评估具有复杂 SQL 工作负载的文本到 SQL 生成的大语言模型
摘要
本研究对复杂的 SQL 基准测试 TPC-DS 与两个现有的文本到 SQL 基准测试 BIRD 和 Spider 进行了比较分析。 我们的研究结果表明,与其他两个基准测试相比,TPC-DS 查询表现出明显更高水平的结构复杂性。 这强调需要更复杂的基准来有效地模拟现实场景。 为了促进这种比较,我们设计了几种结构复杂性的衡量标准,并将它们应用于所有三个基准。 这项研究的结果可以指导未来开发更复杂的文本到 SQL 基准的研究。
我们利用 11 种不同的语言模型(大语言模型)根据 TPC-DS 基准测试提供的查询描述生成 SQL 查询。 即时工程过程结合了 TPC-DS 规范中概述的查询描述和 TPC-DS 的数据库模式。 我们的研究结果表明,当前最先进的生成式人工智能模型在生成准确的决策查询方面存在不足。 我们使用一系列基于查询特征的模糊结构匹配技术,将生成的查询与 TPC-DS 黄金标准查询进行了比较。 结果表明,生成的查询的准确性不足以满足实际应用。
关键词 Text-to-SQL、评估、大语言模型、生成式人工智能
1简介
从自然语言(NL)生成SQL查询的任务一直是自然语言处理(NLP)和数据库领域中长期存在的问题。 这项任务很重要,因为它可以使非专家用户无需学习 SQL 即可与数据库交互。 该任务对于数据库管理员也很重要,他们可以使用生成的 SQL 查询作为进一步优化的起点。 这项任务对于数据科学家来说也很重要,他们可以使用生成的 SQL 查询来分析数据并生成见解。
近年来,大型语言模型(大语言模型)在广泛的 NLP 任务上表现出了令人印象深刻的性能。 大语言模型经过大量文本数据的预训练,并针对特定任务进行了微调。 大语言模型已被证明可以在各种 NLP 任务(包括文本到 SQL 生成)上实现最先进的性能。 然而,由于 SQL 查询的复杂结构和准确决策的需要,从 NL 生成 SQL 查询的任务具有挑战性。
为了评估大语言模型在从 NL 生成 SQL 查询的任务上的性能,提出了两个主要基准:BIRD 和 Spider。 BIRD 是文本到 SQL 生成的基准,由超过 12,000 个 NL 问题及其相应的 SQL 查询组成。 Spider 是文本到 SQL 生成的基准,由对应 5693 个 SQL 查询的 10,000 个 NL 问题组成。 这两个基准已广泛用于评估大语言模型在从 NL 生成 SQL 查询的任务上的性能。
在本研究中,我们对 TPC-DS 基准[Poess and Floyd(2000)]与 BIRD [Li 等人(2024)Li, Hui, Qu, Yang 进行了比较分析、Li、Li、Wang、Qin、Geng、Huo、等人] 和 Spider [Yu 等人(2018)Yu、Zhang、Yang、Yasunaga、Wang、Li、Ma、Li、Yao、 Roman,等人] 基准。 TPC-DS 基准是广泛使用的用于评估数据库系统性能的基准。 该基准测试由一组模拟现实决策查询的复杂 SQL 查询组成。 我们的研究结果表明,与 BIRD 和 Spider 基准测试相比,TPC-DS 查询表现出明显更高水平的结构复杂性。 这强调需要更复杂的基准来有效地模拟现实场景。 此外,我们利用 11 个不同的大语言模型根据 TPC-DS 基准测试提供的查询描述生成 SQL 查询。 即时工程过程结合了 TPC-DS 规范中概述的查询描述和 TPC-DS 的数据库模式。 我们的研究结果表明,当前最先进的生成式人工智能模型在生成准确的决策查询方面存在不足。 我们使用一系列基于查询特征的模糊结构匹配技术,将生成的查询与 TPC-DS 黄金标准查询进行了比较。 结果表明,生成的查询的准确性不足以满足实际应用。
