语言模型物理学:第 2.1 部分,
小学数学和隐藏的推理过程
我们要感谢林晓、周春亭进行的许多有益的对话。 我们要特别感谢 Meta FAIR 的 Lucca Bertoncini、Liao Hu、Caleb Ho、Wil Johnson、Apostolos Kokolis、Parth Malani、Alexander Miller、Junjie Qi 和 Shubho Sengupta; Meta Cloud 基金会团队的 Henry Estela、Rizwan Hashmi、Lucas Noah 和 Maxwell Taylor;以及来自 W&B 的 Ian Clark、Gourab De、Anmol Mann 和 Max Pfeifer。 如果没有他们的宝贵支持,本文中的实验就不可能实现。 )
摘要
语言模型的最新进展已经证明了它们解决数学推理问题的能力,在 GSM8K 等小学水平的数学基准上实现了近乎完美的准确性。 在本文中,我们正式研究语言模型如何解决这些问题。 我们设计了一系列对照实验来解决几个基本问题:(1)语言模型能否真正培养推理能力,还是只是记住模板? (2)模型的隐藏(心理)推理过程是什么? (3) 模型是否使用与人类相似或不同的技能来解决数学问题? (4) 在类 GSM8K 数据集上训练的模型是否能够发展出超出解决 GSM8K 问题所需的推理能力? (5)什么心理过程导致模型出现推理错误? (6) 模型必须有多大或深度才能有效解决 GSM8K 级别的数学问题?
我们的研究揭示了语言模型解决数学问题的许多隐藏机制,提供了超出当前对大语言模型理解的见解。
1简介
近年来,语言模型领域取得了重大进展。 像 GPT-4 [openai2023gpt4] 这样的大型模型已经显示出通用智能的初步迹象[bubeck2023sparks],而较小的模型通过解决具有挑战性的编码和数学问题表现出了良好的推理能力[li2023教科书,gunasekar2023教科书,liu2023tinygsm]。
在本文中,我们关注小语言模型解决小学数学问题的能力。 与以前的工作不同,这些工作在小学数学基准上凭经验提高模型的准确性,例如 GSM8K [cobbe2021training] 及其增强(例如,[liu2023tinygsm, zhang2024careful]),我们采用更有原则性的方法。 我们的目标是了解以下基本问题:
-
1.
语言模型如何学习解决小学水平的数学问题? 他们只是记住模板,还是学习类似于人类的推理技能? 或者他们是否发现了解决问题的新技能?
-
2.
仅针对小学数学问题训练的模型是否只能学会解决这些问题,还是会发展出一些更通用的智能?
-
3.
在解决小学数学问题的同时,语言模型可以有多小? 深度(层数)比宽度(每层神经元数量)更重要,还是像实践者[kaplan2020scaling]所建议的那样,只有大小才重要?
这些问题对于理解语言模型的智能至关重要。 为了研究它们,似乎很容易从预先训练的模型开始,并在 GSM8K 或 GPT-4 增强数据集等现有数据集上对其进行训练(例如,[liu2023tinygsm, zhang2024careful])。 然而,这种方法有很大的局限性:
-
•
数据污染。 现有模型的预训练数据大多来自公开的互联网[gao2020pile],是一堆乱七八糟的东西。 我们不知道包含多少数学问题或其结构。 人们非常担心 GSM8K 基准是否已泄露到语言模型的训练数据集[zhang2024careful]。 即使确切的数据不是,预训练的模型也可能看到几乎相同的问题(例如,具有不同数字的相同问题)。 因此,这种方法无法回答问题1-3。 我们不知道模型是否真正学习了推理技能,或者只是在训练过程中记住了问题模板。 因此,我们需要完全控制模型的预训练数据,并且必须从头开始构建语言模型。 最近在[AL2023-knowledge, AL2023-knowledgeUB]中重申了这一点。
-
•
解决方案多样性。 现有的微调数据,例如GSM8K训练集,仅包含7.5K个小学数学问题,不足以从头开始训练模型。 尽管最近的作品使用 GPT-4 来增强 GSM8K,但这对于我们的目的来说还不够。 GPT-4 增强问题可能偏向于少量的解模板,因为原始 GSM8K 数据的解模板很少(显然最多 8K)。 我们需要一组更大、更多样化的小学数学问题。
考虑到这些要点,我们介绍了我们的框架来生成大量不同的小学数学 (GSM) 问题,并使用数据集来训练(从头开始)和测试类似 GPT2 的语言模型。 在该框架中,我们重点关注小学数学问题的“逻辑推理”方面,其中涉及问题陈述中参数的依赖性,例如“爱丽丝的苹果是鲍勃的橙子和查尔斯的香蕉之和的三倍”。我们使用合成句来减少常识带来的难度,例如“a Candleburned for 12hours at 1inch Per hour”(暗示蜡烛的长度正在减少)。 我们还消除了纯算术的困难:我们只考虑整数和算术。111有大量文献研究语言模型如何更好地学习算术和长度泛化,请参阅[zhou2023algorithms, jelassi2023length]及其参考文献。 现代语言模型还配备了检索增强生成(RAG),允许将算术计算委托给计算器。
此外,我们的框架确保生成的数学问题高度多样化,并且不是来自模板的一小部分。 即使忽略所有算术、英文、变量名和未使用的参数,我们的问题仍然有超过 90 万亿个解决方案模板(参见Proposition 2.2),远大于大小GPT2-小(100M)。 因此,语言模型无法通过简单地记住解决方案模板来解决我们案例中的数学问题。
在本文中,我们使用 GPT2 模型[radford2019language],但将其位置嵌入替换为旋转嵌入(RoPE)[su2021roformer, gpt-neox-20b]。 为了简洁起见,我们仍然将其称为 GPT2。 我们总结了我们的主要贡献:
