通过 ML 预测改进在线算法 † †thanks: 本文的会议版本 [18] 发表在 2018 年 NeurIPS 上。
摘要
在这项工作中,我们研究了使用机器学习预测来提高在线算法性能的问题。 我们考虑了两个经典问题:滑雪租赁和非先见之明的作业调度,并获得了使用预测做出决策的新在线算法。 这些算法对预测器的性能一无所知,在预测更准确的情况下会得到改善,但如果预测不准确,也不会严重下降。
1 介绍
处理不确定性是现实世界计算任务(除了人类)面临的最具挑战性问题之一。 从“下周会下雪吗?”到“我应该租公寓还是买房子?”,有一些问题无法在没有未来知识的情况下可靠地回答。 同样,“我应该运行哪个作业?”这个问题对于 CPU 调度程序来说很难,因为调度程序不知道此作业将运行多长时间以及未来可能会到达哪些其他作业。
有两种有趣且经过充分研究的计算范式旨在解决不确定性。 第一个是机器学习领域,其中通过对未来做出预测来解决不确定性。 这通常通过检查过去并根据数据构建稳健模型来实现。 然后使用这些模型对未来进行预测。 人类和现实世界应用程序可以使用这些预测来调整他们的行为:知道下周可能会下雪可以用来计划滑雪旅行。 第二个领域是算法设计。 在这里,努力在于发展一个关于算法优劣的竞争比率的概念, 1 11非正式地说,竞争比将在线算法的最坏情况性能与知道未来的最佳离线算法进行比较。 针对未知的未来,并开发在线算法,这些算法在不考虑未来的情况下做出决策,但在最坏情况下具有可证明的优越性,即即使在最悲观的未来情况下也是如此。 这种在线算法在现实世界系统中很流行且成功,并且已被用于模拟包括分页、缓存、作业调度等问题(参见 Borodin 和 El-Yaniv 的书[5])。
最近,人们对使用机器学习预测来提高在线算法的质量很感兴趣[21, 19]。 这条研究路线的主要动机是双重的。 首先是设计新的在线算法,这些算法可以避免假设最坏情况,从而在理论和实践中都具有更好的性能保证。 第二个是利用机器学习中大量的建模工作,这些工作正是处理如何进行预测。 此外,由于机器学习模型通常会在新数据上重新训练,因此这些算法可以自然地适应不断变化的数据特征。 使用预测时,重要的是在线算法不知道预测器的性能,并且不假设预测错误的类型。 此外,我们希望算法具有两个关键属性:(i)如果预测器很好,那么在线算法应该接近最佳离线算法的性能(一致性),以及(ii)如果预测器很差,那么在线算法应该优雅地退化,即它的性能应该接近没有预测的在线算法的性能(稳健性)。
我们的问题。 我们考虑在线算法中的两个基本问题,并展示如何使用机器学习预测以可证明的方式提高它们的性能。 第一个是滑雪租赁,其中滑雪者将滑雪未知天数,每天可以选择以单位价格租赁滑雪板,或者以更高的价格购买,从那时起免费滑雪。 不确定性在于滑雪天数,预测器可以估计该天数。 例如,可以通过构建基于天气预报和其他滑雪者过去行为的模型来合理地进行这种预测。 滑雪租赁问题是这类在线租用或购买问题的典型例子,这类问题在需要在廉价的短期解决方案(“租赁”)和昂贵的长期解决方案(“购买”)之间做出选择时出现。 滑雪租赁问题已经过多种扩展和概括,导致了许多应用,例如动态 TCP 确认[11],购买停车许可证[22],租赁云服务器[14],嗅探缓存[13]等等。 滑雪租赁最著名的确定性算法是盈亏平衡算法:在最初的天租赁,并在第天购买。 很容易观察到,盈亏平衡算法的竞争比为 2,并且没有确定性算法可以做得更好。 另一方面,Karlin 等人[12]设计了一种随机算法,其竞争比为,这也是最优的。
