可以是连续的。 这种顺序交互的简单形式已经存在于多跳问答的环境中。 在推理会话期间使用预测模型提供的反馈及其用户来调整 REML 输出对于开发有效的交互式 REML 系统至关重要。
9.6.3. 有效近似优化反馈
端到端和条件优化方法都需要来自 REML 系统不同组件的反馈。 随着该领域朝着更大、更昂贵的方向发展,开发高效、准确的反馈近似值可以大大降低 REML 的成本。 这不仅会降低与 REML 训练相关的金钱成本,还会加快研究进展并带来更加可持续和环境友好的系统。
9.6.4. 一种信息访问和多种预测模型
大多数研究都集中在为一项任务开发 REML 系统。 另一方面,信息访问系统可以服务于多种预测模型,类似于当前服务于数十亿用户的搜索引擎,如 Salemi 和 Zamani (2024b) 中的研究。 优化为多个预测模型提供服务的信息访问组件、聚合和校准跨预测模型的反馈以及“个性化”每个预测模型的检索结果列表是未来研究的重要方向。
10. 结论
在这项工作中,我们调查了当前有关检索增强机器学习(REML)的文献,并将其合成为一致的数学概念,为研究人员提供了 REML 的形式化框架。 此外,通过将信息检索研究和 REML 联系起来,我们为这一新兴研究范式的未来研究找到了新的机会和开放的途径。
参考
- (1)
- Aksitov et al. (2023) Renat Aksitov, Chung-Ching Chang, David Reitter, Siamak Shakeri, and Yunhsuan Sung. 2023. Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models. arXiv:2302.05578 [cs.CL]
- Alani et al. (2018) Harith Alani, Zhaochen Guo, and Denilson Barbosa. 2018. Robust named entity disambiguation with random walks. Semant. Web 9, 4 (jan 2018), 459–479. https://doi.org/10.3233/SW-170273
- Alon et al. (2022) Uri Alon, Frank F. Xu, Junxian He, Sudipta Sengupta, Dan Roth, and Graham Neubig. 2022. Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval. In ICML 2022 Workshop on Knowledge Retrieval and Language Models. https://openreview.net/forum?id=ZJZmKGM6UB
- Arcadinho et al. (2022) Samuel David Arcadinho, David Aparicio, Hugo Veiga, and Antonio Alegria. 2022. T5QL: Taming language models for SQL generation. In Proceedings of the 2nd Workshop on Natural Language Generation, Evaluation, and Metrics (GEM). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates (Hybrid), 276–286. https://doi.org/10.18653/v1/2022.gem-1.23
- Arnab et al. (2021) Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. 2021. ViViT: A Video Vision Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 6836–6846.
- Asai et al. (2022) Akari Asai, Matt Gardner, and Hannaneh Hajishirzi. 2022. Evidentiality-guided Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Seattle, United States, 2226–2243. https://doi.org/10.18653/v1/2022.naacl-main.162
- Asai et al. (2023a) Akari Asai, Sewon Min, Zexuan Zhong, and Danqi Chen. 2023a. Retrieval-based Language Models and Applications. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts). Association for Computational Linguistics, Toronto, Canada, 41–46. https://doi.org/10.18653/v1/2023.acl-tutorials.6
- Asai et al. (2023b) Akari Asai, Timo Schick, Patrick Lewis, Xilun Chen, Gautier Izacard, Sebastian Riedel, Hannaneh Hajishirzi, and Wen-tau Yih. 2023b. Task-aware Retrieval with Instructions. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 3650–3675. https://doi.org/10.18653/v1/2023.findings-acl.225
- Asai et al. (2024) Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=hSyW5go0v8
- Attar and Fraenkel (1977) R. Attar and A. S. Fraenkel. 1977. Local Feedback in Full-Text Retrieval Systems. J. ACM 24, 3 (jul 1977), 397–417. https://doi.org/10.1145/322017.322021
- Baek et al. (2023) Jinheon Baek, Alham Fikri Aji, and Amir Saffari. 2023. Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering. In Proceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE). Association for Computational Linguistics, Toronto, Canada, 78–106. https://doi.org/10.18653/v1/2023.nlrse-1.7
- Bahri et al. (2020) Dara Bahri, Yi Tay, Che Zheng, Donald Metzler, and Andrew Tomkins. 2020. Choppy: Cut Transformer for Ranked List Truncation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 1513–1516. https://doi.org/10.1145/3397271.3401188
- Bertsch et al. (2023) Amanda Bertsch, Uri Alon, Graham Neubig, and Matthew R. Gormley. 2023. Unlimiformer: Long-Range Transformers with Unlimited Length Input. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=lJWUJWLCJo
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. 2022. Improving language models by retrieving from trillions of tokens. In International conference on machine learning. PMLR, 2206–2240.
- Burtsev et al. (2021) Mikhail S. Burtsev, Yuri Kuratov, Anton Peganov, and Grigory V. Sapunov. 2021. Memory Transformer. arXiv:2006.11527 [cs.CL]
- Cai et al. (2023) Yucheng Cai, Hong Liu, Zhijian Ou, Yi Huang, and Junlan Feng. 2023. Knowledge-Retrieval Task-Oriented Dialog Systems with Semi-Supervision. arXiv:2305.13199 [cs.CL]
- Campos et al. (2016) Daniel Fernando Campos, Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, Li Deng, and Bhaskar Mitra. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. 30th Conference on Neural Information Processing Systems, NIPS (2016).
- Carlini et al. (2021) Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21). 2633–2650.
- Chen et al. (2017a) Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017a. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vancouver, Canada, 1870–1879. https://doi.org/10.18653/v1/P17-1171
- Chen et al. (2017b) Hongshen Chen, Xiaorui Liu, Dawei Yin, and Jiliang Tang. 2017b. A Survey on Dialogue Systems: Recent Advances and New Frontiers. SIGKDD Explor. Newsl. 19, 2 (nov 2017), 25–35. https://doi.org/10.1145/3166054.3166058
- Chen et al. (2023d) Hung-Ting Chen, Fangyuan Xu, Shane Arora, and Eunsol Choi. 2023d. Understanding Retrieval Augmentation for Long-Form Question Answering. arXiv:2310.12150 [cs.CL]
- Chen et al. (2023b) Jifan Chen, Grace Kim, Aniruddh Sriram, Greg Durrett, and Eunsol Choi. 2023b. Complex Claim Verification with Evidence Retrieved in the Wild. arXiv:2305.11859 [cs.CL]
- Chen et al. (2023a) Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W. Cohen. 2023a. Re-Imagen: Retrieval-Augmented Text-to-Image Generator. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=XSEBx0iSjFQ
- Chen et al. (2023c) Wenhu Chen, Pat Verga, Michiel de Jong, John Wieting, and William W. Cohen. 2023c. Augmenting Pre-trained Language Models with QA-Memory for Open-Domain Question Answering. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, Dubrovnik, Croatia, 1597–1610. https://doi.org/10.18653/v1/2023.eacl-main.117
- Chen et al. (2022) Xiang Chen, Lei Li, Ningyu Zhang, Xiaozhuan Liang, Shumin Deng, Chuanqi Tan, Fei Huang, Luo Si, and Huajun Chen. 2022. Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning. In Advances in Neural Information Processing Systems, Vol. 35. Curran Associates, Inc., 23908–23922. https://proceedings.neurips.cc/paper_files/paper/2022/file/97011c648eda678424f9292dadeae72e-Paper-Conference.pdf
- Chen et al. (2018) Xu Chen, Hongteng Xu, Yongfeng Zhang, Jiaxi Tang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2018. Sequential Recommendation with User Memory Networks. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining (Marina Del Rey, CA, USA) (WSDM ’18). Association for Computing Machinery, New York, NY, USA, 108–116. https://doi.org/10.1145/3159652.3159668
- Cheng et al. (2024) Xin Cheng, Di Luo, Xiuying Chen, Lemao Liu, Dongyan Zhao, and Rui Yan. 2024. Lift yourself up: Retrieval-augmented text generation with self-memory. Advances in Neural Information Processing Systems 36 (2024).
- Chuang et al. (2023) Yung-Sung Chuang, Wei Fang, Shang-Wen Li, Wen-tau Yih, and James Glass. 2023. Expand, Rerank, and Retrieve: Query Reranking for Open-Domain Question Answering. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 12131–12147. https://doi.org/10.18653/v1/2023.findings-acl.768
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. arXiv:1803.05457 [cs.AI]
- Cramer (2021) Patrick Cramer. 2021. AlphaFold2 and the future of structural biology. Nature structural & molecular biology 28, 9 (2021), 704–705.
