STAB:语音符元评估基准
摘要
将语音表示为离散符元提供了一个框架,将语音转换为与文本非常相似的格式,从而能够将语音用作广泛成功的大型语言模型 (LLM) 的输入。 目前,虽然已经提出了几种语音符元器,但对于特定下游任务所需的符元器属性及其整体泛化能力存在歧义。 评估符元器在不同下游任务中的性能是一项计算密集型工作,这对可扩展性提出了挑战。 为了规避这一要求,我们提出了 STAB(语音符元评估基准),这是一个系统化的评估框架,旨在全面评估语音符元器,并阐明其固有特征。 该框架提供了对语音符元化基础机制的更深入理解,从而为加快未来符元器模型的进展提供了宝贵的资源,并能够使用标准化基准进行比较分析。 我们评估了 STAB 指标,并将此与一系列语音任务和符元器选择中的下游任务性能相关联。
索引词:
语音符元化、评估基准、多模态表示学习I 简介
语音表示学习,即开发能够为下游任务提取语音简洁特征表示的模型的任务,近年来一直是人们关注的焦点。 受零资源语音处理的启发,开发可以直接从未标记的原始语音中学习子词或词语单元的方法[1],已经提出了几种无监督方法来学习连续表示[2, 3]和离散声学单元[4]。 基于预测编码[5]和自监督学习的技术,例如 wav2vec 模型类[6],已被开发用于推导出音频的量化表示。 最近,离散单元和声学表示的迭代学习,例如 HuBERT [7] 和 wavLM 中的去噪和自监督的联合学习[8],已经显示出令人鼓舞的结果。
离散表示自然适合语音和语言,因为它们能够表示为符号、音韵、音素或子词/词语单元的序列。 将语音表示为离散符元的形式,通过将语音转换为与文本相似的格式,从而利用语音作为各种大型语言模型 (LLM) 的输入,这种方法具有显著的优势 [9, 10]. 此外,语音符元能够捕捉到非语言线索,如情绪和节奏,与文本对应物相比,这些线索包含更多信息 [11, 12]. 利用离散语音符元已被证明在自动语音翻译和语音到语音翻译等任务中具有优势,同时在自动语音识别方面也展现出可比的性能 [13, 14]. 这也有助于多模态 LLM 的发展 [15].
针对特定下游任务优化的语音分词器已存在 [16],然而,衡量其泛化能力仍然是一个具有挑战性的问题。 评估所有分词器在各种下游任务中的性能是一项计算量巨大的工作,这对可扩展性提出了挑战。 此外,语音分词器通常被用作黑盒,对其生成的符元的性质或其对特定属性的遵守程度进行的检查有限 [17]. 因此,创建用于评估跨多个维度进行分词器的低计算量评估基准已成为当务之急。 我们的贡献可以概括如下:
-
•
我们提出了 STAB,一个语音分词器评估基准,用于评估给定语音分词器的能力。
-
•
STAB 提供了一种经济高效的评估方法,并有可能加速语音分词研究。
-
•
通过大量实验,我们证明 STAB 可以可靠地指示语音分词器在一系列下游任务上的性能。
II 相关工作
语音词元化: 历史上,语音的自监督学习依赖于音频嵌入的对比损失,例如 wav2vec [18]。 Vq-wav2vec [19] 和 DiscreteBERT [20] 引入了基于词元化的目标,用于学习更好的语音表示。 继此,HuBERT [7] 在掩码语言模型 (MLM) 框架内引入了语音词元的迭代细化。 W2v-BERT [21] 将对比方法和 MLM 的优势与单个模型中的语音词元相结合。 有趣的是,BEST-RQ [22] 利用随机投影生成目标词元。 因此,语音词元已成为自监督预训练模型的核心,通常通过 K 均值或向量量化等方法获得 [23]。 AudioLM [13] 和 AudioPaLM [14] 自回归地对来自音频编码模型生成的聚类表示的语音词元序列进行建模。 在本研究中,我们评估了现有方法中使用的各种语音词元器。
语音基准 随着各种表示学习框架的开发,人们也一直在努力评估和基准化语音表示。 在最新版的零资源语音挑战赛中,评估重点是探索无文本语音语言建模任务 [24]。 语音处理通用性能基准 (SUPERB) 考虑了大量下游评估任务,包括语义和副语言任务 [25]。 在 ML-SUPERB [26] 中对多语言任务的扩展进行了基准测试。 为了在零样本设置中进行多任务评估,最近引入了 Dynamic-SUPERB [27]。 还为音频表示提出了一个非语义评估基准,即 NOSS [28]。
