yuxiaoq@andrew.cmu.edu;这项工作是在卡内基梅隆大学完成的。
递归内省:教授语言模型代理如何自我改进
摘要
在基础模型中实现智能代理行为的核心部分是使它们能够在更多计算或交互可用时反思自己的行为、推理并纠正错误。 即使是最强大的专有大语言模型(大语言模型)也没有完全表现出连续改进其响应的能力,即使在明确告知他们犯了错误的情况下也是如此。 在本文中,我们开发了RISE: R递归IntroSpEction,一种微调大语言模型以引入这种能力的方法,尽管之前的工作假设这种能力可能无法实现。 我们的方法规定了一个迭代微调过程,该过程试图教导模型在执行先前不成功的尝试解决硬测试时问题后如何改变其响应,并可选择附加环境反馈。 RISE 将单轮提示的微调视为解决多轮马尔可夫决策过程 (MDP),其中初始状态是提示。 受在线模仿学习和强化学习原理的启发,我们提出了多轮数据收集和训练的策略,以使大语言模型具有在后续迭代中递归检测和纠正先前错误的能力。 我们的实验表明,RISE 使 Llama2、Llama3 和 Mistral 模型能够通过数学推理任务的更多回合来改进自身,在推理时间计算量相同的情况下,其性能优于几种单回合策略。 我们还发现 RISE 具有良好的扩展性,通常可以通过功能更强大的模型获得更大的收益。 我们的分析表明,RISE 对响应进行了有意义的改进,以针对具有挑战性的提示得出正确的解决方案,而不会因表达更复杂的分布而破坏一回合能力。
1简介
利用和部署基础模型,特别是大型语言模型(大语言模型)的一种有前途的方法是将它们视为通用决策机器或“代理”。 为了获得成功,大语言模型智能体不仅必须为输入文本提供合理的补全,还必须表现出交互式、目标导向的行为来完成给定的任务。 简而言之,这需要掌握两个品质:(a) 生成明确寻求有关任务信息的响应,然后 (b) 做出决策并通过“改进决策”思考”并在推理时验证它们。 例如,为了成功使用新的编码库,有效的大语言模型代理应该首先综合程序,然后针对编译器尝试最有希望的子集,使用生成的反馈来改进程序,并多次重复该过程。 在测试时,有能力在连续尝试中成功改进响应相当于一种“自我改进”。
为了实现测试时的自我改进,最近的方法尝试通过少样本提示[15,31,52,64,7]来重新利用已存储在预训练模型中的知识。 尽管及时调整与反馈相结合可以有效地提高有能力的模型的响应,但它无法产生能够通过纠正自己的错误来成功完成复杂任务的模型,例如那些需要逻辑推理的模型 [21, 55]. 在许多此类问题中,模型包含回答具有挑战性的提示所需的“知识”,但即使被要求顺序纠正错误,也无法引出这些知识。 在特定领域的问答数据上微调大语言模型[39,6,29]可以提供帮助,但它仍然无法教会智能体测试时的改进策略(参见6)。 在测试时改进连续尝试的响应策略对于解决具有挑战性的提示至关重要,因为一次性直接尝试问题可能基本上是徒劳的。
我们能否训练模型提高其自己的反应能力? 如果正确地处理不同的问题和场景,这可以在大语言模型中引入一个“如何”的通用程序,它可以通过改进自身而不是监督它来解决困难提示回答“什么”,随着测试提示不再分发,这可能无法概括。 尽管将这种功能引入模型的一种直接方法是生成数据来展示多个连续回合的改进(可能来自高性能模型),但我们发现简单地模仿这些数据不足以启用这种功能(第 6.4 很好,这是由于两个原因:首先,来自不同模型的多轮数据不会显示学习者可能犯的错误类型的改进,因此与学习者无关[24] 。 其次,从专有模型收集的顺序多轮数据通常质量也不高,因为这些模型通常不擅长对自身错误提出有意义的改进[21],尽管它们仍然可以提供有用的信息对当前问题的回应。 因此,我们需要一种不同的策略来赋予模型自我改进的能力。 我们的主要见解是以迭代方式监督学习者自身反应的改进,从在线模仿学习[36]和强化学习(RL)[45]方法中汲取灵感>。 这种监督可以采用预言机响应提示采样 i.i.d 的形式。 来自更强大的模型,或者由学习者本身生成。
我们的贡献是一种算法RISE: 递归内省(图1),它利用这些见解来提高大语言模型的自我改进能力在给定提示的多次尝试过程中。 在每次迭代中,我们的方法都会引导学习者进行按策略部署,并在下一轮中通过对从学习者本身采样获得的多个修订候选运行 best-of-N(使用任务的成功指标)获得更好的响应,或者使用功能更强大的模型的响应,以更方便的为准。 通过这种方式,我们能够构建展示学习者如何在其自己的分布下改进其响应的推出。 然后,我们使用奖励加权回归 (RWR [35, 34]) 目标来对这些数据进行学习,该目标能够从此类推出的高质量和低质量部分中学习。 通过迭代地重复这个过程,我们能够将一般的自我改进能力灌输到大语言模型中。 我们的结果表明,通过 RISE 训练的大语言模型可以对更多提示做出正确的反应,提高对更具挑战性的提示的反应。
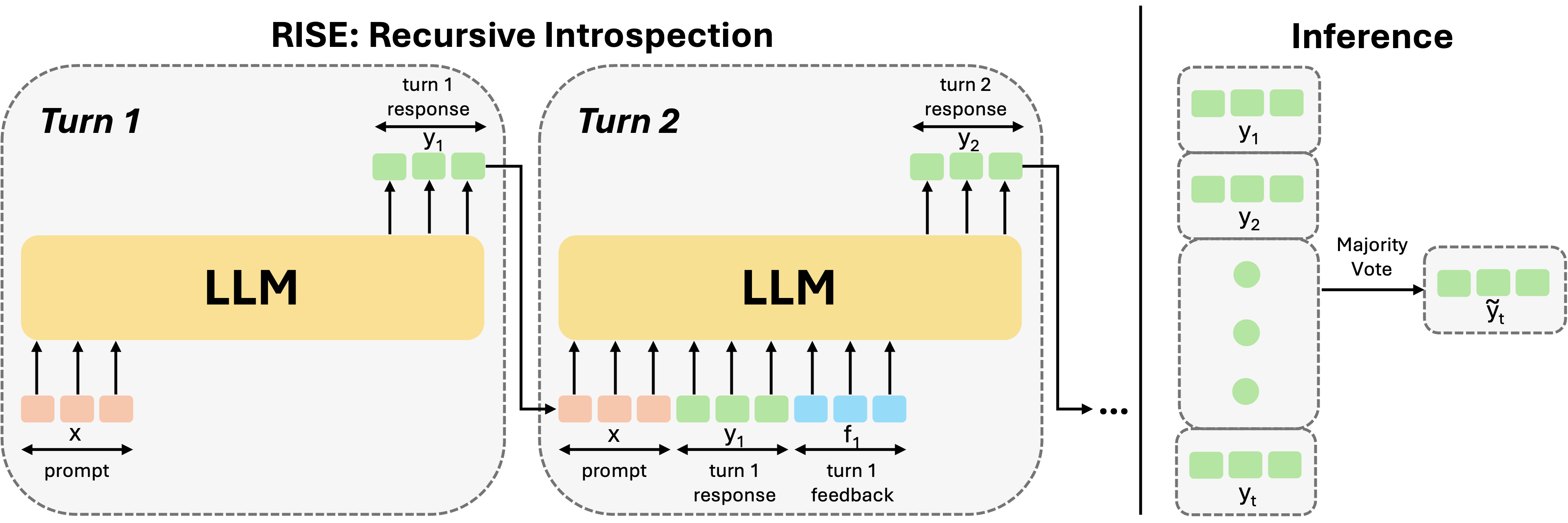
尽管强大的基础和指令调整的大语言模型 [23, 58] 通常无法在多次连续尝试中提高他们的反应(即使之前明确告知他们的错误),RISE成功地赋予了类似大小的大语言模型自我改进的能力,导致每轮后任务绩效单调递增。 具体来说,在 GSM8K [11] 数据集上,RISE 表现出相对于各种模型的显着改进。 RISE 完全使用自己的数据,将 LLaMa3-8B 的性能提高了 8.2%,将 Mistral-7B 的性能提高了 6.6%。 RISE 在 5 轮内省过程中,LLaMa2-7B 获得了 17.7% 的改进(优于第一轮的并行采样),Mistral-7B 获得了 23.9% 的改进。 相比之下,GPT-3.5 本身在五回合内仅提高了 4.6%。 我们在 MATH 数据集 [18] 上看到了类似的趋势,其中 RISE 在五轮内将 LLaMa2-7B 提高了 4.6%,将 Mistral-7B 提高了 11.1%。 我们还研究了 RISE 为何以及如何能够诱发自我完善能力,并表明这种能力也可以推广到分布外提示。 这些结果一致证明了 RISE 在增强不同模型的数学推理能力方面的有效性。
2相关工作
之前的几项工作构建了技术来提高下游应用程序基础模型的推理和思维能力。 通常,这些工作侧重于构建与外部工具进行有效多轮交互的提示技术[54,7,5,32,56,49,14],通过反映操作来依次完善预测 [7, 15, 63],要求模型用语言表达自己的想法[52, 33, 65],要求模型自我批判和修正[31, 40] 或使用其他模型来批评主要模型的响应[12, 54, 2, 20]。 尽管这项工作的一部分确实改进了自己的响应,但这种自我纠正能力通常需要访问详细的错误跟踪(例如,来自代码编译器 [31, 7] 的执行跟踪)才能成功。 事实上,[21]和表1都表明,以大语言模型本身为导向的自我完善(即“内在的自我修正”)往往是不可行的。现成的大语言模型,即使它们包含处理给定提示所需的知识,但使用 RISE 进行微调会产生这种能力,正如我们在本文中所示。
除了提示之外,之前的工作还尝试通过大语言模型来获得自我改进能力[39,6,62]。 这些作品试图通过训练自我生成的响应[58,60,30,46,57]来提高推理性能。 为了实现这一目标,这些作品结合了学习验证器[50,28,47]、搜索[26,33,13,38]、负面数据的对比提示[9, 48],以及迭代监督或强化学习 (RL) [8, 59, 37]。 尽管我们的方法也对模型生成的数据进行训练,但我们的目标是引入补充功能来提高交互顺序轮次的性能,而不是单独提高单轮性能。 其他工作直接通过 RL [41, 66] 微调大语言模型以实现多轮交互:虽然这确实相关,但多轮场景中提出的单轮问题需要解决与通用多轮强化学习:(i) 样本效率不是问题,因为整个环境完全由提示的训练数据集表征,预言机答案和动态是确定性的,并且 (ii )我们需要推广到新颖的测试提示。 多轮强化学习侧重于样本效率,这在我们的设置中并不那么重要,尽管学习从有限数量的初始状态进行泛化当然会很有吸引力。 我们的主要重点是表明可以通过适当设计多轮微调目标来训练模型以进行自我改进。 这与训练方法(RL 或非 RL)的选择是正交的。
