UTF8gbsn
AutoLegend:用于可视化的用户反馈驱动的自适应图例生成器
摘要
我们建议 AutoLegend 使用在线学习和用户反馈来生成交互式可视化图例。 AutoLegend 从可视化中准确提取符号和通道,然后生成高质量图例。 AutoLegend 支持图例和交互之间的双向交互,包括突出显示、过滤、数据检索和重定向。 在分析了过去20年IEEE VIS论文中的可视化图例后,我们总结了可视化尤其是图表中图例设计的设计空间和评估指标。 生成过程由三个相互关联的组件组成:图例搜索代理、反馈模型和对抗性损失模型。 搜索代理通过探索设计空间来确定合适的图例解决方案,并通过标量分数接收来自反馈模型的指导。 对抗性损失模型根据用户输入不断更新反馈模型。 用户研究表明,AutoLegend 可以通过图例编辑来了解用户的偏好。
索引术语:
深度学习、交互、可视化、图例1 简介
图例在数据可视化中起着不可或缺的作用,使用户能够掌握数据属性与视觉通道之间的映射关系。 他们通过说明所涉及的属性和数据范围,阐明了可视化的目的和意义。 尽管图例在可视化中起着至关重要的作用,但大量静态可视化缺乏适当的图例或设计不准确,即使在学术论文和广泛使用的工具中也观察到这种趋势。 尽管许多可视化工具包提供了生成图例的功能,但图例不充分或缺失的情况仍然普遍存在。 这归因于实现精心设计的图例所需的时间和精力。 制作有效图例所固有的挑战源于图例设计领域的复杂性和标准化的缺乏。 一方面,图例的设计前景广阔,涵盖多个维度,例如视觉通道、视觉标记、元素布局、文本排列以及涉及多个符号或通道时的布局考虑。 这些维度上的多种选项的融合创造了广泛的设计领域,使最佳设计解决方案的识别变得复杂。 另一方面,图例设计缺乏标准化方法导致不同创作者之间的偏好不同。 此外,缺乏可靠的评估指标也加剧了这种情况。 如果没有明确的评估标准,比较和识别最有效的图例设计的任务就变得具有挑战性。
我们提出了一种自动生成有效的交互式图例的方法,并考虑用户反馈。 对设计空间的理解是自动方法的开始。 我们研究了 IEEE VIS 过去二十年的可视化,总结了可视化图例的设计空间。 可视化图例设计空间由五个维度组成,即视觉标记、视觉通道、符号布局、文本布局和多通道布局。 为了确定最常见的问题,我们调查了广泛使用的可视化工具库中的图例(例如 D3 [1]、Vega-lite [2] 和 EChart [3])。 在702个可视化中,只有466个带有图例;在带有图例的可视化中,有 53 个图例不恰当。 我们还检查了学生的作业,以找出不适当的传说。 在 1,368 个可视化中,有 122 个图例不正确。 此外,我们提出了可视化图例的评估指标,例如防止现有通道重叠、墨水平衡、空间占用、图例组织、图例文本可读性和空间对应性。
基于设计空间和评估指标,我们开发了人机协作可视化图例生成器 AutoLegend。 AutoLegend 将可视化作为输入,生成尽可能符合评估指标的图例。 图例生成过程包括三个部分:提取标志性符号和映射通道,在高维图例空间中搜索合适的解决方案,并基于奖励模型对这些解决方案进行评分。 奖励模型以评价指标为输入,通过多层神经网络输出综合得分。 基于遗传算法的搜索网络支持在包括离散空间(例如排列方向、符号布局、文本布局)和连续空间(例如位置)的混合空间中搜索解。 考虑到不同的用户可能有不同的偏好,奖励模型还纳入了偏好指标(例如水平、垂直、中心或边缘偏好)。 我们的方法在人机循环框架中实现了机器学习方法,支持在线用户交互调整和质量评估模型的动态更新。
总之,我们的贡献如下:
-
•
我们分析了可视化图例的设计空间,并确定了包含可视化图例范围的五个维度。
-
•
我们开发了一个工具 AutoLegend,这是一个实时反馈系统,用于通过提取标记和通道并确定位置、符号布局、文本布局和多图例布局来生成可视化图例。 AutoLegend 使用户能够根据自己的喜好修改图例并相应更新后端模型。
在section 2中,我们讨论了AutoLegend的相关工作。 section 3总结并介绍了可视化图例的设计空间。 在section 4中,我们介绍了用于评估可视化图例的评估指标。 section 5详细介绍了我们的自动可视化图例生成方法,该方法基于设计空间和评估指标,采用人机交互方法。 随后,section 6 描述了 AutoLegend 生成的图例支持的交互。 section 7展示了 AutoLegend 生成的各种图例示例。 section 8 概述了 AutoLegend 的用户研究。 在section 9中,我们讨论了未来潜在的方向。 我们在section 10中结束我们的工作。
2 相关工作
AutoLegend 是一个生成交互式图例以进行可视化的系统。 由于AutoLegend提取可视化的内容并支持与图例上的可视化交互,因此也与提取和交互增强有关。
2.1 可视化图例
以往关于可视化图例的工作主要基于地图。 随着地图迅速向多媒体、三维可视化和交互性发展,Sieber[4]提出了“智能图例”的概念,作为数字地图的中央控制单元。 该方法包括针对最佳地图元素描述的自动适应和一系列用户交互功能。 Gobel 等人[5]专注于通过根据用户的注视调整地图图例的位置和内容来改善与地图图例的交互。 Dykes 等人[6]提出了在源自制图文献的可视化上下文中图例设计的指南。 这些指南涉及选择、布局、符号、位置、动态、设计和过程,可应用于制图和信息可视化中的各种图例和键。 关于图例放置,Imhof [7] 引入了视觉权重的概念,并建议将图例放置在视觉中心对面。 Edler 等人[8]发现位于地图字段右侧的图例解码速度更快,而不会影响识别记忆性能。
近年来,交互式图例已成为促进用户与可视化交互的有效手段。 Riche等人[9]证明,交互式图例不仅可以改善数据值和视觉编码之间映射的感知,而且还会根据数据类型不同地影响交互时间。 此外,他们的研究强调了序数控制相对于当今系统中主要使用的数值技术的优越性。
2.2 可视化提取
近年来,从可视化中提取数据[10]一直是人们非常感兴趣的话题,一些研究人员致力于开发提高可访问性[11]、可搜索性的方法,以及可视化的可重用性。 Savva 等人[12]和Poco等人[13]提出了从位图图像进行逆向工程可视化的方法,该方法识别图表的分类和视觉元素的位置通过分析图像中的信息来提取可视化的映射关系。 然而,这些方法主要关注轴映射信息,缺乏对图例信息的分析。
