经济学家的深度学习
摘要
深度学习提供了强大的方法来从大规模非结构化文本和图像数据集中推断结构化信息。 例如,经济学家可能希望检测卫星图像中经济活动的存在,或者衡量社交媒体、国会记录或公司文件中提到的主题或实体。 这篇综述介绍了深度神经网络,涵盖了分类器、回归模型、生成式人工智能和嵌入模型等方法。 应用包括分类、文档数字化、记录链接以及大规模文本和图像语料库中的数据探索方法。 当使用合适的方法时,深度学习模型的调整成本很低,并且可以经济地扩展到涉及数百万或数十亿数据点的问题。 该评论还附带一个配套网站 EconDL,其中包含用户友好的演示笔记本、软件资源以及提供技术详细信息和其他应用程序的知识库。
深度神经网络最近取得了许多科学成就——从在崎岖的火星地形上着陆漫游车到创建功能强大的聊天机器人,再到改变疾病的诊断方式。 深度神经网络通常将非结构化数据(例如文本、文档图像扫描、卫星和其他图像、视频和音频)映射到连续向量空间。 在上面的示例中,这些向量用于计算引导航天器的指令,自回归预测给出提示的下一个单词,或识别图像是否包含肿瘤。 类似地,经济学家可能会使用神经网络来检测街景图像中非正式供应商的存在,或者衡量公司文件或政府文件中提到的主题或人物。
从本质上讲,深度学习是一种从经验示例中学习数据表示的方法(LeCun、Bengio 和 Hinton,2015)。 这些表示将高维非结构化数据简化为连续向量。 深度神经网络学习多个抽象层的表示,结合非线性神经网络模块,每个模块使用学习权重将神经网络前一层的表示转换为稍微抽象的表示(术语“深度”表示这些层转化)。 这些权重是通过最小化损失函数来估计的,该函数将某些任务的模型预测与真实示例进行比较。
为什么要使用神经网络将原始数据转换为这些矢量表示,而不是直接处理原始文本或图像? 首先,深度神经网络不仅仅从当前的问题中学习。 相反,它们将来自大规模数据的相关信息纳入其参数中。 在预训练期间,现代语言模型或视觉模型将接触数百万文本或图像,学习语言或视觉的基本结构。 在处理非结构化数据时,接触大量数据对于提高性能至关重要,因为人类语言和视觉非常复杂。 这一原理称为迁移学习,是深度神经方法成功的核心。
此外,原始像素或单词缺乏解释其含义所必需的上下文。 深度神经网络提供了一种强大的方法来计算上下文化表示。 它们将术语或像素映射到依赖于其他附近术语或像素的向量,参数主要通过大规模预训练学习。
最后,原始文本和图像在计算上难以处理。 相比之下,有用于连续向量计算的极其优化的工具。 例如,Silcock 等人 (2023) 在单个中档 GPU 上在 3 小时内完成 精确的向量相似度计算。 这意味着可以以前所未有的规模分析数据。 理论是用数据来检验的,虽然更多的数据并不能解决因果关系的挑战,但总的来说,它将为经济学家提供更细粒度的信息来检验各种假设。
本综述旨在弥合最先进的深度学习研究与经济应用之间的差距。 它专注于从非结构化文本或图像中输入低维结构化数据,在基本事实没有争议但由于问题规模庞大而需要自动化提取的情况下。 然后,将这些结构化数据用于因果分析或描述性分析,无论是作为结果、内生变量、工具还是对照。 经济学家已经通过手工或传统方法完成的任务(例如,记录链接、文本分类、文档扫描数字化)可以更准确地大规模自动化,深度学习也有助于提取新数据。 与 Gentzkow、Kelly 和 Taddy (2019) 之前的评论一样,这篇评论强调文本即数据,但采用了自该文章发表以来开发的方法。
本次评论中的许多应用程序都属于分类的广泛范畴:将高维非结构化数据映射到离散类。 这些类可以识别卫星图像中存在的对象类型或文档图像扫描中的数字和文字。 或者,类可以识别文本的主题、复制文本的潜在来源,或者文本中引用的独特个人或位置。 语言模型可用于将原始文本编码为低维密集向量表示,一个用于全文,一个用于每个单独的术语(其中“密集”意味着向量在每个位置都有非零值)。 通过向语言模型添加分类器层,研究人员可以使用这些向量表示来预测文本是否与给定主题有关、引用了哪些位置等。 图像分类的工作原理类似。 还可以提示生成人工智能模型来估算这些分类。 或者,可以直接使用密集向量表示,这被称为嵌入。
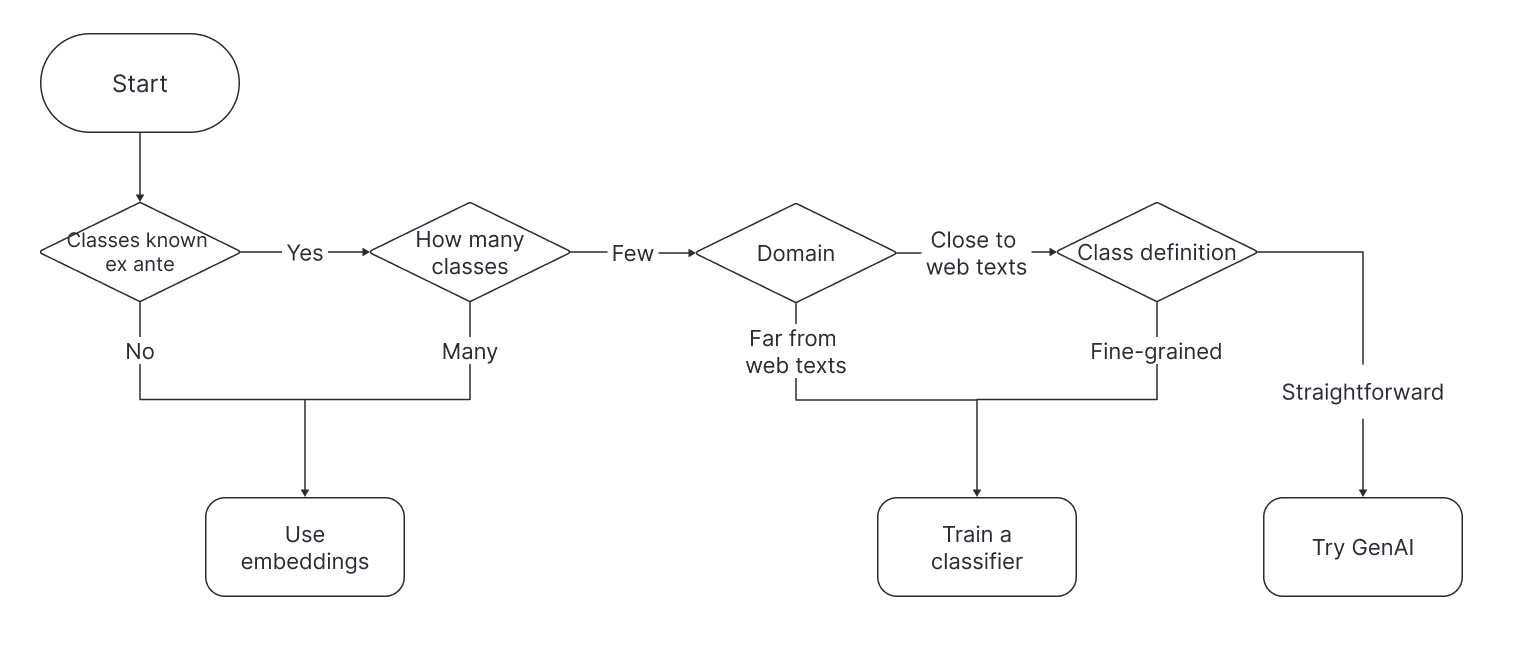
图1提供了接近分类的流程图。 要问的第一个问题是:“这些类是事前枚举的吗?”有时,类别是未知的,或者研究人员可能希望在将模型应用到新设置时添加类别,而不需要重新训练它。 分类器使用语言或视觉模型的最后一层计算每个类别的分数。 因此,只有在指定类别并在训练中看到时才能进行估计。 如果未指定类别,研究人员将需要直接使用嵌入。 如果有许多类,例如,与记录链接一样,其中每个唯一实体都可以被视为一个类,由于估计分类器时的计算限制,研究人员将再次需要使用嵌入。
当类别是事先指定的且数量适中时,分类器或生成式人工智能可能非常适合解决该问题。 如果应用程序与用于预训练神经网络的数据不同(在处理历史数据、文档扫描或某些专门设置时很常见),则预训练语料库会出现显着的域转移,并且可能需要调整定制的分类器才能获得强大的性能。 类定义的细微差别也很重要。 对于简单的任务,使用现成的生成式 AI 模型(如 OpenAI 的 GPT)将分类框架化为文本生成可能效果很好。 对于更细致的任务,定制训练的分类器可以通过接触细粒度的示例来更好地捕捉细微差别。 如果有疑问,研究人员可以尝试现成的方法,如果性能不令人满意,则改用定制的分类器。 这篇评论表明,虽然定制训练的分类器在文本分类任务上通常优于 GPT,但生成式 AI 和定制分类器在简单的任务上都表现良好。 审查还考虑了这些方法的成本。
| Problem | Modality | Application(s) | Section |
|---|---|---|---|
| Classifiers and GenAI | |||
| Sequence | Text | Classify news | 6.3 |
| classification | article topics | ||
| Token | Text | Tag people, | 6.4 |
| classification | locations, orgs | ||
| Paired text | Text | Text b | 6.5 |
| classification | entails a? | ||
| Embedding Models | |||
| Link | Text, | Link | 7.2 |
| structured | Images | firms, products, | |
| data | locations | ||
| Link | Text | Link people | 7.3 |
| unstructured | mentions to | ||
| data | Wikipedia | ||
| Classification | Text | Track content | 7.4 |
| w/ unknown | Images | dissemination; | |
| categories | data exploration | ||
| Retrieval | Images | Optical character | 7.5 |
| recognition | |||
| Regression | |||
| Object | Images | Detect document | 8 |
| detection | layouts | ||
Applications covered in this review.
表1总结了本次审查的应用。 大多数问题都可以被视为分类问题,本文还回顾了回归,其中神经网络用于从文本或图像中估算连续值。
在前深度学习时代,不同领域的问题以非常不同的方式解决,使用针对给定语言或特定类型图像等的特定特征精心设计的规则;而深度学习具有非凡的泛化能力。 例如,自然语言处理 (NLP)、计算机视觉和音频处理都使用相同的最先进的神经网络架构。 这种普遍性在本次评论中讨论的各种应用中是显而易见的。
各种神经网络应用超出了本次综述的范围。 正如 Korinek (2023) 所讨论的,它没有涵盖如何更广泛地使用语言模型来提高经济学家的生产力。 它还不涵盖深度学习之外的机器学习方法,例如应用于结构化数据的方法(通常使用较浅的网络),如 Athey 和 Imbens(2019) 的评论中所总结的那样。 此外,它没有研究使用深度神经网络来计算组合优化和高维 DSGE 问题的近似解。 逼近这些解决方案需要学习神经网络将原始问题映射到保留问题基本属性的连续向量空间。 这很有用,因为在这个空间中计算近似解比传统方法要快得多,可以近似解决更大的问题。 与本综述中介绍的方法有许多相似之处,但应用程序有很大不同,因此需要单独处理。 读者不妨查阅 Fernández-Villaverde (2024) 和 Vitercik (2023) 的课程。 最后,有一篇小文献直接在因果框架中使用深度神经网络。 例如,Lynn、Kummerfeld 和 Mihalcea (2020) 使用分类器和实验来研究文本的变化如何因果影响决策。 虽然在实验性操作文本时有一定作用,但研究人员通常希望从高维非结构化数据中提取低维表示(例如文本的主题、卫星图像中的对象、数字在表格扫描中,文本记录指的是同一家公司)并在因果估计方程中使用这些数据(而不是非结构化数据)。 因此,这里的重点是预测这些低维特征。 该评论并不试图总结这些预测如何在经济研究中使用,因为这些文献是新的并且发展迅速。
读者可能想知道这篇评论多久就会过时。 考虑一下神经网络就像乐高积木这样的流行比喻是有帮助的:不同的神经网络组件可以以各种方式配置以实现不同的目的,或者实现同一目的的更先进的版本。 本综述重点关注随着文献的进展可以直接更换新的神经网络组件的框架,例如用视觉 Transformer 替换旧的卷积神经网络(Dosovitskiy 等人,2020) ,或使用最新的语言模型更新 BERT 语言模型主干(Devlin 等人,2019)。 随附的 EconDL 网站上提供了技术和实现细节(随着文献的进展,这些细节最有可能发生变化):https://econdl.github.io/。 它提供了一个按核心主题组织的知识库,以及面向经济学家的开源包的链接以及通过深度学习构建大规模数据集的管道。 感兴趣的读者可以找到讲义以及博客文章、教科书处理、开放课件和原始论文的链接。 EconDL 还链接到本评论中许多应用程序的演示笔记本。 该网站将不断更新,随着文献的进展,一些软件包明确支持交换新的神经网络。
本文的结构如下:1 节概述了深度学习,2 节介绍了基础架构。 3 部分讨论深度学习的数据要求,4 部分考虑偏差和不确定性量化,5 部分讨论可重用性和可重复性。 接下来我们转向应用程序。 第6节介绍了分类问题,其中类是事前定义的并且类不是太多,比较分类器和生成式人工智能。 接下来,第 7 节深入研究嵌入模型,当类数量很大或未事先指定类时,嵌入模型非常有用。 8 部分考虑回归问题。 还有其他方法可以处理本次审查中涵盖的应用程序。 9部分强调了为什么所强调的方法最有可能适合学术研究人员面临的限制。 10 部分结束。
1 深度学习概述
1.1什么是深度学习?
深度神经网络学习原始数据的表示,提取对特定任务有用的信息。 深度学习使用多层神经网络将原始数据映射到这些表示,将高维非结构化数据简化为连续向量。
为了对给定任务有意义地表示数据,神经网络一层中的节点(向量表示中的数字)通过将其与权重为学习参数的非线性函数组合而转换为下一层中的节点。 这些参数(数百万到数十亿)是通过最小化成本函数来估计的,该成本函数将某些任务的模型预测(例如,预测文本中的屏蔽术语)与真实示例进行比较。 对于那些不熟悉神经网络的人,我推荐 Sanderson (2017) 的介绍视频。
新颖架构和方法的发展使得优化具有数百万至数十亿参数的神经网络成为可能。 这些进步虽然很大程度上超出了这个相对广泛的综述的范围,但在 EconDL 知识库中进行了讨论。 特别是,有关卷积神经网络的文献在估计深度网络方面做出了许多开创性贡献,并在知识库的该帖子中进行了讨论。
从头开始训练深度神经网络需要大量数据,而一些大型数据集是文献的支柱:ImageNet——用于图像分类和相关任务的 1400 万图像数据集(Deng 等人, 2009 )——以及爬行语料库(例如,清理后的巨大通用爬行(Raffel等人,2019;Dodge等人,2021))——海量公共领域文本数据集这本质上是对互联网的快照。 API 背后的商业模型也可能会许可专有的训练数据。 从头开始训练深度神经模型可能需要高达数百万美元的计算资源,但幸运的是,这很少有必要。
由于迁移学习的力量,深度学习已经改变了许多领域:在一个领域训练的深度网络可以适应许多其他领域,而经验训练示例要少得多(通常是几百到几千)比从头开始训练模型所需的时间要多。 例如,需要训练主题分类器的研究人员可以前往 Hugging Face——NLP 的中心枢纽(第 3 节)——并下载预先训练的最先进的语言模型由 Google、Meta 和 Microsoft 等实体公开提供。 语言模型在庞大的语料库上进行训练,以预测从文本中随机屏蔽的标记(单词或子词)。 通过这次训练,它学会了生成有意义的文本向量表示。 研究人员可以将分类器层添加到预训练的语言模型中,并使用相对适量的标记数据对分类任务中生成的神经网络进行调整。 数百万个模型参数中的大多数将保持不变,因为模型对语言的基本理解不需要更新,但与手头任务最相关的参数将更新以改进模型预测(Merchant 等人,2020)。
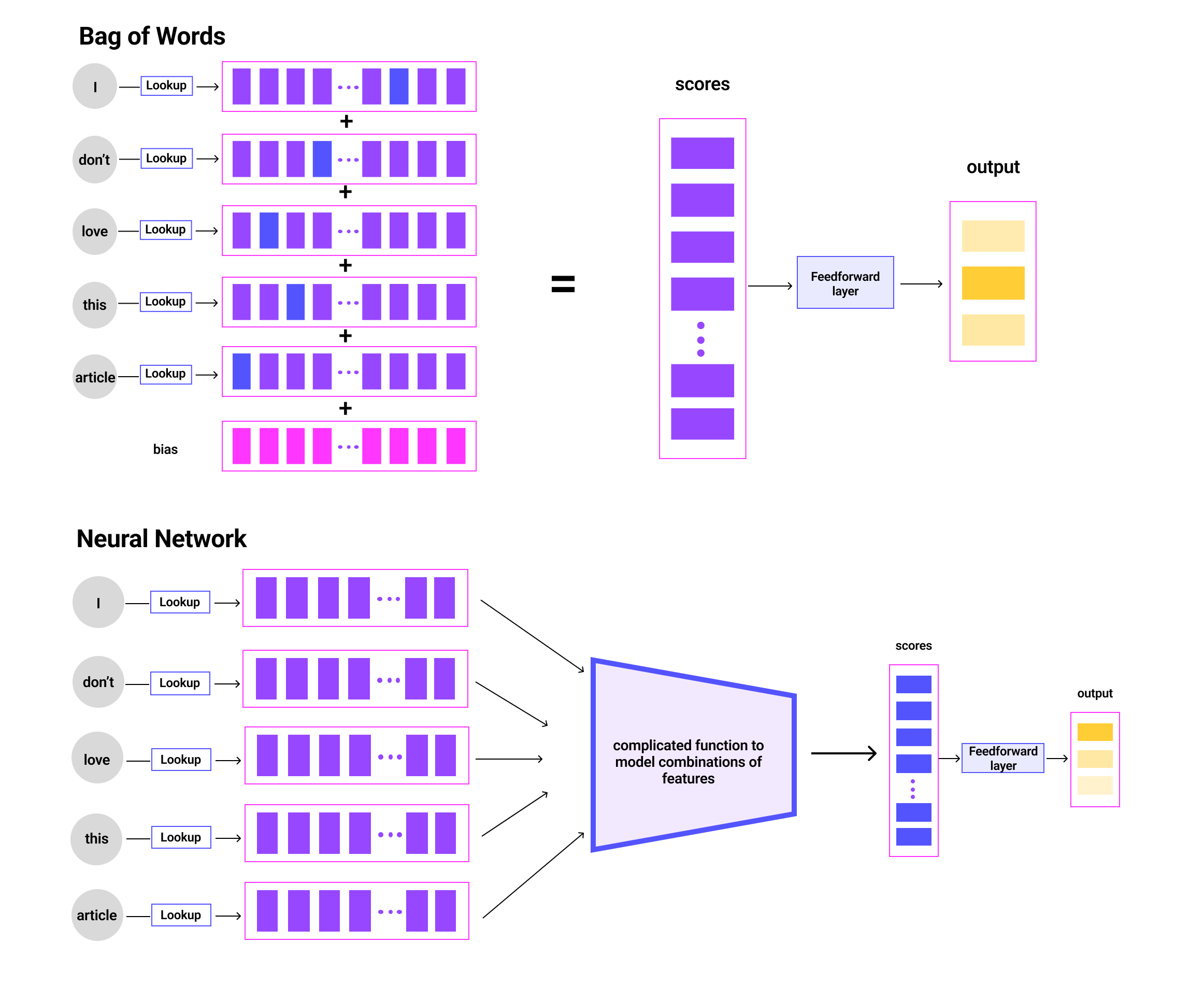
近年来深度学习出现的一个惊人发现是,即使模型非常大(例如数十亿个参数),增加模型大小的回报也可以继续增加(Raffel 等人,2020)。 人类视觉和语言是复杂的,需要丰富的表达模型来捕捉这种复杂性。 例如,假设我们希望执行一个简单的任务,即对图像中包含十个对象(马、汽车等)中的哪一个进行分类。 分类器的输入是每个像素 的 RGB 值。 假设我们使用这些输入估计线性分类器。 每个类的分数为,其中和是估计参数。 分类器预测分配到得分最高的班级。 对于该类中的对象往往位于的像素,该类的权重参数将更大。 这本质上是脆弱的,因为对于每一类,每个像素只有一个参数,但马的姿势、大小、图像中的位置、颜色或体型等可能会有所不同。 在 图中,人们可能会看到一匹马站在图像中间,两个头朝任一方向,因为线性分类器很难为马在经验上可能出现的像素分配高值。位于。 大型神经网络有效地允许使用许多这样的“过滤器”来预测图像中是否有马。
或者,假设我们想要分析陈述(例如,调查数据中的)是否具有积极、消极或中性情绪。 经济学文献中常用的传统方法是词袋法。 研究人员在查找表中查找每个单词的情感,并将它们聚合在一起以衡量句子的情感(图2)。
很容易看出这种方法的局限性。 考虑以下句子:“我喜欢这篇文章”、“我不喜欢这篇文章”、“我不讨厌这篇文章”、“这篇文章没有什么是我不喜欢的。”通过将每个单词的独立表示相加,即使在这些非常简单的句子中,也可以表达不同的情感。 相反,我们需要对单词的非线性组合进行建模,而神经网络是逼近复杂非线性函数的最先进工具。
当使用现代语言模型处理文本时(图 2 的底部面板),分词器首先将输入中的每个单词映射到查找字典分配的数字(如果该单词不在字典中) ,它被分成子词,即)。 使用学习的参数将这些数字转换为向量,然后通过神经网络传递,神经网络在每一层将它们增量地转换为输入标记的语义丰富的表示。 视觉模型大致相似,将像素或图像块作为输入。
神经网络的主要替代方案是使用人工设计的特征。 换句话说,研究人员预先指定了处理原始信息的规则。 例如,可以通过编写规则来检测分隔行和列的连接空白来自动化表格数字化。 通过深度学习,模型会显示带注释的表格布局示例。 深度学习革命在许多不同的任务中一遍又一遍地表明,在处理非结构化数据时,从经验示例中学习远远优于人工设计的特征提取。 其中一些证据在 EconDL 知识库中进行了讨论。
在许多经济应用中,深度学习也可能优于特征工程。 经济学家想要处理的信息通常是复杂且嘈杂的。 例如,通过老化、扫描和历史打印技术将噪声引入到文档扫描中;或者,文本数据可能包含 OCR 错误或拼写错误。 人类语言很复杂,有许多不同的方式来表达相同的情感和单词,这些单词可以根据上下文显着改变含义。 噪音和复杂性为人类设计的规则创造了例外,这些规则也必须是硬编码的,同样,例外也有例外。 当研究人员试图对这些异常进行硬编码时,最初看似简单的任务很快就会变得复杂。 即使结果令人满意,人工设计的系统也可能会根据当前的情况进行大量定制,并且无法很好地转换为具有不同类型的复杂性和噪声的其他数据。
深度学习的另一个潜在优势是训练和实现神经网络的方法是标准的且可重复的,而人为设计的特征提取中固有的很大的自由裁量权。 即使抛开研究人员的自由度,设计规则也需要大量的领域知识。 例如,在统计机器翻译领域,大量研究人员花费了数十年的时间来设计复杂的机器翻译统计规则。 这些系统的性能优于一些研究人员在几个月内开发的神经网络。 神经翻译领域的后续进展催生了 Transformer 架构(Vaswani 等人,2017),它彻底改变了自然语言处理、计算机视觉、音频和其他领域。
2 基础深度学习架构
本节简要介绍神经网络架构。 对于不熟悉的读者,我建议查阅 EconDL 知识库和那里提供的资源,以获得更详细的处理。
2.1 神经网络基础知识
神经网络由互连的节点层组成,这些节点称为神经元。 每个神经元都有一个值。 神经元的值是通过使用激活函数和学习权重组合前一层神经元的值来计算的。 这些层将输入(例如,词符化文本)转换成有助于执行所需任务的向量。
激活函数示例是修正线性单元 (ReLU):,其中
| (1) |
和 是学习的权重和偏差项, 是网络中前一层神经元的输入值。 当我们将数据输入神经网络时,输入值会由每一层的激活函数进行转换。 最后一层的节点是输出。
激活函数是神经网络的重要组成部分,因为它们引入了非线性,使网络能够捕获数据中的非线性关系。 知识库中的卷积神经网络帖子提供了对激活函数的进一步介绍。
为了优化神经网络,使用损失函数将输出与地面真实标签进行比较。 这些标签所衡量的内容取决于目标:例如,为语言模型预测屏蔽词,或为图像模型预测图像类别。 与任何优化问题一样,我们需要知道每个权重的损失梯度,以最小化函数。 对于从输出层开始并通过网络向后移动到输入层的每一层,我们计算损失相对于该层权重的梯度。 这就需要用到链式法则。 链式法则允许我们通过将逐层计算的导数相乘来计算损失相对于网络中任何权重的导数。 这称为反向传播。 使用梯度下降算法调整权重。
我们鼓励不熟悉反向传播的读者查阅 Sanderson (2017) 以获取高产值的图形介绍。 希望获得更深入理解的读者可以阅读高级反向传播教程 Karpathy (2022)。 Nielsen (2015) 为那些不熟悉神经网络的人提供了教科书式的处理方法。 Goodfellow、Bengio 和 Courville(2016) 为那些已经熟悉并想要深入回顾的人提供了教科书式的处理,而 Stevens、Antiga 和 Viehmann(2020) 的目标是适合那些想要通过 PyTorch 中的实践实现来学习关键概念的人。
2.2卷积神经网络
