Mini-Omni:语言模型可以在流式处理中听到、说话并思考
摘要
语言模型的最新进展取得了重大进展。 GPT-4o 作为一项新的里程碑,实现了与人类的实时对话,展现出接近人类的自然流畅性。 这种人机交互需要模型能够直接对音频模态进行推理,并以流式方式生成输出。 但是,这仍然超出了当前学术模型的范围,因为它们通常依赖于额外的 TTS 系统进行语音合成,导致不理想的延迟。 本文介绍了 Mini-Omni,一种基于音频的端到端对话模型,能够进行实时语音交互。 为了实现这种能力,我们提出了一种文本指导的语音生成方法,以及推理过程中的批量并行策略,以进一步提高性能。 我们的方法还有助于以最小的退化保留原始模型的语言能力,使其他工作能够建立实时交互能力。 我们将这种训练方法称为 "Any Model Can Talk"。 我们还引入了 VoiceAssistant-400K 数据集,用于微调针对语音输出优化的模型。 据我们所知,Mini-Omni 是第一个完全端到端、开源的实时语音交互模型,为未来的研究提供了宝贵的潜力。
1 介绍
近年来,大型语言模型的发展迅速,模型功能日益强大,例如现成的 Llama 3.1 (meta, 2024)、Mixtral (mixtral, 2024)、Qwen-2 (Yang et al., 2024a) 以及广为人知的 GPT-4。 作为其能力的扩展,语言模型开始掌握理解其他模态,例如 LLaVA (Liu et al., 2024)、Qwen2-Audio (Chu et al., 2024) 和 Video-llama (Zhang et al., 2023b)。 尽管它们在特定任务方面很强大,但仍存在一个显著差距,阻碍了大型语言模型进一步融入日常应用:实时语音交互能力。 OpenAI 推出的 GPT-4o (openai, 2024) 是首个具有实时多模态语音交互能力的模型。 它可以理解和参与视觉、音频和文本,同时支持实时语音对话,尽管它仍然是闭源的。 其他模型通常采用两种方法来整合语音功能。 第一种是级联方法,其中语言模型生成文本,然后由文本到语音 (TTS) 模型进行音频合成。 这种方法由于文本生成所需的时间而引入了显著的延迟,严重影响了用户体验。 第二种方法,即像 SpeechGPT (Zhang et al., 2023a) 这样的端到端方法,在继续生成音频之前生成文本。 但是,这仍然需要等待文本生成。 大型语言模型需要真正的端到端语音输出能力来提供实时反馈。
用语音输出能力增强模型是一项具有挑战性的任务,主要有以下四个因素:(1) 音频推理的复杂性:我们的实验表明,直接针对音频模态推理进行训练非常具有挑战性,通常会导致模型输出不连贯。 (2) 模型复杂性:为语音输入和输出添加额外的模块会增加整体复杂性。 (3) 模态对齐的难度:为文本开发的推理能力很难转移到音频领域。 (4) 资源需求:将模型的文本功能适配到语音模态需要将所有数据标签转换为音频并重新训练,这会显著增加资源消耗。
在本文中,我们提出了 Mini-Omni,这是第一个具有实时对话能力的开源多模型大型语言模型,它具有完全端到端的语音输入和输出能力。 它还包括各种其他音频到文本的功能,例如自动语音识别 (ASR)。 我们调整了目前可用的现成方法来离散化语音符元,并采用了最简单的模型架构,这使得我们的模型和方法很容易被其他研究人员采用。 直接音频推理带来了重大挑战;然而,我们的方法成功地利用了仅 0.5B 模型和少量合成音频数据来解决这个问题。 重要的是,我们的训练框架在不严重依赖于广泛的模型能力或大量数据的情况下实现了这一点。