-
–
结果2。 我们证明,在我们的合成数据集上进行预训练的 GPT2 模型不仅可以在解决相同分布的数学问题时达到 99% 的准确率,而且还可以进行分布外泛化,例如推理长度比训练期间所见的推理长度更长的问题。 这类似于算术中的长度泛化 [anil2022exploring, jelassi2023length],但是,在我们的例子中,模型 从未见过任何 与测试时长度相同的训练示例。 这意味着模型可以真正学习一些推理技能,而不是记住解决方案模板。
-
–
结果3。 至关重要的是,该模型可以学习生成最短的解决方案,几乎总是避免不必要的计算。 这表明模型在生成之前制定了计划,以避免计算解决基础数学问题不需要的任何量。
-
–
结果 4. 我们通过探测来检查模型的内部状态,引入六个探测任务来阐明模型如何解决数学问题。 例如,我们发现了模型(在心理上!) 在开始任何生成之前预处理全套必要参数。 同样,人类也会进行这种预处理,尽管我们将其写在草稿本上。
-
–
结果5。 令人惊讶的是,该模型在预训练后还学习了不必要但重要的技能,例如全对依赖。 在提出任何问题之前,它已经(在心理上!) 即使解决数学问题不需要某些参数,也可以高精度计算哪些参数取决于哪些参数。 请注意,计算全对依赖性是一项不需要的技能来适应数据中的所有解决方案。 据我们所知,这是第一个证据表明语言模型可以学习超出适合其预训练数据所需的有用技能。222在我们的例子中,无需计算全对依赖性即可解决所有数学问题。 我们的预训练数据从不包含此类信息——所有解决方案仅计算必要的变量。 这可能是AGI中的G的来源的预备知识信号。333事实上,对上下文中的对象之间的关系进行排序的技能是一项通用技能,通过指令微调,它可能会导致解决其他任务的技能,例如发现因果关系、确定参数变化的影响等。
-
–
结果 6. 我们解释为什么会出现错误。 例如,该模型会出现系统错误,这些错误可以通过探测其内部状态来解释。 有时,可以在模型生成答案之前预测这些错误,使它们独立于随机生成过程。 我们将其与实践联系起来,注意到 GPT-4/4o 也犯了类似的错误(尽管我们无法探测它们的内部状态)。
-
–
结果7+8。 语言模型的深度对其推理能力至关重要。 例如,一个 16 层、576 维的 Transformer 比一个 4 层、1920 维的 Transformer 解决了更难的问题(推理长度),尽管后者的大小是后者的两倍。 即使使用思想链 (CoT),这一点也成立。 我们通过所涉及的心理过程的复杂性来深入解释这种必要性。 我们主张使用受控的合成数据作为更原则的方法来得出此类主张,这与基于使用互联网预训练数据[kaplan2020scaling]基于训练损失的预测“只有大小很重要”形成鲜明对比。
虽然我们不会夸大我们的发现直接适用于 GPT-4 等基础模型或更具挑战性的数学推理任务,但我们相信我们的工作极大地推动了对语言模型如何发展其数学推理技能的理解,而这必须以不同于推动基准的方式来完成。
2 结果1:数据生成
动机。 回想一下 GSM8K 数据集中的一个标准小学数学问题 [cobbe2021training] 如下所示:
| 贝蒂正在存钱买一个价值 100 美元的新钱包。 贝蒂只有她需要的一半钱。 为此,她的父母决定给她 15 个,而她的祖父母是她父母的两倍。 贝蒂还需要多少钱才能买这个钱包? |
这个问题涉及到多个参数,参数的值通过各种等式联系起来,比如“贝蒂现在的钱=0.5钱包的成本”和“祖父母给的钱=2给的钱”由父母。”受此启发,我们通过捕获参数依赖性的合成生成管道构建了类似 GSM8K 的数学数据集。 我们希望至少捕获以下三种类型的依赖关系。
-
1.
直接依赖():如,因此可以在和之后计算。
-
2.
实例依赖():如“每个教室有X把椅子,有Y个教室”。在这里,模型必须通过 X 乘以 Y 来推断椅子的总数。
-
3.
隐式依赖():例如“Bob 的水果比 Alice 多 3 倍。 爱丽丝有 3 个苹果、4 个鸡蛋和 2 个香蕉。”在这里,模型必须知道苹果和香蕉是水果,而鸡蛋不是,而“爱丽丝的水果”是从问题陈述中派生的摘要参数。
2.1 第1步:图构建和问题生成
层次分类。 我们使用categories的分层结构,每个类别都包含可能的items。 例如,categories = (School, Classroom, Backpack) 有三层;类别学校 = {中央高中,河景高中,…};类别课堂 = {舞蹈工作室、电影工作室、…};类别背包 = {学校背包0>,信使背包1>,...}。 我们准备了 4 个预定义的层次分类,每个分类有 4 层,每层有 100 个项目;这代表了世界知识。
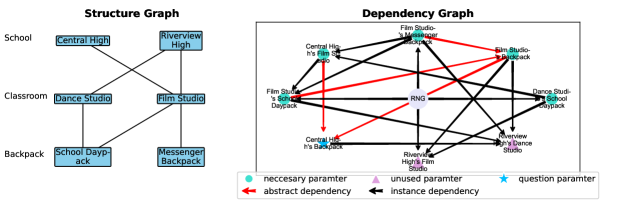
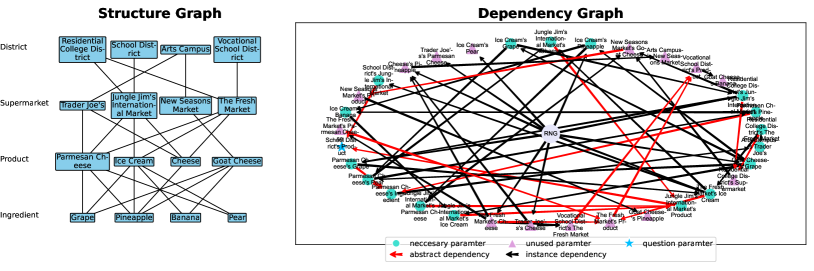
结构图。 在每个数学问题中,只存在特定的项目,从而形成一个structure graph,概述哪些子项目可以出现在哪些项目下,请参阅Figure 1(左)。 例如,
-
•
用边连接 Dance Studio 和 School Daypack 表示 instance parameter,“每个舞蹈工作室中的 school daypack 数量”,这是一个可以赋值的可量化变量。444尽管 Central High 和 Rivierside High 都可以拥有(可能有多个)舞蹈工作室,但为简单起见,我们假设每个舞蹈工作室拥有相同数量的学校背包。 如上所述,这捕获了实例依赖项 ()。
-
•
Abstract parameters,例如“中部高中的教室总数”,无法分配并被排除在结构图中。 它们反映了隐式依赖 ()。
Remark 2.1.
