构建 CORD-19 疫苗数据集
摘要
我们推出新数据集“CORD-19-Vaccination”111Our dataset is available at https://github.com/manisha-Singh-UW/CORD-19-Vaccination 以满足专门研究 COVID-19 疫苗相关研究的科学家的需求。 该数据集是从 CORD-19 数据集 (Wang 等人,2020) 中提取的,并增加了语言详细信息、作者人口统计、关键词和每篇论文主题的新列。 Facebook 的 fastText 模型用于识别语言(Joulin 等人,2016)。 为了确定作者人口统计(作者隶属关系、实验室/机构位置以及实验室/机构国家/地区列),我们处理了每篇论文的 JSON 文件,然后使用 Google 的搜索 API 进一步增强以确定国家/地区值。 使用“Yake”从每篇论文的标题、摘要和正文中提取关键词,并使用LDA(潜在狄利克雷分配)算法添加主题信息(Campos等人, 2020, 2018a, 2018b). 为了评估数据集,我们演示了一个问答任务,就像 CORD-19 Kaggle 挑战中使用的任务(Goldbloom 等人,2022)。 为了进一步评估,使用Dernoncourt等人(2016)的模型对每篇论文的摘要进行顺序句子分类。 我们对训练数据集进行了部分手工注释,并使用了预先训练的 BERT-PubMed 层。 “CORD-19-Vaccination”包含 3 万篇研究论文,对于特定于 COVID-19 疫苗研究领域的文本挖掘、信息提取和问答等 NLP 研究非常有价值。
1简介
2021 年初发布的一份报告宣称,“到 2025 年,世界将花费 1,570 亿美元用于 COVID-19 疫苗”(Mishra,2021)。 尽管如此,还没有专门针对 COVID-19 疫苗研究的数据集。 COVID-19 开放研究数据集 (CORD-19) (Wang 等人,2020) 是有关冠状病毒研究的学术论文语料库。 然而,CORD-19数据集(发布版本109)的元数据文件由超过一百万个期刊组成,导致大数据问题和信息过载。 总体目标是创建一个基于 CORD-19 的数据集,但仅包含与疫苗研究相关的论文。 在这项工作中,我们引入了一个从 CORD-19 数据集整理而来的数据集,该数据集专门用于帮助 COVID-19 疫苗的研究。
我们的方法利用信息提取、数据增强和任务实施的管道:
萃取阶段: 在此阶段,我们创建了一个 SQLite 数据管道来管理大量的 CORD-19 数据集。 每篇论文摘要的语言都是使用 Facebook 的 fastText 库(Joulin 等人,2016) 确定的。 随后,我们使用 SQLite 查询创建了 CORD-19 数据集的子集,仅获取起始“发布时间”为“2020”且“摘要”或“标题”包含“疫苗”或“疫苗接种”一词的论文' 在 CORD-19 中的所有语言中。