- Croft and Harper (1979) W. B. Croft and D. J. Harper. 1979. Using Probabilistic Models of Document Retrieval Without Relevance Information. J. of Documentation 35, 4 (1979), 285–295.
- Dai et al. (2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc Le, and Ruslan Salakhutdinov. 2019. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 2978–2988. https://doi.org/10.18653/v1/P19-1285
- Das et al. (2020) Rajarshi Das, Ameya Godbole, Shehzaad Dhuliawala, Manzil Zaheer, and Andrew McCallum. 2020. A Simple Approach to Case-Based Reasoning in Knowledge Bases. In Automated Knowledge Base Construction. https://openreview.net/forum?id=AEY9tRqlU7
- Das et al. (2019) Rajarshi Das, Ameya Godbole, Dilip Kavarthapu, Zhiyu Gong, Abhishek Singhal, Mo Yu, Xiaoxiao Guo, Tian Gao, Hamed Zamani, Manzil Zaheer, and Andrew McCallum. 2019. Multi-step Entity-centric Information Retrieval for Multi-Hop Question Answering. In Proceedings of the 2nd Workshop on Machine Reading for Question Answering. Association for Computational Linguistics, Hong Kong, China, 113–118. https://doi.org/10.18653/v1/D19-5816
- Dasigi et al. (2021) Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. 2021. A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Online, 4599–4610. https://doi.org/10.18653/v1/2021.naacl-main.365
- De Jong et al. (2023) Michiel De Jong, Yury Zemlyanskiy, Nicholas FitzGerald, Joshua Ainslie, Sumit Sanghai, Fei Sha, and William W. Cohen. 2023. Pre-Computed Memory or on-the-Fly Encoding? A Hybrid Approach to Retrieval Augmentation Makes the Most of Your Compute. In Proceedings of the 40th International Conference on Machine Learning (Honolulu, Hawaii, USA) (ICML’23). JMLR.org, Article 290, 14 pages.
- Dehghani et al. (2017) Mostafa Dehghani, Hamed Zamani, Aliaksei Severyn, Jaap Kamps, and W. Bruce Croft. 2017. Neural Ranking Models with Weak Supervision. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (Shinjuku, Tokyo, Japan) (SIGIR ’17). Association for Computing Machinery, New York, NY, USA, 65–74. https://doi.org/10.1145/3077136.3080832
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. https://doi.org/10.18653/v1/N19-1423
- Dinan et al. (2019) Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli, and Jason Weston. 2019. Wizard of Wikipedia: Knowledge-Powered Conversational Agents. In International Conference on Learning Representations. https://openreview.net/forum?id=r1l73iRqKm
- Dong et al. (2023) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, Lei Li, and Zhifang Sui. 2023. A Survey on In-context Learning. arXiv:2301.00234 [cs.CL]
- Dosovitskiy et al. (2021) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations. https://openreview.net/forum?id=YicbFdNTTy
- Dou et al. (2023) Longxu Dou, Yan Gao, Mingyang Pan, Dingzirui Wang, Wanxiang Che, Jian-Guang Lou, and Dechen Zhan. 2023. Unisar: A unified structure-aware autoregressive language model for text-to-sql semantic parsing. International Journal of Machine Learning and Cybernetics 14, 12 (2023), 4361–4376.
- Douze et al. (2024) Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. arXiv:2401.08281 [cs.LG]
- Drozdov et al. (2023) Andrew Drozdov, Nathanael Schärli, Ekin Akyürek, Nathan Scales, Xinying Song, Xinyun Chen, Olivier Bousquet, and Denny Zhou. 2023. Compositional Semantic Parsing with Large Language Models. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=gJW8hSGBys8
- Elsahar et al. (2018) Hady Elsahar, Pavlos Vougiouklis, Arslen Remaci, Christophe Gravier, Jonathon Hare, Frederique Laforest, and Elena Simperl. 2018. T-REx: A Large Scale Alignment of Natural Language with Knowledge Base Triples. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). European Language Resources Association (ELRA), Miyazaki, Japan. https://aclanthology.org/L18-1544
- Eric et al. (2017) Mihail Eric, Lakshmi Krishnan, Francois Charette, and Christopher D. Manning. 2017. Key-Value Retrieval Networks for Task-Oriented Dialogue. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue. Association for Computational Linguistics, Saarbrücken, Germany, 37–49. https://doi.org/10.18653/v1/W17-5506
- Es et al. (2024) Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. RAGAs: Automated Evaluation of Retrieval Augmented Generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics, St. Julians, Malta, 150–158. https://aclanthology.org/2024.eacl-demo.16
- Fan et al. (2021) Angela Fan, Claire Gardent, Chloé Braud, and Antoine Bordes. 2021. Augmenting Transformers with KNN-Based Composite Memory for Dialog. Transactions of the Association for Computational Linguistics 9 (03 2021), 82–99. https://doi.org/10.1162/tacl_a_00356 arXiv:https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl_a_00356/1924032/tacl_a_00356.pdf
- Fan et al. (2019) Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. 2019. ELI5: Long Form Question Answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 3558–3567. https://doi.org/10.18653/v1/P19-1346
- Fernández and Veloso (2006) Fernando Fernández and Manuela Veloso. 2006. Probabilistic Policy Reuse in a Reinforcement Learning Agent. In Proceedings of the Fifth International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS ’06). ACM, New York, NY, USA, 720–727.
- Formal et al. (2021) Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (, Virtual Event, Canada,) (SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 2288–2292. https://doi.org/10.1145/3404835.3463098
- Freitag and Al-Onaizan (2017) Markus Freitag and Yaser Al-Onaizan. 2017. Beam Search Strategies for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation. Association for Computational Linguistics, Vancouver, 56–60. https://doi.org/10.18653/v1/W17-3207
- Gao et al. (2022) Feng Gao, Qing Ping, Govind Thattai, Aishwarya Reganti, Ying Nian Wu, and Prem Natarajan. 2022. A Thousand Words Are Worth More Than a Picture: Natural Language-Centric Outside-Knowledge Visual Question Answering. arXiv:2201.05299 [cs.CV]
- Gao et al. (2023a) Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. 2023a. RARR: Researching and Revising What Language Models Say, Using Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 16477–16508. https://aclanthology.org/2023.acl-long.910
- Gao et al. (2023b) Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023b. Enabling Large Language Models to Generate Text with Citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 6465–6488. https://doi.org/10.18653/v1/2023.emnlp-main.398
- Geva et al. (2021) Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics 9 (2021), 346–361.
- Glass et al. (2021) Michael Glass, Gaetano Rossiello, Md Faisal Mahbub Chowdhury, and Alfio Gliozzo. 2021. Robust Retrieval Augmented Generation for Zero-shot Slot Filling. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 1939–1949. https://doi.org/10.18653/v1/2021.emnlp-main.148
- Goyal et al. (2022) Anirudh Goyal, Abram Friesen, Andrea Banino, Theophane Weber, Nan Rosemary Ke, Adrià Puigdomènech Badia, Arthur Guez, Mehdi Mirza, Peter C Humphreys, Ksenia Konyushova, Michal Valko, Simon Osindero, Timothy Lillicrap, Nicolas Heess, and Charles Blundell. 2022. Retrieval-Augmented Reinforcement Learning. In Proceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162). PMLR, 7740–7765.
- Grave et al. (2017) Edouard Grave, Armand Joulin, and Nicolas Usunier. 2017. Improving Neural Language Models with a Continuous Cache. In International Conference on Learning Representations. https://openreview.net/forum?id=B184E5qee
- Graves et al. (2014) Alex Graves, Greg Wayne, and Ivo Danihelka. 2014. Neural Turing Machines. arXiv:1410.5401 [cs.NE]
- Graves et al. (2016) Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, et al. 2016. Hybrid computing using a neural network with dynamic external memory. Nature 538, 7626 (2016), 471–476.