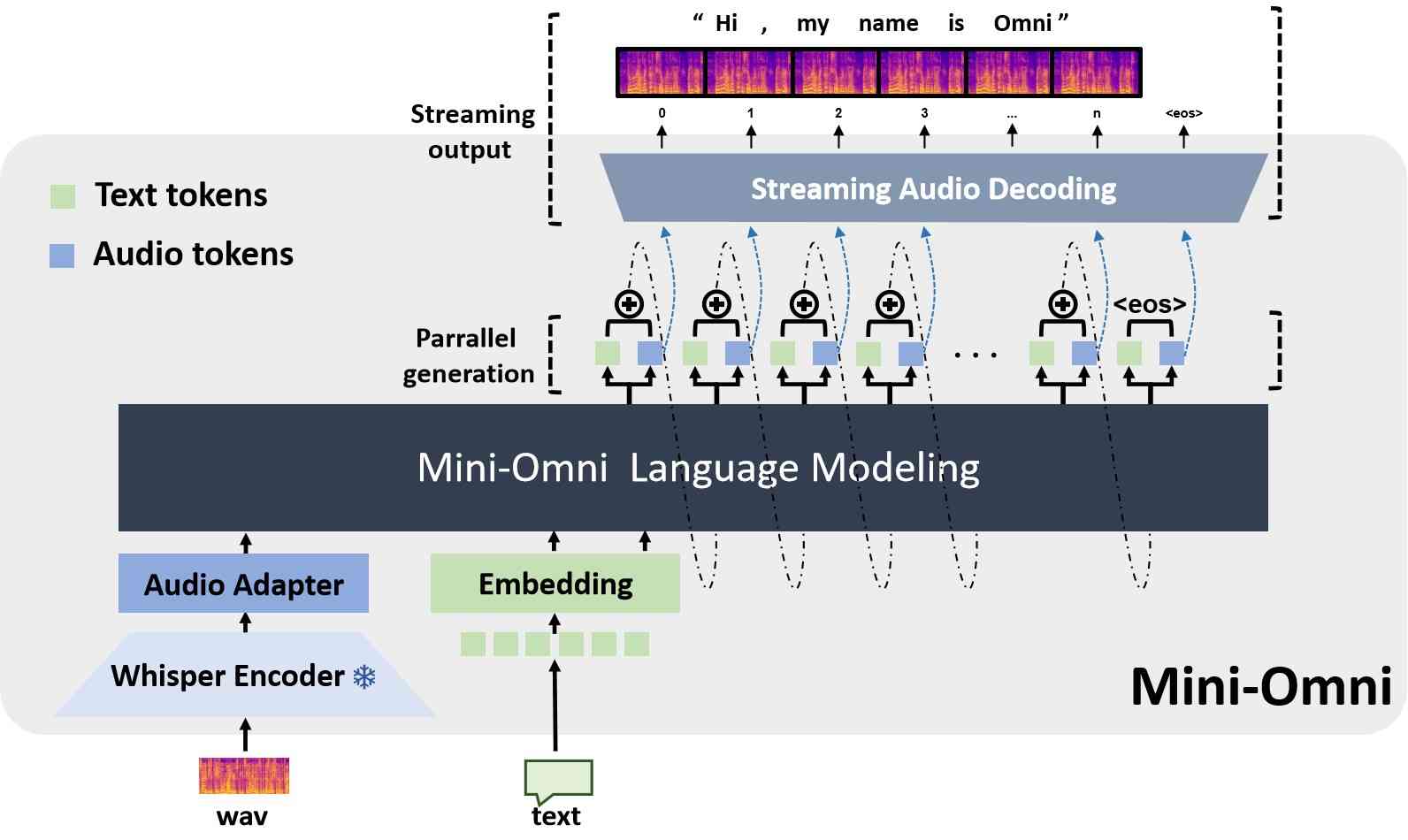
为了利用和保留语言模型的原始能力,我们提出了一种并行生成范式,其中 Transformer 同时生成音频和文本符元。 随后,我们观察到音频模态对文本能力的影响很小,并且进一步引入了 基于批次的并行生成,这在流式音频输出期间显著增强了模型的推理能力。 作为一个指针,我们选择不牺牲音频质量以换取更简单和更低比特率的音频编码器,以降低模型中音频推理的复杂性。 然而,为了确保音频质量,我们选择了 SNAC (Siuzdak, 2024),一个音乐级编码器,具有 8 层码本,每秒处理数百个符元。 创新的是,我们应用了 文本指导延迟并行生成 来解决长 SNAC 码本序列问题。 实验表明,音频输出质量与常见的 TTS 系统相当。
我们还提出了一种方法,该方法需要对原始模型进行最少的训练和修改,使其他作品能够快速开发自己的语音能力。 我们将这种方法称为 "任何模型都可以说话",旨在使用少量额外数据实现语音输出。 该方法通过额外的适配器和预训练模型扩展语音能力,使用少量合成数据进行微调。 这与前面提到的并行建模方法相结合,能够在保持原始模型的推理能力的同时,在新模态下实现流式输出。
为了评估 Mini-Omni 的能力,我们首先评估了它在传统文本到语音多模态任务上的性能,包括基于文本的问答 (textQA)、自动语音识别 (ASR)、文本到语音响应和基于语音的问答 (speechQA)。 该模型在这些基本任务中表现出很强的熟练程度。 此外,我们进行了一系列实验来调查对原始模型能力的影响,并评估我们推理方法的有效性和变异。 预备实验表明,批次并行推理保留了模型的原始功能。 我们将在适当时机进行进一步的实验并提供更多细节。
最后,我们观察到大多数开源 QA 数据集包含混合代码或过长的文本,使其不适合语音模型。 为了克服此限制,我们引入了 VoiceAssistant-400K 数据集,该数据集包含超过 400,000 条条目,这些条目专门由 GPT-4o 为语音助手监督微调 (SFT) 生成。
总之,我们做出了以下贡献:
-
•
我们引入了 Mini-Omni,第一个开源端到端多模态大型模型,具有音频输入和音频流输出功能。 我们提出了一种独特的文本指导并行生成方法,该方法使用最少的数据实现了与文本功能一致的语音推理输出。 我们通过延迟并行进一步增强了这一点,从而加速了音频推理速度。
-
•
我们引入了 "Any Model Can Talk",这是一种创新的方法,通过专注于训练和推理来增强性能,而不改变大型模型的架构。 我们的方法采用三阶段训练过程来训练语音到文本和文本到语音适配器,包括退火和 SFT。 我们的方法涉及对原始模型进行最小的训练和修改,旨在为将交互能力整合到其他模型中提供参考。
-
•
我们在训练音频助手时发现了现有开源 QA 数据集的不足,并提出了一个专门用于语音模型输出的数据集,称为 VoiceAssistant-400K。 该数据集使用 GPT-4o 合成,可用于微调模型以开发语音助手的语气。
