NEST:自监督快速 Conformer 作为语音处理任务的通用调味料
摘要
自监督学习已被证明有利于广泛的语音处理任务,例如语音识别/翻译、说话人验证和区分等。 但是,由于缺乏子采样或使用基于聚类的语音量化,大多数当前方法在计算上都很昂贵。 在本文中,我们提出了一种简化且更有效的自监督学习框架,称为 NeMo 编码器用于语音任务 (NEST)。 具体来说,我们采用 FastConformer 架构,该架构具有 8 倍的子采样率,并且比 Transformer 或 Conformer 架构更快。 而不是基于聚类的令牌生成,我们求助于固定随机投影,因为它简单有效。 我们还提出了一种通用的噪声语音增强方法,该方法可以教会模型从噪声或其他说话者中分离出主要说话者。 实验表明,NEST 在各种语音处理任务上优于现有的自监督模型。 代码和检查点将通过 NVIDIA NeMo 工具包提供111https://github.com/NVIDIA/NeMo。
索引词:
自监督学习、语音识别、说话人区分、口语理解I 引言
最近的大多数语音自监督模型都受到 BERT 模型[1]的启发,该模型通过预测给定未屏蔽位置的上下文掩盖位置的目标来学习文本令牌嵌入。 其中,是 对比 和 预测 模型的两个主要流派。 对比 方法[2, 3, 4, 5] 将语音特征量化为一组目标特征向量,并使用正负目标特征进行对比损失训练。 同时,预测性 方法 [6, 7, 8, 9] 将语音特征量化为 符元,并使用 BERT [1] 中的掩码符元预测损失进行训练。 除了这两种方法之外,一些工作也从掩码自编码 [10] 方法中学习,并使用 重建 目标 [11, 5] 训练语音自监督模型。
对比 模型的一个代表性工作是 Wav2vec-2.0 [2],它证明了从 SSL 检查点初始化 ASR 模型可以胜过以前的半监督和从头训练的 ASR 模型。 后来,Wav2vec-C [3] 在 Wav2vec-2.0 的基础上,通过添加一致性损失来重建量化嵌入,类似于 VQ-VAE [12]。 XLS-R [13] 将 Wav2vec-2.0 扩展到多语言环境,并在多语言语音识别和翻译方面表现出令人印象深刻的性能。
HuBERT [6] 作为 预测性 方法的先驱性工作,通过对从另一个经过少量步骤预训练的 SSL 模型中提取的中层特征运行 k 均值聚类来生成目标符元。 然后,W2v-BERT [14] 提议通过在中层输出上应用对比损失,而在最终输出层上应用预测损失来结合 Wav2vec-2.0 [2] 和 HuBERT [6] 的训练目标。 后来,BEST-RQ [7] 表明,基于聚类的符元生成可以被简单的固定随机投影量化所取代,这种简单的修改能够在 ASR 上匹配或超过 HuBERT。
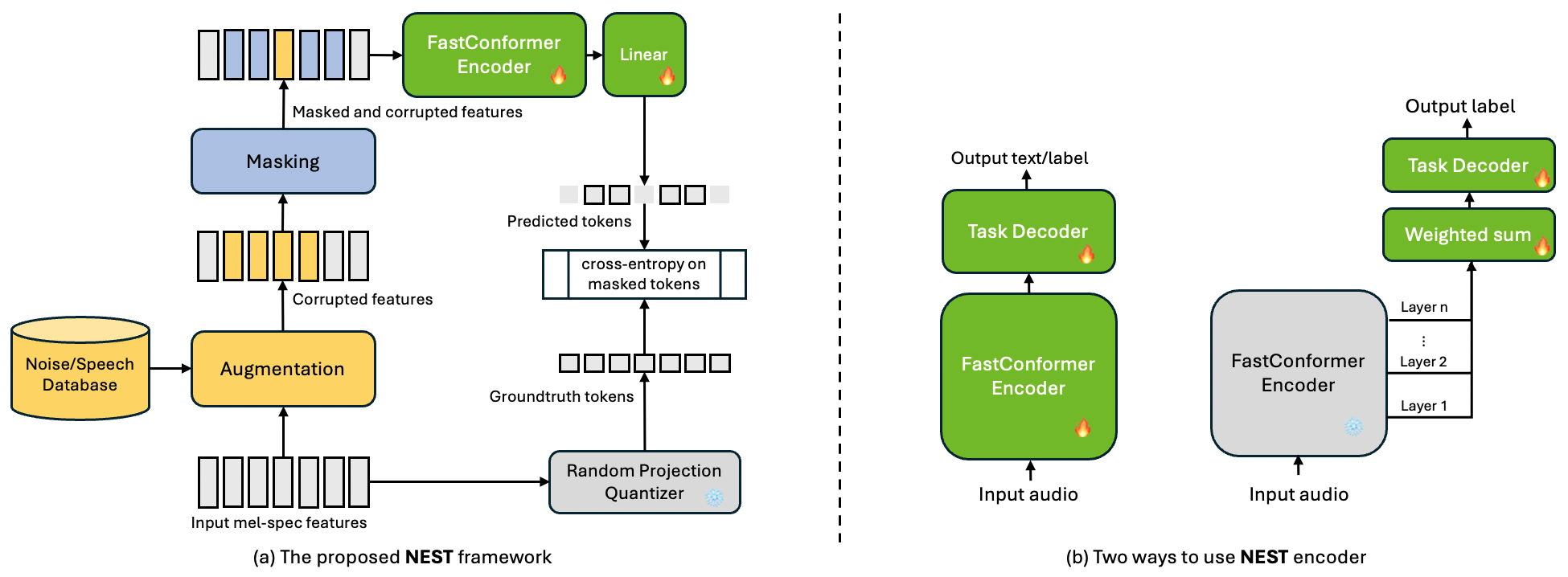
为了提高说话人任务的性能,WavLM [8] 提出了一个噪声语音增强技术和一个 去噪掩码符元预测 目标,通过将不同说话人的语音片段添加到当前语音并训练模型来预测使用原始干净语音生成的 target 符元。 XEUS [9] 通过添加去混响任务并将扩展到 100 万小时的多语言数据进一步扩展了 WavLM [8]。
然而,以前的 SSL 模型也存在不同的局限性。 首先,一些模型 [2, 6, 8] 使用 CNN+Transformer 架构,其帧长度为 20ms,这降低了模型的推理速度。 其次,HuBERT 样式的量化非常昂贵,根据 XEUS [9],它可能占用总训练时间的 20%。 第三,尽管 BEST-RQ [7] 使用 Conformer [15] 编码器,帧长为 40ms,并采用简单的随机量化,但它缺乏明确区分不同说话者的能力,这限制了其在说话人任务上的性能(例如,说话人识别)。
在本文中,我们解决了所有这些挑战,并借鉴了之前工作的最佳实践,构建了所提出的 NeMo 编码器用于语音任务 (NEST) 框架。 我们的贡献总结如下:
-
•
一个新的语音 SSL 模型,它在简化且更有效的框架下实现了 SOTA 性能。
