思想链检索增强生成的实证研究
摘要
自2022年底ChatGPT上线以来,以ChatGPT为代表的生成对话模型迅速成为日常生活中必不可少的工具。 随着用户期望的提高,增强生成对话模型解决复杂问题的能力已成为当前研究的重点。 本文深入研究了 RAFT(检索增强微调)方法在提高生成对话模型性能方面的有效性。 RAFT将思想链与模型监督微调(SFT)和检索增强生成(RAG)相结合,显着增强了模型的信息提取和逻辑推理能力。 我们在多个数据集上评估了 RAFT 方法,并分析了其在各种推理任务中的性能,包括长格式 QA 和短格式 QA 任务、中文和英文任务以及支持和比较推理任务。 值得注意的是,它弥补了先前有关长格式 QA 任务和中文数据集的研究中的空白。 此外,我们还评估了 RAFT 方法中思想链(CoT)的好处。 这项工作为专注于提高生成对话模型性能的研究提供了宝贵的见解。
索引术语:生成对话模型、大语言模型、思维链、检索增强生成
1简介
近年来,随着人机对话的快速发展,该领域的一项关键技术——生成对话模型[1, 2]显示出巨大的潜力和广泛的应用前景。 从早期的序列到序列(Seq2Seq)[3]架构到最近基于具有注意力机制的Transformer[4]模型的创新,更先进的模型不断涌现。 然而,生成对话模型在准确性、一致性、连贯性、安全性和资源效率方面仍然面临重大挑战。 提高他们的绩效是一个需要关注的关键问题。
为了解决更复杂和多样化的自然语言处理任务,提出了思想链(CoT)方法[5,6,7,8]。 思维链将复杂的推理任务分解为多个中间步骤,这些步骤顺序计算以获得最终结果。 它不仅提高了模型响应的逻辑一致性,还增强了用户交互体验。 然而,最近的研究表明,思路链提示方法需要约1000亿个参数的模型才能充分释放其推理能力[5],因此对计算资源会有很大的需求。
检索增强生成(RAG)[9]也是一种有前途的提高生成对话模型性能的方法[10,11,12,13]。 检索增强生成方法通过集成外部数据库的知识来增强生成对话模型的性能和可靠性。 这种方法不仅提高了生成文本的准确性和相关性,而且能够持续更新特定领域的知识,尤其是在知识密集型任务中表现出色。 然而,RAG 仍然面临着一些挑战。 由于检索增强生成的性能取决于检索器的准确性和效率,因此质量差或不相关的检索结果可能会对生成的内容产生负面影响。 此外,如何有效地将检索到的信息与模型的先验知识相结合仍然是一个重大挑战。
本文研究了一种将思路链与检索增强生成相结合的方法,用于监督微调(SFT)小规模模型,以优化其在推理任务中的性能,称为 RAFT(检索增强微调)[14]。 该方法不仅避免了思路链提示对大规模模型的依赖,而且减轻了RAG中知识检索过程的幻觉[15]和维护挑战,增强了模型的可操作性。提取信息和执行逻辑推理的能力。 在这项工作中,我们提供了跨不同类型推理任务的 RAFT 方法的全面优化和评估,包括短式 QA 和长式 QA、英语任务和中文任务、桥梁类型和比较任务,特别关注长式 QA和中文数据集。 此外,我们还评估了 RAFT 方法中思想链的好处,并对上述各种类型任务的性能进行了详细分析。
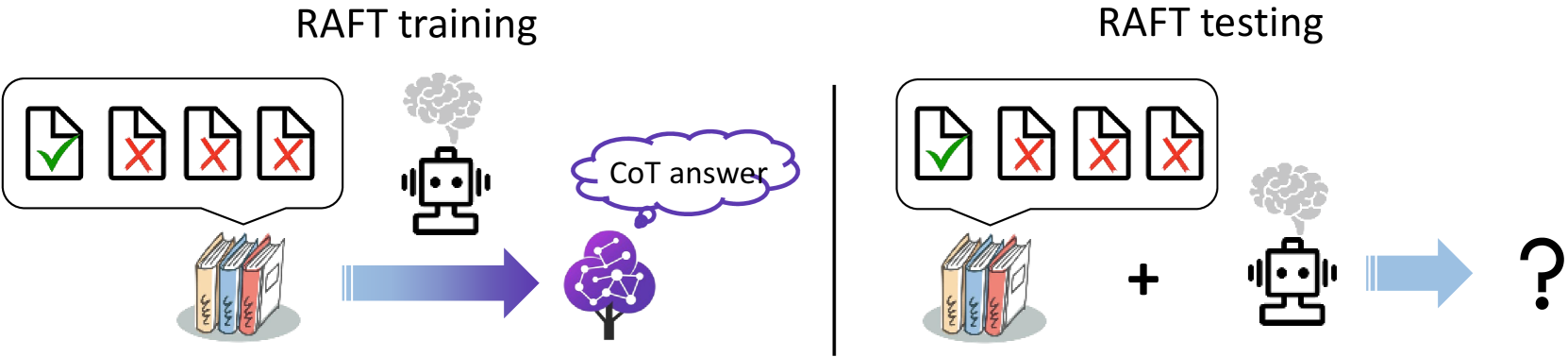
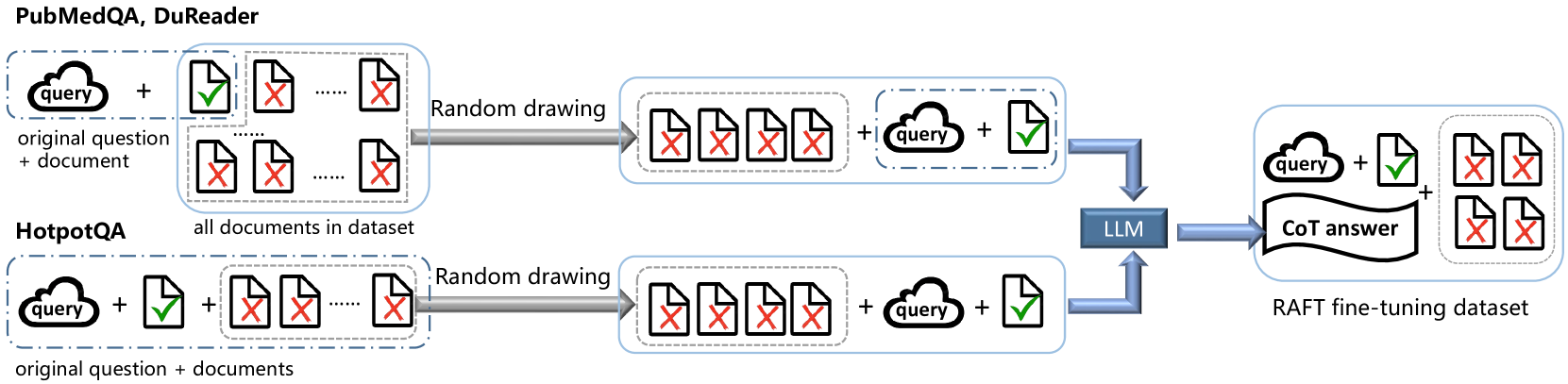
2方法
2.1 RAFT微调
RAFT[14]源自RAG+SFT,结合了检索增强生成(RAG)和监督微调(SFT)。 为了更好地理解,让我们将生成对话模型中的这些建模技术与人类面临的各种检查进行类比。
对于监督微调,通过引入针对特定任务定制的标记数据集,对预训练的语言模型进行微调。 监督微调类似于课后闭卷考试,学生只使用课堂上学到的解题方法来回答问题,没有任何参考资料。
