redacted tcb@breakable ∗ 在 Google DeepMind 实习期间完成的工作。 Gemma-2 结果尚未得出,一份预备草案已于 7 月初在内部流传。 通信作者:wx13@illinois.edu, tongzhang@tongzhang-ml.org, tianqiliu@google.com。
基于多轮迭代偏好学习构建数学代理
摘要
最近的研究表明,通过整合外部工具(如代码解释器)并采用多轮思维链(CoT)推理,可以增强大型语言模型 (LLM) 的数学问题解决能力。 虽然当前的方法侧重于合成数据生成和监督微调 (SFT),但本文研究了互补的直接偏好学习方法,以进一步提高模型性能。 然而,现有的直接偏好学习算法最初是为单轮聊天任务设计的,并没有完全解决多轮推理和工具集成数学推理任务所需的外部工具集成的复杂性。 为了填补这一空白,我们介绍了一种针对此场景的多轮直接偏好学习框架,该框架利用了来自代码解释器的反馈并优化了轨迹级偏好。 此框架包括多轮 DPO 和多轮 KTO 作为具体实现。 我们通过使用来自 GSM8K 和 MATH 数据集的增强提示集训练各种语言模型来验证我们框架的有效性。 我们的结果表明,显著改善了模型性能:在 GSM8K 上,监督微调的 Gemma-1.1-it-7B 模型的性能从 77.5% 提高到 83.9%,在 MATH 上从 46.1% 提高到 51.2%。 同样,Gemma-2-it-9B 模型在 GSM8K 上从 84.1% 提高到 86.3%,在 MATH 上从 51.0% 提高到 54.5%。
关键词:
RLHF,代理学习,数学推理1 简介
大语言模型 (LLM) 已在各种语言任务中展现出非凡的能力,展示了其在自然语言处理方面的广泛能力。 值得注意的模型包括 ChatGPT (OpenAI, 2023)、Claude (Anthropic, 2023) 和 Gemini (Team et al., 2023)。 然而,尽管取得了这些进步,即使是最先进的闭源 LLM 在需要多轮决策的复杂推理任务中仍然难以应对。 特别是,对于数学问题求解这一代表性任务,LLM 往往会在基本的算术和符号计算方面失败 (Hendrycks et al., 2021; Cobbe et al., 2021b; Zheng et al., 2021)。 为了解决这个问题,最近的研究建议将外部工具(例如,计算器、计算 Python 库和符号求解器)整合到 LLM 中,以增强其数学问题求解能力 (Cobbe et al., 2021b; Shao et al., 2022; Mishra et al., 2022; Zhang et al., 2024a)。 具体来说,通过将自然语言推理与这些外部工具的使用相结合,这些增强型 LLM 可以接收来自工具交互的外部消息,并根据先前生成的符号和外部消息进行推理,这显著提高了它们在数学任务中的性能 (Gou et al., 2023b; Toshniwal et al., 2024; Shao et al., 2024)。
工具集成 LLM 的这些成功带来了一个自然的研究问题:我们如何才能更好地训练 LLM 将工具使用与内在推理相结合,以应对复杂的推理任务? 对于数学问题求解任务,现有工作主要集中于合成数据生成(由强教师模型生成)和监督微调 (SFT),如 ToRA (Gou et al., 2023b)、MetaMathQA (Yu et al., 2023)、MAmmoTH (Yue et al., 2023, 2024) 和 Open-MathInstruct (Toshniwal et al., 2024)。 这些方法和合成数据集在标准基准测试(如 MATH (Hendrycks et al., 2021) 和 GSM8K (Cobbe et al., 2021a))上取得了显著的测试精度提高。