这种结构允许我们描述摘要参数,并增加 2 个级别的复杂性,而不是使用 Alice's apple 这样的简单对象或 Items A/B/C/D 这样的假物品。数据:
-
•
该模型必须隐式学习英语概念,例如一个课堂类别包括 100 种不同的课堂类型。 这些概念不能从单个数学问题中推导出来,因为每个问题中只会提到有限的教室选择。
-
•
该模型需要分层访问多个项目来计算摘要参数,而不是在上下文中直接检索“爱丽丝的苹果”。555例如,Figure 1 中河湾中学的背包总数计算公式为 ,其中 、、 和 , 为实例参数, 摘要为参数。 在这里,模型不仅必须检索 ,还要分层计算 。
依赖图。 dependency graph是一个有向无环图,概述了参数之间的依赖关系。 对于每个实例参数,我们选择它可以依赖的一组随机参数(最多4个) - 可能包括代表随机数生成器的特殊顶点。 例如,如果随机生成的的“[param A]是大于[param B]和[param C]的差值,那么我们从B绘制边缘、C 和 到参数 A。 摘要参数的依赖关系是由实例参数的依赖关系所隐含的。 如上所述,这捕获了直接依赖关系 ()。 我们在Figure 1右侧给出了一个例子,如何随机生成这样的依赖图的细节在Appendix D.2。
问题产生。 problem通过用英语描述依赖图来阐明,每个实例参数一个句子。666我们使用简单的英语句子模板来描述问题,并且不担心诸如单复数形式等语法错误。 除了依赖图之外,还有其他随机性,例如当参数 依赖于 时,它可能是 或 。 (摘要参数没有描述,因为它们是由结构图继承的。) 我们随机排列句子顺序以进一步增加难度。 选择一个参数并在最后(或开始时)提出一个问题。 下面是一个对应Figure 1的简单示例; Figure 11中是一个更难的例子。 (问题 - 简单) 每个Riverview High电影制片厂的数量等于每个电影制片厂背包和每个舞蹈工作室学校背包总和的5倍。 每个电影制片厂的学校背包数量比每个电影制片厂的斜挎包和每个中央高中的电影制片厂的总和还多12个。 每个中央高中电影制片厂的数量等于每个舞蹈工作室的学校背包和每个电影制片厂的信使背包的总和。 每个 Riverview High 舞蹈室的数量等于每个电影制片厂背包、每个电影制片厂信使背包、每个电影制片厂学校背包和每个中央高中背包的总和。 每个舞蹈工作室的学校背包数量为 17 个。 每个电影制片厂的斜挎背包数量为 13 个。 中央高中有多少个背包? (2.1)
2.2第2步:解决方案构建(CoT)
令solution为描述解决给定问题的必要步骤的句子序列,其中句子遵循任何拓扑顺序 - 也称为思想链,CoT。 对于回答最终问题所需的每个参数 necessary,我们从 52 个选项(a...z 或 A...Z)中随机分配一个字母,并用一句话来描述其计算过程:777格式化 CoT 解决方案的方法有多种。 我们注意到,从“将[param]定义为X”而不是[中间步骤]开始可以提高模型的准确性,因此我们坚持这种CoT格式。
| Define [param] as X; [intermediate steps]; so X = … |
在本文中,我们考虑算术 mod 以避免涉及大数的计算中的错误。 直接看解决方案示例可能是最简单的(对应(2.1)),更复杂的示例在Figure 11: (解决方案 - 简单) 将舞蹈工作室的学校背包定义为 p;所以 p = 17。 将电影工作室的斜挎包定义为W;所以W = 13。 定义中高电影制片厂为B;所以 B = p + W = 17 + 13 = 7。 将电影制片厂的学校背包定义为 g; R=W+B=13+7=20;所以 g = 12 + R = 12 + 20 = 9。 将电影制片厂的背包定义为w;所以 w = g + W = 9 + 13 = 22。 定义Central High的背包为c;所以 c = B * w = 7 * 22 = 16。 答案:16。 (2.2)
我们强调:
-
•
该解决方案仅包含计算最终查询参数necessary参数。
-
•
该解决方案遵循正确的逻辑顺序:即计算中使用的所有参数必须事先出现并计算。
-
•
我们将计算分解为二进制操作:在上述解决方案中, 被分解为 和 。 分号“;”的数量等于operations的数量。 这降低了解决方案的算术复杂度,这不是本文的重点。888即使GPT-4在不使用外部计算器的情况下计算“3 * (4+10) + 12 * (5+6)”时也会出错。
2.3难度控制
尽管将所有伪代码推迟到Appendix D,但我们在下面总结了数据生成过程中使用的主要随机性。 这包括随机选择分层分类(即英语部分);结构图(即实例参数);依赖图;对依赖图进行算术计算;整数(即 );问题句子排列;和查询参数。
我们使用两个参数来控制数据的难度:ip是实例参数的数量,op是求解操作的数量;数据的难度是它们的递增函数。 我们将我们的数据集称为iGSM,以反映此类合成数据集可以具有无限大小的性质。 我们使用 表示使用约束 和 生成的数据,并使用 表示限制 999我们非均匀地选择op;例如,我们让表示两次随机抽奖。 这确保了数据集拥有更简单的数据——这使得训练速度更快。 (另请参阅算术 [jelassi2023length] 的类似行为。)

2.4 训练和测试数据集
我们考虑两个数据集系列。
-
•
在iGSM-med数据系列中,我们使用。
训练数据为。 We evaluate the pretrained model both in-distribution, on and , and out-of-distribution (OOD), on for and . 这里,reask表示首先从生成问题,然后重新采样查询参数。101010由于我们的数据/解决方案生成过程的拓扑性质,reask极大地改变了数据分布和所需操作的数量。 它为评估提供了一个优秀的 OOD 样本。 详情请参阅Appendix D。
-
•
在iGSM-hard数据系列中,我们使用。
训练数据为。 我们在 和 上对预训练模型进行分布式评估,并在 上对 和 进行 OOD 评估。
此外,我们使用表示将问题放在问题之后,则相反(与iGSM-hard类似) )。 iGSM-med的难度对于人类来说已经相当不小了(至少无法通过使用GPT-4/4o的少样本学习来解决,参见Figure 2)。
Proposition 2.2.
