1193 研究 请具体说明 曾兴辰,林海川,叶一林,曾炜均为香港科技大学(广州)的研究人员,中国广州。 叶一林和曾炜也隶属于香港科技大学,中国香港特别行政区。 电子邮件:{xzeng159@connect., hlin386@connect., yyebd@connect., weizeng@}hkust-gz.edu.cn 曾炜是通讯作者。 Biv 等人:全球照明,乐趣与利益兼得
利用可视化参考指令调优推进图表问答中的多模态大语言模型
摘要
新兴的多模态大语言模型(MLLM)在图表问答(CQA)领域展现出巨大潜力。 最近的努力主要集中在通过数据收集和合成扩展训练数据集(例如,图表、数据表和问答(QA)对)。 然而,我们对现有 MLLM 和 CQA 数据集的实证研究揭示了显著的差距。 首先,当前的数据收集和合成侧重于数据量,缺乏对细粒度视觉编码和 QA 任务的考虑,导致数据分布不平衡,偏离实际 CQA 场景。 其次,现有工作遵循为自然图像设计的基准 MLLM 的训练方法,对适应独特图表特征(如丰富的文本元素)的探索不足。 为了填补这一空白,我们提出了一种可视化参考指令调优方法来指导训练数据集增强和模型开发。 具体来说,我们提出了一种新颖的数据引擎,可以有效地从现有数据集过滤出多样化和高质量的数据,随后使用基于 LLM 的生成技术细化和增强数据,使其更好地与实际 QA 任务和视觉编码相符。 然后,为了促进对图表特征的适应,我们利用丰富的数据通过解冻视觉编码器并结合混合分辨率自适应策略来训练 MLLM,以增强细粒度识别。 实验结果验证了我们方法的有效性。 即使训练样本更少,我们的模型在既定基准上始终优于最先进的 CQA 模型。 我们还贡献了一个数据集拆分,作为未来研究的基准。 本文的源代码和数据集可在 https://github.com/zengxingchen/ChartQA-MLLM 获取。
关键词:
图表问答,多模态大型语言模型,基准![[Uncaptioned image]](x1.png)
将我们的模型与图表问答领域最先进的 MLLMs 进行比较。 现有的 MLLMs 通常无法理解视觉映射,例如反转的 Y 轴、截断的轴、气泡大小和面积堆叠。 相反,我们的模型,在使用我们构建的包含可视化参考的数据集进行训练后,展示了对可视化领域知识的更好理解。
1 简介
多模态大型语言模型 (MLLMs),如 GPT4-Vision[3],在理解和解释自然图像方面取得了显著进展,在各种视觉语言任务(例如,视觉问答[4])方面取得了突破。 这些模型通过将预训练的视觉编码器的图像表示与 LLMs 的强大语言理解能力对齐,获得了优异的效果。 因此,MLLMs 在涉及使用自然语言解释图表的可视化任务中展现出巨大的潜力,例如图表问答 (CQA)、图表摘要[74] 和图表逆向工程[64]。 CQA 提出了一些错综复杂的挑战,要求既要理解复杂的自然语言,又要识别来自图表的信息,还要具备推理能力来推导出准确的答案[27]。
构建专门用于 CQA 的 MLLMs 需要高质量的训练数据集和基准。 该领域最近的研究[24, 57, 45] 主要集中在扩展包含图表、数据表和问答对的训练数据集上,采用人工标注和数据合成技术。 这些努力提高了 MLLMs 在传统 CQA 基准[54, 58] 中的性能。 然而,也出现了瓶颈,给进一步提高性能和适应现实场景带来了挑战。 仅扩大训练数据集而不实施质量控制措施,会在训练效率和将这些数据集成到一般MLLM训练的可行性方面带来重大挑战。
最近的研究[20]强调了不同QA类型对模型性能的影响,发现推理导向的[20]和复杂度增强的[63]指令集在提高MLLM性能方面特别有用。 在CQA的背景下,现有的用于CQA的MLLM包含以<图表,问题,答案>格式的视觉指令。 图表和问答(QA)对的质量对于MLLM的有效性和泛化性至关重要。 然而,利用视觉指令数据来增强CQA仍然很大程度上未被探索,关于是什么构成良好的视觉指令以及如何从视觉指令的角度改进数据集,仍然存在未解之谜。
为了解决这些问题,我们对MLLM在CQA上的表现进行了全面评估(第 4节),旨在找出不足之处并确定能够提高MLLM性能的视觉指令。 该研究使用了ChartQA数据集[54],这是一个广泛采用的CQA基准测试。 通过实证分析(第 4.1.1节),我们发现ChartQA数据集中图表和QA对之间存在显著的分布偏差,与Beagle图像数据集[6]和视觉素养评估数据集[36, 21, 60]等实际数据集相比。 彻底的实验(第 4.1.2节)揭示了分布偏差对MLLM在CQA中的性能的显著影响,突出了将更多指令纳入组合和视觉组合问题的必要性。 消融研究(第 4.2节)进一步证实,与包含数据检索QA相比,包含更多推理导向的QA可以显着提高模型性能。
从结果中汲取灵感,我们引入了一种新颖的数据引擎(第 5节)来生成指令增强的CQA数据集。 该引擎包含一个数据过滤组件(第 5.1节),利用具有细粒度图表特征的分类器来揭示分布并过滤现有的图表数据集。 为了减轻图表分布中的偏差并生成不可用的图表任务,我们进一步设计了一个数据生成组件(第 5.2节),采用图表空间引导的数据增强策略来确保现实世界中可能存在的图表的多样性。 我们进一步丰富了为生成的图表生成的推理导向的 QA,为新的 CQA 数据集和基准做出贡献(第 5.3节),该数据集和基准具有更广泛的图表类型和更多包含有效视觉指令的 QA。
现有的 MLLM,主要依赖于在自然图像上训练的 CLIP 编码器,由于其固有的差异,并不适合于可视化图表。 认识到这些限制,我们开发了一个新的 MLLM(第 6节),它解冻 CLIP 中的视觉编码器,以更好地适应图表特有的特征。 我们的 MLLM 使用新策划的 CQA 数据集进行训练,该数据集包含更有效的视觉指令。 此外,我们还结合了一种混合分辨率自适应策略[52] 来增强图表元素的细粒度识别能力。 定量实验(第 7节)表明,即使在 CQA 数据量明显较小的数据集上进行训练,我们的模型在已有的基准测试中始终优于最先进的 CQA 模型。
总之,我们的贡献有三点:
-
•
一项实证研究,确定了当前 MLLM 和 ChartQA 数据集的局限性以及有助于 MLLM 理解图表有效视觉指令的关键因素(即,识别和推理)。
-
•
一个新颖的数据引擎,涵盖数据过滤 和数据生成,使用可视化参考指令调整,生成高质量的数据集和基准。
-
•
一个超越现有开源 CQA 模型在现有 CQA 基准上的性能,并且在我们提出的基准上与最好的商业模型相当的 MLLM。
2 MLLM 的背景
最近,LLM[67, 8] 展示了强大的文本生成和理解能力。 然而,原生 LLM 存在于纯文本世界中,无法处理其他常见的模态,例如图像和视频,从而限制了它们的应用范围[5]。 为了打破这一限制,一组 MLLM(例如,LLaVA[48]、Qwen-VL[5] 和 GPT4-Vision[3])已经出现,赋予 LLM 感知和理解视觉图像的能力。
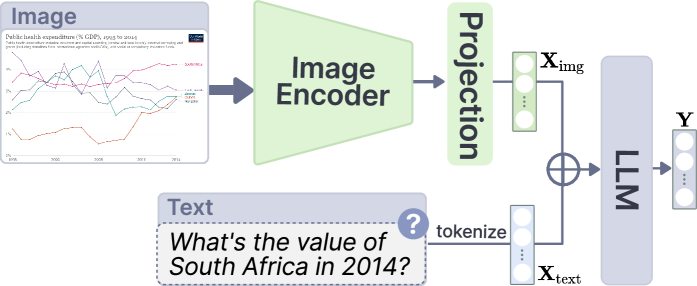
 表示图像 和文本符元 的串联过程。
表示图像 和文本符元 的串联过程。 受 LLaVA[48] 的启发,当前的开源 MLLM 采用类似的架构来对齐视觉和文本特征。 图 1 说明了典型的 MLLM 架构,它包含三个模块:视觉编码器、投影层 和 大型语言模型。 特别是,视觉编码器(例如,CLIP-Vit[61])从输入图像中提取一系列视觉特征。 然后,投影层(例如,多个线性层[48] 和查询 Transformer[40])将视觉特征转换为 LLM 词嵌入空间,从而生成兼容的视觉符元,用于后续的 LLM(例如,Vicuna-1.5[77])。 最后,LLM 处理串联的视觉 和文本符元 ,即,,然后自回归地生成响应。 形式上,语言模型预测响应 以多模态输入 为条件,其中 表示响应中的符元数量。 因此,响应通过最大化来预测
| (1) |
其中 是可训练参数。
尽管架构已经协调,但训练通用 MLLM 的最大挑战是收集高质量的视觉指令数据,即,。 视觉指令促进了多模态(即,语言-图像)空间的 alignment,从而保留和融合预训练视觉编码器和 LLM 中的知识和能力,使 MLLM 具备基于图像的对话能力。 一般而言,视觉指令由 <目标图像、文本任务描述、文本输出> 组成,在 CQA 中即为 <图表、问题、答案>。
3 相关工作