-
•
实验表明,NEST 可以帮助在各种下游任务(ASR、AST、SLU、SD 等)上实现 SOTA 性能。
-
•
与之前主要关注数据有限的下游任务的 SSL 工作不同,我们还表明,NEST 即使在数据相对较大的情况下,也能有利于语音识别和翻译。
-
•
据我们所知,我们是第一个证明在英语数据上训练的 SSL 模型也能帮助提高其他语言的语音识别性能的人。
II 方法
所提出的 NEST 框架如图 1(a) 所示。
II-A 语音编码器
当前的 SOTA 语音 SSL 模型 [8, 6] 主要使用 transformer 编码器 [16] 或 Conformer [15] 作为语音编码器,它们具有 20ms 或 40ms 的帧长。 在这里,我们选择了更高效的 FastConformer [17],它在接下来的 FastConformer 层之前对输入的梅尔谱图应用 8 倍卷积子采样,从而产生了 80ms 的帧长,可以显著减少自注意力层要处理的序列长度。
II-B 语音增强
我们使用随机噪声或另一个说话人的语音来增强输入语音,类似于 WavLM [8] 中提出的技术。 然而,我们以三种方式对数据增强进行了推广:(1)增强音频的长度在原始音频长度的 0.4 到 0.6 之间采样,而不是固定比例的 0.5;(2)增强音频的长度随机地分成 1、2 或 3 个片段,概率相同,这样增强就会分散到原始音频的不同位置;(3)而不是使用单个负面说话者,对于每个有说话者增强的片段,我们从同一个批次中的其他说话者中随机选择一个不同的说话者,这样在结果音频中可以有更多说话者。
| Model | Params | SSL Data (hrs) | Speaker | Content | ParaLinguistics | ||||
|---|---|---|---|---|---|---|---|---|---|
| SID (Acc ) | SV (EER ) | SD (DER ) | PR (PER ) | ASR (WER ) | KS (Acc ) | ER (Acc ) | |||
| WavLM-base++ [8] | 95M | En-96K | 86.84 | 4.26 | 4.07 | 4.07 | 5.59 | 96.69 | 67.98 |
| WavLM-large [8] | 316M | En-96K | 95.25 | 4.04 | 3.47 | 3.09 | 3.44 | 97.40 | 70.03 |
| XEUS [9] | 577M | MulLing-1M | 91.70 | 4.16 | 3.11 | 3.21 | 3.34 | 98.32 | 71.08 |
| NEST-L | 108M | En-100K | 94.94 | 3.85 | 2.28 | 1.95 | 3.49 | 96.85 | 68.12 |
| NEST-XL | 600M | En-100K | 95.76 | 2.49 | 1.89 | 1.80 | 3.19 | 97.11 | 69.94 |
| Model | Params | Data (hrs) | En | De | Es | Fr | Avg | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MCV16.1 | Voxpopuli | MCV16.1 | Voxpopuli | MCV16.1 | Voxpopuli | MCV16.1 | Voxpopuli | ||||
| SeamlessM4T-medium-v1 [19] | 1.2B | 4M | 14.20 | 10.02 | 11.25 | 16.20 | 11.43 | 12.01 | 17.34 | 12.49 | 13.11 |
| SeamlessM4T-large-v2 [19] | 2.3B | 4M | 11.13 | 7.77 | 7.53 | 13.39 | 8.671 | 10.53 | 14.37 | 10.13 | 10.44 |
