MooER:来自 Moore Threads 的基于 LLM 的语音识别和翻译模型
摘要
在本文中,我们提出了MooER,一种基于LLM的Moore Threads大规模自动语音识别(ASR)/自动语音翻译(AST)模型。 训练使用包含开源和自行收集的语音数据的 5000h 伪标记数据集。 我们获得的性能可与使用长达数十万小时的标记语音数据训练的其他开源模型相媲美。 同时,在 Covost2 Zh2en 测试集 [1] 上进行的实验表明,我们的模型优于其他开源语音大语言模型。 可获得 25.2 的 BLEU 分数。 本文的主要贡献总结如下。 首先,本文提出了一种编码器和大语言模型在语音相关任务(包括 ASR 和 AST)上的训练策略,使用少量的伪标记数据,无需任何额外的手动标注和选择。 其次,我们发布了 ASR 和 AST 模型,并计划在不久的将来开源我们的训练代码和策略。 此外,计划稍后发布基于 8wh 规模训练数据训练的模型。
1 动机
2024年5月,OpenAI发布GPT-4o,支持端到端语音输入和输出,开创了基于大语言模型的端到端语音交互技术。 从此,语音这一最自然的人机交互方式进入了“GPT时刻”的新时代。 为此,研究人员一直在不断探索大规模语音模型。 但模型结构(如大语言模型的选择、语音编码器的选择、语音编码器与大语言模型的连接关系)、训练方法(如训练的哪些阶段)仍存在不确定性。划分,分别调整哪些参数,需要的数据大小、计算资源和成本)等等。 特别是在开源社区,现有的与语音大模型相关的工作主要可以分为两类:第一类使用开源训练数据集来验证其在学术基准上的表现,例如 Salmonn [2];第二种类型使用大量数据和训练资源来训练多个语音相关任务的模型,例如耳语[3]、SeamlessM4T [4]、Qwen-audio [5]、SenseVoice [6]、SpeechLlama [7]目前,在资源限制下,能够针对特定垂直类实现产业规模应用的大规模语音模型还很少。
我们发布的工作将语音大模型技术在以下两个方面应用到语音ASR和AST任务中。 首先,在模型结构和训练方面,我们使用开源的Qwen2-7B-instruct模型[8]和开源的Paraformer[9]模型编码器进行模型初始化。 在训练过程中,仅对语音适配器和大语言模型Lora [10]参数进行微调。 此外,为了提高训练速度、稳定性以及推理速度,还应用了 DeepSpeed [11]、Dataloader 加速、梯度检查点、梯度累积和 BF16 加速等优化技术。 其次,在训练资源上,我们只使用了摩尔线程开发的8块国产S4000 GPU进行计算。 我们的大型音频理解模型在 38 小时内训练了 5000 个小时(由部分开源数据集和伪标记数据集组成)。 第三,在 ASR 任务上,6 个普通话测试集的 CER 为 4.21%,6 个英语测试集的 WER 为 17.98%。 同时,我们在Covost2 Zh2en翻译测试集上也取得了25.2的BLEU分数,满足工业应用的要求。 第四,这项工作的训练和推理是基于摩尔线程GPU的。 据我们所知,这是第一个使用国产GPU进行训练和推理的语音大规模模型。 我们还展示了基于 80000 小时数据训练的音频理解模型的有效性,该模型在 ASR 任务的 6 个普通话测试集上实现了 3.5% 的 CER,在 6 个英语测试集上实现了 12.66% 的 WER。
我们在这项工作中发布了推理代码和使用 5000 小时数据训练的模型,并计划在不久的将来开源训练代码和使用 80000 小时数据训练的模型。 我们希望这项工作能够在语音建模的方法和技术实现方面为社区做出贡献。
2方法
MooER 受到了以下令人惊叹的作品和团队的极大启发:SLAM-LLM [12],我们感谢所有开源贡献者。 我们更关注ASR和AST的任务,针对模型结构提出了一些相应的优化方法,以及针对大规模工业数据的训练策略。 例如,DeepSpeed、Dataloader 加速、梯度检查点、梯度累积、BF16 训练,在 5000 小时训练数据的微调过程中结合在一起。 所提出的模型由编码器、适配器和解码器(大语言模型)组成,如图1。 编码器实现音频的特征提取和嵌入,适配器执行音频模态的下采样和文本模态的融合。 大语言模型根据输入的音频和文本提示执行相应的任务,如ASR、AST等。
