探索 Kolmogorov-Arnold 网络在分类中的局限性:对软件和硬件实现的见解
摘要
柯尔莫哥洛夫-阿诺德网络(KAN)是一种新型神经网络,由于能够以更高的准确性和互操作性替代人工智能(AI)中的多层感知(MLP),因此最近受到了欢迎和关注。 然而,KAN评估仍然有限,无法提供特定领域的深入分析。 此外,还没有对 KAN 在硬件设计中的实现进行研究,这可以直接证明 KAN 在实际应用中是否真正优于 MLP。 因此,在本文中,我们重点关注验证 KAN 的分类问题,这是人工智能中使用四种不同类型的数据集的常见但重要的主题。 此外,还考虑使用 Vitis 高级综合(HLS)工具来考虑相应的硬件实现。 据我们所知,这是第一篇为 KAN 实现硬件的文章。 结果表明,在高度复杂的数据集中,KAN 无法在利用更高的硬件资源的情况下实现比 MLP 更高的准确性。 因此,MLP 仍然是在软件和硬件实现中实现准确性和效率的有效方法。
索引术语:
Kolmogorov-Arnold 网络、KAN、神经网络、分类、FPGA、硬件我简介
如今,人工智能(AI)日益展现出解决人类生活问题的先进性[1]。 在人工智能模型中,多层感知器(MLP)或全连接神经网络提供了可学习的能力,并作为逼近非线性函数[2]的最重要组成部分。 然而,柯尔莫哥洛夫-阿诺德网络(KANs)[3],一种新兴起的人工智能和科学神经网络架构,最近基于柯尔莫哥洛夫-阿诺德表示定理[4, 5]而发展起来。 ] 由于其在准确性和可解释性方面的优势而取代 MLP。 事实上,[3] 中的 KAN 通过应用于偏微分方程 (PDE) [6]、持续学习 [7]< 等问题,展示了其强大功能/t2>、纽结理论[8]、安德森定位[9]等。
尽管 KAN 可以应用于许多应用程序,但由于可能场景的数量和复杂性有限,其背书仍然不够充分。 因此,需要进行更多的评估,以公平地评估 KAN 与 MLP 相比的优缺点。 此外,没有对 KAN 的硬件设计进行评估,这对于确保 KAN 能够有效且经济高效地应用于实际应用至关重要。 因此,有必要从硬件设计角度分析 KAN,以澄清有关准确性和硬件资源利用率之间权衡的任何潜在问题。
尽管 KAN 刚刚开发和发布,但已经有许多工作将 KAN 应用于广泛的应用。 在[10]中,Bozorgasl和Chen开发了小波Kolmogorov-Arnold网络来改进小波变换的原始KAN,与MLP相比取得了更好的精度和更短的训练时间。 此外,[11] 中的作者演示了如何使用 KAN 来分析卫星流量预测任务的时间序列数据。 他们的研究结果表明,KAN 在更低的误差指标、更高的准确度和更少的可学习参数数量方面优于 MLP。 此外,KAN 还用于求解偏微分方程,并且与[12]中的 MLP 相比,除了复杂的几何问题外,获得了出色的精度。 此外,[13]的作者在量子架构搜索(QAS)中使用了KAN,并获得了显着的结果,尽管基于KAN的系统的执行时间比基于MLP的系统要长。 此外,[14, 15]中的工作使用 KAN 来解决分类问题,这是基于 MLP 的模型中常见但重要的问题,并且与 MLP 相比取得了良好的结果。 然而,实验结果仍然仅限于小范围的分类问题,不能保证KAN在其他分类问题中的适用性。 此外,上述所有先前的工作都只是在软件平台上实现他们的想法以获得准确性,并且没有对硬件设计对准确性和硬件资源使用之间的权衡进行评估。