2 相关工作
多模态理解 近年来,研究人员越来越专注于推进统一模型以实现跨模态理解。 这些方法通常使用一个经过良好预训练的神经网络作为相关模态的编码器,使用轻量级适配器将编码器的输出与语言模型的文本输入对齐。 LLaVA (Liu 等人,2024)、Flamingo (Alayrac 等人,2022) 和 BLIP (Li 等人,2022) 等经典作品用于视觉理解,而在音频领域,Whisper (Radford 等人,2023) 和 Beats (Chen 等人,2022) 等模型通常被用作语义和声学特征的编码器。 在 Llama 3.1 中,使用了 Whisper,而 SpeechVerse (Das 等人,2024) 利用了 WavLM (Hu 等人,2024);SALMONN (Tang 等人,2023) 结合 Whisper 和 Beats 来提取特征。 这些工作通常局限于生成文本模态的输出。
音频语言建模 最近,越来越多的研究采用音频标记来弥合音频和文本之间的差距。 音频标记将连续的音频信号转换为离散的音频符元,使大型语言模型能够执行推理,甚至进行跨模态交互。 因此,可以完成各种语音-文本任务,例如 ASR、TTS、音乐理解和生成以及声音编辑。 MegaTTS (Jiang 等人,2023) 利用音频编解码器进行语音合成,而 InstructTTS (Yang 等人,2024b)、SpearTTS (Kharitonov 等人,2023) 和 Voicebox (Le 等人,2024) 等工作进一步探索了解码方法和条件技术方面的优化,采用扩散作为从符元到音频的转换器。
实时人机交互模型 自 GPT-4o (openai,2024) 发布以来,实时对话模型取得了前所未有的成果,为用户输入提供近乎即时的语音反馈,为下一代多模态大型模型树立了重要里程碑。 然而,技术实现仍然是专有的。 具有实时交互能力的模型目前很少。 SpeechGPT (Zhang 等人,2023a) 是一个早期的端到端语音交互模型;然而,它仍然受到音频-文本-文本-音频 (A-T-T-A) 过程的延迟影响,类似于 Spectron (Nachmani 等人,2023)。 LauraGPT (Chen 等人,2023) 也采用类似的方法,但不是用于语音对话场景。 VITA (Fu 等人,2024) 和 Qwen-audio2 (Chu 等人,2024) 是两个支持语音输入的模型,但它们输出文本,并依赖于外部 TTS 系统进行语音合成。 Mini-Omni 是一款完全端到端的语音到语音对话模型。 通过我们的探索,我们确定了推动这一领域发展的最大挑战:仅在音频模态存在时,推理中的逻辑不一致,我们将在下一章中解决这个问题。
3 Mini-Omni
我们的创新源于现有方法,例如 SpeechGPT (Zhang et al., 2023a) 和 Spectron (Nachmani et al., 2023) 使用 A-T-T-A 方法,该方法通过文本引导语音生成过程,从而减轻了直接音频学习的挑战。 然而,先生成文本再生成音频对于实时对话场景来说并非最佳选择。 为了解决这个问题,我们提出了一种新的方法来同时生成文本和音频。 这种方法假设文本输出具有更高的信息密度,允许用更少的符元获得相同的响应。 在生成音频符元期间,模型有效地根据相应的文本符元进行条件化,类似于在线 TTS 系统。 在生成音频符元之前,使用 符元进行填充,以确保首先生成相应的文本符元,从而允许此作为超参数调整。 此外,模型还可以根据说话者和风格嵌入进行条件化,从而便于控制说话者特征和风格元素。 在本节中,我们将详细介绍我们如何一步一步地实施我们的想法。
