用于离线强化学习的数据集蒸馏
摘要
离线强化学习通常需要一个高质量的数据集,我们可以在该数据集上训练策略。 然而,在许多情况下,不可能获得这样的数据集,也不容易训练出在给定离线数据的实际环境中表现良好的策略。 我们建议使用数据蒸馏来训练和蒸馏更好的数据集,然后将其用于训练更好的策略模型。 我们表明,我们的方法能够合成一个数据集,其中训练的模型与在完整数据集上训练的模型或使用百分位数行为克隆训练的模型具有相似的性能。 我们的项目网站位于此处。 我们还在此 GitHub 存储库 中提供了我们的实现。
1简介
强化学习(RL)的一个重大挑战是数据生成过程与训练过程耦合在一起,而数据生成需要与环境进行频繁的在线交互,这在许多设置中是不可能的。 离线强化学习旨在通过将两者解耦并在给定的静态固定数据集上训练智能体来解决这个问题(Levine 等人 (2020),Prudencio 等人 (2023))。 然而,离线强化学习依赖于良好的专家策略生成的数据集。 我们常常无法获得良好政策生成的数据,只能获得平庸政策生成的数据。 离线训练还意味着我们面临分布转移问题,即在数据集上训练的策略会产生与数据集中不同的数据分布。
我们没有采用通常的离线 RL 方法来寻找更好的方法来训练给定离线数据集的模型,而是采取另一种方法来询问,是否有一种方法可以提取更好的离线数据集来训练? 我们相信,与寻找更好的训练方法相比,这种方法具有多种优势。 首先,与经过更好训练的模型相比,解释精炼数据集更容易。 其次,由于我们学习了输入空间的关键特征,蒸馏往往会带来更好的泛化能力(Stanton 等人 (2021)、Sachdeva 和 McAuley (2023))。 第三,蒸馏后的数据集比原始离线数据集小得多,从而提高了样本效率。
我们建议使用数据蒸馏 Wang 等人 (2018) 中的一种称为梯度匹配的方法,在离线数据集上训练较小的合成数据集。 我们评估了在 Procgen 环境 Cobbe 等人 (2020) 上使用我们的程序训练的学生,该环境由程序生成的游戏组成。 具体来说,学生只能访问一些程序生成的地图上的离线专家政策数据,并且必须将他们在这些地图上学到的知识推广到其他看不见的、分布外的设置。 我们表明,使用合成数据训练的学生能够比使用原始离线政策数据集训练的学生或使用百分位行为克隆训练的学生在分布内和分布外表现相似或更好,尽管事实上他们是 在较小的数据集上进行训练。
为什么在较小的数据集上进行训练对 RL 设置特别有帮助? 强化学习是一种学习范式,由于代理还可以控制数据生成过程,因此很容易出现随机性和过度拟合。 我们在这里得到的见解是,较小且控制良好的数据集可以减少随机性和过度拟合。 就像人类通过阅读一本写得好的书而不是阅读许多低质量的文章来更有效地学习一样,强化学习代理也可以通过在高质量数据集上进行训练来学习更好、更通用的策略。
总而言之,我们的主要贡献如下:
-
•
我们提出了一种新方法Synthetic,该方法根据专家策略使用数据集蒸馏生成的离线轨迹数据集来合成新的数据集。
-
•
我们证明,在使用我们的方法合成的数据集上训练的强化学习模型能够在环境中比直接在专家数据或其他技术(例如百分位数行为克隆)上表现相似或更好
-
•
我们演示了在我们的合成数据集上训练 RL 模型时如何能够使用小得多的数据集实现类似的性能
2方法论
我们在这里描述了我们的一般问题设置、解决问题的基线方法以及我们的方法。
2.1离线强化学习问题设置
在我们的强化学习设置中,环境被模拟为一个 Markov 决策过程 (MDP) ,其状态空间为 ,行动空间为 ,为概率转换函数,为直接转换奖励,为起始状态,为结束状态,因为我们处于偶发设置中。 策略函数是从状态到动作空间上的概率分布的映射。 我们假设 和 在我们的设置中都是离散的。 当策略可以通过某些参数 进行参数化时,我们将该策略表示为 。 由于我们使用深度强化学习,因此 将是一个具有权重 的神经网络。