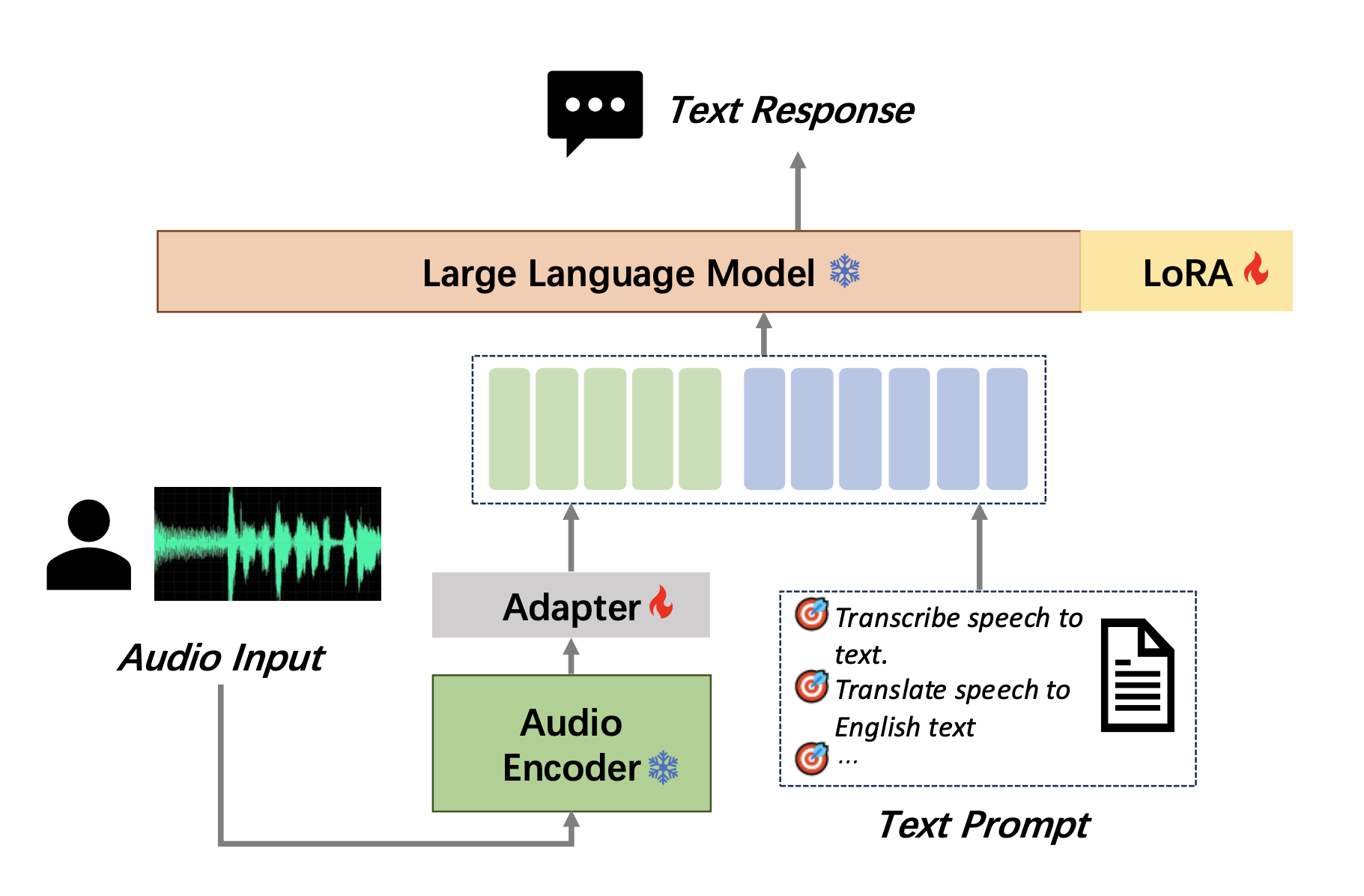
我们尝试了不同的编码器,包括Whisper、W2v-Bert2.0 [13]、Paraformer等。 最终,我们选择了 Paraformer 的编码器来对音频进行建模。 我们使用Qwen2-7B-instruct作为大语言模型解码器。 在进入 Paraformer 之前,音频将使用 LFR(低帧率)进行下采样,下采样率为 6。 Encoder输出的音频向量将被Adapter进一步下采样,从而降低与文本嵌入的融合密度。 适配器会将音频下采样 2 倍,并将其通过两个线性层以获得最终的音频提示嵌入。 因此,音频的建模粒度是每个嵌入的。 将音频提示嵌入和文本提示嵌入拼接后,发送至大语言模型进行相应的识别或翻译操作。 在训练过程中,Encoder始终有固定的参数,而Adapter和大语言模型(Lora)参与训练和梯度更新。
3数据集
我们构建了 MT5K 训练数据集,其中包含表 1 中以下来源的总共 5000 小时的语音数据:
| source | duration/ |
|---|---|
| Aishell2 [14] | 137 |
| Librispeech [15] | 131 |
| multi_cn [16] | 100 |
| wenetspeech [17] | 1361 |
| in-house | 3274 |
开源数据集中的数据是从整个数据集中随机选择的。 内部数据是内部采集的,其ASR伪标签是通过第三方云服务的录音文件识别接口获取的。 我们会用对应的ASR伪标签调用第三方翻译接口来获取对应的AST伪标签。 我们没有使用任何数据过滤方法来选择爬取的数据和伪标签,这可能会减少工业生产环境中的手动流程。 我们还展示了我们的 ASR 模型在测试集上经过 80000 小时内部数据训练的性能。
4实验
我们的模型结构如下。 我们使用 Paraformer 大型编码器作为我们的音频编码器。 Paraformer 只有 158M 参数,更轻,并且没有 padding 到 30s 的限制(私语),使得训练和推理都更加高效。 音频编码器的输出将由适配器进一步下采样,从而降低与文本嵌入的融合密度。 适配器会将音频下采样 2 倍,并将其通过两个线性层以获得最终的音频提示嵌入。 我们的音频特征帧平移10ms,前端使用LFR进行下采样,下采样率为6。 因此,音频的建模粒度为每次嵌入 120ms。 音频嵌入将直接拼接在文本提示嵌入之前发送到大语言模型进行训练。 我们使用Qwen2-7B指令作为我们的大语言模型解码器。
大语言模型最终的输入形式为:
<语音嵌入><|im_start|>system \n 你是一个有用的助手。
<|im_end|>\n<|im_start|>用户\n将语音翻译成英文文本。<|im_end|>\n<|im_start|>助理\n UTF8gbsn 你叫什么名字? \n你叫什么名字?<|im_end| >
在训练过程中,我们将冻结编码器的参数并训练适配器和大语言模型(lora)。 我们的实验发现,如果训练过程中有大语言模型的参与,可以利用其语义理解能力来提高最终的音频理解效果。 训练 Lora 的配置如附录 A 所示。 最终,大语言模型参数的2%将参与训练。 我们的模型具有以下参数范围,如表2所示。
| Module | Params() | trainable Params() |
|---|---|---|
| Encoder | 158 | 0 |
| Adapter | 9.44 | 9.44 |
| LLM | 7615.62 | 161.48 |
为了提高训练速度并减少 GPU 内存使用,我们在 DeepSpeed 框架内使用 Zero2 优化进行训练。 我们观察到 Paraformer 在使用 Fp16 时往往会出现向上溢出的情况,因此我们使用 Bf16 进行训练和推理。 我们使用了摩尔线程开发的8块国产S4000 GPU,基于KUAE框架对其进行了训练,耗时38小时。 我们的 Deepspeed 配置显示在 Applendix B 中。
4.1ASR