数据增强阶段: 在此阶段,我们向数据集添加了新列。 保留上一阶段确定的语言 ID。 关于作者隶属关系的数据是从每篇研究论文的研究论文网络搜索的“json parse”文件中收集的。 使用“Yake”添加关键字(Campos 等人,2020)。 最后,我们实现了“主题建模”,使用 LDA 模型(Dernoncourt 等人,2016)根据“摘要”将数据集分类为主题。
任务实施阶段: 我们使用 CORD-19-Vaccination 数据集实现了“问答”和“序列句子分类”任务。
以下各节详细介绍了每个步骤的实现。 图 1 显示了数据集创建的直观概览。
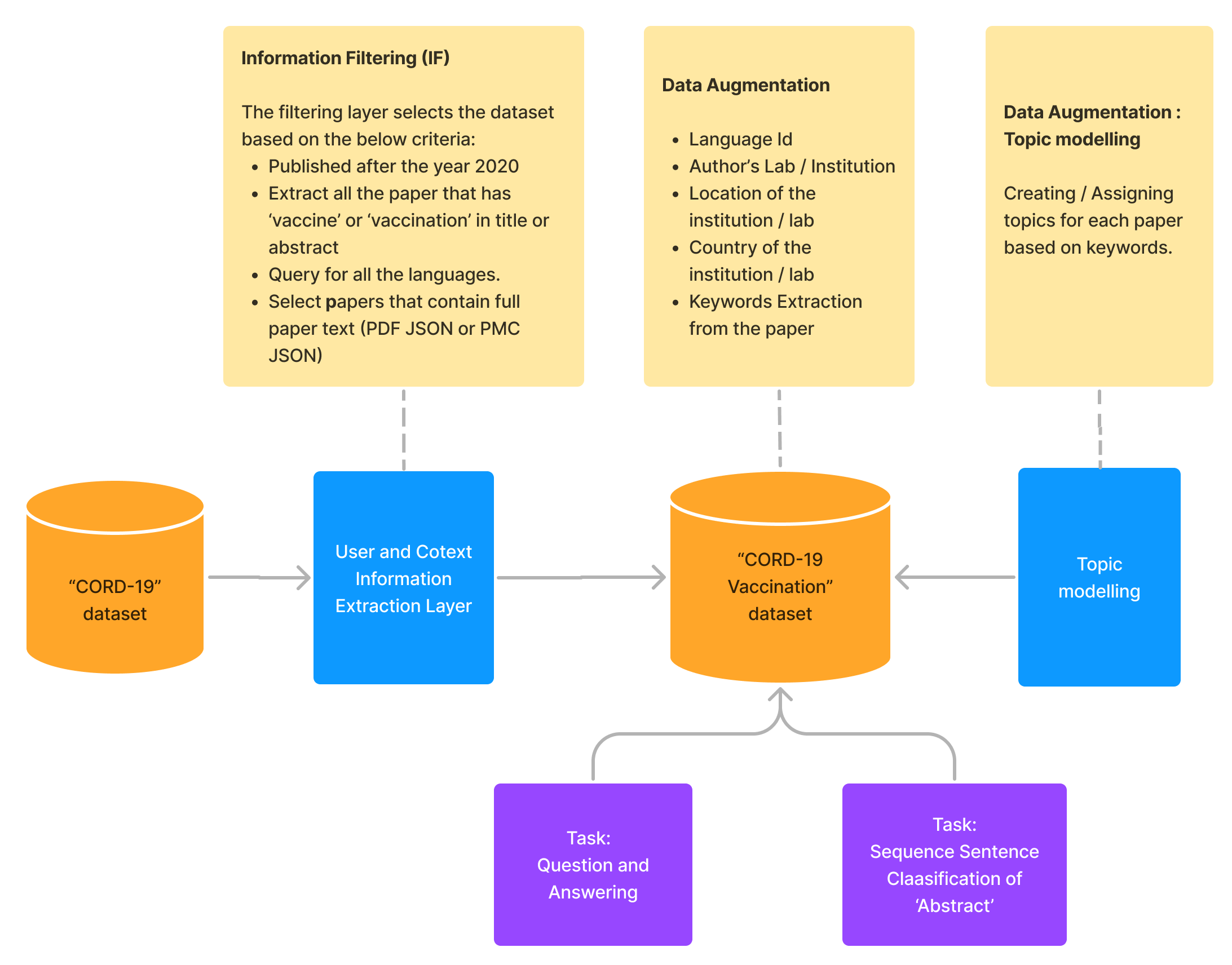
接下来,我们将激励并描述每个阶段,重点介绍每个步骤的发现。 然后,我们展示了该数据集在问答和顺序句子分类任务中的实用性。
2 提取阶段:从 CORD-19 中提取用户和上下文信息
CORD-19-Vaccination 数据集是根据以下过滤标准从 CORD-19 数据集中提取的:
发布时间:
CORD-19metadata.csv 有一个列 publish_time。 提取过滤器提取 publish_time 大于或等于“2020”的所有数据。
模式搜索:
标题或摘要中的“疫苗”/“疫苗接种”:CORD-19metadata.csv不指示论文的语言。 图2展示了使用fastText模型的CORD-19的语言分布。 CORD-19-疫苗接种数据集是从 CORD-19 数据集中提取的。 为了提取每种语言中含有“疫苗/疫苗接种”一词的论文,定制了信息提取查询以搜索每种语言中“疫苗/疫苗接种”的模式。 此查询应用于列标题和摘要。 语言 ID 缩写取自 ISTD 。


Pdf_json_文件 / pmc_json_文件:
CORD-19 metdata.csv 具有列 pdf_json_files 和 pmc_json_files。 这些列给出了 CORD-19 数据集中 json 文件的路径。 所有选定的论文均包含 pdf_json_file 或 pmc_json_files。
摘要不为空:
所有入选的论文都有摘要专栏。 我们的探索性数据分析表明,几乎所有标准发表的论文都必须遵循特定的模板,其中必须存在摘要。 没有摘要的论文大多是未发表的论文。 这提高了我们数据集的质量,因为它只包含研究论文。
由于多个“CORD-19-Vaccination”色谱柱基于 CORD-19,因此 CORD-19 的预处理详细信息请参见 Wang 等人 (2020)。
3 数据增强阶段:语言细节、作者人口统计、关键词和主题