与我们的工作最相关的是 GLoRE [17] 和 Self-Correct [53],它们训练单独的模型来识别错误并完善其他大语言模型的错误答案。 与这些作品不同,我们的方法训练单个模型来产生答案并在两轮以上改进它们,这是这些作品中研究的最大轮数。 我们表明,成功做到这一点需要仔细的设计选择:迭代的政策数据生成策略以及可以从成功和不成功的部署中学习的训练目标。 从算法的角度来看,RISE 类似于在线模仿学习[36, 44],因为它查询专家对策略推出所达到的状态的监督。 大语言模型[1, 4]的在策略蒸馏利用了这个想法,但询问专家提供部分响应的完成,而不是我们在这项工作中所做的连续尝试。
3 问题设置和预备知识
我们工作的目标是提高大语言模型在给定问题上连续尝试/轮次的性能。 具体来说,给定问题和预言机响应的数据集,我们的目标是获得一个大语言模型,给定问题,先前的模型尝试解决问题,以及辅助指令(例如,发现错误并改进响应的指令;或附加指令)来自环境的编译器反馈)尽可能正确地解决给定的问题。 为此,我们将此目标编码为我们希望优化的以下学习目标:
| (3.1) |
与训练模型 以在给定 的情况下生成单个响应 的标准监督微调不同,方程 3.1 训练 还可以对其自己之前的尝试中的给定响应历史做出适当的反应。 方程 3.1 最接近 RL 目标,我们确实会通过将单轮问题转换为多轮 MDP 来开发我们的方法。 最后,请注意,基于提示的方法(例如 Self-Refine [31])仍然可以被视为训练 来优化 ,但仅当仅允许时调制提示以优化方程3.1。 当然,由于参数不变,这对于完全优化目标是无效的。
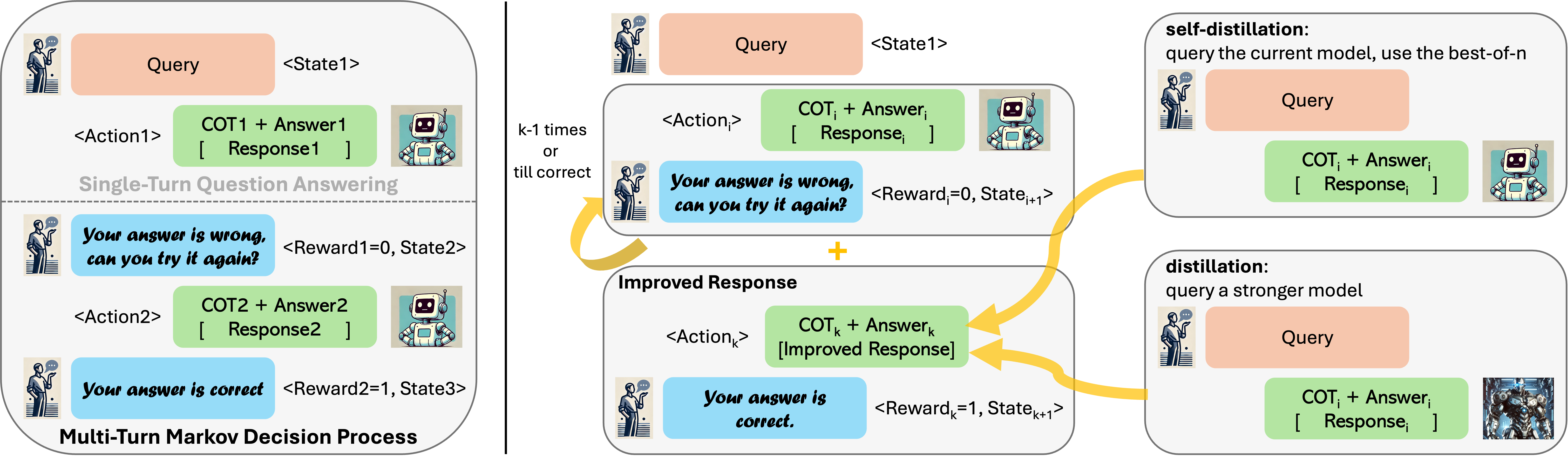
4RISE:自我完善的递归内省
由于即使是强大的现成模型在针对给定问题[21]进行连续尝试时也无法表现出有效的自我改进能力,因此下一步自然是询问如何训练模型诱发这种能力。 在本节中,我们将开发我们的方法 RISE,用于微调基础模型,以改进其多轮预测。 我们的方法首先将问题转换为多轮 MDP,然后收集数据,最后在该多轮 MDP 中运行离线奖励加权监督学习以诱导这种能力。
4.1 将单轮问题转化为多轮马尔可夫决策过程(MDP)
构建我们的方法的第一步是根据提示和预言机响应的单轮数据集按程序构建多轮 MDP(图2,左)。 给定一个数据集 ,其中包含提示 和相应的预言响应 (例如,数学问题和对这些问题的自然语言响应),我们将构建来自的诱导 MDP ,然后学习该MDP中的策略。 该MDP中的初始状态是可能的提示。 我们将基础模型的输出响应表示为操作 。 给定一个状态,可以通过将表示的标记与模型提出的操作连接起来获得下一个状态,并附加一个固定提示要求模型自省,例如,“此响应不正确,请自省并更正您的答案。”(具体提示见附录D.4 奖励函数是给定状态 、 下答案正确性的稀疏二进制指示器,并且是从答案检查函数获得的。 从数据集 到 MDP 的构造如下所示:
| (4.1) | ||||
| (4.2) | ||||
| (4.3) |
4.2多轮MDP中的学习
MDP 构建到位后,下一步涉及训练模型以在推出过程中自我改进。 我们采用下面描述的离线学习方法。
第1步:收集数据以进行自我改进。 为了确保来自多轮 MDP 的 rollout 数据可用于教授模型如何自我改进,它必须满足一些需求:(1) 它必须说明学习者可能会犯的错误为了在下一次尝试中做出并展示如何改进它们,(2)数据必须说明与给定问题和上下文中先前尝试的模型相关的响应,并且(3 ) 它不得包含任何在后续回合中降级的推出。 我们的数据收集策略(图2,右)满足了这些需求。
在给定回合中,对于给定问题,我们展开当前模型以产生多个连续尝试,表示为由。 在可以使用外部输入(例如编译器反馈)的问题中,我们还观察到可变长度的自然语言外部输入 (例如,在数学问题中我们要求模型自行纠正)。 我们还观察到标量奖励值,简称为。 让我们将这个“on-policy”模型推出的数据集表示为。
对于每个时间步,我们构建响应 的改进版本,我们将用 表示。 我们还将与此改进的响应相关的奖励分数记录为 ,或简称为 。 为了获得响应 的改进版本,我们可以采用多种策略。 也许最直接的方法就是查询一个现成的功能更强的模型,让它在给出提示 、前一个响应 和一个可选的外部反馈 的情况下提供一个正确的响应。 我们将此称为我们方法的蒸馏变体,因为它使用强大的“教师”模型来指导自我改进(请注意,这与知识蒸馏的经典概念不同,我们将事实上,6.1 节中显示的结果将有助于理解差异)。
| (4.4) |
我们方法的第二种变体减轻了对教师模型的需求,涉及通过对学习者本身进行多次采样来构建改进的响应。 我们将这种方法称为自蒸馏变体。 具体来说,对于数据集中的每个状态 ,我们对 响应 进行采样,并使用这些 候选者中的最佳响应(通过相关奖励值 衡量)在改进轨迹的下一步 重新标记模型响应。 正式来说,比如说 ,然后我们在步骤 的数据集中 中标记响应,并使用改进的响应及其相关的奖励值 :
| (4.5) |
第二步:政策完善。 通过上述数据构建方案,我们现在可以在这些数据集上训练模型。 一般来说,任何离线 RL 方法都可以用于对这些数据进行训练,但在我们的实验中,由于实验方便且简单,我们采用了基于加权监督学习的方法[35]。 特别是,我们执行加权监督回归,其中权重由 中奖励值的指数变换给出。
| (4.6) |
其中是一个温度参数,用于进一步扩大或缩小好动作和坏动作之间的差异。 在我们的预备知识实验中,我们发现方程 4.6 通常会导致奖励高时增加响应对数可能性的偏差,优先更新奖励已经很高的简单问题。 为了解决这个问题,我们对方程4.6进行了轻微修改,并将指数奖励集中在给定提示上所有尝试的平均值周围,类似于优势加权回归[34] 。 我们发现,用优势代替奖励有助于我们避免容易出现问题的“富者愈富”现象。
4.3 部署时推理
RISE 在推理时可以以两种模式运行。 也许运行 RISE 训练的策略 的最直接方法是在多轮部署中,其中模型根据过去的上下文(即多轮 MDP 中的状态)对新响应进行采样。 过去的上下文由有关响应 的外部反馈 组成,一旦根据环境的答案验证功能判断当前响应正确,转出就会终止。 换句话说,一旦奖励等于预言机响应的奖励:,我们就会终止推出。 该协议在每次推出后都会调用对奖励函数的查询。 由于执行了多次奖励函数查询,因此我们将这种方法称为“使用预言机”。
RISE 还可以在避免在部署中查询答案检查器或奖励函数的需要的模式下运行。 在这种情况下,我们通过强制模型重试来运行完整的推出,忽略响应的正确性。 然后,我们利用基于多数投票的自洽机制[51]来决定每轮结束时的候选人响应。 具体来说,在每个回合结束时,我们通过对前一轮()(包括回合)的所有响应候选者进行多数投票来确定响应t2>。 我们称之为“没有预言机”。 这些方法的示意图如图3所示。 我们的大多数评估都没有使用预言机。
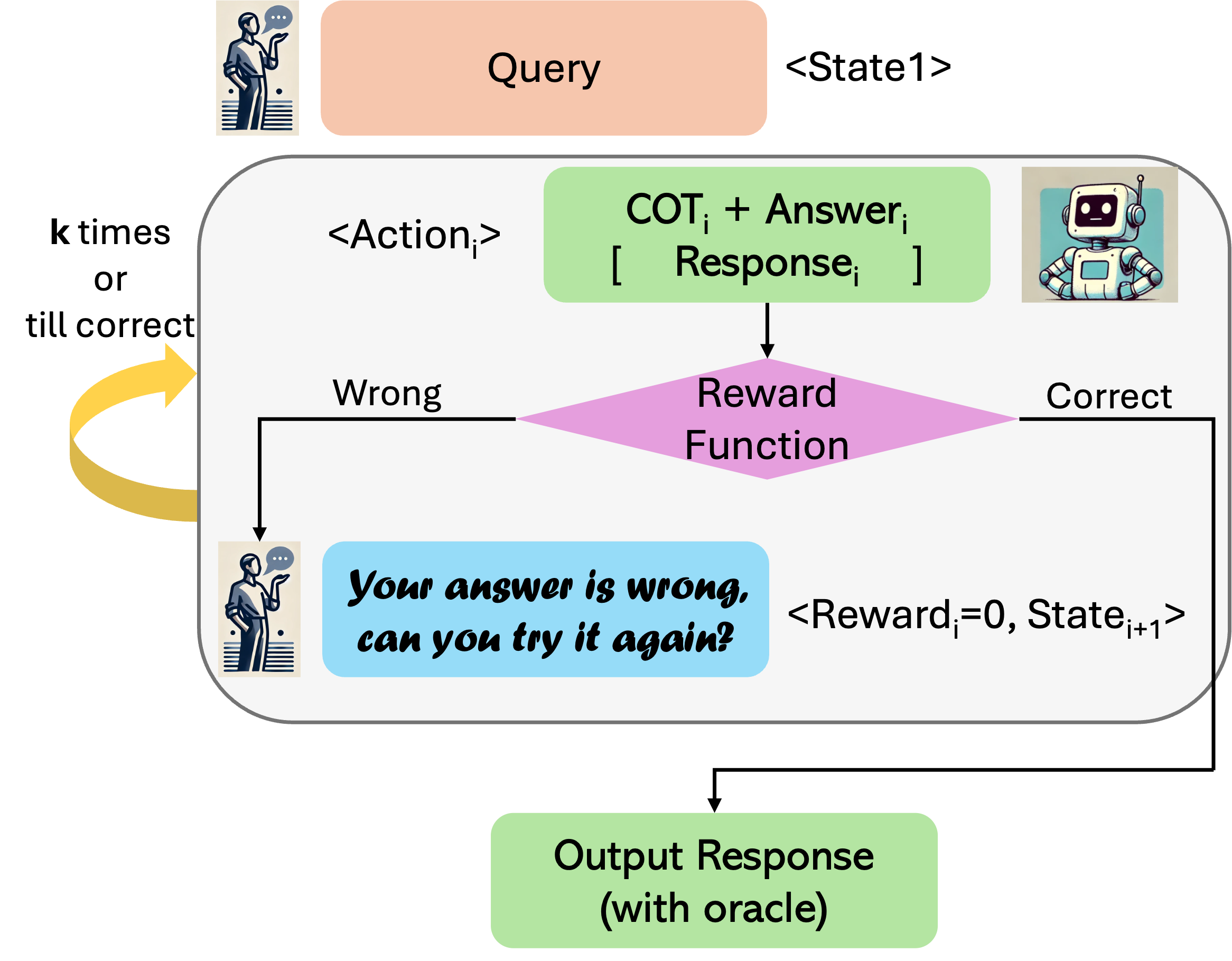
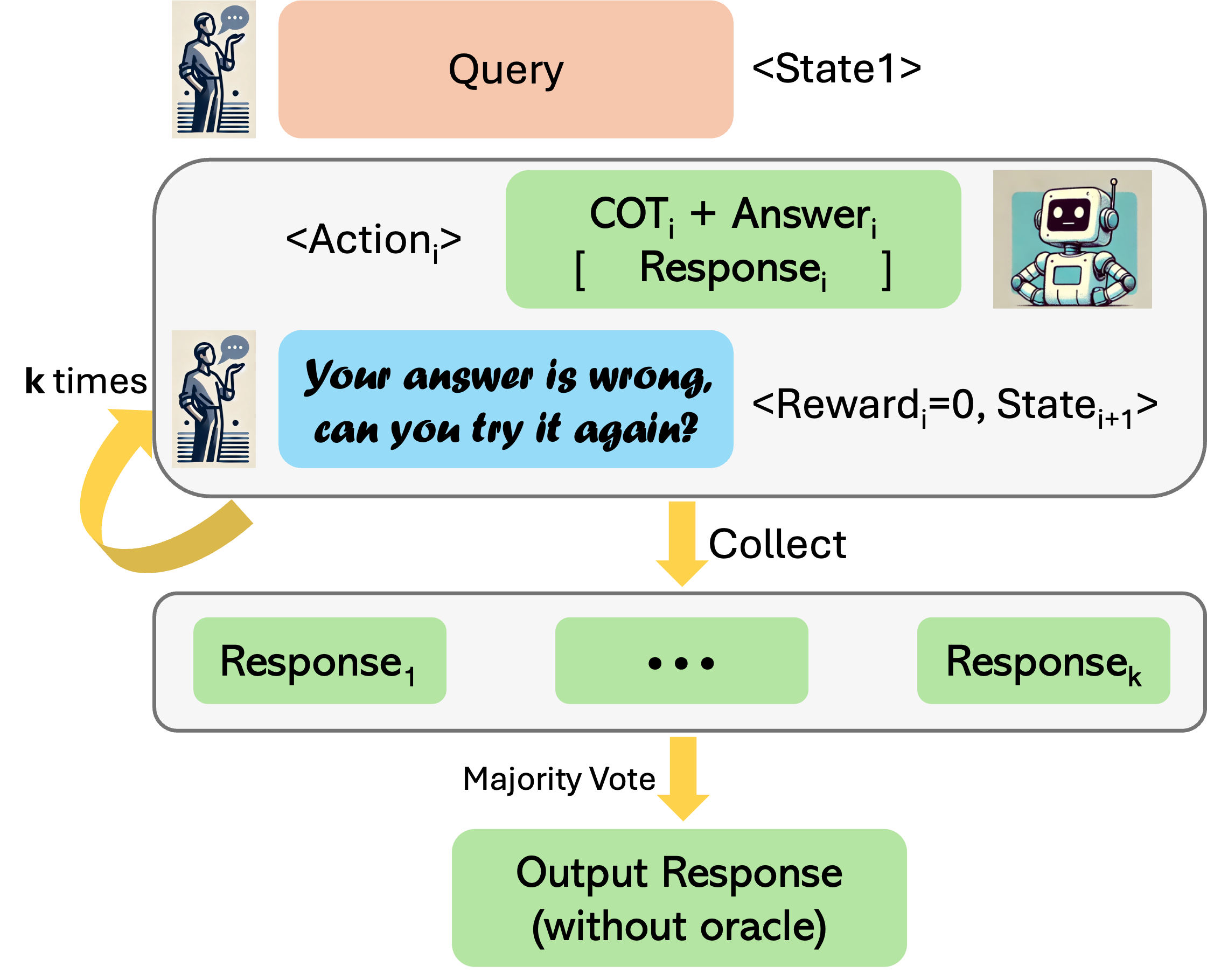
4.4实用算法和实现细节
5 何时以及为何可以实现自我完善转变?
