用于检索增强型大型语言模型的元知识
摘要。
检索增强型生成 (RAG) 是一种用于增强大型语言模型 (LLM) 的技术,它使用与上下文相关的、时间敏感的或特定领域的信息,而无需改变底层模型参数。 然而,构建能够有效地从大型和多样化的文档集中综合信息的 RAG 系统仍然是一个重大挑战。 我们为 LLM 引入了一种新颖的数据中心 RAG 工作流程,将传统的 检索-然后-阅读 系统转变为更先进的 准备-然后-重写-然后-检索-然后-阅读 框架,以实现对知识库更高水平的领域专家级理解。 我们的方法依赖于为每个文档生成元数据和合成问答 (QA),以及为基于元数据的文档集群引入元知识摘要 (MK 摘要) 的新概念。 提出的创新使个性化的用户查询增强和跨知识库的深入信息检索成为可能。 我们的研究做出了两项重要贡献:使用 LLM 作为评估器并采用新的比较性能指标,我们证明了 (1) 使用合成问题匹配的增强型查询明显优于依赖文档分块的传统 RAG 管道 (),以及 (2) 元知识增强的查询进一步显著提高了检索精度和召回率,以及最终答案的广度、深度、相关性和特异性。 我们的方法具有成本效益,使用 Claude 3 Haiku,每 2000 篇研究论文的成本不到 20 美元,并且可以适应任何语言或嵌入模型的微调,以进一步提高端到端 RAG 管道的性能。
测试
1. 绪论
检索增强生成 (RAG) 是一种标准技术,用于增强大型语言模型 (LLM),使其能够集成上下文相关、时间关键或特定领域的信息,而无需改变底层模型权重。 这种方法对于需要专有或及时数据来指导语言模型响应的知识密集型任务特别有效,并且已成为减少模型幻觉和确保与当前任务最相关信息的对齐的有效解决方案。 在实践中,RAG 管道由几个模块组成,这些模块围绕传统的检索然后阅读框架结构化 (lewis2020retrieval, )。 给定一个用户问题,检索器的任务是动态地搜索相关的文档片段,并将它们作为 LLM 预测答案的上下文,而不是仅仅依靠预训练模型的知识(也称为上下文学习)。 一个简单而强大且具有成本效益的检索器框架涉及使用双编码密集检索模型来分别将查询和文档编码到高维向量空间中,并计算它们的内积作为相似性的度量 (karpukhin2020dense, )。
然而,一些挑战具体阻碍了知识增强上下文的质量。 首先,知识库文档可能包含大量噪声,这些噪声可能是任务本身固有的,也可能是由于感兴趣文档(来自各种文档布局或格式,例如 .pdf、.ppt、.wordx 等)之间缺乏标准化造成的。 其次,通常没有人类标注的信息或相关性标签来支持文档分块、嵌入和检索过程,这使得整个检索问题成为一种很大程度上无监督的方法,并且难以针对特定用户进行个性化。 第三,对长文档进行分块和单独编码对提取与检索模型相关的的信息构成了挑战 (gao2023retrieval, )。 事实上,文档片段不会保留整个文档的语义上下文,而且片段越大,在进一步检索时保留的片段上下文越不精确。 这使得对于给定用例的文档分块策略的选择并不简单,尽管对于后续步骤的质量至关重要,因为可能会造成重大的信息丢失。 第四,用户查询通常很短、含糊不清、可能包含词汇不匹配,或者复杂到需要多个文档来解决,这使得通常难以准确地捕捉用户意图并随后识别出最合适的文档来检索 (zhu2023large, )。 最后,不能保证相关信息集中在知识库中,而是分散在多个文档中。 因此,使用自动化信息检索系统,域专家级别的知识库使用变得更加困难。 在知识库中进行如此高级的推理是一个尚未解决的问题,也是最近基于 LLM 的检索代理框架研究的基础。
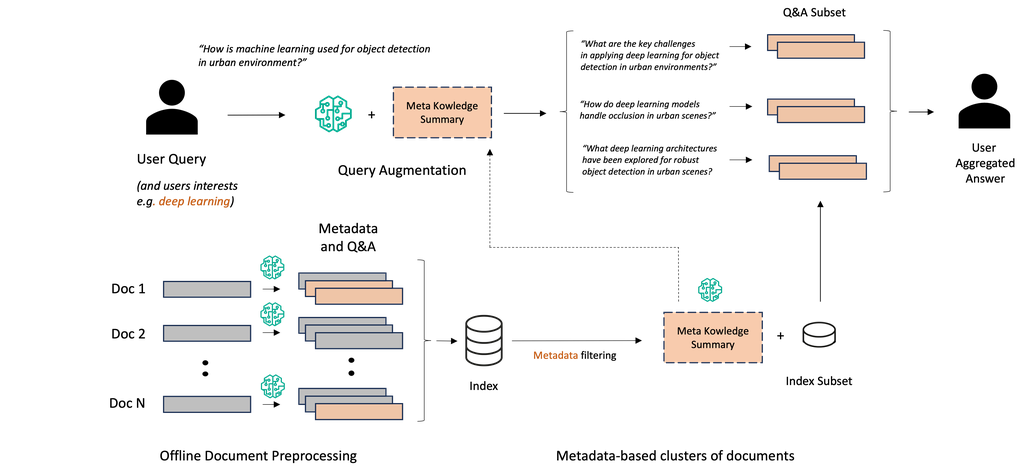