用于图表理解的视觉-语言模型。 研究人员长期致力于开发在图表相关任务(例如,CQA 和图表摘要)方面具有强大功能的视觉-语言(VL)模型。 之前的工作分为两类:1) 两阶段方法,使用视觉模型将图表转换为数据表,以便后续与语言模型进行处理 [54, 43, 19, 15]; 以及 2) 统一的 VL 模型,在单个集成阶段直接处理和解释融合的图表和文本特征[55, 44, 57]。
两阶段管道在执行图表到表的转换时,难以保留视觉信息(例如,颜色和空间位置)[43],这固有地限制了它们在特定场景中的适用性。 对于统一模型,Matcha[44] 将数学推理和图表数据提取任务集成到预训练的通用 VL 模型 Pix2Struct[35] 中,因此在 CQA 和图表摘要方面表现出色。 UniChart[55] 遵循 Matcha,同时收集更多数据以进行多任务指令微调,以处理更多图表相关任务。 然而,它们有限的语言模型性能带来了挑战,尤其是在需要数值计算的推理问题中[54]。
MLLM 的出现改变了这种模式,在视觉问答方面取得了突破[4]。 值得注意的是,开源通用模型 Qwen-VL[5] 在 ChartQA 基准测试[54] 中展示了优于所有专业图表模型的性能, 尤其是那些由人类提出而非机器生成的的问题。 尽管取得了这些进展,但我们广泛的实证研究发现,当前的 MLLM 在处理现实世界的 CQA 任务方面存在局限性,尤其是那些超出训练数据分布的任务。 纠正这些局限性需要在构建训练数据时考虑可视化参考模型[9],这阐明了从原始数据到最终图形表示的实际映射过程。 因此,本研究通过将可视化参考过程中的知识整合到训练数据生成和增强中,有助于提高 MLLM 在 CQA 中的性能。
增强MLLM的能力. 在特定场景(如医学图像和文本密集型图像)中增强MLLM,可以归纳为两种主要方法:以模型为中心 的工作旨在提高视觉编码器或投影器的性能和效率; 以数据为中心 的工作试图通过提高训练数据的数量和质量来提高模型性能。 在以数据为中心的发展中,一些研究采用强大的LLM(例如,GPT-4[3])来生成各种指令格式的VL任务,例如标题生成[48]。 另一系列研究探索了将经典的VL任务数据集(例如,COCO[42])转换为使用预定义模板的指令遵循格式。 在此背景下,为了增强图表理解能力,ChartLLaMA[24] 使用 GPT-4 生成的 160K 指令数据对 LLaVA 进行微调。 同样,ChartAst[57] 从 arXiv 中抓取了大量表格,然后使用表格为大规模图表到表格的预训练生成图表。 ChartAst 还基于收集到的表格生成问答对。 尽管有这些努力,但影响图表理解有效指令数据的因素仍然不清楚。
我们的研究试图通过一项实证研究来弥合这一差距,该研究重新审视了使用不同类型的 CQA 任务数据来提高模型性能的差异。 结果强调了整合复杂图表推理问题的重要性,促使我们开发一个富含现实世界图表任务的数据引擎。 此外,我们还通过调整基础 MLLM 的训练方法,最初针对自然图像定制,使其适合可视化上下文,对模型中心方面进行了改进。
可视化数据集和基准. 数据集是模型训练的基础,结构良好的基准有助于研究人员评估和选择适合下游任务的模型。 针对可视化场景,目前的基准主要集中在通过图表到表格转换[54, 58]、CQA 任务[54, 58] 和图表摘要[66, 30, 62] 来评估图表理解性能。
ChartQA[54] 和 PlotQA[58] 代表了 QA 数据集和基准。 ChartQA 具有部分高质量的人工标注的 QA 对,而 PlotQA 提供了更多使用模板制作的低质量项目的集合。 除了问答任务,VisText[66] 引入了一个全面的基准测试,它包含多级和细粒度的图表标记,涵盖图表构建、摘要统计、关系和复杂趋势等方面。 这些数据集的主要优势是其庞大的规模和用于数据生成精心设计的模板。 但是,它们也有一些局限性,包括图表类型的范围有限、维护高质量问题和答案的挑战,以及过度关注从图表中获取基本数据的倾向。
在可视化领域,现实世界图像数据集,如 Beagle[6]、VisImage[18]、Vis30K[12]、多视图[14] 和复合可视化[16, 22] 以及仪表盘[17, 65],以及用于视觉素养测试的实用问答基准[36, 60, 21],已被引入。 挑战在于如何将它们转换为高质量的指令数据,因为标签注释稀疏。 我们的研究借鉴了利用 GPT 生成代码格式的图表和相关指令数据的 методологии。 具体来说,我们旨在用定义明确的图表任务空间[36] 指导数据生成过程,以贡献一个包含现实世界图表特征和问答任务范围的数据集,从而提高当前 MLLM 的图表理解能力。
4 实证研究:重温用于 CQA 的 MLLM
我们进行了一项实证研究,以重新审视现有 MLLM 用于 CQA 的有效性,旨在识别局限性并为进一步改进获得见解。 该研究借鉴了 CQA 排行榜111https://paperswithcode.com/task/chart-question-answering 和最近的研究[47, 5, 3],其中强调 ChartQA[54] 是 MLLM 在图表理解中的主要训练和测试数据集。 ChartQA 包含从在线平台获取的大规模真实世界图表,以及数据表和人工编写和机器生成的问答对。 然而,深入分析对于确保在 ChartQA 上表现出良好基准性能的 MLLM 能够可靠地过渡到现实世界场景至关重要。 本实证研究尤其旨在解决以下研究问题:
-
•
RQ1:如何改进 ChartQA 以更好地反映现实世界场景? 我们旨在改进 ChartQA,使其更贴近现实世界环境。 虽然 ChartQA 中的图表来自在线平台,但它们并不包含所有图表设计的范围,因为最近的一项研究[75] 发现在线图表存在偏向分布。 具体而言,我们将探索图表设计和问答对的多样性,这两个方面对于提高 CQA 模型的有效性至关重要。
-
•
RQ2:什么是有效的 CQA 可视化指令? 虽然问答对本身可以作为指令数据,但它们包含各种问题类型(例如,数据检索和视觉)。 探索哪些特定的问答特征可以更好地提高可视化指令的有效性,这方面值得进一步研究。 此外,以前的研究[43, 54]表明,结合图表到表格的翻译任务可以提高 VL 模型的整体图表理解性能,但它在 MLLM 环境下的效果需要更深入的调查。
4.1 ChartQA 数据集的计算分析
为了解决RQ1,我们对 ChartQA 在图表和问答对方面的分布进行了计算分析。 我们通过将它们与实际图表和视觉素养数据进行比较来识别分布偏差。 随后,我们评估了各种 MLLM 在 ChartQA 上的性能,并将这些结果与现实世界场景中的性能进行对比,重点强调分布偏差对模型性能的影响。
4.1.1 图表和问答对中的分布偏差

| Model | ChartQA-M | ChartQA-H | Literacy | |||
|---|---|---|---|---|---|---|
| Data Retrieval | Compositional | Visual | Visual-Compositional | |||
| LLaVA-1.6-13b | ||||||
| LLaVA-1.6-34b | ||||||
| Qwen-VL-Chat | ||||||
| Qwen-VL-Plus | ||||||
| GPT-4-vision-preview | ||||||
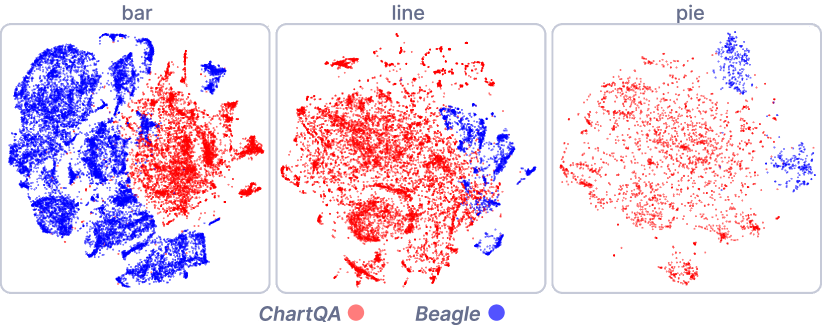
图表分布。 ChartQA 主要包含来自在线平台的条形图、折线图和饼图。 这些图表具有相似的视觉风格(例如,颜色主题)并且缺乏对各种图表类型的覆盖,例如面积图和散点图。 此外,即使在其包含的图表类型中,与实际图表相比,细粒度图表特征也可能存在显著差异。 为了调查这些差异,我们利用 Beagle[6] 作为对照组来比较它们的图表特征分布。 Beagle 使用关键字搜索从网络爬取可视化内容,在可用的可视化数据集[75] 中被认为是比较多样化的,涵盖了来自各种可视化工具和库的图表(例如,D3[7] 和 Chartblocks[11])。 具体来说,我们使用预训练的 CLIP-Vit[61],一个常用的 MLLMs 视觉编码器,从图像中提取高维特征。 然后,我们使用 t-SNE[68] 将特征投影到二维空间。 图 2 展示了投影结果,展示了特定图表类型内的分布偏差。
重要的是,图表类型充当广泛的分类,限制了在构建视觉指令时利用细粒度图表特征。 例如,数字标注允许 MLLMs 直接识别和检索数据。 相反,当缺少数字标注时,MLLMs 必须根据轴和视觉元素的位置来近似数据值,这将构成一项明显更复杂的任务。 这突出了在制定 CQA 数据集时需要考虑细粒度图表特征,如第 5.1.