因此,在本文中,我们介绍了四种不同分类问题的分析,以评估 KAN 在分类问题上的有效性。 这些分类问题包括卫星二元分类[16]、三标签葡萄酒分类[17]、七标签干豆分类[18],以及蘑菇二元分类[19]。 此外,我们还根据上面给出的四个数据集执行 MLP 和 KAN 的硬件设计,以评估硬件的效率并阐明准确性和硬件资源之间的关系。
本文后续各节的组织如下:第 II 节提供有关 KAN 的背景知识。 第III节提供了对所提出方法的深入描述,其中包括有关软件和硬件实现的信息。 在第 V 节中,我们广泛评估和比较了 MLP 和 KAN。 最后,第VI节对本文进行了总结。 代码位于:github.com/Zeusss9/KAN_Analysis
II 背景知识
与基于万能逼近定理的 MLP 不同,KAN 是一种新的有前景的架构,它专注于 Kolmogorov-Arnold 表示定理来逼近非线性函数。 然后,本节将介绍 Kolmogorov-Arnold 表示定理以及基于该定理的 KAN 实现方式。
II-A 柯尔莫哥洛夫-阿诺德表示定理
柯尔莫哥洛夫-阿诺德表示定理,也称为叠加定理,由弗拉基米尔·阿诺德和安德烈·柯尔莫哥洛夫建立。 它指出有界域上的任何多元连续函数都可以表示为单变量连续函数和加法二元运算的有限组合。
| (1) |
其中 和 。 该公式表明,任何多元函数从根本上都可以表示为单变量 (1D) 函数的适当组合。
II-B 柯尔莫哥洛夫-阿诺德网络架构
KAN 是一种从 Kolmogorov-Arnold 表示定理发展而来的神经网络[3],与之前与 KAN 相关的现有工作相比有了巨大的改进。 具体来说,每个一维函数都可以参数化为具有局部 B 样条基函数的可学习系数的 B 样条曲线。 这是因为方程中需要学习的所有函数。 1 是单变量函数。 此外,KAN 利用 MLP 架构构建更宽、更深的 KAN,而不是常见大小的网络 (, ,1)。 KAN 架构由堆叠的 KAN 层组成,形成完整的网络。 然后,具有 维输入和 维输出的 KAN 层可以在一维函数矩阵中描述如下:
| (2) |
其中 函数是由可训练参数组成的样条函数。 因此,方程中的柯尔莫哥洛夫-阿诺德表示。 (1) 是两个这样的 KAN 层的组合,可以变得更宽更深。 那么,如图1所示的广义KAN模型可以清楚地表示为,分别为每层的节点数。 请注意,是KAN架构中除输入层之外的层数。
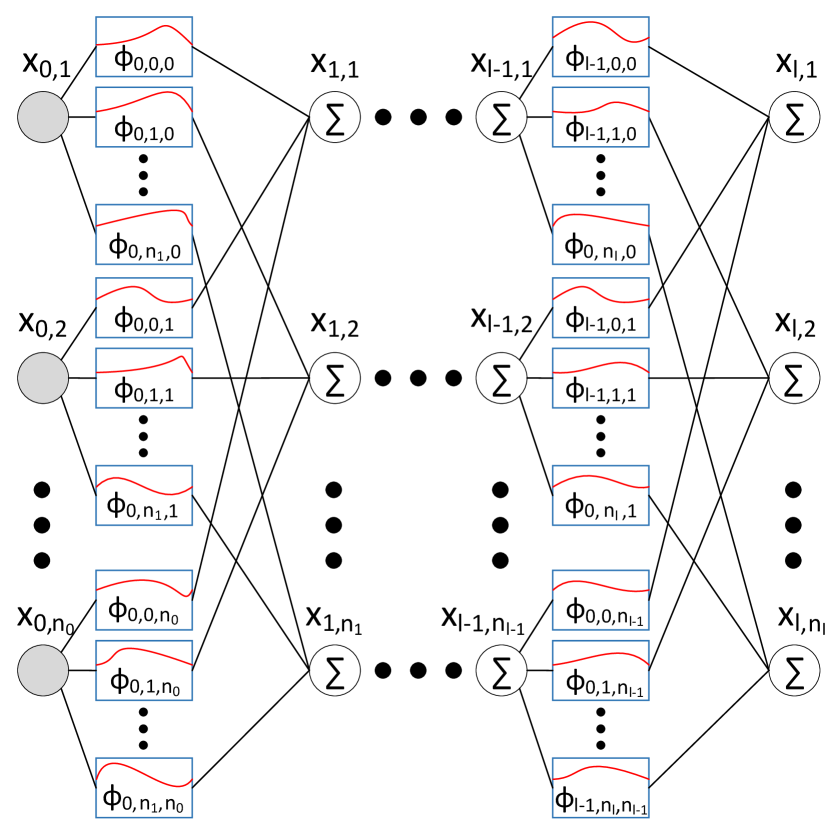
在这个 KAN 架构中,层 的神经元 和层 的神经元 之间存在 功能。 它们取代了典型 MLP 模型中权重的作用,并成为如上所述的可训练参数。 一般来说,可以使用B样条曲线(样条曲线的一种)来近似,B样条曲线是由控制点组成的平滑曲线。 更详细地说,样条曲线是用于平滑且连续地插值或近似数据点的数学函数。 样条曲线由两个参数确定:k,表示用于插值或近似的多项式函数的次数;G,表示相邻控制点之间的子区间的数量。 使用子区间,样条插值连接数据点以生成由 G + 1 个网格点组成的平滑曲线。