为了解决这些限制,最近的工作利用深度学习方法从可视化中提取信息。 例如,袁等人[14]使用深度学习方法提取颜色映射,而罗等人[15]使用深度学习方法提取文本和图形信息图表。 同样,Lai 等人[16]使用OCR方法从可视化图表中提取视觉元素,而Zhou等人[17]使用神经网络从条形图中提取信息。 张等人[18]专注于从古代可视化中提取具有更大多样性的数据,使用交互和机器学习相结合的方法进行数据提取。 Liu 等人[19]使用单个神经网络从可视化中提取信息。 Poco等人[20]提出了一种从位图图像中提取颜色映射的方法。 Hoque 等人[21]支持D3可视化的重用。 Cui等人[22]从信息图形中提取可重用的模板,而Chen等人[23]从时间轴中提取相应的模板。 这些努力旨在增强可视化的可用性和可访问性,使用户能够轻松地创建、重新设计可视化或与可视化交互。
2.3 交互增强
已经提出了用于可视化的交互增强方法,用于将动画添加到现有的可视化中,以增加可读性或强调特定的数据属性。 Kong 和 Agrawala [24] 在可视化中添加了各种动画以提高可读性。 卢等人[25]通过对数据属性进行动画编码,强调静态图表上的数据属性。
近年来,一些方法旨在通过交互或动画来增强现有的可视化效果。 VisDock[26] 被提议作为一个系统,允许程序员使用代码在现有可视化上添加交互(例如,选择、过滤、导航等)。 基于 DOM 元素上的 D3 规范的特征,Harper 和 Agrawala[27, 28] 开发了通过将给定数据与视觉属性相匹配来解构现有 D3 可视化的工具。 提取的映射关系可以与 Vega-lite[2] 的模板重用。 Interaction+[29] 通过解析视觉标记的属性并向可视化应用额外的交互插件,增强了网络可视化的交互。 Interaction+关注颜色和不透明度等非空间属性,而Liu等人[30]提出了一种基于空间约束的方法,用于将空间相关的交互添加到静态可视化中。

3 传奇设计空间
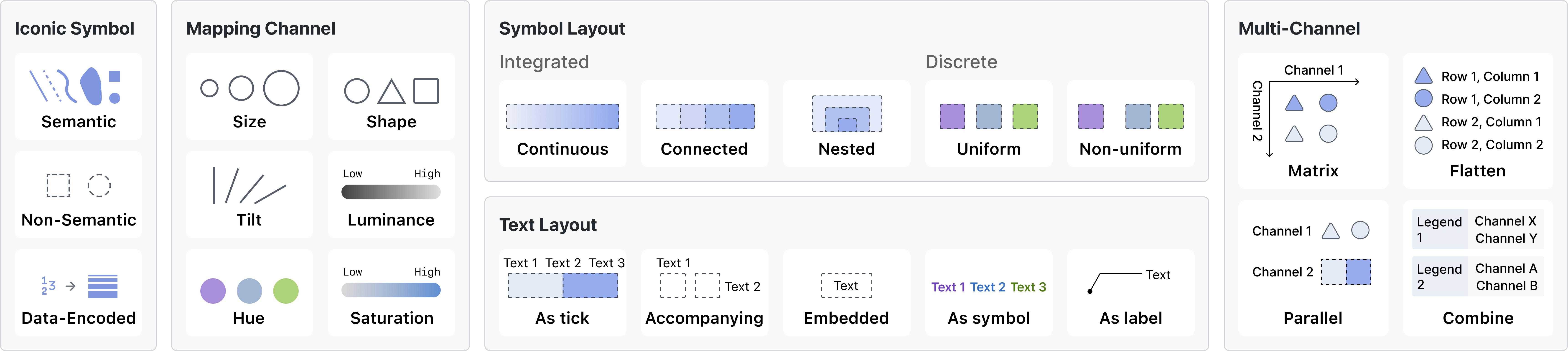
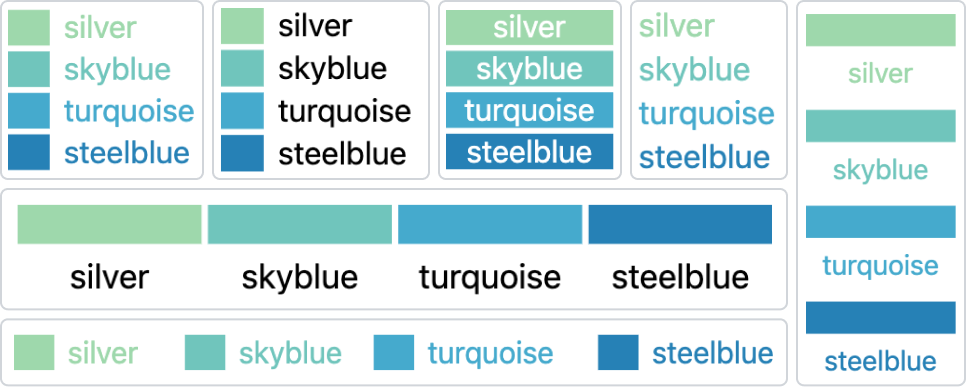
为了研究图例的设计空间,我们从 VisImages [45] 数据集中审查了过去 22 年 1,397 个 VAST 和 InfoVis 出版物中的 12,267 张图像。 这些图像中,只有 2,327 张( 19%)带有图例,其余图像因各种原因丢失。 作者可能忽视了传说的必要性,或者由于时间限制而没有投入精力去创造它们。 这显示了自动图例生成对于可视化利益相关者的重要性。 我们从图像中识别出 2,392 个图例,并根据视觉编码、空间布局和文本位置对它们进行分类。 Figure 1 显示了捕获的图例的一些示例。 随后,我们总结了Figure 2所示的设计空间,并标记了这些图例中的五个维度。 这些注释可在网站111Legends in VIS Publications: https://autolegend.github.io/legends_in_vis_publications/index.html。
为了调查图例在可视化实践中的使用,我们收集了过去 10 年(2012-2022)两门可视化课程中的 1,368 个学生项目,以及来自三个公共库库的可视化,其中 168 个来自 D3 库 222D3 gallery: https://observablehq.com/@d3/gallery, 339 来自 Echarts333Echarts gallery: https://echarts.apache.org/examples/,以及 195 来自 Vega-lite45>44Vega-lite gallery: https://vega.github.io/vega-lite/examples/ 在我们收集的 2,070 个可视化中,有 1,256 个缺乏相应的图例。 在确实有图例的可视化中,有 175 个表现出不一致。 这里的不一致涉及图例和图表显示不同视觉编码的情况,破坏了用户建立视觉相关性的能力,并且在某些情况下导致数据的误解。 这种不一致问题主要体现在标志性符号和映射通道维度上。 以这些有问题的图例为特色的可视化集已向公众开放555Inconsistent Legend: https://autolegend.github.io/inconsistent_legends/。 对于可视化新手和专家来说,在适当的场景中创建适当的图例仍然是一项具有挑战性的任务。 我们在图例中观察到的常见问题包括标签不明确或具有误导性、符号或颜色令人困惑以及多个可视化中图例的使用不一致。 这些发现强调需要在可视化课程中对图例设计进行更好的教育和指导,以及开发自动化方法来帮助用户生成适当且一致的图例。
3.1 标志性符号与映射通道
可视化图例包括用于映射的标志性符号和通道。 标志性符号可以分为语义符号、非语义符号和数据编码符号。 语义符号使用相似的形状来表示视觉元素,而非语义符号不提供形状对应。 数据编码符号添加了额外的维度来呈现额外的数据属性。 映射通道包括大小、位置、旋转和颜色。 图例包含两种类型的通道:用于映射数据属性的通道和保持不变的通道。 VIS论文上的2,392个图例中,有886个带有语义符号,1,505个带有非语义符号,只有1个带有数据编码符号象征。
3.2 符号布局
我们总结了四种不同类型的视觉表示:连续的、连接的、嵌套的和离散的。
-
•
连续符号表现为利用连续视觉通道的细长形式,擅长表示定量数据属性。 广泛采用的方法包括利用色彩空间中的亮度、饱和度和其他连续轨迹。 在连续分布中,可以使用各种单调性替代方案,包括单向单调序列、由可辨别的零点锚定的双向序列,以及从零点发出的两个方向上的独特偏移(例如,通过表示上方和下方区域的不同色调来说明)低于海平面。
-
•
连接布局由多个以细长形状链接在一起的符号组成,保持一致的视觉通道。 它经常用于定量数据属性,可以表示离散定量数据或采样的连续定量数据。 连接的图形通常具有相等的长度,尽管有些可能使用长度来表示统计值或嵌入文本长度。
-
•
嵌套符号具有多个嵌套、堆叠的采样元素,较大的元素位于下方,较小的元素位于上方。 为了避免被较低的元素完全覆盖,通常使用嵌套表示来描述与尺寸相关的视觉通道。
-
•
离散布局由组织在列表中的多个采样符号组成,每个文本对应一个符号。 它主要用于分类和有序数据属性。 符号通常均匀分布,但在某些情况下,它们可能不均匀分布以对应视觉元素。 当空间位置受到限制时,可能会出现换行。
VIS论文上的2,392个图例中,有464个带有连续符号,422个带有连接符号,1个带有嵌套符号,1,505个带有符号>离散符号(1,351 均匀和154 非均匀)。
3.3 文本布局
可视化图例中的文本布局具有多种作用,例如用作刻度、伴随图形元素、覆盖图形元素、将颜色表示为图形元素以及用作标签的自由间隔。
-
•