我们考虑的第二个问题是非先知作业调度。 在这个问题中,必须在一台机器上调度一组作业,所有作业都立即可用;任何作业都可以被抢占并在以后恢复。 目标是最小化作业的完成时间之和。 这个问题的不确定性在于,调度程序在作业实际完成之前不知道作业的运行时间。 请注意,在这种情况下,预测器可以通过构建基于作业的特性、资源需求及其过去行为的模型,来预测作业的运行时间。 由 Motwani 等人[24]提出的非先知作业调度是在线算法中的一个基本问题,它有着悠久的历史,除了它在现实世界系统中的明显应用外,它的许多变体和扩展在文献中得到了广泛的研究[9, 3, 1, 10]。 Motwani 等人[24]表明,循环算法的竞争比为 2,这是最优的。
主要结果。 在介绍我们的主要结果之前,我们需要一些正式的概念。 在在线算法中,算法的 竞争比 被定义为算法成本与离线最优解之间的最坏情况比率。 在我们的设置中,这是一个 预测器误差 的函数。 2 22预测误差的定义是特定于问题的。 在本文中考虑的这两个问题中,被定义为误差的范数。 . 我们说一个算法是 -鲁棒的 ,如果 对于所有 ,并且它是 -一致的 ,如果 。 所以一致性衡量的是算法在完美预测的最佳情况下表现如何,而鲁棒性衡量的是算法在糟糕预测的最坏情况下表现如何。
令 为超参数。 对于带有预测器的滑雪租赁问题,我们首先获得一个确定性的在线算法,该算法是 -鲁棒的和 -一致的(第 2.2 节)。 接下来,我们通过获得一个 -鲁棒和 -一致的随机算法来改进这些界限,其中 是购买成本(第 2.3 节)。 对于非先见调度问题,我们获得一个 -鲁棒和 -一致的随机算法。 请注意,所有这些算法的一致性界限都规避了较低的界限,这只有因为预测才有可能。
事实证明,对于这些问题,人们必须谨慎地使用预测。 我们通过一个例子说明,如果天真地使用预测,则无法保证鲁棒性(第 2.1 节)。 我们的算法通过打开这些问题的经典在线算法并以明智的方式使用预测来进行。 我们还进行了实验以表明我们开发的算法是实用的,并且与不使用任何预测的算法相比,它们实现了良好的性能。
相关工作。 与我们最接近的工作是 Medina 和 Vassilvitskii [21] 以及 Lykouris 和 Vassilvitskii [19] 的工作。 前者使用预测预言机来改进保留价格优化,将预期出价与收入之间的差距与平均预测器损失相关联。 从某种意义上说,这篇论文开启了对配备机器学习预测的在线算法的研究。 后者进一步发展了这一框架,引入了鲁棒性和一致性的概念,并考虑了带有预测的在线缓存问题。 它修改了著名的 Marker 算法,使用预测来确保鲁棒性和一致性。 虽然我们在同一个框架内运行,但他们的技术都不适用于我们的设置。 最近的另一项工作是 Kraska 等人的工作。 [17] 通过实证表明可以使用机器学习模型构建更好的索引;它没有为其方法提供任何可证明的保证。
还有一些其他计算模型试图解决不确定性问题。 鲁棒优化领域 [16] 考虑不确定的输入,并旨在设计能够针对输入的任何潜在实现提供良好性能保证的算法。 已经有一些关于在输入是随机的或来自已知分布的情况下分析算法的工作 [20, 23, 6]。 在优化领域,整个在线随机优化领域关注在线决策下的不确定性,通过假设未来输入的分布;参见 Russell Bent 和 Pascal Van Hentenryck 的著作 [4]。 我们的工作不同于这些,因为我们不假设输入有任何东西;事实上,我们也不假设预测器有任何东西!
2 带有预测的滑雪租赁
在滑雪租赁问题中,假设每天的租赁费用为一个单位, 是购买的成本, 是实际的滑雪天数,该天数对算法是未知的,而 是预测的天数。 那么 是预测误差。 请注意,我们没有对它的分布做出任何假设。 最佳成本为 。
2.1 预热:一个简单的、一致的、非鲁棒的算法
我们首先表明,一个简单地使用预测天数来决定是否购买的算法是 1-一致的,即,当 时,它的竞争比率为 1。 但是,该算法并不健壮,因为在预测错误的情况下,竞争比率可以任意大。
Lemma 2.1.