表 1 包含添加到 CORD-19-Vaccination 数据集的字段列表。 生成这些增强字段的代码可在 GitHub 存储库中获取222The code for the data augmentation is available at https://github.com/manisha-Singh-UW/CORD-19-Vaccination获取。
| Language Detail | Author Demography | Keywords | Topic |
| lang_id, lang_id_confidence, lang_id_predictions | aff_lab_inst, aff_location, aff_country | keywords | topic, topic_index, topic_prob |
3.1 语言 ID
数据集中包含语言 ID 以支持文本人口统计。 fastText 模型的输入是每篇论文的“摘要”文本,输出是表 2 中所示的三个字段。
| lang_id | lang_id_confidence | lang_id_predictions |
| en | 0.9167 | en=0.9167, id=0.0055, fr=0.0043 |
3.2 作者的人口统计(实验室/机构位置和国家/地区)
CORD-19 数据集包含每篇论文的作者和期刊名称。 然而,为了获得有关作者人口统计的更多详细信息,我们用作者的“实验室/机构隶属关系”、“实验室/机构位置”和“实验室/机构国家/地区”来扩充数据。 作者人口统计的详细信息可用于构建合作网络,以说明机构之间的合作或共同作者关系,如文章陈海华(2022)中所述。
| aff_lab_inst | aff_location | aff_country | ||||
|---|---|---|---|---|---|---|
|
|
USA |
CORD-19 元数据文件中未提及作者的“实验室/机构隶属关系”、“实验室/机构位置”和“实验室/机构国家/地区”。 然而,为了进行描述性分析,例如每个机构贡献的论文数量、机构的地理分布以及来自不同国家/地区的机构之间的合作,我们需要与论文的每个作者相关的机构详细信息。
此外,由于所属国家/地区元数据仅适用于大约 63% 的 JSON 文件,因此进行了进一步的数据扩充,以通过网络抓取提取第一作者的国家/地区。 在这个过程中,通过Python的Google搜索API搜索缺少国家数据的论文标题,并使用Selenium和Beautiful Soup解析第一个查询结果对应的网页的HTML源代码。 存储从搜索查询中抓取的标题及其链接的所属国家/地区,然后通过比较原始 CORD-19 论文标题和抓取标题之间的相似性进行验证。 相似度低于 0.4 的条目(使用 Python diff lib 库中的序列匹配器模块计算)被排除在外。
作者人口统计:
演讲者/作者人口统计主要通过检查第一作者所属国家的分布来评估。 我们最初从全文 JSON 文件中提取国家/地区数据,覆盖率达到论文总数的 63%。 通过网络抓取,我们确定了另一组论文的所属国家/地区,将覆盖率提高到 93%。
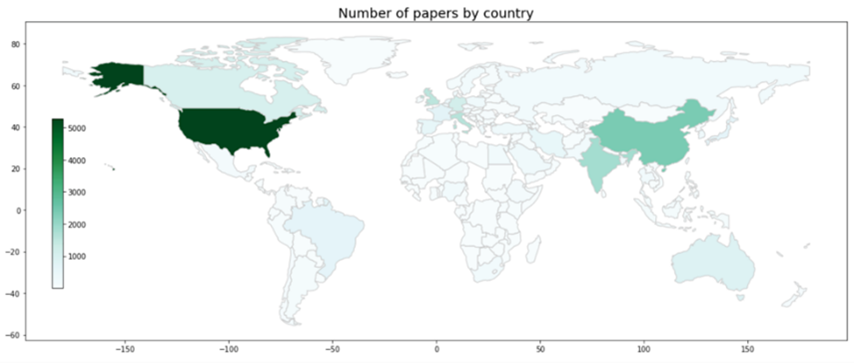
论文总数的 50% 集中在 7 个国家:美国、中国、印度、意大利、英国、德国和加拿大,其中美国占数据集的 20%。 图4显示了按第一作者所在国家/地区划分的论文数量分布的完整地图。 最值得注意的是,除了研究集中在前面提到的国家之外,南半球国家(巴西除外)的代表性也明显缺乏。
作者的详细信息存在于每篇论文的关联 JSON 文件中,其中提取了所属机构、地点和国家/地区。 输入是 JSON 文件,输出是与每个作者和论文 ID 对应的列。
3.3 来自“摘要”、“标题”和“文本正文”的关键字
使用Yake库提取了前20个关键词。 每篇论文中的关键词都可以进一步用于主题建模和关键词搜索,从而了解论文的主要内容。
使用 Yake 是因为它使用无监督方法,该方法与语料库无关,并且与领域和语言无关。 Yake 采用无监督方法,该方法基于从文本中提取的特征,使其适用于用不同语言编写的文档,而不需要特定领域的知识。
Yake 对象的输入是文本字符串,由论文的“标题”、“摘要”和“正文”生成。 输出是关键字列表。 可以自定义顶级关键词和 n-gram 的数量。 对于我们当前的实现,我们选择了前 20 个关键字,并将 n 元语法大小设置为“3”。 Yake 的其余参数均为默认值。 关键字提取的示例结果如表4所示。
| Keywords | ||||||
|
3.4主题建模
我们通过实施主题建模算法(潜在狄利克雷分配)进一步扩充了数据集。 生成主题标签有双重目的:首先,考虑到论文中可能主题的多样性(即使过滤为仅包括与疫苗相关的文档),它提供了重复主题的全面概述,并允许轻松检查主题之间的分布他们。 其次,它有助于快速对数据进行子设置,以允许潜在用户适应更多范围的任务。
LDA 的训练是在完整的论文摘要集上进行的,这些摘要被预处理为小写;并删除了停用词、标点符号和小词(例如字符长度低于 3)。 我们测试了一系列“主题数量 (n)”参数(从 n=5 到 n=14),并通过 Röder 等人 (2015) 描述的 Coherence 分数评估每个模型,最终选择由于其较高的分数和简约性,n=5 作为最终参数。
为了给每个训练过的主题分配一个标签,我们选择了每个主题的前 20 个单词,并将该列表与与特定主题相关的概率最高的文档的论文标题进行交叉引用。 通过对每个文档的主题分布向量应用降维(通过 t-SNE)并绘制它们(按标签着色),以视觉方式进行附加评估,以评估可能的主题重叠。 生成的主题标签及其在数据集中的分布如表5所示。
| Topic | % of dataset |
|---|---|
| T1: Vaccine development | 20% |