CNN 利用图像中存在的空间结构,在引领深度学习革命中发挥了核心作用。 尽管出现了更新的图像处理架构——视觉 Transformer(第 2.6 节)——但它们仍然被广泛使用,在适当现代化时可以获得接近最先进的性能,并且可以比视觉 Transformer 重量更轻,更容易调整。 本节提供简要介绍。 我建议那些不熟悉 CNN 的人参考 Sanderson (2020) 对卷积的简短图形介绍,因为对下面描述的概念的直观介绍特别有帮助。 其他资源位于 EconDL 知识库的“卷积神经网络”页面。
视觉问题从给定高度(像素)、宽度(像素)和深度(例如, 3 表示 RGB 图像)的图像开始。 卷积层是 CNN 的核心构建块。 该层的参数由一组可学习的过滤器组成,例如、3 3、5 5 或 7 7权重矩阵。 这些过滤器仅在计算下一层的输出时应用于紧邻给定节点的节点,并扩展到输入的整个深度。 每个滤波器在输入上进行卷积(移动),在每个空间位置产生激活。 与全连接层相比,对不同空间位置使用相同的权重可以大大减少参数的数量。 此外,参数共享确保无论特征在图像中的位置如何都可以被检测到。 这为 CNN 提供了一定程度的平移不变性,这是理想的,因为例如一匹马无论其在图像中的位置如何都是一匹马。
小型卷积滤波器固有的局部性偏差是合乎逻辑的,因为像素的解释更多地受到其邻近像素的影响,而不是远处像素的影响。 尽管这些滤波器具有局部性,CNN 仍然通过网络深度实现了广泛的感受野。 CNN 擅长学习分层特征:较低的层具有更有限的感受野,捕获边缘等简单模式,而更深的层捕获日益复杂的结构。
除了卷积层之外,CNN 还使用池化层。 如果不同的卷积滤波器应用于神经网络层,则下一层的深度将为,因为每个滤波器都会为每个空间位置产生激活。 池化层减少了这个深度,防止参数数量变得过大。 通常,CNN 由交替的卷积层和池化层组成。
估计多层神经网络的核心挑战是梯度消失问题(Bengio、Simard 和 Frasconi,1994)。 反向传播计算成本函数相对于网络中每个权重的梯度。 这需要应用链式法则来找到损失相对于每层输出的梯度,然后找到每层输出相对于其输入的梯度。 对于输入的极值,衍生品可能会变得非常小。 反向传播将小梯度相乘。 因此,当梯度流回较早的层时,梯度可能会呈指数级减小。 如果初始层的梯度变得非常小,学习将非常缓慢或完全停止。 EconDL 上关于“卷积神经网络”的帖子探讨了 CNN 架构的演变,包括允许优化更深、更具表现力的网络、规避梯度消失问题的关键创新(Krizhevsky、Sutskever 和 Hinton,2012 年; Simonyan 等人,2014;何等人,2016;Howard 等人,2019;。
2.3 循环神经网络
CNN 需要固定大小的输入,因为神经网络是使用固定维度的权重矩阵初始化的(可变大小的图像需要调整大小或填充)。 相反,递归神经网络(RNN)旨在处理不同大小的输入和输出。 它们在历史上在 NLP 中发挥了重要作用(Hochreiter 和 Schmidhuber,1997;Greff 等人,2016),尽管它们后来被 Transformer 取代。 虽然研究人员通常应该在 NLP 应用中使用 Transformer,但我引入 RNN 作为与 Transformer 的比较点。
RNN 逐次处理输入序列--例如,文本中的词符。 在每个时间步,它们都会维护一个捕获有关输入序列的历史信息的状态。 当网络处理序列中的每个元素时,该状态会迭代更新,从而允许网络“记住”可变长度输入中的先前元素。
远程依赖性对于人类语言很重要。 借用 Vaswani 等人 (2017) 中的一个突出例子,“动物没有过马路,因为它太累了”与“动物没有过马路,因为它太宽了” “它”指的是动物还是道路? 这取决于输入中“it”和其他标记之间的依赖关系。 最著名的 RNN 是双向 LSTM(长短期记忆)(Hochreiter 和 Schmidhuber,1997)。 双向性通过向前和向后馈送输入序列来捕获两个方向上的依赖性。 读者可以在 EconDL 知识库中找到有关 LSTM 的更详细介绍。
2.4 Transformer
Transformer (Vaswani 等人,2017) 彻底改变了 NLP,并在深度学习的几乎所有领域取得了进展,包括视觉、音频、图形和强化学习。 对于不熟悉的读者,我推荐 (Alammar,2018b) 撰写的 Illustratored Transformer 博客文章,它被广泛认为是最容易理解的介绍。 Rush (2018) 原论文的标注也是经典参考。
最初的 Transformer 是一个神经翻译模型,其关键要素是注意力。 序列中的所有标记(单词或子词)都会并行输入到模型中,并且模型会处理上下文中的所有其他标记,为每个词符创建上下文化表示。 语境化表征与传统的单词静态表征(Mikolov 等人,2013 年;Pennington、Socher 和 Manning,2014 年;Olah,2014 年)形成了鲜明对比,其中一个给定的单词在一个训练语料库中总是具有相同的表征。 Transformer 解决了 RNN 的局部性偏差(当隐藏状态传递到每个顺序词符时信息会丢失),因为它可以处理序列中的任何词符,无论是否附近。
自注意力是二次的,这限制了一次可以传递到模型中的文本长度(上下文窗口)。 开源模型中典型的上下文窗口长度是 512 个 Token 。 对于许多问题来说,这已经足够了(例如文本可以被分块,或者前 512 个标记足以形成有意义的文档表示)。 还有一些具有稀疏注意力机制的模型,允许较长的上下文窗口。
输入并行地输入到 Transformer 中,而不是像 RNN 中那样按顺序输入,从而使训练能够充分利用 GPU 的并行计算能力。 这使得在更多数据上训练更大的模型更长时间在计算上是可行的,所有这些都提高了性能(Raffel等人,2020)。
2.5 Transformer 大型语言模型
大多数现代 NLP 应用程序都使用基于 Transformer 的大语言模型(大语言模型)。 对于那些不熟悉大语言模型或需要复习的人,我强烈推荐 Jay Alammar 的“Illustration GPT-2/3”(Alammar, 2019, 2020) 和“Illustration BERT”(Alammar, 2018a) 博客文章,以直观的图形方式介绍 Transformer 大语言模型架构。
Transformer 大语言模型主要有两种类型。 生成(解码器)模型预测序列中的下一个单词(Radford等人,2019;Brown等人,2020)。 它们通常用于文本生成。 由于它们是通过预测下一个单词来训练的,因此在为给定词符创建上下文表示时只能关注先前的标记。 这称为因果注意力。
相比之下,屏蔽(编码器)语言模型是双向的:在创建序列中单词的上下文表示时,它们可以关注序列中的所有单词(屏蔽注意力)。 该模型通过预测屏蔽标记进行训练(Devlin 等人,2019;Liu 等人,2019;Sanh 等人,2019a;Lan 等人,2019;He 等人,2020)。 当研究人员旨在创建需要将整个文本输入模型的文本表示时,通常会使用编码器模型。 双向性对于此类任务很有帮助,因为单词前后的上下文对于创建它的语义上有意义的表示很有用。 语言模型还可以组合编码器和解码器 Transformer 块,例如 Raffel 等人 (2019)。
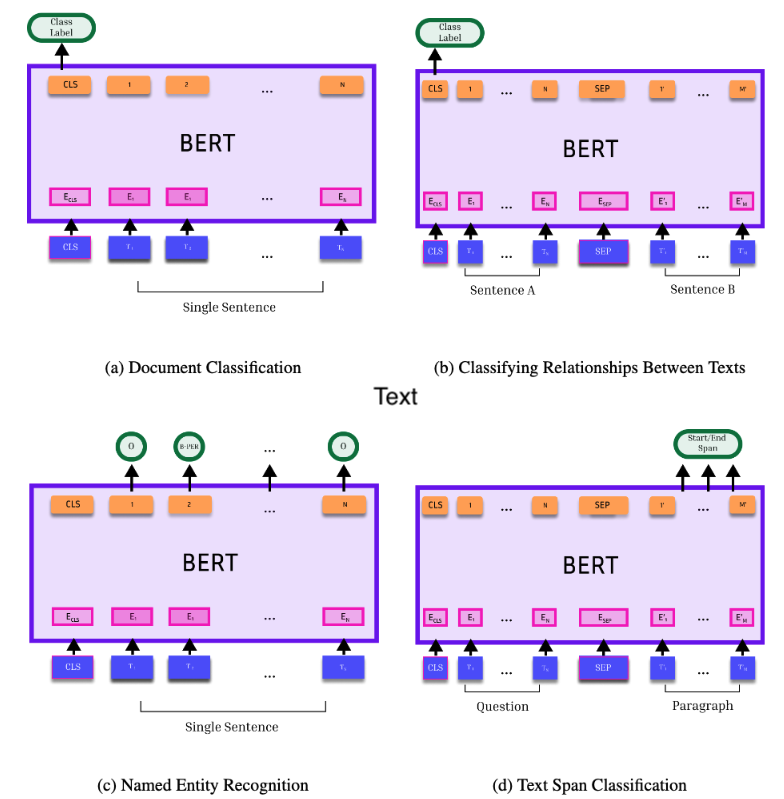
借助 Transformer 架构,相同的预训练语言模型可以用作各种任务的“骨干”,从而促进迁移学习。 图3对此进行了说明,该图改编自原始 BERT 论文(Devlin 等人,2019)中的插图。 Transformer 语言模型会为其输入中的每个词符(单词或子单词)生成一个向量表示,以及一个表示整个输入文本的 <cls> 表示。 第一幅图显示,通过在 <cls> 词符中添加分类器头,可以对全文序列进行分类。 分类器是一个前馈神经网络,它利用学习到的权重,将最终变换器层的 <cls> 向量中的节点聚合成每个类别的得分。 或者,也可以将两个文本联合嵌入--用特殊的词符 <sep> 分隔--然后在 <cls> 词符中添加分类器,对文本之间的关系进行分类(面板 b)。 或者,可以通过向每个词符嵌入添加分类器头来对每个词符进行分类(例如标记它是否指的是个人、位置等)(面板 c)。 文本的跨度也可以被识别(例如,问题的答案;面板 d)。
EconDL 知识库文章“Transformer 语言模型”详细介绍了各种不同的 Transformer 预训练语言模型。
2.6视觉和音频 Transformer
Transformer 改变了深度学习的许多其他领域,包括计算机视觉(Dosovitskiy 等人, 2020; Touvron 等人, 2021; Grill 等人, 2020; Caron 等人, 2021; Ali 等人, 2021; He 等人,2022;陈、谢、何,2021)。 Vision Transformers (ViTs) 使用与 Transformer 语言模型相同的 Transformer 架构,并进行了一些调整以使其适合图像。 与 NLP 中 Transformer 语言模型大大超越了现有技术不同,在视觉方面,Transformer 相对于 CNN 的收益更为温和(Liu 等人,2022)。 适当现代化的 CNN 通常可以与类似规模的 ViT 竞争。 此外,最小的 CNN(例如 Howard 等人 (2019))比轻量级 ViT(例如 Mehta 和 Rastegari (2021)) 目前,在简单的任务上也能表现良好。 实际上,我建议从轻量级 CNN 开始(这样训练和部署起来会更容易且成本更低),如果轻量级模型不够充分,则检查更大的 CNN 或 ViT 模型的性能。 关于 Vision Transformers 的 EconDL 帖子提供了有关 ViT 架构的更多详细信息。
Transformer 可在多大程度上用于处理高度多样化类型的非结构化数据,这一点在其音频应用中得到了惊人的体现。 通过将 ViT 应用于音频 的频谱图图像,实现了最先进的性能(Gong、Chung 和 Glass,2021)。 更引人注目的是,通过在 ImageNet 上进行预训练,性能得到了最大化,ImageNet 是视觉的主要基准,由超过 1400 万张自然图像(例如, 的狗、食物等)组成,有力地说明了甚至跨模式的迁移学习。
2.7优化神经网络
能够优化神经网络显然是在研究中使用它们的核心。 优化器(参见例如, Kingma and Ba (2014); Goh (2017))、初始化(He 等人, 2015),以及标准化(Ioffe 和 Szegedy,2015;Santurkar 等人,2018)都很重要。 要估计深度神经模型,研究人员还必须选择各种超参数(例如, Li 等人(2017);Falkner、Klein 和 Hutter(2018))。 有兴趣的读者可以参考 EconDL 配套知识库中关于“训练和优化神经网络基础知识”的文章。 EconDL 上的软件包为各种超参数选择合理的默认值,以使训练神经网络更加用户友好。
虽然有各种各样的细节在起作用,但我在指导许多学生优化神经网络时的主要实际收获是,当性能出乎意料地差时,最常见的原因是学习率选择不当或输入数据格式不正确。 学习率决定了训练优化器在 期间调整权重时所采取的步骤的大小。 如果太低,模型将不会更新;如果太高,模型权重会剧烈振荡。 此外,数据预计采用特定格式,并且可以动态执行转换(例如,许多神经网络需要固定大小的输入)。 神经网络从经验示例中学习,而出乎意料的糟糕性能往往是由于向它们提供格式错误的示例而导致的。
我还建议那些刚接触深度学习的人使用专门为此目的设计的云服务器来训练和部署模型。 EconDL 教程使用 Google Colab。 在本地安装深度学习包需要解决广泛的依赖关系,这对于经验有限的人来说可能具有挑战性。 对于在研究中大量使用深度学习的经验丰富的用户来说,购买自己的 GPU 通常可以显着节省成本。
3训练数据
高质量的训练和评估数据是深度学习的实用性不可或缺的一部分。 在监督学习中,数据被划分为标记集和未标记集。 未标记集由深度学习模型将应用的所有数据组成,通常比标记集大得多。 当从数据本身自动收集相关标签时,深度学习是自我监督的。 例如,可以通过预测从大量文本语料库中随机屏蔽的单词来预训练语言模型。 类似地,可以将掩蔽策略应用于图像,以进行视觉模型的自监督预训练(He等人,2022)。 自监督学习最常用于预训练,然后将预训练模型转移到另一个域并应用于未标记的数据(可能是在对来自目标域的适量数据进行额外的监督调整之后)。 最后,在无监督学习中,没有真实标签,因为目标是发现数据中的底层结构,并根据相似性对它们进行分组。 例如,可以对嵌入进行聚类来发现这些关系。
监督方法在经济应用中很常见,因为目标通常是使用神经网络从未标记的数据中提取一些特征。 经济学家也可能会继续进行自我监督的预培训。 当应用程序的领域与模型在 Gururangan 等人 (2020) 上预训练的领域发生很大变化时,这种情况最为常见。 例如,分析 18 世纪法律文本的经济历史学家可能首先继续在该数据库上预训练语言模型(通过预测屏蔽标记),以便更好地理解 18 世纪法律术语。
无监督学习对于数据探索最有用。 在实证经济学中,规范是指定一个狭义定义的假设并对其进行统计检验,这通常适合监督应用。 然而,使用无监督方法的系统数据探索可以成为从新颖的非结构化数据中收集程式化事实的强大工具。
在进行监督学习时,标记数据进一步分为训练数据(用于训练模型)、验证数据(用于调整模型超参数或选择提示)和测试数据-仅用于计算将在结果中报告的模型评估。 研究人员应该始终拥有高质量、有代表性的测试集来评估模型性能。 如果用于评估模型性能的数据不能代表未标记数据集,特别是如果未标记数据的某些明显部分在标记数据中没有支持,则评估数据上的模型性能可能与评估数据上的模型性能有很大差异。未标记的数据,这是感兴趣的基础对象。
在理想情况下,可以通过随机抽样创建代表性测试集。 然而,这并不总是可能的,特别是当研究人员想要测量的类别高度不平衡时。 假设研究人员需要从海量网络语料库中提取感兴趣主题的文本,而相关主题每万条文本中仅出现一次。 随机抽取足够阳性样本的标签要求显然是不可行的。 这种情况在社会科学中很常见,研究人员经常需要对海量语料库(例如,媒体或政府文件)中的相关信息进行分类,而其中只有极少部分内容与感兴趣的主题有关。
虽然抽取信息量最大的样本进行标注的策略已经产生了大量关于主动学习的机器学习文献(EconDL 在文本分类的背景下提供了详细的讨论),但在类不平衡严重时,选择代表性样本进行训练、评估或去重的工作却很少。 判别式主动学习(Gissin 和 Shalev-Shwartz,2019) 选择要标记的样本,最大限度地提高区分标记数据和未标记数据的难度,并且可以很好地处理相对平衡的数据。 它不适用于严重的类别不平衡,因为它无法对稀有类别进行充分采样。 其他主动学习方法寻求在分类器的决策边界附近进行采样,这将对稀有类别进行采样并可以最大限度地提高预测准确性。 然而,这将提供不具有代表性的样本。
相反,社会科学家经常使用某些关键字的存在来选择要标记的内容。 然而,通过构造,这无法在所有实例上放置正采样概率,从而增加了某些类型的未标记数据在标记数据中不支持的可能性。 这可能会产生与下游因果估计方程中的误差项系统相关的预测偏差(研究人员打算使用深度学习模型预测),因为语义和遗漏变量通常都会随空间和时间而变化。
嵌入模型(第7节) - 深度神经网络,创建一个空间,其中文本或图像的向量表示之间的距离有意义 - 提供可用于数据分层采样的度量,以标记训练或评估。 文本/图像与有关某个类别的一组查询越接近(例如,“本文是关于税收政策”),它来自该类别的概率就越高,从而使该类别中的距离对于分层抽样有用的空间。 分层抽样方法还可以为训练提供信息性的负样本:预先训练的模型放置在查询附近的样本,但与研究人员预期的方式与该查询无关。 这是一个活跃的研究领域,经济学家有潜力做出重要贡献。 EconDL 网站将随着文献的进展更新该文献。
考虑到迁移学习的力量,训练数据不需要从与未标记数据相同的分布中提取,尽管预测准确性通常会随着目标数据和训练数据之间域转移的幅度而下降。 通常,已经存在的数据集或可以从网络文本中提取的数据集可以廉价地创建比研究人员手动标记的数据集大得多的数据集。 然后,通过进一步调整目标数据中较小的一组手工制作的标签,确保目标数据集的高性能。
一致性标记——当两个(或更多)注释者标记相同的数据点时——对于确保训练和评估数据的质量非常重要。 一旦处理现实世界的非结构化数据,即使看似简单的任务也往往比预期的更加混乱。 一致性标签还可以确保注释者理解任务并生成高质量的标签。 在具有挑战性的标记任务中,研究人员可能希望对所有标记数据进行双重注释,从而手动解决差异。 在更简单的情况下,一致性标记可能只需要较小的数据子集,以确保任务定义明确并且注释者正确理解指令。 在机器学习论文中,研究人员通常需要报告注释器之间的一致性,并发布注释器指令,这在经济应用中也很有用。
4 偏差和不确定性量化
使用深度学习解决社会或经济问题存在许多局限性(例如,请参阅 ACM 公平、问责和透明度会议的论文 https://facctconference.org/ 和 Cui 和 Athey (2022))。 在这里,我们的重点要窄得多:在原始数据集的大小大到无法手动提取特征的情况下,估算或探索人类可能同意的非结构化数据的特征。
将深度学习应用于需要主观判断的环境时必须谨慎。 例如,研究人员表明,注释者自我认同的政治倾向会影响他们在政治情绪标签上的不一致(Shen and Rose,2021)。 深度学习文献中的情感分类主要是围绕笔记本电脑、餐厅和电影评论而设计的,这些背景通常对产品有明确的情感,可以由明星验证。 在经济学家关心的许多应用中——例如媒体数据中的情绪、政治演讲、公司报告等——情绪可能更加隐含,而人类可能不会同意这一点。 如果一个模型所输入的注释反映了注释者的主观偏见(而不是明确定义的基本事实),或者如果它只是因为要进行的区分很复杂而没有足够的示例,那么它就会做出不准确的预测,而这些预测可能会被系统性地影响。有偏见。 模型也可以从预训练中继承偏差,并且有大量关于人工智能中的偏差和公平性的文献(Mehrabi等人,2021)。 通过坚持执行具有明确定义的基本事实的简单任务,可以缓解这些挑战。
经济学家可以在不确定性量化方面做出有价值的贡献,这在许多深度学习文献中并不常见。 共形推理可以为预测任务提供不确定性量化。 通过收集地面实况校准数据集,保形方法可以在温和条件下生成具有边际覆盖保证的预测集。 规范的教程是 Shafer 和 Vovk (2008);请参阅 Chernozhukov、Wüthrich 和 Zhu (2021)、Cattaneo 等人 (2022) 以及 Lei 和 Candès (2020) 了解最新贡献。
渐近动机推理通常要求模型参数的估计是无偏的,这给“黑盒”机器学习预测器带来了问题,这些预测器通常会权衡偏差和方差以产生低均方误差的预测。 半参数推理方面的长篇文献(例如, Robins、Rotnitzky 和Zhao (1994))致力于解决这些问题,最终形成了关于除偏机器学习(例如, Chernozhukov 等人 (2018);Chernozhukov、Newey 和 Singh (2022))。
