用词汇量扩展定律:
较大的模型需要更大的词汇量
摘要
扩展大型语言模型(大语言模型)的研究主要集中在模型参数和数据大小上,而忽略了词汇量大小的作用。 我们通过对具有各种词汇配置的多达 500B 字符的从 33M 到 3B 参数的训练模型来研究词汇大小如何影响大语言模型缩放法则。 我们提出了三种预测计算最佳词汇量大小的补充方法:IsoFLOPs 分析、导数估计和损失函数的参数拟合。 我们的方法集中在相同的结果上,即最佳词汇量取决于可用的计算预算,并且较大的模型需要更大的词汇量。 然而,大多数大语言模型使用的词汇量太小。 例如,我们预测 Llama2-70B 的最佳词汇量应该至少为 216K,是其词汇量 32K 的 7 倍。 我们通过在不同的 FLOPs 预算中使用 3B 参数的训练模型来验证我们的预测。 与常用词汇量相比,采用我们预测的最佳词汇量可以持续提高下游性能。 通过将词汇量从传统的 32K 增加到 43K,我们将 ARC-Challenge 的性能从 29.1 提高到 32.0,同时 FLOP 数相同为 2.3e21。 我们的工作强调了共同考虑模型参数和词汇量大小以实现有效扩展的必要性。
1简介
大型语言模型(大语言模型)通过使用大量计算资源对海量文本语料库进行预训练,取得了显着的性能[43]。 大语言模型的大量先前工作集中于推导所谓的缩放定律:一组用于预测模型性能如何缩放的经验公式,主要是计算浮点运算(FLOP)、模型参数和训练数据量变化[28,24,60,2,40,54]。 这些工作表明,幂律拟合可以有效地预测语言建模损失并扩展下游性能[21, 51]。 然而,这些缩放法则通常忽略词汇量大小的影响。 例如,在Kaplan等人[28]中,其预测公式仅考虑非词汇参数。 这种疏忽导致了当前大语言模型词汇量的巨大变化。 例如,Llama2-7B 采用 32K [64] 的词汇量,而 Gemma-7B [61] 采用更大的词汇量 256K,尽管两者具有相似的词汇量总参数数量。 大语言模型中词汇量大小的这种变化提出了一个研究问题: 大语言模型的计算最佳词汇量是多少?
词汇量的大小对性能的影响非常大。 直观上,最佳词汇量既不能太大也不能太小。 较大的词汇量可以提高标记化的生育能力,即将句子分成更少的标记,从而提高标记化效率。 此外,更大的词汇量增强了模型的表示能力,使其能够捕获语料库中更广泛的概念和细微差别。 然而,稀有标记的欠拟合表示的风险随着词汇量的增大而增加,特别是在数据受限的情况下[40, 66]。 因此,需要通过考虑训练数据和非词汇参数的数量来确定最佳词汇量。
在本文中,我们表明词汇量对缩放法则的影响被低估了,并且我们量化了这种影响以得出最佳词汇量的预测。 我们首先引入标准化损失公式,以确保具有不同词汇量大小的模型之间的公平比较。 利用归一化损失函数,我们分析和讨论了最佳词汇量存在背后的基本原理,这取决于可用的计算预算。
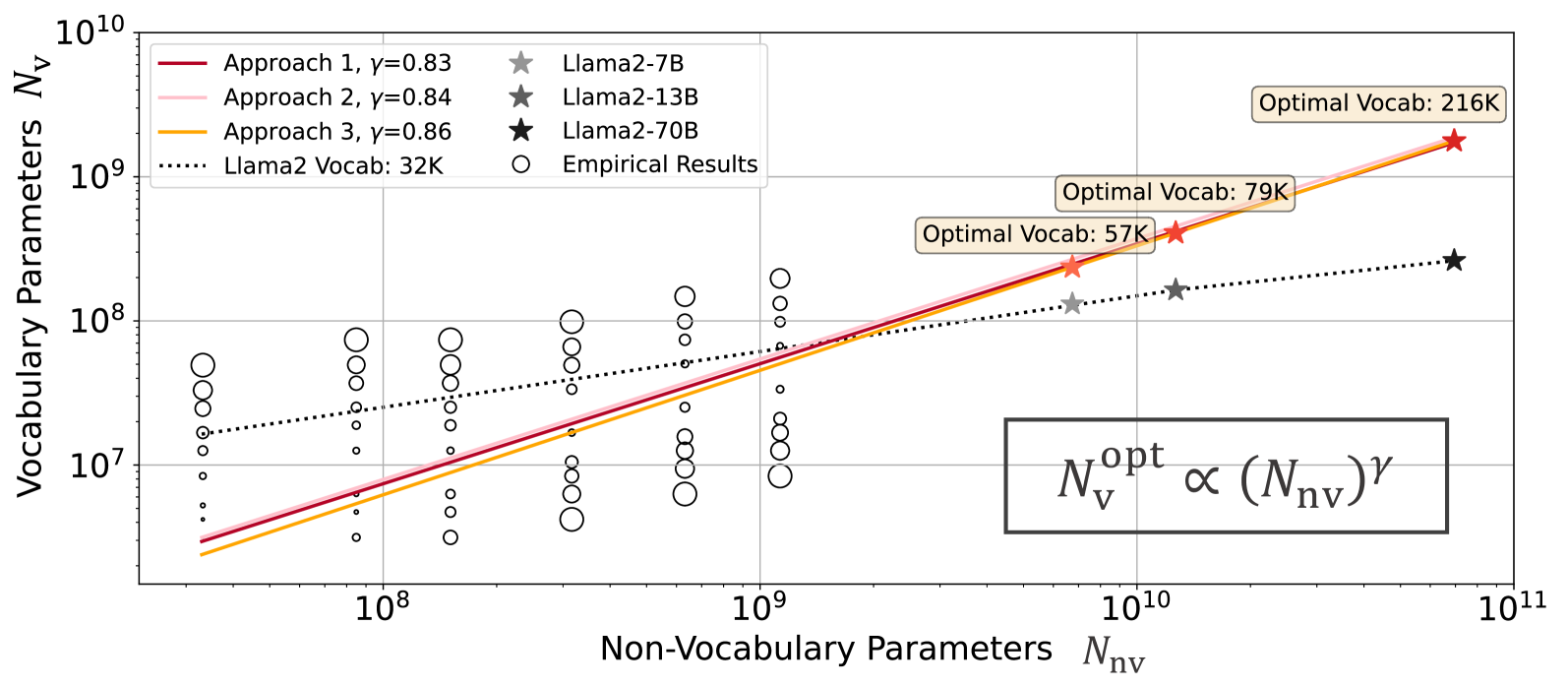
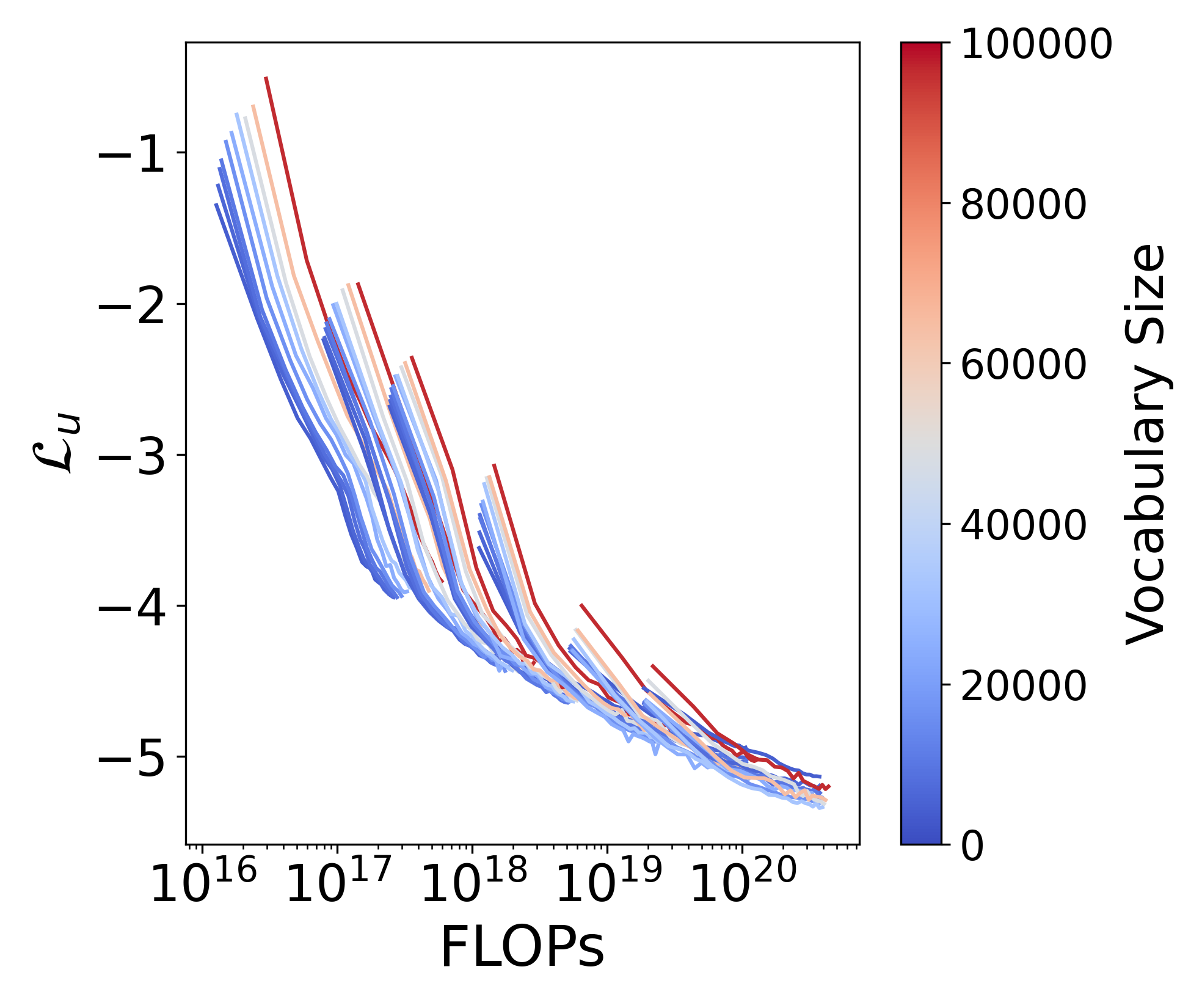
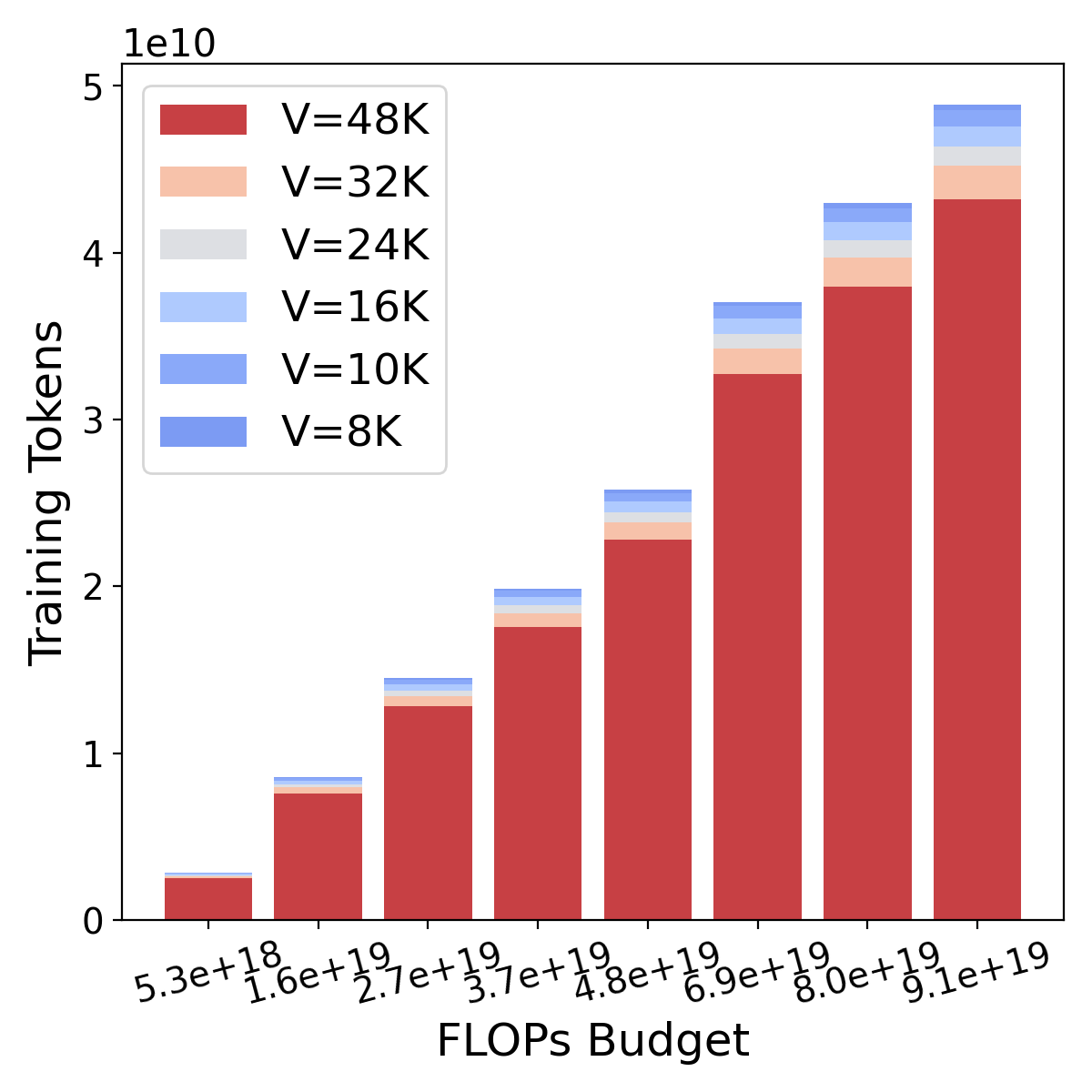
为了预测给定计算预算的最佳词汇量,我们提出了三种方法。 方法 1(通过 IsoFLOP 估计幂律):我们使用范围从 33M 到 1.13B 的非词汇参数预训练模型,模型组共享相同的 FLOP(“IsoFLOP”)但不同词汇配置。 然后,我们分别将 FLOP 与非词汇参数、词汇参数和训练数据相关的幂律拟合。 我们的分析表明,最佳词汇参数在计算预算方面呈现出幂律增长,但增长速度低于非词汇参数,如Figure 1所示。 方法 2(基于导数的估计):我们引入了一种基于导数的方法,该方法通过使用 FLOPs 的导数来估计最佳词汇量。 词汇量大小并找到相应的零解。 方法 3(损失公式的参数拟合):我们修改 Chinchilla 缩放法则 [24] 以合并词汇,并将结果公式拟合到我们的模型上,以预测基于标准化损失函数共同考虑非词汇参数、词汇参数和训练字符数量。 虽然前两种方法仅限于计算最佳设置,但这种方法还允许我们在分配次优时确定最佳词汇表,即模型参数要么针对太多标记进行训练(“过度训练”),要么针对太少标记进行训练(“过度训练”)。 “训练不足”)。 过度训练非常常见[21],例如 Llama 2 7B [64],它接受了 2 万亿个 Token 的训练,远远超过了 70 亿个 Token 的计算最优分配约150B Token 的参数模型。
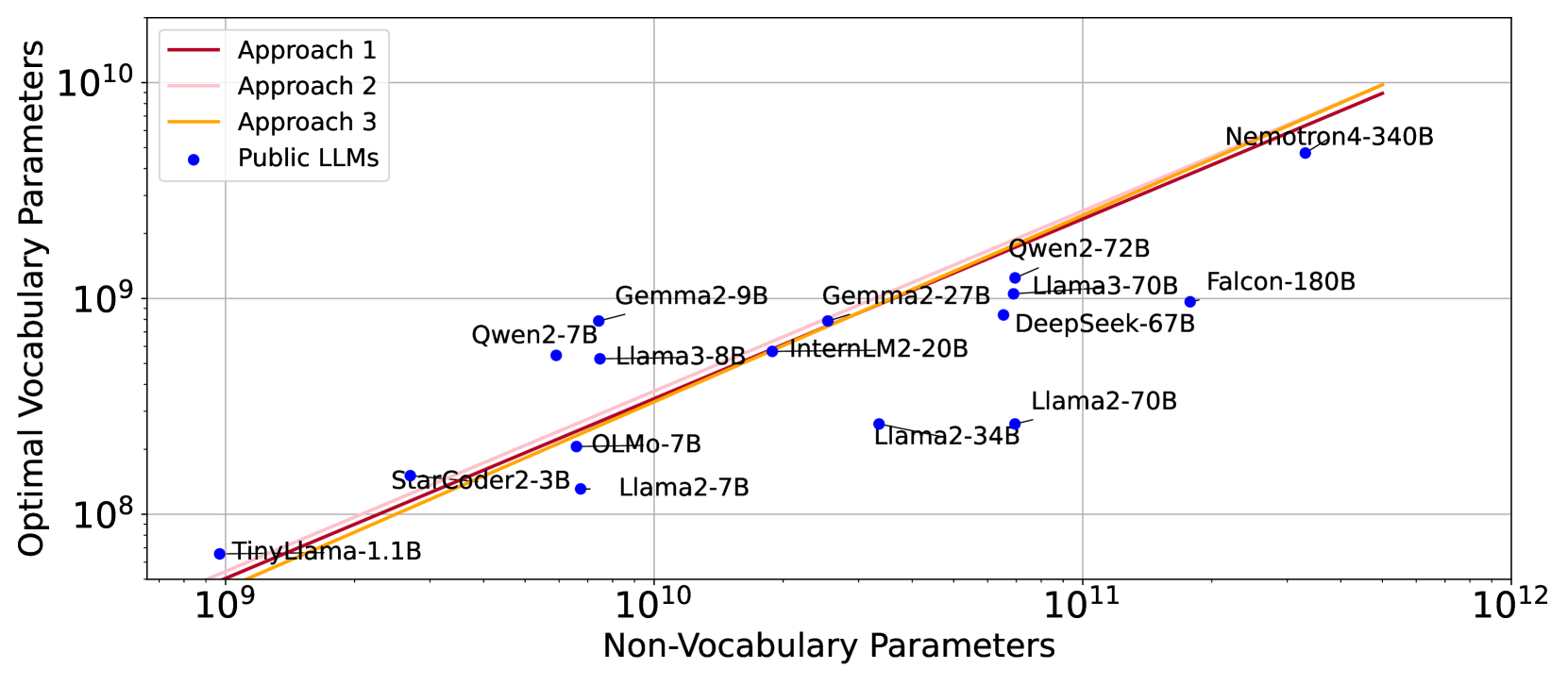
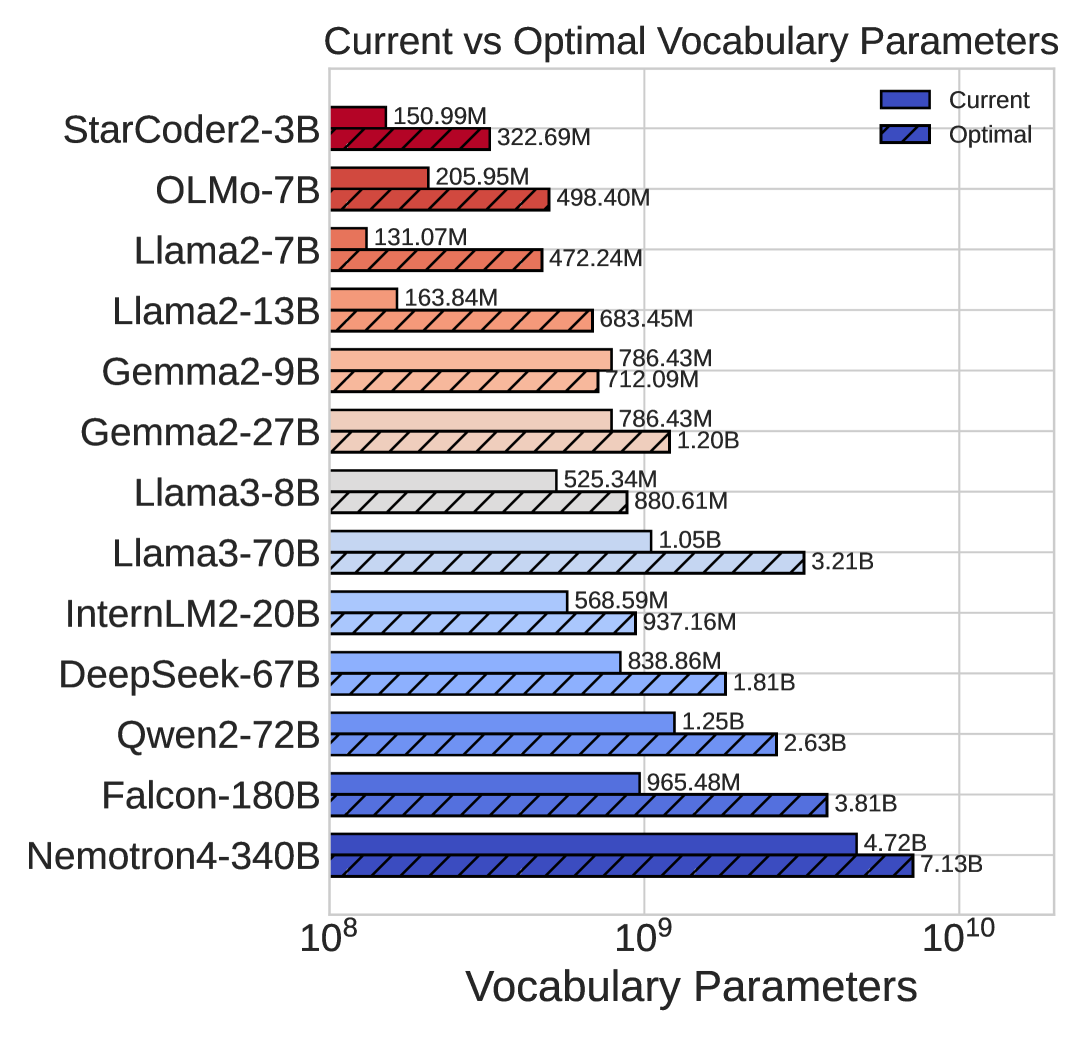
如图Figure 1所示,我们观察到非词汇参数与其对应的最佳词汇参数之间的关系遵循幂律,根据我们所有的方法。 我们的预测还表明词汇参数的缩放速度应慢于非词汇参数,即 其中 。 然而,大多数现有的大语言模型 [31,73,61,37,4,23,13,7,42,76] 忽视了词汇的重要性,分配的词汇参数少于建议,如 Figure 2 所示。 请注意,我们假设这些模型的训练数据量根据 Hoffmann 等人 [24] 进行最佳分布。 考虑到几个大语言模型的训练数据远多于最佳模型(例如 Llama2),最佳词汇量可能会比当前估计的要大。
最后,我们用 3B 参数模型实证验证了我们对模型的预测。 通过使用我们的方法来预测各种实际情况下的预期词汇量,当(1)数据不足(“训练不足”); (2) 训练数据与模型参数等比例缩放,遵循 Chinchilla 定律(“compute-optimal 训练”)[24]; (3) 训练数据过于充足,如 Llama [64](“过度训练”)。 结果表明,在相同的 FLOP 预算下,采用我们建议的词汇量大小的模型的性能稳定优于采用常用词汇配置的基线。 我们的研究强调了词汇训练的重要性被忽视,以及需要共同考虑词汇大小、模型参数和数据以进行有效扩展。
2 初步
在本节中,我们首先提出常用缩放定律的一般公式,然后演示如何修改它以合并词汇表。
2.1 缩放定律
缩放法则考虑计算预算 ,以 FLOP 为单位进行测量。 目标是将计算预算最佳地分配给模型参数 和训练标记的数量 [28, 6, 24, 40]。 它可以表述为:
| (1) |
按照Radford等人[47],损失函数通常是语言建模损失,可以写为:
| (2) |