作为刻度线:文本可以起到图例上刻度线的作用。 勾选文本表示图例采样位置的值。 它表示采样位置或边界的值。 图例中其他位置的值需要用户插值。 刻度文本适用于编码定量属性的连续或连接的图例。
-
•
伴随:文本可以与其相应的符号一起显示,代表符号的值。 文本排列有两种选择:交叉排列和并排排列。 在交叉排列中,文本和符号出现在同一行或同一列中,并且相互交叉。 另一方面,在并排排列中,文本以与符号列表平行的单独序列排列。 交叉布局使图例更薄,更适合放置在可视化的边缘。 同时,并排排列可以保持符号和文字之间的对应关系。
-
•
嵌入:文本可以覆盖在其相应符号的顶部,指示符号的语义。 叠加的文本信息呈现出文本与符号之间的高度对应性。 然而,当文本和符号的颜色相似时,易读性可能会降低。
-
•
作为符号:文本组件本身可以充当符号表示,其中文本被赋予与其相关的视觉元素相匹配的颜色。 这种对应关系是通过文本颜色与相关视觉元素颜色的对齐来传达的。 然而,这种以字体颜色和背景颜色接近为特征的对齐方式可能会破坏易读性。
-
•
作为标签:文本也可以通过辅助线或位置关系来表达对应关系,这种组织方式是利用现有的视觉元素作为符号。 标签式图例不是图例的常见形式,可以被视为注释或标签。
在 VIS 出版物上出现的 2,392 个图例中,592 个图例中的文本为"√",1,467 个图例中的文本为 "伴随",133 个图例中的文本为 "嵌入",63 个图例中的文本为 "符号",1 个图例中的文本为 "标签",其他图例中没有文本。
3.4 多图例布局
当可视化图例包含多个符号或单个符号具有多个通道时,单个图例可能不足以映射它们之间的关系。 为了解决这个问题,可以使用矩阵来表示这些关系,将单个符号的多个通道视为矩阵的不同维度。 当可能性数较少时,可以采用矩阵形式或扩展形式。 然而,当数量较大时,不同尺寸的图例可以被视为单独的图例并并行放置。
-
•
矩阵:通过同一标记的两个垂直排列的视觉通道构造出矩阵形状的图例。 这种形式通常具有少量离散或连续值,并遍历所有可能的值选项。
-
•
扁平化:矩阵形式的扁平化表示也是表达多通道的一种方式。 这种形式类似于典型的列表形式,但跨两个或多个维度对信息进行编码。
-
•
并行:两个通道分别表示,并行放置。 这种方法将同一视觉元素的两个通道解耦。 用户需要单独解释它们。
-
•
组合:此结构将两个图例彼此平行放置,这可能对应于可视化中的不同视觉元素,例如区域的颜色和边缘的颜色。 需要有一个清晰的指示来区分每个图例所代表的不同视觉元素。
VIS论文2392个图例中的390个多通道图例中,文本矩阵布局50个,扁平化布局74个,平行布局47个,和 219 是组合布局。
4 图例质量评估
在本节中,我们根据可视化中出现的常见问题总结了可视化图例的评估指标。 这些指标包括视觉元素无阻碍、视觉平衡、文本易读性和对应性的原则。
减少阻碍:有效的图例不应妨碍关键信息的呈现。 为了防止关键细节被遮挡,我们计算图例所在区域像素值的标准差,量化图例的覆盖程度。 标准差 0 表示均匀区域。 在评估图例区域的均匀性时,我们计算原始图像中图例区域内的 R、G 和 B 通道的平均像素值,用 表示。 图例的宽度和高度分别由 和 表示,而坐标 (, 处的像素值图例中相应通道的 ) 用 表示。 阻塞程度可定义为:
墨水平衡:图例的集成应该增强可视化中的墨水分布。 Imhof [7] 引入了视觉权重的概念,建议将图例放置在地图视觉权重中心的对面。 通过包含图例,可视化的整体平衡应该得到改善。 空间平衡通常与墨水重量的质心相关。 油墨重量的质心越接近几何中心,图像越平衡。 为了计算墨水重量质心,RGB 图像被转换为灰度图像,其中白色被视为零。 根据灰度图像计算视觉权重质心,其中坐标(,)处的灰度值为。 图像的油墨重量平衡通过油墨重量的质心与几何中心之间的距离来测量。 墨水平衡指标定义为:
文本可读性:文本通常用于显示图例的视觉通道。 在图例的设计空间中,文字可以叠加或伴随图例,甚至充当图例。 因此,图例文本的可读性应该是高质量的,避免因前景和背景颜色不匹配而可能导致的任何字体识别问题。 这里,文本可读性是通过文本与其背景之间的对比度来衡量的。 W3C666W3C Web Content Accessibility Guidelines (WCAG) 2.0: https://www.w3.org/TR/WCAG20/ 定义对比度 如下,其中 是屏幕较亮部分的相对亮度颜色, 是较暗颜色的相对亮度。 计算相对亮度的公式也可以在 W3C6 中找到。
对比度通常为 1 到 21,根据 W3C6,对比度至少应为 4.5:1,以获得更好的可读性。
尺寸最小化:在可视化中包含图例时,避免引入大量未使用的空间非常重要。 例如,在可视化右侧添加宽图例可能会使其更宽并产生大量不必要的空间。 为了评估图例的有效性,我们计算图例添加后的边界框与原始边界框的比率。 具体来说,我们将“尺寸最小化”() 定义为:
其中边界框的面积计算为其宽度和高度的乘积。 值越高,表示由于添加图例而导致未使用空间的增加越大,这会降低可视化所传达的信息的有效性。
对应原则:对应原则强调在可视化中的视觉元素与其随附图例中的符号之间保持清晰一致的关系的重要性。 这涉及确保两个组件的颜色、形状和空间位置之间存在对应关系。 颜色对应要求图例中的符号使用与可视化中使用的颜色相同的颜色,以便用户轻松识别图例的哪些部分对应于可视化中的哪些视觉元素。 空间位置对应有两个组成部分:结构对应和邻近对应。 结构对应确保符号和视觉元素具有相同的顺序,使用户能够轻松找到特定视觉元素对应的图例项。 对应原则定义为颜色、形状和符号顺序对应的总和,表示为
5 自动图例生成

近年来,许多方法都集中在自动化可视化工作流程的各个方面,包括推荐可视化[46]、描述可视化[47]、回答有关可视化 [48],并为可视化 [49] 生成自动标题。 这些努力旨在提高更广泛的用户对数据和可视化的可访问性。 尽管有许多提供图例生成功能的可视化工具可用,但仍然有大量可视化缺乏适当的图例。 鉴于此,我们提出了一种自动方法来生成适合给定可视化的可视化图例。 在section 3和section 4中,我们总结了可视化图例的设计空间以及影响其质量的几个因素。 然而,虽然我们认识到这些因素的重要性,但在广阔的设计空间中找到一个好的图例并不容易,并且手动探索可能具有挑战性。