忽略未使用的参数、数字、句子顺序、英语单词、a-z 和 A-Z 字母选择, 仍然拥有至少 十亿个solution templates和 至少拥有万亿solution templates。111111通过将所有数字替换为“0”、用变量(a-z 或 A-Z)按其出现顺序排列的字母替换以及将参数更改为其类型(实例或摘要)来创建解决方案模板。 例如,“将猫头鹰森林的大象定义为 y;所以 y = 11。 定义Parrot Paradise的浣熊为t;所以 t = y = 11。”变为“将 Inst 定义为;所以 a = 0。 定义 Inst 为 b;所以 b = a = 0。”我们使用生日悖论来估计解决方案模板的数量。 如果 随机生成的问题会产生不同的模板,这表明模板总数很有可能超过。
无数据污染。 综合数学数据生成的一个目标是防止基于互联网的数学数据集中的数据污染,如[zhang2024careful]中所述。 虽然可能无法证明在互联网数据上训练的模型不受污染,但在我们的设置中,我们可以证明这一点:
-
1.
我们执行 OOD 评估,例如对 训练,同时仅提供 样本。
-
2.
我们使用解决方案模板(参见Footnote 11)的哈希值为的数据进行训练,并使用这些。 这可以确保训练和测试之间没有模板级重叠。
3结果2-3:总结模型的行为过程
我们使用 GPT2 架构 [radford2019language],但将其绝对位置嵌入替换为旋转嵌入 [su2021roformer, gpt-neox-20b],但仍简称为 GPT2 。121212我们还使用 Llama 架构进行了测试(尤其是 具有门控 MLP 层)并且没有看到使用它的任何好处。 对于知识任务[AL2024-knowledgeScaling],GPT2-rotary 的表现并不比 Llama/Mistral 差。 目前,我们受资源限制,无法使用与 GPT2-rotary 有细微差别的其他架构重复本文中的所有实验。 我们主要坚持使用 12 层、12 头、768 维的 GPT2(又称为 GPT2)。 GPT2-small)用于实验,但我们在Section 6中探索更大的模型。 我们使用上下文长度 768 / 1024 进行 上的预训练,使用 2048 进行评估。 更多详细信息请参见Appendix LABEL:app:pretrain。


结果2:准确率。 经过充分的预训练后,我们给模型一个测试集中的问题(没有解决方案)并让它继续生成(据称是一个解决方案,然后是一个答案)。 因为我们将自己限制在固定的解决方案格式上,所以语言模型可以轻松学习该格式,从而使我们能够编写解决方案解析器来检查解决方案是否完全正确。131313我们不仅检查最终答案 0..22 的正确性,还检查计算和参数依赖性。 语言模型可以学习非常复杂的语法,请参阅[AL2023-cfg]及其中的参考文献。
Result 2。
图3 显示 GPT2 在使用 iGSM-med 或 iGSM-hard 数据进行预训练时表现良好,即使在更难的情况下(即较大的 op) 数学问题。 因此,模型可以真正学习一些推理技能,而不是记住解决方案模板。141414Llama(具有相同模型大小)提供相似的性能,但我们避免使用另一个模型重复所有实验。 我们对这项理论研究中的微小模型差异不感兴趣;相反,我们更关心(自回归)语言模型的一般行为。
这可能让人想起语言模型在算术计算上的长度泛化能力[zhou2023algorithms, jelassi2023length];然而,在我们的例子中,op捕获了小学数学中的“推理长度”,而我们的模型从未见过任何的训练示例与测试时间相同的长度。151515其他一些(例如 anil2022exploring)从根据互联网数据预训练的 Transformer 开始;虽然 Transformer 在训练期间可能没有看到相同的任务,但模型可能已经看到了具有相同(甚至更长)长度的其他任务并学会了从那里进行转移。
这样的准确性也表明我们的iGSM数据族确实适合预训练目的,使我们能够研究大语言模型如何解决小学数学问题。
结果3:解冗余。 我们通过以下方式检查 GPT2 是否实现了高精度:
-
•
在生成过程中强制计算所有参数(“0 级”推理技能),或者
-
•
仅计算必要的参数来给出最短的解决方案(“1 级”推理技能)。
回想一下我们的iGSM(预训练)数据仅包含必要的解决方案步骤(即 CoT)来模拟我们在数学问题的教科书解决方案中看到的内容。 例如,如果问题描述 X =3+2、E =3+X、Y =X+2 并要求 Y 的值,那么最短的解决方案将是“X =3+2=5 并且 Y =X” +2 =7” 无需计算 E。
Result 3。
图4 表明 GPT2 主要通过“1 级”推理技能解决 iGSM 问题,避免不必要的计算,即使在分布外评估时也是如此。这一发现很重要,因为它表明,与通常依靠“向后推理”和便签本通过回溯问题[rips1994psychology]的依赖关系来写下必要参数的人类不同,语言模型可以无需使用便签本即可直接生成最短解决方案。 但是,它是如何做到这一点的呢? 我们将在下一节中进行调查。
4结果4-5:发现模型的心理过程
为了了解模型如何学习解决数学问题,我们建议研究以下探索任务,这些任务与人类解决问题的策略密切相关:
-
•
:如果计算答案需要参数。
-
•
:如果参数(递归地)取决于给定问题陈述的参数。
-
•
:如果参数已经计算出来。
-
•
:参数的值(0-22之间的数字,如果则为23)。
-
•
:如果可以在下一个解决方案语句中计算(即它的前一个都已计算)。 请注意, 可能不是回答问题所必需的。
-
•
:如果参数同时满足和。
为了使模型生成最短的解决方案,它必须在其心理过程中识别所有 的 。 这是因为是否为真直接对应于是否有解句来计算。 然而,模型多久识别到这一点,以及它是如何存储的? 同样,它是否识别参数之间的依赖关系(dep)? 如果是这样,这个心理过程多久完成? 此外,在解决方案生成过程中,模型是否始终跟踪每个参数的值(值,已知)? 模型是否知道所有可能的参数可以在下一个句子(can_next)中计算? 或者它只关注已准备好且必要的(nece_next)?