参数化强化学习的目标是学习最大化一个episode的累积的最佳。 我们根据策略 引起的轨迹分布来定义累积奖励。 轨迹是一系列状态和动作,以开始并以结束,即。 那么由策略和环境引起的轨迹分布由下式给出
那么期望的累积奖励是
我们的目标是找到
在离线强化学习中,代理不允许与环境交互并通过环境交互收集数据。 相反,我们获得一个静态转换数据集 来学习最佳策略 ,其中 是情节 。 有时,数据集还包括当前状态和整个剧集的未来返回 ,因此 。 我们假设数据是使用某种策略生成的,即。
2.2行为克隆
实现离线强化学习的一种常见方法是简单地尝试训练策略 来模仿 。 这是通过训练 以监督学习方式完成的,以预测给定 的 并最小化损失
| (1) |
其中 是暗示某种距离概念的范数, 是 中数据点的一些权重。 通常我们取统一权重。 由于我们通常使用随机梯度下降(SGD)来最小化损失,因此在这种情况下我们可以简单地使用作为选择样本的概率。
由于 可能不是最佳的,我们可以尝试通过过滤掉 中导致不良结果的观察来训练更好的策略 。 换句话说,我们令 其中 是好结果与坏结果的某个阈值。 我们调用选择 的方法,这样我们最终只得到初始数据集的 x%,并使用 BC 作为 BCx% 或 训练策略 百分位行为克隆。 换句话说,百分位数行为克隆的目标是筛选出更好的数据集。
2.3 综合数据集
我们的方法直接学习一个好的样本,而不是过滤掉坏样本来创建好的训练数据集。 这是通过数据集蒸馏来完成的,这是一种用于监督学习的技术Wang 等人 (2018)。 我们描述了如何在此处“训练”合成数据集 ,并在给定离线数据集 的情况下通过 进行参数化。 我们的方法旨在根据某种分布 相对于模型权重 的随机初始化来减少 的梯度匹配损失。 给定一些模型参数 ,我们首先获得 相对于我们在 1 中定义的真实数据集 ,以及我们的合成。 然后我们将梯度匹配损失定义为
| (2) |
然后我们使用 SGD 来尽量减少这种损失。 此方法有助于保证在训练模型时,合成数据集 将产生与 类似的梯度。

3实验设置
我们在下面提供了如何实施实验的详细信息,包括我们测试方法的环境、模型的架构以及我们如何训练模型。
3.1环境
我们使用了 OpenAI 开发的 Procgen 环境,这是一套由 16 个程序生成的环境组成的套件,允许使用不同的种子 Cobbe 等人 (2020) 创建自适应环境。 这些环境的固有机制是评估学生模型学习和适应不同种子引入的变化的能力的理想平台。 此外,多样化的环境有助于我们的研究,因为代理接受了针对标准训练程序中可能不会出现的各种挑战的培训。 这样我们就可以在实际实施中可能出现的不同场景中仔细检查代理的表现。 图 2 显示了 Procgen 环境中的一些示例游戏。

在 Procgen 环境中,状态空间由 64x64 像素图像(具有三个通道和值 到 的 RGB 数组)组成。 动作空间本质上是离散的,通常包括移动(上、下、左、右)和交互,例如收集物品或打开门。 在我们的实验中,我们考虑了三种程序生成的游戏:Bigfish、Starpilot 和 Jumper。 例如,在《Starpilot》中,玩家必须驾驶一艘太空飞船以避免被子弹击中,并以街机游戏的方式击落敌人。 敌人和障碍物是按程序生成的,因此每个“地图”都是不同的。 Procgen 基准测试的关键特征是,给定不同的种子,尽管游戏规则不变,但玩家会遇到不同的“地图”。 人工智能代理面临的一个关键挑战在于它们如何适应以前从未见过的种子。
3.2 模型架构和训练
3.2.1 模型训练
我们考虑两种模型架构——专家政策模型和学生政策模型。 专家模型是我们用作专家策略的神经网络,然后用于生成离线数据集。 学生模型是我们在离线数据上训练以生成策略的神经网络。 回想一下,离线强化学习的目标是优化参数 以产生良好的策略,如 2.1 节中所述。