其中 是给定上下文 和词汇量大小 的分词器的单词 的输出概率。一般来说,越低表明语言模型的性能越好。 然而,由于的依赖,不能用于比较不同词汇量大小的语言模型。 因此,我们稍后在§2.2中提出了调整。 拟合缩放定律通常需要针对不同配置进行训练的各种模型[21]。 一种常见的方法是选择多个计算预算和训练模型,每个预算的 和 不同,以找到最佳的一个,即损失最低的模型(“IsoFLOPs”) [24]。 然后,使用拟合技术,我们可以估计一个函数,该函数从计算预算映射到 和 的最佳分配。
2.2 词汇量缩放法则
由于先前的工作通常假设词汇量是固定的,因此我们不能直接采用其缩放法则和评估指标中的属性。 因此,我们详细介绍了几个使我们能够研究词汇量缩放法则的考虑因素。
属性
缩放法则通常处理属性、模型参数 () 和训练标记数量 () [24, 40]。 我们根据词汇量大小对它们进行调整以进行分析。 (1) 我们将总模型参数 () 分解为非词汇参数 () 和词汇参数 ()。 为了理解词汇参数的重要性,我们将它们与其他模型参数分开,其中。 我们使用 来表示输出层中的词汇参数 111词汇参数通常包含词嵌入层和输出层。 在本文中,为了清晰和分析简单起见,我们使用 而不是 来表示词汇参数。 这种方法选择基于经验观察:主要的计算负担(以 FLOP 为单位)与输出层相关,而词嵌入层的计算成本相对较小。 因此,对词汇表参数或其相关 FLOP 的引用主要与输出层中的那些相关,用 表示。. 值得注意的是,要更改 ,我们仅改变词汇量 并根据经验采用基于 给出的嵌入维度 ,请参阅§A.5.2 了解详细信息。 这是基于Kaplan等人[28]的观察,即具有不同深宽比的模型的性能收敛于单一趋势。 (2) 我们不是以标记 () 而是以训练字符 () 来测量数据。 标记的数量取决于标记器的词汇,因此我们需要与词汇无关的数据测量。 通过研究训练字符,我们可以更好地了解数据量如何影响性能,无论词汇量大小如何。
从训练字符 () 到标记 () 的映射
如上所述,我们以训练字符 () 来测量训练数据。 尽管如此,为了将我们的发现与缩放定律 [24, 40] 的现有研究联系起来,我们需要能够从 映射到 。该映射是分词器的压缩比,可以通过 计算。 分词器需要表示 的标记越多, 就越大,因此压缩得越少。 我们开发了一个简单的函数 来仅根据所选词汇量 来估计该比率。具体来说,我们发现 对数值的二次函数可以实现准确的预测:
| (3) |
通过将多个标记器与 进行拟合,范围从 到 ,我们得到 、 和 。 我们发现我们的函数能够以较低的相对均方误差 (RMSE) 和较高的确定系数 () 准确预测压缩比。 在 §A.7 中,我们可视化拟合结果,并表明我们的近似适用于不同的分词器,并且对不同的 具有鲁棒性。对于我们所有的主要实验,我们使用 BPE 算法进行标记化[55]。
词汇不敏感的损失
为了公平地评估中变化的模型,Equation 2中常用的语言模型损失是不合适的。 使用较大的 训练的模型自然会产生更高的损失,因为词汇表中有更多的可能性可以预测。 然而,这并不意味着该模型更糟糕。 因此,我们需要根据词汇量对损失进行标准化。 我们将一元标准化度量 [50] 重新表述为损失函数。 假设我们有一个长度的序列,我们将一元标准化语言模型损失设计为:
| (4) |
其中 是单词 在标记化语料库中的频率,给定标记生成器的词汇量大小 。这一损失表明上下文感知语言模型比没有上下文的一元模型提供的概率有所提高,使我们能够评估语言模型的功效。 根据先前工作[50]的理论,对于具有跨不同词汇量大小的固定非词汇成分的给定模型,归一化损失保持一致。 的差异来自于语言模型本身的能力。 与相比,的值要小得多,并且可以为负数,因为添加了负项。 人们还可以采用每个字符的平均位数 (BPC),这是一种文本压缩的常用度量[25],作为词汇不敏感损失。 唯一的区别在于标准化。 BPC 表示语料库中原始的每字符语言模型损失,而我们的 相当于按每个字符的频率标准化的每字符语言模型损失。 由于我们为训练的每个模型使用相同的语料库,因此在我们的案例中,两个指标之间没有太大差异。
3 分析:为什么最佳词汇量受到计算的限制
在本节中,我们将进行分析来解释为什么最佳词汇量受到计算预算的限制。
3.1分析一:固定归一化损失视角
3.2分析2:固定FLOP预算的视角
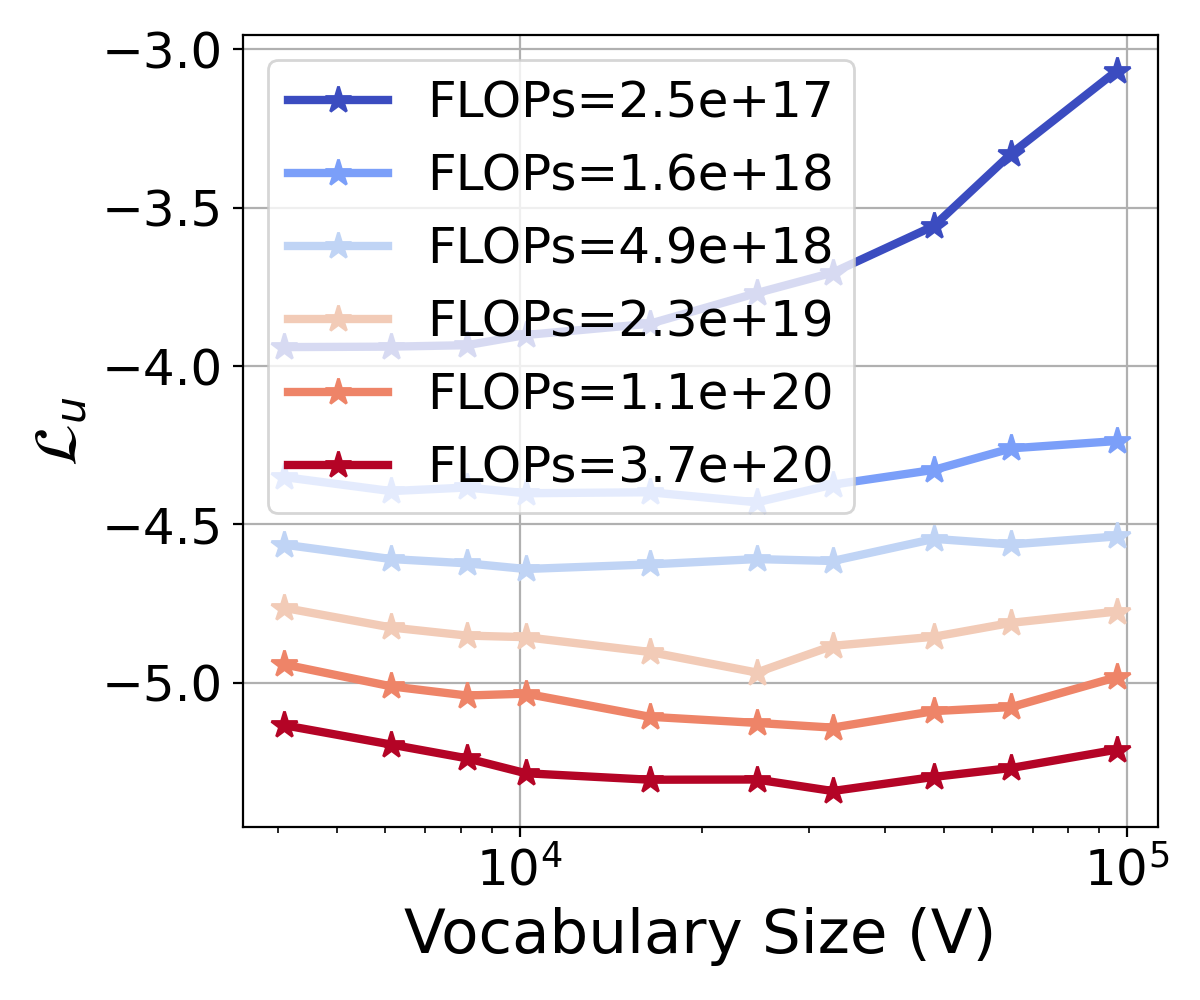
给定固定的 FLOP 预算,我们隔离 FLOP 并研究词汇如何影响损失。 在实践中,我们设置了几个固定的 FLOP 预算。 对于每个预算,我们采用一组总参数相似且词汇量从 4K 到 96K 不等的模型。 在Figure 3(右)中,我们绘制了损失与损失之间的关系。 词汇量。 它表明,随着 FLOPs 预算的增加,损失曲线上最低点对应的词汇量也会增加。 这表明,通过更多的计算资源,大语言模型可以有效地利用更大的词汇量来减少损失。 然而,仅仅扩大词汇量并不总能降低损失。 对于固定的 FLOP 预算,损失最初随着词汇量的增加而减小,然后开始上升,表明词汇量存在一个最佳点。 这表明需要在模型复杂性和计算约束之间进行权衡,其中过大的词汇量无法得到有效利用,从而导致模型性能不佳。
3.3分析3:参数增长视角
传统上,扩大语言模型中的模型参数有两种方法:增加深度(即层数)或宽度(即隐藏大小)。 虽然人们对这些方法进行了广泛的研究,但当前的经验实践通常涉及同时扩展这两种方法[60]。 然而,这种方法可能会忽略不同参数如何从这些扩展中受益的关键区别。
非词汇参数可以受益于深度和宽度的增加,从而允许更复杂的层次表示和更广泛的特征捕获。 相比之下,与词嵌入和语言模型头相关的词汇参数通常局限于单层,限制了它们从模型深度增加中受益的能力。 他们扩张的主要途径是增加宽度。 非词汇和词汇参数之间增长潜力的差异表明,为了保持均衡的增长率,可能有必要在扩大词汇量的同时扩大词汇量。 这将使词汇参数部分能够跟上非词汇参数的增长。
4 估计最佳词汇量
在本节中,我们描述了三种估计最佳词汇量的补充方法。
4.1 方法 1:通过 IsoFLOP 估计幂律
我们定义了6组模型,范围从33M到1.13B。 在每组中,我们仅将词汇量 从 变为 ,并在相同的 FLOPs 预算下评估不同的模型。 我们在保留的验证数据集上评估标准化损失。 这种方法使我们能够直接回答这个问题:对于给定的 FLOPs 预算,非词汇参数、词汇参数和训练数据的最佳分配是什么?