计量经济学中的机器学习文献与深度学习领域中的 "预测驱动推理 "文献之间有许多相似之处(例如, Angelopoulos等人(2023年);Zrnic和Candès(2023年))。 从广义上讲,从非结构化数据中估算结构化特征(深度学习文献的重点)和因果推理(计量经济学文献的重点)是估算缺失数据的更普遍问题的特例。 在因果推理中,潜在的结果缺失,而在许多深度学习预测应用中,低维结构化特征缺失,因为手动从高维非结构化数据中提取它们的成本极高。 预测驱动的推理文献研究了如何使用感兴趣群体的地面真实标签的高质量辅助样本来消除深度学习预测的偏差。 该信息用于测量插补引起的偏差,然后进行纠正,最终使研究人员能够执行有效的推理,而不会牺牲使用在较大数据集上预先训练的模型所获得的信息,该模型会做出有偏差的预测。 深度学习模型被视为黑匣子。 可以证明,预测驱动的推理框架相当于去偏机器学习。
5 深度学习中的可重用性和可重复性
深度学习在很大程度上建立在开放科学和开放数据的基础上,尽管近年来随着该技术的商业潜力日益明显,该技术已明显转向专有模型和数据。 然而,开放资源的数量是惊人的,如果没有模型和数据集的广泛共享,深度学习就不会取得今天的进步。 鉴于迁移学习和大规模预训练的核心地位,如果没有开放科学,这个领域就不会存在。
只要数据隐私问题允许,经济学越能围绕大数据创建开放的科学文化,我们作为一个职业就越能从迁移学习的积极外部性中受益。 例如,深度学习研究人员通常会被激励尽快在 GitHub 上分享他们的代码,作为证明其贡献的一种方式,或者在构建数据集后立即发布数据集,以便快速发展的文献可以使用时间更长。 此外,深度学习的发布场所通常要求遵守商定的元数据以及数据和代码发布的道德框架(Gebru等人,2021;MLCommons,2024;Mitchell等人,2019;Holland等人,2018). 虽然我不主张经济学大规模采用这些标准,但值得考虑的是是否存在可以促进经济学中深度神经模型的可重复性和可重用性的模型和数据集发布标准。
最大的深度学习模型和数据中心是 Hugging Face。 在那里可以找到大量的语言模型和文本数据,其中一些示例可以在通过 EconDL 链接的演示笔记本中进行检查。 Hugging Face 最近收购了视觉模型中央存储库 timm,使 Hugging Face 成为许多语言和视觉任务的一站式商店。
6 分类器
介绍了深度学习之后,我现在转向应用程序。 分类通常是经济分析不可或缺的一部分。 在大数据时代,研究人员可能首先需要使用分类来提取相关数据。 例如,他们可能从大规模的新闻、社交媒体帖子、财报电话会议或立法记录开始,只需要从数百万甚至数十亿的文本中提取有关利率、移民或高等教育的报道。完整的语料库。 然后,使用这个更加有限的语料库来提取要在某些下游因果估计方程中使用的度量。 虽然此步骤通常很少受到关注,但有偏差的分类将导致下游因果估计方程中使用的样本出现选择偏差,可能会严重影响结论。 或者,研究人员可以使用分类来估算结构化数据,例如文本中提到的地理位置、其情绪或主题,或者卫星图像中出现的对象类型。
本节首先介绍分类器(6.1 节),并描述生成式 AI 进行分类的使用(6.2 节)。 然后,它引入了序列分类,其中为文本序列输入类标签:例如句子、段落或文档(第6.3 它将定制训练的分类器与生成式 AI 在 19 种不同文本分类任务上的性能进行了比较。 分类也可以应用于文本中的单个术语(第 6.4 节)。 最后,分类器可用于相互比较文本(第 6.5 节)。 为了便于阐述,我专注于文本分类。 图像分类(完整图像或图像中的像素或对象)是类似的,使用 CNN 或视觉 Transformer,而不是语言 Transformer。 标题为“卷积神经网络”的 EconDL 知识库文章对此进行了深入介绍。
6.1 分类器简介
在传统分类中,神经网络预测每个 类别的分数,并将输入分配给分数最高的类别。 对于那些不熟悉分类器的人,Sanderson (2017) 在对数字图像进行分类的背景下提供了出色的分类图形处理。
回想一下神经网络就像乐高积木的类比。 Transformer 模型的核心功能是能够使用相同的预训练语言模型作为各种分类任务的骨干。 如图3所示。 Transformer 语言模型会为其输入中的每个词符(单词或子单词)生成一个向量表示,以及概括整个输入文本的 <cls> 表示。 在<cls>表示法中添加分类器头可对文本序列进行分类(面板 a)。 分类器是一个前馈神经网络,利用学习到的权重将 <cls> 向量中的节点汇总为每个类别的得分。 如图 3 的面板 c 所示,各个标记同样可以通过将分类器头添加到其向量表示来进行分类。 或者,可以将两个文本联合嵌入,然后在 <cls> 表示中添加分类器,对它们之间的关系进行分类(b 面板)。
训练分类器是深度学习中最简单的任务之一。 开源包 LinkTransformer 可用于训练文本序列分类器,并通过 EconDL 提供演示。 虽然在训练分类器时可以冻结基本 Transformer 语言模型,并且 Transformer 的各个层可以用作分类器的输入,但通常所有参数都允许更新,分类器层附加到 Transformer 的最后一层。
分类器训练是一项监督任务,模型必须在训练过程中看到每个类别的足够数量的示例,以便在未标记的数据上表现良好。 创建分类标签时,不同类别的标记数据应相对平衡(例如,二元分类中的正样本和负样本)。
为了训练分类器,我们还需要一个适当的损失函数。 分类中最常见的两种损失是支持向量机 (SVM) 损失,也称为铰链损失和交叉熵损失。
给定一个具有真实标签 的样本以及神经网络生成的类别分数的分数向量 ,SVM 损失为:
| (2) |
错误类别的损失总和,如果正确类别的分数未比不正确类别的分数至少高出某个阈值,则施加惩罚。 阈值可以设置为 1,而不会影响通用性,因为它只是缩放学习到的权重。
交叉熵损失衡量预测分数分布与真实分布之间的差异。 考虑用于具有 类的多类分类问题的神经网络。 令 为样本的真实标签,表示为 one-hot 编码向量。 对于属于 类的示例, 属于 类和 类。 令 为神经网络为该样本生成的原始数字(通常称为 logits)。 分类层将为每个类别产生一个分数。 使用softmax函数获得的类的预测分数为:
| (3) |
虽然班级分数在文献中经常被称为“概率”,但它们并不是统计意义上的概率。 它们的峰值程度取决于神经网络的正则化。
真实标签和预测分布之间的交叉熵损失为:
| (4) |
由于 是一个热向量,因此可以简化为:
| (5) |
其中 是正确类别的预测概率。
对于SVM损失,一旦正确类别的分数超过阈值,就不会再进一步提高正确类别的分数。 另一方面,交叉熵损失将正确的类别推向 1。 这意味着在训练的早期阶段,准确性可能会突然增加,而损失却没有显着变化。 在现实场景中,两种损失通常会产生类似的结果。
二元分类器使用 F1 分数进行评估,F1 分数是结合了召回率(真阳性除以真阳性加上假阴性)和精度(真阳性除以真阳性加上假阳性)的指标。
| (6) |
完美的精确度和召回率产生的 F1 分数为 1,而最差分数为 0。 F1 是精确率和召回率的调和平均值,因此往往更接近这两个指标中较小的一个。 如果精度或召回率较低,则 F1 分数也会较低。 F1 优于准确度,因为如果类别不平衡,只需始终预测多数类别即可提高准确度。
6.2 用于分类的生成式人工智能
GPT、Claude 或 Llama(在文献中通常称为基础模型)等大型生成式 AI 模型使用解码器 Transformer 架构(第 2.5 节)来自回归生成给定的文本一个提示。 实际上,它们还可以通过检索增强语言建模 (RALM) 设置连接到外部数据库(例如互联网)(EconDL 中有关检索的帖子包含有关 RALM 的更多信息)。 从根本上讲,这些模型正在执行分类,在每个时间步自回归预测离散词汇中最有可能的下一个词符。 默认情况下,GPT 等模型是随机的;他们从最可能的标记的分布中预测下一个词符。111在撰写本文时,将 top_p 设置为 0 会使 GPT 具有确定性。
要使用生成式人工智能执行分类任务,用户需要提示模型。 在很多方面,提示生成语言模型不如通过梯度下降调整分类器那么简单,因为离散提示的空间是无限的,并且提示已经产生了大量且笨重的文献。
不过,有一些清晰的见解值得强调。 集中而言,应在验证集上进行及时调整,而不是在用于评估性能的测试集上进行。 后者可能会使提示过度适应测试集的特性,从而使其性能无法代表未标记数据的性能。
一篇关于思维链提示的文献建议将任务分解为简单的步骤,使它们更容易理解(Wei等人,2022)。 这与我的经验非常吻合,简单的提示比更长、更详细的提示效果更好。 如果一个问题需要冗长的说明,请尝试将其分解为多个问题,并在每一步提示模型。 还有关于生成大语言模型演示任务的文献(例如, Khattab 等人 (2022))。 这是否有用取决于您的任务的性质,我建议检查演示是否有助于使用验证集。 Liu 等人 (2023) 对即时工程进行了回顾。 对于像 GPT 这样的自回归模型,他们推荐使用前缀提示; 例如,“我喜欢这门课。 这篇评论的观点是什么?”这与完形填空提示形成对比:“我喜欢这个类,它是一个 类。”
本文研究了截至 2024 年 6 月 GPT-3.5 和 GPT-4o 在历史报纸文章主题分类上的表现。 在过去的一年里,我使用旧型号以及 GPT-4 和 GPT-4 Turbo 进行了这项练习。 GPT-4 和 GPT-4o 的性能相似,略胜 Turbo。 我没有看到新版本有任何系统性改进。 您的里程可能会有所不同,因为毫无疑问,在某些任务中,更大、更新(因此更昂贵)的型号会表现更好。
我还研究了来自 Anthropic 的另外两个领先的人工智能模型:Claude Haiku 和 Claude Opus。 这些导致性能显着下降(F1 分数通常比 GPT 低 10-40 分),并且由于篇幅限制没有报告。 造成性能下降的原因有两个。 首先,克劳德拒绝为其评估为有害的文本提供输出。 Claude 的一个显着特点是其“宪法人工智能”框架,该框架规定了某些道德原则(例如无害性要求响应应该是和平的、道德的,并避免可能被认为具有冒犯性的内容)西方文化)。 一些关于过去冲突的文章(主要是客观地报道事件)和一系列其他主题(例如,在 20 世纪 60 年代撰写的关于引入避孕措施的内容)被认为是有害的。 此外,克劳德并不总是生成所需的“是/否”格式,因此无法提取文章是否切中主题。 GPT 不会出现这些行为。 也许可以通过更及时的调整来解决这个问题,或者它可能会随着未来的更新而改变。
无论如何,使用分类器,通常可以相当简单地解释为什么会出现特定错误以及如何修复这些错误(通过为令人困惑的实例类型添加更多数据),而 GenAI 目前感觉更像是一个黑匣子。 幕后还有更多的事情发生,通过强化学习训练模型,以产生训练模型的商业实体认为理想的响应。 这可能会或可能不会对给定的学术应用造成问题,并强调使用测试集进行严格评估的重要性。
用于分类的生成式人工智能的优点是:1)启动成本低,需要最少的编程专业知识或了解幕后发生的事情,2)它可以使用零样本(无需用户提供训练数据),而调整分类器需要训练数据。 我们将看到,如果有的话,定制训练的分类器往往在文本分类方面具有性能优势,尽管最简单的任务可以通过生成人工智能很好地执行。 这与广泛的共识是一致的,即只要有足够的、高质量的数据,监督任务通常可以达到人类水平的训练表现。
这给我们带来了生成式人工智能的潜在缺点。 在 API 后面使用大型模型无法提供与分类器相同的细粒度控制。 虽然 GPT 等模型允许用户将模型暴露给经验示例,但对于本文的实验来说,这并没有带来性能的提高。 目前尚不完全理解如何通过提示条件演示这些模型,但很清楚提供训练示例如何通过梯度下降更新分类器。 当接触相同数量的训练数据时,并非所有模型都能平等地学习(如 9 节中的经验证明),并且像与自定义分类器一起使用的轻量级模型往往会非常有效地更新。 自定义分类器在可解释性和可重复性方面也具有优势。 如果模型被弃用,商业 API 的结果可能不再可重现,并且如上所述,商业 GenAI 模型可能更像是一个黑匣子。 这些担忧可以通过使用开源基础模型来缓解,例如 Meta AI 的 Llama (Touvron 等人,2023)。 然而,启动成本和硬件要求抵消了易用性优势。 最后,使用 RoBERTa (Liu 等人,2019) 等轻量级主干的分类器在大量文本上部署成本低廉,而目前的商业模型可能非常昂贵。 如果竞争加剧并且廉价部署研究取得进展,这种情况可能会改变。
为了确定分类器还是生成式人工智能最适合某项任务,我建议首先进行粗略计算,以确保生成式人工智能在预算范围内。 如果是这样,请创建测试和验证集、调整提示并评估其性能。 如果性能不够,则需要训练集来调整自定义分类器。 如果用户事先知道保证训练的可重复性是必要的,网络文本存在大量的领域转移,或者任务需要细粒度的控制,他们可能会直接使用自定义分类器。 数据隐私要求可以为处理机密数据的人员添加额外的考虑因素。
6.3序列分类
经济学家可能希望在文本层面上估算各种结构化信息:例如其主题、其包含的内容类型或其情绪。 为了说明文本序列分类,本节训练了 19 个不同的二元主题分类器,应用于历史新闻的大规模数据库(Dell 等人,2023;Silcock 等人,2024),并将它们与生成式进行比较人工智能。 对于注释者来说,记住 19 个不同的主题定义来创建多类标签是非常困难的;因此,使用二元分类。 二元分类器不能组合成多类分类器,因为一个主题的否定可能对另一个主题是肯定的。 保持生成人工智能的提示简单也建议使用二进制类。
带注释的数据由技艺精湛的注释者进行一致性标记,并手动解决差异。 一致性标签确保了高质量的数据并促进了明确定义的发展。 例如,就犯罪分类器而言,注释者对于有关水门事件的文章是否应被视为主题存在分歧,零样本模型显示 1974 年由于水门事件,犯罪覆盖率大幅上升。 虽然可能是一个合理的定义,但我不希望犯罪报道受到政治丑闻(政治丑闻的广泛报道)的影响,并且分类器很快就通过少量标签了解了这一点。
一个常见的问题是需要多少个标签。 这会有所不同。 更多样化或需要学习更复杂定义的主题将需要更多标签。 在语言模型预训练中多次出现的主题可能需要更少的标签。 幸运的是,训练分类器的计算效率很高。 如果第一轮训练后结果不理想,可以直接添加更多标签并重新训练。 错误分析可以让您了解哪些类型的文本需要更多训练示例。 由于标签成本高昂,我们建议从较少的标签开始,并根据需要添加更多标签。
表2提供了本节中检查的各种主题分类任务的分割统计信息。222政治分类器取自已发表的论文(Dell 等人, 2023),其目标不同,因此分割份额和整体注释数量略有不同。 标记数据随机分为训练数据、验证数据和测试数据。 验证数据用于选择超参数、选择模型检查点(何时停止训练)以及调整提示,而测试数据仅用于计算表2。 表2 的提示列在补充材料中。
分类器使用 LinkTransformer 进行训练,它支持使用 Hugging Face 上可用的任何基本语言模型。 我们使用了 DistilRoBERTa(82M 参数)(Sanh 等人, 2019b) 和 RoBERTa Large(335M 参数)。 RoBERTa (Liu 等人, 2019) 是广泛使用的 BERT 改进版本。 蒸馏语言模型是较小的模型,经过训练以匹配较大模型的性能。 精简版本运行速度更快,但通常会带来性能损失。 我们在分类任务中使用了一组一致的超参数,这些超参数似乎在更普遍的情况下工作得很好(学习率为或,批量大小为8)。
| Topic | F1 on test set | # of labels | ||||||
|---|---|---|---|---|---|---|---|---|
| GPT-3.5 | GPT-4 | GPT-3.5 Trained Model† | Distil RoBERTa | RoBERTa Large | Train | Eval | Test | |
| advice | 0.72 | 0.85 | 0.55 | 0.87 | 0.97 | 319 | 68 | 68 |
| antitrust | 0.85 | 0.94 | 0.84 | 0.92 | 0.94 | 329 | 70 | 70 |
| bible | 0.52 | 0.81 | 0.10 | 0.85 | 0.87 | 314 | 67 | 67 |
| civil rights | 0.59 | 0.87 | 0.54 | 0.85 | 0.87 | 943 | 202 | 202 |
| contraception | 0.83 | 0.91 | 0.72 | 0.88 | 0.97 | 597 | 127 | 127 |
| crime | 0.85 | 0.80 | 0.85 | 0.85 | 0.90 | 463 | 98 | 98 |
| horoscope | 1.00 | 1.00 | 0.92 | 0.96 | 1.00 | 288 | 61 | 61 |
| labor movement | 0.77 | 0.90 | 0.79 | 0.89 | 0.94 | 253 | 54 | 54 |
| obituaries | 0.98 | 1.00 | 1.00 | 0.96 | 1.00 | 272 | 57 | 57 |
| pesticide | 0.58 | 0.91 | 0.71 | 0.89 | 0.98 | 873 | 187 | 187 |
| polio vaccine | 0.92 | 0.99 | 0.94 | 0.96 | 0.97 | 350 | 74 | 74 |
| politics | 0.67* | 0.62* | 0.74 | 0.86 | 0.85 | 2,418 | 498 | 1,473 |
| protests | 0.74 | 0.81 | 0.79 | 0.90 | 0.91 | 351 | 75 | 75 |
| Red Scare | 0.81 | 0.86 | 0.79 | 0.90 | 0.91 | 1,852 | 396 | 396 |
| schedules | 0.79 | 0.95 | 0.81 | 0.95 | 0.96 | 346 | 74 | 74 |
| sports | 0.80 | 0.92 | 0.88 | 0.94 | 0.94 | 339 | 72 | 72 |
| Vietnam War | 0.91 | 0.94 | 0.98 | 0.98 | 0.99 | 738 | 157 | 157 |
| weather | 0.94 | 0.92 | 0.94 | 0.94 | 0.95 | 569 | 57 | 57 |
| World War I | 0.72 | 0.74 | 0.51 | 0.89 | 0.92 | 690 | 164 | 192 |
†This column reports the F1 for trained models (based on either DistilRoBERTa or RoBERTa-Large, whichever works better) using labels generated by GPT-3.5.
* The results with asterisks were produced on a random sample of 500 out of total 1,473 articles in the test set.