III STAB 细节
III-A 不变性
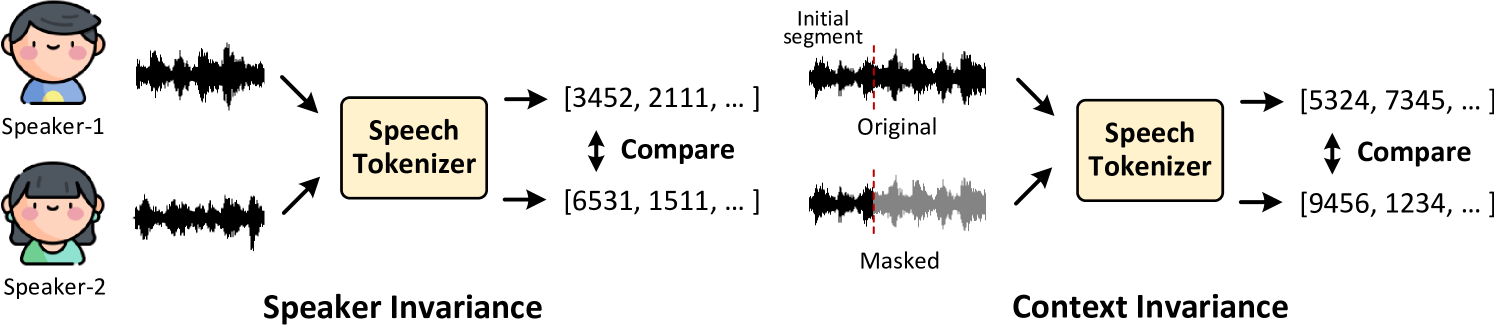
对于诸如自动语音识别 (ASR) 之类的任务,从语音中提取语义意义至关重要。 之前的研究引入了语义和声学语音标记化的概念[13, 14]。 语义标记仅侧重于从语音信号中提取语义信息,而声学标记则捕获其他属性,例如说话者信息、语言和情绪。 在这里,我们通过以下几个方面来评估语音标记器准确捕获语义的能力。
-
•
说话者不变性: 检查两个不同说话者说出相同句子的标记化差异,例如比较女性/男性说话者说出的句子。
-
•
上下文不变性: 分析当部分语音上下文被屏蔽时标记如何改变。 此度量反映了标记的邻域影响。 我们将从语句片段(前 4 秒)中提取的标记与具有其原始上下文的相同片段进行比较。
-
•
语言不变性: 衡量相同概念用两种不同语言表达时的标记化差异。 例如,比较英语中的”Cat is drinking the milk”和德语中的”Eine Katze trinkt Milch”的标记。
III-B 鲁棒性
我们评估了语音分词器对语音信号中不同类型噪声和声学变化的恢复能力。 这对于有效处理现实世界数据至关重要,现实世界数据可能包含来自各种麦克风和说话人的录音。
-
•
音调变化: 音调变化是语音中常见的现象,通常是由于设备缺陷或信号处理 [29] 造成的。 我们研究了当修改语音信号的音调时分词如何变化,同时确保音频保持可理解。
-
•
播放速度: 修改音频的播放速度涉及调整音频的播放速率。 我们检查了当我们改变这一点时分词是如何变化的。
-
•
背景噪声: 在这里,我们引入背景噪声 其中 是 s.t. SNR = 10dB 到原始语音信号中,并评估语音分词器对添加噪声的响应行为。
| 8k-Tokenizers | 32k-Tokenizers | |||||||
| Dimensions | Metrics | w2v2 | w2v-BERT | BEST-RQ | USM-v1 | USM-v2 | USM-v3 | |
| Invariance | Speaker Invariance | chrF | 7.5 | 13.0 | 4.7 | 15.8 | 36.6 | 13.9 |
| Context Invariance | chrF | 27.8 | 45.6 | 48.4 | 73.2 | 45.8 | 50.9 | |
| Language Invariance | chrF | 5.2 | 7.5 | 4.6 | 6.9 | 4.3 | 4.6 | |
| Robustness | Pitch Change | chrF | 10.2 | 21.4 | 8.1 | 25.1 | 33.3 | 19.7 |
| Gaussian Noise (10 dB) | chrF | 42.5 | 48.3 | 39.7 | 67.2 | 72.5 | 57.0 | |
| Speed Change (0.8) | chrF | 26.0 | 23.8 | 24.9 | 30.3 | 30.9 | 27.0 | |
| Compressibility | Huffman Efficiency | % | 13.9 | 16.9 | 11.4 | 13.5 | 16.8 | 16.0 |
| Byte-pair Efficiency | % | 2.6 | 9.8 | 6.1 | 6.3 | 8.8 | 4.2 | |
| De-duplication Efficiency | % | 1.4 | 9.1 | 10.9 | 4.3 | 6.0 | 4.8 | |
| Vocabulary | Per-language Utilization | % | 75.3 | 56.8 | 87.2 | 21.7 | 42.4 | 44.5 |