设置
给定一定的,嵌入维度是固定的,因此随着的增加而增加。 对于所有实验,我们对 SlimPajama 数据集 [57] 中不同域的训练数据进行统一采样。 所有其他超参数均已修复,更多详细信息请参见§A.5。
配件
我们为每个 FLOP 预算选择具有最小 的数据点,所有运行都在Figure 4 中可视化。 这些点是对 (, , ) 的计算最佳分配。 继Kaplan等人[28]和Hoffmann等人[24]之后,我们假设最优词汇参数满足幂律w.r.t。 FLOPs 训练,就像非词汇参数和数据量一样。 具体来说,、 和 。 由于模型大小和训练数据应同等缩放以实现计算最佳训练 [24],因此我们设置 。 由于我们的新属性 显着增加了可能的实验配置的数量,因此我们采用跨数据点插值来以低成本获得更多配置。 拟合的实现细节参见§A.5.4。
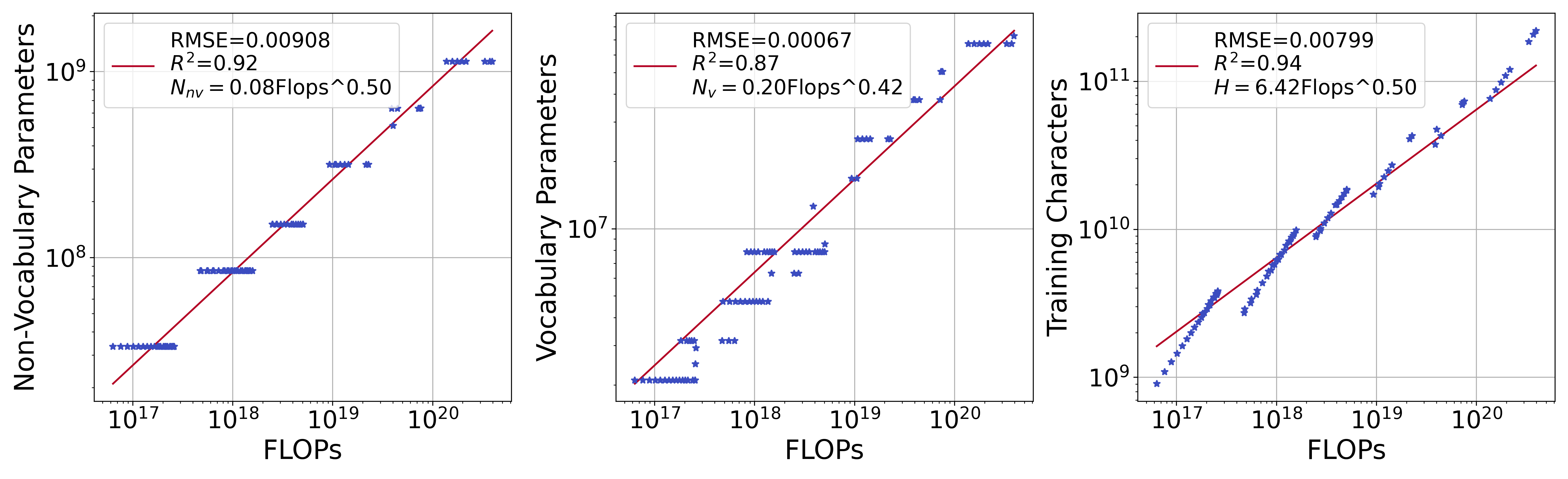
结果
在Figure 5中,我们显示了拟合的幂律:、和,其中是 FLOPs 预算。低 和高 值表明我们的拟合强度。 给定一定的 FLOPs 预算,我们可以利用上述关系来获得最优分配(、、)。 我们还得出以下结论: (1) 大语言模型需要数据。 与非词汇参数相比,实践者应该为数据[72, 40]分配更多的计算量。 (2) 词汇参数与 FLOP 呈幂律关系 ()。 随着模型的计算量越来越大,更大的词汇量可以增强模型理解更多样化文本的能力,因此词汇量的大小对于扩展至关重要。 (3) 词汇参数 的缩放速度应慢于非词汇参数 。 这种差异可以从它们的幂律指数中看出,即。 我们假设原因是:一旦通过大量词汇提供了足够丰富的嵌入空间,那么通过 Transformer 块缩放非词汇参数以学习语言复杂的句法和语义结构就变得更加关键。
4.2方法2:基于导数的快速估计
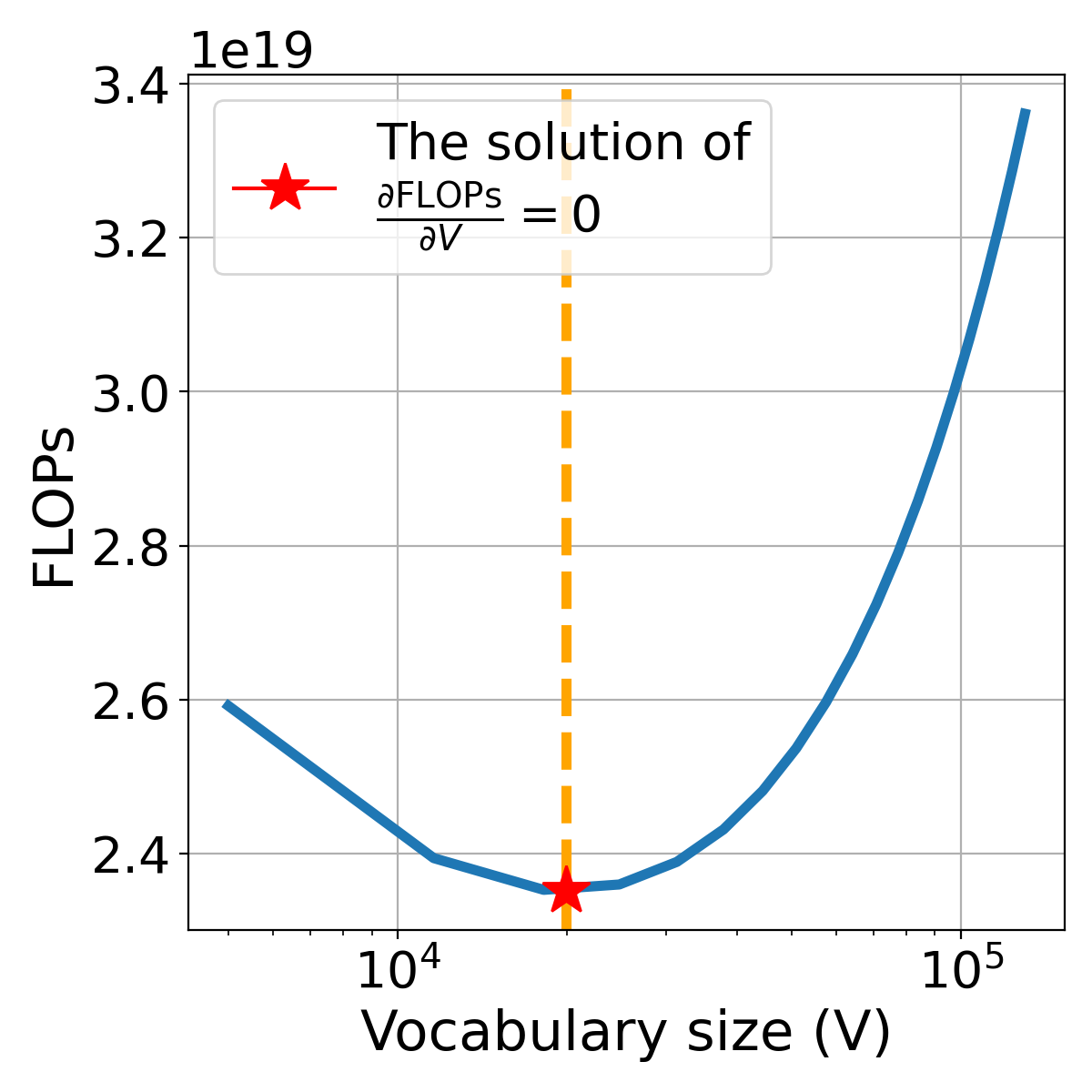
我们提出了一种利用 FLOP 本身估计的见解的替代方法。 之前的工作[24, 28] 通常考虑以 FLOP 为单位的固定计算预算,然后通过找到模型参数和训练词符的最优分配来最小化损失。在此,我们将根据最近的研究 [53] 颠覆这一方法。 我们的目标是通过词汇量大小的优化分配来找到实现一定损失的最小FLOP:
| (6) |
通过导数计算相对于 的 FLOPs 的最小点 :
| (7) |
我们可以在能够实现一定损失的假设下估计最优的。 参数、和可以通过构建(§2.2)轻松获得。 理论上,只要提供非词汇参数,就可以通过的解对进行数值搜索。 更多详细信息请参见§A.1。
用法
请注意,最佳词汇量大小应主要由归一化损失 确定,而不是由计算预算 FLOP 确定。 然而,当计算分配接近最优时,损失相对于 FLOP 预算呈现幂律关系,如缩放定律 [28] 所描述。 这种关系使我们能够使用具有计算最优分配的 FLOP 作为观察最佳词汇参数的缩放行为的可靠代理。 在实践中,我们首先可以在低成本设置中确定经验上的最佳词汇量(例如,在具有等效 FLOP 的小模型上找到计算最佳词汇参数)。 然后,当我们增加非词汇参数时,我们可以按比例缩放最佳词汇参数。 具体来说,我们针对不同的非词汇参数获得一组导数最优词汇参数,表示为。 然后,我们使用幂律函数 拟合 和 之间的关系。 这导致缩放方程:,其中是一个相对较小的模型(例如33M),是搜索到的最佳词汇参数,具有足够的训练量具有相同 FLOP 预算的角色。 通过结合从导数获得的 值和小模型上的经验解,我们可以估计任何大型模型的最佳词汇量,而无需进行以下广泛的参数搜索:
其中拟合后的缩放比例 。 与方法 1 中的观察结果一致,我们发现非词汇参数的缩放速度应比词汇参数更快才能实现最佳分配。
4.3方法3:损失公式的参数拟合
最后,我们直接预测给定非词汇参数、词汇参数和训练字符数量的损失。 然后,可以通过找到词汇损失最小点来预测最佳词汇配置。 遵循Hoffmann等人[24]中使用的经典风险分解,我们将词汇相关损失公式设计为:
| (8) |
其中。 第一项捕获数据分布的理想生成过程的归一化损失。 后续项分别反映非词汇参数、词汇参数和训练数据数量对损失的影响。 是学习参数。
配件
我们使用为§4.1中的实验收集的点(、、)。 请注意,我们不仅考虑每个 FLOP 预算损失最低的点,因为我们想要预测 (、、 的任意组合的损失>)。 我们在 Muennighoff 等人 [40] 之后添加约束 。 我们还过滤掉 Hoffmann 等人 [24] 之后 FLOP 非常小的点。 拟合产生、、、、、。 详细的拟合过程写在§A.5.4中。
用法
在拟合Equation 8中的参数后,可以通过在FLOPs预算的约束下找到与词汇表大小相关的最低损失来获得最佳词汇表大小。 例如,给定 和 FLOPs 预算 ,通过用 替换 并找到 的解> 通过数值搜索,我们可以得到预测。 的详细内容写在§A.2中。 请注意,所有提出的方法都可以一起用于最优分配 (),而方法 3 在预测局部最优 时更加灵活 () >,)不遵循钦奇拉定律[24],即等比例定律。 原因是方法3中的损失公式不仅仅考虑在给定一定训练预算的情况下达到最优的组合()。 通过在方法3中固定并改变,我们可以预测具有不同训练字符数量的局部最优词汇量。 这一特性使得方法 3 更有价值,因为现代训练大语言模型 [64, 61, 3, 4, 8] 通常利用过于充足的数据来构建强大的模型,而推理成本相对较低。
在Figure 6中,我们删除了假设[24],因为实际原因是参数和训练数据的缩放比例不同。 然后,我们预测局部最优词汇参数。 可以看出,词汇参数的分配通常被低估。
5讨论
| -App1 | -App2 | -App3 | Dim. | -App1 | -App2 | -App3 | FLOPs Budget | |
| 3B | 0.1B | 0.1B | 0.1B | 3200 | 39K | 43K | 37K | |
| 7B | 0.3B | 0.3B | 0.2B | 4096 | 62K | 67K | 60K | |
| 13B | 0.4B | 0.5B | 0.4B | 5120 | 83K | 91K | 81K | |
| 30B | 0.9B | 0.9B | 0.9B | 6048 | 142K | 154K | 142K | |
| 70B | 1.7B | 1.9B | 1.8B | 8192 | 212K | 231K | 218K | |
| 130B | 2.9B | 3.2B | 3.0B | 12888 | 237K | 258K | 248K | |
| 300B | 5.8B | 6.4B | 6.3B | 16384 | 356K | 389K | 383K |
预测较大模型的分配
Table 1 报告了基于所提出的三种方法预测的最佳词汇参数和大小,其中训练数据量得到最佳分配,即与非词汇参数同等缩放[24]。 如图Figure 1 所示,所有提出的方法的预测紧密一致。 的缩放速度应比 更快。 值得注意的是,主流大语言模型通常为词汇分配的参数少于最佳参数。 然而,社区开始转向更大的词汇表,例如 Llama3 [37] 的词汇量从 Llama2 [64] 的 32K 增加到了 128K。 但数据扩展仍然是最关键的部分,解决数据稀缺问题应该是未来工作的重点[66]。
| ARC-C | ARC-E | Hellaswag | OBQA | WG | PIQA | BoolQ | Average | ||||
| FLOPs Budget 1.2e21 (Optimally-Allocated Training Data) | |||||||||||
| =32K | 0.10B | 67.3B | 266.6B | 28.51.3 | 49.21.0 | 47.50.5 | 31.62.1 | 50.41.4 | 71.41.1 | 56.40.9 | 47.9 |
| =35K | 0.11B | 67.1B | 268.2B | 29.11.3 | 50.61.0 | 48.10.5 | 31.62.1 | 51.91.4 | 71.41.1 | 57.10.9 | 48.5 |
为了凭经验验证我们的预测,我们在计算最佳 FLOPs 预算下使用 训练模型,并使用 lighteval 222https://github.com/huggingface/lighteval。 对于基线模型,我们使用常见词汇量。 另一个模型使用 ,如方法 3 所预测的那样。 在Table 2中,我们表明根据词汇预测分配的模型在多个下游任务中产生了更好的性能。 这证实了我们的预测在规模上是成立的。
使用稀缺和过多的训练数据进行实验
我们之前的实验侧重于训练计算预算是主要约束的设置,我们寻求将其最佳地分配给参数和数据。 这是标度律研究中的典型设置[28,24,48]。 然而,在现实世界中,我们经常处理稀缺数据(“数据受限[40]”),迫使我们训练次优,或者想利用过多的数据来训练更小的数据。使用 [76] 更便宜的模型。 为了验证我们的方法 3 可以处理这些实际场景,我们将模型与 和模型与方法 3 预测的词汇量 进行比较。 如表 3 所示,我们的预测仅通过调整不同 FLOP 预算中的词汇量即可实现更好的模型。
| ARC-C | ARC-E | Hellaswag | OBQA | WG | PIQA | BoolQ | Average | ||||
| FLOPs Budget 2.8e20 (Insufficient Training Data, “Undertraining”) | |||||||||||
| =32K | 0.10B | 15.7B | 62.2B | 23.61.2 | 40.81.0 | 34.40.5 | 29.02.0 | 49.71.4 | 64.91.1 | 59.80.9 | 43.2 |
| =24K | 0.08B | 15.8B | 60.8B | 24.21.3 | 42.21.0 | 36.00.5 | 28.62.0 | 50.01.4 | 64.91.1 | 61.50.9 | 43.9 |
| FLOPs Budget 2.3e21 (Overly Sufficient Training Data, “Overtraining”) | |||||||||||
| =32K | 0.10B | 128.5B | 509.1B | 29.11.3 | 53.51.0 | 53.00.5 | 33.02.1 | 52.01.4 | 72.01.1 | 59.50.9 | 50.3 |
| =43K | 0.14B | 127.0B | 517.5B | 32.01.4 | 54.71.0 | 54.10.5 | 33.02.1 | 52.81.4 | 72.61.0 | 61.90.9 | 51.6 |
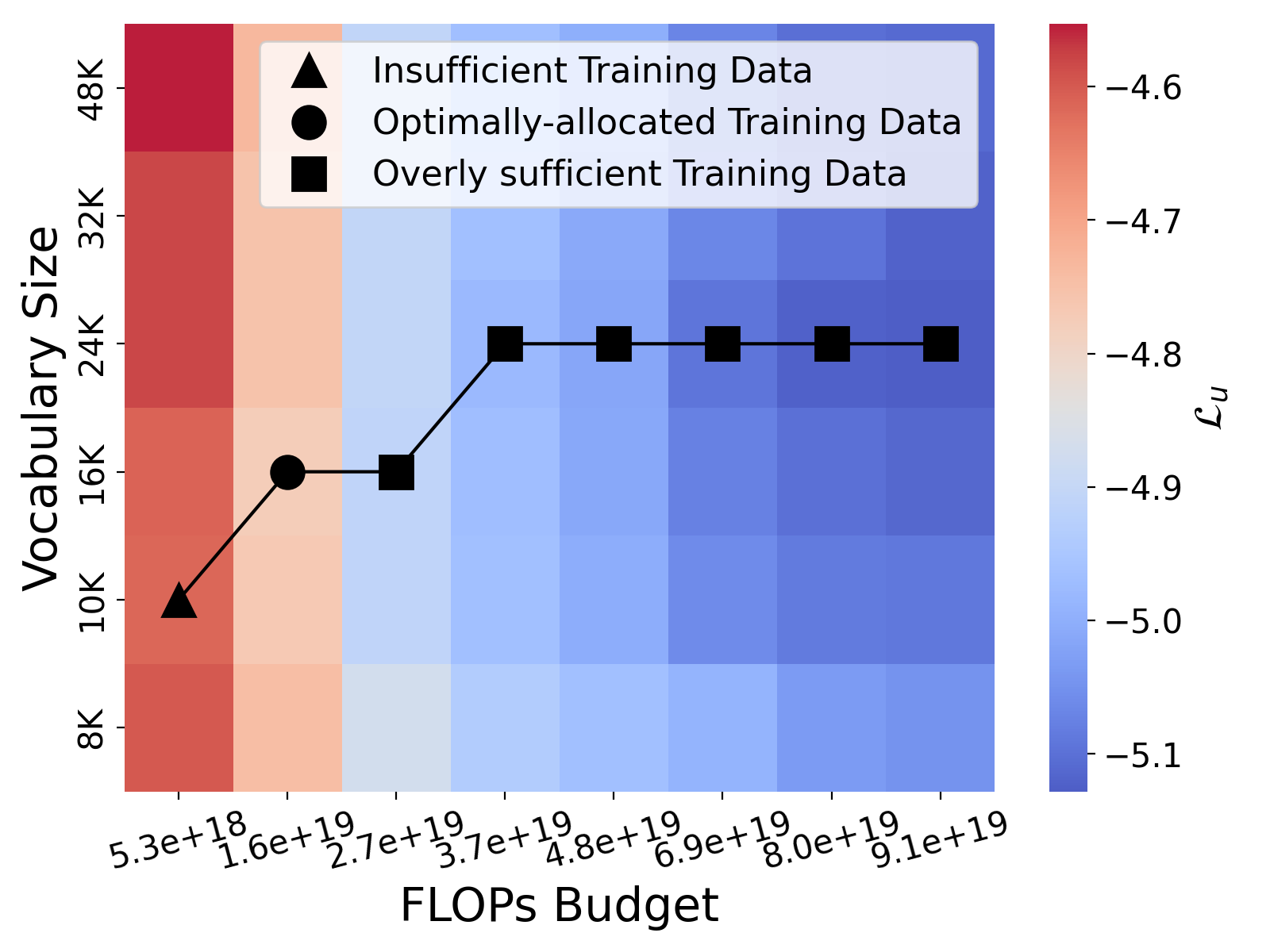
在Figure 7中,我们进一步研究了最佳词汇量随着不同数量的训练数据的变化趋势。 我们仅改变数据量,但保持非词汇参数固定。 词汇大小的选择有、、、、和. 以为例,当可用数据成为瓶颈时,最优词汇量会根据经验减小,即。 这是一种防止过度拟合的机制。 相反,当训练大量数据时,例如,Llama3-8B 使用的训练标记比其预算的计算最佳标记多得多,最佳词汇量会增加 ,即。 请注意,这里我们仅关注计算最优训练。 同样重要的是要注意,扩大词汇量也会增加推理过程中的计算需求。 因此,我们建议使用与给定,假设训练数据的最佳分配,即使在可能发生过度训练的情况下也是如此。
6相关工作
大型语言模型
Transformer [65] 已被证明是一种非常可扩展的架构,具有一致的性能增益,从而催生了一系列大型语言模型(大语言模型)[12, 15, 48, 43 、18、27、49、64、67、37、9、4、34、23、58、61、8、35、30、79]。 通过预测序列中后续标记的训练,这些模型获得了对语言的深入理解,使它们能够在预训练后直接执行各种语言任务。 它们的功能包括代码生成[31, 3, 39, 78, 77]、数学推理[69, 5]、问题回答[44, 41]等等。 在我们的工作中,我们在英语语料库上从头开始预训练大型语言模型,并重点关注它们在训练过程中的损失以及训练后常见任务的下游表现。
缩放定律
缩放法则旨在开发一个预测框架,以找到计算资源的最佳分配,从而最大限度地提高模型性能。 除了语言模型之外,还研究了扩散模型[36]、视觉自回归建模[62]和对比语言图像学习[14]. 对于语言模型,Kaplan 等人 [28] 表明,模型性能随着幂律的增加而提高,更多的计算分配给参数或数据。 Hoffmann 等人[24]表明,计算的分配应该使参数和数据等比例缩放。 其他工作研究预测其他属性,例如下游性能[21,26,51]或考虑推理时间[53]。 一些研究还预测了数据约束下的预期收益和最优分配[40, 72]。 在所有这些作品中,词汇量通常被忽略。 Kaplan等人[28]甚至明确只考虑非嵌入参数。 我们的工作强调了词汇在扩展大语言模型中的关键作用。 通过我们确定最佳词汇量的预测框架,我们希望未来的研究能够更多地关注词汇量。
语言模型中的词汇
语言模型的词汇量对其性能有显着影响[59,68,71]。 较大的词汇量有助于覆盖更多单词,从而降低出现词汇外 (OOV) 情况的可能性[19]。 Takahashi 和 Tanaka-Ishii [59] 发现较大的词汇量能够更好地捕捉语言的真实统计分布。 同样,扩展多语言模型中的词汇量[68]可以提高性能,尤其是对于资源匮乏的语言。 然而,大词汇表[29]会增加训练和生成阶段的计算开销。 Liao 等人[32]表明,低频词在数据中的实例很少,如果词汇量太大,则导致训练鲁棒表示的信息不足。 为此,我们的工作填补了一个尚未探索的空白:如何优化分配词汇量?
字节级语言模型
最近的工作探索了字节级语言模型[74, 70],与 Token 级模型相比,它在解码效率和噪声鲁棒性方面具有优势。 然而,这些模型通常仅限于 1B 以下的参数,尚未有效扩展。 我们的缩放法则表明,有限的词汇量(即字节级语言模型中的 256 个)可能会限制其性能,尤其是对于较大的模型。 这一见解为扩展字节级模型的挑战提供了潜在的解释,并意味着成功扩展语言模型可能需要按比例增加词汇量。
7结论
我们研究了缩放语言模型时词汇量大小的影响。 我们分析并验证对于给定的 FLOPs 预算是否存在最佳词汇量。 随后,我们开发了 3 种方法来预测最佳词汇量。 我们的第一种方法使用一组跨不同 IsoFLOPs 机制的经验训练来适应缩放法则。 第二种方法研究 FLOPs w.r.t. 词汇量并用导数估计词汇量。 第三种方法由参数函数组成,用于直接预测不同属性对损失的影响。 在所有方法中,我们发现虽然词汇参数的缩放速度应该比其他参数慢,但它们对于性能仍然至关重要,并且我们可以准确预测它们的最佳分配。 我们对更大的模型进行预测,并根据最多 3B 个参数和不同数量的训练数据来验证我们的方法。 我们的结果表明,在相同的 FLOPs 预算下,使用我们的方法预测的最佳词汇量训练的模型优于使用传统词汇量训练的模型。
参考
- Aghajanyan et al. [2022] Armen Aghajanyan, Bernie Huang, Candace Ross, Vladimir Karpukhin, Hu Xu, Naman Goyal, Dmytro Okhonko, Mandar Joshi, Gargi Ghosh, Mike Lewis, et al. 2022. Cm3: A causal masked multimodal model of the internet. arXiv preprint arXiv:2201.07520.