令 表示由 算法 1 获得的解的成本,并令 表示同一实例上的最优解成本。 那么 。
证明。
我们根据预测 和实例的实际天数 的相对值来考虑不同的情况。 回想一下,当预测至少为 时,算法 1 会产生 的成本,否则会产生 的成本。
-
•
。
-
•
-
•
-
•
∎
算法 1 的一个主要缺点是缺乏鲁棒性。 特别是,如果预测 很小,但 ,那么它的竞争比率将是无界的。 我们的下一个目标是获得一种既一致又鲁棒的算法。
2.2 一种确定性的鲁棒且一致的算法
在本节中,我们证明了对算法 1 的一个小修改可以产生一种既一致又鲁棒的算法。 令 为一个超参数。 正如我们稍后将看到的那样,改变 会使算法的鲁棒性和一致性之间产生平滑的权衡。
证明。
我们从第一个界限开始。 假设 且算法在第 天开始购买滑雪板。 由于算法在 时会产生 的成本,因此当 时,会得到最差的竞争比,对于这种情况,。 在这种情况下,我们有 。 另一方面,当 时,算法在第 天开始购买滑雪板,并在之前租用。 在这种情况下,当 时,会达到最差的竞争比,因为我们有 和 。
为了证明第二个界限,我们需要考虑以下两种情况。 假设 。 那么,对于所有 ,我们有 。 另一方面,对于 ,我们有 。 第二个不等式成立是因为要么 (如果 )要么 (如果 )。 假设 。 那么,对于所有 ,我们有 。 同样,对于所有 ,我们有 。 最后,对于所有 ,注意到 ,我们有 。 因此,我们得到 ,完成了证明。 ∎
因此,算法 2 提供了一个权衡一致性和鲁棒性的选择。 特别地,对预测者更加信任意味着将 设置为接近零,因为当 很小时,这将导致更好的竞争比。 另一方面,将 设置为接近一是保守的,并且会产生更稳健的算法。
2.3 一种随机的鲁棒且一致的算法
在本节中,我们考虑一类随机算法,并将其性能与一个无知对手进行比较。 特别地,我们设计了鲁棒且一致的算法,这些算法比上述确定性算法具有更好的权衡。 令 为一个超参数。 对于给定的 ,算法 3 根据接收到的预测,基于两种不同的概率分布对购买滑雪板的日期进行采样,并在该日期之前进行租赁。
证明。
我们根据 和 的相对值考虑不同的情况。
(i)。 在这里,我们有 . 由于算法在第 天开始购买时会产生 的成本,所以我们有
(ii) . 在这里,我们有 . 另一方面,该算法仅在第 天开始购买时才会产生 的成本。 特别地,我们有
这就建立了鲁棒性。 为了证明一致性,我们可以将 RHS 重写如下
因为 和 .