问答对分布。 ChartQA 包含两个测试问答数据集:ChartQA-H 用于人工编写的问答,ChartQA-M 用于机器生成的问答。 这些问答被分为数据检索、视觉、组合 和 视觉和组合 类型,如 [31] 中所定义。
-
•
数据检索:通过图表中的实体名称查找对应元素的值。
-
•
视觉:利用视觉通道,例如颜色识别,使用视觉属性比较实体(例如,哪个是最右边、最高或最大)。
-
•
组合:需要数学运算,如求和、求差和平均值。
-
•
视觉和组合:视觉和组合的融合。
然而,ChartQA 并没有为每个问答对标注问题类型,这阻碍了基于问题类型的细粒度精度分析。 为了解决这个问题,我们手动标记了 ChartQA-H 和 ChartQA-M 测试集中的问题,每个测试集包含 1250 个问答对。 统计数据显示,数据检索 任务 (1035/1250) 在 ChartQA-M 集中占主导地位。 这种分布可能是由于用于生成语言模型的性能有限,这限制了 ChartQA-M 对特定问题模板的使用。 相反,人工编写的 ChartQA-H 集具有更广泛的分布,包含 (251) 数据检索、(476) 视觉、(251) 组合 和 (272) 视觉和组合 类型。 多样化的分布促使我们对模型的图表理解能力进行更全面的评估,涵盖不同的问题类型,如下一节所述。
4.1.2 分布偏差的影响
我们进一步研究了上述部分中确定的分布偏差如何影响模型性能。
模型。 我们选择的 MLLM 包括专门针对 ChartQA 训练的开源模型:LLaVA-1.6-13b[47]、LLaVA-1.6-34b[47] 和 Qwen-VL-Chat[5]; 以及主流商业 模型:Qwen-VL-Plus[5] 和 GPT-4-vision-preview[59]。 商业 模型 通过其官方 API 访问。
评估指标。 遵循现有研究[55, 54, 24],我们采用广泛使用的宽松正确性[54],该正确性要求文本响应完全匹配,但数字响应允许 5% 的误差。
提示设置。 CQA 评估要求模型用单个单词或短语回答。 遵循 LLaVA 为简短答案设置[46],我们用 "请用一个词或短语回答" 提示模型进行指标评估,并用 "请逐步思考" 进行零样本思维链 (CoT)[70],以调查模型推理过程中的关键步骤和错误步骤。
数据集。 除了 ChartQA-H 和 ChartQA-M 测试集之外,我们还混合了关于 视觉素养[36, 21, 60] 的研究中的 QA 对,创建了一个包含 131 个 QA 对的新数据集。 视觉素养 QA 用于评估个人阅读、理解和解释数据可视化的能力。 这些是涵盖大多数图表任务空间[36] 的真实世界 QA 的代表性示例。
| Model | Data Retrieval | Compositional | Visual | Visual-Compositional |
|---|---|---|---|---|
| Baseline LLaVA-1.5 | 24.50% | 9.27% | 28.60% | 13.51% |
| LLaVA-1.5 + ChartQA-H | 32.93% | 15.73% | 47.25% | 8.11% |
| LLaVA-1.5 + ChartQA-M | 31.33% | 10.08% | 38.77% | 8.11% |
| LLaVA-1.5 + Chart2Table | 36.55% | 9.68% | 47.46% | 13.51% |
| LLaVA-1.5 + ChartQA-H & ChartQA-M | 43.37% | 15.73% | 51.91% | 5.41% |
| LLaVA-1.5 + ChartQA-H & Chart2Table | 42.17% | 16.94% | 51.91% | 13.51% |
| LLaVA-1.5 + ChartQA-H & ChartQA-M & Chart2Table | 48.59% | 18.55% | 54.66% | 13.51% |
结果分析。 表 1 展示了实验结果,表明所有 MLLM 在 ChartQA-M 和 视觉素养 之间表现出性能差异。 一个合理的假设是 ChartQA-M 中问题类型的分布不均匀。 为了验证这一假设,我们对 ChartQA-H 中不同问题类型的性能进行了细化。 结果揭示了各种问题类型之间存在显著差异。 具体而言,所有模型在数据检索和视觉问题上都表现出较高的性能,而在组合和视觉-组合问题上的性能则明显下降。 通常,数据检索和视觉问题主要需要图表识别的能力。 相反,组合问题需要图表识别,然后进行计算和推理,严重依赖于MLLM的推理能力。 这证实了该假设的有效性。
为了深入了解造成该问题背后的原因,我们研究了配备了CoT的MLLM生成的响应。 图3说明了三种典型案例,突出了三个类别的缺陷:识别错误、数值计算的推理错误以及图表知识的推理错误。 多个因素导致了这些错误。 首先,错误通常发生在视觉素养中常见的图表类型,但在ChartQA中很少见,例如堆积条形图。 此外,ChartQA中不常见的问题,例如准确地确定数据值的范围,可能会导致MLLM难以识别正确的范围。
摘要。 这些见解突出了ChartQA的一个关键问题:虽然它包含了各种现实世界的图像和QA,但图表和QA分布中的偏差限制了其通用性。 这强调了需要一个包含更多图表类型和QA的数据集。 这样的数据集可以潜在地增强MLLM解决现实世界场景中固有复杂挑战的能力。
4.2 指令微调消融
为了解决RQ2,我们设计了一系列消融研究,以检查不同问题类型和与图表相关的任务对CQA的影响,旨在识别有效的视觉指令。
4.2.1 实验设置
主干MLLM: 我们选择LLaVA-1.5[46]作为基线,因为它训练数据不包含特定的图表数据集,因此更容易研究不同训练数据组合的影响。 我们遵循LLaVA-1.5的官方微调设置,其中我们冻结视觉编码器,只更新投影器和LLM的参数。 具体来说,我们采用低秩自适应(LoRA)[28]策略来训练LLM以减少训练工作量。
数据集控制: 尽管ChartQA的图表分布有偏差,但由于它适合检查MLLM如何从特定数据分布中学习并对其做出反应,因此我们将其用于指令微调消融测试。 除了ChartQA-H和ChartQA-M之外,ChartQA中的每个图表都与其数据表相关联,构成一个图表到表的翻译任务,记为Chart2Table。 研究[54, 43]表明,Chart2Table有可能增强图表识别能力,这证明了它在我们消融研究中的必要性。 具体来说,Chart2Table的指令数据结构为 <图表,"请从给定的图表中提取基础数据表",数据表>。
消融模型: 我们使用没有微调的主干MLLM作为基线。 此外,我们使用ChartQA-H、ChartQA-M和Chart2Table的单个和不同组合对主干模型进行微调,最终得到六个微调后的MLLM。
4.2.2 结果和分析
表格 2显示了基线和微调后的MLLM在ChartQA-H测试集中不同问题类型上的消融实验结果。 总体而言,使用更多训练数据(单个vs.组合数据集)进行微调的模型能够达到更高的准确率。 具体来说,包含人类生成的ChartQA-H数据集能够显著提高模型在所有问题类型上的性能。 相反,ChartQA-M数据集效率较低,主要提高了数据检索和视觉问题。 这种差异进一步突出了数据检索问题在解决 CQA 挑战方面的有限影响,以及与简单识别问题相比,多样化、推理密集型问题的重要作用。 此外,如果数据表可用,Chart2Table可以作为一项辅助的有效指令任务。
总之,为了增强 MLLM 的图表理解能力,需要关注多样性,特别是在需要推理的问题类型上,而不是扩大数据检索为主的训练样本的数量。
5 数据引擎
收集所有可用的 CQA 数据来训练 MLLM 是低效的,并且不能解决固有的分布缺陷。 首先,研究表明数据平衡在训练通用 MLLM[10] 中的重要性。 如果没有精确的标注,聚合所有数据会导致庞大的数据集,造成 MLLM[26] 的学习效率低下和训练成本高昂。 例如,作为领先的通用 MLLM,LLaVA[48] 只需要 1223K 指令数据,而 UniChart[55] 和 ChartAssistant[57] 使用了大约 6900K 和 39.4M 的图表相关指令数据。 这种差异突出了将所有可用图表数据纳入通用 MLLM 训练数据的不切实际性。 此外,我们的实证研究已经证明了现有 CQA 数据中的分布缺陷,强调了生成新数据的必要性。