- Aghajanyan et al. [2023] Armen Aghajanyan, Lili Yu, Alexis Conneau, Wei-Ning Hsu, Karen Hambardzumyan, Susan Zhang, Stephen Roller, Naman Goyal, Omer Levy, and Luke Zettlemoyer. 2023. Scaling laws for generative mixed-modal language models. In International Conference on Machine Learning, pages 265–279. PMLR.
- Allal et al. [2023] Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, et al. 2023. SantaCoder: don’t reach for the stars! arXiv preprint arXiv:2301.03988.
- Almazrouei et al. [2023] Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, et al. 2023. The falcon series of open language models. arXiv preprint arXiv:2311.16867.
- Azerbayev et al. [2023] Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q Jiang, Jia Deng, Stella Biderman, and Sean Welleck. 2023. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631.
- Bahri et al. [2021] Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. 2021. Explaining neural scaling laws. arXiv preprint arXiv:2102.06701.
- Bi et al. [2024a] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, Huazuo Gao, Kaige Gao, Wenjun Gao, Ruiqi Ge, Kang Guan, Daya Guo, Jianzhong Guo, Guangbo Hao, Zhewen Hao, Ying He, Wenjie Hu, Panpan Huang, Erhang Li, Guowei Li, Jiashi Li, Yao Li, Y. K. Li, Wenfeng Liang, Fangyun Lin, Alex X. Liu, Bo Liu, Wen Liu, Xiaodong Liu, Xin Liu, Yiyuan Liu, Haoyu Lu, Shanghao Lu, Fuli Luo, Shirong Ma, Xiaotao Nie, Tian Pei, Yishi Piao, Junjie Qiu, Hui Qu, Tongzheng Ren, Zehui Ren, Chong Ruan, Zhangli Sha, Zhihong Shao, Junxiao Song, Xuecheng Su, Jingxiang Sun, Yaofeng Sun, Minghui Tang, Bingxuan Wang, Peiyi Wang, Shiyu Wang, Yaohui Wang, Yongji Wang, Tong Wu, Y. Wu, Xin Xie, Zhenda Xie, Ziwei Xie, Yiliang Xiong, Hanwei Xu, R. X. Xu, Yanhong Xu, Dejian Yang, Yuxiang You, Shuiping Yu, Xingkai Yu, B. Zhang, Haowei Zhang, Lecong Zhang, Liyue Zhang, Mingchuan Zhang, Minghua Zhang, Wentao Zhang, Yichao Zhang, Chenggang Zhao, Yao Zhao, Shangyan Zhou, Shunfeng Zhou, Qihao Zhu, and Yuheng Zou. 2024a. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. CoRR, abs/2401.02954.
- Bi et al. [2024b] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. 2024b. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954.
- Biderman et al. [2023] Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. 2023. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR.
- Bisk et al. [2020] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439.
- Blevins et al. [2024] Terra Blevins, Tomasz Limisiewicz, Suchin Gururangan, Margaret Li, Hila Gonen, Noah A Smith, and Luke Zettlemoyer. 2024. Breaking the Curse of Multilinguality with Cross-lingual Expert Language Models. arXiv preprint arXiv:2401.10440.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Cai et al. [2024] Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, Xiaoyi Dong, Haodong Duan, Qi Fan, Zhaoye Fei, Yang Gao, Jiaye Ge, Chenya Gu, Yuzhe Gu, Tao Gui, Aijia Guo, Qipeng Guo, Conghui He, Yingfan Hu, Ting Huang, Tao Jiang, Penglong Jiao, Zhenjiang Jin, Zhikai Lei, Jiaxing Li, Jingwen Li, Linyang Li, Shuaibin Li, Wei Li, Yining Li, Hongwei Liu, Jiangning Liu, Jiawei Hong, Kaiwen Liu, Kuikun Liu, Xiaoran Liu, Chengqi Lv, Haijun Lv, Kai Lv, Li Ma, Runyuan Ma, Zerun Ma, Wenchang Ning, Linke Ouyang, Jiantao Qiu, Yuan Qu, Fukai Shang, Yunfan Shao, Demin Song, Zifan Song, Zhihao Sui, Peng Sun, Yu Sun, Huanze Tang, Bin Wang, Guoteng Wang, Jiaqi Wang, Jiayu Wang, Rui Wang, Yudong Wang, Ziyi Wang, Xingjian Wei, Qizhen Weng, Fan Wu, Yingtong Xiong, Chao Xu, Ruiliang Xu, Hang Yan, Yirong Yan, Xiaogui Yang, Haochen Ye, Huaiyuan Ying, Jia Yu, Jing Yu, Yuhang Zang, Chuyu Zhang, Li Zhang, Pan Zhang, Peng Zhang, Ruijie Zhang, Shuo Zhang, Songyang Zhang, Wenjian Zhang, Wenwei Zhang, Xingcheng Zhang, Xinyue Zhang, Hui Zhao, Qian Zhao, Xiaomeng Zhao, Fengzhe Zhou, Zaida Zhou, Jingming Zhuo, Yicheng Zou, Xipeng Qiu, Yu Qiao, and Dahua Lin. 2024. InternLM2 Technical Report. arxiv.
- Cherti et al. [2023] Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. 2023. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829.
- Chowdhery et al. [2023] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Clark et al. [2019] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- Du et al. [2021] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. 2021. Glm: General language model pretraining with autoregressive blank infilling. arXiv preprint arXiv:2103.10360.
- Enarvi et al. [2017] Seppo Enarvi, Peter Smit, Sami Virpioja, and Mikko Kurimo. 2017. Automatic speech recognition with very large conversational finnish and estonian vocabularies. IEEE/ACM Transactions on audio, speech, and language processing, 25(11):2085–2097.
- Esser et al. [2021] Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883.
- Gadre et al. [2024] Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, et al. 2024. Language models scale reliably with over-training and on downstream tasks. arXiv preprint arXiv:2403.08540.
- Gao et al. [2019] Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. 2019. Representation degeneration problem in training natural language generation models. arXiv preprint arXiv:1907.12009.
- Groeneveld et al. [2024] Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. 2024. Olmo: Accelerating the science of language models. arXiv preprint arXiv:2402.00838.
- Hoffmann et al. [2022] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
- Huang et al. [2024] Yuzhen Huang, Jinghan Zhang, Zifei Shan, and Junxian He. 2024. Compression Represents Intelligence Linearly. CoRR, abs/2404.09937.
- Isik et al. [2024] Berivan Isik, Natalia Ponomareva, Hussein Hazimeh, Dimitris Paparas, Sergei Vassilvitskii, and Sanmi Koyejo. 2024. Scaling Laws for Downstream Task Performance of Large Language Models. arXiv preprint arXiv:2402.04177.
- Jiang et al. [2023] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7B. arXiv preprint arXiv:2310.06825.
- Kaplan et al. [2020] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
- Le Scao et al. [2023] Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2023. Bloom: A 176b-parameter open-access multilingual language model.
- Li et al. [2024] Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Chandu, Thao Nguyen, Igor Vasiljevic, Sham Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Zettlemoyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldaini, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G. Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, and Vaishaal Shankar. 2024. DataComp-LM: In search of the next generation of training sets for language models.
- Li et al. [2023] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161.