| Overall Utilization | % | 99.7 | 95.4 | 99.8 | 47.5 | 99.3 | 96.4 | |
| Vocabulary Entropy | Score | 95.0 | 91.0 | 97.3 | 82.8 | 94.4 | 90.6 | |
III-C 可压缩性
在自然语言处理(NLP)中,基于单词或子词的模型已被证明优于基于字符的模型 [30, 31]。 然而,大多数语音分词器在低于音位的级别进行分词。 以前的研究 [32] 表明,在语音序列上训练句子片段分词器会生成子词级别的词元,从而在后续任务中带来改进。 然而,不同分词器之间的可压缩程度各不相同。 因此,我们建议使用以下维度来衡量此属性。
-
•
哈夫曼编码效率: 哈夫曼编码算法 [33] 广泛用于无损数据压缩。 我们使用哈夫曼编码算法压缩特定语言的语音序列语料库,然后计算压缩效率。
-
•
字节对编码效率: 字节对编码 (BPE) [34, 35] 是一种分词技术,它涉及迭代地合并最频繁的连续词元对以创建新词元。 该合并过程重复进行,直到达到预定义的词汇量大小。 使用 BPE,可以通过合并语音词元序列中发现的重复模式来学习子词级别的词元。
-
•
去重效率: 我们通过合并相邻的重复词元来评估语音序列的可压缩性。
III-D 词汇
在这里,我们评估语音标记器如何利用其词汇,以及这种利用方式如何在不同语言之间变化。 语音标记器中更大的词汇量会增加语音语言模型 (SLM) 中的参数数量。 因此,分析词汇的使用方式并确保不存在模式坍塌问题至关重要。 为此,我们从以下方面分析标记器,
-
•
每种语言的利用率: 我们考虑固定数量(500k)的观察到的标记,检查每种语言所使用的词汇量占总词汇量的比例。
-
•
总体利用率和熵: 我们探索所有语言的词汇利用率,并计算词汇分布的熵,以评估对部分标记的任何偏差。
-
•
跨语言的词汇分布比较: 我们调查标记器是否捕获语言之间的关系,并假设为考虑语言相似性而设计的标记器应该对相关语言表现出相似的词汇分布。
IV 实验设置
IV-A 数据集
STAB 数据集: 在我们提出的基准测试中,我们采用了 FLEURS 数据集 [36],它是 FLoRes-101 机器翻译数据集 [37] 的语音对应物。 FLEURS 包含以 102 种语言 spoken 的 2,000 个 n 路平行句子,可以根据语言意识等指标进行评估。 此外,我们采用 TIMIT 数据集 [38],其中包括 630 位说话者朗读 10 句话的录音,以及每句话的转录本。 这使我们能够评估说话者感知。
预训练数据集: 在我们的实验中,我们使用 AudioPaLM 模型 [14],它涉及使用预训练的文本解码器 (PaLM-2 [10]) 进行初始化,然后通过扩展其词汇量并在语音文本数据混合物上对其进行训练使其成为多模态。 我们的数据混合物由 75% 的原始文本数据 [10] 和 25% 的来自 Babel [39]、VoxPopuli ASR、多语言 Librispeech [40]、FLEURS 和 YouTube ASR 数据集 [41] 的自动语音识别 (ASR) 数据组成。 总共,语音数据集包含跨越 100 种语言的 221,000 小时的 ASR 数据。
评估数据集: 除了 STAB 基准之外,我们还在多个下游任务上评估了我们的模型,例如 ASR、情感识别、说话人识别和意图分类。 对于 ASR,我们利用跨越 14 种语言的转录 VoxPopuli 数据集和 CoVoST-2 [42] 数据集进行 AST。 我们使用 IEMOCAP 数据集 [43] 进行情感识别,并使用 VoxCeleb [44] 进行说话人识别。 由于 AudioPaLM 是一种仅解码器模型,因此我们将分类任务视为 seq2seq 任务。 对于所有这些数据集,我们对它们的训练拆分进行微调,然后在相应的开发/测试拆分上进行评估。
IV-B 基线系统
在我们的实验分析中,我们比较了研究界常用的几种语音分词器。
-
•