在大多数情况下(跨越各种主题),调整后的分类器往往优于或等于 GPT 的性能,尽管对于更简单的任务,GPT 的性能可能非常好,特别是在 GPT-4o 的情况下(GPT-4 执行相似地)。 用于生成这些分类器的训练数据是高质量的。 对于质量较低的标签,例如那些使用在线标签平台创建的标签,其质量非常差,定制训练的分类器很可能始终比 GPT 差。 这些比较将来也可能会发生变化。
更一般地说,生成式人工智能在预训练期间可能广泛接触的简单主题上表现最好。 领域从训练数据(主要是现代网络文本)转移得越远,性能就越差。 对于星座运势、讣告和有关脊髓灰质炎疫苗的文章(所有这些都非常简单),GPT 的表现几乎完美(分类器也是如此)。 然而,GPT 也有一些表现不佳的主题;例如,政治,这个话题具有挑战性,因为它广泛且多样化,内容取自 19 世纪末和 20 世纪初,包括地方和国家政治。 第一次世界大战的两个 GPT 模型的 F1 分数都在 70 左右,比越南战争差得多,而越南战争在训练语料库中的代表性可能更高。 此外,自第一次世界大战以来,语言发生了更大的变化,转化为更大的领域转移。 然而,只需最少的标签,RoBERTa 分类器就可以适应这种域转变。
目前,GPT 可能远远超出大多数社会科学研究人员对大型语料库的预算,但我不会在这里引用数字,因为价格会波动,并且可能会根据竞争和技术进步而发生很大变化。 相比之下,根据此处显示的标签数量训练 RoBERTa 分类器非常便宜(在撰写本文时,使用每月 9.99 美元的 Google Colab 计划或中档 Nvidia GPU 卡可以在几分钟内完成)。 我也有学生耐心地在笔记本电脑上训练类似的模型,不过通过云计算或专用硬件访问像样的 GPU 更好。 即使在数百万篇文章中部署分类器也很便宜,并且可以使用云 CPU 或中档 GPU 卡在数小时内完成。 人们可以通过在 GPT 预测的标签上训练分类器来规避生成式 AI 的成本。 表 2 显示当 GPT 生成非常高质量的标签时,这可以发挥作用。 然而,在 GPT 表现较差的情况下,对噪声数据进行训练可能会放大错误。
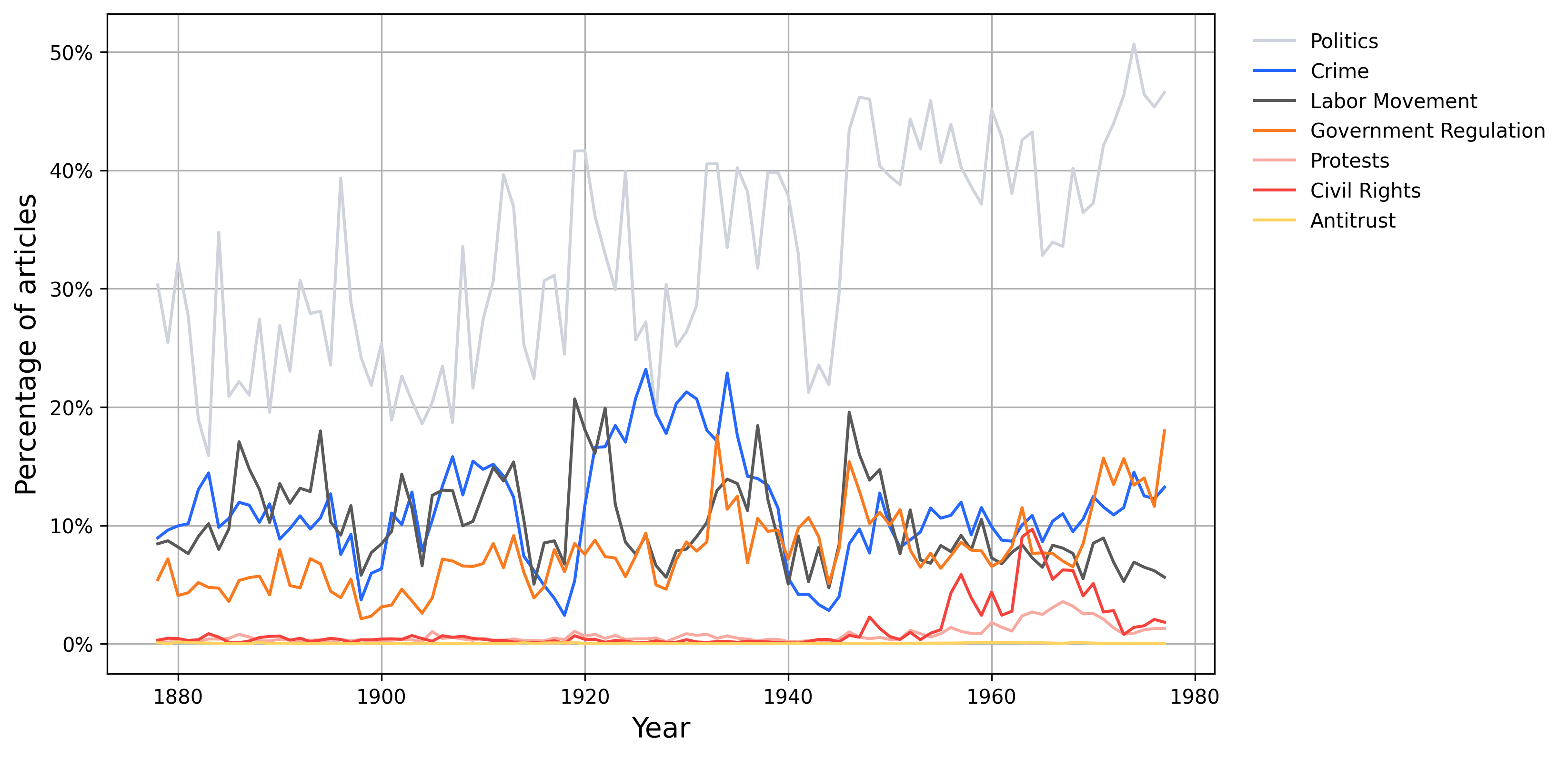
图 4 取自 Silcock 等人 (2024),采用跨时间应用的二元分类器,并将其部署到包含 1878 年至 1977 年间发表的 270 万篇独特新闻专线文章的数据集中。 各种趋势都很明显,例如 20 年代与禁酒令相关的犯罪报道激增,或 1960 年代民权和抗议报道激增。
值得一提的是,神经方法与文本分类的稀疏方法有何不同,稀疏方法(复杂程度不同)依赖于关键字。 例如,一种常见的稀疏方法是 TF-IDF:词频 (TF) 是文档 中术语 的原始计数。逆文档频率(IDF)衡量术语在整个语料库中的重要性。 如果一个单词出现在许多文档中,那么它就不是给定文档的良好标识符。 语料库 的术语 的 IDF 由 给出。 术语的 TF-IDF 分数只是其 TF 和 IDF 分数的乘积。 TF-IDF 分数越高,相对于整个语料库的上下文,术语对于特定文档越重要。 为了使用 TF-IDF 根据语料库中的文档与查询的相似度对文档进行排名,每个文档和查询都表示为稀疏的高维向量,每个维度对应于语料库中的唯一术语。 向量中每一项的权重就是它的 TF-IDF 分数。 任意两个向量之间的角度捕获文本之间的相似性。 人们可以将其视为类似于关键字搜索,它会降低语料库中出现的术语的权重。
我们将 TF-IDF 等方法称为稀疏方法,因为语料库中的每个术语在向量空间中形成一个维度。 词汇表中的大多数术语不会出现在单个文档中,导致术语向量中的大多数条目为零。
当精确的术语重叠信息量很大时,稀疏方法非常有用。 然而,由于语言很复杂,依赖术语重叠往往是一个主要缺点。 同一事物有多种表达方式,同一术语也可能有不同的含义。 此外,噪音(例如,打字错误、OCR 错误、缩写)无处不在。 语义随着时间和空间的不同而变化,许多省略的变量也是如此。 这可能会导致预测误差与使用关键字预测的因果估计方程中的误差项之间存在相关性。 此外,虽然术语可以被挖掘,但更多时候它们只是被简单地选择,从而产生了研究人员的自由度问题。
神经方法通过使用大型语言模型将文本映射到密集的向量表示(例如,一个由非零项组成的 768 维向量)来解决这些缺陷。 该向量的维数取决于基本语言模型。 预训练的语言模型充满了语言理解,因此密集的方法可以解释上下文和语义的相似性。 这使得它们能够概括同义词和语义相似的短语,并且对其他噪音更加鲁棒。
Dell 等人 (2023) 将如上所示的政治神经分类器与挖掘的关键字以及 ChatGPT 建议的关键字进行比较。 神经方法可以使预测更加准确。
6.4 Token 分类
研究人员可能需要提取文本中各个术语的信息,而不是整个文本。 这个问题与序列分类类似,不同之处在于分类头被添加到变换器最后一层中每个词符的表示中,而不是只添加到 <cls> 表示中(图 3,c 面板)。
本节开发一个词符分类示例,命名实体识别(NER),它检测文本中的命名实体。 只要存在清晰、一致的定义和足够的训练标签,研究人员就可以根据需要定义这些实体。 例如,研究人员可能想要识别社交媒体帖子中提到的位置。 或者,从讣告数据中提取家庭关系的研究人员可能希望标记个人与死者的关系(孩子、父母、兄弟姐妹、主礼人等)。 或者,希望将传记文本转换为结构化数据集的研究人员可能会标记出生地、母亲、父亲、大学、配偶和雇主。
NER 是一个经典任务,已经产生了非常多的文献,并且 Hugging Face 上有很多开源的预训练模型和数据集。 在本文中,实体类通常包括人员、位置和组织。 CoNLL 是一个著名的基准(Sang 和 De Meulder,2003),用于在 Hugging Face 上预训练各种模型。 WNUT 是另一个(Nguyen 等人, 2020),它专注于嘈杂的用户生成文本(推文)。 如果研究人员偏离基准所强调的实体类型,则需要创建标签。 NER 通常使用 BIO 标记 - 实体中的第一个词符标记为 B(表示开始),后续标记标记为 I(表示内部),不感兴趣的标记标记为 O。 如果感兴趣的实体类型是人 (P) 和位置 (L),则标签将为 B-P、B-L、I-P、I-L 和 O。
图5展示了将NER应用于历史新闻专线文章的结果,绘制了超过2700万个实体的份额,分为四类:人员、位置、组织和杂项。 结果是合理的,例如,在第二次世界大战期间,地点和杂项命名实体(例如,飞机名称)的数量激增。
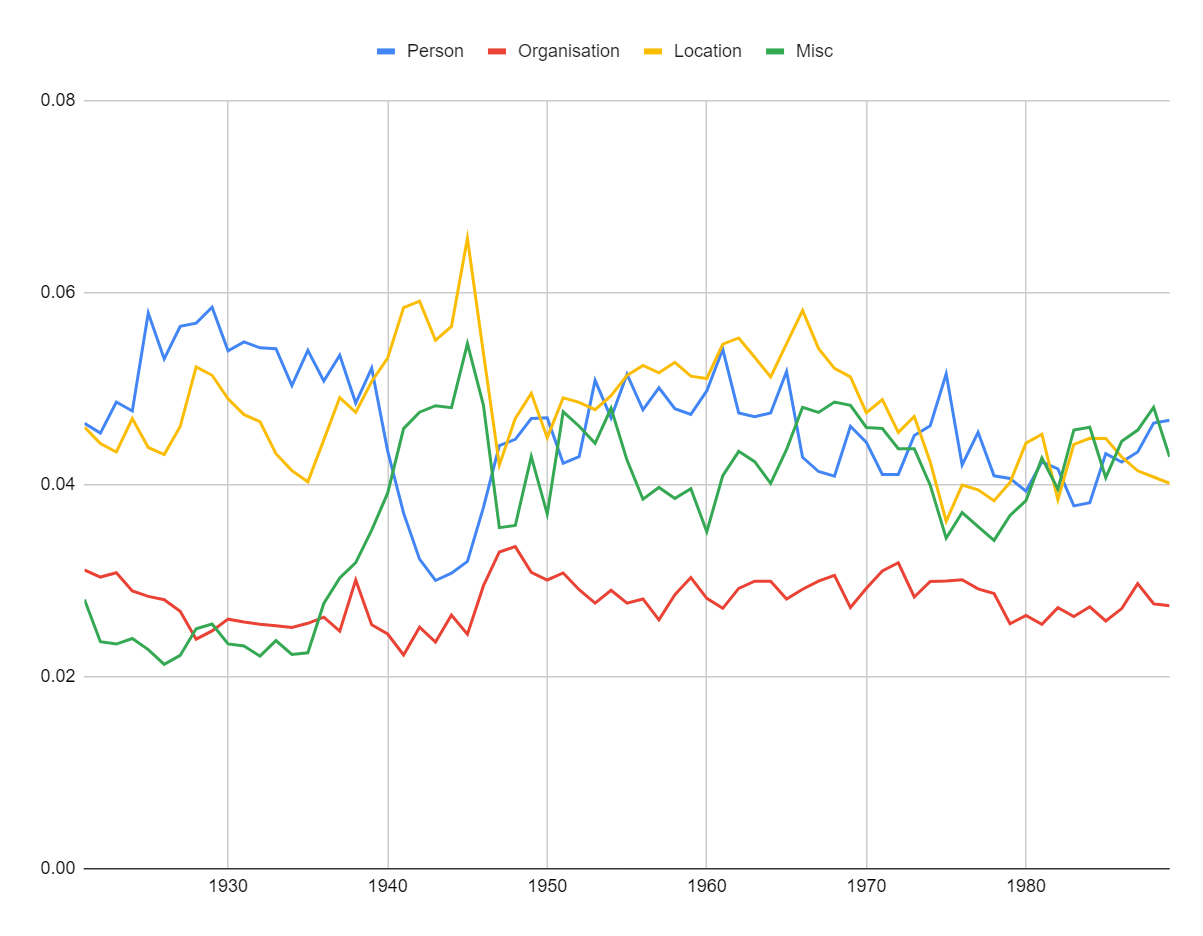
人们还可以要求生成人工智能识别文本中的实体并将输出转换为表格。 与序列分类一样,研究人员可以通过构建代表性验证和测试集来测试性能是否足以满足他们的需求。
6.5 文本之间的关系
我们希望在多种上下文中衡量两个文本是否以某种预先指定的方式相关。 例如,我们可以将主题分类表述为一项任务,在该任务中我们想要对一个陈述是否包含另一个陈述进行分类:文章文本是否包含“本文是关于货币政策”的陈述? 或者,两个文本是否彼此重复? 他们在政治问题上持相同立场吗? 一个人跟随另一个人吗?
图6说明了比较文本的两种方法。 顶部显示的是 交叉编码器:两个文本连接在一起,中间有一个 <sep> 词符。 这些文本被共同传递到 Transformer 中,分类器头对它们的相关性进行分类。 这种方法允许每个文本中的所有标记之间完全交叉关注。 下图展示了一种双编码器方法:文本分别嵌入,然后我们使用一些距离度量(例如余弦相似度)计算它们之间的相似度。 双编码器非常有用,我们将在第 7 节中对其进行详细说明。
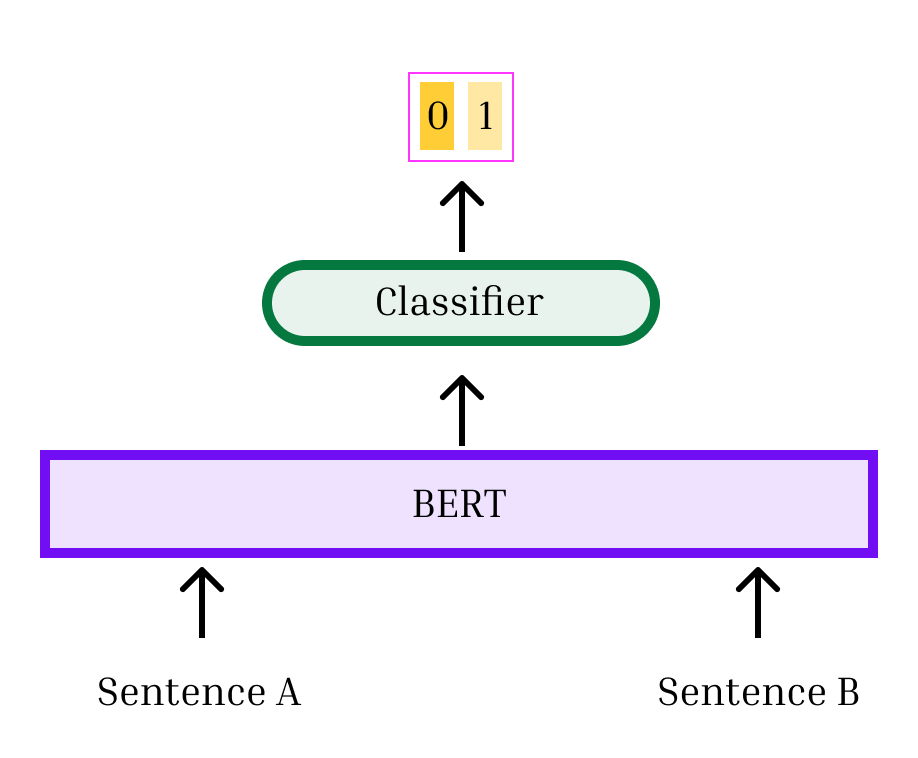
Cross-encoder
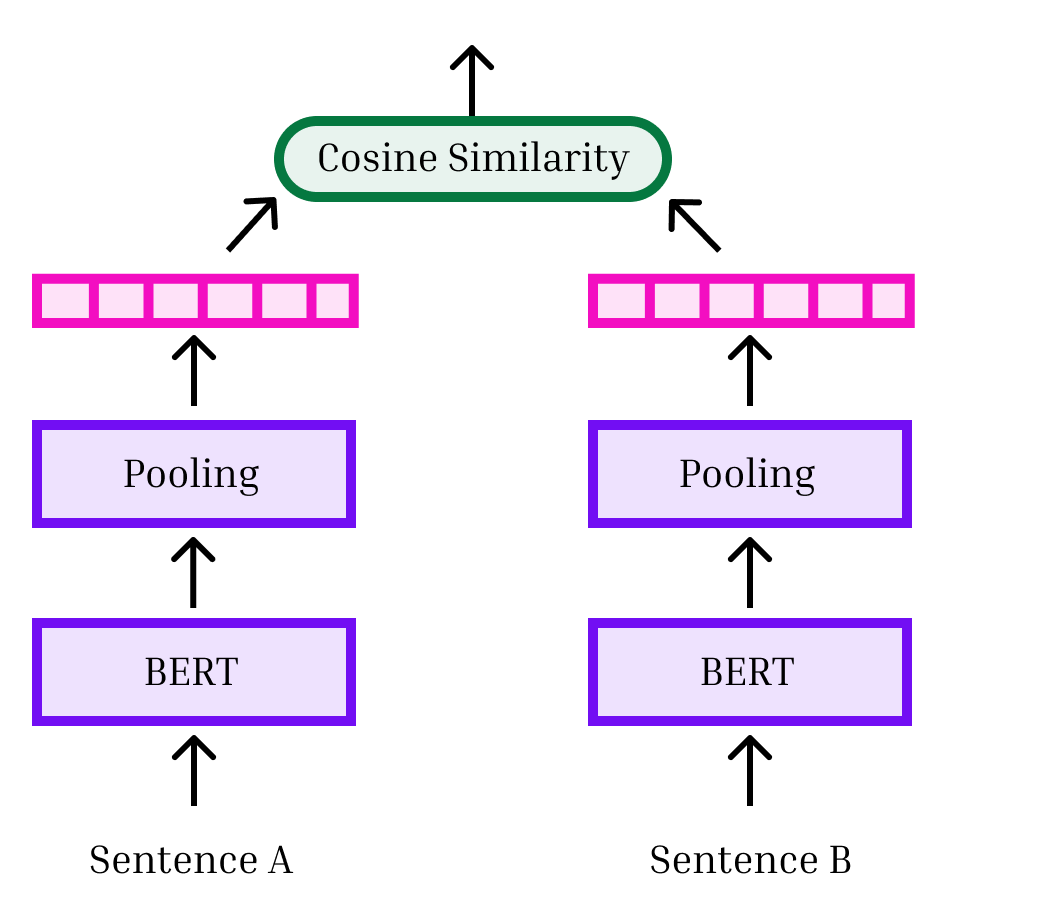
Bi-encoder
交叉编码器允许术语之间完全交叉关注。 因为它们是共同嵌入的,所以在创建表示时,被比较文本中的术语可以灵活地相互关联。 相反,双编码器分别计算每个文本的单个表示,然后比较这些表示。 因此,交叉编码器往往具有更高的精度。 然而,它们也有明显的缺点。 最重要的是,如果我们需要将 文本与 其他文本进行比较,则需要嵌入 文本。 这种二次成本很快就变得不可行,因为每个文本都通过具有数亿个参数的神经网络。333此外,如果我们要求交叉编码器进行分类,如果与、 与 相同, 与 相同,可能会导致不及物性。 相反,对于将 文本与 其他文本进行比较的双编码器,仅需要 嵌入,从而使该方法具有高度可扩展性。 为了两全其美,文献通常使用双编码器来获取与查询文本最相似的 文本(对于一些小的 ),然后重新编码使用交叉编码器对这些匹配进行排名。
7 嵌入模型
为了估计分类器,必须事先指定类,因为类的数量决定了神经网络中参数的数量,并且类必须在训练中看到。 促进生成人工智能进行分类任务还需要指定感兴趣的类别。 然而,存在各种问题,其中类别事先未知,或者研究人员希望稍后添加新类别而不必重新训练模型。 此外,如果类的数量很大,计算损失函数的所有类的 softmax 可能会变得计算困难。
这些常见场景可以通过直接使用 Transformer 或 CNN 最后一层的嵌入来解决,而不是估计将嵌入映射到类别分数的附加神经网络层(分类器)。 这避免了类的预先指定。 此外,向量相似度计算经过高度优化,可以解决数百万甚至数十亿类规模的问题。
本节介绍了可以使用嵌入模型来处理的各种应用程序。 记录链接(例如,数据集中的个人、公司、位置或产品)是一项常见任务,可以将其构建为具有许多类的分类问题(例如,每个个人、公司等)。 它特别适合嵌入方法(7.2 节)。 这些方法可以处理设置(例如多语言链接或与多个嘈杂文本描述的链接),而传统的字符串匹配方法很难处理这些设置。 类似的方法也可用于将非结构化文本(例如,社会或印刷媒体、公司文件、传记、政府文件)中提及的个人、公司等内容与维基百科等外部知识库链接起来(第 7.3)。 跟踪文本或图像通过媒体的传播是另一个潜在兴趣的应用,其中的类别通常是事前未知的(第 7.4 节)。 在某些情况下,目标可能是探索性的,以揭示大量小说文本或图像数据集中的程式化事实,而嵌入方法非常适合此类描述性分析。 最后,光学字符识别(OCR)可以被构建为图像分类任务,研究人员可能希望随后添加字符或单词而不重新训练模型,建议嵌入方法(第 7.5 节)。
直接使用嵌入需要向量表示之间的距离有意义。 预训练的 Transformer 语言模型的几何属性不太适合这项任务。 例如,低频词的表示在超球面上被向外推。 低频词的稀疏性违反了凸性,嵌入之间的距离与词汇相似度相关。 这会导致语义相似文本的嵌入之间的对齐不良,并且当汇集各个术语表示来创建文本序列的平均表示时,性能较差(Ethayarajh,2019;Reimers 和 Gurevych,2019)。
从数学上讲,问题在于预训练的 Transformer 模型创建的嵌入空间不是各向同性,这意味着表示不是均匀分布的。 当嵌入是各向同性时,没有特定的方向是有利的。 这种均匀分布确保向量之间的距离准确反映它们的关系,使空间对于依赖这些距离的任务更有效。 对比学习是一种广泛使用的方法,可以提高各向同性,在转向嵌入模型应用之前会对其进行讨论。
7.1 对比学习
对比学习的目的是学习语义相似输入的相似表示和语义不同输入的不同表示,其中相似性的定义由经验训练示例给出。 对比损失函数鼓励模型减少正例(例如,相似的文本或图像)之间的嵌入空间距离,并增加负例(例如不相似的文本)之间的距离。文本或图像)。 对比训练减少了各向异性(Wang and Liu,2021),显着改善了文本序列的池表示(Reimers and Gurevych,2019),并改善了语义相似文本表示之间的对齐。
对比学习遵循图 6 所示的双编码器设置。 双编码器通过 Transformer 传递并池化(平均)术语级嵌入,为每个实例形成单一表示。444代表是集合在一起的,而不是使用<cls>词符,因为这已被证明具有更好的性能(Reimers 和 Gurevych,2019 年)。 可以通过计算向量相似度来比较表示。 在实践中,经常使用余弦相似度,因为表示位于单位超球面上。