为此,我们选择为一个适当大小的数据集设计一个数据引擎,同时涵盖图表特征和问答任务的现实世界范围。 该数据引擎包含两个模块:数据过滤 (第 5.1 节) 旨在高效利用现有数据,并确保适当的训练成本;以及 数据生成 (第 5.2 节) 旨在优化数据分布。 最后,我们展示了获得的 可视化参考数据集 和 基准(第 4 节)。
| Dataset |
|
|
||
|---|---|---|---|---|
| Statista, OECD, OWID | 144,147 | 679,420 | ||
| PlotQA | 155,082 | 2,414,359 | ||
| Unichart | 189,792 | 2,218,468 | ||
| Beagle | 3,972 | 51 | ||
| ChartInfo | 1,796 | 21,949 | ||
| VisText | 9,969 | 0 | ||
| ExcelChart | 106,897 | 0 | ||
| Total existing | 611,655 | 5,334,247 | ||
| Filtered dataset | 69,418 | 68,223 |
5.1 数据过滤
该模块旨在从现有的 CQA 数据集中过滤代表性数据。 我们首先建立构成适当图表分布的原则。 具体而言,借鉴 [36] 提出的图表分类和相应任务类型(见表 4), 我们的方法涉及分析以下方面的分布:
-
•
可视化素养论文[36, 21] 中总结的图表类型(有关详细信息,请参见表 4);
-
•
在可视化检索任务[72] 中识别出的细粒度图表属性,例如,颜色、趋势和布局;以及
-
•
显着影响 MLLM 图表理解的图表属性,即,注释数量(存在或不存在)和数据分组(单个或多个)。
鉴于研究表明常见的预训练视觉特征提取器(例如,CLIP-Vit[61])对细粒度图表属性不敏感[72], 在预训练特征空间中对数据进行采样的传统过滤方法会导致这些属性的不均匀性。 此外,大多数现有数据集缺乏超出粗粒度图表类型(例如,条形图、折线图和饼图)的详细标注,这对分层抽样提出了挑战。 为了缓解这个问题,我们构建了分类器以监督方式学习这些属性,然后根据分类器预测的标签进行分层抽样。
5.1.1 图像分类器
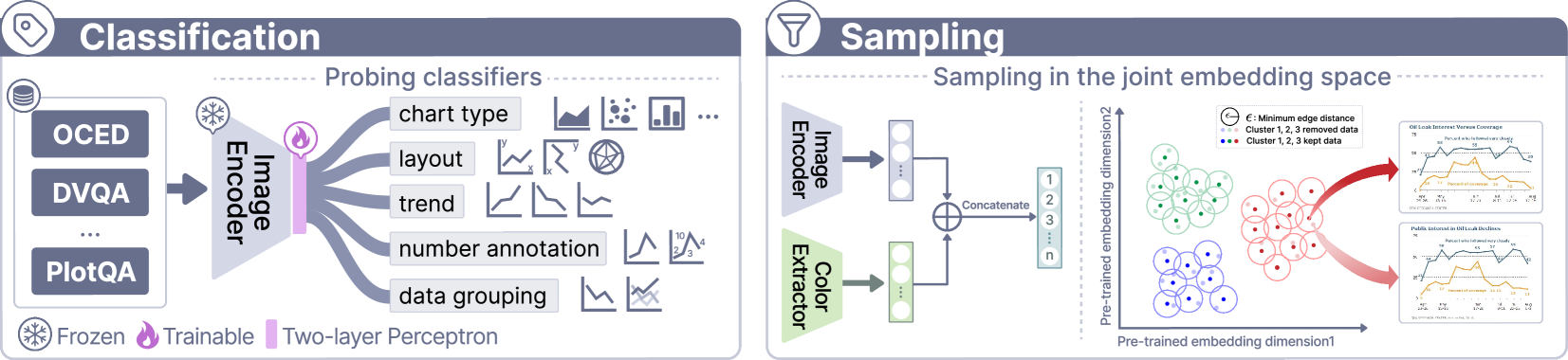
如图 4 ![]() 所示,我们基于冻结的 ConvNeXt[71] 主干构建了探测分类器(即,两层感知器),以准确评估这些细粒度图表类型和属性的分布。
我们收集了来自 [72] 的训练数据以及手动收集的子集。
为了缓解缺乏一些属性标注的问题,我们手动标记了每个图像以补充缺失的属性。
由于图表类型和属性分布的不平衡性(例如,数字标注),我们选择使用 focal loss[41] 作为损失函数,旨在关注不平衡的图像类型。
Focal loss 定义为:
所示,我们基于冻结的 ConvNeXt[71] 主干构建了探测分类器(即,两层感知器),以准确评估这些细粒度图表类型和属性的分布。
我们收集了来自 [72] 的训练数据以及手动收集的子集。
为了缓解缺乏一些属性标注的问题,我们手动标记了每个图像以补充缺失的属性。
由于图表类型和属性分布的不平衡性(例如,数字标注),我们选择使用 focal loss[41] 作为损失函数,旨在关注不平衡的图像类型。
Focal loss 定义为:
其中表示类别的估计概率,表示缩放因子,表示调制因子。 其中, 由反类频率设置。 因此,学习参数倾向于为样本较少的类别做出贡献,而 则有助于上调分配给分类错误示例的损失,避免大量分类正确的样本主导训练过程的可能性。 我们在表 5 中经验性地比较了主干模型的几种设计方案(例如,CLIP-Vit[61] 和 ResNet50[25])以及可训练模块(例如,线性探测[61])。
请注意,并非所有图表类型都具有相同的细粒度属性集。 例如,饼图没有趋势属性,因此趋势分类器的训练将不会考虑饼图。 我们利用训练好的分类器对我们收集的现有数据进行标记,提供了对图表属性的清晰检查,并为后续抽样中的数据平衡奠定了基础。
5.1.2 图像采样和指令数据采样
图 4 ![]() 说明了图像采样过程。
我们使用 CLIP-Vit[61] 和一个颜色提取器 [1] 来提取每张图像的整体特征和颜色特征,然后将这两个特征向量连接起来形成一个联合嵌入空间。
受到 Bunny[26] 和 SemDeDup[2] 的启发,
我们在联合嵌入空间内通过 -means 将图像聚类成 个集群,旨在将具有相似特征的图表分组。
为了确保图表属性平衡,我们在每个集群中都采用了分层采样。
具体来说,我们在每个集群内根据预测的图表属性创建分层,并在每个分层中进一步执行采样。
我们通过构建一个无向图来识别重复项,其中边连接余弦相似度高于指定阈值 的图像对,表示高特征相似度。
我们通过直接保留每个语义重复集与分层中心距离余弦相似度最低的图像来简化流程,
从而有效地减少数据集大小,同时保留多样性。
最后,我们手动调整 以获得大约 69K 个图表,确保适当的训练成本。
说明了图像采样过程。
我们使用 CLIP-Vit[61] 和一个颜色提取器 [1] 来提取每张图像的整体特征和颜色特征,然后将这两个特征向量连接起来形成一个联合嵌入空间。
受到 Bunny[26] 和 SemDeDup[2] 的启发,
我们在联合嵌入空间内通过 -means 将图像聚类成 个集群,旨在将具有相似特征的图表分组。
为了确保图表属性平衡,我们在每个集群中都采用了分层采样。
具体来说,我们在每个集群内根据预测的图表属性创建分层,并在每个分层中进一步执行采样。
我们通过构建一个无向图来识别重复项,其中边连接余弦相似度高于指定阈值 的图像对,表示高特征相似度。
我们通过直接保留每个语义重复集与分层中心距离余弦相似度最低的图像来简化流程,
从而有效地减少数据集大小,同时保留多样性。
最后,我们手动调整 以获得大约 69K 个图表,确保适当的训练成本。
对于指令数据,第 4.2 节总结了现有数据集不同组件的影响。 基于经验研究的见解,我们保留所有采样图像的表格数据用于 Chart2Table 任务,并在其附加的 QA 对中进一步采样数值和视觉推理问题。
5.2 数据生成
该模块旨在生成包含真实世界图表类型和 QA 任务的数据集, 因此缓解了现有数据集的分布偏差问题。 具体来说,我们参考了可视化素养研究[36]中总结的图表任务空间类型(参见表4)。
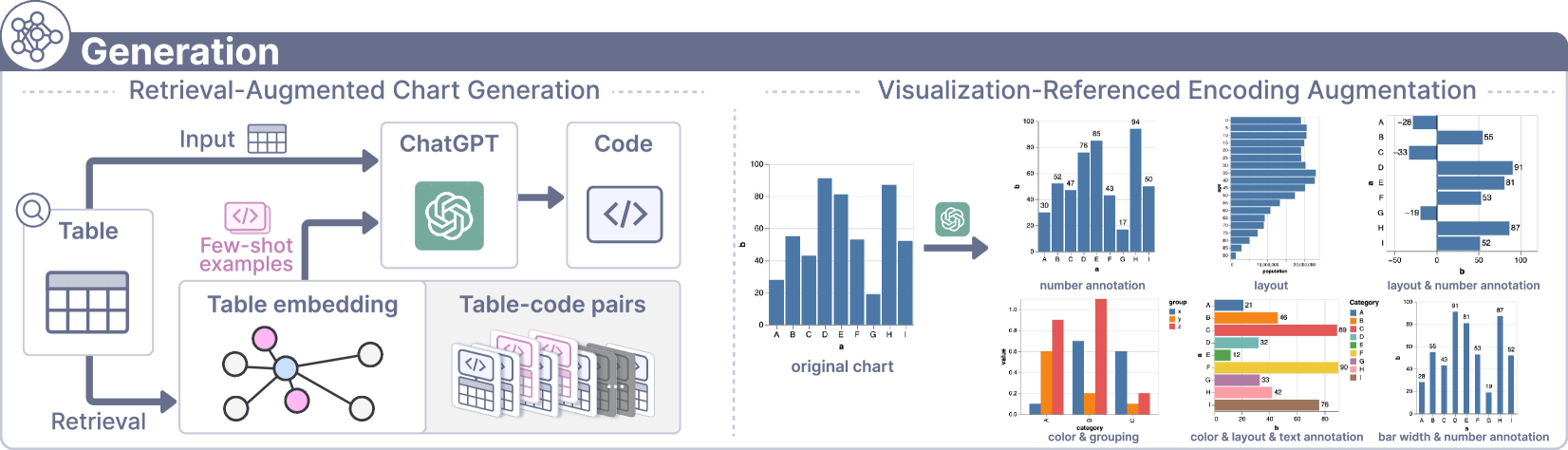
借助收集到的表格,先前的工作已经探索了使用 LLM[24, 57] 生成图表和 QA 对。 但是,他们忽略了语言模型输出固有的不稳定性带来的潜在质量失真, 也没有考虑通过对图表空间的了解来指导生成过程。 我们利用 LLM 的上下文学习能力来遵循可视化参考过程[9],确保生成图表的丰富性,从而覆盖图表空间。 图5概述了我们的图表生成流水线,它包含两个阶段:检索增强图表生成和可视化参考编码增强。 本节中为 LLM 输入构建的提示模板可在补充部分 S1 中找到。
5.2.1 种子图表的收集和扩展
生成图表始于聚合一组多样化且高质量的种子示例,这些示例涵盖了广泛的样式和图表类型。 这些示例是从各种权威图表库中收集的表格代码对,例如 Vega-Lite222https://vega.github.io/vega-lite/examples、 Matplotlib333https://matplotlib.org/stable/gallery、Seaborn444https://seaborn.pydata.org/examples和 ECharts555https://echarts.apache.org/examples。 此外,我们从以前的研究[34]中收集高质量的表格代码对,并从网络上精心挑选一些示例。 为了进一步扩展我们的种子示例,我们还从各种来源[53, 75]收集高质量的表格数据。 值得注意的是,此处不使用从现有数据集中过滤的图表,因为它们大多数不是代码格式。
如图 5(左)所示,扩展过程采用检索增强生成(RAG)方法[37], 该方法通过在生成过程中为 LLM 提供与上下文相关的示例,提高了生成图表的准确性和质量。 为实现此目的,我们首先提取表格特征以识别并匹配每个收集的表格与现有表格代码对中最相似的表格。 具体来说,遵循可视化推荐研究[29, 39, 69],我们提取了 30 个跨列数据特征,这些特征捕获了列之间的关系,以及 81 个单列数据特征,这些特征量化了每列的属性。 这些特征使我们能够在向量空间中表示种子示例的表格特征,从而能够基于余弦相似度检索最近邻。 在构建种子图表扩展的提示时,这些匹配的种子示例的相应代码作为少样本示例与新表格一起使用。
