利用大型语言模型来增强生成的单元测试的可理解性
摘要
自动化单元测试生成器,特别是基于搜索的软件测试工具,如 EvoSuite,能够生成具有高覆盖率的测试。 尽管这些生成器减轻了编写单元测试的负担,但它们通常会给软件工程师在理解生成的测试方面带来挑战。 为了解决这个问题,我们引入了 UTGen,它将基于搜索的软件测试和大型语言模型结合起来,以增强自动生成的测试用例的可理解性。 我们通过对测试数据进行情景化,改进标识符命名以及添加描述性注释来实现这种增强。 通过一项来自学术界和工业界的 32 名参与者的对照实验,我们调查了单元测试的可理解性如何影响软件工程师执行错误修复任务的能力。 我们选择错误修复来模拟一个现实场景,该场景强调了可理解的测试用例的重要性。 我们观察到,与基线测试用例相比,使用 UTGen 测试用例完成作业的参与者修复的错误多达 33%,并且花费的时间少至 20%。 从测试后的问卷中,我们了解到参与者发现增强的测试名称、测试数据和变量名称改善了他们的错误修复过程。
索引词:
自动测试生成,大型语言模型,单元测试,可读性,可理解性I 介绍
在当今软件主导的世界中,软件的可靠性和正确性非常重要 [1]。 因此,以单元测试形式进行的自动化测试已成为软件工程师确保高质量软件的关键要素 [2, 3, 4]。 尽管测试的重要性得到广泛认可,但编写测试却很繁琐且耗时 [5, 6, 7, 8]。 为了减轻开发人员和测试人员的负担,研究界投入了大量精力研究自动测试生成方法 [9, 10, 11, 12, 13, 14]。 著名的测试生成器包括 Randoop [15] 和 EvoSuite [11]。 例如,EvoSuite 是一种基于搜索的测试生成器,它利用遗传算法构建测试套件 [16],并在覆盖率方面取得了良好的效果 [17, 18]。
然而,根据工业案例研究获得的见解,在生成测试用例的质量方面存在局限性 [19, 20, 21, 22, 23, 24, 25]。 一个关键的局限性围绕着生成的测试用例的可理解性,这涉及到各个方面,例如有意义的测试数据、适当的断言、定义明确的模拟对象、描述性的标识符和测试名称,以及信息丰富的注释。 此外,难以遵循测试用例中描述的场景以及围绕测试数据的模糊性极大地阻碍了清晰度 [25, 26]。
图 1 提供了一个 EvoSuite 生成的测试用例示例。 此测试用例检查了 equals 方法,它使用两个具有不同最小伤害值的 weaponGameData 对象。 在这里,我们看到了几个理解方面的挑战: 1. 用五个参数命名且“调用 equals3”的测试方法的用途和功能尚不清楚, 2. 所选测试数据的理由仍不清楚, 3. 标识符没有提供任何额外信息,以及 4. 缺乏注释使得测试用例没有必要的解释性上下文。
为了解决这些问题,我们旨在通过关注上下文测试数据、清晰的测试方法和标识符名称以及添加描述性注释来增强自动生成的测试用例。 在本研究中,我们研究了基于搜索的软件测试 (SBST) 和大型语言模型 (LLM) 的协同作用。 虽然自然语言处理 (NLP) 技术在文本生成和优化方面展现出了潜力 [27, 28],并且 LLM 具有先进的基于文本的功能 [29, 30, 31, 32, 33],但它们在为复杂系统生成高覆盖率测试用例方面的影响仍然有限 [34, 35]。 相反,SBST 虽然在覆盖率方面很有效,但在测试用例的可理解性方面往往表现不佳。
我们的方法,UTGen,将 LLM 集成到 SBST 测试生成过程中。 我们假设这种结合方法可以利用这两种技术的优势来生成有效且易于理解的测试用例。 我们的研究由三个研究问题 (RQ) 指导,这些问题考虑了 UTGen 方法的有效性和生成的测试用例的可理解性。
- 请求1
-
UTGen 是否能够通过利用 LLM 和 SBST 的组合来生成有效的单元测试?
对该方法有效性的调查旨在确定 SBST 和 LLM 组件的非确定性是否会影响生成可编译且覆盖率高的单元测试的能力。
- 请求2
-
LLM 改进的单元测试的可理解性对开发人员修复错误的效率有什么影响?
在生成的测试用例的可理解性方面,我们打算通过软件工程师执行涉及失败测试用例的错误修复任务的难易程度来衡量可理解性,这是一种以前由 Panichella 等人使用的方法。 [36]。
- 请求3
-
UTGen 的哪些元素影响生成的单元测试的可理解性?
我们构建 RQ3 以更深入地了解 UTGen 方法的哪些元素决定了生成的测试用例的可理解性。
我们论文的主要贡献概述如下:
-
•
UTGen,我们新颖的方法,将 LLM 集成到 SBST 过程中以增强生成的单元测试的可理解性。
-
•
将 UTGen 应用于 346 个类,以检查生成的单元测试的有效性。
-
•
在一个修复 bug 的场景中,一项受控实验和一项针对来自工业界和学术界的 32 位参与者的事后问卷调查旨在评估 LLM 改进测试用例在可理解性方面的影响。
-
•
我们发布了一个复制包,该包在我们实施的基础上公开提供,以及来自我们评估的详细数据和结果 [37]。

II 背景
II-A 基于搜索的软件测试
为了减少测试工作量,已经开发了自动测试生成方法。 像 EvoSuite [11] 和 Randoop [15] 这样的工具使用基于搜索或随机的方法从 Java 源代码生成测试套件 [17, 18]。 几项研究已经揭示了与自动生成的测试相关的挑战 [20, 21, 22, 23, 24, 25],一个重要的挑战是 生成的测试通常比人工编写的测试可读性更差 [38]。 在这种情况下, Almasi 等人 [25] 已经 观察到开发人员 1. 发现测试用例场景难以遵循, 2. 发现测试数据不清楚,以及 3. 在生成的断言的有意义性方面存在困难。
II-B 大型语言模型
大型语言模型是人工智能系统的一个子集,主要基于 Transformer 架构 [39]。 这些 LLM 在海量数据上进行训练,通过这些数据,它们学习文本、代码、对话等固有的底层模式,因此能够根据用户的提示生成(某种程度上)相关的响应 [40]。 LLM 的运行基于预测序列中的后续符元,并通过再次将扩展的序列运行通过模型来预测后续的符元(称为自回归)。 此过程一直持续到达到所需的符元最大数量或生成终止符为止。
自 LLM 出现以来,软件工程师一直利用它们来丰富和简化开发过程 [41, 42, 43]。 与此一致,各种开源模型,例如 Code Llama [44] 和 StarCoder [45],以及闭源模型,例如 Codex [46] 和 GPT4 [40],已经过训练和微调以实现这一目的。
研究界最近一直在研究将 LLM 纳入测试生成过程。 特别是,已经尝试评估利用现有 LLM 生成单元测试的有效性 [29, 35],以及训练专门用于测试生成的 LLM [47]。 然而,这些(混合)测试的可理解性和可用性尚不清楚。 此外,CodaMosa [48] 和 TestPilot [29] 等方法分别提出将 LLM 添加到基于搜索的流程中以解决停滞问题,以及完全自动化测试生成流程,这已经被证明是有用的。 然而,鉴于结果的非确定性 [49, 35],所有这些添加都会出现关于可靠性、正确性和复杂性方面的问题。
最近的研究指出,设计良好的提示对于获得高质量的结果至关重要 [49]。 例如, 使用思维链推理 (CoT) 方法已被证明可以在模型的零样本性能方面带来重大改进 [50, 51]。 此外,最近提出的指南表明,包含关于目标、上下文甚至模型人物的更多信息会影响获得的结果质量 [52]。 虽然这些指南为构建高质量提示提供了良好的起点,但在大多数情况下,这项任务本质上仍然是一个经验过程 [53]。
III UTGen 方法

图 2 概述了我们方法的概况,该方法名为 UTGen。 我们框架的核心是基于搜索的方法,其中我们在测试生成过程的各个阶段整合了 LLM(用绿色突出显示)。 我们使用 EvoSuite [11] 作为首选的基于搜索的测试生成框架,并且我们开发了其他功能,这些功能促进了 EvoSuite 与 LLM 的集成(用蓝色突出显示)。
我们方法 UTGen 的目标是通过改进生成测试的四个关键要素来增强测试用例的可理解性:1)提供丰富的测试数据,2)包含信息性注释,3)使用描述性变量名,以及 4)选择有意义的测试名称。 这些目标定义了我们方法的各个阶段。
作为第一步,在遗传算法结束且测试用例在基于搜索的过程中成熟之后,我们的方法专注于改进测试数据(图 2 中的 )。 UTGen 使用 LLM 生成与上下文相关的测试数据,这与通常依赖随机值的传统基于搜索方法不同。 在这种细化之后,搜索过程结束,我们过渡到后处理任务。 在这里,EvoSuite 最小化了测试套件中的测试用例数量,缩短了单个测试的长度,并添加了断言。