专家模型是 IMPALA Espeholt 等人 (2018) 中发现的具有卷积架构的智能体,遵循 Procgen 论文 Cobbe 等人 (2020) 中的约定。 我们使用近端策略优化 (PPO) Schulman 等人 (2017) 来训练环境专家策略。 我们使用 PFRL 包,并遵循 GitHub Fujita 等人 (2021) 上社区创建的 pytorch 实现;莱里唐。 我们对专家模型在 200 个种子上训练了 2500 万步,直到它在环境中达到令人满意的性能水平。 因此,我们为这三种环境中的每一种环境总共训练了三个专家模型。 该 IMPALA 网络具有三个卷积块。 第一个卷积块具有输出通道 16,接下来的两个块具有输出通道 32。 此设置共有 个可训练参数。 表1显示了有关专家模型的更多详细信息。
对于学生(试图模仿专家的模型),我们使用 CNN(卷积神经网络)作为基础模型。 CNN 模型有 4 个卷积模块,后面是一个到 logits 的全连接层。 卷积层利用具有 输出通道的 内核,并与 ReLU 激活和具有池内核大小 和跨度 的平均 维池层相结合。 对于前层,输出通道的尺寸是输入通道的倍。 对于最后的层,输出通道的尺寸比输入通道的尺寸小倍。 所以最后一层的输出通道与第一层的输入通道相同。 然后,卷积层的输出被传递到全连接层,该层映射到逻辑。 这种更精简的设置总共有 个可训练参数,减少了全连接层的大小。 与专家模型相比,学生模型的可训练参数要少得多。 表1包含训练学生模型的超参数。
对于每种数据库收集方法,我们训练 10 名学生,并取奖励平均值和奖励标准差的平均值。 我们使用学习率为 5e-3 Kingma 和 Ba (2017) 的 Adam 优化器。 对于行为克隆学生,我们用 1000 个步骤和 256 的批量大小对他们进行训练。 对于综合学生,我们仅使用 100 个步骤和批量大小 15 来训练他们。
| Expert | BC Student | Synthetic Student | |
| Model Params | 621632 | 6966 | 6966 |
| Optimizer | Adam | Adam | Adam |
| Learning Rate | 1e-5 | 5e-3 | 5e-3 |
| Batch Size | 8 | 256 | 15 |
| Steps | 25M | 1000 | 100 |
3.2.2数据构建
4结果
我们将我们的方法与(1)我们通过与环境交互以在线方式训练的专家策略进行比较,直到我们取得良好的性能,然后将其用于生成离线数据集和(2)学生使用百分位行为克隆对具有不同过滤级别的数据集进行训练,如 2.2 节中所述。 换句话说,我们希望对我们的训练方法在生成可用于离线强化学习模型的高质量数据集方面的表现进行基准测试。
对于所有基线方法,学生模型都使用相同数量的随机梯度下降步骤和相同的批量大小进行训练。 我们在表2和图4中显示了各种方法的分布内性能,即离线数据集中包含的种子的性能。 我们在这里看到,在 Jumper 和 Bigfish 环境中,Synthetic 优于所有百分位行为克隆方法。 合成 在 Starpilot 上的表现并不优于百分位数 BC。 我们观察到,与 Bigfish 和 Jumper 相比,Starpilot 专家在游戏过程中主要采取一种行动——“射击”行动,而 Bigfish 和 Jumper 中专家采取的行动分布更均匀。 因此,由于不同动作的样本不平衡,数据集很难提取。
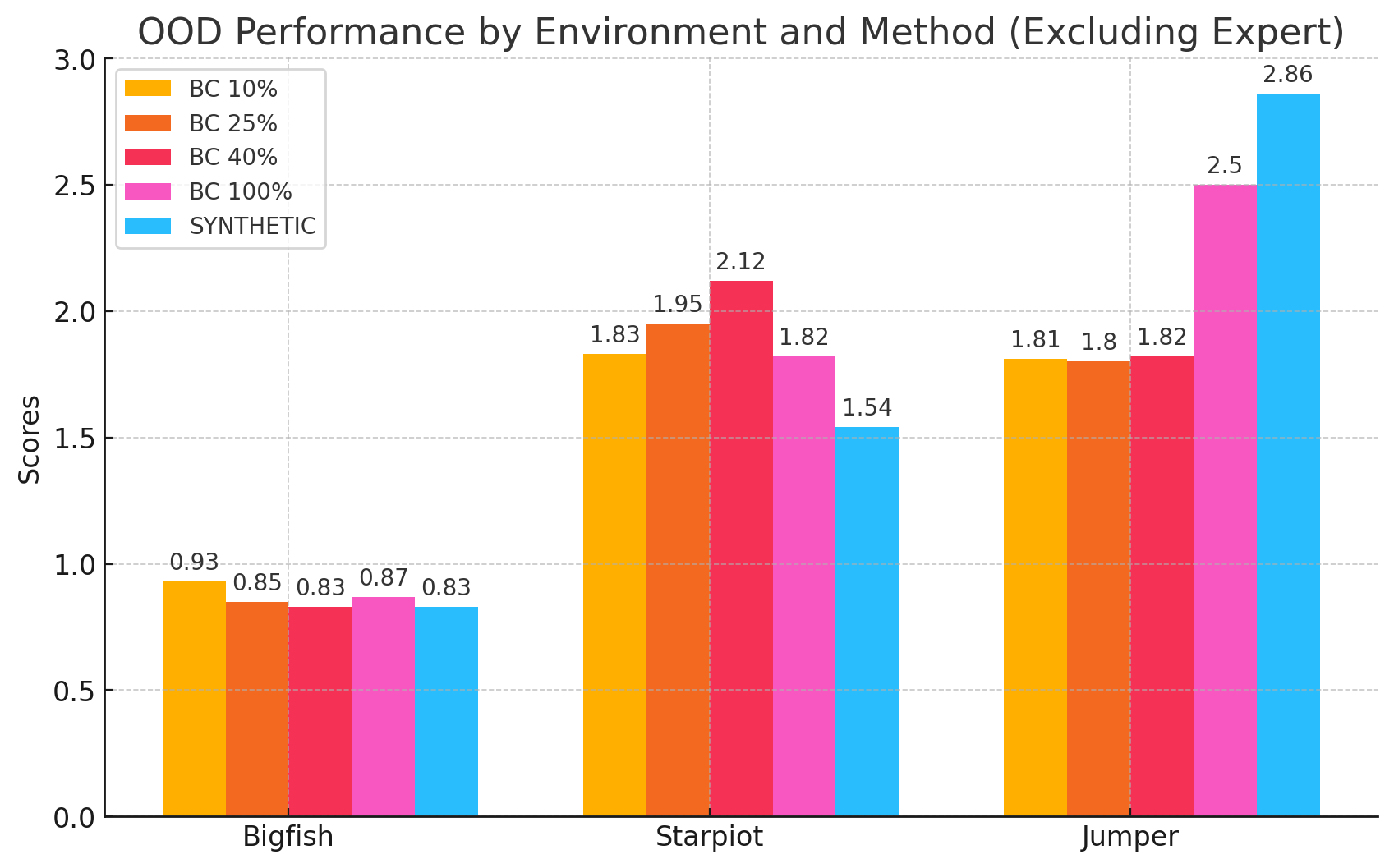
由于我们可以在Procgen中按程序生成分布外(OOD)场景,因此我们还测试了各种数据集生成方法的OOD性能,如表3和图4所示。 我们在这里看到,类似的,合成在 Jumper 环境中优于百分位行为克隆方法。 Synthetic 还匹配 Bigfish 上的所有百分位 BC 表现。 Synthetic 在 Starpilot 上的表现并不优于百分位数 BC,因为 Starpilot 的数据集不平衡。