根据训练数据,损失函数有不同的选项。 对比损失(Chopra、Hadsell 和 LeCun,2005) 使用正负对,激励正数具有相同的表示形式,而负数之间的距离高于阈值距离。 余弦损失使用实例之间差异的连续度量。 对于三元组损失(Hermans,Beyer 和 Leibe,2017),训练数据由三元组组成:一个锚点、一个锚点的正例和一个负例。 正样本的嵌入被激励为与锚点比负样本更相似。 通过 InfoNCE 损失 (Oord、Li 和 Vinyals,2018),将多个负面示例与单个正面示例进行比较。 监督对比损失(Khosla 等人,2020)概括了 InfoNCE 以允许多个正例和负例。 EconDL 知识库中的“对比学习”帖子提供了更多详细信息,包括数学公式。
神经网络创建的度量空间应根据用于训练网络的对比损失函数进行解释。 例如,对于对比损失,同一类中的实例被激励具有相似的表示,而不同的实例被激励为相距超过阈值距离。 因此,局部距离是有意义的,但全局距离则没有意义,因为超过阈值的不同程度不会影响损失。
当在配对数据上进行对比训练时,用于嵌入每个实例的两个编码器的权重可以相同(对称编码器)或不同(非对称编码器,如 Karpukhin 等人 (2020))。 对称编码器提供了更简洁的模型,因此需要更少的数据和计算来训练。 实际上,即使对两种不同类型的实例进行编码(例如搜索查询和包含其答案的文档),它们也可以表现良好。
选择信息丰富的反例对于对比学习很重要。 如果负数太“简单”——训练,它们在用于初始化的预训练模型的嵌入空间中是不同的——则学到的东西很少。 在某些情况下,研究人员可以使用先验知识来选择训练的“硬”否定。 在其他情况下,可以通过使用预先训练的模型来选择具有相似嵌入的负面示例来挖掘它们。 如果研究人员事先知道哪些实例是负面的,那么这种方法就可以很好地发挥作用,就像在综合生成的数据上进行训练时的情况一样。 然而,当从未标记的数据中提取负样本时,在没有人参与的情况下挖掘硬负样本可能会无意中选择正样本。 有时,对随机负数进行训练可能就足够了,尽管这通常需要大批量(例如,具有大量内存的 GPU 卡),这不符合学术计算预算。 本节的应用程序考虑如何选择底片。
嵌入也可以现成使用。 Sentence-BERT (Reimers 和 Gurevych,2019) 是一个著名且得到良好支持的开源模型。 (在本文中,术语“句子”用于指代任何文本序列,可以是短语、句子或整个文档。) 此外,OpenAI 销售的句子嵌入价格相当实惠。
虽然人们对开发可以在任何任务上表现出色的零样本(Cao,2023)的通用嵌入模型抱有很大兴趣,并且较大的模型平均会优于较小的模型零样本 - 精细 -经过调整的轻量级嵌入模型比零样本嵌入具有重要优势。 直观上,嵌入为每个文本(或图像)提供了单一表示。 现成的表示将捕获有关文本/图像的许多不同信息。 然而,研究人员通常对其某些狭义的方面感兴趣。 微调将强调相关维度,从而在嵌入空间中的类之间创建更好的分离。
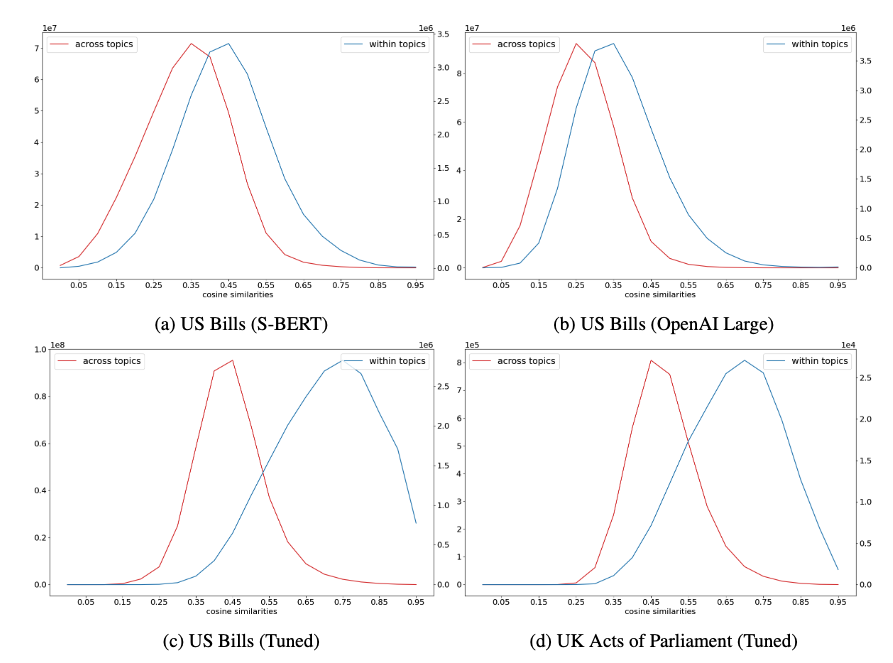
考虑以下经验示例。 我采用美国立法的比较议程数据集(Wilkerson等人,2023),该数据集为国会法案分配主题标签,并使用三种不同的模型计算立法描述的嵌入之间的成对相似性:现成的轻量级 S-BERT 嵌入(图 7,图 a)、OpenAI 大型嵌入(图 b),以及通过对来自 a 的成对正值和(随机)负值账单调整 S-BERT 生成的嵌入训练这些数据的分割(面板c)。 蓝色分布绘制了主题内的余弦相似度,红线绘制了主题之间的余弦相似度。 相同的表示的相似度为 1。
使用现成的模型,主题内的嵌入确实比主题间的嵌入更相似(例如,蓝色分布向红色分布的右侧移动),但差异并不明显。 SBERT 和 OpenAI 的表现类似。 相比之下,一旦模型在目标数据上进行了调整,主题内的嵌入比主题之间的嵌入更加相似,因为对比训练强调了主题在确定语言模型如何将文本映射到嵌入空间方面的重要性。 分布中的大部分重叠来自边缘情况,即文章落在主题之间或涵盖多个主题。 小组(d)使用根据美国法案调整的模型来比较英国议会法案在主题内和跨主题的嵌入。 虽然存在一些领域转移,但仍然存在明显的分离,显示了微调模型泛化到类似问题的能力。
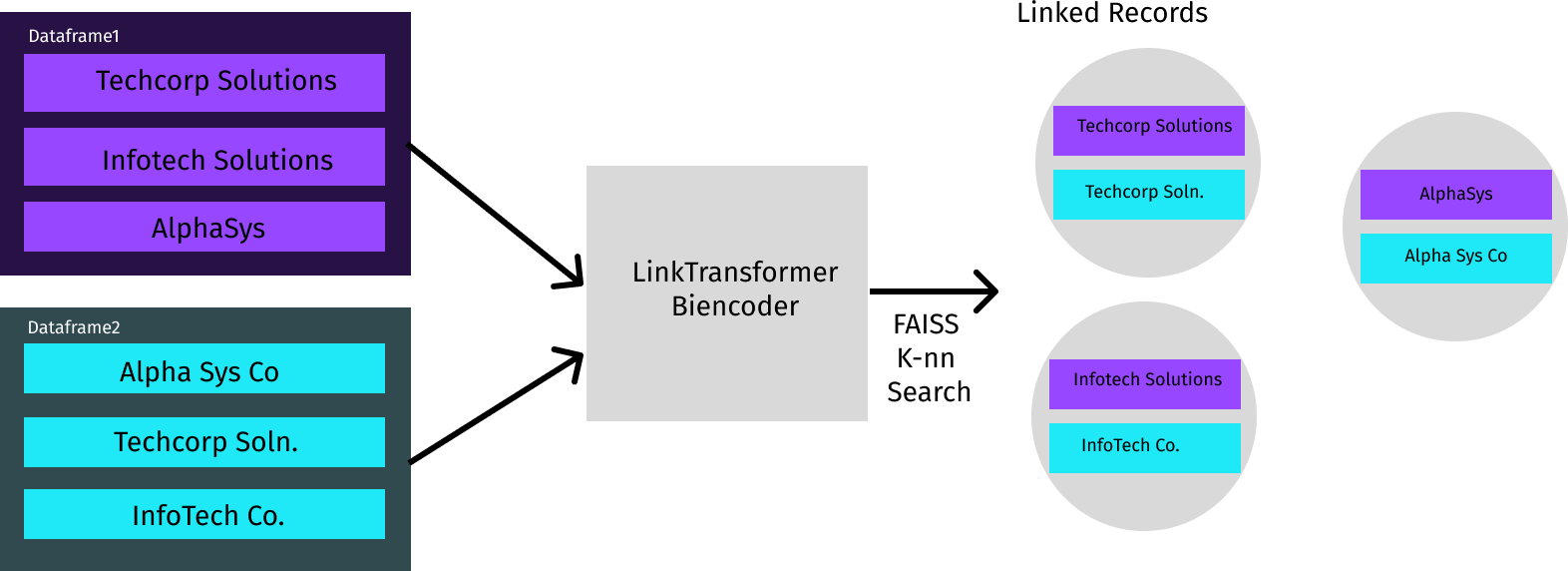
7.2 记录与结构化数据的链接
记录关联是许多经济分析的核心。 研究人员可能需要跨数据集链接个人、地点、公司、组织、产品描述或学术论文。 传统上,记录是使用 Levenshtein 编辑距离(计算字符插入、删除和替换的数量以将一个字符串转换为另一个字符串)或 Jaccard 相似度(计算字符串的子字符串 n 元语法表示之间的相似性)等度量来链接的。 最近的一篇专注于跨电子商务数据集匹配的机器学习文献显示了 Transformer 大语言模型在改善记录链接方面的前景。 然而,在撰写本文时,这些方法尚未在社会科学领域取得广泛进展,基于规则的方法继续占据压倒性优势(例如参见Binette 和 Steorts 的评论(2022) ; Abramitzky 等人 (2021); Bailey 等人 (2020))。
为了使这些方法更易于使用,Arora 和 Dell (2024) 设计了 LinkTransformer,这是一个使用 Transformer 模型进行记录链接的包,面向社会科学家。 该研究证明, Transformer 在各种任务和语言中的表现都优于传统的字符串匹配方法,而且通常差距很大。 应用包括使用多个噪声字段链接 1940 年墨西哥关税表和链接 1950 年日本公司级记录,以及跨六种语言链接现代公司和产品。 多语言模型可以跨语言链接产品,而无需翻译。
这项工作的动机是我在前深度学习时代不得不放弃的各种项目,因为稀疏方法表现不佳并且手动链接不可行。 与任何预测任务一样,研究人员有责任使用测试集来评估性能是否可接受。
LinkTransformer模型架构如图8所示。 需要匹配的文本使用 Transformer 语言模型进行编码。 对于每个查询,LinkTransformer 会根据嵌入之间的余弦相似度来测量语料库中最近的邻居。 这是非常快的,因为它使用高度优化的 FAISS(Facebook 人工智能相似性搜索)后端(Johnson、Douze 和 Jégou,2019)。 LinkTransformer 返回排名以及余弦相似度分数,可用于 1-1、1-many 或多对多合并,包括不匹配(当与最近记录的相似度时捕获)低于某个阈值)。
正如编辑距离返回记录之间的距离等传统稀疏方法一样,LinkTransformer 计算由预训练语言模型中体现的所有语义知识以及通过对比训练获得的任何附加知识提供支持的距离度量。 。 例如,ABC Corporation、ABC Co. 和 ABCC 在语义上非常相似,因此在嵌入空间中非常相似,因为“Co.”和“C”代表“Corporation”,但这些字符串具有较高的编辑距离。 由于缩写的普遍存在、描述同一产品或公司名称的不同方式、OCR 错误和拼写错误,此类示例在记录链接任务中很常见。 嵌入相似性的使用类似于研究人员使用字符串距离度量的方式。
链接转换器(LinkTransformer)无缝支持使用多个字段进行链接,通过将字段与软件包自动选择的 <sep> 词符串联来序列化字段,从而与基础语言模型词符器兼容。 该研究提供了一个例子,使用公司名称、地点、产品、股东和银行将 20 世纪 50 年代的日本公司连接到不同的大规模、嘈杂的数据库中。 由于字段存在噪声(例如,不同数据集对产品的描述方式不同,列出的经理和股东子集也不同,等等),因此使用字符串匹配方法来解决这类关联问题会非常复杂。 大型语言模型可以轻松应对这些挑战,因为它捕获了语义相似性。
LinkTransformer 允许用户使用 Sentence Transformer 模型、OpenAI 嵌入、针对目标任务调整的模型或 Hugging Face 上可用的任何 Transformer 语言模型。 在 20 个不同的链接任务中,总体情况是,在少量标签上进行自定义训练的模型往往表现最佳,其次是 OpenAI 的现成嵌入,然后是现成的 Sentence Transformer 模型(尽管不同任务之间存在一些差异)。 结果与上面对现成嵌入模型与定制嵌入模型的讨论一致。
LinkTransformer 还提供 API 以使用 Transformer 大语言模型执行其他数据处理任务,例如、分类、聚合和重复数据删除,如 EconDL 链接的教程笔记本中所述。 用户还可以找到“训练您自己的 LinkTransformer 模型”教程,以供需要自定义时使用。 对比训练需要正负对(在本例中为链接记录和不同记录)。 用户可以仅提供正数(在这种情况下,LinkTransformer 会随机选择负数),或者如果存在硬负数,则可以同时提供正数和负数。 为了提高可重用性、可重复性和可扩展性,可以使用一行代码将模型共享到 Hugging Face 中心。
当任务是链接扫描文档时(如许多经济史),计算机视觉也可能有用。 在Arora等人(2023)开发的仅视觉记录链接模型中,记录链接是无OCR的,仅使用要链接的公司名称的图像裁剪。 这是在一个具有挑战性的环境中进行探索的,将日本历史出版物之间的公司联系起来,其中一份出版物是水平书写的,另一份出版物是垂直书写的。 一般来说,仅视觉联动会带来相当高的精度。 然而,有一些匹配是愿景模型无法解决的,因为公司可以用不同的方式书写其名称。
嵌入模型可以结合视觉和语言转换器,利用对语义和视觉相似性的理解。 Arora 等人 (2023) 表明,多模式模型可以极其准确地链接经过 OCR 处理的日本公司级客户和供应商记录,而不太准确的字符串距离指标会产生不同的供应链网络,可能会导致下游经济分析出现偏差。
当嵌入空间对齐时,组合文本和图像嵌入是最简单的。 换句话说,同一事物的图像和文本需要具有相似的嵌入;例如,当图像和文本编码器分别将鳄梨的图片和文本 "avocado "映射到矢量空间时,它们具有相似的嵌入。 Arora 等人 (2023) 从日语版的 CLIP 开始,CLIP 代表对比语言-图像预训练。 CLIP 是一种 OpenAI 模型,使用从网络上抓取的 4 亿个图像标题对进行对比训练来对齐文本和图像编码器(Radford 等人,2021)。 Arora 等人 (2023) 对合成噪声的文档裁剪对及其相应的 OCR 文本进行进一步的预训练。 然后使用合并的文本图像表示来链接公司。
还有其他方法可以将视觉相似性合并到链接中,当存在 OCR 错误时,这些方法可能会有所帮助。 近似字符串匹配方法计算将一个字符串转换为另一个字符串所需的编辑(插入、删除和替换)次数(Levenshtein 等人,1966)。 实际上,并非所有字符串替换的可能性都相同,构建改变其成本的列表的努力至少可以追溯到 1918 年,当时 Russell 和 Odell 为 Soundex 申请了专利(Russell,1918;档案与管理,2023),一个完善的标准化工具包,可以解释人口普查员经常根据名字的发音拼写错误的事实。 此类方法可以显着提高其定制上下文中编辑距离链接的准确性,但由于使用手工制作的特征,因此扩展到新设置需要耗费大量人力。 这使得使用关联数据进行的研究(检查许多经济问题所必需的)偏向于不代表人类社会多样性的更高资源环境。
Yang 等人 (2023) 开发了一种可扩展的自我监督方法,用于确定使用 OCR 创建的数据库中字符替换的相对成本。 OCR 经常将字符与其同形文字混淆,这些同形文字具有相似的视觉外观(例如“0”和“O”)。 Yang 等人 (2023) 增强数字字体以对比学习度量空间,其中字符的不同增强(例如使用不同字体呈现的相同字符)具有相似的向量表示。 可以使用生成的空间和参考字体来测量不同字符之间的视觉相似性。 同形文字空间中的字符及其最近邻的示例如图9所示。
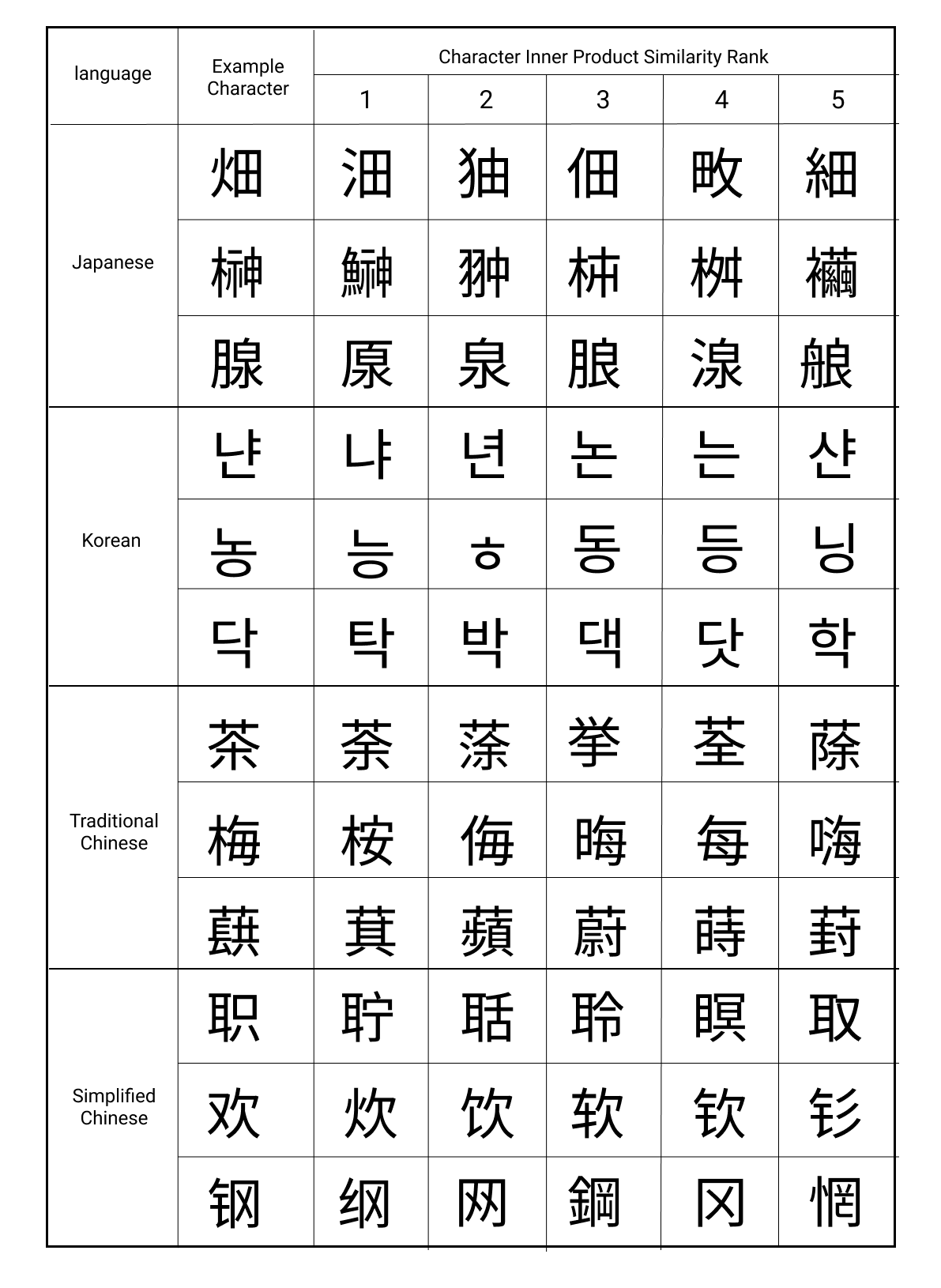
使用同形字空间中字符之间的余弦距离作为 Levenshtein 编辑距离框架内的替换成本(Levenshtein 等人,1966) 显着改善了公司和地名的链接。 这项研究的重点是 CJK,因为该脚本中的字符数量极其庞大,因此手动计算同形字完全不可行,但表明该方法可以通过计算古汉字和所有 Unicode 的同形字来扩展。 更广泛的结论是,即使传统方法(如弦距离)是首选,深度学习也可以提供一种将这些方法廉价地扩展到新环境的方法。