w2v2:与 Rubenstein 等人 [14] 类似,我们使用 wav2vec 2.0 [6] 对语音进行编码,该模型在多语言数据上进行训练。 随后,对模型生成的嵌入进行 k-means 聚类(k=8k)训练,并提取质心索引作为语义符元。
-
•
w2v-BERT: 与 w2v2 相同,但语音编码器被预训练的 w2v-BERT 编码器 [21] 替换,该编码器使用掩码语言建模 (MLM) 目标进行训练。
-
•
BEST-RQ: 在这里,我们使用基于 MLM 的 BEST-RQ 模型 [22] 作为语音编码器。
-
•
USM-v1: 遵循 Rubenstein 等人 [14],我们使用 Google 通用语音模型 (USM) [41],该模型使用 MLM 目标来编码语音。 对于 USM-v1 及后续的词元化器,词表大小为 32k。
-
•
USM-v2 [14]: 与 USM-v1 类似,这包括 USM,但在训练期间添加了辅助 ASR 损失。 此外,使用向量量化 [23] 来离散化表示,而不是 K-means。
-
•
USM-v3: 这与 USM-v2 词元化器相同。 但是,除了 ASR 之外,它还使用训练有频谱图重建 [45] 损失的 USM。
实现细节: 大多数超参数直接从 AudioPaLM [14] 中采用。 我们报告了大小为 1B 的模型的结果,这些模型使用 PaLM-2 检查点初始化,并在我们的语音-文本混合数据上预训练 30k 步。 对于每个下游评估任务,我们先在相应的训练集上对预训练模型进行微调,然后再进行评估。 请注意,STAB 不需要微调,因为指标可以直接在原始词元上计算。
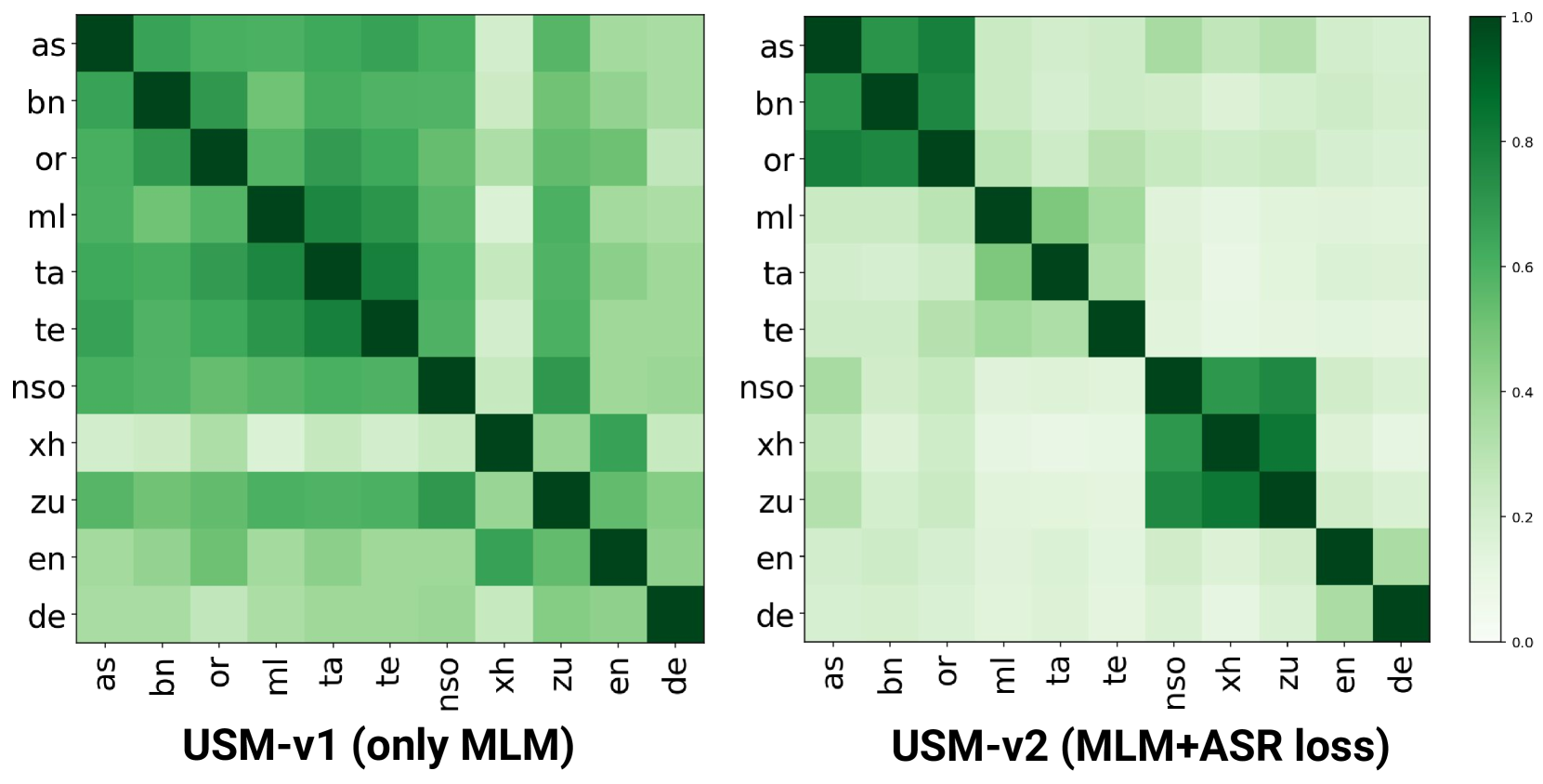
V 结果
V-A STAB 性能比较
在本节中,我们评估了不同的分词器,如第 IV-B 节所述,在各种 STAB 维度上。 结果总结如表 I 所示。 如前所述,w2v2 使用对比损失进行训练,而 w2v-BERT、BEST-RQ 和 USM-v1 使用掩码语言建模 (MLM) 损失进行训练。 此外,USM-v2 结合了 MLM 和自动语音识别 (ASR) 损失,而 USM-v3 还包括重建损失。 请注意,w2v2、w2v-BERT 和 BEST-RQ 分词器的词汇量为 8k,而基于 USM 的分词器使用 32k 的词汇量。 因此,我们的大多数结论都是从具有相同词汇量的分词器组内的比较中得出的。
不变性: 结果表明,包含 ASR 损失(例如在 USM-v2 中)使得分词器对说话人信息更加不变。 此外,它增强了上下文依赖性,因为它需要对所有帧进行语义理解。 这在 32k-tokenizers 中的 USM-v2 上上下文不变性指标下降中很明显。 此外,与 w2v-BERT 和 BEST-RQ 中基于 MLM 的损失相比,w2v2 的对比损失大大增加了对上下文的依赖。 关于语言不变性,大多数分词器为不同的语言生成不同的词元序列。 然而,ASR 损失似乎减少了语言不变性,因为它需要根据语音中使用的特定语言生成正确脚本的文本。
鲁棒性: 我们观察到,与其他分词器相比,基于 USM 的分词器对噪声表现出更高的鲁棒性,这可能是由于预训练期间使用了更多的数据。 此外,在训练期间加入 ASR 损失可以增强分词器对噪声语音信号的抵抗力。 相反,使用频谱图重建损失进行训练似乎会增加模型对噪声的敏感性。 在 8k-tokenizers 中,w2v-BERT 分词器相对于其对应分词器表现出优异的噪声鲁棒性。
可压缩性: 结果表明,与 32k-tokenizers 相比,8k-tokenizers 表现出更高的可压缩性,这可以归因于它们较小的词汇量。 在 8k-tokenizers 中,w2v-BERT 表现出更高的整体可压缩性。 此外,与之前的发现类似,加入 ASR 损失可以增强分词器的可压缩性。
词汇量: 在所有 32k-tokenizers 中,USM-v1 表现出最低的每语言和整体词汇利用率。 这是由于它使用 K 均值量化,而 USM-v2 和 USM-v3 使用的是矢量量化。 这表明简单的 K 均值表示在充分利用整个词汇量方面无效,可能导致模型参数的浪费。 考虑到 8k-tokenizers 的词汇量较小,它们的词汇利用率更高。