(iii)。 在这里,我们有 . 另一方面,该算法的预期成本可以类似于 (ii) 计算
(iv)。 在这里,我们有 . 该算法产生的预期成本与 (i) 中相同。
| where the last inequality is proven in Lemma A.2 in the Appendix. This completes the proof of robustness. To prove consistency, we rewrite the RHS as follows. | ||||
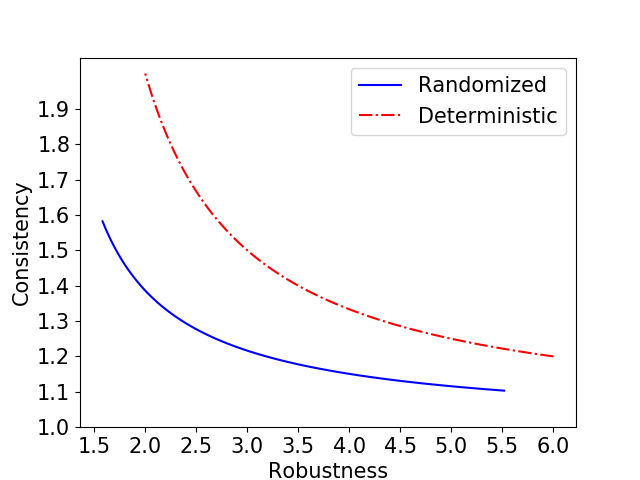
算法 2 和 3 都为滑雪租赁问题提供了鲁棒性和一致性保证之间的平滑权衡。 如图 1 所示,随机算法通过始终保证给定鲁棒性保证下的较小一致性,提供了更好的权衡。 我们注意到,在算法 2 和 3 中设置 允许我们恢复经典滑雪租赁问题中最佳确定性和随机算法,而无需使用预测。
2.4 扩展
考虑滑雪租赁问题的一般化,其中我们每天 对计算资源的需求 不同。 这种情況模拟了在设计小型企业数据中心时所面临的问题。 系统设计人员可以选择以高设置成本购买机器,或者从云服务提供商租用机器来处理企业的计算需求。 可以通过两种方式满足需求:要么支付 租用一台机器,并满足一天的需求量为一个单位;要么支付 购买一台机器,并使用它来满足未来所有天数的需求量为一个单位。 通过将前 天的 设置为 0,然后将其设置为 0,可以轻松地在此框架中解决经典的滑雪租赁问题。 Kodialam [15] 考虑了这种推广,并给出了具有 2 的竞争比率的确定性算法,以及具有 的竞争比率的随机算法。
3 带有预测的非先知作业调度
我们考虑非先知作业调度的最简单变体,即在没有发布日期的情况下,在单台机器上调度 个作业。 作业 的处理需求 对算法未知,只有在作业完成处理后才能知道。 任何作业都可以在任何时候被抢占并在稍后时间恢复,而不会产生任何成本。 目标函数是最小化作业完成时间的总和。 请注意,如果不允许抢占,则没有任何算法可以产生任何非平凡的保证。
令 表示 个作业的实际处理时间,这些时间对非先知算法是未知的。 在先知情况下,当处理时间事先已知时,最佳算法是简单地按照作业长度的非递减顺序调度作业,即最短作业优先。 一种称为 轮循 (RR) 的确定性非先知算法产生了 2 [24] 的竞争比,这被认为是最好的。
现在,假设算法没有真正非先知,而是有一个预言机来预测每个作业的处理时间。 令 表示 个作业的预测处理时间。 那么 是作业 的预测误差,而 是总误差。 我们假设没有零长度作业,并且单位被归一化,使得最短作业的实际处理时间至少为 1。 本节的目标是设计既健壮又一致的算法,即可以利用良好的预测来突破 2 的下界,同时保证最坏情况下的常数竞争比。
3.1 优先轮循算法
在具有抢占的调度问题中,我们可以通过谈论机器上同时运行的多个作业来简化说明,这些作业的速率之和最多为 1。 例如,在循环算法中,在任何时刻,所有 在机器上以相同的 运行。 这只是为了简便起见,表示在任何无穷小的时段内, 的一部分用于运行每个作业。
如果一个非先见调度算法具有以下性质,我们称其为 单调的:给定两个具有相同输入和实际作业处理时间的实例 和 ,使得 对于所有 成立,则该算法针对第一个实例找到的目标函数值不高于针对第二个实例的值。 很容易看出循环算法是单调的。
我们考虑 最短预测作业优先 (SPJF) 算法,该算法按作业的 预测 处理时间 的升序排序作业,并按此顺序执行作业直至完成。 请注意,SPJF 是单调的,因为如果处理时间 变小(预测 保持不变),所有作业只会更早完成,从而减少总完成时间目标。 SPJF 在预测完美的条件下产生最佳调度,但对于错误的预测,其最坏情况性能不受常数限制。 为了兼顾两全其美,即对良好的预测获得良好的性能以及在最坏情况下获得常数因子近似,我们将 SPJF 与 RR 相结合,使用以下方法,将该算法称为 优先循环 (PRR)。
Lemma 3.1.