- Liao et al. [2021] Xianwen Liao, Yongzhong Huang, Changfu Wei, Chenhao Zhang, Yongqing Deng, and Ke Yi. 2021. Efficient estimate of low-frequency words’ embeddings based on the dictionary: a case study on Chinese. Applied Sciences, 11(22):11018.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Lozhkov et al. [2024] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. StarCoder 2 and The Stack v2: The Next Generation. arXiv preprint arXiv:2402.19173.
- Luukkonen et al. [2023] Risto Luukkonen, Ville Komulainen, Jouni Luoma, Anni Eskelinen, Jenna Kanerva, Hanna-Mari Kupari, Filip Ginter, Veronika Laippala, Niklas Muennighoff, Aleksandra Piktus, et al. 2023. Fingpt: Large generative models for a small language. arXiv preprint arXiv:2311.05640.
- Mei et al. [2024] Kangfu Mei, Zhengzhong Tu, Mauricio Delbracio, Hossein Talebi, Vishal M Patel, and Peyman Milanfar. 2024. Bigger is not Always Better: Scaling Properties of Latent Diffusion Models. arXiv preprint arXiv:2404.01367.
- Meta AI [2024] Meta AI. 2024. Meta LLaMA-3: The most capable openly available LLM to date. https://ai.meta.com/blog/meta-llama-3/.
- Mihaylov et al. [2018] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789.
- Muennighoff et al. [2023a] Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro Von Werra, and Shayne Longpre. 2023a. Octopack: Instruction tuning code large language models. arXiv preprint arXiv:2308.07124.
- Muennighoff et al. [2024] Niklas Muennighoff, Alexander Rush, Boaz Barak, Teven Le Scao, Nouamane Tazi, Aleksandra Piktus, Sampo Pyysalo, Thomas Wolf, and Colin A Raffel. 2024. Scaling data-constrained language models. Advances in Neural Information Processing Systems, 36.
- Muennighoff et al. [2023b] Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, Xiangru Tang, Dragomir Radev, Alham Fikri Aji, Khalid Almubarak, Samuel Albanie, Zaid Alyafeai, Albert Webson, Edward Raff, and Colin Raffel. 2023b. Crosslingual Generalization through Multitask Finetuning.
- Nvidia et al. [2024] Nvidia, :, Bo Adler, Niket Agarwal, Ashwath Aithal, Dong H. Anh, Pallab Bhattacharya, Annika Brundyn, Jared Casper, Bryan Catanzaro, Sharon Clay, Jonathan Cohen, Sirshak Das, Ayush Dattagupta, Olivier Delalleau, Leon Derczynski, Yi Dong, Daniel Egert, Ellie Evans, Aleksander Ficek, Denys Fridman, Shaona Ghosh, Boris Ginsburg, Igor Gitman, Tomasz Grzegorzek, Robert Hero, Jining Huang, Vibhu Jawa, Joseph Jennings, Aastha Jhunjhunwala, John Kamalu, Sadaf Khan, Oleksii Kuchaiev, Patrick LeGresley, Hui Li, Jiwei Liu, Zihan Liu, Eileen Long, Ameya Sunil Mahabaleshwarkar, Somshubra Majumdar, James Maki, Miguel Martinez, Maer Rodrigues de Melo, Ivan Moshkov, Deepak Narayanan, Sean Narenthiran, Jesus Navarro, Phong Nguyen, Osvald Nitski, Vahid Noroozi, Guruprasad Nutheti, Christopher Parisien, Jupinder Parmar, Mostofa Patwary, Krzysztof Pawelec, Wei Ping, Shrimai Prabhumoye, Rajarshi Roy, Trisha Saar, Vasanth Rao Naik Sabavat, Sanjeev Satheesh, Jane Polak Scowcroft, Jason Sewall, Pavel Shamis, Gerald Shen, Mohammad Shoeybi, Dave Sizer, Misha Smelyanskiy, Felipe Soares, Makesh Narsimhan Sreedhar, Dan Su, Sandeep Subramanian, Shengyang Sun, Shubham Toshniwal, Hao Wang, Zhilin Wang, Jiaxuan You, Jiaqi Zeng, Jimmy Zhang, Jing Zhang, Vivienne Zhang, Yian Zhang, and Chen Zhu. 2024. Nemotron-4 340B Technical Report. arxiv.
- OpenAI et al. [2023] OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
- Peng et al. [2023] Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, et al. 2023. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048.
- Peng et al. [2024] Bo Peng, Daniel Goldstein, Quentin Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, Eugene Cheah, Teddy Ferdinan, Haowen Hou, Przemysław Kazienko, et al. 2024. Eagle and Finch: RWKV with matrix-valued states and dynamic recurrence. arXiv preprint arXiv:2404.05892.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. 2018. Improving language understanding by generative pre-training.
- Rae et al. [2021] Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. 2021. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446.
- Ren et al. [2023] Xiaozhe Ren, Pingyi Zhou, Xinfan Meng, Xinjing Huang, Yadao Wang, Weichao Wang, Pengfei Li, Xiaoda Zhang, Alexander Podolskiy, Grigory Arshinov, et al. 2023. Pangu-Sigma: Towards trillion parameter language model with sparse heterogeneous computing. arXiv preprint arXiv:2303.10845.