语言关系: ASR损失提高了分词器对语言关系的感知。 如图2所示,USM-v2在密切相关的语言中表现出更高的词汇分布相似性,而USM-v1分词器中的词元则没有这种特征。 这证明了ASR训练的分词器在跨语言知识迁移方面具有更大的潜力。
V-B 与下游任务的相关性
我们在多个下游任务上评估了各种分词器:自动语音识别 (ASR)、自动语音翻译 (AST)、情感分类 (EC)、说话人识别 (SID) 和语言识别 (LID)。 对于每个任务,我们在评估之前对已经预先训练好的模型进行微调,以适应相应数据集的训练集。
下游任务的结果总结在表II中。 总体而言,我们发现STAB指标与下游任务的性能高度相关。 在ASR和AST任务上,w2vBERT和USM-v2表现最佳,它们对说话人更具不变性,并且对噪声更鲁棒。 相反,说话人不变性较低的分词器在说话人识别任务上的表现如预期般更好。 以前关于使用IEMOCAP数据集进行情感分类的研究[46]表明,与直接使用语音模态的模型相比,利用ASR系统的输出可以获得更好的结果。 我们的发现支持这一观察结果,因为在我们的实验中,w2v-BERT和USM-v2优于其他分词器。 如图2所示,USM-v2还能更好地捕捉语言相似性,这反映在其改进的语言识别性能中。
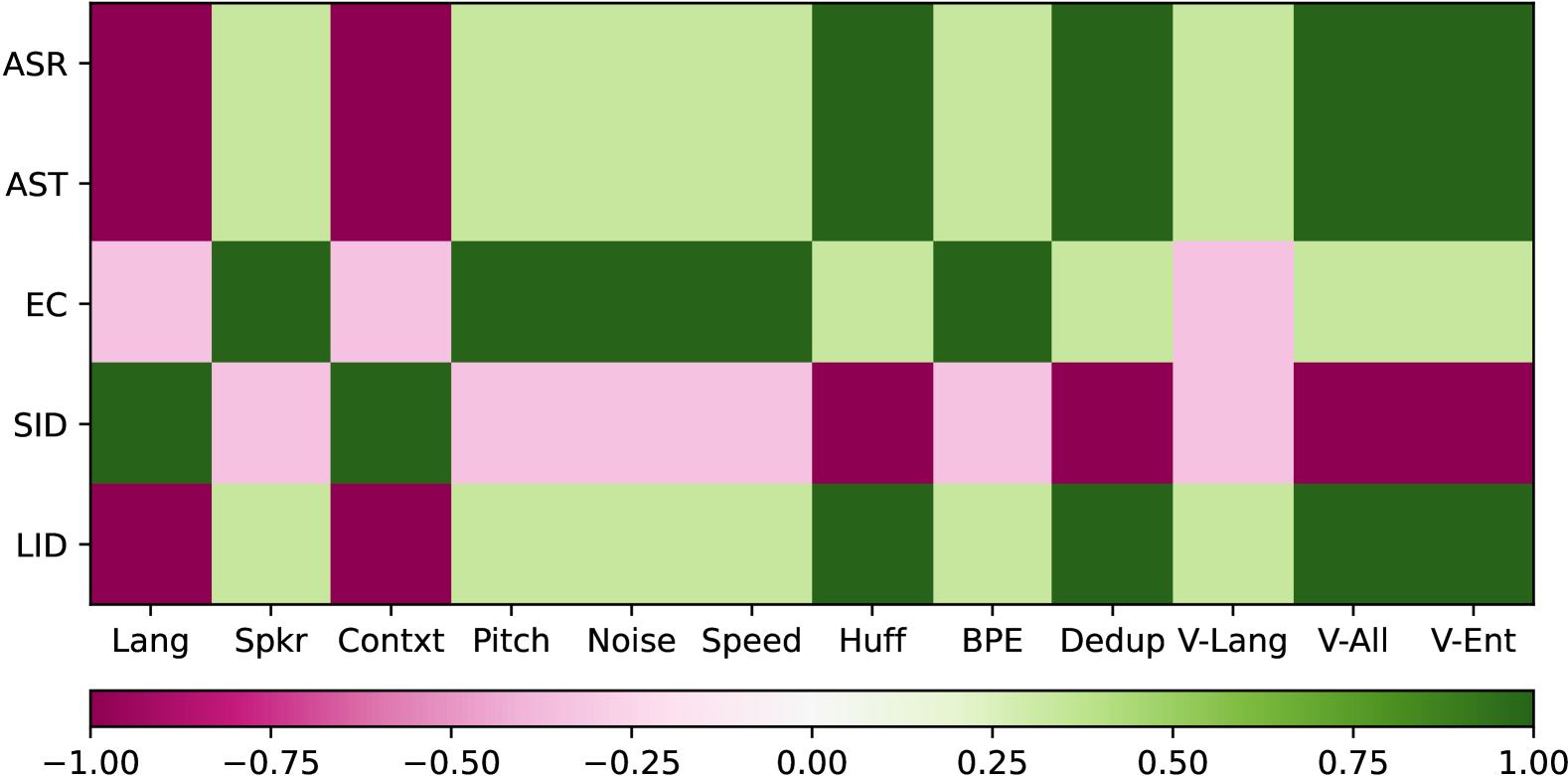
为了确定STAB指标(表I)和下游任务(表II)之间的耦合关系,我们考虑分词器对(例如 USM-v1、USM-v2)。 对于这对,我们计算了 STAB 指标中二值化相对改进与下游任务性能的相对改进之间的相关性。 通过这种方式,使用所有 32k 个标记器对的平均相关性,针对不同 STAB 指标和下游任务的选择,生成相关性图(图 3)。 如图所示,ASR 和 AST 任务遵循相同的趋势,词汇利用指标显示出最大的相关性,而语言/上下文不变性被认为具有最大的负相关性。 LID 任务也显示出类似的趋势。 EC 任务显示出对说话人和噪声不变性的最高相关性,这实质上允许模型将注意力集中在标记音频信号中的情感相关线索上。 SID 任务显示出与大多数其他考虑的任务略微相反的趋势,其中语言和上下文不变性呈正相关,而整体词汇利用与 SID 性能呈负相关。 这些发现表明 STAB 指标与下游任务相关,并提供对标记器在下游应用中性能的见解。
| Tokenizers | ASR | AST | EC | SID | LID |
| WER | BLEU | Accuracy | |||
| w2v2 | 73.8 | 2.4 | 50.8 | 65.0 | 16.0 |
| w2v-BERT | 53.4 | 7.4 | 55.0 | 38.2 | 28.8 |
| BEST-RQ | 66.6 | 4.1 | 54.0 | 49.8 | 17.2 |
| USM-v1 | 49.3 | 3.6 | 55.9 | 53.0 | 79.4 |
| USM-v2 | 11.8 | 16.8 | 60.0 | 16.3 | 97.1 |
| USM-v3 | 16.5 | 10.2 | 50.9 | 24.6 | 91.8 |
STAB 的成本效益: 对于任何标记器,每个 STAB 指标在我们基于 Apache Beam 的实现中都需要不到 15 分钟的 CPU 计算。 相比之下,评估每个标记器的下游任务涉及在跨多个数据集的 256 个加速硬件芯片上进行大约 16 小时的预训练,然后在 128 个加速硬件芯片上进行 22 小时的微调。 因此,与下游评估相比,STAB 在计算和数据资源方面至少高效 100 倍。 因此,提出的基准有潜力成为推进语音标记器设计的重要工具。
VI结论
在本文中,我们介绍了 STAB(语音标记器评估基准),这是一个全面的基准,用于评估语音标记器并阐明其固有特性。 该基准测试可以更深入地了解语音分词器的内部运作机制,并且 STAB 指标与多个下游任务的性能相关。 在计算和数据方面,STAB 的效率比使用下游任务来比较语音分词器高出 100 倍,这使其成为语音分词器发展的潜在催化剂。