此外,正常MLP模型中层神经元处的激活函数也转化为结果的求和,并表示为如下:
| (3) |
另一方面,这可以用矩阵形式表示如下:
| (4) |
其中是根据 KAN层的函数矩阵。 因此,一个常见的 KAN 模型可以由带有输入向量 的 KAN 层组成:
| (5) |
最后,隐藏层和输出层中每个节点的函数将被符号函数逼近。 输出层的节点数量将对应于在那里形成的最终符号公式的数量。 然后,符号公式将用于预测数据,输入数据作为每个符号公式的变量。
III 建议的方法
在本节中,我们详细介绍I节中提到的四种分类数据集的软件训练方法和硬件实现方法。
III-A 软件训练方法
确保测试数据集的多样性、复杂性和真实性对于证明某种神经网络的能力至关重要。 因此,在本节中,我们继续在复杂性和现实性不断增加的四个不同数据集上分析 KAN 和 MLP,如下所示:
III-A1 卫星二元分类
Moons 数据集是通过使用 scikit-learn 的 make_moons 生成任何所需数量的数据(在本例中生成 10000 个数据样本)而创建的合成数据集。 它包括两个相交的半圆,对每个输入进行二元分类,并具有两个特征。 此外,Moons 数据集的复杂性相对较低,因为它具有分隔两类的明显非线性边界。 因此,它完全适合评估神经网络(特别是本例中的 KAN)的基本能力和初始效率。 对于MLP模型,每层神经元数量分别为2、8、4和2,隐藏层使用ReLU激活函数,输出层使用Sigmoid激活函数。 另一方面,KAN模型由、配置,模型大小为(2,2,1)。
III-A2 三标酒分类
葡萄酒数据集是关于葡萄酒品质的数据集,包含通过化学分析得出的三个标签和 13 个特征。 因此,与 Moons 数据集相比,Wine 数据集具有中等程度的复杂性。 尽管如此,即使我们使用smote方法增加样本数量(213),Wine数据集中的模式数量仍然相对较低(178)。 尽管如此,Wine 数据集足以评估 KAN 在这种复杂程度下的效率。 为了进行评估,MLP 模型由四层组成,分别具有 13、32、8 和 3 个神经元,隐藏层使用 ReLU 函数,输出层使用 Softmax。 同时,KAN模型已配置和,模型大小为(13,4,1)。
III-A3 七标干豆分类
Dry Bean 数据集比前两个数据集更复杂,因为它由每个数据样本的 7 个类和 16 个特征组成。 此外,它具有 13,611 个数据模式,足以通过要求模型有效处理更多数量的特征和更多样化的类别分布来评估 KAN。 因此,它可以确定模型是否有效地适用于现实世界中更复杂的情况。 在训练过程中,MLP模型由五层组成,分别有16、20、15、10和7个神经元,ReLU作为隐藏层的激活函数,Softmax作为输出层的激活函数。 此外,KAN模型有、,模型大小为(16,2,7)。
III-A4 蘑菇二元分类
Mushroom 数据集也是一个实用数据集,由 8,124 个蘑菇实例组成。 数据集中的每个数据样本都有八个特征,并分为两类之一:可食用或有毒。 尽管Mushroom数据集用于二元分类任务,但其复杂性来自于各种实际特征和海量的数据样本。 因此,它可以用来验证 KAN 与 MLP 相比的性能。 为了进行评估,MLP 模型每层有 16、20、15、10 和 7 个神经元,隐藏层使用 ReLU,输出层使用 Softmax。 此外,KAN模型的网格为6,k=3,模型大小为(8,24,2)。