本节提出探测技术来回答所有这些问题。
4.1 V-Probing:一种近线性探测方法


如图Figure 5所示,我们在dep任务的问题描述结束时进行探测,并在问题描述结束必需的任务。161616如果问题格式是qp(问题之前提出的问题),那么我们探测nece和dep两者问题描述后。 对于其他任务,我们在每个解决方案句子的末尾(包括第一个解决方案句子的开头)探测它们。
回想一下,标准线性探测涉及冻结预训练的语言模型并检查给定词符位置的属性是否在隐藏层(通常是最后一层)进行线性编码。 这是通过在隐藏状态上引入可训练的线性分类器并为此属性执行轻量级微调任务来完成的(请参阅[hewitt-manning-2019-structural]及其中的参考文献)。
我们的设置更加复杂,因为属性有一个或两个条件变量 和 ,用简单的英语描述。 为了解决这个问题,我们将数学问题截断到探测位置,并在 的描述周围附加标记 [START] 和 [END](或者)。 然后我们从[END]的词符位置开始探测,看看该属性是否在最后一层进行了线性编码。
与标准线性探测不同,为了考虑输入变化,我们在输入嵌入层上引入了一个小的可训练的 8 级(线性)更新。 我们冻结预训练的语言模型,并对线性分类器和所需属性的 8 级更新进行微调。 我们将此称为 V(ariable) 探测,并在Appendix B 中提供详细信息。 探测任务的图示如图Figure 6 所示。
我们计算从 iGSM 预训练的语言模型上的 V 探测精度,并将其与随机初始化的 Transformer 模型上的 V 探测精度进行比较。 如果前者的精度明显更高,我们得出结论,探测信号必须(或非常接近)来自预训练的权重,而不是(轻量级)微调阶段。
4.2探索结果和发现



我们在Figure 7中展示了我们的探测结果。 与多数猜测和随机模型探测相比,所有任务的探测精度都很高,除了非常困难的 OOD 情况(即,对于大型 op ,模型的生成精度下降到 80%无论如何,在Figure 3中),
结果 4:模型像人类一样解决数学问题。 我们提出以下观察:
-
•
在生成解决方案时,模型不仅会记住哪些参数已计算,哪些参数尚未计算 (),而且还知道接下来可以计算哪些参数 ()。 这些能力确保模型能够逐步解决给定的数学问题,类似于人类解决问题的能力。
-
•
在问题描述结束时,模型已经知道必要参数的完整列表 (nece)。 这表明模型已经学会提前计划,在开始生成解决方案之前确定必要的参数。 这与人类行为一致,只不过模型会在心里进行计划,而人类通常会写下来。 这进一步证实了模型达到了Section 3节中讨论的“1级”推理能力。
Remark 4.1.
所描述的心理过程可以与(断章取义)知识操纵 [AL2023-knowledgeUB]进行比较,其中涉及检索事实知识并执行单步计算(例如,检索两个人的出生日期以确定谁出生较早)。 AL2023-knowledgeUB 发现,如果没有大量的预样本,即使是单步计算也无法在心理上执行。 相比之下,本文研究了上下文推理,并证明该模型可以执行非常复杂的心理计算。
结果 5:模型的学习能力超出了人类的推理能力。 值得注意的是,模型学习了 和 ,即使对于回答问题不需要的参数 也是如此,如图 Figure 7(b)。 这与人类解决问题不同,在人类解决问题时,我们通常使用问题的后向推理来识别必要的参数,而常常忽略不必要的参数[rips1994psychology]。 相比之下,语言模型甚至可以在提出问题之前就在心里预先计算出全对依赖图。 我们认为这是一种“2 级”推理技能,与人类行为或心理过程非常不同。
因此,尽管解决数学问题不需要这项技能,并且虽然没有预训练数据教导模型计算“全对依赖性”——拟合数据只需要计算必要的参数——模型仍然在训练后发现它。 这使得模型能够对它听到的事物之间的关系进行排序,这项技能对未来的任务很有用(通过指令微调)。 据我们所知,这可能是语言模型获得的技能超出学习其预训练数据所需的技能的第一个证据;这可能是 AGI 中 G 的来源的预备知识信号(泛化到预训练数据中未教授的技能)。
推论:落后的思维过程。 AGI 成功的一个关键问题是“逆向思维过程”(例如,“因为我想计算 X,但 X 依赖于 Y,Y 依赖于 Z,所以让我先计算 Z”)是否需要明确包含在训练数据。 这与 CoT 不同,CoT 将复杂的计算分解为更简单的步骤,但仍然需要进行规划来决定首先计算哪个步骤。
我们的研究结果表明,至少对于小学数学问题,在数据丰富的情况下,这种逆向思维过程可以通过语言建模自主学习,而不需要直接包含在训练数据中。
5结果6:解释模型的错误
我们进一步检查探测结果与模型生成的解决方案之间的关系,重点关注两个问题:(1)模型何时正确回答但包含不必要的参数? (2)什么原因导致答案不正确? 我们的目标是确定模型的这种错误行为是否与模型心理过程中的错误一致(通过探测)。
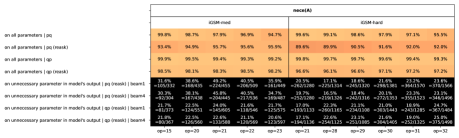
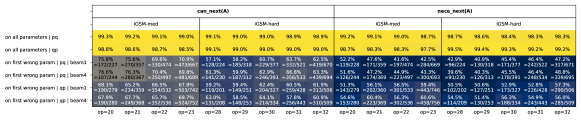
对于第一个问题,鉴于模型很少会生成超过必要时间的解决方案(参见Figure 4),我们转向分布外reask评估数据。171717回想一下,这会在生成问题后重新采样查询,从而产生一组不同的必要参数。 根据这些数据,预训练模型平均会为每个解决方案生成 个不必要的参数,即使对于 也是如此(参见Figure 4)。 我们检查了这些不必要的参数是否在探测任务中被错误地预测为。 Figure 8(a)表明情况确实如此,因此语言模型由于心理规划阶段的错误而产生了带有不必要步骤的解决方案>。
对于第二个问题,我们重点关注模型的错误解决方案及其第一个错误参数。 (使用合成数据,我们可以轻松识别这些参数。)
