曼巴调查
摘要。
深度学习(DL)作为一项重要技术,引发了人工智能(AI)领域的一场重大革命,给人类生活方式带来了巨大改变。 作为最具代表性的深度学习技术之一,Transformer架构赋能了众多先进模型,特别是包含数十亿参数的大语言模型,成为深度学习的基石。 尽管取得了令人瞩目的成就,Transformers 仍然面临着固有的局限性,特别是注意力计算的二次计算复杂性导致的耗时推理。 最近,一种名为 Mamba 的新颖架构从经典状态空间模型 (SSM) 中汲取灵感,已成为构建基础模型的有前途的替代方案,提供与 Transformer 相当的建模能力,同时保留有关以下方面的近线性可扩展性:序列长度。 这引发了越来越多的研究积极探索 Mamba 在不同领域取得令人印象深刻的表现的潜力。 鉴于如此快速的发展,迫切需要进行系统审查,以整合现有的 Mamba 授权模型,从而全面了解这种新兴模型架构。 因此,在本次调查中,我们对最近与 Mamba 相关的研究进行了深入调查,涵盖三个主要方面:基于 Mamba 的模型的进展、使 Mamba 适应不同数据的技术,以及Mamba 擅长的应用。 具体来说,我们首先回顾一下各种代表性深度学习模型的基础知识以及Mamba-1&2的细节作为基础知识。 然后,为了展示 Mamba 对于人工智能的意义,我们全面回顾了 Mamba 模型的架构设计、数据适应性和应用等方面的相关研究。 最后,我们讨论了当前的局限性,并探索了各种有前景的研究方向,为未来的研究提供更深入的见解。
1. 介绍
在过去的二十年里,深度学习(DL)作为最突出的人工智能(AI)技术,给医疗保健(Jones等人,2024)、自主驾驶等各个领域带来了革命。系统(关等人,2024;范等人,2024a)、推荐系统(李等人,2024a;赵等人,2024b)和金融服务(Prata 等人,2024;Zhang 等人,2024d)。 这一时期见证了众多深度神经网络(DNN)的出现,它们极大地改变了人类的生活方式,为个人提供了巨大的便利。 一个著名的例子是 U-Net (Ronneberger 等人, 2015; Si 等人, 2024),这是一种视觉领域强大的深度学习模型,广泛应用于医学成像领域,用于检查放射扫描,如 MRI 和 CT 扫描。 其应用有助于疾病的识别和诊断,展示了其在这一关键医疗保健领域的有效性(Williams等人,2024;Lin等人,2022)。 此外,图神经网络(GNN)用于处理图结构数据以支持智能服务,例如向用户推荐个性化内容、产品或服务的推荐系统(Fan等人,2020,2019b;Wu等人,2019)。 此外,循环神经网络(RNN)因其能够捕获准确翻译所必需的顺序和上下文信息的能力而被广泛应用于机器翻译(Liu等人,2014;Su等人,2017),使来自不同语言背景的个人能够有效地沟通和理解彼此的想法、意见和信息。
在各种深度学习架构中,Transformers 最近脱颖而出,并在广泛的应用中确立了主导地位(Dong 等人,2023;Vert,2023)。 例如,作为最具代表性的大型基础模型,像 ChatGPT 和 GPT4 这样的大型语言模型,其根本上是建立在 Transformer 架构上的(Achiam 等人,2023;Qu 等人,2024a;Zhao 等人, 2024b)。 通过将模型规模扩展到数十亿并在不同数据源的混合上进行训练,这些基于 Transformer 的模型在语言理解、常识推理和内容学习方面表现出了令人印象深刻的能力(张等人,2023;范等人,2024b)。 这一显着的成功得益于注意力机制(Vaswani等人,2017),它使基于 Transformer 的模型能够专注于输入序列的相关部分,并促进更好的上下文理解。 然而,注意力机制也引入了显着的计算开销,该开销随着输入大小(Lu等人,2021;Zhu等人,2021)的输入大小呈二次方增加,这给处理冗长的输入带来了挑战。 例如,计算成本的快速增长使得 Transformers 不切实际或不可行地处理大量序列,从而限制了它们在文档级机器翻译(Maruf等人,2021)或长文档摘要等任务中的适用性(Koh等人,2022)。
最近,一种很有前景的架构——结构化状态空间序列模型(SSM)(Gu 等人,2021a)已经出现,可以有效地捕获序列数据中的复杂依赖关系,成为 Transformer 的强大竞争对手。 这些模型受到经典状态空间模型(Kalman,1960)的启发,可以被认为是循环神经网络和卷积神经网络的融合。 它们可以使用递归或卷积运算进行有效计算,实现序列长度的线性或近线性缩放,从而显着降低计算成本。 更具体地说,作为最成功的 SSM 变体之一,Mamba 实现了与 Transformer 相当的建模能力,同时保持序列长度的线性可扩展性(Gu 和 Dao,2023),推动了它的发展进入焦点话题领域。 Mamba 首先引入了一种简单而有效的选择机制,通过根据输入对 SSM 参数进行参数化,使模型能够过滤掉不相关的信息,同时无限期地保留必要的相关数据。 然后,Mamba 提出了一种硬件感知算法,通过扫描而不是卷积来循环计算模型,从而在 A100 GPU 上实现高达 3 的计算速度。 如图1所示,针对复杂且冗长的顺序数据的强大建模功能以及近线性的可扩展性,使 Mamba 成为一种新兴的基础模型,有望彻底改变各个研究和应用领域,例如如计算机视觉(徐等人,2024b;朱等人,2024)、自然语言处理(Lieber等人,2024;赵等人,2024c)、医疗保健(Ruan和Xiang,2024;Xing等人,2024;Wang等人,2024g)等。例如,Zhu等人(2024)提出Vim,为2.8 比 DeiT (Touvron 等人, 2021) 更快,并且在提取高分辨率图像特征时节省 86.8% GPU 内存。 Dao 和 Gu (2024) 展示了 SSM 与注意力变体之间的联系,并提出了一种改进选择性 SSM 的新架构,将语言建模速度提高了 2-8。
受 Mamba 强大的长序列建模能力及其高效性的推动,大量文献涌现,重点关注在各种下游任务中使用和改进 Mamba。 鉴于与曼巴相关的研究大幅增加,对现有文献进行全面回顾并思考未来研究的潜在方向至关重要。 在本次调查中,我们从多个角度对 Mamba 进行了全面的回顾,让新手对 Mamba 的内部工作原理有一个基本的了解,同时帮助经验丰富的从业者了解 Mamba 的最新发展。 具体来说,剩余的调查组织如下:在第2节中,我们回顾了各种代表性深度神经网络的背景知识,包括RNN、Transformers和状态空间模型,同时介绍了Mamba的详细信息在第 3 节中。 随后,我们在4节中从块设计、扫描模式和内存管理等角度总结了基于Mamba的研究的最新进展。 然后,第 5 节介绍了使 Mamba 适应各种数据(包括顺序数据和非顺序数据)的技术。 此外,第6节介绍了Mamba模型的代表性应用,第7节介绍了挑战和未来方向。 最后,我们在8部分总结了整个调查。
与我们的调查同时,还发布了几项相关调查,纯粹关注状态空间模型(Patro和Agneeswaran,2024;Wang等人,2024f)和Vision Mamba (Zhang等人,2024h) ;刘等人,2024e;徐等人,2024b)。 与这些调查不同,本文主要关注曼巴的相关研究。 它从新颖的角度系统地分析了现有文献,以探索Mamba 架构的演变和基于 Mamba 的模型中使用的数据适应方法。
2. 初步知识
Mamba 与循环神经网络 (RNN) 的循环框架、Transformer 的并行计算和注意力机制以及状态空间模型 (SSM) 的线性特性紧密交织在一起。 因此,本节旨在概述这三种著名的架构。
2.1. 循环神经网络 (RNN)
RNN 因其保留内部记忆的能力而在处理顺序数据方面表现出色(Graves and Graves,2012)。 这种网络在涉及分析和预测序列的众多任务中表现出了显着的有效性,例如语音识别、机器翻译、自然语言处理和时间序列分析(Sutskever等人,2011;Hermans和Schrauwen,2013) )。 为了掌握循环模型的基础,本节将简要概述标准 RNN 公式。
具体来说,在每个离散时间步,标准RNN专门处理向量以及上一步的隐藏状态以产生输出向量 并将隐藏状态更新为 。 隐藏状态充当网络的记忆,并保留有关其所看到的过去输入的信息。 这种动态内存允许 RNN 处理不同长度的序列。 形式上,它可以写成
| (1) | ||||
| (2) |
其中是负责将模型输入处理为隐藏状态的权重矩阵,是隐藏状态之间的循环连接,表示用于生成输出的权重从隐藏状态导出, 和 对应偏差,tanh 表示向 RNN 模型引入非线性的双曲正切激活函数。 换句话说,RNN 是非线性循环模型,通过利用隐藏状态中存储的历史知识来有效捕获时间模式。
然而,RNN 存在一些局限性。 首先,RNN 有效提取输入序列中的远程动态的能力有限。 当信息遍历连续的时间步长时,网络中权重的重复相乘可能会导致信息的稀释或丢失。 因此,RNN 在进行预测时保留和回忆早期时间步骤的信息变得具有挑战性。 其次,RNN 增量地处理顺序数据,限制了它们的计算效率,因为每个时间步骤都依赖于前一个时间步骤。 这使得并行计算对他们来说充满挑战。 此外,传统的 RNN 缺乏内置的注意力机制,该机制允许网络捕获输入序列中的全局信息。 注意力机制的缺乏阻碍了网络选择性地对数据关键部分进行建模的能力。 为了克服这些限制, Transformer 和状态空间模型出现了,它们各自从不同的角度应对这些挑战。 这两种方法将在后续小节中进一步阐述。
2.2. 变形金刚
Transformer (Vaswani 等人,2017)是深度学习领域的突破性模型,彻底改变了各种人工智能应用。 Its introduction marked a significant departure from traditional sequence-to-sequence models by employing a self-attention mechanism, facilitating the capture of global dependencies within model inputs. 例如,在自然语言处理中,这种自注意力能力使模型能够理解序列中各个位置之间的关系。 它通过根据每个位置相对于其他位置的重要性为每个位置分配权重来实现这一点。 更具体地说,输入向量x序列首先被转换为三种类型的向量:Query 、Key 和 Value 通过利用原始输入的线性变换,定义为:
| (3) |
其中 、 和 是可训练参数。 通过计算 和 的点积,然后按 缩放结果来计算注意力分数,其中 是关键向量的维度。 然后,此类过程通过 Softmax 函数来标准化分数 并生成注意力权重,定义如下:
| (4) |
除了执行单一注意力功能外,还引入了多头注意力来增强模型捕获不同类型关系并提供输入序列的多个视角的能力。 在多头注意力中,输入序列由多组自注意力模块并行处理。 每个头独立运行,像标准的自注意力机制一样执行精确的计算。 然后将每个头的注意力权重组合起来以创建值向量的加权和。 此聚合步骤允许模型利用来自多个头的信息并捕获输入序列中的不同模式和关系。 从数学上讲,多头注意力计算如下:
| (5) | ||||
其中 是注意力头的数量, 是串联操作, 是将多头注意力分数投影到最终的线性变换价值观。
2.3. 状态空间模型
状态空间模型 (SSM) 是一种传统的数学框架,用于描述系统随时间的动态行为(Kalman,1960)。 近年来,SSM在控制理论、机器人学、经济学等多个领域得到了广泛的应用(Gu等人,2021b,a)。 SSM 的核心是通过一组称为“状态”的隐藏变量来体现系统的行为,使其能够有效地捕获时间数据依赖性。 与 RNN 不同,SSM 是具有关联属性的线性模型。 具体来说,在经典状态空间模型中,建立两个基本方程,即状态方程和观测方程,来模拟当前时刻输入和输出之间的关系,通过一个N维隐藏状态。 该过程可以写成
| (6) | ||||
| (7) |
其中 是当前状态 的导数, 是描述状态如何随时间变化的状态转换矩阵, 是输入矩阵,控制输入如何影响状态变化,表示输出矩阵,指示如何根据当前状态生成输出,表示决定输入如何影响的命令系数直接输出。 一般来说,大多数SSM排除了观测方程中的第二项,即集合,它可以被识别为深度学习模型中的跳跃连接。
2.3.1. 离散化
为了满足各种现实场景的机器学习设置要求,SSM 必须经历一个离散化过程,将连续参数转换为离散参数。 离散化方法通常旨在将连续时间划分为积分面积尽可能相等的个离散区间。 为了实现这一目标,作为最具代表性的解决方案之一,零阶保持(ZOH)(Zhang and Chong,2007;Pechlivanidou and Karampetakis,2022)被成功地应用于SSM,它假设函数值在时间间隔 内保持恒定。 ZOH离散化后,SSM方程可以重写为
| (8) | ||||
| (9) |
其中和、是离散时间步长。 从这些公式可以清楚地看出,离散 SSM 与递归神经网络具有相似的结构,因此,与基于 Transformer 的模型(在每个自回归解码中计算所有输入的注意力)相比,离散 SSM 可以更高效地完成推理过程。迭代。
2.3.2. 卷积计算
离散 SSM 作为一个线性系统,拥有相关的属性,因此可以与卷积计算无缝集成。 更具体地说,它可以独立计算每个时间步的输出,如下所示:
| (10) | ||||
| (11) | ||||
| (12) | ||||
| (13) | ||||
| (14) |
通过创建一组卷积核,循环计算可以转换为卷积形式:
| (15) |
其中和分别表示输入和输出序列,而是序列长度。 这种卷积计算允许 SSM 充分利用现代矩阵计算硬件(例如 GPU)在训练过程中实现并行计算,而这对于利用非线性激活函数的 RNN 来说是不可能的。 值得注意的是,给定一个具有 维度的输入 ,SSM 计算将为每个维度单独计算,以产生 维度的输出 . 在这种情况下,输入矩阵、输出矩阵和命令矩阵,而状态转移矩阵保持不变,即。
2.3.3. RNN、Transformer、SSM之间的关系
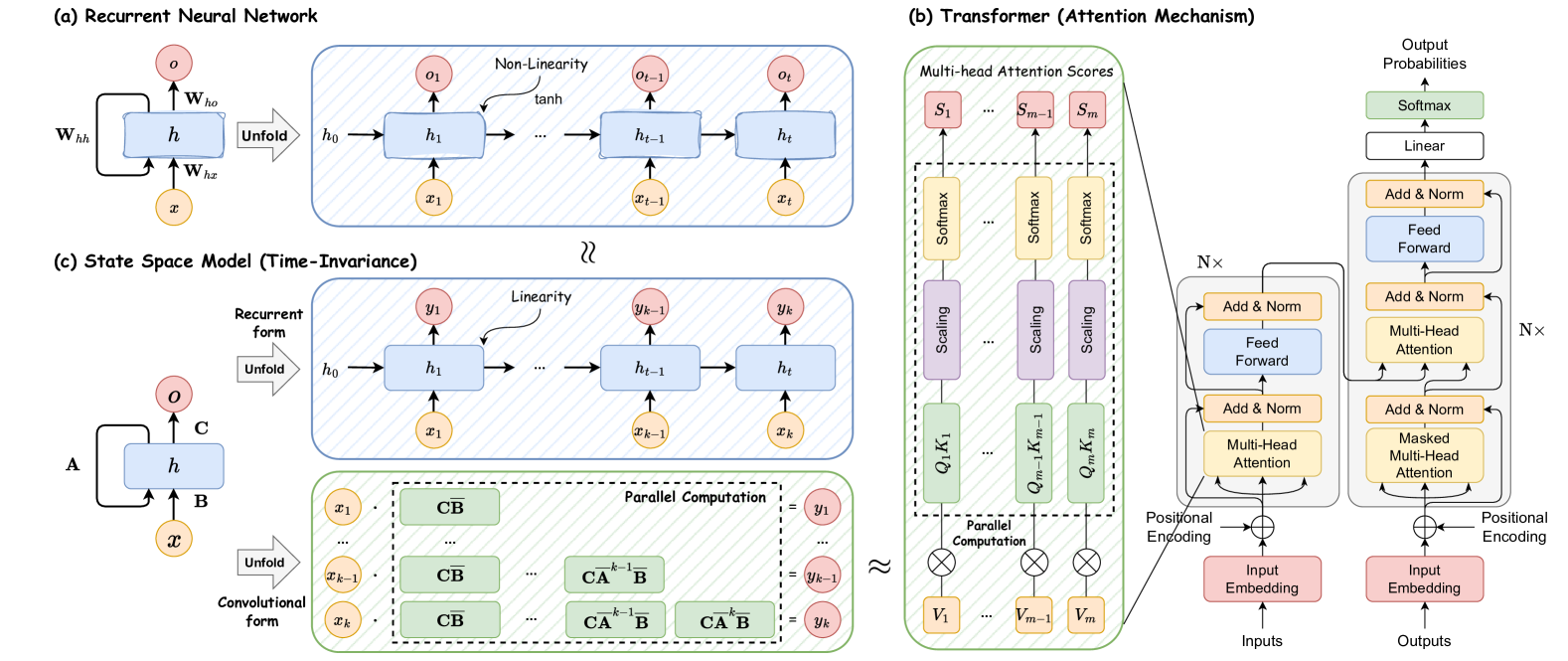
RNN、Transformer 和 SSM 的计算算法如图2所示。 一方面,传统的 RNN 在非线性循环框架内运行,其中每次计算仅取决于先前的隐藏状态和当前输入。 虽然这种格式允许 RNN 在自回归推理期间快速生成输出,但它妨碍了它们充分利用 GPU 并行计算的能力,导致模型训练速度变慢。 另一方面,Transformer 架构跨多个查询密钥对并行执行矩阵乘法,可以有效地分布在硬件资源上,从而能够更快地训练基于注意力的模型。 然而,当涉及到从基于 Transformer 的模型生成响应或预测时,推理过程可能非常耗时。 例如,语言模型的自回归设计需要顺序生成输出序列中的每个词符,这需要在每一步重复计算注意力分数,导致推理时间变慢。 如表1所示,与仅限于支持一种类型计算的 RNN 和 Transformer 不同,鉴于其线性特性,离散 SSM 可以灵活地支持循环计算和卷积计算。 这种独特的功能使 SSM 不仅能够实现高效的训练推理,而且能够实现并行。 然而,应该注意的是,最传统的 SSM 是时不变的,这意味着它们的 、、 和 与模型输入 无关。 这将限制上下文感知建模,从而导致 SSM 在选择性复制等某些任务中性能较差(Gu 和 Dao,2023)。
| Comparison | RNNs | Transformers | SSMs |
|---|---|---|---|
| Training Speed | Slow (Recurrent) | Fast (Parallel) | Fast (Convolutional) |
| Inference Speed | Fast (Recurrent) | Slow (Quadratic-Time) | Fast (Recurrent) |
| Complexity | |||
| Modeling Capabilities | (Hidden State) | (Attention) | (Time-Invariance) |
3. 曼巴
为了解决传统 SSM 上下文感知能力较差的上述缺点,(Gu 和 Dao,2023) 提出了 Mamba 作为一种潜在的替代方案,它有望是通用序列基础模型的骨干。 最近,Mamba-2 (Dao 和 Gu,2024) 提出了结构化空间状态二元性(SSD),建立了一个连接结构化 SSM 和各种形式的注意力的强大理论框架,使我们能够将最初为 Transformers 开发的算法和系统优化转移到 SSM。 在本节中,我们将对 Mamba 和 Mamba-2 进行简洁明了的介绍。
3.1. Mamba-1:具有硬件感知算法的选择性状态空间模型
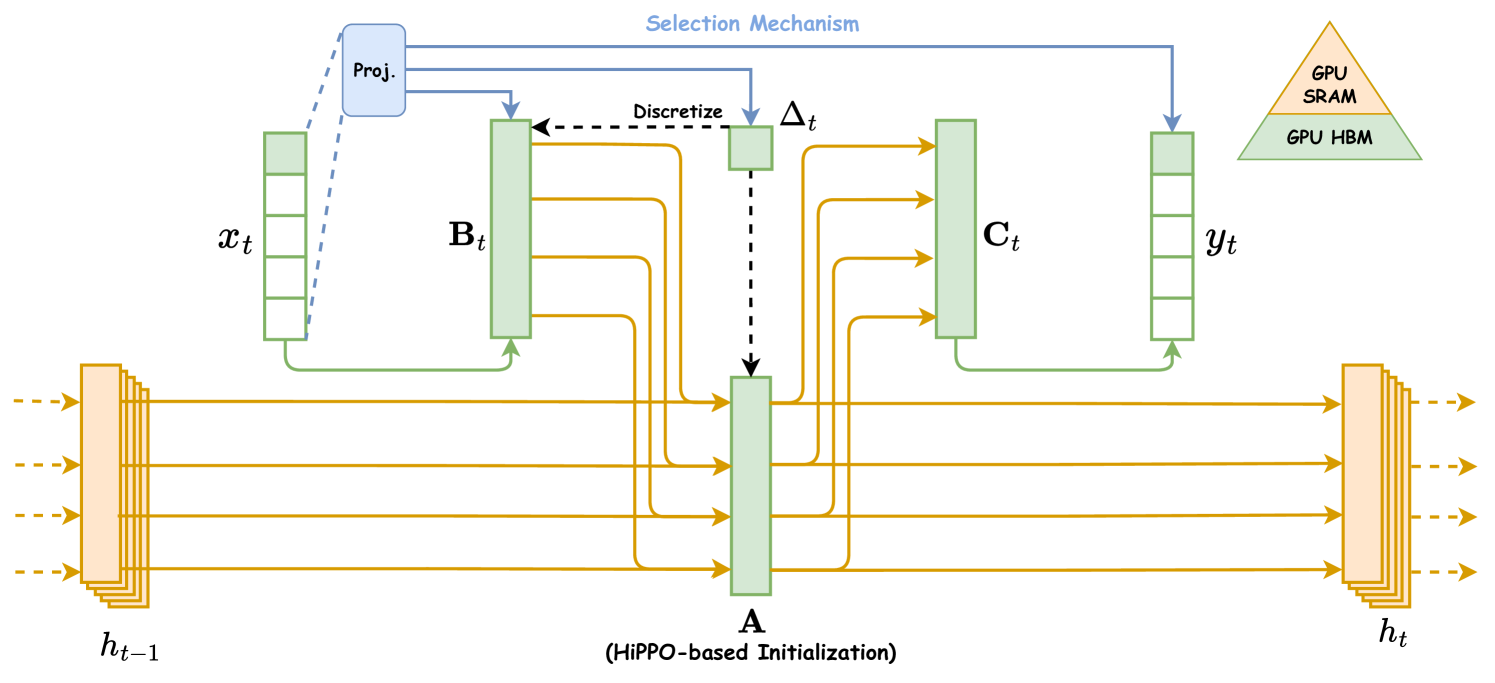
传统的 SSM 在对文本和其他信息密集数据进行建模方面表现出有限的效果(Gu and Dao,2023),阻碍了它们在深度学习方面的进展。 为了让SSM具有Transformers的建模能力,Gu and Dao (2023)引入了三种基于结构化状态空间模型的创新技术,即基于高阶多项式投影算子(HiPPO)的内存初始化、选择机制和硬件感知计算,如图3所示。 这些技术旨在增强 SSM 在远程线性时间序列建模中的能力。 特别是,初始化策略建立了一个连贯的隐藏状态矩阵,有效地促进了远程记忆。 然后,选择机制使 SSM 能够获取内容感知的表示。 最后,Mamba 精心设计了两种硬件感知计算算法:并行关联扫描和内存重新计算,以提高训练效率。
3.1.1. 基于HiPPO的内存初始化
序列数据的建模和学习代表了当代机器学习的基本挑战,构成了各种任务的基础,包括语言建模、语音识别和视频处理。 建模复杂且长期的时间依赖性的一个基本组成部分在于内存,包括存储和集成先前时间步骤信息的能力(Hu 和 Qi,2017)。 与 RNN 类似,保留和忘记历史隐藏状态(即矩阵 )在 SSM 中发挥着关键作用,以实现令人满意的性能。 在以前的结构化状态空间序列模型(SSM)中,已经提出了特殊初始化的建议,特别是在复值模型的情况下。 事实证明,这些特殊的初始化在各种场景中都是有益的,包括数据可用性有限的情况。 类似地,Mamba 主要关注隐藏状态矩阵 的初始化以捕获复杂的时间依赖性。 这是通过利用 HiPPO 理论(顾等人,2020)和创新的比例勒让德测度(LegS)来实现的,确保仔细考虑完整的历史背景而不是有限的滑动窗口。 具体来说,HiPPO-LegS为所有历史数据点分配统一的权重,可以表示为:
| (16) |
其中是多项式的数量,表示特定的离散时间步长。 基于 HiPPO 理论,Mamba 针对复杂和真实的情况引入了两种简单的初始化方法,即 S4D-Lin 和 S4D-Real (Gu 等人, 2022),如
| (17) |
其中 是所有输入维度 的 的第 元素。 给定这样的初始化,模型可以通过压缩和重建输入信息信号来学习长期依赖的记忆,该记忆经历较新步骤的较小退化和较旧步骤的较大退化。 根据公式,HiPPO-LegS 具有有利的理论特性:它在输入时间尺度上保持一致并提供快速计算(Gu 等人,2020)。 此外,它具有有界梯度和近似误差,有利于参数学习过程。
3.1.2. 选择机制
由于时间不变性的特性,传统的状态空间模型无法根据特定的模型输入(即内容感知建模能力)产生个性化的输出。 为了给 SSM 提供类似于注意力机制的能力,Mamba 设计了一种时变选择机制,根据模型输入参数化权重矩阵。 这种创新使 SSM 能够过滤掉无关信息,同时无限期保留相关细节。 形式上,选择机制涉及将间隔和矩阵、设置为输入的函数,可以是表述为:
| (18) | ||||
| (19) | ||||
| (20) |
其中 、 和 是选择性空间矩阵,它们作用于输入以实现内容感知建模。 、、和分别表示批量大小、输入长度、输入特征大小和隐藏通道数。 值得注意的是,、和是相应组件的选择权重(即线性参数化投影),表示将结果广播到所有维度。随后,选择性 SSM 使用通用统计技术零阶保持 (ZOH) (Pechlivanidou 和 Karampetakis,2022) 进行离散化,如
| (21) | ||||
| (22) |
其中和分别是选择性状态转移矩阵和输入矩阵,它们成为输入的函数。 通过这样做,离散 SSM 已从时不变变为时变(即内容感知),如下所示
| (23) |
它根据输入 生成输出 。 请注意,Mamba 中的时变选择机制与 Transformer 中的注意力机制具有类似的结构,即都基于输入及其投影执行操作,这使得 Mamba 的 SSM 能够实现灵活的内容感知建模。 然而,它失去了与卷积的等价性,这对其效率产生了负面影响。
3.1.3. 硬件感知计算
选择机制的设计旨在超越线性时不变模型的局限性。 尽管如此,它还是对高效训练提出了挑战:SSM 的卷积核变得依赖于输入,导致无法执行并行计算。 为了解决这个问题,Mamba 使用了两种计算技术,即并行关联扫描(也称为并行前缀求和)(Harris 等人, 2007) 和 内存重新计算。 首先,并行关联扫描利用线性关联计算的特性和现代加速器(GPU 和 TPU)的并行性,以内存高效的方式执行选择性 SSM 的计算。 更具体地说,并行关联扫描将模型训练的计算复杂度从降低到。 扫描的核心是在给定输入上构建平衡二叉树,并将其扫描到根或从根扫描。 换句话说,并行关联扫描首先从叶遍历到根(即向上扫描),在树的内部节点处创建部分和。 然后,它反转遍历,从根向上移动到树上,以使用部分和构建整个扫描(即向下扫描)。
另一方面,Mamba 利用传统的重新计算方法来减少训练选择性 SSM 层的总体内存需求。 特别是,Mamba 在前向传递过程中避免存储大小为 (、、、 的中间状态。并行关联扫描可防止内存扩展。 相反,它在反向传递中重新计算这些中间状态以进行梯度计算。 通过这样做,重新计算就避免了读取 GPU 内存单元之间的 元素的必要性。 除了优化扫描操作的内存需求之外,Mamba-1 还扩展了重新计算的使用,以提高整个 SSM 层的效率。 这种优化包括投影、卷积和激活,这些通常需要大量的内存资源,但可以快速重新计算。
3.2. Mamba-2:状态空间对偶性
Transformer 在各个领域深度学习的成功中发挥了至关重要的作用,激发了各种技术的发展,例如参数高效微调(Kojima 等人,2022)、灾难性优化遗忘缓解(Korbak等人,2022a)和模型量化(Xiao等人,2023),旨在从不同角度提高模型性能。 为了使状态空间模型能够访问并受益于最初为 Transformers 开发的有价值的技术,Mamba-2 (Dao 和 Gu,2024) 引入了一个名为结构化状态空间对偶 (SSD) 的综合框架,它在 SSM 和不同形式的注意力之间建立了理论联系。 正式地,
| (24) |
其中表示使用顺序半可分离表示的SSM的矩阵形式,表示。 值得注意的是,和分别表示与输入标记和相关联的选择性空间状态矩阵。 表示对应于从到的输入标记的隐藏状态的选择矩阵。 从本质上来说,SSD 证明了 Transformers 使用的注意力机制和 SSM 中使用的线性时变系统都可以看作是半可分离矩阵变换。 此外,Dao and Gu (2024)还证明选择性SSM等效于用半可分离掩蔽矩阵实现的结构化线性注意机制。
基于SSD,Mamba-2通过块分解矩阵乘法算法设计了更硬件高效的计算。 具体来说,通过矩阵变换将状态空间模型视为半可分离矩阵,Mamba-2 将计算分解为矩阵块,其中对角块表示块内计算。 相比之下,非对角线块表示通过 SSM 隐藏状态分解的块间计算。 这种方法使 Mamba-2 的训练过程比 Mamba-1 的并行关联扫描快 2-8,同时保持与 Transformers 的竞争力。
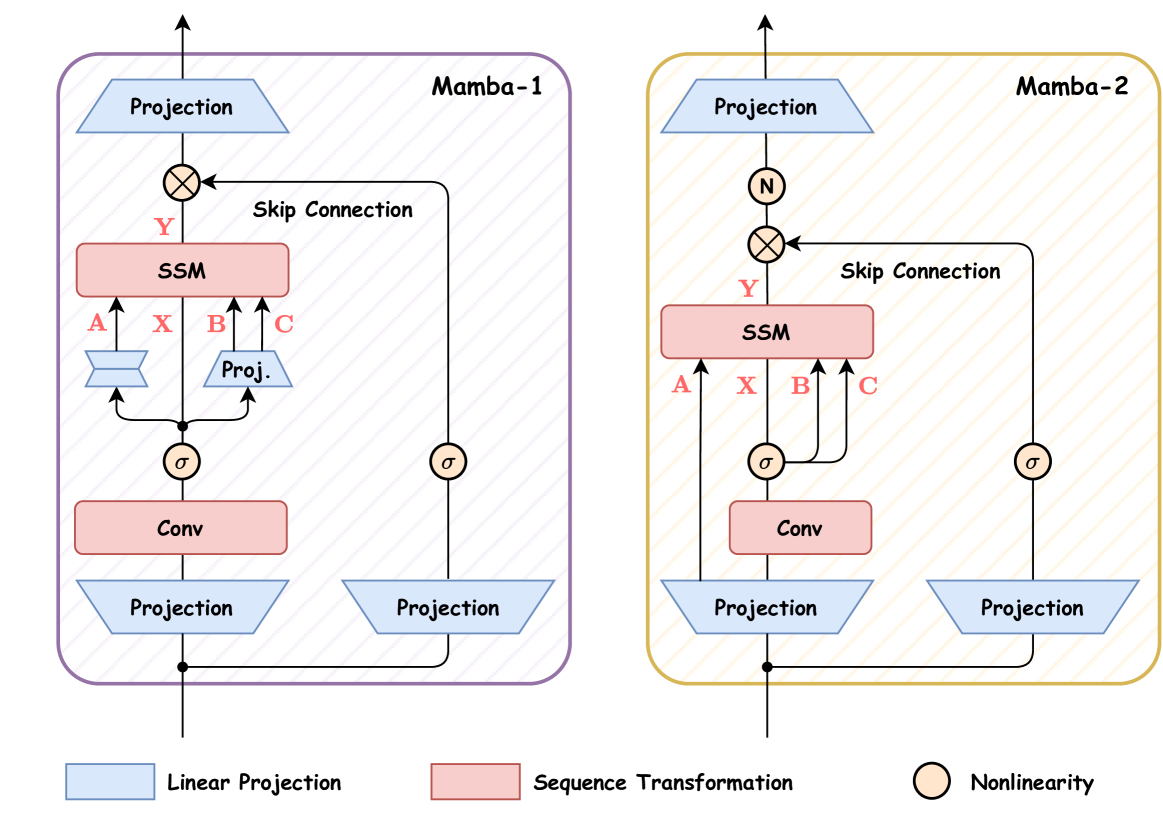
3.3. 曼巴块
在本小节中,我们总结了 Mamba-1 和 Mamba-2 的模块设计。 图4展示了这两种架构的比较。 Mamba-1 的动机是以 SSM 为中心的观点,其中选择性 SSM 层的任务是进行从输入序列 到 的映射。 在此设计中,在创建 的初始线性投影之后应用 (、、) 线性投影。 然后,利用并行关联扫描,输入 Token 和状态矩阵通过选择性 SSM 单元,以产生输出 。 之后,Mamba-1 采用跳跃训练来鼓励特征重用并缓解模型过程中经常出现的退化问题。 最后,通过堆叠与标准归一化和残差连接交错的块来构建曼巴模型。
至于 Mamba-2,它引入了 SSD 层,旨在创建从 、、、 到 。 这是通过在块的开头使用单个投影同时处理 、、、 来实现的,类似于标准注意力架构如何并行生成 、、 投影。 换句话说,Mamba-2 块通过删除顺序线性投影来简化 Mamba-1 块。 与 Mamba-1 中的并行选择性扫描相比,这使得 SSD 结构的计算速度更快。 此外,在跳跃连接之后添加了归一化层,旨在提高训练稳定性。
| Name | Modality | Affiliations | Sizes | Access Link |
| Mamba 1&2 | Language | Carnegie Mellon University & Princeton University | 130M-2.8B | 1 |
| Falcon Mamba 7B | Language | Technology Innovation Institute | 7B | 2 |
| Mistral 7B | Language | Mistral AI & NVIDIA | 7B | 3 |
| Vision Mamba | Vision | Huazhong University of Science and Technology | 7M-98M | 4 |
| VideoMamba | Video | OpenGVLab, Shanghai AI Laboratory | 28M-392M | 5 |
| 1. https://github.com/state-spaces/mamba | ||||
| 2. https://huggingface.co/tiiuae/falcon-mamba-7b | ||||
| 3. https://huggingface.co/mistralai/Mistral-7B-v0.1 | ||||
| 4. https://huggingface.co/hustvl/Vim-base-midclstok | ||||
| 5. https://huggingface.co/OpenGVLab/VideoMamba | ||||
4. 曼巴模型的进步
状态空间模型和 Mamba 最近得到了探索,并已成为作为基础模型骨干的一种有前途的替代方案。 如表2所示,基于Mamba的大型模型不仅在学术研究中蓬勃发展,而且在工业界也取得了重大进展,例如Falcon Mamba 7B和Mistral 7B,通过 GPU 上的成功训练展示了其功效。 尽管如此,Mamba 架构仍然面临着内存损失、泛化到不同任务以及基于 Transformer 的语言模型捕获复杂模式的能力较差等挑战。 为了克服这些挑战,人们做出了大量努力来改进 Mamba 架构。 现有的研究主要集中在修改块设计、扫描模式和内存管理方面。 本节将从这三个方面介绍一些重要的技术,相关研究的总结如表3所示。
| Modules | Methods | Classes | Representative References |
| Block | Integration | Transformer | (Lieber et al., 2024; Xu et al., 2024a; Pilault et al., 2024; Hatamizadeh and Kautz, 2024; Pitorro et al., 2024; Gao et al., 2024b) |
| Convolutional Neural Network (CNN) | (Li et al., 2024e; Wang and Ma, 2024; Yue and Li, 2024; Yang et al., 2024f; Gong et al., 2024; Li et al., 2024e; Sheng et al., 2024; Yuan et al., 2024b) | ||
| Graph Neural Network (GNN) | (Liu et al., 2024a; Li et al., 2024f; Behrouz and Hashemi, 2024; Wang et al., 2024e; Yang et al., 2024d) | ||
| Recurrent Neural Network (RNN) | (Tang et al., 2024; Dolga et al., 2024; Huang et al., 2024c) | ||
| Spiking Neural Network (SNN) | (Li et al., 2024b; Bal and Sengupta, 2024) | ||
| Substitution | U-Net | (Sepehri et al., 2024; Shi et al., 2024b; Wang et al., 2024g, a; Liu et al., 2024d; Ruan and Xiang, 2024; Liao et al., 2024; Ma and Wang, 2024; Sanjid et al., 2024; Deng and Gu, 2024; Ji et al., 2024; Hosseini et al., 2024) | |
| Diffusion Models | (Oshima et al., 2024; Fu et al., 2024; Fei et al., 2024; Ye and Chen, 2024; Wang and Ma, 2024) | ||
| Others | (Chen et al., 2024b; Li and Chen, 2024) | ||
| Modification | Mix-of-Expert | (Lieber et al., 2024; Anthony et al., 2024) | |
| K-way/Parallel Structure | (Wu et al., 2024; Wan et al., 2024; Zou et al., 2024; Huang et al., 2024b; Lin et al., 2024a) | ||
| Register | (Wang et al., 2024g; Yang et al., 2024b) | ||
| Scan | Flatten | Bidirectional Scan | (Zhu et al., 2024; Jiang et al., 2024b; Li and Chen, 2024; Li et al., 2024g) |
| Sweeping Scan | (Liu et al., 2024c; Wang et al., 2024h; Yue and Li, 2024) | ||
| Continuous Scan | (Yang et al., 2024a; Hu et al., 2024; He et al., 2024a) | ||
| Efficient Scan | (Pei et al., 2024; Xie et al., 2024a) | ||
| Stereo | Hierarchical Scan | (Chen et al., 2024e; Wang et al., 2024a; Bhirangi et al., 2024; Chen et al., 2024f; Han et al., 2024; Shi et al., 2024a) | |
| Spatiotemporal Scan | (Li et al., 2024c; Chen et al., 2024d; Yao et al., 2024; Yang et al., 2024e) | ||
| Hybrid Scan | (Behrouz et al., 2024; Shi et al., 2024b; Gong et al., 2024; He et al., 2024b; Dong et al., 2024; Deng and Gu, 2024) | ||
| Memory | Initialization (Ezoe and Sato, 2024), Compression (Long et al., 2024; Nawrot et al., 2024), Connection (He et al., 2024c; Ren et al., 2024b) | ||
| Others | Autoregressive Pretraining (Ren et al., 2024a), Explainability (Jafari et al., 2024) | ||
4.1. 区块设计
Mamba 模块的设计和结构对 Mamba 模型的整体性能产生重大影响,使其成为新兴的研究热点。 如图5所示,根据构建新Mamba块的不同方法,现有研究可以分为三类:a)集成方法旨在将Mamba块与其他知名模型,从而在效果和效率之间取得平衡; b) 替换方法尝试利用 Mamba 块作为高级模型框架中主要层的替换; c) 修改方法侧重于修改经典 Mamba 块内的组件。 因此,我们将在以下小节中详细回顾这些方法。
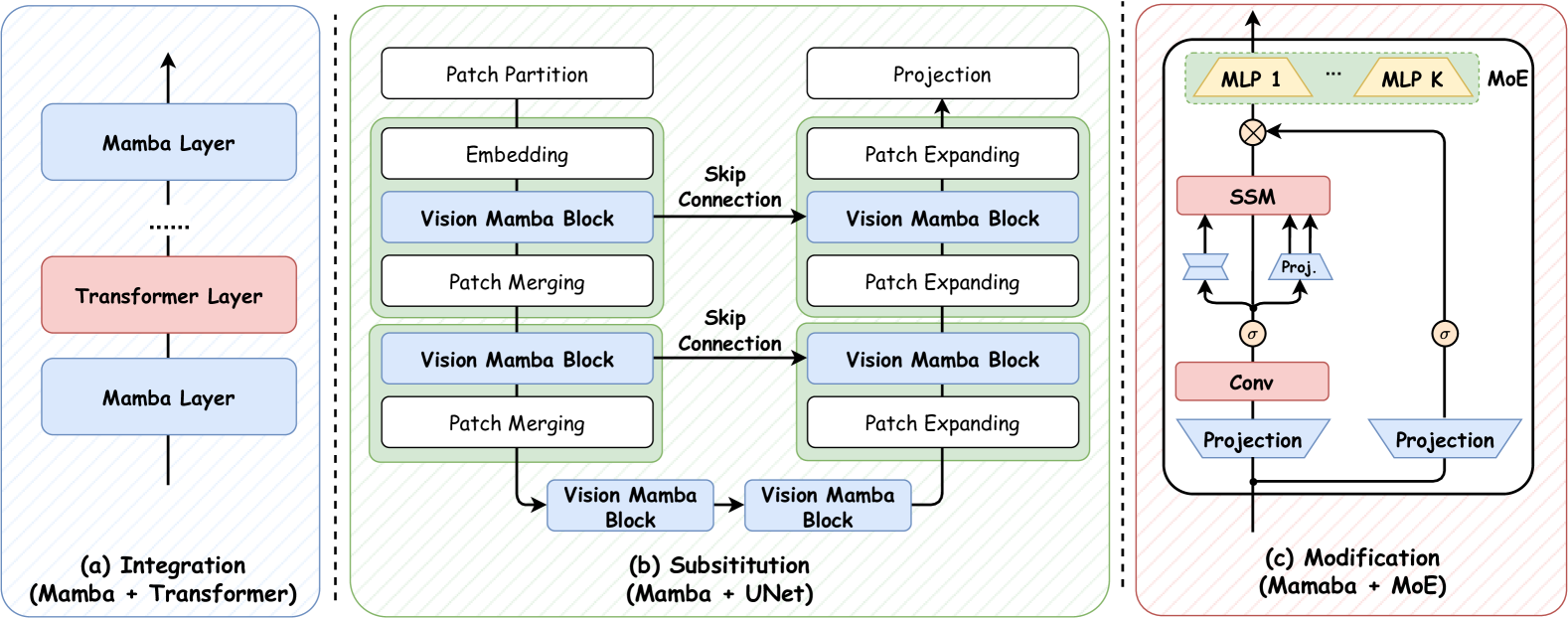
4.1.1. 集成
鉴于 Mamba 具有捕捉长期动态的卓越能力,它已与其他模型广泛集成,利用其优势提供针对特定场景的强大框架。 该集成具体涵盖 Transformers、图神经网络 (GNN)、循环神经网络 (RNN)、卷积神经网络 (CNN) 和尖峰神经网络 (SNN) 等高级模型。 下面描述具体示例。
-
•
基于Transformer的模型在众多任务中表现出了卓越的性能,但其二次计算复杂性仍然在推理过程中阻碍了它们(Gu等人,2021a)。 为了追求高效生成,一些研究人员提出将 Mamba 块与基于 Transformer 的模型结合起来。 例如,Jamba (Lieber 等人,2024) 结合了 Transformer 和 Mamba 层块来处理长内容的自然语言处理任务,充分利用了两个模型系列的优势。 与独立的 Transformer 和 Mamba 模型相比,Attention-Mamba 混合模型表现出了卓越的性能,比普通 Transformer 模型实现了更好的吞吐量。 Mambaformer (Xu 等人, 2024a) 利用混合框架来预测多个时间序列,包括汇率、每小时用电量和电力负荷,其内部结合了 Mamba 块和 Transformer 层进行长期和短期- 范围依赖性,分别。 由于 Mamba 和 Transformer 的集成,Mambaformer 在长短期时间序列预测方面优于基于 Transformer 的预测器。
-
•
GNN 在通过消息传递机制捕获邻近关系方面表现出了巨大的潜力,其中信息通过堆叠层在连接图上传播。 尽管如此,这些模型面临着一个重大限制,即过度平滑(Chen等人,2020),特别是在尝试捕获高阶邻接信号时。 为了应对这一挑战,Mamba 被用于图表示学习(Liu 等人,2024a;Li 等人,2024f;Yang 等人,2024d;Wang 等人,2024e)。 例如,Graph Mamba (Behrouz 和 Hashemi,2024) 将图结构数据按特定顺序重新格式化为连续 Token ,并利用 Mamba 块内的选择性 SSM 层构建新颖的 Graph Mamba 网络(GMN) )架构,它实现了卓越的图表示学习能力,特别是在节点之间需要高阶依赖关系的数据集中。
-
•
基于RNN的模型在捕捉时间动态方面取得了出色的成果。 尽管如此,RNN 仍然面临重大挑战,包括耗时的循环训练和隐藏状态内存容量的限制。 受到最近出现的基于 Mamba 的架构的启发,一些研究人员开发了 Mamba 块和 RNN 的融合。 例如,VMRNN (Tang 等人, 2024) 在时空预测方面实现了最先进的性能,同时与基于循环和无循环的浮点运算 (FLOP) 最小化方法。 它通过引入一种新颖的循环单元来实现这一目标,该单元将 Mamba 块与长短期记忆 (LSTM) 相结合。
-
•
基于CNN的方法受到局部感受野的限制,导致捕获全局和远程语义的性能不佳(Gu and Dao,2023)。 状态空间模型以学习远程模式的卓越能力而闻名,一些研究(Wang and Ma, 2024; Li 等人, 2024e; Yang 等人, 2024f) 探索了利用状态空间模型的潜力Mamba 致力于增强基于 CNN 的模型,尤其是在计算机视觉领域。 例如,MedMamba (Yue 和 Li,2024) 和 nnMamba (Gong 等人,2024) 展示了视觉 Mamba 模块的集成如何提高 CNN 在图像分析中的性能任务。
-
•
SNN 最近被提出作为一种有前途的网络架构,其灵感来自于大脑中生物神经元的行为:通过离散尖峰在神经元之间传输知识。 SNN 的主要优势之一在于其低功耗实现的潜力,因为它们可以利用神经活动的稀疏性和事件驱动的性质。 在 SNN 和 SSM 卓越的远程学习能力的节能实施的推动下,开创性研究已经深入研究了这两种方法的集成。 例如,SpikeMba (Li 等人, 2024b) 将它们结合起来,以处理对突出对象的置信度偏差,并捕获视频序列中持久的依赖关系。 通过广泛的评估,作者声称集成这两个模型可以提高时间视频基础任务、精确时刻检索和亮点检测的有效性。
4.1.2. 替换
受到选择性SSM在高效计算和长序列学习方面的出色能力的启发,采用Mamba模块来替代U-Net等经典建模框架中的关键组件(Ronneberger等人,2015)和扩散模型(Ho等人,2020)引起了广泛关注。 通过引入选择性 SSM 层,这些方法实现了针对特定任务的远程学习和高效计算。 下面,我们演示使用 Mamba 模块的替换实例,特别是针对 U-Net 和 Diffusion 模型等高级框架。
-
•
U-Net。 人们做出了许多努力(石等人,2024b;王等人,2024g,a;廖等人,2024),以协同U-Net和Mamba捕获复杂和广泛语义的能力,从而提高计算机视觉任务中的模型性能。 例如,Mamba-UNet (Wang 等人, 2024g)专门利用 Visual Mamba 块为医学图像构建类似 U-Net 的模型(即注入跳跃连接的编码器-解码器模型)分割。 他们的评估表明,Mamba-UNet 超越了几个 U-Net 变体,这可以归因于 Mamba 块在处理远程补丁序列方面的功效和效率。
-
•
扩散模型。 一些努力(Fu 等人, 2024; Fei 等人, 2024; Oshima 等人, 2024)已经被采取建立一种新型的扩散模型,扩散状态空间模型(DiS),它取代具有状态空间主干的典型主干(例如 CNN、Attentions、U-Net)。 鉴于 Mamba 块在适应远程依赖性方面的显着效率和功效,DiS 的特点是使用扩散模型生成更长的序列(Fei 等人,2024)。 例如,Oshima 等人 (2024) 提出了一种基于 Mamba 的扩散模型,该模型可大幅降低长视频序列的内存消耗,同时与基于 Transformer 的模型相比仍保持有竞争力的性能指标。 此外,MD-Dose (Fu 等人, 2024) 和 P-Mamba (Ye and Chen, 2024) 在扩散模型的后向过程中使用 Mamba 块构建噪声预测器,最终生成用于医学图像处理的特定目标。
-
•
其他。 除了 U-Net 和扩散模型之外,还有一些替代模型。 例如,Res-VMamba (Chen 等人, 2024b) 在残差学习框架中采用 Visual Mamba 块进行食品类别分类。 此外,SPMamba (Li and Chen,2024)采用了最近开发的时频模型 TF-GridNet (Wang 等人,2023a),其基础架构遵循通过使用双向 Mamba 块继承 Transformer 组件。 这种适应使模型能够有效地包含更广泛的上下文信息,以完成语音分离任务。
4.1.3. 修改
除了直接使用 Mamba 块的集成和替代方法之外,还进行了一些其他努力来修改 Mamba 块,以增强其在不同场景下的性能。 例如,Jamba (Lieber 等人, 2024) 借用了 Mix-of-Experts (MoE) 的概念 (Jacobs 等人, 1991; Fedus 等人, 2022)使其混合(Transformer-Mamba)解码器模型能够以更少的计算量进行预训练,并允许灵活的特定目标配置。 值得注意的是,与代表性的基于 Transformer 的语言模型 LLaMA-2-7B(6.7B 可用参数、12B 活动参数、128GB)相比,Jamba 模型(56B 可用参数、12B 活动参数、4GB KV 缓存)需要小 32 倍的 KV 缓存KV 缓存),同时提供更广泛的可用和活动参数。 这使得 Jamba 在单个 A100 GPU (80GB) 上能够吞咽 140K 的上下文长度,是 LLaMA-2-70B 支持的长度的七倍。 除了 MoE 之外,一些研究建议将 SSM 层修改为 K-way 结构,其中涉及使用并行 SSM 单元处理模型输入,从而允许从多个角度捕获信息和知识。 例如,Sigma (Wan 等人,2024)开发了一种新颖的基于 Mamba 的视觉编码器,该编码器通过利用并行 SSM 层处理多模态输入。 UltraLight VM-UNet (Wu 等人, 2024)提出了一种视觉 Mamba 层,具有并行 SSM 单元,可处理不同通道中的深层特征。 回顾一下,通过实施此类修改(即 K-way、MoE),这些基于 Mamba 的模型获得了增强的学习能力,特别是在处理多模式输入和快速适应多尺度任务方面。 此外,一项开创性的研究 Mamba® 引入了一种新颖的方法,该方法建议在通过 SSM 层传递输入之前将寄存器均匀地合并到视觉输入 Token 中。 此修改旨在增强图像块的序列方向的表示,从而使 Mamba 块的单向推理范式适用于视觉任务。 尽管取得了这些成功,修改曼巴区块的探索仍然是一个有前途但尚未充分探索的领域。
4.2. 扫描方式
并行关联扫描操作是 Mamba 模型中的关键组成部分,旨在解决选择机制引起的计算问题,加速训练过程并减少内存需求。 它通过利用时变 SSM 的线性特性在硬件级别设计内核融合和重新计算来实现这一目标。 然而,Mamba 的单向序列建模范式阻碍了对图像和视频等各种数据的全面学习过程。 为了缓解这个问题,一些研究重点关注设计高效的扫描方法,以增强模型性能并促进 Mamba 模型的训练过程。 如图6所示,现有的专注于开发扫描模式技术的研究可以分为两类:1)Flatten Scan从平面角度处理过程模型输入词符序列; 2) 立体扫描方法跨维度、通道或尺度扫描模型输入。
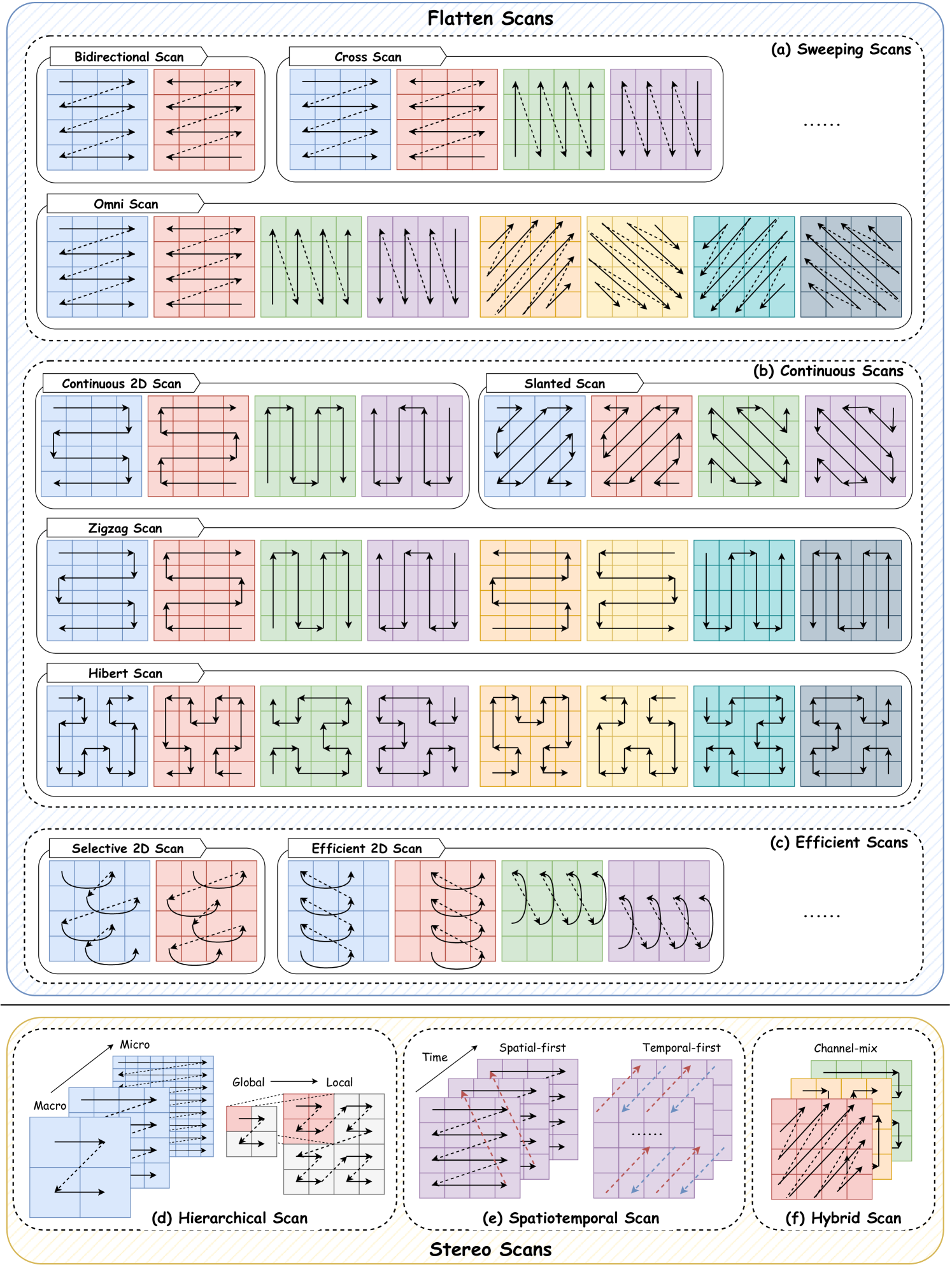
4.2.1. 展平扫描
扁平化扫描是指将输入的模型扁平化为词符序列,并从不同方向进行相应扫描的过程。 这种类型的扫描通常用于一维(例如时间序列)和二维(例如图像)数据。 在本节中,我们进一步将其分为四类,即双向扫描、扫掠扫描、连续扫描和高效扫描.
-
•
双向扫描。 借用双向循环神经网络(Bi-RNN)(Schuster and Paliwal, 1997)的概念,Visual Mamba (朱等人,2024)引入了一种视觉扫描方法数据,称为双向扫描(Bi-Scan),涉及使用同时前向和后向 SSM 处理输入标记,从而增强模型的空间感知处理能力。 最近,许多研究利用 Bi-Scan 方法来提高基于 Mamba 的模型的学习能力(Li 等人,2024g)。 例如,DPMamba (Jiang 等人,2024b)和SPMamba (Li and Chen,2024)都利用了一对双路径(前向和后向)选择性SSM对语音信号的依赖性进行建模,从而实现语音分离的双向知识处理。 如此显着的成功归功于 Bi-Scan 的有效性及其易于部署。
-
•
扫一扫。 如图6所示,扫频扫描技术在特定方向上处理模型输入,类似于清洁工仔细地清扫地板(Yue和Li,2024;Wang等人,2024h) 。 例如,交叉扫描(Liu等人,2024c)需要将输入图像划分为多个块,然后沿着四个不同的路径将其展平,这被视为两个双向扫描的融合。 通过采用这些互补的遍历路径,交叉扫描使图像中的每个块能够有效地集成来自不同方向的相邻块的信息,从而促进信息丰富的感受野的建立。 Omni-Scan (石等人, 2024b; 赵等人, 2024a)结合了多个方向图像信息流的建模,例如2(向前和向后) 4 (左-右、上-下、右上-左下、左上-右下)。 这种策略增强了各个方向上下文信息的全局建模能力,从而能够提取全面的全局空间特征。
-
•
连续扫描。 为了保证输入序列的连续性,连续扫描技术会扫描列或行之间的相邻标记(He等人,2024a),如图6所示。 例如,为了更好地应对 2D 空间输入,PlainMamba (Yang 等人, 2024a) 引入了一种连续扫描方法,称为 Continuous Scan,它扫描列(或行)之间的相邻 token ,而不是在交叉扫描中前往相反的标记。 此外,希尔伯特扫描(He等人, 2024a)基于希尔伯特矩阵行进一条蜿蜒的路径。 根据他们的评估结果,可以推断,增强输入标记的语义连续性可以使基于 Mamba 的模型在各种视觉识别任务中表现出色。
-
•
高效扫描。 与上述专注于实现更全面的输入建模的扫描方法相比,高效的扫描方法旨在加速训练和推理过程。 通常,高效扫描将给定输入分成几个部分并并行处理它们,从而减少计算时间。 例如,高效二维扫描(Pei等人,2024)通过跳过补丁来处理图像,从而在保留全局特征图的同时减少四倍的计算需求。 此外,Gao 等人(2024c)在他们的 Mamba 框架内引入了一种有效的双向子空间扫描方案。 该方案旨在为 4D 光场超分辨率任务有效捕获长期空间角度对应关系。 具体来说,它将补丁序列分解为两部分,并通过两种双向扫描方案对其进行处理。 通过这样做,扫描方法降低了输入长度并解决了长期记忆问题,而无需牺牲完整的 4D 全局信息。
4.2.2. 立体扫描
与平面扫描方法相比,通过从其他角度对输入进行建模,立体扫描方法能够在扫描过程中捕获更广泛的知识。 这种增强的功能可以更全面地理解模型输入。 具体来说,这些方法可以分为三大类:分层扫描、时空扫描和混合扫描。 分层扫描处理来自不同级别的输入,而时空扫描从时间和空间角度考虑输入模式。 此外,混合扫描结合了多种扫描方法,以充分利用不同扫描技术的优势。
-
•
分层扫描方法涉及采用不同大小的扫描内核来捕获从全局到局部或从宏观到微观的语义知识(Wang 等人, 2024a; Chen 等人, 2024f; Han 等人,2024;石等人,2024a)。 例如,(Chen等人,2024e)提出了一种用于红外小目标检测的Mamba-in-Mamba分层编码器,结合了内部和外部选择性SSM块。 内部的一个是专门定制的,用于捕获视觉块之间的相互作用以进行局部模式提取。 相反,外部块旨在表征视觉句子之间的关系以捕获全局特征。 HiSS (Bhirangi 等人, 2024) 将输入序列划分为块,并对块特征进行分层建模以进行连续顺序预测。 这些块首先由低级 SSM 单元处理,处理后的特征由高级 SSM 块映射到输出序列。
-
•
时空扫描。 在现实世界中动态系统盛行的推动下,人们对时空扫描方法来增强曼巴块的性能越来越感兴趣(Yao等人,2024;Yang等人,2024e)。 例如,VideoMamba (Li 等人, 2024c) 将图像的原始 2D 扫描扩展为两种 3D 扫描:空间优先扫描和时间优先扫描。 VideoMamba 结合这两种扫描方法,在处理长、高分辨率视频方面表现出卓越的效率。 此外,ChangeMamba (陈等人,2024d)集成了三种时空扫描机制(顺序建模、交叉建模和并行建模),以实现多时相特征之间的上下文信息交互,用于遥感变化检测。
-
•
混合扫描。 为了追求全面的特征建模,许多努力集中在结合不同扫描方法的优点(Zhen等人,2024;Shi等人,2024b;Gong等人,2024;Dong等人,2024;Deng和Gu,2024),所谓的混合扫描。 例如,Mambamixer (Behrouz 等人, 2024) 提出了 Scan 的 Switch,动态地采用一组图像扫描方法,即 Cross-Scan、Zigzag Scan 和 Local Scan 来遍历图像块。 Mambamixer 还引入了双重选择机制来混合跨 Token 和通道的信息。 通过这样做,它们表现出了与其他视觉模型竞争的性能。 Pan-Mamba(何等人,2024b)引入了两种基于Mamba架构的扫描方法:通道交换扫描和跨模态扫描。 通过结合这两种扫描方法,Pan-Mamba 增强了高效的跨模式信息交换和图像全色锐化融合的能力。
4.3. 内存管理
与 RNN 一样,状态空间模型中隐藏状态的记忆有效地存储了先前步骤的信息,从而在 SSM 的整体功能中发挥着至关重要的作用。 虽然 Mamba 引入了基于 HiPPO 的内存初始化方法(Gu and Dao,2023),但 SSM 单元的内存管理仍然存在挑战,包括在层之间传输隐藏信息和实现无损内存压缩。 为此,一些开创性的研究提出了不同的解决方案,包括内存初始化、压缩和连接。 例如,Ezoe 和 Sato (2024) 尝试在模型再训练期间使用平衡截断方法来改进选择性 SSM 的初始化过程。 此外,DGMamba (Long 等人, 2024) 引入了隐藏状态抑制方法来增强状态空间模型中隐藏状态的域泛化能力。 该方法致力于减轻这些隐藏状态带来的负面影响,从而缩小不同域之间隐藏状态之间的差距。 类似地,DenseMamba (He 等人, 2024c)提出了一种密集连接方法来增强 SSM 中各层之间隐藏信息的传播。 该策略旨在通过选择性地将浅层的隐藏状态集成到更深的层中来减轻记忆退化并保留用于输出生成的详细信息。
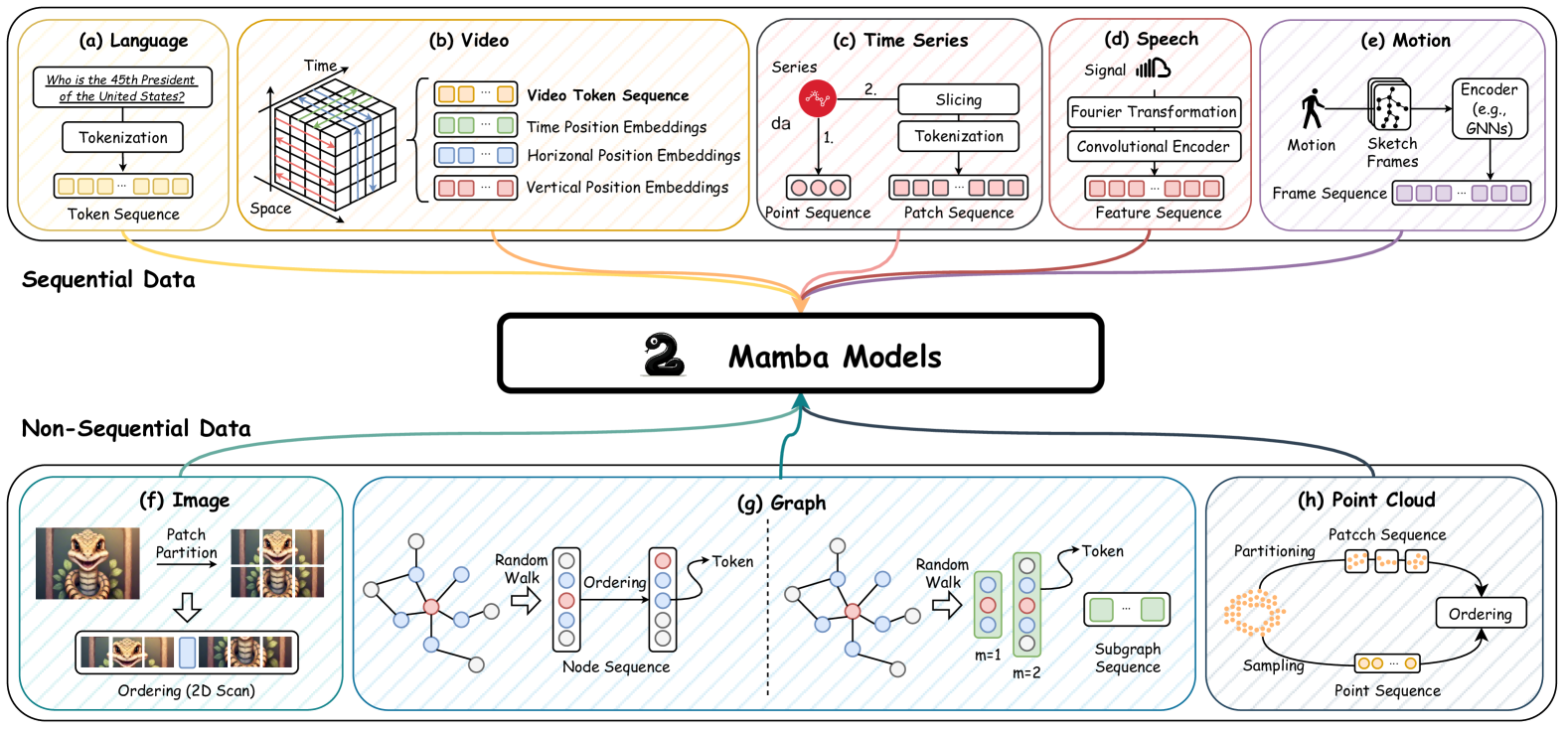
5. 让 Mamba 适应不同的数据
Mamba 架构代表了选择性状态空间模型的扩展,它具有循环模型的基本属性,这使其非常适合作为对文本、时间序列、语音等序列进行操作的通用基础模型。 与此同时,最近的开创性研究将 Mamba 架构的应用扩展到顺序数据之外,涵盖图像和图形等领域,如图 7 所示。 这些研究旨在利用 Mamba 捕获远程依赖关系的卓越能力,同时利用其学习和推理过程的效率。 因此,在本节中,我们的目标是研究使 Mamba 适应各种类型数据的新兴技术。 相关研究总结如表4所示。
| Category | Data | Typical Tasks | Representative References |
|---|---|---|---|
| Sequential Data | Language | Long-Context Language Modelling | (Shen et al., 2021; Poli et al., 2023; Gu et al., 2021a; Behrouz et al., 2024; Bhirangi et al., 2024; Nawrot et al., 2024; He et al., 2024c; Lieber et al., 2024; Anthony et al., 2024) |
| Video | Long Video Generation | (Yang et al., 2024e; Li et al., 2024b; Oshima et al., 2024; Zou et al., 2024; Arnab et al., 2021; Liu et al., 2022a; Li et al., 2024c) | |
| Time Series | Long-Term Forecasting | (Xu et al., 2024a; Ahamed and Cheng, 2024a; Liang et al., 2024a; Ahamed and Cheng, 2024b; Zhou et al., 2021; Ahamed and Cheng, 2024a; Sanjid et al., 2024; Yuan et al., 2024b) | |
| Speech | Speech Separation | (Abdel-Hamid et al., 2014; Chen et al., 2024g; Li and Chen, 2024; Jiang et al., 2024b) | |
| Motion | Continuous Human Motion Understanding | (Wang et al., 2024d; Zhang et al., 2024c; Zeng et al., 2024) | |
| Non-Sequential Data | Image | High-Resolution Medical Vision | (Yue and Li, 2024; Chen et al., 2024a, d; Lin et al., 2024b; Wang et al., 2024g, g; Ruan and Xiang, 2024; Zhu et al., 2024; Touvron et al., 2021) |
| Graph | Large Graph Learning | (Fan et al., 2019b; Huang et al., 2020; Liu et al., 2024a; Ye and Ji, 2021; Wang et al., 2024e; Behrouz and Hashemi, 2024; Huang et al., 2024a) | |
| Point Cloud | Efficient 3D Point Cloud Restoration | (Guo et al., 2020; Yu et al., 2022; Yi et al., 2024; Han et al., 2024; Zhou et al., 2024; Liang et al., 2024b; Zhang et al., 2024a) | |
| Multimodal Data | Vision-Languge | Visual and Linguistic Awareness | (Yang et al., 2024c; Liu et al., 2024b; Wu et al., 2023; Wang et al., 2024d; Qiao et al., 2024) |
| Multimodality | Semantic Recognition | (Dong et al., 2024; Wan et al., 2024) |
5.1. 顺序数据
顺序数据是指以特定顺序收集或组织的数据,其中数据点的顺序很重要。 为了探索利用 Mamba 作为序列数据相关任务的基础模型的潜力,我们在后续章节中提供了全面的回顾,其中涵盖了各种序列数据,包括自然语言、视频、时间序列、语音和人体动作。
5.1.1. 自然语言
作为最具代表性的架构之一,Mamba 在保证效率的同时进行基于内容的推理,被认为是大型语言模型主干网解决 Transformers 在长序列上计算效率低下问题的有前途的替代方案。 基于这一见解,许多研究探索了 Mamba 在自然语言处理 (NLP) 中各种下游任务中的潜力(Behrouz 等人, 2024; Bhirangi 等人, 2024; Nawrot 等人, 2024; He 等人, 2024c)。 例如,MambaByte (Wang 等人, 2024b) 被提出在字节序列上使用 Mamba,旨在利用 Mamba 在捕获无 Token 语言模型的远程依赖关系方面的优势。 他们的评估表明,MambaByte 避免了子词标记化的归纳偏差,并且在长期语言建模任务上优于最先进的子词 Transformer。 此外,Jamba (Lieber 等人, 2024) 和 BlackMamba (Anthony 等人, 2024) 融入了 Mix-of-Experts (MoE) 的概念,以增强 Mamba 在通过将 SSM 的线性复杂度生成与 MoE 提供的快速且经济的推理能力相集成来进行语言处理。
5.1.2. 视频
视频理解和生成的核心目标在于学习时空表示,这本质上提出了两个艰巨的挑战:短视频片段中的大量时空冗余和长上下文之间复杂的时空依赖性(Arnab等人,2021;Liu等人,2022a)。 在同时解决这两个挑战的过程中,Mamba 以其区分短期动作和解读长视频的能力脱颖而出(Li 等人,2024b;Oshima 等人,2024;Zou 等人,2024;Gao 等人,2024b)。 例如,VideoMamba (Li 等人, 2024c) 首先通过 3D 卷积将输入视频投影到一组不重叠的时空块中,然后利用堆叠的双向 Mamba 块将这些块编码为矢量化表示用于视频理解和生成等下游任务。 此外,Vivim (Yang 等人,2024e) 提出了一种新颖的时间 Mamba 块,可以有效地将广泛的时空表示压缩为多尺度序列,用于医学视频分割。
5.1.3. 时间序列
作为典型的序列数据,时间序列数据在我们生活的各个方面无处不在,包括股市分析、交通建模和天气预报(周等人,2021;曲等人,2024b)。 受 Mamba 在远程序列建模方面最新进展的推动,人们做出了许多努力来研究其在时间序列数据方面的潜力(Xu 等人,2024a;Ahamed 和 Cheng,2024a;Liang 等人,2024a;艾哈迈德和程,2024b)。 例如,TimeMachine (Ahamed 和 Cheng,2024a) 利用 Mamba 捕获多元时间序列数据中的持久模式,确保线性复杂度计算和最小的内存占用,以实现简化的时间序列处理。 此外,Mambaformer (Xu 等人, 2024a) 结合了选择性 SSM 和 Attention 层,用于天气、交通流量等的长期和短期预测。
5.1.4. 演讲
语音特指人类交流的发声形式,涉及使用特定语音、单词、语法和语调模式的发声表达(Abdel-Hamid 等人,2014)。 最近,在语音相关任务领域,研究人员(Chen等人,2024g)在开发基于Mamba的模型以解决现有模型架构(例如RNN)遇到的新挑战方面取得了重大进展和变形金刚。 例如,SPMamba (Li and Chen,2024)和 DPMamba (Jiang 等人,2024b)利用双向 Mamba 模块来捕获更广泛的上下文信息以进行语音分离,在处理语音分离任务时,与基于 Transformer 的基线相比,模型性能显着提高了 13%,计算复杂度降低了 566%。
5.1.5. 动作
人体运动理解和生成是广泛的实际应用中的一个重要追求,包括计算机动画、游戏开发和机器人操纵。 然而,在冗长的运动序列中很少出现的语义动作使得远程运动建模变得困难。 为了解决这个问题,一些研究提出使用 Mamba 来捕获运动序列中的时空模式(Wang 等人,2024d)。 例如,Motion Mamba (Zhang 等人, 2024c)提出了一种混合 Mamba 模型,该模型利用分层 SSM 层来捕获时间模式,并引入双向 SSM 层来学习空间知识,从而保持之间的运动一致性帧。 基于综合实验,基于 Mamba 的模型在人体运动生成任务中优于基于扩散的代表性方法,实现了 50% 的 FID 改进和四倍的性能提升。 此外,MambaMOS (Zeng 等人,2024) 设计了一种运动感知状态空间模型,该模型明确专注于捕获连续时间步之间的运动变化,这进一步强调了 Mamba 在实现高速度方面的卓越能力。高质量、冗长的序列运动建模。
5.2. 非顺序数据
非顺序数据与顺序数据的不同之处在于不遵循特定的顺序。 其数据点可以按任何顺序组织或访问,而不会显着影响数据的含义或解释(Huang 和 Schneider,2011)。 这种固有顺序的缺失给专门设计用于捕获数据中的时间依赖性的循环模型(例如 RNN 和 SSM)带来了困难。 令人惊讶的是,代表 SSM 的 Mamba 在最近的发展中在有效处理非序列数据方面表现出了显着的成功。 在本节中,我们将回顾有关 Mamba 如何有效处理非序列数据(包括图像、图形和点云)的相关研究。
5.2.1. 图片
作为最流行的模式之一,图像数据构成了各种计算机视觉应用的基础,例如人脸识别、医学视觉(Yue和Li,2024)和遥感(Chen等)人,2024a,d)。 从 Mamba 在序列建模方面的成功中汲取灵感,存在将这一成就从文本处理转移到图像分析的有趣机会。 它涉及将图像视为一系列补丁,这可能为计算机视觉领域的新探索途径铺平道路。 因此,最近开发了许多基于 Mamba 的视觉模型,以减轻繁重的计算资源和内存压力,同时展现出有竞争力的建模能力(Lin 等人,2024b;Wang 等人,2024g,g;Ruan 和Xiang,2024) 。 例如,Vision Mamba (Zhu 等人,2024) 结合了双向 SSM 来促进全局视觉语义建模,并结合位置嵌入来实现位置感知的视觉理解。 Vision Mamba 不需要注意力机制,可与 Vision Transformers 的建模能力相匹配,同时将计算时间大幅减少到次二次级水平并保持线性内存复杂性。 具体来说,它在速度方面优于最先进的基线 DeiT (Touvron 等人,2021),快了 2.8 倍,并且 GPU 内存显着减少了 86.8%在高分辨率图像(1248×1248)上进行特征提取的批量推理期间的使用。 此外,VMamba (Liu 等人, 2024c) 引入了 2D 选择性扫描 (SS2D),作为 1D 阵列扫描和 2D 平面遍历之间的桥梁,使 Mamba 能够有效地处理视觉数据。
5.2.2. 图结构数据
图建模在管理复杂结构和关系方面具有广泛的用途,包括社交网络(范等人,2019b,2020)、推荐系统(范等人,2022)等领域的应用 和分子相互作用(Huang 等人, 2020)。 由于 Mamba 强大的远程建模能力和高效率,一些开创性的研究已经采用了非序列图数据的选择性状态空间模型(SSM)(刘等人,2024a)。 这些研究利用状态空间模型在循环扫描期间通过隐藏状态对上下文进行编码,从而允许输入流控制,这类似于图上的注意力稀疏化,在图建模上下文中呈现依赖于数据的节点选择过程(Ye和Ji,2021) )。 此外,Mamba 有望提高大图训练任务中的模型效率。 例如,Graph-Mamba (Wang 等人, 2024e) 引入了一种新颖的基于 Mamba 的块作为图建模的基础组件。 该块将图展平机制与 Mamba 提供的选择机制相结合,分别将子图转换为节点序列并促进依赖于输入的上下文过滤。 在最近的一项工作中,Behrouz 和 Hashemi(2024)提出了图曼巴网络(GMN),这是一种基于选择性 SSM 的新图神经网络格式。 作者将选择性 SSM 重新表述为图学习格式,并为所提出的网络的强大功能提供了理论依据。 通过解决图消息传递关键步骤中出现的挑战,GMN 在各个方面都取得了显着的性能,在具有不同图尺度的多个基准数据集中超越了 GNN 和基于 Transformer 的模型。 此外,黄等人(2024a)引入了图状态空间卷积(GSSC)作为针对图结构数据定制的SSM的系统扩展。 具体来说,GSSC 将基于距离的图卷积核合并到 SSM 单元中,旨在增强表达能力并捕获长程依赖性。 通过对十个基准数据集进行评估,该研究(黄等人,2024a)强调了 GSSC 作为图机器学习的有效且可扩展模型的潜力。
5.2.3. 点云
点云是计算机视觉中的一种重要模式,在机器人、自动驾驶和增强现实等领域拥有大量实际应用(Guo 等人,2020)。 与图像处理和图形学习不同,点云的分析提出了独特的挑战,这些挑战源于点云固有的不规则性和稀疏性,即 3D 非结构化数据。 为了应对这些挑战,基于深度学习的方法取得了显着的进步,特别是基于 Transformer 的模型(Yu 等人,2022)。 然而,注意力机制的复杂度是二次的,带来巨大的计算成本,这对于低资源设备并不友好。 随着状态空间模型 (SSM) 在处理 1D 序列(例如语言和语音)和 2D 数据(例如图像和图形)方面的最新进展,人们一直在努力将 Mamba 的应用扩展到 3D 点云(易等人,2024)。 一般来说,这些基于 Mamba 的点云分析方法采用两步过程(Han 等人,2024;Zhou 等人,2024)。 首先,使用特定的扫描方法将点云数据标记为离散标记。 然后,Mamba 用于捕获这些 Token 内的底层模式。 例如,PointMamba (Liang 等人,2024b)提出了一种分层扫描策略来编码 3D 点云的局部和全局信息,然后利用普通 Mamba 作为主干从序列化点 Token 中提取特征,而无需合并额外的复杂技术。 点云 Mamba (Zhang 等人,2024a) 将 Mamba 作为基础模型骨干,显着减少内存使用,与基于 Transformer 的同类产品相比,表现出可比(或优越)的性能。
5.3. 多模态数据
集成语言(序列数据)和图像(非序列数据)等多种模态,为人工智能感知和场景理解提供有价值的补充信息。 最近,多模态大型语言模型(MLLM)受到了广泛的研究关注,它继承了大型语言模型的先进能力(吴等人,2023),包括强大的语言表达和逻辑推理。 虽然 Transformer 一直是该领域的主导方法,但 Mamba 在对齐混合源数据和实现序列长度的线性复杂度缩放方面表现出色,已成为强大的竞争对手,这使得 Mamba 成为多模态学习中 Transformer 的有前途的替代方案(杨等人,2024c;刘等人,2024b)。 例如,乔等人(2024)提出VL-Mamba探索利用Mamba的高效架构来解决视觉语言任务,利用预先训练的Mamba模型进行语言理解并结合连接器模块将视觉补丁与语言标记对齐。 Wang 等人 (2024d) 提出文本控制的 Motion Mamba (Wang 等人, 2024d),它利用 Mamba 基于文本查询动态捕获全局时间信息,以增强人类运动理解。 此外,Fusion-Mamba (Dong 等人,2024) 和 Sigma (Wan 等人,2024) 尝试融合来自不同模态的互补信息,例如热、深度、和RGB。 Fusion-Mamba 专注于改进对象检测,而 Sigma 旨在增强语义分割。
6. 应用领域
在本节中,我们将介绍基于 Mamba 的模型的几个值得注意的应用。 为了提供全面的概述,我们将这些应用程序分类为:自然语言处理、计算机视觉、语音分析、药物发现、推荐系统和机器人和自主系统。
6.1. 自然语言处理
在自然语言处理领域,最近出现了一些基于 Mamba 的模型作为基于 Transformer 的模型的替代品进行语言建模(Waleffe 等人,2024;Zhao 等人,2024c;Anthony 等人,2024;Bronnec 等人, 2024; Lieber 等人, 2024; He 等人, 2024c; Xu, 2024),特别是在涉及广泛上下文的应用中,例如问答系统和文本摘要.
6.1.1. 问答系统。
问答 (QA) 涉及人工智能模型使用广泛的知识库进行理解、推理和响应,从而实现连贯且上下文丰富的对话,广泛应用于聊天机器人和虚拟助手。 结合先前交互中的上下文对于准确解决多轮对话中的后续问题至关重要。 然而,现有模型在推理速度和计算效率方面面临挑战,特别是在复杂的推理任务中。 这会导致大量的内存使用和计算开销,从而限制了可扩展性和实时应用程序效率。 为了解决这些局限性,最近的研究探索了基于 Mamba 的模型来改进 QA 系统中的长期对话管理(Mattern 和 Hohr,2023;Lieber 等人,2024,2024)。 例如,Mamba-Chat (Mattern 和 Hohr,2023) 是第一个利用状态空间框架的聊天语言模型。 该模型通过采用状态空间表示来维护和更新其对对话的理解,确保上下文感知。 Jamba (Lieber 等人, 2024) 战略性地在 Transformer 层和 Mamba 层之间交替,结合 MoE 来增强模型容量,同时优化参数利用率。 在常识推理和阅读理解任务中,Jamba 的性能可与较大的 Llama-2 模型相媲美,但参数较少,展示了效率和有效性。 类似地,DenseMamba (He 等人, 2024c) 引入了一种新颖的方法,通过选择性地将浅层的隐藏状态合并到更深的层中来丰富 SSM 中隐藏信息跨层的传播。 与传统的基于 Transformer 的模型相比,这保留了关键的细粒度信息,以在问答任务中获得卓越的性能。 总体而言,集成基于 Mamba 的模型显示出通过改进对话管理和提高复杂推理任务性能来推进 QA 系统的巨大潜力。
6.1.2. 文本摘要。
文本摘要旨在通过保留基本信息来压缩长文本。 保持一致性和相关性对于这项任务至关重要。 基于 Transformer 的模型通常会遇到长序列依赖性,可能会损害连贯性和相关性。 相比之下,基于 Mamba 的模型利用强大的长序列处理功能,使其非常适合处理连贯且上下文丰富的文本。 其强大的架构使他们能够准确捕获和浓缩大量文档的本质,从而在总结任务中表现出色。 例如,基于状态空间模型的 LOCOST (Bronnec 等人, 2024) 处理的序列比稀疏注意力模型要长得多。 在长文档抽象摘要中,LOCOST 的性能可与同等维度的最高性能稀疏变换器相媲美,同时在训练期间减少高达 50% 的内存使用量,在推理期间减少高达 87% 的内存使用量。 此外,SAMBA (Ren 等人, 2024b) 将 Mamba 与滑动窗口注意力集成,实现选择性序列压缩到循环隐藏状态,同时通过注意力机制保留精确的记忆回忆。 在处理 128K 输入长度时,SAMBA 的吞吐量比 Transformers 高出 3.73 倍,在需要长上下文摘要的任务中展现出卓越的性能。
6.2. 计算机视觉
除了 NLP 应用之外,基于 Mamba 的模型在计算机视觉领域也显示出了潜力,代表性应用包括疾病诊断和运动识别与生成。
6.2.1. 疾病诊断。
在临床实践中,医学图像和视频提供了对器官或组织形态的重要见解。 对生物医学对象(例如大规模 2D/3D 图像或视频中的病变)的有效分析可显着增强疾病诊断和临床治疗。 然而,像 UNet 这样基于 CNN 的模型由于其感受野有限,在处理远程依赖关系方面面临着挑战。 由于医学图像通常比自然图像更大的尺寸和更高的分辨率,加剧了这一挑战。 同时,基于 Transformer 的算法计算量大,限制了它们在资源有限的临床环境中的实用性。 为了克服这些局限性,大量研究在真实医疗环境中采用了基于 Mamba 的模型(马等人,2024a;阮和翔,2024;王和马,2024;廖等人,2024)。 例如,U-Mamba (Ma 等人, 2024a) 和 SegMamba (Xing 等人, 2024) 都集成了混合 CNN-SSM 模块,合并了局部特征提取卷积层的功能与 SSM 提供的远程依赖建模。 这种混合方法在 CT 和 MR 图像中腹部器官的 3D 分割、内窥镜图像中的器械分割以及显微镜图像中的细胞分割等任务中优于现有模型。 同样,CMViM (Yang 等人,2024b) 通过利用屏蔽 Vim 自动编码器和跨模态对比学习来解决阿尔茨海默氏病 (AD) 诊断成像的挑战,在 AD 诊断成像分类中实现最佳性能。 此外,ProMamba (Xie 等人, 2024b) 专注于息肉分割。 通过结合 Vision-Mamba 架构和提示技术,该模型比以前的方法实现了更高的准确性和更好的泛化性。 对于视频中的动态医疗对象分割,Vivim (Yang 等人, 2024e) 使用 Temporal Mamba Block 有效地将不同尺度的长期时空表示压缩为序列。 这种方法展示了疾病诊断中增强的性能和计算效率,例如超声乳腺病变分割和结肠镜检查视频中的息肉分割。
6.2.2. 运动识别和生成。
运动识别和生成对于运动监控(Golestani 和 Moghaddam,2020)、计算机动画(Siarohin 等人,2021)、游戏开发(Nasri 等人)至关重要,2020),以及电影制作(王等人,2023b)。 然而,基于 Transformer 的模型遇到了与计算和内存需求相关的挑战,限制了它们在资源受限环境中的适用性。 此外,Transformers 和基于 GCN 的模型难以有效捕获视频和 4D 点云中的长运动序列和复杂的时空模式。 最近的研究探索了利用 Mamba 来应对这些挑战,利用其强大的性能和较低的计算需求(Li 等人,2024g;Chaudhuri 和 Bhattacharya,2024;Zhang 等人,2024c,b)。 例如,HARMamba (Li等人,2024g)利用双向SSM架构来处理来自可穿戴传感器的数据,显着减少计算负载和内存使用,同时保持实时人体动作识别的高精度。 同样,Simba (Chaudhuri 和 Bhattacharya,2024) 将 Mamba 集成到 U-ShiftGCN 框架中,有效处理更长的序列和复杂的时空交互,在视频中的骨骼动作识别中取得最佳效果。 此外,Motion Mamba (Zhang 等人, 2024c) 和 InfiniMotion (Zhang 等人, 2024b) 都是用于运动生成的。 具体来说,Motion Mamba (Zhang 等人, 2024c) 利用分层时间 Mamba 块处理时间数据,利用双向空间 Mamba 块处理潜在姿势,确保跨帧的运动一致性并增强时间帧内的运动生成准确性。 InfiniMotion (Zhang 等人, 2024b) 推出具有双向 Mamba Memory 的运动记忆 Transformer ,提高了 Transformer 的记忆能力,可高效生成连续、长时间的人体运动(长达 1 小时、80,000 帧),而无需任何操作。压倒性的计算资源。
6.3. 语音分析
语音信号本质上由数千个样本组成。 虽然这种广泛的时间背景提供了丰富的声学特征,但它也提出了巨大的计算需求。 为了有效地处理语音信号,多种基于 Mamba 的模型已成功应用于各种语音应用中,特别是在语音分离和标记和语音增强中。
6.3.1. 语音分离和标记。
语音分离涉及将单个语音信号与多说话者环境隔离。 它对于提高音频通信的清晰度和质量至关重要。 同时,音频标记或分类涉及将音频样本映射到其相应的类别。 这两项任务都依赖于捕获短距离和长距离音频序列模式。 尽管基于 Transformer 的模型一直是这些应用程序的主要架构,但由于其自注意力机制,它们在二次计算和内存成本方面面临着重大挑战。 最近,人们开始转向采用状态空间模型进行语音分离(Jiang等人,2024b;Li和Chen,2024)和音频标记(Zhang等人,2024g;Bhati等人,2024)。 具体来说,DPMamba (Jiang 等人,2024b) 利用选择性状态空间来捕获语音信号中的动态时间依赖性,包括短期和长期的前向和后向依赖性。 SPMamba (Li 和 Chen,2024) 集成了 TF-GridNet 模型,用双向 Mamba 模块替换其 Transformer 组件。 DASS (Bhati 等人,2024) 将知识蒸馏与状态空间模型相结合,允许在持续长达 2.5 小时的音频文件中标记声音事件。 同时,MAMCA(张等人,2024g)重点关注自动调制分类(AMC),引入选择性状态空间模型作为骨干,有效解决长序列AMC的准确性和效率挑战。 通过采用状态空间模型,这些模型展示了质的改进,捕获了更广泛的上下文信息并提高了整体有效性,从而证明了 SSM 在处理长持续时间方面的卓越可扩展性。
6.3.2. 语音增强。
语音增强(SE)旨在从失真信号中提取清晰的语音成分,产生具有改善声学特性的增强信号。 作为前端处理器,SE 在众多语音应用中发挥着关键作用,包括辅助听力技术(Kumar 等人,2022)、说话人识别(Bai 和Zhang,2021) ,以及自动语音识别(Malik等人,2021)。 由于资源有限,移动音频设备面临挑战。 最近的研究探索了 Mamba 的应用,利用其强大的性能并减少 SE 任务中的计算需求(Sui 等人,2024;Quan 和 Li,2024;Chao 等人,2024;Zhang 等人,2024f;Shams 等人,2024)。 例如,TRAMBA (Sui 等人,2024) 利用 Transformers 和 Mamba 相结合的混合架构来提高移动和可穿戴平台的语音质量,特别针对声学和骨传导。 与当前领先型号相比,它的内存消耗显着减少了十倍。 此外,oSpatialNet-Mamba (Quan 和 Li,2024) 利用 Mamba 进行长期多通道语音增强,为静态和移动扬声器取得了出色的效果。
6.4. 药物发现
蛋白质设计、分子设计和基因组分析对于推进药物发现和生物技术至关重要(Scott 等人,2016;Li 等人,2024d)。 利用基于 Mamba 的模型显着降低了这些领域中长序列建模的复杂性(Peng 等人,2024, 2024;Guo 和 Schwaller,2024;Schiff 等人,2024, 2024)。 具体来说,PTM-Mamba (Peng 等人, 2024) 和 ProtMamba (Sgarbossa 等人, 2024) 是基于 Mamba 架构的蛋白质语言模型。 PTM-Mamba 利用双向门控 Mamba 块和结构化状态空间模型,有效处理长序列,同时减少计算需求。 ProtMamba 被设计为具有同源意识但无需比对,擅长处理数百个蛋白质序列的广泛上下文。 即使在处理大型数据集时,这两种模型也能保持高效率和准确性,为蛋白质设计提供关键工具。 同时,生成分子设计旨在模拟具有特定分布的定制属性概况的分子。 然而,当前模型缺乏优化高保真预言机所需的效率,直接导致成功率低下。 Saturn(Guo 和 Schwaller,2024),应用 Mamba 架构,利用其线性复杂性和计算效率超越了药物发现中的 22 个竞争模型。 此外,了解基因组对于深入了解细胞生物学至关重要。 基因组建模的挑战包括捕获遥远标记之间的相互作用、考虑上游和下游区域的影响以及确保 DNA 序列的互补性。 Caduceus (Schiff 等人,2024) 和 MSAMamba (Thoutam 和 Ellsworth,[n. d.]) 都利用 Mamba 模型,擅长应对这些挑战。 Caduceus 是一种 DNA 基础模型,通过 BiMamba 和 MambaDNA 组件增强了 Mamba 架构,用于双向建模并确保反向补体等变,在远程基因组任务中显着优于现有模型。 类似地,MSAMamba (Toutam 和 Ellsworth,[n. d.]) 通过沿序列维度实施选择性扫描操作,解决了基于 Transformer 的 DNA 多序列比对模型的局限性。 这种设计将之前方法的训练上下文长度延长了八倍,从而可以对大量 DNA 序列进行更全面的分析。
6.5. 推荐系统
推荐系统广泛应用于电子商务(Zhang 等人,2024e;Zhou 等人,2018;Chen 等人,2023)和社交网络(Fan 等人,2019c,a, 2018),旨在捕捉用户不断变化的偏好及其过去行为之间的相互依赖性(Zhao等人,2024b;Fan等人,2022)。 尽管基于 Transformer 的模型已在推荐系统中证明了有效性(Sun 等人,2019),但由于注意力机制的二次复杂性,特别是在处理较长的行为序列时,它们面临着计算效率的挑战。 最近,一些基于 Mamba 的模型已被应用于分析长期用户行为以进行个性化推荐(Yang 等人,2024d;Liu 等人,2024a;Wang 等人,2024c;Su 和 Huang,2024;Cao 和张,2024)。 例如,Mamba4Rec (Liu 等人, 2024a) 开创性地使用选择性状态空间模型进行高效顺序推荐,在提高模型性能的同时保持推理效率。 类似地,RecMamba (Yang 等人, 2024d) 探索了 Mamba 在终身顺序推荐场景(即序列长度 2k)中的有效性,在减少训练训练的同时实现了与基准模型相当的性能时间减少 70%,内存成本减少 80%。 此外,EchoMamba4Rec (Wang 等人,2024c) 将双向 Mamba 模块与频域滤波集成,以准确捕获用户交互数据中的复杂模式和相互依赖性。 它展示了优于现有模型的卓越性能,提供更精确和个性化的建议。 此外,Mamba4KT (Cao 和Zhang,2024) 专为智能教育中的知识追踪而设计,利用 Mamba 模型来捕获练习与学生知识水平之间的持久相关性。 随着教育数据集的扩展,该方法为提高知识追踪研究中的预测准确性、模型效率和资源利用率提供了一条有前途的途径。
6.6. 机器人和自主系统
机器人和自主系统的主要目标是开发能够理解视觉环境并执行复杂动作的模型。 目前机器人技术中使用的多模态大型语言模型 (MLLM) 在两个主要方面面临重大挑战:1)处理需要高级推理的复杂任务的能力有限,2)微调和推理任务的大量计算费用。 由于在推理速度、内存利用率和整体效率方面的优势,基于 Mamba 的模型正在成为自主和智能系统的有前景的基础(Cao 等人,2024;Liu 等人,2024b;Jia 等人, 2024),有望提供卓越的性能和巨大的可扩展性潜力。 例如,RoboMamba (Liu 等人, 2024b) 将视觉编码器与 Mamba 集成,创建端到端机器人 MLLM。 该方法通过协同训练将视觉数据与语言嵌入对齐,利用视觉常识和机器人特定推理增强模型,同时确保高效的微调和推理能力。 同样,Jia 等人 (2024) 介绍了 MaIL,一种以 Mamba 作为骨干的模仿学习 (IL) 策略架构。 Mail 弥合了处理观察序列的效率和性能之间的差距。 对真实机器人实验的广泛评估表明,MaIL 为传统、大型且复杂的基于 Transformer 的 IL 策略提供了一种有竞争力的替代方案。
7. 挑战与机遇
前面的部分已经深入研究了与 Mamba 相关的最新先进技术和各种应用。 然而,曼巴的研究仍处于起步阶段,未来存在相当大的挑战和机遇。
7.1. 基于 Mamba 的基础模型
通过将大规模混合源语料库的模型规模扩大到十亿级,基础模型 (FM) 展现出令人印象深刻的零样本学习能力,这使得 FM 在各种一般任务中表现出色( Bommasani 等人,2021)。 作为一个典型例子,近年来基于 Transformer 的大语言模型尤其是 ChatGPT 的蓬勃发展,激发了人们对各个领域基础模型探索的热情。 尽管 Transformers 是成功的主要推动力,但它们也面临着紧迫的计算和内存效率问题(Tay 等人,2022),这些问题伴随着与基于注意力的模型成正比的指数增长的训练内存大小以及推理过程中费力的自回归解码。 针对这些问题,最近出现了一种有前景的基础模型替代主干,即 Mamba (Gu and Dao,2023;Dao and Gu,2024)。 Mamba 提供 Transformer 的内容感知学习功能,同时根据输入长度线性扩展计算,使其能够有效捕获远程依赖性并提高训练和推理的效率。 鉴于这些优势,为特定领域开发基于 Mamba 的基础模型具有巨大的潜力,这为解决基于 Transformer 的模型所面临的问题提供了机会。
7.2. 硬件感知计算
基础模型的特点是尺寸大和矩阵乘法和卷积等密集矩阵运算,需要 GPU 和 TPU 等尖端硬件来进行高吞吐量训练和推理。 这些先进的硬件使研究人员能够处理更大的数据集,并在各个领域实现最先进的性能。 尽管如此,现有的基础模型仍然未能充分利用硬件的计算能力,导致模型效率有限(Tay等人,2022)。 作为提高计算效率的有前途的替代方案,Mamba-1 (Gu 和 Dao,2023) 和 Mamba-2 (Dao 和 Gu,2024) 提出了硬件感知计算算法,即并行关联扫描和块分解矩阵乘法。 这些算法考虑了 GPU 和 TPU 的固有特性,包括设备之间的消息传输等因素,为解决计算效率问题提供了全新的视角。 受此启发,探索新颖的硬件高效算法,例如 FlashButterfly (Fu 等人,2023),以优化硬件利用率,为节省资源和加速计算提供了一条有前途的途径,不仅使 SSM 受益,而且其他架构,如 Transformer 和 RNN。
7.3. 值得信赖的曼巴模特
SSM的发展预计将为电子商务、医疗保健和教育等各个行业带来显着的效益。 同时,与许多现有架构一样,Mamba 模型是一种依赖于数据的模型,可能会对用户和社会构成严重威胁(Marques-Silva 和 Ignatiev,2022)。 这些威胁源于多种因素,例如不稳定的决策、隐私问题等。 因此,确保 Mamba 模型的可信度对于四个关键维度至关重要(刘等人,2022b):安全性和鲁棒性、公平性、可解释性 和隐私。
7.3.1. 安全性和稳健性
大型基础模型已被证明非常容易受到对抗性扰动的影响,当部署在安全关键型应用中时,这可能会危及这些模型的安全性和鲁棒性(Wei 等人,2024;Ning 等人,2024;Fan 等人,2023)。 同时,基于 Mamba 的模型也不能免于这些漏洞(Malik 等人,2024)。 为了成为 Transformer 的可靠替代品,有必要研究和增强基于 Mamba 的模型的安全性和稳健性。 具体来说,模型输出应该对其输入中的小扰动具有鲁棒性。 一种潜在的解决方案可能涉及在将提示输入基于 Mamba 的模型之前自动对其进行预处理。 此外,作为代表性技术,对抗机器训练(Huang等人,2011)可以用来增强Mamba模型的安全性和鲁棒性。
7.3.2. 公平性
在广泛的数据集上进行训练的大型基础模型往往会无意中暴露于广泛的训练语料库(Ma等人,2024b)中存在的偏见和刻板印象,这可以在生成的输出中体现出来。 例如,在大语言模型领域,偏见可能会导致受性别和年龄等用户个人资料属性影响的歧视性反应,强化刻板印象并不公平地对待特定用户群体(Jiang等人,2024a) 。 虽然最近人们在解决大语言模型的公平性问题上做出了努力,但关于曼巴模型的非歧视性和公平性的研究仍然存在差距。 因此,需要进一步的探索和研究来弥补这一差距。
7.3.3. 可解释性
深度学习模型经常因其“黑箱”性质而受到批评,而深度学习模型的可解释性已成为研究界的热门话题,这表明理解和解释模型生成的决策或预测的能力(多西洛维奇等人,2018)。 通过解释模型预测,用户可以根据模型的输出做出更明智的决策。 为此,人们提出了几种技术来为基于注意力机制的神经架构提供合理的固有解释(Hu等人,2023)。 此外,研究人员还研究了基于 Transformer 的语言模型生成自然语言描述来解释其答案的能力(Yuan 等人,2024a)。 尽管越来越多的研究试图充分利用 Mamba,但理解 Mamba 模型功能的研究仍处于早期阶段,仍需要进一步研究。
7.3.4. 隐私
隐私保护在用户和基于 Mamba 的模型之间建立了信任。 当用户确信自己的隐私受到尊重时,他们更有可能与人工智能系统互动、分享相关信息并寻求帮助,而不必担心数据被滥用。 因此,这种信任对于 Mamba 模型的广泛采用和接受至关重要。 降低隐私风险的一种有效策略是交叉验证 Mamba 模型的输出并筛选敏感内容(Kim 等人,2024)。 此外,联邦学习有望在 Mamba 模型训练期间增强隐私性,其中该模型在众多分散的边缘设备或容纳本地数据样本的服务器上进行训练,无需进行数据交换。 这种方法有助于保护数据的本地化和隐私。 此外,在训练期间集成隐私意识正则化技术(例如差异隐私约束)有望防止敏感数据的过度拟合。
7.4. 将 Transformer 的新兴技术应用于 Mamba
Transformer 作为主导支柱,引导人工智能社区开发了许多独特的工具,旨在提高基于注意力的模型的性能。 幸运的是,通过连接 SSM 和注意力,Mamba-2 (Dao 和 Gu,2024) 引入的 SSD 框架允许我们为 Transformer 和 Mamba 开发共享词汇表和技术库。 鉴于此,未来一个重要的方向出现了,即探索为基于 Transformer 的模型设计的新兴技术如何有效地应用于基于 Mamba 的模型。
7.4.1. 参数高效的微调
大型基础模型将参数扩大到数十亿,在多个领域取得了突破性进展。 然而,在针对特定下游任务定制它们时,它们的广泛规模和计算要求提出了重大挑战。 为此,一些参数高效的微调(PEFT)技术,包括 LoRA (Hu 等人,2021) 和 Adapter 系列 (Gao 等人,2024a;Karimi Mahabadi 等人,2021) ),已经被提出,其中涉及最小化参数的调整或微调期间对大量计算资源的需求。 受到近期将 PEFT 用于使用 Transformer 层构建的大型语言模型所取得的成就的启发,将 PEFT 用于 Mamba 模型已成为一个有趣的话题,其目标是扩大其在下游任务中的应用范围。 例如,LoRA(低秩适应)的部署预计将有助于 SSD 模型的快速微调,从而使 Mamba 在各个领域得到广泛应用。 然而,针对基于 Mamba 的模型实施这些 PEFT 技术的具体细节尚未确定,需要进一步研究。
7.4.2. 灾难性遗忘缓解
灾难性遗忘,也称为灾难性干扰,是指在机器学习模型中观察到的一种现象,即在新任务上进行训练时,机器学习模型在先前学习的任务上的表现会出现显着下降(Kemker等人,2018)。 这个问题对基础模型提出了挑战,因为它们需要保留来自预训练任务的知识,并在不同下游领域展示一致的性能。 作为一个有前景的基础模型架构,Mamba 需要进行彻底的调查来解决灾难性的遗忘问题。 最近的研究建议通过奖励最大化和分配匹配策略封装特定任务的需求来解决这一挑战(Korbak等人,2022b,a)。 此外,还开发了持续学习方法来减轻基于 Transformer 的语言模型中的灾难性遗忘(Wang 等人,2022;Kar 等人,2022)。 这些技术也可以通过连接 SSM 和注意力来应用于 Mamba 模型,但仍有待探索。
7.4.3. 检索增强生成(RAG)
作为人工智能中最复杂的技术之一,RAG 可以提供可靠且最新的外部知识,为多种任务提供重要的实用性(Lewis 等人,2020;Ding 等人,2024)。 大型语言模型最近展示了突破性的语言理解和生成能力,尽管遇到了幻觉和过时的内部知识等固有的限制。 鉴于 RAG 提供当前和有价值的补充信息的强大能力,检索增强大语言模型应运而生,利用外部知识数据库来提高大语言模型的生成质量(陈等人,2024c) 。 同样,RAG 可以与 Mamba 语言模型结合,帮助它们产生高质量的输出,这是未来一个有前途的研究方向。
8. 结论
Mamba 是一种新兴的深度学习架构,凭借其强大的建模能力和计算效率,在语言生成、图像分类、推荐和药物发现等多个领域取得了显着的成功。 近年来,人们越来越多地致力于开发基于 Mamba 的深度学习模型,使其具有更强大的表示学习能力和更低的计算复杂度。 鉴于 Mamba 的快速发展,迫切需要系统的概述。 为了弥补这一差距,在本文中,我们对 Mamba 进行了全面的回顾,重点关注其架构进步、数据适应性和应用领域,为研究人员提供了深入了解和概述 Mamba 的最新发展。 此外,鉴于曼巴研究仍处于起步阶段,我们还讨论了当前的局限性并为未来的研究提出了有希望的方向。
参考
- (1)
- Abdel-Hamid et al. (2014) Ossama Abdel-Hamid, Abdel-rahman Mohamed, Hui Jiang, Li Deng, Gerald Penn, and Dong Yu. 2014. Convolutional neural networks for speech recognition. IEEE/ACM Transactions on audio, speech, and language processing 22, 10 (2014), 1533–1545.
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- Ahamed and Cheng (2024a) Md Atik Ahamed and Qiang Cheng. 2024a. Timemachine: A time series is worth 4 mambas for long-term forecasting. arXiv preprint arXiv:2403.09898 (2024).
- Ahamed and Cheng (2024b) Md Atik Ahamed and Qiang Cheng. 2024b. TSCMamba: Mamba Meets Multi-View Learning for Time Series Classification. arXiv preprint arXiv:2406.04419 (2024).
- Anthony et al. (2024) Quentin Anthony, Yury Tokpanov, Paolo Glorioso, and Beren Millidge. 2024. BlackMamba: Mixture of Experts for State-Space Models. arXiv preprint arXiv:2402.01771 (2024).
- Arnab et al. (2021) Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. 2021. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision. 6836–6846.
- Bai and Zhang (2021) Zhongxin Bai and Xiao-Lei Zhang. 2021. Speaker recognition based on deep learning: An overview. Neural Networks 140 (2021), 65–99.
- Bal and Sengupta (2024) Malyaban Bal and Abhronil Sengupta. 2024. Rethinking Spiking Neural Networks as State Space Models. arXiv preprint arXiv:2406.02923 (2024).
- Behrouz and Hashemi (2024) Ali Behrouz and Farnoosh Hashemi. 2024. Graph Mamba: Towards Learning on Graphs with State Space Models. arXiv preprint arXiv:2402.08678 (2024).
- Behrouz et al. (2024) Ali Behrouz, Michele Santacatterina, and Ramin Zabih. 2024. Mambamixer: Efficient selective state space models with dual token and channel selection. arXiv preprint arXiv:2403.19888 (2024).
- Bhati et al. (2024) Saurabhchand Bhati, Yuan Gong, Leonid Karlinsky, Hilde Kuehne, Rogerio Feris, and James Glass. 2024. DASS: Distilled Audio State Space Models Are Stronger and More Duration-Scalable Learners. arXiv preprint arXiv:2407.04082 (2024).
- Bhirangi et al. (2024) Raunaq Bhirangi, Chenyu Wang, Venkatesh Pattabiraman, Carmel Majidi, Abhinav Gupta, Tess Hellebrekers, and Lerrel Pinto. 2024. Hierarchical State Space Models for Continuous Sequence-to-Sequence Modeling. arXiv preprint arXiv:2402.10211 (2024).
- Bommasani et al. (2021) Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258 (2021).
- Bronnec et al. (2024) Florian Le Bronnec, Song Duong, Mathieu Ravaut, Alexandre Allauzen, Nancy F Chen, Vincent Guigue, Alberto Lumbreras, Laure Soulier, and Patrick Gallinari. 2024. LOCOST: State-Space Models for Long Document Abstractive Summarization. arXiv preprint arXiv:2401.17919 (2024).
- Cao et al. (2024) Jiahang Cao, Qiang Zhang, Ziqing Wang, Jiaxu Wang, Hao Cheng, Yecheng Shao, Wen Zhao, Gang Han, Yijie Guo, and Renjing Xu. 2024. Mamba as Decision Maker: Exploring Multi-scale Sequence Modeling in Offline Reinforcement Learning. arXiv preprint arXiv:2406.02013 (2024).
- Cao and Zhang (2024) Yang Cao and Wei Zhang. 2024. Mamba4KT: An Efficient and Effective Mamba-based Knowledge Tracing Model. arXiv preprint arXiv:2405.16542 (2024).
- Chao et al. (2024) Rong Chao, Wen-Huang Cheng, Moreno La Quatra, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Szu-Wei Fu, and Yu Tsao. 2024. An Investigation of Incorporating Mamba for Speech Enhancement. arXiv preprint arXiv:2405.06573 (2024).
- Chaudhuri and Bhattacharya (2024) Soumyabrata Chaudhuri and Saumik Bhattacharya. 2024. Simba: Mamba augmented U-ShiftGCN for Skeletal Action Recognition in Videos. arXiv preprint arXiv:2404.07645 (2024).
- Chen et al. (2024b) Chi-Sheng Chen, Guan-Ying Chen, Dong Zhou, Di Jiang, and Dai-Shi Chen. 2024b. Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning. arXiv preprint arXiv:2402.15761 (2024).
- Chen et al. (2020) Deli Chen, Yankai Lin, Wei Li, Peng Li, Jie Zhou, and Xu Sun. 2020. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 3438–3445.
- Chen et al. (2024d) Hongruixuan Chen, Jian Song, Chengxi Han, Junshi Xia, and Naoto Yokoya. 2024d. Changemamba: Remote sensing change detection with spatio-temporal state space model. arXiv preprint arXiv:2404.03425 (2024).
- Chen et al. (2024c) Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024c. Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17754–17762.
- Chen et al. (2024a) Keyan Chen, Bowen Chen, Chenyang Liu, Wenyuan Li, Zhengxia Zou, and Zhenwei Shi. 2024a. Rsmamba: Remote sensing image classification with state space model. arXiv preprint arXiv:2403.19654 (2024).
- Chen et al. (2024e) Tianxiang Chen, Zhentao Tan, Tao Gong, Qi Chu, Yue Wu, Bin Liu, Jieping Ye, and Nenghai Yu. 2024e. Mim-istd: Mamba-in-mamba for efficient infrared small target detection. arXiv preprint arXiv:2403.02148 (2024).
- Chen et al. (2023) Xiao Chen, Wenqi Fan, Jingfan Chen, Haochen Liu, Zitao Liu, Zhaoxiang Zhang, and Qing Li. 2023. Fairly adaptive negative sampling for recommendations. In Proceedings of the ACM Web Conference 2023. 3723–3733.
- Chen et al. (2024f) Ying Chen, Jiajing Xie, Yuxiang Lin, Yuhang Song, Wenxian Yang, and Rongshan Yu. 2024f. Survmamba: State space model with multi-grained multi-modal interaction for survival prediction. arXiv preprint arXiv:2404.08027 (2024).
- Chen et al. (2024g) Yujie Chen, Jiangyan Yi, Jun Xue, Chenglong Wang, Xiaohui Zhang, Shunbo Dong, Siding Zeng, Jianhua Tao, Lv Zhao, and Cunhang Fan. 2024g. RawBMamba: End-to-End Bidirectional State Space Model for Audio Deepfake Detection. arXiv preprint arXiv:2406.06086 (2024).
- Dao and Gu (2024) Tri Dao and Albert Gu. 2024. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. In International Conference on Machine Learning (ICML).
- Deng and Gu (2024) Rui Deng and Tianpei Gu. 2024. CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration. arXiv preprint arXiv:2404.11778 (2024).
- Ding et al. (2024) Yujuan Ding, Wenqi Fan, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meets llms: Towards retrieval-augmented large language models. arXiv preprint arXiv:2405.06211 (2024).
- Dolga et al. (2024) Rares Dolga, Kai Biegun, Jake Cunningham, and David Barber. 2024. RotRNN: Modelling Long Sequences with Rotations. arXiv preprint arXiv:2407.07239 (2024).
- Dong et al. (2024) Wenhao Dong, Haodong Zhu, Shaohui Lin, Xiaoyan Luo, Yunhang Shen, Xuhui Liu, Juan Zhang, Guodong Guo, and Baochang Zhang. 2024. Fusion-mamba for cross-modality object detection. arXiv preprint arXiv:2404.09146 (2024).
- Dong et al. (2023) Xin Luna Dong, Seungwhan Moon, Yifan Ethan Xu, Kshitiz Malik, and Zhou Yu. 2023. Towards next-generation intelligent assistants leveraging llm techniques. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5792–5793.
- Došilović et al. (2018) Filip Karlo Došilović, Mario Brčić, and Nikica Hlupić. 2018. Explainable artificial intelligence: A survey. In 2018 41st International convention on information and communication technology, electronics and microelectronics (MIPRO). IEEE, 0210–0215.
- Ezoe and Sato (2024) Haruka Ezoe and Kazuhiro Sato. 2024. Learning method for S4 with Diagonal State Space Layers using Balanced Truncation. arXiv preprint arXiv:2402.15993 (2024).
- Fan et al. (2024a) Lili Fan, Junhao Wang, Yuanmeng Chang, Yuke Li, Yutong Wang, and Dongpu Cao. 2024a. 4D mmWave radar for autonomous driving perception: a comprehensive survey. IEEE Transactions on Intelligent Vehicles (2024).
- Fan et al. (2019a) Wenqi Fan, Tyler Derr, Yao Ma, Jianping Wang, Jiliang Tang, and Qing Li. 2019a. Deep Adversarial Social Recommendation. In 28th International Joint Conference on Artificial Intelligence (IJCAI-19). International Joint Conferences on Artificial Intelligence, 1351–1357.
- Fan et al. (2018) Wenqi Fan, Qing Li, and Min Cheng. 2018. Deep modeling of social relations for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32.
- Fan et al. (2022) Wenqi Fan, Xiaorui Liu, Wei Jin, Xiangyu Zhao, Jiliang Tang, and Qing Li. 2022. Graph Trend Filtering Networks for Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 112–121.
- Fan et al. (2019b) Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. 2019b. Graph neural networks for social recommendation. In The world wide web conference. 417–426.
- Fan et al. (2020) Wenqi Fan, Yao Ma, Qing Li, Jianping Wang, Guoyong Cai, Jiliang Tang, and Dawei Yin. 2020. A graph neural network framework for social recommendations. IEEE Transactions on Knowledge and Data Engineering 34, 5 (2020), 2033–2047.
- Fan et al. (2019c) Wenqi Fan, Yao Ma, Dawei Yin, Jianping Wang, Jiliang Tang, and Qing Li. 2019c. Deep social collaborative filtering. In Proceedings of the 13th ACM Conference on Recommender Systems. 305–313.
- Fan et al. (2024b) Wenqi Fan, Shijie Wang, Jiani Huang, Zhikai Chen, Yu Song, Wenzhuo Tang, Haitao Mao, Hui Liu, Xiaorui Liu, Dawei Yin, et al. 2024b. Graph machine learning in the era of large language models (llms). arXiv preprint arXiv:2404.14928 (2024).
- Fan et al. (2023) Wenqi Fan, Xiangyu Zhao, Qing Li, Tyler Derr, Yao Ma, Hui Liu, Jianping Wang, and Jiliang Tang. 2023. Adversarial Attacks for Black-Box Recommender Systems Via Copying Transferable Cross-Domain User Profiles. IEEE Transactions on Knowledge and Data Engineering (2023).
- Fedus et al. (2022) William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research 23, 120 (2022), 1–39.
- Fei et al. (2024) Zhengcong Fei, Mingyuan Fan, Changqian Yu, and Junshi Huang. 2024. Scalable Diffusion Models with State Space Backbone. arXiv preprint arXiv:2402.05608 (2024).
- Fu et al. (2023) Daniel Y Fu, Elliot L Epstein, Eric Nguyen, Armin W Thomas, Michael Zhang, Tri Dao, Atri Rudra, and Christopher Ré. 2023. Simple hardware-efficient long convolutions for sequence modeling. In International Conference on Machine Learning. PMLR, 10373–10391.
- Fu et al. (2024) Linjie Fu, Xia Li, Xiuding Cai, Yingkai Wang, Xueyao Wang, Yali Shen, and Yu Yao. 2024. MD-Dose: A Diffusion Model based on the Mamba for Radiotherapy Dose Prediction. arXiv preprint arXiv:2403.08479 (2024).
- Gao et al. (2024a) Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. 2024a. Clip-adapter: Better vision-language models with feature adapters. International Journal of Computer Vision 132, 2 (2024), 581–595.
- Gao et al. (2024c) Ruisheng Gao, Zeyu Xiao, and Zhiwei Xiong. 2024c. Mamba-based Light Field Super-Resolution with Efficient Subspace Scanning. arXiv preprint arXiv:2406.16083 (2024).
- Gao et al. (2024b) Yu Gao, Jiancheng Huang, Xiaopeng Sun, Zequn Jie, Yujie Zhong, and Lin Ma. 2024b. Matten: Video Generation with Mamba-Attention. arXiv preprint arXiv:2405.03025 (2024).
- Golestani and Moghaddam (2020) Negar Golestani and Mahta Moghaddam. 2020. Human activity recognition using magnetic induction-based motion signals and deep recurrent neural networks. Nature communications 11, 1 (2020), 1551.
- Gong et al. (2024) Haifan Gong, Luoyao Kang, Yitao Wang, Xiang Wan, and Haofeng Li. 2024. nnmamba: 3d biomedical image segmentation, classification and landmark detection with state space model. arXiv preprint arXiv:2402.03526 (2024).
- Graves and Graves (2012) Alex Graves and Alex Graves. 2012. Long short-term memory. Supervised sequence labelling with recurrent neural networks (2012), 37–45.
- Gu and Dao (2023) Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023).
- Gu et al. (2020) Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré. 2020. Hippo: Recurrent memory with optimal polynomial projections. Advances in neural information processing systems 33 (2020), 1474–1487.
- Gu et al. (2022) Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré. 2022. On the parameterization and initialization of diagonal state space models. Advances in Neural Information Processing Systems 35 (2022), 35971–35983.
- Gu et al. (2021a) Albert Gu, Karan Goel, and Christopher Ré. 2021a. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396 (2021).
- Gu et al. (2021b) Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. 2021b. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems 34 (2021), 572–585.
- Guan et al. (2024) Yanchen Guan, Haicheng Liao, Zhenning Li, Jia Hu, Runze Yuan, Yunjian Li, Guohui Zhang, and Chengzhong Xu. 2024. World models for autonomous driving: An initial survey. IEEE Transactions on Intelligent Vehicles (2024).
- Guo and Schwaller (2024) Jeff Guo and Philippe Schwaller. 2024. Saturn: Sample-efficient Generative Molecular Design using Memory Manipulation. arXiv preprint arXiv:2405.17066 (2024).
- Guo et al. (2020) Yulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. 2020. Deep learning for 3d point clouds: A survey. IEEE transactions on pattern analysis and machine intelligence 43, 12 (2020), 4338–4364.
- Han et al. (2024) Xu Han, Yuan Tang, Zhaoxuan Wang, and Xianzhi Li. 2024. Mamba3d: Enhancing local features for 3d point cloud analysis via state space model. arXiv preprint arXiv:2404.14966 (2024).
- Harris et al. (2007) Mark Harris, Shubhabrata Sengupta, and John D Owens. 2007. Parallel prefix sum (scan) with CUDA. GPU gems 3, 39 (2007), 851–876.
- Hatamizadeh and Kautz (2024) Ali Hatamizadeh and Jan Kautz. 2024. MambaVision: A Hybrid Mamba-Transformer Vision Backbone. arXiv preprint arXiv:2407.08083 (2024).
- He et al. (2024a) Haoyang He, Yuhu Bai, Jiangning Zhang, Qingdong He, Hongxu Chen, Zhenye Gan, Chengjie Wang, Xiangtai Li, Guanzhong Tian, and Lei Xie. 2024a. Mambaad: Exploring state space models for multi-class unsupervised anomaly detection. arXiv preprint arXiv:2404.06564 (2024).
- He et al. (2024c) Wei He, Kai Han, Yehui Tang, Chengcheng Wang, Yujie Yang, Tianyu Guo, and Yunhe Wang. 2024c. Densemamba: State space models with dense hidden connection for efficient large language models. arXiv preprint arXiv:2403.00818 (2024).
- He et al. (2024b) Xuanhua He, Ke Cao, Keyu Yan, Rui Li, Chengjun Xie, Jie Zhang, and Man Zhou. 2024b. Pan-Mamba: Effective pan-sharpening with State Space Model. arXiv preprint arXiv:2402.12192 (2024).
- Hermans and Schrauwen (2013) Michiel Hermans and Benjamin Schrauwen. 2013. Training and analysing deep recurrent neural networks. Advances in neural information processing systems 26 (2013).
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840–6851.
- Hosseini et al. (2024) Alireza Hosseini, Amirhossein Kazerouni, Saeed Akhavan, Michael Brudno, and Babak Taati. 2024. SUM: Saliency Unification through Mamba for Visual Attention Modeling. arXiv preprint arXiv:2406.17815 (2024).
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- Hu and Qi (2017) Hao Hu and Guo-Jun Qi. 2017. State-frequency memory recurrent neural networks. In International Conference on Machine Learning. PMLR, 1568–1577.
- Hu et al. (2023) Lijie Hu, Yixin Liu, Ninghao Liu, Mengdi Huai, Lichao Sun, and Di Wang. 2023. Seat: stable and explainable attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 12907–12915.
- Hu et al. (2024) Vincent Tao Hu, Stefan Andreas Baumann, Ming Gui, Olga Grebenkova, Pingchuan Ma, Johannes Fischer, and Bjorn Ommer. 2024. Zigma: Zigzag mamba diffusion model. arXiv preprint arXiv:2403.13802 (2024).
- Huang et al. (2024c) Chensen Huang, Guibo Zhu, Xuepeng Wang, Yifei Luo, Guojing Ge, Haoran Chen, Dong Yi, and Jinqiao Wang. 2024c. Recurrent Context Compression: Efficiently Expanding the Context Window of LLM. arXiv preprint arXiv:2406.06110 (2024).
- Huang et al. (2020) Kexin Huang, Cao Xiao, Lucas M Glass, Marinka Zitnik, and Jimeng Sun. 2020. SkipGNN: predicting molecular interactions with skip-graph networks. Scientific reports 10, 1 (2020), 21092.
- Huang et al. (2011) Ling Huang, Anthony D Joseph, Blaine Nelson, Benjamin IP Rubinstein, and J Doug Tygar. 2011. Adversarial machine learning. In Proceedings of the 4th ACM workshop on Security and artificial intelligence. 43–58.
- Huang et al. (2024b) Tao Huang, Xiaohuan Pei, Shan You, Fei Wang, Chen Qian, and Chang Xu. 2024b. Localmamba: Visual state space model with windowed selective scan. arXiv preprint arXiv:2403.09338 (2024).
- Huang and Schneider (2011) Tzu-Kuo Huang and Jeff Schneider. 2011. Learning auto-regressive models from sequence and non-sequence data. Advances in Neural Information Processing Systems 24 (2011).
- Huang et al. (2024a) Yinan Huang, Siqi Miao, and Pan Li. 2024a. What Can We Learn from State Space Models for Machine Learning on Graphs? arXiv preprint arXiv:2406.05815 (2024).
- Jacobs et al. (1991) Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. 1991. Adaptive mixtures of local experts. Neural computation 3, 1 (1991), 79–87.
- Jafari et al. (2024) Farnoush Rezaei Jafari, Grégoire Montavon, Klaus-Robert Müller, and Oliver Eberle. 2024. MambaLRP: Explaining Selective State Space Sequence Models. arXiv preprint arXiv:2406.07592 (2024).
- Ji et al. (2024) Zexin Ji, Beiji Zou, Xiaoyan Kui, Pierre Vera, and Su Ruan. 2024. Self-Prior Guided Mamba-UNet Networks for Medical Image Super-Resolution. arXiv preprint arXiv:2407.05993 (2024).
- Jia et al. (2024) Xiaogang Jia, Qian Wang, Atalay Donat, Bowen Xing, Ge Li, Hongyi Zhou, Onur Celik, Denis Blessing, Rudolf Lioutikov, and Gerhard Neumann. 2024. MaIL: Improving Imitation Learning with Mamba. arXiv preprint arXiv:2406.08234 (2024).
- Jiang et al. (2024a) Meng Jiang, Keqin Bao, Jizhi Zhang, Wenjie Wang, Zhengyi Yang, Fuli Feng, and Xiangnan He. 2024a. Item-side Fairness of Large Language Model-based Recommendation System. In Proceedings of the ACM on Web Conference 2024. 4717–4726.
- Jiang et al. (2024b) Xilin Jiang, Cong Han, and Nima Mesgarani. 2024b. Dual-path mamba: Short and long-term bidirectional selective structured state space models for speech separation. arXiv preprint arXiv:2403.18257 (2024).
- Jones et al. (2024) Charles Jones, Daniel C Castro, Fabio De Sousa Ribeiro, Ozan Oktay, Melissa McCradden, and Ben Glocker. 2024. A causal perspective on dataset bias in machine learning for medical imaging. Nature Machine Intelligence (2024), 1–9.
- Kalman (1960) RE Kalman. 1960. A new approach to linear filtering and prediction problems. Trans. ASME, D 82 (1960), 35–44.
- Kar et al. (2022) Sudipta Kar, Giuseppe Castellucci, Simone Filice, Shervin Malmasi, and Oleg Rokhlenko. 2022. Preventing catastrophic forgetting in continual learning of new natural language tasks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3137–3145.
- Karimi Mahabadi et al. (2021) Rabeeh Karimi Mahabadi, James Henderson, and Sebastian Ruder. 2021. Compacter: Efficient low-rank hypercomplex adapter layers. Advances in Neural Information Processing Systems 34 (2021), 1022–1035.
- Kemker et al. (2018) Ronald Kemker, Marc McClure, Angelina Abitino, Tyler Hayes, and Christopher Kanan. 2018. Measuring catastrophic forgetting in neural networks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32.
- Kim et al. (2024) Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, and Seong Joon Oh. 2024. Propile: Probing privacy leakage in large language models. Advances in Neural Information Processing Systems 36 (2024).
- Koh et al. (2022) Huan Yee Koh, Jiaxin Ju, Ming Liu, and Shirui Pan. 2022. An empirical survey on long document summarization: Datasets, models, and metrics. ACM computing surveys 55, 8 (2022), 1–35.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems 35 (2022), 22199–22213.
- Korbak et al. (2022a) Tomasz Korbak, Hady Elsahar, German Kruszewski, and Marc Dymetman. 2022a. Controlling conditional language models without catastrophic forgetting. In International Conference on Machine Learning. PMLR, 11499–11528.
- Korbak et al. (2022b) Tomasz Korbak, Hady Elsahar, Germán Kruszewski, and Marc Dymetman. 2022b. On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting. Advances in Neural Information Processing Systems 35 (2022), 16203–16220.
- Kumar et al. (2022) L Ashok Kumar, D Karthika Renuka, S Lovelyn Rose, I Made Wartana, et al. 2022. Deep learning based assistive technology on audio visual speech recognition for hearing impaired. International Journal of Cognitive Computing in Engineering 3 (2022), 24–30.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459–9474.
- Li et al. (2024d) Jiatong Li, Yunqing Liu, Wenqi Fan, Xiao-Yong Wei, Hui Liu, Jiliang Tang, and Qing Li. 2024d. Empowering molecule discovery for molecule-caption translation with large language models: A chatgpt perspective. IEEE Transactions on Knowledge and Data Engineering (2024).
- Li and Chen (2024) Kai Li and Guo Chen. 2024. SPMamba: State-space model is all you need in speech separation. arXiv preprint arXiv:2404.02063 (2024).
- Li et al. (2024c) Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao. 2024c. Videomamba: State space model for efficient video understanding. arXiv preprint arXiv:2403.06977 (2024).
- Li et al. (2024f) Lincan Li, Hanchen Wang, Wenjie Zhang, and Adelle Coster. 2024f. Stg-mamba: Spatial-temporal graph learning via selective state space model. arXiv preprint arXiv:2403.12418 (2024).
- Li et al. (2024a) Shiwei Li, Huifeng Guo, Xing Tang, Ruiming Tang, Lu Hou, Ruixuan Li, and Rui Zhang. 2024a. Embedding Compression in Recommender Systems: A Survey. Comput. Surveys 56, 5 (2024), 1–21.
- Li et al. (2024g) Shuangjian Li, Tao Zhu, Furong Duan, Liming Chen, Huansheng Ning, and Yaping Wan. 2024g. Harmamba: Efficient wearable sensor human activity recognition based on bidirectional selective ssm. arXiv preprint arXiv:2403.20183 (2024).
- Li et al. (2024b) Wenrui Li, Xiaopeng Hong, and Xiaopeng Fan. 2024b. Spikemba: Multi-modal spiking saliency mamba for temporal video grounding. arXiv preprint arXiv:2404.01174 (2024).
- Li et al. (2024e) Zhe Li, Haiwei Pan, Kejia Zhang, Yuhua Wang, and Fengming Yu. 2024e. Mambadfuse: A mamba-based dual-phase model for multi-modality image fusion. arXiv preprint arXiv:2404.08406 (2024).
- Liang et al. (2024a) Aobo Liang, Xingguo Jiang, Yan Sun, and Chang Lu. 2024a. Bi-Mamba4TS: Bidirectional Mamba for Time Series Forecasting. arXiv preprint arXiv:2404.15772 (2024).
- Liang et al. (2024b) Dingkang Liang, Xin Zhou, Xinyu Wang, Xingkui Zhu, Wei Xu, Zhikang Zou, Xiaoqing Ye, and Xiang Bai. 2024b. PointMamba: A Simple State Space Model for Point Cloud Analysis. arXiv preprint arXiv:2402.10739 (2024).
- Liao et al. (2024) Weibin Liao, Yinghao Zhu, Xinyuan Wang, Cehngwei Pan, Yasha Wang, and Liantao Ma. 2024. Lightm-unet: Mamba assists in lightweight unet for medical image segmentation. arXiv preprint arXiv:2403.05246 (2024).
- Lieber et al. (2024) Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al. 2024. Jamba: A hybrid transformer-mamba language model. arXiv preprint arXiv:2403.19887 (2024).
- Lin et al. (2022) Ailiang Lin, Bingzhi Chen, Jiayu Xu, Zheng Zhang, Guangming Lu, and David Zhang. 2022. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Transactions on Instrumentation and Measurement 71 (2022), 1–15.
- Lin et al. (2024a) Baijiong Lin, Weisen Jiang, Pengguang Chen, Yu Zhang, Shu Liu, and Ying-Cong Chen. 2024a. MTMamba: Enhancing Multi-Task Dense Scene Understanding by Mamba-Based Decoders. arXiv preprint arXiv:2407.02228 (2024).
- Lin et al. (2024b) Wei-Tung Lin, Yong-Xiang Lin, Jyun-Wei Chen, and Kai-Lung Hua. 2024b. PixMamba: Leveraging State Space Models in a Dual-Level Architecture for Underwater Image Enhancement. arXiv preprint arXiv:2406.08444 (2024).
- Liu et al. (2024a) Chengkai Liu, Jianghao Lin, Jianling Wang, Hanzhou Liu, and James Caverlee. 2024a. Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models. arXiv preprint arXiv:2403.03900 (2024).
- Liu et al. (2022b) Haochen Liu, Yiqi Wang, Wenqi Fan, Xiaorui Liu, Yaxin Li, Shaili Jain, Yunhao Liu, Anil Jain, and Jiliang Tang. 2022b. Trustworthy ai: A computational perspective. ACM Transactions on Intelligent Systems and Technology 14, 1 (2022), 1–59.
- Liu et al. (2024b) Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Lily Lee, Kaichen Zhou, Pengju An, Senqiao Yang, Renrui Zhang, Yandong Guo, and Shanghang Zhang. 2024b. RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation. arXiv preprint arXiv:2406.04339 (2024).
- Liu et al. (2024d) Jiarun Liu, Hao Yang, Hong-Yu Zhou, Yan Xi, Lequan Yu, Yizhou Yu, Yong Liang, Guangming Shi, Shaoting Zhang, Hairong Zheng, et al. 2024d. Swin-umamba: Mamba-based unet with imagenet-based pretraining. arXiv preprint arXiv:2402.03302 (2024).
- Liu et al. (2014) Shujie Liu, Nan Yang, Mu Li, and Ming Zhou. 2014. A recursive recurrent neural network for statistical machine translation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1491–1500.
- Liu et al. (2024e) Xiao Liu, Chenxu Zhang, and Lei Zhang. 2024e. Vision Mamba: A Comprehensive Survey and Taxonomy. arXiv preprint arXiv:2405.04404 (2024).
- Liu et al. (2024c) Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu. 2024c. Vmamba: Visual state space model. arXiv preprint arXiv:2401.10166 (2024).
- Liu et al. (2022a) Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. 2022a. Video swin transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3202–3211.
- Long et al. (2024) Shaocong Long, Qianyu Zhou, Xiangtai Li, Xuequan Lu, Chenhao Ying, Yuan Luo, Lizhuang Ma, and Shuicheng Yan. 2024. Dgmamba: Domain generalization via generalized state space model. arXiv preprint arXiv:2404.07794 (2024).
- Lu et al. (2021) Jiachen Lu, Jinghan Yao, Junge Zhang, Xiatian Zhu, Hang Xu, Weiguo Gao, Chunjing Xu, Tao Xiang, and Li Zhang. 2021. Soft: Softmax-free transformer with linear complexity. Advances in Neural Information Processing Systems 34 (2021), 21297–21309.
- Ma and Wang (2024) Chao Ma and Ziyang Wang. 2024. Semi-Mamba-UNet: Pixel-Level Contrastive and Pixel-Level Cross-Supervised Visual Mamba-based UNet for Semi-Supervised Medical Image Segmentation. arXiv e-prints (2024), arXiv–2402.
- Ma et al. (2024b) Huan Ma, Changqing Zhang, Yatao Bian, Lemao Liu, Zhirui Zhang, Peilin Zhao, Shu Zhang, Huazhu Fu, Qinghua Hu, and Bingzhe Wu. 2024b. Fairness-guided few-shot prompting for large language models. Advances in Neural Information Processing Systems 36 (2024).
- Ma et al. (2024a) Jun Ma, Feifei Li, and Bo Wang. 2024a. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722 (2024).
- Malik et al. (2024) Hashmat Shadab Malik, Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar, Fahad Shahbaz Khan, and Salman Khan. 2024. Towards Evaluating the Robustness of Visual State Space Models. arXiv preprint arXiv:2406.09407 (2024).
- Malik et al. (2021) Mishaim Malik, Muhammad Kamran Malik, Khawar Mehmood, and Imran Makhdoom. 2021. Automatic speech recognition: a survey. Multimedia Tools and Applications 80 (2021), 9411–9457.
- Marques-Silva and Ignatiev (2022) Joao Marques-Silva and Alexey Ignatiev. 2022. Delivering trustworthy AI through formal XAI. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 12342–12350.
- Maruf et al. (2021) Sameen Maruf, Fahimeh Saleh, and Gholamreza Haffari. 2021. A survey on document-level neural machine translation: Methods and evaluation. ACM Computing Surveys (CSUR) 54, 2 (2021), 1–36.
- Mattern and Hohr (2023) Justus Mattern and Konstantin Hohr. 2023. Mamba-Chat. GitHub. https://github.com/havenhq/mamba-chat
- Nasri et al. (2020) Nadia Nasri, Sergio Orts-Escolano, and Miguel Cazorla. 2020. An semg-controlled 3d game for rehabilitation therapies: Real-time time hand gesture recognition using deep learning techniques. Sensors 20, 22 (2020), 6451.
- Nawrot et al. (2024) Piotr Nawrot, Adrian Łańcucki, Marcin Chochowski, David Tarjan, and Edoardo M Ponti. 2024. Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference. arXiv preprint arXiv:2403.09636 (2024).
- Ning et al. (2024) Liang-bo Ning, Zeyu Dai, Jingran Su, Chao Pan, Luning Wang, Wenqi Fan, and Qing Li. 2024. Interpretation-Empowered Neural Cleanse for Backdoor Attacks. In Companion Proceedings of the ACM on Web Conference 2024. 951–954.
- Oshima et al. (2024) Yuta Oshima, Shohei Taniguchi, Masahiro Suzuki, and Yutaka Matsuo. 2024. Ssm meets video diffusion models: Efficient video generation with structured state spaces. arXiv preprint arXiv:2403.07711 (2024).
- Patro and Agneeswaran (2024) Badri Narayana Patro and Vijay Srinivas Agneeswaran. 2024. Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, applications, and challenges. arXiv preprint arXiv:2404.16112 (2024).
- Pechlivanidou and Karampetakis (2022) Georgia Pechlivanidou and Nicholas Karampetakis. 2022. Zero-order hold discretization of general state space systems with input delay. IMA Journal of Mathematical Control and Information 39, 2 (2022), 708–730.
- Pei et al. (2024) Xiaohuan Pei, Tao Huang, and Chang Xu. 2024. Efficientvmamba: Atrous selective scan for light weight visual mamba. arXiv preprint arXiv:2403.09977 (2024).
- Peng et al. (2024) Zhangzhi Peng, Benjamin Schussheim, and Pranam Chatterjee. 2024. PTM-Mamba: A PTM-Aware Protein Language Model with Bidirectional Gated Mamba Blocks. bioRxiv (2024), 2024–02.
- Pilault et al. (2024) Jonathan Pilault, Mahan Fathi, Orhan Firat, Chris Pal, Pierre-Luc Bacon, and Ross Goroshin. 2024. Block-state transformers. Advances in Neural Information Processing Systems 36 (2024).
- Pitorro et al. (2024) Hugo Pitorro, Pavlo Vasylenko, Marcos Treviso, and André FT Martins. 2024. How Effective are State Space Models for Machine Translation? arXiv preprint arXiv:2407.05489 (2024).
- Poli et al. (2023) Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. 2023. Hyena hierarchy: Towards larger convolutional language models. In International Conference on Machine Learning. PMLR, 28043–28078.
- Prata et al. (2024) Matteo Prata, Giuseppe Masi, Leonardo Berti, Viviana Arrigoni, Andrea Coletta, Irene Cannistraci, Svitlana Vyetrenko, Paola Velardi, and Novella Bartolini. 2024. Lob-based deep learning models for stock price trend prediction: a benchmark study. Artificial Intelligence Review 57, 5 (2024), 1–45.
- Qiao et al. (2024) Yanyuan Qiao, Zheng Yu, Longteng Guo, Sihan Chen, Zijia Zhao, Mingzhen Sun, Qi Wu, and Jing Liu. 2024. VL-Mamba: Exploring State Space Models for Multimodal Learning. arXiv preprint arXiv:2403.13600 (2024).
- Qu et al. (2024a) Haohao Qu, Wenqi Fan, Zihuai Zhao, and Qing Li. 2024a. TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendation. arXiv preprint arXiv:2406.10450 (2024).
- Qu et al. (2024b) Haohao Qu, Haoxuan Kuang, Qiuxuan Wang, Jun Li, and Linlin You. 2024b. A physics-informed and attention-based graph learning approach for regional electric vehicle charging demand prediction. IEEE Transactions on Intelligent Transportation Systems (2024).
- Quan and Li (2024) Changsheng Quan and Xiaofei Li. 2024. Multichannel long-term streaming neural speech enhancement for static and moving speakers. arXiv preprint arXiv:2403.07675 (2024).
- Ren et al. (2024b) Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, and Weizhu Chen. 2024b. Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling. arXiv preprint arXiv:2406.07522 (2024).
- Ren et al. (2024a) Sucheng Ren, Xianhang Li, Haoqin Tu, Feng Wang, Fangxun Shu, Lei Zhang, Jieru Mei, Linjie Yang, Peng Wang, Heng Wang, et al. 2024a. Autoregressive Pretraining with Mamba in Vision. arXiv preprint arXiv:2406.07537 (2024).
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 234–241.
- Ruan and Xiang (2024) Jiacheng Ruan and Suncheng Xiang. 2024. Vm-unet: Vision mamba unet for medical image segmentation. arXiv preprint arXiv:2402.02491 (2024).
- Sanjid et al. (2024) Kazi Shahriar Sanjid, Md Tanzim Hossain, Md Shakib Shahariar Junayed, and Dr Mohammad Monir Uddin. 2024. Integrating mamba sequence model and hierarchical upsampling network for accurate semantic segmentation of multiple sclerosis legion. arXiv preprint arXiv:2403.17432 (2024).
- Schiff et al. (2024) Yair Schiff, Chia-Hsiang Kao, Aaron Gokaslan, Tri Dao, Albert Gu, and Volodymyr Kuleshov. 2024. Caduceus: Bi-directional equivariant long-range dna sequence modeling. arXiv preprint arXiv:2403.03234 (2024).
- Schuster and Paliwal (1997) Mike Schuster and Kuldip K Paliwal. 1997. Bidirectional recurrent neural networks. IEEE transactions on Signal Processing 45, 11 (1997), 2673–2681.
- Scott et al. (2016) Duncan E Scott, Andrew R Bayly, Chris Abell, and John Skidmore. 2016. Small molecules, big targets: drug discovery faces the protein–protein interaction challenge. Nature Reviews Drug Discovery 15, 8 (2016), 533–550.
- Sepehri et al. (2024) Mohammad Shahab Sepehri, Zalan Fabian, and Mahdi Soltanolkotabi. 2024. Serpent: Scalable and Efficient Image Restoration via Multi-scale Structured State Space Models. arXiv preprint arXiv:2403.17902 (2024).
- Sgarbossa et al. (2024) Damiano Sgarbossa, Cyril Malbranke, and Anne-Florence Bitbol. 2024. ProtMamba: a homology-aware but alignment-free protein state space model. bioRxiv (2024), 2024–05.
- Shams et al. (2024) Siavash Shams, Sukru Samet Dindar, Xilin Jiang, and Nima Mesgarani. 2024. Ssamba: Self-supervised audio representation learning with mamba state space model. arXiv preprint arXiv:2405.11831 (2024).
- Shen et al. (2021) Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. 2021. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. 3531–3539.
- Sheng et al. (2024) Jiamu Sheng, Jingyi Zhou, Jiong Wang, Peng Ye, and Jiayuan Fan. 2024. DualMamba: A Lightweight Spectral-Spatial Mamba-Convolution Network for Hyperspectral Image Classification. arXiv preprint arXiv:2406.07050 (2024).
- Shi et al. (2024a) Yuheng Shi, Minjing Dong, and Chang Xu. 2024a. Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model. arXiv preprint arXiv:2405.14174 (2024).
- Shi et al. (2024b) Yuan Shi, Bin Xia, Xiaoyu Jin, Xing Wang, Tianyu Zhao, Xin Xia, Xuefeng Xiao, and Wenming Yang. 2024b. Vmambair: Visual state space model for image restoration. arXiv preprint arXiv:2403.11423 (2024).
- Si et al. (2024) Chenyang Si, Ziqi Huang, Yuming Jiang, and Ziwei Liu. 2024. Freeu: Free lunch in diffusion u-net. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4733–4743.
- Siarohin et al. (2021) Aliaksandr Siarohin, Oliver J Woodford, Jian Ren, Menglei Chai, and Sergey Tulyakov. 2021. Motion representations for articulated animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13653–13662.
- Su and Huang (2024) Jinzhao Su and Zhenhua Huang. 2024. MLSA4Rec: Mamba Combined with Low-Rank Decomposed Self-Attention for Sequential Recommendation. arXiv preprint arXiv:2407.13135 (2024).
- Su et al. (2017) Jinsong Su, Zhixing Tan, Deyi Xiong, Rongrong Ji, Xiaodong Shi, and Yang Liu. 2017. Lattice-based recurrent neural network encoders for neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 31.
- Sui et al. (2024) Yueyuan Sui, Minghui Zhao, Junxi Xia, Xiaofan Jiang, and Stephen Xia. 2024. TRAMBA: A Hybrid Transformer and Mamba Architecture for Practical Audio and Bone Conduction Speech Super Resolution and Enhancement on Mobile and Wearable Platforms. arXiv preprint arXiv:2405.01242 (2024).
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Sutskever et al. (2011) Ilya Sutskever, James Martens, and Geoffrey E Hinton. 2011. Generating text with recurrent neural networks. In Proceedings of the 28th international conference on machine learning (ICML-11). 1017–1024.
- Tang et al. (2024) Yujin Tang, Peijie Dong, Zhenheng Tang, Xiaowen Chu, and Junwei Liang. 2024. Vmrnn: Integrating vision mamba and lstm for efficient and accurate spatiotemporal forecasting. arXiv preprint arXiv:2403.16536 (2024).
- Tay et al. (2022) Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. 2022. Efficient transformers: A survey. Comput. Surveys 55, 6 (2022), 1–28.
- Thoutam and Ellsworth ([n. d.]) Vishrut Thoutam and Dina Ellsworth. [n. d.]. MSAMamba: Adapting Subquadratic Models To Long-Context DNA MSA Analysis. In ICML 2024 Workshop on Theoretical Foundations of Foundation Models.
- Touvron et al. (2021) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. Training data-efficient image transformers & distillation through attention. In International conference on machine learning. PMLR, 10347–10357.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Vert (2023) Jean-Philippe Vert. 2023. How will generative AI disrupt data science in drug discovery? Nature Biotechnology 41, 6 (2023), 750–751.
- Waleffe et al. (2024) Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, et al. 2024. An Empirical Study of Mamba-based Language Models. arXiv preprint arXiv:2406.07887 (2024).
- Wan et al. (2024) Zifu Wan, Yuhao Wang, Silong Yong, Pingping Zhang, Simon Stepputtis, Katia Sycara, and Yaqi Xie. 2024. Sigma: Siamese mamba network for multi-modal semantic segmentation. arXiv preprint arXiv:2404.04256 (2024).
- Wang et al. (2024e) Chloe Wang, Oleksii Tsepa, Jun Ma, and Bo Wang. 2024e. Graph-mamba: Towards long-range graph sequence modeling with selective state spaces. arXiv preprint arXiv:2402.00789 (2024).
- Wang et al. (2024g) Feng Wang, Jiahao Wang, Sucheng Ren, Guoyizhe Wei, Jieru Mei, Wei Shao, Yuyin Zhou, Alan Yuille, and Cihang Xie. 2024g. Mamba-R: Vision Mamba ALSO Needs Registers. arXiv preprint arXiv:2405.14858 (2024).
- Wang et al. (2024a) Jinhong Wang, Jintai Chen, Danny Chen, and Jian Wu. 2024a. Large window-based mamba unet for medical image segmentation: Beyond convolution and self-attention. arXiv preprint arXiv:2403.07332 (2024).
- Wang et al. (2024b) Junxiong Wang, Tushaar Gangavarapu, Jing Nathan Yan, and Alexander M Rush. 2024b. Mambabyte: Token-free selective state space model. arXiv preprint arXiv:2401.13660 (2024).
- Wang et al. (2024d) Xinghan Wang, Zixi Kang, and Yadong Mu. 2024d. Text-controlled Motion Mamba: Text-Instructed Temporal Grounding of Human Motion. arXiv preprint arXiv:2404.11375 (2024).
- Wang et al. (2024f) Xiao Wang, Shiao Wang, Yuhe Ding, Yuehang Li, Wentao Wu, Yao Rong, Weizhe Kong, Ju Huang, Shihao Li, Haoxiang Yang, et al. 2024f. State space model for new-generation network alternative to transformers: A survey. arXiv preprint arXiv:2404.09516 (2024).
- Wang et al. (2023b) Yuwei Wang et al. 2023b. 3D dynamic image modeling based on machine learning in film and television animation. Journal of Multimedia Information System 10, 1 (2023), 69–78.
- Wang et al. (2024c) Yuda Wang, Xuxin He, and Shengxin Zhu. 2024c. EchoMamba4Rec: Harmonizing Bidirectional State Space Models with Spectral Filtering for Advanced Sequential Recommendation. arXiv preprint arXiv:2406.02638 (2024).
- Wang et al. (2022) Zhen Wang, Liu Liu, Yiqun Duan, Yajing Kong, and Dacheng Tao. 2022. Continual learning with lifelong vision transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 171–181.
- Wang and Ma (2024) Ziyang Wang and Chao Ma. 2024. Weak-Mamba-UNet: Visual Mamba Makes CNN and ViT Work Better for Scribble-based Medical Image Segmentation. arXiv preprint arXiv:2402.10887 (2024).
- Wang et al. (2024h) Ziyang Wang, Jian-Qing Zheng, Chao Ma, and Tao Guo. 2024h. Vmambamorph: a visual mamba-based framework with cross-scan module for deformable 3d image registration. arXiv preprint arXiv:2404.05105 (2024).
- Wang et al. (2023a) Zhong-Qiu Wang, Samuele Cornell, Shukjae Choi, Younglo Lee, Byeong-Yeol Kim, and Shinji Watanabe. 2023a. TF-GridNet: Making time-frequency domain models great again for monaural speaker separation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5.
- Wei et al. (2024) Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2024. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems 36 (2024).
- Williams et al. (2024) Christopher Williams, Fabian Falck, George Deligiannidis, Chris C Holmes, Arnaud Doucet, and Saifuddin Syed. 2024. A Unified Framework for U-Net Design and Analysis. Advances in Neural Information Processing Systems 36 (2024).
- Wu et al. (2023) Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and S Yu Philip. 2023. Multimodal large language models: A survey. In 2023 IEEE International Conference on Big Data (BigData). IEEE, 2247–2256.
- Wu et al. (2024) Renkai Wu, Yinghao Liu, Pengchen Liang, and Qing Chang. 2024. Ultralight vm-unet: Parallel vision mamba significantly reduces parameters for skin lesion segmentation. arXiv preprint arXiv:2403.20035 (2024).
- Wu et al. (2019) Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. 2019. Session-based recommendation with graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 346–353.
- Xiao et al. (2023) Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning. PMLR, 38087–38099.
- Xie et al. (2024b) Jianhao Xie, Ruofan Liao, Ziang Zhang, Sida Yi, Yuesheng Zhu, and Guibo Luo. 2024b. ProMamba: Prompt-Mamba for polyp segmentation. arXiv preprint arXiv:2403.13660 (2024).
- Xie et al. (2024a) Xinyu Xie, Yawen Cui, Chio-In Ieong, Tao Tan, Xiaozhi Zhang, Xubin Zheng, and Zitong Yu. 2024a. Fusionmamba: Dynamic feature enhancement for multimodal image fusion with mamba. arXiv preprint arXiv:2404.09498 (2024).
- Xing et al. (2024) Zhaohu Xing, Tian Ye, Yijun Yang, Guang Liu, and Lei Zhu. 2024. Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. arXiv preprint arXiv:2401.13560 (2024).
- Xu et al. (2024b) Rui Xu, Shu Yang, Yihui Wang, Bo Du, and Hao Chen. 2024b. A survey on vision mamba: Models, applications and challenges. arXiv preprint arXiv:2404.18861 (2024).
- Xu et al. (2024a) Xiongxiao Xu, Yueqing Liang, Baixiang Huang, Zhiling Lan, and Kai Shu. 2024a. Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting. arXiv preprint arXiv:2404.14757 (2024).
- Xu (2024) Zhichao Xu. 2024. RankMamba, Benchmarking Mamba’s Document Ranking Performance in the Era of Transformers. arXiv preprint arXiv:2403.18276 (2024).
- Yang et al. (2024a) Chenhongyi Yang, Zehui Chen, Miguel Espinosa, Linus Ericsson, Zhenyu Wang, Jiaming Liu, and Elliot J Crowley. 2024a. Plainmamba: Improving non-hierarchical mamba in visual recognition. arXiv preprint arXiv:2403.17695 (2024).
- Yang et al. (2024b) Guangqian Yang, Kangrui Du, Zhihan Yang, Ye Du, Yongping Zheng, and Shujun Wang. 2024b. CMViM: Contrastive Masked Vim Autoencoder for 3D Multi-modal Representation Learning for AD classification. arXiv preprint arXiv:2403.16520 (2024).
- Yang et al. (2024d) Jiyuan Yang, Yuanzi Li, Jingyu Zhao, Hanbing Wang, Muyang Ma, Jun Ma, Zhaochun Ren, Mengqi Zhang, Xin Xin, Zhumin Chen, et al. 2024d. Uncovering Selective State Space Model’s Capabilities in Lifelong Sequential Recommendation. arXiv preprint arXiv:2403.16371 (2024).
- Yang et al. (2024f) Judy X Yang, Jun Zhou, Jing Wang, Hui Tian, and Alan Wee Chung Liew. 2024f. Hsimamba: Hyperpsectral imaging efficient feature learning with bidirectional state space for classification. arXiv preprint arXiv:2404.00272 (2024).
- Yang et al. (2024e) Yijun Yang, Zhaohu Xing, and Lei Zhu. 2024e. Vivim: a video vision mamba for medical video object segmentation. arXiv preprint arXiv:2401.14168 (2024).
- Yang et al. (2024c) Zhe Yang, Wenrui Li, and Guanghui Cheng. 2024c. SHMamba: Structured Hyperbolic State Space Model for Audio-Visual Question Answering. arXiv preprint arXiv:2406.09833 (2024).
- Yao et al. (2024) Jing Yao, Danfeng Hong, Chenyu Li, and Jocelyn Chanussot. 2024. Spectralmamba: Efficient mamba for hyperspectral image classification. arXiv preprint arXiv:2404.08489 (2024).
- Ye and Ji (2021) Yang Ye and Shihao Ji. 2021. Sparse graph attention networks. IEEE Transactions on Knowledge and Data Engineering 35, 1 (2021), 905–916.
- Ye and Chen (2024) Zi Ye and Tianxiang Chen. 2024. P-Mamba: Marrying Perona Malik Diffusion with Mamba for Efficient Pediatric Echocardiographic Left Ventricular Segmentation. arXiv preprint arXiv:2402.08506 (2024).
- Yi et al. (2024) Xuanyu Yi, Zike Wu, Qiuhong Shen, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Shuicheng Yan, Xinchao Wang, and Hanwang Zhang. 2024. MVGamba: Unify 3D Content Generation as State Space Sequence Modeling. arXiv preprint arXiv:2406.06367 (2024).
- Yu et al. (2022) Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. 2022. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19313–19322.
- Yuan et al. (2024a) Chenhan Yuan, Qianqian Xie, Jimin Huang, and Sophia Ananiadou. 2024a. Back to the future: Towards explainable temporal reasoning with large language models. In Proceedings of the ACM on Web Conference 2024. 1963–1974.
- Yuan et al. (2024b) Doncheng Yuan, Jianzhe Xue, Jinshan Su, Wenchao Xu, and Haibo Zhou. 2024b. ST-Mamba: Spatial-Temporal Mamba for Traffic Flow Estimation Recovery using Limited Data. arXiv preprint arXiv:2407.08558 (2024).
- Yue and Li (2024) Yubiao Yue and Zhenzhang Li. 2024. Medmamba: Vision mamba for medical image classification. arXiv preprint arXiv:2403.03849 (2024).
- Zeng et al. (2024) Kang Zeng, Hao Shi, Jiacheng Lin, Siyu Li, Jintao Cheng, Kaiwei Wang, Zhiyong Li, and Kailun Yang. 2024. MambaMOS: LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model. arXiv preprint arXiv:2404.12794 (2024).
- Zhang et al. (2024d) Cheng Zhang, Nilam Nur Amir Sjarif, and Roslina Ibrahim. 2024d. Deep learning models for price forecasting of financial time series: A review of recent advancements: 2020–2022. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 14, 1 (2024), e1519.
- Zhang et al. (2023) Hanqing Zhang, Haolin Song, Shaoyu Li, Ming Zhou, and Dawei Song. 2023. A survey of controllable text generation using transformer-based pre-trained language models. Comput. Surveys 56, 3 (2023), 1–37.
- Zhang et al. (2024h) Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, and Zi Ye. 2024h. A survey on visual mamba. arXiv preprint arXiv:2404.15956 (2024).
- Zhang et al. (2024e) Jiahao Zhang, Rui Xue, Wenqi Fan, Xin Xu, Qing Li, Jian Pei, and Xiaorui Liu. 2024e. Linear-Time Graph Neural Networks for Scalable Recommendations. In Proceedings of the ACM on Web Conference 2024. 3533–3544.
- Zhang et al. (2024a) Tao Zhang, Xiangtai Li, Haobo Yuan, Shunping Ji, and Shuicheng Yan. 2024a. Point Could Mamba: Point Cloud Learning via State Space Model. arXiv preprint arXiv:2403.00762 (2024).
- Zhang et al. (2024f) Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, and Julien Epps. 2024f. Mamba in Speech: Towards an Alternative to Self-Attention. arXiv preprint arXiv:2405.12609 (2024).
- Zhang et al. (2024g) Yezhuo Zhang, Zinan Zhou, Yichao Cao, Guangyu Li, and Xuanpeng Li. 2024g. MAMCA–Optimal on Accuracy and Efficiency for Automatic Modulation Classification with Extended Signal Length. arXiv preprint arXiv:2405.11263 (2024).
- Zhang and Chong (2007) Zheng Zhang and Kil To Chong. 2007. Comparison between first-order hold with zero-order hold in discretization of input-delay nonlinear systems. In 2007 International Conference on Control, Automation and Systems. IEEE, 2892–2896.
- Zhang et al. (2024b) Zeyu Zhang, Akide Liu, Qi Chen, Feng Chen, Ian Reid, Richard Hartley, Bohan Zhuang, and Hao Tang. 2024b. InfiniMotion: Mamba Boosts Memory in Transformer for Arbitrary Long Motion Generation. arXiv preprint arXiv:2407.10061 (2024).
- Zhang et al. (2024c) Zeyu Zhang, Akide Liu, Ian Reid, Richard Hartley, Bohan Zhuang, and Hao Tang. 2024c. Motion mamba: Efficient and long sequence motion generation with hierarchical and bidirectional selective ssm. arXiv preprint arXiv:2403.07487 (2024).
- Zhao et al. (2024c) Han Zhao, Min Zhang, Wei Zhao, Pengxiang Ding, Siteng Huang, and Donglin Wang. 2024c. Cobra: Extending mamba to multi-modal large language model for efficient inference. arXiv preprint arXiv:2403.14520 (2024).
- Zhao et al. (2024a) Sijie Zhao, Hao Chen, Xueliang Zhang, Pengfeng Xiao, Lei Bai, and Wanli Ouyang. 2024a. Rs-mamba for large remote sensing image dense prediction. arXiv preprint arXiv:2404.02668 (2024).
- Zhao et al. (2024b) Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, et al. 2024b. Recommender systems in the era of large language models (llms). IEEE Transactions on Knowledge and Data Engineering (2024).
- Zhen et al. (2024) Zou Zhen, Yu Hu, and Zhao Feng. 2024. Freqmamba: Viewing mamba from a frequency perspective for image deraining. arXiv preprint arXiv:2404.09476 (2024).
- Zhou et al. (2021) Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, Vol. 35. 11106–11115.
- Zhou et al. (2018) Meizi Zhou, Zhuoye Ding, Jiliang Tang, and Dawei Yin. 2018. Micro behaviors: A new perspective in e-commerce recommender systems. In Proceedings of the eleventh ACM international conference on web search and data mining. 727–735.
- Zhou et al. (2024) Qingyuan Zhou, Weidong Yang, Ben Fei, Jingyi Xu, Rui Zhang, Keyi Liu, Yeqi Luo, and Ying He. 2024. 3dmambaipf: A state space model for iterative point cloud filtering via differentiable rendering. arXiv preprint arXiv:2404.05522 (2024).
- Zhu et al. (2021) Chen Zhu, Wei Ping, Chaowei Xiao, Mohammad Shoeybi, Tom Goldstein, Anima Anandkumar, and Bryan Catanzaro. 2021. Long-short transformer: Efficient transformers for language and vision. Advances in neural information processing systems 34 (2021), 17723–17736.
- Zhu et al. (2024) Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. 2024. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417 (2024).
- Zou et al. (2024) Bochao Zou, Zizheng Guo, Xiaocheng Hu, and Huimin Ma. 2024. Rhythmmamba: Fast remote physiological measurement with arbitrary length videos. arXiv preprint arXiv:2404.06483 (2024).