我们使用 Paraformer-large、SenseVoice Small、Qwen-audio、WhperV3 和 SeamlessM4T2 比较了 6 个普通话测试集和 6 个英语测试集的 ASR 性能。 我们还展示了我们的 ASR 模型在测试集上经过 80000 小时内部数据训练的性能。 我们比较了 ASR/AST 阶段不同模型使用的数据。 ASR结果如表3所示。
-
•
Paraformer-large:60,000 小时 ASR 数据
-
•
SenseVoice Small:30万小时ASR数据
-
•
Qwen-audio:53,000 小时 ASR 数据 + 3700 小时 S2TT 数据 + …
-
•
WhisperV3:1000,000小时弱标签,4000,000小时伪标签
-
•
SeamlessM4T2:351,000小时S2TT数据,145,000小时S2ST数据
-
•
MooER-5K:5000小时伪标签
-
•
MooER-80K:80,000小时伪标签
| testsets | Paraform. | SenseV. | Qwen | Whisper | Seamless | MooER | MooER | |
|---|---|---|---|---|---|---|---|---|
| large | small | audio | v3 | M4T2 | 5k | 8w | ||
| ZH | aishell1 | 1.93 | 3.03 | 1.43 | 7.86 | 4.09 | 1.93 | 1.25 |
| aishell2 | 2.85 | 3.79 | 3.57 | 5.38 | 4.81 | 3.17 | 2.67 | |
| thchs | 3.99 | 5.17 | 4.86 | 9.06 | 7.14 | 4.11 | 3.14 | |
| t_mdata | 3.66 | 3.81 | 5.31 | 8.36 | 9.69 | 3.48 | 2.52 | |
| f_c_dev | 5.56 | 6.39 | 10.54 | 4.54 | 7.12 | 5.81 | 5.23 | |
| f_c_test | 6.92 | 7.36 | 11.07 | 5.24 | 7.66 | 6.77 | 6.18 | |
| AVG. | 4.15 | 4.93 | 6.13 | 6.74 | 6.75 | 4.21 | 3.50 | |
| EN | lib_t_clean | 14.15 | 4.07 | 2.15 | 3.42 | 2.77 | 7.78 | 4.11 |
| lib_t_other | 22.99 | 8.26 | 4.68 | 5.62 | 5.25 | 15.25 | 9.99 | |
| f_e_dev | 24.93 | 12.92 | 22.53 | 11.63 | 11.36 | 18.89 | 13.32 | |
| f_e_test | 26.81 | 13.41 | 22.51 | 12.57 | 11.82 | 20.41 | 14.97 | |
| giga_dev | 24.23 | 19.44 | 12.96 | 19.18 | 28.01 | 23.46 | 16.92 | |
| giga_test | 23.07 | 16.65 | 13.26 | 22.34 | 28.65 | 22.09 | 16.64 | |
| AVG. | 22.7 | 12.46 | 13.02 | 12.46 | 14.64 | 17.98 | 12.66 |
4.2AST
我们使用 Zh2en 翻译的三个测试集来评估 AST 的性能。 其中,我们在他们的论文中使用了SpeechLlaMA和Qwen2-audio的数值。 我们在三个测试集上测试了 WhisperV3、SeamlessM4T2 和 Qwen-audio 的 BLEU 分数。 我们使用 ASR 和 AST 多任务学习方法(MTL)来提高 AST 的最终性能,如表 4 所示。
| Models | Speech | Whisper | Qwen | Qwen2 | Seamless | MooER | MooER |
|---|---|---|---|---|---|---|---|