- Gui et al. (2022) Liangke Gui, Borui Wang, Qiuyuan Huang, Alexander Hauptmann, Yonatan Bisk, and Jianfeng Gao. 2022. KAT: A Knowledge Augmented Transformer for Vision-and-Language. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Seattle, United States, 956–968. https://doi.org/10.18653/v1/2022.naacl-main.70
- Gulcehre et al. (2017) Caglar Gulcehre, Sarath Chandar, and Yoshua Bengio. 2017. Memory Augmented Neural Networks with Wormhole Connections. arXiv:1701.08718 [cs.LG]
- Guo et al. (2020a) Jiafeng Guo, Yixing Fan, Liang Pang, Liu Yang, Qingyao Ai, Hamed Zamani, Chen Wu, W. Bruce Croft, and Xueqi Cheng. 2020a. A Deep Look into neural ranking models for information retrieval. Information Processing & Management 57, 6 (2020), 102067. https://doi.org/10.1016/j.ipm.2019.102067
- Guo et al. (2020b) Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020b. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. arXiv:1908.10396 [cs.LG]
- Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. REALM: Retrieval-Augmented Language Model Pre-Training. In Proceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 368, 10 pages.
- Hashemi et al. (2020) Helia Hashemi, Hamed Zamani, and W. Bruce Croft. 2020. Guided Transformer: Leveraging Multiple External Sources for Representation Learning in Conversational Search. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 1131–1140. https://doi.org/10.1145/3397271.3401061
- Hashemi et al. (2021) Helia Hashemi, Hamed Zamani, and W. Bruce Croft. 2021. Learning Multiple Intent Representations for Search Queries. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (Virtual Event, Queensland, Australia) (CIKM ’21). Association for Computing Machinery, New York, NY, USA, 669–679. https://doi.org/10.1145/3459637.3482445
- He et al. (2021) Junxian He, Graham Neubig, and Taylor Berg-Kirkpatrick. 2021. Efficient Nearest Neighbor Language Models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 5703–5714. https://doi.org/10.18653/v1/2021.emnlp-main.461
- Ho et al. (2020) Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. In Proceedings of the 28th International Conference on Computational Linguistics. International Committee on Computational Linguistics, Barcelona, Spain (Online), 6609–6625. https://doi.org/10.18653/v1/2020.coling-main.580
- Hoffart et al. (2011) Johannes Hoffart, Mohamed Amir Yosef, Ilaria Bordino, Hagen Fürstenau, Manfred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum. 2011. Robust Disambiguation of Named Entities in Text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Edinburgh, Scotland, UK., 782–792. https://aclanthology.org/D11-1072
- Hofstätter et al. (2023) Sebastian Hofstätter, Jiecao Chen, Karthik Raman, and Hamed Zamani. 2023. Fid-light: Efficient and effective retrieval-augmented text generation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1437–1447.
- Hokamp and Liu (2017) Chris Hokamp and Qun Liu. 2017. Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vancouver, Canada, 1535–1546. https://doi.org/10.18653/v1/P17-1141
- Holtzman et al. (2020) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The Curious Case of Neural Text Degeneration. In International Conference on Learning Representations. https://openreview.net/forum?id=rygGQyrFvH
- Hu et al. (2019) J. Edward Hu, Huda Khayrallah, Ryan Culkin, Patrick Xia, Tongfei Chen, Matt Post, and Benjamin Van Durme. 2019. Improved Lexically Constrained Decoding for Translation and Monolingual Rewriting. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 839–850. https://doi.org/10.18653/v1/N19-1090
- Hu et al. (2023) Linmei Hu, Zeyi Liu, Ziwang Zhao, Lei Hou, Liqiang Nie, and Juanzi Li. 2023. A survey of knowledge enhanced pre-trained language models. IEEE Transactions on Knowledge and Data Engineering (2023).
- Hui et al. (2022a) Kai Hui, Tao Chen, Zhen Qin, Honglei Zhuang, Fernando Diaz, Mike Bendersky, and Don Metzler. 2022a. Retrieval Augmentation for T5 Re-ranker using External Sources. arXiv:2210.05145 [cs.IR]
- Hui et al. (2022b) Kai Hui, Honglei Zhuang, Tao Chen, Zhen Qin, Jing Lu, Dara Bahri, Ji Ma, Jai Gupta, Cicero Nogueira dos Santos, Yi Tay, and Donald Metzler. 2022b. ED2LM: Encoder-Decoder to Language Model for Faster Document Re-ranking Inference. In Findings of the Association for Computational Linguistics: ACL 2022. Association for Computational Linguistics, Dublin, Ireland, 3747–3758. https://doi.org/10.18653/v1/2022.findings-acl.295
- Humphreys et al. (2022) Peter Conway Humphreys, Arthur Guez, Olivier Tieleman, Laurent Sifre, Theophane Weber, and Timothy P Lillicrap. 2022. Large-Scale Retrieval for Reinforcement Learning. In Advances in Neural Information Processing Systems.
- Huo et al. (2023) Siqing Huo, Negar Arabzadeh, and Charles Clarke. 2023. Retrieving Supporting Evidence for Generative Question Answering. In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region (, Beijing, China,) (SIGIR-AP ’23). Association for Computing Machinery, New York, NY, USA, 11–20. https://doi.org/10.1145/3624918.3625336
- Izacard and Grave (2021a) Gautier Izacard and Edouard Grave. 2021a. Distilling Knowledge from Reader to Retriever for Question Answering. In International Conference on Learning Representations. https://openreview.net/forum?id=NTEz-6wysdb
- Izacard and Grave (2021b) Gautier Izacard and Edouard Grave. 2021b. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Association for Computational Linguistics, Online, 874–880. https://doi.org/10.18653/v1/2021.eacl-main.74
- Izacard et al. (2024) Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2024. Atlas: few-shot learning with retrieval augmented language models. J. Mach. Learn. Res. 24, 1, Article 251 (mar 2024), 43 pages.
- Jeong et al. (2024) Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C. Park. 2024. Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. arXiv:2403.14403 [cs.CL]
- Jiang et al. (2024) Fan Jiang, Tom Drummond, and Trevor Cohn. 2024. Pre-training Cross-lingual Open Domain Question Answering with Large-scale Synthetic Supervision. arXiv:2402.16508 [cs.CL]
- Jiang et al. (2023) Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Augmented Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 7969–7992. https://doi.org/10.18653/v1/2023.emnlp-main.495
- Jin et al. (2024) Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu. 2024. Genegpt: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics 40, 2 (2024), btae075.
- Jing et al. (2022) Baoyu Jing, Si Zhang, Yada Zhu, Bin Peng, Kaiyu Guan, Andrew Margenot, and Hanghang Tong. 2022. Retrieval Based Time Series Forecasting. arXiv:2209.13525 [cs.AI]
- Joachims (2002) Thorsten Joachims. 2002. Optimizing Search Engines Using Clickthrough Data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Edmonton, Alberta, Canada) (KDD ’02). Association for Computing Machinery, New York, NY, USA, 133–142. https://doi.org/10.1145/775047.775067
- Joachims et al. (2017) Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. 2017. Unbiased Learning-to-Rank with Biased Feedback. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (Cambridge, United Kingdom) (WSDM ’17). Association for Computing Machinery, New York, NY, USA, 781–789. https://doi.org/10.1145/3018661.3018699
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vancouver, Canada, 1601–1611. https://doi.org/10.18653/v1/P17-1147
- Ju et al. (2022) Mingxuan Ju, Wenhao Yu, Tong Zhao, Chuxu Zhang, and Yanfang Ye. 2022. Grape: Knowledge Graph Enhanced Passage Reader for Open-domain Question Answering. In Findings of the Association for Computational Linguistics: EMNLP 2022. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 169–181. https://doi.org/10.18653/v1/2022.findings-emnlp.13
- Kang et al. (2023) Minki Kang, Jin Myung Kwak, Jinheon Baek, and Sung Ju Hwang. 2023. Knowledge Graph-Augmented Language Models for Knowledge-Grounded Dialogue Generation. arXiv:2305.18846 [cs.CL]
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 6769–6781. https://doi.org/10.18653/v1/2020.emnlp-main.550
- Kasai et al. (2023) Jungo Kasai, Keisuke Sakaguchi, yoichi takahashi, Ronan Le Bras, Akari Asai, Xinyan Velocity Yu, Dragomir Radev, Noah A. Smith, Yejin Choi, and Kentaro Inui. 2023. RealTime QA: What’s the Answer Right Now?. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=HfKOIPCvsv
- Kassner and Schütze (2020) Nora Kassner and Hinrich Schütze. 2020. BERT-kNN: Adding a kNN Search Component to Pretrained Language Models for Better QA. In Findings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, Online, 3424–3430. https://doi.org/10.18653/v1/2020.findings-emnlp.307
- Khandelwal et al. (2021) Urvashi Khandelwal, Angela Fan, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. 2021. Nearest Neighbor Machine Translation. In International Conference on Learning Representations. https://openreview.net/forum?id=7wCBOfJ8hJM
- Khandelwal et al. (2020) Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. 2020. Generalization through Memorization: Nearest Neighbor Language Models. In International Conference on Learning Representations. https://openreview.net/forum?id=HklBjCEKvH
- Khashabi et al. (2017) Daniel Khashabi, Tushar Khot, Ashish Sabharwal, and Dan Roth. 2017. Learning What is Essential in Questions. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017). Association for Computational Linguistics, Vancouver, Canada, 80–89. https://doi.org/10.18653/v1/K17-1010
- Khattab et al. (2024) Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2024. DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=sY5N0zY5Od
- Khattab and Zaharia (2020) Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 39–48. https://doi.org/10.1145/3397271.3401075
- Khramtsova et al. (2023) Ekaterina Khramtsova, Shengyao Zhuang, Mahsa Baktashmotlagh, Xi Wang, and Guido Zuccon. 2023. Selecting which Dense Retriever to use for Zero-Shot Search. In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. 223–233.