| Whisper-large-v3 [20] | 1.5B | 5M | 15.73 | 13.42 | 9.24 | 21.41 | 10.95 | 14.31 | 17.35 | 13.58 | 14.49 |
| Canary-1b [21] | 1B | 86k | 12.46 | 7.52 | 8.71 | 15.32 | 8.28 | 9.56 | 15.46 | 8.78 | 10.76 |
| FastConformer-XL-hybrid (ASR init) | 600M | 14K | 16.78 | 8.21 | 9.17 | 12.69 | 9.75 | 10.19 | 17.42 | 9.89 | 11.76 |
| NEST-XL-hybrid | 600M | 14K | 14.43 | 7.58 | 8.07 | 11.83 | 8.70 | 9.27 | 16.18 | 9.74 | 10.72 |
II-C 语音量化
我们使用 BEST-RQ [7] 作为我们的语音量化方法。 具体来说,我们使用了一个包含 8192 个词汇表和 16 维特征的单个随机初始化和冻结码本。 一个随机初始化和冻结的线性层被应用于输入的梅尔谱图特征,将它们投影到与码本相同的维度,然后应用最近邻搜索来获得目标符元。 由于有 8 倍下采样,我们在将特征送入线性层之前,将每 8 帧连续帧的特征进行通道连接,这样目标符元和输入特征的长度就相等了。
II-D 特征掩蔽
我们在输入梅尔谱图特征上采用随机块掩蔽机制,其中输入中的每一帧都有一个 的概率被选择为掩蔽块的开始。 随机选择一组起始帧后,我们对每个起始帧的 连续帧进行掩蔽。 注意,两个掩码块之间可能存在重叠,这允许在生成的掩码段中存在任意长度,并且这些段彼此之间不重叠。 在我们所有的实验中,我们都使用 和 。
II-E 训练
由于掩码是在卷积下采样之前执行的,因此预测和掩码之间的长度存在不匹配。 为了匹配序列长度,将每个 8 帧的掩码平均,然后应用 0.9 的阈值来选择要用于损失计算的帧。 交叉熵损失应用于由平均输入掩码确定的选定位置。
III 实验
III-A 数据集和设置
我们使用 100,000 小时英语语音数据训练 NEST-L (108M) 和 NEST-XL (600M) 模型,包括来自 LibriLight [22] 的 60,000 小时,来自 Voxpopuli [23] 的英语子集的 24,000 小时,以及来自 Fisher [24]、Switchboard [25]、WSJ [26]、NSC [27]、People’s Speech [28] 组合的约 20,000 小时样本数据。 语音增强的音频在每个批次中随机选择,而我们使用来自 MUSAN [29] 和 Freesound [30] 的噪声音频。 我们使用 128 个 NVIDIA A100 GPU 在 80,000 步上训练模型,全局批次大小为 2048,使用 Noam 退火 [16] 和 0.004 的峰值学习率,1e-3 的权重衰减,1.0 的梯度裁剪和 25,000 步的预热。 我们将语音增强的概率设置为 0.2,其中我们将噪声和语音增强的概率设置为 0.1 和 0.9。
III-B SUPERB 多任务语音处理结果
我们在 SUPERB [18] 基准上评估了我们的模型在自监督语音模型的多任务评估上的性能。 对于语音识别 (ASR)、音素识别 (PR) 和说话人分离 (SD) 任务,我们使用图 1(b) 左侧部分的架构以及一个简单的线性层作为任务解码器。 我们使用 CTC [31] 损失训练 ASR 和 PR,而 SD 任务则使用排列不变损失 (PIL) [32] 进行训练。 对于说话人识别/验证 (SID/SV)、关键词识别 (KS) 和情感识别 (ER) 任务,我们采用图 1(b) 右侧部分所示的架构,并使用 ECAPA-TDNN-small [33] 作为任务解码器。 我们遵循 SUPERB [18] 中的相同训练/验证/测试分割,并训练模型 100 个 epochs。