一旦测试用例完全形成,在 阶段,UTGen 利用 LLM 添加描述性注释并增强变量名。 在 阶段,UTGen 使用 LLM 建议测试的合适名称,反映断言和内部逻辑。 最后,为了确保测试用例在这些增强之后是可编译的且稳定的,UTGen 编译它们( 阶段),并且在出现编译问题的情况下,该过程迭代地重新访问 阶段进行调整。
我们首先解释提示工程组件,然后根据每个阶段描述我们的测试生成过程。
III-A 提示生成
UTGen 的提示组件使用来自 Meta 的 code-llama:7b-instruct 模型 [44] ,由 Ollama 提供111Ollama: https://ollama.com/。 我们设计 UTGen 的方式, 使 Code-llama 可以轻松地替换为其他 LLM。 在 UTGen 方法中,有三个阶段使用提示组件: 1. 测试数据的细化, 2. 测试的后处理,以及 3. 测试命名的。 通用提示组件包含两个不同的部分,即 ,它负责生成提供给 LLM 的提示,以及 ,它管理请求并确保返回的响应的正确性。
对于每个阶段,我们根据最近的提示工程研究的指南设计了专门的提示 [52, 50, 51]。 如图 3 所示,这些指南强调以下几点:使用动作词写明清晰的指令(如 ),为模型采用角色(如 ),通过思维链 (CoT) 等技术允许足够长的处理时间(如 ),标准化输入和输出格式,以及以积极的方式构思请求(如 )。 每个提示的起点类似于图 3 中呈现的提示。 由于每个模型都有其复杂性、缺陷和首选输入格式,因此不存在适用于所有情况的提示工程解决方案,但是,上述指南为我们提供了指导。 我们遵循了一个迭代的提示工程过程,其中每个提示的调整都会经过仔细考虑,然后由作者根据结果的潜在改进进行接受或拒绝。 我们最初观察到的一种新兴模式是,LLM 无法始终遵守为其描述的输出格式。 因此,我们制定了指南来处理此类不匹配;例如,我们必须处理将纯文本放置在代码块中的情况,或者 LLM 未使用预期的分隔符的情况。 我们的复制包包含我们设计的提示的最终版本,以及其他采取的措施 [37]。

III-B 第 1 阶段:测试数据细化
在此阶段,我们专注于从 LLM 请求上下文化的测试数据,以提高测试数据对于测试场景的领域相关性。 我们设计了一个解析器,它将 LLM 的响应转换为 EvoSuite 所需的结构化格式。
测试数据细化阶段应被视为搜索过程中的另一个迭代,其中新的和原始的测试用例在测试群体中并存。 细化的测试用例能够改变原始测试的逻辑,并且它们涵盖了被测方法的不同部分。
图 4 的阶段 展示了细化阶段的一个示例,其中原始测试数据和增强测试数据并排显示。 基于上下文,LLM 将 WeaponGameData 构造函数调用中的第四个参数从 "N&zMn$@6gffi<" 更改为 "Ninja Sword",这在 WeaponGameData 的上下文中更有意义。
然而,重要的是要承认 LLM 响应中存在某些限制。 偶尔,LLM 可能会出现幻觉 [54],例如,生成与原始测试用例偏差的行,或者更改方法调用中参数的数量。 为了缓解这些不一致性,我们设计了我们的解析器,如果原始测试用例中存在与之对应的行,则用原始测试用例中的对应行替换错误行。 如果原始测试用例中没有对应行,解析器将跳过解析这些错误行,并继续解析 LLM 生成的测试用例的其余部分。 这增加了即使是包含遗漏的测试用例也有效编译的可能性。 例如,如果 LLM 的响应添加了一个不存在的语句,例如 weaponGameData0.increaseDmg(10),解析器将跳过此行并继续处理。 同样,如果 LLM 改变了方法的参数计数,例如将 weaponGameData0.getDmgBonus() 更改为 weaponGameData0.getDmgBonus(10), 解析器将使用原始方法调用,参数为零。 这些策略确保解析器从 LLM 响应中提取最大数量的语句,最大程度地减少重新提示的需要。
在后优化中,EvoSuite 优化测试用例集并向其中添加断言。 优化包括缩短测试用例,并从用例集中消除重复的测试用例。 选择保留哪个重复测试用例以及消除哪个测试用例由一个次要目标决定,该目标优先选择最小化重复测试用例集中所有测试用例的总长度的测试用例。

III-C 阶段 2:后处理
在此阶段,我们通过使代码的各个方面更易理解,使最终选择的测试尽可能易于理解。 UTGen 通过添加描述性注释以及使变量名更清晰来实现这一点。
后优化完成后,断言将添加到测试用例中,并且测试用例在覆盖率方面已达到成熟, 它们将被提供给 LLM 进行改进。 指示 LLM 添加注释(使用 Given、When、Then 约定 - 被视为更易于理解 [55])并专门更改变量的命名,但让数据和逻辑保持不变,因为这可能会影响某些测试的预期行为。
为了确保原始测试用例和增强测试用例之间的最大逻辑相似性,我们使用 CodeBLEU 指标,该指标有效地评估两个序列之间的句法和语义相似性 [56]。 我们选择控制相似性以增加生成测试用例和改进测试用例之间的一致性,并最大程度地减少 LLM 幻觉的影响。 CodeBLEU 得分低于 会触发重新提示过程。
我们将重新提示限制为三次迭代,因为我们的研究结果表明,此限制保留了逻辑连贯性,并仍然有助于改进测试。 如果 LLM 在三次尝试后仍未达到阈值,则提示会简化,删除注释结构约束,从而允许偏离初始格式。 如果 LLM 的响应在总共六次尝试后仍未达到令人满意的水平,则保留原始测试用例。 每种提示策略三次尝试的值也是为了平衡有效性和执行成本而选择的。
此外,正如之前文献所指出的,给定未修改的模型温度,LLM 的结果可能是不可预测的,这反过来会导致结果偏离原始测试,或者测试没有正确的语法。 为了确保返回结果的一致性和可靠性,我们采用了一套启发式保护措施,以促进控制此类异常的过程。 对于 LLM 的每次响应,我们 1. 尝试识别和删除 LLM 在代码中常见的错误,例如,将注释作为纯文本而不是注释放置在代码中, 2. 尝试纠正代码中任何缺少的闭合括号, 3. 使用 CodeBLEU 验证代码,如前所述,以及 4. 使用解析器生成工具 ANTLR222ANTLR: https://www.antlr.org/ 检查返回结果的语法正确性。
此外,如果之前描述的任何安全措施未能改进响应,未能实现语法正确性或 CodeBLEU 的值低于阈值,我们将重新提示 LLM。 我们限制了递归调用的数量,以避免单个改进请求使整个过程停滞。 以上解释的所有过程都与图 2 中标有 的组件相关。
此步骤的示例显示在图 4 中的 中: 以 Given-when-then 格式添加注释,并将变量名从 weaponGameData0 和 weaponGameData1 更改为 defaultWeapon 和 customWeapon,匹配测试用例的逻辑。 此外,断言消息是从 LLM 响应中添加的。
III-D 第 3 阶段:测试方法名称建议
在此阶段,UTGen 向 LLM 提供测试的完整方法体,并要求它推导出一个描述性的名称。 我们选择将此阶段放在测试方法体的后处理之后,因为这样测试用例就包含了注释,这些注释为 LLM 生成描述性测试方法名称提供了更多上下文。 如果另一个测试用例已经具有类似的测试名称,我们将重新提示,直到它具有唯一的名称。
例如,在图 4 中的 中,LLM 建议使用 testEqualsWithDifferentMinDmgValues()。 此名称反映了测试的功能,即检查 equals 方法在不同的最小伤害值范围内的表现。 相比之下,EvoSuite 将此测试命名为 testCreatesWeaponGameDataTaking6ArgumentsAndCallsEquals3。
III-E 第 4 阶段:编译和验证
在成功地通过安全措施之后,测试用例仍然有可能无法编译。 因此,我们编译所有测试用例,并且对于无法编译的测试用例,我们会重复进行后处理和测试方法名称建议,默认的后处理预算为 2 次迭代。
然后评估编译的测试用例的稳定性。 如果测试用例因与 JUnit 断言无关的异常而失败,则认为该测试用例不稳定。 所有既可编译又稳定的测试用例都会被保存。
IV 实验设置
本节将描述我们方法的评估方法。 我们研究以下研究问题:
- 请求1
-
UTGen 是否能够通过结合 LLM 和 SBST 生成有效的单元测试?