我们通过Synthetic训练的学生模型仅使用数据样本,如表4所示。 鉴于表 1 中提到的数据集大小小得多(不到 BC10% 的一半)和训练步骤少得多,综合 与不同设置中的行为克隆相比,取得了有竞争力的结果。 合成也能很好地概括出分布,因为 OOD 性能与 ID 结果相匹配,并且 Starpilot 和 Jumper 中的性能常常优于 ID 结果。
| ID Performance | ||||||
|---|---|---|---|---|---|---|
| Environment | Expert | BC 10% | BC 25 % | BC 40 % | BC 100 % | Synthetic |
| Bigfish | 14.27 15.53 | 0.90 1.44 | 0.93 1.47 | 1.01 1.62 | 1.00 1.67 | 1.03 1.99 |
| Starpilot | 28.88 19.41 | 1.73 2.20 | 2.10 2.66 | 2.17 2.58 | 1.85 2.22 | 1.5 1.96 |
| Jumper | 8.79 3.26 | 1.79 3.54 | 2.15 4.12 | 1.95 3.86 | 2.32 4.13 | 2.76 4.40 |
| OOD Performance | ||||||
|---|---|---|---|---|---|---|
| Environment | Expert | BC 10% | BC 25 % | BC 40 % | BC 100 % | Synthetic |
| Bigfish | 6.03 9.84 | 0.93 1.38 | 0.85 1.19 | 0.83 1.28 | 0.87 1.32 | 0.83 1.04 |
| Starpilot | 23.34 18.30 | 1.83 2.39 | 1.95 2.39 | 2.12 2.35 | 1.82 2.20 | 1.54 1.93 |
| Jumper | 5.61 4.96 | 1.81 3.51 | 1.8 3.73 | 1.82 3.70 | 2.50 4.26 | 2.86 4.43 |
| Dataset Size | |||||
|---|---|---|---|---|---|
| Environment | BC 10% | BC 25 % | BC 40 % | BC 100 % | Synthetic |
| Bigfish | 2027 | 5014 | 7336 | 10450 | 150 |
| Starpilot | 1116 | 2796 | 4192 | 6830 | 150 |
| Jumper | 392 | 919 | 1337 | 4837 | 150 |

5相关工作
5.1深度强化学习
深度强化学习最近在解决广泛的问题方面取得了令人难以置信的成功,从国际象棋和围棋到 Atari 游戏和机器人Silver 等人 (2016)。 我们还看到了用于设计此类代理的架构的巨大改进,从 PPO Schulman 等人 (2017) 到决策转换器 Chen 等人 (2021)。 随着深度神经网络在各种任务中显示出其有效性,强化学习的研究人员越来越多地将注意力转向它们。 许多复杂的强化学习情况需要这些多功能神经网络来完成诸如编码代理状态、学习复杂策略和评估其性能等任务。 Arulkumaran 等人 (2017) 很好地概述了将深度神经网络纳入强化学习设置的各种方式。
5.2知识蒸馏