III-B 硬件实现方式
手动将算法或软件程序实现到硬件设计中总是需要花费大量的精力和时间。 因此,高级综合(HLS)似乎可以将用 C/C++ 等语言编写的高级算法描述转换为硬件描述语言(HDL)。 与手动硬件描述语言(HDL)编码相比,HLS具有减少开发时间、简化设计修改、便于系统维护的优点。 通过将复杂的 C/C++ 程序自动映射到硬件,高级综合 (HLS) 提供了快速实施各种优化策略的能力,以实现卓越的性能和效率。 因此,HLS 成为实现硬件设计的卓越方法。
Vitis HLS [20] 是最好的 HLS 软件工具之一,由 Xilinx 开发,允许使用 C/C++ 等高级编程语言进行设计,而不是 Verilog 和 Very 等传统 HDL高速集成电路硬件描述语言(VHDL)。 因此,从 Vitis HLS 生成的 HDL 可以直接在现场可编程门阵列 (FPGA) 设备上实现。 此外,它还提供了强大的开发环境,可以缩短设计周期并提高生产率。 它还包括 Vitis HLS 流程和用于模拟、综合、修改和优化逻辑电路的工具,以比手动编写 HDL 代码更快地实现所需的架构。 因此,Vitis HLS 是快速有效实施硬件的绝佳选择。
IV 实验设置
为了评估KAN和MLP在软件训练过程中的性能,利用III-A节中提到的四个数据集来评估KAN在处理各种类型的复杂数据集时的能力。 此外,训练过程是在配备 NVIDIA RTX 3060 图形处理单元 (GPU) 的 Windows 11 计算机上进行的。
此外,我们在整个硬件实现过程中利用Vitis HLS 2023.1工具在C/C++程序中综合KAN和MLP。 具体来说,Python中符号转换后的符号公式将被手动转换为C/C++,而我们使用Py2C将Python中的MLP转换为C/C++程序。 它可以确保与软件精度值相比保持正确性,同时也可以快速有效地实现硬件设计。 为了在 KAN 和 MLP 之间进行公平比较,KAN 和 MLP 的所有硬件实现均根据以下配置进行设置:
| Dataset | Model | Model | Spline | No. | Accuracy | ET** (s) | Power (W) | PDP† (W*s) | ||||
| Type | Size | Info | Params | Pre* | Post | Pre* | Post | Pre* | Post | Pre* | Post | |
| Moons | MLP | 2,8,4,1 | N/A | 65 | 0.968 | 0.262 | 19.52 | 5.114 | ||||
| KAN | 2,2,1 | G=3/k=3 | 36 | 0.969 | 0.968 | 0.32 | 95.942 | 20.41 | 21.48 | 6.531 | 2060.83 | |
| Wine | MLP | 13,32,8,3 | N/A | 739 | 0.984 | 0.089 | 20.38 | 1.813 | ||||
