ToolACE: 赢得大语言模型函数调用的关键
摘要
函数调用显著扩展了大型语言模型的应用边界,其中高质量和多样化的训练数据对于释放这种能力至关重要。 然而,真实的函数调用数据收集和标注非常具有挑战性,而现有管道生成的合成数据往往缺乏覆盖范围和准确性。 在本文中,我们提出了ToolACE,一个旨在生成准确、复杂和多样化的工具学习数据的自动代理管道。 ToolACE 利用新颖的自我进化合成过程来整理一个包含 26,507 个不同 API 的综合 API 池。 对话通过多个代理之间的交互生成,并由形式化的思考过程引导。 为了确保数据准确性,我们实施了一个双层验证系统,结合了基于规则和基于模型的检查。 我们证明,即使只有 80 亿个参数,在我们的合成数据上训练的模型,在伯克利函数调用排行榜上也取得了最先进的性能,与最新的 GPT-4 模型相媲美。 我们的模型和数据子集可在 https://huggingface.co/Team-ACE/ 公开获取。
1 引言
为大型语言模型 (LLM) 配备外部工具已显著增强了 AI 代理解决复杂现实世界任务的能力 [10, 15, 16]。 函数调用的集成使 LLM 能够访问最新信息、执行精细计算并利用第三方服务,从而解锁各个领域的广泛潜在应用,例如工作流程自动化[26]、财务报告[20]和旅行计划[6]。
受到实际应用的驱动,由于现实世界 API 的多样性、复杂性和交互性 [15],函数调用可能相当复杂。 1 11在本报告中,API、工具、函数和插件是可互换的。 例如,现实世界 API 参数通常超出简单的字符串或数字,包括列表、字典、嵌套参数,甚至这些的组合。 这些 API 参数的数量可以从零到几十个不等,这些 API 的应用领域涵盖了广泛的业务和行业 [24]。 此外,单个 API 通常不足以完成一项任务;相反,需要多个工具协同使用才能执行现实世界中的任务 [10]。 一个 API 的输入甚至可能取决于另一个 API 的输出 [15],这使得函数调用更加复杂和具有挑战性。
考虑到这种多样性和复杂性,针对特定任务或用户查询的函数调用通常可以分为三类: 单一函数调用、 并行函数调用 和 依赖函数调用。 在单一函数调用中,LLM 选择并执行一个函数来完成用户的任务。 对于并行函数调用,LLM 在一次操作中同时执行多个独立函数调用。 而依赖函数调用涉及 LLM 进行一系列顺序调用,每次后续调用都依赖于前一个调用的输出。
然而,当前的工具增强型 LLM 主要集中在简单函数调用场景,多样性和复杂性有限 [16]。 表 1 概述了这些代表性工具增强型 LLM 中使用的数据统计信息。 虽然在一次操作中执行一个 API 的单一函数调用已经取得了令人满意的性能,但并行和依赖函数调用的能力在很大程度上被忽视了。 此外,受限的 API 领域、简单的参数类型和统一的数据格式可能会阻碍函数调用对更复杂、现实世界任务的适用性。 执行现实世界中的函数调用需要精确的 API 选择和准确的参数配置,这两者都与底层数据的准确性密切相关。 然而,确保工具数据的准确性仍然是一个具有挑战性的问题,尤其是在处理多样化和复杂的任务时。
| Model | #API | #Domain | Nested | Parallel | Dependent | Multi-type |
| Gorilla [14] | 1645 | 3 | ✗ | ✗ | ✗ | ✗ |
| ToolAlpaca [19] | 3938 | 50 | ✗ | ✗ | ✗ | ✗ |
| ToolLLM [15] | 16464 | 49 | ✗ | ✗ | ✓ | ✗ |
| Functionary [12] | n/a | n/a | ✗ | ✓ | ✗ | ✗ |
| xLAM [11] | 3673 | 21 | ✗ | ✓ | ✗ | ✗ |
| Granite [1] | n/a | n/a | ✗ | ✓ | ✗ | ✓ |
| ToolACE | 26507 | 390 | ✓ | ✓ | ✓ | ✓ |
因此,在本报告中,我们提出了 ToolACE,一个系统性的工具学习管道,涵盖了合成数据生成和数据验证,展示了具有增强的 准确性、多样性和复杂性的强大性能。
多样性。 使 LLM 暴露于各种函数调用场景中,有助于更全面地掌握工具使用的认知技能集 [25]。 在 ToolACE 中,我们建议强调函数调用多样性的三个维度:工具多样性、格式多样性和对话多样性。 工具多样性是通过我们的工具自我进化合成方法 (TSS) 实现的,该方法从各种领域合成具有不同数据类型和约束条件的工具。 为了格式多样性,我们提出了一种工具格式泛化方法,以支持 ToolACE 中的任何主流工具描述和工具调用格式 (例如,Json、YAML、XML、markdown)。 对话多样性包括简单、并行、依赖函数调用和非工具使用对话,涵盖了广泛的函数调用用例。
复杂性。 在 ToolACE 中,我们强调数据的复杂性,其中指令遵循数据应具有足够的复杂性,以发展函数调用所需的技能。 我们还发现,当数据复杂性略高于 LLM 的当前能力水平时,它们学习得更有效。 事实证明,太简单或太复杂的数据对于 LLM 来说是没有生产力的。 这与教育心理学中的最近发展区 (ZPD) 理论相一致,该理论指出,当任务略微超出学习者当前独立能力水平但可以在适当支持的情况下实现时,学习效果最佳 [17]。
准确度。 数据准确性是工具增强 LLM 有效性的基础。 为了获得高质量的数据,我们首先实施了一种正式的思维和自一致性策略,以提高数据生成过程中的可靠性。 然后,我们部署了一个双层验证(DLV)系统,该系统集成了基于规则和基于模型的检查,以进一步提高准确性。
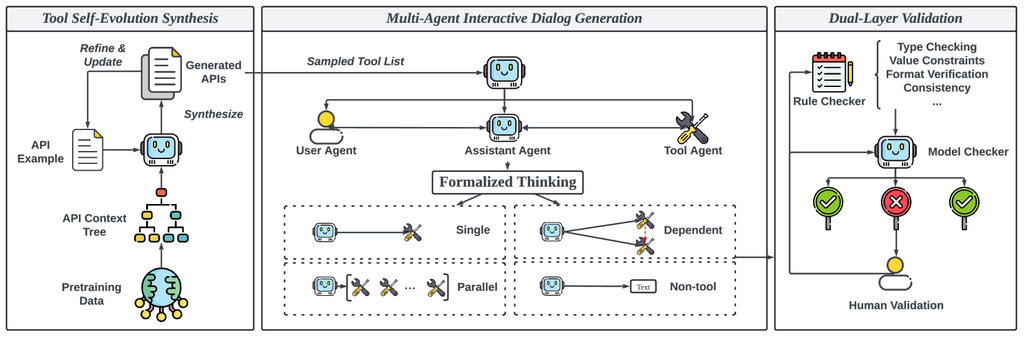
2 数据生成管道
有效利用合成数据显著增强了大型语言模型 (LLM) 的能力 [13]。 因此,在 ToolACE 中,我们提出了一个用于工具学习的自动化代理框架,以利用高级 LLM 生成高质量、多样化和复杂的数据,如图 1 所示。 所提出的框架部署了各种代理来递归地合成不同的 API,协作构建形式化的对话,并严格地反思数据质量。 以下部分介绍了我们的工具自我进化合成 (TSS) 模块、多代理交互式对话生成 (MAI) 模块和双层验证过程 (DLV)。
2.1 工具自我进化合成
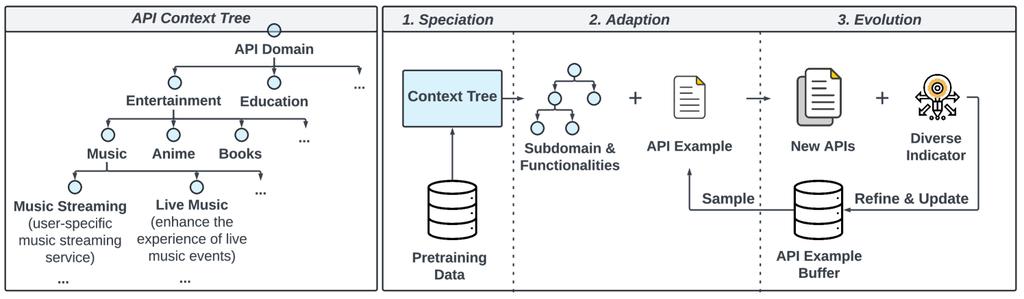