在这项工作中,我们对用户查询需要将信息搜索特定于用户兴趣或个人资料,存在歧义,并且需要跨文档进行高级推理的情况感兴趣(例如:“将机器学习应用于营销有哪些挑战?”),使召回率、特异性和深度成为我们关注的指标。 为了提高跨这些指标的搜索结果性能,查询增强已成为传统信息检索 (IR) 用例(如电子商务搜索 (peng2024large, ))以及最近利用 LLM 的 RAG 框架 (gao2022precise, ) 中广泛使用的技术。 查询增强包括显式地重写或扩展原始用户查询,将其转换为一个或多个定制的查询,这些查询更匹配搜索结果,从而缓解与查询规格不足相关的问题。 此调整向 RAG 框架添加了一个模块,并将其转换为更复杂的重写-检索-读取工作流程。 利用其庞大的底层参数化世界知识,LLM 是理解和增强用户查询的合适选择,随后可以提高检索步骤的相关性 (gao2022precise, ; ma2023query, ; mackie2023generative, ; mackie2023grm, ; shen2023large, ; jagerman2023query, ; srinivasan2022quill, )。 我们的方法引入了一种新的数据中心 RAG 工作流程,准备-重写-检索-读取 (PR3),其中每个文档都由 LLM 处理,以创建针对用户特征的自定义元数据和 QA 对,以通过查询增强解锁新的知识库推理功能。 我们的数据准备和检索管道缓解了大型文档分块和嵌入固有的信息丢失,因为只有 QA 被编码而不是文档块,同时充当针对手头任务的噪声和不相关文档的噪声过滤方法。 通过引入基于元数据的 QA 集群和元知识摘要,我们的框架有条件地将初始用户查询增强为多个专用查询,从而提高知识库搜索的特异性、广度和深度(参见图 1)。 所提出的现成方法很容易应用于新的数据集,不依赖于手动数据标记或模型微调,并且是朝着使用 LLM 进行自主的、基于代理的文档数据库推理迈出的一步,目前这方面的文献仍然有限 (zhu2023large, )。
2. 相关工作
我们的工作整合了从方法中获得的概念,这些方法从文档集合中生成 QA,用于对 LLM 或编码器模型进行下游微调,以及利用查询增强来提高 RAG 管道中检索器性能的技术。 以下概述了与这两个 RAG 增强领域相关的相关工作。
2.1. 使用微调增强 RAG
旨在基于微调改进 RAG 管道的方法通常构成了执行初始参数更新以及随着时间的推移维护模型对新文档的准确性的更高进入壁垒。 它们需要仔细的数据清理和(通常是手动)整理,以及跨训练超参数集进行手动迭代,才能成功地使模型适应手头的任务,而不会导致预训练模型知识的灾难性遗忘 (luo2023empirical, )。 此外,模型微调可能无法持续满足频繁的知识库更新,并且由于计算资源的底层要求,即使是最近的 参数高效微调 (PEFT) 技术 (hu2021lora, ; dettmers2024qlora, ),也会带来更高的成本。
在电子商务检索框架中,淘宝创建了一个基于公司日志和拒绝采样的查询重写框架,以监督方式微调 LLM, 而不进行 QA 生成。 他们进一步引入了一种新的对比学习方法来校准查询生成概率,使其与所需的搜索结果一致, 从而显著提高商品销量、交易量和独立访客数量 (peng2024large, )。 作为一种替代方案,基于黑盒 LLM 评估的强化学习方法也被用于训练更小的查询重写器 LLM, 该方法在网络搜索中的开放域和多项选择问答 (QA) 中表现出持续的性能改进 (ma2023query, )。 然而,基于强化学习的方法在训练阶段更容易出现不稳定,需要仔细研究下游任务之间泛化和 特化的权衡 (ma2023query, )。 其他方法专注于专门改进用户查询和现有文档之间的嵌入空间,而不是增强查询本身。 InPars 的作者 (bonifacio2022inpars, ) 通过以无监督方式生成合成问答对来增强他们的文档知识库, 然后使用这些问答对来微调 T5 基础嵌入模型。 他们表明,使用微调后的嵌入模型,然后使用诸如 ColBERT (khattab2020colbert, ) 之类的 神经重排序器,其性能优于诸如 BM25 (robertson2009probabilistic, ) 之类的强大基线。