我们在Figure 8(b)中的发现表明,模型的错误主要源于错误地预测了或当此类 尚未准备好进行计算时,其内部状态为 true。181818在Figure 8(b)中,我们重点关注这些“第一个错误的参数”,正确的标签是 或 并呈现其探测也正确预测 的概率。 低准确度表明模型“认为”这些参数已准备好进行计算,但事实并非如此。
Result 6 (Figure 8)。
结合这些,我们得出结论:
•
语言模型所犯的许多推理错误都是系统性的,源于t0>其心理过程的错误,不仅仅是生成过程中随机的。
•
模型的一些错误可以通过探测其内部状态来发现甚至在模型开口之前 (即,在它说第一个解决方案步骤之前)。
我们还观察到 GPT-4/4o 通过输出不必要的参数或坚持用 计算参数 也犯了类似的错误(参见Appendix LABEL:app:gpt-4)。 这进一步暗示我们的研究结果可能具有更广泛的适用性。
6 结果 7-8:深度与深度 推理长度
我们的受控数据集可以系统地探索语言模型的深度与其推理长度之间的关系。
最近的研究表明,对于知识存储和提取,只有模型大小很重要(即使对于 2 层转换器)[AL2024-knowledgeScaling]。 此外,OpenAI 的开创性缩放定律论文[kaplan2020scaling]和深度学习的理论研究[als18dnn]都表明模型深度/宽度可能产生的普遍影响很小。 与这些发现相反,我们提出的证据表明 191919数学推理数据仅占语言模型预训练数据的一小部分,因此如果我们只看原始数据中的困惑度,可能不会观察到差异缩放定律论文[kaplan2020scaling]。
Result 7 (Figure 9)。
语言模型深度对于数学推理至关重要。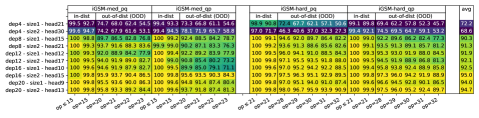
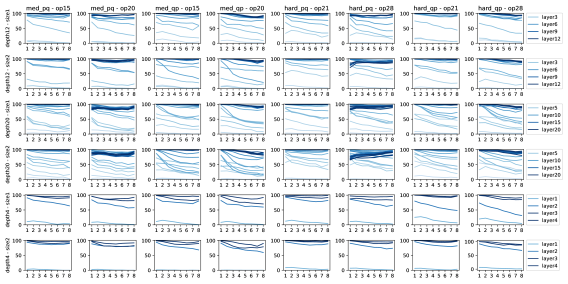
具体来说,我们尝试了深度 4/8/12/16/20 和两种尺寸(较小尺寸 1 和较大尺寸 2)的模型。202020GPT2--表示层,-head,-维GPT2模型。 Size-1 型号为 GPT2-4-21、GPT2-8-15、GPT2-12-12、GPT2-16-10、GPT2-20-9,参数数量相似; 2 号型号为 GPT2-4-30、GPT2-8-21、GPT2-12-17、GPT2-16-15、GPT2-20-13,大约是 1 号型号尺寸的两倍。 从Figure 9中,我们观察到 4 层 Transformer 即使具有 1920 个隐藏维度,在我们的数学数据集上的表现也不佳。 相反,更深但更小的模型(例如 20 层 576 维)表现非常好。 垂直比较准确度揭示了模型深度和性能之间的明显相关性。 因此,我们推断深度对于推理任务(例如解决小学数学问题)可能至关重要。
接下来,我们尝试揭示“为什么”会发生这种情况。 我们通过 nece 探测任务深入研究了深度如何影响数学问题解决技能,重点关注距离查询参数 处的必要参数,例如 。 这些参数都有 ,但我们可以探测模型以查看它们在不同隐藏层预测 时的正确性。
Figure 10显示了我们的结果。 它揭示了模型的层次结构、推理准确性和心理推理深度之间的相关性。 较浅的层擅长预测距离查询较近的参数 的 ,而较深的层则更准确,可以预测距离查询较远的参数 。 这表明该模型在规划阶段采用逐层推理来递归地识别查询所依赖的所有参数,并且:
Result 8 (Figure 10+14)。
语言模型的深度至关重要,可能是由于其隐藏(心理)推理过程的复杂性。 步心理推理,例如对距查询距离的参数进行心理计算,可能需要假设所有其他超参数保持不变,则可以为更大的 建立更深的模型。我们在此做出两项免责声明。 首先,如果将“逆向思维过程”作为 CoT 添加到数据中(参见Section 4.2),则不再需要深入的心理思考,从而减少了语言模型的深度要求。 然而,在实践中,许多这样的“思维过程”可能不包含在标准数学解决方案或一般语言中。
其次,上述主张并不意味着“步的心理思维需要深度 Transformer”。 单个 Transformer 层(包含许多子层)实现 心理思维步骤是合理的,尽管随着 的增加,准确性可能会降低。 我们在本文中避免提供精确的相关性,因为它在很大程度上取决于数据分布。

7结论
我们使用综合设置来证明语言模型可以通过真正的泛化来学习解决小学数学问题,而不是依赖于数据污染或模板记忆。 我们开发探测技术来检查模型隐藏的推理过程。 我们的研究结果表明,这些模型可以学习与人类认知过程一致的数学技能,以及训练数据中不存在的“新思维过程”。 此外,我们提出了一种方法,可以在模型开始解决问题之前预测模型的错误,并解释模型发生错误的原因。 基于这一发现,我们单独撰写了一篇论文来提高语言模型的数学推理准确性[YXLZ2024-gsm2]。 我们还提供了一种原则性方法,将模型的深度与其有效的推理长度联系起来。 我们相信,与推动数学基准相比,这项研究为从不同角度研究语言模型的数学推理技能打开了大门。
有人可能会说,iGSM可能与现代大语言模型使用的预训练数据有很大不同。 虽然这可能是真的,但我们正在展望未来。 回想一下,即使是今天的 GPT-4/4o 也无法通过少样本学习解决(参见Figure 2)。 从这个角度来看,有理由相信未来版本的大语言模型将依靠综合数学预训练数据来提高推理能力。 虽然人们可能不会直接使用iGSM,但很容易使用现有的大语言模型(例如Llama-3)将iGSM转换为更自然的格式,同时保留逻辑链。 另一方面,我们发现纯粹基于iGSM数据训练的模型与GPT-4/4o相比会犯类似的错误(参见Section 5 和Appendix LABEL:app:gpt-4)。 这进一步证实了我们的发现确实与模型隐藏推理过程的实践相关。