API 的多样性极大地支撑了函数调用数据的多样性和复杂性。 如表 1 所示,ToolACE 建立了一个全面的 API 池,在数量和领域覆盖范围方面都超过了其他代表性的工具增强型 LLM,包括真实和合成 API。 除了收集真实的 API 数据外,我们还开发了一个工具自我进化合成 (TSS) 模块,该模块可以合成具有各种数据类型和约束的 API 定义。 具体来说,我们利用预训练数据提取一个 API 上下文树,其中每个节点代表函数调用潜在的应用领域和功能,例如,金融、医疗保健和运输。 通过结合采样的功能和 API 示例,一个由前沿 LLM 支持的代理可以合成新的 API。 API 的多样性和复杂性通过递归的自我进化和更新逐渐增加。 此过程通过三个主要步骤完成:1) 物种形成,2) 适应,以及 3) 进化。 详细过程如图 2 所示。
物种形成。
覆盖广泛领域的 API 使工具增强型 LLM 能够从各种应用和行业中学习更广泛的用例,从而显着增强其泛化能力。 在物种形成步骤中,我们建议创建一个分层的 API 上下文树,以指导合成过程,包括可能的 API 领域和功能。
我们观察到,LLM 的预训练数据包含了人类语料库中最多样化的来源之一,为提取各种 API 领域和用例提供了坚实的基础。 从预训练数据中开始,从与 API 相关的原始文档(例如技术手册、API 文档、产品规格、用户指南和教程)中,我们提示 LLM 从每个文档中提取 API 领域以及所有可能的 API 功能或用例。 上下文树的子节点在每一步递归地生成。 我们最终的上下文树包含一个全面的结构,涵盖 30 个主要领域 (e.g.,娱乐、教育),分为 390 个粗粒度子域 (e.g.,音乐、动漫、书籍),并进一步细化为 3,398 个不同的细粒度域 (e.g.,音乐流媒体、现场音乐)。 这棵庞大的上下文树包含估计十万个特定的功能。 图 2 的左侧展示了 娱乐 领域下的子树作为示例。
适应。
在适应步骤中,我们指定每个 API 的领域和复杂度级别。 为了确定单个 API 的复杂度级别,我们从 API 上下文树的细粒度领域级别的子节点中采样一个子树并获得唯一的功能,确保同一领域内的 API 拥有不同的功能。 具体来说,更复杂的 API 应该覆盖更多的上下文树节点,从而获得更多领域特定的和详细的功能。 相反,更简单的 API 可能只包含来自上下文树的单个子节点,专注于一个简单直接的目的。
演化。
演化步骤涉及基于结果和多样性与复杂性的新需求对 API 进行持续改进和调整。 指令 LLM 根据 API 上下文树的采样子树和 API 示例来合成新的 API。 新 API 的生成定义需要清晰完整。 然后,我们应用一组多样性指标,e.g.,添加新功能或参数,包括额外的约束,修改参数类型,并更新返回的结果,以使生成的 API 多样化。 我们维护一个包含各种 API 示例的 API 示例缓冲区。 我们迭代地从缓冲区中采样一个示例,将其调整到当前功能子树,并生成下一代 API。
提出的 TSS 模块有助于高效地生成一组多样化且复杂的 API 文档,其中包含嵌套类型,包括列表列表或字典列表。 通过此过程,我们已经整理了一组包含 26,507 个不同 API 的集合。
2.2 多智能体交互式对话生成
涉及函数调用的现实世界任务通常包含复杂的意图和各种需求。 为了解决这些现实世界任务,工具增强型 LLM 应能准确识别何时、什么和需要多少个函数调用。 为了更好地代表现实世界场景,我们提出了一个多智能体交互式 (MAI) 对话生成模块来合成函数调用对话。 这些对话涵盖了多种类型,包括简单的函数调用、并行函数调用、依赖函数和非工具使用对话。 MAI 模块旨在确保在整个生成过程中准确性、复杂性和多样性。
2.2.1 对话生成概述
图 1 的中间部分说明了我们的对话生成过程。 最初,我们从精心策划的 API 池中采样一个或多个 API 候选者,确保所选 API 共享相同的领域。 这有助于维护单个对话内的主题一致性。 此外,同一领域内的 API 更可能具有相似的功能。 基于类似 API 的对话可以增强模型区分不同 API 的细微差别。
然后,我们通过三个不同代理(用户、助手和工具)之间的相互作用来生成对话,每个代理都由一个 LLM 模拟。 用户代理 主要提出请求或提供附加信息,由多模式提示和相似性引导的复杂化来增强多样性和复杂性。 助手代理 使用给定的 API 来解决用户的查询。 助手代理的动作空间包括:调用 API、请求更多信息、总结工具反馈以及提供非工具使用的答案。 每个动作都是通过 形式化的思考 过程确定的,并通过 自一致性 进行验证,以确保准确性。 工具代理 充当 API 执行器,处理助手提供的工具描述和输入参数,并输出潜在的执行结果。 最后,在生成对话后,可以使用我们设计的工具格式泛化将它们转换为不同的格式。 算法 1概述了整个对话生成过程。
在接下来的部分,我们将详细阐述 MAI 模块,并解释在生成过程中如何确保准确性、多样性和复杂性。
2.2.2 确保准确性、多样性和复杂性的生成
MAI 模块使用多种策略来生成函数调用对话,以确保准确性、多样性和复杂性。 我们将在下面依次介绍这些策略。
多模式提示。
MAI 生成首先确定每个样本的目标对话模式。 我们的多模式提示允许我们通过改变给用户代理的指令来创建各种对话类型。 我们根据指令中指定的回合长度,生成单回合和多回合对话。
为了进一步使对话类型多样化,我们调整了提示期间所需的工具调用次数以及这些调用之间的关系,从而产生了单一、并行和依赖的函数调用。 此外,我们还生成了不使用工具的对话,这些对话分为两种情况:没有合适的工具可用,以及信息不足以调用工具。
这种多样化的对话对于开发 LLM 在工具使用方面的全面技能至关重要。
相似性引导的复杂化。
在指令的指导下,用户代理能够生成一个需要特定函数类型的适当查询。 除此之外,我们还考虑了语言级别的复杂性,这可以通过相似性度量来识别(有关详细信息,请参阅第 4.2 节)。 为了捕捉不同复杂程度的查询,我们采用了一系列模板,以不同的语言风格提示用户代理。 查询的复杂度可以在对话结束后计算出来,然后作为数据选择标准。
正式思考.
在用户代理生成查询后,助手代理必须确定适当的响应操作。 研究表明,鼓励大型语言模型在采取行动之前进行思考——例如通过思维链提示[21]——可以增强其推理能力。 我们采用类似的策略来提高助手代理的工具调用决策的准确性。 与传统的思维链提示不同,传统的思维链提示通常鼓励一般的反思性思维(例如,仅仅添加“让我们一步一步地思考”),我们实现了一个专门的、结构化的思维过程,专门针对函数调用。 此过程包括:1) 评估用户查询,2) 评估工具要求,以及 3) 确保提供所有必需参数。