一个自然要问的问题是为什么可以通过 RISE 进行自我改进。 人们可能会猜测,如果模型无法在第一轮中正确回答问题,那么它可能根本没有足够的知识来纠正其自己的错误。 那么,为什么可以教会模型纠正自己的错误呢? 在本节中,我们提供了这种自我改进是可能的原因,并用经验证据来证明我们的假设是正确的。
当表示目标分布 需要比模型 仅以输入提示标记为条件所提供的容量更大的容量时,迭代地教导模型如何对给定响应进行更新可能至关重要。 当目标分布需要更大的容量时,学习一系列条件条件 ,然后进行边缘化,预计会在给定 的情况下在 上产生更灵活的边缘分布。 该假设类似于图像生成中的扩散模型 [42] 和变分自动编码器 (VAE) [25] 之间的差异:迭代拟合中间噪声上的生成分布序列尽管扩散模型仍然利用证据下界目标(ELBO),但扩散模型中的输入比整体变分自动编码产生更灵活的分布[43]。 虽然扩散过程利用手工设计的噪声计划,但 RISE 利用基本模型本身来引发迭代改进。
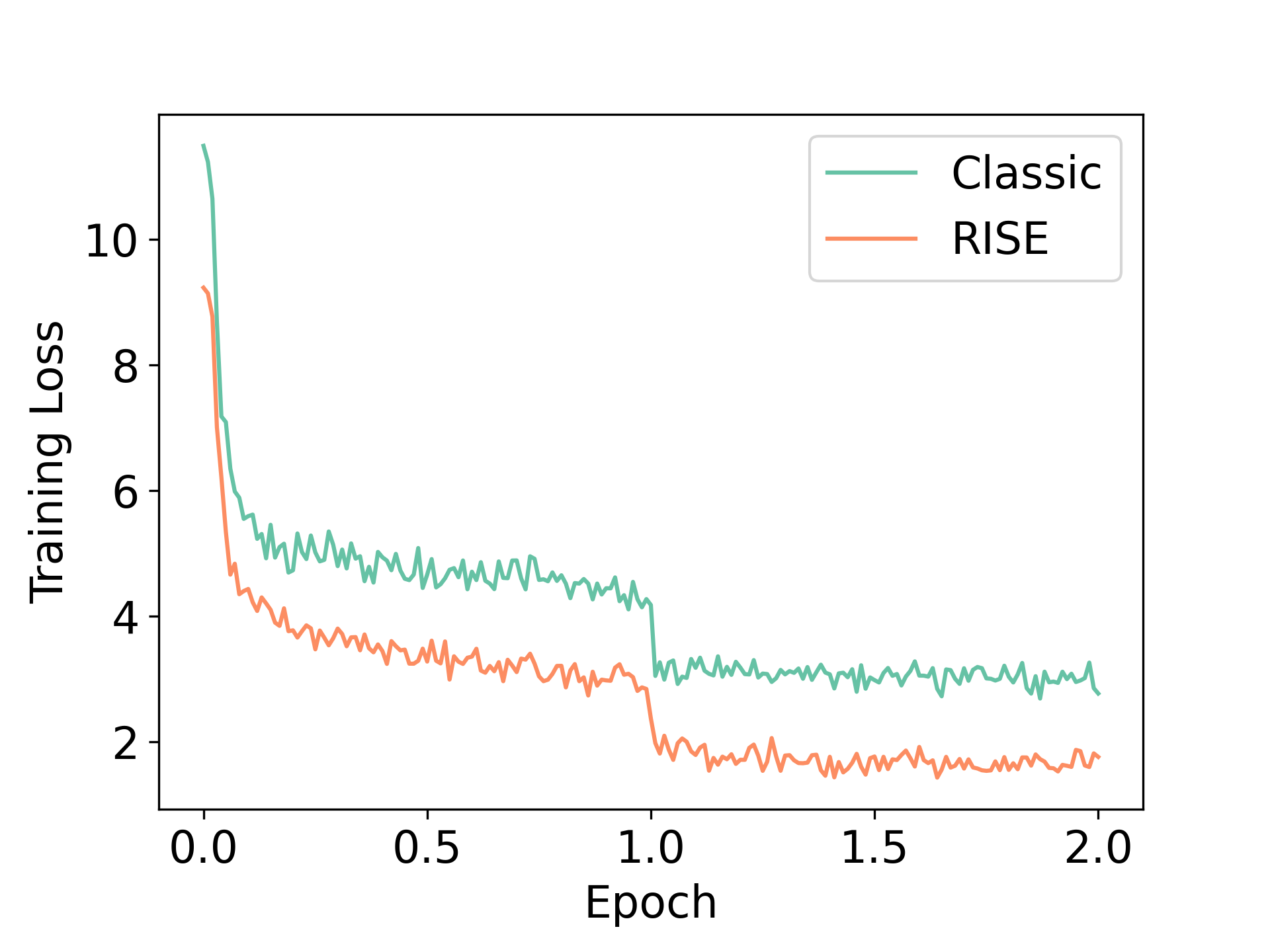
为了验证这个假设是否成立,我们跟踪了预言机响应的训练未加权负对数似然损失(NLL)值,给定输入提示边缘化超过中间值多轮部署中的步骤,并将其与通过直接尝试预测图 5 中的最终响应(标记为“经典”)获得的 NLL 值 进行比较。 具体来说,我们采样了 256 个提示 及其预言机响应 ,并计算了所有 的平均值 ,以及 95%训练期间不同检查点的置信区间。 我们发现,对于任何给定数量的纪元(包括 x 轴上的纪元分数),与从专家获得的提示的预言机响应相比,当以 RISE 生成的多轮数据为条件时,NLL 值较低。 这表明 RISE 能够利用之前轮次的 Token 计算来对目标分布进行建模。 我们还通过训练、采样 i.i.d 来测量所有样本的平均 NLL 损失。 从 RISE 和经典微调的训练数据集中观察到类似的趋势:RISE 能够比标准方法更多地减少损失,获得更低的困惑度值(图 5)。
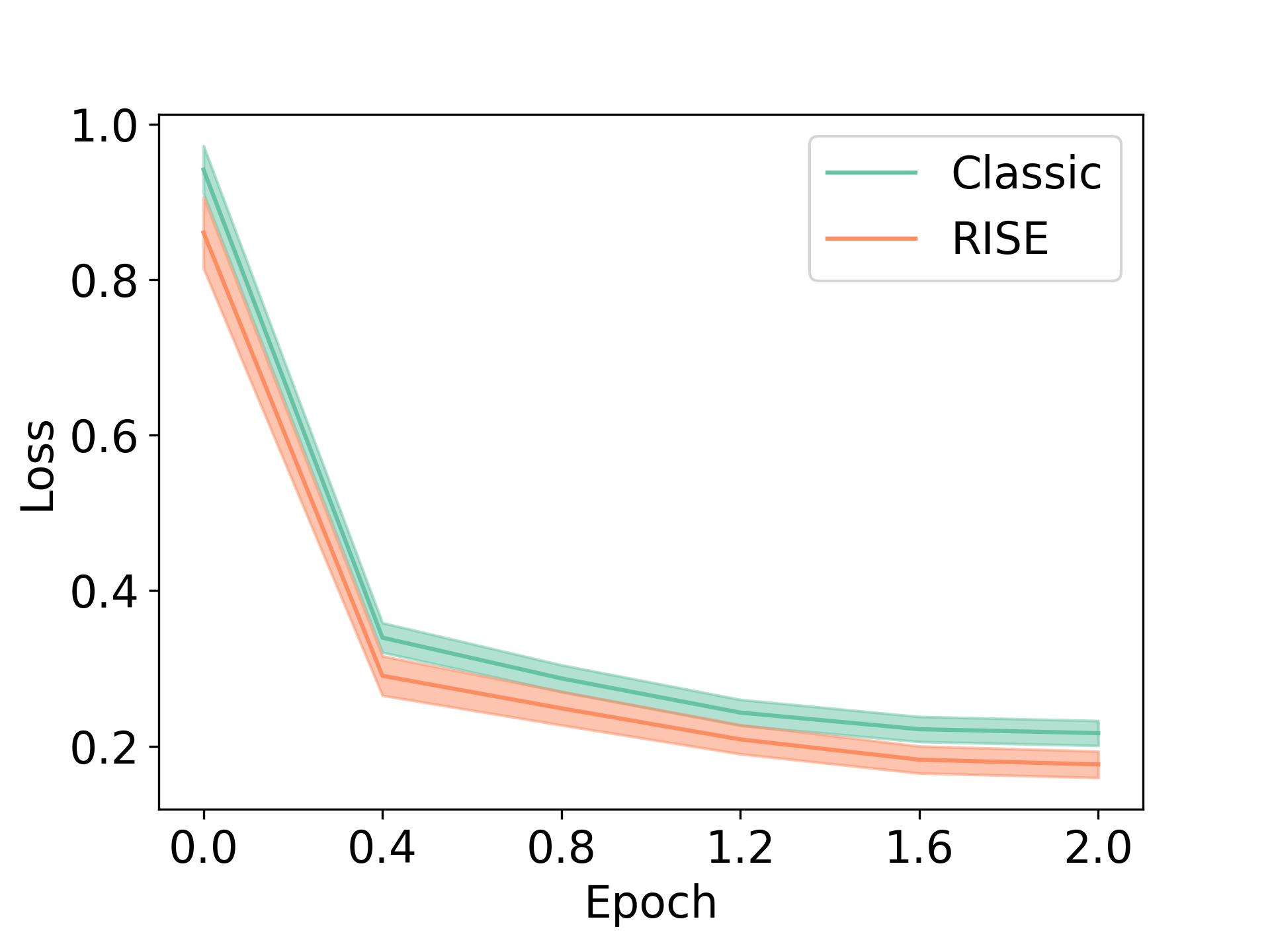
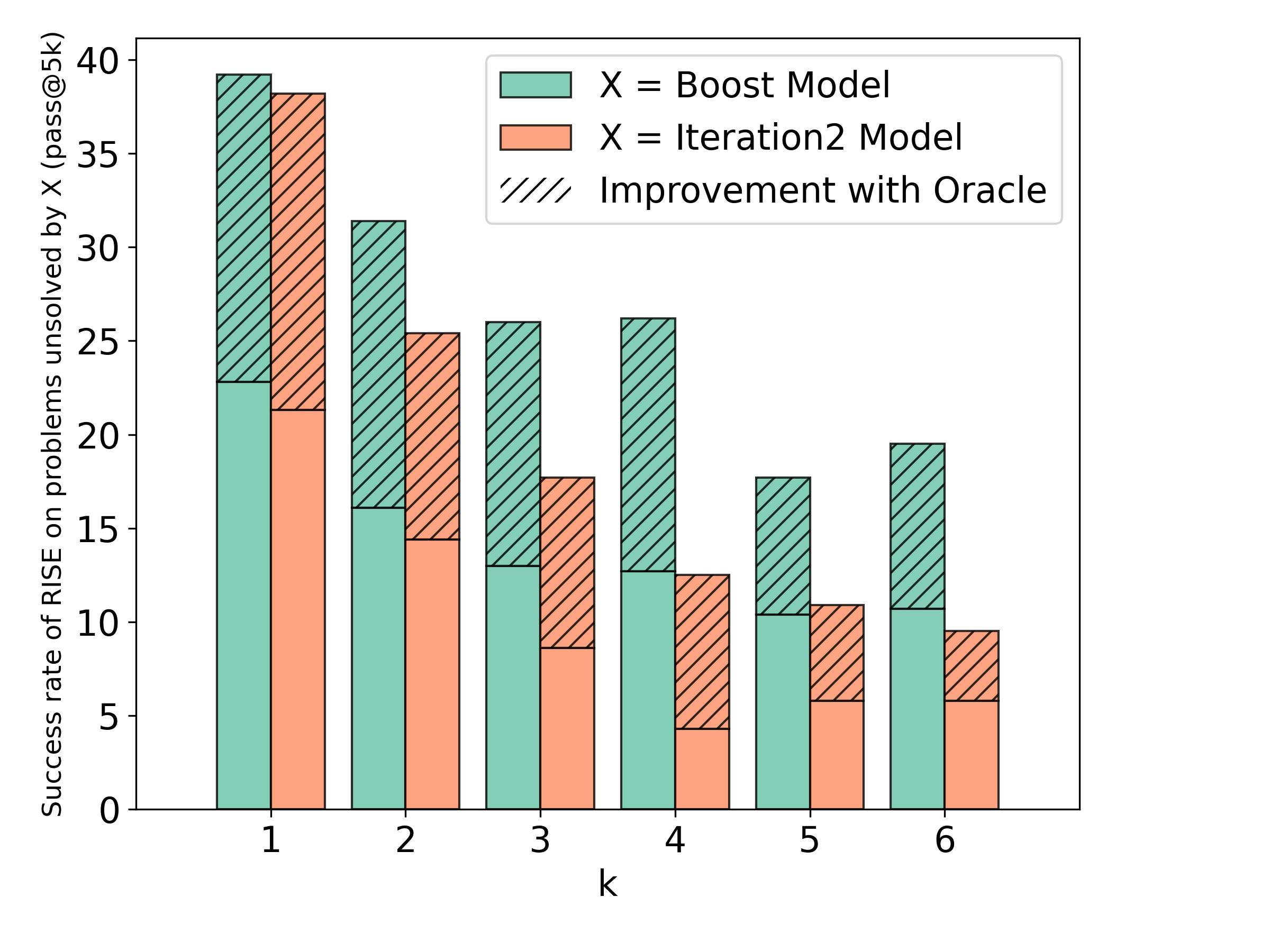
当然,在需要“基于知识”的问答问题中,模型不可能产生任何有意义的改进,因为学习不受能力不足的限制。 ,但由于缺乏对于学习从 到 的正确映射至关重要的功能,因此无法匹配 。 我们预计,在这种情况下,使用 RISE 进行训练只会激发幻觉[24],因为之前尝试中出现的更多输入标记只会提供更简单的方法来识别虚假相关性。 然而,这不是推理问题[27]的失败模式,其中第 1 轮的 maj@K 速率往往高于 pass@1,正如我们在实验中发现的那样(表明性能可以是通过对模型本身进行采样来改进)。 事实上,在图 6 中,我们还表明,RISE 学习的顺序过程甚至可以解决 pass@B 对于更大的 中无法解决的大部分问题。第一轮,表明它学会以不同的方式索引模型的预训练知识,而不是简单地将 pass@K 性能转换为模型的 pass@1 性能,大多数单轮方法都是相信正在做。
6实验评估
我们实验的目的是证明 RISE 在向语言模型灌输自我改进其反应能力方面的功效。 我们的实验回答了以下问题:(1) 在给定的提示下,RISE 在多次连续尝试(即回合)中如何有效地提高性能?; (2) 训练 RISE 的性能是否会随着迭代次数的增加而提高?; (3) RISE 引入的自我改进策略是否可以推广到训练领域之外的新问题? 最后; (4) RISE 的最佳训练数据组合是什么? 为此,我们将 RISE 与其他先前和基线方法进行比较,并对 GSM8K [11] 和 MATH [18] 进行消融。
基线、比较和评估。 我们将 RISE 与尝试诱导类似自我改进能力的几种先前方法进行比较:(a) 自我完善 [31, 21] 提示基础模型批评并修正其错误; (b) 格洛雷 [17],训练一个单独的奖励模型来定位错误,并训练一个细化模型来改进基本大语言模型的响应;和(c) 自我一致性 [51],它对第一轮的多个响应进行多数投票,作为与我们的顺序策略进行比较的基线。 我们试图通过使用类似大小的模型 [58, 23] 来构建 RISE 和这些方法之间的公平比较,但基础模型、训练数据和评估设置的差异仍然阻止我们执行在某些情况下进行同类比较。 尽管如此,我们仍然希望通过将我们的结果与这些先前的工作联系起来,了解改进的大致情况。 我们还与 V-STaR [19] 进行比较,但由于这不是一个公平的比较,因此我们将其推迟到附录 B。
我们在推理时评估两种模式下的 RISE:在五轮结束时使用或不使用预言机(第 4.3 节)。 具体来说,这些指标定义如下:
-
•
对于 oracle,“p1@t5”:一旦响应正确,此运行就会终止推出。 换句话说,该指标允许在每轮结束时向最终答案验证者进行查询。
-
•
没有预言机,“m1@t5”:此运行不会在五轮之前终止推出,我们将每轮产生的候选者的 maj@1 性能计算为详细信息请参见第 4.3 节。
我们还比较了我们训练的所有模型(“m1@t1”、“m5@t1”)在第一轮的 maj@K 性能。
| Approach | GSM8K [10] | MATH [18] | ||||||
|---|---|---|---|---|---|---|---|---|
| w/o oracle | w/ oracle | w/o oracle | w/ oracle | |||||
| m1@t1 | m5@t1 | m1@t5 | p1@t5 | m1@t1 | m5@t1 | m1@t5 | p1@t5 | |
| RISE (Ours) | ||||||||
| Llama2 Base | 10.5 | 22.8 (+12.3) | 11.1 (+0.6) | 13.9 (+3.4) | 1.9 | 5.1 (+3.2) | 1.4 (-0.5) | 2.3 (+0.4) |
| +Boost | 32.9 | 45.4 (+12.5) | 39.2 (+6.3) | 55.5 (+22.6) | 5.5 | 6.8 (+1.3) | 5.5 (0.0) | 14.6 (+9.1) |
| +Iteration 1 | 35.6 | 49.7 (+14.1) | 50.7 (+15.1) | 63.9 (+28.3) | 6.3 | 8.8 (+2.5) | 9.7 (+3.4) | 19.4 (+13.1) |
| +Iteration 2 | 37.3 | 51.0 (+13.7) | 55.0 (+17.7) | 68.4 (+31.1) | 5.8 | 10.4 (+4.6) | 10.4 (+4.6) | 19.8 (+14.0) |
| SFT on oracle data | ||||||||
| Only correct data | 27.4 | 42.2 (+14.9) | 34.0 (+6.6) | 43.6 (+16.2) | 5.8 | 7.9 (+2.1) | 5.5 (-0.3) | 12.1 (+6.2) |
| Correct and incorrect | 25.7 | 41.8 (+16.1) | 31.2 (+5.5) | 41.5 (+15.8) | 5.0 | 5.2 (+0.2) | 5.0 (+0.0) | 13.1 (+8.1) |
| RISE (Ours) | ||||||||
| Mistral-7B | 33.7 | 49.4 (+15.7) | 39.0 (+5.3) | 46.9 (+13.2) | 7.5 | 13.0 (+5.5) | 8.4 (+0.9) | 13.0 (+5.5) |
| + Iteration 1 | 35.3 | 50.6 (+15.3) | 59.2 (+23.9) | 68.6 (+33.3) | 6.7 | 9.5 (+2.8) | 18.4 (+11.1) | 29.7 (+22.4) |
| 7B SoTA [58] | ||||||||
| Eurus-7B-SFT | 36.3 | 66.3 (+30.0) | 47.9 (+11.6) | 53.1 (+16.8) | 12.3 | 19.8 (+7.5) | 16.3 (+4.0) | 22.9 (+10.6) |
| Self-Refine [31] | m1@t3 | p1@t3 | m1@t3 | p1@t3 | ||||
| Base | 10.5 | 22.4 (+11.9) | 7.1 (-3.4) | 13.0 (+2.5) | 1.9 | 5.1 (+3.2) | 1.9 (0.0) | 3.1 (+1.2) |
| +Iteration 2 | 37.3 | 50.5 (+13.2) | 33.3 (-4.0) | 44.5 (+7.2) | 5.8 | 9.4 (+3.6) | 5.7 (-0.1) | 9.5 (+3.7) |
| GPT-3.5 | 66.4 | 80.2 (+13.8) | 61.0 (-5.4) | 71.6 (+5.2) | 39.7 | 46.5 (+6.8) | 36.5 (-3.2) | 46.7 (+7.0) |
| Mistral-7B | 33.7 | 48.5 (+14.8) | 21.2 (-12.5) | 37.9 (+4.2) | 7.5 | 12.3 (+4.8) | 7.1 (-0.4) | 11.4 (+3.9) |
| Eurus-7B-SFT | 36.3 | 65.9 (+29.6) | 26.2 (-10.1) | 42.8 (+6.5) | 12.3 | 19.4 (+7.1) | 9.0 (-3.3) | 15.1 (+2.8) |