参考文献
- [1] M. Versteegh, X. Anguera, A. Jansen, and E. Dupoux, “The zero resource speech challenge 2015: Proposed approaches and results,” Procedia Computer Science, vol. 81, pp. 67–72, 2016.
- [2] D. Renshaw, H. Kamper, A. Jansen, and S. Goldwater, “A comparison of neural network methods for unsupervised representation learning on the zero resource speech challenge,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
- [3] W.-N. Hsu, Y. Zhang, and J. Glass, “Unsupervised learning of disentangled and interpretable representations from sequential data,” Advances in neural information processing systems, vol. 30, 2017.
- [4] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3156–3164.
- [5] Y.-A. Chung and J. Glass, “Generative pre-training for speech with autoregressive predictive coding,” in ICASSP 2020. IEEE, 2020, pp. 3497–3501.
- [6] A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “Wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proceedings of the 34th NeurIPS Conference, 2020.
- [7] W.-N. Hsu and et al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Processing.
- [8] S. Chen and et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, 2022.
- [9] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,” ArXiv, vol. abs/2302.13971, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257219404
- [10] R. A. et al., “Palm 2 technical report,” ArXiv, vol. abs/2305.10403, 2023.
- [11] F. Kreuk, A. Polyak, J. Copet, E. Kharitonov, T. Nguyen, M. Rivière, and et al., “Textless speech emotion conversion using decomposed and discrete representations,” ArXiv, vol. abs/2111.07402, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:244117178