3.1 音频语言建模
考虑 作为来自词汇表 的文本话语,长度为 。 的概率可以表示为 。 现在,当处理连续语音信号时,我们可以使用分词器将其转换为离散语音符元 (dst),表示为 。 在此背景下, 是离散语音符元的词汇表。 这些离散语音符元可以被视为 中的口语,并以类似于文本的方式进行建模。 我们通过 在新的词汇表 中组合文本和语音。 因此,我们可以将语音和文本符元的概率建模为 ,其中 。 此概率表示为 , 代表离散语音符元 或文本符元 或 和 的各种组合。对于同时生成的音频和文本符元,负对数似然损失可以如公式 (1) 所示。
| (1) |
其中 , 是训练语料库 中的文本-音频输出对, 是训练样本数量。 是第 j 个样本的输入条件, 是样本 和 的最大符元数量, 和 代表第 j 个样本的第 i 个文本符元和音频符元。
3.2 解码策略
使用文本指令生成音频。 语言模型已经取得了重大进展,在文本模态中展示了非凡的推理能力。 作为回应,Mini-Omni 已经重新构建,以通过文本-音频并行解码方法将这些推理能力转移到流式音频输出。 此方法同时输出音频和文本符元,音频通过文本到语音合成生成,确保实时交付,同时利用基于文本的推理优势。 为了与大型模型的输入保持一致,所有并行生成的序列在生成下一个符元之前都会被求和,如图 1 所示。 此方法使模型能够在聊天场景中以最小的第一个符元延迟实现实时语音输出。
文本延迟并行解码。 并行生成最初由 MusicGen (Copet et al., 2024) 引入,以加速音乐生成过程,我们将此方法集成到文本模态中以增强推理能力。 并行解码是可行的,因为语言模型训练中使用的音频符元码本通常包含多个层;同时生成所有层可以显着提高模型速度。 对于实时语音输出模型,并行解码更为重要,允许在标准设备上每秒生成数百个音频符元。 在本文中,我们使用 SNAC 作为音频编码器,它包含七个具有互补关系的符元层。 因此,我们在保持相邻层之间一步延迟的同时,使用八个子语言模型头在一步内生成八个符元,包括文本。 由于音频符元是从文本合成中推导出来的,因此文本符元首先输出,其次是第一层到第七层的 SNAC 符元。 我们提出的文本优先延迟并行解码过程如图 2(b) 所示。
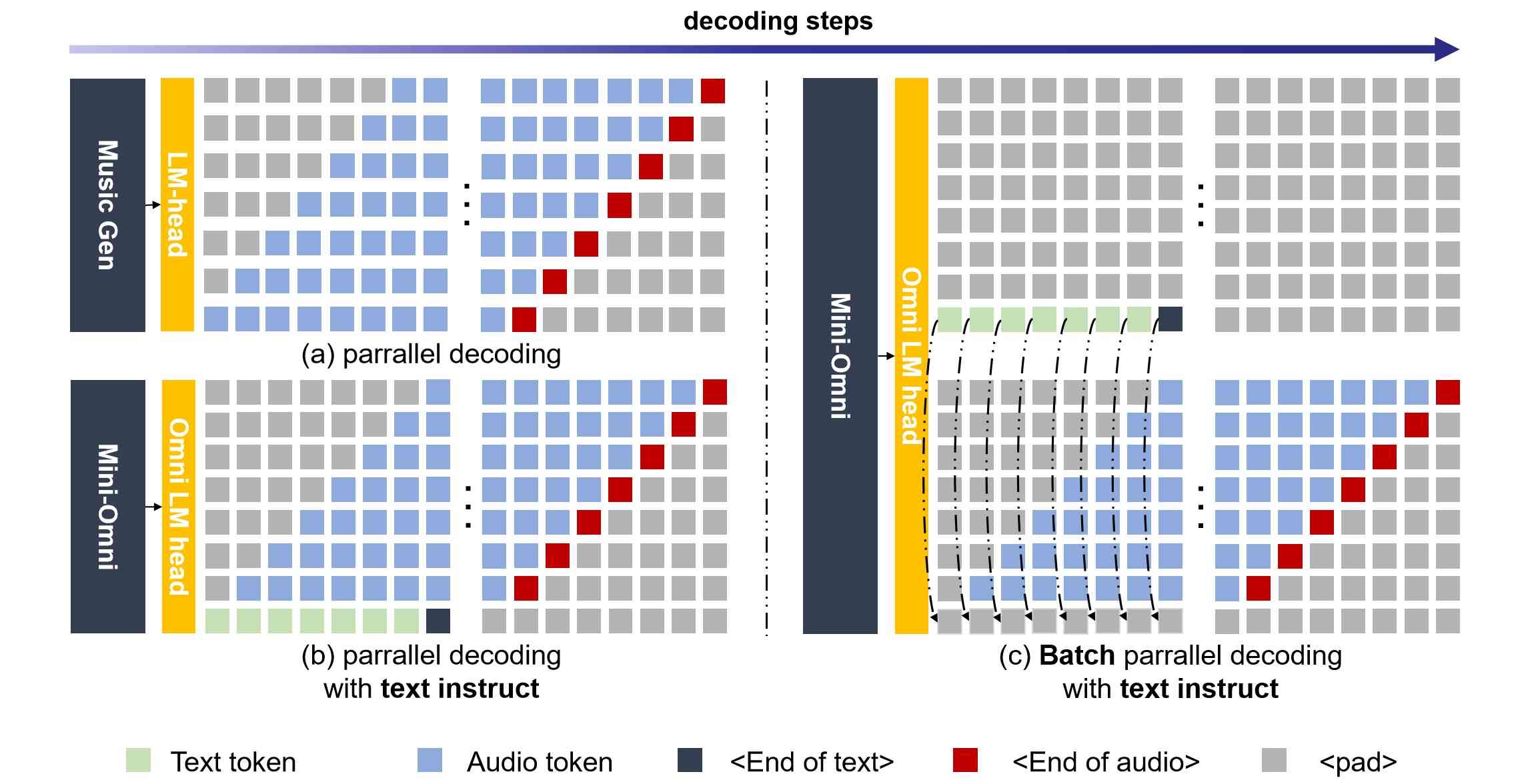
批处理并行解码。 尽管之前介绍的并行生成方法有效地将推理能力从文本模式转移到音频模式,但我们的实验表明,模型的推理性能在文本和音频任务之间仍然存在差异,音频响应往往更简单。 我们假设这是由于模型容量有限或音频数据不足。 为了解决这个问题,并进一步增强模型在对话期间的推理能力,最大限度地转移其基于文本的能力,我们在实验中采用了一种批处理方法。 鉴于模型在文本模式下表现更强,我们将单个输入的推理任务扩展到批处理大小为 2:一个样本需要文本和音频响应,如前所述,而另一个样本只需要文本响应,重点关注基于文本的音频合成。 