最近,已经开发了其他类型的用于改进端到端管道性能的方法,例如 RAFT (zhang2024raft, ), 它专门训练一个阅读器来区分相关和不相关的文档,或者 QUILL (srinivasan2022quill, ),它旨在使用 RAG 增强 的蒸馏训练另一个 LLM 来完全替换 RAG 管道。
2.2. 不进行微调的 RAG 增强
作为微调 LLM 或编码器模型的替代方法,已经开发了查询增强方法来提高检索器的性能, 方法是通过转换用户查询预编码来实现。 这些方法可以进一步分为两类:要么利用对文档的检索过程,要么进行零样本(没有任何示例文 档)。
在零样本方法中,HyDE (gao2022precise, ) 引入了一种数据增强方法,该方法通过利用 LLM 来生成 用户查询的假设响应文档。 根本思想是将用户查询和感兴趣的文档在嵌入空间中拉近,从而提高检索过程的性能。 他们的实验表明,该方法在各种任务中的性能与微调后的检索器相当。 然而,生成的文档是一种天真的数据增强,因为它不会根据当前任务的底层嵌入数据而改变, 因此在多种情况下会导致性能下降,因为生成的 内容与知识库之间必然存在差距。 或者,有人提出了方法,首先在文档的嵌入空间中执行初始传递,然后随后增强初始查询以执行更明智的搜索。 这些伪相关反馈 (PRF) (mackie2023generative, ) 和生成相关反馈 (GRF) 建模方法 (mackie2023grm, ) 通常依赖于用于首先为其查询增强设定条件的排名最高的文档的质量,因此容易在查询之间出现显著的性能差异,甚至可能忘记原始查询的本质。
3. 方法
在上面引用的两种 RAG 管道增强方法中,检索器通常不知道目标文档集合的分布,尽管它们已经通过检索管道进行了初始传递。 在我们提出的框架中,对于每个文档,在推理之前,我们创建一组专用元数据,然后使用 Claude 3 Haiku 的思维链 (CoT) 提示 (anthropic2024claude, ; wei2022chain, ) 生成跨文档的引导式 QA。 然后对合成问题进行编码,并将元数据用于过滤目的。 对于任何与用户相关的元数据组合,我们都使用 Claude 3 Sonnet 创建一个元知识摘要 (MK 摘要),该摘要包含数据库中针对给定过滤器提供的关键概念的摘要。 在推理时,用户查询通过依赖于感兴趣的元数据的个性化 MK 摘要进行动态增强,因此为该用户提供定制的响应。 通过这样做,我们为检索器提供了跨多个文档进行推理的能力,而这些文档原本可能需要多次检索和推理。 我们的目标是最终通过定制搜索和利用元知识信息,提高端到端检索管道在深度、覆盖率和相关性等多个指标上的质量,从而实现跨数据库的复杂推理。 重要的是,我们的方法不依赖于任何模型权重更新,并且可以很好地与任何语言模型或编码模型的任何领域的微调相结合,以进一步提高端到端 RAG 管道的性能 (gupta2024rag, )。 我们在图 1 中展示了我们的方法管道,并描述了合成 QA 生成过程和 MK 摘要的概念。
3.1. 数据集
我们的公共基准用例包含一个由 2024 年的 2,000 篇研究论文组成的数据集,这些论文使用 arXiv API 收集。 此数据集代表了统计学、机器学习、人工智能和计量经济学领域研究的多样化范围 1 11使用 Arxiv API 上的以下类别过滤数据集:”stat.ML”,”stat.TH”,”stat.AP”,”stat.ME”,”math.ST”,”cs.AI”,”cs.LG”,”econ.EM”。 感谢 arXiv 允许我们使用其开放访问互操作性。 ,总计约 3500 万个符元。
3.2. 合成问答生成