建立在强大的 SFT 模型的基础上,来自人类反馈的强化学习 (RLHF) 被证明是引导 LLM 在训练后阶段获取知识的关键技术,并且已成为 LLM 训练流程中的标准做法 (Bai et al., 2022; Ouyang et al., 2022; Touvron et al., 2023; Team et al., 2023)。 广义来说,RLHF 学习范式最初是为将大型语言模型 (LLM) 与人类价值观和偏好相一致而设计的 (Bai et al., 2022; Ouyang et al., 2022),它与 SFT 不同,因为它从 相对反馈 (Christiano et al., 2017; Ziegler et al., 2019) 中学习。 它显著增强了 ChatGPT、Claude 和 Gemini 等模型的能力,使它们能够生成更有帮助、无害和诚实的响应 (Bai et al., 2022)。 受 RLHF 在一般聊天应用程序中成功的启发,本文探索了 RLHF 在 LLM 配备外部工具的情况下改善其数学问题求解能力的应用。 特别是,由于深度强化学习方法(例如,近端策略优化 (PPO) 算法 (Schulman et al., 2017))通常样本效率低且不稳定 (Choshen et al., 2019),我们的目标是推导出直接偏好学习算法,这些算法直接从偏好数据集中学习 (Zhao et al., 2023; Rafailov et al., 2023; Azar et al., 2023)。
贡献。
我们首先将学习过程表述为马尔可夫决策过程 (MDP),这与 RLHF 通常用于创建没有外部环境交互的通用聊天机器人的上下文老虎机方法不同 (Xiong et al., ; Rafailov et al., 2023)。 然后,我们推导优化问题的最优性条件,并开发结合外部消息的多轮直接对齐算法(M-DPO 和 M-KTO),其中主要修改是在训练期间屏蔽掉不相关的标记。 此外,我们将我们的方法扩展到其在线迭代变体,最近的研究表明这些变体很有前景 (Xiong 等人,;Guo 等人,2024b)。 最后,我们通过使用来自 MATH 和 GSM8K 基准的增强训练集的案例研究来评估我们的方法,并采用了各种基础模型,例如 Gemma (Team 等人,2024)、CodeGemma (Team,2024) 和 Mistral (Jiang 等人,2023)。 例如,在 GSM8K 上,经过监督微调的 Gemma-1.1-it-7B 模型的性能从 77.5% 提高到 83.9%,在 MATH 上从 46.1% 提高到 51.2%。 同样,Gemma-2-it-9B 模型在 GSM8K 上从 84.1% 提高到 86.3%,在 MATH 上从 51.0% 提高到 54.5%。 这些经验结果表明,与标准 SFT 模型相比,性能有显着提高,证明了 RLHF 在复杂推理任务中的潜力。 我们还提供了关于在线迭代多轮方法的实际实施的综合方案,并公开了我们的模型、数据集和代码,以供进一步研究和开发。
1.1 问题公式
我们将提示表示为 ,并假设交互最多运行 轮。 在第一步中,从某个分布 中采样一个提示 作为初始状态 (我们使用术语“状态”而不是“上下文”,因为我们关注的是 MDP 而不是上下文老虎机)。 然后,在每一步 ,
-
•
行动: 代理观察当前状态 ,即与外部环境的前 次交互的历史,并根据某个策略 采取行动 。 通常,行动采用 ReAct 方式,包括推理步骤 和执行步骤 (例如,编写 Python 代码) (Yao 等人,2022)。
-
•
观察: 作为对代理行动的响应,环境根据历史 和当前行动 返回观察结果 。
然后,我们过渡到一个新的状态,即到步骤 为止的历史:
并开始一个新的步骤。 这个过程总共重复 轮,最终,我们收集了一个轨迹:
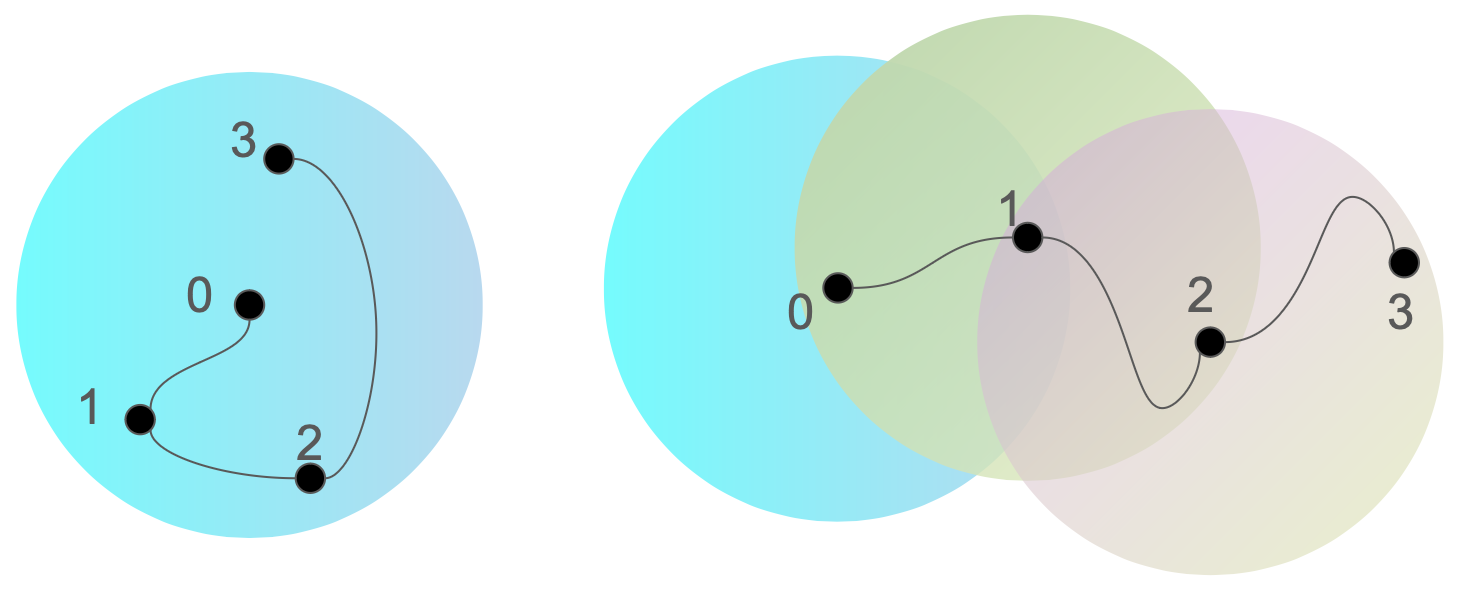
参见图 1 举个例子。 这里提出的框架是马尔可夫决策过程(MDP),它提供了与中讨论的上下文强盗模型不同的方法。 Xiong 等人 . 正式地,我们定义以下 MDP。
Definition 1.