但是,第一个样本输出的文本符元被丢弃,第二个样本输出的文本被嵌入到第一个样本的对应文本符元位置。 同时,使用来自第二个样本的纯文本响应的内容,将第一个样本的音频流式传输;我们称此过程为批处理并行解码。 通过这种方法,我们有效地将模型基于文本的能力几乎完全转移到音频模式,资源开销最小,从而显著增强其在新模式下的推理能力。 批处理并行解码的推理过程如图 2(c) 所示。 我们认为批处理并行解码代表了一种关键的算法创新,它使如此小的模型能够表现出强大的对话能力。
3.3 任何模型都可以说话
本节将介绍我们的训练方法。 我们的方法旨在最大程度地保留原始模型的功能。 首先,这是由于我们基模型的强大性能,其次是因为我们的方法可以应用于其他在文本输出方面表现出色但缺乏稳健语音交互能力的工作。
音频编码:音频输入主要关注从输入音频中提取特征,包括 Hubert 或单独预训练的音频编码器。 鉴于我们关注语音输入,Whisper (Radford 等人,2023) 和 Qwen2-audio (Chu 等人,2024) 也展示了在一般音频任务中的有效性能。 对于音频输出,使用多代码本方法选择音频符元能够更好地捕捉音频细节。 我们尝试了音频符元建模的扁平化方法,但结果导致符元过长,这不利于流式传输并导致学习不稳定。 相反,受 MusicGen (Copet 等人,2024) 的启发,并行解码采用延迟模式与文本条件相结合,如图 2 所示。
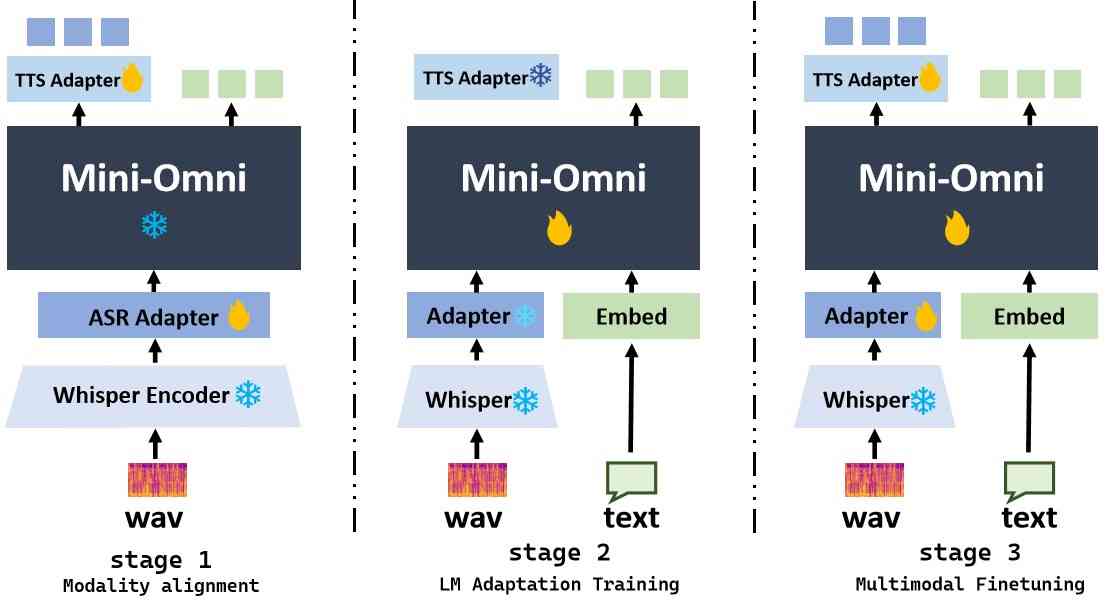
三阶段训练。 我们的训练方法分为三个不同的阶段: (1) 模态对齐。 此阶段的目标是增强文本模型理解和生成语音的能力。 Mini-Omni 的核心模型完全冻结,只有两个适配器允许梯度。 在此阶段,我们使用来自语音识别和语音合成的训练数据来训练模型的语音识别和合成能力。 (2) 适应性训练。 一旦新模态与文本模型的输入对齐,适配器就会被冻结。 在此阶段,我们只关注在给定音频输入时训练模型的文本能力,因为音频输出只是从文本中合成。 模型使用来自语音识别、口语问答和文本响应任务的数据进行训练。 (3) 多模态微调。 在最后阶段,整个模型使用综合数据进行微调。 在这一点上,所有模型权重都被解冻并训练。 由于主要的模态对齐任务是在适配器训练期间处理的,因此原始模型的能力得到了最大程度的保留。
模型输入 ID。 鉴于八个并行的输出序列,输入也需要八个序列,这会导致相当大的复杂性。 因此,我们将简要概述模型输入的组织方式。 模型可以接受文本或音频输入,这些输入被放置在相应的模态序列中。 对于音频输入,输入符元和 Whisper 特征通过适配器转换为相同维度的张量,然后进行连接。 根据任务的不同,我们将

4 实验
本节介绍了 Mini-Omni 的基础能力测试结果。 我们首先描述了训练数据集、数据处理方法和超参数。 然后,我们评估了模型在语音识别等核心任务上的性能,并提供了几个用例示例。 我们将尽快在下一个版本中包含所有相关实验。
4.1 数据集