首先,对于每个文档,我们使用 CoT 提示生成一组元数据和随后的问答(参见附录 A)。 该提示旨在通过将文档分类到一组预定义的类别(例如,研究领域或我们研究论文基准的应用类型)来创建元数据的列表。 依靠这些元数据,我们使用师生提示生成一组合成问题和答案,并评估学生对文档的知识。 我们特别利用 Claude 3 Haiku 的长上下文推理能力,并有可能创建跨文档的合成问答对。 生成的元数据既用作增强搜索的过滤参数,也用于以元知识信息(MK 摘要)的形式选择用于用户查询增强的合成问答。 此外,合成问答用于检索,但只有问题被向量化以用于下游检索。 对于我们公开的科学研究论文用例,从 2000 份研究文档中总共生成了 8657 个问答,占 70% 的情况的 5 到 6 个问题,占 21% 的情况的 2 个问题。 合成问题和答案的示例在附录 B 中提供。 作为处理步骤的一部分生成的符元总数约为 800 万个输出符元,对应于使用 Amazon Bedrock 对所有 2000 个文档(包括输入符元)的整个处理流程的总计 20.17 美元 (pricingbedrock, )。 我们使用 e5-mistral-7b-instruct (wang2023improving, ) 在问题的嵌入空间中使用层次聚类来调查文档之间生成的问答的冗余性,但由于问答重叠率低,我们没有对生成的问答进行去重。 问答过滤可以是特定于应用程序和元数据的,其他高维方法(如确定性点过程 (DPP) (kulesza2012determinantal, ))留待将来工作,连同元数据主题的自动发现和自校正问答生成 (pan2023automatically, )。
3.3. 元知识摘要生成
对于给定的元数据组合,我们创建了一个元知识摘要(MK 摘要),旨在支持给定用户查询的数据增强阶段。 对于我们的研究论文用例,我们将元数据限制在研究的特定领域(例如,强化学习、监督与无监督学习、贝叶斯方法、计量经济学等),这些领域是在文档处理阶段由 Claude 3 Haiku 识别的。 对于这项研究,我们通过使用 Claude 3 Sonnet 总结一系列带有感兴趣元数据的标记问题来创建 MK 摘要。 未来工作的另一种选择是提示调整,以优化摘要提示的内容 (tam2022parameter, )。
3.4. 查询和检索的增强生成
给定一个用户查询和一组预先选择的感兴趣元数据,我们检索相应的预先计算的 MK 摘要,并使用它将用户查询增强到数据库子集中。 对于我们的研究论文基准,我们创建了一组 20 个 MK 摘要,对应于研究领域(例如,计算机视觉的深度学习、统计方法、贝叶斯分析等),这些摘要依赖于处理阶段创建的元数据。 我们利用“计划和执行”提示方法来解决复杂查询,跨文档推理,并最终提高提供的答案的召回率、准确率和多样性 (sun2023pearl, )。 例如,对于与强化学习研究主题相关的用户查询,管道将首先检索数据库中关于强化学习的元知识(MK 摘要),根据 MK 摘要的内容将用户查询增强为多个子查询,并在与制造问题相关的过滤后的数据库中执行并行搜索。 为此,合成问题被嵌入并替换了原始文档的块级相似性匹配,从而减轻了由于文档块不连续性造成的的信息丢失。 一旦找到合成问题的最佳匹配,相应的问答将与原始文档标题一起检索。 检索结果仅返回文档标题、合成问题和答案。 我们使用 JSON 格式化来进行下游摘要性能。 RAG 管道的最终响应是通过提供原始查询、增强查询、检索的上下文和少样本示例获得的(参见图 1)。
4. 评估
4.1. 生成评估查询
为了评估我们的数据中心增强检索管道,我们使用 Claude 3 Sonnet 为 arXiv 数据集生成了 200 个问题(参见附录 C)。 此外,我们将我们的方法与传统文档分块、使用文档分块的查询增强以及使用文档的 QA 处理进行朴素(不使用 MK 摘要)增强的传统方法进行了比较。 作为比较,我们创建了由 256 个符元组成的文档块,重叠率为 10%。 在我们的用例中,传统分块产生了 69,334 个文档块。