- 请求2
-
LLM 增强单元测试的可理解性对开发者修复 bug 的效率有什么影响?
- 请求3
-
UTGen 的哪些元素影响生成的单元测试的可理解性?
现在我们将讨论 RQ1 到 RQ3 的评估策略。
| Attendance | Academia | Industry | |
|---|---|---|---|
| In Person | 17 | 4 | 21 |
| Remote | 3 | 8 | 11 |
| 20 | 12 | 32 |
| Experience | Academia | Industry | ||
|---|---|---|---|---|
| In Java | In Testing | In Java | In Testing | |
| 0-2 years | 5 | 9 | 0 | 2 |
| 3-6 years | 11 | 9 | 8 | 5 |
| 7-10 years | 2 | 1 | 3 | 2 |
| 10 years | 2 | 1 | 1 | 3 |
| Affiliation | Academia | Industry | ||
|---|---|---|---|---|
| Role | Number | Role | Number | |
| PhD Student | 9 (45%) | Developer | 6 (50%) | |
| MSc Student | 8 (40%) | Senior Researcher | 3 (25%) | |
| BSc Student | 1 (5%) | Scientific Dev. | 1 (8%) | |
| Post Doc | 1 (5%) | Team Lead | 2 (17%) | |
| Scientific Dev. | 1 (5%) | |||
IV-A 效力评估设置 (RQ1)
我们从两个方面探索了 UTGen 的有效性:LLM 增强测试用例的可编译性比率,以及基线测试用例和 UTGen 测试用例覆盖率的比较。
IV-A1 数据集
我们利用 DynaMOSA 数据集,其中包含来自 个开源项目的 个非平凡 Java 类,用于 RQ1 [18]。 这些类是从四个不同的基准测试中选取的,其中主要来源是 SF110 的 204 个非平凡类 [57]。
IV-A2 评估
我们使用 EvoSuite 框架作为基线评估了 UTGen。 我们在数据集上应用 UTGen,并生成了两种类型的测试用例:原始 EvoSuite 测试用例和 LLM 改进的测试用例。 然后,我们通过衡量这两个类型的测试用例来比较它们 1. 成功编译的 LLM 改进测试用例数量, 2. 分支和指令测试覆盖率,以及 3. 通过/失败率。
IV-A3 参数配置
我们决定使用 EvoSuite 的默认配置参数,这些参数已被经验性地证明可以提供良好的结果 [58]。 我们确实将测试预算(max_time)从 60 秒增加到 200 秒,以确保搜索算法有足够的时间生成能够实现合理覆盖率的测试群体。
IV-B 受控实验 (RQ2)
我们进行了一个受控实验,以评估测试用例在现实场景中的可理解性,即错误修复 [59]。 这扩展了 Panichella 等人的工作,他们调查了在错误修复的背景下为自动生成的测试生成文档的影响 [36]。
该实验涉及 32 名参与者。 实验组使用 UTGen 测试用例,而对照组使用 EvoSuite 测试用例。 我们使用 基于覆盖率的测试命名 配置了 EvoSuite,它生成的测试名称比默认设置更易读 [60]。
我们在实验中检查了两个因变量: 1. 修复的错误数量,以及 2. 时间效率,以修复错误所需的时间来衡量。
IV-B1 参与者
我们招募了具有学术和工业背景的参与者。 表 I 展示了他们的统计数据。 为了吸引学术参与者,实验通过大学的通讯渠道进行宣传。 此外,还征募了来自工业合作伙伴的开发人员。 此外,所有作者都联系了他们的软件工程师专业网络。 我们确保向具有 Java 和测试经验的个人发出邀请。
IV-B2 对象
| Project | Class | LOC | Methods | Branches |
|---|---|---|---|---|
| caloriecount | Budget | 152 | 21 | 16 |
| twfbplayer | JSWeaponData | 177 | 19 | 44 |
为了设计错误修复任务并比较实验组和对照组,选择两个项目作为基础以了解错误修复的背景至关重要。 为此,我们分析了 SF110 数据集中所有类,收集了代码行 (LOC) 分布的洞察力,代码行作为复杂性的指标 [61]。 利用这些数据,我们计算了每个分布的平均值 () 和标准差 ()。 然后,我们确定了所有指定指标中落入 范围内的所有类别。 此过程产生了 个类。 通过对这些类进行手动检查,我们选出了两个类进行考虑: 1. 预算,其中包含用于计算时间间隔内的卡路里的方法,以及 2. JS武器数据 ,其中包含与 Java 游戏中的武器对象相关的功能。 表 II 提供了这两个类的详细信息。 我们在每个类中注入四个错误,每个错误位于测试中的不同方法。 注入的错误包括算术运算的替换 (2 个错误)、语句删除 (1 个错误)、布尔关系替换 (2 个错误) 和变量替换 (3 个错误)。 虽然两个类中的故障类型相似,但由于其详细的时间计算,修复 Budget 类中的故障可能更具挑战性。
IV-B3 实验设计
我们的实验采用了 2 × 2 析因交叉设计;它包含两个时期,并包括一个基于对象的双水平阻断变量。 在每个时期,受试者将不同的技术(处理)应用于不同的对象(分配)。 与组间设计相比,我们更倾向于交叉设计,因为组间设计需要更多的参与者才能获得足够的统计功效。 实验的设计在表 III 中有详细说明,其中概述了使用的四种序列。 我们遵循 Vegas 等人 [62] 提供的实验设计指南。
为了最大限度地减少学习效应,参与者在每个时期都获得了涉及不同对象的任务。 此外,为了避免最佳排序带来的任何潜在偏差,我们根据参与者人数、学术背景和行业背景对参与者进行了序列平衡。 对于来自学术界的参与者,每个序列执行了 5 次,而对于工业参与者,每个序列执行了 3 次。
IV-B4 实验程序
参与者可以通过面对面或通过视频会议远程执行控制实验。 在实际实验之前,我们要求参与者填写一份预测试卷,以评估他们的经验。 在实验开始前一天,我们向他们发送了 1. 同意书, 2. 实验执行的说明和材料,包括两个作业, 3. 一个表示序列的数字(参见表 III),以及 4. 一个指向在线调查平台的链接。 这种提前准备是必要的,因为我们在试点评估中观察到,在实验开始前才收到项目会导致额外的准备时间,从而增加疲劳的威胁。 这也会导致参与者在遇到困难时产生压力。
在实验过程中,一名考官会持续在场,解释期望并控制可能影响实验的任何外部因素,例如,确保参与者不使用外部资源来修复错误。
在实验中,我们要求参与者完成两个任务;每个任务包括在 30 分钟内修复四个错误。 我们假设延长时间或拥有一个无限的窗口框会加剧学习效果,并引入疲劳/无聊的威胁。 如果参与者表示已在 30 分钟内修复了所有 4 个错误,考官会对此进行复核,参与者可以继续下一步。 每位参与者收到两个任务: 1. 一项包含一个 Java 类及其对应测试类的任务,该测试类由 UTGen 生成,以及 2. 一个 Java 类,以及由基线方法(即 EvoSuite)生成的相应测试类。
| #Seq | Order | Period 1 | Period 2 | ||
|---|---|---|---|---|---|
| Object | Technique | Object | Technique | ||
| I | U-E | Budget | UTGen | JSWeaponData | EvoSuite |
| II | E-U | Budget | Evosuite | JSWeaponData | UTGen |
| III | U-E | JSWeaponData | UTGen | Budget | Evosuite |
| IV | E-U | JSWeaponData | Evosuite | Budget | UTGen |
IV-B5 预备测试
我们让 4 名参与者(不属于 32 名参与者的一部分)进行了预备测试。 在预备测试运行后,我们将任务从 20 分钟内修复 5 个错误改为 30 分钟内修复 4 个错误,并通过 Javadoc 文档阐明了预期行为。 我们还缩小了代码范围,将其分成 绝对良好 和 可能存在错误 的代码部分。 因此确保了任务在 30 分钟的时间范围内是可行的。 最后,我们改进了任务描述,提前向参与者发送详细说明和实验概述。
IV-B6 分析方法
我们进行了统计测试,以确定在 LLM 改进的测试用例中发现的错误数量与修复错误所需的时间与基准测试用例之间是否存在显着差异。 由于我们的交叉设计,我们考虑了潜在的累积效应,这要求将数据视为依赖数据。 因此,适用于独立样本的非参数假设检验,如 Wilcoxon 秩和检验并不适用 [62]。
相反,我们在分析中采用了混合模型。 具体来说,对于我们每个因变量:
-
1.