| GloRE [17] | m1@t3 | p1@t3 | ||||||
| +ORM | 48.2 | 49.5 (+1.3) | 57.1 (+8.9) | |||||
| +SORM | 48.2 | 51.6 (+3.4) | 59.7 (+11.5) | Not studied in [17] | ||||
| +Direct | 48.2 | 47.4 (-0.8) | 59.2 (+11.0) | |||||
6.1 与其他方法相比,RISE 能否提高多轮性能?
主要结果。 我们在表 1 中列出了比较结果。 首先,请注意,RISE(“迭代 1”和“迭代 2”)将 LLama2 基础模型的五圈性能分别提升了 15.1% 和 17.7%,在 GSM8K 上每次迭代,在 MATH 上分别提升 3.4% 和 4.6%,w/o任何神谕。 有趣的是,我们发现使用仅提示自我优化 [31] 会大幅降低整体性能,即使使用强大的专有模型 GPT-3.5 也是如此。 最强的 7B 基础模型 Mistral-7B 和 Eurus-7B-SFT [58] 在与标准提示相结合时,只能提高其性能,但仅提高了 5.3% / 11.6% 和 0.9 GSM8K 和 MATH 上分别为 % / 4.0%,这明显低于我们的方法。 GLoRE 的性能在 GSM8K 上仅提高了 3.4%(超过两圈),但这仍然低于我们的方法,我们的方法在两圈内提高了 6.3%,在三圈内提高了 13.4%(参见附录 B.1)。 这表明RISE在教导模型如何改善自身错误方面是有效的。 总而言之,与使用或不使用预言机的其他方法相比,使用 RISE 进行训练可提供最大的性能提升收益,并且这些收益会转移到其他基础模型。
人们还可能假设,这里 RISE 的性能提升很大程度上是利用对现成的更强大模型的查询来提供监督的结果,而不是用于数据收集和训练的算法方法。 为了解决这个假设,我们存储 RISE 从功能更强大的模型中生成的所有数据,并通过标准单轮 SFT(“预言机数据上的 SFT)来处理这些数据。 由于并非所有这些数据都保证是正确的,因此我们也仅对这些预言数据中的正确响应运行此实验。 从表 1 中观察,与简单采样相比,此过程仍然无法灌输自我改进能力,很大程度上保留或降低了顺序(“maj@1@turn5”)性能第一回合的反应。 这意味着RISE的算法设计对于使其能够学习自我改进能力至关重要,而不是简单地使用专家监督。
6.1.1RISE能否有效利用错误并纠正错误?
先前关于自我改进或自我修正的结果引起的一个担忧是,模型是否能够真正地自我修正,或者改进是否来自于采样更多答案并选择最佳答案的效果。 在表1中,我们看到通过RISE(“maj@1@turn5”)连续改进响应优于在第一轮并行采样5个响应并应用多数投票在他们身上(“maj@5@turn1”)。 请注意,此比较使用相同数量的样本,唯一的区别是,在一种情况下,这些样本是在第一轮时并行抽取的,而在另一种情况下,这些样本是在五轮结束时依次抽取的。 比较 1 转 和 5 转 结束时的 maj@5 性能,我们观察到 GSM8K 上一致提高了 4% 到 8%,MATH 上提高了 6.5%(其中Mistral-7B 型号)。 这意味着RISE可以赋予模型自我改进的能力,而在任何模型上单独运行并行采样并不能赋予相同的能力。 即使 RISE 使用的数据上标准单转 SFT 的 maj@5@turn1 性能也比 RISE 的顺序 maj@1@turn5 性能差很多,这意味着RISE的算法协议起着至关重要的底层作用。 最后,我们还指出,在图 6 中,我们表明,RISE 在五轮中学习的顺序过程可以解决 pass@B 对于更大的 在第一轮中,这意味着顺序 RISE 实际上可以解决通过简单地在第一轮中采样更多响应而无法解决的提示。
人们还可能推测这些连续改进能力的改进是否很大程度上是以首轮性能改进减少为代价的。 此外,我们还观察到运行 RISE 的多次迭代仍然保留了首轮性能,同时提高了 5 轮性能。
| RISE (Self) | w/o oracle | w/ oracle | ||
|---|---|---|---|---|
| m1@t1 | m5@t1 | m1@t5 | p1@t5 | |
| Mistral-7B | 33.7 | 49.4 (+15.7) | 39.0 (+5.3) | 46.9 (+13.2) |
| + Iteration 1 | 36.8 | 44.4 (+7.6) | 39.5 (+6.6) | 48.7 (+15.9) |
| Llama-3-8B | 45.3 | 69.7 (+24.4) | 52.5 (+7.2) | 61.0 (+15.7) |
| + Iteration 1 | 65.6 | 80.7 (+15.1) | 73.8 (+8.2) | 81.2 (+15.6) |
6.1.2 基础模型如何影响RISE?
RISE 与 Llama2-7B 的绝对性能低于专门针对数学数据进行微调的最佳模型(例如 Eurus-7B-SFT 或 Mistral-7B)。 然而,我们发现 RISE 在 Mistral-7B 基础模型之上仍然有效。 事实上,我们在五回合结束时的表现优于针对数学推理定制的最佳 7B SFT 模型之一。 比较Eurus-7B-SFT和Mistral-7B在RISE(我们的)中的m1@t5性能,发现Mistral-7B + RISE优于Eurus-7B-SFT。
6.1.3RISE自蒸馏版本
我们还将 RISE 的性能与完全自行生成的数据和监督(方程 4.4,)进行了一次迭代后直接在功能更强大的模型之上进行比较:Mistral-7B 和 Llama表 2 中 GSM8K 上的 -3-8B,没有任何知识提升阶段。 我们发现,与第一轮相比,该变体还提高了基础模型的 5 轮性能:比较模型 Llama-3-8B 和 Mistral-7B 的“m1@t5”与“m1@t1”,其中 RISE与没有任何预言机的第 1 轮性能相比,连续自我改进性能提高了 1% 以上。
当然,我们也注意到这个版本的RISE并没有优于微调模型的“m5@t1”性能。 我们预计这在很大程度上是训练的一次迭代的函数。 由于 RISE 的自蒸馏版本利用同一模型的 best-of-N 采样来产生自我改进的监督,因此 RISE 首先必须匹配 best-of-N 采样的性能,然后才能开始改进通过奖励最大化。 由于基础模型的 m5@t1 和 m1@t5 性能之间存在显着差距,我们预计这将需要相当多的迭代或完全在线的 RL 算法。 我们没有计算资源和基础设施来运行多次迭代,但这是未来工作的一个有趣的途径。 在这种自蒸馏设置中,我们还可以将计算分为顺序采样策略和并行采样策略,以便在五轮结束时获得最佳结果。 尽管如此,这个结果表明,即使通过在自生成样本上进行训练,RISE 实际上也可以增强基础模型的顺序采样性能。
6.2 迭代训练后RISE的性能会提高吗?
接下来,我们尝试了解 RISE 是否可以通过对策略数据进行多轮训练来改进。 如表1和2所示,RISE的性能在迭代过程中不断提高。 无论有或没有预言机,RISE 的 5 轮性能随着轮数的增加而表现出明显的改善。 这意味着 STaR [61] 形式的迭代自我训练程序也可以与 RISE 结合起来训练模型以进行自我改进。 这或许也强烈暗示了完整在线强化学习(RL)技术的潜在效用。
| RISE | w/o oracle | w/ oracle | |
|---|---|---|---|
| m1@t1 | m1@t5 | p1@t5 | |
| GSM8K | |||
| Llama2 Base | 10.5 | 11.1 (+0.6) | 13.9 (+3.4) |
| Iteration 1 RISE Model trained on MATH | 19.3 | 32.6 (+13.3) | 48.4 (+29.1) |
| MATH | |||
| Llama2 Base | 1.9 | 1.4 (-0.5) | 2.3 (+0.4) |
| Iteration 1 RISE Model trained on GSM8K | 4.3 | 4.4 (+0.1) | 12.1 (+7.8) |
| SVAMP | |||
| Llama2 Base | 29.2 | 30.5 (+1.3) | 34.0 (+4.8) |
| Iteration 1 RISE Model trained on MATH | 30.1 | 31.4 (+1.2) | 45.9 (+15.8) |
| Iteration 1 RISE Model trained on GSM8K | 42.2 | 50.0 (+7.8) | 63.6 (+21.4) |
6.3 RISE 是否还可以提高分布外提示的顺序性能?
在表 3 中,我们的目的是评估 RISE 针对新的、未见过的提示所诱导的策略的稳健性。 具体来说,我们根据另一个数据集的评估提示,比较了使用一个数据集训练的 RISE 模型的性能。 请注意,在表 3 中,这些数据集包括 MATH、GSM8K 和 SVAMP。 一般来说,我们观察到在一个数据集上训练的模型在连续五轮的过程中仍然能够提高基础模型在另一数据集上的性能。 更具体地说,虽然基本 Llama2 模型的第 1 轮性能比第 5 轮性能大幅下降,但使用 RISE 训练的模型可以在这些分布外提示上实现积极的性能改进。 这意味着,即使这些模型没有看到与评估数据集类似的查询,简单地在某种类型的数学提示上使用 RISE 进行训练仍然可以提高自我改进策略在新的测试分布上的有效性提示。 这一发现表明,RISE 能够灌输自我改进程序,可以推广到微调数据中提示的分布之外。
6.4哪些数据构成和数据量对 RISE 至关重要?