MDP 由一个元组 指定,其中 是动作空间, 是情节长度 111 实际上,情节长度在轨迹之间可能有所不同。 我们还可以定义,输出最终答案的较短轨迹处于吸收状态。 我们考虑固定情节长度以简化后续的数学分析。 , 是状态转移核, 表示提示 的分布。 对于每个 , 是在步骤 处给定状态-动作对 的下一个状态的分布。 在我们的设置中,轨迹 由: 生成,并且对于所有 ,其中 。 当没有歧义时,缩写 也被采用。

最近,Zhong 等人 (2024);Rafailov 等人 (2024);Xie 等人 (2024a) 研究了偏好学习的 MDP 公式,但重点关注单轮聊天任务,并未明确考虑外部消息。 与传统的 RL 研究相比,RLHF 的一个独特特征是通过比较具有相同初始状态(提示)的两条轨迹获得的相对反馈。 我们遵循Ziegler 等人 (2019);Ouyang 等人 (2022);Bai 等人 (2022) 的假设,即偏好信号是由所谓的 Bradley-Terry 模型生成的。
Definition 2 (Bradley-Terry 模型).
我们表示 ,其中提示已从轨迹中排除。 我们假设轨迹 存在一个效用函数,使得给定 ,一个响应 比另一个响应 更受偏好,表示为 ,概率为
| (1) |
其中 是 sigmoid 函数 。 同样,给定 ,我们将采样的偏好信号表示为 ,其中 表示 ,而 表示 。
根据这个定义,我们只假设可以访问轨迹级偏好,但不能访问动作级偏好。 这应该将我们的方法与单轮 RLHF 的直接扩展区分开来 (Christiano 等人,2017;Ziegler 等人,2019),它固定一个提示,该提示可能包括轨迹中间步骤,例如 ,并查看下一个单步 。 但是,我们注意到效用函数本身可以以逐步的方式定义。 为了进一步说明轨迹级比较中 BT 模型的概念,我们在这里提供一些效用函数的示例。
Example 1 (数学中的结果检查).
由于数学推理数据集 GSM8K (Cobbe 等人,2021a) 和 MATH (Hendrycks 等人,2021) 有黄金答案,我们可以检查最终答案以确定奖励。 在这种情况下,。
Example 2 (结果监督奖励模型 (ORM)).
最终结果检查并不完全可靠,因为我们可能会遇到有正确答案但推理轨迹不正确的假阳性解。 相反,如 Cobbe 等人 (2021b); Lightman 等人 (2023) 所示,我们可以均匀地对每个提示抽取 个轨迹,并训练一个 ORM 来预测每个解是否正确。 然后,我们可以将 ORM 在最终符元处的预测作为效用函数。
Example 3 (过程监督奖励模型 (PRM) 和无人类标注的 PRM)。.
Lightman 等人 (2023) 认为,如果我们可以提供逐步监督信号,效用函数将更加有效。 但是,这需要更细粒度的人类标签来对轨迹的每一步进行评分。 Wang 等人 (2023a) 研究了如何自动构建带有黄金答案的数学问题的过程标记数据。 具体来说,对于 ,我们生成具有最终答案 的 个轨迹。 我们可以定义代理奖励值:
| (2) |
我们也可以使用一个硬版本
| (3) |
然后,我们可以通过以下方式训练 PRM:
| (4) |
在这种情况下,我们可以使用 (Lightman 等人,2023),其中 是构建的逐步奖励函数。
符号。 为了提高本文的可读性,我们在表 6 中提供了一个显著的表格。
1.2 相关工作
用于数学问题求解的大语言模型。
一系列工作建议通过提示大语言模型以逐步的方式解决复杂的推理任务,这被称为“思维链”(CoT)提示 (Wei et al., 2022; Zhou et al., 2022; Zhu et al., 2022; Tong et al., 2024),这已成为推理任务的标准做法。 然而,当仅依靠内部知识和自然语言推理时,大语言模型在基本算术和符号操作方面往往很吃力,正如标准基准所测量的 (Cobbe et al., 2021a; Hendrycks et al., 2021)。 为了克服这些局限性,一些研究探索了使用外部工具来增强大语言模型的解决问题能力。 这包括计算器 (Cobbe et al., 2021b; Shao et al., 2022)、符号求解器 (Zhang, 2023) 和代码解释器 (Mishra et al., 2022; OpenAI, 2023)。 一种特别有效的方法是基于程序的方法(PoT),它通过编写代码并使用所写代码的输出作为最终答案来执行 CoT 推理 (Gao et al., 2023a; Chen et al., 2022)。 这种方法在数学问题求解方面明显优于传统的基于 CoT 的技术。 