正式思考只在数据生成期间使用,并且从训练数据形成中排除,以保持简洁性。
自一致性.
为了进一步确保准确性,我们在决定操作时实施了一种自一致性机制。 助手代理的每个响应都会生成多次。 只有当操作决策(包括是否进行工具调用以及要填充的参数值)在至少两个实例中一致时,才采用响应。 如果一致性得到实现,我们将应用多数投票来选择最终响应。 如果不满足一致性,则对话的当前回合将被丢弃,或者应用损失掩码以防止模型学习潜在的错误内容。
如果助手代理确定的操作涉及工具调用,则工具代理将提供模拟结果,然后助手代理将其汇总并呈现给用户(对于需要依赖函数调用的查询,助手和工具代理之间需要额外的交互)。 生成过程将继续进行,直到达到目标回合长度为止,用户代理会再次查询或响应助手的询问。
工具格式泛化.
在生成对话的最后,可以应用格式泛化来增加格式的多样性。 所有生成的对话最初都存储在 JSON 格式中,这种格式易于处理和验证(详细信息将在下一节中展示)。 为了支持工具定义和函数调用的灵活和用户特定格式,我们进一步将生成的对话和 API 列表转换为各种格式 (例如,JSON、YAML、XML、Markdown)。 我们观察到,随着格式多样性的增加,模型的指令遵循能力有所提高。
3 数据验证
影响 LLM 函数调用能力的一个关键因素是训练数据的准确性和可靠性。 不一致或不准确的数据会阻碍模型解释和执行函数的能力 [11]。 与一般的问答数据不同,验证正确性可能具有挑战性,函数调用数据更易于验证。 这是因为成功的函数调用必须严格匹配 API 定义中指定的格式。 基于这一见解,我们提出了一种自动双层验证系统(DLV)来验证我们合成的數據,如图 1 的右部分所示,该系统包括 规则验证层 和 模型验证层,其中所有结果均由人工专家监督。

数据结构。
每个数据样本包含三个组件:系统提示、工具列表和对话,所有这些都存储在 JSON 格式中,并包含 ToolACE 所需的模式要求。 JSON 格式天生易于解析,并保持清晰的分层结构。 图 3 显示了我们 API 定义和函数调用的数据示例。 每个函数调用也以 JSON 格式在助手角色的 tool_usage 字段中进行格式化,其中显式列出了 API 名称和参数。
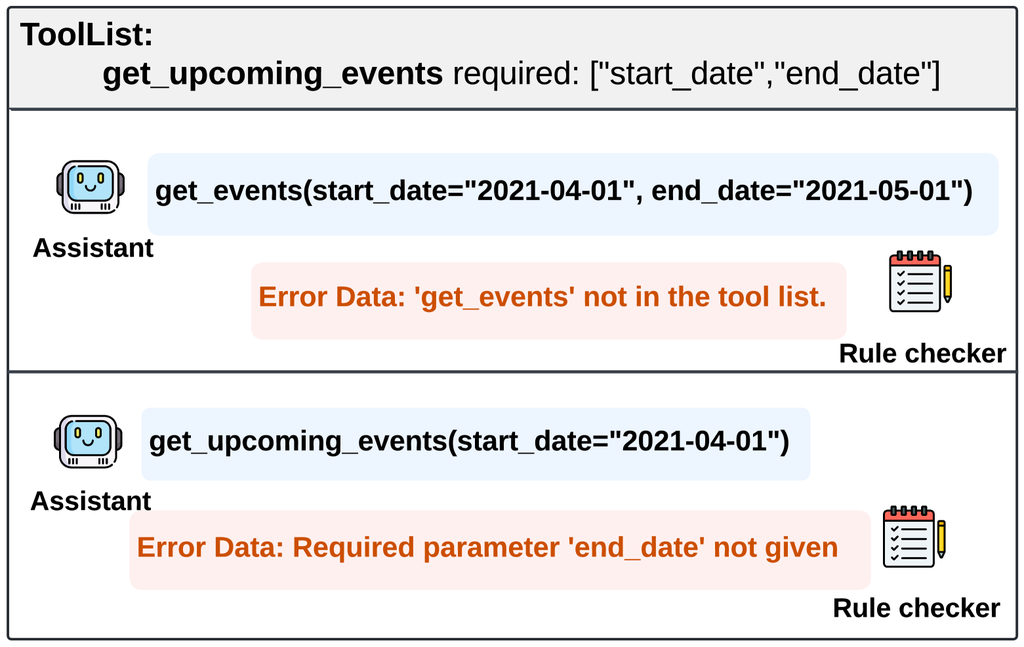
规则验证层。
规则验证层部署了一个规则检查器,以确保数据严格遵守 API 预定义的语法和结构要求。 数据质量从四个关键方面进行评估:API 定义清晰度、函数调用可执行性、对话正确性和数据样本一致性,这些评估由精心策划的一组规则指导,如附录 A 中所列。
例如,为了验证函数调用可执行性,我们执行以下步骤:首先,我们确认 API 名称与给定工具列表中的一个名称匹配。 接下来,我们验证是否准确提供了所有必需的参数。 最后,我们使用正则表达式确保参数格式和模式符合 API 文档中指定的格式和模式。 这些步骤使我们能够验证函数调用的正确性和可执行性,而无需实际执行,从而提高效率并降低部署开销。 图 5 显示了规则验证层检测到的可能错误示例。
模型验证层。
模型验证层进一步整合了 LLMs,以过滤掉规则检查器无法检测到的错误数据,主要关注内容质量。 但是,我们发现将数据样本直接提供给 LLM 以进行正确性评估过于复杂,通常会导致不令人满意的结果。 为了解决这个问题,我们将模型验证任务分解为几个子查询,主要涵盖三个关键方面:
-
•
幻觉检测: 识别函数调用中输入参数的值是否被捏造——既未在用户查询中提及,也未在系统提示中提及。
-
•
一致性验证: 验证响应是否能有效地完成用户的任务,并确保对话内容符合用户查询和系统提示中的约束和指令。
-
•
工具响应检查: 确保模拟的工具响应与 API 定义一致。
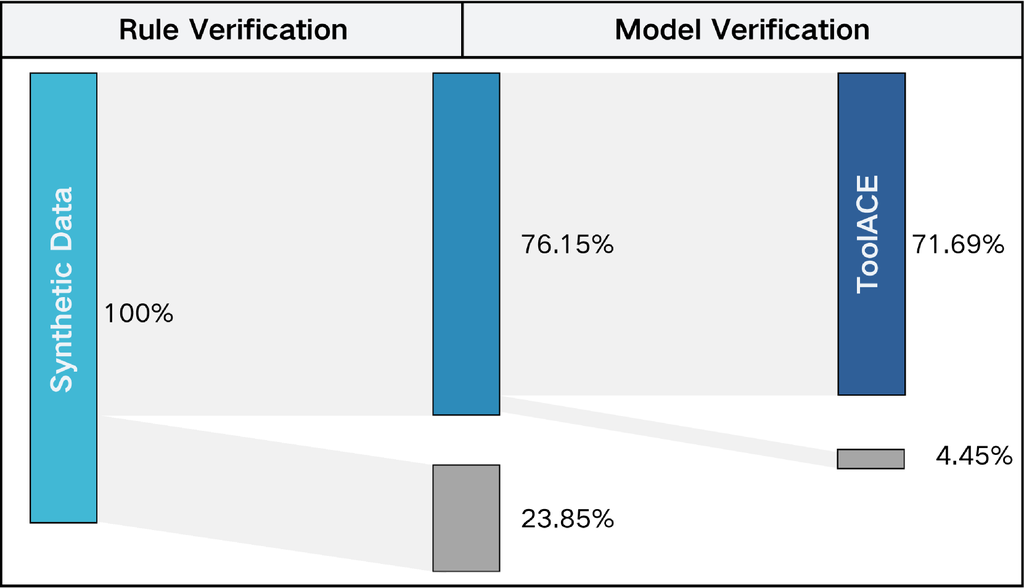
每个方面都由一个由 LLM 驱动的独立专家代理进行评估。 我们还整合了其他一些数据质量验证查询,以消除数据中的重复响应和无意义的符元。 图 5 分别展示了我们的数据在规则验证和模型验证方面的通过率。 此外,我们还应用了第 2.2 节中提到的自一致性策略,并使用多数投票来提高决策准确性。
4 数据分析
本节对验证后的最终数据进行了深入分析,重点关注了跨多个维度的分布,涵盖了多样性和复杂性两个方面。
4.1 多样性
本节对我们数据的三个维度进行了量化分析,并展示了其多样性:工具多样性、格式多样性 和 对话多样性。 这些维度对于评估数据集的丰富程度及其支持稳健工具学习的能力至关重要。
4.1.1 工具多样性
大量 API 池。
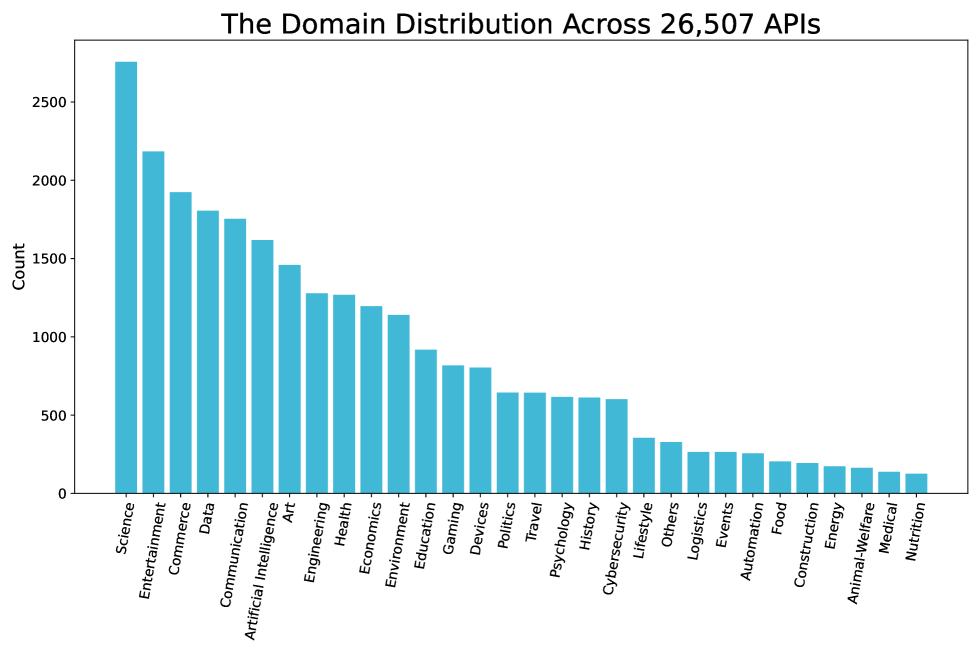
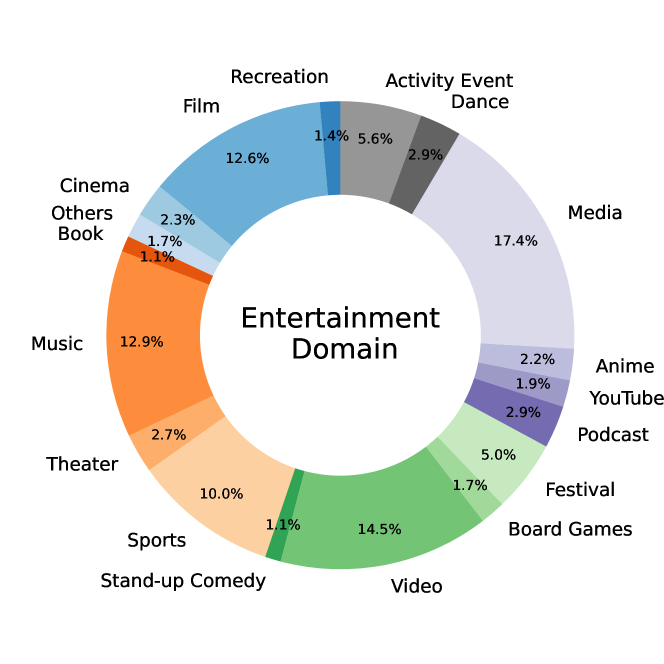
通过我们在第 2.1 节中的 TSS 模块,我们整理了包含 26,507 个不同 API 的综合集合,涵盖了真实世界和合成 API 定义。 我们的 API 跨越 30 个一级粗粒度域、390 个二级域和 3,398 个三级域,极大地丰富了我们的工具学习数据的多样性。 图 6 中的左图说明了 26,507 个 API 在 30 个一级域(包括科学、数据和旅行等)中的分布。 右图详细说明了“娱乐”域内二级域的分布。 API 的多样性为整个数据集的多样性奠定了坚实的基础,使模型能够有效地推广到新的 API 和任务。
参数类型。
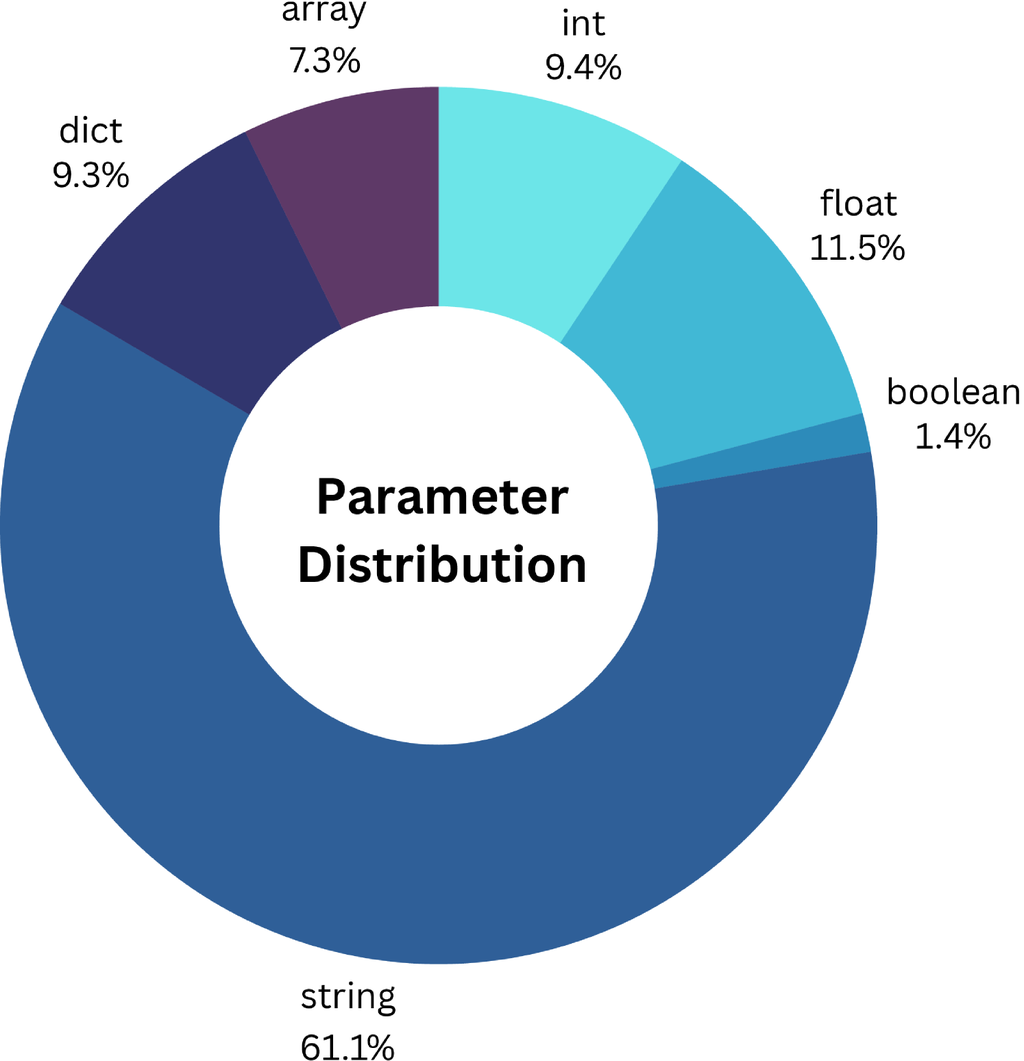
我们的目标是在 API 中保持参数类型的平衡分布。 为了防止字符串参数过度表示,我们在 API 合成过程中有意增加了非字符串类型(例如,整数、布尔值、浮点数、数组、字典)的比例。 图 8 中描述了由此产生的分布。
我们数据集中的工具多样性增强了 API 覆盖面的广度和参数多样性的丰富程度。 这种多样性对于开发能够适应各种场景和输入以用于现实世界任务的模型至关重要。
4.1.2 格式多样性
工具描述。
函数调用。
我们通过各种组合创建了数百种独特的函数调用格式。 这些格式要求在系统提示中明确声明,确保对话数据符合指定的函数调用格式,从而有效地增强函数调用的格式遵从能力。 这些格式的示例在图 9 中提供。
格式多样性增强了模型理解不同场景下各种需求的能力,从而提高其有效遵循任何特定格式指令并避免捷径的能力。
4.1.3 对话多样性
对话模式。