对于检索增强生成方法,RAG模型使用输入提示作为查询关键字来检索相关文档。 这些检索到的内容被添加到模型的输入中,模型根据增强的输入生成响应。 在考试类比中,这种方法可以看作是根据问题从开卷知识中找到相关段落并推理出答案。
RAFT方法结合了检索增强生成和监督微调,并融入了思想链的思想。 这类似于在参加考试之前训练模型根据相关信息计算结果。 因此,在开卷考试中,模型可以利用参考资料更快、更准确地推导出正确答案。 综上所述,RAFT方法有两个关键特征。 首先,除了预言文档之外,参考文档中还包含不相关的干扰文档,以提高模型对检索过程中检索到的不相关信息的鲁棒性。 其次,在微调数据集中使用思维链式响应作为目标文本,而不是简单的简短答案,以提高模型的推理能力。 具体来说,RAFT数据集中的每个数据都包含一个问题()、若干分散注意力的文档()、包含回答问题的有效信息的甲骨文文档()以及由甲骨文文档生成的思维链式回答()()。图1 显示 RAFT 的概述。
| (1) |

2.2数据集构建
图2 展示了我们的 RAFT 微调数据集构建过程。 为了使数据集适合 RAFT 微调,我们使用两种方法来处理开源数据集。 当处理一个问题对应多个参考文档(包括oracle文档和distractor文档)的数据集时,我们使用第一种方法:对于每个问题,我们从问题对应的文档中提取所有oracle文档,然后随机选择指定数量剩余的相应文档中的文档作为干扰文档。 当处理一个问题只对应一个oracle文档的数据集时,我们使用第二种方法:对于每个问题,我们将其对应的文档作为oracle文档,并从其中随机选择指定数量的文档 其他 问题的参考文档作为问题的干扰文档。 在本研究中,数据集 HotpotQA [16] 采用第一种方法处理,而 PubMedQA [17] 和 DuReader_robust [18] 等数据集采用第一种方法处理。 > 使用第二种方法进行处理。 在我们的 RAFT 实验中,我们对每个问题使用四个干扰文档。
3实验设置
3.1数据集
-
•
HotpotQA [16]:HotpotQA 数据集包含来自维基百科的 113,000 个多跳推理问答对。 它包括两种类型的 QA 任务:桥梁和比较。 桥接 QA 任务要求模型从多个参考文档中查找相关信息以提供答案,而比较 QA 任务则要求模型比较多个实体或事件。 每个数据项包括一个问题、几个参考文档和一个简短的答案。
-
•
PubMedQA [17]:生物医学问答数据集。 它从 PubMed 摘要中提取数据,并根据这些摘要回答研究问题。 答案以“是/否/也许”的形式呈现。每个数据项由一个问题、一个参考文档、一个长答案和一个简短答案组成。
-
•
DuReader_robust [18]:DuReader_robust是一个中文数据集,用于评估模型阅读理解功能的鲁棒性和泛化能力。 每个数据项包括一个问题、一个参考文档和一个简短的答案。 所有数据项均来源于百度用户的搜索查询和回复。
3.2基线
在本研究中,我们使用 Qwen-1.5-7B-chat [19] 评估中文数据集 DuReader_robust,使用 LLaMA2-7B-chat [20, 21] 评估英文数据集 HotpotQA 和 PubMedQA ]。
-
•
LLaMA2-7B-chat / Qwen-1.5-7B-chat + 零样本提示:为模型提供清晰的说明和需要回答的问题,无需提供任何外部参考文档,并要求模型生成答案。
-
•
LLaMA2-7B-chat / Qwen-1.5-7B-chat + RAG:为模型提供说明和问题,辅以外部参考文档,并要求模型使用这些参考文档中的内容得出答案。
-
•
DSF(Domain Specific Finetuning)+零样本提示:对于每个数据集,在没有参考文档的情况下进行标准监督微调,以问题作为输入文本,答案作为目标文本进行微调。 然后向经过微调的模型提出问题和说明,并要求其在不参考外部文档的情况下做出回应。
