66email: wangk229@mail2.sysu.edu.cn, chenglc@hfut.edu.cn, chenwk891@gmail.com, zhpp@dlut.edu.cn, linliang@ieee.org, {isszf, liguanbin}@mail.sysu.edu.cn
MarvelOVD:将目标识别与视觉语言模型结合用于鲁棒的开放词汇目标检测
摘要
近期研究表明,利用视觉语言模型 (VLM) 生成的伪标签学习,成为辅助开放词汇检测 (OVD) 的一种很有前途的解决方案。 但是,由于 VLM 和视觉检测任务之间的领域差异,VLM 生成的伪标签容易出现噪声,而检测器的训练设计则进一步放大了偏差。 在这项工作中,我们调查了 VLM 在 OVD 环境下偏差预测的根本原因。 我们的观察结果导致了一个简单而有效的范式,即代码 MarvelOVD,它通过将检测器的能力与视觉语言模型相结合,以在线方式生成显著更好的训练目标并优化学习过程。 我们的关键见解是,检测器本身可以充当强大的辅助引导,以弥补 VLM 在理解图像中提议的“背景”和上下文方面的不足。 基于此,我们通过在线挖掘大幅度地净化了噪声伪标签,并提出了自适应加权,以有效地抑制与目标物体不匹配的偏差训练框。 此外,我们还识别了一个被忽视的“基础-新颖-冲突”问题,并引入了分层标签分配来防止这个问题。 在 COCO 和 LVIS 数据集上进行的大量实验表明,我们的方法显著优于其他最先进的方法。 代码可在 https://github.com/wkfdb/MarvelOVD 获取。
关键词:
伪标签开放词汇目标检测1 介绍
开放词汇目标检测 (OVD) [37] 由于其在测试时检测新颖物体的能力而受到越来越多的关注。 在典型的 OVD 设置中,目标类别中只有一小部分被标注(称为基本类别),而 OVD 的目标是在推理时识别一组新的类别。 新类别对象的图像可能出现在训练图像中,但不会收到任何标注。 为了增强 OVD 检测器的泛化能力,最近的研究工作提议将视觉语言模型 (VLMs) [25, 13, 38](这些模型已被验证具有出色的零样本识别能力)纳入现有 OVD 管道中。
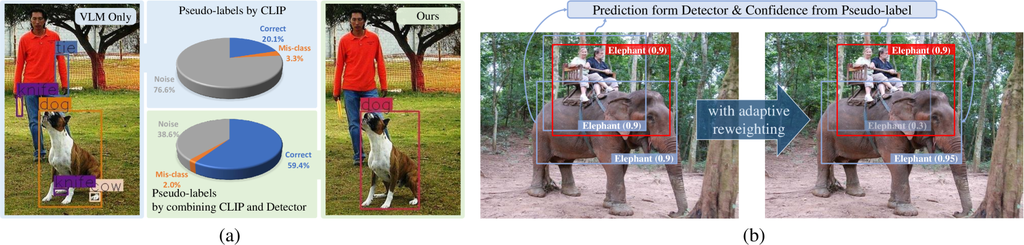
对于具有已知新概念的 OVD 任务,一种常见的做法是使用 VLMs(例如 CLIP [25]) 以离线方式 [41]. 然而,由于对比语言-图像预训练和目标检测任务之间的领域迁移,使用图像级数据训练的 VLM 在应用于裁剪后的部分图像时,不可避免地会引入噪声标注。 我们在图 1(a) 中展示了对 CLIP 模型生成的伪标签的深入分析。 我们将错误分类为其他类别的有效新颖目标建议表示为 “Mis-class”,将不应被视为包含新颖目标的框表示为 “Noise”。 事实上,基于 VLM 的方法的错误分类率相当低(仅 )。 错误的主要来源是其无法区分“噪声”框(错误率 ),例如图 1(a) 中的狗腿,不应该被视为有效的感兴趣目标。
VLMs 难以识别噪声建议的主要原因有两个。 1) 缺乏上下文信息来理解局部裁剪的图像。 CLIP 模型不是使用图像块进行训练,而是使用与文本配对的完整图像进行训练。 因此,它无法利用输入建议之外的图像上下文,而这对于解释候选框的语义可能至关重要。 例如,在图 1(a) 中,CLIP 模型错误地将男人的手臂分类为“领带”,因为它无法识别出看似“领带”的物体实际上与人体相连。 2) 对“背景”元素的无知。 CLIP 模型通过计算查询图像特征与候选类别文本嵌入之间的相似度来生成类别预测。 由于“背景”是根据感兴趣的前景类别相对定义的,因此在推理过程中没有预定义的文本嵌入来表示“背景”的概念。 然而,即使输入内容与任何目标类别无关,CLIP 模型仍然必须提供预测。 在图 1(a) 中,狗腿属于这种情况——它被识别为“牛”,仅仅因为它看起来更像牛,而不是其他任何类别,从而导致噪声框。
与 CLIP 模型不同,检测器中的 RoI 对齐技术自然地为局部区域提供了丰富的上下文信息。 此外,检测器在推理过程中意识到了“背景”的概念。 因此,会让 VLM 困惑的噪声框可以被检测器以高置信度识别为“背景”。 受此关键观察的启发,我们提出了 MarvelOVD,这是一个专门针对开放词汇检测的框架,它可以通过结合目标检测器和视觉语言模型的优点来产生高质量的伪标签和惊人的性能。 特别是,我们利用检测器对“上下文和背景”的感知作为强有力的辅助指导,以全面改进 伪标签生成 管道和 训练 过程。
对于伪标签生成,预测的类别置信度基于检测器和 VLM 输出的加权和,倾向于使用 VLM 模型进行可靠的分类,同时使用检测器排除噪声框。 为了加速训练,我们在所有候选框上预先生成 VLM 预测,并在每次训练迭代中,在检测器的指导下动态挖掘可信的伪标签。 检测器和 VLM 的互补能力显着提高了伪标签的准确性,即使在训练早期阶段也是如此。 此外,随着检测器在训练过程中的改进,生成的伪标签质量也会提高,最终会提高最终性能,如 图 1(a) 所示。
目标检测器的传统训练设计 [10] 等同地对待每个与一个训练目标匹配的提议。 这种设计不适合从伪标签中学习。 具体来说,生成的伪框可能与真实新对象的边界框偏差很大。 因此,如图 1(b) 所示,训练框与实际新对象之间的重叠通常呈现出较大的方差。 这意味着这些训练框不应该对最终损失做出同等的贡献,即使它们匹配相同的伪标签。 为此,我们不是对伪标签进行加权 [41],而是自适应地计算与伪标签匹配的每个训练框的个体权重。 如图 1(b) 所示,位置不准确的训练框将获得较小的权重,反之亦然。 请注意,训练框是通过分层标签分配策略生成的,该策略消除了伪标签和基础标注之间的冲突,从而防止了噪声伪标签对基础类别检测性能的负面影响。 我们在 COCO 和 LVIS 数据集上进行了大量的实验。 MarvelOVD 在很大程度上始终优于最先进的方法。 总之,我们的贡献如下。
-
•
我们确定了 VLM 预测偏差的根本原因并进行了深入分析。
-
•
我们提出了 MarvelOVD,这是一种新颖的 OVD 框架,它通过利用检测器作为辅助指导来生成高质量的伪标签,以减轻 VLM 在图像块预测方面的领域差距。
-
•
一种新颖的提案重新加权机制和分层标签分配方法,以提高 OVD 训练性能。
-
•
我们在 MS-COCO 和 LVIS 基准测试中创造了新的技术水平。
2 相关工作
视觉语言预训练
视觉语言预训练旨在对齐视觉和文本表示,在大型图像-字幕对上采用对比学习 [6, 12, 14]。 重大研究已经使用视觉语言模型增强了各种下游任务 [16, 17, 24]。 值得注意的是,像 CLIP [25] 和 ALIGN [13] 这样的模型利用了数十亿级的图像-文本对进行视觉语言表示学习,在零样本图像分类和图像-文本检索方面取得了显著成功。 这种成功激发了视觉语言模型 (VLM) 在增强密集识别任务的范围和准确性方面的应用,例如目标检测 [29, 31, 8, 27] 和语义分割 [35, 43, 26]。 然而,VLM 通常通过考虑整个图像进行预训练,在密集预测任务中面临领域差距。 我们的研究调查了 VLM 在局部区域中进行目标检测的应用,旨在拓宽检测器的认知范围,而无需依赖手动标注。
开放词汇目标检测
开放词汇目标检测 (OVD) 旨在通过利用辅助数据或模型来扩展检测器对训练数据中不存在的类别的识别能力。 该概念最初由 OVR-CNN [37] 引入,该方法利用在图像-文本对上预先训练的视觉和文本编码器,使检测器能够识别不同的目标概念。 随后,开发了几种 OVD 方法。 OVD 的最新研究探索了各种形式的辅助数据,包括使用图像-文本对的迁移学习 [20, 2, 3]、从预先训练的视觉-语言模型中进行知识蒸馏 [29, 30, 4, 1, 8]、从图像分类数据中生成伪标签 [44, 1] 以及使用接地数据进行预训练 [19, 39]。 除了基于 CNN 的检测器之外,基于 Transformer 的开放词汇检测器 [18, 36, 31] 也得到了广泛的应用。 除了标准的 OVD 场景(假设在训练期间新类别是未知的)之外,一些现有的工作 [41, 5] 也探索了具有关于潜在新概念的先验知识的开放词汇检测。 通常,在这种情况下,在训练之前使用视觉-语言模型 (VLM) 生成新类别的伪标签。 但是,视觉-语言预训练和目标检测之间的领域差距引入了噪声伪标签,极大地限制了现有方法的性能。 为了应对这一挑战,我们确定了将 VLM 应用于局部区域的严重局限性,并提出了一种解决方案,该解决方案涉及整合检测器的功能以有效地减轻这种噪声,从而导致性能大幅提升。
3 预备知识
开放词汇目标检测旨在通过利用数据集 和辅助弱监督数据(例如图像-文本对、VLM 等)来训练检测模型,其中 表示图像, 包括图像中包含的对象的位置和类别。 与传统的检测任务不同,图像的标注只覆盖基本类别 ,而 OVD 任务要求检测器在测试时额外检测新类别 。 注意, 和标签空间 在训练期间是已知的。
为了在开放词汇标签空间中实现检测,检测器中的分类头被设计为比较基于区域的视觉嵌入和文本嵌入之间的相似性 [37]。 特别地,区域嵌入 是通过 RoI Align 和以下特征提取器获得的,其中 是图像中区域框的数量。 文本嵌入由 组成,其中 是通过将类别名称与模板提示(例如,“场景中 {类别名称} 的照片”)馈送到预训练的文本编码器中获得的,而 是类别的数量。 被初始化为可学习的嵌入。 基于区域和文本嵌入,区域 被分类为类别 的概率被定义为
| (1) |
比较区域和文本嵌入之间的相似性使检测器能够识别无限标签空间中的物体。
4MarvelOVD
为了促进与开放类别相关的语义的学习,而无需手动标注,现有方法通常采用预训练的视觉语言模型 (VLM) 来发现潜在的新颖物体 [44, 41, 7, 5] 并为后续训练生成伪标签。 典型的过程涉及使用基本标注训练提案生成器,以识别可能包含新颖物体的局部区域,然后根据这些裁剪区域内的 VLM 推断结果生成伪标签。 但是,由于 VLM 是在整个图像上预训练的,因此将其应用于局部区域不可避免地会引入噪声伪标签,从而导致新颖类别的学习过程出现中断。 为了增强新颖概念的学习,我们提出了 MarvelOVD,它在优化后续学习阶段的同时,将检测器的能力动态集成到伪标签生成过程中。 图 2 提供了我们框架的概述,并在以下部分中进行详细解释。
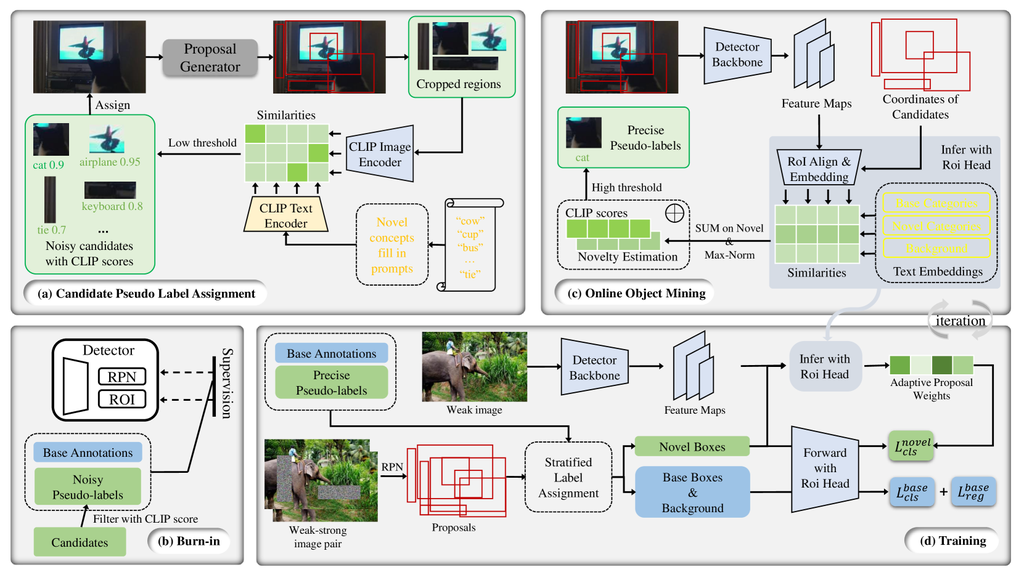
4.1 候选伪标签分配
我们提出的 MarvelOVD 在检测器和预训练的 VLM 的指导下,在每次训练迭代中动态生成更好的伪标签。 由于在训练期间使用 VLM 预测裁剪区域需要不可接受的时间开销,因此我们在训练之前为每个图像分配候选伪标签,然后在每次迭代中选择精确的标签来训练检测器。
遵循现有方法 [41],我们首先使用基本标注训练一个类别无关的提案生成器,以生成每个图像的区域框。 然后根据这些区域裁剪图像补丁,并将其输入 CLIP 图像编码器以获得区域视觉嵌入。 同时,我们利用相应的 CLIP 文本编码器和模板文本提示对每个新类别进行编码。 之后,通过点积计算相似度矩阵,以描述每个视觉嵌入和文本嵌入之间的相似度。 最后,应用 softmax 获得每个区域对新类别的分布。 基于此,传统的 [41, 7] 方法对框进行后处理,并选择高置信度伪标签来训练检测器。 问题是,域差异很容易导致 CLIP 对噪声区域产生高置信度预测,这极大地限制了现有方法的性能。 相反,我们记录 CLIP 预测,并使用低阈值 (例如 0.5) 将候选框分配给图像,然后在检测器的指导下,从候选框中动态选择精确的伪标签,这将在下一节中详细介绍。
4.2 在线伪标签挖掘
候选伪标签可以分为两组:真实框(那些紧紧包围实际新对象的框)和噪声框(那些不应该被指定为新对象的框)。 主要目标是在保留真实框作为可靠的伪标签进行训练的同时,消除噪声候选框。 检测器和 CLIP 在推断局部区域时的关键区别在于上下文信息和“背景”概念。 检测器采用的 RoI Align 机制擅长从框中提取上下文特征,而仅根据坐标裁剪图像则没有这种能力。 此外,检测任务包含一个特定的任务特定类别,称为“背景”,而 CLIP 在推断局部区域时没有意识到这个概念。 无法识别“背景”对象以及缺乏上下文特征是 CLIP 模型对噪声框产生错误预测的根本原因。 虽然 CLIP 模型难以处理噪声框,但它对真实框的预测非常准确。 利用这一见解,我们建议利用检测器对这些候选框的预测来估计一个框是否包含真正的全新对象。 随后,我们结合 CLIP 的分类结果来选择高质量的伪标签。
预热。
为了估计候选框的新颖性,检测器首先需要学习“什么是新颖的”。 为此,我们首先利用 top-1 CLIP 得分(CLIP 的图像编码器和文本编码器预测的分布的最高得分)和一个固定阈值 0.8(之前工作 [41] 中的最佳阈值)来初步选择伪标签,以便在 步内预热检测器。 在预热阶段之后,模型将初步获得区分基础对象、新对象和背景的能力。
在线对象挖掘。
在线对象挖掘在预热阶段之后正式开始。 我们从半监督学习 [28] 中汲取灵感,为训练推导出弱强图像对,这增强了对伪标签的学习。 特别是,我们首先使用检测器对弱增强特征预测候选框。 据此,我们计算每个候选框的新颖性得分,如下所示:
| (2) |
其中 是由检测器计算的视觉嵌入,而 是类别的文本嵌入。 和 分别是基本类别和新类别集。 新颖性评分 相对估计了候选框相对于基本类别和背景的新颖性。 但是,它的值随着不同程度的收敛而发生巨大变化。 为了解决这个问题,我们进一步将最大范数应用于候选者的新颖性评分,以获得稳定的估计:
| (3) |
其中 表示候选者的数量。 得益于检测器的上下文推理能力和对背景的感知,检测器计算的新颖性估计 可以更准确地区分真实/噪声候选。 结合 CLIP 模型生成的准确分类预测,我们最终计算每个候选框的置信度评分,如下所示:
| (4) |
在上述等式中, 表示前 1 CLIP 评分, 是一个控制两个不同模型依赖关系的标量。 我们利用一个固定的阈值 来选择高质量的伪标签。 然后在弱增强和强增强图像上进行训练。
检测器的加入显着降低了噪声候选的置信度,即使在初始训练阶段也极大地提高了所选伪标签的准确性。 此外,随着模型随着训练的收敛,新颖性估计 将更加准确,从而导致更高质量的伪标签,并最终提高模型对新类别的检测性能。
4.3 训练
在本节中,我们将描述我们对检测器传统训练设计 [10] 的改进。 本节中提出的所有方法都应用于预热阶段和随后的在线对象挖掘阶段。
分层标签分配。
学习新概念不应该影响模型识别基本对象的性能。 然而,一个容易被忽视的现象是,当在训练中应用新的伪标签时,基本类别的mAP会下降。 原因是新伪标签可能与基本标注重叠,导致基于IoU的标签分配中出现“基本-新-冲突”。 为了解决这个问题,我们提出了分层标签分配,它首先通过IoU匹配分配具有基本标注的建议,然后在第一步被标记为背景的框与伪标签进行第二次匹配。 实验表明,分层标签分配有助于在不影响估计基本类别性能的情况下,实现检测新对象的较高准确率。
自适应提案重加权。
由于伪标签的定位质量有限,框中心可能远离地面实况目标中心。 因此,与定位错误的伪标签匹配的训练框与地面实况目标共享极不平衡的重叠。 然而,检测器 [10] 的传统训练设计对这些不平衡的框平等地推导出训练损失,这阻碍了学习过程。 为了解决这个问题,我们提出了自适应提案重加权,为每个与伪标签匹配的训练框分配独立的损失权重。
使用自适应提案重加权训练检测器的损失函数计算如下:
| (5) |
其中 ( 包括背景框)是训练框的总数, 是新概念学习的总权重, 表示每个新训练框的独立权重。 特别是,我们遵循等式 4 的设计来定义单个权重 为:
| (6) |
5 实验
在本节中,我们将评估我们的 MarvelOVD 框架与标准基准,将其与当前最先进的方法进行比较。 此外,我们的消融研究对导致传统基于 CLIP 的伪标签生成中噪声的主要问题进行了深入分析,并详细说明了我们的框架如何有效地解决这些挑战。
5.1 数据集
我们的主要实验使用 COCO-2017 数据集 [22] 在开放词汇设置 [37] 中,将 48 个基础类别和 17 个新颖类别划分为评估。 为基础类别提供注释,而新颖类别仅提供类别名称。 我们计算 ,分别代表新颖类别、基础类别和所有类别的在 IoU 为 0.5 时的平均精度均值。 此外,LVIS-v1 数据集 [9] 在标准开放词汇检测 (OVD) 设置 [8] 中使用,将 337 个罕见类别视为新颖类别,其余类别视为基础类别。 对于 LVIS,我们报告了从 0.5 到 0.95 的 IoU 平均的框平均精度 (AP),用于罕见 (新颖) 类别、常见类别、频繁类别和所有类别,分别表示为 和 。
5.2 实现细节
我们使用 ViT-B/32 CLIP 作为预训练的视觉语言模型 (VLM) 及其文本编码器来编码类别概念。 与现有方法 [41] 一致,我们在 COCO 数据集上的实验使用 Mask-RCNN [10],其中 ResNet50-FPN [11, 21] 作为基础检测器。 对于训练,我们最初选择 CLIP 得分高于 0.8 的噪声伪标签,并将此设置用于 次迭代的预热阶段。 随后,我们将 设置为将检测器与 CLIP 集成,并将 设置为生成精确的伪标签。 我们将 设定为新概念学习的整体权重。 训练在 4 个 GPU 上进行,总批次大小为 16,跨越 90,000 次迭代(包括 0.5k 次预热),使用初始学习率为 0.02,在 60,000 次和 80,000 次迭代时降低 10 倍。 图像输入大小符合标准配置,短边范围为 [640, 800],长边小于 1333。 此外,我们在伪标签学习中应用了半监督目标检测文献 [23, 33] 中常见的弱强增强。 对于 LVIS 数据集,我们复制了 Detic 的实验设置 [44] 并将我们的方法应用于 CenterNet2 [45] 基线。 模型在 4 个 GPU 上训练,同时保持总批次大小不变。 所有实验都在 Detectron2 [32] 中进行,更多细节请参见补充材料。
| Methods | Training Source | |||||||||||||
| RegionCLIP [42] |
|
31.4 | 57.1 | 50.4 | ||||||||||
| Gao et al. [7] |
|
30.8 | 46.1 | 42.1 | ||||||||||
| PromptDet [5] |
|
26.6 | - | 50.6 | ||||||||||
| OADP [29] |
|
35.6 | 55.8 | 50.5 | ||||||||||
| Rasheed et al. [1] |
|
36.6 | 54.0 | 49.4 | ||||||||||
|
|
|
|
|
5.3 主要结果
我们的方法整合了检测器来细化伪标签生成和后续学习阶段,显著降低了伪标签和训练框中的噪声。 如表 6 所示,我们的方法在推断基础类别和新类别方面均大幅优于基线方法 [41]。 基础类别的改进源于分层标签分配,确保了尽管存在伪标签,基础类别的学习不受干扰。 检测器的集成有效地缓解了 CLIP 在区分局部区域中的噪声方面的不足,提高了伪标签的质量,进而增强了检测器识别新物体的能力。 我们还将我们的方法与表 6 中利用伪标签的其他最先进的开放词汇检测技术进行了比较。 虽然现有方法通常依赖于辅助数据或监督,例如互联网来源的图像-文本对 [7, 5],伪区域-文本对预训练 [42] 或辅助图像级标签 [1],但我们的方法解决了伪标签生成和传统训练设计 [10] 中的根本问题,在没有额外数据或监督的情况下取得了显著的收益。 表 7 展示了我们在 LVIS 数据集上的结果,将我们的方法与常见的 CenterNet2 基线 [44] 进行了比较。 与现有的使用图像级标签的附加分类数据来增强新物体检测的方法 [44, 1] 相反,我们的方法利用了原始训练数据中的潜在新物体。 表 7 中的结果表明,我们的方法在大型标签空间中也表现出色。
| Methods | AP | |||
|---|---|---|---|---|
| VLDet [20] | 22.4 | - | - | 34.4 |
| Detic [44] | 24.6 | 32.5 | 35.6 | 32.4 |
| Rasheed et al. [1] | 25.2 | 33.4 | 35.8 | 32.9 |
| MarvelOVD(Ours) | 26.0 | 34.2 | 36.9 | 34.2 |
6 消融研究
我们在 COCO 数据集上进行实验,以评估我们方法的关键组件的有效性,补充材料中详细介绍了其他消融研究。
6.1 每个组件的效果
表 8 展示了每个提出的算法组件对最终性能的贡献。 最初,我们改变了 VL-PLM [41] 的全局训练设置,包括总的新损失权重 和数据增强。 较大的新损失权重不会影响性能,而弱强增强则增强了伪标签的学习。 然后,我们实施分层标签分配来解决新伪标签和基本标注之间的冲突。 这种调整在不影响新类别检测的情况下,将基本类别检测恢复到监督性能水平。 之后,我们引入了在线物体挖掘来净化伪标签,这在对新类别的检测准确率上带来了显著的改进,表明我们的方法通过利用检测器的能力来抵消 CLIP 的局限性是有效的。 基于此,应用自适应提案重加权进一步提高了新类别的平均精度。 这种提升来自自适应重加权计算的独立权重,它迫使模型关注与实际新颖物体重叠更大的框。 总之,我们的方法为基于伪标签的新颖概念学习提供了一个偏差较小的管道,它不仅有效地净化了训练目标,而且优化了学习过程,并在不需要额外数据或预训练的情况下显著提高了基础类别和新颖类别的性能。
| Supervised by base annotations | - | 56.4 | - | |
|
32.7 | 54.0 | 48.5 | |
|
32.5 | 54.0 | 48.4 | |
|
34.2 | 53.9 | 49.1 | |
|
34.4 | 56.4 | 50.5 | |
|
37.8 | 56.5 | 51.3 | |
|
38.9 | 56.6 | 51.8 |
6.2 伪标签分析

我们使用包含 2064 张包含新颖物体的图像的 COCO 评估集,对不同训练阶段的伪标签质量进行了深入分析。 相对于地面真实 (GT) 新颖物体,IoU 得分高于 0.5 且分类正确的伪标签被归类为真阳性 (TP)。 这些发现如图 3 所示。 为了进行公平的比较,我们将基于 CLIP 的伪标签 () 的阈值与我们的动态伪标签 () 对齐,以保持可比的召回率。 最初,预热阶段赋予了新颖物体判别能力,导致该阶段之后伪标签质量的稳定提升。 随后,增强后的伪标签细化了检测器识别新颖物体的能力,表现为训练初期伪标签精度的显著提高。 如图 3 所示,随着训练的进行,检测器越来越多地将新颖框与背景和基础物体区分开来,动态地增强了伪标签的质量。
6.3 不同阈值和预热步骤的影响
| 0.8 | 0.85 | 0.9 | 0.95 | 0.5k | 1k | 2k | 5k | ||
| 37.0 | 38.2 | 38.9 | 38.4 | 38.9 | 38.7 | 38.7 | 38.5 |
我们评估了各种阈值和预热步骤对性能的影响,详细内容见表 9。 我们的基本设置使用阈值 和 预热步骤。 值得注意的是,伪标签选择的阈值显着影响模型性能;虽然 0.8 对我们的基线来说是最佳的,但由于伪标签置信度偏差较小,阈值约为 0.9 对我们的方法更有效。 关于预热步骤,它们指导从 CLIP 生成的伪标签的初始学习,它们对最终性能的影响很小。 随着模型收敛,这些伪标签的质量会提高,这表明不同的初始设置最终会产生相似的性能结果。
6.4 和 的依赖性分析
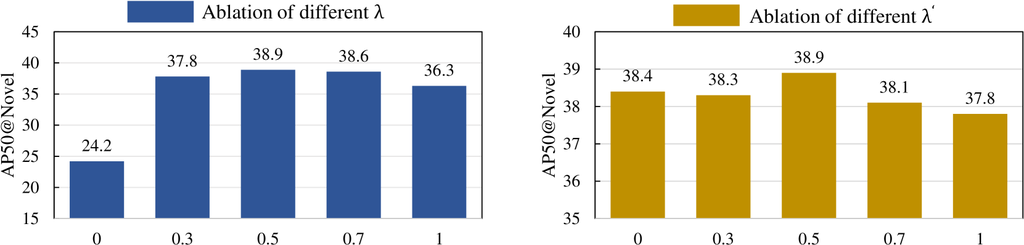
我们使用公式 4 计算每个候选伪标签的置信度,并使用公式 6 计算每个新框的训练权重,其中 和 决定了对不同模型或测量的依赖程度。 图 4 记录了 和 变化的影响。 最佳性能在 和 范围内观察到,产生可比的结果。 具体来说,还测试了极端值: 表示仅依赖于预热后的检测器,这会导致性能下降,强调了 CLIP 在区分新类别的重要性。 相反,在 处,伪标签生成回归到传统的 [41, 7, 5] 方法,这些方法完全依赖于 CLIP 模型。 虽然性能在这种情况下下降,但它仍然超过基线,表明自适应提案重新加权有效地抵消了噪声框的影响。 通过设置 ,自适应重新加权会改变原始训练设计 [10],使用加权伪标签 [41],它限制了模型对新概念的学习,导致性能显著下降。
7 结论
在本文中,我们解决了预训练视觉语言模型(VLMs)在生成用于局部区域的准确伪标签方面的局限性,方法是整合目标检测器的功能。 VLMs 的关键问题在于它们缺乏上下文感知能力,无法区分“背景”,导致伪标签有偏差。 通过利用检测器的上下文特征提取和背景区分能力,我们通过在线对象挖掘显著提高了伪标签质量,并通过自适应提案重新加权优化了学习过程。 我们的大量实验表明,这种方法不仅增强了检测器对新对象的识别能力,而且在没有额外数据或监督的情况下,其性能优于最先进的方法,为通过伪标签学习开放词汇表概念提供了一种高效且有效的解决方案。
致谢。
本工作部分由广东省重点领域研发计划(NO. 2021B0101420004)支持,部分由国家自然科学基金(NO. 62322608,NO. 62106235,NO. 62325605)支持,部分由广西科技计划项目(NO. GuikeAD23026034)支持,部分由深圳市科技计划项目(NO. JCYJ20220530141211024)支持,部分由辽宁省感知与理解人工智能重点实验室(AIPU)开放项目计划(NO. 20230003)支持。
附录 0.A 进一步消融研究
0.A.1 用于自适应重新加权的不同指标
| 39.8 | 37.8 | 37.6 | 38.0 |
我们检查了几个其他测量方法来估计自适应重新加权的可靠性得分 ,包括:
-
•
伪标签的置信度 (): 为了比较。 通过设置 ,自适应重新加权退化为传统的训练设计 [10],使用加权伪标签 [41]。
-
•
交并比 (): 伪标签中重叠更大的框获得更大的权重,反之亦然。
-
•
新颖性估计 (): 在主论文的等式 3 中定义,估计包含真实新颖物体的概率,我们在此设置中重复使用它进行伪标签挖掘和自适应重新加权。
如表 5 所示,使用弱增强图像预测的背景得分取得了最佳性能,并且它显著优于使用加权伪标签 [41] 的传统训练设计 [10]。
0.A.2 对全局新颖损失权重 的消融
| Models | VL-PLM | MarvelOVD | ||
|---|---|---|---|---|
| 32.7 | 54.0 | 37.8 | 57.0 | |
| 32.5 | 53.9 | 38.9 | 56.5 | |
| - | - | 38.6 | 56.0 | |
传统方法 [41, 7, 5] 通常将噪声伪标签视为地面实况,并将其与基本标注相结合以训练检测器。 相反,我们提出的 MarvelOVD 努力在利用伪标签和训练框进行训练之前减少它们中的噪声,从而取得了更有希望的结果。 我们检查了不同的全局新颖损失权重,并在表 6 中报告了性能。 结果表明,将全局新颖权重设置为 进一步提高了 MarvelOVD 的性能,同时略微降低了基线方法的性能。 原因是基线方法中包含的大量噪声阻碍了进一步改进。 相反,我们的方法通过在线挖掘和自适应加权有效地净化了伪标签并去除了后续训练设计的偏差,从而在更大的新颖损失权重下获得了更好的性能。 也测试了更高的新颖权重,但它们并没有带来更好的结果。
0.A.3 定性结果

0.A.4 弱强增强的影响
| Models | VL-PLM | MarvelOVD | ||
|---|---|---|---|---|
| w/o WSA | 32.7 | 54.0 | 37.2 | 56.4 |
| w/ WSA | 34.2 | 53.9 | 38.9 | 56.5 |
我们应用了其他 OVD 作品未采用的弱强增强。 这种动机来自最近的半监督学习方法(例如 fixmatch [28]、unbiased-teacher [23]),这些方法表明,在弱强增强特征之间强制执行相同的监督可以为伪标签学习带来更好的性能。 我们在传统 OVD 方法 [41] 和 MarvelOVD 上应用了弱强增强,以评估其影响,结果如表 7 所示。 弱强增强几乎不影响基础类别的平均精度,而在 VL-PLM 和我们的 MarvelOVD 中都同样提高了新类别的性能。 在没有增强的情况下,我们的框架仍然比基线方法有显著的提升。
| Methods | Training Source | |||||||||||||||||
|
|
|
|
|
||||||||||||||
| Detic [44] |
|
27.8 | 47.1 | 45.0 | ||||||||||||||
|
|
|
|
|
||||||||||||||
| RegionCLIP [42] |
|
31.4 | 57.1 | 50.4 | ||||||||||||||
| Gao et al. [7] |
|
30.8 | 46.1 | 42.1 | ||||||||||||||
| PromptDet [5] |
|
26.6 | - | 50.6 | ||||||||||||||
| OADP [29] |
|
35.6 | 55.8 | 50.5 | ||||||||||||||
| Rasheed et al. [1] |
|
36.6 | 54.0 | 49.4 | ||||||||||||||
| SAS-Det [40] |
|
37.4 | 58.0 | 53.0 | ||||||||||||||
|
|
|
|
|
附录 0.B 与现有 OVD 工作的比较和兼容性
0.B.1 性能比较
我们主要在主文中将我们的方法与其他基于伪标签的 OVD 工作进行比较。 表 8 展示了我们 MarvelOVD 与其他现有 OVD 工作的更完整比较,包括迁移学习和知识蒸馏方法。 其中,我们的方法在性能上仍然优于最先进的方法。 伪标签在最近的 OVD 工作中起着重要作用,其中大多数先进的方法从预训练的 VLM 生成的伪标签中学习新概念。 关于 VLM 生成的伪标签,我们的 MarvelOVD 识别了其噪声的根本原因,并通过整合检测器的上下文感知能力提出了专门的噪声去除策略,这在很大程度上持续地提高了最近的先进方法。
特别是,从基于 CNN 的 CLIP 主干中通过 roi-align 提取 CLIP 嵌入在最近的研究中得到应用 [15, 34],这为伪标签生成提供了一种替代的上下文感知操作。 即使这样,我们的方法仍然稳定地优于使用这种操作的方法(例如最近在 arxiv 上发表的 SAS-Det [40])。 结果进一步表明了我们的 MarvelOVD 在去噪基于伪标签的学习范式方面的有效性。
附录 0.C 更多实现细节
| Weak Augmentation | |||
| Process | Probability | Parameters | |
| Horizontal Flip | 0.5 | None | |
| Strong Augmentation | |||
| Process | Probability | Parameters | |
| Color Jittering | 0.8 |
|
|
| Grayscale | 0.2 | None | |
| GaussianBlur | 0.5 | (sigma_x, sigma_y) = (0.1, 2.0) | |
| CutoutPattern1 | 0.7 | scale=(0.05, 0.2), ratio=(0.3, 3.3) | |
| CutoutPattern2 | 0.5 | scale=(0.02, 0.2), ratio=(0.1, 6) | |
| CutoutPattern3 | 0.3 | scale=(0.02, 0.2), ratio=(0.05, 8) | |
0.C.1 弱强增强
我们方法中采用的详细的弱强增强在表 9 中进行了说明,它与半监督目标检测工作无偏教师 [23] 相同。 我们只将其应用于 COCO 数据集。 LVIS 数据集上的增强遵循常见的 CenterNet2 基准 [44]。
0.C.2 候选伪标签分配
我们遵循 VL-PLM 中的伪标签生成管道,在训练之前为每张图像分配候选伪标签。 特别地,类别无关的提案生成器实际上是一个用基础标注训练的检测器(将所有基础标注视为一个类别)。 然后我们用提案生成器推断训练图像,并用 RoI 头部递归地细化预测框 10 次。 递归细化提高了框的定位质量。 收集候选区域后,每个框的预测概率分布 由 CLIP ViT-B/32 编码如下:
| (7) | ||||
是 CLIP 的图像编码器和文本编码器, 是提案生成器生成的框, 是由 裁剪的区域,大小为 。 获取每个框的概率分布后,我们用阈值 0.5 对它们进行过滤,并用 NMS 对剩余的框进行后处理,以获得候选伪标签。 我们记录候选者的 TOP-1 CLIP 得分和预测类别,并将它们分配给图像,然后在检测器的指导下动态地选择可靠的候选者进行训练。 阈值 0.5 不是影响性能的特殊超参数,它用于去除永远不会被选为伪标签的冗余框,从而加速训练速度。 通过 RoI 头部细化定位并使用更大区域提取区域嵌入是基础方法 VL-PLM 采用的现有技术。 我们也在我们的候选伪标签分配过程中保留了它们。
附录 0.D 局限性
我们提出的 MarvelOVD 提供了一个更好的度量来从固定的候选框中净化伪标签。 它不能提高伪标签的定位质量。 由于候选框是由仅使用基础标注训练的提案生成器生成的,因此对新对象的定位质量有限。 随着检测器在训练期间从伪标签中获得更多关于新对象的知识,它定位新对象的能力也应该得到增强。 如何合理利用检测器动态优化伪标签的定位质量值得在未来探索。
参考文献
- [1] Bangalath, H., Maaz, M., Khattak, M.U., Khan, S.H., Shahbaz Khan, F.: Bridging the gap between object and image-level representations for open-vocabulary detection. Advances in Neural Information Processing Systems 35, 33781–33794 (2022)
- [2] Bravo, M.A., Mittal, S., Brox, T.: Localized vision-language matching for open-vocabulary object detection. In: DAGM German Conference on Pattern Recognition. pp. 393–408. Springer (2022)
- [3] Chen, P., Sheng, K., Zhang, M., Lin, M., Shen, Y., Lin, S., Ren, B., Li, K.: Open vocabulary object detection with proposal mining and prediction equalization. arXiv preprint arXiv:2206.11134 (2022)
- [4] Du, Y., Wei, F., Zhang, Z., Shi, M., Gao, Y., Li, G.: Learning to prompt for open-vocabulary object detection with vision-language model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14084–14093 (2022)
- [5] Feng, C., Zhong, Y., Jie, Z., Chu, X., Ren, H., Wei, X., Xie, W., Ma, L.: Promptdet: Towards open-vocabulary detection using uncurated images. In: European Conference on Computer Vision. pp. 701–717. Springer (2022)
- [6] Frome, A., Corrado, G.S., Shlens, J., Bengio, S., Dean, J., Ranzato, M., Mikolov, T.: Devise: A deep visual-semantic embedding model. Advances in neural information processing systems 26 (2013)
- [7] Gao, M., Xing, C., Niebles, J.C., Li, J., Xu, R., Liu, W., Xiong, C.: Open vocabulary object detection with pseudo bounding-box labels. In: European Conference on Computer Vision. pp. 266–282. Springer (2022)
- [8] Gu, X., Lin, T.Y., Kuo, W., Cui, Y.: Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921 (2021)
- [9] Gupta, A., Dollar, P., Girshick, R.: Lvis: A dataset for large vocabulary instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5356–5364 (2019)
- [10] He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 2961–2969 (2017)
- [11] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
- [12] Jayaraman, D., Grauman, K.: Zero-shot recognition with unreliable attributes. Advances in neural information processing systems 27 (2014)
- [13] Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021)
- [14] Kim, W., Son, B., Kim, I.: Vilt: Vision-and-language transformer without convolution or region supervision. In: International Conference on Machine Learning. pp. 5583–5594. PMLR (2021)
- [15] Kuo, W., Cui, Y., Gu, X., Piergiovanni, A., Angelova, A.: F-vlm: Open-vocabulary object detection upon frozen vision and language models. arXiv preprint arXiv:2209.15639 (2022)
- [16] Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International Conference on Machine Learning. pp. 12888–12900. PMLR (2022)
- [17] Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., Hoi, S.C.H.: Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems 34, 9694–9705 (2021)
- [18] Li, L., Miao, J., Shi, D., Tan, W., Ren, Y., Yang, Y., Pu, S.: Distilling detr with visual-linguistic knowledge for open-vocabulary object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6501–6510 (2023)
- [19] Li, L.H., Zhang, P., Zhang, H., Yang, J., Li, C., Zhong, Y., Wang, L., Yuan, L., Zhang, L., Hwang, J.N., et al.: Grounded language-image pre-training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10965–10975 (2022)
- [20] Lin, C., Sun, P., Jiang, Y., Luo, P., Qu, L., Haffari, G., Yuan, Z., Cai, J.: Learning object-language alignments for open-vocabulary object detection. arXiv preprint arXiv:2211.14843 (2022)
- [21] Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
- [22] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. pp. 740–755. Springer (2014)
- [23] Liu, Y.C., Ma, C.Y., He, Z., Kuo, C.W., Chen, K., Zhang, P., Wu, B., Kira, Z., Vajda, P.: Unbiased teacher for semi-supervised object detection. In: Proceedings of the International Conference on Learning Representations (ICLR) (2021)
- [24] Lu, J., Batra, D., Parikh, D., Lee, S.: Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems 32 (2019)
- [25] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- [26] Rao, Y., Zhao, W., Chen, G., Tang, Y., Zhu, Z., Huang, G., Zhou, J., Lu, J.: Denseclip: Language-guided dense prediction with context-aware prompting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18082–18091 (2022)
- [27] Shi, H., Hayat, M., Wu, Y., Cai, J.: Proposalclip: Unsupervised open-category object proposal generation via exploiting clip cues. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9611–9620 (2022)
- [28] Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C.A., Cubuk, E.D., Kurakin, A., Li, C.L.: Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in neural information processing systems 33, 596–608 (2020)
- [29] Wang, L., Liu, Y., Du, P., Ding, Z., Liao, Y., Qi, Q., Chen, B., Liu, S.: Object-aware distillation pyramid for open-vocabulary object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11186–11196 (2023)
- [30] Wu, S., Zhang, W., Jin, S., Liu, W., Loy, C.C.: Aligning bag of regions for open-vocabulary object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15254–15264 (2023)
- [31] Wu, X., Zhu, F., Zhao, R., Li, H.: Cora: Adapting clip for open-vocabulary detection with region prompting and anchor pre-matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7031–7040 (2023)
- [32] Wu, Y., Kirillov, A., Massa, F., Lo, W.Y., Girshick, R.: Detectron2. https://github.com/facebookresearch/detectron2 (2019)
- [33] Xu, M., Zhang, Z., Hu, H., Wang, J., Wang, L., Wei, F., Bai, X., Liu, Z.: End-to-end semi-supervised object detection with soft teacher. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3060–3069 (2021)
- [34] Yu, Q., He, J., Deng, X., Shen, X., Chen, L.C.: Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip. Advances in Neural Information Processing Systems 36 (2024)
- [35] Yun, S., Park, S.H., Seo, P.H., Shin, J.: Ifseg: Image-free semantic segmentation via vision-language model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2967–2977 (2023)
- [36] Zang, Y., Li, W., Zhou, K., Huang, C., Loy, C.C.: Open-vocabulary detr with conditional matching. In: European Conference on Computer Vision. pp. 106–122. Springer (2022)
- [37] Zareian, A., Rosa, K.D., Hu, D.H., Chang, S.F.: Open-vocabulary object detection using captions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14393–14402 (2021)
- [38] Zhai, X., Wang, X., Mustafa, B., Steiner, A., Keysers, D., Kolesnikov, A., Beyer, L.: Lit: Zero-shot transfer with locked-image text tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18123–18133 (2022)
- [39] Zhang, H., Zhang, P., Hu, X., Chen, Y.C., Li, L., Dai, X., Wang, L., Yuan, L., Hwang, J.N., Gao, J.: Glipv2: Unifying localization and vision-language understanding. Advances in Neural Information Processing Systems 35, 36067–36080 (2022)
- [40] Zhao, S., Schulter, S., Zhao, L., Zhang, Z., G, V.K.B., Suh, Y., Chandraker, M., Metaxas, D.N.: Taming self-training for open-vocabulary object detection (2023)
- [41] Zhao, S., Zhang, Z., Schulter, S., Zhao, L., Vijay Kumar, B., Stathopoulos, A., Chandraker, M., Metaxas, D.N.: Exploiting unlabeled data with vision and language models for object detection. In: European Conference on Computer Vision. pp. 159–175. Springer (2022)
- [42] Zhong, Y., Yang, J., Zhang, P., Li, C., Codella, N., Li, L.H., Zhou, L., Dai, X., Yuan, L., Li, Y., et al.: Regionclip: Region-based language-image pretraining. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16793–16803 (2022)
- [43] Zhou, C., Loy, C.C., Dai, B.: Extract free dense labels from clip. In: European Conference on Computer Vision. pp. 696–712. Springer (2022)
- [44] Zhou, X., Girdhar, R., Joulin, A., Krähenbühl, P., Misra, I.: Detecting twenty-thousand classes using image-level supervision. In: European Conference on Computer Vision. pp. 350–368. Springer (2022)
- [45] Zhou, X., Koltun, V., Krähenbühl, P.: Probabilistic two-stage detection. arXiv preprint arXiv:2103.07461 (2021)