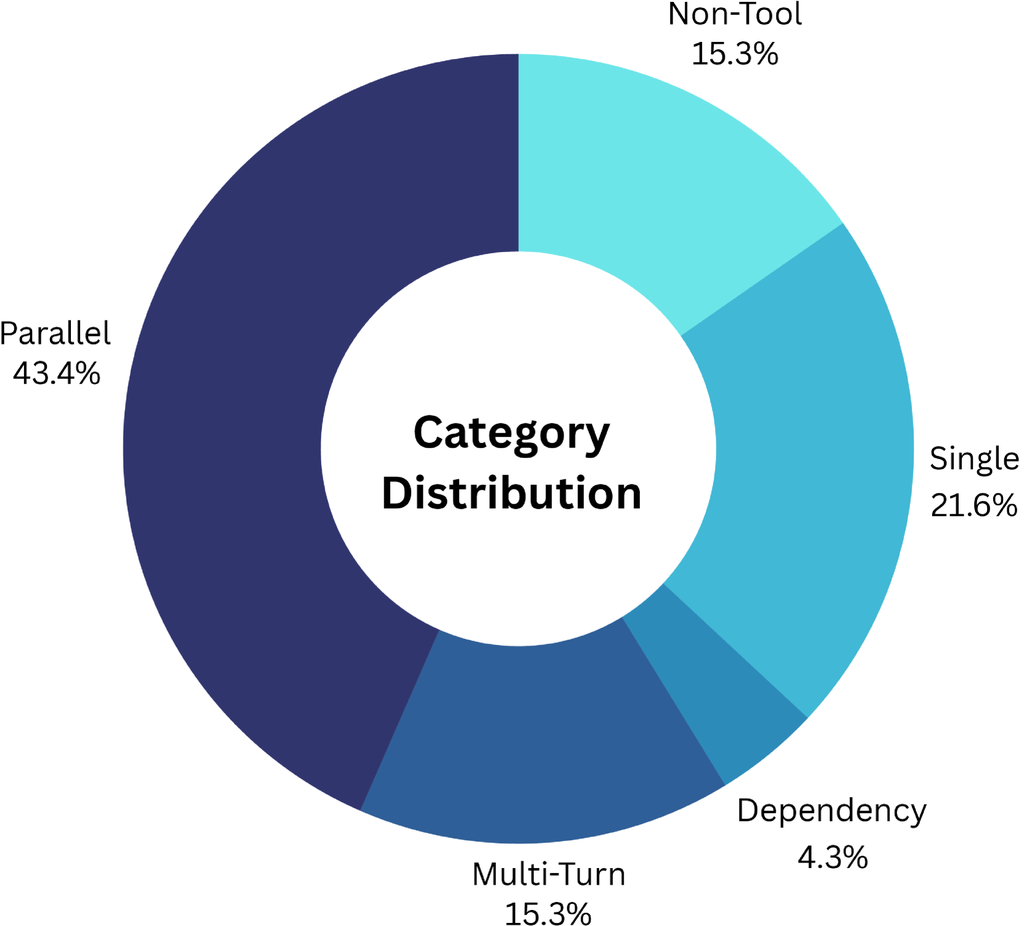
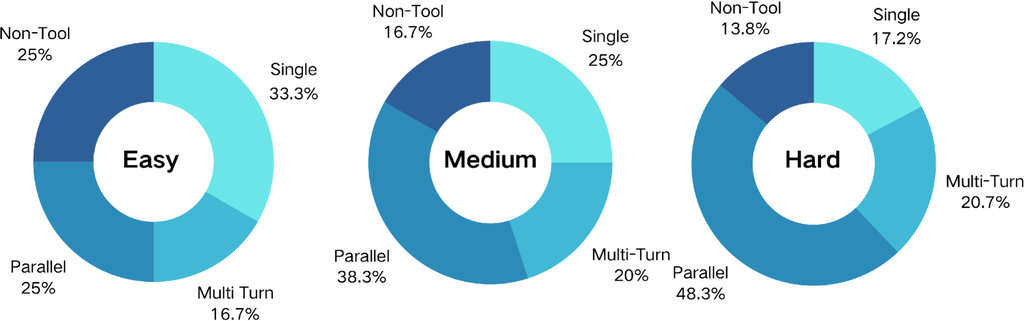
ToolACE 支持多种函数调用模式,包括单一、并行、依赖函数调用和非工具使用对话。 它还涵盖了不同的交互类型,例如单轮和多轮对话。 图 8 说明了这些对话模式的分布,突出了 ToolACE 中函数调用用例的广泛覆盖。

4.2 复杂性
适当的复杂性水平对于提高模型对更具挑战性的函数调用场景的适应性至关重要。 我们从两个角度探讨影响复杂性的因素:查询级复杂性 和 数据集级复杂性。
4.2.1 查询级复杂性
我们建议通过评估用户查询与所用工具描述之间的相关性来衡量单个查询的复杂性。 一般来说,这两个元素之间更高的亲和性会增加模型选择正确工具的可能性。 相反,更大的差异表明需要更高级的推理才能识别合适的函数,从而表明这是一个更具挑战性和更复杂的查询。
为了量化这种相关性,我们使用 BGE [22] 提取嵌入,并利用余弦相似度来评估相似度。 令 和 分别为查询和 API 描述的嵌入。 复杂度定义如下:
| (1) |
图 10 显示了结果复杂度评分的分布,平均评分为 0.439。
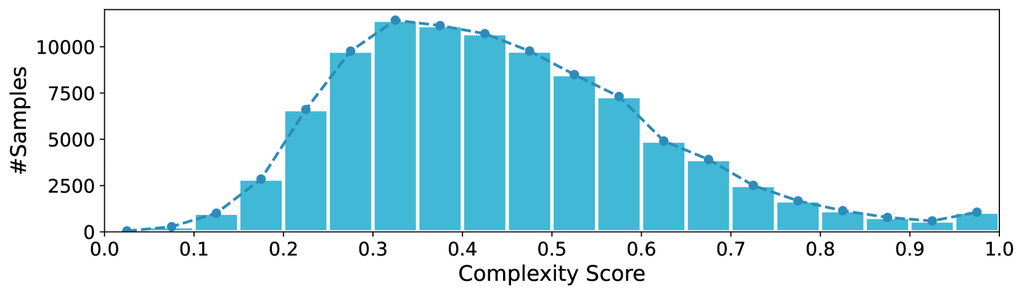
4.2.2 数据集级复杂度
我们发现,基本工具功能(例如单个函数调用)只需要最少的数据就能有效地进行模型学习。 相比之下,更高级和更复杂的功能(例如并行函数调用和多轮对话)通常需要更多的训练数据。 因此,我们增加了数据集中复杂数据的比例(i.e.,并行函数调用和多轮对话)。 图 8 显示了这些对话模式的分布。
对话模式的分布对于确定数据集的复杂性至关重要。 通过仔细平衡对话模式的组成,我们可以根据模型的需求调整数据集的复杂度,确保模型能够得到足够的挑战,以有效地学习。
5 实验
5.1 实验设置
为了验证我们方法的有效性,我们通过使用生成的数据训练 LLM 进行了广泛的实验。 我们以监督微调 (SFT) 的方式训练开源 LLM,LLaMA3.1-8B-Instruct [2]。 我们将使用我们的数据训练的模型称为 ToolACE-8B。 由于资源有限,我们采用了参数高效训练策略 LoRA [9] 来微调模型。 至于超参数设置,我们采用了最常见的设置之一,即为模型中的所有模块将秩设置为 16,alpha 设置为 32。 更多详细的训练设置见表 2。 我们将整体性能与最先进的开源和基于 API 的模型进行了比较,包括 GPT-4 系列 222https://chatgpt.com、Gemini 系列 333https://gemini.google.com/ 和 Claude-3 系列 444https://www.anthropic.com/,以及微调的函数调用模型,包括 Gorilla-OpenFunctions-v2 [14]、xLAM 系列 [11] 和 Functionary 系列 [12]。 然后我们进行了深入的消融研究,以揭示准确性、多样性和复杂性的有效性。
| Learning Rate | WarmUp Ratio | LR Scheduler | Batch Size | Epochs | LoRA rank | LoRA alpha |
| cosine | 48 | 3 | 16 | 32 |
5.2 整体性能分析
为了评估所提出的 ToolACE 系列模型在功能调用能力方面的有效性,我们使用 BFCL 基准 [23] 进行了评估,包括 BFCL-v1 和 BFCL-v2 5 55整体性能在 和 上进行评估,随后的研究仅在 BFCL-v1 上进行评估。 . 该基准是一个综合且可执行的函数调用评估,专门用于评估 LLM 调用函数的能力。 我们的 ToolACE-8B 模型在 BFCL-v1 和 BFCL-v2 上的结果,以及各种代表性模型的结果,分别总结在表 3 和表 4 中。
研究结果表明,基于 API 的模型比开源模型(如 Claude 系列和 GPT-4 系列)具有明显的优势。 这种优势可能是由于它们更大的模型尺寸。 针对函数调用进行微调的开源模型,例如 Functionary 和 xLAM,表现出极具竞争力的性能,但仍不及领先模型,尤其是在 BFCL-v2 中。 我们的 ToolACE-8B 模型在 BFCL-v1 的 AST 和 Exec 类别中均优于所有其他基于 API 和开源模型,并且在 BFCL-v2 的背景下继续表现出相对于大多数模型的显著优势,证明了我们的训练数据对函数调用的有效性。 此外,ToolACE 在检测工具相关性(或在 v2 中的不相关性)方面表现出色,得分达到 89.17%,超过所有其他模型。 ToolACE-8B 在所有类别中也始终如一地显著优于 Functionary-Small-v3.2,后者也是从 LLaMA3.1-8B-Instruct 微调而来的,这提供了令人信服的证据证明其优越性。
| Rank | Model | Overall Accuracy | AST Category | Exec Category | Relevance | ||||||
| Simple | Multiple | Parallel |
|
Simple | Multiple | Parallel |
|
||||
| 1 | ToolACE-8B (FC) | 91.41 | 89.09 | 95.50 | 92.50 | 90.50 | 98.24 | 94.00 | 90.00 | 85.00 | 89.17 |
| 2 | Claude-3.5-Sonnet-0620 (Prompt) | 90.53 | 88.55 | 95.00 | 91.50 | 92.50 | 100 | 96 | 84 | 80 | 84.17 |
| 3 | Functionary-Medium-v3.1 (FC) | 88.88 | 86.18 | 95.00 | 93.00 | 89.5 | 95.88 | 94.00 | 90.00 | 80.00 | 81.25 |
| 4 | xLAM-7b-fc-r (FC) | 88.76 | 86.36 | 93.50 | 92.00 | 87.50 | 96.47 | 88.00 | 88.00 | 80.00 | 85.00 |
| 5 | GPT-4-1106-Preview (Prompt) | 88.53 | 88.91 | 95.50 | 89.00 | 91.50 | 99.41 | 94.00 | 82.00 | 82.50 | 72.50 |