2相关工作
由于大型语言模型(大语言模型)的集成,文本到 SQL 领域取得了重大进展[Naveed 等人(2023)Naveed, Khan, Qiu, Saqib, Anwar, Usman, Barnes, and Mian, Bae 等人(2024)Bae, Kyung, Ryu, Cho, Lee, Kweon, Oh, Ji, Chang, Kim, 等人]。 人们提出了创新技术来提高自然语言输入生成 SQL 查询的准确性和效率。 我们讨论了该领域的几项关键工作,并介绍了他们的贡献以及它们与我们的工作的关系。
Owda 等人[Owda 等人(2011)Owda、Bandar 和 Crockett] 提出了一种早期系统,该系统将信息提取 (IE) 技术纳入增强型基于对话的关系数据库接口 (C-BIRD) ) 生成动态 SQL 查询。 他们的方法允许会话代理以自然语言与用户交互,生成 SQL 查询,而无需用户具备任何 SQL 知识。 从那时起,基于 LLM 的解决方案在文本到 SQL 领域占据了主导地位。 此外,还提出了两个主要基准(BIRD 和 Spider)来评估大语言模型在从 NL 生成 SQL 查询的任务上的性能。 于等人[Yu 等人(2018)Yu,Zhang,Yang,Yasunaga,Wang,Li,Ma,Li,Yao,Roman,等人]介绍蜘蛛,一种大规模、复杂、以及跨域语义解析和文本到 SQL 数据集。 Spider 包括 10,181 个问题和 5,693 个独特的复杂 SQL 查询,涉及 200 个数据库,涵盖 138 个不同的领域,要求模型能够很好地泛化到新的 SQL 查询和数据库模式。 这项工作是文本到 SQL 领域的基础,展示了处理复杂且多样化的 SQL 查询的挑战。 李等人 [Li 等人(2024)Li, Hui, Qu, Yang, Li, Li, Wang, Qing, Geng, Huo, 等人] 介绍大规模文本基准BIRD -to-SQL 任务旨在弥合学术研究和实际应用程序之间的差距。 BIRD 基准测试衡量文本转 SQL 模型的准确性和效率,提供对模型性能的全面评估。
已经提出了许多文本到 SQL 模型和技术,并且很大程度上基于 BIRD 和 Spider 基准测试。 Li 等人 [Li 等人(2019)Li, Li, Li, andzhong] 介绍了模糊语义到结构化查询语言 (F-SemtoSql) 神经方法,旨在解决复杂且跨领域的问题文本到 SQL 生成的域任务。 Pourreza 和 Rafiei [Pourreza 和 Rafiei(2024)] 提出了 DIN-SQL,这是一种通过将任务分解为更小的子任务并使用自我上下文学习来提高文本到 SQL 性能的方法-更正。 Chen 等人 [Chen 等人(2024)Chen、Wang、Qiu、Qin 和 Yang] 提出 Open-SQL 框架,旨在增强开源大语言上的文本到 SQL 性能模型。 他们引入了用于监督微调的新颖策略和用于有效问题表示的openprompt策略。 Li 等人 [Li 等人(2023)Li、Zhang、Li 和 Chen] 提出了 ResdSQL,这是一个解耦文本到 SQL 任务的模式链接和骨架解析的框架。 通过分别解决模式项和 SQL 骨架解析的复杂性,他们的方法提高了 SQL 查询生成的准确性。