| T2: Vaccination side-effects | 14% |
| T3: Vaccination efficacy | 16% |
| T4: Methodologies for COVID studies (e.g. simulations) | 25% |
| T5: Vaccine uptake (by factors of age, sex, race, etc.) | 25% |
4任务执行阶段
CORD-19-Vaccination 数据集包含大约 3 万篇研究论文的元数据。 下一步,我们通过执行“问答”和“顺序句子分类”任务来评估数据集。
4.1问答任务
我们在 CORD-19 上设计了一个类似于 Goldbloom 等人 (2022) 的 Kaggle 竞赛挑战的任务。 “Covid-19 疫苗”问答系统是一项特定领域的任务。 在理想情况下,我们需要医学专家来设计问题并评估答案。 然而,在没有医学专家的情况下,我们设计了一个简单的疫苗特定问题。 我们尝试遵循 Diekema 等人 (2004) 中的“基于用户的方法”来评估答案。
问答任务由“问题”、“上下文”和“答案”三部分组成。 模型的输入是 covid-19 疫苗特定问题和上下文。 在此实现中,我们假设问题包含在上下文中。 我们需要保持较小的上下文才能在 30k 篇论文上实现这个模型。 这是通过使用“Okapi BM25”(维基百科,2022)选择与答案类似的论文来完成的。 Okapi BM25 是搜索引擎用来估计文档与给定搜索查询的相关性的排名函数。 对于每个问题和上下文,我们使用“Huggingface Transformer 库”来预测答案(Wolf 等人,2020)。 我们使用了预训练的 QA 模型“bert-large-uncased-whole-word-maskingfinetuned-squad”。 此任务的解决方案是针对“CORD-19-vaccination”数据集定制的,该数据集的灵感来自于 Besomi (2020) 的 Kaggle 笔记本。
图 5 是针对“covid-19 疫苗安全吗?”问题的“问答”任务的输出。

| Question | Papers | Citation | Viewed | Downloads |
|---|---|---|---|---|
| Is Covid-19 vaccine safe? | 10.1038/s41577-021-00525-y | 111 | ||
| 10.1016/j.puhe.2020.05.007 | 9 | |||
| 10.1093/jlb/lsaa024 | 3 | 1146 | 435 | |
| 10.3390/vaccines10020298 | 627 | |||
| 10.1111/jdv.17499 | 3 | |||