7.3 链接非结构化数据
还有大量关于链接非结构化文本(例如,新闻、社交媒体等)中提到的实体的 NLP 文献,这项任务称为实体消歧。 将原始文本中提到的实体(通过 NER - 第 6.4 部分标记)链接到维基百科或其他知识库非常有用,因为这些包含结构化传记数据等信息。 个人是否处于外部知识库中本身也可能令人感兴趣。
研究人员可能还希望在语料库中对各文档中提及的实体进行核心参照(例如,查找历史新闻中对约翰-肯尼迪总统的所有提及)。 这被称为 共指解析。
尽管数字化程度不断提高,但历史文献通常缺乏文本中提到的个人的跨文档标识符,以及来自维基百科等外部知识库的标识符,这两者都将使经济学家更容易从这些来源中提取结构化数据。
Arora 等人 (2024) 开发了一种双编码器嵌入模型,用于在文本中引用实体并消除维基百科的歧义。 该模型在维基百科上超过 1.9 亿个实体对上进行了对比训练。 正对来自维基百科中的上下文(段落),其中包含指向同一页面的超链接(用于共指),或者来自上下文及其链接到的相关实体的第一段(用于消歧)。 硬否定是从维基百科消歧页面中大规模挖掘的,该页面列出了具有易混淆名称或别名的实体。 例如,消歧页面“约翰·肯尼迪”包括总统约翰·F·肯尼迪、约翰·肯尼迪(路易斯安那州政治家)、小约翰·F·肯尼迪以及各种其他约翰·肯尼迪。 硬否定对提及约翰·肯尼迪的上下文进行采样(例如,带有指向约翰·肯尼迪页面的超链接),并将它们与提及约翰·肯尼迪消歧页面中其他实体的上下文配对。 来自家庭(例如,小亨利·福特和老亨利·福特)的硬负面因素在维基数据中挖掘家庭成员的比例过高。 此外,还必须包含随机负值,否则模型就会失去区分简单情况的初始能力,这种现象在深度学习文献中被称为灾难性遗忘。
这说明了如何挖掘现有知识来为对比训练创建信息丰富的否定。 更一般地说,维基百科是训练数据的有用来源(例如训练LinkTransformer模型的公司别名也取自维基数据)。
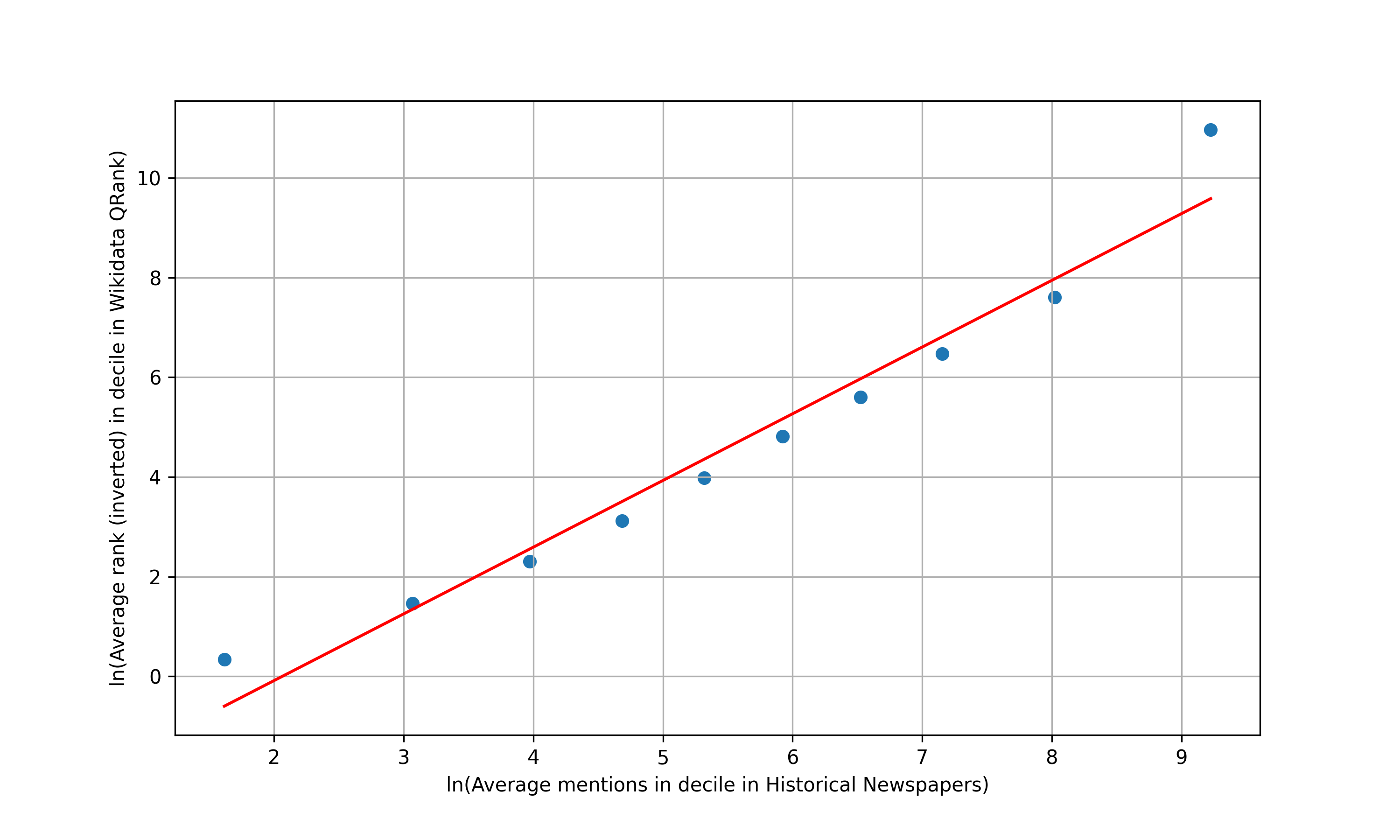
通过将实体提及的上下文嵌入消歧模型并在嵌入空间中检索其最近的维基百科邻居来消除实体提及的歧义。 如果它们与最近的维基百科嵌入的余弦相似度低于阈值,则它们被标记为不在知识库中。 图 10 显示,在 1878 年至 1977 年的 100 年新闻专线报道中提及的实体与维基百科 Qrank 密切相关,后者根据维基宇宙中的聚合页面浏览量对维基数据实体进行排名 Arora 等人 (2024 年) )。 Silcock 等人 (2024) 发现这 100 年来被提及最多的实体是德怀特·艾森豪威尔(Dwight Eisenhower)——排挤阿道夫·希特勒(Adolf Hitler)、理查德·尼克松(Richard Nixon)和哈里·杜鲁门(Harry Truman)——而新闻专线文章中只有 4.7% 的消除歧义实体是女性。
7.4 类别未知时的分类
研究人员想要从非结构化数据中推断出的类别可能事先是未知的。 当目标是描述新颖的非结构化语料库中的程式化事实时,这种情况尤其可能发生,但也可能更普遍地出现。 本节提供了来自媒体经济学的几个示例:检测复制的文章文本和图像,对历史上最大的新闻故事进行分类,以及检索在语义上与现代新闻故事相似的历史新闻故事。
复制内容是媒体的基本特征——无论是传统媒体还是通过社交媒体共享的时代。 媒体历史学家 Julia Guarneri (2017) 写道:“到 1910 年代和 1920 年代,美国人在当地报纸上读到的大多数文章要么在全国新闻市场上购买要么出售……这构建了一个广泛的市场了解美国的‘生活方式’,这将成为整个二十世纪美国国内政治和国际关系的试金石。”假设我们希望能够识别通过新闻专线发送的每一篇独特的文章和图像,测量其被转载的范围,并观察哪些报纸转载了它。 这个问题比看起来更具挑战性。 文本通常被大量删节,并且可能包含严重的 OCR 错误。 图像经常被裁剪,并且质量可能极低。
Silcock 等人 (2023) 表明,在检测嘈杂重复文本方面,深度神经方法可以显着优于非神经方法,并应用于历史新闻专线、现代新闻和专利数据库。 训练和评估数据是通过将数千份数字化当地报纸的文章分组为来自同一新闻专线来源的文章组来手工策划的。 来自同一来源的文章是积极的。 -gram 重叠度高但来源不同的文章(通常是来自不同新闻专线服务或文章更新的类似文章)形成硬底片。 训练中也使用随机否定。
双编码器嵌入模型经过对比训练,使得来自同一有线文章源的文章(无论噪声和删节)具有相似的向量表示,而来自不同源的文章(即使关于相同的底层故事)具有不同的表示。 然后可以使用高效的单链接聚类对这些表示进行聚类,以量化哪些文章来自相同的底层新闻专线或联合文章源,哪些来自不同的文章源。 社区检测用于打破虚假链接,这是单链接聚类的潜在缺点。555其他常见的聚类方法(例如层次凝聚聚类)无法很好地扩展。 与记录链接一样,Sentence-BERT 库(Reimers 和 Gurevych,2019) 是一个重要资源。 该模型使用 S-BERT MPNet 双编码器进行初始化,这是一种轻量级、高性能的语义相似性模型。
神经方法大大优于传统的 -gram 和散列方法(依靠术语重叠来检测噪声重复的稀疏方法)。 正如 6.5 节中所建议的,添加一个重新排序步骤(将交叉编码器应用于阈值双编码器距离内的文章)会产生适度的增益。
嵌入方法的优势在于其可扩展性。 聚类密集向量表示需要高度优化的相似性搜索,因为传统的聚类库无法很好地扩展。 Facebook AI 相似性搜索 (FAISS)(Johnson、Douze 和 Jégou,2019),一个用于计算向量相似性的开源库,进行了 精确的相似性比较——聚类 10 所需大约 3 小时内在单个 GPU 卡上呈现 100 万篇文章。 通过使用近似向量搜索(使用适当调整的超参数),这可以显着加快速度,而对准确性的影响很小。
Silcock 等人 (2024) 发布了 1878 年至 1977 年间 270 万篇独特的新闻专线文章(结束日期因版权法变化而定)。 它包括主题标签、命名实体标签、维基百科的个人消歧以及文章运行的县。
检测图像的噪声再现类似于检测再现的文本。 视觉模型可以进行对比训练,将同一图像的再现版本映射到相似的矢量表示,将不同的图像映射到不同的表示,而不是训练语言模型。 轻量级 CNN 在实践中效果很好(Howard 等人,2019),使用更大的 ViT 几乎没有什么好处。 训练数据主要由合成增强图像组成——模拟实际图像中存在的噪声。 当可以模拟真实的合成数据时,这可以节省大量的标注费用,尽管从目标数据中添加适量的标记示例仍然可以提供性能提升。
嵌入模型非常适合大规模评估非结构化数据中的程式化事实。 深度学习使得在经济研究中使用各种新颖的非结构化数据集成为可能。 虽然我们的重点通常是使用因果估计来测试精确定义的假设,但理解程式化事实是制定这些假设的重要的第一步。
考虑 Dell 等人 (2023) 的一个应用程序,该应用程序构建了一个历史报纸数据集,其中包含超过 4.3 亿篇美国历史报纸文章。 该练习的目的是确定每年最大的新闻报道,而无需事先了解这些新闻报道的内容。 该研究对比性地使用来自 AllSides 的数据训练模型,AllSides 是一个现代新闻网站,它将不同来源的新闻文章分组为故事(通常对同一事件有不同的观点)。666https://www.allsides.com/unbiased-balanced-news 分组故事形成正对对于训练,模型通过这些经验示例学习什么构成“同一个故事”。 训练好的模型用于嵌入文章,通过聚类形成故事。 表3报告了每年最大的集群(戴尔等人,2023)。 出现了一些有趣的程式化事实,特别是对劳工运动的广泛报道。 如果研究人员想要创建一种劳动力流动的衡量标准以用于因果估计方程,他们可能会训练一个带有精心设计的标签的分类器来预测哪些文章是关于劳动力流动的。 相比之下,这个练习首先激发了为什么劳工运动是重要的研究对象。
| Year | Biggest story |
|---|---|
| 1885 | Death of General Grant |
| 1886 | Southwest Railroad Strike |
| 1887 | Vatican supports Knights of Labor |
| 1888 | Rail strikes |
| 1889 | Samoan Crisis |
| 1890 | 1893 World’s Fair planning |
| 1891 | New Orleans Lynchings |
| 1892 | Homestead Steel Strike |
| 1893 | World’s Fair, Chicago |
| 1894 | Wilson–Gorman Tariff Act |
| 1895 | British occupation of Nicaragua |
| 1896 | Bimetallism Movement |
| 1897 | Coal Miners’ Strike |
| 1898 | Cuban War of Independence |
| 1899 | Philippine-American War |
| 1900 | Anglo-Boer War |
| 1901 | U.S. Steel Recognition Strike |
| 1902 | Anthracite Coal Strike |
| 1903 | Panama Canal Treaty |
| 1904 | Russo-Japanese War |
| 1905 | Russo-Japanese Peace Process |
| 1906 | Hepburn Railroad Rate Bill |
| 1907 | Mining accidents |
| 1908 | Taft presidential victory |
| 1909 | Race to the North Pole |
| 1910 | Rail strikes |
| 1911 | Canadian Reciprocity Bill |
| 1912 | Republican National Convention |
| 1913 | Underwood-Simmons Tariff Act |
| 1914 | World War I |
| 1915 | World War I |
| 1916 | Pancho Villa Expedition |
| 1917 | World War I |
| 1918 | World War I |
| 1919 | Treaty of Versailles |
| 1920 | Rail strikes |
Franklin 等人 (2024) 使用此模型进行额外的数据探索,首先屏蔽掉所有命名实体(人、组织、位置和其他杂项专有名词),然后查询最相似的历史新闻文章嵌入空间中的现代新闻文章查询。 由此产生的 News Déjà Vu 开源包和网站提供了一种新颖的工具,用于探索人们如何看待过去和现在的相似之处。
7.5光学字符识别
光学字符识别(OCR)对于经济学家,尤其是经济史学家来说是一项重要任务。 文档在字符集、语言、字体或手写、打印技术以及扫描和老化伪影方面极其多样化。 现成的 OCR 技术主要是为英语等高资源语言的小规模商业应用而开发的,其使用的架构并不适合将 OCR 扩展到低资源语言和环境中,这一点将在第 9 节中详细阐述。 当远离英语和其他一些高资源语言时,OCR 质量可能会迅速恶化(Carlson、Bryan 和 Dell,2024;Hegghammer,2021)。 例如,在 20 世纪 50 年代印刷的日语文档中,性能最好的现有 OCR 会错误预测超过一半的字符。 性能不佳的情况很普遍,催生了大量 OCR 后纠错文献 (Lyu 等人, 2021; Nguyen 等人, 2021; van Strien. 等,2020).