5.2.2 通过视觉映射变化进行增强
为了扩大种子示例的收集范围,我们利用 LLM 在图表的视觉映射或编码中引入变化。 此阶段遵循可视化参考过程[9],对于涵盖更广泛的可能图表表示方式以及与现实世界数据的不同分布保持一致至关重要。 我们通过指定每种图表类型可以采用的视觉映射以及将具有不同视觉编码的实例合并到输入上下文中以供参考来指导 LLM。 例如,如图 5(右)所示,LLM 被指示修改图表元素,例如数字注释、分组和条形宽度,以及截断或反转条形图中的轴。 这种方法通过改变与数据相关的编码(例如条形的高度)来促进生成更丰富的表格代码对。 同时记录修改后的数据表。
5.2.3 问答对的生成
我们进一步基于丰富的表格代码对生成 QA 对,这些对预计将是准确的,并且涵盖图表任务空间。 具体来说,对于每种类型的图表,我们使用 LLM 生成 Q&A 对,方法是使用表格(用于数字信息)、代码(用于编码的视觉信息)以及相应的图表任务空间作为上下文提示它。 我们还要求 LLM 根据图表任务分类法对生成的 Q&A 对进行分类标签 (e.g.,数据检索 和 查找极值),平衡不同任务的分布。 在生成过程中,我们随机选择一些问答对进行人工检查,并确保它们达到预期准确性。
推理过程。 最近的研究表明,不必要的逐步训练标注会导致泛化能力和指令遵循能力下降。 对于简单的问题 (e.g.,柱状图数据检索),与单字答案相比,推理过程没有提供有用的信息。 我们只将推理过程附加到需要数值计算和视觉参考的问题。 对于视觉参考,我们主要考虑以前工作中较少使用的视觉通道,例如气泡图的点区域以及折线图的截断或倒置轴。
5.3 基于可视化的数据集和基准
| Visualization | Visualization Task | Note of | |||||||||||||||||||||||||
|
|
|
|
|
|
|
|
ETC | |||||||||||||||||||
| Line Chart | X | X | X | X | X | ||||||||||||||||||||||
| Bar Chart | X | X | |||||||||||||||||||||||||
| Stacked Bar Chart | X | X |
|
||||||||||||||||||||||||
| 100% Stacked Bar Chart | Only Relative Value | ||||||||||||||||||||||||||
| Pie Chart | Only Relative Value | ||||||||||||||||||||||||||
| Histogram | X |
|
Only Derived Value | ||||||||||||||||||||||||
| Scatterplot | X | X | X | X | X | X | X | X | |||||||||||||||||||
| Area Chart | X | X | X | X | X | ||||||||||||||||||||||
| Stacked Area Chart | X | X | X |
|
|||||||||||||||||||||||
| Bubble Chart | X | X | X | X | X | X | X | X | |||||||||||||||||||
| Treemap |
|
Only Relative Value |
数据集概述. 我们生成的数据集包含 11 种图表类型和 8 个任务类别,如视觉素养研究 [36, 21, 60] 中所述。 表 4 说明了图表-任务空间。 生成的数据集包含 10,385 个表格-图表对和 51,245 个图表-问答对。 通过将生成的数据集与过滤后的数据集(如表 LABEL:tab:existing-datasets 所示)集成,我们最终生成一个包含 199K 个样本的数据集,其中包括 80K 个表格-图表对和 119K 个图表-问答对。 与早期依赖于单一来源或模板驱动设计的数据集相比,我们的方法有效地将我们生成的数据集与来自广泛的真实世界和合成来源的现有数据集相结合。 此集成包含各种视觉编码,参考来自多个来源的真实世界图表。 我们已尽力确保图表类型和 QA 对的公平分配,特别注重当前数据集中代表性不足的图表类型和问题类型,例如范围确定和分布特征,以提供更全面、更平衡的资源。 可以在补充材料第 S2 节中找到详细的图表和问答示例。
基准。 为了建立涵盖图表任务空间的基准,我们精心策划了另外 368 个表格-图表对和 736 个图表-QA 对,这些对高度代表了我们的数据集。 我们专注于在每个图表类别中实现多样性,选择具有各种视觉编码的图表,并保持对图表子类型的覆盖。 此外,我们还考虑了问题的复杂性,旨在在实体数量和呈现的数量范围内广泛地进行表示。
指标。 我们的数据集旨在反映在基于图表的问答中遇到的真实场景,为此,我们选择使用 GPT 进行评估[49]。 此方式适用于我们的基准,因为它可以适应各种答案格式,包括模棱两可或长文本。 GPT 准确性指标将文本响应与标准预期答案进行比较,确保基于语义等效性的匹配。 对于数字响应,我们允许 5% 的容差水平,这与以前的作品一致[54]。 但是,此误差幅度可能会在特定情况下进行调整,在这些情况下它是不合适的。 例如,在涉及年份或可数数量的情况下,精度至关重要,因此需要绝对准确性,不允许任何误差幅度。
6 模型
为了增强 MLLM 在现实世界环境中的图表理解能力,我们考虑了在模型架构及其训练中进行的两种设计改进。 特别是,我们采用了分辨率混合自适应策略[52],以增强细粒度识别(第 6.1 节)。 此外,为了更好地表示图表中的视觉特征,我们在训练期间解冻视觉编码器,并利用第 5 节中描述的以可视化为参考的数据集进行训练(第 6.2 节)。
6.1 模型架构
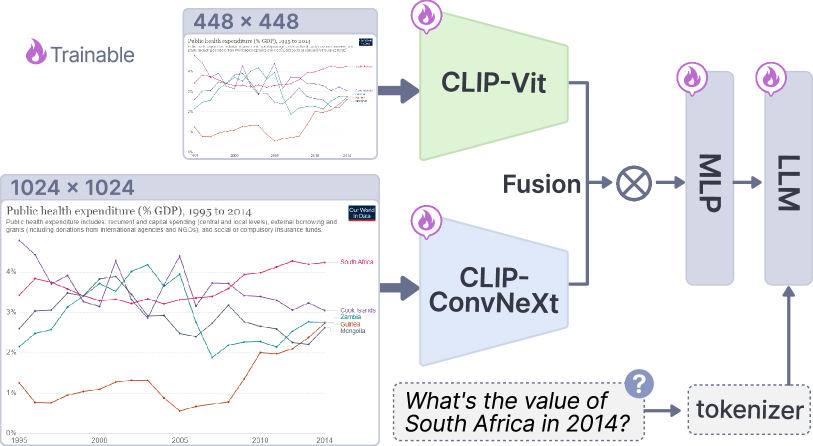
基础模型。 我们使用 LLaVA-1.5[48] 作为基础模型架构,它采用 CLIP-Vit-334px 作为视觉编码器,两层 MLP 作为投影器,以及 Vicuna-13B[77] 作为 LLM。
通过混合视觉编码器和符元压缩来实现高分辨率输入。 所采用的两层 MLP 有效地连接了视觉编码器和 LLMs 的特征空间,但导致视觉符元与图像分辨率呈正相关。 例如,对于 1,022×1,022 分辨率的图像,CLIP-Vit-L-14 会生成 5,329 个符元,因为每个符元对应一个 14×14 的图像块[52],这对于 MLLMs 来说计算量很大。 用于实现高分辨率输入的流行基于查询的策略,QFormer[40],需要大规模的预训练来实现视觉语言对齐,这对于可视化场景来说是不切实际的,因为高质量的数据稀缺。 因此,我们采用了一种分辨率适应策略[52] 来提高分辨率,同时支持在正常规模数据上进行训练。 该策略通过适配器将高分辨率特征嵌入到低分辨率特征中,从而减少视觉特征符元。 具体来说,遵循 LLaVA-HR[52] 的设置,我们将 CLIP-ViT-L[61] 和 CLIP-ConvNeXt[50] 整合为视觉编码器的混合,然后使用自适应策略混合它们的特征,从而控制视觉符元序列的长度。 ViT 和 CNN 的分辨率分别设置为 448×448 和 1,024×1,024。
6.2 训练设置
解冻视觉编码器。 以前的工作[48, 24, 45] 选择在整个训练过程中冻结视觉编码器,因为预训练的 CLIP 已经擅长捕捉自然图像的特征。 它们的 MLLM 训练目标是通过调整投影仪和 LLM,使 CLIP 提取的特征与 LLM 嵌入空间对齐。 然而,以前的研究[72] 发现 CLIP 在可视化图像中的表现要差得多,因为它的预训练语料库中包含的图表数量相对较少,而且标注粗略,导致在没有进一步微调的情况下,图表识别能力有限。 解冻 CLIP 的参数可以更好地适应图表特征,并提高 MLLM 图表理解的整体性能,从而提高图表识别能力。
训练数据。 我们跳过预训练过程,直接利用 LLaVA-HR[52] 的初始投影仪权重进行指令调优。 我们的研究旨在提高通用 MLLM 的图表理解能力。 因此,我们的训练数据包含两个部分:LLaVA-1.5 的 665K 个原始指令调优数据和第199K节中描述的与图表相关的数据。 4.