- [12] E. Kharitonov, A. Lee, A. Polyak, Y. Adi, J. Copet, K. Lakhotia, T. Nguyen, M. Rivière, A. rahman Mohamed, E. Dupoux, and W.-N. Hsu, “Text-free prosody-aware generative spoken language modeling,” ArXiv, vol. abs/2109.03264, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:237439400
- [13] Z. Borsos and et al., “Audiolm: A language modeling approach to audio generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2523–2533, 2022.
- [14] P. K. Rubenstein and et al., “Audiopalm: A large language model that can speak and listen,” ArXiv, vol. abs/2306.12925, 2023.
- [15] R. A. et al., “Gemini: A family of highly capable multimodal models,” ArXiv, vol. abs/2312.11805, 2023.
- [16] R. Eloff and et al., “Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks,” arXiv preprint arXiv:1904.07556, 2019.
- [17] M. Ravanelli and et al., “Neurips workshop on interpretability and robustness in audio, speech, and language.”
- [18] S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised Pre-Training for Speech Recognition,” in Proc. Interspeech 2019, 2019, pp. 3465–3469.
- [19] A. Baevski, S. Schneider, and M. Auli, “vq-wav2vec: Self-supervised learning of discrete speech representations,” ArXiv, vol. abs/1910.05453, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:204512445
- [20] A. Baevski, M. Auli, and A. rahman Mohamed, “Effectiveness of self-supervised pre-training for speech recognition,” ArXiv, vol. abs/1911.03912, 2019.
- [21] Y.-A. Chung and et al., “w2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” 2021 IEEE ASRU Workshop, pp. 244–250, 2021.
- [22] C.-C. Chiu and et al., “Self-supervised learning with random-projection quantizer for speech recognition,” in Proc. 39th ICML, ser. Proc. Mach. Learn. Res. PMLR, 2022, pp. 3915–3924.