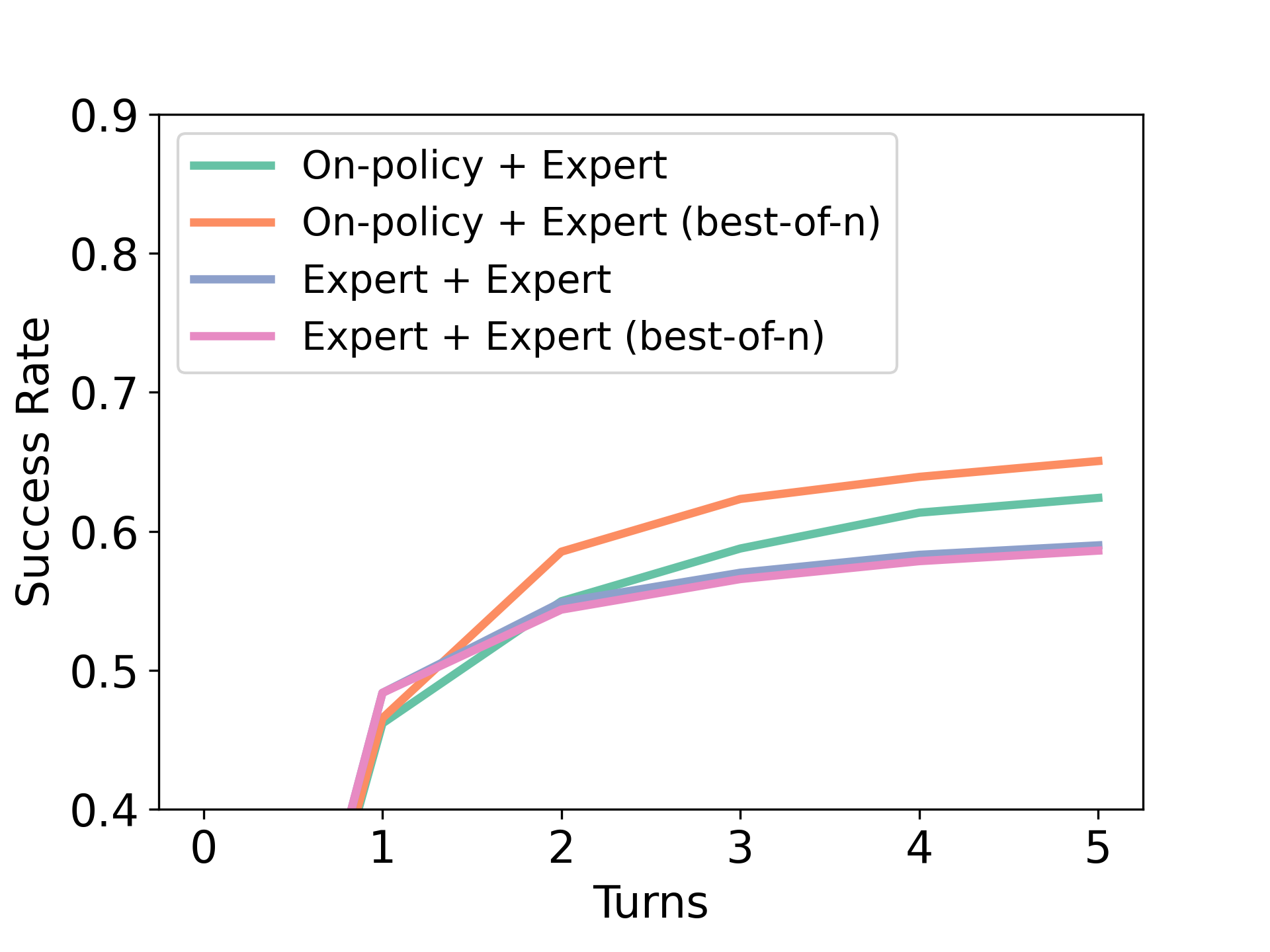
我们现在研究不同的数据组成如何影响 RISE 的性能,目的是回答以下问题: 我们应该收集像 DAgger [36] 这样的同策略纠错数据还是应该偏向于高质量的离策略数据?. 为了理解不同数据组合的效用,我们列举了三个方面的 RISE:(a) 使用多轮 rollout 数据进行微调,(b)与仅利用成功的推出进行微调的朴素监督学习相比,通过加权监督微调来使用不成功/次优的推出; (c) 使用同策略部署和自行生成的数据或预言机数据。 我们现在将进行对照实验,以了解每个因素对 RISE 整体性能的影响。
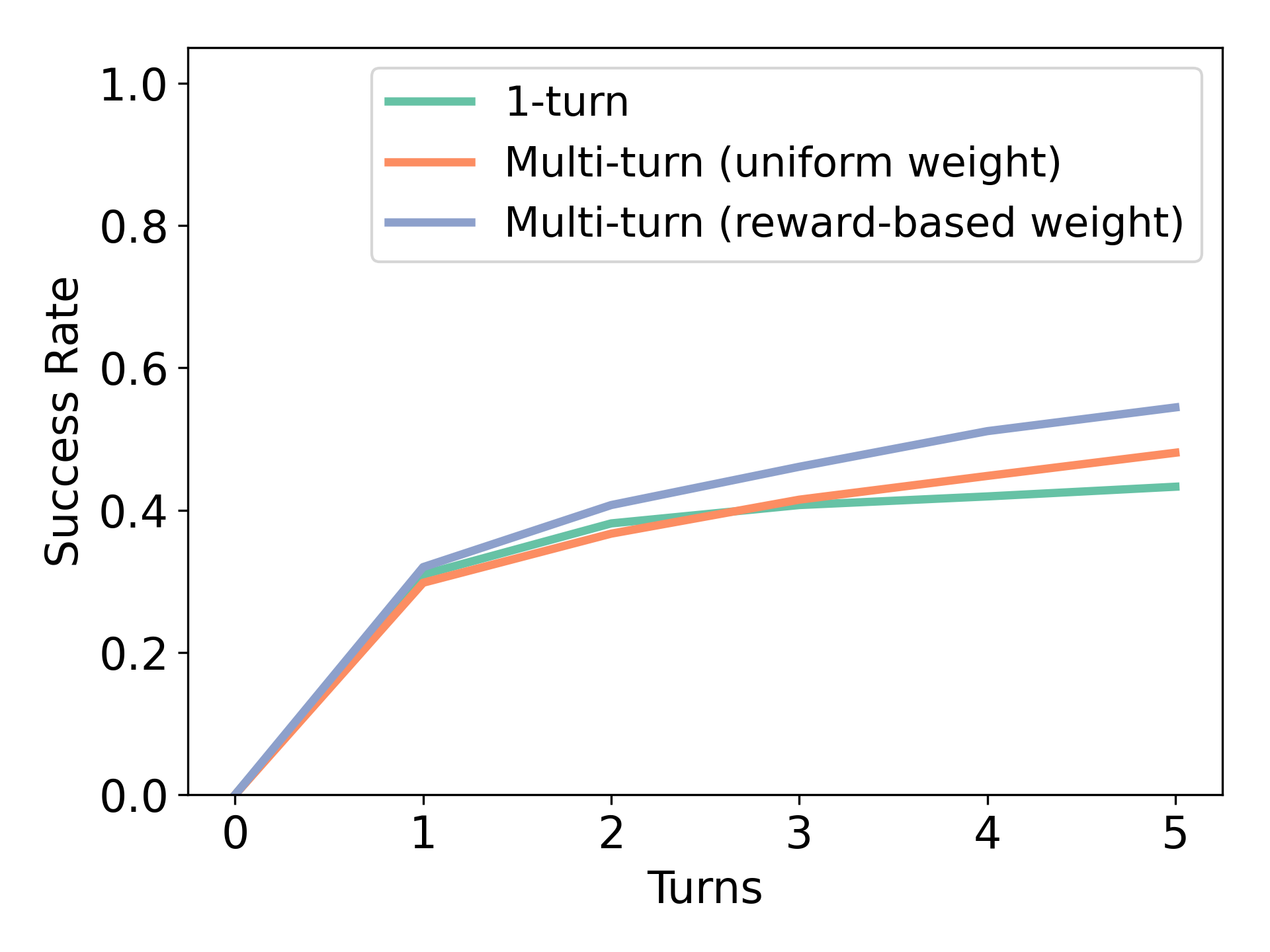
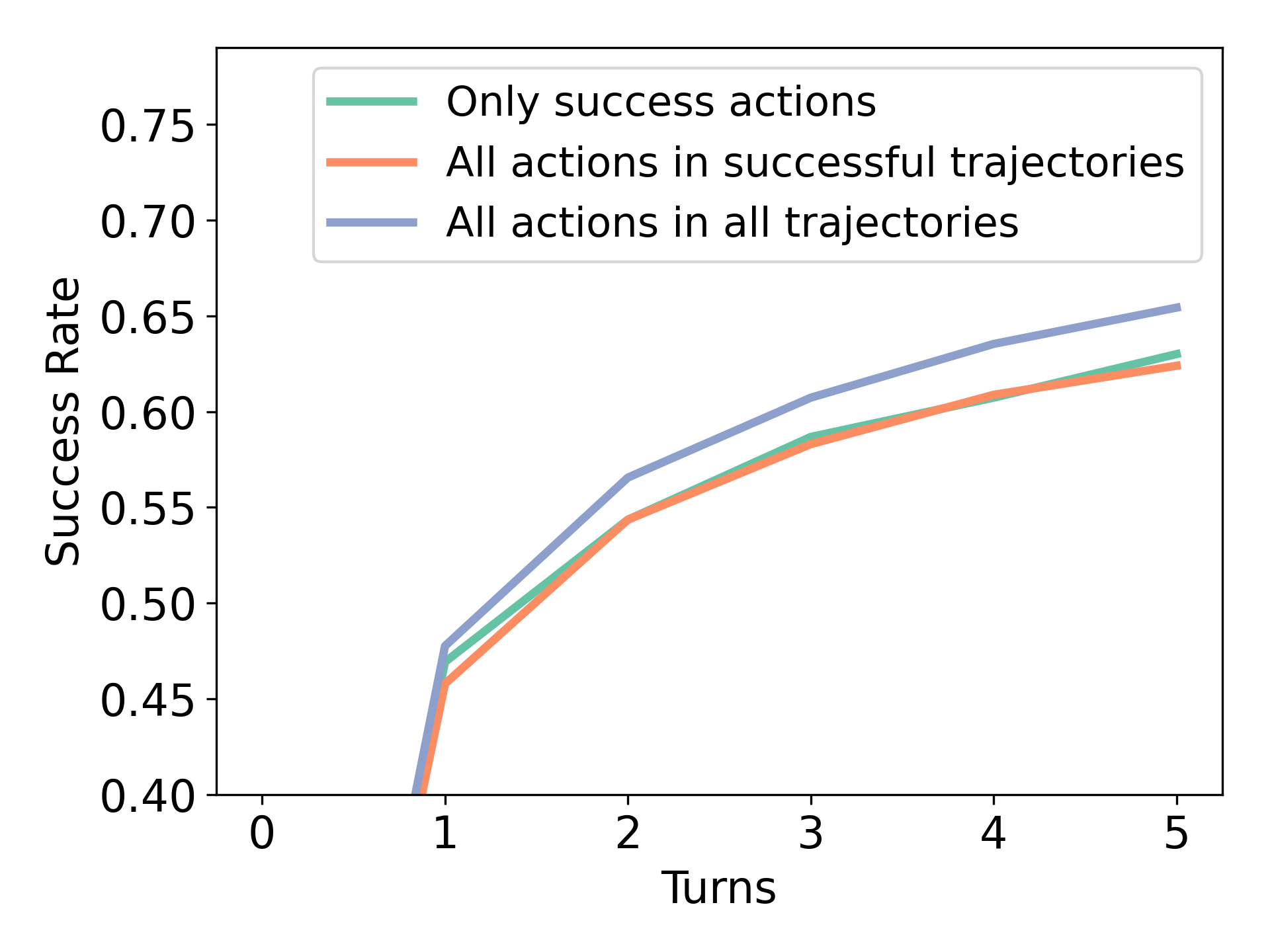
(a) 用于微调的数据组合。 我们首先研究在图7(左)中训练RISE时使用纠错历史交互的必要性。 我们比较两种方法:使用查询后立即显示的预言机答案(“1 轮”)和中间失败尝试后显示的预言机答案(“多轮”)训练的模型,如图 7(左) 。 尽管后者训练的中间反应可能并不总是正确的,但它比简单地训练给定提示的正确反应获得了更高的性能。 这凸显了在包括描述学习者错误的多回合交互历史的上下文中进行训练的重要性,以提高自我改进能力。
(b) 加权监督学习与非加权监督学习。 接下来,我们研究奖励加权强化学习对 RISE 中多轮数据的影响,而不是简单地模仿过滤后的成功数据。 我们发现,与简单地过滤图7(右)中的良好数据相比,使用所有数据可以提高性能,从而减少样本量。 在图7(左)中,我们发现奖励加权训练提高了后面回合的表现,使我们能够更好地利用所有次优数据。
(c) 在政策与离政策数据;自行生成的数据与专家数据。 RISE 运行按策略部署,并寻求改进学习者的反应。 如图8(左)所示,“DAgger [36]”式的方法寻求对政策推出中出现的响应的改进,从而提高性能(绿色/橙色)与单独使用专家数据(蓝色/粉色)相比。 从概念上讲,这解决了上下文标记分布之间的训练测试不匹配问题,使模仿学习方法现在能够瞄准正确的分布。 此外,最近的工作[24]表明,大语言模型经常记住预言机模型生成的“不熟悉”的例子;通过对策略推出的训练,我们应该能够消除任何此类潜在问题。 因此,虽然通过离线模仿训练的模型能够减少损失,但这些改进并不能推广到新问题。
6.5 Pass@K 与通过 RISE 的顺序采样
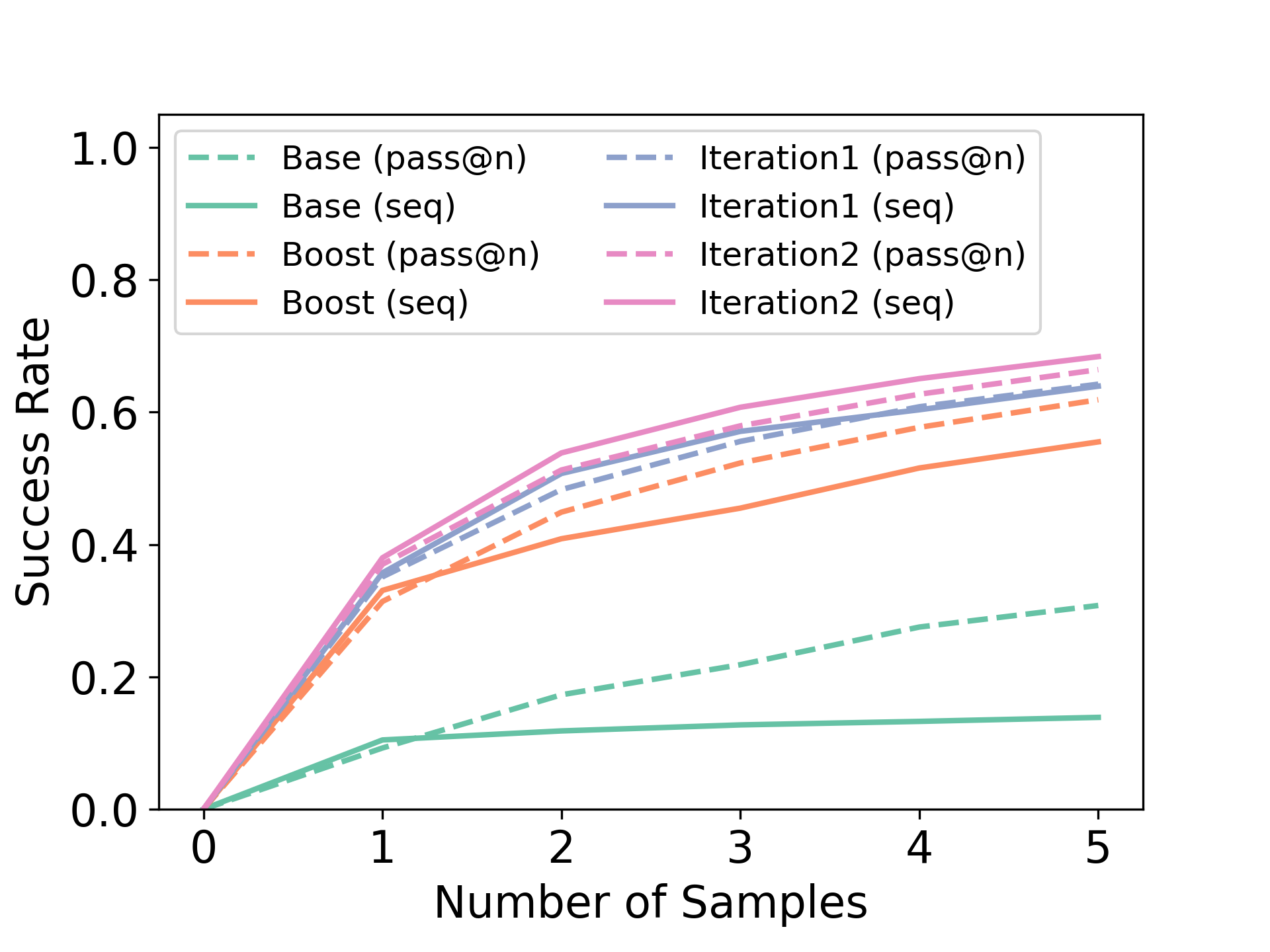
我们现在研究 GSM8K 中具有预言机反馈的顺序采样的性能,这与表 1 中依赖多数投票不同。 具体来说,我们将提前终止评估推出的 RISE 性能与 RISE 模型在第一轮的 pass@5(而不是 maj@5)性能进行比较(这对真实正确性指标进行了相同数量的查询)。 毫不奇怪,访问真实正确性指标预计会提高并行和顺序采样的性能,但我们在图8(右)中看到,RISE 能够提高性能,而不仅仅是简单地在以下位置采样更多样本尽管有通过并行采样方法访问预言机最终答案验证器的强烈假设,但第一回合和计算通过@K。
我们希望通过 pass@K 进行的并行采样在提供 Oracle 答案检查的访问权限时性能最佳,因为模型可以选择简单地对 独立 响应进行采样(如果基本模型准确度)对这个任务的理解是合理的。 Pass@K @turn 1 还限制了任何不查询预言机的过程的第一轮准确性的上限(例如,使用验证者、多数投票等)。 因此,对每个单独的回答进行甲骨文答案检查,可以在一个回合中呈现出并行采样所能预期的最强结果。 另一方面,顺序采样会产生相关样本,因此原则上应该无法改进并行采样,除非模型无法使用额外的标记和计算提供的反馈自我改进提示有意义地纠正自己。 由于模型的顺序性能大于上面的并行性能,这意味着RISE确实成功地做到了这一点。
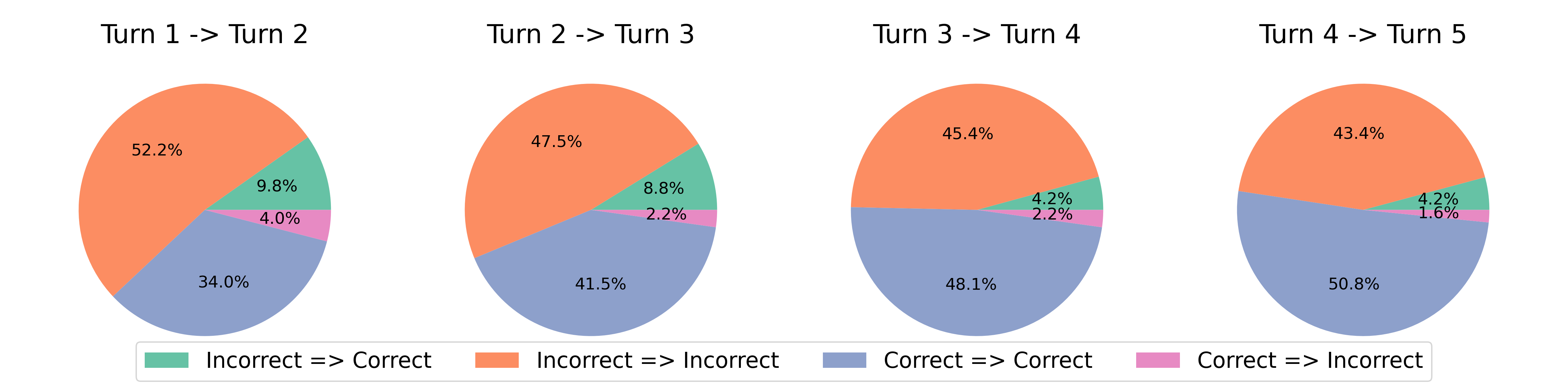
6.6RISE翻转误差分析
遵循Huang等人[21]的协议,在本节中,我们对RISE执行的改进进行错误分析(没有任何预言机反馈),以了解错误和正确响应的比例如何变化当没有预言机用于提前终止时,就会发生翻转。 我们以图 9 中的维恩图的形式演示了这一点。 首先请注意,保持正确的问题部分持续增加,而保持不正确的问题部分持续减少,这意味着随着轮数的增加,模型能够回答越来越多的问题。 其次,从正确变为错误的问题数量持续减少,而对于强大的专有大语言模型,例如Huang等人[21]中的GPT,情况往往并非如此。 。 我们还注意到,在后续回合中变为正确的错误问题总数有所减少,但这是错误响应集大小随着更多问题在回合中变为正确而缩小的直接结果。 这表明,即使在评估过程中没有提供外部环境输入,也可以通过 RISE 微调来诱导“内在”自我改进(根据 Huang 等人[21]的术语)。
定性的例子。 我们还检查了 GSM8K 测试集中的几个示例,以定性地了解 RISE 翻转的行为并观察不同的行为模式,如附录 B.2 中所示。 例如,如果之前的响应完全不正确,则经过训练的模型可能会选择完全重写其先前的响应,以便获得正确的答案,或者如果先前的响应大部分是正确的,则可以进行少量编辑。 我们注意到的另一个有趣的模式是,该模型隐式具有定位先前响应中的错误并仅改进错误步骤的能力。 此外,当没有预言机辅助的提前终止时,该模型可以容忍嘈杂的环境反馈。
7 讨论、未来方向和局限性
我们提出了 RISE,一种微调大语言模型的方法,能够连续提高其在多个回合中的反应。 RISE 在策略推出数据之上制定了迭代 RL 配方,并通过专家或自我生成的监督来引导自我改进。 RISE 显着提高了 7B 模型在推理任务(GSM8K 和 MATH)上的自我改进能力,取得了之前的工作[21]在强大的专有模型中未观察到的改进。 此外,RISE 优于之前尝试解决类似细化和校正问题的方法,同时更简单,因为它不需要运行多个模型并且仅适用于一个模型。
尽管取得了这些良好的成果,但仍然存在许多悬而未决的问题和限制。 由于计算限制,我们无法使用 RISE 执行超过两次的训练迭代,并且当监督来自学习器本身时,也不能执行超过一次迭代。 通过自我生成的监督进行改进可能需要更多的计算和更多的迭代,因为它会比使用现成的专家模型慢。 RISE 需要运行手动迭代,因此,从长远来看,更“在线”的 RISE 变体可能是解决方案,特别是当我们希望以数据高效的方式扩展策略学习时。 此外,虽然我们的工作一次针对一项任务对模型进行微调,但将 RISE 指定的协议中的数据包含到通用指令调整和训练后管道中肯定会很有趣。 考虑到对 RISE 规定的数据进行微调不会损害我们训练的任何模型的首轮性能的结果,我们假设在通用指令调整管道中添加此类数据也不应该损害,同时启用顺序自我-当今模型基本上不具备的改进能力。
致谢
这项工作是在 CMU 完成的。 我们感谢 Fahim Tajwar、Abitha Thanaraj、Amrith Setlur 和 Charlie Snell 的反馈和内容丰富的讨论。 这项工作得到了 ONR 的 N000142412206、OpenAI 超级对齐快速资助的支持,并通过 CIS240249 和 CIS230278 在国家超级计算应用中心使用了 Delta 系统和 JetStream2 [16],并得到了国家科学基金会的支持。 我们感谢 OpenAI 提供用于学术用途的 GPT-4 学分。
参考
- Agarwal et al. [2023] Rishabh Agarwal, Nino Vieillard, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. Gkd: Generalized knowledge distillation for auto-regressive sequence models. arXiv preprint arXiv:2306.13649, 2023.