给定两个具有竞争比 和 的单调算法,用于具有抢占的最小总完成时间问题,以及参数 ,可以获得一个竞争比为 的算法。
证明。
结合后的算法并行运行两个给定的算法。 近似值(称为 )以 的速率运行,而 近似值 () 以 的速率运行。 与以速率 1 运行相比,如果算法 以较慢的速率 运行,所有完成时间都会增加 倍,因此它成为一个 近似值。 现在,由于一些作业正在由算法 并行执行,因此从 的角度来看,它们的处理时间只会减少,因此根据单调性,这不会使 的目标函数更糟糕。 同样,当算法 以较低的速率 运行时,它成为一个 近似值,并且根据单调性,它只会从与 的并发中得到改进。 因此,这两个边界同时成立,整体保证是它们的最小值。 ∎
接下来,我们分析 SPJF 的性能。
Lemma 3.2。
SPJF 算法的竞争比最多为 。
证明。
假设不失一般性。 作业按其实际处理时间的非递减顺序编号,即 。 对于任何一对作业 ,定义 为作业 在作业 完成时间之前已执行的量。 换句话说, 是 延迟 的时间量。 令 表示 SPJF 的输出。 然后
对于 满足 的情况,较短的作业先调度,因此 ,但对于预测错误的作业对,较长的作业先调度,因此 。 这将产生
这将产生 。 现在,根据我们的假设,所有作业的长度至少为 1,我们有 。 这产生了 SPJF 竞争比的 的上限。 ∎
我们给出一个例子,表明这个界限是渐近紧密的。 假设有 个作业,处理时间为 ,还有一个作业,处理时间为 ,并假设所有作业的预测长度为 。 然后是 、,并且,如果 SPJF 碰巧先安排了最长的作业,则将 作业的完成时间增加 每个,。 这就得到了 的比率,当 增加而 减小时,该比率接近引理 3.2 中的界限。
最后,我们限制了优先轮循算法的性能。
Theorem 3.3.
带有参数 的优先轮循算法的竞争比率最多为 。 特别地,它是 -鲁棒的和 -一致的。
设置 给出一种算法,在预测足够好的情况下,该算法优于轮循的比率 。 对于零预测误差的特殊情况(或者更一般地,如果按 排序的作业顺序与按 排序的作业顺序相同),我们可以通过更复杂的分析获得 的改进竞争比率。
Theorem 3.4.
带有参数 的优先轮循算法的竞争比率最多为 ,当 时。
证明。
假设 w.l.o.g。 任务按照非递减的任务长度(实际和预测的)排序,即 和 。 由于最佳解决方案是按顺序调度任务,因此我们有
| (1) |
如果一个任务尚未完成,我们称其为 活动 任务。 当有 个活动任务时,优先级轮循算法以 的速率执行所有活动任务,并将预测处理时间最短的活动任务(我们称此任务为 当前 任务)以额外的 的速率执行。 注意,每个任务 在成为当前任务时完成。 这可以归纳地表示:假设作业 在时间 完成。然后,到时间 时,作业 收到的处理量严格少于 ,但其大小至少一样大。 因此,它还有一些剩余的处理时间,这意味着它在时间 成为当前任务,并保持当前任务状态直到完成。 令 阶段 表示算法中任务 为当前任务的时间间隔。
对于任何一对任务 ,定义 为在 完成时间之前执行的任务 的数量。 换句话说, 是 延迟 的时间。 现在我们可以将算法的成本表示为
| (2) |
4 实验结果
4.1 滑雪租赁
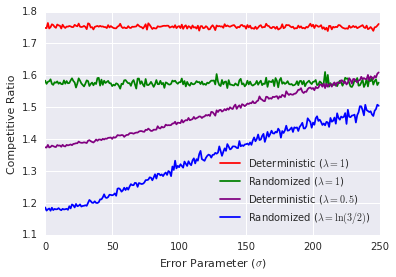
我们通过模拟测试了我们的算法在滑雪租赁问题上的性能。 对于所有实验,我们将购买成本设定为 ,实际滑雪天数 是从 中随机均匀抽取的整数。 预测的滑雪天数 模拟为 ,其中 从均值为 0,标准差为 的正态分布中随机抽取。 我们考虑了两种不同权衡参数 值的随机和确定性算法。 回想一下,通过设置 ,我们的算法忽略了预测,并简化为已知的最佳算法(分别是确定性和随机的)[12]。 我们将 设置为保证最坏情况竞争比为 3 的确定性算法。 为了获得相同的最坏情况竞争比,我们将 设置为随机算法。 对于每个 ,我们在图 2(a) 中绘制了每个算法在 10000 次独立试验中获得的平均竞争比。 我们观察到,即使对于相当大的预测误差,我们的算法也比其经典对应算法表现得明显更好。 特别地,即使是使用预测的确定性算法,其在误差高达标准差为 时,也比经典随机算法表现得更好。