3 SQL 查询的功能和复杂性度量
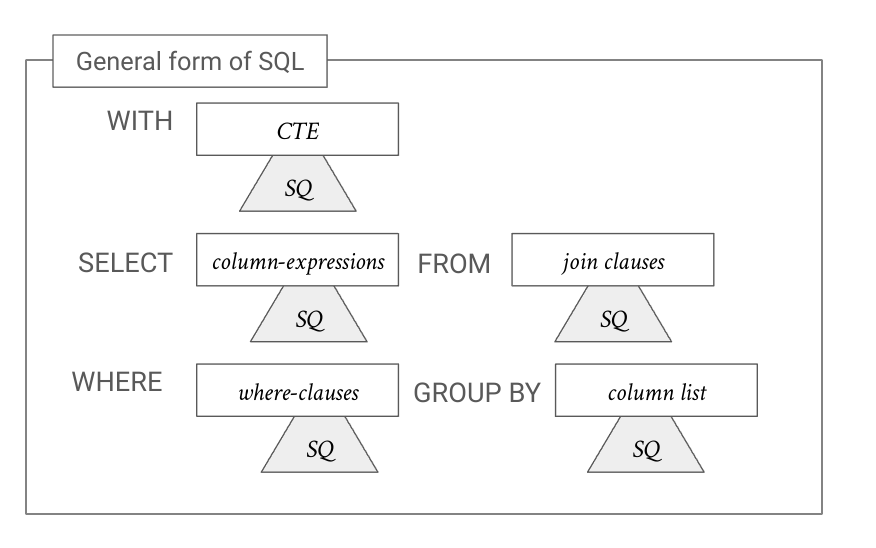
考虑一个 SQL 查询 ,如图 1 所示。 考虑到 SQL 的嵌套结构, 可以是 SQL 查询的复杂自引用树。 在本节中,我们将定义许多可用于表征 SQL 查询的结构复杂性的特征。 我们认为包值特征对于执行 SQL 查询对的语义比较很有用。
令 为 中的所有子查询,无论它出现在 中的何处。 我们定义了从 及其子查询派生的特征集合。 这些特征分为两类:袋值特征和数字特征。 即,特征 是一个映射:
我们注意到,任何包特征 自然也是数字特征 :。
3.1袋值功能
列:及其子查询的选择列表达式中包含的不同列的集合。
关系: SQL 查询中不同关系的集合。 计算如下:
Where 谓词: SQL 查询及其子查询中不同的 where 基本谓词的集合。 每个基本谓词以以下形式给出
其中 是 SQL 支持的布尔运算符, 是列名、常量和函数的表达式。 所有列别名都标准化为规范形式。
JOIN:是的连接集合,被定义为参与JOIN的物理关系对 及其子查询的逻辑查询计划。
聚合:是及其子查询中聚合列的集合。 每个聚合列以 的形式给出,其中 是聚合函数(例如,SUM、AVG、COUNT 等), 是聚合函数列名、常量和函数的表达式。
函数:是出现在及其子查询中的一组SQL函数。
3.2数字特征
公共表表达式:是定义的公共表表达式的数量。 我们使用 CTE 计数作为查询的结构复杂性和可读性的指标。
子查询:我们测量,即的子查询数量,作为结构复杂性的指标。
4 TPC-DS 作为复杂的文本到 SQL 基准
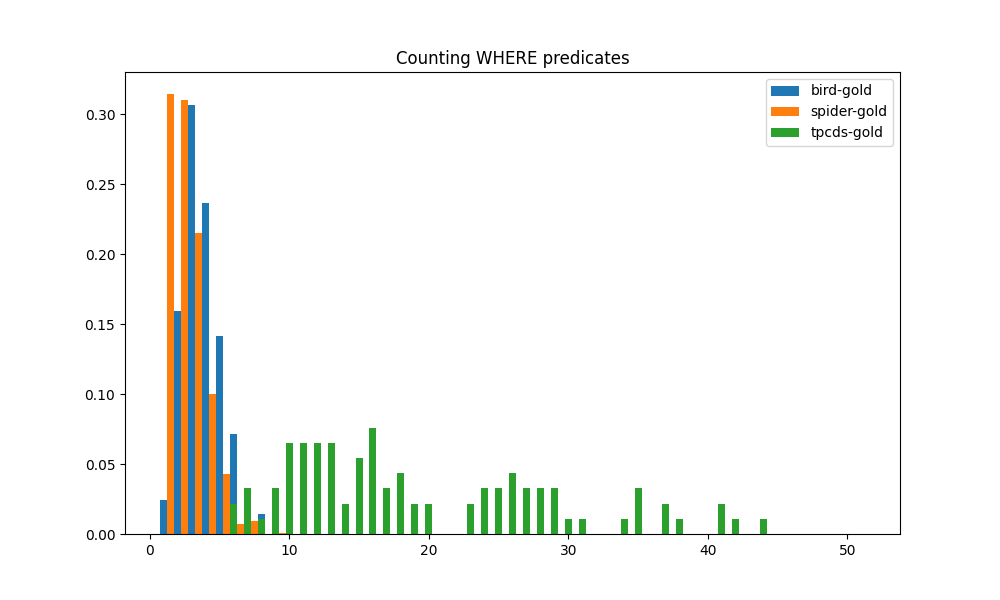
我们比较了三个 SQL 基准测试中 SQL 查询中 WHERE 子句的复杂性。 WHERE 子句的复杂性通过 WHERE 子句中基本谓词的数量来衡量。 基本谓词是具有单一条件的谓词,例如year = 1998。 包含多个条件的复合谓词,如year = 1998 AND ss_quantity BETWEEN 81 AND 100,算作多个基本谓词。 三个基准的 WHERE 子句中基本谓词的计数如图 4(d) 中的直方图所示。 虽然 BIRD 和 SPIDER 基准测试在 WHERE 子句谓词计数的分布方面相似,但 TPC-DS 基准测试在其 SQL 查询中明显表现出更高的 WHERE 子句复杂性。 TPC-DS 比其他两个基准具有更高的 WHERE 子句复杂性,以至于其计数分布几乎与其他基准不重叠。 几乎所有 TPC-DS 查询的 WHERE 谓词计数都是其他两个基准测试中所有查询的数倍。
| CTE | Selected Columns | Functions | Nested Select | Aggregation | joinCount | Where | Joins | |
|---|---|---|---|---|---|---|---|---|
| dataset | ||||||||
| tpcds-gold | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| gemini-1.5 | 2.38 | 0.79 | 0.62 | 1.01 | 0.95 | 0.91 | 0.55 | 0.87 |