然而,PoT 在规划和错误处理方面也面临挑战,而这些方面更适合自然语言推理 (Gou et al., 2023a)。 鉴于此,人们提出了工具集成推理,将基于自然语言的内在推理与外部工具相结合 (Gou et al., 2023b),并在最近的研究中取得了很大进展 (Gou et al., 2023b; Yue et al., 2023; Yu et al., 2023; Shao et al., 2024; Toshniwal et al., 2024)。 虽然这些努力主要集中在用于工具集成推理的合成数据生成上,但我们的工作旨在通过 RLHF 进一步提高工具集成大语言模型的性能。
RLHF 和 RLHF 算法。
RLHF 中的主要方法是深度强化学习方法,即近端策略优化算法(PPO) (Schulman et al., 2017),它在 Chat-GPT (OpenAI, 2023)、Gemini (Team et al., 2023) 和 Claude (Anthropic, 2023) 中取得了巨大成功。 然而,应用 PPO 需要大量的努力和资源 (Choshen et al., 2019; Engstrom et al., 2020),这往往超出了开源能力的范围。 鉴于此,人们开发了替代方法。 拒绝采样微调最初是在 RLHF 中以 RAFT(奖励排序微调)的名义提出的 (Dong et al., 2023),后来扩展到机器翻译 (Gulcehre et al., 2023) 和数学问题求解 (Yuan et al., 2023a)。 它的理论优势在 Gui et al. (2024) 中进行了探讨。 随后,另一长期的研究方向是提出直接偏好学习算法,包括 SLiC (Zhao 等人,2023)、DPO (Rafailov 等人,2023)、IPO (Azar 等人,2023)、KTO (Ethayarajh 等人,2024) 和 GPO (Tang 等人,2024)。 这些算法绕过了奖励建模步骤,直接在偏好数据集上优化精心设计的损失目标,因此被称为直接偏好学习。 也有一些研究工作关注更一般的偏好结构 (Munos 等人,2023;Swamy 等人,2024;Ye 等人,2024;Rosset 等人,2024),超出了基于奖励的框架或模型的后处理 (Lin 等人,2023;Zheng 等人,2024)。
新提出的直接偏好学习算法在很大程度上推动了 RLHF 领域的发展,尤其是开源模型的后期训练,其中 Zephyr 项目是一个值得注意的例子 (Tunstall 等人,2023)。 之后,一系列研究工作 (例如,Liu 等人,2023b;Xiong 等人,;Guo 等人,2024b;Xu 等人,2023;Tajwar 等人,2024;Xie 等人,2024a;Zhang 等人,2024b;Liu 等人,2024a,b;Meng 等人,2024) 展示了在线策略采样(样本由要训练的策略生成)和在线探索在增强直接偏好学习中的有效性。 特别是,在线迭代 DPO (Xiong 等人,;Xu 等人,2023;Hoang Tran,2024) 及其变体 (例如,Chen 等人,2024b;Rosset 等人,2024;Cen 等人,2024;Zhang 等人,2024c) 已经使最先进的开源模型 (Dong 等人,2024) 甚至行业模型 (qwe,2024;Meta,2024) 成为可能。 尽管取得了这些进展,但大多数算法都是针对单轮交互和聊天提出的和设计的。 现有文献中尚未探索单轮聊天之外的场景。 一个例外是 (Shani 等人,2024) 最近发表的一篇研究论文,该论文研究了在一般偏好下的多轮聊天任务。 相反,本文旨在探索 RLHF 在包含与外部工具交互的多轮任务中的应用。 同时,他们推导出了一种基于镜像下降的策略优化算法,这与我们的算法不同。
用于数学问题解决的 RLHF。
传统上用于通用聊天机器人的算法已被改编,以增强 LLM 在数学背景下的推理能力。 例如,RAFT(奖励排名微调)(Dong 等人,2023;Yuan 等人,2023b;Touvron 等人,2023) 被广泛用于合成数据生成,无论是通过在线策略(自我改进)(Yuan 等人,2023a) 还是离线策略(知识蒸馏)方法 (Gou 等人,2023b;Yu 等人,2023;Toshniwal 等人,2024;Singh 等人,2023;Tong 等人,2024)。 这些场景中的奖励信号通常源于最终结果检查或结果监督奖励模型 (ORM) (Uesato 等人,2022;Zelikman 等人,2022)。 (Lightman 等人,2023) 提出了一种新方法,引入了过程监督奖励模型 (PRM),该模型在思维链的每一步提供反馈,与拒绝采样相结合时,与 ORM 相比取得了显著改进 (Lightman 等人,2023;Wang 等人,2023a)。