| KAN | 13,4,3 | G=3/k=4 | 448 | 0.984 | 0.973 | 0.081 | 1.696 | 21.48 | 22.41 | 1.739 | 38.007 | |
| Dry Bean | MLP | 16,20,15,10,7 | N/A | 892 | 0.921 | 0.37 | 21.33 | 7.892 | ||||
| KAN | 16,2,7 | G=6/k=3 | 414 | 0.924 | 0.919 | 0.3 | 520.56 | 22.78 | 21.81 | 6.834 | 11353.5 | |
| Mushroom | MLP | 8,64,64,2 | N/A | 4866 | 0.99 | 1.067 | 21.09 | 22.5 | ||||
| KAN | 8,24,2 | G=6/k=3 | 2160 | 0.994 | 0.558 | 0.57 | 4501.3 | 43.96 | 21.03 | 25.057 | 94662.3 | |
| Pre*: KANs before transforming to the symbolic formula; Post: KANs after transforming to the symbolic formula. | ||||||||||||
| ET**: Execution time of a datasetl; PDP†: Power Delay Product = ET * Power. | ||||||||||||
-
•
工作频率:100 MHz。
-
•
利用 FPGA 进行综合和实现:Xilinx Zynq Ultrascale+ ZCU104 现场可编程门阵列 (FPGA) 板。
-
•
数据处理的数字类型:浮点32位。
V 结果与讨论
本节介绍并分析软件训练和硬件实施后的结果。 然后,我们可以明确 KAN 与 MLP 相比的有效性。
V-A 软件结果
为了确保公平比较,我们使用 0.0002 的学习率对所有 KAN 和 MLP 模型进行了 200 多个 epoch 的训练。 此外,我们对所有 MLP 模型使用 Adam 优化器,而对 KAN 模型使用 L-BFGS 优化器(KAN 的默认优化器)。
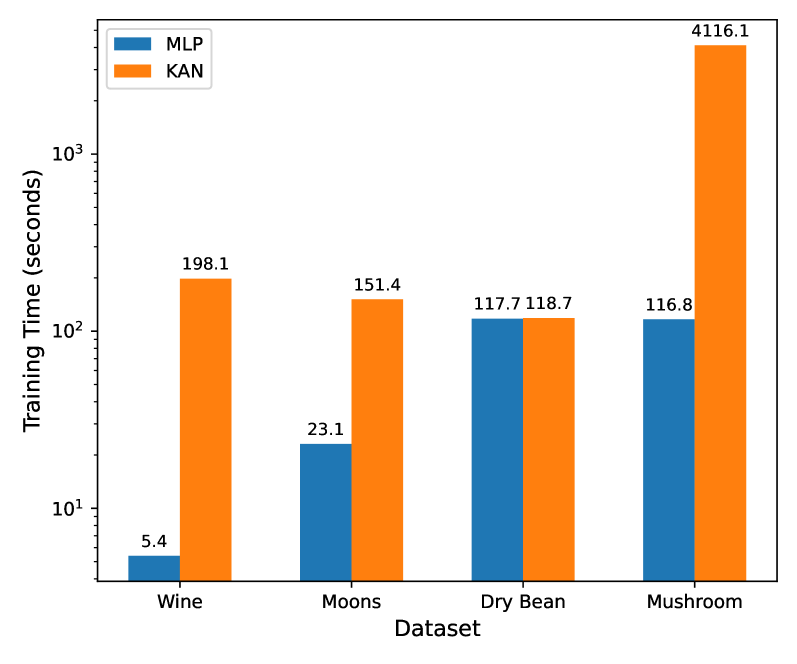
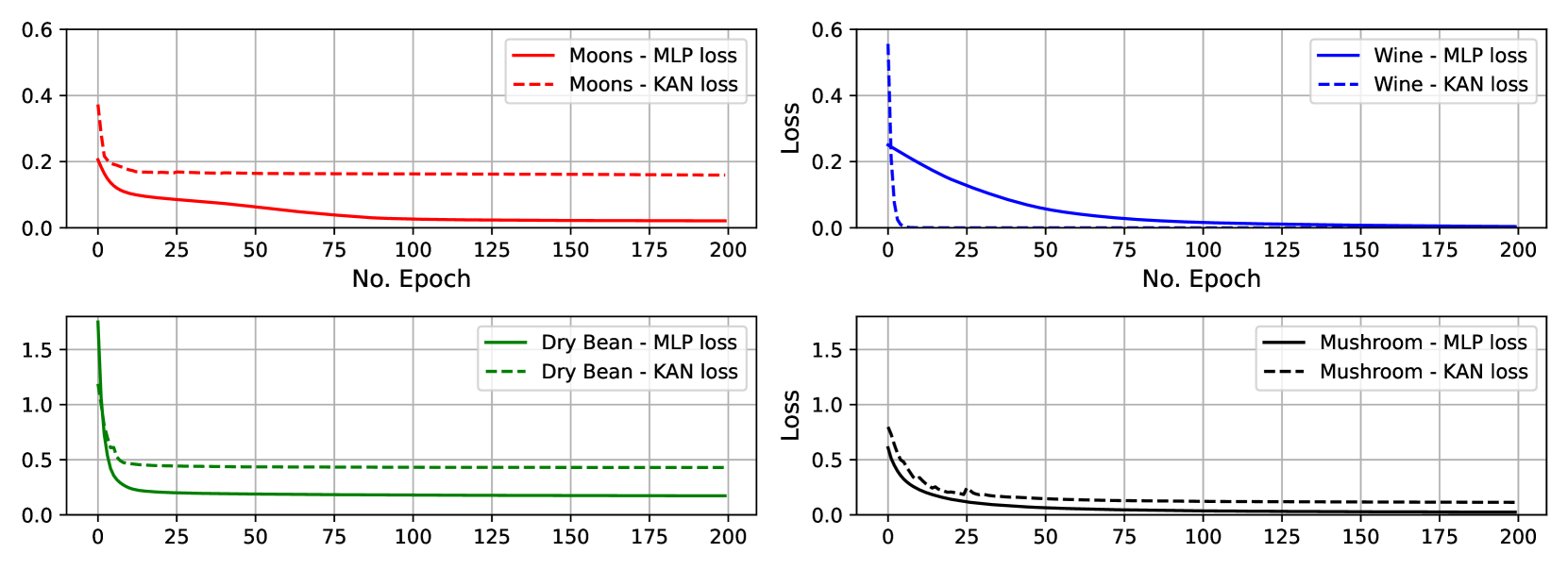
图2展示了四个数据集的MLP和KAN之间的训练时间差异。 除了 Dry Bean 数据集的训练时间外,所有其他三个数据集始终表明 KAN 需要比 MLP 更长的训练时间,范围从 6.55 倍(151.4 vs 23.1 s)到 36.68 次(198.1 与 5.4 秒)。 这是因为 [3] 中提到的 KAN 中的可训练样条函数。 此外,图3展示了训练过程中的损失值。 特别是,我们对干豆和蘑菇数据集使用交叉熵损失函数,对月亮和葡萄酒数据集使用均方误差损失函数。 除了 Wine 数据集之外,MLP 持续比 KAN 具有更快的损失减少速度和更低的损失值。 总体而言,在训练时间和损失减少方面,KAN 并不比 MLP 更好。
| (6) |
其中 是层数,而 是 层中神经元的数量。 此外,每个样条线的阶数为,并由间隔组成。