如表 I 所示,我们的 NEST-L 模型能够在所有任务上超越参数规模相似的 WavLM-base++ [8],并且在说话人验证 (SV)、说话人分离 (SD) 和音素识别 (PR) 上也超越了规模大 3 倍的 WavLM-large [8]。 与在 10 倍数据上训练的 XEUS [9] 模型相比,我们可以看到我们的 NEST-XL 模型仍然能够在所有说话人和内容任务上取得更好的性能,在说话人验证、说话人分离和音素识别方面尤为显著。 总体而言,与数据规模相同的 WavLM [8] 以及在更大数据上训练的 XEUS [9] 相比,我们在 SID、SV、SD、PR 和 ASR 任务上取得了新的最先进的结果,证明了 NEST 应用于各种下游语音处理任务时的有效性。
| Model | Params | Data (hrs) | Europarl | mExpresso | Fleurs | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EnDe | EnEs | EnFr | EnDe | EnEs | EnFr | EnDe | EnEs | EnFr | EnDe | EnEs | EnFr | |||
| SeamlessM4T-medium | 1.2B | 4M | 28.03 | 38.44 | 30.50* | 9.65 | 16.23 | 8.64 | 28.30 | 21.05 | 37.36 | 21.99 | 25.24 | 25.50 |
| SeamlessM4T-v2-large | 2.3B | 4M | 19.96 | 32.32 | 23.33 | 21.48 | 34.89 | 26.04 | 33.17 | 23.72 | 43.05 | 24.87 | 30.31 | 30.80 |
| Canary-1B [21] | 1B | 86K | 32.53 | 40.84 | 30.65 | 23.83 | 35.73 | 28.28 | 32.15* | 22.66* | 40.76* | 29.50 | 33.07 | 33.23 |
| NEST-XL-Transformer | 1B | 42K | 30.87* | 39.95* | 30.01 | 22.82* | 34.92* | 27.99* | 29.50 | 22.61 | 39.27 | 27.73* | 32.51* | 32.42* |
| Model | DIHARD3 eval | CALLHOME-part2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
||||||||
| EEND-EDA [34, 35] | 15.55 | 7.83* | 12.29 | 17.59 | |||||||
| NeMo MSDD [36] | 29.40 | 11.41 | 16.45 | 19.49* | |||||||
| RandFC-L-MLP | 21.71 | 11.60 | 15.89 | 24.34 | |||||||
| NEST-L-MLP | 16.83 | 7.88 | 11.71* | 23.46 | |||||||
| RandFC-L-Sortformer | 18.93 | 9.39 | 13.56 | 23.30 | |||||||
| NEST-L-Sortformer [sortformer] | 16.06* | 6.40 | 11.02 | 20.10 | |||||||
III-C 多语言语音识别结果