4.2. 评估指标和提示
在没有相关性标签的情况下,我们使用 Claude 3 Sonnet 作为可信评估器 (anthropic2024claude, ) 来比较所有四种基准方法的性能:没有任何查询增强的传统分块,使用朴素查询增强的传统文档分块,使用我们的 PR3 管道进行增强搜索(不使用 MK 摘要),以及使用我们的 PR3 管道进行增强搜索(使用 MK 摘要)。 查询增强提示在附录 D 中给出。我们直接在提示中使用下面定义的自定义性能指标来比较检索模型和最终响应的结果,范围从 0 到 100。 Claude 3 Sonnet 比较答案的示例在附录 E 中给出。
- 召回率:评估检索到的文档中包含的关键、高度相关信息的覆盖范围
- 精确率:评估相关文档与不相关文档的比率
- 特异性:评估最终答案对当前查询的聚焦程度,提供清晰、直接的信息来回答问题
- 广度:评估对与问题相关的所有相关方面或领域的覆盖范围,提供完整概述
- 深度:评估最终答案通过对主题的详细分析和见解提供深入理解的程度
- 相关性:评估最终答案对受众或环境的需求和兴趣的契合度,专注于提供直接适用且必不可少的信息,同时省略与解决特定问题无关的无关细节
5. 结果
我们考虑了 4 种情况来评估我们的检索管道:(1)传统的文档分块,没有任何增强,(2)传统的文档分块和增强,(3)基于 QA 的搜索和检索,使用朴素增强(我们的第一个提议),以及(4)基于 QA 的搜索和检索,使用 MK 摘要(我们的第二个提议)。 对于单个查询,端到端管道的计算延迟约为 20-25 秒。
5.1. 检索和端到端评估指标
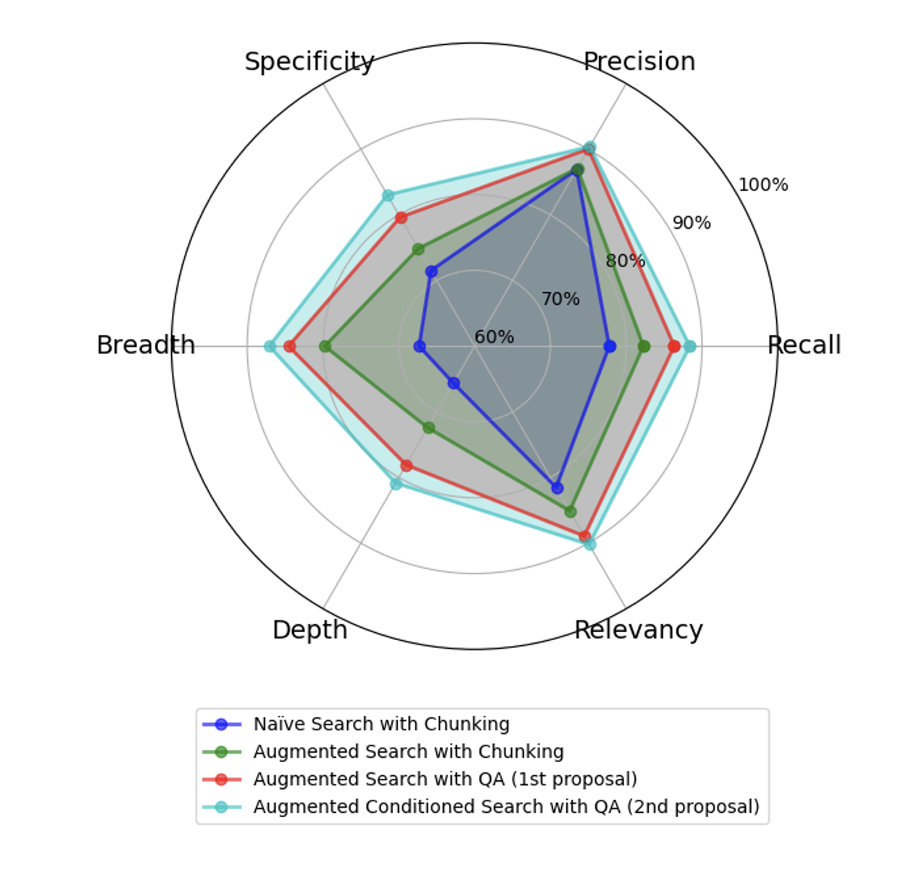
对于每个生成的合成用户查询,我们运行了一个比较提示,其中包括作为每种方法一部分检索到的上下文,以及它们的最终答案。 我们提示 Claude 3 Sonnet 在 0 到 100 的范围内对每个指标进行评分,并提供一个理由文本。 附录 E 中提供了一个评估响应示例。然后将获得的指标在所有查询中平均,并在下面的图 2 中显示。 我们观察到所有指标都具有明显的好处,但我们提出的两种基于 QA 的方法检索到的文档的准确性除外。 精度指标没有显著改善,这与使用单个编码模型一致,并表明只有很少的文档被认为是完全不相关的。 具体来说,我们注意到最终 LLM 响应的广度和深度都有显著的性能提升。 这个结果表明 MK 摘要提供了额外的信息,这些信息被查询增强步骤利用。 最后,MK 摘要对搜索本身条件化的贡献在所有指标中都具有统计学意义,但检索器的准确性除外 ( 在增强的 QA 搜索和 MK 增强的 QA 搜索之间)(见表 1)。 我们观察到,所提出的方法显著提高了搜索的广度(与传统的基于分块的朴素搜索相比,提高了 20% 以上),这与我们的直觉一致,即我们的提议允许有效地从数据库的内容中综合更多信息,并更广泛地利用其内容。
| Public Research Benchmark | Recall (%) | Precision (%) | Specificity (%) |
|---|---|---|---|
| Naïve Search with Chunking | 77.76 | 86.91 | 71.51 |
| Augmented Search with Chunking | 82.27 | 87.09 | 74.86 |
| Augmented QA Search | 86.33 | 90.04 | 79.64 |
| MK-Augmented QA Search | 88.39 | 90.40 | 83.03 |
| Public Research Benchmark | Breadth (%) | Depth (%) | Relevancy (%) |