- Khramtsova et al. (2024) Ekaterina Khramtsova, Shengyao Zhuang, Mahsa Baktashmotlagh, and Guido Zuccon. 2024. Leveraging LLMs for Unsupervised Dense Retriever Ranking. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA) (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 1307–1317. https://doi.org/10.1145/3626772.3657798
- King and Flanigan (2023) Brendan King and Jeffrey Flanigan. 2023. Diverse Retrieval-Augmented In-Context Learning for Dialogue State Tracking. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 5570–5585. https://aclanthology.org/2023.findings-acl.344
- Kočiský et al. (2018) Tomáš Kočiský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. 2018. The NarrativeQA Reading Comprehension Challenge. Transactions of the Association for Computational Linguistics 6 (2018), 317–328. https://doi.org/10.1162/tacl_a_00023
- Komeili et al. (2022) Mojtaba Komeili, Kurt Shuster, and Jason Weston. 2022. Internet-Augmented Dialogue Generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Dublin, Ireland, 8460–8478. https://doi.org/10.18653/v1/2022.acl-long.579
- Kumar et al. (2016) Ankit Kumar, Ozan Irsoy, Peter Ondruska, Mohit Iyyer, James Bradbury, Ishaan Gulrajani, Victor Zhong, Romain Paulus, and Richard Socher. 2016. Ask me anything: Dynamic memory networks for natural language processing. In International conference on machine learning. PMLR, 1378–1387.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics 7 (2019), 452–466. https://doi.org/10.1162/tacl_a_00276
- Labruna et al. (2024) Tiziano Labruna, Jon Ander Campos, and Gorka Azkune. 2024. When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively. arXiv preprint arXiv:2404.19705 (2024).
- Lample et al. (2019) Guillaume Lample, Alexandre Sablayrolles, Marc' Aurelio Ranzato, Ludovic Denoyer, and Herve Jegou. 2019. Large Memory Layers with Product Keys. In Advances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2019/file/9d8df73a3cfbf3c5b47bc9b50f214aff-Paper.pdf
- Lan et al. (2023) Tian Lan, Deng Cai, Yan Wang, Heyan Huang, and Xian-Ling Mao. 2023. Copy is All You Need. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=CROlOA9Nd8C
- Lavrenko et al. (2002) Victor Lavrenko, Martin Choquette, and W. Bruce Croft. 2002. Cross-lingual relevance models. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (Tampere, Finland) (SIGIR ’02). Association for Computing Machinery, New York, NY, USA, 175–182. https://doi.org/10.1145/564376.564408
- Lavrenko and Croft (2001) Victor Lavrenko and W. Bruce Croft. 2001. Relevance based language models. In Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval. ACM Press, 120–127.
- Lazaridou et al. (2022) Angeliki Lazaridou, Elena Gribovskaya, Wojciech Stokowiec, and Nikolai Grigorev. 2022. Internet-augmented language models through few-shot prompting for open-domain question answering. arXiv:2203.05115 [cs.CL]
- Lee et al. (2019) Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent Retrieval for Weakly Supervised Open Domain Question Answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 6086–6096. https://doi.org/10.18653/v1/P19-1612
- Lee et al. (2018) Sangho Lee, Jinyoung Sung, Youngjae Yu, and Gunhee Kim. 2018. A memory network approach for story-based temporal summarization of 360 videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 1410–1419.
- Levy et al. (2017) Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. 2017. Zero-Shot Relation Extraction via Reading Comprehension. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017). Association for Computational Linguistics, Vancouver, Canada, 333–342. https://doi.org/10.18653/v1/K17-1034
- Lewis et al. (2020a) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020a. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459–9474.
- Lewis et al. (2020b) Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020b. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
- Li et al. (2023) Cheng Li, Mingyang Zhang, Qiaozhu Mei, Yaqing Wang, Spurthi Amba Hombaiah, Yi Liang, and Michael Bendersky. 2023. Teach LLMs to Personalize – An Approach inspired by Writing Education. arXiv:2308.07968 [cs.CL]
- Li et al. (2022) Zonglin Li, Ruiqi Guo, and Sanjiv Kumar. 2022. Decoupled Context Processing for Context Augmented Language Modeling. In Advances in Neural Information Processing Systems. https://openreview.net/forum?id=02dbnEbEFn
- Liao et al. (2023) Lizi Liao, Grace Hui Yang, and Chirag Shah. 2023. Proactive Conversational Agents in the Post-ChatGPT World. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (, Taipei, Taiwan,) (SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 3452–3455. https://doi.org/10.1145/3539618.3594250
- Lien et al. (2024) Yen-Chieh Lien, Hamed Zamani, and Bruce Croft. 2024. Generalized Weak Supervision for Neural Information Retrieval. ACM Trans. Inf. Syst. 42, 5, Article 121 (apr 2024), 26 pages. https://doi.org/10.1145/3647639
- Lin et al. (2024) Chyi-Jiunn Lin, Guan-Ting Lin, Yung-Sung Chuang, Wei-Lun Wu, Shang-Wen Li, Abdelrahman Mohamed, Hung-yi Lee, and Lin-shan Lee. 2024. SpeechDPR: End-to-End Spoken Passage Retrieval for Open-Domain Spoken Question Answering. arXiv preprint arXiv:2401.13463 (2024).
- Lin and Byrne (2022) Weizhe Lin and Bill Byrne. 2022. Retrieval Augmented Visual Question Answering with Outside Knowledge. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 11238–11254. https://aclanthology.org/2022.emnlp-main.772
- Lin et al. (2023) Weizhe Lin, Jinghong Chen, Jingbiao Mei, Alexandru Coca, and Bill Byrne. 2023. Fine-grained Late-interaction Multi-modal Retrieval for Retrieval Augmented Visual Question Answering. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=IWWWulAX7g
- Liu et al. (2022) Linqing Liu, Minghan Li, Jimmy Lin, Sebastian Riedel, and Pontus Stenetorp. 2022. Query Expansion Using Contextual Clue Sampling with Language Models. arXiv:2210.07093 [cs.CL]
- Liu (2009) Tie-Yan Liu. 2009. Learning to Rank for Information Retrieval. Found. Trends Inf. Retr. 3, 3 (mar 2009), 225–331. https://doi.org/10.1561/1500000016
- Lv and Zhai (2009) Yuanhua Lv and ChengXiang Zhai. 2009. Positional language models for information retrieval. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval (Boston, MA, USA) (SIGIR ’09). Association for Computing Machinery, New York, NY, USA, 299–306. https://doi.org/10.1145/1571941.1571994
- Lyu et al. (2023) Xiaozhong Lyu, Stefan Grafberger, Samantha Biegel, Shaopeng Wei, Meng Cao, Sebastian Schelter, and Ce Zhang. 2023. Improving Retrieval-Augmented Large Language Models via Data Importance Learning. arXiv:2307.03027 [cs.LG]
- Madaan et al. (2022) Aman Madaan, Niket Tandon, Peter Clark, and Yiming Yang. 2022. Memory-assisted prompt editing to improve GPT-3 after deployment. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 2833–2861. https://doi.org/10.18653/v1/2022.emnlp-main.183
- Madaan et al. (2024) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2024. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems 36 (2024).