超参数设置。 AdamW[33] 被用作优化器,学习率 (LR) 和全局批次大小分别设置为 2e-5 和 128。 训练时期设置为 1。 LR 调度器是余弦衰减,预热率为 0.03。 该训练在 16×NVIDIA A800 上运行,大约需要 19 个小时。
7 评估
我们首先展示了分类器的准确性,以证明它在衡量图表分布方面的有效性。 然后,我们将我们的模型与传统基准和我们的基准中的先前工作进行比较。 此外,我们还提供了一组消融研究,以显示我们的数据引擎的有效性。
7.1 图表属性分类
我们比较了不同主干 (i.e., ResNet50[25], ConvNeXt[50] 和 CLIP-Vit[61]) 和可训练模块(线性探测[61] 和带有焦点损失的两层 MLP[41])的分类器的性能。 表 5 列出了每个属性的宏 F1 分数,表明 ConvNeXt 始终优于其他主干。 因此,我们采用指定焦点的 ConvNeXt,它始终表现良好。
| Models |
|
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50+Linear Probe | 90.4 | 86.8 | 85.8 | 75.2 | 95.1 | ||||||||
| ResNet50+Focal Loss | 90.6 | 84.3 | 87.0 | 72.9 | 94.1 | ||||||||
| CLIP-Vit+Linear Probe | 93.0 | 87.6 | 92.7 | 70.8 | 94.4 | ||||||||
| CLIP-Vit+Focal Loss | 92.7 | 89.7 | 93.8 | 72.2 | 95.3 | ||||||||
| ConvNeXt+Linear Probe | 93.7 | 90.6 | 89.2 | 75.9 | 96.2 | ||||||||
| ConvNeXt+Focal Loss | 94.3 | 92.4 | 91.3 | 75.8 | 97.7 |
| Models |
|
|
|
|
|
|
|
|
||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA1.6-34b | 37.69 | 35.83 | 3.85 | 20.00 | 21.43 | 27.27 | 51.95 | 48.84 | ||||||||||||||||||
| GPT-4-vision-preview | 56.92 | 60.96 | 30.77 | 36.67 | 42.86 | 36.36 | 68.83 | 56.40 | ||||||||||||||||||
| Qwen-VL-Plus | 43.08 | 21.39 | 11.54 | 10.00 | 7.14 | 13.64 | 41.56 | 34.30 | ||||||||||||||||||
| Our model | 46.15 | 53.48 | 35.57 | 30.00 | 42.86 | 36.36 | 64.94 | 58.14 |
| ChartQA | ||||
| Model | Aug. | Human | Average | Chart-to-table |
| Chart-T5 | 74.4 | 31.8 | 52.95 | 37.5 |
| Donut | 78.1 | 29.8 | 53.95 | 38.2 |
| Matcha | 88.9 | 38.8 | 63.85 | 39.4 |
| Unichart | 87.8 | 43.9 | 65.85 | 91.1 |
| ChartLLaMa | 90.4 | 48.9 | 69.7 | 90.0 |
| ChartAst-D (39.4M CQA data) | 91.3 | 45.3 | 68.3 | 92.0 |
| ChartAst-S (39.4M CQA data) | 92.0 | 58.2 | 75.1 | 91.6 |
| No Unfreezing vision encoder | 77.4 | 47.1 | 62.3 | 44.6 |
| No High Resolution | 88.6 | 55.8 | 72.2 | 87.9 |
| No Filtered Data | 91.5 | 60.9 | 76.2 | 90.9 |
| No Generation Data | 92.6 | 62.7 | 77.65 | 91.2 |
| Our model (199K CQA data) | 93.6 | 63.6 | 78.6 | 91.8 |
7.2 与最先进技术的比较
7.2.1 基准测试
ChartQA。 数据集信息、宽松准确率指标和短答案提示已在第 4.1.2 节中说明。 ChartQA 的训练集包含在我们的训练数据中。
Chart-to-table。 为了评估 MLLM 对图表识别能力,我们遵循 DePlot[43] 的评估框架,并报告了图表到表格数据提取的 F1 分数, 该分数通过比较表的结构和值来衡量表的相似性,但对列/行排列保持不变。
我们的基准测试。 为了评估 MLLM 在真实世界图表和任务分布上的性能,我们采用了第 4.
7.2.2 基线
我们选择并将 MLLM 组织成两组,用于我们的比较实验。 对于传统基准测试,我们将我们的模型与传统的图表专用模型进行比较,包括 Chart-T5[54]、Donut[32]、Matcha[44]、Unichart[55]、ChartLlama[24] 和 ChartAssistant[57]。 对于我们的基准测试(测试之前图表特定模型训练中通常不包含的任务),我们与 SOTA 通用模型进行比较,包括 LLaVA1.6-34b[46]、GPT-4-vision-preview[59] 和 Qwen-VL-Plus[5]。
7.2.3 结果
表格 7 展示了我们模型与其他模型性能的比较。 它表明我们的模型在所有任务中始终优于基线模型。 特别是,我们在使用明显更少的数据的情况下,超越了当前的领先模型,展示了我们的数据过滤和生成效果。 此外,消融研究证明了解冻视觉编码器和混合用于高分辨率的视觉编码器的有效性。
表格 6 展示了我们基准上的比较结果,说明了我们的模型在大多数任务中优于基线模型。 这些结果突出了我们模型的强大性能,这在诸如数据检索之类的常见任务以及确定范围和描述分布之类的不太常见的任务中都表现得很明显。 然而,包括我们的模型在内的当前 MLLM 在特定任务中仍然表现不佳。 例如,查找异常值 和 查找聚类,与散点图和气泡图相关,仍然具有挑战性。 这两种图表类型都使用点对数据进行编码,这需要极其强大的识别能力才能以细粒度级别识别和关联数据-视觉映射,因为视觉“点”的尺寸很小。 这突出了某些 CQA 任务的难度,这些任务要求精确识别小的图形元素,特别是在解决刚刚察觉差异问题的挑战时[23, 51]。 相反,对于像查找散点图或折线图的相关性/趋势这样的任务,答案空间是有限的(例如,正相关和负相关),并且可以根据图像的整体特征而不是图像的特定小区域来推断。
7.2.4 案例
图 Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning展示了最先进的 MLLM(Qwen-VL-Max[5] 和 GPT-4-vision-preview[59])与我们的模型在需要对视觉编码进行细粒度理解的常见困难图表问题上的比较。 在第一个例子中,折线图具有反向的 y 轴,这会混淆其他模型。 第二个条形图示例包含一个截断的 y 轴,这会导致识别难度。 在第三个气泡图示例中,其他 MLLM 无法理解气泡大小和员工人数之间的映射。 在最后一个例子中,GPT-4-vision-preview 和 Qwen-VL-Max 也误解了堆叠区域的含义。 相比之下,我们的模型能够成功应对这些问题,因为其对视觉编码的理解有所增强。
8 讨论
视觉编码器增强 . 我们的研究发现,解冻视觉编码器显着增强了 MLLM 的图表识别能力,表明原始 CLIP-Vit 在图表图像中的表现不佳[72]。 一种直观的替代设计是用专门针对图表图像预先训练的编码器替换 CLIP-Vit。 例如,ChartInstruct-LLaMA [56] 用 UniChart 视觉编码器[55] 替换 LLaVA 中的 CLIP-Vit。 然而,研究人员没有观察到与 Unichart 相比的模型性能改进。 这突出了通用视觉编码器的优越性,通用视觉编码器从数百万自然图像中学习到强大的图像解释能力( 例如 、定位)。 此外,理解一些真实世界的图表需要广泛的视觉知识。 例如,信息图表可能会包含自然图像以生动地描绘某些图表元素[73]。 借鉴 LLaVA-Med 在初始化 CLIP-Vit 中的经验[38],开发具有增强基本图表解释性能的视觉域 CLIP 是一个很有前景的未来工作。
更好的图表理解文本表示。 使语言模型与视觉编码器保持一致至关重要,而密集的图像表示(例如高质量标题)在这个过程中起着至关重要的作用。 通常,数据表用于图表,因为它们包含丰富的信息。 然而,数据表的内在局限性在于丢失了所有视觉信息。 虽然图表标题保留了某些视觉信息,但数字信息难以完全保留。 Vistext[66] 探索了使用场景图作为数据表的潜在替代方案。 尽管如此,语言模型的数据格式选择仍然是一个重要的考虑因素,还需要深入研究场景图格式是否能够有效地整合到多语言大型模型 (MLLMs) 的背景中。
关于将 MLLMs 应用于复杂推理可视化任务的见解 . 我们的研究发现,当前的 MLLMs 在分析任务(例如,查找异常 和 确定范围)中仍然面临挑战。 最近,已证明参考性问答 [76, 13] 有助于理解复杂的空间关系。 它需要在图像中标注边界框和箭头,并在问题中引用这些元素。 由于缺乏具有参考性标注的图表数据,此任务在我们的训练数据中没有被考虑。 然而,参考性问答在现实世界的视觉分析中很常见,并且可能对 查找异常 等任务有益。 例如,我们可以使用边界框标记异常点或突出显示一系列数据元素,从而增强 MLLMs 对相关任务的理解。 我们将针对图表的参考性和其他可能的复杂问答格式的探索留待未来工作。 此外,端到端 MLLM 输出本身就存在不确定性。 在复杂的可视化分析场景中,将图表的黄金表格和代码与 MLLM 整合用于交互应用程序可能更稳健。
9 结论
本研究解决了推进 MLLMs 在 CQA 中性能方面的重要挑战。 本研究进行了一项实证研究,以调查现有的多模态大型语言模型 (MLLM) 和图表问答 (CQA) 数据集的局限性。 我们发现,现有的数据收集和合成方法忽略了对视觉编码和 QA 任务的细粒度考虑,导致数据分布不平衡和数据质量不一致。 我们使用了一个两阶段的数据引擎,通过过滤和生成,对现有数据集进行了过滤,并通过基于大型语言模型 (LLM) 的生成技术对其进行了扩展,从而确保了涵盖图表特征的更广泛的高质量数据范围。 通过将混合分辨率适应策略和解冻视觉编码器融入模型训练,我们显著提高了 MLLM 在 CQA 任务上的性能。 实验表明,即使使用更紧凑的数据集,我们的模型也超越了 SOTA CQA 模型,突出了我们方法的有效性。 我们还为未来 CQA 任务 MLLM 的进步贡献了一个基准。
致谢
本项工作得到了国家自然科学基金 (62172398) 和广州基础与应用基础研究基金 (2024A04J6462, 2023A03J0142) 的部分资助。参考文献
- [1] Color histograms in image retrieval, 2024. https://www.pinecone.io/learn/series/image-search/color-histograms/, last accessed on 29/06/2024.