随着大型深度神经网络开始在与大规模数据相关的多个现实场景中取得显着成功,在移动设备和嵌入式系统中部署深度模型变得非常重要。 Bucilua 等人 (2006) 首先解决了这个问题,并提出了对大型模型进行压缩,以将信息从大型模型传输到训练小型模型,从而不影响准确性。 Hinton等人(2015)将“知识蒸馏”一词普及化为从大模型(老师)到小学生模型学习小模型的过程。 近年来,知识蒸馏有了许多扩展,重点是压缩深度神经网络。 轻量级学生模型为将知识蒸馏集成到各种应用中铺平了道路,例如对抗性攻击 Papernot 等人 (2016)、数据安全和隐私 Wang 等人 (2019) 、数据增强Lee 等人 (2020) 等。KD 一直是自然语言处理(NLP)研究的关键工具Devlin 等人 (2018)。 Sun 等人 (2019) 和 Tang 等人 (2019) 通过知识蒸馏使用了 BERT 的一些轻量级变体(称为 BERT 模型压缩)。 Jiao等人(2019)提出了TinyBERT,一种两阶段的Transformer知识蒸馏,使框架变得更加轻量。
5.3政策蒸馏
也有人尝试将专家(教师)网络的策略直接提炼为学生网络Rusu 等人(2015),称为策略提炼。 策略蒸馏是知识蒸馏的一种专门应用,它在强化学习的背景下采用了 KD 的原理。 它用于在深度强化学习中将知识从一种策略转移到另一种策略。 Czarnecki 等人 (2019)确定了 DRL 中的三种蒸馏技术,通过理论和实证分析比较了它们的动机和优势,其中包括期望熵正则化蒸馏,它可以在快速学习的同时确保收敛。 策略蒸馏还可以用于提取 RL 代理的策略,以训练一个更高效、更小的网络,该网络可以熟练地执行 Rusu 等人 (2015)。
虽然我们的工作还向学生教授基于某些教师政策的政策,但我们采取更间接的离线方法,其中只允许学生看到专家(老师)生成的离线数据。
5.4 数据集蒸馏
数据集蒸馏是一种合成较小数据集的数据集缩减方法。 在最初的工作中,这是通过将来自真实数据的样本和来自合成数据集的样本输入随机初始化的模型,并获取模型相对于这两个数据样本的梯度Wang 等人 (2018). 两个梯度之间的差异被视为损失,并且使用 SGD 更新合成数据集中的数据值(同时保持模型权重固定)。从那时起,人们提出了各种不同的蒸馏方法(于等人(2023),雷和涛(2023))。 在这样的工作中,不是匹配单个样本的梯度,而是匹配一系列样本训练后的梯度总和(模型参数的总变化)(Cazenavette 等人 (2022))。 尽管最近人们对这项技术很感兴趣,但据作者所知,目前还没有任何数据集蒸馏在强化学习中的应用。
5.5 任务泛化
任务泛化的目标是将完成一项任务所学到的知识转移到其他任务中,从而扩展模型的功能。 在理想情况下,学习到的模型应该能够通过使用学到的核心知识将其知识应用于不断变化的任务。 (Taylor and Stone (2007)) 提出了一种称为“规则迁移”的新迁移方法,旨在学习源任务的规则并将其应用于其他目标任务。 (Taylor 等人 (2008)) 旨在学习从源任务到目标任务的转换之间的映射。 在(Oh等人(2017))中提出的问题中,智能体需要在掌握子任务解决技能后学习执行指令序列。 该问题为推广到未见过的任务提供了良好的基础。 在 (Lehnert 等人 (2020)) 中,作者建议使用奖励预测赋予代理更好的泛化能力。
5.6其他作品
在论文(Yuan 等人 (2021))中,作者针对多位教师的场景提出了一种基于强化学习的知识蒸馏方法。 他们的工作重点是 NLP,并使用 BERT 和 RoBERTa 等大型预训练模型,其中框架动态地将权重分配给每个训练实例上的不同教师模型,以最大限度地提高经过提炼的学生模型的性能。 在 (Xie 等人 (2021)) 中,作者提出了一种新颖的框架 (DRL-Rec),用于列表式推荐中基于 RL 的模型之间的知识蒸馏,其中他们引入了一个模块,通过该模块,教师决定向学生教授哪节课,并进行另一个以信心为导向的提炼,通过该提炼来确定学生应该从每节课中学到多少。