- Maekawa et al. (2024) Seiji Maekawa, Hayate Iso, Sairam Gurajada, and Nikita Bhutani. 2024. Retrieval Helps or Hurts? A Deeper Dive into the Efficacy of Retrieval Augmentation to Language Models. arXiv:2402.13492 [cs.CL]
- Majumder et al. (2024) Bodhisattwa Prasad Majumder, Bhavana Dalvi, Peter Jansen, Oyvind Tafjord, Niket Tandon, Li Zhang, Chris Callison-Burch, and Peter Clark. 2024. CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization. https://openreview.net/forum?id=d5DGVHMdsC
- Malkov and Yashunin (2020) Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 42, 4 (apr 2020), 824–836. https://doi.org/10.1109/TPAMI.2018.2889473
- Mallen et al. (2023) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 9802–9822. https://doi.org/10.18653/v1/2023.acl-long.546
- Mao et al. (2021) Yuning Mao, Pengcheng He, Xiaodong Liu, Yelong Shen, Jianfeng Gao, Jiawei Han, and Weizhu Chen. 2021. Generation-Augmented Retrieval for Open-Domain Question Answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, Online, 4089–4100. https://doi.org/10.18653/v1/2021.acl-long.316
- Marino et al. (2019) Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. 2019. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition. 3195–3204.
- Martins et al. (2022) Pedro Henrique Martins, Zita Marinho, and Andre Martins. 2022. -former: Infinite Memory Transformer. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Dublin, Ireland, 5468–5485. https://doi.org/10.18653/v1/2022.acl-long.375
- Meng et al. (2024) Chuan Meng, Negar Arabzadeh, Arian Askari, Mohammad Aliannejadi, and Maarten de Rijke. 2024. Ranked List Truncation for Large Language Model-based Re-Ranking. In SIGIR.
- Menick et al. (2022) Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, and Nat McAleese. 2022. Teaching language models to support answers with verified quotes. arXiv:2203.11147 [cs.CL]
- Metzler and Croft (2005) Donald Metzler and W. Bruce Croft. 2005. A Markov random field model for term dependencies. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (Salvador, Brazil) (SIGIR ’05). Association for Computing Machinery, New York, NY, USA, 472–479. https://doi.org/10.1145/1076034.1076115
- Mialon et al. (2023) Grégoire Mialon, Roberto Dessi, Maria Lomeli, Christoforos Nalmpantis, Ramakanth Pasunuru, Roberta Raileanu, Baptiste Roziere, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, and Thomas Scialom. 2023. Augmented Language Models: a Survey. Transactions on Machine Learning Research (2023). https://openreview.net/forum?id=jh7wH2AzKK
- Min et al. (2023) Sewon Min, Weijia Shi, Mike Lewis, Xilun Chen, Wen-tau Yih, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2023. Nonparametric Masked Language Modeling. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 2097–2118. https://doi.org/10.18653/v1/2023.findings-acl.132
- Min et al. (2019) Sewon Min, Victor Zhong, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2019. Multi-hop Reading Comprehension through Question Decomposition and Rescoring. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 6097–6109. https://doi.org/10.18653/v1/P19-1613
- Mishra et al. (2022) Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. 2022. Cross-Task Generalization via Natural Language Crowdsourcing Instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Dublin, Ireland, 3470–3487. https://doi.org/10.18653/v1/2022.acl-long.244
- Mitra and Craswell (2018) Bhaskar Mitra and Nick Craswell. 2018. An Introduction to Neural Information Retrieval. Found. Trends Inf. Retr. 13, 1 (dec 2018), 1–126. https://doi.org/10.1561/1500000061
- Musa et al. (2019) Ryan Musa, Xiaoyan Wang, Achille Fokoue, Nicholas Mattei, Maria Chang, Pavan Kapanipathi, Bassem Makni, Kartik Talamadupula, and Michael Witbrock. 2019. Answering Science Exam Questions Using Query Reformulation with Background Knowledge. In Automated Knowledge Base Construction (AKBC). https://openreview.net/forum?id=HJxYZ-5paX
- Nakano et al. (2022) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2022. WebGPT: Browser-assisted question-answering with human feedback. arXiv:2112.09332 [cs.CL]
- Nekvinda and Dušek (2022) Tomáš Nekvinda and Ondřej Dušek. 2022. AARGH! End-to-end Retrieval-Generation for Task-Oriented Dialog. In Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue. Association for Computational Linguistics, Edinburgh, UK, 283–297. https://doi.org/10.18653/v1/2022.sigdial-1.29
- Newman et al. (2023) Benjamin Newman, Luca Soldaini, Raymond Fok, Arman Cohan, and Kyle Lo. 2023. A Question Answering Framework for Decontextualizing User-facing Snippets from Scientific Documents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 3194–3212. https://doi.org/10.18653/v1/2023.emnlp-main.193
- Ni et al. (2019) Jianmo Ni, Chenguang Zhu, Weizhu Chen, and Julian McAuley. 2019. Learning to Attend On Essential Terms: An Enhanced Retriever-Reader Model for Open-domain Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 335–344. https://doi.org/10.18653/v1/N19-1030
- Nogueira and Cho (2019) Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085 (2019).
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, Vol. 35. Curran Associates, Inc., 27730–27744. https://proceedings.neurips.cc/paper_files/paper/2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf
- Pan et al. (2023) Xiaoman Pan, Wenlin Yao, Hongming Zhang, Dian Yu, Dong Yu, and Jianshu Chen. 2023. Knowledge-in-Context: Towards Knowledgeable Semi-Parametric Language Models. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=a2jNdqE2102
- Park et al. (2023) Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (, San Francisco, CA, USA,) (UIST ’23). Association for Computing Machinery, New York, NY, USA, Article 2, 22 pages. https://doi.org/10.1145/3586183.3606763
- Parton et al. (2008) Kristen Parton, Kathleen R. McKeown, James Allan, and Enrique Henestroza. 2008. Simultaneous multilingual search for translingual information retrieval. In Proceedings of the 17th ACM Conference on Information and Knowledge Management (Napa Valley, California, USA) (CIKM ’08). Association for Computing Machinery, New York, NY, USA, 719–728. https://doi.org/10.1145/1458082.1458179
- Perez et al. (2020) Ethan Perez, Patrick Lewis, Wen-tau Yih, Kyunghyun Cho, and Douwe Kiela. 2020. Unsupervised Question Decomposition for Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 8864–8880. https://doi.org/10.18653/v1/2020.emnlp-main.713
- Petroni et al. (2023) Fabio Petroni, Samuel Broscheit, Aleksandra Piktus, Patrick Lewis, Gautier Izacard, Lucas Hosseini, Jane Dwivedi-Yu, Maria Lomeli, Timo Schick, Michele Bevilacqua, et al. 2023. Improving wikipedia verifiability with ai. Nature Machine Intelligence 5, 10 (2023), 1142–1148.
- Petroni et al. (2021) Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rocktäschel, and Sebastian Riedel. 2021. KILT: a Benchmark for Knowledge Intensive Language Tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Online, 2523–2544. https://doi.org/10.18653/v1/2021.naacl-main.200
- Ponte and Croft (1998) Jay M. Ponte and W. Bruce Croft. 1998. A Language Modeling Approach to Information Retrieval. In SIGIR’98 (Melbourne, Australia). 275–281.
- Post and Vilar (2018) Matt Post and David Vilar. 2018. Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Association for Computational Linguistics, New Orleans, Louisiana, 1314–1324. https://doi.org/10.18653/v1/N18-1119
- Pradeep et al. (2023) Ronak Pradeep, Kai Hui, Jai Gupta, Adam Lelkes, Honglei Zhuang, Jimmy Lin, Donald Metzler, and Vinh Tran. 2023. How Does Generative Retrieval Scale to Millions of Passages?. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 1305–1321. https://doi.org/10.18653/v1/2023.emnlp-main.83
- Qi et al. (2019) Peng Qi, Xiaowen Lin, Leo Mehr, Zijian Wang, and Christopher D. Manning. 2019. Answering Complex Open-domain Questions Through Iterative Query Generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 2590–2602. https://doi.org/10.18653/v1/D19-1261
- Qin et al. (2023) Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2023. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. arXiv:2307.16789 [cs.AI]
- Qu et al. (2020) Chen Qu, Liu Yang, Cen Chen, Minghui Qiu, W. Bruce Croft, and Mohit Iyyer. 2020. Open-Retrieval Conversational Question Answering. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 539–548. https://doi.org/10.1145/3397271.3401110
- Qu et al. (2021) Chen Qu, Hamed Zamani, Liu Yang, W. Bruce Croft, and Erik Learned-Miller. 2021. Passage Retrieval for Outside-Knowledge Visual Question Answering. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (Virtual Event, Canada) (SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 1753–1757. https://doi.org/10.1145/3404835.3462987
- Rae et al. (2016) Jack W Rae, Jonathan J Hunt, Tim Harley, Ivo Danihelka, Andrew Senior, Greg Wayne, Alex Graves, and Timothy P Lillicrap. 2016. Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes. In Proceedings of the 30th International Conference on Neural Information Processing Systems (Barcelona, Spain) (NIPS’16). Curran Associates Inc., Red Hook, NY, USA, 3628–3636.