具体来说,由于[3]中提到的网络规模较小,与 MLP 模型相比,KAN 模型的可训练参数数量大约是 MLP 模型的一半。 此外,预准确率表明,在从月球到蘑菇数据集的分类问题上,KAN 并没有明显优于 MLP(0.969 与 0.968 / 0.984 对比 0.984 / 0.921 对比 0.924 / 0.99 对比 0.994)。 此外,当训练过程后使用符号函数而不是矩阵乘法时,后精度显示与预精度相比精度值有所下降。 当数据集的复杂性从月亮数据集上升到蘑菇数据集时,这种现象变得更加明显。 特别是,数据具有随机形状,使得任何单个符号函数完美拟合数据都具有挑战性。 因此,即使付出相当大的努力来找出最合适的单个符号函数或复杂的符号公式,准确性也不可避免地受到影响。 此外,当模型大小由于数据集的复杂性而增加时,由于整个网络的损失累积而导致的精度损失也会相应增加。 此外,将 KAN 转换为符号公式的过程需要开发人员付出巨大的努力来手动调整 KAN 模型并最大程度地减少准确性损失。 因此,训练过程不仅耗时,而且需要大量时间将 KAN 模型转换为符号公式。 此外,功率延迟积 (PDP) 表明,在所有情况下,具有所有 Pre 和 Post 值,MLP 几乎优于 KAN。 这表明与 MLP 相比,KAN 随着时间的推移会消耗更多的功耗。
一般来说,KAN 未能表现出比 MLP 更高的准确性,并且 KAN 的符号公式表示在分类挑战中的表现甚至比 MLP 更差。 此外,KAN 还需要开发人员投入大量的时间和精力来在最后阶段创建符号公式。 基于上述发现,与 KAN 相比,MLP 仍然是分类任务的有效选择。
V-B 硬件结果
| Dataset | Model | Freq. | Hardware Resources | Power | Latency | ||||
| Type | (MHz) | #BRAMs | #DSPs | #FFs | #LUTs | (W) | #Cycles | Time (ns) | |
| Moons | MLP | 100 | 0 | 17 | 3364 | 3809 | 0.663 | 149 | 1490 |
| KAN | 10 | 120 | 8622 | 17877 | 0.717 | 128 | 1280 | ||
| Wine | MLP | 2 | 17 | 9936 | 6974 | 0.675 | 699 | 6990 | |
| KAN | 132 | 950 | 74741 | 146843 | 1.349 | 688 | 6880 | ||
| Dry Bean | MLP | 0 | 17 | 11328 | 8894 | 0.67 | 835 | 8350 | |
| KAN | 781 | 9111 | 734544 | 1677558 | 14.802 | 1896 | 18960 | ||
| Mushroom | MLP | 4 | 17 | 18903 | 10932 | 0.673 | 3128 | 31280 | |
| KAN | 1347 | 16299 | 1337291 | 3112275 | - | 3434 | 34340 | ||