- Bai et al. [2022] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- Burns et al. [2023] Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeff Wu. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023. URL https://arxiv.org/abs/2312.09390.
- Chang et al. [2024] Jonathan D Chang, Wenhao Shan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D Lee, and Wen Sun. Dataset reset policy optimization for rlhf. arXiv preprint arXiv:2404.08495, 2024.
- Charalambous et al. [2023] Yiannis Charalambous, Norbert Tihanyi, Ridhi Jain, Youcheng Sun, Mohamed Amine Ferrag, and Lucas C Cordeiro. A new era in software security: Towards self-healing software via large language models and formal verification. arXiv preprint arXiv:2305.14752, 2023.
- Chen et al. [2023a] Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. Fireact: Toward language agent fine-tuning, 2023a.
- Chen et al. [2023b] Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128, 2023b.
- Chen et al. [2024] Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335, 2024.
- Chia et al. [2023] Yew Ken Chia, Guizhen Chen, Luu Anh Tuan, Soujanya Poria, and Lidong Bing. Contrastive chain-of-thought prompting. arXiv preprint arXiv:2311.09277, 2023.
- Cobbe et al. [2019] Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. arXiv preprint arXiv:1912.01588, 2019.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Du et al. [2023] Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. arXiv preprint arXiv:2305.14325, 2023.
- Gandhi et al. [2024] Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah D Goodman. Stream of search (sos): Learning to search in language. arXiv preprint arXiv:2404.03683, 2024.
- Gao et al. [2023] Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. In International Conference on Machine Learning, pages 10764–10799. PMLR, 2023.
- Gou et al. [2023] Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large Language Models can Self-Correct with Tool-Interactive Critiquing. arXiv preprint arXiv:2305.11738, 2023.
- Hancock et al. [2021] David Y. Hancock, Jeremy Fischer, John Michael Lowe, Winona Snapp-Childs, Marlon Pierce, Suresh Marru, J. Eric Coulter, Matthew Vaughn, Brian Beck, Nirav Merchant, Edwin Skidmore, and Gwen Jacobs. Jetstream2: Accelerating cloud computing via jetstream. In Practice and Experience in Advanced Research Computing, PEARC ’21, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450382922. 10.1145/3437359.3465565. URL https://doi.org/10.1145/3437359.3465565.
- Havrilla et al. [2024] Alex Havrilla, Sharath Raparthy, Christoforus Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, and Roberta Railneau. Glore: When, where, and how to improve llm reasoning via global and local refinements. arXiv preprint arXiv:2402.10963, 2024.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021.
- Hosseini et al. [2024] Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal. V-star: Training verifiers for self-taught reasoners. arXiv preprint arXiv:2402.06457, 2024.
- Huang et al. [2023a] Dong Huang, Qingwen Bu, Jie M Zhang, Michael Luck, and Heming Cui. Agentcoder: Multi-agent-based code generation with iterative testing and optimisation. arXiv preprint arXiv:2312.13010, 2023a.
- Huang et al. [2023b] Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798, 2023b.
- Huang et al. [2022] Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR, 2022.