- Rae et al. (2020) Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. 2020. Compressive Transformers for Long-Range Sequence Modelling. In International Conference on Learning Representations. https://openreview.net/forum?id=SylKikSYDH
- Raghu et al. (2021) Dinesh Raghu, Shantanu Agarwal, Sachindra Joshi, and Mausam. 2021. End-to-End Learning of Flowchart Grounded Task-Oriented Dialogs. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 4348–4366. https://doi.org/10.18653/v1/2021.emnlp-main.357
- Ram et al. (2023) Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics 11 (2023), 1316–1331.
- Ramos et al. (2023) Rita Ramos, Bruno Martins, and Desmond Elliott. 2023. LMCap: Few-shot Multilingual Image Captioning by Retrieval Augmented Language Model Prompting. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 1635–1651. https://aclanthology.org/2023.findings-acl.104
- Robertson et al. (1995) Stephen Robertson, S. Walker, S. Jones, M. M. Hancock-Beaulieu, and M. Gatford. 1995. Okapi at TREC-3. In Proceedings of the Third Text REtrieval Conference (TREC-3). Gaithersburg, MD: NIST, 109–126.
- Rocchio (1971) J. J. Rocchio. 1971. Relevance Feedback in Information Retrieval. In The SMART Retrieval System - Experiments in Automatic Document Processing. Prentice Hall.
- Rubin and Berant (2023) Ohad Rubin and Jonathan Berant. 2023. Long-range Language Modeling with Self-retrieval. arXiv:2306.13421 [cs.CL]
- Saad-Falcon et al. (2024) Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. 2024. ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Association for Computational Linguistics, Mexico City, Mexico, 338–354. https://aclanthology.org/2024.naacl-long.20
- Sachan et al. (2021) Devendra Sachan, Mostofa Patwary, Mohammad Shoeybi, Neel Kant, Wei Ping, William L. Hamilton, and Bryan Catanzaro. 2021. End-to-End Training of Neural Retrievers for Open-Domain Question Answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, Online, 6648–6662. https://doi.org/10.18653/v1/2021.acl-long.519
- Salemi et al. (2023a) Alireza Salemi, Juan Altmayer Pizzorno, and Hamed Zamani. 2023a. A Symmetric Dual Encoding Dense Retrieval Framework for Knowledge-Intensive Visual Question Answering. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (Taipei, Taiwan) (SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 110–120. https://doi.org/10.1145/3539618.3591629
- Salemi et al. (2024a) Alireza Salemi, Surya Kallumadi, and Hamed Zamani. 2024a. Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA) (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 752–762. https://doi.org/10.1145/3626772.3657783
- Salemi et al. (2024b) Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024b. LaMP: When Large Language Models Meet Personalization. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL ’24). Association for Computational Linguistics.
- Salemi et al. (2023b) Alireza Salemi, Mahta Rafiee, and Hamed Zamani. 2023b. Pre-Training Multi-Modal Dense Retrievers for Outside-Knowledge Visual Question Answering. In Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval (Taipei, Taiwan) (ICTIR ’23). Association for Computing Machinery, New York, NY, USA, 169–176. https://doi.org/10.1145/3578337.3605137
- Salemi and Zamani (2024a) Alireza Salemi and Hamed Zamani. 2024a. Evaluating Retrieval Quality in Retrieval-Augmented Generation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA) (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 2395–2400. https://doi.org/10.1145/3626772.3657957
- Salemi and Zamani (2024b) Alireza Salemi and Hamed Zamani. 2024b. Towards a Search Engine for Machines: Unified Ranking for Multiple Retrieval-Augmented Large Language Models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA) (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 741–751. https://doi.org/10.1145/3626772.3657733
- Salton and Buckley (1988) Gerard Salton and Christopher Buckley. 1988. Term-Weighting Approaches in Automatic Text Retrieval. Inf. Process. Manage. 24, 5 (Aug. 1988), 513–523. https://doi.org/10.1016/0306-4573(88)90021-0
- Samarinas and Zamani (2024) Chris Samarinas and Hamed Zamani. 2024. ProCIS: A Benchmark for Proactive Retrieval in Conversations. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA) (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 830–840. https://doi.org/10.1145/3626772.3657869
- Sanabria et al. (2023) Ramon Sanabria, Ondrej Klejch, Hao Tang, and Sharon Goldwater. 2023. Acoustic Word Embeddings for Untranscribed Target Languages with Continued Pretraining and Learned Pooling. arXiv preprint arXiv:2306.02153 (2023).
- Santoro et al. (2016) Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. 2016. Meta-Learning with Memory-Augmented Neural Networks. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48 (New York, NY, USA) (ICML’16). JMLR.org, 1842–1850.
- Sarthi et al. (2024) Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=GN921JHCRw
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=Yacmpz84TH
- Schuster et al. (2024) Tal Schuster, Adam Lelkes, Haitian Sun, Jai Gupta, Jonathan Berant, William Cohen, and Donald Metzler. 2024. SEMQA: Semi-Extractive Multi-Source Question Answering. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Association for Computational Linguistics, Mexico City, Mexico, 1363–1381. https://aclanthology.org/2024.naacl-long.74
- Sciavolino et al. (2021) Christopher Sciavolino, Zexuan Zhong, Jinhyuk Lee, and Danqi Chen. 2021. Simple Entity-Centric Questions Challenge Dense Retrievers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 6138–6148. https://doi.org/10.18653/v1/2021.emnlp-main.496
- Sen et al. (2023) Priyanka Sen, Sandeep Mavadia, and Amir Saffari. 2023. Knowledge Graph-augmented Language Models for Complex Question Answering. In Proceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE). Association for Computational Linguistics, Toronto, Canada, 1–8. https://doi.org/10.18653/v1/2023.nlrse-1.1
- Shi et al. (2024) Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. 2024. REPLUG: Retrieval-Augmented Black-Box Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Association for Computational Linguistics, Mexico City, Mexico, 8364–8377. https://aclanthology.org/2024.naacl-long.463
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=vAElhFcKW6
- Shrestha et al. (2024) Robik Shrestha, Yang Zou, Qiuyu Chen, Zhiheng Li, Yusheng Xie, and Siqi Deng. 2024. FairRAG: Fair Human Generation via Fair Retrieval Augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11996–12005.
- Shuster et al. (2022a) Kurt Shuster, Mojtaba Komeili, Leonard Adolphs, Stephen Roller, Arthur Szlam, and Jason Weston. 2022a. Language Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion. In Findings of the Association for Computational Linguistics: EMNLP 2022. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 373–393. https://aclanthology.org/2022.findings-emnlp.27
- Shuster et al. (2022b) Kurt Shuster, Jing Xu, Mojtaba Komeili, Da Ju, Eric Michael Smith, Stephen Roller, Megan Ung, Moya Chen, Kushal Arora, Joshua Lane, Morteza Behrooz, William Ngan, Spencer Poff, Naman Goyal, Arthur Szlam, Y-Lan Boureau, Melanie Kambadur, and Jason Weston. 2022b. BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage. arXiv:2208.03188 [cs.CL]
- Singh et al. (2021) Devendra Singh, Siva Reddy, Will Hamilton, Chris Dyer, and Dani Yogatama. 2021. End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering. In Advances in Neural Information Processing Systems, Vol. 34. Curran Associates, Inc., 25968–25981. https://proceedings.neurips.cc/paper_files/paper/2021/file/da3fde159d754a2555eaa198d2d105b2-Paper.pdf
- Song and Croft (1999) Fei Song and W. Bruce Croft. 1999. A general language model for information retrieval. In Proceedings of the Eighth International Conference on Information and Knowledge Management (Kansas City, Missouri, USA) (CIKM ’99). Association for Computing Machinery, New York, NY, USA, 316–321. https://doi.org/10.1145/319950.320022
- Sparck-Jones and Galliers (1996) Karen Sparck-Jones and Julia R. Galliers. 1996. Evaluating Natural Language Processing Systems: An Analysis and Review. Springer-Verlag, Berlin, Heidelberg.