修复的错误数量:此变量是离散的,介于 0-4 之间,我们将它视为序数变量。 因此,我们使用累积链接混合模型 [63],它们适合此类型的数据。
-
2.
时间效率:此变量代表修复错误所需的时间,我们使用具有伽马分布的广义线性混合模型,该模型适用于时间相关数据 [64]。
我们将技术、对象、技术:对象、顺序(与遗留混淆)和周期视为固定效应,并将参与者(#id)视为随机效应。 顺序效应嵌入在变量顺序和技术:对象中。 我们将两个模型的显著性水平设置为 。
此外,我们还检查了参与者的背景、Java 和测试编程经验,以及会议是现场参加还是远程参加等因素是否与技术对修复的错误数量产生交互作用。 在这些情况下,我们通过将这些因素添加到混合模型中来扩展它,以评估它们与技术的交互作用。
我们还使用 Cohen 的 d 来衡量效应大小,范围从非常小 () 到小 ()、中 () 和大 () [65]。
IV-C 考试后问卷(RQ3)
我们使用考试后问卷从受控实验的参与者那里获取反馈,了解 UTGen 的哪些方面影响了测试用例的可理解性(见表 IV)。 我们专注于衡量三个方面: 1. 参与者对测试用例的可理解性如何影响其修复错误有效性的看法, 2. 他们对测试代码中哪些因素有助于生成测试用例的可理解性的看法,以及 3. 他们对在有和没有 LLM 改进增强的情况下,测试用例中这些因素质量的评价。
IV-C1 问卷
在 Q1 中,我们要求参与者识别他们认为会影响修复错误有效性的因素。 重要的是,在这个阶段,参与者并不知道实验的重点是生成测试用例的可理解性,从而确保他们的回应真实地反映了他们对修复错误的最初想法。 在 Q2 中,我们询问参与者是否认为生成的测试用例的清晰度会影响错误修复。 Q3 和 Q4 衡量哪些因素对可理解性影响最大。 在 Q5 中,我们要求参与者使用李克特量表和开放式反馈来评估两个任务的可理解性。 最后,在 Q6 和 Q7 中,我们要求参与者对两个任务测试用例中的特定元素(如注释、测试数据、测试名称和变量命名)进行评分,评分标准包括完整性、简洁性、清晰度和自然性,从而旨在对测试用例质量的不同方面进行详细评估[28, 66, 36]。
| # | Title | Type of Question | Aspect |
|---|---|---|---|
| Q1 | In your opinion, what factors make finding bugs easier for you? | Open | 1 |
| Q2 | Do you think the understandability of the test cases affects your bug fixing? | Likert | 1 |
| Q3 | Prioritize the elements in helping understandability | Ranking | 2 |
| Q4 | How important are the following elements in the understandability of the test case | Likert | 2 |
| Q5 | How do you judge the understandability of the provided test case (Task 1 and 2) | Likert, Open | 3 |
| Q6 | Evaluate how good you think the first task is in each item | Matrix Table, Open | 3 |
| Q7 | Evaluate how good you think the second task is in each item | Matrix Table, Open | 3 |
IV-C2 分析方法
对于开放式问题,我们使用卡片分类法将数据分类,并计算每个类别的频率。 两位作者独立审阅了卡片分类过程,一致性达到 84%。 对于李克特量表问题,我们确定了每个答案的平均值和百分比。 对于 Q6 和 Q7,由于数据不符合正态分布(由 Shapiro-Wilk 检验确定, 值 ),我们使用 Wilcoxon 秩和检验, 为 0.05。 我们使用 Cohen 的 d 效应量来确定差异的程度。
V 结果
在下面,我们将讨论每个研究问题的结果。
V-A RQ1: 集成 LLMs 和基于搜索的方法来生成单元测试的有效性
我们将有效性定义为 UTGen 生成可编译且可靠执行的单元测试的能力,以及它们覆盖被测类的能力。 成功率,定义为执行后通过的生成测试的比例,反映了功能正确性。 重要的是要注意,虽然所有生成的测试都可以编译,但成功率仅与它们的执行结果有关。
UTGen 成功地生成了总共 8430 个测试,通过率为 73.27%,而 EvoSuite 生成了 8315 个测试,通过率略高,为 79.01%。 在第 III-C 节中描述的启发式保护措施确保了测试用例的语法正确性和可编译性,但也导致 27.52% 的测试被归类为“增强停滞”,即 LLM 无法改进测试用例,或“回退”,即我们回到了 EvoSuite 基线测试用例,因为测试用例无法编译。 因此,这 27.52% 的测试用例可以编译,但不会受到 UTGen 的显著影响。
某些测试用例不会受到 UTGen 的显著影响的根源在于 LLMs 的非确定性。 由于我们无法保证给定 LLMs 的测试在改进后会编译,因为 LLM 可能出现幻觉,因此我们采用了多种保护措施。 虽然第 III-C 节中解释的保护措施确实设法捕获了大部分无法编译的测试,但有些测试还是会漏掉。 因此,我们执行编译检查(图 2 中的 )。 如果任何(改进的)测试无法编译,我们就会回退到 EvoSuite 生成的测试用例。
在 UTGen 生成的总共 8430 个测试中,有 11.77% 的测试无法编译,因此回退到 EvoSuite 生成的初始测试用例。 剩余的 15.75% 的测试是由于增强过程停滞,LLM 无法做出重大贡献。
| # | 1. Pass/Failed | Test Count | Pass Rate |
| 1. | EvoSuite | 8315 | 79.01% |
| 2. | UTGen | 8430 | 73.27% |
| # | 2. Improved Tests | Test Count | Percentage |
| 1. | Improved Tests | 6110 | 72.48% |
| 2. | Reverted Tests | 992 | 11.77% |
| 3. | Enhancment Stagnation | 1328 | 15.75% |
| # | 3. Coverage | Instruction Coverage | Branch Coverage |
| 1. | EvoSuite | 25.03% | 18.68% |
| 2. | UTGen | 24.43% | 17.87% |
最后, 从表 V 中我们可以观察到,与 UTGen 相比,EvoSuite 达到了略高的覆盖率:指令覆盖率为 25.03%,而 UTGen 为 24.43%,分支覆盖率为 18.68%,而 UTGen 为 17.87%。 在对覆盖率差异原因的进一步调查中,我们发现,后处理步骤中的细微变化,例如参数值的变化,会影响所实现的总体覆盖率。
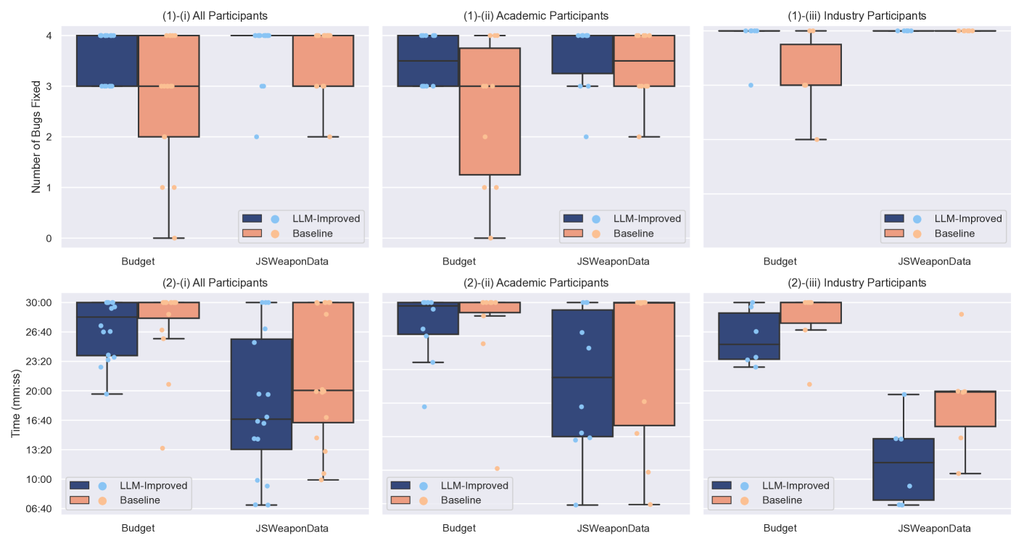
V-B RQ2: 对漏洞修复的影响
图 5 展示了受控实验的结果,结果基于两个因变量: 1. 修复的漏洞数量,以及 2. 时间效率,通过完成任务所需的时间来衡量。 结果分别针对整个群体、学术参与者和行业参与者进行报告。
对于这两个对象,与基线测试用例相比,参与者在使用 LLM 改进的测试用例的任务中修复了更多漏洞。 对于 Budget 类,差异更为明显,因为参与者使用 LLM 改进的测试用例修复了 4 个漏洞的中位数,而基线测试用例修复了 3 个漏洞的中位数。 对于 JSWeaponData 类,差异很小,因为参与者使用任何一种测试用例修复了 4 个漏洞的中位数。 根据表 VI 中展示的固定效应检验,我们在修复的漏洞列中观察到,技术 () 和对象 () 都会显著影响修复的漏洞数量。 这意味着使用 LLM 改进的测试用例显著提高了修复更多错误的可能性。 同样,当对象为 JSWeaponData 时,修复更多错误的概率也显著提高。 治疗的 Cohen’s d 效应量结果为 0.59,属于中等水平。
关于时间效率,使用 LLM 改进测试用例的参与者通常花费更少的时间来修复两个类别中的所有错误。