最后,本工作系列的第 2 部分重点介绍语言模型如何解决小学数学问题(包括第 2.2 部分[YXLZ2024-gsm2])。 我们还在第 1 部分 [AL2023-cfg] 中介绍语言模型如何学习语言结构(特别是它们如何在心理上执行动态编程),并在第 3 部分 [AL2023-knowledge 中学习世界知识、AL2023-knowledgeUB、AL2024-knowledgeScaling]。
附录
附录 A 结果 1 — iGSM-hard 中使用 的示例
附录 B结果 4-5 — 有关 V 探测的详细信息
回想一下,我们希望在 nece 和 dep 任务的问题描述结束时进行探测(在 nece 的解决方案之前;在解决方案,甚至是 dep 的问题)。 对于其他任务,我们在每个解决方案句子的末尾进行探测(包括第一个解决方案句子的开头)。 目标是冻结预训练的语言模型,然后在其之上引入非常少量数量的额外可训练参数,并针对每个探测任务对它们进行微调。
具体来说,我们采用预训练的语言模型,例如,根据 iGSM-hard 训练数据进行预训练。 我们完全冻结其参数,除了在嵌入层上添加可训练的排名-更新以考虑任务变化(从下一个 Token 预测到探测)。 在本文中,我们使用一个小值。 我们向该网络提供与iGSM-hard相同的训练数据,但在我们希望探测的位置被截断。 重要的是,我们在此类输入后附加一个特殊的起始词符 [START] 以及参数名称(或两个名称,如果是 任务)。 然后,我们提取最后一个 Transformer 层最后一个词符位置的隐藏状态,并添加一个可训练的线性层(又名: 线性头)对六个探测任务之一执行分类。
这种探测方法如图Figure 13所示。 我们将其称为 V(ariable)-Probing,因为它可以采用任意数量的变量(即本文中的参数)来允许我们在 Transformer 内部执行功能探测。
请注意,如果它只是一个可训练的线性头,则此类探测将被称为线性探测[hewitt-manning-2019-structural]。 与传统的线性探测不同,我们在模型的嵌入层上添加了一个小的低秩更新。 这可以说是所需的最小更改(考虑到任务更改,对于像 [START] 这样的特殊标记 [中] [END] 等)以便执行任何重要的探测。 这与AL2023-cfg,AL2023-knowledge中介绍的近线性探测方法相关但不同,因为它们不支持将变量作为探测输入。212121在AL2023-cfg,AL2023-knowledge中,作者有兴趣通过固定的分类任务(例如 100 -类分类任务)给定与预训练数据相同或几乎相同的数据。 在本文中,我们感兴趣的是模型相对于给定变量的行为(例如参数名称,可以有 可能性);我们将这样的变量名称附加到输入中,以使训练输入看起来与原始预训练数据非常不同。
探测任务不平衡。 我们对六项任务的探测精度如图Figure 7所示。 不过,我们注意到 dep 和 nece_next 任务的标签并不平衡,即使猜测 "所有 "也会为 带来 83% 的准确率,为 带来 的准确率。 因此,我们还在Figure 12中分别展示了仅限于正/负标签的探测精度。




附录 C结果 8 — 附加图
x轴表示参数与查询参数的距离,颜色从浅到深过渡代表第1层到最大层。 (模型架构详细信息参见Footnote 20和Appendix LABEL:app:pretrain。)
附录 D结果 1 详细信息 - 数学数据生成
符号。 在本节中,为了描述简洁,当我们在伪代码中说“随机采样”时,除非另有说明,否则我们指的是均匀随机。 每当我们考虑一个(有向)图 时,稍微滥用符号,我们写 来指示 是 中的顶点和表示中存在从到的边缘。
D.1 生成结构图
我们使用来表示这种结构图,它是根据hyperparameters定义的随机分布生成的。 在较高层次上,我们构造 ,使其具有 层、 边缘,并且每个层在 和 项。
具体来说,假设表示每层的项目数。 在此配置中,必须至少有 条边以确保图是“连通的”,并且最多必须有 条边。 使用这个公式,我们首先随机选择一个配置,以便适合给定参数。然后,在选择配置后,我们相应地随机生成边缘。 详细信息在Algorithm 1中给出。
D.1.1 附上英文
如Section 2.1 节所述,我们准备了 4 个预定义的层次分类,每个分类总共有 4 层类别: [basicstyle=] [ ["District" 、“超市”、“产品”、“成分”]、[“动物园”、“围栏”、“动物”、“骨头”]、[“学校”、“教室”、“背包”、“文具”]、 [“生态系统”、“生物”、“器官”、“细胞”] ] 在上述16个类别中,我们准备了大约100个项目(进一步分解为5个子类别)。 下面是它们的展示:[basicstyle=] “区”:“住宅区”:[...]、“商业区”:[“购物区”、“商务区”、“金融区”、“工业区”、“仓储区”、“市场区” ”、“餐饮区”、“娱乐区”、“艺术区”、“时尚区”、“硅谷”、“华尔街”、“科技园”、“汽车区”、“珠宝区”、“医疗区” ”、“法律区”、“媒体区”、“研究园”、“制造区”]、“历史区”:[...]、“教育区”:[...]、“政府区”: [...]、“超市”:...、“产品”:“罐头食品”:[...]、“休闲食品”:[“薯片”、“椒盐卷饼”、“爆米花”、“糖果”棒”、“软糖”、“饼干”、“薄脆饼干”、“格兰诺拉麦片棒”、“水果零食”、“芝士泡芙”、“坚果”、“什锦杂果”、“牛肉干”、“年糕”、 “酸奶葡萄干”、“巧克力椒盐卷饼”、“玉米饼片”、“莎莎酱”、“鹰嘴豆泥”、“干果”]、“饮料”:[...]、“烘焙食品”:[... ],“乳制品”:[...],“成分”:...,“动物园”:...,“外壳”:...,“动物”:...,“骨头”:。 ..、“学校”:...、“教室”:...、“背包”:...、“文具”:...、“生态系统”:...、“生物”:... ,“器官”:...,“细胞”:...