|---|---|---|---|
| Naïve Search with Chunking | 67.32 | 65.62 | 81.51 |
| Augmented Search with Chunking | 79.77 | 72.41 | 85.08 |
| Augmented QA Search | 84.55 | 78.08 | 88.92 |
| MK-Augmented QA Search | 87.09 | 80.84 | 90.22 |
6. 结论和讨论
我们提出了一种新的以数据为中心的 RAG 工作流程,它利用合成 QA 生成而不是传统的文档分块框架,并基于内容元数据集群文档的高级摘要,采用了一种基于查询增强的方案,以提高端到端 LLM 增强管道的准确性和质量。 我们的方法显著优于依赖于文档分块和简单用户查询增强的传统 RAG 管道。 我们引入了 MK 摘要的概念,以进一步提升知识库中的零样本搜索增强,这随后提高了我们测试用例中端到端 RAG 管道的性能。 从本质上讲,我们的方法改进了文档编码向量空间中的简单语义匹配信息检索,其中我们允许进行更多样化但高度相关的文档搜索,从而为用户查询提供更全面、更具领域专家水平和更全面的答案。 在所有考虑的指标中,召回率、精确率、特异性、广度、深度和相关性,所提出的方法都改进了最先进的工作。 最后,这种方法具有成本效益,2000 篇研究论文的成本为 20 美元。 作为一项局限性,虽然我们认识到在文档处理之前创建一组元数据很困难,但元数据生成可以成为一种迭代方法,在发现时生成元数据。 此外,我们留下了多跳迭代搜索和改进聚类知识库摘要以供将来研究。
参考文献
- [1] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [2] Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020.
- [3] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
- [4] Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Zhicheng Dou, and Ji-Rong Wen. Large language models for information retrieval: A survey. arXiv preprint arXiv:2308.07107, 2023.
- [5] Wenjun Peng, Guiyang Li, Yue Jiang, Zilong Wang, Dan Ou, Xiaoyi Zeng, Derong Xu, Tong Xu, and Enhong Chen. Large language model based long-tail query rewriting in taobao search. In Companion Proceedings of the ACM on Web Conference 2024, pages 20–28, 2024.
- [6] Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496, 2022.
- [7] Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283, 2023.
- [8] Iain Mackie, Shubham Chatterjee, and Jeffrey Dalton. Generative and pseudo-relevant feedback for sparse, dense and learned sparse retrieval. arXiv preprint arXiv:2305.07477, 2023.