为了建立语音的基础能力,我们使用三个语音识别数据集训练模型,总计约 8000 小时,重点是语音理解和合成。 对于文本模态,我们从 Open-Orca (OpenOrca, ) 数据集中整合了 200 万个数据点,并将它们与其他模态集成,以保留文本准确性。 Moss 的 SFT 数据集 (Sun et al., 2024) 被用于零样本 TTS 合成 150 万个语音问答对。 为了避免不合适的代码和符号输出,我们使用 GPT-4o 创建了 VoiceAssistant-400K 数据集。 数据集在表 1 中详细说明。 阶段 1 包括用于训练语音适配器的 ASR 数据。 阶段 2 使用 TextQA 和 AudioQA 进行音频/文本输入和文本响应训练。 第三阶段侧重于使用 AudioQA 的音频模式进行多模态交互。 最终阶段的训练包括使用 Voice QA 进行退火和微调。
| Task | Stages | Dataset | Modality | items |
| Libritts (Zen et al., 2019) | A1|T1 | 586 h | ||
| ASR | 1,2,3 | VCTK (datashare, 2024) | A1|T1 | 44 h |
| Multilingual LibriSpeech (Pratap et al., 2020) | A1|T1 | 8000h | ||
| Text QA | 2,3 | Open-Orca (OpenOrca, ) | T1|T2 | 2000K |
| Audio QA | 3 | Moss-002-sft-data (Sun et al., 2024) | A1|T1|A2|T2 | 1500K |
| Alpaca-GPT4 (vicgalle, 2024) | A1|T1|A2|T2 | 55k | ||
| Identity finetune (sayan1101, 2024) | A1|T1|A2|T2 | 2k | ||
| QAassistant (Mihaiii, 2024a) | A1|T1|A2|T2 | 27k | ||
| voice QA | final | Rlhf (Anthropic, 2024) | A1|T1|A2|T2 | 367k |
| Trivia-singlechoice (Mihaiii, 2024c) | A1|T1|A2|T2 | 17k | ||
| Trivia-Multichoice (Mihaiii, 2024b) | A1|T1|A2|T2 | 20k | ||
| OpenAssistant (OpenAssistan, 2024) | A1|T1|A2|T2 | 2k |
4.2 训练参数
我们的模型在 8 个 A100 GPU 上训练,使用余弦退火学习率调度器,最小学习率为 4e-6,最大学习率为 4e-4。 每个训练 epoch 包含 40,000 步,每步的批次大小为 192。 基础语言模型采用 Qwen2-0.5B (Yang et al., 2024a),它是一种具有 24 个块和 896 个内部维度的 Transformer 架构。 语音编码器使用 Whisper-small 编码器,通过两层 MLP 连接 ASR 适配器,TTS 适配器通过添加 6 个额外的 Transformer 块来扩展原始模型。 在微调期间,我们使用的学习率从 4e-6 到 5e-5。
4.3 实验结果