6 结论和局限性
我们的研究有几个局限性。 第一个是,由于我们拥有的计算资源和时间,我们只在 Procgen 中的三个环境上进行了测试。 然而,我们相信这些环境上的实验证明了我们方法的潜力,我们期待未来在其他环境上的工作。 我们在工作中还专注于模仿政策学习,因为我们的重点是数据集蒸馏,而不是政策学习方法。 然而,也可以使用其他 RL 方法(例如 q-learning 或 actor-critic)在合成数据集上训练策略。 我们主要针对百分位行为克隆进行基准测试,因为这是现有文献中最接近的方法,可以“过滤”以获得更好质量的训练数据集。
总之,我们提出并测试了一种为离线强化学习合成质量更好的训练数据集的方法。 我们方法的性能表明数据集的质量是训练更好模型的关键组成部分,与较大的数据集相比,较小但质量较高的数据集可以带来相似或更好的性能。 我们相信,这些方法在数据量少或数据嘈杂以及无法在线收集数据的情况下非常有效。 这个研究领域还有很多值得探索的地方。
参考
- Arulkumaran et al. (2017) Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath. Deep reinforcement learning: A brief survey. IEEE Signal Processing Magazine, 34(6):26–38, 2017.
- Bucilua et al. (2006) C Bucilua, R Caruana, and A Niculescu-Mizil. Model compression, in proceedings of the 12 th acm sigkdd international conference on knowledge discovery and data mining. New York, NY, USA, 4, 2006.
- Cazenavette et al. (2022) George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4750–4759, 2022.
- Chen et al. (2021) Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling, 2021.
- Cobbe et al. (2020) Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 2048–2056. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/cobbe20a.html.
- Czarnecki et al. (2019) Wojciech M Czarnecki, Razvan Pascanu, Simon Osindero, Siddhant Jayakumar, Grzegorz Swirszcz, and Max Jaderberg. Distilling policy distillation. In The 22nd international conference on artificial intelligence and statistics, pages 1331–1340. PMLR, 2019.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Espeholt et al. (2018) Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Volodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures, 2018.