- Jiang et al. [2023] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Kang et al. [2024] Katie Kang, Eric Wallace, Claire Tomlin, Aviral Kumar, and Sergey Levine. Unfamiliar finetuning examples control how language models hallucinate, 2024.
- Kingma and Welling [2022] Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2022. URL https://arxiv.org/abs/1312.6114.
- Lehnert et al. [2024] Lucas Lehnert, Sainbayar Sukhbaatar, Paul Mcvay, Michael Rabbat, and Yuandong Tian. Beyond a*: Better planning with transformers via search dynamics bootstrapping. arXiv preprint arXiv:2402.14083, 2024.
- Li et al. [2024] Chen Li, Weiqi Wang, Jingcheng Hu, Yixuan Wei, Nanning Zheng, Han Hu, Zheng Zhang, and Houwen Peng. Common 7b language models already possess strong math capabilities. arXiv preprint arXiv:2403.04706, 2024.
- Lightman et al. [2023] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- Liu et al. [2023] Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688, 2023.
- Luo et al. [2023] Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Madaan et al. [2023] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023.
- Nijkamp et al. [2023] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. ICLR, 2023.
- Nye et al. [2021] Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021.
- Peng et al. [2019] Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177, 2019.
- Peters and Schaal [2007] Jan Peters and Stefan Schaal. Reinforcement learning by reward-weighted regression for operational space control. In Proceedings of the 24th international conference on Machine learning, pages 745–750. ACM, 2007.
- Ross et al. [2011] Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Geoffrey Gordon, David Dunson, and Miroslav Dudík, editors, Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 of Proceedings of Machine Learning Research, pages 627–635, Fort Lauderdale, FL, USA, 11–13 Apr 2011. PMLR. URL http://proceedings.mlr.press/v15/ross11a.html.
- Rosset et al. [2024] Corby Rosset, Ching-An Cheng, Arindam Mitra, Michael Santacroce, Ahmed Awadallah, and Tengyang Xie. Direct nash optimization: Teaching language models to self-improve with general preferences. arXiv preprint arXiv:2404.03715, 2024.
- Saha et al. [2023] Swarnadeep Saha, Omer Levy, Asli Celikyilmaz, Mohit Bansal, Jason Weston, and Xian Li. Branch-solve-merge improves large language model evaluation and generation. arXiv preprint arXiv:2310.15123, 2023.
- Schick et al. [2023] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Shinn et al. [2023] Noah Shinn, Beck Labash, and Ashwin Gopinath. Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366, 2023.
- Snell et al. [2022] Charlie Snell, Ilya Kostrikov, Yi Su, Mengjiao Yang, and Sergey Levine. Offline rl for natural language generation with implicit language q learning. arXiv preprint arXiv:2206.11871, 2022.
- Sohl-Dickstein et al. [2015] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics, 2015. URL https://arxiv.org/abs/1503.03585.
- Song and Kingma [2021] Yang Song and Diederik P. Kingma. How to train your energy-based models, 2021. URL https://arxiv.org/abs/2101.03288.
- Sun et al. [2018] Liting Sun, Cheng Peng, Wei Zhan, and Masayoshi Tomizuka. A fast integrated planning and control framework for autonomous driving via imitation learning. In Dynamic Systems and Control Conference, volume 51913, page V003T37A012. American Society of Mechanical Engineers, 2018.
- Swamy et al. [2024] Gokul Swamy, Sanjiban Choudhury, J. Andrew Bagnell, and Zhiwei Steven Wu. Inverse reinforcement learning without reinforcement learning, 2024. URL https://arxiv.org/abs/2303.14623.
- Toshniwal et al. [2024] Shubham Toshniwal, Ivan Moshkov, Sean Narenthiran, Daria Gitman, Fei Jia, and Igor Gitman. Openmathinstruct-1: A 1.8 million math instruction tuning dataset. arXiv preprint arXiv:2402.10176, 2024.
- Uesato et al. [2022] Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- Wang et al. [2022a] Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. Towards understanding chain-of-thought prompting: An empirical study of what matters. arXiv preprint arXiv:2212.10001, 2022a.
- Wang et al. [2023a] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv: Arxiv-2305.16291, 2023a.
- Wang et al. [2023b] Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Y Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. CoRR, abs/2312.08935, 2023b.
- Wang et al. [2022b] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022b.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS, 2022.
- Welleck et al. [2023] Sean Welleck, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, and Yejin Choi. Generating sequences by learning to self-correct. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=hH36JeQZDaO.
- Yang et al. [2023a] Hui Yang, Sifu Yue, and Yunzhong He. Auto-gpt for online decision making: Benchmarks and additional opinions. arXiv preprint arXiv:2306.02224, 2023a.
- Yang et al. [2023b] Kaiyu Yang, Aidan M Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. arXiv preprint arXiv:2306.15626, 2023b.
- Yao et al. [2022] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Yu et al. [2023] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Yuan et al. [2024a] Lifan Yuan, Ganqu Cui, Hanbin Wang, Ning Ding, Xingyao Wang, Jia Deng, Boji Shan, Huimin Chen, Ruobing Xie, Yankai Lin, et al. Advancing llm reasoning generalists with preference trees. arXiv preprint arXiv:2404.02078, 2024a.
- Yuan et al. [2024b] Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. arXiv preprint arXiv:2401.10020, 2024b.
- Yue et al. [2023] Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023.
- Zelikman et al. [2022] Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
- Zeng et al. [2023] Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms. arXiv preprint arXiv:2310.12823, 2023.
- Zhang et al. [2022] Tianjun Zhang, Xuezhi Wang, Denny Zhou, Dale Schuurmans, and Joseph E Gonzalez. Tempera: Test-time prompting via reinforcement learning. arXiv preprint arXiv:2211.11890, 2022.
- Zhang et al. [2024] Tianjun Zhang, Aman Madaan, Luyu Gao, Steven Zheng, Swaroop Mishra, Yiming Yang, Niket Tandon, and Uri Alon. In-context principle learning from mistakes. arXiv preprint arXiv:2402.05403, 2024.
- Zhou et al. [2023] Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning acting and planning in language models. arXiv preprint arXiv:2310.04406, 2023.
- Zhou et al. [2024] Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar. Archer: Training language model agents via hierarchical multi-turn rl. arXiv preprint arXiv:2402.19446, 2024.
附录
附录 A 关于数据组合和弱到强泛化的额外消融
A.1 包含正确到正确的数据
直观地说,只有当模型能够学习验证其先前响应的正确性并决定适当修改其响应以实现正确性时,自我改进在很大程度上才有可能实现。 到目前为止,RISE 仅对显示如何将错误响应转换为正确响应的数据进行了训练,但从未说明模型如何对正确响应采取行动。 为了了解是否可以通过举例说明模型如何对正确响应采取行动来提高性能,我们进行了多次消融。 我们使用 Llama2-7B 获取了在 GSM8K 上训练第 1 次迭代期间生成的 RISE 数据,并修改了多轮部署以创建多个案例。 首先,我们复制了每次成功的多轮部署结束时出现的正确响应,并进行了额外一轮的训练。 这应该告诉模型不应修改正确的响应,这与之前推出的轮次中出现的错误响应不同。 其次,我们还运行了一个变体,其中每次成功推出结束时出现的正确响应后面跟着一个不同正确响应。 这个变体应该告诉模型,如果它选择修改正确的响应,它仍然必须产生另一个正确的响应。
如表4所示,所有方法都比基本模型提高了性能,尽管仅附加成功的推出和新颖的正确响应才能获得最佳性能。 主要论文中 RISE 的默认设计紧随其后,在成功推出后重复正确的响应会大大降低性能。 我们怀疑重复相同正确响应的不良性能很大程度上是由于数据重复引起的虚假相关性的结果。
| RISE (Llama2) | w/o oracle | w/ oracle | ||
|---|---|---|---|---|
| m1@t1 | m5@t1 | m1@t5 | p1@t5 | |
| Boost | 32.9 | 45.3 (+12.4) | 26.5 (-6.4) | 40.9 (+8.0) |
| +RISE (default) | 35.6 | 49.7 (+14.1) | 50.7 (+15.1) | 63.9 (+28.3) |
| +Repeating a correct response | 34.2 | 48.9 (+14.6) | 46.2 (+12.6) | 57.7 (+23.5) |
| +Appending a different correct response | 33.1 | 49.3 (+16.2) | 51.1 (+18.0) | 64.9 (+31.8) |
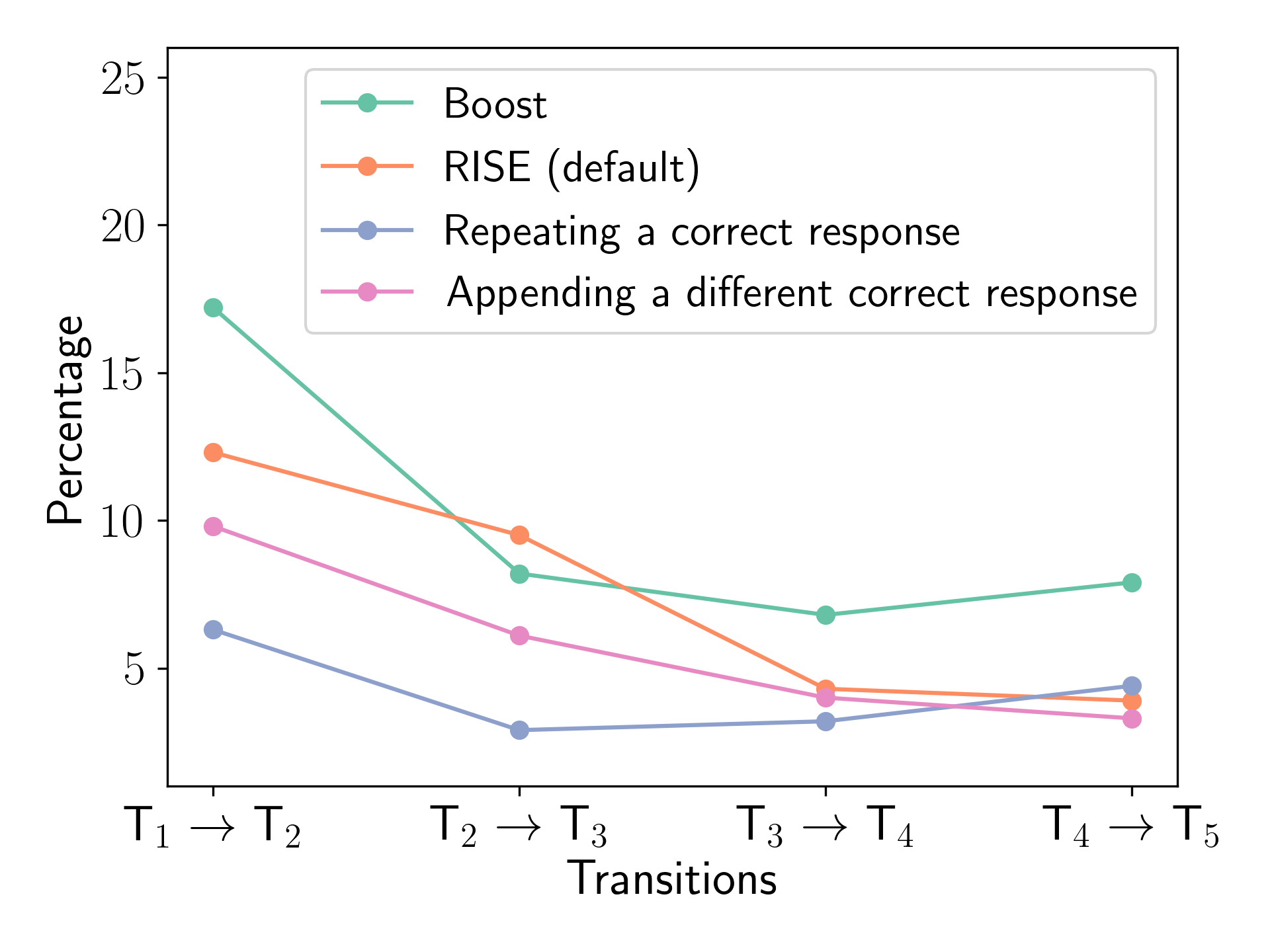