除了多任务评估之外,我们还研究了在单一语言上训练的 SSL 模型是否可以帮助其他语言。 为此,我们在四种不同的语言上训练了 ASR 模型:英语 (En)、德语 (De)、法语 (Fr)、西班牙语 (Es)。 具体来说,我们使用 NEST-XL 作为权重初始化,并使用混合 CTC-RNNT 损失 [37] 训练了一个 ASR 模型。 训练数据包含 2.5K 小时的德语语音 (MCV、MLS、Voxpopuli)、8.5K 小时的英语语音 (MCV [38]、MLS [39]、Voxpopuli [23]、SPGI [40]、Europarl [41]、LibriSpeech [42]、NSC1 [27])、1.4K 小时的西班牙语语音 (MCV、MLS、Voxpopuli、Fisher [24]) 和 1.9K 小时的法语语音 (MCV、MLS、Voxpopuli)。 对于基线,我们使用英语 ASR 模型 [43] 作为权重初始化训练了另一个模型,还包括一些最佳的 ASR 模型,如 Whisper [20]、SeamlessM4T [19] 和 Canary [21]。 我们在 MCV-16.1 [38] 和 Voxpopuli [23] 的测试集上运行所有模型,束大小相同 (5),没有语言模型。
从表 II 的最后两行可以看出,与使用 ASR 预训练初始化的模型相比,NEST 在所有数据集上都能获得更好的 WER,这表明 NEST 可以帮助提高未在 SSL 预训练期间看到的语言的 ASR 性能。 此外,与使用更多参数和数据训练的其他 SOTA ASR 模型 (Whisper [20]、SeamlessM4T [19]、Canary [21]) 相比,我们仍然能够在所有语言的平均 WER 上达到 Canary [21] 的性能。 在一些数据集上,尽管我们的模型性能与使用更多数据训练的 SOTA 模型相比仍存在差距,但我们仍然可以看出,NEST 可以用作一种有效的方法来获得与在海量数据集上训练的模型相当的优异 ASR 性能。
III-D 语音翻译结果
我们进一步研究了 NEST 如何帮助语音到文本翻译 (AST),并在表 III 中展示了结果。 我们使用与 Canary [21] 中提出的相同的模型架构和训练过程,而训练数据包含 42K 小时的英语 ASR 数据,这些数据来自英语 (En) 到德语 (De)、法语 (Fr) 和西班牙语 (Es) 文本的机器翻译 [44]。 我们在 Europarl [41]、mExpresso [45] 和 FLEURS [46] 测试集上将我们的模型与其他 SOTA AST 模型 SeamlessM4T [19] 和 Canary [21] 进行了比较。 由于训练数据量少得多,在相同参数数量的情况下,在所有评估的数据集上,Canary [21] 和我们的模型之间仍然存在差距。 此外,鉴于 Canary [21] 初始化了一个多语言 ASR 编码器,该编码器在所有评估语言上都进行了预训练,因此预计 Canary 的性能优于 NEST 初始化。 尽管如此,我们的模型仍然能够胜过 SeamlessM4T [19],并在 EnDe、EnEs 和 EnFr 翻译中取得了第二好的平均 BLEU 分数,这表明提出的 NEST 模型能够在数据量较少的情况下帮助实现令人印象深刻的 AST 性能。
III-E 语音说话人分离结果
为了评估我们模型在说话人分离方面的性能,我们训练了两种端到端分离模型变体:(1)在 FastConformer 编码器之上使用简单的两层多层感知器 (MLP),并使用 PIL 进行训练;(2)更复杂的 Sortformer [sortformer] 模型,在编码器之上使用 18 层 Transformer,并使用混合 PIL 和排序损失进行训练。 我们还将 NEST 和随机初始化应用于这两种方法,以进行比较。 对于训练数据,我们使用真实数据(Fisher [24]、AMI Mix-Headset [47]、ICSI [48]、DIHARD3 dev [49]、VoxConverse v0.3 [50]、AISHELL [51])和由 NeMo 语音数据模拟器 [54] 生成的模拟数据(由 LibriSpeech [42]、SRE [52, 53] 组成)的组合,总共 6.4K 小时。 我们在 DIHARD3-eval [49] 和 CALLHOME-part2222We used splits from the Kaldi x-vector recipe [55]: Part 1 for training and Part 2 for evaluation [56] 上评估模型的性能。