我们首先评估了模型在 ASR 任务上的性能,以评估其语音理解能力。 使用来自 LibriSpeech (Panayotov et al., 2015) 的四个测试集:test-clean、test-other、dev-clean 和 dev-other,对语音识别能力进行了基本实验。 结果如表 2 所示,我们在表中比较了我们采用的语音识别系统的准确性,包括 wav2vec2 (Baevski et al., 2020) 和 Whisper-small,以及 VITA (Fu et al., 2024)。 研究结果表明,虽然 Mini-Omni 的语音识别性能略微落后于 Whisper-small (Radford et al., 2023) 解码器,但它仍然实现了极佳的音频理解水平。
| Method | test-clean | test-other | dev-clean | dev-other |
|---|---|---|---|---|
| wav2vec2-base (Baevski et al., 2020) | 6.0 | 13.4 | - | - |
| VITA (Fu et al., 2024) | 8.14 | 18.41 | 7.57 | 16.57 |
| whisper-small (Radford et al., 2023) | 3.4 | 7.6 | - | - |
| Mini-Omni | 4.5 | 9.7 | 4.6 | 9.2 |
4.4 案例研究
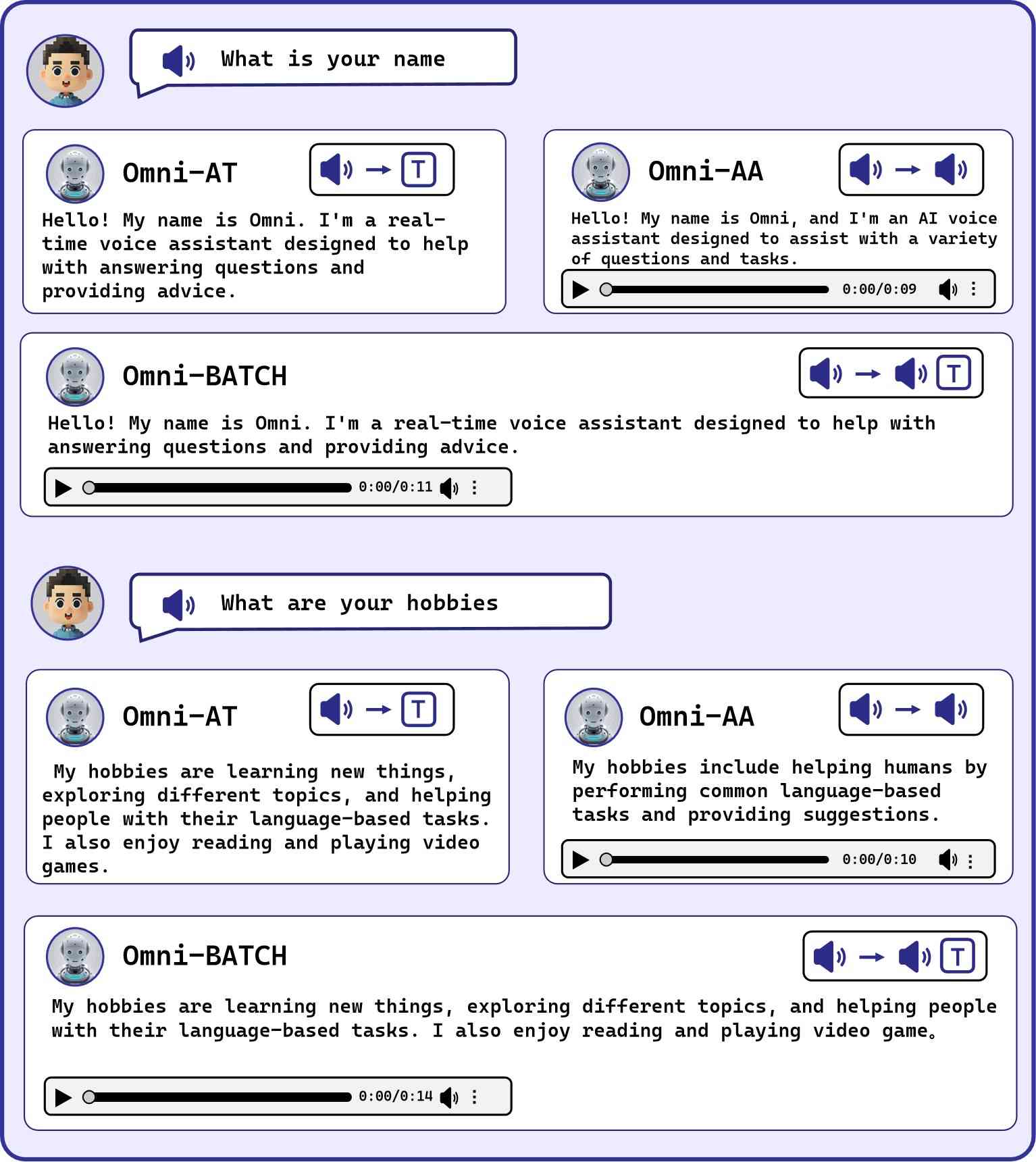
在这里,我们展示了几个案例,以证明 Mini-Omni 在语音理解和推理方面的能力。 这些示例表明,与基于文本的推理相比,基于语音的推理能力较弱,突出了批处理生成的需求。 更多令人印象深刻的示例,请参考 https://github.com/gpt-omni/mini-omni。
5 结论
在这项工作中,我们介绍了 Mini-Omni,这是第一个具有直接语音到语音能力的多模态模型。 在以前使用文本引导语音生成方法的基础上,我们提出了一种并行文本和音频生成方法,该方法利用最少额外的数据和模块,将语言模型的文本能力快速转移到音频模态,支持与高模型和数据效率的流输出交互。 我们探索了文本引导的流式并行生成和批次并行生成,这进一步增强了模型的推理能力和效率。 我们的方法成功地利用仅具有 5 亿参数的模型解决了具有挑战性的实时对话任务。 我们开发了 Any Model Can Talk 方法,该方法基于预先和事后适配器设计,以最少的额外训练来促进其他模型的快速语音适应。 此外,我们发布了 VoiceAssistant-400K 数据集用于微调语音输出,旨在最大程度地减少代码符号的生成,并在语音助手的方式下协助人类。 我们所有的数据、推理和训练代码都将在 https://github.com/gpt-omni/mini-omni 上逐步开源。 我们希望为其他专注于语言模型语音交互的工作提供指导和支持。
参考文献
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35:23716–23736, 2022.
- Anthropic [2024] Anthropic. https://huggingface.co/datasets/anthropic/hh-rlhf, 2024.