| 10.1111/dth.15146 | 6 |
表 6 给出了回答“Covid-19 疫苗安全吗?”问题的论文列表。 ’。 根据“基于用户的方法”的评估,我们可以说结果中的论文似乎是相关的,因为大多数论文都是最近发表的。
对于疫苗接种相关的“问答”任务,“CORD-19-Vaccination”数据集优于“CORD-19”,原因如下:“CORD-19-Vaccination”使用表 5 中的字段进行了扩充>。 这些字段不存在于“CORD-19”中。 使用“CORD-19-疫苗接种”的研究人员可以利用这些增强字段来获得更好的答案。
“CORD-19-Vaccination”数据集中的keyword列是使用“Yake”从文本论文正文中提取的关键字列表,因此如果我们使用“Title”/'提取上下文搜索摘要'/'关键词',答案应该比较准确。
4.2序列句子分类任务
文本分类是自然语言处理 (NLP) 中的一项非常重要的任务,其中为文本分配标签或类别。 在当前任务中,重点是医学摘要中的句子分类。 摘要中的句子按顺序出现,因此该任务称为“顺序句子分类任务”。 此任务将非结构化文本块摘要转换为结构化摘要(文本组织成语义标题,例如背景、方法、结果和结论),从而可以轻松快速地查找相关信息。 该任务基于论文Dernoncourt 等人 (2016)。 此任务的输出已作为数据集中名为 labeled_abstract 的新列提供。
用于训练此任务模型的数据是从 PubMed 200k RCT 数据集 Dernoncourt 和 Lee (2017) 以及 CORD-19 数据集本身获得的。 CORD-19 数据集中 11.58% 的摘要(大约 117,000 个样本)被发现具有由语义标题构成的摘要。 同样,CORD-19-Vaccine 数据集中 14.66% 的记录(4294 个样本)被发现具有由语义标题构成的摘要。 这些记录被分为模型训练的测试和验证数据集。 单个数据样本包含目标标签、摘要中的句子以及句子顺序的信息,与Dernoncourt等人(2016)兼容。 pubmed_id 和 cord_uid 字段可用作注释,而不是训练模型的输入。 根据 PubMed 200k RCT 论文的指导,数据集中的数字已替换为 @ 符号。
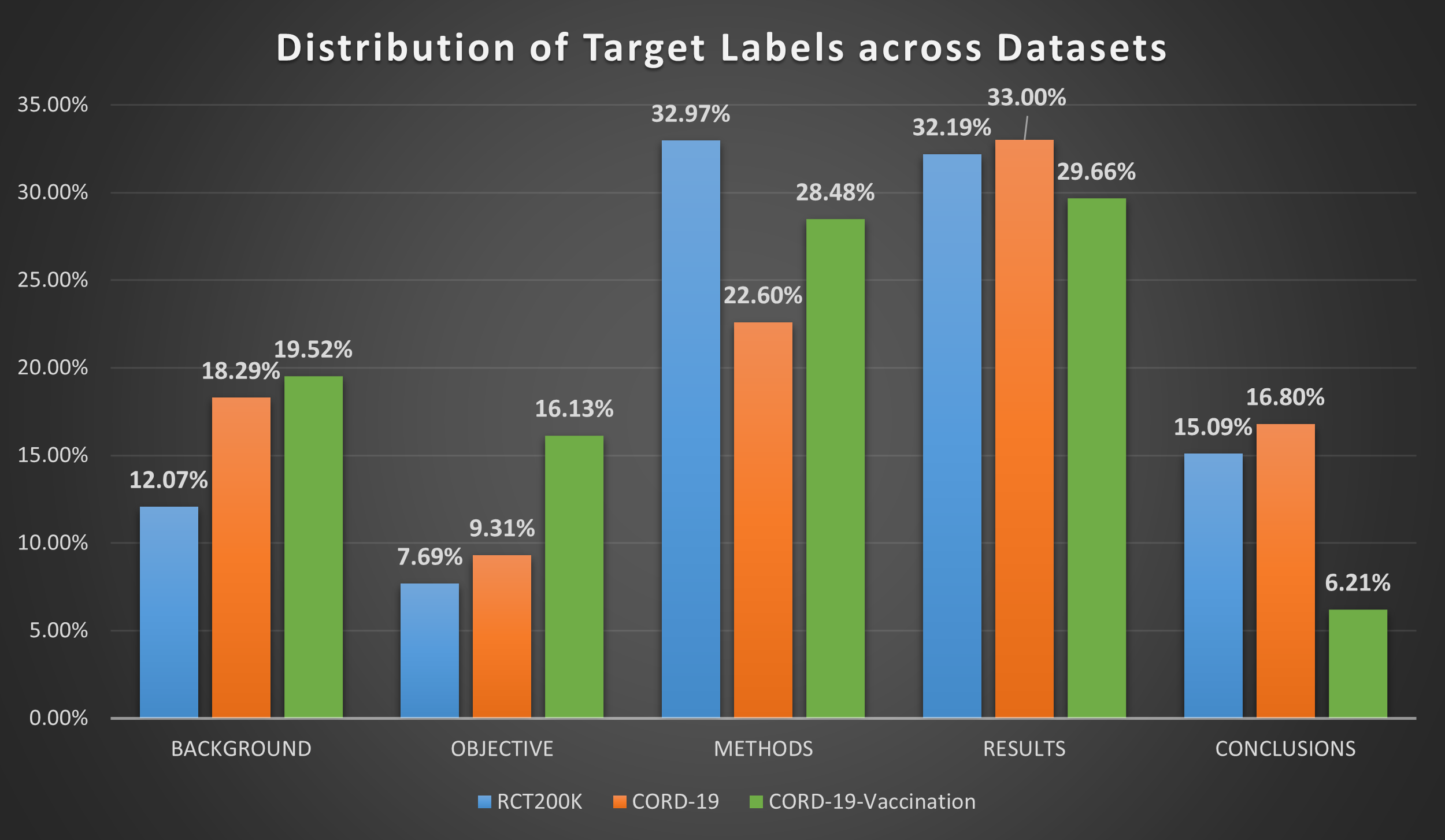
图6显示了数据集中各种目标标签的分布。 值得注意的是,与 PubMed RCT200k 和 CORD-19 相比,CORD-19-Vaccination 数据集中的 OBJECTIVE 标签的百分比相当高(为 16.13%),而 CONCLUSION 标签的百分比相当低(为 6.21%)数据集。
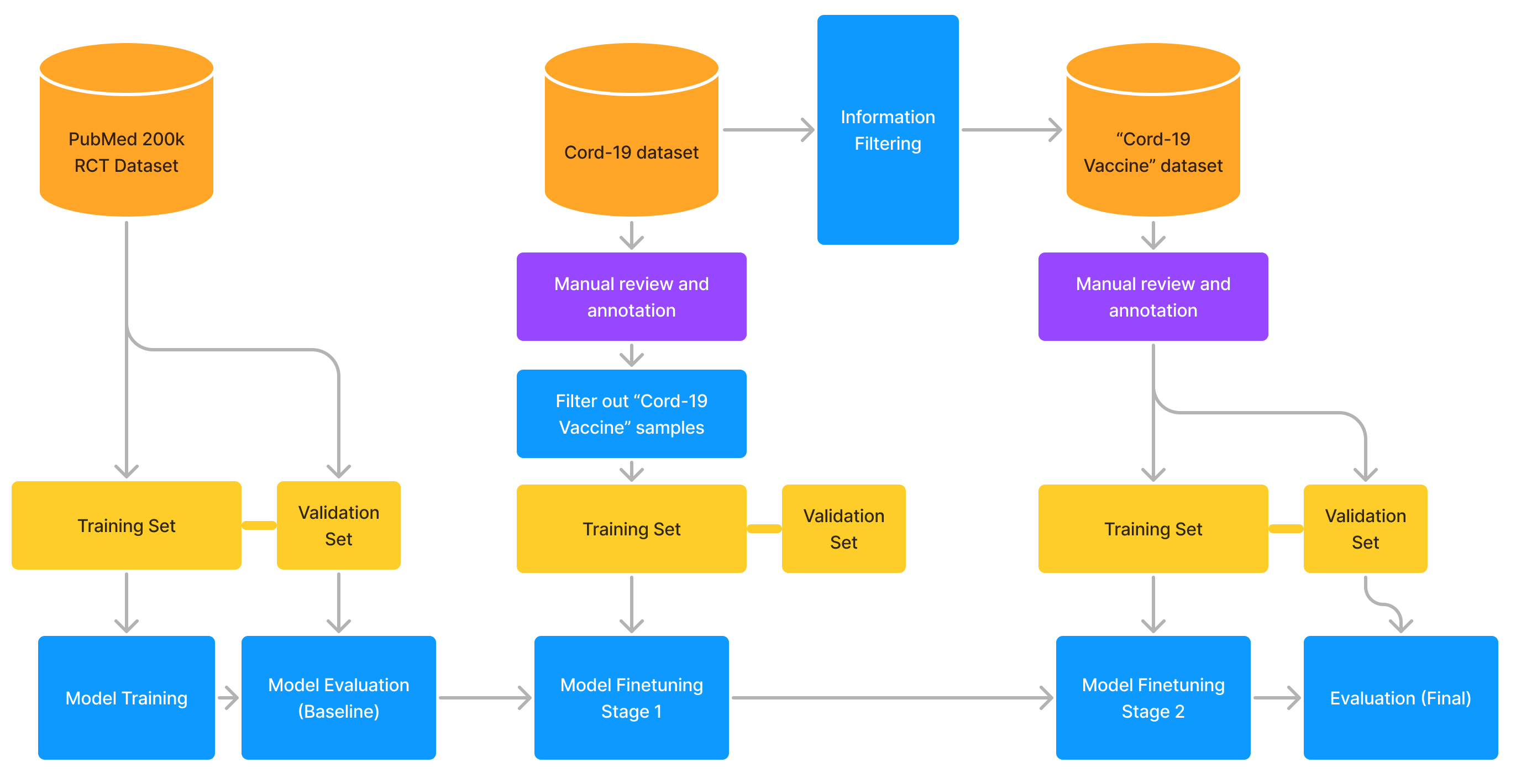
任务工作流程:
图7中的工作流程显示了模型训练和后续微调期间执行的任务顺序。 选择这个特定的工作流程是为了允许从粗粒度到细粒度的模型训练。
训练所用的模型架构基于Dernoncourt 等人 (2016) 论文。 使用预训练和冻结的 BERT-PubMed 层来提高性能。 第一轮训练使用 PubMed 200k RCT 数据集的原始训练/验证数据分割。 对于微调,第 1 阶段使用 70-30 的随机分割,第 2 阶段使用 50-50 的随机分割。 模型训练最初以 1e-4 的学习率进行,后来为了微调而降低到 1e-4。 训练使用基于 Nvidia Tesla P100 GPU 的系统。
输出:
表7显示了该模型在 CORD-19-Vaccine 数据集上的性能指标。
| Accuracy | F1-score | Precision | Recall |
| 0.7618 | 0.7569 | 0.7569 | 0.7618 |
评估:
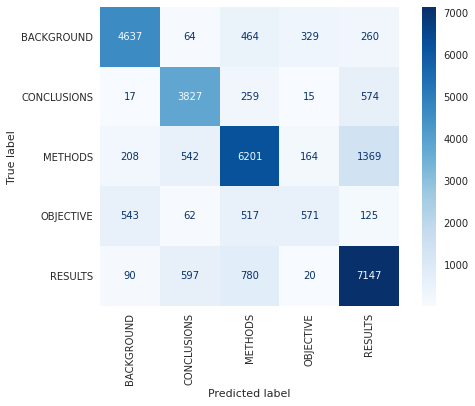
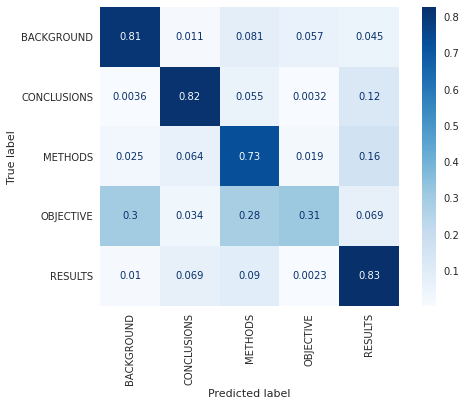
从混淆矩阵中我们可以观察到,目标标签经常与背景和方法混淆。 同样,方法标签经常与结果混淆。
通过手动审查最错误的预测来进行额外的评估。 我们在这些预测中发现的一些模式是仅由几个单词组成的短句子被错误预测,不合语法或歧义的句子被错误分类。
5许可证
“CORD-19-Vaccination”数据集是从“CORD-19”数据集提取的,因此“CORD-19-Vaccination”数据集也遵循所有许可333CORD-19 Dataset License: https://ai2-semanticscholar-cord-19.s3-us-west-2.amazonaws.com/2020-03-13/COVID.DATA.LIC.AGMT.pdf,后跟“CORD-19”。
6结论
在本文中,我们将介绍新的数据集“CORD-19-Vaccination”。 该数据集由大约 30,000 行科学研究论文元数据组成,专门针对 COVID-19 疫苗研究领域,使其成为该领域已知最大的精选资源。 该数据集增加了有价值的细节,扩展了 CORD-19 数据集中存在的信息。 “问答”和“序列句子分类”评估结果进一步凸显了该数据集对于各种 NLP 任务的价值。 我们希望该数据集的发布对 COVID-19 疫苗研究社区具有巨大价值,并可用于特定于 COVID-19 疫苗研究领域的文本挖掘、信息提取和问答等 NLP 研究。
参考
- Besomi [2020] Jonathan Besomi. A qa model to answer them all, 2020. URL https://www.kaggle.com/code/jonathanbesomi/a-qa-model-to-answer-them-all/comments.