| LLAMA | V3 | audio | audio | M4Y2 | 5k | 5k-MTL | |
| Covost1_Zh2en | - | 13.5 | 13.5 | - | 25.3 | - | 30.2 |
| Covost2_Zh2en | 12.3 | 12.2 | 15.7 | 24.4 | 22.2 | 23.4 | 25.2 |
| CCMT2019_dev | - | 15.9 | 12.0 | - | 14.8 | - | 19.6 |
5讨论
5.1 编码器的选择
我们在内部验证测试集上选择了不同的编码器。 我们发现,如果使用半监督学习(SSL)编码器,编码器需要参与训练,否则损失将难以收敛。 考虑到性能、参数大小和效率,我们最终选择 Paraformer 作为我们的编码器。 本次实验我们固定了大语言模型,只有适配器参与训练。 (W2v-Bert2.0除了作为编码器之外,编码器也参与训练)。 结果如表5所示。
| W2v-Bert2 | WhisperV3 | Paraformer | |
| In-house-dev | 11.04% | 7.20% | 5.56% |
5.2 音频建模的粒度
我们尝试对240ms、180ms和120ms的粒度进行建模,发现这个参数对于音频和文本的融合至关重要。 最终,我们选择每120ms输出一次音频嵌入。 本实验中,我们固定了大语言模型,仅适配器参与训练,如表6所示。
| 240ms | 180ms | 120ms | |
| In-house-dev | no-converge | 5.56% | 5.22% |
5.3快速适应垂直领域
| ASR-ENG | Paraformer-large | MooER-5k |
|---|---|---|
| Librispeech-test-clean | 14.15 | 7.78 |
| Librispeech-test-other | 22.99 | 15.25 |
| fleurs_eng_dev | 24.93 | 18.89 |
| fleurs_eng_test | 26.81 | 20.41 |
| gigaspeech_dev | 24.23 | 23.46 |
| gigaspeech_test | 23.07 | 22.09 |
s
我们基于 Paraformer 大型编码器进行训练。 我们使用了大约 小时的英语数据,并在英语测试集上取得了更好的结果,如表 7 所示。 同时,我们尝试迁移到其他任务,例如 AST,并在 Covost2 Zh2en 翻译测试集上取得了 25.2 的 BLEU 分数。 我们相信这种方法也可以应用于其他低资源音频理解任务领域,例如少数民族语言、方言等,如表8所示。
| AST-C2E | Speech | Whisper | Qwen | Qwen2 | Seamless | MooER |
|---|---|---|---|---|---|---|
| LLAMA | V3 | audio | audio | M4T2 | 5k-MTL | |
| Covost2_Zh2en | 12.3 | 12.2 | 15.7 | 24.4 | 22.2 | 25.2 |
5.4充分利用大模型的能力
我们发现,将大语言模型纳入音频理解训练中可以带来更快、更稳定的收敛,最终取得更好的结果。 而且,最终效果会随着大语言模型效果的提高而增加,如表9。
| ASR | MooER-Qwen1.5 | MooER-Qwen2 | MooER-Qwen1.5 | MooER-Qwen2 |
|---|---|---|---|---|
| frozen | frozen | lora | lora | |
| In-house-dev CER | 5.22% | 5.17% | 4.72% | 4.32% |
5.5加速方式
我们优化了dataloader部分,在相同配置下可以将训练速度提升4-5倍。 同时,我们根据 5000h 的训练优化了 Deepspeed 的训练策略,并在我们的 8wh 内部数据训练中重复使用。 对于需要解冻编码器的训练,我们使用梯度检查点来减少内存使用。 我们使用基于摩尔线程的KUAE平台来加速大型模型的训练。
6演示