然而,时间上的差异对于该技术 () 来说并不显著,只有对象 () 存在显著差异。 这种差异在 JSWeaponData 类中更为明显,其中修复所有错误的平均时间为 18:22(LLM 改进)对比基线测试用例的 22:06(减少 20% 的时间)。 对于 Budget 类,平均值较为接近:LLM 改进为 27:06,基线测试用例为 27:51。 这主要是由于 30 分钟的截止时间限制了可观察的差异。
此外,对估计边际均值的事后分析,包括针对每个特定对象级别进行的不同技术级别的成对比较,表明在 Budget 类中,治疗(LLM 改进测试用例)具有显著性 (),而在 JSWeaponData 类中则不显著 ()。 治疗在 Budget 类的 Cohen’s d 效应量很大,为 。 我们假设,与 JSWeaponData 相比,在 Budget 任务中修复的错误数量的统计学上显著的改善,是由于 Budget 类中场景和错误的复杂性更高。 这种复杂性很可能会增加对更清晰、更易理解的测试用例的需求。
此外,无论是周期 ( 和 ) 还是顺序 ( 和 ) 都不显著影响修复的错误数量和时间效率。 这表明治疗之间不存在残留效应。 技术和对象之间的交互并不显著,这表明技术对修复的错误数量和时间效率的影响不依赖于对象。 此外,我们的分析发现,技术与协变量(如参与者的背景、Java 和测试经验,以及他们是在远程还是线下参加会议)之间不存在显著交互 ()。
| Source | Fixed Bugs | Time Efficiency | ||
|---|---|---|---|---|
| Estimate | Estimate | |||
| Technique | 2.997 | 0.024 | -0.116 | 0.063 |
| Object | 2.903 | 0.025 | 0.133 | 0.031 |
| Technique: Object | 0.951 | 0.401 | 0.088 | 0.408 |
| Order | 1.588 | 0.138 | -0.069 | 0.517 |
| Period | 0.951 | 0.176 | -0.114 | 0.068 |
最后,就我们参与者背景的影响而言,我们观察到,与基线测试用例相比,两组人群在使用LLM改进的测试用例时,在修复的错误数量和修复错误所花费的时间方面都表现出更好的性能。 我们观察到,学术参与者似乎从LLM改进的测试用例中受益更多,这有助于他们修复错误。 另一方面,对于工业参与者来说,节省时间的效果更为明显。 图5提供了更详细的概述。
V-C RQ3:UTGen不同元素对可理解性的影响
后测问卷的结果显示三个方面: 1. 参与者对测试用例的可理解性如何影响他们的错误修复效率的看法, 2. 他们对测试代码中哪些因素有助于可理解性的看法 以及 3. 他们对带有和不带有LLM改进增强功能的测试用例中元素质量的评价。
方面1:测试用例的可理解性如何影响错误修复
我们通过对问卷中问题1和2的回答来回答第一个方面。 我们观察到,参与者发现编写良好的测试套件对于修复错误很重要:他们经常强调(14次提及)测试名称的描述性和清晰性、断言的适当使用以及测试套件中精心选择的测试数据的重要性。 这一方面优先于其他因素,例如高质量的生产代码(10 次提及)。 我们还注意到,总体上(强烈)一致认为测试用例的可理解性在修复错误的背景下很重要,如表 VII 中的平均得分为 5 分中的 4 分(Q2)所示。
| Q2. The effect of understandability on bug fixing | Strongly disagree | Disagree | Neither agree nor disagree | Agree | Strongly agree |
|---|---|---|---|---|---|
| 6.2% | 9.3% | 6.2% | 34.4% | 43.7% | |
| Q3. Prioritize the elements in helping understandability | Rank 4 | Rank 3 | Rank 2 | Rank 1 | |
| 1. Comment | 9.3% | 25% | 31.2% | 34.3% | |
| 2. Test Name | 34.3% | 9.3% | 15.6% | 40.6% | |
| 3. Variable Naming | 21% | 34.3% | 34.3% | 9.3% | |
| 4. Test Data | 34.3% | 31.2% | 18.7% | 15.6% | |
| Q4. How important are the elements in the understandability | Not important | Slightly important | Moderately important | Very important | Extremely important |
| 1. Comment | 6.2% | 15.6% | 21.8% | 34.3% | 21.8% |
| 2. Test Name | 6.2% | 21.8% | 21.8% | 12.5% | 34.3% |
| 3. Variable Naming | 3.1% | 12.5% | 34.3% | 31.2% | 18.7% |
| 4. Test Data | 0% | 12.5% | 28.1% | 43.7% | 15.6% |
| Q5. The quality of test cases | Very low | Low | Moderate | High | Very high |
| LLM-improved | 3.13% | 6.25% | 25.0% | 50.0% | 15.63% |
| Baseline | 6.25% | 18.75% | 25.0% | 43.75% | 6.25% |
方面 2:测试代码中的哪些因素有助于可理解性
我们分析了参与者对问题 3 和 4 的回答,他们在这些问题中对要素的重要性进行了排名和评分。 从表 VII 中我们可以观察到,参与者更重视注释和测试名称,而不是变量命名和测试数据。 具体来说,在问题 3 中,34.3% 的参与者将注释列为最重要的因素,而 40.6% 的参与者将测试名称列为优先考虑的事项。
方面 3:带有和不带 LLM 增强功能的测试用例中因素的质量
在表 VII 的 Q5 中,我们看到参与者对 LLM 改进的测试的可理解性评价略高于基线测试用例。
我们在 Q6 和 Q7 中要求参与者根据不同的标准,特别是针对每个测试元素,评估 LLM 改进的基线测试用例和作业。 这些标准包括 完整性、简洁性、清晰度 和 自然性。

图 6 显示了 Q6 和 Q7 的结果。 结果表明,对于每个标准(第一行),LLM 改进的测试用例始终比基线测试用例的评分更高。 Wilcoxon 检验证实了所有标准的统计学显著差异 (-value )。 简洁性的效应量很小,而完整性、自然性和清晰度的效应量很大。 值得注意的是,在开放式回答中,一些参与者提到,LLM 改进的测试用例中的一些评论过于笼统,价值不大。 受访者确实赞赏 Given-When-Then 结构的评论。
当我们放大到测试元素时,我们看到 LLM 改进的测试用例在所有领域都有改进:评论、测试数据、测试名称和变量命名。 所有这些元素的 Wilcoxon 检验在统计学上都具有显著性,-value 为 。 评论、测试数据和测试名称的效应量中等,而变量命名的效应量非常大 ()。
通过分析对问题 5-7 的开放式回答,我们发现测试用例的复杂性会影响评论的必要性。 对于更简单的测试用例,使用 Given-When-Then(Arrange/Act/Assert)结构通常就足够了。 然而,对于更复杂的用例,需要更详细的评论来确保最佳理解。 总的来说,参与者提到了这一点 18 次,其中一位参与者说:“测试代码行很简单,所以评论是不必要的。” 类似地,对于更简单的测试用例,变量命名的质量并不那么重要:参与者在评定一个简短的基线测试用例时,只提到了这个因素 4 次。
VI 讨论
在本节中,我们将讨论我们的结果、其含义以及对我们研究有效性的威胁。
VI-A 回顾研究问题