-
•
DSF + RAG:在没有每个数据集参考文档的情况下执行标准监督微调,但在测试过程中,微调模型会补充问题的参考文档。 该模型需要使用外部知识得出答案。
3.3评估方法
在我们的实验中,我们主要使用F1分数和EM分数(精确匹配)来评估模型的性能。 我们通过几个步骤标准化答案文本来标准化答案,包括将所有文本转换为小写、删除标点符号、删除冠词 (a、an、the) 以及标准化空格,这确保答案的格式更加统一 [22, 23]。 随后,标准化答案用于计算他们的 EM 分数和 F1 分数。
4实验结果
| PubMedQA | HotpotQA[Oracle] | HotpotQA | |
|---|---|---|---|
| zero-shot | 50.50 | 15.06 | 15.06 |
| RAG | 56.42 | 12.07 | 8.72 |
| DSF + zero-shot | 53.91 | 20.04 | 20.04 |
| DSF + RAG | 71.71 | 45.26 | 27.40 |
| RAFT w.o. CoT | 54.80 | 52.38 | 28.74 |
| RAFT | 74.36 | 54.20 | 39.48 |
| PubMedQA[long] | HotpotQA[Oracle] | HotpotQA | DuReader | |
|---|---|---|---|---|
| zero-shot | 1.09 | 22.63 | 22.63 | 13.47 |
| RAG | 3.05 | 25.05 | 18.39 | 26.06 |
| DSF + zero-shot | 7.95 | 27.63 | 27.63 | 20.90 |
| DSF + RAG | 10.68 | 58.67 | 34.52 | 39.91 |
| RAFT w.o. CoT | —— | 64.47 | 37.48 | 42.25 |
| RAFT | 14.09 | 67.83 | 51.33 | 57.81 |
我们比较了使用 RAFT 方法和基线的模型的性能。 桌子 1 和表 2 分别显示 EM 分数和 F1 分数的结果。 在火锅QA中[甲骨文] 实验组在RAG实验中仅提供oracle文档作为模型参考。 对于所有其他组,RAG 实验中的干扰文档与参考文档一起包含在内。
从实验结果中,我们可以看到,RAFT 方法在所有数据集上始终优于四种基线方法,在使用 RAFT 方法微调的模型中展示了卓越的信息提取和复杂问题推理能力。 在 HotpotQA 数据集上,与普通 RAG 基线(不使用 DSF 模型)实验相比,RAFT 方法(使用 CoT)在 EM 分数中实现了 42.13% 的性能增益,在 F1 分数中实现了 42.78% 的性能增益。 即使包含干扰文档,它的 EM 分数仍然提高了 30.76%,F1 分数提高了 32.94%。 此外,我们观察到,尽管 RAFT 的分数随着实验中添加干扰文档而降低(比较 HotpotQA 对应的表列)[甲骨文] 和 HotpotQA),它比 DSF+RAG 基线获得了更高的性能增益。 这表明RAFT方法可以显着增强模型在RAG中检索过程中的鲁棒性。
在微调之前,无论是否包含 RAG,模型的性能都很差。 针对特定领域(即 DSF)微调模型可以通过将模型输出与这些领域的回答模式对齐来显着提高其性能。 通过RAFT方法(带有CoT),该模型不仅学习了特定领域的回答模式,而且显着提高了从复杂数据中提取有效信息的能力。
4.1 长篇 QA 评估