现在,给定一个构造的结构图 ,我们首先随机选择四个类别之一,然后随机选择 连续层类别,接下来随机选择五个子类别之一,然后最后为每个层选择该子类别中的随机项目名称。
D.2 生成依赖关系图
结构图定义了我们考虑的一组可能的参数,而依赖图定义了这些参数如何相互依赖。 我们使用边来指示参数取决于;有一个特殊的顶点并且可能发生。 摘要参数所依赖的内容继承自结构图。 对于每个实例参数,我们将随机添加边来指示它依赖于哪些参数。
高层计划。 我们将使用 来表示依赖图,我们从一个空图开始,然后增量且随机地添加顶点/边。 我们的流程如下:
-
•
生成一个必要的依赖图 ,它涵盖了计算查询参数所需的所有顶点和节点。
-
–
生成必要的 Abstract 参数(并添加它们所依赖的参数);将此图称为。
-
–
生成必要的实例参数并将其添加到中;将此图称为。
-
–
为参数 生成拓扑顺序,并确保所有参数都是计算查询参数所必需的(这是此拓扑顺序中的最后一个参数)。 在此过程中,我们将从 添加额外的边来创建 。
-
–
生成额外必要的边并将其添加到;将此图称为。
-
–
-
•
将所有剩余的(不必要的)参数和边添加到 中以形成 。
在高层次上,我们的问题描述应仅依赖于 ——通过使用句子描述其中的每个实例参数,而我们的解决方案描述应仅依赖于 ——通过描述使用句子计算其中的每个参数。
在开始搭建之前我们先正式介绍一下:
Definition D.1 (操作)。
给定任何依赖图,
-
•
For an (abstract or instance) parameter that has in-degree , we define which is the number of operations needed to compute .222222例如,在Figure 1中,等于为、、、,其中为实例参数,为摘要参数。 在这种情况下,这个 Abstract 参数依赖于其他 4 个参数,并且需要 3 次算术运算。
-
•
我们使用来表示计算中所有参数所需的(算术)运算总数.
Remark D.2.
在我们最终设计的中,我们要保证每个参数(特殊顶点除外)的入度至少为;然而,在构造过程中,由于我们增量添加边,某些(实例)参数可能暂时具有入度。 为了符号简单起见,在这种情况下我们仍然说。
超参数。 我们使用超参数来控制的难度。
-
•
我们应确保并尽可能接近;
-
•
我们应确保并尽可能接近;
-
•
我们将确保 准确。
换句话说,超参数精确地控制了计算查询参数需要多少次操作,这是控制问题难度的主要因素。
D.2.1 构建
给定一个结构图,回想一下它的边代表我们将使用的所有实例参数。 它的摘要参数是那些描述跨 1 层或多层的数量的参数:例如在Figure 1 中,Central High 的 教室横跨1层,中央高中的背包数量横跨2层。 我们将这个数字定义为 Abstract 参数的difficulty level。
有了这个概念,我们的和的构造在Algorithm 2中一起描述。
在较高层次上,我们尝试在保持 的同时,增量且随机地将 Abstract 参数添加到 中。 我们无法做到完全相等,因为添加单个 Abstract 参数时还需要(递归地)添加它可能依赖的所有其他参数。 我们尝试优先添加难度级别较高的 Abstract 参数。 一旦我们完成 的构造,我们就会从 中随机添加额外的实例参数以使其成为 。
D.2.2 构建
接下来我们的目标是在 中选择一个随机 参数,并为 中的所有参数构建随机拓扑排序 ,以确保所有参数都是计算所必需的。
我们从 开始,将参数一一附加到其左侧。 在这个过程中,我们还可能随机引入新的边;我们从 开始并逐渐添加边缘。 此过程可能并不总是成功 - 有时创建的拓扑排序无法提供计算 所需的所有参数。 如果发生这种情况,我们宣布失败。232323稍后出现的外部伪代码将返回重新生成结构图并重新开始。
我们引入两个概念(我们使用 来表示 中不在 中的顶点集):
-
•
直观上,如果 那么我们不能立即将 附加到 的前面,因为对于 的计算还没有必要>。
-
•
直观上,如果 那么我们不能立即将 附加到 前面,因为一些其他参数依赖于它并且尚未添加到 。 (显然我们总是有 除非 所以我们就完成了。)
现在我们的生成算法很容易描述:我们不断地将中的参数添加到的前面;如果我们遇到困难,我们会向 引入新的边(或声明失败)。 伪代码位于Algorithm 3中。