| gpt-4 | 1.11 | 0.77 | 0.63 | 0.69 | 0.80 | 0.73 | 0.53 | 0.90 |
| codestral | 0.19 | 0.67 | 0.69 | 0.53 | 0.63 | 0.63 | 0.53 | 0.90 |
| mixtral-8x22b | 1.99 | 0.96 | 0.70 | 1.04 | 1.06 | 0.96 | 0.67 | 0.90 |
| llama3-70b | 2.03 | 0.81 | 0.75 | 1.37 | 1.02 | 1.04 | 0.67 | 0.94 |
| llama3-8b | 0.51 | 0.63 | 0.63 | 0.67 | 0.65 | 0.59 | 0.52 | 0.84 |
| codellama-7b | 0.03 | 0.39 | 0.29 | 0.28 | 0.32 | 0.24 | 0.25 | 0.55 |
| feature | Tables | Columns | Where Predicates | Constants | Functions | Aggregation | Joins | Average |
|---|---|---|---|---|---|---|---|---|
| model | ||||||||
| gemini-1.5 | 0.74 | 0.26 | 0.04 | 0.27 | 0.67 | 0.29 | 0.06 | 0.33 |
| gpt-4 | 0.76 | 0.22 | 0.02 | 0.32 | 0.65 | 0.25 | 0.04 | 0.32 |
| codestral | 0.67 | 0.22 | 0.04 | 0.27 | 0.62 | 0.23 | 0.05 | 0.30 |
| mixtral-8x22b | 0.69 | 0.17 | 0.02 | 0.30 | 0.60 | 0.24 | 0.06 | 0.30 |
| mistral-large | 0.66 | 0.19 | 0.06 | 0.22 | 0.54 | 0.24 | 0.08 | 0.28 |
| llama3-70b | 0.63 | 0.13 | 0.04 | 0.25 | 0.60 | 0.12 | 0.12 | 0.27 |
| codellama-70b | 0.36 | 0.12 | 0.03 | 0.13 | 0.44 | 0.11 | 0.11 | 0.18 |
| llama3-8b | 0.36 | 0.05 | 0.01 | 0.16 | 0.47 | 0.05 | 0.07 | 0.17 |
| codellama-13b | 0.28 | 0.08 | 0.02 | 0.10 | 0.34 | 0.05 | 0.07 | 0.13 |
| codellama-34b | 0.24 | 0.06 | 0.01 | 0.09 | 0.32 | 0.05 | 0.07 | 0.12 |
| codellama-7b | 0.20 | 0.05 | 0.01 | 0.05 | 0.32 | 0.04 | 0.04 | 0.10 |
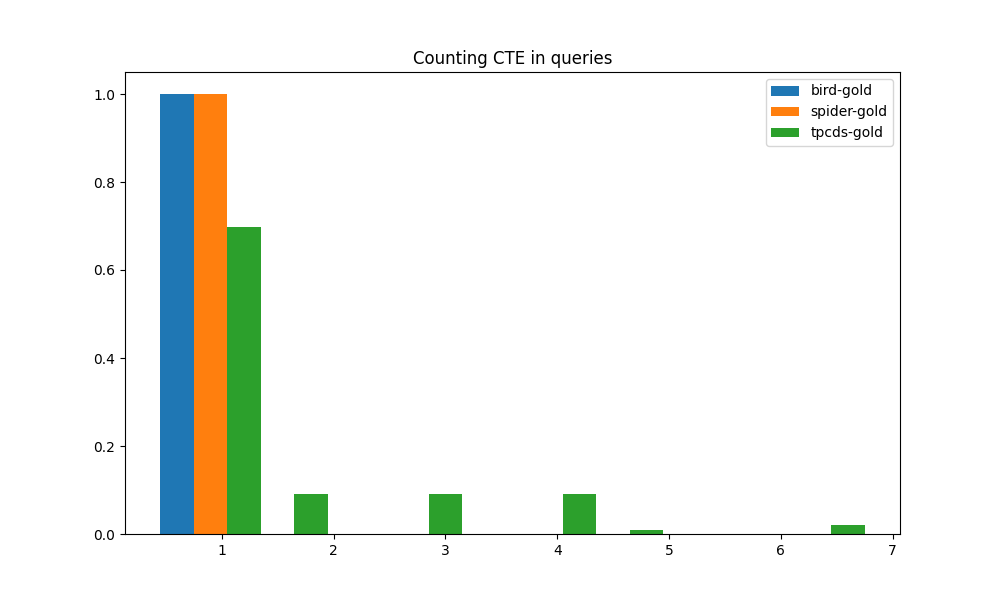
用于衡量 SQL 查询复杂性的另一个指标是公共表表达式 (CTE) 的数量。 CTE 的作用是最大限度地减少子查询的重复,并使整个 SQL 语句更加结构化,从而更易于维护。 我们从三个基准中计算每个查询中的 CTE 数量,并在图 4(e) 中绘制直方图。 可以看出,由于语义复杂度较低,BIRD 和 SPIDER 工作负载都不需要 CTE。 相比之下,TPC-DS 在黄金查询中大量使用了 CTE。