由于 PubMedQA 的“是/否”QA 和 HotpotQA 的 QA 都是短格式的,因此我们还在数据集 PubMedQA 中评估了长格式的 QA。 实验结果见表 2 PubMedQA[long] 团体。 长式 QA 的 F1 分数结果表明,与零样本提示基线相比,RAFT 方法使长答案问题的性能提高了 13%。 然而,与 DSF+RAG 基线相比,性能提升不如简短的 QA 显着。 这是因为长答案的内容更倾向于归纳总结的形式,而不是像短答案那样通过推理得出一定的结果。 具有思想链的长篇问答研究还需要进一步探索。
4.2中文数据集评估
我们还对 DuReader_robust 进行了评估,以评估 RAFT 方法在中文数据集上的有效性。 由于该数据集中的问题严重依赖于参考文献中的信息,因此使用 DSF 带来的增益仅比零样本提示基线提高了 7.43%(见表) 2 比较 DuReader 组中的“零样本”和“DSF+零样本”行)。 在这种情况下,使用RAG来补充带有问题的参考文档更为有效,与零样本基线相比获得了12.59%的性能增益。 经过RAFT微调后,模型提取和处理信息的能力以及推理能力都可以得到显着提升。 与零样本提示基线和 DSF+RAG 基线相比,它的 F1 分数性能分别提高了 44.34% 和 19.9%。 这些结果表明 RAFT 方法在英语和中文数据集上都表现得非常好。
4.3 RAFT在不同类型推理任务中的表现
我们在 HotpotQA 数据集中分别对桥型 QA 和比较型 QA 的 RAFT 方法进行了评估,如表3. 结果表明 RAFT 在比较类型的问题上表现更好。 这可能是因为比较类型的问题通常涉及比较两个或多个实体之间的特征,这可以依赖于直接信息检索和简单的比较操作。 相比之下,桥梁类问题往往需要模型从多个文档中提取相关信息,推理链较长,中间步骤较多,对模型的理解和推理能力要求较高。
| bridge | comparison | |
|---|---|---|
| RAFT-EM score | 36.25 | 50.72 |
| RAFT-F1 score | 48.80 | 60.11 |
4.4 CoT的影响
为了评估 RAFT 方法中思想链 (CoT) 的好处,我们进行了消融实验 (RAFT w.o.) 科特)。 在这个实验中,我们从 RAFT 训练数据集中删除了思想链式响应,只将每个问题的最终答案作为微调过程中的目标文本。 比较仅使用 RAG 的 oracle 文档测试的 HotpotQA 数据集和使用干扰文档测试的 HotpotQA 数据集,CoT 方法在后一种设置中获得了更显着的性能提升。 这表明CoT在面对更复杂的知识和更严重的信息噪声时可以获得更可观的收益。 此外,在各种数据集上,RAFT 的性能始终优于没有 CoT 的 RAFT 的性能。 因此,加入CoT可以有效引导模型从复杂的输入中获取正确的信息,增强模型的逻辑严密性和准确性。
5结论
在本研究中,我们跨多个数据集评估了 RAFT 方法,弥补了之前有关长格式 QA 和中文数据集的研究中的空白。 结果表明,RAFT方法结合CoT不仅提高了模型面对噪声时鲁棒地提取和处理信息的能力,而且增强了其在推理任务中的逻辑推理能力。 在英语和中文数据集以及长格式 QA 和短格式 QA 的评估中观察到显着的性能提升。 此外,我们还进行了一项消融实验,从 RAFT 数据集中删除了思想链式响应,以对模型进行修改。 该实验验证了思想链在增强生成对话模型性能方面的关键作用。
参考
- [1] Y. Zhang, Z. Ou, and Z. Yu, “Task-oriented dialog systems that consider multiple appropriate responses under the same context,” in Proc. AAAI, 2020.