- [2] A. Abbas, K. Tirumala, D. Simig, S. Ganguli, and A. S. Morcos. Semdedup: Data-efficient learning at web-scale through semantic deduplication. arXiv, 2023. doi: 10 . 48550/arXiv . 2303 . 09540
- [3] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report. arXiv, 2023. doi: 10 . 48550/arXiv . 2303 . 08774
- [4] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh. Vqa: Visual question answering. In Proc. ICCV, pp. 2425–2433, 2015. doi: 10 . 1109/ICCV . 2015 . 279
- [5] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv, 2023. doi: 10 . 48550/arXiv . 2308 . 12966
- [6] L. Battle, P. Duan, Z. Miranda, D. Mukusheva, R. Chang, and M. Stonebraker. Beagle: Automated extraction and interpretation of visualizations from the web. In Proc. ACM CHI, pp. 594:1–594:8, 2018. doi: 10 . 1145/3173574 . 3174168
- [7] M. Bostock, V. Ogievetsky, and J. Heer. D3 data-driven documents. IEEE Trans. Vis. Comput. Graph., 17(12):2301–2309, 2011.
- [8] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. In Proc. NeurIPS, vol. 33, pp. 1877–1901, 2020.
- [9] S. K. Card, J. D. Mackinlay, and B. Shneiderman. Readings in information visualization: using vision to think. Morgan Kaufmann, San Francisco, 1999.
- [10] J. Cha, W. Kang, J. Mun, and B. Roh. Honeybee: Locality-enhanced projector for multimodal llm. In Proc. CVPR, 2024 To appear.
- [11] Chartblocks. Online chart builder, 2017. https://www.chartblocks.io/, last accessed on 29/06/2024.
- [12] J. Chen, M. Ling, R. Li, P. Isenberg, T. Isenberg, M. Sedlmair, T. Möller, R. S. Laramee, H.-W. Shen, K. Wünsche, et al. Vis30k: A collection of figures and tables from ieee visualization conference publications. IEEE Trans. Vis. Comput. Graph., 27(9):3826–3833, 2021. doi: 10 . 1109/TVCG . 2021 . 3054916
- [13] K. Chen, Z. Zhang, W. Zeng, R. Zhang, F. Zhu, and R. Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv, 2023. doi: arXiv:2306 . 15195
- [14] X. Chen, W. Zeng, Y. Lin, H. M. Al-maneea, J. Roberts, and R. Chang. Composition and configuration patterns in multiple-view visualizations. IEEE Trans. Vis. Comput. Graph., 27(2):1514–1524, 2021. doi: 10 . 1109/TVCG . 2020 . 3030338
- [15] Z.-Q. Cheng, Q. Dai, and A. G. Hauptmann. ChartReader: A unified framework for chart derendering and comprehension without heuristic rules. In Proc. ICCV, pp. 22202–22213, 2023. doi: 10 . 1109/ICCV51070 . 2023 . 02029
- [16] D. Deng, W. Cui, X. Meng, M. Xu, Y. Liao, H. Zhang, and Y. Wu. Revisiting the design patterns of composite visualizations. IEEE Trans. Vis. Comput. Graph., 29(12):5406–5421, 2023. doi: 10 . 1109/TVCG . 2022 . 3213565
- [17] D. Deng, A. Wu, H. Qu, and Y. Wu. DashBot: Insight-driven dashboard generation based on deep reinforcement learning. IEEE Trans. Vis. Comput. Graph., 29(1):690–700, 2023. doi: 10 . 1109/TVCG . 2022 . 3209468
- [18] D. Deng, Y. Wu, X. Shu, J. Wu, S. Fu, W. Cui, and Y. Wu. VisImages: A fine-grained expert-annotated visualization dataset. IEEE Trans. Vis. Comput. Graph., 29(7):3298–3311, 2023. doi: 10 . 1109/TVCG . 2022 . 3155440
- [19] X. L. Do, M. Hassanpour, A. Masry, P. Kavehzadeh, E. Hoque, and S. Joty. Do LLMs work on charts? designing few-shot prompts for chart question answering and summarization. arXiv, 2023. doi: 10 . 48550/arXiv . 2312 . 10610
- [20] Y. Du, H. Guo, K. Zhou, W. X. Zhao, J. Wang, C. Wang, M. Cai, R. Song, and J.-R. Wen. What makes for good visual instructions? synthesizing complex visual reasoning instructions for visual instruction tuning. arXiv, 2023. doi: 10 . 48550/arXiv . 2311 . 01487
- [21] L. W. Ge, Y. Cui, and M. Kay. CALVI: Critical thinking assessment for literacy in visualizations. In Proc. ACM CHI, pp. 815:1–815:18, 2023. doi: 10 . 1145/3544548 . 3581406
- [22] E. D. Giacomo, W. Didimo, G. Liotta, F. Montecchiani, and A. Tappini. Comparative study and evaluation of hybrid visualizations of graphs. IEEE Trans. Vis. Comput. Graph., 30(7):3503–3515, 2024. doi: 10 . 1109/TVCG . 2022 . 3233389
- [23] D. Haehn, J. Tompkin, and H. Pfister. Evaluating ‘graphical perception’with cnns. IEEE Trans. Vis. Comput. Graph., 25(1):641–650, 2018. doi: 10 . 1109/TVCG . 2018 . 2865138
- [24] Y. Han, C. Zhang, X. Chen, X. Yang, Z. Wang, G. Yu, B. Fu, and H. Zhang. Chartllama: A multimodal llm for chart understanding and generation. arXiv, 2023. doi: 10 . 48550/arXiv . 2311 . 16483
- [25] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proc. CVPR, pp. 770–778, 2016. doi: 10 . 1109/CVPR . 2016 . 90
- [26] M. He, Y. Liu, B. Wu, J. Yuan, Y. Wang, T. Huang, and B. Zhao. Efficient multimodal learning from data-centric perspective. arXiv, 2024. doi: 10 . 48550/arXiv . 2402 . 11530
- [27] E. Hoque, P. Kavehzadeh, and A. Masry. Chart question answering: State of the art and future directions. Comput. Graph. Forum, 41(3):555–572, 2022. doi: 10 . 1111/cgf . 14573
- [28] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. In Proc. ICLR, 2022.
- [29] K. Hu, M. A. Bakker, S. Li, T. Kraska, and C. Hidalgo. VizML: A machine learning approach to visualization recommendation. In Proc. ACM CHI, pp. 128:1–128:12, 2019. doi: 10 . 1145/3290605 . 3300358
- [30] S. Kantharaj, R. T. Leong, X. Lin, A. Masry, M. Thakkar, E. Hoque, and S. Joty. Chart-to-text: A large-scale benchmark for chart summarization. In Proc. ACL, pp. 4005–4023, 2022. doi: 10 . 18653/v1/2022 . acl-long . 277
- [31] D. H. Kim, E. Hoque, and M. Agrawala. Answering questions about charts and generating visual explanations. In Proc. ACM CHI, pp. 340:1–340:13, 2020. doi: 10 . 1145/3313831 . 3376467
- [32] G. Kim, T. Hong, M. Yim, J. Nam, J. Park, J. Yim, W. Hwang, S. Yun, D. Han, and S. Park. Ocr-free document understanding transformer. In Proc. ECCV, pp. 498–517, 2022. doi: 10 . 1007/978-3-031-19815-1_29
- [33] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv, 2014. doi: 10 . 48550/arXiv . 1412 . 6980
- [34] H.-K. Ko, H. Jeon, G. Park, D. H. Kim, N. W. Kim, J. Kim, and J. Seo. Natural language dataset generation framework for visualizations powered by large language models. In Proc. ACM CHI, pp. 843:1–843:22, 2024. doi: 10 . 1145/3613904 . 3642943
- [35] K. Lee, M. Joshi, I. R. Turc, H. Hu, F. Liu, J. M. Eisenschlos, U. Khandelwal, P. Shaw, M.-W. Chang, and K. Toutanova. Pix2Struct: Screenshot parsing as pretraining for visual language understanding. In Proc. ICML, pp. 18893–18912, 2023.
