[affiliation=]松浦浩平
[affiliation=]芦原孝徳
[affiliation=]守屋隆史
[affiliation=]三村正人
[affiliation=]
狩野隆友
[affiliation=]小川敦範
[affiliation=]马克·德鲁克罗瓦
逐句语音摘要:
任务、数据集和基于语言模型知识蒸馏的端到端建模
摘要
本文介绍了一种称为逐句语音摘要 (Sen-SSum) 的新方法,该方法以逐句的方式从语音文档中生成文本摘要。 Sen-SSum 将自动语音识别 (ASR) 的实时处理与语音摘要的简洁性相结合。 为了探索这种方法,我们为 Sen-SSum 提供了两个数据集:Mega-SSum 和 CSJ-SSum。 利用这些数据集,我们的研究评估了两种类型的基于 Transformer 的模型:1) 将 ASR 和强大的文本摘要模型相结合的级联模型,以及 2) 直接将语音转换为文本摘要的端到端 (E2E) 模型。 虽然 E2E 模型对于开发计算效率高的模型很有吸引力,但它们的性能不如级联模型。 因此,我们建议使用级联模型生成的伪摘要对 E2E 模型进行知识蒸馏。 我们的实验表明,这种提出的知识蒸馏有效地提高了 E2E 模型在两个数据集上的性能。
关键词:
逐句语音摘要,端到端建模,知识蒸馏,吉加词库,CSJ1 引言
自动语音识别 (ASR) 在过去几十年中取得了重大进展 [1], 主要目的是生成逐字的转录, 但对于人类来说,此类转录可能难以阅读 由于口语风格和冗余表达。 另一方面,语音摘要 (SSum) 将语音文档压缩为简洁的书面风格摘要 提供信息丰富且易于理解的摘要, 并已越来越受到人们的关注,用于处理来自各种领域(如会议 [2] 和讲座 [3])的语音。 然而,与 ASR 不同,SSum 不适合实时应用 因为它通常一次处理整个语音文档, 这表明缺乏技术来生成实时且简洁的语音内容摘要。
为了解决这个问题,我们提出 句子级语音摘要 (Sen-SSum) 来弥合 ASR 和 SSum 之间的差距。 图 1 对比了 ASR、SSum 和 Sen-SSum 以及示例。 Sen-SSum 超越了相关的技术,例如停顿检测和去除 [4],并提供更简洁明了的输出。 此外,用户可以立即访问摘要,无需等到整个会议或讲座结束,因为 Sen-SSum 在每个语音句子后增量式地生成摘要。 因此,作为个人笔记的替代品,Sen-SSum 可以帮助用户稍后回顾会议流程,或者在中途加入讲座时赶上讨论。 尽管 Sen-SSum 有很多有希望的应用,但由于缺乏公开的 Sen-SSum 数据集,这项任务还没有得到很好的探索。
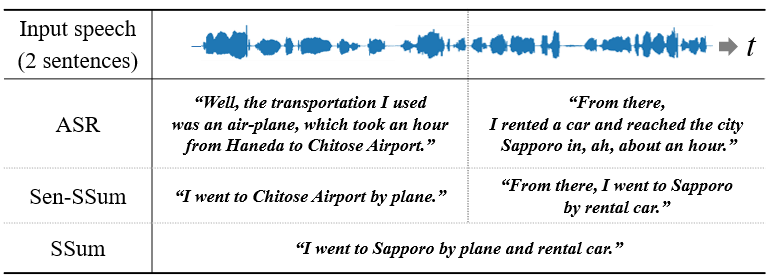
在本文中,我们介绍了一个新的 Sen-SSum 数据集:Mega-SSum。 Mega-SSum 数据集基于 Gigaword 数据集 [5, 6],包含 380 万个英语三元组,包括合成语音、转录和摘要。111https://huggingface.co/datasets/komats/Mega-SSum 我们使用最先进的多说话人文本到语音模型 [7] 来合成高质量的自然语音。 这个数据集使我们能够大规模地探索训练数据可用性带来的影响。 为了提高我们使用更实用数据集进行实验的有效性,我们还使用了内部日语 Sen-SSum 语料库 CSJ-SSum,该语料库基于自发日语语料库 [8],包含 38000 个真实语音三元组。
我们研究了 Sen-SSum 的两种方法:1) 级联和 2) 端到端 (E2E) 模型。 级联模型结合了 ASR 和文本摘要 (TSum) 模型 [9],由于在大型文本数据上预训练的 TSum 模型,可以输出高质量的摘要。 E2E 模型使用单个编码器-解码器模型 [10] 直接从输入语音生成文本摘要。 这种方法在参数效率和潜在的快速解码方面很有前景,但它需要大量的昂贵的语音摘要对进行训练,而缺乏如此大的训练数据集阻碍了端到端模型的性能。
为了解决这个问题,我们提出了端到端模型的知识蒸馏。 我们假设一个实际场景,其中训练集的一个小子集(“核心集”)包含摘要和转录标签,而其余样本则缺少一个或两个标签。 我们使用在核心集上训练的级联模型,从未标记的语音中创建伪摘要,从而增加了训练数据。 随后,我们使用核心集和伪摘要训练端到端模型。 我们预计强大的语言模型(LM),即TSum模型的丰富语言知识将通过伪摘要蒸馏到端到端模型中。 实验评估表明,它显着提高了端到端模型在两个数据集上的性能。 此外,我们发现,在某些情况下,伪摘要比手动摘要导致更好的摘要准确性。
| dataset | lang. | orig. data | split | #samples | #speakers | total dur. (hrs) | ave. dur. (sec) | CR (%) |
|---|---|---|---|---|---|---|---|---|
| Mega-SSum | En | Gigaword | train | 3,800,000 | 2,559 | 11,678.2 | 11.1 | 26.2 |
| core set* | 50,000 | 2,559 | 154.6 | 11.1 | 25.8 | |||
| DUC2003 | eval | 624 | 80 | 2.1 | 12.2 | 27.5 | ||
| CSJ-SSum | Ja | CSJ | train | 38,515 | 726 | 115.8 | 10.8 | 43.1 |
| eval-CSJ | 467 | 9 | 1.4 | 10.8 | 42.8 | |||
| TED | eval-TED | 1329 | 10 | 2.5 | 6.9 | 51.1 |
2 相关工作
文本句子摘要已在自然语言处理 (NLP) 领域得到广泛研究 [6, 11],但很少有研究涉及音频模态。 [12] 与我们的工作最密切相关,他们使用合成的 Gigaword 数据集对 Sen-SSum 进行了实验。 但是,他们只研究了级联建模,并没有发布 Sen-SSum 数据集。 此外,他们的数据集是我们数据集的十分之一,并且具有很高的词错误率 (WER),这表明语音质量很差。
Sen-SSum 任务也与不流畅检测和去除 [4]相关,因为它排除了不重要的词语,并提高了 ASR 转录的理解力。 但是,不流畅去除的主要目标不是使文档更短。 事实上,根据 [14],在消除不流畅后,Switchboard 数据集 [13]的压缩率为 86%,CSJ 数据集的压缩率为 92%。 其他相关研究,例如口语到书面语转换 [15, 16]、字幕 [17]和其他综合后处理 [18, 19],具有相似的压缩率,尽管它们还涉及改写以生成更友好的转录。 另一方面,我们在第 3节中介绍的 Sen-SSum 数据集的压缩率较低,仅为 20% (Mega-SSum) 和 40% (CSJ-SSum)。 因此,Sen-SSum 是一项截然不同的任务,更适合快速理解口语内容。
3 Sen-SSum 的数据集
高质量数据集的可用性对于推动 Sen-SSum 任务的研究和发展至关重要。 我们引入了一个新数据集 Mega-SSum 来研究 Sen-SSum。 我们还使用内部日语数据集 CSJ-SSum 在 Mega-SSum 上验证我们的实验结果。 表格 1 展示了这些数据集的概述和统计信息。
Mega-SSum 是一个用于 Sen-SSum 的大型英语数据集,包含 380 万个合成的口语句子以及相应的转录和摘要。 它基于 Gigaword 数据集 [5, 6], 由新闻文章的第一句话及其标题组成, 并被广泛用于文本句子摘要研究 [11]。 DUC2003 数据集 [20] 类似于 Gigaword,但每个输入句子有四个手动摘要,而不是标题,被用作评估集。 摘要非常简洁,压缩率 (CR) 2 22压缩率定义为 (摘要中的词数) / (输入文本中的词数), 遵循 [21]。 更短的摘要具有更低的比率。 约为 20%。 为了从文本句子中合成高质量且听起来自然的语音, 一个多说话人文本到语音模型 VITS [7] 是使用 LibriTTS-R 数据集 [22] 从头开始训练的, 它是一个声质量改进版的 LibriTTS [23]。 合成的语音保留了语言信息,使我们能够对 Sen-SSum 进行合理的调查。 例如, 使用 Whisper (small.en) ASR 模型 [24] 解码时,没有进行微调, 评估集上的 WER 仅为 7.8%,与典型的自然语音一样低。 为了模拟现实环境, 训练集被分为一个包含前 50k 个样本的核心集 和一个包含 3.75M 个样本的剩余集。 核心集用于调查低资源和实际情况。
我们使用一个名为 CSJ-SSum 的内部 Sen-SSum 数据集验证了在 Mega-SSum 数据集上获得的结果, 该数据集包含 38k 个日语真实语音句子、转录和摘要。 它基于 CSJ [8] 的 SPS 子集, 由自发独白和相应的转录组成, 涉及日常一般主题,如对近期新闻的评论。 此外,它还有一个基于 10 个日语 TED 演讲(“eval-TED”)的域外评估集。 专业标注人员被雇用来提供遵循以下两个指令的摘要: 1) 通过手动插入句号来将语音及其转录分段为句子。 2) 为每个转录句子提供简洁的书面风格摘要, 保留最基本的信息。 该数据集使我们能够确认 Sen-SSum 在真实数据上以及不同语言上的可能性。 顺便说一句,由于该数据集要小得多, 它证明了我们在第 4.2 节中提出的知识蒸馏方案的实际必要性。
4 方法
4.1 级联和端到端建模
我们使用两种不同的方法来实现 Sen-SSum:级联 [9] 和 E2E [10] 语音到文本摘要。
级联模型结合了 ASR 和 TSum 模型。 ASR 模型 首先将输入语音 转录成相应的文字记录, 然后 TSum 模型 预测目标摘要:
| (1) |
其中 表示摘要假设。 我们使用基于 Transformer 的编码器-解码器架构 [25] 来实现 ASR 和 TSum 模型,并使用交叉熵损失进行训练。 级联建模的主要优势在于,通过使用在大量未标记文本语料库上训练的 LM 初始化 TSum 模型,使其能够获得强大的 NLP 功能。 鉴于传统的 SSum 通常采用级联建模 [26, 27],因此级联建模是 Sen-SSum 的自然选择。
在 E2E 建模中,编码器-解码器模型 直接从输入语音 中预测目标摘要:
| (2) |
请注意,我们通过微调 ASR 模型来构建 E2E 模型,遵循 [10]。 E2E 建模以其紧凑且参数高效的结构以及降低解码延迟的潜力而具有吸引力。 此外,它可以缓解 ASR 错误的传播,并利用输入语音中的声学信息来预测摘要。 尽管有其优势,但 E2E 建模需要大量的语音-摘要对,这些对的收集成本很高且通常有限,导致其摘要能力较差。
4.2 用于 E2E 模型的序列级知识蒸馏
为了缓解 E2E 模型的训练数据稀缺问题, 我们建议利用级联模型来生成额外的训练数据。 具体来说, 级联模型在少量可用数据集(即核心集)上进行训练,通过使用 ASR 模型对其进行转录,然后使用 TSum 模型对转录结果进行摘要,从而从未标记的语音句子中生成伪摘要。 这些伪摘要以及核心集中的人工摘要被用于训练一个 E2E 模型。 我们预期,TSum 模型中嵌入的丰富语言知识将通过伪摘要被蒸馏到 E2E 模型中。 尽管这种方法的灵感来自于 E2E 语音翻译领域的成功 [28, 29],并且被广泛称为 序列级知识蒸馏 [30],但这是它首次应用于 E2E SSum。
4.3 利用自监督模型
我们还调查了整合 WavLM large333https://huggingface.co/microsoft/wavlm-large [31](一个最先进的语音自监督学习 (SSL) 模型,因其在低资源口语理解任务中的有效性而闻名)对我们使用 Mega-SSum 数据集增强 E2E 模型的影响。 具体来说, 我们首先使用 WavLM 作为特征提取器, 然后与下游 E2E 模型一起进行微调。 语音 SSL 模型有望成为我们提出的方法的潜在替代方案,因为它们从对大量语音数据进行预训练中获得了固有的语言知识 [32]。
5 实验
5.1 设置
5.1.1 模型架构
我们为 ASR、TSum 和 E2E Sen-SSum 实施了三种编码器-解码器模型。 ASR 和 E2E 模型都包含 一个具有 4 的下采样率的 2 层卷积神经网络,用于初始特征提取, 一个具有 512 模型维度和 31 核大小的 12 层 Conformer 编码器, 以及一个 12 层 Transformer 解码器。 编码器和解码器都具有 2048 维的前馈 (FF) 层。 遵循 [33], Conformer 块中的批量归一化层被 替换为层归一化层, 并且可学习的位置嵌入被用于解码器。 对于 TSum 模型, 我们使用 T5 模型 [34],包括一个具有 768 模型维度和 3072 维 FF 层的 12 层 Transformer 编码器和解码器。 级联模型和 E2E 模型中的参数数量分别为 362M (=142M+220M) 和 139M。
5.1.2 训练细节:数据集和超参数
针对 Mega-SSum 上的实验,我们首先在 Librispeech 数据集 [35] 的 960 小时音频上训练了一个 ASR 模型,并使用核心集中 50k 个语音转录对对其进行了微调。 我们进一步使用 50k 个语音-摘要对对 ASR 模型进行微调,以获得一个 E2E 模型。 我们将这个基线模型命名为“E2E-base”。 我们通过使用 50k 个转录-摘要对对英语 T5 模型 444https://huggingface.co/google-t5/t5-base 进行微调,准备了一个 TSum 模型。 ASR 和 TSum 模型的组合被命名为“Cascade-base”。 为了研究训练数据量的影响,我们还准备了使用前 100k、500k、1M 或 3.8M 个样本训练的 ASR、E2E 和 TSum 模型。 我们将它们命名为“E2E-HS”和“Cascade-HS”,因为它们是用 人类摘要 训练的,与第 4.2 节中使用伪摘要训练的模型相反。 这些 ASR 模型的 WER 分别为评估集的 11.7%、10.7%、9.2%、9.4% 和 7.7%。
对于所提出的知识蒸馏,我们假设包含 50k 个样本的核心集是完全可用的,并且仅剩余集中前 50k、450k、950k 或 3.75M 个样本的语音数据额外可用。 转录和摘要的准备方式如第 4.2 节所述。 由于添加了核心集中 50k 个样本,因此训练样本总数为 100k、500k、1M 或 3.8M。 我们将这些使用提出的知识蒸馏的 E2E 模型命名为“E2E-KD”。 为了评估 ASR 错误对所提出方法的影响,我们还研究了使用从参考转录生成的伪摘要训练的 E2E 模型,命名为“E2E-KD (ref)”。
对于 CSJ-SSum,我们使用了完整的 CSJ 数据集 [8] 和来自我们内部 ASR 数据集的 1M 个语音-转录对来训练一个 ASR 模型。 eval-CSJ/TED 上的字符错误率分别为 3.1% 和 16.7%。 然后,我们使用所有 38k 个语音-摘要对对其进行微调,以获得基线 E2E 模型。 日本 T5 模型555https://huggingface.co/sonoisa/t5-base-japanese 使用 38k 个转录-摘要对进行微调,以获得基线 TSum 模型。 对于知识蒸馏,我们利用了与用于训练 ASR 模型相同的 1M 个语音-转录对。 我们使用基线 TSum 模型从参考转录中生成了 1M 个伪摘要, 然后将这些伪摘要与 38k 个人工摘要一起用于训练提议的 E2E 模型。 请注意,1M 个对是从我们内部的 ASR 数据集中选择的, 以确保每个参考转录的长度都超过 10 个字符,并包含句子结束表达式,使 TSum 模型能够生成合理的摘要。
我们为 Mega-SSum 和 CSJ-SSum 采用了相同的超参数,除非另有说明。 为了获得 ASR 模型, 我们利用 WarmupLR 调度器和 Adam 优化器,将最大学习率 (LR) 设置为 2x 并将预热步数设置为 40k。 平均批次大小设置为 LibriSpeech 的 168 和 CSJ 的 350。 我们还应用了连接主义时间分类 (CTC) 辅助损失,权重为 0.3, SpecAugment [36],以及速度扰动。 词汇量大小设置为使用字节对编码的 Mega-SSum 的 5,000 [37] 以及使用字符单元的 CSJ-SSum 的 3,262。 对于微调,我们将 LR 调整为 2x,将预热步数调整为 1k,将批次大小缩减五分之一,并使用 AdamW 优化器。 在 E2E Sen-SSum 模型训练期间,CTC 损失被省略。 为了获得 TSum 模型,我们利用了从 5x 开始的线性衰减 LR。 我们使用基于验证损失的提前停止,耐心设置为 5 个 epoch。
5.1.3 评估细节
在评估中,我们始终将 ASR、E2E 和 TSum 模型的束宽度设置为 4。 为了客观评估,我们使用了 ROUGE-L (R-L) [38] 和 BERTScore (BScr) [39], 它们在之前的 TSum 和 SSum 研究中被广泛使用。 R-L 分数衡量的是表面的词语匹配, 而 BScr 利用 BERT 嵌入来捕捉词语的语义含义。 此外,受 [40] 的启发,我们使用 ChatGPT API666https://platform.openai.com/docs/api-reference 进行 A/B 测试,以进行更全面的评估。 具体来说,GPT4-turbo (gpt-4-1106-preview) 被指示在考虑参考转录的情况下选择两个摘要中更好的一个。
| Model | ROUGE-L | BERTScore | CR (%) |
|---|---|---|---|
| Cascade-base | 36.01.5 | 62.60.8 | 25.00.7 |
| E2E-base | 30.71.5 | 58.00.8 | 21.30.6 |
| + WavLM | 30.41.5 | 58.20.8 | 21.70.6 |
| E2E-KD3.8M | 35.61.6 | 61.90.8 | 23.50.6 |
5.2 结果
5.2.1 Mega-SSum 上的结果
表格 2 中的前三列显示了 在核心集上训练的级联和 E2E 模型的 R-L 和 BScr 分数以及 CR 的 95% 置信区间。 正如预期,由于预先训练的 TSum 模型强大的 NLP 能力,级联模型的表现优于 E2E 模型。 事实上,基线 E2E 模型偶尔只生成一个或两个词作为摘要, 这可能是由于其有限的泛化能力, 导致其 CR 比级联模型低。 尽管 WavLM 也在大量未标注语音上进行了预训练, 但将其与 E2E 模型结合并没有提高分数。 其语言知识似乎不足以帮助 E2E 模型解决摘要任务。 最后一列“E2E-KD3.8M”显示了使用来自核心集的 50k 个人类摘要和额外的 3.75M 个伪摘要训练的 E2E 模型的性能。 这种提出的方法显著增强了 E2E 模型,使其性能水平与级联模型相当。
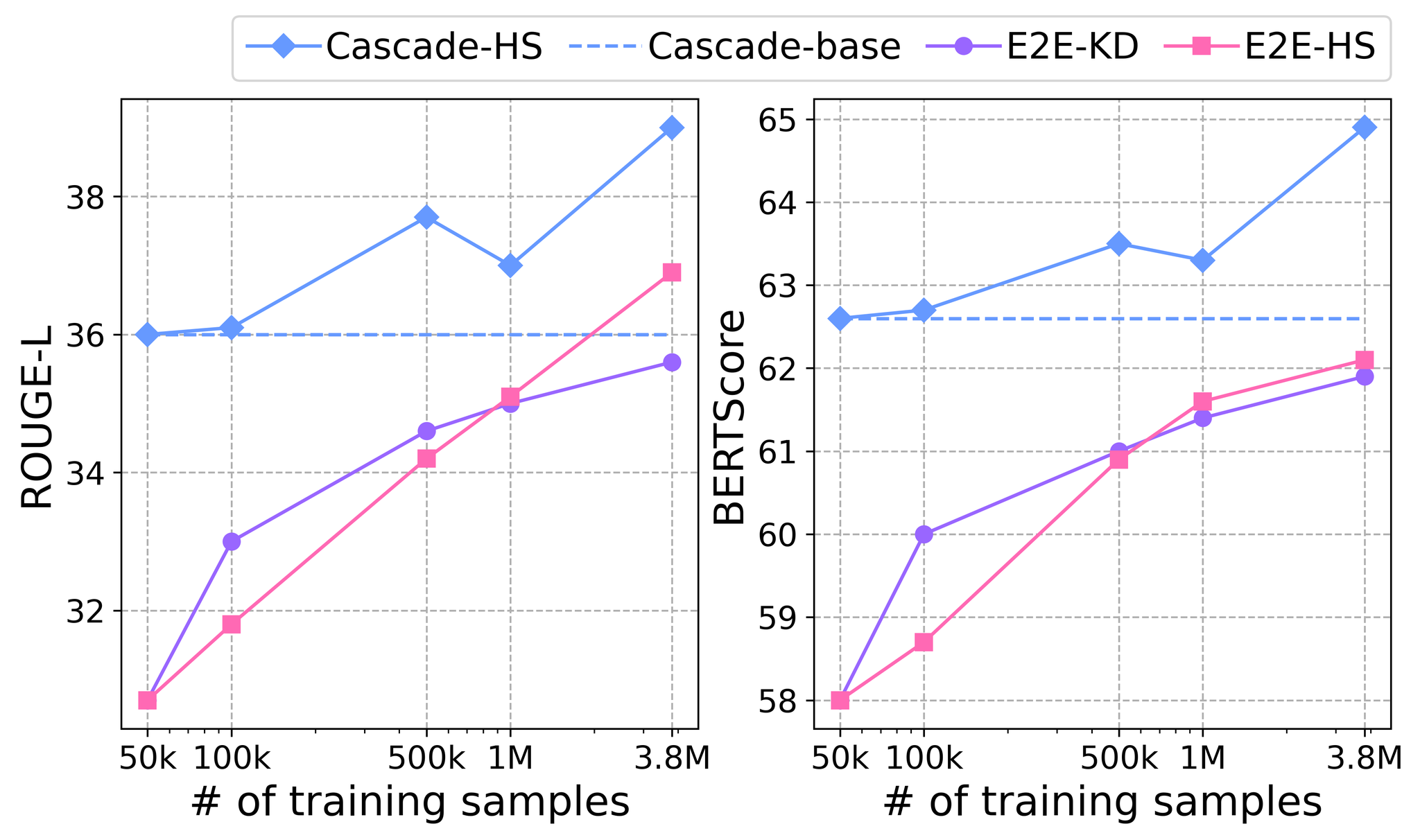
图 2 展示了当级联模型和端到端模型在不同数量的训练数据上训练时的 R-L 和 BScr 分数, 包括使用伪摘要训练的端到端模型的分数。 从 Cascade-HS 和 E2E-HS 的结果可以明显看出, 级联模型和端到端模型在训练样本更多的情况下生成了更好的摘要。 此外,伪摘要有效地改进了端到端模型 E2E-KD, 其分数逐渐接近生成伪摘要的 cascade-base 模型的分数。
有趣的是,使用伪摘要进行训练,端到端模型在最多 500k 个样本的情况下获得了更好的分数。 这可能是因为与人工摘要相比,伪摘要更容易让端到端模型学习。 例如,R-L 分数考虑了两个序列的最长公共子序列, 在伪摘要和转录之间(34.60.94,在评估集上) 明显高于人工摘要和转录之间的分数(27.21.03)。 这表明伪摘要使 Mega-SSum 成为一个更具提取性的摘要任务,这与 ASR 任务更相似,更容易复制。 然而,使用 1M 或更多的人工摘要,E2E-HS 的得分高于 E2E-KD,因为它可以复制更多类似人类的摘要, 而这些摘要无法通过错误且简化的伪摘要完全学习。
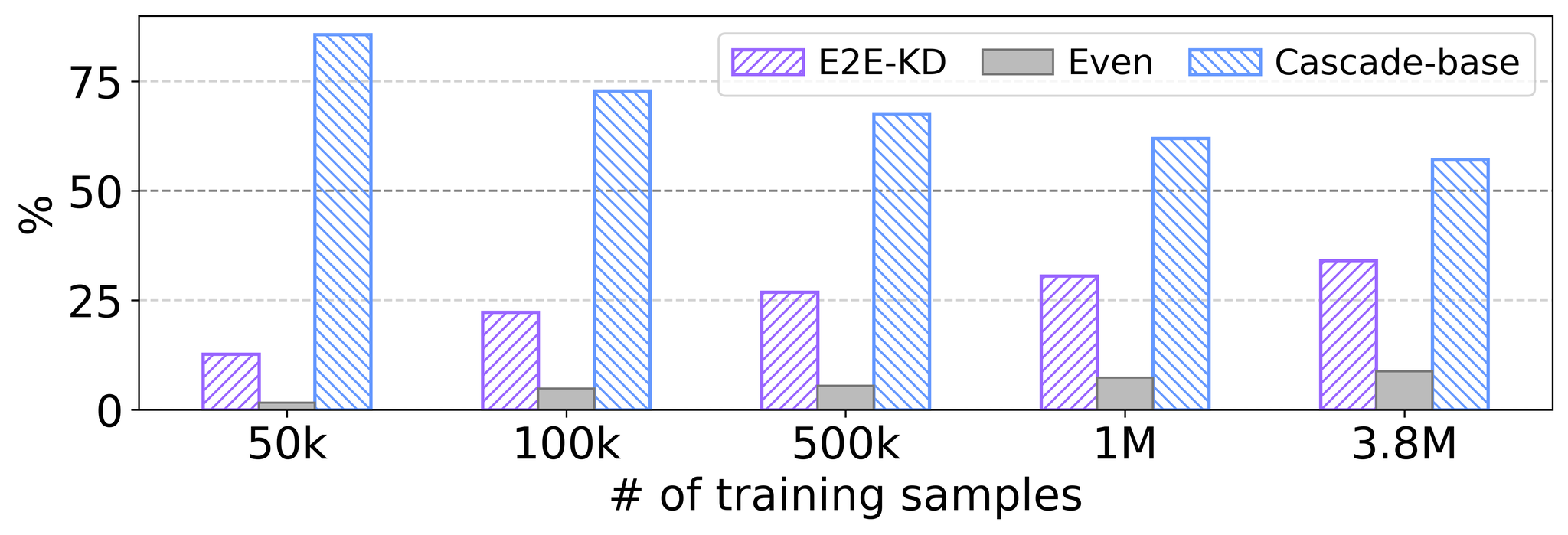
图 3 展示了 ChatGPT 进行的 A/B 测试的偏好百分比, 比较了基线级联模型生成的摘要与使用不同数量的伪摘要训练的端到端模型生成的摘要。 随着数据集的扩展,偏好逐渐转向端到端模型的摘要,而不是级联模型的摘要。 然而,即使使用 3.8M 个训练样本, 端到端模型的摘要经常被认为不如级联模型的摘要好。 通过 R-L 或 BScr 等传统指标,这种性能差距并不明显,表明可能需要更有效的知识蒸馏方法。
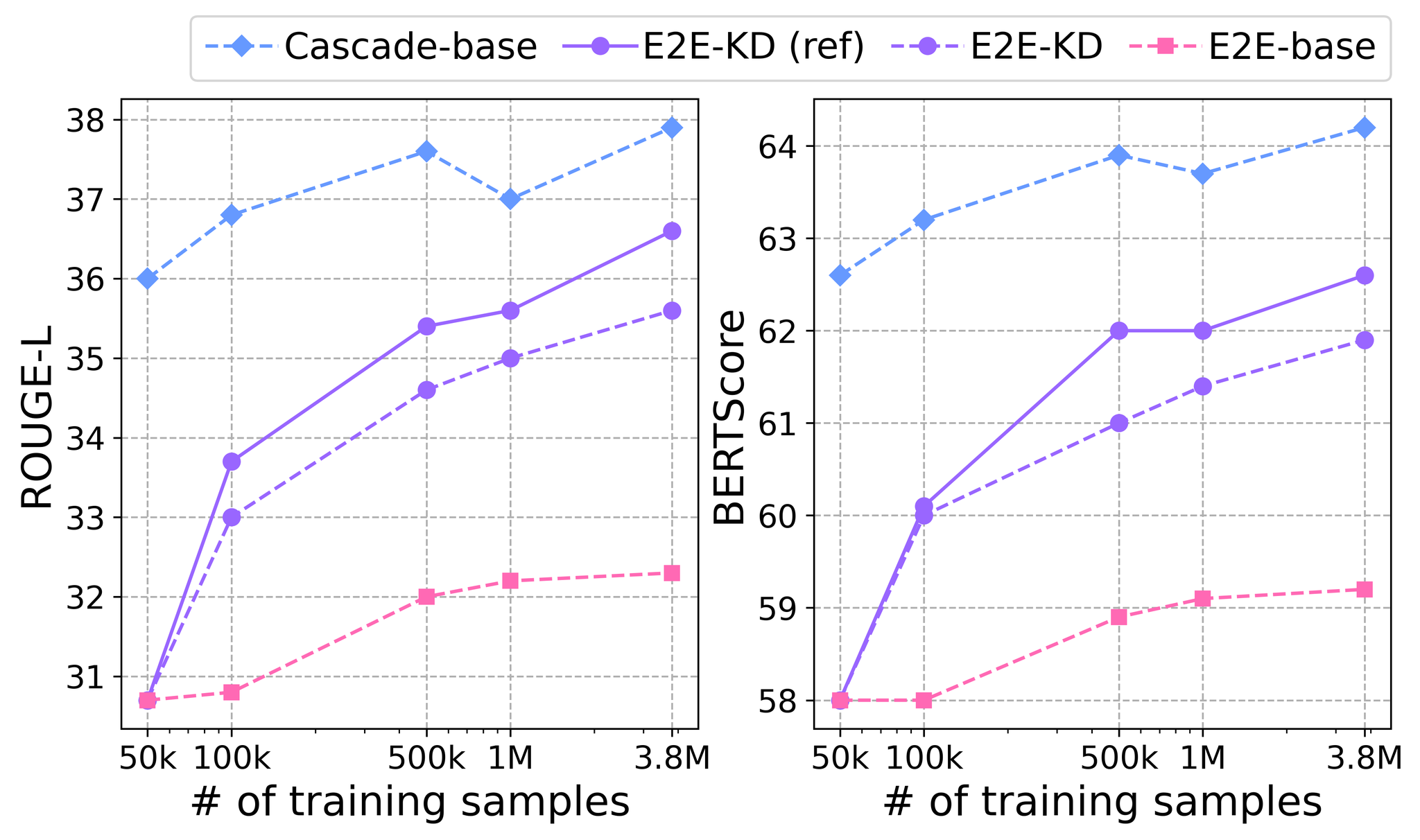
图 4 显示了当除了语音之外,还提供剩余集的参考转录时,知识蒸馏的效果。 请注意,基线级联模型和 E2E 模型,即 Cascade-base 和 E2E-base 也得到了改进,因为 ASR 模型是在更大的数据集上训练的。 虽然仅使用语音数据得到了显著的改进,但从参考转录中获得的更高质量的伪摘要很重要,并最终获得了更好的分数。
5.2.2 CSJ-SSum 上的结果
表 3 显示了 CSJ-SSum 数据集上的 R-L 和 BScr 分数。 由于 CSJ-SSum 数据集中摘要的提取性质更强,结构也更简单,因此得分显著高于 Mega-SSum。 尽管如此,所提出的方法显著提高了两个评估集上的得分,表明其在现实世界场景中的有效性。 与域内 eval-CSJ 集相比,我们在域外 eval-TED 集上获得了更多改进。 这种差异可能归因于所提出方法的固有泛化能力,该方法更适合于适应域外数据集中不同的词汇。
| Model | eval-CSJ | eval-TED | ||
|---|---|---|---|---|
| R-L | BScr | R-L | BScr | |
| Cascade | 66.92.1 | 84.70.9 | 63.31.2 | 82.60.6 |
| E2E | 63.12.3 | 82.81.0 | 60.11.3 | 80.70.6 |
| + KD | 65.72.2 | 84.01.0 | 63.11.3 | 82.10.6 |
6 结论
本研究中,我们介绍了 Sen-SSum 以及两个支持数据集 Mega-SSum 和 CSJ-SSum。 我们展示了级联模型和端到端模型在 Sen-SSum 中的潜力,以及使用级联模型对端到端模型进行知识蒸馏的有效性。 未来工作可以探索更有效的方法,例如 [41],它将 LMs 直接集成到端到端 SSum 模型中,并且不依赖于伪摘要。 开发上下文感知模型 [42] 也很重要,以便以句子为单位一致地处理长语音文档,这代表了一个更实用的设置。
参考文献
- [1] R. Prabhavalkar, T. Hori, T. N. Sainath, R. Schlüter, and S. Watanabe, “End-to-end speech recognition: A survey,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, pp. 325–351, 2024.
- [2] V. Rennard, G. Shang, J. Hunter, and M. Vazirgiannis, “Abstractive Meeting Summarization: A Survey,” Transactions of the Association for Computational Linguistics, pp. 861–884, 2023.
- [3] T. Kano, A. Ogawa, M. Delcroix, and S. Watanabe, “Attention-based multi-hypothesis fusion for speech summarization,” in ASRU, 2021, pp. 487–494.
- [4] P. Jamshid Lou and M. Johnson, “Disfluency detection using a noisy channel model and a deep neural language model,” in ACL, 2017, pp. 547–553.
- [5] D. Graff, J. Kong, K. Chen, and K. Maeda, “English Gigaword,” vol. 4, 2003, p. 34.
- [6] A. M. Rush, S. Chopra, and J. Weston, “A neural attention model for abstractive sentence summarization,” pp. 379–389, 2015.
- [7] J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in ICML, M. Meila and T. Zhang, Eds., 2021, pp. 5530–5540.
- [8] K. Maekawa, “Corpus of spontaneous Japanese: its design and evaluation,” in ISCA/IEEE Workshop on Spontaneous Speech Processing and Recognition, 2003, pp. 7–12.
- [9] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in ACL, 2020, pp. 7871–7880.
- [10] R. Sharma, S. Palaskar, A. Black, and F. Metze, “End-to-end speech summarization using restricted self-attention,” in ICASSP, 2022, pp. 8072–8076.
- [11] S. Chopra, M. Auli, and A. M. Rush, “Abstractive sentence summarization with attentive recurrent neural networks,” in NAACL, 2016, pp. 93–98.
- [12] Z. Huang, M. Rao, A. Raju, Z. Zhang, B. Bui, and C. Lee, “MTL-SLT: Multi-task learning for spoken language tasks,” in Workshop on NLP for Conversational AI, 2022, pp. 120–130.
- [13] J. Godfrey, E. Holliman, and J. McDaniel, “SWITCHBOARD: Telephone speech corpus for research and development,” in ICASSP, 1992, pp. 517–520.
- [14] H. Futami, E. Tsunoo, K. Shibata, Y. Kashiwagi, T. Okuda, S. Arora, and S. Watanabe, “Streaming joint speech recognition and disfluency detection,” in ICASSP, 2023, pp. 1–5.
- [15] M. Ihori, A. Takashima, and R. Masumura, “Large-context pointer-generator networks for spoken-to-written style conversion,” in ICASSP, 2020, pp. 8189–8193.
- [16] M. Sunkara, C. Shivade, S. Bodapati, and K. Kirchhoff, “Neural inverse text normalization,” in ICASSP, 2021, pp. 7573–7577.
- [17] D. Liu, J. Niehues, and G. Spanakis, “Adapting end-to-end speech recognition for readable subtitles,” in ICSLT, 2020, pp. 247–256.
- [18] G. Neubig, Y. Akita, S. Mori, and T. Kawahara, “A monotonic statistical machine translation approach to speaking style transformation,” Computer Speech & Language, vol. 26, no. 5, pp. 349–370, 2012.
- [19] J. Liao, S. Eskimez, L. Lu, Y. Shi, M. Gong, L. Shou, H. Qu, and M. Zeng, “Improving readability for automatic speech recognition transcription,” ACM Transactions on Asian and Low-Resource Language Information Processing, vol. 22, no. 5, pp. 1–23, 2023.
- [20] P. Over, H. Dang, and D. Harman, “DUC in context,” Special issue of Information Processing and Management on Text Summarization, pp. 1506–1520, 2007.
- [21] J. Goldstein, M. Kantrowitz, V. Mittal, and J. Carbonell, “Summarizing text documents: Sentence selection and evaluation metrics,” in SIGIR, 1999, pp. 121–128.
- [22] Y. Koizumi, H. Zen, S. Karita, Y. Ding, K. Yatabe, N. Morioka, M. Bacchiani, Y. Zhang, W. Han, and A. Bapna, “LibriTTS-R: A restored multi-speaker text-to-speech corpus,” in INTERSPEECH 2023, 2023, pp. 5496–5500.
- [23] H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “LibriTTS: A corpus derived from librispeech for text-to-speech,” in INTERSPEECH, 2019, pp. 1526–1530.
- [24] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in ICML, 2023, pp. 28 492–28 518.
- [25] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in NeurIPS, 2017.
- [26] G. Murray, S. Renals, and J. Carletta, “Extractive summarization of meeting recordings,” in EUROSPEECH, 2005, pp. 593–596.
- [27] J. J. Zhang, H. Y. Chan, and P. Fung, “Improving lecture speech summarization using rhetorical information,” in ASRU, 2007, pp. 195–200.
- [28] M. Gaido, M. A. Di Gangi, M. Negri, and M. Turchi, “End-to-end speech-translation with knowledge distillation: FBK@IWSLT2020,” in ICSLT, 2020, pp. 80–88.
- [29] H. Inaguma, T. Kawahara, and S. Watanabe, “Source and target bidirectional knowledge distillation for end-to-end speech translation,” in NAACL-HLT, 2021, pp. 1872–1881.
- [30] Y. Kim and A. M. Rush, “Sequence-level knowledge distillation,” in EMNLP, 2016, pp. 1317–1327.
- [31] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y. Qian, Y. Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, pp. 1505–1518, 2022.
- [32] T. Ashihara, T. Moriya, K. Matsuura, T. Tanaka, Y. Ijima, T. Asami, M. Delcroix, and Y. Honma, “SpeechGLUE: How well can self-supervised speech models capture linguistic knowledge?” in INTERSPEECH, 2023, pp. 2888–2892.
- [33] K. Matsuura, T. Ashihara, T. Moriya, T. Tanaka, A. Ogawa, M. Delcroix, and R. Masumura, “Leveraging large text corpora for end-to-end speech summarization,” in ICASSP, 2023, pp. 1–5.
- [34] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., 2020.
- [35] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “LibriSpeech: An asr corpus based on public domain audio books,” in ICASSP, 2015, pp. 5206–5210.
- [36] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “SpecAugment: A simple data augmentation method for automatic speech recognition,” in INTERSPEECH, 2019, pp. 2613–2617.
- [37] R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in ACL, 2016, pp. 1715–1725.
- [38] C. Lin, ROUGE: A Package for Automatic Evaluation of Summaries, 2004.
- [39] T. Zhang, V. Kishore, F. Wu, K. Weinberger, and Y. Artzi, “BERTScore: Evaluating text generation with bert,” in ICLR, 2020.
- [40] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-judge with MT-bench and chatbot arena,” in NeurIPS Datasets and Benchmarks Track, 2023.
- [41] K. Matsuura, T. Ashihara, T. Moriya, T. Tanaka, T. Kano, A. Ogawa, and M. Delcroix, “Transfer Learning from Pre-trained Language Models Improves End-to-End Speech Summarization,” in INTERSPEECH, 2023, pp. 2943–2947.
- [42] J. Tiedemann and Y. Scherrer, “Neural machine translation with extended context,” in Workshop on Discourse in Machine Translation, pp. 82–92.