除了 RAFT 之外,Shao 等人 (2024) 中提出的 GRPO 算法研究多轮数学问题求解,但侧重于无需外部输入的 CoT 格式,所得模型达到了状态 -同类产品中最先进的性能。 GRPO 是 Williams(1992) 中提出的 Reinforce 的变体,因此属于深度强化学习方法的范围。
进一步的进展包括将直接偏好学习算法应用于数学问题求解。 例如,Jiao 等人(2024);Yuan 等人(2024) 通过将轨迹完成作为“元”动作,应用了原始的 DPO 或 KTO。 Xie 等人(2024b);Pang 等人(2024) 进一步改进了最初为聊天 (Xiong 等人,; Xu 等人,2023; Hoang Tran,2024) 设计的在线迭代 DPO,并在 CoT 推理方面取得了更好的性能。 受 PRM 成功启发,最近的研究探索了为推理轨迹的中间步骤生成代理分步标签。 例如,Xie 等人(2024b);Chen 等人(2024a);Lai 等人(2024) 利用蒙特卡洛树搜索(MCTS)并使用估计的 Q 值为中间步骤生成代理标签。 Lai 等人(2024) 提议使用 GPT-4 等 AI 反馈 (Lai 等人,2024) 来查找轨迹中的第一个错误步骤。 同时,Lu 等人(2024) 将具有正确最终答案且没有错误的轨迹识别为首选,并以高温度提示 SFT 模型,从某个中间步骤开始收集带有错误的拒绝轨迹 (Pi 等人,2024)。 最后,Chen 等人(2024a) 的一项最新研究提议使用 MCTS 从最终叶节点进行反向迭代,以计算每个节点的代理未正则化值。 然后通过固定前缀并比较 下一个单一推理步骤 从树中提取偏好对。 然后,他们使用来自 MCTS 的代理标签,对这些中间动作运行原始 DPO。 总之,这些工作展示了不同的偏好数据收集方式,并应用了原始的 DPO 算法(带有从文献中适应的一些额外的边缘损失和正则化),因此在算法概念和应用范围方面都与我们的工作不同。 相反,我们研究了轨迹级比较中的偏好学习,我们推导出最优条件,并在在线迭代框架中引入了多轮 DPO,专门用于工具集成数学问题求解。 但是,我们注意到,虽然我们专注于轨迹级比较,但偏好信号本身可以以分步监督的方式生成(有关详细示例,请参见第 1.1 节)。 当存在具有共享前缀的部分轨迹的偏好信号时,我们的方法也可以适应学习这些步骤级信号(参见 (11) 中的最优条件)。 特别地,本文提出的算法设计可以很容易地与最近文献中概述的基于 MCTS 的数据收集策略相结合,我们将其留待将来工作。
2 算法开发
我们在本节中开发本文的主要算法。 我们继续处理第 1.1 节中提出的通用 MDP 公式,它将工具集成数学推理问题作为一个特殊例子。 因此,这些算法也可以应用于具有外部消息的更一般场景。
2.1 使用固定模型进行规划:最优条件
遵循 Rafailov 等人 (2023),我们首先建立任何模型 与其关联的最优策略之间的联系。 特别地,我们对以下关于参考策略 的 KL 正则化规划问题感兴趣:
| (5) |
在单轮情况下(即 且没有转换 ),Rafailov 等人 (2023);Azar 等人 (2023) 表明关于效用函数 的最优解具有闭式解,即 吉布斯分布(参见引理 3):
从单步到多步场景的转变,我们首先表明我们仍然关注吉布斯分布,但以动态规划的方式。 结果本质上来自熵正则化 MDP 的研究 (Williams 和 Peng, 1991; Ziebart, 2010)。
为了说明这个想法,我们首先考虑 的最简单情况,其中模型只允许调用工具一次。 然后,我们的目标是最大化以下目标:
这个想法是从 到 进行反向迭代。 具体来说,当我们固定 并考虑内循环时,我们可以利用引理 3 来解决
然后,我们可以将与 相关的内循环的值定义为
然后,对于步骤 ,我们关注以下 KL 正则化优化问题:
通过构造,可以观察到 是最优的,因为它最大化了 KL 正则化的目标。
对于一般的 步 MDP,我们可以重复上述过程 次,从 开始,我们递归地定义
| (6) |
这里最优策略和 值由下式给出:
| (7) | ||||
其中 是归一化常数。 值定义中的第二个等式来自引理 3。 然后,根据定义, 是最优策略。 本质上,我们用 值来求解 个 Gibbs 分布 2 22 值的定义不同于 Ziebart (2010) 中的定义,因此最优策略可以被解释为 值的 Gibbs 分布。 .