- Roh et al. [2020] Jihyeon Roh, Sang-Hoon Oh, and Soo-Young Lee. 2020. Unigram-normalized perplexity as a language model performance measure with different vocabulary sizes. arXiv preprint arXiv:2011.13220.
- Ruan et al. [2024] Yangjun Ruan, Chris J. Maddison, and Tatsunori Hashimoto. 2024. Observational Scaling Laws and the Predictability of Language Model Performance.
- Sakaguchi et al. [2021] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Sardana and Frankle [2023] Nikhil Sardana and Jonathan Frankle. 2023. Beyond chinchilla-optimal: Accounting for inference in language model scaling laws. arXiv preprint arXiv:2401.00448.
- Scao et al. [2022] Teven Le Scao, Thomas Wang, Daniel Hesslow, Lucile Saulnier, Stas Bekman, M Saiful Bari, Stella Biderman, Hady Elsahar, Niklas Muennighoff, Jason Phang, et al. 2022. What language model to train if you have one million gpu hours? arXiv preprint arXiv:2210.15424.
- Sennrich et al. [2016] Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, Volume 1: Long Papers. The Association for Computer Linguistics.
- Shoeybi et al. [2019] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053.
- Soboleva et al. [2023] Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob R Steeves, Joel Hestness, and Nolan Dey. 2023. SlimPajama: A 627B token cleaned and deduplicated version of RedPajama.
- Soldaini et al. [2024] Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, et al. 2024. Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. arXiv preprint arXiv:2402.00159.
- Takahashi and Tanaka-Ishii [2017] Shuntaro Takahashi and Kumiko Tanaka-Ishii. 2017. Do neural nets learn statistical laws behind natural language? PloS one, 12(12):e0189326.
- Tay et al. [2023] Yi Tay, Mostafa Dehghani, Samira Abnar, Hyung Chung, William Fedus, Jinfeng Rao, Sharan Narang, Vinh Tran, Dani Yogatama, and Donald Metzler. 2023. Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling? In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 12342–12364, Singapore. Association for Computational Linguistics.
- Team et al. [2024] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295.
- Tian et al. [2024] Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. 2024. Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. arXiv preprint arXiv:2404.02905.
- Touvron et al. [2023a] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. [2023b] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Villalobos et al. [2022] Pablo Villalobos, Jaime Sevilla, Lennart Heim, Tamay Besiroglu, Marius Hobbhahn, and Anson Ho. 2022. Will we run out of data? an analysis of the limits of scaling datasets in machine learning. arXiv preprint arXiv:2211.04325.
- Wan et al. [2023] Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, et al. 2023. Efficient large language models: A survey. arXiv preprint arXiv:2312.03863, 1.
- Wang et al. [2019] Hai Wang, Dian Yu, Kai Sun, Janshu Chen, and Dong Yu. 2019. Improving pre-trained multilingual models with vocabulary expansion. arXiv preprint arXiv:1909.12440.
- Wang et al. [2023] Haiming Wang, Ye Yuan, Zhengying Liu, Jianhao Shen, Yichun Yin, Jing Xiong, Enze Xie, Han Shi, Yujun Li, Lin Li, et al. 2023. Dt-solver: Automated theorem proving with dynamic-tree sampling guided by proof-level value function. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12632–12646.
- Wang et al. [2024] Junxiong Wang, Tushaar Gangavarapu, Jing Nathan Yan, and Alexander M Rush. 2024. Mambabyte: Token-free selective state space model. arXiv preprint arXiv:2401.13660.
- Xu et al. [2020] Jingjing Xu, Hao Zhou, Chun Gan, Zaixiang Zheng, and Lei Li. 2020. Vocabulary learning via optimal transport for neural machine translation. arXiv preprint arXiv:2012.15671.
- Xue et al. [2024] Fuzhao Xue, Yao Fu, Wangchunshu Zhou, Zangwei Zheng, and Yang You. 2024. To repeat or not to repeat: Insights from scaling llm under token-crisis. Advances in Neural Information Processing Systems, 36.
- Yang et al. [2024] An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng Xue, Na Ni, Pei Zhang, Peng Wang, Ru Peng, Rui Men, Ruize Gao, Runji Lin, Shijie Wang, Shuai Bai, Sinan Tan, Tianhang Zhu, Tianhao Li, Tianyu Liu, Wenbin Ge, Xiaodong Deng, Xiaohuan Zhou, Xingzhang Ren, Xinyu Zhang, Xipin Wei, Xuancheng Ren, Yang Fan, Yang Yao, Yichang Zhang, Yu Wan, Yunfei Chu, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zhihao Fan. 2024. Qwen2 Technical Report. arxiv.