- [9] Iain Mackie, Ivan Sekulic, Shubham Chatterjee, Jeffrey Dalton, and Fabio Crestani. Grm: generative relevance modeling using relevance-aware sample estimation for document retrieval. arXiv preprint arXiv:2306.09938, 2023.
- [10] Tao Shen, Guodong Long, Xiubo Geng, Chongyang Tao, Tianyi Zhou, and Daxin Jiang. Large language models are strong zero-shot retriever. arXiv preprint arXiv:2304.14233, 2023.
- [11] Rolf Jagerman, Honglei Zhuang, Zhen Qin, Xuanhui Wang, and Michael Bendersky. Query expansion by prompting large language models. arXiv preprint arXiv:2305.03653, 2023.
- [12] Krishna Srinivasan, Karthik Raman, Anupam Samanta, Lingrui Liao, Luca Bertelli, and Mike Bendersky. Quill: Query intent with large language models using retrieval augmentation and multi-stage distillation. arXiv preprint arXiv:2210.15718, 2022.
- [13] Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747, 2023.
- [14] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [15] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- [16] Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. Inpars: Data augmentation for information retrieval using large language models. arXiv preprint arXiv:2202.05144, 2022.
- [17] Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020.
- [18] Stephen Robertson, Hugo Zaragoza, et al. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009.
- [19] Tianjun Zhang, Shishir G Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E Gonzalez. Raft: Adapting language model to domain specific rag. arXiv preprint arXiv:2403.10131, 2024.
- [20] AI Anthropic. The claude 3 model family: Opus, sonnet, haiku. Claude-3 Model Card, 1, 2024.