| 6 | GPT-4-0613 (Prompt) | 88.53 | 87.27 | 92.50 | 91.00 | 89.00 | 97.06 | 88.00 | 88.00 | 77.5 | 81.67 |
| 7 | GPT-4-0125-Preview (Prompt) | 88.12 | 88.55 | 95.00 | 90.00 | 93.00 | 99.41 | 96.00 | 84.00 | 80.00 | 68.33 |
| 8 | Claude-3-Opus-20240229 (Prompt) | 88.00 | 86.36 | 94.5 | 87.50 | 86.50 | 96.47 | 94.00 | 80.00 | 75.00 | 84.58 |
| 9 | GPT-4o-mini-2024-07-18 (Prompt) | 87.35 | 86.91 | 93.00 | 86.00 | 88.50 | 99.41 | 96.00 | 82.00 | 82.50 | 75.42 |
| 10 | Nemotron-4-340b-instruct (Prompt) | 87.18 | 84.36 | 93.50 | 88.50 | 86.50 | 97.65 | 96.00 | 84.00 | 80.00 | 80.42 |
| 11 | GPT-4-turbo-2024-04-09 (Prompt) | 87.12 | 87.45 | 96.50 | 91.00 | 90.50 | 99.41 | 96.00 | 82.00 | 77.50 | 64.58 |
| 12 | GPT-4-1106-Preview (FC) | 86.65 | 83.09 | 92.50 | 90.00 | 86.50 | 91.76 | 94.00 | 86.00 | 77.50 | 83.75 |
| 13 | GPT-4o-2024-08-06 (FC) | 85.59 | 82.18 | 90.50 | 93.00 | 84.50 | 80.59 | 90.00 | 86.00 | 77.50 | 87.92 |
| 14 | GPT-4-0125-Preview (FC) | 85.47 | 82.73 | 92.50 | 91.00 | 86.50 | 78.24 | 92.00 | 88.00 | 80.00 | 84.58 |
| 15 | Gorilla-OpenFunctions-v2 (FC) | 85.41 | 87.82 | 95.50 | 87.00 | 87.00 | 97.06 | 96.00 | 80.00 | 77.50 | 60.83 |
| 16 | Granite-20b-FunctionCalling (FC) | 85.24 | 82.73 | 90.5 | 85.00 | 81.00 | 87.65 | 90.00 | 86.00 | 80.00 | 88.33 |
| 17 | yi-large (FC) | 85.24 | 83.09 | 93.50 | 90.00 | 86.50 | 92.94 | 96.00 | 82.00 | 82.50 | 71.67 |
| 18 | Meta-Llama-3-70B-Instruct (Prompt) | 84.94 | 84.36 | 92.50 | 91.00 | 87.00 | 91.76 | 90.00 | 88.00 | 77.50 | 67.92 |
| 19 | GPT-4-turbo-2024-04-09 (FC) | 84.41 | 78.73 | 92.00 | 90.50 | 85.50 | 85.29 | 86.00 | 84.00 | 77.50 | 85.42 |
| 20 | GPT-4o-2024-05-13 (FC) | 84.12 | 80.55 | 91.00 | 90.00 | 83.00 | 90.59 | 88.00 | 90.00 | 77.50 | 77.08 |
| 21 | Functionary-Small-v3.2 (FC) | 82.82 | 82.73 | 91.00 | 90.00 | 78.50 | 84.12 | 92.00 | 80.00 | 75.00 | 72.92 |
| Rank | Model | Overall Accuracy | AST Category | Exec Category | Irrelevance | Relevance | ||||||
| Simple | Multiple | Parallel |
|
Simple | Multiple | Parallel |
|
|||||
| 1 | ToolACE-8B (FC) | 85.77 | 71.03 | 85.78 | 87.13 | 80.17 | 96.86 | 94.00 | 86.00 | 87.50 | 81.44 | 87.80 |
| 2 | GPT-4-1106-Preview (Prompt) | 85.65 | 79.01 | 89.90 | 82.25 | 83.00 | 99.29 | 94.00 | 88.00 | 82.50 | 61.04 | 97.56 |
| 3 | GPT-4o-mini-2024-07-18 (Prompt) | 84.35 | 79.32 | 84.24 | 87.50 | 86.67 | 98.29 | 94.00 | 80.00 | 80.00 | 68.09 | 85.37 |
| 4 | GPT-4-0613 (Prompt) | 84.23 | 76.90 | 82.32 | 90.50 | 80.42 | 97.50 | 88.00 | 88.00 | 75.00 | 70.95 | 92.68 |
| 5 | GPT-4-turbo-2024-04-09 (Prompt) | 84.11 | 79.34 | 90.63 | 82.75 | 83.25 | 98.50 | 92.00 | 82.00 | 80.00 | 55.05 | 97.56 |
| 6 | GPT-4-0125-Preview (Prompt) | 84.09 | 78.61 | 89.30 | 85.62 | 81.42 | 98.50 | 94.00 | 86.00 | 75.00 | 54.93 | 97.56 |