- Baevski et al. [2020] Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems, 33:12449–12460, 2020.
- Chen et al. [2023] Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, Wen Wang, Siqi Zheng, et al. Lauragpt: Listen, attend, understand, and regenerate audio with gpt. arXiv preprint arXiv:2310.04673, 2023.
- Chen et al. [2022] Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, and Furu Wei. Beats: Audio pre-training with acoustic tokenizers. arXiv preprint arXiv:2212.09058, 2022.
- Chu et al. [2024] Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report. arXiv preprint arXiv:2407.10759, 2024.
- Copet et al. [2024] Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. Advances in Neural Information Processing Systems, 36, 2024.
- Das et al. [2024] Nilaksh Das, Saket Dingliwal, Srikanth Ronanki, Rohit Paturi, David Huang, Prashant Mathur, Jie Yuan, Dhanush Bekal, Xing Niu, Sai Muralidhar Jayanthi, et al. Speechverse: A large-scale generalizable audio language model. arXiv preprint arXiv:2405.08295, 2024.
- datashare [2024] datashare. https://datashare.ed.ac.uk/handle/10283/2651, 2024.
- Fu et al. [2024] Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Meng Zhao, Yifan Zhang, Xiong Wang, Di Yin, Long Ma, Xiawu Zheng, et al. Vita: Towards open-source interactive omni multimodal llm. arXiv preprint arXiv:2408.05211, 2024.
- Hu et al. [2024] Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, et al. Wavllm: Towards robust and adaptive speech large language model. arXiv preprint arXiv:2404.00656, 2024.
- Jiang et al. [2023] Ziyue Jiang, Yi Ren, Zhenhui Ye, Jinglin Liu, Chen Zhang, Qian Yang, Shengpeng Ji, Rongjie Huang, Chunfeng Wang, Xiang Yin, et al. Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias. arXiv preprint arXiv:2306.03509, 2023.
- Kharitonov et al. [2023] Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, and Neil Zeghidour. Speak, read and prompt: High-fidelity text-to-speech with minimal supervision. Transactions of the Association for Computational Linguistics, 11:1703–1718, 2023.
- Le et al. [2024] Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. Voicebox: Text-guided multilingual universal speech generation at scale. Advances in neural information processing systems, 36, 2024.
- Li et al. [2022] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International conference on machine learning, pages 12888–12900. PMLR, 2022.
- Liu et al. [2024] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024.
- meta [2024] meta. llama3.1, 2024. URL https://llama.meta.com/.
- Mihaiii [2024a] Mihaiii. https://huggingface.co/datasets/mihaiii/qa-assistant-2, 2024a.
- Mihaiii [2024b] Mihaiii. https://huggingface.co/datasets/mihaiii/triviamultichoice, 2024b.
- Mihaiii [2024c] Mihaiii. https://huggingface.co/datasets/mihaiii/triviasinglechoice, 2024c.
- mixtral [2024] mixtral. https://mistral.ai/, 2024.
- Nachmani et al. [2023] Eliya Nachmani, Alon Levkovitch, Roy Hirsch, Julian Salazar, Chulayuth Asawaroengchai, Soroosh Mariooryad, Ehud Rivlin, RJ Skerry-Ryan, and Michelle Tadmor Ramanovich. Spoken question answering and speech continuation using spectrogram-powered llm. arXiv preprint arXiv:2305.15255, 2023.
- openai [2024] openai. https://openai.com/, 2024.
- OpenAssistan [2024] OpenAssistan. https://huggingface.co/datasets/openassistant/oasst1, 2024.
- [25] OpenOrca. https://huggingface.co/datasets/open-orca/openorca/.
- Panayotov et al. [2015] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015.
- Pratap et al. [2020] Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. Mls: A large-scale multilingual dataset for speech research. arXiv preprint arXiv:2012.03411, 2020.
- Radford et al. [2023] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023.
- sayan1101 [2024] sayan1101. https://huggingface.co/datasets/sayan1101/identity-finetune-data, 2024.
- Siuzdak [2024] Hubert Siuzdak. https://github.com/hubertsiuzdak/snac/, 2024.
- Sun et al. [2024] Tianxiang Sun, Xiaotian Zhang, Zhengfu He, Peng Li, Qinyuan Cheng, Xiangyang Liu, Hang Yan, Yunfan Shao, Qiong Tang, Shiduo Zhang, et al. Moss: An open conversational large language model. Machine Intelligence Research, pages 1–18, 2024.
- Tang et al. [2023] Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models. arXiv preprint arXiv:2310.13289, 2023.
- vicgalle [2024] vicgalle. https://huggingface.co/datasets/vicgalle/alpaca-gpt4, 2024.
- Yang et al. [2024a] An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024a.
- Yang et al. [2024b] Dongchao Yang, Songxiang Liu, Rongjie Huang, Chao Weng, and Helen Meng. Instructtts: Modelling expressive tts in discrete latent space with natural language style prompt. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024b.
- Zen et al. [2019] Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. Libritts: A corpus derived from librispeech for text-to-speech. arXiv preprint arXiv:1904.02882, 2019.
- Zhang et al. [2023a] Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv preprint arXiv:2305.11000, 2023a.
- Zhang et al. [2023b] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023b.