- [21] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [22] Aman Gupta, Anup Shirgaonkar, Angels de Luis Balaguer, Bruno Silva, Daniel Holstein, Dawei Li, Jennifer Marsman, Leonardo O Nunes, Mahsa Rouzbahman, Morris Sharp, et al. Rag vs fine-tuning: Pipelines, tradeoffs, and a case study on agriculture. arXiv preprint arXiv:2401.08406, 2024.
- [23] https://aws.amazon.com/bedrock/pricing/. 2024.
- [24] Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Improving text embeddings with large language models. arXiv preprint arXiv:2401.00368, 2023.
- [25] Alex Kulesza, Ben Taskar, et al. Determinantal point processes for machine learning. Foundations and Trends® in Machine Learning, 5(2–3):123–286, 2012.
- [26] Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies. arXiv preprint arXiv:2308.03188, 2023.
- [27] Weng Lam Tam, Xiao Liu, Kaixuan Ji, Lilong Xue, Xingjian Zhang, Yuxiao Dong, Jiahua Liu, Maodi Hu, and Jie Tang. Parameter-efficient prompt tuning makes generalized and calibrated neural text retrievers. arXiv preprint arXiv:2207.07087, 2022.
- [28] Simeng Sun, Yang Liu, Shuohang Wang, Chenguang Zhu, and Mohit Iyyer. Pearl: Prompting large language models to plan and execute actions over long documents. arXiv preprint arXiv:2305.14564, 2023.
- [29] Van Pham and Scott Cunningham. Chatgpt can predict the future when it tells stories set in the future about the past. arXiv preprint arXiv:2404.07396, 2024.
- [30] Shawn Im and Yixuan Li. Understanding the learning dynamics of alignment with human feedback. arXiv preprint arXiv:2403.18742, 2024.
附录 A 附录
A.1。 提示
附录 B 合成问答示例
我们将在下面展示从 2,000 篇研究论文中生成的合成问答样本。 这些问题和答案是使用元数据和问答生成提示(附录 A)生成的。
- 问题 #1:“研究人员对 ChatGPT-4 中未来叙事提示方法似乎比直接提示解锁了改进的预测能力的原因有何推测?”(来自 [29])
- 答案 #1:“研究人员推测,叙事提示方法可能利用了 ChatGPT-4 的“幻觉”叙事构建能力,使其能够更有效地从其训练数据中合成和推断,从而做出更准确的预测,而直接提示方法则无法做到这一点。 这表明模型的创造力可以被战略性地用于预测任务。”
- 问题 #2:“偏好数据集的分布如何影响使用直接偏好优化 (DPO) 目标时模型更新的速度和训练准确性? 对实际对齐方法有何影响?”(来自 [30])
- 答案 #2:“本文提供了理论分析,表明偏好数据集的分布(以“偏好可区分性”为特征)对 DPO 目标下模型更新的速度和训练准确性有很大影响。 行为的可区分性越高,损失减少和参数更新的速度就越快。 这会导致一种错综复杂的优先级效应,即 DPO 倾向于优先学习可区分性更高的行为,而可能降低对可区分性较低但至关重要的行为的优先级。”
附录 C 基准用户查询
我们将在下面展示使用 Claude 3 Sonnet 生成的 200 个基准研究查询的样本。
- 研究领域 (元数据) #1 : 强化学习
- 合成基准查询 #1: 强化学习如何在自适应交通管理系统中使用?
- 研究领域 (元数据) #2 : 计量经济学
- 合成基准查询 #2: 计量经济学如何应用于理解消费者需求弹性?
- 研究领域 (元数据) #3 : 统计异常检测
- 合成基准查询 #3: 如何在图像和视频等非结构化数据中识别异常?
- 研究领域 (元数据) #4 : 监督学习与无监督学习
- 合成基准查询 #4: 如何将监督学习技术应用于复杂、高维数据?
- 研究领域 (元数据) #5 : 自动驾驶中的 AI
- 合成基准查询 #5: 自动驾驶中使用 AI 集成传感器数据的最新进展有哪些?