| 7 | Functionary-Medium-v3.1 (FC) | 81.73 | 74.03 | 87.37 | 81.38 | 78.83 | 97.29 | 90.00 | 88.00 | 75.00 | 72.24 | 73.17 |
| 8 | Claude-3-Sonnet-20240229 (Prompt) | 80.52 | 71.59 | 79.77 | 79.62 | 82.00 | 93.00 | 92.00 | 88.00 | 80.00 | 48.96 | 90.24 |
| 9 | Claude-3.5-Sonnet-20240620 (Prompt) | 80.34 | 76.07 | 85.07 | 77.25 | 71.00 | 98.00 | 92.00 | 82.00 | 72.50 | 78.77 | 70.73 |
| 10 | Claude-3-Opus-20240229 (Prompt) | 79.75 | 72.25 | 83.07 | 74.50 | 73.42 | 98.79 | 92.00 | 82.00 | 80.00 | 78.03 | 63.41 |
| 11 | GPT-4-1106-Preview (FC) | 79.65 | 68.89 | 83.58 | 80.62 | 70.83 | 89.86 | 90 | 84 | 70 | 73.36 | 85.37 |
| 12 | yi-large (FC) | 79.53 | 67.84 | 82.68 | 82.5 | 77.33 | 91.86 | 94 | 82 | 85 | 68.68 | 63.41 |
| 13 | Functionary-Small-v3.2 (FC) | 79.45 | 68.29 | 81.54 | 77 | 71.42 | 88.29 | 92 | 86 | 77.5 | 72.02 | 80.49 |
| 14 | GPT-4-0125-Preview (FC) | 79.41 | 67.97 | 84.3 | 80.12 | 76.83 | 73.29 | 90 | 86 | 75 | 75.26 | 85.37 |
| 15 | xLAM-7b-fc-r (FC) | 79.36 | 68.43 | 79.3 | 73.88 | 68.5 | 94.21 | 88 | 88 | 75 | 80.24 | 78.05 |
| 16 | Functionary-Small-v3.1 (FC) | 78.86 | 70.07 | 83.21 | 83 | 72.92 | 83.93 | 88 | 84 | 70 | 68.09 | 85.37 |
| 17 | mistral-large-2407 (FC Any) | 78.82 | 80.59 | 87.42 | 84.25 | 83.25 | 96.86 | 92 | 86 | 77.5 | 0.29 | 100 |
| 18 | Gorilla-OpenFunctions-v2 (FC) | 78.64 | 72.89 | 79.8 | 78.38 | 66.42 | 94.36 | 92 | 78 | 72.5 | 64.25 | 87.8 |
| 19 | GPT-4-turbo-2024-04-09 (FC) | 78.57 | 63.29 | 83.23 | 83 | 75 | 81.57 | 88 | 84 | 75 | 79.47 | 73.17 |
| 20 | Command-R-Plus (Prompt) | 78.49 | 71.28 | 79.69 | 81.38 | 75.33 | 91.36 | 92 | 82 | 77.5 | 51.47 | 82.93 |
| 21 | GPT-4o-2024-08-06 (FC) | 78.29 | 69.95 | 80.37 | 84 | 75 | 77.5 | 90 | 86 | 72.5 | 81.71 | 65.85 |
5.3 消融研究
为了进一步验证数据生成和验证中引入的各种机制的效果,我们分别从准确性、复杂性和多样性的角度进行了深入的消融研究。
5.3.1 准确性消融
正式化思维的影响。 本部分探讨了正式化思维对对话生成过程的影响。 我们随机选择了 个由我们的用户代理生成的用户信息查询,并在两种不同的情况下继续生成过程:一种是使用正式化思维,另一种是不使用正式化思维。 然后,我们使用 DLV 数据验证模块评估了生成的输出。 表 5 展示了两个生成数据集的通过率。 结果表明,使用形式化思维生成的数据在两个验证层中始终达到更高的通过率,最终通过率有显著的 绝对提升。 对特定错误的详细分析揭示了两个数据集在以下方面的明显差距:是否调用工具、工具选择以及对可选参数的处理。 这些差异突出了形式化思维在决策中的优势,因此将形式化思维融入对话生成过程的有效性。
| Method | Rule-based Pass Rate | Model-based Pass Rate | Final Pass Rate |
| With FT | |||
| W/O FT |
验证系统的影响。 如前几节所述,我们的验证系统包含两个层:规则检查器和模型检查器。 为了评估每层的有效性,我们使用 LoRA 对 LLaMA3.1-8B-Instruct 进行训练,使用三个不同的数据集:(1)没有任何验证的数据(表示为 w.o. dual),(2)没有模型检查的数据(表示为 w.o. model),以及(3)经过双层验证的数据(表示为 Final)。 使用 BFCL 基准评估得到的微调模型,结果总结在图 11 中。 比较分析表明,在可执行性和整体准确性方面,在没有模型检查的数据上训练的模型优于在未经验证的数据上训练的模型,从而验证了规则检查器的有效性。 此外,在双重验证数据上训练的模型在 AST 和整体准确性方面都显著优于两种消融模型,突出了模型检查器的不可或缺作用。
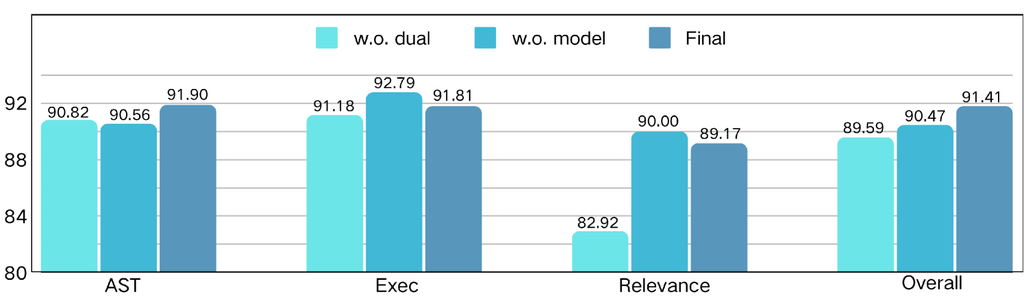
5.3.2 复杂度消融研究
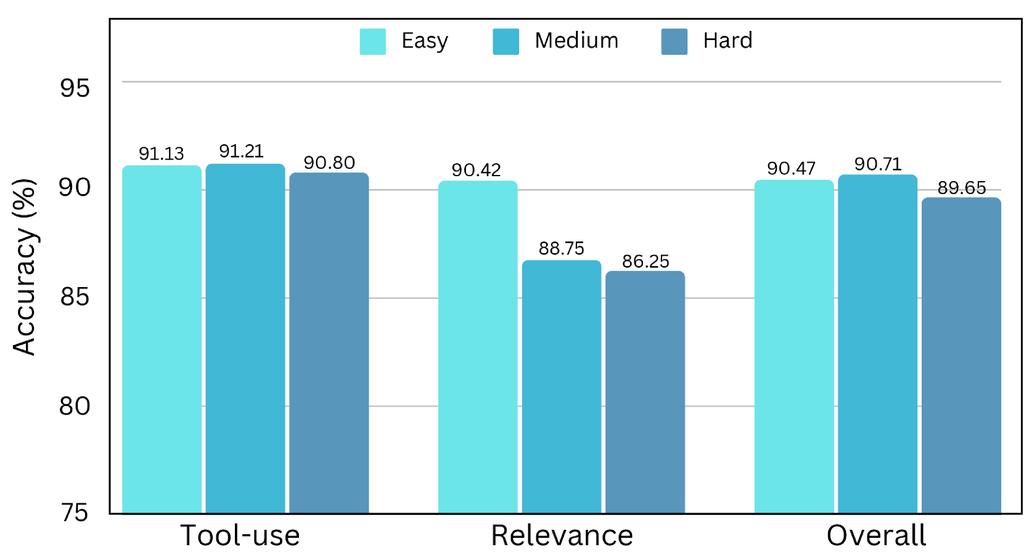
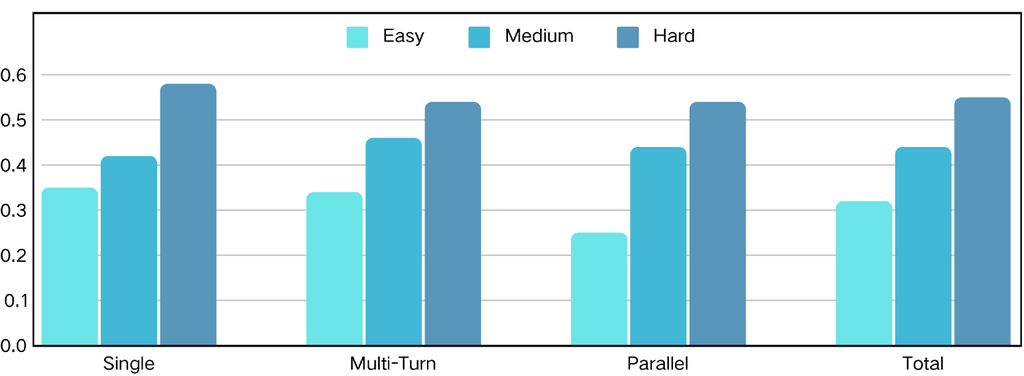