我们的演示是基于Moore Threads国产的S4000 GPU构建的。 https://mooer-speech.mthreads.com:10077/
7型号
Huggingface:https://huggingface.co/mtspeech/MooER-MTL-5K
致谢和资金披露
SLAM- LLM 、FunASR、Qwen
参考
[1] Wang C, Wu A, Gu J, 等人 CoVoST 2 与大规模多语言语音翻译[C]//Interspeech. 2021:2247-2251。
[2] Tang C, Yu W, Sun G, 等人 Salmonn: 大语言模型的通用听力能力[J]. arXiv 预印本 arXiv:2310.13289, 2023。
[3] Radford A, Kim J W, Xu T, 等人 通过大规模弱监督的鲁棒语音识别[C]//机器学习国际会议。 PMLR,2023:28492-28518。
[4] Barrault L, Chung Y A, Meglioli MC, 等人无缝:多语言表达和流式语音翻译[J]. arXiv 预印本 arXiv:2312.05187, 2023。
[5] Chu Y, Xu J, Zhou X, 等人 Qwen-audio: 通过统一的大规模音频语言模型促进通用音频理解[J]. arXiv 预印本 arXiv:2311.07919, 2023。
[6] SpeechTeam T. FunAudioLLM:人与大语言模型自然交互的语音理解和生成基础模型[J]. arXiv 预印本 arXiv:2407.04051, 2024。
[7] Wu J, Gaur Y, Chen Z, 等人关于语音转文本和大语言模型集成的仅解码器架构[C]//2023 IEEE自动语音识别和理解研讨会(ASRU)。 IEEE,2023:1-8。
[8] 杨A,杨B,辉B,等人Qwen2技术报告[J]. arXiv 预印本 arXiv:2407.10671, 2024。
[9] 高Z,李Z,王J,等人Funasr:一个基本的端到端语音识别工具包[J]. arXiv 预印本 arXiv:2305.11013, 2023。
[10] Hu E J, Shen Y, Wallis P, 等人 Lora: 大语言模型的低秩自适应[J]. arXiv 预印本 arXiv:2106.09685, 2021。
[11] Rasley J, Rajbhandari S, Ruwase O, 等人 Deepspeed:系统优化支持训练超过 1000 亿个参数的深度学习模型[C]//第 26 届 ACM SIGKDD 国际知识发现与数据挖掘会议论文集。 2020:3505-3506。
[12]马Z,杨G,杨Y,等人一种强ASR能力的大语言模型的简单方法[J]。 arXiv 预印本 arXiv:2402.08846, 2024。
[13] Barrault L, Chung Y A, Meglioli MC, 等人无缝:多语言表达和流式语音翻译[J]. arXiv 预印本 arXiv:2312.05187, 2023。
[14] 杜静,那新,刘新,等人 Aishell-2:将普通话 ASR 研究转化为产业规模[J]. arXiv 预印本 arXiv:1808.10583, 2018。
[15] Panayotov V,Chen G,Povey D,等人 Librispeech:基于公共领域有声读物的 ASR 语料库[C]//2015 IEEE 声学、语音和信号处理国际会议(ICASSP)。 IEEE,2015:5206-5210。
[17] 张波,吕红,郭鹏,等人Wenetspeech:用于语音识别的10000+小时多域普通话语料库[C]//ICASSP 2022-2022 IEEE声学、语音与信号处理国际会议(ICASSP) 。 IEEE,2022:6182-6186。
[18] Conneau A, Ma M, Khanuja S, 等人 Fleurs: 语音通用表征的少样本学习评估[C]//2022 IEEE Spoken Language Technology Workshop (SLT)。 IEEE,2023:798-805。