我们还计算 SQL 查询中引用的不同列的数量。 查询中涉及的不同列的数量是该查询的语义复杂性的指标。 无论列出现在 SELECT 投影、JOIN 条件还是 WHERE 谓词中,都包含在计数中。 基准的列数分布如图4(f)所示。 该图与 WHERE 子句谓词计数的图类似。 同样,在大多数情况下,TPC-DS 黄金查询中使用的列数比 BIRD 和 SPIDER 查询中的列数大一个数量级。 重叠很小,这意味着绝大多数 TPC-DS 工作负载引用的列集比 BIRD 和 SPIDER 工作负载大得多。 这是 TPC-DS 查询复杂性显着提高的另一个迹象。
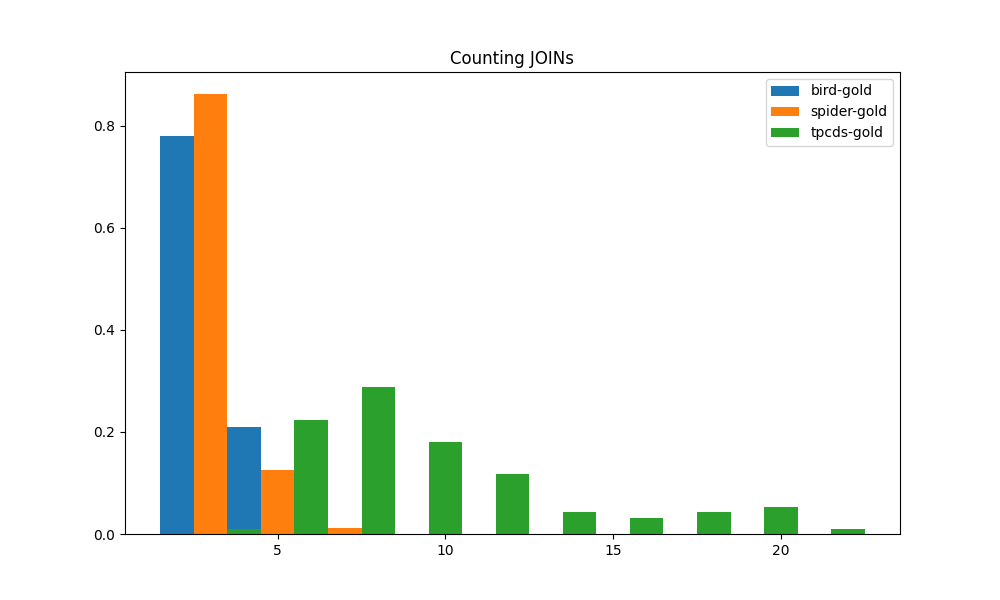
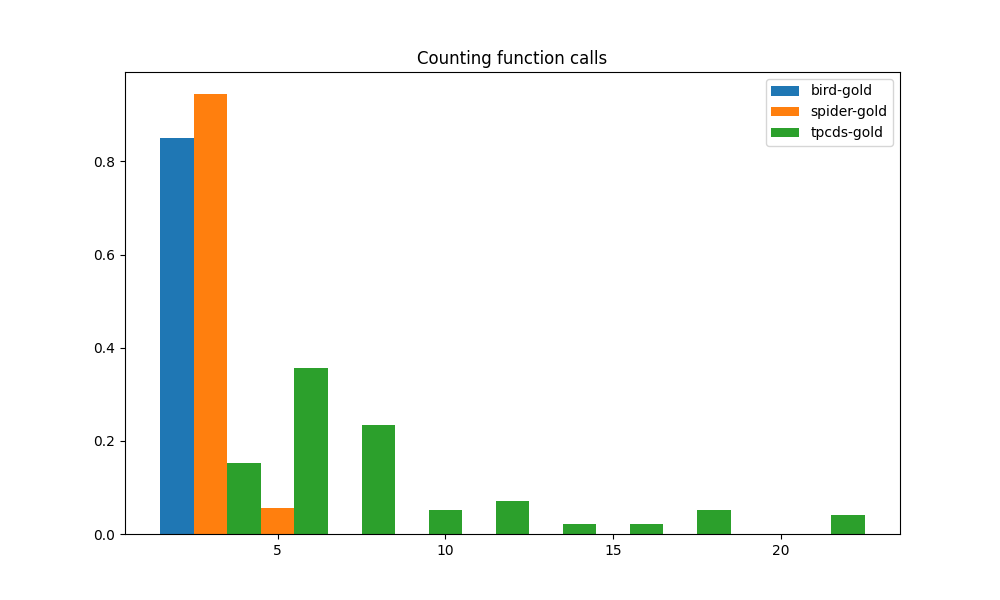
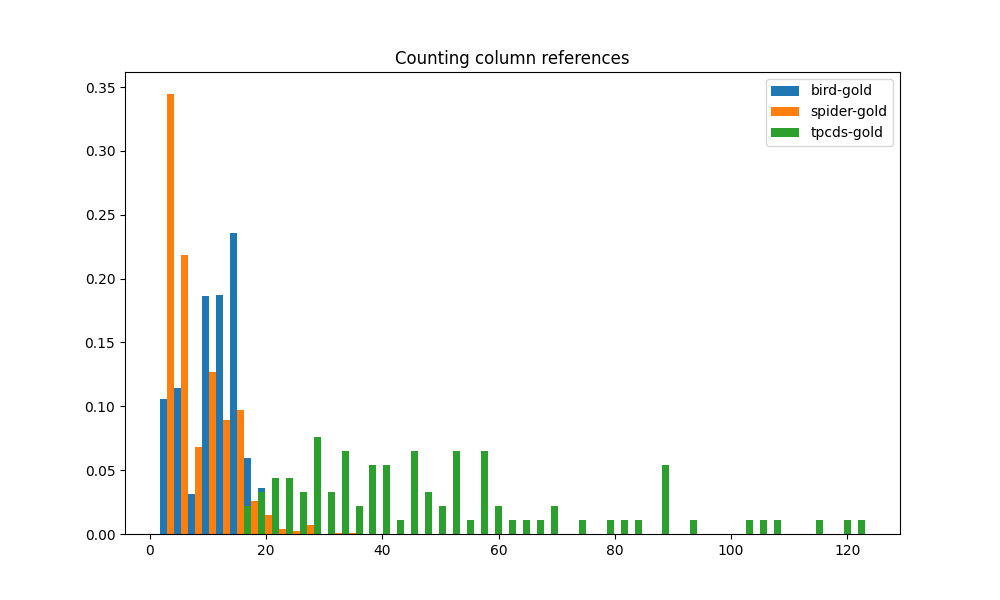
除了上述之外,我们还考虑了另外三个指标来评估整体查询复杂性。 SQL 查询通常包括对执行数据转换的函数的调用。 这些函数包括标量函数和聚合函数。 它们增加了整体查询的复杂性。 因此,我们计算包含函数调用的表达式的数量,无论它们是 SELECT 投影、WHERE 子句还是聚合的一部分。 另外,子查询无疑是查询语义复杂度的标志之一,因此我们统计每个查询中子查询的数量。 我们进一步考虑 JOIN 的存在,因为 JOIN 意味着需要额外的源表,并且会增加查询的复杂性。 通过计算 JOINS 的数量,我们可以衡量需要组合多少个数据源才能生成最终结果。
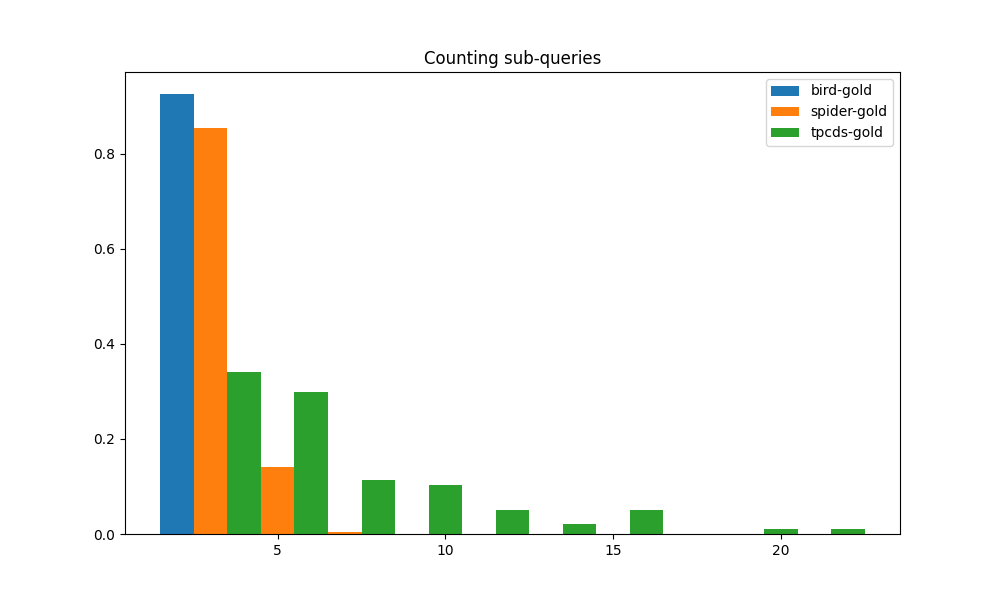
这三个指标应用于三个基准的直方图分别如图4(c)、4(a)、4(b). 函数调用、子查询和连接的分布都非常相似。 TPC-DS 工作负载与 BIRD 和 SPIDER 工作负载之间的差距甚至比上面 CTE 指标中的差距还要大。 大多数 TPC-DS 查询具有超过 5 个函数调用,其中一些超过 10 个。 相比之下,大多数 BIRD 和 SPIDER 都有 3 个或更少的函数调用,并且绝不会超过 5 个。 TPC-DS 是三者中唯一经常使用子查询的。 其他两个工作负载似乎很少使用子查询。 就像子查询和函数调用一样,TPC-DS 在 JOIN 数量上明显超过 BIRD 和 SPIDER。 这意味着来自 TPC-DS 的查询几乎总是需要来自大量表的数据才能获得结果。
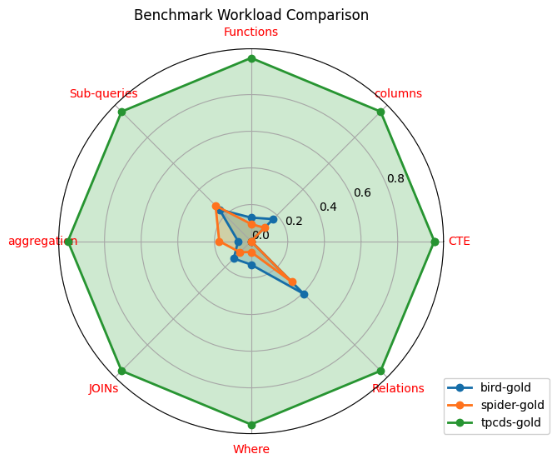
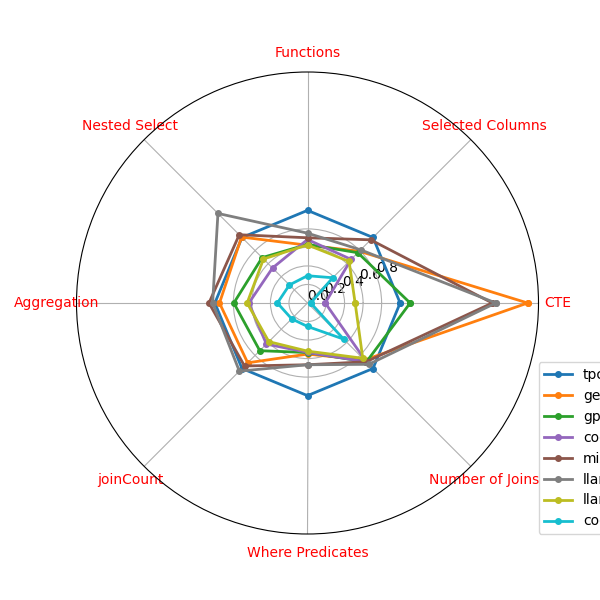
总体而言,在我们考虑的每个指标中,TPC-DS 查询都比 BIRD 和 SPIDER 查询复杂得多,如图 2 中的雷达图所示。
比较结果汇总在图 2 中,该图显示了三个基准的查询复杂性每个指标的平均计数,并通过 TPC-DS 的平均计数进行归一化。 TPC-DS 在每个指标中都明显表现出更高的查询复杂性。 它的平均指标不仅高于 BIRD 和 SPIDER,而且每个指标都高出数倍。 这表明 TPC-DS 是一个比 BIRD 和 SPIDER 复杂得多的基准测试,并且 AI 模型根据 TPC-DS 工作负载生成查询可能更具挑战性。
5 使用 TPC-DS 工作负载评估大语言模型