如表 IV 所示,通过比较 RandFC-L-MLP 与 NEST-L-MLP,以及 RandFC-L-Sortformer 与 NEST-L-Sortformer,我们可以看到 NEST 能够显着降低使用随机初始化编码器的模型的 DER,这表明在说话人分离中使用 NEST 的重要性。 我们还可以注意到,使用 NEST 初始化的 Sortformer [sortformer] 能够在 DIHARD3 评估集上取得第二好的结果,并且在 CALLHOME-part2 的 2 个和 3 个说话人设置中优于 EEND-EDA [34]。
| Model |
|
|
|
|
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SpeechBrain-Hubert-large [58] | LL-60K | 89.37 | 80.54 | 77.44 | 78.96 | ||||||||||
| ESPnet-Conformer [59] | N/A | 86.30 | N/A | N/A | 71.40 | ||||||||||
| Open-BEST-RQ [60] | LS-960 | 74.80 | N/A | N/A | N/A | ||||||||||
| Wav2vec-CTI-RoBERTa [61] | LS-960 | 86.92 | N/A | N/A | 74.66 | ||||||||||
| NeMo-SSL-FC-Trans-L [62] | LL-60K | 89.40 | 77.90 | 76.65 | 77.22 | ||||||||||
| NEST-L-Transformer | En-100K | 89.79 | 80.55 | 78.70 | 79.61 | ||||||||||
| NEST-XL-Transformer | En-100K | 89.04 | 82.35 | 78.36 | 80.31 |
III-F 语音语言理解结果
对于语音语言理解,我们关注 联合意图检测和槽填充 任务,并使用 SLURP [57] 数据集评估我们模型的性能。 具体来说,我们将一个 Transformer 解码器附加到 NEST 编码器,并使用与 NeMo-SLU [62] 中相同的超参数设置。 我们将其与其他基于SSL的端到端SLU模型进行比较,并在表V中显示结果。为了公平比较,我们不包括ASR预训练基线[62],因为我们专注于SSL。
正如我们所见,在所有基于SSL的SLU模型中,所提出的NEST模型在意图检测准确率和槽填充F1得分方面都取得了最佳性能。 我们还注意到,从NEST-L扩展到NEST-XL确实在槽填充的精度得分上带来了一些改进,但对其他指标没有显著影响。 此外,与NeMo-SSL-FC-Trans-L [62] 基线相比,仅仅用NEST替换SSL语音编码器,同时保持其他超参数不变,我们就可以看到F1得分绝对提高了2%以上,这证明了NEST可以为现有的语音处理模型带来立竿见影的效果。
IV 结论
在本文中,我们提出了一种名为NEST的语音自监督框架,并且在多个语音处理任务上的大量实验表明,NEST模型可以帮助实现最先进的性能。 代码、配置和检查点可通过NVIDIA NeMo工具包获取。
参考文献
- [1] J. Devlin, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [2] A. Baevski et al., “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020.