2.2 用固定模型进行规划:实用算法
虽然可以用标准的深度强化学习方法近似地求解 (7),但我们这里对以直接偏好学习方式(如 SLiC (Zhao et al., 2023)、DPO (Rafailov et al., 2023) 或 IPO (Azar et al., 2023))进行实现感兴趣。 现有的尝试 (e.g., Yuan et al., 2024) 将完成 视为“元动作”,并将其插入单步 DPO 损失中。 换句话说,他们将外部消息视为模型本身生成的常规文本。 另一个自然的想法是将轨迹的概率插入单步 DPO 损失中。 具体来说,对于一对 ,其中 指的是首选(即获胜)轨迹,我们有:
| (8) | ||||
不幸的是,正如我们将在下面解释的那样,由此产生的算法并不总是导致最优策略。 特别地,我们可以将 值求解为
| (9) | ||||
其中两个等式分别使用最佳策略 和 值 在 (7) 中的定义。 此外,根据 值 在 (6) 中的定义,我们有
| (10) | ||||
对 求和,我们有
| (11) | ||||
这里,项 是单步 DPO 推导中 的对应项,如果我们考虑具有相同提示 的两个轨迹的奖励差异,则项 将被抵消。 不幸的是,在实践中,项 通常无法直接计算。 特别地,使用切比雪夫不等式的一些简单数学运算表明,概率至少为 ,
其中 是 的条件方差。 因此,偏差项 与外部环境的随机性相关。
对于用于数学推理的工具集成 LLM 的大多数情况,即这项工作的重点,幸运的是,代码执行结果由历史(LLM 编写的代码)决定。 换句话说,给定历史 ,外部观察是确定性的,这会导致 。 因此,使用包含 的数据集 ,可以采用以下多回合 DPO (M-DPO) 损失:
| (12) |
我们再次强调,虽然 (12) 中的损失与 (8) 中的损失相同,但提供了一个严格的推导过程(而不是直接插入)。 据我们所知,(12) 在具有外部消息的多回合推理任务的背景下是新的。 特别地,需要注意的是,这种 M-DPO 损失仅在确定性转换下有效,即项 。
此外,(11) 意味着用项 ,隐式奖励由 给出,KTO 的多回合版本 (Ethayarajh 等人,2024),表示为 M-KTO,也可以自然地推导出:
| (13) |
其中
以及
这里 和 是两个超参数。 我们注意到 Mitra 等人 (2024) 为 CoT 格式推理任务开发了一个 KTO 的在线迭代版本。 在这里,我们将它扩展到构建工具集成推理代理。
上述讨论,特别是 (12) 和 (13) 中提供的 M-DPO 和 M-KTO 损失,侧重于确定性观察,因为用于数学推理的工具集成 LLM 的确定性性质。 相反,一些其他应用程序可能会遇到随机观察,例如,与人类或另一个 LLM 提供的外部消息进行的多回合聊天 (Shani 等人,2024)。 在这些情况下,(12) 有偏差,并且由于 ,不能导致最优策略。 相反,应该首先根据 (6) 和 (7) 中提供的贝尔曼方程构建一个价值网络,类似于 Richemond 等人 (2024) 中的方法。 随后, 可以使用蒙特卡罗方法进行估计,并作为偏好训练中的自适应边界。 特别是,直接偏好学习算法和经典深度强化学习方法之间的区别变得越来越模糊。 对这种更复杂算法的探索及其在一般多回合学习场景中的应用留待未来的研究。
我们注意到,上述 MDP 公式和相关讨论之前已由 Zhong 等人 (2024); Rafailov 等人 (2024); Xie 等人 (2024a) 在令牌级 MDP 或具有确定性转移的更通用 MDP 的背景下推导出来,但他们的重点都集中在单回合聊天任务上。 虽然数学公式看起来相似,但我们的主要重点在于工具集成推理任务,这些任务结合了额外的外部消息 。
2.3 在线迭代训练的学习
在直接偏好学习文献中,大量工作表明,在线单回合 RLHF 在其离线对应物中表现明显优于,无论是在直接偏好学习文献中 (Xiong 等人,; Ye 等人,2024; Guo 等人,2024b; Rosset 等人,2024; Dong 等人,2024; Tajwar 等人,2024) 还是基于 DRL 的方法或拒绝采样微调 (Bai 等人,2022; Ouyang 等人,2022; Touvron 等人,2023)。 受这些成功的启发,我们建议将在线交互式学习进一步整合到本文研究的多轮 RLHF 中。 下面,我们将主要从两个方面说明所提出的想法:两个学习目标和一个统一的算法框架。
学习目标。
我们考虑两种不同的学习目标。 第一个是 KL 正则化的目标:
| (14) |
也就是说, 其中 是真实环境,而 是 RLHF 开始的初始策略(例如,来自 SFT)。 这个目标在实践中被广泛采用 (Christiano 等人,2017;Ouyang 等人,2022;Bai 等人,2022;Rafailov 等人,2023;Dong 等人,2024),并且要求我们仅在以 SFT 策略 为中心的 固定 KL 球中搜索最优策略 (Xiong 等人,;Ye 等人,2024;Xie 等人,2024a)。
相反,第二个是非正则化的目标,即直接优化奖励:
| (15) |
这个目标是规范 RL 研究中的标准目标 (Sutton 和 Barto,2018)。 这个目标的一个动机是,在推理任务中,与聊天任务相比,奖励函数更易于解释(例如,最终结果检查)。
算法框架。