- Yu et al. [2024] Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. 2024. Megabyte: Predicting million-byte sequences with multiscale transformers. Advances in Neural Information Processing Systems, 36.
- Zellers et al. [2019] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830.
- Zhang et al. [2024] Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. 2024. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385.
- Zhuo et al. [2024a] Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, David Lo, Binyuan Hui, Niklas Muennighoff, Daniel Fried, Xiaoning Du, Harm de Vries, and Leandro Von Werra. 2024a. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions.
- Zhuo et al. [2024b] Terry Yue Zhuo, Armel Zebaze, Nitchakarn Suppattarachai, Leandro von Werra, Harm de Vries, Qian Liu, and Niklas Muennighoff. 2024b. Astraios: Parameter-Efficient Instruction Tuning Code Large Language Models.
- Üstün et al. [2024] Ahmet Üstün, Viraat Aryabumi, Zheng-Xin Yong, Wei-Yin Ko, Daniel D’souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Kayid, Freddie Vargus, Phil Blunsom, Shayne Longpre, Niklas Muennighoff, Marzieh Fadaee, Julia Kreutzer, and Sara Hooker. 2024. Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model.
附录A附录
A.1 根据方法 2 的词汇量大小推导 FLOP
这里我们提供了如何计算相对于 的 FLOPs 极值点的详细过程。从Kaplan等人[28]中,我们知道:
| (9) |
然后我们计算导数 如下:
的解对应于 FLOP 的最小点。 由于该方程中的变量不方便分离,因此我们使用数值搜索方法,即scipy.optimize.fsolve来求解。
示例演示
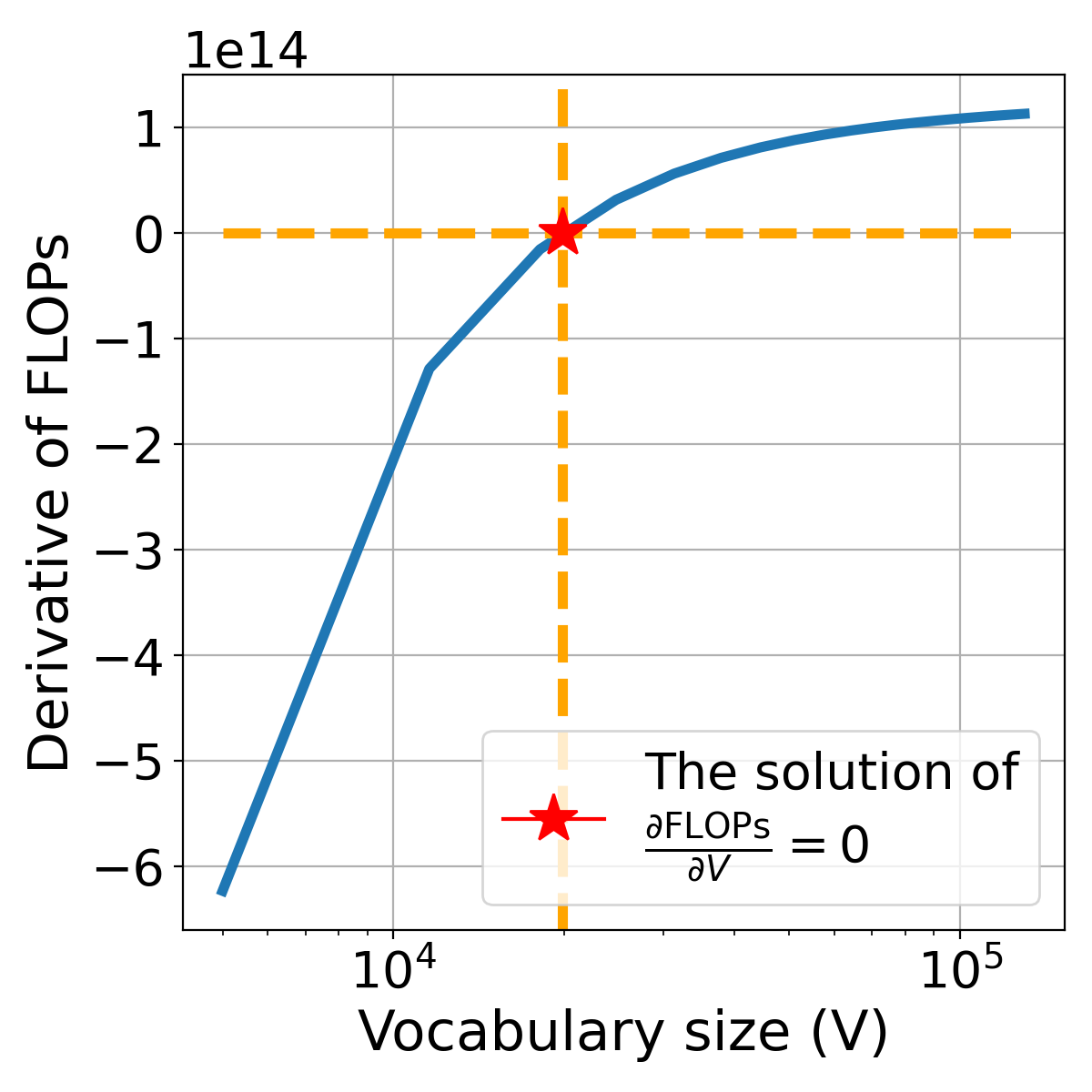
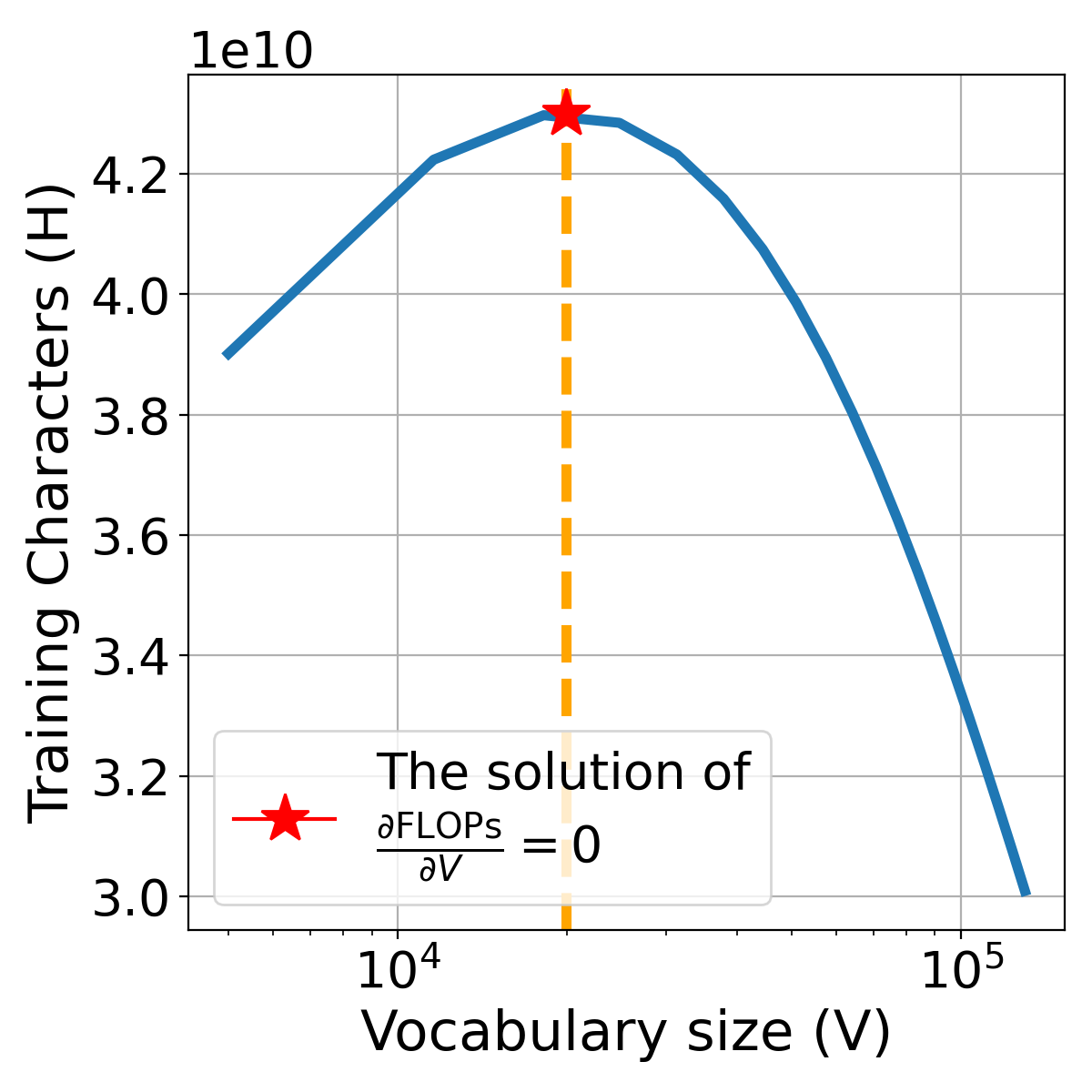
Figure 8说明了FLOPs的导数相对于词汇量和本身的关系。 将设置为的解,我们找到FLOPs最小化的点。 如 Figure 8(右图)所示,FLOPs 预算是固定的,我们可以观察到训练字符是如何随 变化的。值得注意的是,在最佳词汇量 时,模型在给定预算下消耗的训练字符数最多。 这一观察结果让我们深入了解为什么在给定的 FLOPs 预算下存在最佳词汇量。
A.2 方法 3 中关于词汇量的损失的推导
在这里,我们提供了如何在方法 3 中给定 FLOPs 预算 的情况下得出与词汇量相关的损失。 根据Equation 9将替换为后:
| (10) |
给定 时,损失完全取决于 。 导数 w.r.t. 是:
的解对应于最优。与方法2类似,我们使用scipy.optimize.fsolve来求解。
A.3 更多可视化分析:为什么最佳词汇量受到计算的限制
当 FLOP 受到限制时,大词汇量中的词嵌入很难学习
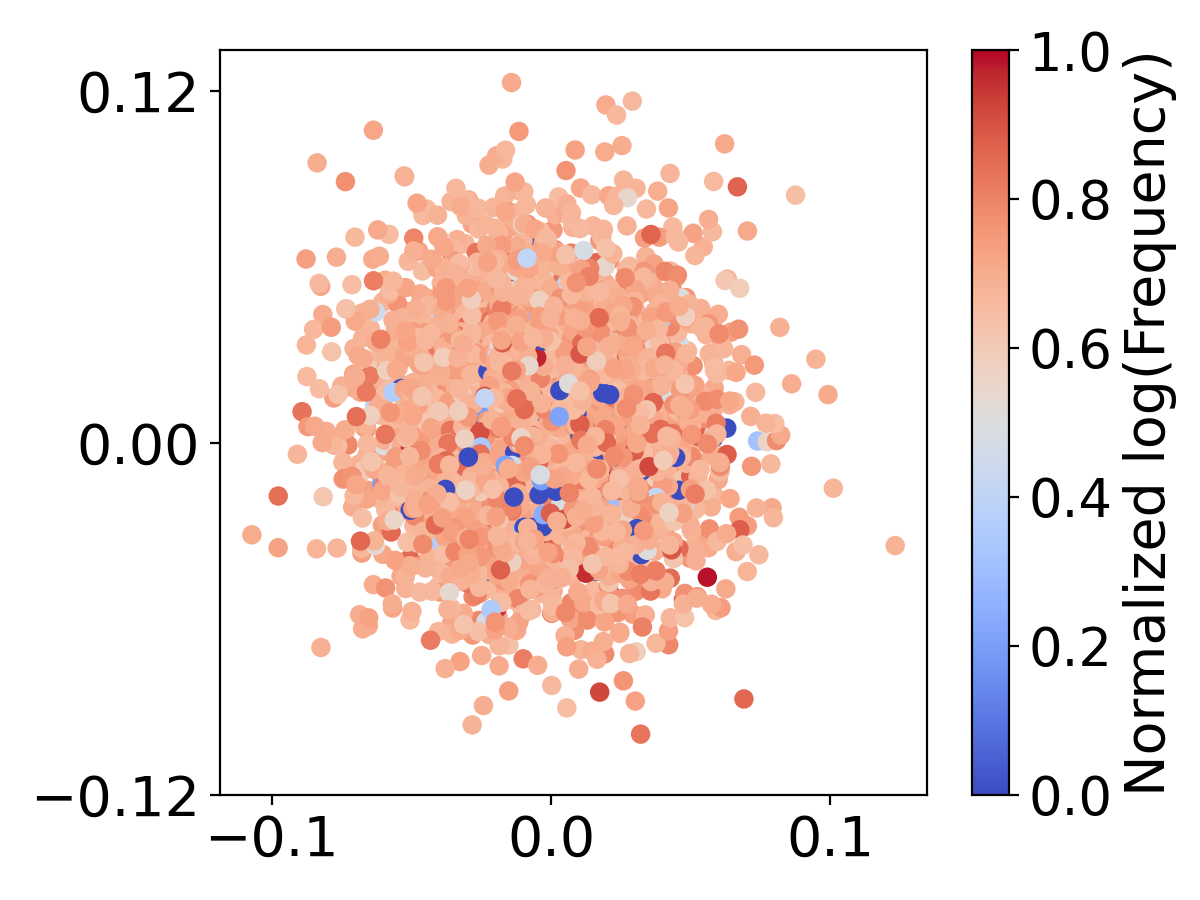
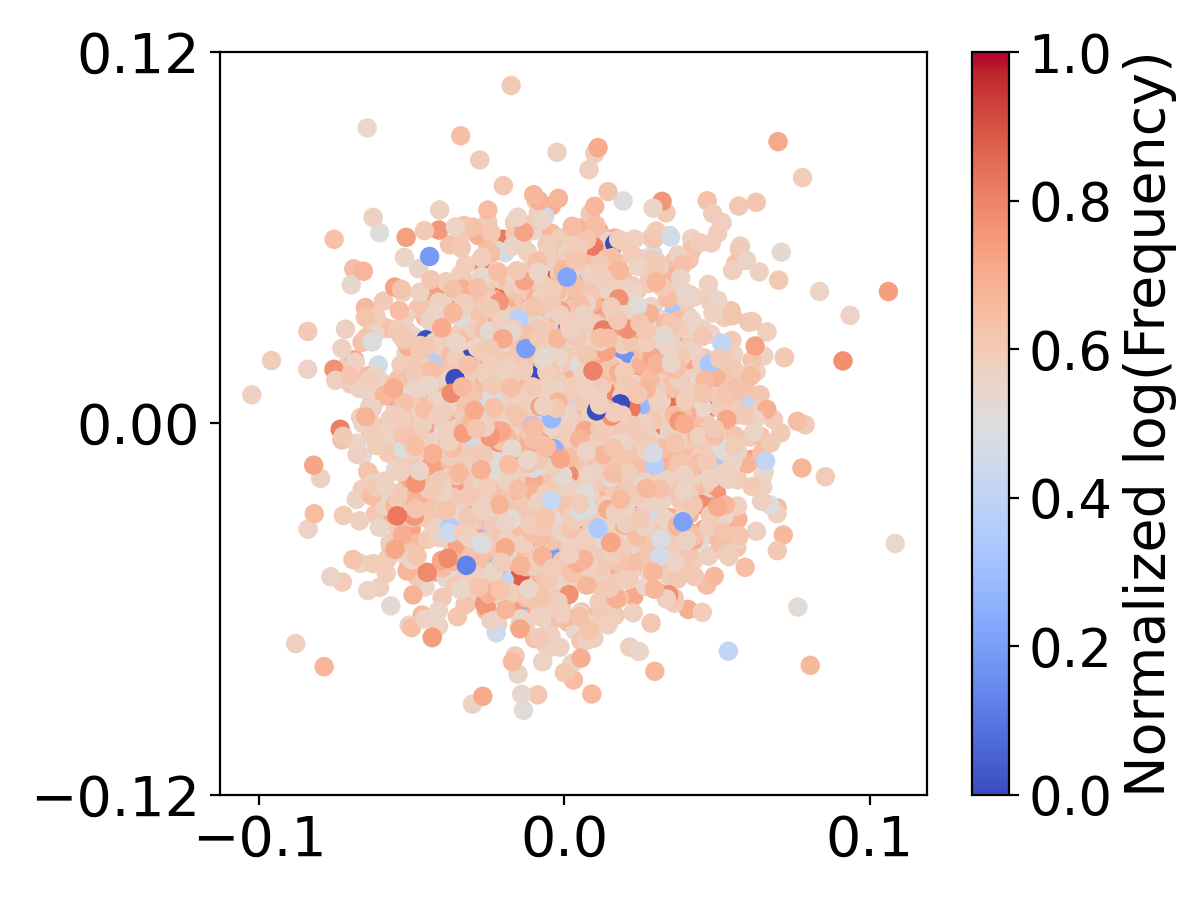
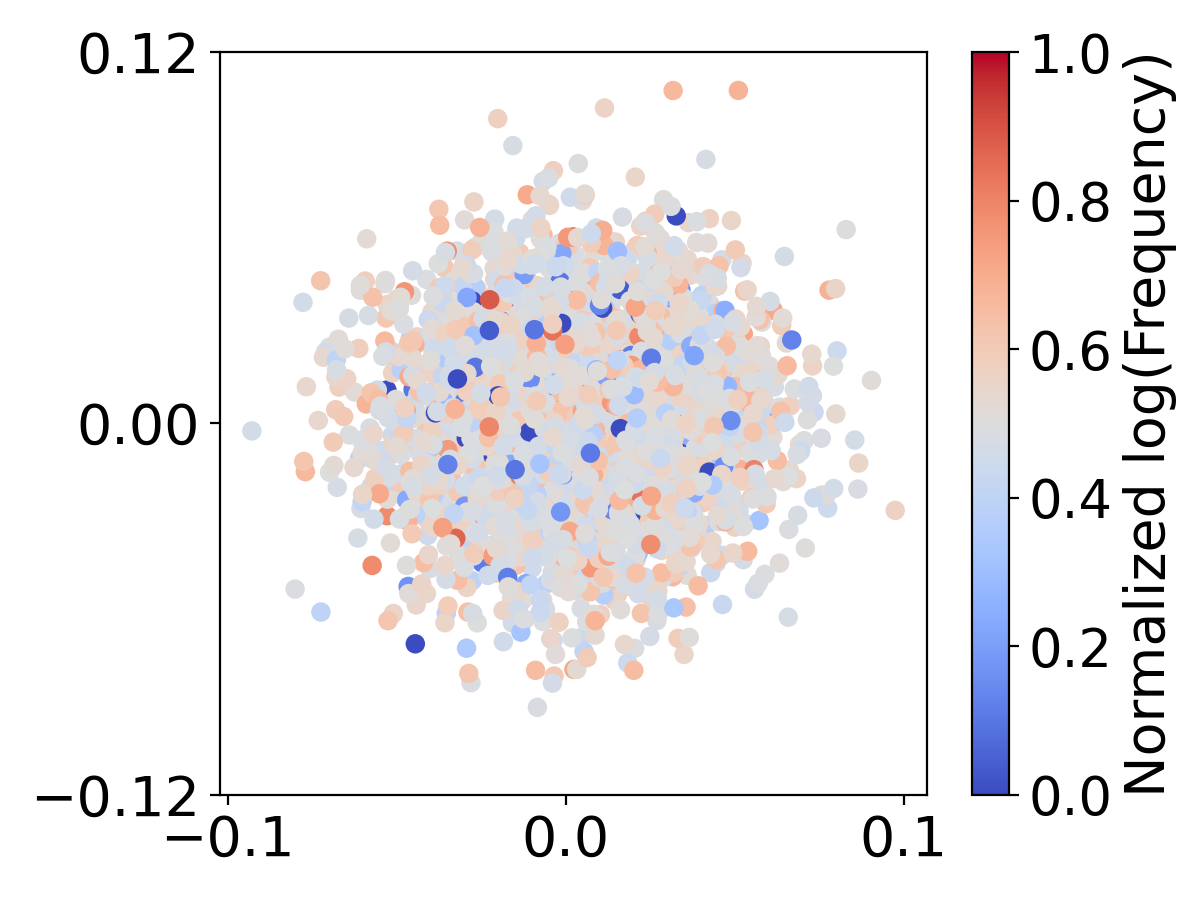
先前的研究表明嵌入会遭受表示退化的影响,其中低频词嵌入由于有限的参数更新而聚集在一起[22]。 在Figure 9 中,我们可视化了词嵌入如何使用不同的词汇量大小进行分布。 我们使用所有嵌入之间的平均欧氏距离来量化聚类程度,、的聚类程度分别为1.067、1.011和0.952和,分别。 较大的词汇表 () 会导致更多的嵌入聚类,尤其是对于不常见的单词。 这种聚集表明他们没有受到足够的培训。 相反,小型词汇表 () 和中型词汇表 () 显示出更分散的嵌入分布。 这些观察结果表明,存在一个最佳词汇量,可以平衡词典覆盖率和词嵌入的充分更新。 词汇量大的语言模型可能具有更好的词典覆盖率,但另一方面,却阻碍了模型充分更新词嵌入的能力,特别是对于低频词。
A.4更大范围词汇量的探索
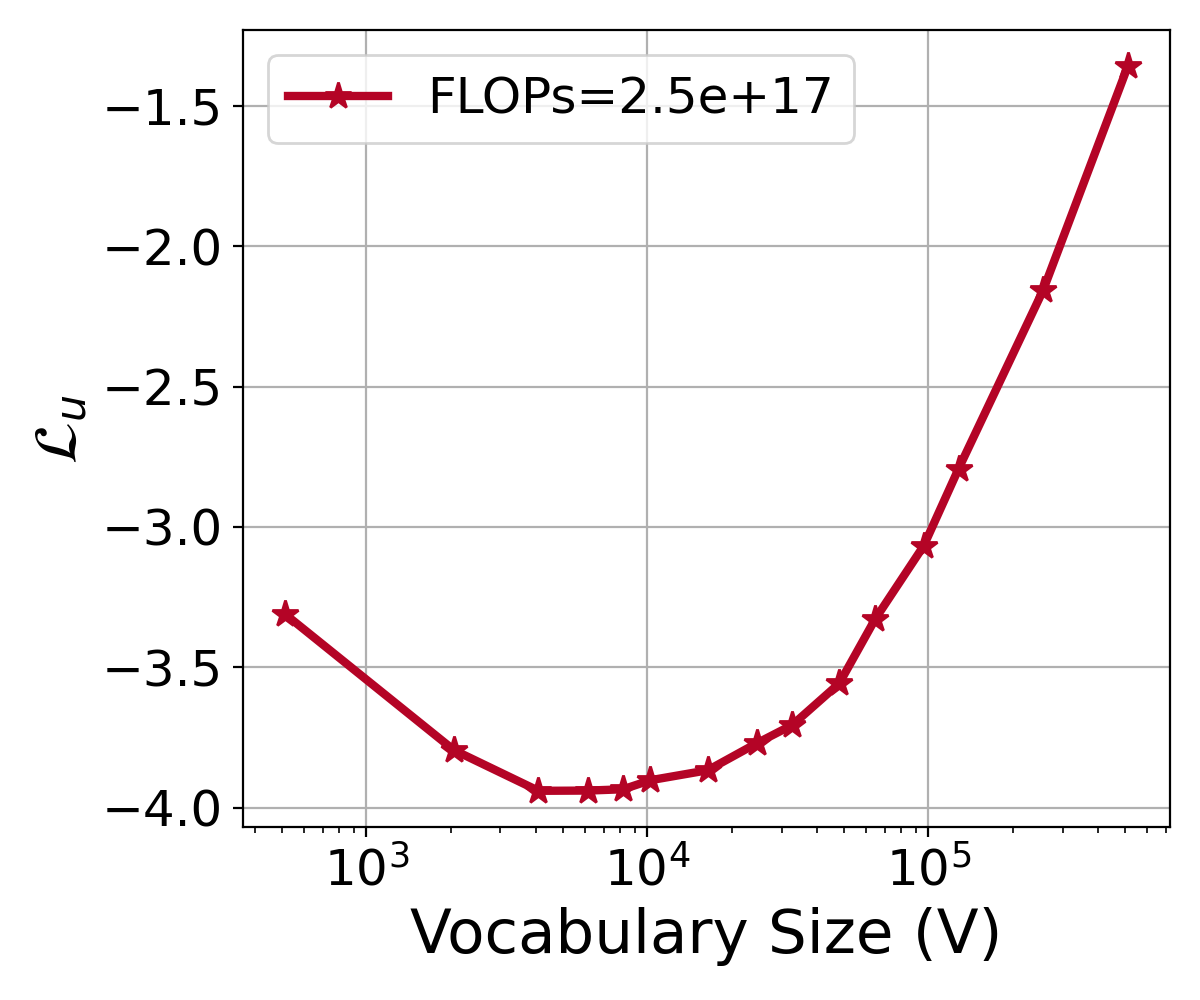
由于计算资源的限制,我们用于拟合缩放定律的词汇量大小在 4K 到 96K 的范围内。 这个范围足以适应,因为我们使用的所有训练配置的最佳词汇量都在这个范围内。
为了进一步验证对于更大范围的词汇列表,总有一个最佳词汇大小,我们将词汇大小范围从 1K 增加到 512K,其中 固定为 33M。 如图Figure 10 所示,随着词汇量的增加超出最佳配置,模型的性能持续下降。 该图显示了在给定特定 FLOP 预算的情况下词汇量高达 512K 的损失曲线。 数据表明,随着词汇量远离最佳词汇量,模型性能持续下降。 它表明存在一个临界点,超过该临界点,模型处理词汇的效率就会降低。 这一探索强调了仔细选择词汇量大小以在给定计算预算的限制内保持最佳模型性能的重要性。
A.5实施细节
A.5.1 模型架构、词汇量和训练字符的设置
我们在Table 4中列出了模型的架构和相应的训练字符数。 对于每个模型系列,我们修复非词汇参数 并改变词汇大小。 我们采用 Llama 架构[63],除了词汇量大小。 对于词汇表大小,我们使用可被 128 整除的数字,以便与 NVIDIA 张量核心兼容,以加速矩阵乘法 333https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html。 具体来说,我们为每个模型系列采用的词汇量为 4096、6144、8192、10240、16384、24576、32768、48128、64512 和 96256。 给定固定数量的非词汇参数和 FLOP 预算,训练标记 和字符 的预期数量略有不同。 我们使用 16384 的中等大小的 来确定字符数和相应的 FLOPs 预算,除了 我们使用 。
| (M) | #Sequence Length | #Layers | #Heads | #Embedding Dim. | #Intermediate Size | Training Characters (B) |
| 33 | 2048 | 8 | 8 | 512 | 2048 | 4.3 |
| 85 | 2048 | 12 | 12 | 768 | 2048 | 11.1 |
| 151 | 2048 | 16 | 12 | 768 | 3072 | 19.6 |
| 302 | 2048 | 18 | 16 | 1024 | 4096 | 43.0 |
| 631 | 2048 | 20 | 24 | 1536 | 4800 | 101.6 |
| 1130 | 2048 | 22 | 32 | 2048 | 5632 | 201.3 |
| 2870 | 2048 | 24 | 32 | 3200 | 8192 | 509.3 |
A.5.2 非词汇参数与嵌入维度的关系
根据Kaplan等人[28]的观察,考虑到总的非词汇参数,深宽比对性能的影响相对较小。 因此,为了简化考虑词汇量大小的缩放法则的建模,我们采用先前工作[28,24,40,64,76]给出的宽度(即嵌入维度)。 我们实验中使用的非词汇参数与嵌入维度之间的关系如Table 5所示。
| Non-vocabulary Parameters | #Embedding Dim. |
| 512 | |
| 768 | |
| 1024 | |
| 1536 | |
| 2048 | |
| 3200 | |
| 4096 | |
| 5120 | |
| 6048 | |
| 8192 | |
| 12288 | |
| 16384 | |
| 20480 |
A.5.3培训细节
最大学习率设置为 4e-4 并衰减到 10%,即 4e-5,类似于之前的缩放工作 [24, 40]。 我们使用 AdamW [33] 作为优化器,并通过 bfloat16 混合精度训练加速训练。 对于具有 的模型,我们使用具有 8 个 GPU 的单个节点进行训练。 否则,我们采用用于多节点的 Megatron-LM 训练框架 [56],每个节点上有 8 个 GPU。 对于我们使用 进行的实验,使用总共 64 个 GPU 对超过 个训练字符进行训练大约需要 120 小时。 我们对所有运行使用全局批量大小 512,并在 40GB Nvidia-A100 GPU 上运行所有实验。
A.5.4拟合技术
方法一