- [3] S. Sadhu et al., “Wav2vec-c: A self-supervised model for speech representation learning,” arXiv preprint arXiv:2103.08393, 2021.
- [4] A. Baevski et al., “vq-wav2vec: Self-supervised learning of discrete speech representations,” arXiv preprint arXiv:1910.05453, 2019.
- [5] D. Jiang et al., “Speech simclr: Combining contrastive and reconstruction objective for self-supervised speech representation learning,” arXiv preprint arXiv:2010.13991, 2020.
- [6] W.-N. Hsu et al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021.
- [7] C.-C. Chiu et al., “Self-supervised learning with random-projection quantizer for speech recognition,” in ICML, 2022.
- [8] S. Chen et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- [9] W. Chen et al., “Towards robust speech representation learning for thousands of languages,” arXiv preprint arXiv:2407.00837, 2024.
- [10] K. He et al., “Masked autoencoders are scalable vision learners,” in CVPR, 2022.
- [11] A. Baevski et al., “Data2vec: A general framework for self-supervised learning in speech, vision and language,” in ICML, 2022.
- [12] A. Van Den Oord et al., “Neural discrete representation learning,” Advances in neural information processing systems, vol. 30, 2017.
- [13] A. Babu et al., “Xls-r: Self-supervised cross-lingual speech representation learning at scale,” arXiv preprint arXiv:2111.09296, 2021.
- [14] Y.-A. Chung et al., “W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” in ASRU. IEEE, 2021, pp. 244–250.
- [15] A. Gulati et al., “Conformer: Convolution-augmented transformer for speech recognition,” arXiv preprint arXiv:2005.08100, 2020.
- [16] A. Vaswani, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017.
- [17] D. Rekesh et al., “Fast conformer with linearly scalable attention for efficient speech recognition,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8.
- [18] S.-w. Yang et al., “Superb: Speech processing universal performance benchmark,” arXiv preprint arXiv:2105.01051, 2021.
- [19] L. Barrault et al., “Seamless: Multilingual expressive and streaming speech translation,” arXiv preprint arXiv:2312.05187, 2023.
- [20] A. Radford et al., “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning. PMLR, 2023, pp. 28 492–28 518.
- [21] K. C. Puvvada et al., “Less is more: Accurate speech recognition & translation without web-scale data,” Interspeech, 2024.
- [22] J. Kahn et al., “Libri-light: A benchmark for asr with limited or no supervision,” in ICASSP. IEEE, 2020, pp. 7669–7673.
- [23] C. Wang et al., “Voxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation,” arXiv preprint arXiv:2101.00390, 2021.
- [24] C. Cieri et al., “The fisher corpus: A resource for the next generations of speech-to-text.” in LREC, vol. 4, 2004, pp. 69–71.
- [25] E. H. John J. Godfrey, “Switchboard-1 release 2,” https://catalog.ldc.upenn.edu/LDC97S62.
- [26] J. S. Garofolo et al., “Csr-i (wsj0) complete,” https://catalog.ldc.upenn.edu/LDC93S6A.
- [27] J. X. Koh et al., “Building the singapore english national speech corpus,” Malay, vol. 20, no. 25.0, pp. 19–3, 2019.
- [28] D. Galvez et al., “The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,” arXiv preprint arXiv:2111.09344, 2021.
- [29] D. Snyder et al., “Musan: A music, speech, and noise corpus,” arXiv preprint arXiv:1510.08484, 2015.
- [30] E. Fonseca et al., “Freesound datasets: a platform for the creation of open audio datasets.” ISMIR, 2017.
- [31] A. Graves et al., “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in ICML, 2006.
- [32] Y. Fujita et al., “End-to-end neural speaker diarization with self-attention,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 296–303.
- [33] B. Desplanques et al., “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” arXiv preprint arXiv:2005.07143, 2020.
- [34] S. H. et al., “Encoder-decoder based attractors for end-to-end neural diarization,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1493–1507, 2022.