- [36] S. Lee, S.-H. Kim, and B. C. Kwon. VLAT: Development of a visualization literacy assessment test. IEEE Trans. Vis. Comput. Graph., 23(1):551–560, 2016. doi: 10 . 1109/TVCG . 2016 . 2598920
- [37] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Proc. NeurIPS, vol. 33, pp. 9459–9474, 2020.
- [38] C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. In Proc. NeurIPS, vol. 36, 2024.
- [39] H. Li, Y. Wang, S. Zhang, Y. Song, and H. Qu. KG4Vis: A knowledge graph-based approach for visualization recommendation. IEEE Trans. Vis. Comput. Graph., 28(1):195–205, 2021. doi: 10 . 1109/TVCG . 2021 . 3114863
- [40] J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proc. ICML, pp. 19730–19742, 2023.
- [41] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár. Focal loss for dense object detection. In Proc. ICCV, pp. 2980–2988, 2017. doi: 10 . 1109/ICCV . 2017 . 324
- [42] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In Proc. ECCV, pp. 740–755, 2014. doi: 10 . 1007/978-3-319-10602-1_48
- [43] F. Liu, J. Eisenschlos, F. Piccinno, S. Krichene, C. Pang, K. Lee, M. Joshi, W. Chen, N. Collier, and Y. Altun. DePlot: One-shot visual language reasoning by plot-to-table translation. In Proc. ACL Findings, pp. 10381–10399, 2023. doi: 10 . 18653/v1/2023 . findings-acl . 660
- [44] F. Liu, F. Piccinno, S. Krichene, C. Pang, K. Lee, M. Joshi, Y. Altun, N. Collier, and J. Eisenschlos. MatCha: Enhancing visual language pretraining with math reasoning and chart derendering. In Proc. ACL, pp. 12756–12770, 2023. doi: 10 . 18653/v1/2023 . acl-long . 714
- [45] F. Liu, X. Wang, W. Yao, J. Chen, K. Song, S. Cho, Y. Yacoob, and D. Yu. Mmc: Advancing multimodal chart understanding with large-scale instruction tuning. In Proc. NAACL, 2024 To appear.
- [46] H. Liu, C. Li, Y. Li, and Y. J. Lee. Improved baselines with visual instruction tuning. In Proc. CVPR, 2024 To appear.
- [47] H. Liu, C. Li, Y. Li, B. Li, Y. Zhang, S. Shen, and Y. J. Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024. https://llava-vl.github.io/blog/2024-01-30-llava-next/, last accessed on 29/06/2024.
- [48] H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual instruction tuning. In Proc. NeurIPS, vol. 36, pp. 34892–34916, 2023.
- [49] Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, and C. Zhu. G-eval: NLG evaluation using gpt-4 with better human alignment. In Proc. EMNLP, pp. 2511–2522, 2023. doi: 10 . 18653/v1/2023 . emnlp-main . 153
- [50] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie. A convnet for the 2020s. In Proc. CVPR, pp. 11976–11986, 2022. doi: 10 . 1109/CVPR52688 . 2022 . 01167
- [51] M. Lu, J. Lanir, C. Wang, Y. Yao, W. Zhang, O. Deussen, and H. Huang. Modeling just noticeable differences in charts. IEEE Trans. Vis. Comput. Graph., 28(1):718–726, 2021. doi: 10 . 1109/TVCG . 2021 . 3114874
- [52] G. Luo, Y. Zhou, Y. Zhang, X. Zheng, X. Sun, and R. Ji. Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models. arXiv, 2024. doi: 10 . 48550/arXiv . 2403 . 03003
- [53] Y. Luo, N. Tang, G. Li, C. Chai, W. Li, and X. Qin. Synthesizing natural language to visualization (nl2vis) benchmarks from nl2sql benchmarks. In Proc. ACM SIGMOD, pp. 1235–1247, 2021.
- [54] A. Masry, X. L. Do, J. Q. Tan, S. Joty, and E. Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In Proc. ACL Findings, pp. 2263–2279, 2022. doi: 10 . 18653/v1/2022 . findings-acl . 177
- [55] A. Masry, P. Kavehzadeh, X. L. Do, E. Hoque, and S. Joty. UniChart: A universal vision-language pretrained model for chart comprehension and reasoning. In Proc. EMNLP, pp. 14662–14684, 2023. doi: 10 . 18653/v1/2023 . emnlp-main . 906
- [56] A. Masry, M. Shahmohammadi, M. R. Parvez, E. Hoque, and S. Joty. ChartInstruct: Instruction tuning for chart comprehension and reasoning. arXiv, 2024. doi: 10 . 48550/arXiv . 2403 . 09028
- [57] F. Meng, W. Shao, Q. Lu, P. Gao, K. Zhang, Y. Qiao, and P. Luo. Chartassisstant: A universal chart multimodal language model via chart-to-table pre-training and multitask instruction tuning. arXiv, 2024. doi: 10 . 48550/arXiv . 2401 . 02384
- [58] N. Methani, P. Ganguly, M. M. Khapra, and P. Kumar. PlotQA: Reasoning over scientific plots. In Proc. WACV, pp. 1516–1525, 2020. doi: 10 . 1109/WACV45572 . 2020 . 9093523
- [59] OpenAI. gpt-4-vision-preview, 2024. https://api.openai.com/v1/chat/completions, last accessed on 29/06/2024.
- [60] S. Pandey and A. Ottley. Mini-VLAT: A short and effective measure of visualization literacy. Comput. Graph. Forum, 42(3):1–11, 2023. doi: 10 . 1111/cgf . 14809
- [61] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In Proc. ICML, pp. 8748–8763. PMLR, 2021.
- [62] R. Rahman, R. Hasan, A. A. Farhad, M. T. R. Laskar, M. H. Ashmafee, and A. R. M. Kamal. ChartSumm: A comprehensive benchmark for automatic chart summarization of long and short summaries. In Proc. CCAI, 2023. doi: 10 . 21428/594757db . 0b1f96f6
- [63] D. Schwenk, A. Khandelwal, C. Clark, K. Marino, and R. Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. In Proc. ECCV, pp. 146–162, 2022. doi: 10 . 1007/978-3-031-20074-8_9
- [64] C. Shi, C. Yang, Y. Liu, B. Shui, J. Wang, M. Jing, L. Xu, X. Zhu, S. Li, Y. Zhang, et al. Chartmimic: Evaluating lmm’s cross-modal reasoning capability via chart-to-code generation. arXiv, 2024. doi: 10 . 48550/arXiv . 2406 . 09961
- [65] P. Soni, C. de Runz, F. Bouali, and G. Venturini. A survey on automatic dashboard recommendation systems. Visual Informatics, 8(1):67–79, 2024. doi: 10 . 1016/j . visinf . 2024 . 01 . 002
- [66] B. J. Tang, A. Boggust, and A. Satyanarayan. VisText: A Benchmark for Semantically Rich Chart Captioning. In Proc. ACL, p. 7268–7298, 2023. doi: 10 . 18653/v1/2023 . acl-long . 401
- [67] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv, 2023. doi: 10 . 48550/arXiv . 2307 . 09288
- [68] L. Van der Maaten and G. Hinton. Visualizing data using t-sne. J. Mach. Learn. Res., 9(11):2579–2605, 2008.
- [69] L. Wang, S. Zhang, Y. Wang, E.-P. Lim, and Y. Wang. Llm4vis: Explainable visualization recommendation using chatgpt. In Proc. EMNLP, p. 675–692, 2023. doi: 10 . 18653/v1/2023 . emnlp-industry . 64
- [70] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In Proc. NeurIPS, vol. 35, pp. 24824–24837, 2022.
- [71] S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie. ConvNeXt V2: Co-designing and scaling convnets with masked autoencoders. In Proc. CVPR, pp. 16133–16142, 2023. doi: 10 . 1109/CVPR52729 . 2023 . 01548
- [72] S. Xiao, Y. Hou, C. Jin, and W. Zeng. WYTIWYR: A user intent-aware framework with multi-modal inputs for visualization retrieval. Comput. Graph. Forum, 42(3):311–322, 2023. doi: 10 . 1111/cgf . 14832
- [73] S. Xiao, S. Huang, Y. Lin, Y. Ye, and W. Zeng. Let the chart spark: Embedding semantic context into chart with text-to-image generative model. IEEE Trans. Vis. Comput. Graph., 2023. doi: 10 . 1109/TVCG . 2023 . 3326913
- [74] Y. Ye, J. Hao, Y. Hou, Z. Wang, S. Xiao, Y. Luo, and W. Zeng. Generative AI for visualization: State of the art and future directions. Visual Informatics, 8(2):43–66, 2024. doi: 10 . 1016/j . visinf . 2024 . 04 . 003
- [75] Y. Ye, R. Huang, and W. Zeng. VISAtlas: An image-based exploration and query system for large visualization collections via neural image embedding. IEEE Trans. Vis. Comput. Graph., 30:3224 – 3240, 2024. doi: 10 . 1109/TVCG . 2022 . 3229023
- [76] S. Zhang, P. Sun, S. Chen, M. Xiao, W. Shao, W. Zhang, K. Chen, and P. Luo. Gpt4roi: Instruction tuning large language model on region-of-interest. arXiv, 2023. doi: arXiv:2307 . 03601
- [77] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. In Proc. NeurIPS, vol. 36, pp. 46595–46623, 2023.