| - : The power consumption cannot be aggregated since the hardware resources exceed all of our FPGA boards. | |||||||||
表II中列出了硬件的实现后结果,用于比较 KAN(后)和 MLP。 结果表明,在所有四种数据集中,KAN 的硬件资源均明显大于 MLP,而表I显示 KAN 的参数低于 MLP。 这些结果表明,与 MLP 中的普通矩阵乘法相比,在硬件上实现符号公式需要更多的硬件资源。 此外,当KAN模型规模增大时,所需的硬件资源也会相应增加。 事实上,KAN 中使用的 BRAM 比 MLP 更高,范围从 10 到 1347,而 KAN 中使用的 DSP 显着增加,范围从 7.06 次(120 对比 17)到 958.76 次(16299 对比 17) >) 与 MLP 相比。 此外,KAN 的 FF 显着高于 MLP,在 2.56 倍之间波动(8622 vs. 3364 和 70.74 次(1337291 与 18903)。 另一方面,MLP 的 LUT 远小于 KAN 的 LUT,变化范围为 4.7 倍(3809 vs. 17877 到 284.7 次(10932 与 3112275)。 因此,由于使用大量资源,KAN 的功耗比 MLP 显着。 此外,即使 KAN 的延迟也并不比 MLP 更好,延迟时间较长,范围从 1.1 倍(3434 与 3128 个周期)到 2.27 倍(1896 与 835 周期)。
总体而言,MLP 在性能和硬件资源方面都优于 KAN。 基于此,在处理硬件分类问题时,与 KAN 相比,MLP 仍然是一个明显优越的选择。
六结论
在这项研究中,我们利用四个具有不同复杂程度的不同数据集,针对软件训练和硬件实现中的分类任务,对 KAN 与 MLP 进行广泛的评估。 结果表明,尽管 KAN 在准确性和可解释性方面具有理论上的优势,但在实际分类任务中并没有优于 MLP。 除了硬件实现之外,KAN 在实际应用中效率较低,因为它们使用大量资源并且比 MLP 具有更高的延迟。 总之,尽管 KAN 具有一些理论上的优势,但 MLP 仍然是解决分类问题的更实用、更节省资源的选择。 未来,我们可以在软件训练和硬件实现方面改进 KAN 架构,以提高 KAN 的性能,并增加评估数据集的数量以获得更全面的分析。
致谢
这项工作得到了日本 JST-ALCA-Next 计划拨款号 JPMJAN23F4 的支持。 该研究的部分执行是为了响应 JSPS 的支持,KAKENHI 拨款号: 22H00515,日本。
参考
- [1] E. Elbasi, N. Mostafa, Z. AlArnaout, A. I. Zreikat, E. Cina, G. Varghese, A. Shdefat, A. E. Topcu, W. Abdelbaki, S. Mathew et al., “Artificial intelligence technology in the agricultural sector: A systematic literature review,” IEEE access, vol. 11, pp. 171–202, 2022.