我们使用了 11 个不同的大语言模型来基于 TPC-DS 工作负载生成 SQL 查询。 大语言模型包括:gemini-1.5、gpt-4、codestral、mixtral-8x22b、mistral-large、llama3-70b、codellama-70b、llama3-8b、codellama-13b、codellama-35b 和 codellama-7b。 我们使用以下提示来生成查询。
系统提示:
用户提示:
对于所有的大语言模型,我们都遇到过大语言模型生成的无效查询,要么是语法错误,要么是由于幻觉而包含不正确的模式信息。 我们的实现利用 PostgreSQL 数据库系统来验证生成的查询。 如果查询无效,我们会使用包含 PostgreSQL 报告的错误消息的新用户消息重试生成过程。
附加用户提示:
生成过程最多重试三次。 大语言模型重试3次后成功率不同。 每个大语言模型生成的成功查询数如表3所示。 大语言模型gpt-4、gemini-1.5和mistral-large在基于TPC-DS工作负载生成查询方面具有最高的成功率。 我们可以观察到较小的模型(例如 llama3-8b 和 codellama-34b 或更小)在生成查询时的成功率非常低。
| LLM | Successful queries generated (out of 99) |
|---|---|
| gpt-4 | 94 |
| gemini-1.5 | 86 |
| mistral-large | 75 |
| codestral | 77 |
| mistral-8x22b | 67 |
| llama3-70b | 74 |
| llama4-8b | 8 |
| codellama-70b | 56 |
| codellama-34b | 29 |
| codellama-13b | 18 |
| codellama-7b | 17 |
5.1 生成的查询的结构复杂性
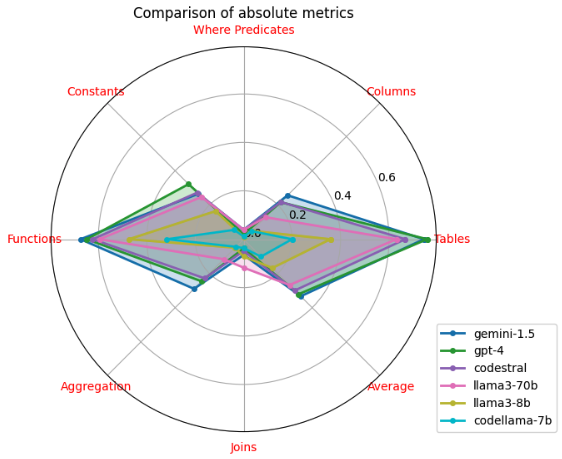
为了比较不同大语言模型生成的查询的结构复杂性,我们再次查看几个计数度量,例如列数和连接数。 对于每种类型的度量和每个大语言模型,计算查询中计数的平均值,然后根据 TPC-DS 查询的平均计数进行归一化。 表中给出了这些归一化平均计数。 1. 我们可以看到gemini 1.5、gpt-4、mixtral和llama3-70b与TPC-DS的结构复杂度最接近。 其他大语言模型生成的查询明显不那么复杂。
令人鼓舞的是,大型大语言模型能够生成与 TPC-DS 工作负载的复杂性相匹配的查询。 但更重要的是,我们希望根据 TPC-DS 给出的黄金查询来评估这些查询的质量。 在下一节中,我们将使用 3 节中定义的包值特征来评估每个生成的查询。
5.2 生成的查询的准确性
我们在 3 节中定义了 7 个包值特征。 每个特征都是一个将 SQL 映射到一包离散值的函数。 为了比较两个查询:由大语言模型生成的查询,以及TPC-DS基准给出的相应黄金查询,我们使用两个包之间的Jaccard相似系数每个特征的值由下式给出:
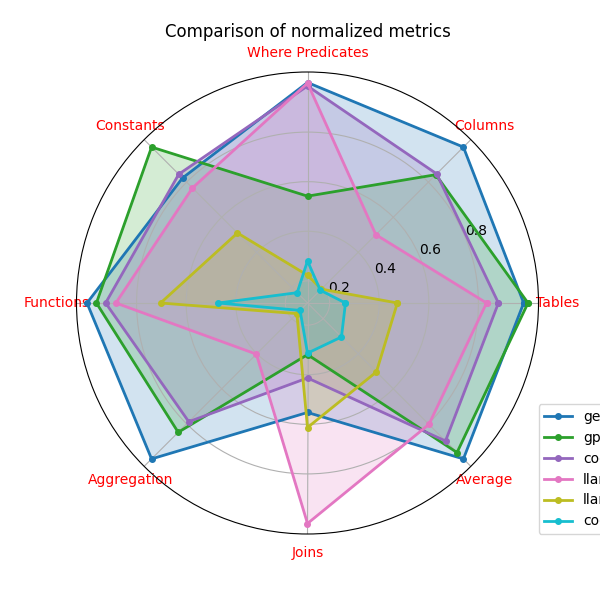
表2显示了11个大语言模型生成的查询与TPC-DS查询之间的平均相似度。 所有大语言模型均按照5节中给出的说明进行指导。 五个表现最好的大语言模型在图 3 和图 5 的雷达图中可视化。 可以看出,生成的查询的准确性不足以满足实际应用的需要。 特别是,没有一个大语言模型能够生成与 TPC-DS 使用的 WHERE 谓词和 JOIN 对匹配的查询。 这突显了 TPC-DS 工作负载与 BIRD 和 SPIDER 基准相比所带来的独特挑战。