- Fujita et al. (2021) Yasuhiro Fujita, Prabhat Nagarajan, Toshiki Kataoka, and Takahiro Ishikawa. Chainerrl: A deep reinforcement learning library. Journal of Machine Learning Research, 22(77):1–14, 2021. URL http://jmlr.org/papers/v22/20-376.html.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network, 2015.
- Jiao et al. (2019) Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. arXiv preprint arXiv:1909.10351, 2019.
- Kingma and Ba (2017) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017.
- Lee et al. (2020) Hankook Lee, Sung Ju Hwang, and Jinwoo Shin. Self-supervised label augmentation via input transformations. In International Conference on Machine Learning, pages 5714–5724. PMLR, 2020.
- Lehnert et al. (2020) Lucas Lehnert, Michael L Littman, and Michael J Frank. Reward-predictive representations generalize across tasks in reinforcement learning. PLoS computational biology, 16(10):e1008317, 2020.
- Lei and Tao (2023) Shiye Lei and Dacheng Tao. A comprehensive survey of dataset distillation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- (16) Lerrytang. Lerrytang/train-procgen-pfrl: Pytorch code to train and evaluate procgen tasks. URL https://github.com/lerrytang/train-procgen-pfrl/tree/main.
- Levine et al. (2020) Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
- Oh et al. (2017) Junhyuk Oh, Satinder Singh, Honglak Lee, and Pushmeet Kohli. Zero-shot task generalization with multi-task deep reinforcement learning. In International Conference on Machine Learning, pages 2661–2670. PMLR, 2017.
- Papernot et al. (2016) Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, and Ananthram Swami. Distillation as a defense to adversarial perturbations against deep neural networks. In 2016 IEEE symposium on security and privacy (SP), pages 582–597. IEEE, 2016.
- Prudencio et al. (2023) Rafael Figueiredo Prudencio, Marcos ROA Maximo, and Esther Luna Colombini. A survey on offline reinforcement learning: Taxonomy, review, and open problems. IEEE Transactions on Neural Networks and Learning Systems, 2023.
- Rusu et al. (2015) Andrei A Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation. arXiv preprint arXiv:1511.06295, 2015.
- Sachdeva and McAuley (2023) Noveen Sachdeva and Julian McAuley. Data distillation: A survey, 2023.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017.
- Silver et al. (2016) David Silver, Aja Huang, Christopher Maddison, Arthur Guez, Laurent Sifre, George Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of go with deep neural networks and tree search. Nature, 529:484–489, 01 2016. doi: 10.1038/nature16961.
- Stanton et al. (2021) Samuel Stanton, Pavel Izmailov, Polina Kirichenko, Alexander A Alemi, and Andrew G Wilson. Does knowledge distillation really work? Advances in Neural Information Processing Systems, 34:6906–6919, 2021.
- Sun et al. (2019) Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for bert model compression. arXiv preprint arXiv:1908.09355, 2019.
- Tang et al. (2019) Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, and Jimmy Lin. Distilling task-specific knowledge from bert into simple neural networks. arXiv preprint arXiv:1903.12136, 2019.
- Taylor and Stone (2007) Matthew E Taylor and Peter Stone. Cross-domain transfer for reinforcement learning. In Proceedings of the 24th international conference on Machine learning, pages 879–886, 2007.
- Taylor et al. (2008) Matthew E Taylor, Gregory Kuhlmann, and Peter Stone. Autonomous transfer for reinforcement learning. In AAMAS (1), pages 283–290, 2008.
- Wang et al. (2019) Ji Wang, Weidong Bao, Lichao Sun, Xiaomin Zhu, Bokai Cao, and S Yu Philip. Private model compression via knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 1190–1197, 2019.
- Wang et al. (2018) Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A Efros. Dataset distillation. arXiv preprint arXiv:1811.10959, 2018.
- Xie et al. (2021) Ruobing Xie, Shaoliang Zhang, Rui Wang, Feng Xia, and Leyu Lin. Explore, filter and distill: Distilled reinforcement learning in recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 4243–4252, 2021.
- Yu et al. (2023) Ruonan Yu, Songhua Liu, and Xinchao Wang. Dataset distillation: A comprehensive review. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- Yuan et al. (2021) Fei Yuan, Linjun Shou, Jian Pei, Wutao Lin, Ming Gong, Yan Fu, and Daxin Jiang. Reinforced multi-teacher selection for knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14284–14291, 2021.