- [2] K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators,” Neural networks, vol. 2, no. 5, pp. 359–366, 1989.
- [3] Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Soljačić, T. Y. Hou, and M. Tegmark, “Kan: Kolmogorov-arnold networks,” arXiv preprint arXiv:2404.19756, 2024.
- [4] A. Kolmogorov, “On the representation of continuous functions of several variables as superpositions of continuous functions of a smaller number of variables,” Dokl. Akad. Nauk, vol. 108, 1956.
- [5] J. Braun and M. Griebel, “On a constructive proof of kolmogorov’s superposition theorem,” Constructive approximation, vol. 30, pp. 653–675, 2009.
- [6] L. C. Evans, Partial differential equations. American Mathematical Society, 2022, vol. 19.
- [7] L. Wang, X. Zhang, H. Su, and J. Zhu, “A comprehensive survey of continual learning: theory, method and application,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
- [8] V. O. Manturov, Knot theory. CRC press, 2018.
- [9] P. W. Anderson, “Absence of diffusion in certain random lattices,” Physical review, vol. 109, no. 5, p. 1492, 1958.
- [10] Z. Bozorgasl and H. Chen, “Wav-kan: Wavelet kolmogorov-arnold networks,” arXiv preprint arXiv:2405.12832, 2024.
- [11] C. J. Vaca-Rubio, L. Blanco, R. Pereira, and M. Caus, “Kolmogorov-arnold networks (kans) for time series analysis,” arXiv preprint arXiv:2405.08790, 2024.
- [12] Y. Wang, J. Sun, J. Bai, C. Anitescu, M. S. Eshaghi, X. Zhuang, T. Rabczuk, and Y. Liu, “Kolmogorov arnold informed neural network: A physics-informed deep learning framework for solving pdes based on kolmogorov arnold networks,” arXiv preprint arXiv:2406.11045, 2024.
- [13] A. Kundu, A. Sarkar, and A. Sadhu, “Kanqas: Kolmogorov arnold network for quantum architecture search,” arXiv preprint arXiv:2406.17630, 2024.
- [14] A. D. Bodner, A. S. Tepsich, J. N. Spolski, and S. Pourteau, “Convolutional kolmogorov-arnold networks,” arXiv preprint arXiv:2406.13155, 2024.
- [15] M. Cheon, “Kolmogorov-arnold network for satellite image classification in remote sensing,” arXiv preprint arXiv:2406.00600, 2024.
- [16] Sklearn Datasets MakeMoons, Online; accessed 12-July-2024, scikit-learn developers, 2024, https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_moons.html.
- [17] S. Aeberhard and M. Forina, “Wine,” UCI Machine Learning Repository, 1991, DOI: https://doi.org/10.24432/C5PC7J.
- [18] “Dry Bean,” UCI Machine Learning Repository, 2020, DOI: https://doi.org/10.24432/C50S4B.
- [19] P. Sawhney, “Mushroom dataset,” 2021, accessed: 2024-07-12. [Online]. Available: https://www.kaggle.com/datasets/prishasawhney/mushroom-dataset
- [20] Xilinx, “Vitis high-level synthesis user guide,” 2023.