即使在最高的资源设置下,现成的解决方案仍然可能会失败,尤其是在准确性至关重要的情况下。 在转录定量数据时尤其如此。 散文中的 OCR 错误通常可以在后处理中直接纠正,但也可能无关紧要。 然而,对于数字,类似的错误(例如在数字开头出现“1”的幻觉)可能会严重影响下游统计分析。
此外,需要数字化的文档收藏规模可能非常巨大。 例如,美国国家档案馆拥有大约 132.8 亿页的文本记录。 将大数据带入经济史需要准确且部署成本低廉的 OCR 技术。
如果经济学家、历史学家和其他人仅仅依赖现成的商业技术,我们最终将专注于看起来很像高资源商业应用的经济应用(例如英文收据)。 这确实是我多年来与学生合作所看到的情况:他们更有可能放弃资源较低语言的项目,因为任何现有现成解决方案的 OCR 质量都很差。 这使得经济知识倾向于看起来更像是高资源商业应用的环境,而这些应用并不代表人类社会的多样性。
为了应对这些挑战,Carlson、Bryan 和 Dell (2024) 开发了一种新颖的开源 OCR 架构,EffOCR (EfficientOCR)。 EffOCR 专为研究人员和档案馆而设计,为各种文档寻求样本高效、可定制、可扩展的 OCR 解决方案。 基于深度学习的对象检测方法(第 8 节)用于定位文档图像中的单个字符或单词。 字符或单词的识别模型主要在增强数字字体上进行对比训练,以将相同字符或单词的图像裁剪映射到类似的矢量表示,而不管字体和其他变化如何。 不同的字符或单词,即使它们具有非常相似的视觉外观,也会被映射得更远。
通过嵌入单词或字符裁剪并在嵌入用数字字体渲染的裁剪的索引中检索它们最近的邻居来转录文档。 新的字符或单词可以在训练后添加到索引中(与分类器不同),这对于经济历史学家来说是一个有用的功能,因为特殊的符号经常出现在历史文献集中。

即使使用专为移动电话设计且训练和部署成本低廉的轻量级模型,EffOCR 的性能也非常准确。 例如,它可以为所有当前解决方案都失败的历史日语文档提供高效、高度准确的 OCR 架构示例。 其准确性和高效运行时间的结合也使其对于以高资源语言进行大规模馆藏数字化具有吸引力。 Dell 等人 (2023) 使用 EffOCR 以低廉的成本将美国国会图书馆收藏的超过 4.3 亿篇历史报纸文章数字化。 TrOCR 是一种具有类似精度的开源解决方案,其部署成本要高出近 50 倍,而商业解决方案的成本甚至更高。
EconDL 链接到演示笔记本,用于使用最少的云计算来训练多调(古)希腊语的自定义 OCR。 Carlson、Bryan 和 Dell (2024) 表明该模型在目标数据上优于 Google Cloud Vision。 该笔记本使用EffOCR包(Bryan等人,2023),它允许用户调整自己的OCR模型并运行现成的现有模型。 EffOCR 不专注于手写;然而,方法是类似的。 合成手写生成器,例如, Bhunia等人(2021),可以为预训练提供大量数据,类似于数字字体的使用。
8回归
回归类似于分类,只不过添加到神经网络的回归层预测连续的数字,而不是一组类别分数。 因此,我们在这里的处理很简短,重点关注单个应用:对象检测。
物体检测问题,顾名思义,定位图像中的物体(Ren 等人,2017;He 等人,2017;Kirillov 等人,2019;Cai 和 Vasconcelos,2019;Redmon 等人,2016;Ultralytics, 2020;卡里恩等人,2020;刘等人,2021)。 例如,数字化公司财务记录的经济学家需要检测不同文档对象的坐标:例如表格标题、列标题和行标题、表格单元格、脚注等。或者,经济学家希望从街景数据中衡量非正式性需要在图像中定位街头小贩。 对于每个对象,神经网络输出四个连续数字(包含该对象的框的 top-x、top-y、高度和宽度)(回归问题)以及该对象的类别(例如, 表头、列头等)——分类问题。

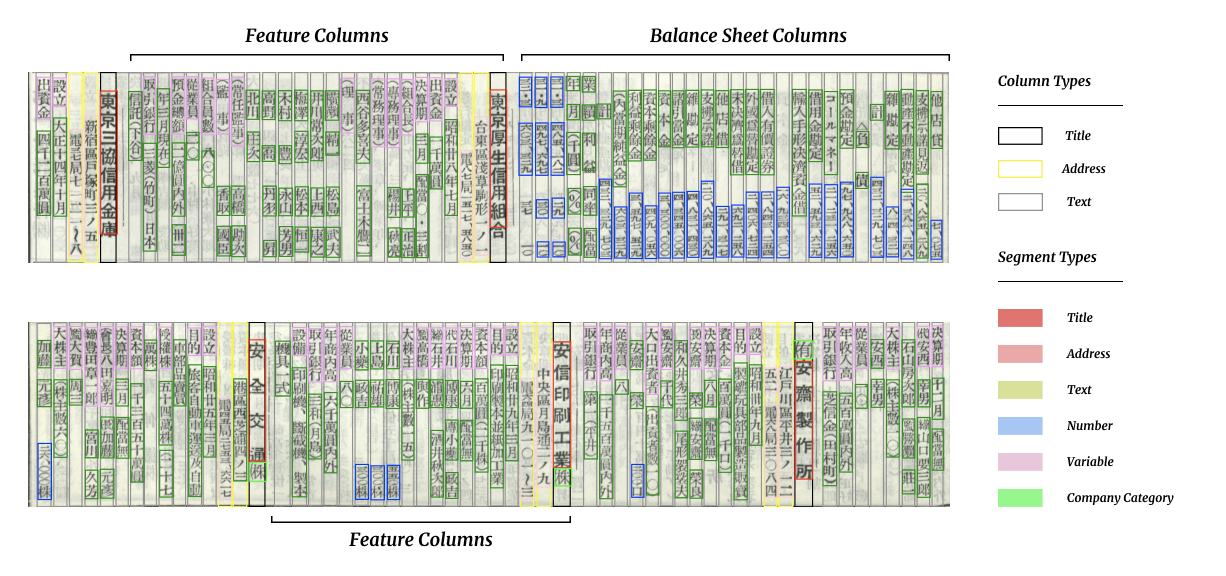
图11显示了如何使用对象检测方法对历史报纸扫描中的文档布局对象(例如、文章、标题等)进行本地化和分类,从而促进创建可以使用现代 NLP 方法进行分析的结构化数字文本。 相比之下,图12提供了一个示例,说明商业 OCR(Google Cloud Vision)如何像单栏书籍一样读取报纸扫描件,无法检测单个文章、标题等。人们可以用这些做所有的事情乱序文本是对关键字的搜索,这在使用历史报纸的经济文献中是典型的(参见 Hanlon 和 Beach (2022) 进行评论)。 在数字化表格数据时,还需要布局检测来提取结构,如图 13 显示的日本公司历史记录。
目前,文档布局检测通常需要定制。 如果目标任务非常接近其微调的目标,那么现成的模型可能会很好地发挥作用。 然而,在计算机视觉中,主要的预训练数据集是ImageNet,它由自然图像组成,例如不同品种的狗。 模型尚未接受过大规模的文档预训练,因此在应用于不同类型的文档时往往会遭受重大的领域转移。 对于异构的历史文献尤其如此。
虽然有一个对象定位的基础模型,即 Meta AI 的 Segment Anything (Kirillov 等人,2023),但在撰写本文时,我还没有发现它对于文档任务非常有用。 它可以定位图像中的对象,但不能将它们分类。 此外,目前文档图像的定位还不是特别准确。
开源包 Layout Parser (Shen 等人, 2021) 降低了深度学习检测文档布局的障碍。 该库包含一个可供现成使用的模型库,并有助于调整定制模型,是通过简单的 Python API 实现的。 更多信息可以在 EconDL 资源页面上找到。 EconDL知识库引入了主动学习进行目标检测(Shen等人,2022),选择模型最不确定的实例来标记,以节省标记成本。
由于空间限制,无法深入研究对象检测模型的架构,但 EconDL 知识库中的对象检测帖子提供了详细的处理。 卫星图像资源包括例如 Aleissaee 等人 (2022);王等人 (2022);班达拉和帕特尔(2022); Fuller、Millard 和 Green (2022) 并从 EconDL 中处理卫星图像的页面链接。
9 替代方法
这篇综述重点关注了一组方法,这些方法虽然是深度学习的支柱,但远非全面。 如果读者深入研究深度学习文献,他们会发现解决上述问题的其他方法,并可能想知道为什么这些方法没有被涵盖。 我专注于分类器和嵌入模型,因为它们通常是样本且计算效率高,这意味着它们可以从有限的数据中很好地学习,并且可以廉价地部署在受限的硬件上。 它们易于训练,并且可以在各种任务中获得最先进的性能。
本节简要介绍了处理 OCR 和实体消歧这两个应用程序的其他方法。 它强调了如何以不同的方式概念化问题,并强调了学术应用中嵌入模型的一些优势。
9.1光学字符识别
7.5 节将 OCR 定义为图像检索问题,使用对比训练的视觉模型。 这与文献不同,文献大多将 OCR 建模为序列到序列 (seq2seq) 问题。 Seq2seq 模型将一个数据序列转换为另一个序列。 当输入和输出数据是长度可能不同的序列时(例如在机器翻译中),经常使用它们。
图 14 突出显示了 OCR 的 EffOCR 和 seq2seq 架构之间的差异。 首先,seq2seq OCR 通常需要行级输入,并且不会本地化单个字符或单词。 相反,它将文本行图像或其表示形式划分为固定大小的块。 相比之下,EffOCR 使用现代对象检测方法(Cai 和 Vasconcelos,2018;Jocher,2020) 来定位输入图像中的字符或单词。
其次,seq2seq 使用学习的语言模型将由学习的视觉模型创建的图像表示顺序解码为文本。 相反,EffOCR 使用对比训练 (Khosla 等人, 2020) 来学习 OCR 的有意义的度量空间。 它的视觉模型将相同字符或单词的作物投影到一起,无论风格如何,同时将不同字符或单词的作物投影到不同的嵌入。 使用 EffOCR,通过从嵌入数字字体创建的索引中检索最近的邻居,仅视觉嵌入就足以推断文本。 相比之下,使用 seq2seq,视觉表示通过语言模型解码为文本,这需要联合估计数百万个附加参数。
seq2seq 架构的一个缺点是扩展和定制新颖的设置具有挑战性(Hedderich 等人,2021),因为训练联合视觉语言模型需要大量标记的图像文本配对和大量计算,特别是在使用最先进的架构时。 TrOCR(由 Microsoft 研究人员创建的 Transformer seq2seq 模型)使用 6.84 亿条英文合成文本行和 32 个 32GB V100 GPU 进行训练,这是一种非常昂贵的设置,任何学术研究人员都无法复制。
这个缺点可以通过样本训练效率来量化,样本效率是指模型在接触有限数量的样本后的表现如何。 有些架构比其他架构学习效率更高。 双编码器往往能够高效学习,这对经济学家来说很重要,因为我们的计算和标注预算受到深度学习标准的严重限制。
图 15 来自 Carlson、Bryan 和 Dell (2024),通过在相同的小型训练集上训练各种开源 OCR 架构来检查样本效率。 x 轴绘制了 EffOCR 训练数据集使用的百分比,y 轴绘制了字符错误率。
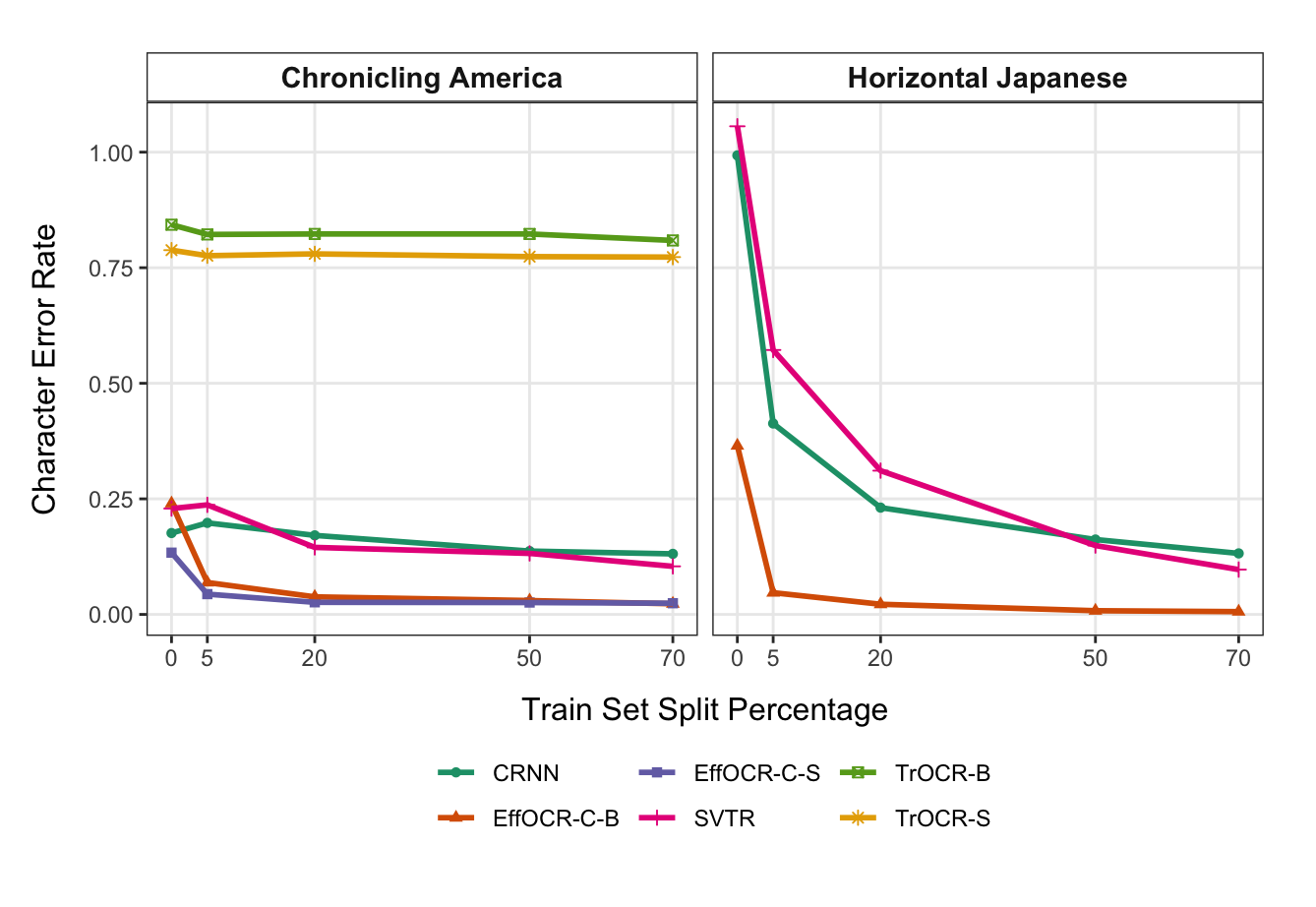
仅在 Chronicling America 集合中的日语表格的 99 个带标签的表格单元格和来自美国报纸的 21 个带标签的行以及数字字体(5% 训练分割)上,EffOCR 的字符错误率约为4%,显示出可行的少样本性能。 其他接受相同数据训练的架构仍然无法使用。 EffOCR 使用 20% 的训练数据时的表现几乎与使用 70% 时的训练数据一样好,并且继续优于所有其他替代方案。 TrOCR 从我们可以公开的数据量中几乎无法学到任何东西(因此微软在 6.84 亿文本行上对其进行训练)。 相比之下,EffOCR 可以使用云中甚至笔记本电脑上的学生帐户进行训练。 CRNN 是一种重量轻得多、较旧的 seq2seq 架构,它可以在有限的数据下学习得更好,但使用 LSTM 而不是 Transformer,导致在完全训练后准确度受到影响。
嵌入模型还可以提供优于 seq2seq 模型的计算优势。 EffOCR 支持跨字符推理并行,从而促进更快的推理,而 seq2seq 需要自回归解码,速度较慢。 EffOCR 的运行速度比 TrOCR 快约 50 倍,TrOCR 是唯一一个在完全训练后准确度可比的开源模型。 我们使用 EffOCR 创建了开源 American Stories 数据集,其中包含超过 4.3 亿条历史新闻文章,预算为 60,000 美元,但实际上无法产生任何大量额外资金,更不用说增加 50 倍的资金了。
样本和计算高效的架构使得在不同环境和大规模文档集合中实现高质量转录成为可能,从而将大数据引入各种经济历史应用。 理论上,从完整的表示序列中进行上下文理解可以带来更好的 OCR。 在实践中,最先进的 Transformer seq2seq 模型的训练和部署成本很高,并且不适用于资源较低的语言,主要在少数语言中取得进展。 通过摆脱 seq2seq 模型,可以实现样本和计算效率的显着提高。 在学术环境中,这些优势尤其重要,因为我们的应用程序高度多样化,而且我们的预算通常非常有限。
9.2 实体消歧
实体消歧——将非结构化文本中的实体提及与维基百科等外部知识库联系起来——导致了各种架构的发展。 其中包括掩码语言模型(LUKE,Yamada 等人(2022))和神经翻译模型(GENRE,De Cao 等人(2020))——它使用序列到序列架构将提及内容转换为维基百科 ID,以及将实体消歧视为最近邻检索问题的双编码器嵌入架构(Wu 等人,2019)。 本文的应用程序使用后一种架构(7.3 节)。
屏蔽语言模型方法屏蔽实体并使用分类器头预测它们的维基百科 ID。 虽然它在某些基准测试中处于领先地位,但实际上它有很大的局限性。 语言模型通过分类来预测屏蔽标记。 由于计算 softmax 时的计算限制,LUKE 仅限于前 50K 维基百科条目。 许多前 5 万条目不是人,历史新闻或政府文件中出现的许多人也不在前 5 万之列。 此外,它不适应知识之外的基础实体,并且需要稀疏实体先验来初始化模型。 在许多应用中,并非所有个人都会在知识库中,并且模型需要能够预测这一点。
神经翻译模型的序列到序列架构在推理过程中速度很慢,运行时间比双编码器嵌入模型长大约 60 倍。 Arora 等人 (2024) 还表明,嵌入模型可以实现更高的消除历史文本歧义的准确度。 简而言之,序列到序列架构的大规模运行成本很高,而且不一定能提供性能优势。
10结论
深度学习为处理非结构化数据提供了强大的工具。 在从文本分类到记录链接、实体消歧以及追踪复制内容的传播等社会科学任务中,深度学习可以大幅优于传统稀疏方法(通常高出 20 个 F1/准确度或更多)( Silcock 等人, 2023; Dell 等人, 2023; Arora 等人, 2024; Arora 等人, 2023, 2024)。
深度学习可以通过提供从大规模非结构化数据中推断结构化信息的工具来促进新颖的分析。 当使用轻量级、样本高效的预训练模型时,即使对于具有数百万或数十亿观察值的数据集,训练和部署也是相当经济实惠的。 对于某些应用,深度学习还为处理来自资源匮乏环境的数据提供了希望,有可能使经济研究更能代表人类社会的多样性。
熟悉深度学习方法需要大量的启动成本。 本文以及随附的开源包、教程和知识库旨在显着降低想要在研究中使用深度学习的经济学家的进入壁垒。
参考
- (1)
- Abramitzky et al. (2021) Abramitzky, Ran, Leah Boustan, Katherine Eriksson, James Feigenbaum, and Santiago Pérez. 2021. “Automated linking of historical data.” Journal of Economic Literature, 59(3): 865–918.
- Alammar (2018a) Alammar, Jay. 2018a. “The illustrated Bert, Elmo, and Co. (how NLP cracked transfer learning).” https://jalammar.github.io/illustrated-bert/.
- Alammar (2018b) Alammar, Jay. 2018b. “The illustrated Transformer.” https://jalammar.github.io/illustrated-transformer/.
- Alammar (2019) Alammar, Jay. 2019. “The illustrated GPT-2 (Visualizing Transformer language models).” http://jalammar.github.io/illustrated-gpt2/.
- Alammar (2020) Alammar, Jay. 2020. “How GPT3 Works - Visualizations and Animations.” https://jalammar.github.io/how-gpt3-works-visualizations-animations/.
- Aleissaee et al. (2022) Aleissaee, Abdulaziz Amer, Amandeep Kumar, Rao Muhammad Anwer, Salman Khan, Hisham Cholakkal, Gui-Song Xia, et al. 2022. “Transformers in remote sensing: A survey.” arXiv preprint arXiv:2209.01206.
- Ali et al. (2021) Ali, Alaaeldin, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Jakob Verbeek, et al. 2021. “Xcit: Cross-covariance image transformers.” Advances in Neural Information Processing Systems, 34: 20014–20027.
- Angelopoulos et al. (2023) Angelopoulos, Anastasios N., Stephen Bates, Clara Fannjiang, Michael I. Jordan, Tijana Zrnic, and Emmanuel J. Candès. 2023. “Prediction-Powered Inference.” arXiv preprint arXiv:2301.09633.
- Archives and Administration (2023) Archives, U.S. National, and Records Administration. 2023. “The Soundex Indexing System.” Accessed: 11/10/2023.
- Arora and Dell (2024) Arora, Abhishek, and Melissa Dell. 2024. “LinkTransformer: A Unified Package for Record Linkage with Transformer Language Models.” Association of Computational Linguistics: Systems Demonstration Track.
- Arora et al. (2024) Arora, Abhishek, Emily Silcock, Leander Heldring, and Melissa Dell. 2024. “Contrastive Entity Coreference and Disambiguation for Historical Texts.” arXiv preprint arXiv:2406.15576.
- Arora et al. (2023) Arora, Abhishek, Xinmei Yang, Shao Yu Jheng, and Melissa Dell. 2023. “Linking representations with multimodal contrastive learning.” arXiv preprint arXiv:2304.03464.
- Athey and Imbens (2019) Athey, Susan, and Guido W Imbens. 2019. “Machine learning methods that economists should know about.” Annual Review of Economics, 11: 685–725.
- Bailey et al. (2020) Bailey, Martha J, Connor Cole, Morgan Henderson, and Catherine Massey. 2020. “How well do automated linking methods perform? Lessons from US historical data.” Journal of Economic Literature, 58(4): 997–1044.
- Bandara and Patel (2022) Bandara, Wele Gedara Chaminda, and Vishal M Patel. 2022. “A transformer-based siamese network for change detection.” 207–210, IEEE.
- Bengio, Simard and Frasconi (1994) Bengio, Yoshua, Patrice Simard, and Paolo Frasconi. 1994. “Learning long-term dependencies with gradient descent is difficult.” IEEE transactions on neural networks, 5(2): 157–166.
- Bhunia et al. (2021) Bhunia, Ankan Kumar, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Fahad Shahbaz Khan, and Mubarak Shah. 2021. “Handwriting transformers.” 1086–1094.
- Binette and Steorts (2022) Binette, Olivier, and Rebecca C Steorts. 2022. “(Almost) all of entity resolution.” Science Advances, 8(12): eabi8021.
- Brown et al. (2020) Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. “Language models are few-shot learners.” Advances in Neural Information Processing Systems, 33: 1877–1901.
- Bryan et al. (2023) Bryan, Tom, Jacob Carlson, Abhishek Arora, and Melissa Dell. 2023. “EfficientOCR: An Extensible, Open-Source Package for Efficiently Digitizing World Knowledge”.” Empirical Methods on Natural Language Processing (Systems Demonstrations Track).
- Cai and Vasconcelos (2018) Cai, Zhaowei, and Nuno Vasconcelos. 2018. “Cascade r-cnn: Delving into high quality object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition, 6154–6162.
- Cai and Vasconcelos (2019) Cai, Zhaowei, and Nuno Vasconcelos. 2019. “Cascade R-CNN: high quality object detection and instance segmentation.” IEEE transactions on pattern analysis and machine intelligence, 43(5): 1483–1498.
- Cao (2023) Cao, Hongliu. 2023. “Recent advances in universal text embeddings: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark.” Amadeus SAS France.
- Carion et al. (2020) Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. “End-to-end object detection with transformers.” 213–229, Springer.
- Carlson, Bryan and Dell (2024) Carlson, Jacob., Tom. Bryan, and Melissa. Dell. 2024. “Efficient OCR for Building a Diverse Digital History.” ACL Anthology.
- Caron et al. (2021) Caron, Mathilde, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. “Emerging properties in self-supervised vision transformers.” 9650–9660.
- Cattaneo et al. (2022) Cattaneo, Matias D., Yingjie Feng, Filippo Palomba, and Rocio Titiunik. 2022. “Uncertainty Quantification in Synthetic Controls with Staggered Treatment Adoption.” Journal of Econometrics, 228(2): 260–279.
- Chen, Xie and He (2021) Chen, Xinlei, Saining Xie, and Kaiming He. 2021. “An empirical study of training self-supervised vision transformers.” 9640–9649.
- Chernozhukov et al. (2018) Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. “Double/debiased machine learning for treatment and structural parameters.” The Econometrics Journal, 21(1): C1–C68.
- Chernozhukov, Wüthrich and Zhu (2021) Chernozhukov, Victor, Kaspar Wüthrich, and Yinchu Zhu. 2021. “An Exact and Robust Conformal Inference Method for Counterfactual and Synthetic Controls.” Journal of the American Statistical Association, 116(536): 1849–1868.
- Chernozhukov, Newey and Singh (2022) Chernozhukov, Victor, Whitney K. Newey, and Rahul Singh. 2022. “Automatic Debiased Machine Learning of Causal and Structural Effects.” Econometrics Journal, 25(3): C1–C38.
- Chopra, Hadsell and LeCun (2005) Chopra, Sumit, Raia Hadsell, and Yann LeCun. 2005. “Learning a similarity metric discriminatively, with application to face verification.” Vol. 1, 539–546, IEEE.
- Cui and Athey (2022) Cui, Peng, and Susan Athey. 2022. “Stable learning establishes some common ground between causal inference and machine learning.” Nature Machine Intelligence, 4(2): 110–115.
- De Cao et al. (2020) De Cao, Nicola, Gautier Izacard, Sebastian Riedel, and Fabio Petroni. 2020. “Autoregressive entity retrieval.” arXiv preprint arXiv:2010.00904.
- Dell et al. (2023) Dell, Melissa, Jacob Carlson, Tom Bryan, Emily Silcock, Abhishek Arora, Zejiang Shen, Luca D’Amico-Wong, Quan Le, Pablo Querubin, and Leander Heldring. 2023. “American Stories: A Large-Scale Structured Text Dataset of Historical US Newspapers.” Advances in Neural Information and Processing Systems, Datasets and Benchmarks.
- Deng et al. (2009) Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. “Imagenet: A large-scale hierarchical image database.” 248–255, IEEE.
- Devlin et al. (2019) Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” 4171–4186, Association for Computational Linguistics.
- Dodge et al. (2021) Dodge, Jesse, Maarten Sap, Ana Marasović, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. 2021. “Documenting large webtext corpora: A case study on the colossal clean crawled corpus.” arXiv preprint arXiv:2104.08758.
- Dosovitskiy et al. (2020) Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929.
- Ethayarajh (2019) Ethayarajh, Kawin. 2019. “How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings.” arXiv preprint arXiv:1909.00512.
- Falkner, Klein and Hutter (2018) Falkner, Stefan, Aaron Klein, and Frank Hutter. 2018. “BOHB: Robust and efficient hyperparameter optimization at scale.” 1437–1446, PMLR.
- Fernández-Villaverde (2024) Fernández-Villaverde, Jesús. 2024. “Deep Learning for Macroeconomists.” https://www.sas.upenn.edu/~jesusfv/teaching.html, https://www.sas.upenn.edu/~jesusfv/teaching.html.