为了避免拟合参数的数值下溢和溢出,我们受Hoffmann等人[24]的启发,以对数形式拟合数据。 以为例,我们通过最小化来学习参数、:
| (11) |
其中和表示Huber损失,其增量值为(在我们的论文中为0.001)。 我们使用 LBFGS 算法来找到函数的局部最小值。 后面的方法2和方法3使用相同的优化算法。 我们初始化来自同一统一网格的所有属性,其中 和 分别使用 20 个初始猜测。 装配时间不到半分钟。
为了廉价地获得更多的实验数据点,我们在对数尺度上对(,,)三元组进行插值,并根据实际情况预测验证损失数据点。 然后,我们使用Equation 5 计算每个数据点所需的 FLOP。
方法2
方法3
我们在这里重新设计了设计的词汇相关损失公式:
| (13) |
其中。 在实践中,我们尽量减少:
其中。 我们从同一统一网格初始化所有属性,其中 、、、、 和 分别有 3 个初始猜测。 考虑到缩放因子通常介于 0 和 1 [24] 之间的先验,我们在拟合期间添加约束 。 装配时间也不到半分钟。
A.6 拟合标记-字符关系函数的详细信息
我们训练了 25 个具有以下词汇量的分词器:1024、2048、3072、4096、5120、6144、7168、8192、9216、10240、12288、16384、20480、24576、28672、32768、4812 8、64512、78848、96256、 128000、256000、512000、1024000。 然后,我们在 Slimpajama 数据集的均匀采样版本上训练分词器。
随后,我们将经过训练的分词器应用到 Slimpajama 数据集的验证集上,并收集词汇量大小为 的每个分词器的分词数 。我们使用 scipy.optimize.curve_fit 来拟合 中的参数 (§2.2)。
A.7 标记-字符关系函数的稳健性
标记器类型的稳健性
除了我们实验中广泛采用的 BPE 分词器之外,我们还考虑了一元分词器和基于单词的分词器。 我们在Figure 11 中可视化了它们的标记字符比率和相应的预测函数。 我们发现,无论使用哪种分词器,我们提出的公式 都是标记字符比率的良好预测器。 这验证了我们提出的公式的有效性。 从相似的 y 轴值可以看出,一元分词器的分词能力与 BPE 分词器的分词能力接近,因为它们都采用基于子字的分词器。 同时,基于单词的标记化的标记化能力较差,因此平均需要更多的标记来压缩字符。
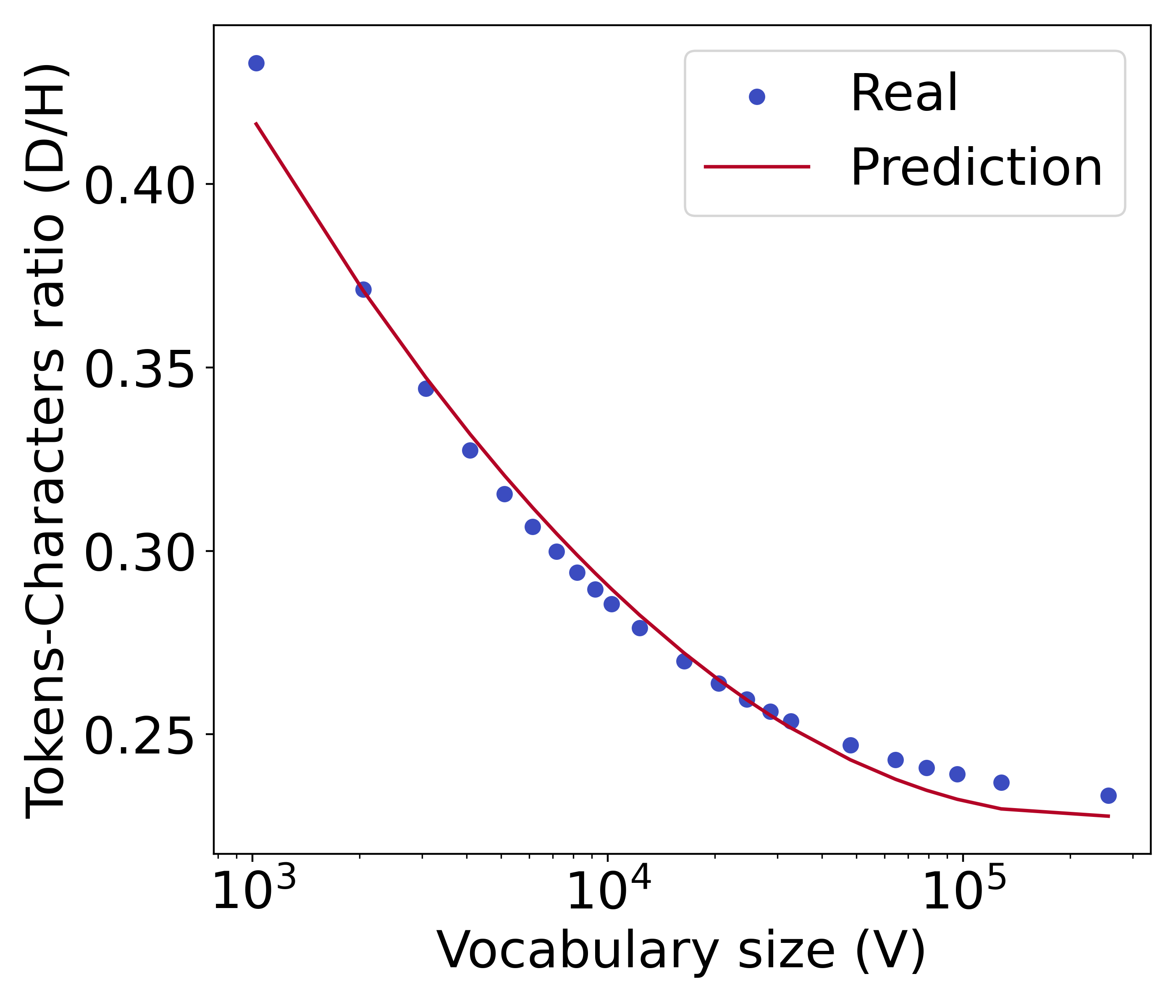
=3.8e-4, =0.99
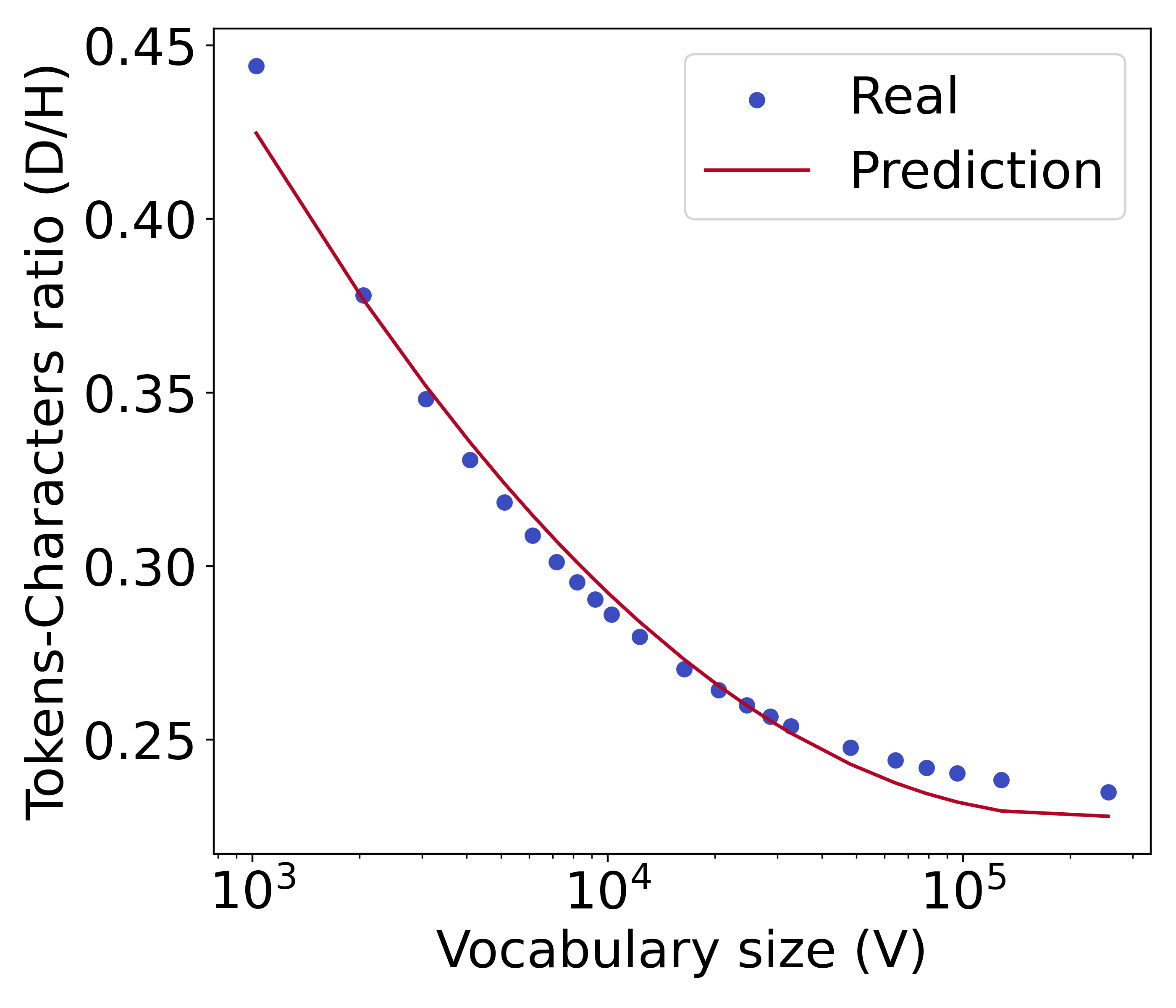
=5.2e-4, =0.98
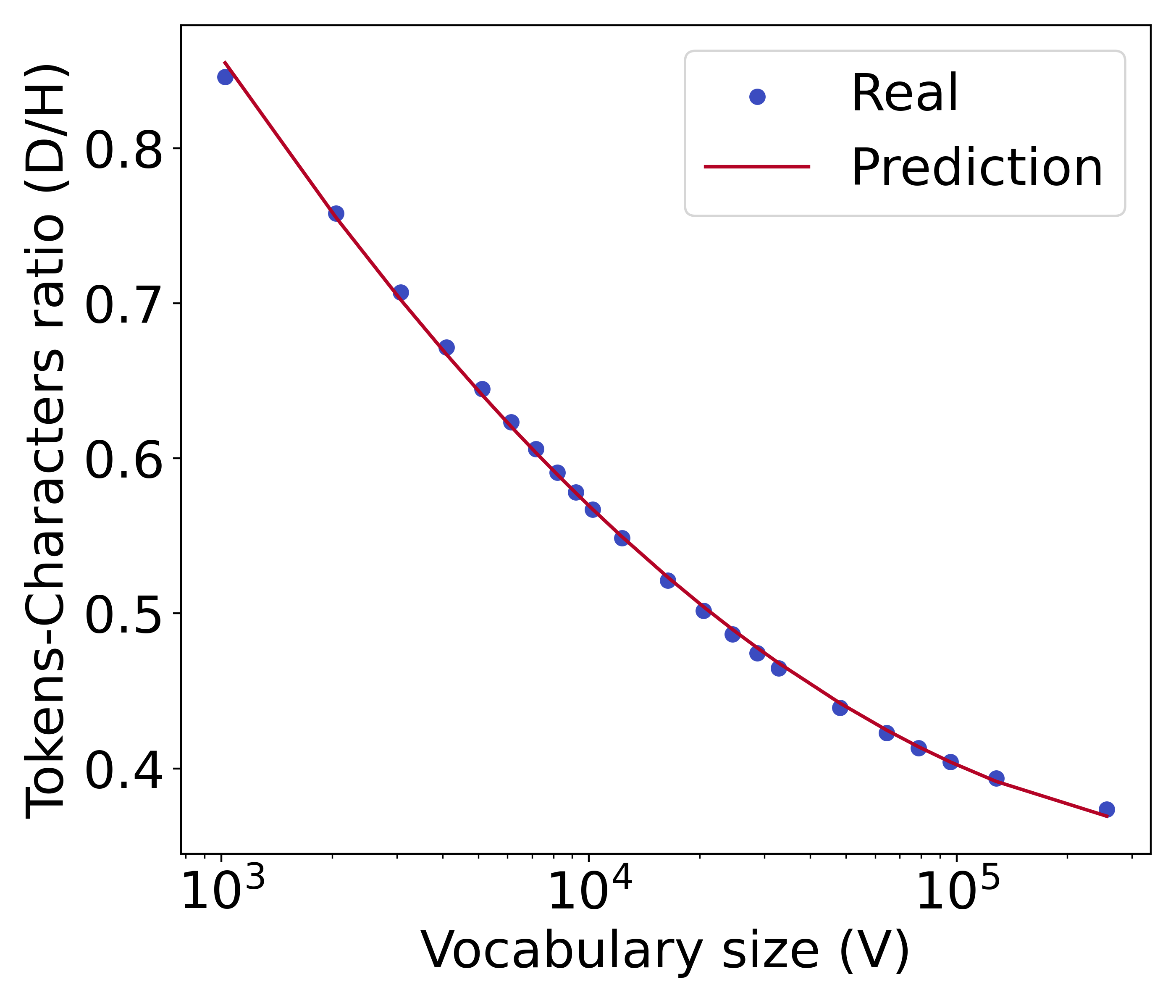
=3.6e-5, =0.99
对词汇量范围的鲁棒性
我们提出的词汇量对数值的二次函数可以精确预测标记字符比,RMSE 为 1.5e-6, 为 0.99。 然而,由于二次函数是单峰的,当非常大时,增加会增加的输出值,例如。 t3> 在我们的例子中。
幸运的是,当足够大时,分词器的分词生育率改进急剧衰减,这导致的值几乎没有变化。 这是因为当词汇量足够大时,训练语料库中的单词已经可以被词汇表有效覆盖。 在这种极端情况下,相应分词器的分词能力已接近饱和,因此进一步增加词汇量很难提高分词能力。
例如,Slimpajama 语料库的验证集中大约有 2300M 个字符。 使用词汇量大小为 2 的分词器将比词汇量为 1 的分词器少生成 140 分词器,但分词器数量仅减少 0.7 当词汇量从 256 变为 257 时。 因此,我们在计算之前添加,以保证其递减性。 根据我们的预测,具有 300 参数的模型在训练数据充足的情况下,最佳词汇量不超过 400。 如果我们将来需要考虑非常大的,我们可以在拟合的过程中训练具有更大的分词器,以达到更精确的预测。
A.8一元归一化语言建模损失公平性的实验验证
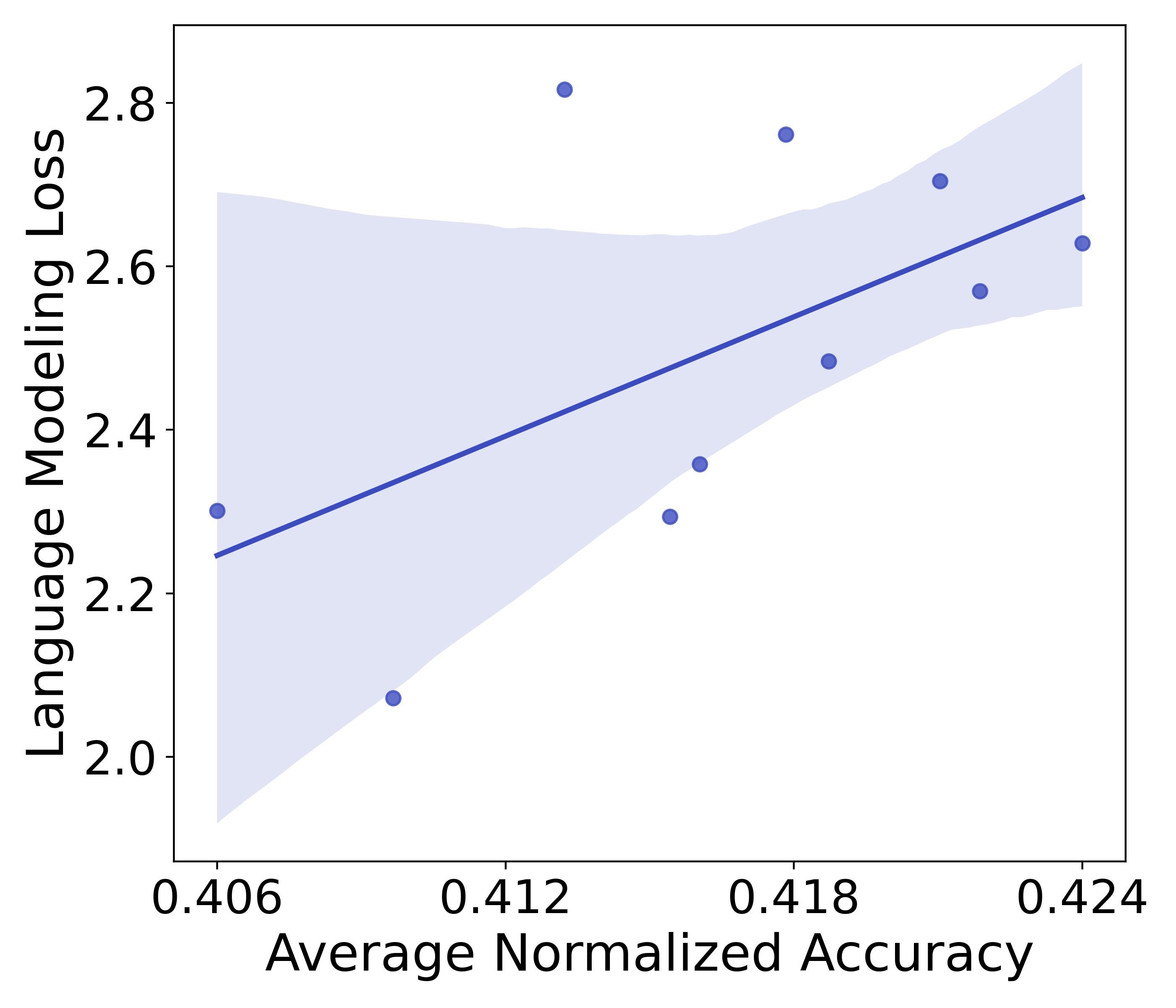
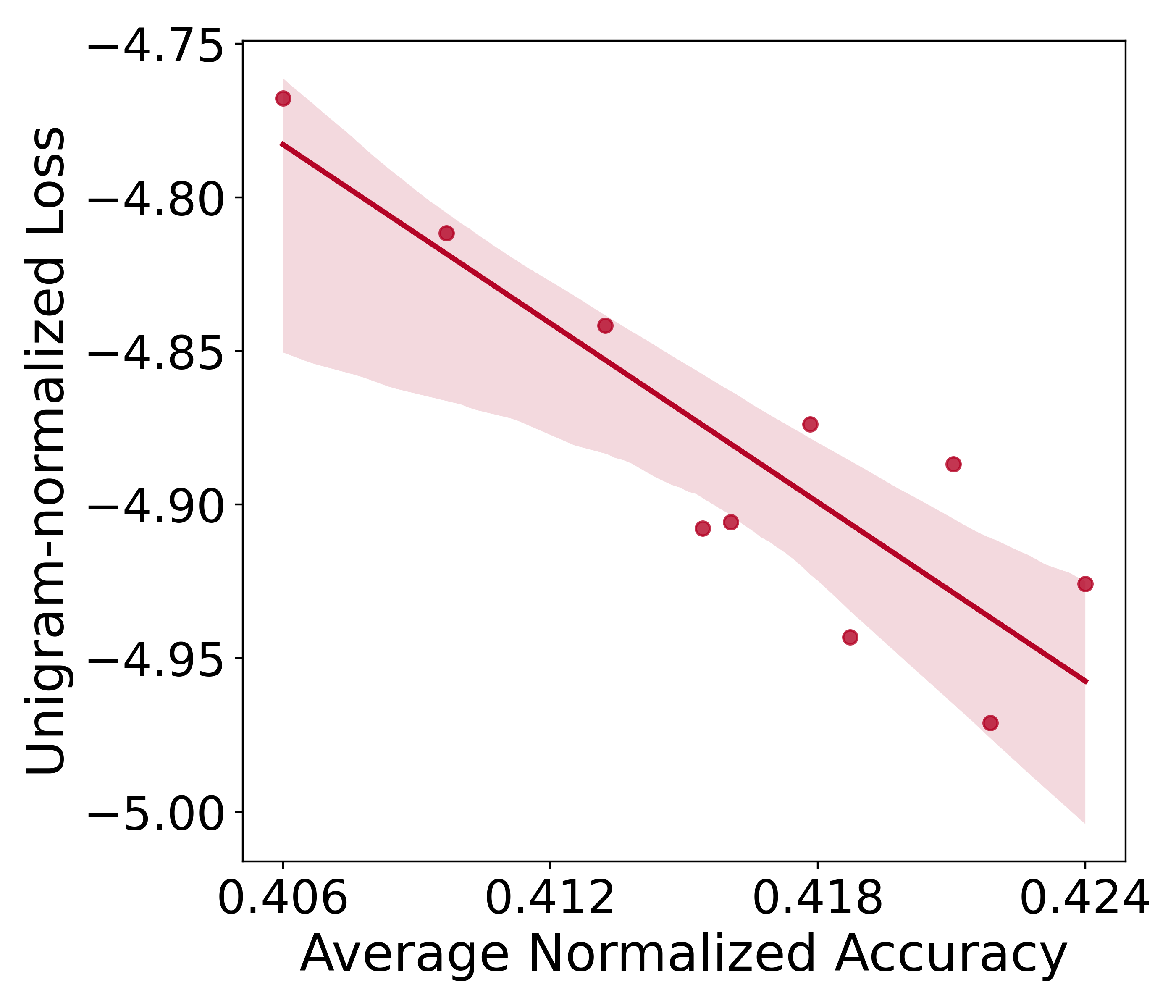
在§2.2中,我们解释了我们使用一元标准化损失来公平地评估词汇量大小不同的模型。 在这里我们通过经验验证这个选择。 我们使用固定数量的非词汇参数 和嵌入维度 但变化的词汇大小 来训练模型。因此,它们的词汇参数也有所不同。 我们在Figure 12 中绘制了与下游性能相比的最终语言模型损失和这些模型的一元标准化损失。 语言建模损失与下游性能呈正相关:语言建模损失较高的模型具有更好的下游性能。 这是因为我们的词汇量较大的模型由于目标函数的原因自然会产生较高的损失,但它们实际上可以是具有更好下游性能的更好模型。 我们的一元标准化损失解决了这个问题,并表现出损失与下游性能之间预期的负相关性:较低的损失伴随着更好的下游性能。 这从经验上证明了我们在整个工作中使用 的合理性。
附录 B限制和未来的工作
B.1 我们提出的方法的局限性
方法一
方法 1 通过根据实验数据点预测非词汇参数、词汇参数和训练数据之间的计算资源分配,提供了更广泛的解决方案。 该方法的优势在于其整体视角,可以实现均衡的资源分配,从而有可能提高模型的效率和性能。 然而,这种方法受到可用实验数据点的粒度和范围的限制,这可能会在拟合过程中引入误差。 执行这些拟合所需的大量计算资源也可能限制其可访问性和可扩展性。 尽管存在这些挑战,当实验数据充足且计算资源充足时,方法1可以显着提高大规模语言模型开发中资源分配决策的精度。
方法2
通过计算 FLOPs 相对于词汇量大小的导数并求解零,该方法从根本上依赖于 FLOPs 方程和我们的标记字符关系函数的精度。 此外,该方法不允许我们独立确定非词汇参数和训练数据大小的最佳分配。 因此,需要从实验拟合的缩放定律中获取有关这些属性与 FLOP 预算之间关系的信息,这使得该方法在实践中不太有用。 尽管存在这些限制,基于导数的方法仍具有显着的优势,包括与方法 2 中实际实验数据得出的标度定律紧密匹配的预测。 此外,它依赖于数值解决方案而不是详尽的深度学习实验,使其能够快速且广泛地适用于各种标记器,突出了它在快速估计是关键的基础知识模型配置阶段的实用性。
方法3
与方法 1 类似,所提出的方法 3 需要针对不同的非词汇参数、词汇大小和训练数据数量进行多次实验运行。 因此,该方法在一定程度上受到可用实验数据点的粒度和范围的限制。 然而,所提出的方法3是灵活的,它考虑到非词汇参数和训练数据的数量并不总是遵循计算最优缩放法则[24],即,在实际应用中等比例缩放。
B.2 更大的模型和不同的架构
我们已经证明,我们的预测适用于具有多达 30 亿个参数的模型 (§5)。 然而,大语言模型往往要大几个数量级,例如4000亿参数的Llama-3模型[37]。 此外,我们决定重点关注密集的 Transformer 语言模型,因为它们最常用于大语言模型。 然而,许多非 Transformer 模型已经被提出并扩展到数十亿个参数[45, 46]。 探索我们的研究结果在更大的模型和不同的架构中的适用程度是未来工作的一个有希望的方向。
B.3 考虑词汇时损失的参数函数
研究人员[24, 40]考虑使用形式的参数函数对语言建模损失进行建模,其中是可学习变量。 损失的第一项代表可实现的最小损失,第二项和第三项代表模型大小 和训练标记数量 对损失的贡献。参数函数允许预测给定 和 的结果 ,即使 (,)没有得到最佳分配。 在之前的工作中,这个损失公式考虑了模型大小和训练数据的变化,但没有明确解决不同词汇量带来的复杂性。 将词汇量大小纳入损失预测器中具有挑战性:词汇量大小直接影响模型以及训练标记的数量和标记器标记化的质量。 词汇量较大的分词器可以更轻松地捕获原始文本中的语义信息,并减少词汇表外单词的出现频率。 例如,较大的词汇量可能涵盖常见短语、常见子词和专业术语。 因此,即使训练相同数量的 token,在不同质量的 token 上训练的模型的性能也会不同。
该领域的未来工作可以探索各种参数非线性损失函数,以预测词汇大小、模型大小和具有不同计算分配的训练数据之间的相互作用,而不仅仅是最优计算分配的情况。 此外,对不同数据集的实证研究可以帮助理解词汇量大小如何在不同数据条件下影响损失,从而指导开发更具适应性的损失预测模型。
B.4 多语言和多模式场景的扩展
未来的工作可以扩展所提出的方法以涵盖多语言和多模式场景。 由于语言多样性,多语言模型需要对词汇有细致入微的理解,这可能会影响不同语言的最佳词汇量和 FLOP 的计算。 调整这些方法来考虑语言特征和标记化变化可以为多语言模型带来更加定制和高效的资源分配。 不同的语言会相互竞争模型分配给该语言的能力[11],这使得在设置不同语言的单词列表大小时需要考虑不同语言之间的关系。多语言场景。
对于将文本与图像或视频等其他数据类型集成的多模态模型,最佳词汇量可能与非语言参数进行独特的交互。 最近的工作[1, 62]通过像文本数据处理一样的标记化以自回归方式对视觉概念进行建模。 在视觉任务和视觉语言任务中,探索视觉词汇量的大小即,代码集的大小[20]是很有意思的。 如何为不同的模态有效地设置词汇量大小和计算资源仍然是一个悬而未决的问题。
附录C潜在的社会影响
这项研究对语言模型缩放中词汇量的积极潜在社会影响是巨大的。 通过联合考虑词汇量和其他属性来优化大型语言模型,本文提供了基础理解,可以导致更轻量级和更具成本效益的预训练大型语言模型。 这种效率可以实现先进语言处理技术的民主化,使小型组织和公众能够从强大的人工智能工具中受益。 这些进步可以使各个领域受益,例如,改善残疾人士的可访问性功能,其中可以使用高效的语言模型来分析医疗记录并协助诊断。 此外,训练这些模型的计算要求的减少可以导致能源使用量的减少,从而为环境可持续发展做出积极贡献。
另一方面,滥用预训练的语言模型可能会带来风险,包括创建高度逼真的深度伪造品,从而传播虚假信息并破坏对媒体和机构的信任。 这些模型可以生成误导性内容,通过令人信服的网络钓鱼方案自动进行网络攻击,并产生大规模垃圾邮件,从而降低在线通信的质量。 此外,它们还可用于生成有害或辱骂性内容,例如仇恨言论,从而使歧视永久化并伤害弱势群体。 为了减轻这些风险,开发值得信赖的语言模型、实施强大的监控系统以及促进研究人员、政策制定者和用户之间的合作至关重要。