- Sukhbaatar et al. (2015) Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. 2015. End-to-end memory networks. Advances in neural information processing systems 28 (2015).
- Sumers et al. (2024) Theodore Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas Griffiths. 2024. Cognitive Architectures for Language Agents. Transactions on Machine Learning Research (2024). https://openreview.net/forum?id=1i6ZCvflQJ Survey Certification.
- Sun et al. (2023) Weiwei Sun, Lingyong Yan, Xinyu Ma, Pengjie Ren, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent. CoRR abs/2304.09542 (2023). https://doi.org/10.48550/ARXIV.2304.09542 arXiv:2304.09542
- Tay et al. (2022) Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W Cohen, and Donald Metzler. 2022. Transformer Memory as a Differentiable Search Index. In Advances in Neural Information Processing Systems, Vol. 35. Curran Associates, Inc., 21831–21843. https://proceedings.neurips.cc/paper_files/paper/2022/file/892840a6123b5ec99ebaab8be1530fba-Paper-Conference.pdf
- Thomas et al. (2023) Paul Thomas, Seth Spielman, Nick Craswell, and Bhaskar Mitra. 2023. Large language models can accurately predict searcher preferences. arXiv:2309.10621 [cs.IR]
- Thoppilan et al. (2022) Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, YaGuang Li, Hongrae Lee, Huaixiu Steven Zheng, Amin Ghafouri, Marcelo Menegali, Yanping Huang, Maxim Krikun, Dmitry Lepikhin, James Qin, Dehao Chen, Yuanzhong Xu, Zhifeng Chen, Adam Roberts, Maarten Bosma, Vincent Zhao, Yanqi Zhou, Chung-Ching Chang, Igor Krivokon, Will Rusch, Marc Pickett, Pranesh Srinivasan, Laichee Man, Kathleen Meier-Hellstern, Meredith Ringel Morris, Tulsee Doshi, Renelito Delos Santos, Toju Duke, Johnny Soraker, Ben Zevenbergen, Vinodkumar Prabhakaran, Mark Diaz, Ben Hutchinson, Kristen Olson, Alejandra Molina, Erin Hoffman-John, Josh Lee, Lora Aroyo, Ravi Rajakumar, Alena Butryna, Matthew Lamm, Viktoriya Kuzmina, Joe Fenton, Aaron Cohen, Rachel Bernstein, Ray Kurzweil, Blaise Aguera-Arcas, Claire Cui, Marian Croak, Ed Chi, and Quoc Le. 2022. LaMDA: Language Models for Dialog Applications. arXiv:2201.08239 [cs.CL]
- Thorne et al. (2018) James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a Large-scale Dataset for Fact Extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Association for Computational Linguistics, New Orleans, Louisiana, 809–819. https://doi.org/10.18653/v1/N18-1074
- Thulke et al. (2021) David Thulke, Nico Daheim, Christian Dugast, and Hermann Ney. 2021. Efficient Retrieval Augmented Generation from Unstructured Knowledge for Task-Oriented Dialog. In Workshop on DSTC9, AAAI.
- Trivedi et al. (2023) Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 10014–10037. https://doi.org/10.18653/v1/2023.acl-long.557
- Vinyals et al. (2015) Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer Networks. In Advances in Neural Information Processing Systems, Vol. 28. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2015/file/29921001f2f04bd3baee84a12e98098f-Paper.pdf
- Vu et al. (2023) Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, and Thang Luong. 2023. FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation. arXiv:2310.03214 [cs.CL]
- Wan et al. (2022) Zhongwei Wan, Yichun Yin, Wei Zhang, Jiaxin Shi, Lifeng Shang, Guangyong Chen, Xin Jiang, and Qun Liu. 2022. G-MAP: General Memory-Augmented Pre-trained Language Model for Domain Tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 6585–6597. https://doi.org/10.18653/v1/2022.emnlp-main.441
- Wang et al. (2024b) Dingmin Wang, Qiuyuan Huang, Matthew Jackson, and Jianfeng Gao. 2024b. LLM Agent - Retrieve What You Need: A Mutual Learning Framework for Open-domain Question Answering. Proceedings of Transactions of the Association for Computational Linguistics (TACL) (April 2024), 247–263. https://www.microsoft.com/en-us/research/publication/retrieve-what-you-need-a-mutual-learning-framework-for-open-domain-question-answering/
- Wang et al. (2023c) Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023c. Voyager: An Open-Ended Embodied Agent with Large Language Models. arXiv preprint arXiv: Arxiv-2305.16291 (2023).
- Wang et al. (2023d) Liang Wang, Nan Yang, and Furu Wei. 2023d. Query2doc: Query Expansion with Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 9414–9423. https://doi.org/10.18653/v1/2023.emnlp-main.585
- Wang et al. (2017) Peng Wang, Qi Wu, Chunhua Shen, Anthony Dick, and Anton Van Den Hengel. 2017. Fvqa: Fact-based visual question answering. IEEE transactions on pattern analysis and machine intelligence 40, 10 (2017), 2413–2427.
- Wang et al. (2023a) Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. 2023a. Augmenting Language Models with Long-Term Memory. In Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=BryMFPQ4L6
- Wang et al. (2023b) Weizhi Wang, Li Dong, Hao Cheng, Haoyu Song, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. 2023b. Visually-Augmented Language Modeling. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=8IN-qLkl215
- Wang et al. (2022) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, Maitreya Patel, Mehrad Moradshahi, Mihir Parmar, Mirali Purohit, Neeraj Varshney, Phani Rohitha Kaza, Pulkit Verma, Ravsehaj Singh Puri, Rushang Karia, Savan Doshi, Shailaja Keyur Sampat, Siddhartha Mishra, Sujan Reddy A, Sumanta Patro, Tanay Dixit, and Xudong Shen. 2022. Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 5085–5109. https://doi.org/10.18653/v1/2022.emnlp-main.340
- Wang et al. (2024a) Zora Zhiruo Wang, Akari Asai, Xinyan Velocity Yu, Frank F. Xu, Yiqing Xie, Graham Neubig, and Daniel Fried. 2024a. CodeRAG-Bench: Can Retrieval Augment Code Generation? arXiv:2406.14497 [cs.SE] https://arxiv.org/abs/2406.14497
- Wei et al. (2022) Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022. Finetuned Language Models are Zero-Shot Learners. In International Conference on Learning Representations. https://openreview.net/forum?id=gEZrGCozdqR
- Weston et al. (2015) Jason Weston, Sumit Chopra, and Antoine Bordes. 2015. Memory Networks. arXiv:1410.3916 [cs.AI]
- White et al. (2003) Ryen W White, Joemon M Jose, Ian Ruthven, GM Rauterberg, M Menozzi, and J Wesson. 2003. A granular approach to web search result presentation. In 9th IFIP TC13 International Conference on Human-Computer Interaction. Interact 2003.
- Wu et al. (2022b) Chao-Yuan Wu, Yanghao Li, Karttikeya Mangalam, Haoqi Fan, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. 2022b. MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition. arXiv preprint arXiv:2201.08383 (2022).