- Campos et al. [2018a] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Mário Jorge, Célia Nunes, and Adam Jatowt. A text feature based automatic keyword extraction method for single documents. In Gabriella Pasi, Benjamin Piwowarski, Leif Azzopardi, and Allan Hanbury, editors, Advances in Information Retrieval, pages 684–691, Cham, 2018a. Springer International Publishing. ISBN 978-3-319-76941-7.
- Campos et al. [2018b] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Mário Jorge, Célia Nunes, and Adam Jatowt. Yake! collection-independent automatic keyword extractor. In Gabriella Pasi, Benjamin Piwowarski, Leif Azzopardi, and Allan Hanbury, editors, Advances in Information Retrieval, pages 806–810, Cham, 2018b. Springer International Publishing. ISBN 978-3-319-76941-7.
- Campos et al. [2020] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Jorge, Célia Nunes, and Adam Jatowt. Yake! keyword extraction from single documents using multiple local features. Information Sciences, 509:257–289, 2020. ISSN 0020-0255. doi: https://doi.org/10.1016/j.ins.2019.09.013. URL https://www.sciencedirect.com/science/article/pii/S0020025519308588.
- Dernoncourt and Lee [2017] Franck Dernoncourt and Ji Young Lee. Pubmed 200k RCT: a dataset for sequential sentence classification in medical abstracts. CoRR, abs/1710.06071, 2017. URL http://arxiv.org/abs/1710.06071.
- Dernoncourt et al. [2016] Franck Dernoncourt, Ji Young Lee, and Peter Szolovits. Neural networks for joint sentence classification in medical paper abstracts, 2016. URL https://arxiv.org/abs/1612.05251.
- Diekema et al. [2004] Anne Diekema, Ozgur Yilmazel, and Elizabeth Liddy. Evaluation of restricted domain question-answering systems. Center for Natural Language Processing, 01 2004.
- Goldbloom et al. [2022] Anthony Goldbloom, Allen Institute for AI, Peijen Lin, Paul Mooney, Carissa Schoenick, Sebastian Kolmeier, Debrishi, Timo Bozsolik, and Ben Hammer. Covid-19 open research dataset challenge (cord-19), 2022. URL https://www.kaggle.com/datasets/allen-institute-for-ai/CORD-19-research-challenge?datasetId=551982&sortBy=dateCreated.
- Haihua Chen [2022] Huyen Nguyen Haihua Chen, Jiangping Chen. Demystifying covid-19 publications: institutions, journals, concepts, and topics, 2022. URL https://jmla.pitt.edu/ojs/jmla/article/view/1141/1342.
- [10] ISTD. Language studies. URL https://www.science.co.il/language/Codes.php.
- Joulin et al. [2016] Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov. Fasttext.zip: Compressing text classification models, 2016. URL https://arxiv.org/abs/1612.03651.
- Mishra [2021] Manas Mishra. World to spend $157 billion on covid-19 vaccines through 2025 -report, 2021. URL https://www.reuters.com/business/healthcare-pharmaceuticals/world-spend-157-billion-covid-19-vaccines-through-2025-report-2021-04-29/.
- Röder et al. [2015] Michael Röder, Andreas Both, and Alexander Hinneburg. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, WSDM ’15, page 399–408, New York, NY, USA, 2015. Association for Computing Machinery. ISBN 9781450333177. doi: 10.1145/2684822.2685324. URL https://doi.org/10.1145/2684822.2685324.
- Wang et al. [2020] Lucy Lu Wang, Kyle Lo, Yoganand Chandrasekhar, Russell Reas, Jiangjiang Yang, Doug Burdick, Darrin Eide, Kathryn Funk, Yannis Katsis, Rodney Michael Kinney, Yunyao Li, Ziyang Liu, William Merrill, Paul Mooney, Dewey A. Murdick, Devvret Rishi, Jerry Sheehan, Zhihong Shen, Brandon Stilson, Alex D. Wade, Kuansan Wang, Nancy Xin Ru Wang, Christopher Wilhelm, Boya Xie, Douglas M. Raymond, Daniel S. Weld, Oren Etzioni, and Sebastian Kohlmeier. CORD-19: The COVID-19 open research dataset. In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, Online, July 2020. Association for Computational Linguistics. URL https://aclanthology.org/2020.nlpcovid19-acl.1.
- Wikipedia [2022] Wikipedia. Okapi bm25, 2022. URL https://en.wikipedia.org/wiki/Okapi_BM25.
- Wolf et al. [2020] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.