6 结论和未来工作
我们将 TPC-DS 与现有的文本到 SQL 基准测试 BIRD 和 SPIDER 进行了比较,发现与其他两个基准测试相比,TPC-DS 查询表现出明显更高水平的结构复杂性。 我们还评估了 11 个大语言模型在基于 TPC-DS 工作负载生成 SQL 查询方面的性能。 我们的研究结果表明,当前最先进的生成式人工智能模型在生成准确的决策查询方面存在不足。 生成的查询的准确性不足以满足实际应用。
为了对复杂 SQL 生成提供令人满意的解决方案,我们确定了未来工作的以下领域。
评估增量 SQL 生成: 我们的实验表明需要增量 SQL 生成来提高生成查询的准确性。 这促使我们研究新颖的提示策略。 基于图3中的观察,我们建议生成WHERE子句和JOIN对作为单独的大语言模型提示,并使用结果来提示大语言模型完成查询的其余部分。
微调较小的模型: 我们的实验表明,在复杂 SQL 生成的情况下,较小的模型无法与较大模型的性能相匹配。 在基于云的大语言模型不可行的情况下(由于成本或隐私问题),我们建议研究较小模型的微调以提高其性能。 特别是,较小的模型在生成过程中肯定可以在语法和模式准确性方面得到改进。 此外,涉及多个微调大语言模型的集成方法可用于组合多个较小模型的输出,以提高整体精度。
Human-in-the-loop:复杂的SQL生成是一项具有挑战性的任务,SQL生成的负担不应该完全由AI模型承担。 我们建议开发一种新颖的人机交互工作流程,其中人工智能模型可以识别查询中难以生成的部分,并提示用户提供附加信息。
参考
- [Poess and Floyd(2000)] Meikel Poess and Chris Floyd. New tpc benchmarks for decision support and web commerce. ACM Sigmod Record, 29(4):64–71, 2000.
- [Li et al.(2024)Li, Hui, Qu, Yang, Li, Li, Wang, Qin, Geng, Huo, et al.] Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems, 36, 2024.
- [Yu et al.(2018)Yu, Zhang, Yang, Yasunaga, Wang, Li, Ma, Li, Yao, Roman, et al.] Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. arXiv preprint arXiv:1809.08887, 2018.
- [Naveed et al.(2023)Naveed, Khan, Qiu, Saqib, Anwar, Usman, Barnes, and Mian] Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435, 2023.