- [35] S. Horiguchi et al., “Online neural diarization of unlimited numbers of speakers using global and local attractors,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 706–720, 2022.
- [36] T. J. Park et al., “Multi-scale speaker diarization with dynamic scale weighting,” arXiv preprint arXiv:2203.15974, 2022.
- [37] V. Noroozi et al., “Stateful conformer with cache-based inference for streaming automatic speech recognition,” in ICASSP, 2024.
- [38] R. Ardila et al., “Common voice: A massively-multilingual speech corpus,” in LREC, 2020, pp. 4211–4215.
- [39] V. Pratap et al., “Mls: A large-scale multilingual dataset for speech research,” arXiv preprint arXiv:2012.03411, 2020.
- [40] P. K. O’Neill et al., “Spgispeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition,” arXiv preprint arXiv:2104.02014, 2021.
- [41] J. Iranzo-Sánchez et al., “Europarl-st: A multilingual corpus for speech translation of parliamentary debates,” in ICASSP, 2020.
- [42] V. Panayotov et al., “Librispeech: an asr corpus based on public domain audio books,” in 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210.
- [43] NVIDIA, “Nemo english fastconformer-rnnt asr model,” https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/megatronnmt_any_en_500m.
- [44] NVIDIA, “Megatron multilingual translation model,” https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/megatronnmt_any_en_500m.
- [45] META, “mexpresso (multilingual expresso),” https://huggingface.co/facebook/seamless-expressive#mexpresso-multilingual-expresso.
- [46] A. Conneau et al., “Fleurs: Few-shot learning evaluation of universal representations of speech,” in SLT, 2023.
- [47] U. of Edinburgh, “The ami corpus,” https://www.openslr.org/16/.
- [48] ——, “The icsi meeting corpus,” https://groups.inf.ed.ac.uk/ami/icsi/.
- [49] N. Ryant et al., “Third dihard challenge evaluation plan,” arXiv preprint arXiv:2006.05815, 2020.
- [50] J. S. Chung et al., “Spot the conversation: speaker diarisation in the wild,” arXiv preprint arXiv:2007.01216, 2020.
- [51] Y. Fu et al., “Aishell-4: An open source dataset for speech enhancement, separation, recognition and speaker diarization in conference scenario,” arXiv preprint arXiv:2104.03603, 2021.
- [52] G. R. Doddington et al., “The nist speaker recognition evaluation–overview, methodology, systems, results, perspective,” Speech communication, vol. 31, no. 2-3, pp. 225–254, 2000.
- [53] NIST, “Nist speaker recognition evaluation (sre),” https://www.nist.gov/itl/iad/mig/speaker-recognition.
- [54] T. J. Park et al., “Property-aware multi-speaker data simulation: A probabilistic modelling technique for synthetic data generation,” arXiv preprint arXiv:2310.12371, 2023.
- [55] Kaldi, “Kaldi x-vector recipe v2,” https://github.com/kaldi-asr/kaldi/tree/master/egs/callhome_diarization/v2.
- [56] M. Przybocki et al., “2000 nist speaker recognition evaluation,” https://catalog.ldc.upenn.edu/LDC2001S97.
- [57] E. Bastianelli et al., “Slurp: A spoken language understanding resource package,” arXiv preprint arXiv:2011.13205, 2020.
- [58] Y. Wang et al., “A fine-tuned wav2vec 2.0/hubert benchmark for speech emotion recognition, speaker verification and spoken language understanding,” arXiv preprint arXiv:2111.02735, 2021.
- [59] S. Arora et al., “Espnet-slu: Advancing spoken language understanding through espnet,” in ICASSP, 2022.
- [60] R. Whetten et al., “Open implementation and study of best-rq for speech processing,” arXiv preprint arXiv:2405.04296, 2024.
- [61] S. Seo et al., “Integration of pre-trained networks with continuous token interface for end-to-end spoken language understanding,” in ICASSP, 2022.
- [62] H. Huang et al., “Leveraging pretrained asr encoders for effective and efficient end-to-end speech intent classification and slot filling,” Interspeech, 2023.