问题一: UTGen 是否能够通过结合 LLM 和 SBST 来生成有效的单元测试? 当我们比较 LLM 启发的 UTGen 方法和 EvoSuite 的有效性时,我们观察到 UTGen 生成的测试用例具有相对相似的结构覆盖率。 然而,我们也注意到了一种我们称为 增强停滞 的现象,这种现象发生在 LLM 即使在多次重新提示后也无法改进测试用例时。 我们分析了这种情况,发现这种停滞与高复杂性有关。 在这种情况下,我们将被测类的复杂性定义为: 1. 方法具有大量参数,以及 2. 方法紧密耦合,即对象之间或对象内部存在大量方法调用。 虽然通常添加更多相关上下文可以帮助 LLM,但高度复杂的项目可能会由于冗长的输入代码和不足的上下文信息而压倒 LLM,从而阻碍后处理过程中的增强过程。 为了克服这个问题,我们建议将检索增强生成 (RAG) 技术纳入其中。 我们假设这些增强可以减少增强停滞的发生,因为它已解决其他领域中类似的停滞问题 [67, 68]。 RAG 通过动态地将数据库、知识图谱或互联网中的知识实时集成到生成过程中来增强 LLM,从而提供更丰富的上下文和更准确的响应。
问题2: LLM 改进的单元测试的可理解性对开发人员修复错误的效率有何影响? 从受控实验的结果来看,我们发现 LLM 基于的增强为生成的单元测试带来了改进,提高了它们在错误修复场景中的可理解性。 具体来说,实验组比对照组修复了多达 33% 的错误,并且完成任务的速度快了 20%。 我们的实验包括两个分别涉及 预算 和 JSWeaponData 类别的任务。 虽然我们在 预算 任务中观察到统计学上的显著改进,但另一个任务并未达到统计学上的显著性。 由于 预算 类包含更多复杂的场景和错误,我们假设测试场景的复杂性会增加对可理解的测试用例的需求。 这一假设在参与者事后问卷调查中得到了证实。
问题3: UTGen 的哪些元素会影响生成的单元测试的可理解性? 通过事后问卷调查,我们了解到参与者认为,与基线测试用例相比,LLM 增强后的测试用例在注释、测试名称、测试数据和变量名称方面有所改进。 在更高层次上,参与者还评价了完整性、简洁性、清晰度和自然性,认为它们有所提高。 然而,来自开放式问题的反馈强调,注释应该更精确、更有信息量。 同样,一些参与者也强调,简单的测试方法可能不需要(广泛的)注释。 在反思这些反馈后,我们假设,虽然通用训练的 LLM 通常很健壮,但它们可能缺乏特定于任务的数据,无法有效地帮助创建注释。
VI-B 意义
我们研究的结果对研究人员和工具构建者具有重要意义。 特别是,我们的研究表明,一个通用的训练 LLM 已经可以显著提高基于搜索生成的测试用例的可理解性。 然而,我们的结果也表明,测试用例注释在某些情况下应该更详细,而在其他情况下则显得多余。 因此,我们看到了为特定软件工程任务创建专门训练的 LLM 的潜力,但也同样看到了将 LLM 响应定制到个人软件工程师的潜力。
VI-C 有效性威胁
结构效度。 对结构效度的威胁与我们研究的设置有关。 我们在现场或远程进行研究,并有考官在场。 为了控制代码库以外的因素,我们确保所有参与者都有一致的设置,并将 IDE 的选择限制为 IntelliJ,提供统一的功能。 但是,这种方法可能会让有其他 IDE 经验的参与者处于不利地位,从而影响他们的表现。
内部效度。 为了减轻对内部效度的威胁,我们在实验和问卷中没有透露工具名称。 为了防止在选择作业类时出现偏差,我们遵循了系统性的选择过程来加强方法论的完整性。 为了弥补学习效应, 我们创建了四个不同的实验设计序列。 使用混合模型,我们发现时期和遗留效应在统计上并不显著,表明它们不会对研究的有效性构成重大威胁。
外部效度。 我们用来确定 RQ1 中测试生成有效性的课程是对我们结果泛化的潜在威胁。 为了解决这个问题,我们使用了来自 117 个开源 Java 项目的 346 个类的数据集,这些数据集构成了代表性样本,并曾在软件测试研究中使用过 [18, 69]。 我们将 RQ2 中的控制实验限制在两个 Java 类。 为了确保它们的代表性,我们从包含真实世界类的 SF110 数据集中仔细选择了它们,并考虑了整个数据集的平均 LOC 来选择“平均类”。 未来工作将探索更复杂的类。 为了减轻实验组和对照组之间潜在的不平衡,我们在经验和背景方面仔细平衡了两个组的参与者。
VII 相关工作
VII-A 提高测试用例的可理解性
Panichella 等人 [36] 引入了 TestDescriber,它生成描述生成的单元测试意图的测试用例摘要;他们证实这些摘要使软件工程师能够更快地解决错误。 同样,Roy 等人 [28] 开发了 DeepTC-Enhancer,利用深度学习为测试用例生成方法级摘要。 这两项努力都突出了总结测试用例的价值。 相反,UTGen 生成 测试用例本身的详细注释 并提供测试场景的叙述。
Zhang 等人 [27] 引入了一种 NLP 技术,用于自动生成描述性单元测试名称。 Daka 等人 [60] 应用覆盖范围标准来命名 自动生成的单元测试, 而 Roy 等人 [28] 通过使用深度学习来重命名测试用例中的标识符以提高可读性,创建了 DeepTC-Enhancer。 与这些依赖于传统 NLP 技术的方法不同, UTGen 利用 LLM 来建议适合测试场景上下文的标识符。
Afshan 等人 [70] 通过将自然语言模型与基于搜索的测试生成相结合,增强了输入的可读性。 Deljouyi 等人 [66] 提出了一种方法,通过端到端的测试场景雕刻,生成具有有意义数据的可理解测试用例。 Baudry 等人 [71] 使用 LLM 开发了一种测试数据生成器,以生成逼真的、特定于领域的约束条件。 我们的方法类似于 Baudry 等人的方法,但我们专注于基于搜索的单元测试生成。
VII-B 通过 LLM 生成测试用例
尽管基于 LLM 的测试生成取得了进展,但据我们所知,还没有研究专注于通过将基于搜索的方法和 LLM 整合来提高单元测试用例的可理解性。 该领域的研究表明方法和结果存在相当大的差异。 Siddiq 等人使用 LLM 生成了测试,并在 SF110 数据集上报告了 2% 的覆盖率 [35]。 相反,Schäfer 等人的 [29] TestPilot for JavaScript 在相对较小的系统上实现了 70% 的语句级覆盖率。 Alshahwan 等人旨在通过 LLM 改进人工编写的测试,并将其提交给人工审查 [72]。 同时,Lemieux 等人探索了用 LLM 克服 SBST 中的覆盖率停滞 [48],而 Moradi 等人则调查了使用 LLM 进行变异测试 [73]。 Steenhoek 等人通过强化学习改进测试生成,从而最大限度地减少测试气味 [74]。 与上述研究不同,UTGen 专注于通过将 LLM 集成到 SBST 过程来提高可理解性。 值得注意的是,UTGen 实现了 17.87% 的分支覆盖率,超过了 Siddiq 等人提出的纯 LLM 方法 [35]。
VIII 结论
最近的研究表明,在自动测试生成的情况下,测试用例的可理解性是优化的一个关键因素 [25]。 因此,在本文中,我们介绍了 UTGen 方法,该方法将大型语言模型 (LLM) 整合到基于搜索的软件测试 (SBST) 过程中。 这样做,UTGen 旨在通过提供内容丰富的测试数据、信息丰富的注释、描述性变量和有意义的测试名称来提高可理解性。
我们首先在 346 个非平凡的 Java 类上评估了 UTGen 的测试生成效果,观察到 UTGen 成功地增强了 72.48% 的测试用例,并且与 EvoSuite 生成的测试相比,覆盖率略有下降 (RQ1)。 然后,我们对来自工业界和学术界的 32 名参与者进行了受控实验;我们观察到,UTGen 生成的测试用例促进了更容易的错误修复,参与者修复了多达 33% 的错误,并且修复速度快了 20% (RQ2)。 测试后问卷中参与者的反馈表明,测试用例的完整性、简洁性、清晰度和自然性显著提高 (RQ3)。
在未来的工作中,我们旨在探索优化策略,例如检索增强生成 (RAG),以提高提示效率,并最大限度地减少重新提示的需要。 此外,我们计划通过创建专门用于测试生成的定制微调 LLM 来改进我们的方法。 这些定制 LLM 将取代我们目前使用的公开可用的预训练 LLM。
致谢
本研究部分由荷兰科学基金会 NWO 通过 Vici “TestShift” 资助 (编号。 VI.C.182.032)。
参考文献
- [1] A. J. Ko, B. Dosono, and N. Duriseti, “Thirty years of software problems in the news,” in Proc. Int’l Workshop on Cooperative and Human Aspects of Software Engineering (CHASE). ACM, 2014, pp. 32–39.