- [Bae et al.(2024)Bae, Kyung, Ryu, Cho, Lee, Kweon, Oh, Ji, Chang, Kim, et al.] Seongsu Bae, Daeun Kyung, Jaehee Ryu, Eunbyeol Cho, Gyubok Lee, Sunjun Kweon, Jungwoo Oh, Lei Ji, Eric Chang, Tackeun Kim, et al. Ehrxqa: A multi-modal question answering dataset for electronic health records with chest x-ray images. Advances in Neural Information Processing Systems, 36, 2024.
- [Owda et al.(2011)Owda, Bandar, and Crockett] Majdi Owda, Zuhair Bandar, and Keeley Crockett. Information extraction for sql query generation in the conversation-based interfaces to relational databases (c-bird). In Agent and Multi-Agent Systems: Technologies and Applications: 5th KES International Conference, KES-AMSTA 2011, Manchester, UK, June 29–July 1, 2011. Proceedings 5, pages 44–53. Springer, 2011.
- [Li et al.(2019)Li, Li, Li, and Zhong] Qing Li, Lili Li, Qi Li, and Jiang Zhong. A comprehensive exploration on spider with fuzzy decision text-to-sql model. IEEE Transactions on Industrial Informatics, 16(4):2542–2550, 2019.
- [Pourreza and Rafiei(2024)] Mohammadreza Pourreza and Davood Rafiei. Din-sql: Decomposed in-context learning of text-to-sql with self-correction. Advances in Neural Information Processing Systems, 36, 2024.
- [Chen et al.(2024)Chen, Wang, Qiu, Qin, and Yang] Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, and Min Yang. Open-sql framework: Enhancing text-to-sql on open-source large language models. arXiv preprint arXiv:2405.06674, 2024.
- [Li et al.(2023)Li, Zhang, Li, and Chen] Haoyang Li, Jing Zhang, Cuiping Li, and Hong Chen. Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13067–13075, 2023.