我们在算法 1 中提出了一个通用的在线迭代算法框架。 该框架被称为来自人类反馈的在线迭代多轮吉布斯采样(M-GSHF),以强调在线迭代训练过程和(7)中导出的最佳条件最优策略是分层吉布斯分布,它概括了老虎机公式 熊等。 . 具体来说,从 开始,在每次迭代中,我们首先通过当前策略对收集一对轨迹,其中偏好信号也根据定义 1 显示。 然后,我们根据迄今为止收集的数据更新策略对,并开始下一轮迭代。 现在我们讨论框架的一些特性,如下所示。
用于探索-利用权衡的策略选择。 我们以非对称的方式更新我们的行为策略。 第一个代理旨在提取我们迄今为止收集的历史信息,根据历史数据集 上的经验最佳模型进行规划以获得 ,其中规划算法已在第 2.2 节中讨论,例如,优化 (12) 或 (13) 中的 M-DPO 或 M-KTO 损失。 但是,在 RL 研究中 (Sutton 和 Barto,2018; Auer 等人,2002) 中广泛认可,仅仅通过遵循经验最佳模型来利用历史数据不足以获得良好的最终策略,而探索环境也是必需的,以便收集新的信息以促进后续学习,即探索-利用权衡。 虽然主要代理针对利用,但我们设计了第二个代理,相反,根据迄今为止收集的历史信息,在策略选择中战略性地将未来的不确定性纳入 。 我们将第二个代理的策略称为 作为探索策略,因为它用于探索底层环境并促进第一个代理的学习。 实际上,这种探索原则通常被解释为最大化两种行为策略之间的差异或增加收集数据的多样性。 我们总结了在线迭代 RLHF 实践中采用的一些流行的启发式探索策略:
-
•
混合采样:在 Claude 项目 (Anthropic,2023) 中,作者选择使用来自不同训练步骤的检查点来收集数据;
-
•
推理参数调整:在LLaMA项目(Touvron 等人,2023)中,作者仔细调整了采样温度,以平衡数据多样性和数据质量;
-
•
西方采样:Xu 等人 (2023); Hoang Tran (2024); Pace 等人 (2024); Dong 等人 (2024) 为每个提示采样 n 个响应,并提取最佳响应和最差响应(基于某些排名标准)以构建一个偏好对。
我们将在实验部分探讨混合采样,并在下一小节提供理论依据。
用于控制正则化级别的参考模型选择。 尽管在 (14) 和 (15) 中分别讨论了两个不同的学习目标,但我们注意到,可以采用一个通用的算法框架,其中参考模型选择作为超参数来控制正则化级别并考虑这两个目标:
图 2 提供了一个图形说明,以方便理解。
2.4 理论结果
本节将展示在学习理论文献中的标准假设下,多回合 RLHF 问题可以以统计上有效的方式解决。 具体来说,为了普遍性,我们将目标设定为具有随机和未知转换的最具挑战性的场景,而如前所述,具有外部工具的多回合数学推理属于具有确定性转换的相对容易的范围。 由于缺乏对其进行理论研究,我们主要研究了 KL 正则化目标。 在 Wang et al. (2023b) 中已经对优化奖励的另一个目标进行了理论研究,而分析镜面下降风格算法和相应保证的技术也在 Cai et al. (2020) 中得到发展,可以迁移到考虑偏好反馈。 此外,为了简化展示,我们考虑了批大小为 的场景,而结果可以轻松推广到大批次。
首先,为了衡量在线学习过程,我们将最优策略定义为
| (16) |
并引入标准的后悔概念为
| (17) |
它表示将学习的策略 与最优策略 进行比较,在 步中累积的性能损失。 此外,我们认为所有 的 有界,以保持合理的效用范围。 此外,假设我们可以访问以下策略改进预言机,它类似于在 熊 等人 .
Definition 3 (策略改进预言机).
对于任何模型 和参考函数 ,我们可以像在 (7) 中一样迭代地计算与模型 相关的最佳策略。
整个算法,即在线迭代 M-GSHF 的理论版本,也在算法 1 中进行了总结。 在每一轮 中,以 作为聚合数据集,它首先对一组 上的奖励函数 进行最大似然估计 (MLE),该组元素在 中有界,如
| (18) |
以及对一组 上的转移核 进行 MLE,如
| (19) |
其中 表示轨迹 在策略 和转移核 下的概率。 使用获得的模型 ,在定义 3 中定义的 Oracle 被调用,其参考策略 被设置为初始策略 ,其输出被用作主策略 。
然后,我们指定如何选择一个理论上合理的探索策略 。 的先前工作 Xiong 等人。 关于单回合 RLHF 已证明了这样一个直觉,即探索策略应该负责收集环境 不确定部分的信息,因此通常选择它来最大化一个不确定性度量。 在这项工作中考虑的多回合 RLHF 设置中,以下命题作为找到合适的用来决定探索策略的不确定性度量的基石。 特别地,我们可以观察到最优策略由最优 -函数参数化。 如果采用不同的 -函数集用于策略参数化,我们可以对其性能进行如下界定。
Proposition 1 (KL 正则化 MDP 的值分解引理).
如果考虑一组 -函数 和一个参考策略 ,其中诱导策略 为
以及相应的 -函数集 为
对于任何比较器策略 ,它都满足
其中期望 是相对于遵循 和 生成的提示和响应(即轨迹)而言的。
基于命题 1,探索策略 被选择为
| (20) |
其中 和 是两个定义为
| (21) | ||||
其中 表示一个绝对常数。 注意,为了理论上的方便,我们假设 和 在这里有限,这可以使用标准的离散化技术扩展到无限的情况。 可以观察到 被选中以最大化来自奖励和转换估计的不确定性的组合。 如果考虑已知的转换(即,不需要估计 ),则来自转换估计的不确定性会减少,这会导致类似的不确定性度量,该度量在 Xiong 等人 .