- [2] K. L. Beck, Test-Driven Development - By Example, ser. The Addison-Wesley signature series. Addison-Wesley, 2003.
- [3] A. Khatami and A. Zaidman, “State-of-the-practice in quality assurance in Java-based open source software development,” Software: Practice and Experience, vol. 54, no. 8, pp. 1408–1446, 2024.
- [4] ——, “Quality assurance awareness in open source software projects on github,” in 2023 IEEE 23rd International Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 2023, pp. 174–185.
- [5] M. Beller, G. Gousios, A. Panichella, S. Proksch et al., “Developer testing in the IDE: patterns, beliefs, and behavior,” IEEE Trans. Software Eng., vol. 45, no. 3, pp. 261–284, 2019.
- [6] M. Beller, G. Gousios, A. Panichella, and A. Zaidman, “When, how, and why developers (do not) test in their IDEs,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE). ACM, 2015, pp. 179–190.
- [7] M. Beller, G. Gousios, and A. Zaidman, “How (much) do developers test?” in 37th IEEE/ACM International Conference on Software Engineering (ICSE). IEEE Computer Society, 2015, pp. 559–562.
- [8] M. F. Aniche, C. Treude, and A. Zaidman, “How developers engineer test cases: An observational study,” IEEE Trans. Software Eng., vol. 48, no. 12, pp. 4925–4946, 2022.
- [9] S. Ali, L. C. Briand, H. Hemmati, and R. K. Panesar-Walawege, “A systematic review of the application and empirical investigation of search-based test case generation,” IEEE Trans. Software Eng., vol. 36, no. 6, pp. 742–762, 2010.
- [10] L. Baresi and M. Miraz, “Testful: automatic unit-test generation for java classes,” in 32nd IEEE/ACM International Conference on Software Engineering (ICSE). ACM, 2010, pp. 281–284.
- [11] G. Fraser and A. Arcuri, “EvoSuite: Automatic test suite generation for object-oriented software,” in Proc. Joint Meeting Symp. Foundations of Software Engineering and the European Softw. Eng. Conf. (ESEC/FSE). ACM, 2011, pp. 416–419.
- [12] G. Fraser, M. Staats, P. McMinn, A. Arcuri, and F. Padberg, “Does automated unit test generation really help software testers? A controlled empirical study,” ACM Trans. Softw. Eng. Methodol., vol. 24, no. 4, pp. 23:1–23:49, 2015.
- [13] P. Derakhshanfar, X. Devroey, A. Panichella, A. Zaidman, and A. van Deursen, “Generating class-level integration tests using call site information,” IEEE Trans. Software Eng., vol. 49, no. 4, pp. 2069–2087, 2023.
- [14] C. E. Brandt, A. Khatami, M. Wessel, and A. Zaidman, “Shaken, not stirred: How developers like their amplified tests,” IEEE Trans. Software Eng., vol. 50, no. 5, pp. 1264–1280, 2024.
- [15] C. Pacheco and M. D. Ernst, “Randoop: Feedback-directed random testing for java,” in Conf. on Object-Oriented Programming Systems and Applications (OOPSLA-Companion). ACM, 2007, pp. 815–816.
- [16] G. Fraser and A. Arcuri, “Achieving scalable mutation-based generation of whole test suites,” Empirical Software Engineering, vol. 20, no. 3, pp. 783–812, 2015.
- [17] ——, “Whole test suite generation,” IEEE Transactions on Software Engineering, vol. 39, no. 2, pp. 276–291, 2013.
- [18] A. Panichella, F. M. Kifetew, and P. Tonella, “Automated test case generation as a many-objective optimisation problem with dynamic selection of the targets,” IEEE Trans. Software Eng., vol. 44, pp. 122–158, 2018.
- [19] A. Arcuri, “An experience report on applying software testing academic results in industry: we need usable automated test generation,” Empirical Software Engineering, vol. 23, no. 4, pp. 1959–1981, 2018.
- [20] F. Palomba, A. Panichella, A. Zaidman, R. Oliveto, and A. De Lucia, “Automatic test case generation: What if test code quality matters?” in Proceedings of the 25th International Symposium on Software Testing and Analysis (ISSTA). ACM, 2016, pp. 130–141.
- [21] F. Palomba, D. Di Nucci, A. Panichella, R. Oliveto, and A. De Lucia, “On the diffusion of test smells in automatically generated test code: An empirical study,” in 2016 IEEE/ACM 9th International Workshop on Search-Based Software Testing (SBST), 2016, pp. 5–14.
- [22] G. Grano, F. Palomba, D. Di Nucci, A. De Lucia, and H. C. Gall, “Scented since the beginning: On the diffuseness of test smells in automatically generated test code,” Journal of Systems and Software, vol. 156, pp. 312–327, 2019.
- [23] G. Fraser and A. Arcuri, “EvoSuite: On the challenges of test case generation in the real world,” in International Conference on Software Testing, Verification and Validation (ICST). IEEE, 2013, pp. 362–369.
- [24] S. Shamshiri, R. Just, J. M. Rojas, G. Fraser et al., “Do automatically generated unit tests find real faults? an empirical study of effectiveness and challenges,” in International Conference on Automated Software Engineering (ASE). IEEE, 2015, pp. 201––211.
- [25] M. M. Almasi, H. Hemmati, G. Fraser, A. Arcuri, and J. Benefelds, “An industrial evaluation of unit test generation: Finding real faults in a financial application,” in Proc. Int’l Conf. on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP). IEEE, 2017.
- [26] C. E. Brandt and A. Zaidman, “Developer-centric test amplification,” Empir. Softw. Eng., vol. 27, no. 4, p. 96, 2022.
- [27] B. Zhang, E. Hill, and J. Clause, “Towards automatically generating descriptive names for unit tests,” in Proc. Int’l Conf. on Automated Software Engineering (ASE). ACM, 2016, pp. 625–636.
- [28] D. Roy, Z. Zhang, M. Ma, V. Arnaoudova et al., “Deeptc-enhancer: Improving the readability of automatically generated tests,” in Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, 2020, pp. 287–298.
- [29] M. Schäfer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,” IEEE Transactions on Software Engineering, vol. 50, no. 1, pp. 85–105, 2024.
- [30] S. Yu, C. Fang, Y. Ling, C. Wu, and Z. Chen, “LLM for test script generation and migration: Challenges, capabilities, and opportunities,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.13574
- [31] A. Mastropaolo, S. Scalabrino, N. Cooper, D. N. Palacio et al., “Studying the usage of text-to-text transfer transformer to support code-related tasks,” 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), 2021.