4.2 非先知调度
N min max mean 50 1 22352 2168 5475.42
我们生成一个包含 50 个作业的合成数据集,其中每个作业的处理时间独立地从帕累托分布中采样,该分布的指数为 . (如先前工作 [7, 8, 2] 中观察到的,在许多情况下,作业大小分布可以通过帕累托分布很好地建模,其中 接近 1.) 生成的数据集的相关特征在表 1 中给出. 为了模拟预测的作业长度并比较不同算法在预测误差方面的性能,我们设置预测的作业长度为 ,其中 从均值为零、标准差为 的正态分布中抽取.
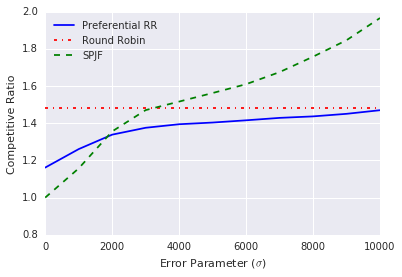
图 2(b) 显示了三种算法在不同预测误差下的竞争比率. 对于参数 ,我们绘制了 1000 次独立试验的平均竞争比率,其中预测误差具有指定的标准差. 正如预期的那样,在误差较低时,按照预测作业长度非递减顺序调度作业的朴素策略 (SPJF) 性能非常好,但随着误差的增加,性能迅速下降. 相反,我们的优先级轮询算法()即使在预测误差非常大的情况下,其性能也不比轮询算法差.
5 结论
在本文中,我们进一步研究了利用机器学习预测来证明改进在线算法的最坏情况性能。 还有许多其他重要的在线算法,包括 -服务器,投资组合优化等,看看预测是否对它们也有用将很有趣。 另一个研究方向是利用机器学习预测器的误差分布来进一步改进界限。
致谢
感谢徐辰阳指出了会议版本中的一个错误 [18],并感谢 Erik Vee 在修复错误方面的帮助。
参考文献
- [1] Nikhil Bansal, Kedar Dhamdhere, Jochen Könemann, and Amitabh Sinha. Non-clairvoyant scheduling for minimizing mean slowdown. Algorithmica, 40(4):305–318, 2004.
- [2] Nikhil Bansal and Mor Harchol-Balter. Analysis of SRPT scheduling: Investigating unfairness. In SIGMETRICS, pages 279–290, 2001.
- [3] Luca Becchetti and Stefano Leonardi. Non-clairvoyant scheduling to minimize the average flow time on single and parallel machines. In STOC, pages 94–103, 2001.
- [4] Russell Bent and Pascal Van Hentenryck. Online Stochastic Combinatorial Optimization. MIT Press, 2009.
- [5] A. Borodin and R. El-Yaniv. Online Computation and Competitive Analysis. Cambridge University Press, 1998.
- [6] Sebastien Bubeck and Aleksandrs Slivkins. The best of both worlds: Stochastic and adversarial bandits. In COLT, pages 42.1–42.23, 2012.