针对不同复杂度的数据采样。 为了有效评估数据集复杂度对模型性能的影响,我们基于上述复杂度评估指标对整个数据集进行了采样。 此过程产生了三个具有不同复杂度水平的独特子集:、 和 ,每个子集包含约 60,000 个实例。 附录 C 中的图 18 和图 19 说明了这些子集在数据集级复杂度和查询级复杂度方面的不同分布。 这种分层采样方法背后的基本原理是创建一个受控的环境,在该环境中可以系统地分析复杂度的影响。 通过在子集之间保持相等的样本大小,我们确保公平的比较,同时改变复杂度,这使得能够更细致地了解复杂度如何影响模型性能。
复杂度影响。 我们对这三个具有不同复杂度的子集进行了实验,并在 BFCL 基准上评估微调后的模型。 结果如图 13 所示。 在 上训练的模型在整体和工具使用准确率方面都略微优于另外两个子集。 这一发现与我们的假设一致,即最佳数据复杂度对于 LLM 训练至关重要;过分简单或复杂的数据会阻碍性能。
5.3.3 消融多样性
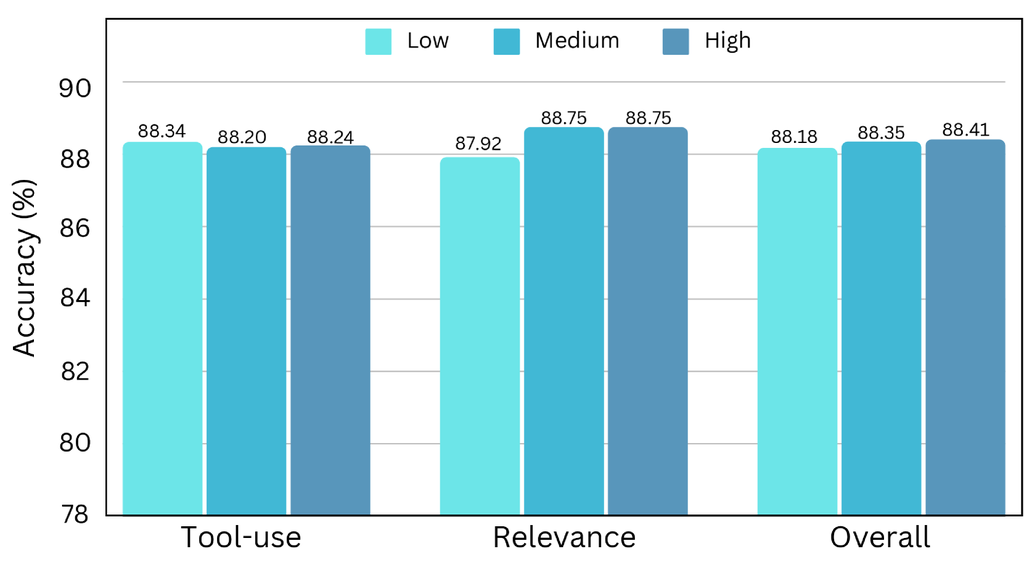
用于各种多样性的数据采样。 为了评估多样性的影响,我们采用了一种采样策略来生成三个具有不同多样性程度的子集,分别是 、 和 。 最初,所有 API 基于其名称和描述使用 K 均值聚类成 30 组。 随后,通过分别从 6、14 和 30 个集群中选择 API 来构建 API 集。 然后根据其关联的 API 将实例分类到三个子集中。 从每个子集中随机选择大约 30,000 个实例,从而得到三个具有不同多样性级别的训练集。
多样性的影响。 实验是在上述三个子集上训练 LLaMA-3.1-8B-Instruct 进行的。 BFCL 上的结果在图 13 中给出。 观察到训练数据多样性与模型整体精度之间存在明确的关联,强调了 API 多样性在模型性能中的关键作用。 值得注意的是,相关性检测方面的改进尤为显著,表明接触更广泛的 API 增强了模型区分细微 API 差异的能力,从而增强了无关性检测的能力。
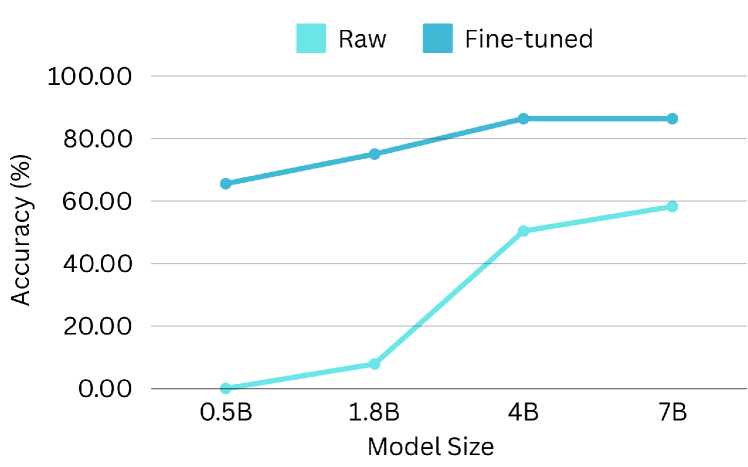
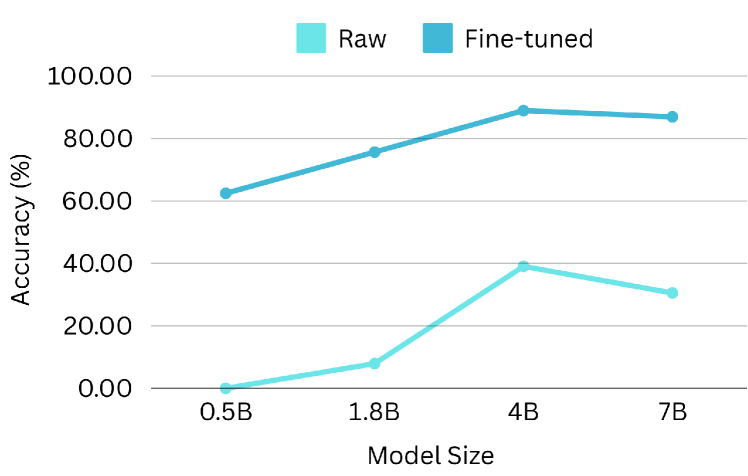
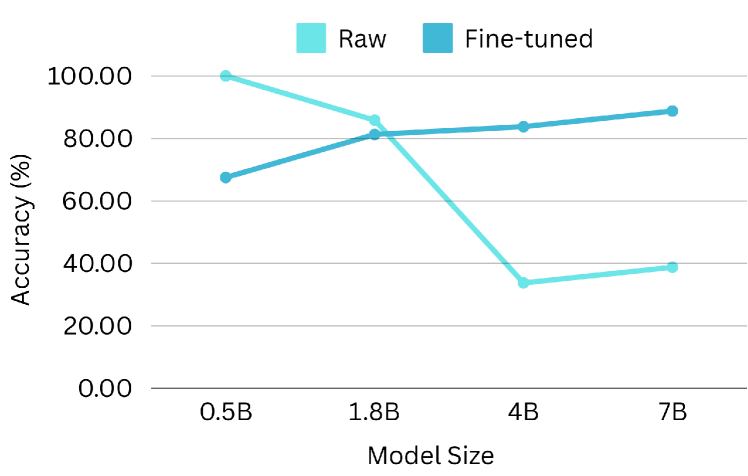
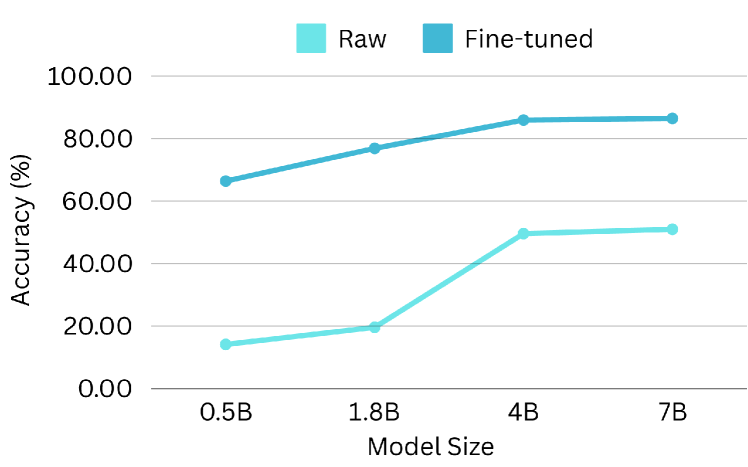
5.4 模型大小的性能扩展
扩展定律假设模型大小与性能之间存在关联。 为了研究功能调用性能的可扩展性,我们使用 Qwen-1.5-xB-Chat 系列进行实验,该系列提供了一系列模型大小(0.5B、1.8B、4B、7B 等)。 在 BFCL 基准上评估了原始模型和微调模型(使用我们的数据集),结果如 图 14 所示。 正如预期的那样,较大的模型在功能调用任务中表现出优异的性能,这可以通过 AST 精度和可执行精度方面的改进得到证明。 较小的原始模型表现出意外的高相关性检测分数,这可能是由于指令遵循能力有限导致生成不可解析的输出。 相反,微调模型在所有评估指标上都显示出一致的缩放行为,突出了 ToolACE 增强大型 LLM 性能的潜力。
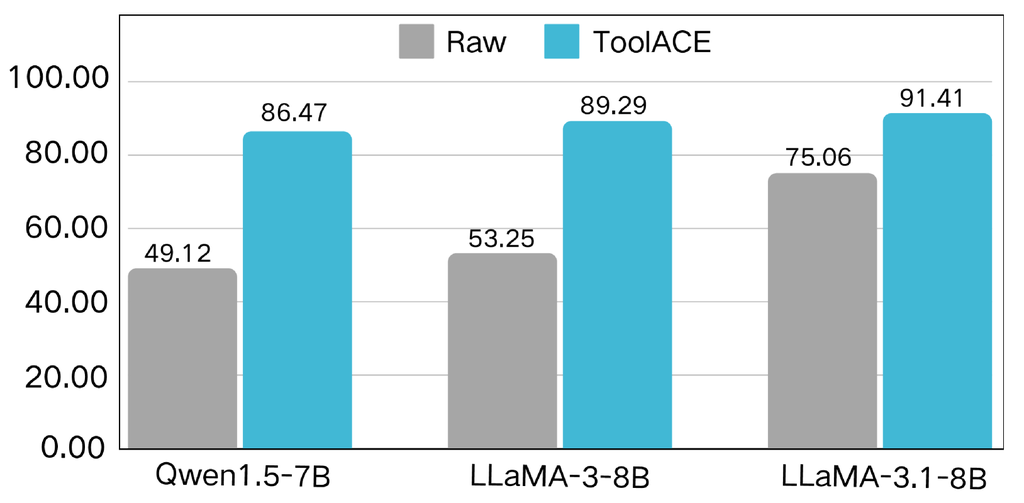
5.5 对各种骨干 LLM 的研究
为了研究 LLM 骨干的影响,我们对几个(大约)8B 规模的模型进行了实验:Qwen1.5-7B-Chat [3]、LLaMA-3-8B-Instruct 和 LLaMA-3.1-8B-Instruct。 在 BFCL 基准上评估了微调模型,结果如 图 16 所示。 在所有模型中,微调都产生了显著的性能提升,突出了 ToolACE 的有效性。 由于预训练语料库的差异,例如 Qwen 使用更多中文对话样本进行训练,原始模型表现出不同的功能调用能力,其中 LLaMA-3.1-8B-Instruct 表现出更优异的性能。 虽然这种等级在微调后仍然存在,但性能差距缩小了,这表明我们的数据集有可能增强那些针对其他技能(例如对话技能)的 LLM 的功能调用能力。
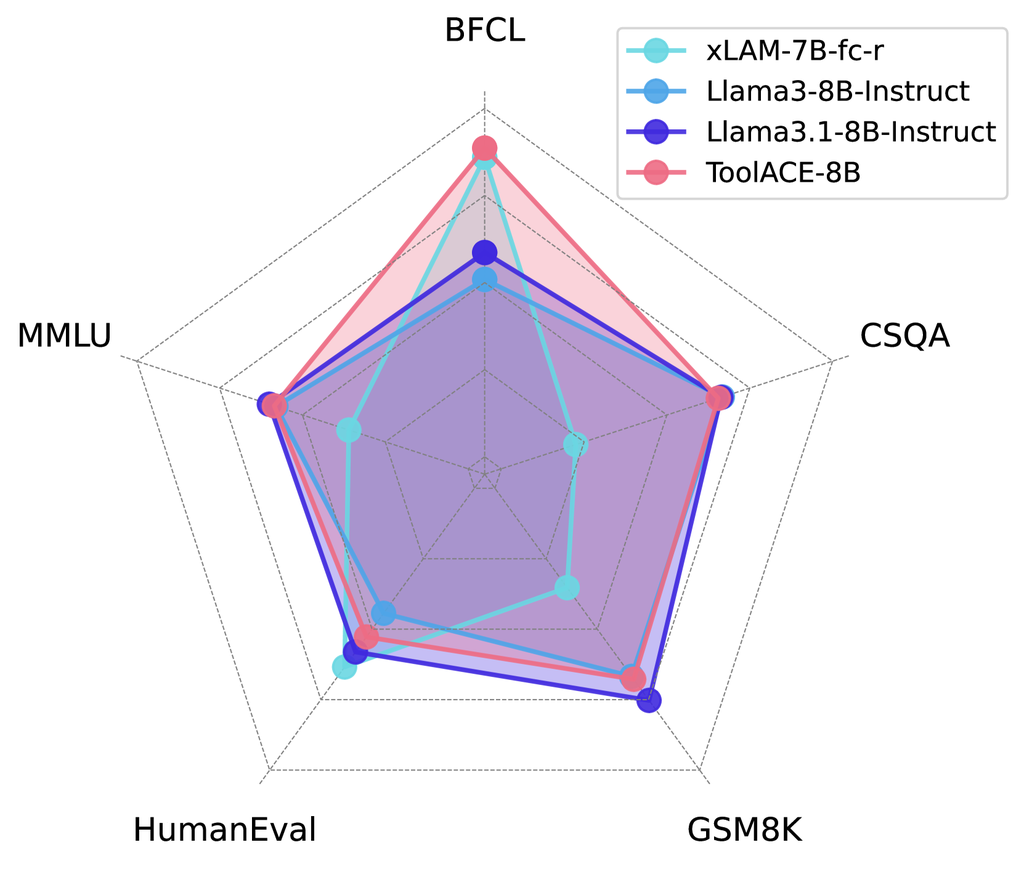
5.6 一般能力研究
为了评估 ToolACE 训练对 LLM 更广泛能力的影响,我们在多个基准上进行了实验,评估了 LLM 的一般能力(MMLU [7, 8])、编码能力(HumanEval [4])、数学能力(GSM8K [5])、推理能力(CommonSenseQA [18])以及函数调用能力(BFCL [23])。 我们将原始的 LLaMA-3-8B-Instruct、LLaMA-3.1-8B-Instruct 和功能专门化的 xLAM-7B-fc-r 作为基线。 结果如 图 16 所示。 ToolACE-8B 在大多数基准测试中都表现出比 xLAM-7B-fc-r 显著的改进,在 MMLU、GSM8K 和 CommonSenseQA 中尤为突出。 与原始的 LLaMA-3.1-8B-Instruct 相比,ToolACE-8B 在一些基准测试中表现出微不足道的性能下降,而在函数调用方面取得了显著的提升。 这些发现表明,ToolACE 数据集有效地增强了函数调用能力,而不会损害底层 LLM 的一般能力。
6 结论
本文介绍了 ToolACE,这是一个自动数据生成管道,旨在增强大型语言模型的函数调用能力。 ToolACE 利用一种新颖的自进化合成过程和一个多代理交互系统来整理准确、复杂和多样化的 API 和对话。 我们的结果表明,即使是使用 ToolACE 训练的较小模型也能达到最先进的性能,从而推动了该领域的发展,并为工具增强的 AI 代理设定了新的基准。
7 致谢
我们感谢 Mei Li、Wei Tang、Xi Wang、Meide Zhang、Ke Xiong 和 Rencong Shi 对这项工作的贡献。
参考文献
- [1] Ibrahim Abdelaziz, Kinjal Basu, Mayank Agarwal, Sadhana Kumaravel, Matthew Stallone, Rameswar Panda, Yara Rizk, GP Bhargav, Maxwell Crouse, Chulaka Gunasekara, et al. Granite-function calling model: Introducing function calling abilities via multi-task learning of granular tasks. arXiv preprint arXiv:2407.00121, 2024.