- [32] V. Liventsev, A. Grishina, A. Härmä, and L. Moonen, “Fully autonomous programming with large language models,” in Proceedings of the Genetic and Evolutionary Computation Conference (GECCO). ACM, 2023, pp. 1146–1155.
- [33] J. Wang, Y. Huang, C. Chen, Z. Liu et al., “Software testing with large language model: Survey, landscape, and vision,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2307.07221
- [34] K. El Haji, C. Brandt, and A. Zaidman, “Using github copilot for test generation in python: An empirical study,” in Proceedings of the International Conference on Automation of Software Test (AST). ACM, 2024.
- [35] M. L. Siddiq, J. C. S. Santos, R. H. Tanvir, N. Ulfat et al., “Using large language models to generate junit tests: An empirical study,” in International Conference on Evaluation and Assessment in Software Engineering (EASE). ACM, 2024.
- [36] S. Panichella, A. Panichella, M. Beller, A. Zaidman, and H. C. Gall, “The impact of test case summaries on bug fixing performance: An empirical investigation,” in Proc. Int’l Conference on Software Engineering (ICSE), 2016, pp. 547–558.
- [37] “Replication package of UTGen,” 2024. [Online]. Available: https://doi.org/10.5281/zenodo.13329464
- [38] G. Grano, S. Scalabrino, H. C. Gall, and R. Oliveto, “An empirical investigation on the readability of manual and generated test cases,” in International Conference on Program Comprehension (ICPC). IEEE, 2018, pp. 348–351.
- [39] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit et al., “Attention is all you need,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.1706.03762
- [40] OpenAI:, J. Achiam, S. Adler, S. Agarwal et al., “Gpt-4 technical report,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.08774
- [41] M. Izadi, R. Gismondi, and G. Gousios, “Codefill: Multi-token code completion by jointly learning from structure and naming sequences,” in Proceedings of the 44th International Conference on Software Engineering, 2022, pp. 401–412.
- [42] M. Izadi, J. Katzy, T. Van Dam, M. Otten et al., “Language models for code completion: A practical evaluation,” in Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13.
- [43] A. Al-Kaswan, T. Ahmed, M. Izadi, A. A. Sawant et al., “Extending source code pre-trained language models to summarise decompiled binaries,” in 2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2023, pp. 260–271.
- [44] B. Rozière, J. Gehring, F. Gloeckle, S. Sootla et al., “Code llama: Open foundation models for code,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.12950
- [45] R. Li, L. B. Allal, Y. Zi, N. Muennighoff et al., “Starcoder: may the source be with you!” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.06161
- [46] M. Chen, J. Tworek, H. Jun, Q. Yuan et al., “Evaluating large language models trained on code,” Arxiv, 2021. [Online]. Available: https://doi.org/10.48550/arXiv.2107.03374
- [47] N. Rao, K. Jain, U. Alon, C. Le Goues, and V. J. Hellendoorn, “Cat-lm training language models on aligned code and tests,” in 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2023, pp. 409–420.
- [48] C. Lemieux, J. P. Inala, S. K. Lahiri, and S. Sen, “Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models,” in IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2023, pp. 919–931.
- [49] S. Ouyang, J. M. Zhang, M. Harman, and M. Wang, “LLM is like a box of chocolates: the non-determinism of ChatGPT in code generation,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2308.02828
- [50] J. Wei, X. Wang, D. Schuurmans, M. Bosma et al., “Chain-of-thought prompting elicits reasoning in large language models,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2201.11903
- [51] J. Li, G. Li, Y. Li, and Z. Jin, “Structured chain-of-thought prompting for code generation,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.06599
- [52] G. Marvin, N. Hellen, D. Jjingo, and J. Nakatumba-Nabende, “Prompt engineering in large language models,” in International Conference on Data Intelligence and Cognitive Informatics. Springer, 2023, pp. 387–402.
- [53] J. Zamfirescu-Pereira, R. Y. Wong, B. Hartmann, and Q. Yang, “Why Johnny can’t prompt: how non-AI experts try (and fail) to design LLM prompts,” in Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023, pp. 1–21.
- [54] A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy et al., “Large language models for software engineering: Survey and open problems,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.03533
- [55] V. Khorikov, Unit Testing Principles, Practices, and Patterns. Manning, 2019.
- [56] S. Ren, D. Guo, S. Lu, L. Zhou et al., “Codebleu: a method for automatic evaluation of code synthesis,” arXiv, 2020. [Online]. Available: https://doi.org/10.48550/arXiv.2009.10297
- [57] G. Fraser and A. Arcuri, “A large scale evaluation of automated unit test generation using evosuite,” ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 24, no. 2, p. 8, 2014.
- [58] A. Arcuri and G. Fraser, “Parameter tuning or default values? an empirical investigation in search-based software engineering,” Empirical Software Engineering, vol. 18, pp. 594–623, 2013.
- [59] A. Zeller, Why Programs Fail: A Guide to Systematic Debugging. Morgan Kaufmann Publishers Inc., 2005.
- [60] E. Daka, J. M. Rojas, and G. Fraser, “Generating unit tests with descriptive names or: Would you name your children thing1 and thing2?” in Proceedings of the International Symposium on Software Testing and Analysis (ISSTA). ACM, 2017, pp. 57–67.
- [61] J. Graylin, J. E. Hale, R. K. Smith, H. David et al., “Cyclomatic complexity and lines of code: empirical evidence of a stable linear relationship,” Journal of Software Engineering and Applications, vol. 2, no. 03, p. 137, 2009.
- [62] S. Vegas, C. Apa, and N. Juristo, “Crossover designs in software engineering experiments: Benefits and perils,” IEEE Transactions on Software Engineering, vol. 42, no. 2, pp. 120–135, 2016.
- [63] R. H. B. Christensen, “Cumulative link models for ordinal regression with the r package ordinal,” Submitted in J. Stat. Software, vol. 35, 2018.
- [64] S. Lo and S. Andrews, “To transform or not to transform: using generalized linear mixed models to analyse reaction time data,” Frontiers in Psychology, vol. 6, 2015.
- [65] G. M. Sullivan and R. Feinn, “Using effect size—or why the p value is not enough,” Journal of graduate medical education, vol. 4, no. 3, pp. 279–282, 2012.
- [66] A. Deljouyi and A. Zaidman, “Generating understandable unit tests through end-to-end test scenario carving,” in Proceedings of the 23rd IEEE International Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 2023, pp. 107–118.
- [67] M. R. Parvez, W. U. Ahmad, S. Chakraborty, B. Ray, and K.-W. Chang, “Retrieval augmented code generation and summarization,” arXiv, 2021. [Online]. Available: https://doi.org/10.48550/arXiv.2108.11601
- [68] S. Liu, Y. Chen, X. Xie, J. Siow, and Y. Liu, “Retrieval-augmented generation for code summarization via hybrid gnn,” 2021.
- [69] J. Campos, Y. Ge, N. Albunian, G. Fraser et al., “An empirical evaluation of evolutionary algorithms for unit test suite generation,” Information and Software Technology, vol. 104, pp. 207–235, 2018.
- [70] S. Afshan, P. McMinn, and M. Stevenson, “Evolving readable string test inputs using a natural language model to reduce human oracle cost,” in International Conference on Software Testing, Verification and Validation (ICST). IEEE, 2013, pp. 352–361.
- [71] B. Baudry, K. Etemadi, S. Fang, Y. Gamage et al., “Generative ai to generate test data generators,” arXiv, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.17626
- [72] N. Alshahwan, J. Chheda, A. Finegenova, B. Gokkaya et al., “Automated unit test improvement using large language models at Meta,” arXiv, 2024. [Online]. Available: https://doi.org/10.48550/ArXiv.2402.09171
- [73] A. M. Dakhel, A. Nikanjam, V. Majdinasab, F. Khomh, and M. C. Desmarais, “Effective test generation using pre-trained large language models and mutation testing,” 2023.
- [74] B. Steenhoek, M. Tufano, N. Sundaresan, and A. Svyatkovskiy, “Reinforcement learning from automatic feedback for high-quality unit test generation,” arXiv, 2023. [Online]. Available: https://doi.org/10.48550/ArXiv.2310.02368