- Wu and Mooney (2022) Jialin Wu and Raymond Mooney. 2022. Entity-Focused Dense Passage Retrieval for Outside-Knowledge Visual Question Answering. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 8061–8072. https://doi.org/10.18653/v1/2022.emnlp-main.551
- Wu et al. (2021) Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, and Paul Christiano. 2021. Recursively Summarizing Books with Human Feedback. arXiv:2109.10862
- Wu et al. (2022a) Qingyang Wu, Zhenzhong Lan, Kun Qian, Jing Gu, Alborz Geramifard, and Zhou Yu. 2022a. Memformer: A Memory-Augmented Transformer for Sequence Modeling. In Findings of the Association for Computational Linguistics: AACL-IJCNLP 2022. Association for Computational Linguistics, Online only, 308–318. https://aclanthology.org/2022.findings-aacl.29
- Wu et al. (2022c) Yuhuai Wu, Markus Norman Rabe, DeLesley Hutchins, and Christian Szegedy. 2022c. Memorizing Transformers. In International Conference on Learning Representations. https://openreview.net/forum?id=TrjbxzRcnf-
- Wu et al. (2022d) Yuxiang Wu, Yu Zhao, Baotian Hu, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2022d. An Efficient Memory-Augmented Transformer for Knowledge-Intensive NLP Tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 5184–5196. https://aclanthology.org/2022.emnlp-main.346
- Xiong et al. (2021) Wenhan Xiong, Xiang Li, Srini Iyer, Jingfei Du, Patrick Lewis, William Yang Wang, Yashar Mehdad, Scott Yih, Sebastian Riedel, Douwe Kiela, and Barlas Oguz. 2021. Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval. In International Conference on Learning Representations. https://openreview.net/forum?id=EMHoBG0avc1
- Yadav et al. (2020) Vikas Yadav, Steven Bethard, and Mihai Surdeanu. 2020. Unsupervised Alignment-based Iterative Evidence Retrieval for Multi-hop Question Answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 4514–4525. https://doi.org/10.18653/v1/2020.acl-main.414
- Yadegari et al. (2022) Mostafa Yadegari, Ehsan Kamalloo, and Davood Rafiei. 2022. Detecting Frozen Phrases in Open-Domain Question Answering. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (Madrid, Spain) (SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 1990–1996. https://doi.org/10.1145/3477495.3531793
- Yamada et al. (2021) Ikuya Yamada, Akari Asai, and Hannaneh Hajishirzi. 2021. Efficient Passage Retrieval with Hashing for Open-domain Question Answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Association for Computational Linguistics, Online, 979–986. https://doi.org/10.18653/v1/2021.acl-short.123
- Yang et al. (2024b) Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and Animashree Anandkumar. 2024b. Leandojo: Theorem proving with retrieval-augmented language models. Advances in Neural Information Processing Systems 36 (2024).
- Yang et al. (2024a) Linyao Yang, Hongyang Chen, Zhao Li, Xiao Ding, and Xindong Wu. 2024a. Give Us the Facts: Enhancing Large Language Models with Knowledge Graphs for Fact-aware Language Modeling. arXiv:2306.11489
- Yang et al. (2022) Sitan Yang, Carson Eisenach, and Dhruv Madeka. 2022. MQRetNN: Multi-Horizon Time Series Forecasting with Retrieval Augmentation. arXiv:2207.10517 [cs.LG]
- Yang and Seo (2020) Sohee Yang and Minjoon Seo. 2020. Is Retriever Merely an Approximator of Reader? arXiv:2010.10999
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Brussels, Belgium, 2369–2380. https://doi.org/10.18653/v1/D18-1259
- Yasunaga et al. (2023) Michihiro Yasunaga, Armen Aghajanyan, Weijia Shi, Rich James, Jure Leskovec, Percy Liang, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. 2023. Retrieval-augmented multimodal language modeling. In Proceedings of the 40th International Conference on Machine Learning (, Honolulu, Hawaii, USA,) (ICML’23). JMLR.org, Article 1659, 15 pages.
- Yogatama et al. (2021) Dani Yogatama, Cyprien de Masson d’Autume, and Lingpeng Kong. 2021. Adaptive Semiparametric Language Models. Transactions of the Association for Computational Linguistics 9 (04 2021), 362–373. https://doi.org/10.1162/tacl_a_00371 arXiv:https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl_a_00371/1924150/tacl_a_00371.pdf
- Yu et al. (2022a) Donghan Yu, Chenguang Zhu, Yuwei Fang, Wenhao Yu, Shuohang Wang, Yichong Xu, Xiang Ren, Yiming Yang, and Michael Zeng. 2022a. KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Dublin, Ireland, 4961–4974. https://doi.org/10.18653/v1/2022.acl-long.340
- Yu et al. (2022b) Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, and Meng Jiang. 2022b. A Survey of Knowledge-Enhanced Text Generation. ACM Comput. Surv. 54, 11s, Article 227 (nov 2022), 38 pages. https://doi.org/10.1145/3512467
- Yu et al. (2022c) Wenhao Yu, Chenguang Zhu, Zhihan Zhang, Shuohang Wang, Zhuosheng Zhang, Yuwei Fang, and Meng Jiang. 2022c. Retrieval Augmentation for Commonsense Reasoning: A Unified Approach. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 4364–4377. https://aclanthology.org/2022.emnlp-main.294
- Zamani and Bendersky (2024) Hamed Zamani and Michael Bendersky. 2024. Stochastic RAG: End-to-End Retrieval-Augmented Generation through Expected Utility Maximization. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA) (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 2641–2646. https://doi.org/10.1145/3626772.3657923
- Zamani et al. (2018) Hamed Zamani, Mostafa Dehghani, W. Bruce Croft, Erik Learned-Miller, and Jaap Kamps. 2018. From Neural Re-Ranking to Neural Ranking: Learning a Sparse Representation for Inverted Indexing. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy) (CIKM ’18). Association for Computing Machinery, New York, NY, USA, 497–506. https://doi.org/10.1145/3269206.3271800
- Zamani et al. (2022) Hamed Zamani, Fernando Diaz, Mostafa Dehghani, Donald Metzler, and Michael Bendersky. 2022. Retrieval-Enhanced Machine Learning. In Proceedings of the 45th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.
- Zaremba and Sutskever (2016) Wojciech Zaremba and Ilya Sutskever. 2016. Reinforcement Learning Neural Turing Machines - Revised. arXiv:1505.00521 [cs.LG]
- Zeng et al. (2024) Hansi Zeng, Chen Luo, Bowen Jin, Sheikh Sarwar, Tianxin Wei, and Hamed Zamani. 2024. Scalable and Effective Generative Information Retrieval. In Proceedings of the 2024 ACM Web Conference (Singapore, Singapore) (WWW ’24). Association for Computing Machinery, New York, NY, USA.
- Zhai and Lafferty (2001) Chengxiang Zhai and John Lafferty. 2001. Model-Based Feedback in the Language Modeling Approach to Information Retrieval. In Proceedings of the Tenth International Conference on Information and Knowledge Management (Atlanta, Georgia, USA) (CIKM ’01). Association for Computing Machinery, New York, NY, USA, 403–410. https://doi.org/10.1145/502585.502654
- Zhang et al. (2023) Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 2471–2484. https://doi.org/10.18653/v1/2023.emnlp-main.151
- Zhang et al. (2022b) Jing Zhang, Xiaokang Zhang, Jifan Yu, Jian Tang, Jie Tang, Cuiping Li, and Hong Chen. 2022b. Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Dublin, Ireland, 5773–5784. https://doi.org/10.18653/v1/2022.acl-long.396
- Zhang et al. (2022a) Yizhe Zhang, Siqi Sun, Xiang Gao, Yuwei Fang, Chris Brockett, Michel Galley, Jianfeng Gao, and Bill Dolan. 2022a. Retgen: A joint framework for retrieval and grounded text generation modeling. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 11739–11747.
- Zhang et al. (2024) Zihan Zhang, Meng Fang, and Ling Chen. 2024. RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering. arXiv:2402.16457 [cs.CL] https://arxiv.org/abs/2402.16457
- Zhao et al. (2024) Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19632–19642.
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023. A Survey of Large Language Models. arXiv:2303.18223
- Zhong et al. (2021) Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir Radev. 2021. QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Online, 5905–5921. https://doi.org/10.18653/v1/2021.naacl-main.472
- Zhong et al. (2022) Zexuan Zhong, Tao Lei, and Danqi Chen. 2022. Training Language Models with Memory Augmentation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 5657–5673. https://aclanthology.org/2022.emnlp-main.382
- Zhou et al. (2022) Ben Zhou, Kyle Richardson, Xiaodong Yu, and Dan Roth. 2022. Learning to Decompose: Hypothetical Question Decomposition Based on Comparable Texts. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 2223–2235. https://doi.org/10.18653/v1/2022.emnlp-main.142
- Zhou et al. (2023) Shuyan Zhou, Uri Alon, Frank F. Xu, Zhengbao Jiang, and Graham Neubig. 2023. DocPrompting: Generating Code by Retrieving the Docs. In The Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=ZTCxT2t2Ru
- Zhu et al. (2021) Yunchang Zhu, Liang Pang, Yanyan Lan, Huawei Shen, and Xueqi Cheng. 2021. Adaptive Information Seeking for Open-Domain Question Answering. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 3615–3626. https://doi.org/10.18653/v1/2021.emnlp-main.293