- [23] R. Gray, “Vector quantization,” IEEE ASSP Magazine, vol. 1, no. 2, pp. 4–29, 1984.
- [24] E. Dunbar and et al., “Self-supervised language learning from raw audio: Lessons from the zero resource speech challenge,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6.
- [25] S.-w. Yang and et al., “Superb: Speech processing universal performance benchmark,” arXiv preprint arXiv:2105.01051, 2021.
- [26] J. Shi and et al., “Ml-superb: Multilingual speech universal performance benchmark,” arXiv preprint arXiv:2305.10615, 2023.
- [27] C.-y. Huang and et al., “Dynamic-superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,” arXiv preprint arXiv:2309.09510, 2023.
- [28] J. Shor, A. Jansen, R. Maor, O. Lang, O. Tuval, F. d. C. Quitry, M. Tagliasacchi, I. Shavitt, D. Emanuel, and Y. Haviv, “Towards learning a universal non-semantic representation of speech,” arXiv preprint arXiv:2002.12764, 2020.
- [29] F. P. Mechel, “Acoustics of moving sources moving source,” 2008.
- [30] P. Bojanowski, A. Joulin, and T. Mikolov, “Alternative structures for character-level rnns,” ArXiv, vol. abs/1511.06303, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:2415419
- [31] T. Nguyen, M. de Seyssel, R. Algayres, P. Roze, E. Dunbar, and E. Dupoux, “Are word boundaries useful for unsupervised language learning?” ArXiv, vol. abs/2210.02956, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:252735287
- [32] R. Algayres and et al., “Generative spoken language model based on continuous word-sized audio tokens,” in EMNLP, 2023.
- [33] D. A. Huffman, “A method for the construction of minimum-redundancy codes,” Proceedings of the IRE, vol. 40, no. 9, pp. 1098–1101, 1952.
- [34] P. Gage, “A new algorithm for data compression,” C Users J., vol. 12, no. 2, p. 23–38, feb 1994.
- [35] R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), K. Erk and N. A. Smith, Eds. Berlin, Germany: Association for Computational Linguistics, Aug. 2016, pp. 1715–1725. [Online]. Available: https://aclanthology.org/P16-1162
- [36] A. Conneau and et al., “Fleurs: Few-shot learning evaluation of universal representations of speech,” 2022 IEEE Spoken Language Technology Workshop, pp. 798–805, 2022.
- [37] N. Goyal and et al., “The flores-101 evaluation benchmark for low-resource and multilingual machine translation,” TACL, vol. 10, pp. 522–538, 2021.
- [38] J. S. Garofolo and et al., “Darpa timit acoustic-phonetic continous speech corpus cd-rom. nist speech disc 1-1.1,” NASA STI/Recon technical report n, vol. 93, p. 27403, 1993.
- [39] M. J. F. Gales and et al., “Speech recognition and keyword spotting for low-resource languages: Babel project research at cued,” in SLTU, 2014.
- [40] V. Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A Large-Scale Multilingual Dataset for Speech Research,” in Proc. Interspeech 2020, 2020, pp. 2757–2761.
- [41] Y. Zhang, W. Han, J. Qin, Y. Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V. Axelrod, G. Wang, Z. Meng, K. Hu, A. Rosenberg, R. Prabhavalkar, D. S. Park, P. Haghani, J. Riesa, G. Perng, H. Soltau, T. Strohman, B. Ramabhadran, T. N. Sainath, P. J. Moreno, C.-C. Chiu, J. Schalkwyk, F. Beaufays, and Y. Wu, “Google usm: Scaling automatic speech recognition beyond 100 languages,” ArXiv, vol. abs/2303.01037, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257280021
- [42] C. Wang, A. Wu, and J. Pino, “Covost 2 and massively multilingual speech-to-text translation,” arXiv preprint arXiv:2007.10310, 2020.
- [43] C. Busso, M. Bulut, C.-C. Lee, E. A. Kazemzadeh, E. M. Provost, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: interactive emotional dyadic motion capture database,” Language Resources and Evaluation, vol. 42, pp. 335–359, 2008. [Online]. Available: https://api.semanticscholar.org/CorpusID:11820063
- [44] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: A large-scale speaker identification dataset,” in Interspeech, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:10475843
- [45] K. W. Cheuk, Y.-J. Luo, E. Benetos, and D. Herremans, “The effect of spectrogram reconstruction on automatic music transcription: An alternative approach to improve transcription accuracy,” 2020 25th International Conference on Pattern Recognition (ICPR), pp. 9091–9098, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:224803213
- [46] S. Dutta and S. Ganapathy, “Multimodal transformer with learnable frontend and self attention for emotion recognition,” ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6917–6921, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:249437569