基于section 3中总结的图例设计空间,我们提出了一种实时生成适应用户偏好的图例的方法。 这种自动化方法通过 SVG 格式的可视化进行了演示。 如Figure 3所示,自动图例生成由四个部分组成:图标符号和通道提取、图例空间搜索代理、用于指导搜索代理的质量评估模型以及可根据用户输入进行调整的对抗模型。 标志性符号和通道提取组件旨在从给定的可视化中识别最具代表性的视觉元素和映射。 图例搜索代理在section 3中提出的可能图例空间中搜索最佳图例,重点是在多个维度上获得高分。 质量评估模型通过对代理搜索的图例进行评分来指导搜索代理。 对抗模型可以根据用户提供的反馈调整搜索策略,以提高生成图例的质量。
5.1 标志性符号和通道提取
本小节旨在概述可视化中标志符号的提取及其信息映射通道的推断。 区分视觉元素和混乱的 DOM 元素以及提取它们的数据编码通道并非易事。 Take bar-chart as an example, some <rect> serves as bars while there might be other <rect> elements serve as background, axis. Also, some visualizations use <path> to render rectangular bars and circle instead of regular <rect> and <circle>. 这使得提取更具挑战性,管道应该能够区分它们。 视觉元素提取过程包括两个主要步骤:图标符号提取和颜色识别(Figure 4)。 第一步涉及识别视觉元素的形状属性,例如元素类型、轮廓和轮廓线宽度。 A visualization contains lots of DOM elements, such as <rect>, <path>, <circle>, <text>. 其中一些充当轴、标题、背景,而另一些则充当编码信息的视觉元素。 此步骤决定哪些 DOM 元素编码信息,并根据这些视觉元素的形状编码通道将其分组。 我们将每组视觉元素称为标志性符号。 第二步,采用颜色识别对每组图标符号内的颜色进行分类。 颜色空间可以表示分类、序数或定量数据属性,在此步骤中考虑颜色映射数据中包含的信息至关重要。
标志性符号提取。 在此过程中,可视化符号通过包含三个连续步骤的管道根据其几何特征进行识别和分类。 从简单到复杂的三个步骤侧重于不同的几何属性。 一旦提取了视觉元素,它们就作为颜色提取过程的输入。
-
•
精确的形状匹配。 In many visualizations, visual elements have exact same shapes, such as a bar chart using <rect> to represent all bars. 我们直接比较几何轮廓来提取具有相同形状的符号。
-
•
变换后的形状匹配。 此步骤致力于发现变换后的几何形状,包括平移、旋转和调整大小。 To remind that, DOM elements whose shape transformation can be easily extracted from “transform” attribute such as <rect> and <text> have been extracted in the previous step. In this step, we mainly focus on <path>. 因为转换可能会直接映射到“d”属性,而不是在 DOM 的样式或属性中显式显示。 为了实现这一点,使用质心顶点向量来表征每个形状,该形状可以抵抗旋转和缩放引起的变化。 通过找到可视化字形的质心,然后计算质心和字形顶点之间的距离,可以获得质心-顶点向量。 具有不同变换的形状之间的向量是相同的。 然而,圆弧和贝塞尔曲线在曲线段上没有顶点,因此对曲线应用多边形近似以获得质心顶点向量。 最后,通过将每个条目除以最大长度来标准化质心顶点向量。
-
•
模糊形状簇。 In some scenarios, subtle disparities exist among <path>, such as every single region in voronoi diagram, different shape of mountains in Figure 9 (e). 我们使用形状聚类来查找所有这些元素,并从聚类中选择一个有代表性的形状。 如果用户选择生成语义图例,我们的系统将使用这种代表性形状而不是普通正方形作为图例,呈现与原始可视化的语义关系。 To accomplish this objective, we employ shape pattern clustering in a two-dimensional space utilizing area and aspect ratios of <path> elements. 我们使用 DBSCAN [50] 对形状进行聚类并消除离群值和与常见形状不同的稀疏分布形状。 根据经验,我们将设置为,其中表示形状的数量,设置为0.07。 每个簇表示一个形状模式,并且随机形状被指定为每个簇的代表。 这里,定义了两个点之间的最大距离,其中一个点被认为是另一个点的邻域,定义了形成密集区域所需的最小点数(簇)。
颜色映射提取。 颜色提取的目标是为之前提取的每个形状找到颜色编码通道。 该过程将在前面的形状提取步骤中识别的几何形状的集合作为输入。 我们的颜色提取过程也包含三个步骤。 在任何步骤中,可以识别并输出具有不同颜色的形状。
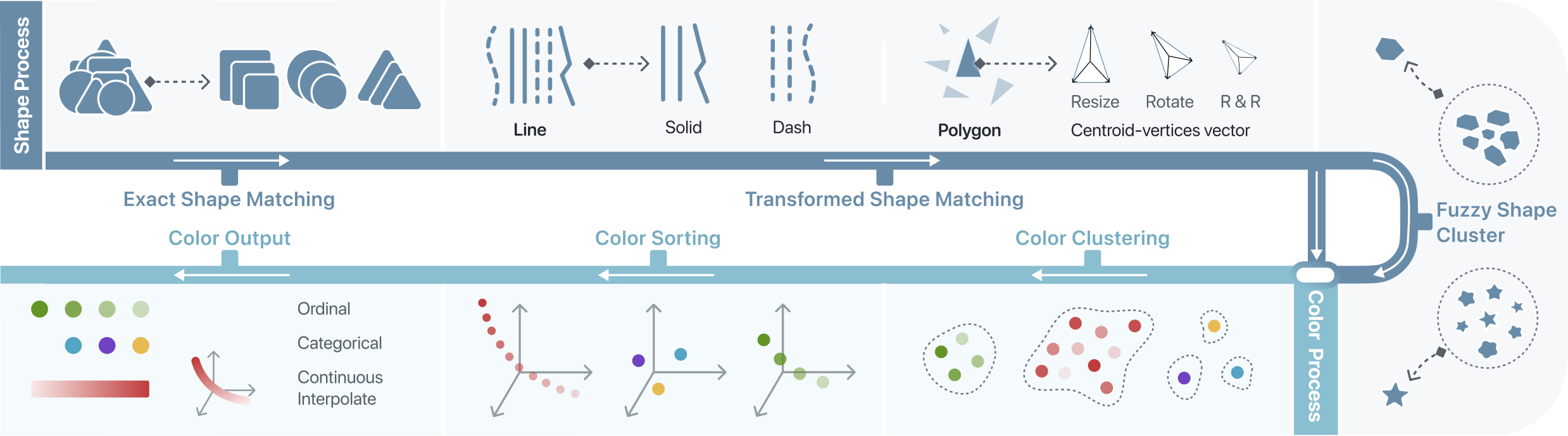
-
•
颜色聚类。 几何形状可以在可视化中带有多种颜色。 这部分的目的是将形状的颜色聚类成组,包括单色调连续颜色、多色调连续颜色、发散连续颜色、有序颜色和分类颜色。 所有 RGB 颜色值都会变换 CIELAB 颜色空间,然后进行标准化过程。 这些颜色点在标准化 LAB 颜色空间内利用 DBSCAN [50] 算法进行聚类。 控制此聚类过程的参数(表示为 和 )分别指定为 和 值。
-
•
颜色订购。 对于连续图例,我们获得具有多个颜色样本的簇。 为了构建连续的图例,应该首先对这些无序的颜色样本进行排序。 该问题可以被视为旅行商问题(TSP)。 目标是找到一次穿过所有颜色点的最短路径。 为此,我们采用近似算法。 首先,使用最近邻算法构造最小邻接矩阵。 距离计算也在 CIELAB 色彩空间中进行。 如果颜色样本数量很大(超过 100),则最小邻居计数将增加到 3,以避免邻接图断开。 由于起始和结束颜色未知,我们从每个节点开始构建最小生成树(MST)并按前序遍历它,获得并记录颜色点序列及其相应的成本。 选择成本最小的序列作为颜色的排序。
-
•
颜色插值。 对颜色进行排序后,对重新排列的颜色进行插值以恢复原始曲线。 我们利用 CIELAB 空间中的三次样条插值来拟合平滑曲线。 然后,我们对曲线上的等距点进行采样。 采样点数默认设置为 512。 由于插值是在 CIELAB 空间中进行的,因此得到的连续图例更符合人类对颜色的感知。