- [2] AI@Meta. Llama 3 model card. 2024.
- [3] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- [4] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. 2021.
- [5] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [6] Yilun Hao, Yongchao Chen, Yang Zhang, and Chuchu Fan. Large language models can plan your travels rigorously with formal verification tools. arXiv preprint arXiv:2404.11891, 2024.
- [7] Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- [8] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- [9] Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
- [10] Shijue Huang, Wanjun Zhong, Jianqiao Lu, Qi Zhu, Jiahui Gao, Weiwen Liu, Yutai Hou, Xingshan Zeng, Yasheng Wang, Lifeng Shang, et al. Planning, creation, usage: Benchmarking llms for comprehensive tool utilization in real-world complex scenarios. arXiv preprint arXiv:2401.17167, 2024.
- [11] Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, et al. Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets. arXiv preprint arXiv:2406.18518, 2024.
- [12] Meetkai. Functionary.meetkai. 2024.
- [13] Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei-ge Chen, Olga Vrousgos, Corby Rosset, et al. Agentinstruct: Toward generative teaching with agentic flows. arXiv preprint arXiv:2407.03502, 2024.
- [14] Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334, 2023.
- [15] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023.
- [16] Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, and Ji-Rong Wen. Tool learning with large language models: A survey. arXiv preprint arXiv:2405.17935, 2024.
- [17] Karim Shabani, Mohamad Khatib, and Saman Ebadi. Vygotsky’s zone of proximal development: Instructional implications and teachers’ professional development. English language teaching, 3(4):237–248, 2010.
- [18] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [19] Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. arXiv preprint arXiv:2306.05301, 2023.
- [20] Adrian Theuma and Ehsan Shareghi. Equipping language models with tool use capability for tabular data analysis in finance. arXiv preprint arXiv:2401.15328, 2024.
- [21] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [22] Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C-pack: Packed resources for general chinese embeddings. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 641–649, 2024.
- [23] Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Berkeley function calling leaderboard. https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html, 2024.
- [24] Junjie Ye, Guanyu Li, Songyang Gao, Caishuang Huang, Yilong Wu, Sixian Li, Xiaoran Fan, Shihan Dou, Qi Zhang, Tao Gui, et al. Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios. arXiv preprint arXiv:2401.00741, 2024.
- [25] Dylan Zhang, Justin Wang, and Francois Charton. Instruction diversity drives generalization to unseen tasks. arXiv preprint arXiv:2402.10891, 2024.
- [26] Ruizhe Zhong, Xingbo Du, Shixiong Kai, Zhentao Tang, Siyuan Xu, Hui-Ling Zhen, Jianye Hao, Qiang Xu, Mingxuan Yuan, and Junchi Yan. Llm4eda: Emerging progress in large language models for electronic design automation. arXiv preprint arXiv:2401.12224, 2023.
附录 A 规则验证层中的规则示例
表 6 列出了我们已应用的检查规则。 例如,为了验证函数调用可执行性,我们执行以下步骤:首先,我们确认 API 名称与给定工具列表中的一个匹配。 接下来,我们验证是否准确提供了所有必需的参数。 最后,我们使用正则表达式来确保参数格式和模式符合 API 文档中指定的那些。 这些步骤使我们能够验证函数调用的正确性和可执行性,而无需实际执行,从而提高效率并降低部署开销。
| Aspect | Rules |
| API Definition Clarity | Check if the API definition complies with JSON Schema specifications. |
| Check if the API definition contains all necessary fields. | |
| Function Calling Executability | Check if the API name is in the tool list. |
| Check if all required parameters are provided. | |
| Check if all the parameter formats and patterns match the API definition. | |
| Dialog Correctness | Check if the dialog contain all necessary fields. |
| Check if the assistant’s response is too long. | |
| Check for invalid characters in the responses. | |
| Check for mixed-language responses. | |
| Check if the response is complete. | |
| Data Sample Consistency | Check if the API names in the function call and the tool response are consistent. |
| Check for format conflicts with the requirements defined in the system prompt. | |
| Check if the order of the dialogue roles is correct. | |
| Check if the tool response follows the function call. |
附录 B 不同 API 格式的示例
图 17 显示了不同格式的 API 定义示例,包括原始 Json、XML、Markdown 和自然语言。

附录 C 复杂度消融研究中的数据分布
附录 D 案例研究
在这里,我们展示了从生成数据中选择的一些案例,展示了工具利用和函数调用的各种示例。
图 20 展示了一个并行函数调用的数据样本。 此类数据侧重于建立模型理解和从用户查询中提取关键参数的能力,这使模型学会反复调用正确的函数以完成任务。 在这个例子中,查询表明用户需要分别获取 2021-04-01 和 2021-05-01 期间戏剧、舞蹈和音乐的活动信息。 助手正确地识别出它需要三次调用 performanceArt.get_upcoming_events,并对参数 "category" 进行不同的分配。
图 21 展示了一个多函数调用的数据样本。 此类数据侧重于赋予模型区分不同函数的能力,这使模型学会选择正确的函数来完成任务。 案例中的工具列表中有五个函数。 用户需要足球的现场赛事数量信息、2025 年赛季的 NBA 统计数据以及湖人队的最新媒体信息。 助手从 toolList 中选择了相应的 Get Live Events Count by Sport、Get All NBA Stats 和 Get Latest Team Media 并调用它们来完成任务。
图 22 展示了侧重于增强模型确定函数与用户查询的相关性的案例。 在第一种情况下,用户请求在特定电影院的电影放映时间。 但是,可用的功能仅设计用于检索事件详细信息或特定书籍角色,这与用户的请求无关。 助手适当地拒绝提供答案,理由是缺乏相关功能。 在第二种情况下,用户要求启动 Android 模拟器,但缺少基本参数——设备名称、系统映像和 API 级别。 助手正确地识别了这一差距,并请求必要的信息,而不是尝试执行不完整的操作。 这种类型的数据对于训练模型识别何时功能不相关或何时缺少必需输入至关重要,确保系统准确响应并避免执行不受支持的任务。
| Case 1: parallel function calling: | |
| ToolList |
performanceArt.get_upcoming_events required: ["start_date", "end_date"] optional: ["category"]
|
| User |
I would like to know about upcoming Theatre, Dance, and Music performance art events happening between 2021-04-01 and 2021-05-01.
|
| Assistant |
performanceArt.get_upcoming_events(start_date="2021-04-01", end_date="2021-05-01", category="Theatre"),
performanceArt.get_upcoming_events(start_date="2021-04-01", end_date="2021-05-01", category="Dance"), performanceArt.get_upcoming_events(start_date="2021-04-01", end_date="2021-05-01", category="Music") |
| Case 2: multiple function calling: | |
| ToolList |
Bet365 Inplay Filter required: optional: ["sport_id"] ["skip_esports"]
Get Live Events Count by Sport required: ["sport", "locale", "timezone"] National Team Statistics required: ["player_id"] Get All NBA Stats required: ["seasons"] optional: ["page", "per_page", "player_ids", "game_ids"] Get Latest Team Media required: ["team_id"] |
| User |
I plan to watch some sports events and want to catch up on the latest NBA stats. Could you find the live event count for soccer, get NBA stats for the 2025 season, and the latest media for the Lakers?
|
| Assistant |
Get Live Events Count by Sport(sport="soccer", locale="en_US", timezone=-4.0),
Get All NBA Stats(seasons=["2025"], page=1, per_page=10), Get Latest Team Media(team_id=13.0) |
| Case 3: relevance | |
| ToolList |
Event optional: ["name", "club", "club_name", "start_time", "end_time", "time_modified", "string_filter"]
Get Character by ID required: ["id"] |
| User |
Can you check the showtimes for the film "Avengers: Endgame" at Cinema 21 and Cinema 45?
|
| Assistant | The provided functions do not support searching for showtimes at specific cinemas. The functions available are limited to retrieving events based on filters or retrieving a specific character from the Throne of Glass series. Therefore, the question lacks the parameters required by the given functions. |
| ToolList |
runAndroidEmulator required: [device_name, system_image, api_level]
|
| User |
Can you start the Android emulator for me?
|
| Assistant | The function runAndroidEmulator can start the Android emulator, but it lacks the required parameters: device_name, system_image, and api_level. Please provide these details to proceed. |