- [2] H. Liu, Y. Cai, Z. Ou, Y. Huang, and J. Feng, “Building markovian generative architectures over pretrained lm backbones for efficient task-oriented dialog systems,” in Proc. SLT, 2023.
- [3] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. NeurIPS, 2014.
- [4] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. NeurIPS, 2017.
- [5] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. H. Chi, Q. V. Le, D. Zhou et al., “Chain-of-Thought prompting elicits reasoning in large language models,” in Proc. NeurIPS, 2022.
- [6] M. Suzgun, N. Scales, N. Schärli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. Le, E. Chi, D. Zhou et al., “Challenging BIG-Bench tasks and whether chain-of-Thought can solve them,” in Proc. ACL, 2023.
- [7] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano et al., “Training verifiers to solve math word problems,” arXiv preprint arXiv:2110.14168, 2021.
- [8] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao, “ReAct: Synergizing reasoning and acting in language models,” in Proc. ICLR, 2022.
- [9] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Proc. NeurIPS, 2020.
- [10] G. Izacard, P. Lewis, M. Lomeli, L. Hosseini, F. Petroni, T. Schick, J. Dwivedi-Yu, A. Joulin, S. Riedel, and E. Grave, “Atlas: Few-shot learning with retrieval augmented language models,” Journal of Machine Learning Research, vol. 24, no. 251, pp. 1–43, 2023.
- [11] S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Millican, G. B. Van Den Driessche, J.-B. Lespiau, B. Damoc, A. Clark et al., “Improving language models by retrieving from trillions of tokens,” in Proc. ICML, 2022.
- [12] K. Guu, K. Lee, Z. Tung, P. Pasupat, and M. Chang, “Retrieval augmented language model pre-training,” in Proc. ICML, 2020.
- [13] U. Khandelwal, O. Levy, D. Jurafsky, L. Zettlemoyer, and M. Lewis, “Generalization through memorization: Nearest neighbor language models,” in Proc. ICLR, 2019.
- [14] T. Zhang, S. G. Patil, N. Jain, S. Shen, M. Zaharia, I. Stoica, and J. E. Gonzalez, “RAFT: Adapting language model to domain specific rag,” arXiv preprint arXiv:2403.10131, 2024.
- [15] L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023.
- [16] Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning, “HotpotQA: A dataset for diverse, explainable multi-hop question answering,” in Proc. EMNLP, 2018.
- [17] Q. Jin, B. Dhingra, Z. Liu, W. Cohen, and X. Lu, “PubMedQA: A dataset for biomedical research question answering,” in Proc. EMNLP, 2019.
- [18] H. Tang, H. Li, J. Liu, Y. Hong, H. Wu, and H. Wang, “DuReader_robust: A chinese dataset towards evaluating robustness and generalization of machine reading comprehension in real-world applications,” in Proc. ACL, 2021.
- [19] J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang et al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023.
- [20] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- [21] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
- [22] Baidu, “Dureader robust,” https://github.com/baidu/DuReader.
- [23] HotpotQA, “Hotpotqa,” https://github.com/hotpotqa/hotpot.