- [7] Mark E Crovella and Azer Bestavros. Self-similarity in world wide web traffic: Evidence and possible causes. Transactions on Networking, 5(6):835–846, 1997.
- [8] Mor Harchol-Balter and Allen B Downey. Exploiting process lifetime distributions for dynamic load balancing. ACM TOCS, 15(3):253–285, 1997.
- [9] Sungjin Im, Janardhan Kulkarni, and Kamesh Munagala. Competitive algorithms from competitive equilibria: Non-clairvoyant scheduling under polyhedral constraints. J. ACM, 65(1):3:1–3:33, 2017.
- [10] Sungjin Im, Janardhan Kulkarni, Kamesh Munagala, and Kirk Pruhs. Selfishmigrate: A scalable algorithm for non-clairvoyantly scheduling heterogeneous processors. In FOCS, pages 531–540, 2014.
- [11] Anna R Karlin, Claire Kenyon, and Dana Randall. Dynamic TCP acknowledgement and other stories about . Algorithmica, 36(3):209–224, 2003.
- [12] Anna R. Karlin, Mark S. Manasse, Lyle A. McGeoch, and Susan Owicki. Competitive randomized algorithms for nonuniform problems. Algorithmica, 11(6):542–571, 1994.
- [13] Anna R. Karlin, Mark S. Manasse, Larry Rudolph, and Daniel Dominic Sleator. Competitive snoopy caching. Algorithmica, 3:77–119, 1988.
- [14] Ali Khanafer, Murali Kodialam, and Krishna P.N. Puttaswamy. The constrained ski-rental problem and its application to online cloud cost optimization. In INFOCOM, pages 1492–1500, 2013.
- [15] Rohan Kodialam. Competitive algorithms for an online rent or buy problem with variable demand. In SIAM Undergraduate Research Online, volume 7, pages 233–245, 2014.
- [16] Panos Kouvelis and Gang Yu. Robust Discrete Optimization and its Applications, volume 14. Springer Science & Business Media, 2013.
- [17] Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. The case for learned index structures. In SIGMOD, pages 489–504, 2018.
- [18] Ravi Kumar, Manish Purohit, and Zoya Svitkina. Improving online algorithms via ML predictions. In NeurIPS, pages 9684–9693, 2018.
- [19] Thodoris Lykouris and Sergei Vassilvitskii. Competitive caching with machine learned advice. In ICML, pages 3302–3311, 2018.
- [20] Mohammad Mahdian, Hamid Nazerzadeh, and Amin Saberi. Online optimization with uncertain information. ACM TALG, 8(1):2:1–2:29, 2012.
- [21] Andres Muñoz Medina and Sergei Vassilvitskii. Revenue optimization with approximate bid predictions. In NIPS, pages 1856–1864, 2017.
- [22] Adam Meyerson. The parking permit problem. In FOCS, pages 274–282, 2005.
- [23] Vahab S. Mirrokni, Shayan Oveis Gharan, and Morteza Zadimoghaddam. Simultaneous approximations for adversarial and stochastic online budgeted allocation. In SODA, pages 1690–1701, 2012.
- [24] Rajeev Motwani, Steven Phillips, and Eric Torng. Nonclairvoyant scheduling. Theoretical Computer Science, 130(1):17–47, 1994.
附录 A 延迟证明
我们首先陈述一些简单的观察结果,这些结果将很有用。
Lemma A.1.
对于 ,
-
(我)
。
-
(二)
。
-
(三)
。
证明。
(i) 对于 ,我们有 ,因此 。
(ii) 对于任何 ,我们有 。 显示 (ii) 等同于显示 。 但由于 ,我们可以代入 以获得
(iii) 我们首先证明 对于 是凹的(由于 ,我们在 处定义 使其连续)。 实际上,考虑 。 注意,对于所有 ,我们有 ,因此我们有 。 因此 在范围 内是凹的。 由于凹性,我们得到对于所有 ,,如预期的那样。 ∎
Lemma A.2。
令 为整数,令 为实数。 那么,