后处理。 同一符号可以同时通过多个视觉通道有效地传达信息,多个通道可能编码相同的数据属性。 例如,利用尺寸和颜色变化来表示单个数据属性作为说明性示例。 在视觉图例创建的上下文中,通常对与相同数据属性关联的内容采用单个图例表示。 为了辨别和提取这些多通道映射和相关性,需要在各个视觉通道上进行相关性分析。 计算并分析旋转角度、颜色和缩放因子之间的相关性。 我们使用“距离相关性”[51]来衡量多维数据之间的非线性相关性。 该方法用于测量三维LAB颜色序列、一维旋转角度序列和缩放因子序列之间的相关性。 实际上,对于其中的任何两个,如果距离向量超过阈值 0.75,则可以识别出非线性相关性。
5.2 图例搜索代理
提取标志性符号和通道后,涉及两个关键组件:图例搜索代理和质量评估模型。 搜索代理的职责是在高维混合空间中选择最合适的图例解决方案。 该空间包括许多维度,例如符号布局(类型和方向)、文本布局(类型和颜色)、多通道布局和图例的全局布局。
图例模型代理在这个混合高维空间中导航,该空间包含离散维度和连续维度。 虽然空间位置是连续的维度,但其他维度是离散的。 为了搜索图例空间,我们使用遗传算法[52, 53],这是一个典型的混合组合优化问题。 通过将可视化图例选择的过程模拟为遗传变异并从质量评估模型中接收分数,搜索代理会随着时间的推移生成更好的解决方案。 质量评估模型在指导这一过程中发挥着至关重要的作用。
5.3 质量评估模型
该模型根据具有默认权重的多个预定义指标,提供搜索代理生成的探索图例结果的反馈。 用户的反馈可以实时更新和调整权重,可以直接应用于探索模型。 我们的质量评估模型是一种轻量级的多层感知,可以看作是一个两层的、完全连接的网络。 该模型采用section 4中提到的指标,通过用户的简单注释来调整具有不同指标的不同指标的权重,可以嵌入专家知识和个性化设置。 这种质量评估模型,结合探索模型的高效探索,可以快速响应用户创建、调整和个性化推荐可视化的需求。
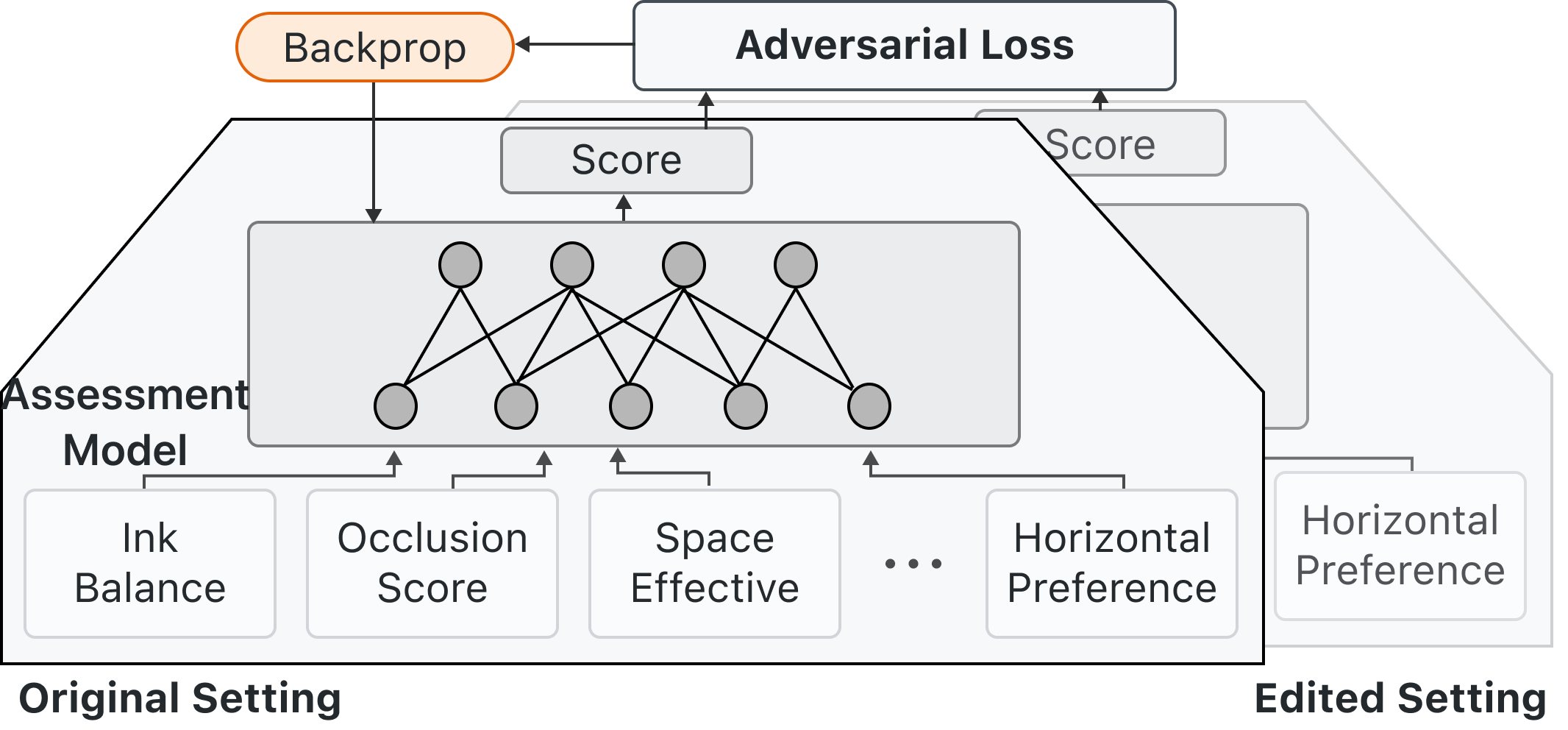
质量评估模型以多个指标作为输入,表示为,即遮挡指数、墨水平衡指数、可视化边界矩形区域指数、水平偏好和垂直偏好。 它输出一个分数 S 来表示当前图例解决方案的分数:
在我们的方法中,我们利用反馈循环传播来实现在线学习质量评估模型。 该模型将section 4中提到的指标作为输入,并输出一个标量分数来表示当前可视化的质量。 质量评估模型是多层感知器。 用户可以在交互界面上直接修改图例设置,包括更改图例的符号、文本排列和位置。 这些变化代表了用户的知识或偏好。 我们收集这些编辑记录,这些记录本质上以偏序关系元组的形式代表用户的偏好。 基于这些元组,我们对质量评估模型进行反向传播,由于模型规模较小,该模型将被实时训练。 后续的继续使用将采用更新后的模型,让模型不断适应用户的偏好。
5.4 根据用户反馈在线更新
我们主张在我们的方法中利用反馈循环传播。 我们实现了一个在线学习质量评估模型,该模型以多个指标作为输入,并输出一个分数来代表当前选择的质量。 质量评估模型是一个轻量级感知器(即全连接网络)。 用户在交互界面上编辑图形的位置和选择后,后端收集并存储编辑记录。 根据编辑记录,我们假设用户的编辑结果比之前的结果更好。 利用这个偏序关系二元元组,我们对模型进行实时对抗训练,以快速更新模型参数。 几秒钟内,后续的图形计算将使用更新的质量评估模型。 通过实验验证了该方法的有效性。
给定一对用户输入 和 ,假设用户认为 更好。 即,用户从调整到。 我们在质量评估模型上施加以下对抗性损失:
该损失函数描述了成对预测任务。 模型需要预测给定元组 的相对顺序 。 具体来说,如果,则表示优先于;如果,则意味着优先于。 损失函数的计算基于模型的预测结果,其中表示输入的预测结果。 对于给定的元组,可以使用模型的预测结果计算相对顺序的概率:
其中表示sigmoid函数,将任何实数映射到区间。 对于,值越大,表明模型更有信心优先选择而不是;相反,较小的值表示模型更有信心认为 与 相比不太受欢迎。 当用户修改图例时,这意味着他们对当前图例有更好的替代方案。 我们可以根据用户的选择获得至少一对用户偏好元组。
6 传奇互动
图例是可视化中数据和视觉标记之间的重要桥梁。 用户将可视化上传到界面后(Figure 6),两种自然的交互类型包括图例到可视化交互和可视化到图例交互。 图例与可视化交互涉及用户在图例上选择相应部分后突出显示可视化中的相应部分。 可视化与图例的交互涉及在用户关注可视化的某些部分后快速检索图例上的数据信息。
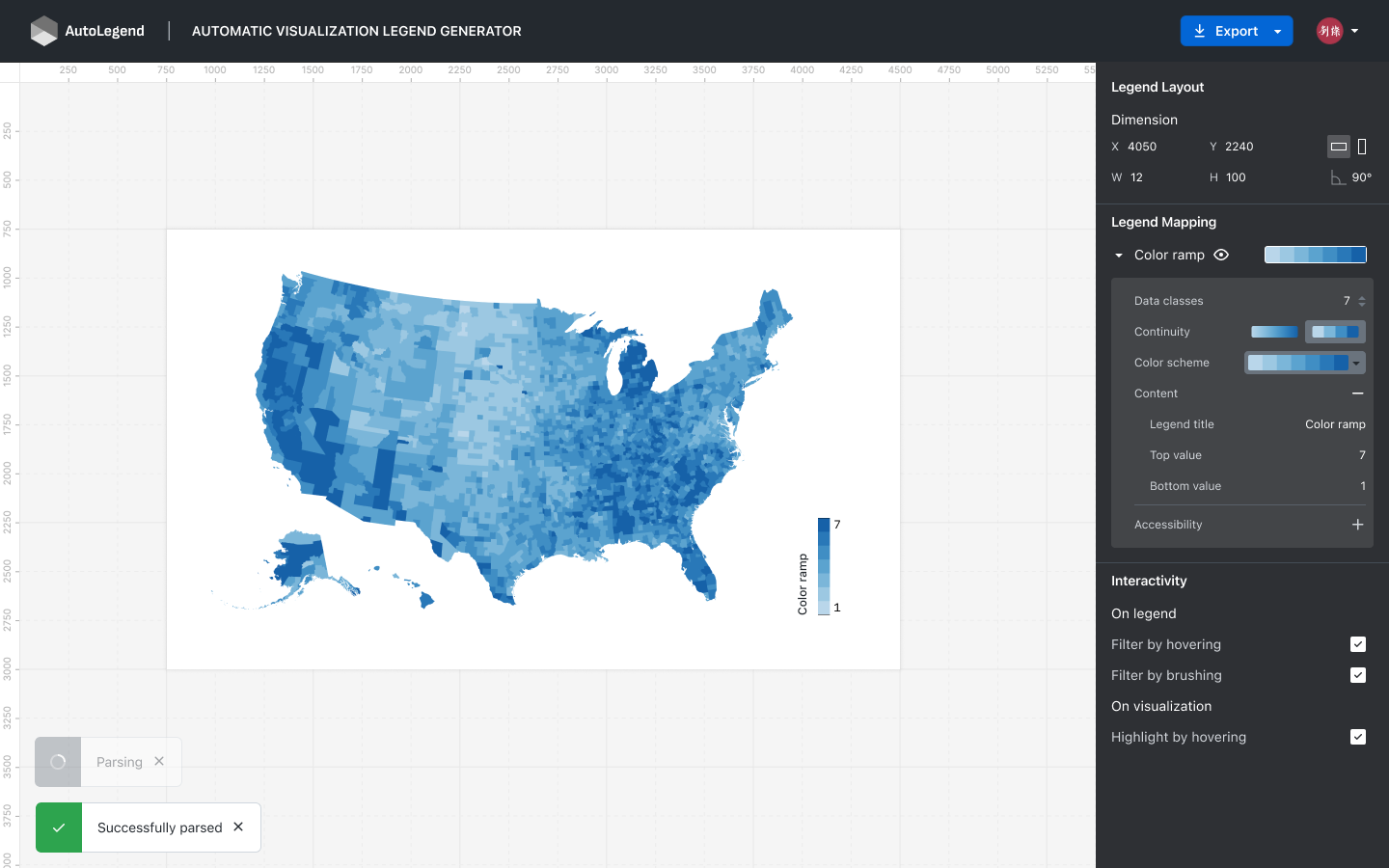
6.1 图例与可视化交互
本节讨论图例与可视化交互的方法,使用户能够选择图例项并将其与可视化空间中的视觉元素相对应。 离散和连续图例需要不同的交互方法。 如图Figure 7所示,对于离散图例,用户通常选择图例的单个项目。 我们通过在图例上进行点击选择来提供此功能,以支持用户选择。 对于连续图例,如 Figure 8 所示,我们用几种不同的状态来表示连续范围的选择。 我们支持用特定的数值或由它们组成的范围来指定上限和下限。
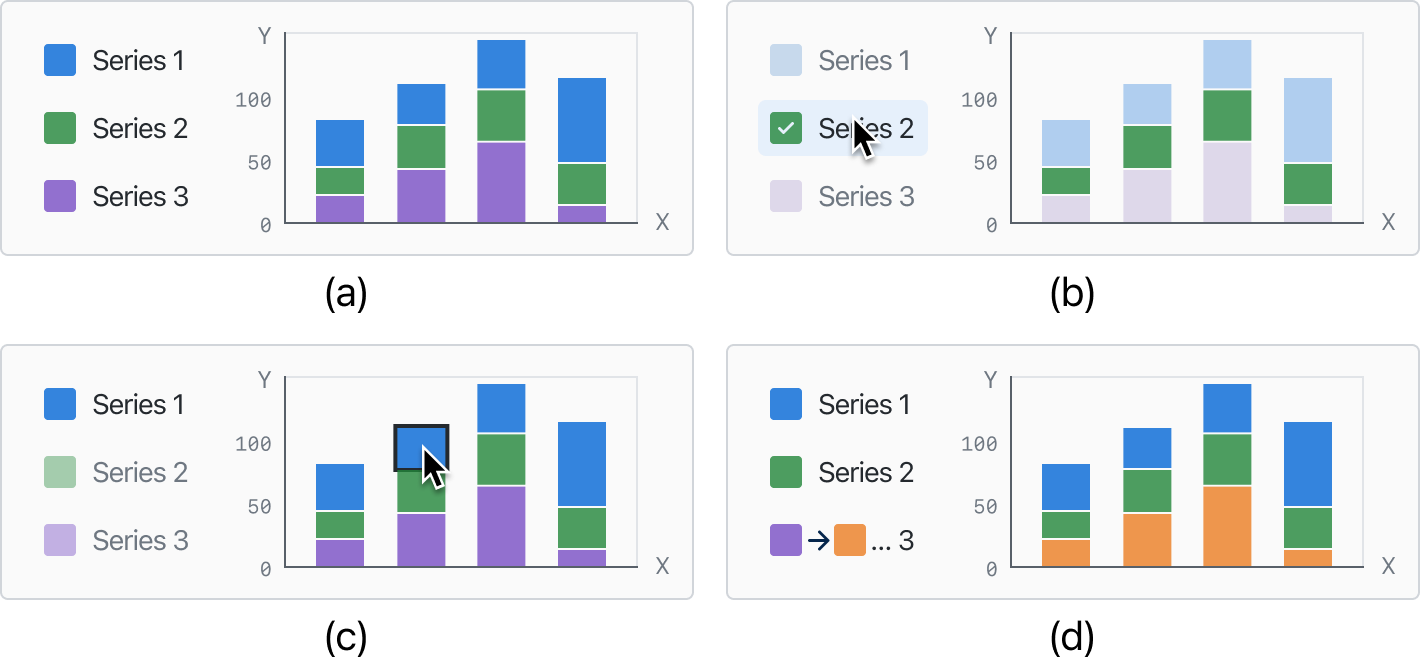
此外,图例还可以作为重新定位可视化的一种手段。 从可视化中提取的映射关系包含有关原始可视化元素及其对应属性值的信息。 我们的图例支持对原始可视化元素的修改,包括但不限于更改颜色通道和描边宽度。 Figure 8 (d) 说明了我们从蓝色配色方案到紫色配色方案的转换。
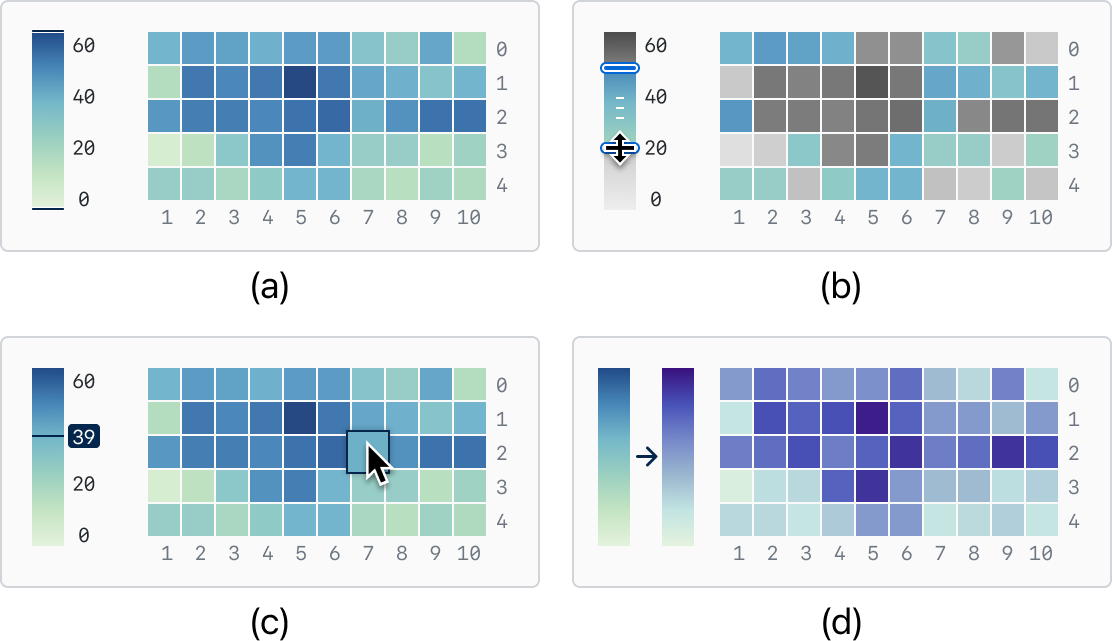
6.2 可视化与图例交互
当用户关注表示数据的可视化的某些部分时,可视化与图例交互支持获取图例上的响应和数据信息。 当用户悬停或点击可视化中的视觉标记后,我们通过统计数据增强和突出显示来增强和突出显示图例上的相应数据。
7 案例
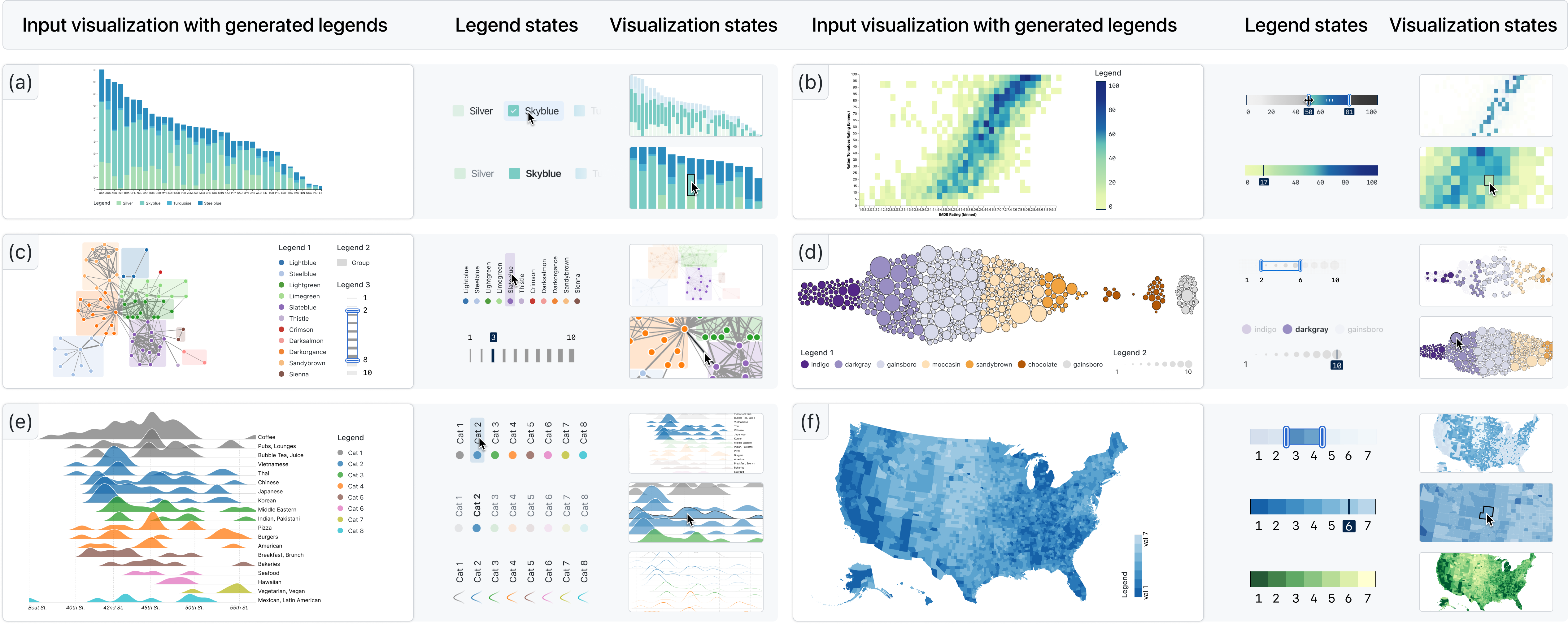
在本节中,我们将演示 AutoLegend 生成的六种可视化图例,包括条形图、网络图、地图、面积图、热图和气泡图。 这些可视化包含各种渠道,例如分类、有序和连续。 它们还包括单个可视化通道以及多个可视化通道的图例。
7.1 单通道传奇
AutoLegend 可以轻松处理单通道可视化,如 Figure 9(a)、(b)、(e)和(f)所示,它们分别显示了离散、序数和连续颜色通道。 这些类型的图表构成了可视化的重要部分,AutoLegend 可以生成相应的图例并为它们选择合适的位置。 AutoLegend可以为可视化生成各种图例,如图Figure 10所示,这是为Figure 9(a)中的堆叠条形图生成的图例。
7.2 多渠道传奇
8 用户研究
我们的目的是探索 AutoLegend 是否可以有效地生成图例并根据用户使用情况进行改进。 该用户研究旨在实现两个目标:首先,评估生成图例的有效性,其次,验证自适应学习算法在符合用户偏好方面的有效性。 这是特别相关的,因为在用户交互过程中会不断更新。
8.1 研究设计
参与者:我们招募了 13 名参与者,其中 4 名是女性。 参加人员包括2名本科生和11名研究生。 我们使用 5 点李克特量表收集了有关他们的学术背景和可视化经验的信息。 结果显示,大多数参与者都有使用编程工具的经验(、)。 所有参与者都同意收集他们的使用记录。
程序:我们向参与者介绍了该系统,并演示了如何上传可视化、生成图例、修改图例以及与他们交互。 我们从 EChart、D3 和 Vega-Lite 库中选择了 24 个具有代表性的可视化,包括条形图、分区统计图、热图和节点链接图等常见类型。 section 7中讨论的案例也包括在内。 随后,我们使用了其中 18 个可视化,让参与者与系统交互并生成图例。 在图例生成过程中,如果用户认为有更好的选择,则允许用户编辑可视化图例的设置,例如更改位置、符号布局和文本布局。 系统不断收集用户反馈并实时更新模型。 AutoLegend 为每个用户生成了一个改编版,并且改编版和原始版都为其余 6 个可视化生成了可视化图例。 为了验证 AutoLegend 了解用户偏好的能力,将两个模型生成的图例呈现给用户进行评估,但不透露哪些图例是由定制模型生成的。
访谈和问卷: 在图例生成过程之后,我们对参与者进行了采访,以评估他们对系统交互性和生成的图例质量的看法。 访谈鼓励参与者自由讨论他们对该系统的想法。 采访结束后,参与者被要求对提取的标记和通道的准确性、图例交互的可用性以及系统的编辑功能进行评分。 具体来说,参与者被要求评估图例交互的可用性,例如突出显示和过滤,以及图例在重定向视觉内容方面的有效性。 这些方面按 1 至 5 分进行评分,其中 1 表示“非常无用”,5 表示“非常有效”。 最后,我们要求参与者对原始图例和改编图例生成的图例进行评分,评分范围为 1 到 5 分。
8.2 反馈
总而言之,AutoLegend 被参与者描述为具有丰富的图例生成方式、高度互动性和非常有帮助。 我们在以下文本中总结了用户反馈。
-
•
有效的偏好获取。 除了上述用于用户交互和训练目的的 18 个可视化之外,我们还对其余 6 个可视化进行了评估。 这些可视化包括堆叠条形图、线图、地图、饼图和条形图。 对于每个单独的用户,我们的系统能够根据用户偏好生成合适的模型。 使用适应模型和系统的默认参数设置,我们为上述 6 个可视化生成了成对的图例集。 随后,每个用户按照 1 到 5 的等级对他们对 12 个可视化图例的偏好程度进行评分,其中 1 表示最不偏好,5 表示最偏好。 共有 13 名参与者在默认风格和偏好调整风格上贡献了 156 个评分。 为了确定默认生成的图例和根据用户偏好调整的图例之间是否存在偏好的显着差异,采用了两个样本 t 检验。 实验结果显示,与默认设置(、)相比,经过偏好调整的图例(、)获得的评分明显更高。 计算出的两侧 t 值为 2.38,导致 p 值为 0.0195,小于显着性阈值 0.05。 因此,证实了两组图例之间存在统计上的显着差异。 尽管我们没有明确告知用户偏好的获取,但我们的结果表明用户在图例选择中表现出一定的偏好,并且 AutoLegend 成功捕获了这些偏好。 例如,P4 倾向于选择靠近右边缘的图例,而 P6 则倾向于选择靠近中间底部的图例。
-
•
准确的编码通道识别。 AutoLegend能够准确地从可视化中提取各种通道并确定这些通道是否映射到数据(,)。 这允许生成与原始视觉元素具有语义联系的多样化图例。 例如,P2 对“山”可视化图例中保留的轮廓表示赞赏。 此外,AutoLegend 可以检测不同通道之间的相关性。 一位用户对系统能够揭示“风”元素的颜色和角度之间的关系并将其反映在图例中的能力印象深刻,他们发现这种映射关系很难识别自己的身份。 另一位用户称赞该系统在提取多种类型元素方面的全面性和对应性,例如提取不同颜色和宽度的线条,以及不同大小的多边形。
-
•
多样化的互动和有效的重定向。 参与者认为AutoLegend可以生成各种图例(,)。 AutoLegend提供可视化和图例之间的双向交互,包括将鼠标悬停在可视化元素上时突出显示相应的图例、将鼠标悬停在图例上时突出显示相应的可视化元素、连续图例过滤和突出显示以及为连续通道元素提供数据提醒。 许多用户注意到 AutoLegend 提供的各种交互,这有助于他们理解可视化。 此外,用户对重定向可视化表达了浓厚的兴趣。 所有用户都渴望尝试通过图例改变可视化颜色,并发现“修改图例中的数据映射”的功能非常有用。
9 讨论和未来的工作
在本节中,我们将深入研究从研究中获得的见解,并确定未来工作的潜在途径。
9.1 编辑子图例
在采访中,用户提到了允许在可视化中操作子图例的愿望,例如合并或删除特定元素。 例如,在某些可视化中,用户可能不希望显示某些频道。 这些编辑操作应该集成到可视化图例的编辑过程中。 未来,我们的目标是使模型能够学习用户编辑各种频道的偏好,而不仅仅是提供编辑功能。 这需要将图例之间的关系合并到用户偏好的表示中。
9.2 绑定外部数据
在我们当前的框架中,我们接受可视化作为输入,并提取在可视化中映射数据的符号和通道。 虽然这种方法具有广泛的应用,但一些用户表示有兴趣支持外部数据的绑定,这将允许向原始可视化添加更多信息。 例如,在节点链接图中,原始可视化可能没有映射到任何其他数据的大小。 然而,现在我们可以允许大小代表附加属性,从而增强系统的重定向能力。
9.3 图例智能交互
目前,我们的模型能够通过使用图例提供交互式可视化。 这包括突出显示相应的视觉元素。 一些参与者提出,子传说之间可能存在更深层次的数据关系,可以同时识别和突出显示。 通过这样做,我们可以为用户提供更丰富的信息体验。 例如,在节点链接图中,同时突出显示节点及其相应的边将提供对底层数据关系的更全面的理解。
未来,我们计划通过解析和识别数据中的常见模式来构建智能连接。 这将使我们能够以更有意义的方式突出显示相关的可视化组件。 通过将这种级别的智能融入到交互过程中,我们可以改善用户体验并促进更全面地理解可视化中的底层数据关系。
9.4 集成人机协作
在传统的机器学习方法中,数据标注和模型训练通常被视为单独的过程。 负责数据标注、质量控制和模型训练的人员与在交互式场景中使用模型的人员不同是很常见的。 因此,用户交互通常依赖于固定的、预先训练的模型,这使得将用户反馈有效地集成到模型中具有挑战性。 交互过程中需要一个重要的循环来获取用户反馈,以向模型提供输入。
此过程需要用户建立合理的反馈规则,确保数据合规性,并对模型进行训练以逐步纳入用户反馈,同时保留以前学习的信息。 此外,模型训练器必须经过训练,并且模型必须在交互环境中重新部署。 但这个循环的持续时间可能会超过允许的交互延迟,导致用户缺乏持续的交互过程。 此过程可能需要多方之间的协作。
在我们的综合循环中,互动、学习和标注应该形成一个内聚循环,其中互动充当标注。 此过程提供了有价值的学习示例,使机器能够不断从用户反馈中学习。
10 结论
在本文中,我们提出了一种新颖的方法来创建可以适应用户偏好的有效可视化图例。 为了实现这一目标,我们首先总结了可视化图例的设计空间,例如视觉通道、视觉标记、元素布局、文本布局和多通道布局。 然后,我们为每个设计元素创建了评估指标,以帮助确定其有效性。 我们的方法通过搜索潜在图例设计的高维空间并根据指标对其进行评分,生成符合既定指标的图例。 我们还纳入了考虑用户反馈的偏好指标,允许实时调整用户交互和动态更新后端模型。
参考
- [1] M. Bostock, V. Ogievetsky, and J. Heer, “D3: Data-Driven Documents,” IEEE Trans. Vis. Comput. Graph., vol. 17, no. 12, pp. 2301–2309, Dec. 2011.
- [2] A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer, “Vega-lite: A grammar of interactive graphics,” IEEE Trans. Vis. Comp. Graph., vol. 23, no. 1, pp. 341–350, 2017.
- [3] D. Li, H. Mei, Y. Shen, S. Su, W. Zhang, J. Wang, M. Zu, and W. Chen, “ECharts: A declarative framework for rapid construction of web-based visualization,” Visual Informatics, vol. 2, no. 2, pp. 136–146, 2018.
- [4] R. Sieber, C. Schmid, and S. Wiesmann, “Smart legend–Smart atlas,” in Proceedings of International Conference of the ICA, 2005.
- [5] F. Göbel, P. Kiefer, I. Giannopoulos, A. T. Duchowski, and M. Raubal, “Improving map reading with gaze-adaptive legends,” in Proceedings of the ACM Symposium on Eye Tracking Research and Applications, 2018.
- [6] J. Dykes, J. Wood, and A. Slingsby, “Rethinking map legends with visualization,” IEEE Trans. Vis. Comput. Graph., vol. 16, no. 6, pp. 890–899, 2010.
- [7] E. Imhof, Thematische Kartographie. Berlin: Walter de Gruyter, 1972.
- [8] D. Edler, J. Keil, M.-C. Tuller, A.-K. Bestgen, and F. Dickmann, “Searching for the ‘right’legend: the impact of legend position on legend decoding in a cartographic memory task,” The Cartographic Journal, vol. 57, no. 1, pp. 6–17, 2020.
- [9] N. H. Riche, B. Lee, and C. Plaisant, “Understanding interactive legends: a comparative evaluation with standard widgets,” Computer Graphics Forum, vol. 29, no. 3, pp. 1193–1202, 2010.
- [10] K. Shahira and A. Lijiya, “Towards assisting the visually impaired: a review on techniques for decoding the visual data from chart images,” IEEE Access, vol. 9, pp. 52 926–52 943, 2021.
- [11] J. Choi, S. Jung, D. G. Park, J. Choo, and N. Elmqvist, “Visualizing for the non-visual: Enabling the visually impaired to use visualization,” Computer Graphics Forum, vol. 38, no. 3, pp. 249–260, 2019.
- [12] M. Savva, N. Kong, A. Chhajta, F.-F. Li, M. Agrawala, and J. Heer, “ReVision: Automated classification, analysis and redesign of chart images,” in Proceedings of ACM UIST, 2011, pp. 393–402.
- [13] J. Poco and J. Heer, “Reverse-engineering visualizations: Recovering visual encodings from chart images,” Computer Graphics Forum, vol. 36, no. 3, pp. 353–363, 2017.
- [14] L.-P. Yuan, W. Zeng, S. Fu, Z. Zeng, H. Li, C.-W. Fu, and H. Qu, “Deep colormap extraction from visualizations,” IEEE Trans. Vis. Comput. Graph., vol. 28, no. 12, pp. 4048–4060, 2022.
- [15] J. Luo, Z. Li, J. Wang, and C.-Y. Lin, “ChartOCR: Data extraction from charts images via a deep hybrid framework,” in Proceedings of IEEE WACV, 2021, pp. 1917–1925.
- [16] C. Lai, Z. Lin, R. Jiang, Y. Han, C. Liu, and X. Yuan, “Automatic annotation synchronizing with textual description for visualization,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, paper No. 316, 2020.
- [17] F. Zhou, Y. Zhao, W. Chen, Y. Tan, Y. Xu, Y. Chen, C. Liu, and Y. Zhao, “Reverse-engineering bar charts using neural networks,” Journal of Visualization, vol. 24, pp. 419–435, 2021.
- [18] Y. Zhang, M. Chen, and B. Coecke, “MI3: Machine-Initiated Intelligent Interaction for Interactive Classification and Data Reconstruction,” ACM Trans. Interact. Intell. Syst., vol. 11, no. 3–4, 2021.
- [19] X. Liu, D. Klabjan, and P. NBless, “Data extraction from charts via single deep neural network,” arXiv preprint arXiv:1906.11906, 2019.
- [20] J. Poco, A. Mayhua, and J. Heer, “Extracting and retargeting color mappings from bitmap images of visualizations,” IEEE Trans. Vis. Comput. Graph., vol. 24, no. 1, pp. 637–646, 2018.
- [21] E. Hoque and M. Agrawala, “Searching the visual style and structure of d3 visualizations,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 1, pp. 1236–1245, 2019.
- [22] W. Cui, J. Wang, H. Huang, Y. Wang, C.-Y. Lin, H. Zhang, and D. Zhang, “A mixed-initiative approach to reusing infographic charts,” IEEE Trans. Vis. Comput. Graph., vol. 28, no. 1, pp. 173–183, 2021.
- [23] Z. Chen, Y. Wang, Q. Wang, Y. Wang, and H. Qu, “Towards automated infographic design: Deep learning-based auto-extraction of extensible timeline,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 1, pp. 917–926, 2019.
- [24] N. Kong and M. Agrawala, “Graphical overlays: Using layered elements to aid chart reading,” IEEE Trans. Vis. Comput. Graph., vol. 18, no. 12, pp. 2631–2638, 2012.
- [25] M. Lu, N. Fish, S. Wang, J. Lanir, D. Cohen-Or, and H. Huang, “Enhancing static charts with data-driven animations,” IEEE Trans. Vis. Comput. Graph., vol. 28, no. 7, pp. 2628–2640, 2022.
- [26] J. Choi, D. G. Park, Y. L. Wong, E. Fisher, and N. Elmqvist, “VisDock: A toolkit for cross-cutting interactions in visualization,” IEEE Trans. Vis. Comput. Graph., vol. 21, no. 9, pp. 1087–1100, 2015.
- [27] J. Harper and M. Agrawala, “Deconstructing and restyling D3 visualizations,” in Proceedings of ACM UIST, 2014, pp. 253–262.
- [28] ——, “Converting basic D3 charts into reusable style templates,” IEEE Trans. Vis. Comput. Graph., vol. 24, no. 3, pp. 1274–1286, 2018.
- [29] M. Lu, J. Liang, Y. Zhang, G. Li, S. Chen, Z. Li, and X. Yuan, “Interaction+: Interaction enhancement for web-based visualizations,” in Proceedings of the IEEE Pacific Visualization Symposium, 2017, pp. 61–70.
- [30] C. Liu, Y. Zhang, C. Wu, C. Li, and X. Yuan, “A spatial constraint model for manipulating static visualizations,” ACM Transactions on Interactive Intelligent Systems, vol. 14, no. 2, pp. 1–29, 2024.
- [31] B. Alper, N. Riche, G. Ramos, and M. Czerwinski, “Design study of linesets, a novel set visualization technique,” IEEE Trans. Vis. Comput. Graph., vol. 17, no. 12, pp. 2259–2267, 2011.
- [32] F. Chevalier, R. Vuillemot, and G. Gali, “Using concrete scales: A practical framework for effective visual depiction of complex measures,” IEEE Trans. Vis. Comput. Graph., vol. 19, no. 12, pp. 2426–2435, 2013.
- [33] Y. Yang, T. Dwyer, S. Goodwin, and K. Marriott, “Many-to-many geographically-embedded flow visualisation: An evaluation,” IEEE Trans. Vis. Comput. Graph., vol. 23, no. 1, pp. 411–420, 2017.
- [34] C. Palomo, Z. Guo, C. T. Silva, and J. Freire, “Visually exploring transportation schedules,” IEEE Trans. Vis. Comput. Graph., vol. 22, no. 1, pp. 170–179, 2016.
- [35] M. Rubio-Sánchez and A. Sanchez, “Axis calibration for improving data attribute estimation in star coordinates plots,” IEEE Trans. Vis. Comput. Graph., vol. 20, no. 12, pp. 2013–2022, 2014.
- [36] M. Jarema, I. Demir, J. Kehrer, and R. Westermann, “Comparative visual analysis of vector field ensembles,” in Proceedings of IEEE VAST, 2015, pp. 81–88.
- [37] Y. Lu, M. Steptoe, S. Burke, H. Wang, J.-Y. Tsai, H. Davulcu, D. Montgomery, S. R. Corman, and R. Maciejewski, “Exploring evolving media discourse through event cueing,” IEEE Trans. Vis. Comput. Graph., vol. 22, no. 1, pp. 220–229, 2016.
- [38] W. Dou, C. Ziemkiewicz, L. Harrison, D. H. Jeong, R. Ryan, W. Ribarsky, X. Wang, and R. Chang, “Comparing different levels of interaction constraints for deriving visual problem isomorphs,” in Proceedings of IEEE VAST, 2010, pp. 195–202.
- [39] J. Zhao, F. Chevalier, C. Collins, and R. Balakrishnan, “Facilitating discourse analysis with interactive visualization,” IEEE Trans. Vis. Comput. Graph., vol. 18, no. 12, pp. 2639–2648, 2012.
- [40] W. Meulemans, J. Dykes, A. Slingsby, C. Turkay, and J. Wood, “Small multiples with gaps,” IEEE Trans. Vis. Comput. Graph., vol. 23, no. 1, pp. 381–390, 2017.
- [41] R. Scheepens, N. Willems, H. van de Wetering, G. Andrienko, N. Andrienko, and J. J. van Wijk, “Composite density maps for multivariate trajectories,” IEEE Trans. Vis. Comput. Graph., vol. 17, no. 12, pp. 2518–2527, 2011.
- [42] P. Bak, F. Mansmann, H. Janetzko, and D. Keim, “Spatiotemporal analysis of sensor logs using growth ring maps,” IEEE Trans. Vis. Comput. Graph., vol. 15, no. 6, pp. 913–920, 2009.
- [43] J. Wood, A. Slingsby, N. Khalili-Shavarini, J. Dykes, and D. Mountain, “Visualization of uncertainty and analysis of geographical data,” in Proceedings of IEEE VAST, 2009, pp. 261–262.
- [44] X. Yuan, P. Guo, H. Xiao, H. Zhou, and H. Qu, “Scattering points in parallel coordinates,” IEEE Trans. Vis. Comput. Graph., vol. 15, no. 6, pp. 1001–1008, 2009.
- [45] D. Deng, Y. Wu, X. Shu, J. Wu, S. Fu, W. Cui, and Y. Wu, “VisImages: A fine-grained expert-annotated visualization dataset,” IEEE Trans. Vis. Comput. Graph., no. 01, pp. 1–1, 2022.
- [46] K. Hu, M. A. Bakker, S. Li, T. Kraska, and C. Hidalgo, “VizML: A machine learning approach to visualization recommendation,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 2019.
- [47] C. Liu, L. Xie, Y. Han, X. Yuan et al., “Autocaption: An approach to generate natural language description from visualization automatically,” in Proceedings of the IEEE Pacific Visualization Symposium (Notes), 2020, pp. 191–195.
- [48] S. E. Kahou, V. Michalski, A. Atkinson, Á. Kádár, A. Trischler, and Y. Bengio, “Figureqa: An annotated figure dataset for visual reasoning,” arXiv preprint arXiv:1710.07300, 2017.
- [49] C. Liu, Y. Guo, and X. Yuan, “AutoTitle: An interactive title generator for visualizations,” IEEE Trans. Vis. Comp. Graph., pp. 1–12, 2023.
- [50] M. Ester, H.-P. Kriegel, J. Sander, X. Xu et al., “A density-based algorithm for discovering clusters in large spatial databases with noise,” in KDD, vol. 96, no. 34, 1996, pp. 226–231.
- [51] G. J. Székely, M. L. Rizzo, and N. K. Bakirov, “Measuring and testing dependence by correlation of distances,” Ann. Stat., vol. 35, no. 6, pp. 2769 – 2794, 2007.
- [52] S. Mirjalili, Genetic Algorithm. Cham: Springer International Publishing, 2019, pp. 43–55.
- [53] A. F. Gad, “Pygad: An intuitive genetic algorithm python library,” Multimedia Tools and Applications, pp. 1–14, 2023.