- Franklin et al. (2024) Franklin, Brevin, Emily Silcock, Abhishek Arora, Tom Bryan, and Melissa Dell. 2024. “News Deja Vu: Connecting Past and Present with Semantic Search.” 99–112.
- Fuller, Millard and Green (2022) Fuller, Anthony, Koreen Millard, and James R Green. 2022. “Transfer Learning with Pretrained Remote Sensing Transformers.” arXiv preprint arXiv:2209.14969.
- Gebru et al. (2021) Gebru, Timnit, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. “Datasheets for datasets.” 1–14.
- Gentzkow, Kelly and Taddy (2019) Gentzkow, Matthew, Bryan Kelly, and Matt Taddy. 2019. “Text as Data.” Journal of Economic Literature, 57(3): 535–574.
- Gissin and Shalev-Shwartz (2019) Gissin, Daniel, and Shai Shalev-Shwartz. 2019. “Discriminative active learning.” arXiv preprint arXiv:1907.06347.
- Goh (2017) Goh, Gabriel. 2017. “Why momentum really works.” Distill, 2(4): e6.
- Gong, Chung and Glass (2021) Gong, Yuan, Yu-An Chung, and James Glass. 2021. “Ast: Audio spectrogram transformer.” arXiv preprint arXiv:2104.01778.
- Goodfellow, Bengio and Courville (2016) Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep learning. MIT press.
- Greff et al. (2016) Greff, Klaus, Rupesh K Srivastava, Jan Koutník, Bas R Steunebrink, and Jürgen Schmidhuber. 2016. “LSTM: A search space odyssey.” IEEE transactions on neural networks and learning systems, 28(10): 2222–2232.
- Grill et al. (2020) Grill, Jean-Bastien, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. 2020. “Bootstrap your own latent-a new approach to self-supervised learning.” Advances in Neural Information Processing Systems, 33: 21271–21284.
- Guarneri (2017) Guarneri, Julia. 2017. Newsprint Metropolis. University of Chicago Press.
- Gururangan et al. (2020) Gururangan, Suchin, Ana Marasovic, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. 2020. “Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks.” arXiv preprint arXiv:2004.10964.
- Hanlon and Beach (2022) Hanlon, W Walker, and Brian Beach. 2022. “Historical Newspaper Data: A Researcher’s Guide and Toolkit.”
- Hedderich et al. (2021) Hedderich, Michael A., Lukas Lange, Heike Adel, Jannik Strötgen, and Dietrich Klakow. 2021. “A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios.” 2545–2568. Online:Association for Computational Linguistics.
- Hegghammer (2021) Hegghammer, Thomas. 2021. “OCR with Tesseract, Amazon Textract, and Google Document AI: A benchmarking experiment.” Journal of Computational Social Science, 5(1): 861–882.
- He et al. (2017) He, Kaiming, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. 2017. “Mask R-CNN.” 2961–2969.
- He et al. (2015) He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.” 1026–1034.
- He et al. (2016) He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep residual learning for image recognition.” 770–778.
- He et al. (2022) He, Kaiming, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. 2022. “Masked autoencoders are scalable vision learners.” 16000–16009.
- He et al. (2020) He, Pengcheng, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020. “Deberta: Decoding-enhanced bert with disentangled attention.” arXiv preprint arXiv:2006.03654.
- Hermans, Beyer and Leibe (2017) Hermans, Alexander, Lucas Beyer, and Bastian Leibe. 2017. “In defense of the triplet loss for person re-identification.” arXiv preprint arXiv:1703.07737.
- Hochreiter and Schmidhuber (1997) Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long short-term memory.” Neural computation, 9(8): 1735–1780.
- Holland et al. (2018) Holland, Sarah, Ahmed Hosny, Sara Newman, Josh Joseph, and Kevin Chmielinski. 2018. “The Dataset Nutrition Label: A Framework to Drive Higher Data Quality Standards.” FAT* ’18, 1–5. New York, NY, USA:Association for Computing Machinery.
- Howard et al. (2019) Howard, Andrew, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. 2019. “Searching for mobilenetv3.” 1314–1324.
- Ioffe and Szegedy (2015) Ioffe, Sergey, and Christian Szegedy. 2015. “Batch normalization: Accelerating deep network training by reducing internal covariate shift.” 448–456, PMLR.
- Jocher (2020) Jocher, Glenn. 2020. “YOLOv5 by Ultralytics.”
- Johnson, Douze and Jégou (2019) Johnson, Jeff, Matthijs Douze, and Hervé Jégou. 2019. “Billion-scale similarity search with gpus.” IEEE Transactions on Big Data, 7(3): 535–547.
- Karpathy (2022) Karpathy, Andrej. 2022. “The spelled-out intro to neural networks and backpropagation.” https://www.youtube.com/watch?v=VMj-3S1tku0.
- Karpukhin et al. (2020) Karpukhin, Vladimir, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. “Dense passage retrieval for open-domain question answering.” arXiv preprint arXiv:2004.04906.
- Khattab et al. (2022) Khattab, Omar, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. “Demonstrate-Search-Predict: Composing Retrieval and Language Models for Knowledge-Intensive NLP.” arXiv preprint arXiv:2212.14024.
- Khosla et al. (2020) Khosla, Prannay, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. 2020. “Supervised contrastive learning.” Advances in Neural Information Processing Systems, 33: 18661–18673.
- Kingma and Ba (2014) Kingma, Diederik P, and Jimmy Ba. 2014. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980.
- Kirillov et al. (2023) Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. 2023. “Segment anything.” arXiv preprint arXiv:2304.02643.
- Kirillov et al. (2019) Kirillov, Alexander, Ross Girshick, Kaiming He, and Piotr Dollár. 2019. “Panoptic feature pyramid networks.” 6399–6408.
- Korinek (2023) Korinek, Anton. 2023. “Generative AI for Economic Research: Use Cases and Implications for Economists.” Journal of Economic Literature, 61(4): 1281–1317.
- Krizhevsky, Sutskever and Hinton (2012) Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” Vol. 25. Curran Associates, Inc.
- Lan et al. (2019) Lan, Zhenzhong, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. “Albert: A lite bert for self-supervised learning of language representations.” arXiv preprint arXiv:1909.11942.
- LeCun, Bengio and Hinton (2015) LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. 2015. “Deep learning.” Nature, 521(7553): 436–444.
- Lei and Candès (2020) Lei, Lihua, and Emmanuel J. Candès. 2020. “Conformal Inference of Counterfactuals and Individual Treatment Effects.” arXiv preprint arXiv:2006.06138.
- Levenshtein et al. (1966) Levenshtein, Vladimir I, et al. 1966. “Binary codes capable of correcting deletions, insertions, and reversals.” Vol. 10, 707–710, Soviet Union.
- Li et al. (2017) Li, Lisha, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. 2017. “Hyperband: A novel bandit-based approach to hyperparameter optimization.” The Journal of Machine Learning Research, 18(1): 6765–6816.
- Liu et al. (2023) Liu, Pengfei, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.” ACM Computing Surveys, 55(9): 1–35.
- Liu et al. (2019) Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692.
- Liu et al. (2021) Liu, Ze, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. “Swin transformer: Hierarchical vision transformer using shifted windows.” 10012–10022.
- Liu et al. (2022) Liu, Zhuang, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. “A convnet for the 2020s.” 11976–11986.
- Lynn, Kummerfeld and Mihalcea (2020) Lynn, Veronica, Jonathan K. Kummerfeld, and Rada Mihalcea. 2020. “A Causal Framework for Uncovering the Effects of Descriptive Text on Decision Making.” 5276–5294.
- Lyu et al. (2021) Lyu, Lijun, Maria Koutraki, Martin Krickl, and Besnik Fetahu. 2021. “Neural OCR Post-Hoc Correction of Historical Corpora.” Transactions of the Association for Computational Linguistics, 9: 479–483.
- Mehrabi et al. (2021) Mehrabi, Ninareh, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2021. “A Survey on Bias and Fairness in Machine Learning.” ACM Computing Surveys (CSUR), 54(6): 1–35.
- Mehta and Rastegari (2021) Mehta, Sachin, and Mohammad Rastegari. 2021. “MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer.” arXiv preprint arXiv:2110.02178.
- Merchant et al. (2020) Merchant, Amil, Elahe Rahimtoroghi, Ellie Pavlick, and Ian Tenney. 2020. “What Happens to BERT Embeddings during Fine-tuning?” arXiv preprint arXiv:2004.14448.
- Mikolov et al. (2013) Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. “Distributed representations of words and phrases and their compositionality.” Advances in Neural Information Processing Systems, 26: 3111–3119.
- Mitchell et al. (2019) Mitchell, Margaret, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. “Model Cards for Model Reporting.” 220–229.
- MLCommons (2024) MLCommons. 2024. “Croissant: A Metadata Framework for ML-Ready Datasets.” https://github.com/mlcommons/croissant, Accessed: 2024-07-09.
- Nguyen et al. (2020) Nguyen, Dat Quoc, Thanh Vu, Afshin Rahimi, Mai Hoang Dao, Linh The Nguyen, and Long Doan. 2020. “WNUT-2020 task 2: identification of informative COVID-19 english tweets.” arXiv preprint arXiv:2010.08232.
- Nguyen et al. (2021) Nguyen, Thi Tuyet Hai, Adam Jatowt, Mickael Coustaty, and Antoine Doucet. 2021. “Survey of Post-OCR Processing Approaches.” ACM Comput. Surv., 54(6).
- Nielsen (2015) Nielsen, Michael A. 2015. Neural Networks and Deep learning. Vol. 25, Determination press San Francisco, CA, USA.
- Olah (2014) Olah, Christopher. 2014. “Deep learning, NLP, and Representations.” GitHub blog, posted on July.
- Oord, Li and Vinyals (2018) Oord, Aaron van den, Yazhe Li, and Oriol Vinyals. 2018. “Representation learning with contrastive predictive coding.” arXiv preprint arXiv:1807.03748.
- Pennington, Socher and Manning (2014) Pennington, Jeffrey, Richard Socher, and Christopher D Manning. 2014. “Glove: Global vectors for word representation.” 1532–1543.
- Radford et al. (2019) Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. “Language models are unsupervised multitask learners.” OpenAI blog, 1(8): 9.
- Radford et al. (2021) Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. “Learning transferable visual models from natural language supervision.” 8748–8763, PMLR.
- Raffel et al. (2019) Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” arXiv e-prints.
- Raffel et al. (2020) Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. “Exploring the limits of transfer learning with a unified text-to-text transformer.” The Journal of Machine Learning Research, 21(1): 5485–5551.
- Redmon et al. (2016) Redmon, Joseph, Santosh Divvala, Ross Girshick, and Ali Farhadi. 2016. “You only look once: Unified, real-time object detection.” 779–788.
- Reimers and Gurevych (2019) Reimers, Nils, and Iryna Gurevych. 2019. “Sentence-bert: Sentence embeddings using siamese bert-networks.” arXiv preprint arXiv:1908.10084.
- Ren et al. (2017) Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. 2017. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” IEEE transactions on pattern analysis and machine intelligence, 39(6): 1137–1149.
- Robins, Rotnitzky and Zhao (1994) Robins, James M., Andrea Rotnitzky, and Lue Ping Zhao. 1994. “Estimation of regression coefficients when some regressors are not always observed.” Journal of the American Statistical Association, 89(427): 846–866.
- Rush (2018) Rush, Alexander M. 2018. “The annotated transformer.” 52–60.
- Russell (1918) Russell, Robert C. 1918. “U.S. Patent No. US1261167A.” U.S. Patent and Trademark Office, https://patents.google.com/patent/US1261167A/en.
- Sanderson (2017) Sanderson, Grant. 2017. “Neural Networks.” https://www.3blue1brown.com/topics/neural-networks.
- Sanderson (2020) Sanderson, Grant. 2020. “Convolutions in Image Processing.” https://www.youtube.com/watch?v=8rrHTtUzyZA.
- Sang and De Meulder (2003) Sang, Erik F, and Fien De Meulder. 2003. “Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition.” arXiv preprint cs/0306050.
- Sanh et al. (2019a) Sanh, Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019a. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108.
- Sanh et al. (2019b) Sanh, Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019b. “DistilRoBERTa: A distilled version of RoBERTa.” https://github.com/huggingface/transformers, Accessed: 2024-07-09.
- Santurkar et al. (2018) Santurkar, Shibani, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. 2018. “How does batch normalization help optimization?” Advances in Neural Information Processing Systems, 31.
- Shafer and Vovk (2008) Shafer, Glenn, and Vladimir Vovk. 2008. “A Tutorial on Conformal Prediction.” Journal of Machine Learning Research, 9: 371–421.
- Shen and Rose (2021) Shen, Qinlan, and Carolyn Rose. 2021. “What Sounds “Right” to Me? Experiential Factors in the Perception of Political Ideology.” 1762–1771, Association for Computational Linguistics.
- Shen et al. (2022) Shen, Zejiang, Jian Zhao, Yaoliang Yu, Weining Li, and Melissa Dell. 2022. “Olala: object-level active learning based layout annotation.” EMNLP Computational Social Science Workshop.
- Shen et al. (2021) Shen, Zejiang, Ruochen Zhang, Melissa Dell, Benjamin Charles Germain Lee, Jacob Carlson, and Weining Li. 2021. “LayoutParser: A unified toolkit for deep learning based document image analysis.” 131–146, Springer.
- Silcock et al. (2024) Silcock, Emily, Abhishek Arora, Luca D’Amico-Wong, and Melissa Dell. 2024. “Newswire: A Large-Scale Structured Database of a Century of Historical News.” arXiv preprint arXiv:2406.09490.
- Silcock et al. (2023) Silcock, Emily, Luca D’Amico-Wong, Jinglin Yang, and Melissa Dell. 2023. “Noise-Robust De-Duplication at Scale.” Vol. 332.
- Simonyan and Zisserman (2014) Simonyan, Karen, and Andrew Zisserman. 2014. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556.
- Stevens, Antiga and Viehmann (2020) Stevens, Eli, Luca Antiga, and Thomas Viehmann. 2020. Deep learning with PyTorch. Manning Publications Company.
- Szegedy et al. (2015) Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. “Going deeper with convolutions.” 1–9.
- Touvron et al. (2021) Touvron, Hugo, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. “Training data-efficient image transformers & distillation through attention.” 10347–10357, PMLR.
- Touvron et al. (2023) Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. “LLaMA: Open and Efficient Foundation Language Models.” arXiv preprint arXiv:2302.13971.
- Ultralytics (2020) Ultralytics. 2020. “Ultralytics/yolov5.” https://github.com/ultralytics/yolov5.
- van Strien. et al. (2020) van Strien., Daniel, Kaspar Beelen., Mariona Coll Ardanuy., Kasra Hosseini., Barbara McGillivray., and Giovanni Colavizza. 2020. “Assessing the Impact of OCR Quality on Downstream NLP Tasks.” 484–496, INSTICC. SciTePress.
- Vaswani et al. (2017) Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention is all you need.” Advances in Neural Information Processing Systems, 30.
- Vitercik (2023) Vitercik, Ellen. 2023. “Machine Learning for Algorithm Design.” https://vitercik.github.io/ml4algs/calendar/, https://vitercik.github.io/ml4algs/calendar/.
- Wang et al. (2022) Wang, Di, Jing Zhang, Bo Du, Gui-Song Xia, and Dacheng Tao. 2022. “An empirical study of remote sensing pretraining.” IEEE Transactions on Geoscience and Remote Sensing.
- Wang and Liu (2021) Wang, Feng, and Huaping Liu. 2021. “Understanding the behaviour of contrastive loss.” 2495–2504.
- Wei et al. (2022) Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. “Chain of Thought Prompting Elicits Reasoning in Large Language Models.” arXiv preprint arXiv:2201.11903.
- Wilkerson et al. (2023) Wilkerson, John, E. Scott Adler, Bryan D. Jones, Frank R. Baumgartner, Guy Freedman, Sean M. Theriault, Alison Craig, Derek A. Epp, Cheyenne Lee, and Miranda E. Sullivan. 2023. “Policy Agendas Project: Congressional Bills.” https://comparativeagendas.net/datasets_codebooks.
- Wu et al. (2019) Wu, Ledell, Fabio Petroni, Martin Josifoski, Sebastian Riedel, and Luke Zettlemoyer. 2019. “Scalable zero-shot entity linking with dense entity retrieval.” arXiv preprint arXiv:1911.03814.
- Xie et al. (2017) Xie, Saining, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. 2017. “Aggregated residual transformations for deep neural networks.” 1492–1500.
- Yamada et al. (2022) Yamada, Ikuya, Koki Washio, Hiroyuki Shindo, and Yuji Matsumoto. 2022. “Global entity disambiguation with BERT.” 3264–3271.
- Yang et al. (2023) Yang, Xinmei, Abhishek Arora, Shao Yu Jheng, and Melissa Dell. 2023. “Quantifying Character Similarity with Vision Transformers.” Empirical Methods on Natural Language Processing.
- Zrnic and Candès (2023) Zrnic, Tijana, and Emmanuel J. Candès. 2023. “Cross-Prediction-Powered Inference.” arXiv preprint arXiv:2309.16598.
| Topic | Prompt |
|---|---|
| advice | We would like to classify whether a text is from an advice column. Advice columns answer letters from a reader seeking advice, or give unsolicited advice to readers. Examples include Dear Abby, Ask Ann Landers, Dear Doctor, etc. Yes/No: |
| antitrust | We would like to classify whether a text is about antitrust action. An article that is about antitrust action covers business practices that stifle competition, or accusations of such practices. It might involve legal action, government regulation, the breaking up of monopolies, or any plans to do so. Yes/No: |
| bible | We would like to classify whether a text reproduces a short religious blurb, like a quote from the Bible, prayer for the day, spiritual thought for the day, without explanations, opinions, interpretations, or discourses. Long sermons, discourse, or longer texts quoting from the Bible won’t count as this ‘short religious blurb.’ This will generally look like ‘X for the day’ - short and crisp with no explanations or opinions at all besides the small blurb. Yes/No: |
| civil rights movement | We would like to classify whether a text is about the Civil Rights movement. This includes articles referring to organizations and individuals that protested racism against Black Americans, and articles discussing racial discrimination in the government, social and educational inequality of African Americans, police brutality against African Americans, the use of federal power to protect civil rights, or segregation. Articles about protests and riots are on topic if they stemmed from conflicts over civil rights or occurred after the death of Martin Luther King Jr., but race riots and acts of violence involving African Americans should not be on topic if they do not refer to discrimination. Some articles may refer to states rights or express anger about rioting—these articles are on topic only if race or federal protection of civil rights is mentioned. Yes/No: |
| contraception | We would like to classify whether a text is about contraception. Abortion is not contraception. Yes/No: |
| Topic | Prompt |
|---|---|
| crime | We would like to classify whether a text covers about crime. This includes reports of crimes and investigations, coverage of court proceedings, law enforcement, and discussions of crime prevention and community safety. Violations of international law are not considered crimes. Nor are actions that may be unethical but are not illegal. Articles about Watergate should not be classified as about crime. Yes/No: |
| horoscope | We would like to classify whether a text is a newspaper horoscope. Horoscopes are articles that make predictions about people’s futures based on astrological signals or signs (sun signs for instance) and are written to entertain and predict future events. They can be of daily frequency, monthly or even yearly. They can also be making astrological predictions for celebrities and known personalities. Yes/No: |
| labor movement | We would like to classify whether a text covers any American labor movements. A text that is on topic may cover unions striking, advocating for workers’ rights, lobbying the government, or speaking about the experience of working in their industry. It may also cover statements by employers that express anger at union action. Articles that express support for or criticize the labor movement should both count as on topic. Yes/No: |
| obituaries | We would like to classify whether a text is an obituary. An obituary is defined as an article which mentions a death of a person and provides their Biographical/Family information or Funeral information. Articles which just mention deaths of individuals in passing and do not summarize information about their life or their funeral services are not obituaries. Yes/No: |
| pesticide | We would like to classify whether an article is about pesticides. Texts are on topic if they mention any chemical attempt to deter pests (insects, other animals, or fungi) that were on a crop or plant. This does not include herbicides, killing insects not on crops, non-chemical bug killing, or anything else about insects. Yes/No: |
| polio vaccine | We would like to classify whether a text is about the polio vaccine. Yes/No: |
| Topic | Prompt |
|---|---|
| politics | We would like to classify whether a text is a political news. Yes/No: |
| protests | We would like to classify whether a text is about protests. Yes/No: |
| Red Scare | We would like to classify whether a text is about the Red Scare or McCarthyism. Any text that reports concerns about Communist infiltration into the U.S. government or institutions will be on topic. In addition, any accusations of U.S. citizens display communist sympathies will be on topic. References to the Korean War or the expansion of Communism abroad are not on topic, though fears of espionage in the U.S. by foreign Communists agents are on topic. Articles casting doubt on the extent of Communist influences in the U.S. should also be on topic. Yes/No: |
| schedules | We would like to classify whether a text is a schedule. This includes TV/Game/Movie/Church and other schedules. Schedules list multiple events or programs on the same medium or by the same organization. They are generally lists of time stamps of events followed by no (or a one line) description about them. A church calendar is a schedule, but a summary of the Sunday service is not. Movie listings are a schedule but a special screening of a particular movie is not. Yes/No: |
| sports | We would like you to classify whether a text is about sports. This does not include fishing, hunting, or flying. Yes/No: |
| Topic | Prompt |
|---|---|
| Vietnam War | We would like you to classify whether a text pertains to (any aspect of) the Vietnam War. Yes/No: |
| weather | We would like to classify texts that contain measurements about the weather. These include the weather forecast as well as texts summarizing what the weather was in the recent past (e.g., temperature, precipitation, visibility). This also includes articles about weather records, like the coldest/hottest days in a decade/year or coldest/hottest places. If the article contains weather measurements but also talks about the consequences of the weather in passing (e.g., damage, events cancelled), we will call it about weather measurements. However, if it just talks about the consequences of the weather (e.g., closures, accidents, damage) without giving the weather measurements, this does not count. As a rule of thumb, if there is precise weather measurement somewhere in the article- call it a weather measurement article. Yes/No: |
| World War I | We would like to classify whether a text is about World War I. Yes/No: |