为了进一步考察自我改进能力,我们分析了连续回合(T到T)中正确答案转变为错误答案的百分比,如图10。 一般来说,下降趋势表明更好的自我改进,而较低的绝对值表明对噪声反馈有更好的抵抗力。 结果揭示了不同配置中意想不到的模式。 Boost 配置显示出最差的性能,总体百分比最高,并且从第 4 圈到第 5 圈有所增加,这表明它很难始终保持正确的响应。 重复正确响应显示出最低的初始百分比 (6.3%),但从第 3 轮开始增加,表明扩展交互中存在潜在问题。 默认上升和附加不同的正确答案都显示出良好的趋势,分别从 12.3% 稳步下降到 3.9% 和从 9.8% 下降到 3.3%,这表明在保持正确答案和允许改进之间取得了良好的平衡。 这些发现为 RISE 的稳定性和自我改进能力提供了细致入微的见解,并与我们之前对其在整体准确性方面的卓越性能的观察结果相一致。
A.2 从弱到强的泛化:弱模型数据上的 RISE 改进了强模型
在本节中,我们将在从弱到强的设置[3]中比较 Llama2 和 Mistral-7B 与 RISE 的性能。 具体来说,我们感兴趣的是使用 RISE 生成的数据将弱模型 (Llama2-7B) 训练为强模型 (Mistral-7B)。 我们的分析揭示了 RISE 生成的数据在不同功能模型之间的可转移性的有趣见解。
| RISE | w/o oracle | w/ oracle | ||
|---|---|---|---|---|
| m1@t1 | m5@t1 | m1@t5 | p1@t5 | |
| Llama2-7B | 10.5 | 22.8 (+12.3) | 11.1 (+0.6) | 13.9 (+3.4) |
| + Iteration 1 | 35.6 | 49.7 (+14.1) | 50.7 (+15.1) | 63.9 (+28.3) |
| + Iteration 1 (Mistral-7B) | 27.1 | 40.1 (+13.0) | 45.2 (+18.1) | 59.1 (+32.0) |
| Mistral-7B | 33.7 | 49.4 (+15.7) | 39.0 (+5.3) | 46.9 (+13.2) |
| + Iteration 1 | 35.3 | 50.6 (+15.3) | 59.2 (+23.9) | 68.6 (+33.3) |
| + Iteration 1 (Llama2-7B) | 38.2 | 55.4 (+17.2) | 62.7 (+24.5) | 73.5 (+35.3) |
如表5所示,我们发现从 Llama2 生成的 Mistral-7B + 迭代 1 数据在所有指标上均优于这些数据上的 Llama2-7B 模型本身(即 Llama2-7B + 迭代 1)据报道,在多轮推理(m1@t5)方面有特别显着的改进。 事实上,Llama2-7B 的多回合部署训练也优于策略 Mistral-7B 部署训练。 有趣的是,我们观察到,在 Mistral-7B 的多轮部署上训练 Llama2-7B 的表现比在策略 Llama2-7B 部署上的训练要差,这表明 Llama2-7B 尽管其绝对性能较低,但表现出更多信息错误,这些错误可以通过更好地提升自我提升能力。 这种现象强调了训练数据中错误的质量和性质的重要性,而不仅仅是生成这些错误的模型的整体性能。 这些发现共同表明,从较弱的 Llama2 模型生成的数据仍然可以用于在更强的模型中诱导自我改进能力,尽管反之亦然(从在训练的提升阶段不会提高表 1 中任何模型的性能。 我们怀疑这是因为相反的情况会带来更难的学习问题,因为弱模型需要内化更强模型的错误,从而导致幻觉和记忆[24]。 请注意,对这些数据进行训练也不会降低单轮性能。 这暗示了使用 RISE 进行训练的另一个好处:从弱到强的泛化,当推出更强的模型成本高昂时,这在实践中非常有用。
附录 B其他结果
B.1 完整比较和讨论:表1的扩展版本
我们提供了表1的扩展版本,清楚地解释了我们如何实现基线并讨论了比较。
| Approach | GSM8K [10] | MATH [18] | ||||||
|---|---|---|---|---|---|---|---|---|
| w/o oracle | w/ oracle | w/o oracle | w/ oracle | |||||
| m1@t1 | m5@t1 | m1@t5 | p1@t5 | m1@t1 | m5@t1 | m1@t5 | p1@t5 | |
| RISE (Ours) | ||||||||
| Llama2 Base | 10.5 | 22.8 (+12.3) | 11.1 (+0.6) | 13.9 (+3.4) | 1.9 | 5.1 (+3.2) | 1.4 (-0.5) | 2.3 (+0.4) |
| +Boost | 32.9 | 45.4 (+12.5) | 39.2 (+6.3) | 55.5 (+22.6) | 5.5 | 6.8 (+1.3) | 5.5 (+0.0) | 14.6 (+9.1) |
| +Iteration 1 | 35.6 | 49.7 (+14.1) | 50.7 (+15.1) | 63.9 (+28.3) | 6.3 | 8.8 (+2.5) | 9.7 (+3.4) | 19.4 (+13.1) |
| +Iteration 2 | 37.3 | 51.0 (+13.7) | 55.0 (+17.7) | 68.4 (+31.1) | 5.8 | 10.4 (+4.6) | 10.4 (+4.6) | 19.8 (+14.0) |
| RISE (Ours) | ||||||||
| Mistral-7B | 33.7 | 49.4 (+15.7) | 39.0 (+5.3) | 46.9 (+13.2) | 7.5 | 13.0 (+5.5) | 8.4 (+0.9) | 13.0 (+5.5) |
| + Iteration 1 | 35.3 | 50.6 (+15.3) | 59.2 (+23.9) | 68.6 (+33.3) | 6.7 | 9.5 (+2.8) | 18.4 (+11.1) | 29.7 (+22.4) |
| SFT on oracle data | ||||||||
| Only correct data | 27.4 | 42.2 (+14.9) | 34.0 (+6.6) | 43.6 (+16.2) | 5.8 | 7.9 (+2.1) | 5.5 (-0.3) | 12.1 (+6.2) |
| Correct and incorrect | 25.7 | 41.8 (+16.1) | 31.2 (+5.5) | 41.5 (+15.8) | 5.0 | 5.2 (+0.2) | 5.0 (+0.0) | 13.1 (+8.1) |
| Baselines | ||||||||
| GPT-3.5 | 66.4 | 80.6 (+14.2) | 71.0 (+4.6) | 74.7 (+8.3) | 39.7 | 47.8 (+8.1) | 45.1 (+5.4) | 54.3 (+14.6) |
| Mistral-7B | 33.7 | 49.4 (+15.7) | 39.0 (+5.3) | 46.9 (+13.2) | 7.5 | 13.0 (+5.5) | 8.4 (+0.9) | 13.0 (+5.5) |
| Eurus-7b-SFT | 36.3 | 66.3 (+30.0) | 47.9 (+11.6) | 53.1 (+16.8) | 12.3 | 19.8 (+7.5) | 16.3 (+4.0) | 22.9 (+10.6) |
| Self-Refine | m1@t3 | p1@t3 | m1@t3 | p1@t3 | ||||
| Base | 10.5 | 22.4 (+11.9) | 7.1 (-3.4) | 13.0 (+2.5) | 1.9 | 5.1 (+3.2) | 1.9 (0.0) | 3.1 (+1.2) |
| +Boost | 32.9 | 45.3 (+12.4) | 26.5 (-6.4) | 40.9 (+8.0) | 5.5 | 6.5 (+1.0) | 2.9 (-2.6) | 7.2 (+1.7) |
| +Iteration1 | 35.6 | 49.5 (+13.9) | 31.7 (-3.9) | 43.7 (+8.1) | 6.3 | 8.7 (+2.4) | 5.9 (-0.4) | 9.9 (+3.6) |
| +Iteration2 | 37.3 | 50.5 (+13.2) | 33.3 (-4.0) | 44.5 (+7.2) | 5.8 | 9.4 (+3.6) | 5.7 (-0.1) | 9.5 (+3.7) |
| GPT-3.5 | 66.4 | 80.2 (+13.8) | 61.0 (-5.4) | 71.6 (+5.2) | 39.7 | 46.5 (+6.8) | 36.5 (-3.2) | 46.7 (+7.0) |
| Mistral-7B | 33.7 | 48.5 (+14.8) | 21.2 (-12.5) | 37.9 (+4.2) | 7.5 | 12.3 (+4.8) | 7.1 (-0.4) | 11.4 (+3.9) |
| Eurus-7b-SFT | 36.3 | 65.9 (+29.6) | 26.2 (-10.1) | 42.8 (+6.5) | 12.3 | 19.4 (+7.1) | 9.0 (-3.3) | 15.1 (+2.8) |
| GloRE | m1@t3 | p1@t3 | ||||||
| +ORM | 48.2 | 49.5 (+1.3) | 57.1 (+8.9) | |||||
| +SORM | 48.2 | 51.6 (+3.4) | 59.7 (+11.5) | N/A | ||||
| +Direct | 48.2 | 47.4 (-0.8) | 59.2 (+11.0) | |||||
| V-STaR | m64@t1 | |||||||
| +STaR | 28.0 | 46.1 (+18.1) | ||||||
| +Verification | 28.0 | 56.2 (+28.2) | N/A | |||||
| +V-STaR | 28.0 | 63.2 (+35.2) | ||||||
与 Self-Refine [31] 的比较。 为了构建自优化基线[31]评估,我们按照自优化方法稍微修改了我们的评估流程。 在此设置中(图11),模型生成初始响应,然后环境提示模型在生成的解决方案中查找错误,并根据初始响应和识别的错误完善其答案。
然而,我们的实验表明,如果没有来自环境或人类反馈的任何预言提示,自我优化方法会导致所有模型的性能下降。 只有当预言机反馈可用于协助提前终止时,自我优化方法才能提供轻微的性能提升。 这凸显了自优化结构在没有外部指导的情况下有效提高模型性能的局限性,这在[22]中也被观察到。
相比之下,使用 RISE 训练的模型可以在不依赖预言机的情况下获得一致的性能改进。 通过训练模型迭代地改进其响应,我们的方法使模型能够自我纠正并提高其多轮性能。 与自我优化基线相比,这展示了我们的方法的有效性,因为它无需预言机帮助即可实现更强大和一致的性能提升。
与 GLoRE [17] 的比较。 GLoRE 是一个多模型系统,它依靠学生模型来提出草稿,基于结果的奖励模型 (ORM) 或逐步 ORM 来定位不同粒度级别的错误,以及用于调整这些错误的全局或局部细化模型。 由于这种方法没有公开可用的代码,因此在我们的实验中,我们与主要论文 Havrilla 等人 [17] 中的数字进行了比较。 虽然与 GLoRE 的比较已经很明显了,因为我们的方法只训练单个端到端模型,而 GLoRE 训练多个模型。 在性能方面,GLoRE 的全局和局部细化模型在没有预言机的情况下几乎没有提高整体精度,甚至在某些情况下表现出精度下降。 然而,当使用预言机来指导细化过程时,GLoRE 在 GSM8K 数据集中的 7B 模型上展示了 10% 的改进。
正如预期的那样,由于我们从不太先进的基础模型 (Llama2 7B) 运行 RISE,因此我们观察到与 GLoRE 相比,绝对性能略低。 然而,RISE 展示了其自我改进的有效性,在没有预言机反馈的情况下,在短短 3 个回合内,其性能连续提高了 13.4%,令人印象深刻,而在 GSM8K 上有预言机的情况下,其性能提高了 23.4%。 考虑到 GLoRE 使用 3 个独立的模型,这种 RISE 功能的展示特别值得注意——一个用于生成候选解决方案,一个用于定位错误的奖励模型,以及一个用于细化的细化模型。
与V-STaR[19]的比较。 V-STAR 需要训练一个额外的验证器模型来对目标模型生成的候选答案进行排名,但它不会对响应进行任何连续的修改或改进。 虽然将 RISE 与使用验证器在第一回合重新排名前 5 个响应(作为基础比较)进行比较会提供丰富的信息,但我们无法在原始 V-STaR 论文中找到这个具体结果。 V-STaR 官方表 6 中给出的结果对应于运行 64 个样本,这使得评估过程中每个提示的基础模型性能提高了 35.2%。 相比之下,我们的方法 RISE 在经过相同数量的微调迭代(3 次迭代)并仅使用 5 个样本后,在基础模型上改进了 44.5%(计算为 55.0% - 10.5% = 44.5%)。 这一比较凸显了与 V-STaR 使用大量样本而不进行顺序细化的方法相比,RISE 以更少的样本和迭代实现了显着改进的效率。
此外,V-STaR 的性能本质上受到候选生成器性能的限制。 正如第 5 节中所讨论的,如果生成的候选者中没有正确的响应,则问题仍然无法解决。 相比之下,我们在图6中显示,RISE还可以在第一轮以更高的预算解决多数投票无法解决的问题。 此外,我们相信将 V-STaR 与 RISE 相结合可以带来更好的性能,因为 RISE 可以生成更好的模型,并且验证器可以补充用于过滤。
与其他基础型号的比较。 Mistral-7B [23] 和 Eurus-7B-SFT [58] 模型在绝对 maj@5 性能方面表现出与我们的方法相当的性能。 然而,值得注意的是,这些基本模型是使用大量数据进行微调的,包括专门针对数学推理性能进行调整的数据[58],而我们的模型是在单一域。 也就是说,我们确实表明,使用 RISE 进行微调仍然可以增强 Mistral-7B 模型的性能。
总而言之,与 GLoRE 和 V-STaR 相比,我们的方法具有多种优势,例如使用单个模型进行端到端纠错、使用更少的样本获得优异的性能,以及能够解决无法解决的问题。在第一轮中通过随机采样来解决。 尽管我们的 maj@1 性能低于 GLoRE 的基本模型 EI(这是苹果与橘子的比较),但我们的最终 5 回合性能在预言机和非预言机场景中都超过了它们的最佳绝对性能。
与 Mistral-7B 和 Eurus-7B-SFT 等其他基础模型相比,我们的方法在单个域上进行微调的同时实现了可比的性能,并且可以推广到更好的基础模型。
B.2 来自 RISE 的定性示例
在本节中,我们提供了一些定性示例,展示了 RISE 对我们训练的各种数据集所做的编辑的性质。 我们利用 RISE 第 2 次迭代中的模型。
附录C伪代码
附录D实验细节
D.1 使用 RISE 进行微调的超参数
为了进行微调,我们利用 FastChat 代码库,但我们自定义损失函数以按奖励加权。 基本模型直接从 Hugging Face 加载:hrefhttps://huggingface.co/meta-llama/Llama-2-7b-hfLlama-2-7b-chat-hf 和 Mistral-7B-Instruct-v0.2 。 用于微调的超参数在表7中指定。
| Hyperparameter | Values |
|---|---|
| bf16 | True |
| epochs | 2 |
| per device train batch size | 1 |
| gpus | 4xA40 |
| gradient accumulation steps | 16 |
| learning rate | 1e-5 |
| weighted decay | 0 |
| warmup ratio | 0.04 |
| learning rate scheduler trype | cosince |
| tf32 | True |
| model max length | 2048 |
D.2 推理超参数
对于基于API的模型,例如GPT-3.5,我们直接查询OpenAI提供的官方Web API。 对于开源模型,我们利用 FastChat 将模型作为 Web API 提供服务,并通过 API 调用与环境交互。 为 7B 模型提供服务需要单个 A100 或 A40 GPU。 为了控制大语言模型生成答案的随机性和长度,我们采用表8中指定的超参数。
| Hyperparameters/Description | Open-source | GPT |
|---|---|---|
| temperature | 1.0 | 0.7 |
| top_p | 1.0 | 1 |
| max_new_tokens | 1000 | 512 |
D.3 数据集
GSM8K 数据集包含训练部分的 7,473 个问题和测试部分的 1,319 个问题。 同样,MATH 数据集分为 7,500 个训练问题和 1,000 个测试问题。 两个数据集的训练部分用于在 RISE 方法的每次迭代中生成轨迹,而测试部分则用于评估模型的性能。 此外,包含 1,000 个问题的 SVAMP 数据集仅用于评估目的,以证明我们方法的普遍性。
为了生成训练轨迹,在迭代时,当前模型将推出最多步。 随后,采用专家模型(例如 GPT-3.5)来获取当前模型与环境之间的对话历史记录并采样 5 个响应。 在这些响应中,选择奖励最高的一个,如果多个响应具有相同的最高奖励,则任意平局打破。
D.4 用于在 GSM8K 和 MATH 任务上播种 RISE 的提示
这里我们展示了用于数据生成和模型评估的提示: