tcb@易碎
LLaVA-OneVision:轻松的视觉任务转移
摘要
我们推出了 LLaVA-OneVision,这是一个开放式大型多模态模型 (LMM) 系列,通过整合我们对 LLaVA-NeXT 博客系列中的数据、模型和视觉表示的见解而开发。 我们的实验结果表明,LLaVA-OneVision 是第一个能够在三个重要的计算机视觉场景(单图像、多图像和视频场景)中同时突破开放式 LMM 性能极限的单一模型。 重要的是,LLaVA-OneVision 的设计允许跨不同模式/场景进行强大的迁移学习,从而产生新的能力。 特别是,通过从图像到视频的任务转移,展示了强大的视频理解和跨场景能力。
1简介
利用大型多模态模型 (LMM) 构建通用助手是人工智能的核心愿望[67]。 LLaVA-OneVision 是一个开放模型,持续推进构建大型视觉和语言助手 (LLaVA) [83] 的研究,该助手可以遵循不同的指令来完成各种计算机视觉任务在野外。 作为一种经济高效的方法,它通常是通过使用简单的连接模块将视觉编码器与大型语言模型(大语言模型)连接起来而开发的。
第一个 LLaVA 模型 [83] 展示了令人印象深刻的多模式聊天能力,有时首次在以前未见过的图像和指令上表现出类似于 GPT-4V 的行为。 LLaVA-1.5 [81] 通过纳入更多与学术相关的指令数据,显着扩展和改进了功能,通过数据高效的配方在数十个基准上实现了 SoTA 性能。 LLaVA-NeXT [82] 继承了这一特性,通过三个关键技术进一步突破性能界限:用于处理高分辨率图像的 AnyRes、扩展高质量指令数据以及利用可用的最佳开放大语言模型当时。
LLaVA-NeXT 提供了一个可扩展的原型,有助于进行多项并行探索,如 LLaVA-NeXT 博客系列[82,168,65,64,68]中所述:
-
•
Video 博客 [168] 表明,由于 AnyRes 的设计,仅图像训练的 LLaVA-NeXT 模型在具有零样本模态传输的视频任务上出奇地强大将任何视觉信号消化为图像序列。
-
•
Stronger博客[65]展示了大语言模型扩展这种经济高效策略的成功。 通过简单地扩展大语言模型,它在选定的基准上实现了与 GPT-4V 相当的性能。
-
•
Ablation博客[64]总结了我们除了视觉指令数据本身之外的实证探索,包括架构的选择(大语言模型和视觉编码器的缩放)、视觉表示(分辨率和#tokens),以及追求数据扩展成功的训练策略(可训练模块和高质量数据)。
-
•
Interleave博客[68]描述了在多图像、多帧(视频)和多视图(3D)等新场景中扩展和改进能力的策略,同时保持单图像性能。
这些探索是在固定的计算预算内进行的,旨在在我们浏览项目的过程中提供有用的见解,而不是突破性能限制。 在此过程中,我们还积累和整理了一月至六月的大量高质量数据集。 通过整合这些见解并在新积累的更大数据集上使用“yolo run”执行实验,我们推出了 LLaVA-OneVision。 我们利用可用的计算来实现新模型,而没有广泛降低各个组件的风险。 这为通过遵循我们的方案的额外数据和模型扩展来进一步改进功能留下了空间,请参阅第 A 节中的详细开发时间表。 特别是,我们的论文做出了以下贡献:
-
•
大型多模态模型。 我们开发了 LLaVA-OneVision,这是一系列开放式大型多模态模型 (LMM),它提高了开放式 LMM 在三个重要视觉设置(包括单图像、多图像和视频场景)中的性能边界。
-
•
任务转移的新兴功能。 我们在建模和数据表示方面的设计允许跨不同场景进行任务转移,这提出了一种产生新的新兴功能的简单方法。 特别是,LLaVA-OneVision 通过图像的任务转移展示了强大的视频理解能力。
-
•
开源。 为了为构建通用视觉助手铺平道路,我们向公众发布了以下资产:生成的多模式指令数据、代码库、模型检查点和视觉聊天演示。
2相关工作
SoTA 专有的 LMM,例如 GPT-4V [109]、GPT-4o [110]、Gemini [131] 和 Claude-3.5 [3],在多种视觉场景中表现出优异的性能,包括单图像、多图像和视频设置。 在开放研究社区中,现有的工作通常分别开发针对每个单独场景的模型。 具体来说,大多数专注于突破单图像场景的性能极限[26,83,172,73,163,35],最近只有少数论文开始探索多图像场景[70, 47]。 虽然视频 LMM 在视频理解方面表现出色,但它们通常会以牺牲图像性能为代价[72, 76]。 很少有一个开放模型能够在所有三种情况下都表现出色。 LLaVA-OneVision 旨在通过在广泛的任务中展示最先进的性能,并通过跨场景任务转移和组合展示有趣的新兴功能来填补这一空白。
据我们所知,LLaVA-NeXT-Interleave [68] 是在所有三种场景中报告良好性能的首次尝试,LLaVA-OneVision 继承了其训练配方和数据以提高性能。 其他具有卓越潜力的多功能开放式 LMM 包括 VILA [77]、InternLM-XComposer-2.5 [161]。 不幸的是,他们的结果没有得到充分的评估和报告;我们在实验中与他们进行比较。 除了构建具有多功能功能的系统外,LLaVA-OneVision 训练还受益于大规模高质量数据,包括模型合成知识和新收集的多样化指令调优数据。 对于前者,我们继承了[64]中的所有知识学习数据。 对于后者,我们的动机是 FLAN [136, 88, 144]。 数据收集过程与 Idefics2 [63] 和 Cambrian-1 [133] 并行,但我们专注于更小但更精心策划的数据集集合。 观察到类似的结论:大量的视觉指令调优数据可以显着提高性能。 为了对 LMM 的设计选择进行全面的研究,我们参考了最近的几项研究[51,63,64,104,133,10]。
3建模
3.1网络架构
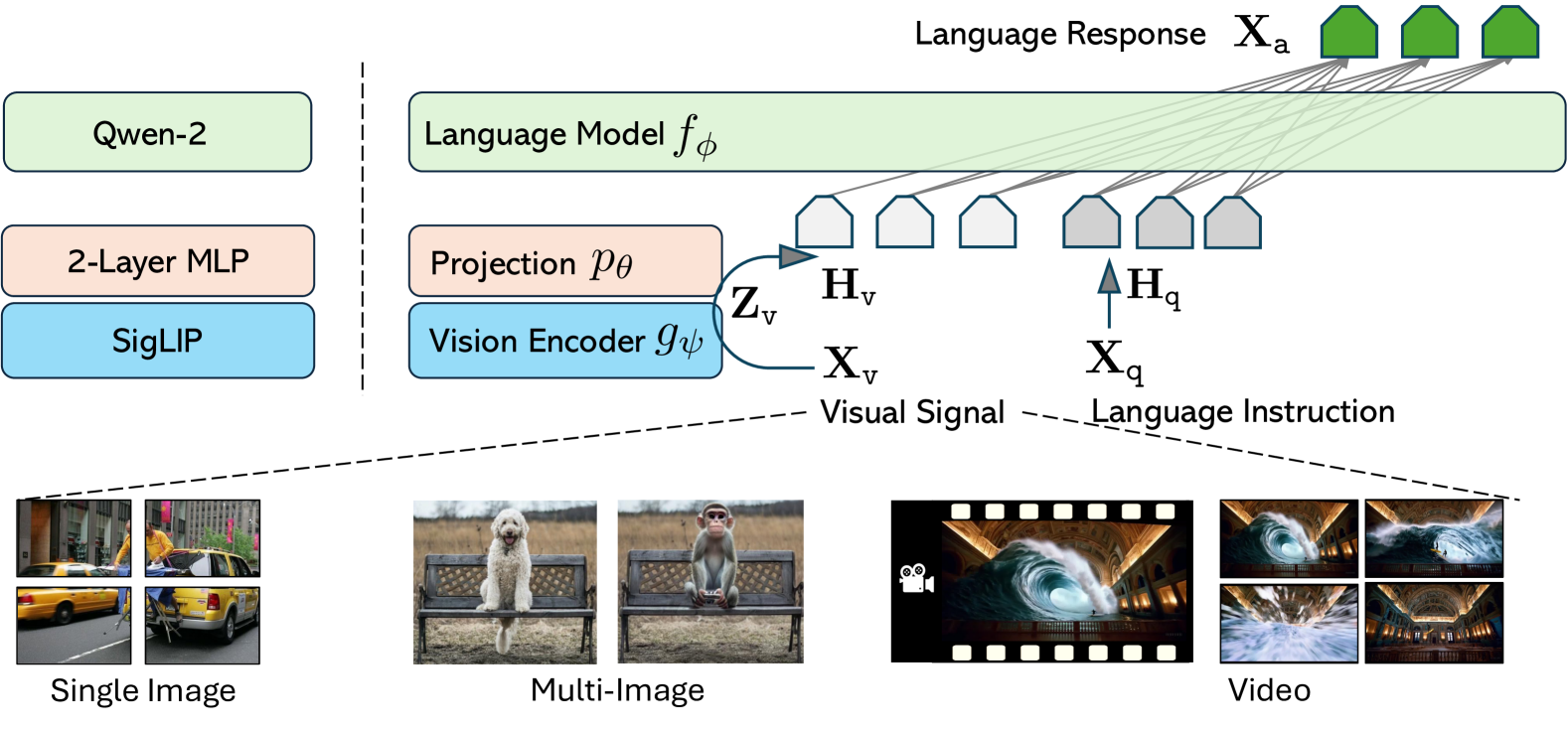
模型架构继承了LLaVA系列的极简设计,其主要目标是有效利用大语言模型和视觉模型的预训练能力,以及方便数据和模型方面都有很强的扩展行为。 网络架构如图1所示。
-
•
大语言模型。 我们选择 Qwen-2 [147] 作为由 参数化的大语言模型 ,因为它提供了各种模型大小并展现了迄今为止强大的语言能力在公开可用的检查点中。
-
•
视觉编码器。 我们将 SigLIP [157] 视为由 参数化的视觉编码器 ,将输入图像 编码为其视觉特征。 我们的实验中考虑了最后一个 Transformer 层之前和之后的网格特征。
-
•
投影层。 我们考虑由 参数化的 2 层 MLP [81] ,将图像特征投影到词嵌入空间中,产生一系列视觉标记。
模型选择基于我们在[65, 64]中的经验见解,即更强的大语言模型通常会在野外增强更强的多模态能力,而SigLIP在开放视觉编码器中产生更高的LMM性能。
对于长度为 的序列,我们通过以下方式计算目标答案 的概率:
| (1) |
其中和分别是当前预测词符之前所有回合中的指令和答案标记。 对于 (1) 中的条件,我们显式添加 以强调视觉信号是所有答案的基础这一事实。 正如3.2节中所解释的,视觉信号的形式是通用的。 馈送到视觉编码器中的视觉输入取决于相应的场景:分别是单图像序列中的单个图像裁剪、多图像序列中的单个图像和视频序列中的单个帧。
3.2视觉表示
视觉信号的表示是视觉编码成功的关键。 它涉及两个因素,原始像素空间中的分辨率和特征空间中的标记数量,从而导致视觉输入表示配置(分辨率,#词符)。 这两个因素的扩展可以提高性能,尤其是在需要视觉细节的任务上。 为了在性能和成本之间取得平衡,我们发现分辨率的缩放比词符数的缩放更有效,并推荐使用池化的 AnyRes 策略。 比较如图2所示。
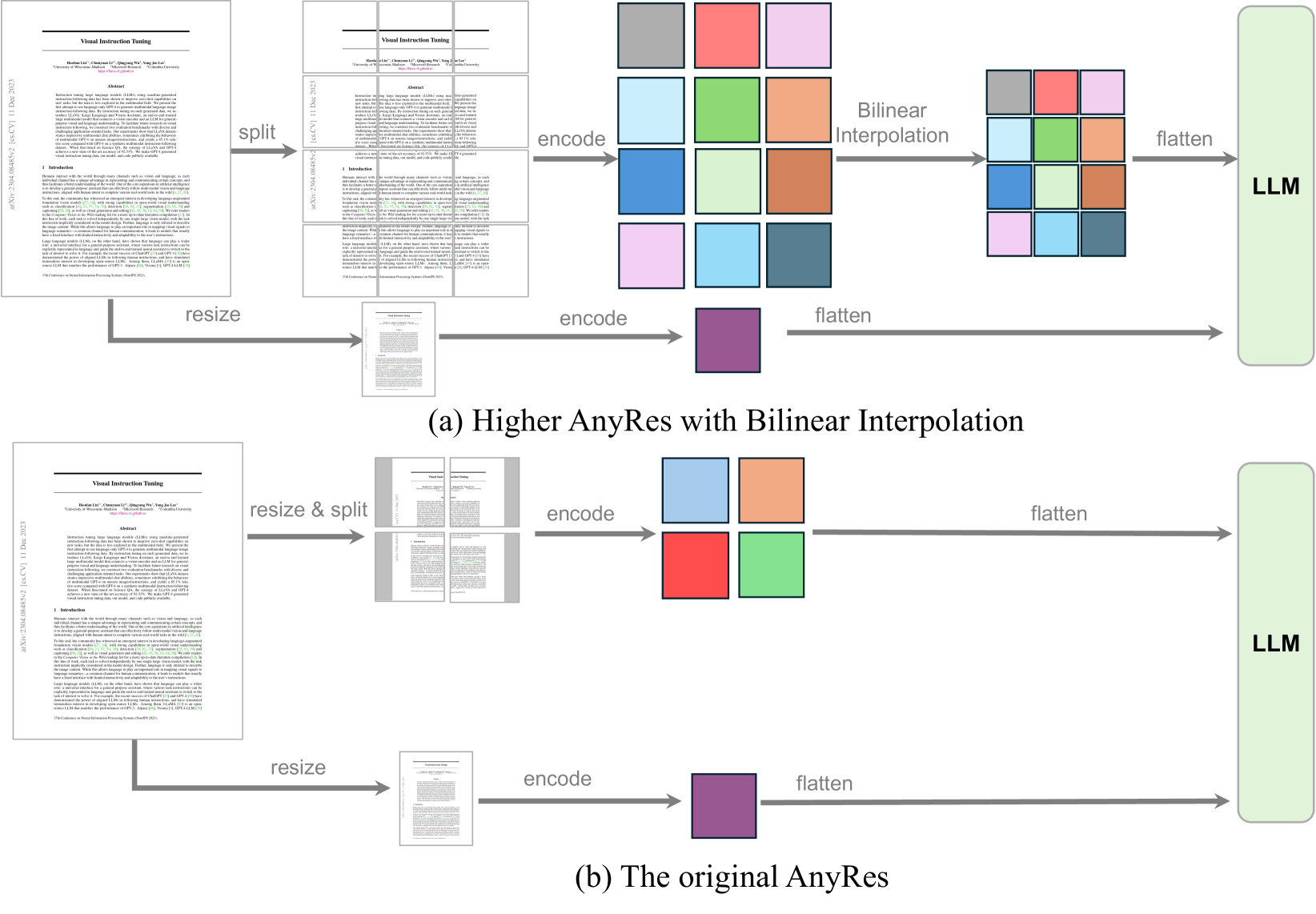

对于配置为宽度 、高度 的 AnyRes,它将图像划分为 个裁剪,每个裁剪的形状为 。 每种作物具有适合视觉编码器的相同分辨率。 假设每个裁剪有 个标记,则视觉标记的总数为 ,其中基础图像在输入视觉编码器之前会调整大小。 我们考虑一个阈值,并减少每次裁剪的#词符,如果需要的话使用双线性插值:
| (2) |
定义了一组空间配置来指定裁剪图像的各种方法,从而适应不同分辨率和长宽比的图像。 其中,选择需要最少作物数量的配置。 请参阅[64]中我们对视觉表示的详细删减。
所提出的Higher AnyRes策略可以作为灵活的视觉表示框架,适用于多图像和视频表示。 可以相应地调整性能和成本的最佳配置。 我们在图3中说明了配置,在C.1节中描述了详细信息,并提供了高级编码策略,如下所示:
-
•
单图像。 我们考虑对单图像表示使用较大的最大空间配置,以保持原始图像分辨率而不调整大小。 此外,我们有目的地为每个图像分配大量视觉标记,从而产生一个长序列来有效地表示视觉信号。 这是基于这样的观察:与视频相比,存在大量具有不同图像指令的高质量训练样本。 通过用模仿视频表示的长序列来表示图像,我们促进了从图像到视频理解的更平滑的能力转移[168, 64]。
-
•
多图像。 仅考虑基础图像分辨率并将其输入视觉编码器以获得特征图,无需对高分辨率图像进行多次裁剪,从而节省计算资源[68]。
-
•
视频。 视频的每一帧都被调整为基本图像分辨率,并由视觉编码器处理以生成特征图。 采用双线性插值来减少 Token 的数量,从而允许通过减少每帧的 Token 来考虑更大数量的帧。 经验证据表明,这在性能和计算成本之间提供了更好的权衡[168]。
这些表示配置是为在我们的实验中具有固定计算预算的能力传输而设计的。 随着计算资源的增加,在训练和推理阶段,每个图像或帧的标记数量都可以增加,以提高性能。
4数据
在大语言模型的多模态训练领域,“质量胜于数量”这一原则尤其正确。 由于预训练的大语言模型和视觉变换器 (ViT) 中存储了广泛的知识,这一原则至关重要。 虽然在LMM的训练生命周期结束时积累平衡、多样和高质量的指令数据是必不可少的,但一个经常被忽视的方面是,无论何时,只要有新的、高质量的数据可用,模型都要不断地暴露于这些数据中,以便进一步获取知识。 在本节中,我们讨论高质量知识学习和视觉指令调整的数据源和策略。
4.1高质量知识
网络规模的公共图文数据通常质量较低,导致多模态预训练的数据扩展效率较低。 相反,在计算预算有限的情况下,我们建议专注于高质量的知识学习。 这种方法承认预训练的大语言模型和 ViT 已经拥有丰富的知识库,目标是通过精心策划的数据来完善和增强这些知识。 通过优先考虑数据质量,我们可以最大限度地提高计算效率。
我们考虑来自三个主要类别的数据来进行高质量的知识学习:
-
•
重新说明详细描述数据。 LLaVA-NeXT-34B [82] 在开源 LMM 中以其强大的详细字幕能力而闻名。 我们使用该模型为来自以下数据集的图像生成新的标题:COCO118K、BLIP558K 和 CC3M。 我们将它们组合起来形成了 Re-Captioned 详细描述数据,总共 350 万个样本。 这可以被视为自我改进人工智能的简单尝试,其中训练数据是由模型本身的早期版本生成的。
-
•
文档/OCR 数据。 我们利用了 UReader 数据集中的文本阅读子集,总计 100K,可以通过 PDF 渲染轻松访问。 我们使用此文本读取数据以及 SynDOG EN/CN 来形成文档/OCR 数据,总共 110 万个样本。
-
•
中文和语言数据。 我们使用原始的ShareGPT4V [20]图像,并利用Azure API提供的GPT-4V生成92K详细的中文字幕数据,旨在提高模型的中文能力。 由于我们使用了大量详细的字幕数据,我们还旨在平衡模型的语言理解能力。 我们从 Evo-Instruct 数据集[16]收集了 143K 样本。
有趣的是,几乎所有(占99.8%)的高质量知识数据都是合成的。 这是由于在野外收集大规模、高质量的数据需要高昂的成本和版权限制。 相比之下,合成数据可以轻松扩展。 我们相信,随着人工智能模型不断变得更加强大,从大规模合成数据中学习正在成为一种趋势。
4.2视觉指令微调数据
视觉指令调整[83]是指LMM理解视觉指令并根据视觉指令采取行动的能力。 这些指令可以采用语言的形式,与图像和视频等视觉媒体相结合,LMM 处理并遵循这些指令来执行任务或提供响应。 这涉及将视觉理解与自然语言处理相结合,以解释指令并执行所需的响应。
数据收集和管理。
正如之前的作品[81,133,63]所证明的那样,视觉指令调整数据对于 LMM 能力至关重要。 因此,维护高质量的数据集收集至关重要并且对社区有益。 我们开始从各种原始来源收集大量指令调优数据集,但类别之间的数据比例不平衡。 此外,我们还利用了 Cauldron [63] 和 Cambrian [133] 数据集集合中的一些新子集。
我们根据三级层次结构对数据进行分类:视觉、指令和响应。
-
•
视觉输入。 根据多模态序列中考虑的视觉输入,考虑三种视觉场景,包括单图像、多图像、视频。
-
•
语言指令。 这些指令通常以问题的形式出现,定义了处理视觉输入要执行的任务。 我们将数据分为五个主要类别:一般 QA、一般 OCR、文档/图表/屏幕、数学推理 和语言。 这些说明定义了经过训练的 LMM 可以涵盖的技能集。 我们使用任务分类来帮助维护和平衡技能分配。
-
•
语言响应。 答案不仅响应用户请求,还指定模型行为。 它大致可分为自由形式和固定形式。
自由格式数据通常由 GPT-4V/o 和 Gemini 等高级模型进行注释,而固定格式数据则源自学术数据集,例如VQAv2、GQA、视觉基因组。 对于自由格式数据,我们保留原始答案。 然而,对于固定形式的数据,我们手动审核内容并对问答格式进行必要的更正。 对于多项选择数据、简答数据和特定任务数据(例如 OCR),我们遵循 LLaVA-1.5 提示策略。 此步骤对于指导模型的行为在更复杂的任务中正确平衡 QA 性能、对话能力和推理技能以及防止不同数据源的潜在冲突至关重要。 我们在附录 E.3 中列出了有关我们集合中每个数据集的完整详细信息及其分类和格式提示。
我们将指令数据分为两组:一组用于单图像场景,另一组用于所有视觉场景。 这种划分是基于我们早期研究[68, 168]的见解,该研究强调了图像和视频模型之间的关系:更强的图像模型可以更好地迁移到多图像和视频任务。 此外,可用于单图像的训练数据集的数量和质量明显高于视频和多图像任务的训练数据集。
单图像数据。 由于单图像数据对于多模态能力至关重要,因此我们明确编译了一个大型单图像数据集用于模型学习。 我们从收集的数据源中进行选择,形成平衡的集合,总共得到 320 万个样本。 单幅图像数据的总体分布如图4所示,详细信息和数据收集路线图参见附录E.1。
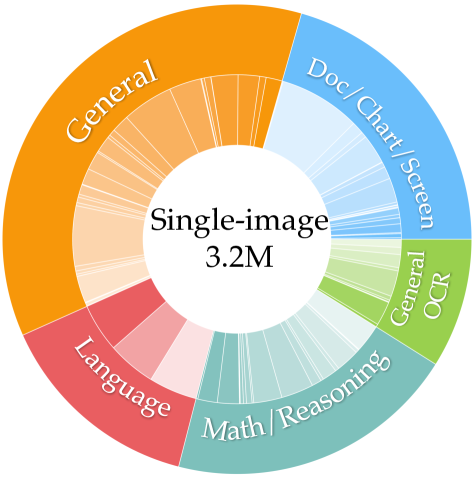
| General (36.1%) | ALLaVA Inst (70.0K) [16] | AOKVQA (66.2 K) | Cambrian (filtered) (83.1 K) |
| CLEVR (0.7 K) | COCO Caption (20.0 K) | Hateful Memes (8.5 K) | IconQA (2.5 K) |
| Image Textualization (99.6 K) | LLaVA-158K (158.0 K) | LLaVA-Wild (train) (54.5 K) | LLaVAR (20.0 K) |
| OKVQA (9.0 K) | RefCOCO (50.6 K) | ScienceQA (5.0 K) | ShareGPT4o (57.3 K) |
| ShareGPT4V (91.0 K) | ST-VQA (17.2 K) | TallyQA (9.9 K) | Vision FLAN (186.1 K) |
| Visual7W (14.4 K) | VisText (10.0 K) | VizWiz (6.6 K) | VQARAD (0.3 K) |
| VQAv2 (82.8 K) | VSR (2.2 K) | WebSight (10.0 K) | InterGPS (1.3 K) |
| Doc/Chart/Screen (20.6%) | AI2D (GPT4V) (4.9 K) | AI2D (InternVL) (12.4 K) | AI2D (Original) (3.2 K) |
| Chart2Text (27.0 K) | ChartQA (18.3 K) | Diagram Image2Text (0.3 K) | Doc-VQA (10.2 K) |
| DVQA (20.0 K) | FigureQA (1.0 K) | HiTab (2.5 K) | Infographic VQA (4.4 K) |
| LRV Chart (1.8 K) | RoBUT SQA (8.5 K) | RoBUT WikiSQL (75.0 K) | RoBUT WTQ (38.2 K) |
| Screen2Words (15.7 K) | TQA (1.4 K) | UReader Caption (91.4 K) | UReader IE (17.3 K) |
| UReader KG (37.6 K) | UReader QA (252.9 K) | VisualMRC (3.0 K) | |
| Math/Reasoning (20.1%) | MAVIS MCollect (87.4 K) | MAVIS Data Engine (100.0 K) | Geo170K QA (67.8 K) |
| Geometry3K (2.1 K) | GEOS (0.5 K) | Geometry3K (MathV360K) (9.7 K) | GeoMVerse (MathV360K) (9.3 K) |
| GeoQA+ (MathV360K) (17.2 K) | MapQA (MathV360K) (5.2 K) | CLEVR-Math (5.3 K) | Geo170K Align (60.3 K) |
| MathQA (29.8 K) | Super-CLEVR (8.7 K) | TabMWP (45.2 K) | UniGeo (12.0 K) |
| GQA (72.1 K) | LRV Normal (10.5 K) | RAVEN (2.1 K) | Visual Genome (86.4K) |
| General OCR (8.9%) | ChromeWriting (8.8 K) | HME100K (74.5 K) | IIIT5K (2.0 K) |
| IAM (5.7 K) | K12 Printing (12.8 K) | OCR-VQA (80.0 K) | Rendered Text (10.0 K) |
| SynthDog-EN (40.1 K) | TextCaps (21.9 K) | TextOCR (25.1 K) | |
| Language (14.3%) | Magpie Pro (L3 MT) (150.0 K) | Magpie Pro (L3 ST) (150.0 K) | Magpie Pro (Qwen2 ST) (150.0 K) |
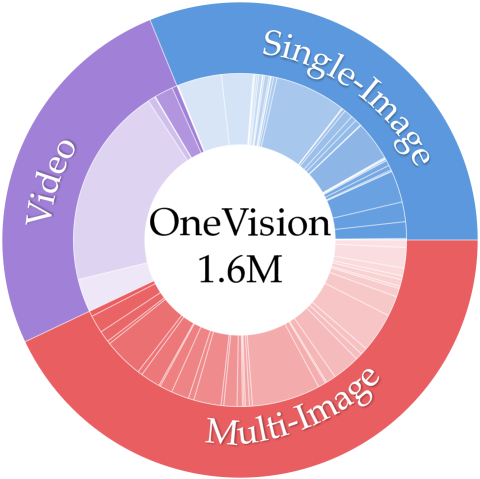
OneVision 数据。 除了单图像阶段训练之外,我们还使用视频、图像和多图像数据的混合进一步调整模型。 我们总共引入了160万个混合数据样本,其中包括来自[68]的56万个多图像数据、本项目收集的35万个视频以及80万个单图像样本。 值得注意的是,在这个阶段,我们没有引入新的单图像数据,而是从之前的单图像数据中采样高质量和平衡的部分,如[68]中所述。 数据分布和详细信息如图5所示,附加信息请参见附录E.2。
| Single-Image (31.2%) | Magpie Pro (90.0K) | Vision FLAN (filtered) (55.8K) | Image Textualization (49.8K) |
| Cauldron (40.2K) | UReader (39.9K) | ShareGPT4V (21.0K) | ALLaVA Inst. (21.0K) |
| Cambrian (filtered GPT4o) (24.9K) | LLAVA-Wild (train) (10.9K) | LAION-GPT4V (8.0K) | LLAVA-158K (7.0K) |
| Geo170K-QA (6.8K) | Geo170K-Align (6.0K) | ShareGPT4o (5.7K) | TabMWP (4.5K) |
| LLAVAR GPT4 (4.0K) | MapQA (4.3K) | MathQA (3.0K) | TextOCR (GPT4V) (2.5K) |
| TextCaps (2.2K) | ScienceQA (1.9K) | FigureQA (1.8K) | GeoQA+ (1.7K) |
| AI2D (InternVL) (1.2K) | UniGeo (1.2K) | IconQA (1.1K) | LRV-Normal (filtered) (1.1K) |
| TQA (1.0K) | Geometry3K (1.0K) | Super-CLEVR (0.9K) | AI2D (GPT4V) (0.7K) |
| VizWiz (0.7K) | VQA-AS (0.6K) | CLEVR-Math (0.5K) | PlotQA (0.5K) |
| GEOS (0.5K) | InfoVQA (0.9K) | PMC-VQA (0.4K) | Geo3K (0.2K) |
| VQA-RAD (0.2K) | LRV-Chart (0.2K) | ||
| Multi-Image (43.0%) | NLVR (86.4K) | Co-Instruct (50.0K) | ScanNet (49.9K) |
| RAVEN (35.0K) | IconQA (34.6K) | VIST (26.0K) | ScanQA (25.6K) |
| ContrastiveCaption (25.2K) | ALFRED (22.6K) | FlintstonesSV (22.3K) | ImageCode (16.6K) |
| DreamSim (15.9K) | Birds-to-Words (14.3K) | PororoSV (12.3K) | Spot-the-Diff (10.8K) |
| nuScenes (9.8K) | VISION (9.9K) | WebQA (9.3K) | RecipeQA-VisualCloze (8.7K) |
| RecipeQA-ImageCoherence (8.7K) | TQA (MI) (8.2K) | AESOP (6.9K) | HQ-Edit-Diff (7.0K) |
| MagicBrush-Diff (6.7K) | COMICS-Dialogue (5.9K) | MultiVQA (5.0K) | VizWiz (MI) (4.9K) |
| CLEVR-Change (3.9K) | NextQA (3.9K) | IEdit (3.5K) | Star (3.0K) |
| DocVQA (MI) (1.9K) | MIT-PropertyCoherence (1.9K) | MIT-StateCoherence (1.9K) | OCR-VQA (MI) (1.9K) |
| Video (25.9%) | ActivityNet (6.5K) | Charades (23.6K) | Ego4D (0.8K) |
| NextQA (9.5K) | ShareGPT4Video (255.0K) | Youcook2 (41.9K) |
5训练策略
为了实现多模态能力的大语言模型,我们确定了三个关键功能,并将它们系统地划分为三个不同的学习阶段,以进行消融研究。 与大多数现有研究一样,先前的 LLaVA 模型主要探索单图像指令调整。 然而,其他部分的研究较少,因此构成本节的主要焦点。
我们通过课程学习原则来训练模型,其中以分阶段的方式观察训练目标和难度增加的示例。 在固定的计算预算下,该策略有助于分解训练过程并生成可在更多实验路径中重复使用的即时检查点。
-
•
第一阶段:语言-图像对齐。 目标是将视觉特征很好地对齐到大语言模型的词嵌入空间中。
-
•
Stage-1.5:高质量知识学习。 为了在计算效率和向 LMM 注入新知识之间取得平衡,我们建议考虑 LMM 学习的高质量知识。 训练配置镜像了阶段 2 中使用的设置,确保一致性并允许模型无缝集成新信息。
-
•
阶段 2:视觉指令微调。 为了教 LMM 解决具有首选响应的多样化视觉任务,我们将指令数据组织成不同的组,如 4.2 节中所述。 该模型计划按顺序对这些组进行训练。
具体来说,视觉指令调优过程包括两个阶段: 单图像训练:模型首先在 320 万条单图像指令上进行训练,从而得到一个具有强大性能的模型。遵循一组不同的指令使用单个图像完成视觉任务的性能。 OneVision 训练:然后在视频、单图像和多图像数据的混合上训练模型。 在这个阶段,模型将其能力从单一图像场景扩展到多样化场景。 它学习遵循指令来完成每个新场景中的任务,并将学到的知识转移到不同的场景中,从而产生新的涌现能力。 需要注意的是,所提出的在后训练阶段进行的OneVision训练,可能是赋予多模态模型(LMMs)多图像和视频理解能力的最简单且最具成本效益的方法。
训练策略总结于表1中。 我们逐步训练模型来处理长序列训练。 随着训练的进行,最大图像分辨率和视觉标记的数量逐渐增加。 在第 1 阶段,基本图像表示被认为有 729 个标记。 在第 2 阶段和第 3 阶段,AnyRes 被认为分别具有最多 5 倍和 10 倍的视觉标记。 对于可训练模块,第一阶段仅更新投影仪,而后续阶段则更新完整模型。 还值得注意的是,视觉编码器的学习率比大语言模型的学习率小 5 倍。
![[Uncaptioned image]](x6.png)
| Stage-1 | Stage-1.5 | Stage-2 | |||
| Single-Image | OneVision | ||||
| Vision | Resolution | 384 | 384{22, 1{2,3}, {2,3}1} | 384{{11}, , {66}} | 384{{11}, , {66}} |
| #Tokens | 729 | Max 7295 | Max 72910 | Max 72910 (See Fig. 3) | |
| Data | Dataset | LCS | Image (Sec. 4.1) | Image (Sec. 4.2) | (Multi)-Image & Video (Sec. 4.2) |
| #Samples | 558K | 4M | 3.2M | 1.6M | |
| Model | Trainable | Projector | Full Model | Full Model | Full Model |
| 0.5B LLM | 1.8M | 0.8B | 0.8B | 0.8B | |
| 7.6B LLM | 20.0M | 8.0B | 8.0B | 8.0B | |
| 72.7B LLM | 72.0M | 73.2B | 73.2B | 73.2B | |
| Training | Batch Size | 512 | 256/512 | 256/512 | 256/512 |
| LR: | 1 | 2 | 2 | 2 | |
| LR: | 1 | 1 | 1 | 1 | |
| Epoch | 1 | 1 | 1 | 1 | |
6实验结果
我们使用 LMMs-Eval [160] 在所有基准上对 LLaVA-OneVision 模型进行标准化和可重复的评估。 为了与其他领先的 LMM 进行公平比较,我们主要报告原始论文的结果。 当结果不可用时,我们将模型加载到 LMMs-Eval 中并使用一致的设置对其进行评估。 除非另有说明,否则我们所有的结果都是在贪婪解码和零样本(0-shot)设置下报告的。
为了揭示设计范例的通用性和有效性,我们在表 2 中全面评估了不同模式的 LLaVA-OneVision 模型,包括单图像、多图像和视频基准。 每种模式的详细结果分别列于表 3、表 4 和表 5 中。 我们将单图像阶段和单视觉阶段之后训练的模型检查点分别表示为LLaVA-OV (SI)或LLaVA-OV
提供三种模型大小(0.5B、7B 和 72B),以适应从边缘设备到云服务的不同性能吞吐量权衡的应用程序。 GPT-4V 和 GPT-4o 结果仅供参考。 我们最大的型号 LLaVA-OneVision-72B 在大多数基准测试中都具有优于 GPT-4V 和 GPT-4o 的性能。 它表明所提出的方案是有效的,揭示了进一步扩展的有希望的路径。 然而,在视觉聊天场景等复杂任务中仍然存在相对较大的差距,我们将其留待未来研究更强的大语言模型、更大的训练数据和更好的偏好学习。
| Capability | Benchmark |
LLaVA
OneVision-0.5B |
LLaVA
OneVision-7B |
LLaVA
OneVision-72B |
GPT-4V
(V-Preview) |
GPT-4o |
| Single-Image |
AI2D [53]
Science Diagrams |
57.1% | 81.4% | 85.6% | 78.2% | 94.2% |
|
ChartQA [101]
Chart Understanding |
61.4% | 80.0% | 83.7% | 78.5% | 85.7% | |
|
DocVQA [103] (test)
Document Understanding |
70.0% | 87.5% | 91.3% | 88.4% | 92.8% | |
|
InfoVQA [102] (test)
Infographic Understanding |
41.8% | 68.8% | 74.9% | - | - | |
|
MathVerse [164] (vision-mini)
Professional Math Reasoning |
17.9% | 26.2% | 39.1% | 32.8% | 50.2% | |
|
MathVista [90] (testmini)
General Math Understanding |
34.8% | 63.2% | 67.5% | 49.9% | 63.8% | |
|
MMBench [86] (en-dev)
Multi-discip |
52.1% | 80.8% | 85.9% | 75.0% | - | |
|
MME [28] (cog./perp.)
Multi-discip |
240/1238 | 418/1580 | 579/1682 | 517/1409 | - | |
|
MMStar [19]
Multi-discip |
37.5% | 61.7% | 66.1% | 57.1% | - | |
|
MMMU [156] (val)
College-level Multi-disp |
31.4% | 48.8% | 56.8% | 56.8% | 69.1% | |
|
MMVet [152]
Multi-discip |
29.1% | 57.5% | 63.7% | 49.9% | 76.2% | |
|
SeedBench [66] (image)
Multi-discip; Large-scale |
65.5% | 75.4% | 78.0% | 49.9% | 76.2% | |
|
ScienceQA [93]
High-school Science |
67.2% | 96.0% | 90.3% | 75.7% | - | |
|
ImageDC [65]
Image Detail Description |
83.3% | 88.2% | 91.2% | 91.5% | - | |
|
RealworldQA [140]
Realwold QA |
55.6% | 66.3% | 71.9% | 61.4% | - | |
|
Vibe-Eval [112]
Chanllenging Cases |
33.8% | 51.7% | 50.7% | 57.9% | 63.1% | |
|
MM-LiveBench [160] (2406)
Internet Content Understanding |
49.9% | 77.1% | 81.5% | - | 92.4% | |
|
LLaVA-Wilder [65] (small)
Realworld Chat |
55.0% | 67.8% | 72.0% | 81.0% | 85.9% | |
| Multi-Image |
LLaVA-Interleave [68]
Out-domain |
33.3% | 64.2% | 79.9% | 60.3% | - |
|
MuirBench [135]
Comprehensive Multi-image |
25.5% | 41.8% | 54.8% | 62.3% | - | |
|
Mantis [47]
Multi-image in the Wild |
39.6% | 64.2% | 77.6% | 62.7% | - | |
|
BLINK [31]
Unusual Visual Scenarios |
52.1% | 48.2% | 55.4% | 51.1% | - | |
|
Text-rich VQA [84]
OCR, Webpage, Ducument |
65.0% | 80.1% | 83.7% | 54.5% | - | |
| Video |
ActivityNetQA [154]
Spatio-Temporal Reasoning |
50.5% | 56.6% | 62.3% | 57.0% | - |
|
EgoSchema [98]
Egocentric Video Understanding |
26.8% | 60.1% | 62.0% | - | - | |
|
PerceptionTest [115]
Perception and Reasoning |
49.2% | 57.1% | 66.9% | - | - | |
|
SeedBench [66] (video)
Multi-discip; Video |
44.2% | 56.9% | 62.1% | 60.5% | - | |
|
MLVU [169]
Long Video Understanding |
50.3% | 64.7% | 68.0% | 49.2% | 64.6% | |
|
MVBench [71]
Multi-discip |
45.5% | 56.7% | 59.4% | 43.5% | - | |
|
VideoChatGPT [97]
Video Conversation |
3.12 | 3.49 | 3.62 | 4.06 | - | |
|
VideoMME [29]
Multi-discip |
44.0% | 58.2% | 66.2% | 59.9% | 71.9% |
| Model | AI2D | ChartQA | DocVQA | InfoVQA | MathVerse | MathVista | MMBench | MME | MMMU |
| test | test | val/test | val/test | mini-vision | testmini | en-dev | test | val | |
| Qwen-VL-Max [8] | 79.3 | 79.8 | -/93.1 | - | 23.0 | 51.0 | 77.6 | 2281 | 51.4 |
| Gemini-1.5-Pro [130] | 94.4 | 87.2 | -/93.1 | -/81.0 | - | 63.9 | - | - | 62.2 |
| Claude 3.5 Sonnet [3] | 94.7 | 90.8 | -/95.2 | 49.7 | - | 67.7 | - | - | 68.3 |
| GPT-4V [109] | 78.2 | 78.5∗ | -/88.4 | - | 32.8 | 49.9 | 75.0 | 517/1409 | 56.8 |
| GPT-4o [110] | 94.2 | 85.7 | -/92.8 | - | 50.2 | 63.8 | - | - | 69.1 |
| Cambrian-34B [133] | 79.7 | 73.8 | -/75.5 | - | - | 53.2 | 81.4 | - | 49.7 |
| VILA-34B [77] | - | - | - | - | - | - | 82.4 | 1762 | 51.9 |
| IXC-2.5-7B [161] | 81.5 | 82.2 | -/90.9 | -/70.0 | 20.0 | 59.6 | 82.2 | 2229 | 42.9 |
| InternVL-2-8B [22] | 83.8 | 83.3 | -/91.6 | -/74.8 | 27.5 | 58.3 | 81.7 | 2210 | 49.3 |
| InternVL-2-26B [22] | 84.5 | 84.9 | -/92.9 | -/75.9 | 31.3 | 59.4 | 83.4 | 2260 | 48.3 |
| LLaVA-OV-0.5B (SI) | 54.2 | 61.0 | 75.0/71.2 | 44.8/41.3 | 17.3 | 34.6 | 43.8 | 272/1217 | 31.2 |
| LLaVA-OV-0.5B | 57.1 | 61.4 | 73.7/70.0 | 46.3/41.8 | 17.9 | 34.8 | 52.1 | 240/1238 | 31.4 |
| LLaVA-OV-7B (SI) | 81.6 | 78.8 | 89.3/86.9 | 69.9/65.3 | 26.9 | 56.1 | 81.7 | 483/1626 | 47.3 |
| LLaVA-OV-7B | 81.4 | 80.0 | 90.2/87.5 | 70.7/68.8 | 26.2 | 63.2 | 80.8 | 418/1580 | 48.8 |
| LLaVA-OV-72B (SI) | 85.1 | 84.9 | 93.5/91.8 | 77.7/74.6 | 37.7 | 66.5 | 86.6 | 563/1706 | 57.4 |
| LLaVA-OV-72B | 85.6 | 83.7 | 93.1/91.3 | 79.2/74.9 | 39.1 | 67.5 | 85.9 | 579/1682 | 56.8 |
| Model | MMVet | MMStar | S-Bench | S-QA | ImageDC | MMLBench | RealWorldQA | Vibe-Eval | LLaVA-W | L-Wilder |
| test | test | image | test | test | 2024-06 | test | test | test | small | |
| Qwen-VL-Max [8] | - | - | - | - | - | - | - | - | - | - |
| Gemini-1.5-Pro [130] | - | - | - | - | - | 85.9 | 70.4 | 60.4 | - | - |
| Claude 3.5 Sonnet [3] | 75.4 | - | - | - | - | 92.3 | 59.9 | 66.2 | 102.9 | 83.1 |
| GPT-4V [109] | 49.9 | 57.1 | 49.9 | 75.7 | 91.5 | - | 61.4 | 57.9 | 98.0 | 81.0 |
| GPT-4o [110] | 76.2 | - | 76.2 | - | 92.5 | 92.4 | 58.6 | 63.1 | 106.1 | 85.9 |
| Cambrian-34B [133] | - | - | - | 85.6 | - | - | 67.8 | - | - | - |
| VILA-34B [77] | 53.0 | - | 75.8 | - | - | - | - | 81.3 | - | - |
| IXC-2.5-7B [161] | 51.7 | 59.9 | 75.4 | - | 87.5 | - | 67.8 | 45.2 | 78.1 | 61.4 |
| InternVL-2-8B [22] | 60.0 | 59.4 | 76.0 | 97.0 | 87.1 | 73.4 | 64.4 | 46.7 | 84.5 | 62.5 |
| InternVL-2-26B [22] | 65.4 | 60.4 | 76.8 | 97.5 | 91.0 | 77.2 | 66.8 | 51.5 | 99.6 | 70.2 |
| LLaVA-OV-0.5B (SI) | 26.9 | 36.3 | 63.4 | 67.8 | 83.0 | 43.2 | 53.7 | 34.9 | 71.2 | 51.5 |
| LLaVA-OV-0.5B | 29.1 | 37.5 | 65.5 | 67.2 | 83.3 | 49.9 | 55.6 | 33.8 | 74.2 | 55.0 |
| LLaVA-OV-7B (SI) | 58.8 | 60.9 | 74.8 | 96.6 | 85.7 | 75.8 | 65.5 | 47.2 | 86.9 | 69.1 |
| LLaVA-OV-7B | 57.5 | 61.7 | 75.4 | 96.0 | 88.9 | 77.1 | 66.3 | 51.7 | 90.7 | 67.8 |
| LLaVA-OV-72B (SI) | 60.0 | 65.2 | 77.6 | 91.3 | 91.5 | 84.4 | 73.8 | 46.7 | 93.7 | 72.9 |
| LLaVA-OV-72B | 63.7 | 66.1 | 78.0 | 90.3 | 91.2 | 81.5 | 71.9 | 50.7 | 93.5 | 72.0 |
6.1 单图像基准
为了验证现实场景中单图像任务的性能,我们考虑表 3 中的一组全面的图像基准。 它可以分为三类:
(1)图表、图表和文档理解。 作为结构化 OCR 数据的主要视觉格式,我们在 AI2D [54]、ChartQA [101]、DocVQA [103] 上评估结果和 InfoVQA [102] 基准测试。 虽然当前的开源模型如 InternVL [22] 和 Cambrian [133] 的性能可与商业模型相媲美,但 LLaVA-OneVision 更进一步,超越了 GPT-4V [109] 并接近 GPT-4o [110] 的性能水平。
(2)感知与多学科推理。 包括视觉感知场景,我们揭示了我们的模型在更复杂和更具挑战性的推理任务中的潜力。 具体来说,我们采用的感知基准包括 MME [150]、MMBench [86] 和 MMVet [153] 以及推理基准,例如MathVerse [164]、MathVista [90] 和 MMMU [156]。 LLaVA-OneVision 在各种基准测试中的结果显着优于 GPT-4V,在 MathVista 上与 GPT-4o 相当。 这进一步证实了我们的框架在视觉感知和推理任务中的优越性。
(3)现实世界理解和视觉聊天。 我们认为 LMM 作为野外通用助手的评估是实验室环境之外最重要的指标。 为了验证现实场景中的功能,我们利用了多个广泛采用的基准测试,包括 RealworldQA [140]、Vibe-Eval [111]、MM-LiveBench [160] 和 LLaVA-Bench-Wilder [65]。 虽然我们的模型与 GPT-4V 和 GPT-4o 相比仍有改进的空间,但它与参数大小相似的开源模型具有竞争性的性能。 值得注意的是,我们的模型在内容不断更新的真实互联网内容基准 MM-LiveBench [160] 上表现良好,展示了模型广泛的世界知识和强大的泛化能力。
6.2 多图像基准
| Model |
IEI |
MI-VQA |
NLVR2 |
Puzzle |
Q-Bench |
Spot-Diff |
TR-VQA |
VST |
3D-Chat |
3D-TD |
ScanQA |
ALFRED |
nuScenes |
BLINK |
Mantis |
MathVerse |
MuirBench |
SciVerse |
| in-domain multi-image | in-domain multi-view | out-domain | ||||||||||||||||
| GPT-4V [109] | 11.0 | 52.0 | 88.8 | 17.1 | 76.5 | 12.5 | 54.5 | 10.9 | 31.2 | 35.4 | 32.6 | 10.3 | 63.7 | 51.1 | 62.7 | 60.3 | 62.3 | 66.9 |
| LLaVA-N-Image-7B† [82] | 13.2 | 39.4 | 68.0 | 9.0 | 51.0 | 12.9 | 59.6 | 10.1 | - | - | - | - | - | 41.8 | 46.1 | 13.5 | - | 12.2 |
| VPG-C-7B [70] | 15.2 | 46.8 | 73.2 | 2.4 | 57.6 | 27.8 | 38.9 | 21.5 | - | - | - | - | - | 43.1 | 52.4 | 24.3 | - | 23.1 |
| Mantis-7B [47] | 11.2 | 52.5 | 87.4 | 25.7 | 69.9 | 17.6 | 45.2 | 12.5 | 2.60 | 14.7 | 16.1 | 14.0 | 46.2 | 46.4 | 59.5 | 27.2 | 36.1 | 29.3 |
| LLaVA-N-Inter-7B [68] | 24.3 | 87.5 | 88.8 | 48.7 | 74.2 | 37.1 | 76.1 | 33.1 | - | - | - | - | - | 52.6 | 62.7 | 32.8 | 38.9 | 31.6 |
| LLaVA-N-Inter-14B [68] | 24.5 | 95.0 | 91.1 | 59.9 | 76.7 | 40.5 | 78.6 | 33.3 | 70.6 | 52.2 | 34.5 | 62.0 | 76.7 | 52.1 | 66.4 | 33.4 | 40.7 | 32.7 |
| LLaVA-OV-0.5B (SI) | 15.6 | 44.8 | 56.1 | 30.0 | 45.8 | 8.5 | 36.7 | 7.6 | 22.1 | 22.1 | 16.9 | 25.5 | 8.2 | 37.9 | 38.2 | 20.9 | 22.7 | 26.7 |
| LLaVA-OV-0.5B | 17.1 | 48.7 | 63.4 | 35.4 | 48.8 | 36.4 | 65.0 | 29.8 | 60.0 | 48.0 | 29.4 | 62.2 | 70.5 | 52.1 | 39.6 | 60.0 | 25.5 | 29.1 |
| LLaVA-OV-7B (SI) | 20.5 | 60.3 | 75.9 | 24.6 | 56.0 | 7.9 | 52.8 | 8.4 | 24.5 | 29.9 | 22.1 | 32.0 | 70.8 | 45.6 | 54.2 | 26.3 | 32.7 | 30.0 |
| LLaVA-OV-7B | 22.2 | 90.2 | 89.4 | 53.3 | 74.5 | 39.2 | 80.1 | 31.7 | 62.8 | 52.6 | 30.1 | 61.0 | 79.8 | 48.2 | 64.2 | 67.6 | 41.8 | 79.1 |
| LLaVA-OV-72B (SI) | 22.1 | 61.2 | 78.9 | 44.2 | 61.5 | 15.6 | 67.9 | 12.1 | 30.8 | 25.4 | 21.9 | 43.5 | 75.5 | 46.0 | 56.8 | 58.6 | 33.2 | 65.8 |
| LLaVA-OV-72B | 22.5 | 95.3 | 93.8 | 63.4 | 83.2 | 43.3 | 83.7 | 34.5 | 63.2 | 53.3 | 35.8 | 66.3 | 78.8 | 55.4 | 77.6 | 91.6 | 54.8 | 94.9 |
我们进一步在多图像交错设置中评估 LLaVA-OneVision,用户可以在多图像交错设置中提出问题。 特别是,我们对 LLaVA-Interleave Bench [68] 的各种子任务进行了全面评估,例如 Spot the Difference [45]、图像编辑指令 (IEI) [68]、视觉叙事 (VST) [40]、文本丰富的 VQA (TR-VQA) [85]、多图像 VQA (MI-VQA) [117]、Raven Puzzle [24]、Q-Bench (QB) [138] 和 NLVR2 [125])。 我们还利用多个多视图基准进行评估,这些基准描述了具有多个视点的 3D 环境,包括来自 3D-LLM [38] 的 3D 对话 (3D-Chat) 和任务分解 (3D-TD), ScanQA [5]、ALFRED [122] 和 nuScenes VQA [9]。 我们将这些数据集称为域内评估,因为我们的训练数据包括它们的训练分割。
此外,我们对不同的外域任务进行了评估,这揭示了我们方法的泛化能力。 它们包括数学 QA 基准 MathVerse [164] 和科学 QA 基准 SciVerse [34] 的多图像分割、多图像感知基准 BLINK [31] 、MMMU-(多图像)[156],包含 MMMU 中的所有多图像 QA,以及跨越 12 个不同多图像的 MuirBench [135]任务。
如表4所示,LLaVA-OneVision (SI) 在所有基准测试中始终优于现有的多图像 LMM。 在对多图像和视频数据进行额外调整后,LLaVA-OneVision 在特定领域比 GPT-4V 有了显着改进,并具有显着的优势。 这突显了其在多图像推理、识别差异和理解 3D 环境等复杂任务中的强大性能。 此外,我们在单视觉训练阶段后观察到一致的性能增强,这在单图像数据中不存在的多视图基准测试中更为明显。 这证明了我们的单一视觉范式对于为 LMM 提供全面的视觉功能的重要性。
6.3 视频基准
| Model |
ActNet-QA |
EgoSchema |
MLVU |
MVBench |
NextQA |
PercepTest |
SeedBench |
VideoChatGPT |
VideoDC |
VideoMME |
| test | test | m-avg | test | mc | val | video | test | test | wo/w-subs | |
| GPT-4V [109] | 57.0 | - | 49.2 | 43.5 | - | - | 60.5 | 4.06 | 4.00 | 59.9/63.3 |
| GPT-4o [110] | - | - | 64.6 | - | - | - | - | - | - | 71.9/77.2 |
| Gemini-1.5-Flash [131] | 55.3 | 65.7 | - | - | - | - | - | - | - | 70.3/75.0 |
| Gemini-1.5-Pro [131] | 57.5 | 72.2 | - | - | - | - | - | - | - | 75.0/81.3 |
| VILA-40B [77] | 58.0 | 58.0 | - | - | 67.9 | 54.0 | - | 3.36 | 3.37 | 60.1/61.1 |
| PLLaVA-34B [142] | 60.9 | - | - | 58.1 | - | - | - | 3.48 | - | - |
| LLaVA-N-Video-34B [168] | 58.8 | 49.3 | - | - | 70.2 | 51.6 | - | 3.34 | 3.48 | 52.0/54.9 |
| LongVA-7B [162] | 50.0 | - | 56.3 | - | 68.3 | - | - | 3.20 | 3.14 | 52.6/54.3 |
| IXC-2.5-7B [161] | 52.8 | - | 37.3 | 69.1 | 71.0 | 34.4 | - | 3.46 | 3.73 | 55.8/58.8 |
| LLaVA-N-Video-32B [168] | 54.3 | 60.9 | 65.5 | - | 77.3 | 59.4 | - | 3.59 | 3.84 | 60.2/63.0 |
| LLaVA-OV-0.5B (SI) | 49.0 | 33.1 | 47.9 | 43.3 | 53.6 | 48.6 | 43.4 | 3.08 | 3.51 | 41.7/40.4 |
| LLaVA-OV-0.5B | 50.5 | 26.8 | 50.3 | 45.5 | 57.2 | 49.2 | 44.2 | 3.12 | 3.55 | 44.0/43.5 |
| LLaVA-OV-7B (SI) | 55.1 | 52.9 | 60.2 | 51.2 | 61.6 | 54.9 | 51.1 | 3.54 | 3.51 | 55.0/59.1 |
| LLaVA-OV-7B | 56.6 | 60.1 | 64.7 | 56.7 | 79.4 | 57.1 | 56.9 | 3.51 | 3.75 | 58.2/61.5 |
| LLaVA-OV-72B (SI) | 62.1 | 58.6 | 60.9 | 57.1 | 67.2 | 62.3 | 60.9 | 3.55 | 3.66 | 64.8/66.9 |
| LLaVA-OV-72B | 62.3 | 62.0 | 68.0 | 59.4 | 80.2 | 66.9 | 62.1 | 3.62 | 3.60 | 66.2/69.5 |
视频也是构建世界模型的常见方式,捕捉现实世界随时间的动态本质。 我们对几个开放式和多选视频基准进行了实验。 其中包括 ActivityNet-QA [154],其中包含源自 ActivityNet 数据集的人工注释的与动作相关的 QA 对、EgoSchema [98] 和 MLVU [169] 专注于长视频理解,PerceptionTest [115] 旨在评估感知能力,VideoMME [29] 和 NeXTQA [141]包含不同的视频域和持续时间(从几分钟到几小时),VideoDetailCaption [87] 和 Video-ChatGPT [96] 分别用于视频详细描述和视觉聊天。
如表5所示,LLaVA-OneVision 与之前的开源模型相比,在大语言模型更大的情况下取得了相当甚至更好的结果。 LLaVA-OneVision 的优越性在 EgoSchema 和 VideoMME 等复杂基准测试中尤为明显。 即使与先进的商业模型 GPT-4V 相比,LLaVA-OneVision 在 ActivityNet-QA、MLVU 和 VideoMME 基准测试上的表现也具有竞争力。
在 LLaVA-OV 拆分中,PerceptionTest 中的性能差异最小,当将大语言模型从 0.5B 扩展到 7B 时,仅提高了 0.5 个点。 相比之下,其他数据集至少提高了 5 个百分点。 PerceptionTest 的小幅增长表明 LLaVA-OV 的感知能力可能主要取决于其视觉模块,支持了 Qiao 等人[116]等最近研究的结果,这些研究将图像的角色分开感知和推理任务中的编码器和大语言模型。 值得注意的是,对于像 EgoSchema 这样需要大量推理的数据集,更大的大语言模型可以显着提高性能。
此外,在将 LLaVA-OV-7B (SI) 与 LLaVA-OV-7B 进行比较时,ActivityNet-QA 的改进最小。 这表明仅在图像上进行训练的 LLaVA-OV-7B (SI) 已经可以在此数据集上表现良好。 深入研究 ActivityNet-QA,很明显,只需观察视频中的单个帧就可以回答许多问题。 例如,“球的颜色是什么?”这个问题可以在整个视频中得到回答,因为球从头到尾都是可见的。 此场景不需要模型理解视频序列,因此 LLaVA-OV-7B (SI) 可以表现良好。
7具有任务转移的新兴能力
除了报告 LLaVA-OneVision 在各种基准上的功能之外,我们还观察了所提出的模型在任务转移和组合方面的新行为,为泛化处理现实世界中的计算机视觉任务铺平了一条有前途的方法。 我们使用下面的示例来说明几种新兴功能。
S1:图与图的共同理解(从单图到多图的转换)
理解表格和图表的能力是从单图像图表和单图像图表理解数据中分别学习的,表格和图表的联合理解任务不会出现在多图像数据中。 如表6所示,LLaVA-OneVision能够对图表的结合进行理解和推理。
S2:多模式代理的 GUI(从单图像和多图像传输)。
了解 GUI 并将多模式模型应用于代理任务非常有价值。 在表7中,LLaVA-OneVision识别iPhone的图形用户界面(GUI)屏幕截图,并提供搜索和打开TikTok应用程序的操作说明。 这项任务需要从单图像场景中学习到的强大 OCR 能力以及从多图像场景中开发出的关系推理技能。 该示例凸显了 LLaVA-OneVision 在 GUI 理解和任务执行方面的熟练程度。
S3:标记集提示(从单图像任务合成转移)。
与现有的开放大语言模型不同,LLaVA-OneVision 展示了出色的标记集(SoM)推理[148],这是一种新兴能力,如表8所示。 据我们所知,这是开放 LMM 第一次报告良好的 SoM 能力,因为我们观察到 LLaVA-OneVision 能够为 [148] 中的许多示例生成 SoM 推理。 该任务并未明确包含在我们的训练数据中,假设该能力由视觉参考和 OCR 组成。
S4:图像到视频编辑指令(从单图和视频转换)。
LLaVA-OneVision 可以根据表9中的静态图像生成详细的视频创建提示。 给定图像和目标视频,该模型为视频构建连贯且生动的叙述,详细说明角色、动作、背景设置和场景细节等元素。 该任务利用单图像分析和视频理解。 假设这种能力是由单图像编辑指令任务和视频详细描述任务的组成概括出来的。
S5:视频到视频差异(从多图像和视频传输)。
S6:自动驾驶中的多摄像头视频理解(从单图、多图到视频的转换)。
理解正常宽高比的视频很简单,那么多视图的视频呢? 在表 12 中,我们观察到 LLaVA-OneVision 可以分析和解释自动驾驶汽车的多摄像头视频片段。 给定显示四个摄像头视图的视频,该模型详细描述每个视图并计划自我汽车的下一步行动。 该任务结合了多面板理解、视频详细描述和时空推理。
S7:组合子视频理解(从多图像传输到视频)。
除了多视图视频之外,我们还看到我们的模型推广到具有两个子场景的垂直视频。 表 13 展示了 LLaVA-OneVision 理解和描述合成子视频的内容和布局的能力。 给定一个垂直视频,该视频具有一系列具有一致背景和前景人物的帧,该模型提供了对视觉元素、它们的排列和叙事上下文的详细分析。 该任务需要单图像分析、多图像序列理解和上下文推理。
S8:视频视觉提示(任务从单图转移到视频)。
在表14中,LLaVA-OneVision能够识别视频中带有半透明圆圈的高亮区域,并清楚地看到播放器背面的数字“10”。 理解视觉提示和 OCR 的能力是单图像 LMM 的能力。 我们的模型显示了理解视频中视觉提示的能力,而无需对带有视觉提示的视频数据进行训练。
S9:视频理解中图像的视觉参考。
在回答有关视频的问题时能够引用图像查询,如表 15 所示。 这种能力在 LLaVA-NeXT 或 LLaVA-Interleave 中没有看到,这可能是因为需要强大的基础单图像训练才能出现这种能力。
8结论
LLaVA-OneVision 是一种新型开放式 LMM,在单图像、多图像和视频场景中的广泛任务中表现出色。 该模型是通过整合 LLaVA-NeXT 博客系列中的见解而开发的,并通过使用更大的数据集和更强大的大语言模型扩展配方来进行训练。 我们的设计允许通过多个场景一起训练和任务转移来出现新的能力,例如从图像到视频的强大视觉理解能力。 我们的结果表明,使用这种开放配方和资源进行训练的 LMM 在各种基准测试中都实现了最先进的性能。 我们还希望 LLaVA-OneVision 能够成为社区构建特定应用程序的宝贵起点,并通过进一步扩展为不同的视觉场景开发更强大的 LMM。
参考
- [1] Manoj Acharya, Kushal Kafle, and Christopher Kanan. Tallyqa: Answering complex counting questions. In AAAI, 2019.
- [2] Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms, 2019.
- [3] Anthropic. Claude-3.5. https://www.anthropic.com/news/claude-3-5-sonnet, 2024.
- [4] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In ICCV, 2015.
- [5] Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129–19139, 2022.
- [6] Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [7] Haoping Bai, Shancong Mou, Tatiana Likhomanenko, Ramazan Gokberk Cinbis, Oncel Tuzel, Ping Huang, Jiulong Shan, Jianjun Shi, and Meng Cao. Vision datasets: A benchmark for vision-based industrial inspection, 2023.
- [8] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. Technical Report, 2023.
- [9] Ankan Bansal, Yuting Zhang, and Rama Chellappa. Visual question answering on image sets. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16, pages 51–67. Springer, 2020.
- [10] Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024.
- [11] Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusinol, Ernest Valveny, CV Jawahar, and Dimosthenis Karatzas. Scene text visual question answering. In ICCV, 2019.
- [12] Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving, 2020.
- [13] Jimmy Carter. Textocr-gpt4v. https://huggingface.co/datasets/jimmycarter/textocr-gpt4v, 2024.
- [14] Shuaichen Chang, David Palzer, Jialin Li, Eric Fosler-Lussier, and Ningchuan Xiao. Mapqa: A dataset for question answering on choropleth maps, 2022.
- [15] Yingshan Chang, Mridu Narang, Hisami Suzuki, Guihong Cao, Jianfeng Gao, and Yonatan Bisk. Webqa: Multihop and multimodal qa. arXiv preprint arXiv:2109.00590, 2021.
- [16] Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, and Benyou Wang. Allava: Harnessing gpt4v-synthesized data for a lite vision-language model. arXiv preprint arXiv:2402.11684, 2024.
- [17] Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression, 2022.
- [18] Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric P. Xing, and Liang Lin. Geoqa: A geometric question answering benchmark towards multimodal numerical reasoning, 2022.
- [19] Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models? arXiv preprint arXiv:2403.20330, 2024.
- [20] Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793, 2023.
- [21] Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, Li Yuan, Yu Qiao, Dahua Lin, Feng Zhao, and Jiaqi Wang. Sharegpt4video: Improving video understanding and generation with better captions. arXiv preprint arXiv:2406.04325, 2024.
- [22] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238, 2023.
- [23] Zhoujun Cheng, Haoyu Dong, Zhiruo Wang, Ran Jia, Jiaqi Guo, Yan Gao, Shi Han, Jian-Guang Lou, and Dongmei Zhang. Hitab: A hierarchical table dataset for question answering and natural language generation. In ACL, 2022.
- [24] Yew Ken Chia, Vernon Toh Yan Han, Deepanway Ghosal, Lidong Bing, and Soujanya Poria. Puzzlevqa: Diagnosing multimodal reasoning challenges of language models with abstract visual patterns. arXiv preprint arXiv:2403.13315, 2024.
- [25] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017.
- [26] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. In NeurIPS, 2024.
- [27] Maxwell Forbes, Christine Kaeser-Chen, Piyush Sharma, and Serge Belongie. Neural naturalist: Generating fine-grained image comparisons, 2019.
- [28] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models, 2024.
- [29] Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024.
- [30] Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data, 2023.
- [31] Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. arXiv preprint arXiv:2404.12390, 2024.
- [32] Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, and Lingpeng Kong. G-llava: Solving geometric problem with multi-modal large language model, 2023.
- [33] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, Vincent Cartillier, Sean Crane, Tien Do, Morrie Doulaty, Akshay Erapalli, Christoph Feichtenhofer, Adriano Fragomeni, Qichen Fu, Abrham Gebreselasie, Cristina Gonzalez, James Hillis, Xuhua Huang, Yifei Huang, Wenqi Jia, Weslie Khoo, Jachym Kolar, Satwik Kottur, Anurag Kumar, Federico Landini, Chao Li, Yanghao Li, Zhenqiang Li, Karttikeya Mangalam, Raghava Modhugu, Jonathan Munro, Tullie Murrell, Takumi Nishiyasu, Will Price, Paola Ruiz Puentes, Merey Ramazanova, Leda Sari, Kiran Somasundaram, Audrey Southerland, Yusuke Sugano, Ruijie Tao, Minh Vo, Yuchen Wang, Xindi Wu, Takuma Yagi, Ziwei Zhao, Yunyi Zhu, Pablo Arbelaez, David Crandall, Dima Damen, Giovanni Maria Farinella, Christian Fuegen, Bernard Ghanem, Vamsi Krishna Ithapu, C. V. Jawahar, Hanbyul Joo, Kris Kitani, Haizhou Li, Richard Newcombe, Aude Oliva, Hyun Soo Park, James M. Rehg, Yoichi Sato, Jianbo Shi, Mike Zheng Shou, Antonio Torralba, Lorenzo Torresani, Mingfei Yan, and Jitendra Malik. Ego4d: Around the world in 3,000 hours of egocentric video, 2022.
- [34] Ziyu Guo, Renrui Zhang, Hao Chen, Jialin Gao, Peng Gao, Hongsheng Li, and Pheng-Ann Heng. Sciverse. https://sciverse-cuhk.github.io, 2024.
- [35] Ziyu Guo, Renrui Zhang, Xiangyang Zhu, Yiwen Tang, Xianzheng Ma, Jiaming Han, Kexin Chen, Peng Gao, Xianzhi Li, Hongsheng Li, et al. Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following. arXiv preprint arXiv:2309.00615, 2023.
- [36] Tanmay Gupta, Dustin Schwenk, Ali Farhadi, Derek Hoiem, and Aniruddha Kembhavi. Imagine this! scripts to compositions to videos, 2018.
- [37] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In CVPR, 2018.
- [38] Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models. Advances in Neural Information Processing Systems, 36:20482–20494, 2023.
- [39] Mehrdad Hosseinzadeh and Yang Wang. Image change captioning by learning from an auxiliary task. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2724–2733, 2021.
- [40] Ting-Hao K. Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Jacob Devlin, Aishwarya Agrawal, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, et al. Visual storytelling. In 15th Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2016), 2016.
- [41] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, 2019.
- [42] Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Yuyin Zhou, and Cihang Xie. Hq-edit: A high-quality dataset for instruction-based image editing, 2024.
- [43] Phillip Isola, Joseph J. Lim, and Edward H. Adelson. Discovering states and transformations in image collections. In CVPR, 2015.
- [44] Mohit Iyyer, Varun Manjunatha, Anupam Guha, Yogarshi Vyas, Jordan Boyd-Graber, Hal Daumé III au2, and Larry Davis. The amazing mysteries of the gutter: Drawing inferences between panels in comic book narratives, 2017.
- [45] Harsh Jhamtani and Taylor Berg-Kirkpatrick. Learning to describe differences between pairs of similar images. arXiv preprint arXiv:1808.10584, 2018.
- [46] Harsh Jhamtani and Taylor Berg-Kirkpatrick. Learning to describe differences between pairs of similar images, 2018.
- [47] Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning. arXiv preprint arXiv:2405.01483, 2024.
- [48] Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In CVPR, 2017.
- [49] Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. Dvqa: Understanding data visualizations via question answering. In CVPR, 2018.
- [50] Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, Akos Kadar, Adam Trischler, and Yoshua Bengio. Figureqa: An annotated figure dataset for visual reasoning, 2018.
- [51] Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. Technical Report, 2024.
- [52] Mehran Kazemi, Hamidreza Alvari, Ankit Anand, Jialin Wu, Xi Chen, and Radu Soricut. Geomverse: A systematic evaluation of large models for geometric reasoning. arXiv preprint arXiv:2312.12241, 2023.
- [53] Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In ECCV, 2016.
- [54] Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pages 235–251. Springer, 2016.
- [55] Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, pages 4999–5007, 2017.
- [56] Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5376–5384, 2017.
- [57] Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. The hateful memes challenge: Detecting hate speech in multimodal memes. In NeurIPS, 2020.
- [58] Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. In European Conference on Computer Vision (ECCV), 2022.
- [59] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Visual genome: Connecting language and vision using crowdsourced dense image annotations, 2016.
- [60] Benno Krojer, Vaibhav Adlakha, Vibhav Vineet, Yash Goyal, Edoardo Ponti, and Siva Reddy. Image retrieval from contextual descriptions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Online, May 2022. Association for Computational Linguistics.
- [61] Shanghai AI Laboratory. Sharegpt-4o: Comprehensive multimodal annotations with gpt-4o, 2023.
- [62] Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images. Scientific data, 5(1):1–10, 2018.
- [63] Hugo Laurençon, Léo Tronchon, Matthieu Cord, and Victor Sanh. What matters when building vision-language models? Technical Report, 2024.
- [64] Bo Li, Hao Zhang, Kaichen Zhang, Dong Guo, Yuanhan Zhang, Renrui Zhang, Feng Li, Ziwei Liu, and Chunyuan Li. Llava-next: What else influences visual instruction tuning beyond data?, May 2024.
- [65] Bo Li, Kaichen Zhang, Hao Zhang, Dong Guo, Renrui Zhang, Feng Li, Yuanhan Zhang, Ziwei Liu, and Chunyuan Li. Llava-next: Stronger llms supercharge multimodal capabilities in the wild, May 2024.
- [66] Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension, 2023.
- [67] Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, Jianfeng Gao, et al. Multimodal foundation models: From specialists to general-purpose assistants. Foundations and Trends® in Computer Graphics and Vision, 2024.
- [68] Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next: Tackling multi-image, video, and 3d in large multimodal models, June 2024.
- [69] Juncheng Li, Kaihang Pan, Zhiqi Ge, Minghe Gao, Wei Ji, Wenqiao Zhang, Tat-Seng Chua, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Fine-tuning multimodal llms to follow zero-shot demonstrative instructions, 2024.
- [70] Juncheng Li, Kaihang Pan, Zhiqi Ge, Minghe Gao, Hanwang Zhang, Wei Ji, Wenqiao Zhang, Tat-Seng Chua, Siliang Tang, and Yueting Zhuang. Empowering vision-language models to follow interleaved vision-language instructions. arXiv preprint arXiv:2308.04152, 2023.
- [71] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark, 2023.
- [72] Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. In European Conference on Computer Vision, 2024.
- [73] Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models. Technical Report, 2024.
- [74] Yitong Li, Zhe Gan, Yelong Shen, Jingjing Liu, Yu Cheng, Yuexin Wu, Lawrence Carin, David Carlson, and Jianfeng Gao. Storygan: A sequential conditional gan for story visualization, 2019.
- [75] Zhuowan Li, Xingrui Wang, Elias Stengel-Eskin, Adam Kortylewski, Wufei Ma, Benjamin Van Durme, and Alan Yuille. Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning, 2023.
- [76] Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122, 2023.
- [77] Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26689–26699, 2024.
- [78] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015.
- [79] Fangyu Liu, Guy Edward Toh Emerson, and Nigel Collier. Visual spatial reasoning. Transactions of the Association for Computational Linguistics, 2023.
- [80] Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang. Aligning large multi-modal model with robust instruction tuning. arXiv preprint arXiv:2306.14565, 2023.
- [81] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In CVPR, 2024.
- [82] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024.
- [83] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023.
- [84] Xuejing Liu, Wei Tang, Xinzhe Ni, Jinghui Lu, Rui Zhao, Zechao Li, and Fei Tan. What large language models bring to text-rich vqa?, 2023.
- [85] Xuejing Liu, Wei Tang, Xinzhe Ni, Jinghui Lu, Rui Zhao, Zechao Li, and Fei Tan. What large language models bring to text-rich vqa? arXiv preprint arXiv:2311.07306, 2023.
- [86] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, and Ziwei Liu. Mmbench: Is your multi-modal model an all-around player? Technical Report, 2023.
- [87] LMMs-Lab. Video detail caption, 2024.
- [88] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. In International Conference on Machine Learning, pages 22631–22648. PMLR, 2023.
- [89] Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, and Yaofeng Sun. Deepseek-vl: towards real-world vision-language understanding. Technical Report, 2024.
- [90] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating math reasoning in visual contexts with gpt-4v, bard, and other large multimodal models. arXiv preprint arXiv:2310.02255, 2023.
- [91] Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning, 2021.
- [92] Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. In ACL, 2021.
- [93] Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In The 36th Conference on Neural Information Processing Systems (NeurIPS), 2022.
- [94] Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. In International Conference on Learning Representations (ICLR), 2023.
- [95] Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. In NeurIPS, 2021.
- [96] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023.
- [97] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), 2024.
- [98] Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems, 36, 2024.
- [99] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In CVPR, 2019.
- [100] U-V Marti and Horst Bunke. The iam-database: an english sentence database for offline handwriting recognition. International journal on document analysis and recognition, 5:39–46, 2002.
- [101] Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In ACL, 2022.
- [102] Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1697–1706, 2022.
- [103] Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. In WACV, 2021.
- [104] Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, et al. Mm1: Methods, analysis & insights from multimodal llm pre-training. arXiv preprint arXiv:2403.09611, 2024.
- [105] A. Mishra, K. Alahari, and C. V. Jawahar. Scene text recognition using higher order language priors. In BMVC, 2012.
- [106] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In ICDAR, 2019.
- [107] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 947–952, 2019.
- [108] Jason Obeid and Enamul Hoque. Chart-to-text: Generating natural language descriptions for charts by adapting the transformer model, 2020.
- [109] OpenAI. Gpt-4v. https://openai.com/index/gpt-4v-system-card/, 2023.
- [110] OpenAI. Hello gpt-4o. https://openai.com/index/hello-gpt-4o/, 2024.
- [111] Piotr Padlewski, Max Bain, Matthew Henderson, Zhongkai Zhu, Nishant Relan, Hai Pham, Donovan Ong, Kaloyan Aleksiev, Aitor Ormazabal, Samuel Phua, et al. Vibe-eval: A hard evaluation suite for measuring progress of multimodal language models. arXiv preprint arXiv:2405.02287, 2024.
- [112] Piotr Padlewski, Max Bain, Matthew Henderson, Zhongkai Zhu, Nishant Relan, Hai Pham, Donovan Ong, Kaloyan Aleksiev, Aitor Ormazabal, Samuel Phua, Ethan Yeo, Eugenie Lamprecht, Qi Liu, Yuqi Wang, Eric Chen, Deyu Fu, Lei Li, Che Zheng, Cyprien de Masson d’Autume, Dani Yogatama, Mikel Artetxe, and Yi Tay. Vibe-eval: A hard evaluation suite for measuring progress of multimodal language models, 2024.
- [113] Dong Huk Park, Trevor Darrell, and Anna Rohrbach. Robust change captioning, 2019.
- [114] Renjie Pi, Jianshu Zhang, Jipeng Zhang, Rui Pan, Zhekai Chen, and Tong Zhang. Image textualization: An automatic framework for creating accurate and detailed image descriptions, 2024.
- [115] Viorica Pătrăucean, Lucas Smaira, Ankush Gupta, Adrià Recasens Continente, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alex Frechette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osindero, Dima Damen, Andrew Zisserman, and João Carreira. Perception test: A diagnostic benchmark for multimodal video models. In Advances in Neural Information Processing Systems, 2023.
- [116] Yuxuan Qiao, Haodong Duan, Xinyu Fang, Junming Yang, Lin Chen, Songyang Zhang, Jiaqi Wang, Dahua Lin, and Kai Chen. Prism: A framework for decoupling and assessing the capabilities of vlms, 2024.
- [117] Harsh Raj, Janhavi Dadhania, Akhilesh Bhardwaj, and Prabuchandran KJ. Multi-image visual question answering. arXiv preprint arXiv:2112.13706, 2021.
- [118] Hareesh Ravi, Kushal Kafle, Scott Cohen, Jonathan Brandt, and Mubbasir Kapadia. Aesop: Abstract encoding of stories, objects, and pictures. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2032–2043, 2021.
- [119] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. In ECCV, 2022.
- [120] Minjoon Seo, Hannaneh Hajishirzi, Ali Farhadi, Oren Etzioni, and Clint Malcolm. Solving geometry problems: Combining text and diagram interpretation. In Proceedings of the 2015 conference on empirical methods in natural language processing, pages 1466–1476, 2015.
- [121] ShareGPT. https://sharegpt.com/, 2023.
- [122] Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020.
- [123] Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: a dataset for image captioning with reading comprehension, 2020.
- [124] Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ivan Laptev, Ali Farhadi, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. ArXiv e-prints, 2016.
- [125] Alane Suhr, Mike Lewis, James Yeh, and Yoav Artzi. A corpus of natural language for visual reasoning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 217–223, 2017.
- [126] Alane Suhr, Stephanie Zhou, Ally Zhang, Iris Zhang, Huajun Bai, and Yoav Artzi. A corpus for reasoning about natural language grounded in photographs, 2019.
- [127] Hao Tan, Franck Dernoncourt, Zhe Lin, Trung Bui, and Mohit Bansal. Expressing visual relationships via language, 2019.
- [128] Ryota Tanaka, Kyosuke Nishida, and Sen Yoshida. Visualmrc: Machine reading comprehension on document images. In AAAI, 2021.
- [129] Benny J. Tang, Angie Boggust, and Arvind Satyanarayan. Vistext: A benchmark for semantically rich chart captioning, 2023.
- [130] Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024.
- [131] Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- [132] Ting-Hao, Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Aishwarya Agrawal, Jacob Devlin, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh, Lucy Vanderwende, Michel Galley, and Margaret Mitchell. Visual storytelling, 2016.
- [133] Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. arXiv preprint arXiv:2406.16860, 2024.
- [134] Bryan Wang, Gang Li, Xin Zhou, Zhourong Chen, Tovi Grossman, and Yang Li. Screen2words: Automatic mobile ui summarization with multimodal learning, 2021.
- [135] Fei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al. Muirbench: A comprehensive benchmark for robust multi-image understanding. arXiv preprint arXiv:2406.09411, 2024.
- [136] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- [137] Chris Wendler. wendlerc/renderedtext, 2023.
- [138] Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai, et al. Q-bench: A benchmark for general-purpose foundation models on low-level vision. arXiv preprint arXiv:2309.14181, 2023.
- [139] Haoning Wu, Hanwei Zhu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Annan Wang, Wenxiu Sun, Qiong Yan, Xiaohong Liu, Guangtao Zhai, Shiqi Wang, and Weisi Lin. Towards open-ended visual quality comparison, 2024.
- [140] x.ai. Grok-1.5 vision preview.
- [141] Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9777–9786, June 2021.
- [142] Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning. arXiv preprint arXiv:2404.16994, 2024.
- [143] Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing. ArXiv, abs/2406.08464, 2024.
- [144] Zhiyang Xu, Chao Feng, Rulin Shao, Trevor Ashby, Ying Shen, Di Jin, Yu Cheng, Qifan Wang, and Lifu Huang. Vision-flan: Scaling human-labeled tasks in visual instruction tuning. arXiv preprint arXiv:2402.11690, 2024.
- [145] Zhiyang Xu, Chao Feng, Rulin Shao, Trevor Ashby, Ying Shen, Di Jin, Yu Cheng, Qifan Wang, and Lifu Huang. Vision-flan: Scaling human-labeled tasks in visual instruction tuning, 2024.
- [146] Semih Yagcioglu, Aykut Erdem, Erkut Erdem, and Nazli Ikizler-Cinbis. Recipeqa: A challenge dataset for multimodal comprehension of cooking recipes, 2018.
- [147] An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024.
- [148] Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023.
- [149] Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Guohai Xu, Chenliang Li, Junfeng Tian, Qi Qian, Ji Zhang, Qin Jin, Liang He, Xin Alex Lin, and Fei Huang. Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model, 2023.
- [150] Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023.
- [151] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expressions, 2016.
- [152] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities, 2023.
- [153] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023.
- [154] Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 9127–9134, 2019.
- [155] Ye Yuan, Xiao Liu, Wondimu Dikubab, Hui Liu, Zhilong Ji, Zhongqin Wu, and Xiang Bai. Syntax-aware network for handwritten mathematical expression recognition. arXiv preprint arXiv:2203.01601, 2022.
- [156] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, and Yuxuan Sun. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In CVPR, 2024.
- [157] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023.
- [158] Chi Zhang, Feng Gao, Baoxiong Jia, Yixin Zhu, and Song-Chun Zhu. Raven: A dataset for relational and analogical visual reasoning. In CVPR, 2019.
- [159] Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing, 2024.
- [160] Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Reality check on the evaluation of large multimodal models. arXiv preprint arXiv:2407.12772, 2024.
- [161] Pan Zhang, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Rui Qian, Lin Chen, Qipeng Guo, Haodong Duan, Bin Wang, Linke Ouyang, et al. Internlm-xcomposer-2.5: A versatile large vision language model supporting long-contextual input and output. arXiv preprint arXiv:2407.03320, 2024.
- [162] Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024.
- [163] Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- [164] Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? arXiv preprint arXiv:2403.14624, 2024.
- [165] Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Yichi Zhang, Ziyu Guo, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Bin Wei, Shanghang Zhang, Peng Gao, and Hongsheng Li. Mavis: Mathematical visual instruction tuning, 2024.
- [166] Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chunyuan Li, Alexander Hauptmann, Yonatan Bisk, et al. Direct preference optimization of video large multimodal models from language model reward. arXiv preprint arXiv:2404.01258, 2024.
- [167] Yanzhe Zhang, Ruiyi Zhang, Jiuxiang Gu, Yufan Zhou, Nedim Lipka, Diyi Yang, and Tong Sun. Llavar: Enhanced visual instruction tuning for text-rich image understanding. arXiv preprint arXiv:2306.17107, 2023.
- [168] Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, April 2024.
- [169] Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264, 2024.
- [170] Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding, 2024.
- [171] Luowei Zhou, Chenliang Xu, and Jason J. Corso. Towards automatic learning of procedures from web instructional videos, 2017.
- [172] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
- [173] Yuke Zhu, Oliver Groth, Michael Bernstein, and Li Fei-Fei. Visual7w: Grounded question answering in images. In CVPR, 2016.
附录 A 从 LLaVA-NeXT 到 LLaVA-OneVision 的开发路线图
LLaVA-OneVision 基于 2024 年 1 月至 6 月 LLaVA-NeXT 博客系列[82,168,65,64,68]开发的技术构建。 最初的 LLaVA-NeXT 提供了一个可扩展的原型,促进了多个并行探索。 这些探索是在固定的计算预算内进行的,旨在提供有用的见解,而不是突破性能限制。 LLaVA-OneVision 整合了这些见解并通过“yolo run”执行——利用可用的计算实现新模型,而无需广泛降低各个组件的风险。
附录 B作者贡献
- Bo Li 致力于维护 LLaVA-OneVision 代码库,在我们之前的基础上,对所有阶段(包括单图像、多图像和视频数据的阶段)的 LLaVA-OneVision 模型进行大规模训练LLaVA-NeXT 系列。 他对 LLaVA-NeXT-Ablations [64] 等单图像开发、高质量复制以及单图像数据混合的收集和管理做出了重大贡献。
- 张远涵在 LLaVA-NeXT-Video [168] 中贡献了一系列工作,包括视频训练和推理代码库、高质量视频数据生成的有效管道以及所有视频训练数据。
- 郭东致力于单图像数据混合的收集和管理,并在整个项目中始终如一地提供技术支持。
- Feng Li、Renrui Zhang 和 Hao Zhu 对 LLaVA-NeXT-Interleave [68] 做出贡献,包括多图像指令数据混合、多图像评估基准和 LLaVA 的早期原型-OneVision,即单图像、多图像和视频的联合训练阶段。 他们还有助于单图像数据混合物的收集和管理。
- Kaichen Zhang 维护训练代码库,并致力于将 LLaVA-OneVision 模型集成到 LMMs-Eval 的评估流程中。
- Yanwei Li 对论文的修改做出了贡献。
- Ziwei Liu 在整个项目中提出了宝贵的建议。
- 李春元发起并领导一系列项目,设计路线图和里程碑,推动执行,并领导论文写作。
附录C实现细节
C.1 混合模态数据的 Token 策略
我们详细解释了在 LLaVA-OneVision 架构中处理混合模态数据的词符策略,如图 3 所示。
对于单图像数据,我们采用 AnyResMax-9 策略,如之前博客[64]中所述。 使用 SO400M [157] 作为视觉编码器,每个输入图像(或网格)被处理为 729 个视觉标记。 因此,单个图像的视觉标记的最大数量为 ,其中 表示基本标记, 表示网格标记。
对于多图像数据,我们使用简单的填充策略。 首先根据 SO400M 的要求,通过零填充调整每个图像的大小以适合 384x384 帧,同时保持纵横比。 经过视觉编码器处理后,从标记中删除零填充。 我们的训练数据每个实例最多包含 12 个图像,从而产生最多 个多图像标记。
对于视频数据,我们采用类似于 LLaVA-NeXT-Video [168] 的策略。 每帧通过视觉编码器进行处理,然后进行双线性插值,得到每帧196个标记。 我们对每个视频最多采样 32 帧,从而产生最多 个视频标记。
如图3所示,不同模态的最大 Token 数量大致相等。 这种设计策略旨在平衡来自各种模式的数据,确保从语言模型的角度可转移的更公平的表示。 例如,高分辨率图像可以被解释为多个图像的合成,而多个图像可以被理解为较短的视频。
C.2 语言模板和特殊标记
我们使用Qwen-2系列[147]语言模型,模板为OpenAI的ChatML111OpenAI Release v0.28.0/chatml.md。 在训练过程中,我们沿用以往的 LLaVA 模型,采用 <image> 作为图像词符的标记。 该图像特殊词符在标记化后在输入索引中表示为。 对于多图像场景,我们使用多个 <图像>与文本交错的方式来表示图像的位置。 对于视频场景,我们会在开头放置一个 <image> 来表示包含视频。
与处理图像词符相关的另一个方面是确保数据中没有多余的 <image> 。 例如,在某些代码编写任务中,可能会出现与 HTML 代码相关的 <image>...</image>。 为了避免潜在的误解,我们从 Magpie [143] 和 Screen2Words [134] 数据集中手动删除了大约 10 个此类样本。
附录D评估引导发展
D.1 作为开发工具的后评估
借助我们的综合评估工具包 LMMs-Eval [160],我们在每次实验结束后对一组选定的基准进行后评估。
我们对选择基准的偏好取决于目标场景是否足够重要和具体。 这些评估不应该过于占用资源,这意味着基准测试不应该包含太多项目、评估时间太长或消耗大量 GPT-4V Token (当使用它作为判断模型时)。
在我们的开发中,我们评估了 AI2D [54]、ChartQA [101]、DocVQA [103] 和 InfoVQA [102 ] 检查模型对表格、图表和图表的细粒度理解,以及用于格式化控制的 MME [28],因为它只需要“是”或“否”答案。 我们还包括 MMBench-Dev [86] 和 MMMU-Val [156] 用于多学科评估。 快速获得这些基准的评估结果将指导我们下一步的模型开发和数据管理。
D.2 提高关键场景的模型性能
在我们的发展过程中,我们逐渐认识到使用静态评估基准作为绩效指标的意义。 我们现阶段的主要目标是不要使模型过度拟合某些数据集以实现异常高性能。 相反,我们根据 GPT-4V 的性能对模型进行基准测试来设定目标阈值(例如,最初为 80%,逐渐增加到 95%-100%)。 一旦模型满足静态评估中的评分要求,则表明该模型在所选场景中具有足够的能力。 另外,我们不能盲目追求benchmark的结果,即使是AI2D的测试数据也可能存在一定的问题222Discussion on AI2D Evaluation。
最终,我们的重点是优化模型的视觉聊天和推理能力。 在这一阶段,我们监测了模型在 MathVista [90] 、LLaVA-Wilder [65] 、MM-LiveBench [170] 和 Vibe-Eval [112] 等基准测试中的性能。 这些基准要求模型能够与具有挑战性的问题进行视觉对话,并需要具有广泛的世界知识的多样化技能。 这有助于我们创建一个在现实场景中具有强大泛化能力的模型。
D.3 评估任务信息
在本节中,我们提供有关评估期间使用的所有任务的信息。 具体来说,我们使用 LMMs-Eval 框架中的默认 post_prompt 和 pre_prompt。 这些提示与我们之前 LLaVA-NeXT [65, 168, 68] 的评估一致。 下表详细介绍了LMMs-Eval中使用的具体任务及其对应的任务名称。
通过这里列出的任务名称,观众可以直接检索到生成参数和具体提示信息。 例如,tasks=ai2d 的详细信息可在 lmms-eval/ai2d 中找到。 通过遵循这些设置,研究人员可以轻松重现我们的结果。
附录ELLaVA-NeXT系列数据管理路线图
在本节中,我们将提供 LLaVA-NeXT 系列中数据管理的深入经验和路线图。 为了实现强大的多模态性能,我们需要从各种来源收集和整理高质量的数据,这对于模型的泛化能力至关重要。
E.1 单图像数据管理
作为主要数据源,我们对单图数据的原则始终是质量重于数量。 在资源有限的情况下,我们努力使用高质量的数据来最大化性能。
LLaVA-NeXT 模型的第一个版本(LLaVA-NeXT-Vicuna-7B/13B、Mistral-7B、Hermes-Yi-34B)包含 76 万个数据样本[82],其中包括来自LLaVA-1.5 [81]、AI2D [53] 中的 3,247 个样本、ChartQA [101] 中的 18,317 个样本、DocVQA [103]、来自 DVQA [49] 的 20,000 个样本、来自 SynthDOG-EN [58] 的 40,093 个样本以及来自 LLaVA 演示中的用户请求的 15,131 个样本,用 GPT-4V 重新注释。 在后续迭代中,我们添加了 COCO Caption [78] 中的 20,000 个样本,形成了新的 790K 版本。 此 790K 数据集支持 LLaVA-NeXT 模型的第二个版本(LLaVA-NeXT-LLaMA3-8B、LLaVA-NeXT-Qwen-72B、LLaVA-NeXT-Qwen-110B)。
在后续的采集中,我们积累了来自互联网的开源数据集,并参考了其他先进LMM的数据集采集流程,如Qwen-VL [8]、DeepSeek-VL [89] 、实习生-VL [22]、Vision-Flan [145]、UReader [149]、Idefics-2(Cauldron )[63],以及寒武纪。 在数据迭代过程中,我们严格遵循最初的LLaVA-1.5策略。 对于每个数据集,我们手动检查并确保其质量和 QA 格式。 我们还设计了特定的格式提示,使不同来源的数据相互兼容,从而避免冲突。
某些数据源(例如 AI2D 和 ChartQA)出现在不同的数据集集合中,并且可能会重复。 由于 Cauldron 包含特殊的格式化提示,因此其数据无法直接重新格式化。 因此,我们优先使用来自其他集合的更接近原始格式的数据。 对于寒武纪数据集,我们只选择了 GPT-4o 重新注释数据的子集。 我们还从 MathV 和 MAVIS 数据集中收集了数学相关数据。
对于纯语言数据,我们替换了 LLaVA 自 1.5 版本以来一直使用的 ShareGPT [121] 文本数据。 鉴于我们最大的Qwen2-72B模型在语言任务中已经达到了接近最新GPT-4模型的性能水平,我们需要使用更高质量的语言数据来维持或进一步增强其语言能力。 为了实现这一目标,我们获取了可用的最高质量的语言 SFT 数据,即 Magpie-Pro 数据集[143]。
经过上述过程,我们获得了约400万个原始SFT数据样本,保证了其质量和准确性。 此外,我们利用 Azure 的 OpenAI GPT-4V 和 GPT-4o 服务重新注释我们的数据,重点关注原始数据未充分覆盖但至关重要的场景。 这些场景包括:
(1)图表详细说明: 对于此场景,我们使用 AI2D 和 InfoVQA 训练集中的图像,并使用 GPT-4V 提供图像的详细描述,从而为 AI2D 提供 4,874 个详细描述,为 InfoVQA 提供 1,992 个样本。
(2) 中文: 我们使用LLaVA-158K数据集的图像,并使用GPT-4o提供详细的中文描述,总共得到91,466个样本。
(3)多轮对话: 此外,在 LLaVA-158K 数据集上,我们使用 GPT-4o 创建长对话,平均每次对话超过 3 轮,总共获得 26,048 个样本。
如果资源允许,我们建议在早期数据采购中使用数据验证流程。 我们从每个新添加的数据源或集合(如果所选数据源可以形成集合)中提取大约 100K 样本,并将它们添加到数据集的 790K 版本中。 我们在 SO400M-Qwen-1.5-0.5B 实验设置下验证新添加的数据。 如果添加新数据导致性能与基线相比下降,我们会对数据进行进一步的手动检查并相应调整格式化提示。 这一步需要丰富的资源,并且必须由高度专业的研究人员来完成,因为它不能被普通的人类注释者替代。
在收集过程中,我们手动为数据集添加了两个标签:{通用、语言、数学/推理、通用 OCR、文档/图表/屏幕}和{固定格式、自由格式}。 基于这些标签,我们形成了320万张单图数据样本的最终分布。
从初始分布开始,我们逐渐增加自由格式(大部分是 GPT-4V/o 注释)数据的数量,并观察模型在各种基准上的性能,并尝试在它们之间进行平衡。 这些基准包括学术数据集,例如 AI2D [54]、MME [28]、MMMU [156]、MathVista [90 ],以及视觉聊天数据集,例如 LLaVA-Wilder [65] 和 Vibe-Eval [112]。 最终,我们逐渐建立了7B设置下单图像任务的最佳数据分布。
E.2 OneVision 数据管理
除了单图像数据之外,我们还结合多图像和视频数据集来支持更广泛的视觉场景。 我们的目标是平衡不同数据模式之间的能力,并通过 LLaVA-OneVision 这样的一个框架实现整体卓越的性能。
对于多图像数据,我们采用 LLaVA-NeXT-Interleave [68] 的 M4-Instruct 数据集中的各种交错多模态任务。 该数据集主要包括一般的多图像任务,例如发现差异、视觉故事讲述、图像编辑指令生成、交错多图像对话、多图像拼图、低级多图像评估等。 此外,我们还利用M4-Instruct中的多视图数据集来指示3D世界中的空间信息,包括体现VQA(对话和规划)和3D场景VQA(字幕和背景)。
对于视频数据,我们首先集成来自 M4-Instruct 的多帧数据,包括 NExT-QA [141] 和 ShareGPT4Video [21]。 然后,为了获得更详细的时间线索,我们选择了最近学术研究中常用的几个数据集进行重新注释,包括 Charades [124]、ActivityNet [154]、YouCook2 [171] 和 Ego4D [33]。 最初,我们对标题进行了注释。 遵循 ShareGPT-4o [61],我们以每秒 1 帧 (FPS) 的速度对视频帧进行采样,并使用预定义的指令提示 GPT-4o 生成视频字幕。 此外,继 LLaVA-Hound [166] 之后,我们使用 GPT-4o 创建的字幕开发了开放式问答对及其相应的多项选择版本。 我们还使用 GPT-4o 生成问答对,为 OneVision 训练获得高质量的视频数据。
E.3 详细数据集统计
我们主要使用表格来呈现 Single-Image 和 OneVision 阶段中使用的所有数据集的统计信息。 这些信息包括数据集类别、数据集名称、样本数量和提示类型。 数据集统计数据总结于表16中。
| Dataset | # Samples | Prompt ID | Dataset | # Samples | Prompt ID |
| General (1.14M, 36.1%) | |||||
| AOKVQA [119] | 66160 | 1 | Cambrian (filtered) [133] | 83131 | - |
| CLEVR [48] | 700 | 1 | COCO Caption [78] | 20000 | 9 |
| Hateful Memes [57] | 8500 | 1 | IconQA [95] | 2494 | 5 |
| Image Textualization [114] | 99583 | 11 | LLaVA-158K [83] | 158000 | - |
| LLaVA-Wild (train) [83] | 54517 | - | LLaVAR [167] | 20000 | - |
| OKVQA [99] | 8998 | 1 | RefCOCO [151] | 50586 | 7,8 |
| ScienceQA [93] | 4976 | 5 | ShareGPT4O [121] | 57289 | 11 |
| ShareGPT4V [121] | 92025 | 11 | ST-VQA [11] | 17247 | 1 |
| TallyQA [1] | 9868 | 1 | Vision FLAN [145] | 186070 | - |
| Visual7W [173] | 14366 | 5 | VisText [129] | 9969 | 15 |
| VizWiz [37] | 6614 | 2 | VQARAD [62] | 313 | 1 |
| VQAv2 [4] | 82783 | 1 | VSR [79] | 2157 | 3 |
| WebSight | 10000 | 18 | InterGPS [91] | 1280 | 5 |
| ALLaVA Instruct [16] | 70000 | - | |||
| Doc/Chart/Screen (20.6%, 647K) | |||||
| AI2D (GPT4V Detailed Caption) | 4874 | 12 | AI2D (InternVL [22]) | 12413 | 4 |
| AI2D (Original) [53] | 3247 | 5 | Chart2Text [108] | 26961 | 13 |
| ChartQA [101] | 18317 | 1 | Diagram Image2Text | 300 | 17 |
| DocVQA [103] | 10194 | 1 | DVQA [49] | 20000 | 1 |
| FigureQA [50] | 1000 | 3 | HiTab [23] | 2500 | 1 |
| Infographic VQA [102] | 4404 | 1 | LRV Chart [80] | 1787 | - |
| RoBUT SQA | 8514 | - | RoBUT WikiSQL | 74989 | - |
| RoBUT WTQ | 38246 | 1 | Screen2Words [134] | 15730 | 10 |
| TQA [55] | 1365 | 5 | UReader Caption [149] | 91439 | 9 |
| UReader IE [149] | 17327 | 1 | UReader KG [149] | 37550 | 14 |
| UReader QA [149] | 252954 | 1 | VisualMRC[128] | 3027 | - |
| Math/Reasoning (20.1%,632K) | |||||
| MAVIS Manual Collection [165] | 87358 | 19 | MAVIS Data Engine [165] | 100000 | 19 |
| CLEVR-Math [48] | 5290 | 2 | Geo170K Align [32] | 60252 | - |
| Geo170K QA [32] | 67833 | 19 | Geometry3K [91] | 2101 | 6 |
| GEOS [120] | 508 | 6 | Geometry3K (MathV360K) [92] | 9734 | 6 |
| GeoMVerse (MathV360K) [52] | 9303 | 20 | GeoQA+ (MathV360K) [18] | 17172 | 6 |
| MapQA (MathV360K) [14] | 5235 | 1 | MathQA [2] | 29837 | 19 |
| Super-CLEVR [75] | 8652 | 2 | TabMWP [94] | 45184 | 2 |
| UniGeo [17] | 11959 | 6 | GQA [41] | 72140 | 1 |
| LRV Normal [80] | 10500 | - | RAVEN [158] | 2100 | 3 |
| Visual Genome [59] | 86417 | 7,8 | |||
| General OCR (8.9%,281K) | |||||
| ChromeWriting [137] | 8835 | 21 | HME100K [155] | 74502 | 21 |
| IIIT5K [105] | 2000 | 22 | IAM [100] | 5663 | 22 |
| K12 Printing | 12832 | 22 | OCR-VQA [106] | 80000 | 1 |
| Rendered Text [137] | 10000 | 22 | SynthDog-EN [58] | 40093 | 16 |
| TextCaps [123] | 21952 | 9 | TextOCR-GPT4V [13] | 25114 | 11 |
| Pure Language (450K) (14.3%, 647K) | |||||
| Magpie Pro [143] (L3 MT) | 149999 | - | Magpie Pro (L3 ST) | 150000 | - |
| Magpie Pro (Qwen2 ST) | 149996 | - | |||
| Dataset | # Samples | Prompt ID | Dataset | # Samples | Prompt ID |
| Multi-image Scenarios | |||||
| Spot-the-Diff [46] | 10.8K | 20 | Birds-to-Words [27] | 14.3K | 21 |
| CLEVR-Change [113, 39] | 3.9K | 22 | HQ-Edit-Diff [42] | 7.0K | 3 |
| MagicBrush-Diff [159] | 6.7K | 4 | IEdit [127] | 3.5K | 19 |
| AESOP [118] | 6.9K | 23 | FlintstonesSV [36] | 22.3K | 24 |
| PororoSV [74] | 12.3K | 25 | VIST [132] | 26K | 4 |
| WebQA [15] | 9.3K | 8 | TQA (MI) [56] | 8.2K | 9 |
| OCR-VQA (MI) [107] | 1.9K | 17 | DocVQA (MI) [103] | 1.9K | 18 |
| RAVEN [158] | 35K | 5 | MIT-StateCoherence [43] | 1.9K | 11 |
| MIT-PropertyCoherence [43] | 1.9K | 12 | RecipeQA ImageCoherence [146] | 8.7K | 14 |
| VISION [7] | 9.9K | 13 | Multi-VQA [69] | 5K | - |
| IconQA [95] | 34.6K | - | Co-Instruct [139] | 50.0K | - |
| DreamSim [30] | 15.9K | - | ImageCoDe [60] | 16.6K | - |
| nuScenes [12] | 9.8K | 10 | ScanQA [6] | 25.6K | 7 |
| ALFRED [122] | 22.6K | 16 | ContrastCaption [47] | 25.2K | - |
| VizWiz (MI) [37] | 4.9K | 6 | ScanNet [25] | 49.9K | 7 |
| COMICS Dialogue [44] | 5.9K | 15 | NLVR2 [126] | 86K | 26 |
| Multi-frame (Video) Scenarios | |||||
| NExT-QA [141] | 9.5K | 2 | ActivityNet [154] | 6.5k | 1 |
| Ego-4D [33] | 0.8K | 2 | Charades [124] | 23.6K | 1 |
| YouCook2 [171] | 41.9K | 2 | ShareGPT4Video [21] | 255K | - |
| ID | Type | Postion | Prompt |
| 1 | VQA | Tail | Answer the question with a single word (or phrase). |
| 2 | VQA | Head | Hint: Please answer the question and provide the final answer at the end. |
| 3 | VQA (Yes/No) | Tail | Answer the question with Yes or No./Yes or No?/… |
| 4 | Choice | Tail | Answer with the given letter directly |
| 5 | Choice (Option Letter) | Tail | Answer with the option letter from the given choices directly. / Please respond with only the letter of the correct answer. |
| 6 | Choice (Option Letter) | Head | Hint: Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end. |
| 7 | Region Caption | All | Provide a short description for this region. |
| 8 | Grounding | All | Provide the bounding box coordinate of the region this sentence describes. |
| 9 | Breif Caption | All | Provide a one-sentence caption for the provided image./Create a compact narrative representing the image presented./… |
| 10 | Screen Summarization | All | Summarize the main components in this picture./Provide a detailed account of this screenshot./… |
| 11 | Detailed Caption | All | Describe this image in detail./Explain the visual content of the image in great detail./… |
| 12 | Science Books | All | Here is a diagram figure extracted from some Grade 1 - 6 science books.\nPlease first describe the content of this figure in detail, |
| including how the knowledge visually displayed in the diagram.\nThen start with a section title \"related knowledge:\", briefly | |||
| and concisely highlight the related domain knowledge and theories that underly this diagram. Note that you do not need to provide | |||
| much detail. Simply cover the most important concepts. | |||
| 13 | Information Extraction | Head | Provide the requested information directly. |
| 14 | Graph Sumarization | All | Please clarify the meaning conveyed by this graph./Explain what this graph is communicating./… |
| 15 | Photo Sumarization | All | Highlight a few significant elements in this photo./Mention a couple of crucial points in this snapshot./… |
| 16 | Chart Sumarization | All | What insights can be drawn from this chart?/Explain the trends shown in this chart./… |
| 17 | OCR | Head | OCR this image section by section, from top to bottom, and left to right. Do not insert line breaks in the output text. If a word is split |
| due to a line break in the image, use a space instead | |||
| 18 | Diagram Linkage | All | Dissect the diagram, highlighting the interaction between elements./Interpret the system depicted in the diagram, detailing component functions./… |
| 19 | Code Generation | All | Compose the HTML code to achieve the same design as this screenshot. |
| 20 | Choice (with Reasoning) | Head | First perform reasoning, then finally select the question from the choices in the following format: Answer: xxx. |
| 21 | Math Computing | Tail | Round computations to 2 decimal places. |
| 22 | LaTeX OCR | All | Please write out the expression of the formula in the image using LaTeX format. |
| 23 | Text Reading | All | What is written in the image? Answer this question using the text in the image directly./Read and list the text in this image. |
| 24 | Choice (Full Option) | Tail | Please provide your answer by stating the letter followed by the full option. |
| ID | Type | Postion | Prompt |
| Video | |||
| 1 | Choice (Option Letter) | Tail | Answer with the option letter from the given choices directly. / Please respond with only the letter of the correct answer. |
| 2 | Choice (Full Option) | Tail | Please provide your answer by stating the letter followed by the full option. |
| Multi-Image | |||
| 3 | Open-Ended | Head | What’s the difference between 2 images? |
| 4 | Open-Ended | Head | Given the stories paired with the first several images, can you finish the story based on the last image?/With the narratives paired with the initial images, how would you conclude the story using the last picture?/… |
| 5 | Multi-Choice | Head | Here is a Raven’s Progressive Matrice in a three-by-three form. You are provided with the first eight elements in eight images, please select the last one from four choices following the structural and analogical relations. |
| 6 | Multi-Choice | All | There are ten possible explanations for the ten different answers to a VQA: … I will give you two sets of pictures, questions, and answers to determine if they belong to the same ’Question-Answer Differences’. You must choose your answer from the Choice List. |
| 7 | Open-Ended | Head | This is a 3D scenario. |
| 8 | Open-Ended | Head | I will give you several images and a question, your job is to seek information in the slide and answer the question correctly./Based on the images, please answer the following question./… |
| 9 | Multi-Choice | Head | Provided with a series of diagrams from a textbook, your responsibility is to correctly answer the following question. You must choose your answer from the Choice List./Using a selection of textbook diagrams, your task is to provide an accurate response to the subsequent query. You must choose your answer from the Choice List./… |
| 10 | Open-Ended | Head | Given six images taken from different cameras on a street view car, your task is to answer questions about the depicted scene. You must choose your answer from the Choice List. /Upon receiving six photographs captured from various cameras on a street-view car, your responsibility is to provide accurate responses to questions about the scene. You must choose your answer from the Choice List. /… |
| 11 | Multi-Choice | Head | I will provide you with two sets of pictures, each of which shows an object in the opposite state. Can you tell me if the states of these two sets of pictures are the same? You must choose your answer from the Choice List. /I have two sets of pictures that show an object in opposite states. Can you tell me if the states of these two sets of pictures are the same? You must choose your answer from the Choice List. /… |
| 12 | Multi-Choice | Head | Are the following four images of the same class? You must choose your answer from the Choice List. /Do the following four images belong to the same category? You must choose your answer from the Choice List. /… |
| 13 | Multi-Choice | Head | Are these two workpieces the same type?/Are these two workpieces of the same kind?/… |
| 14 | Multi-Choice | Head | Presented with a textual recipe tutorial, your task is to scrutinize it carefully and select the image that is incoherent in the provided sequence of images. You must choose your answer from the Choice List. /Given a text-based recipe guide, your responsibility is to meticulously review it and identify the image that doesn’t fit in the following sequence of images. You must choose your answer from the Choice List. /… |
| 15 | Multi-Choice | Head | I will give you a series of comic panels. The dialogue box of the last panel is masked. Can you choose the most relevant one from the candidates? You must choose your answer from the Choice List. /Given previous full panels and one masked panel, your job is to select the most appropriate dialogue among four candidates. You must choose your answer from the Choice List. /… |
| 16 | Open-Ended | Head | Give you a main goal, your job is to figure out what to do now by looking at current envirments. Your past views as well as decisions are also provided./Given a primary objective and your current surroundings, use your previous decisions and perspectives to determine your next move./… |
| 17 | Multi-Choice | Head | I will give you two pictures of the book cover. Please look at the pictures and answer a question You must choose your answer from the Choice List. /I will provide you with two images of the book cover. Please examine the images and answer a question. You must choose your answer from the Choice List. /… |
| 18 | Multi-Choice | Head | I will give you some pictures, and each group of pictures will correspond to a question. Please answer it briefly. You must choose your answer from the Choice List. /For each group of pictures, there is a question. Please give a short answer to it. You must choose your answer from the Choice List. /… |
| 19 | Open-Ended | Head | Please give a editing Request to describe the transformation from the source image to the target image./What is the correct image edit instruction that can transfrom the source image to target image?/… |
| 20 | Open-Ended | Head | What’s the difference between 2 images? /Identify the alterations between these two images. /… |
| 21 | Open-Ended | Head | What’s the difference between 2 birds? /Identify the alterations between these two birds. /… |
| 22 | Open-Ended | Head | What’s the difference between 2 images? /Identify the alterations between these two images. /… |
| 23 | Open-Ended | Head | Given the stories paired with the first several images, can you finish the story based on the last image?/With the narratives paired with the initial images, how would you conclude the story using the last picture?/… |
| 24 | Open-Ended | Head | Given the stories paired with the first several images, can you finish the story based on the last image?/With the narratives paired with the initial images, how would you conclude the story using the last picture?/… |
| 25 | Open-Ended | Head | Given the stories paired with the first several images, can you finish the story based on the last image?/With the narratives paired with the initial images, how would you conclude the story using the last picture?/… |
| 26 | Multi-Choice | All | Answer the following multiple-choice question: Here is a statement describing 2 images: … Is it true or false? |
E.4政策信息和再现性
我们将开源我们使用的大部分公共数据集。 这些图像和数据已经公开用于学术研究;我们将它们合并并转换为我们使用的格式。 但是,我们的一小部分与用户数据相关的数据源以及通过Azure OpenAI服务获得的数据,由于公司政策而无法直接发布。 我们将提供最终复制脚本中使用的确切数据 YAML 文件,并将在我们的计算资源允许的情况下使用完全公开的数据提供可复制的实验脚本、训练日志和最终版本检查点。