以下定理为发生的遗憾建立了严格的保证。
我们注意到,规避系数和广义规避型条件是 RL (张,2023;钟等人,2022;刘等人,2023a;谢等人,2022;阿加瓦尔等人,2023) 和 RLHF (詹等人,2023;王等人,2023b;叶等人,2024) 理论研究中的标准且被广泛采用的条件。 此外,对于一类广泛的 RL 问题(有关更多详细信息,请参阅 张 (2023);刘等人 (2023a)),规避系数 很小,并且该条件满足 ,这意味着算法 1 的理论版本的遗憾在 中是亚线性的,进一步证明了其统计效率。
3 实验
3.1 实验设置
任务和数据集。
我们使用 MATH (Hendrycks 等人,2021) 和 GSM8K (Cobbe 等人,2021a) 的测试集来衡量模型解决数学问题的能力。 MATH 数据集包含 5K 个涵盖代数、几何、概率、数论和微积分等不同数学领域的数学问题。 GSM8K 测试集包含 1319 个小学数学应用题,这些问题一般比 MATH 数据集中的问题更简单。 以下是每个数据集的示例:
-
•
GSM8K:娜塔莉亚在 4 月份卖给了 48 个朋友别针,然后她在 5 月份卖出的别针数量是 4 月份的一半。 娜塔莉亚在 4 月和 5 月总共卖出了多少个别针?
-
•
MATH:求方程 所表示的圆的圆心。
为了有效地解决这些问题,模型需要在得到最终答案之前进行多轮推理和算术运算。 为了构建训练提示集,我们遵循 Gou 等人 (2023b); Yu 等人 (2023); Yue 等人 (2023); Liu 和 Yao (2024); Toshniwal 等人 (2024) 的做法,使用来自 MATH 的 7.5K 个训练问题和 GSM8K 的 7.47K 个训练问题构成的增强提示集。 特别地,我们使用了 MetaMathQA (Yu 等人,2023) 和 MMIQC (Liu 和 Yao,2024) 中的提示。 新问题包括:改写问题、逆向问题(从最终答案开始,向后推理以确定原始问题中的未知变量)、通过上下文学习和迭代式问题组合进行引导问题 (Liu 和 Yao,2024)。 我们删除了重复的问题,并确保 MATH 和 GSM8K 的测试集中没有使用任何问题。 最终,我们总共获得了 60K 个用于训练的训练提示,并将其随机分成三个不相交的集合以进行迭代训练。 我们还保留了 1K 个提示作为模型选择,用于训练过程中。
基础模型。
我们使用了一系列基础模型进行训练,包括 Gemma-1.1-it-7B (Team 等人,2024)、CodeGemma-1.1-it-7B (Team,2024)、Mistral-7B-v0.3 (Jiang 等人,2023) 和 Gemma2-it-9B。 我们使用 Mistral 的预训练版本,而不是指令版本,因为其 huggingface 检查点和其自身代码库的聊天模板不一致,因此我们从预训练模型开始,并自行对其进行微调。
数据格式和生成。
我们将数据格式化为多轮聊天,其中用户最初向 LLM 提出问题,并在随后的聊天用户回合中提供 Python 解释器返回的消息。 在每个模型回合中,模型根据迄今为止收集的历史进行推理,并可以输出一个用 方框括起来的最终答案,或者通过编写用 ```python 和 ``` 括起来的代码来调用 Python 解释器。 在收到模型的响应后,如果模型调用了工具,我们将返回代码的执行结果,如果模型输出最终答案或达到最大轮数 H(在我们设置中为 6),则停止。 请参阅图 1 以了解说明。 我们使用温度设置为 1.0,不使用 top-K 或 top-p 采样,为每次迭代每个提示生成了 N=30 个样本。 我们采用混合采样策略,其中最新模型仅生成 20 条轨迹,其余部分(10 条轨迹)使用上一次迭代的模型收集。 对于初始迭代,我们分别使用经过 3 个 epoch 和 1 个 epoch 微调的模型进行混合采样。 直观地说,混合采样有助于提高收集样本的多样性,并且已应用于以前的 RLHF 实践 (Bai 等人,2022; Dong 等人,2024)。 对于所有数据生成过程,我们采用以下约束:(1)对于每个回合,模型最多可以生成 512 个符元;(2)最大步骤数为 H=6;(3)每条轨迹的最大符元数为 2048。
监督微调(SFT)。
我们首先使用 Open-MathInstruct 数据集的一个子集,该数据集由允许许可的 Mixtral-8x7B 模型通过上下文学习生成,对模型进行工具集成推理任务的微调 (Gou 等人,2023b)。 这些问题来自 MATH 和 GSM8K 数据集的训练集。 我们将每个问题的样本数量限制为 并删除近似重复的响应。 最终,我们在 SFT 数据集中获得了 510K 个样本。 我们最多训练模型 4 个 epoch,Gemma 指令模型 (Team 等人,2024) 的学习率为 5e-6,Mistral-v0.3 模型 (Jiang 等人,2023) 的学习率为 1e-5。 学习率通过搜索 {2e-6, 5e-6, 1e-5} 确定。 我们使用 Mistral 的预训练模型,因为 Mistral 指令模型的聊天模板在我们的实验期间的不同代码库(huggingface 和官方代码库)中不一致。 我们使用余弦学习率调度器,并将预热步数设置为 100。 样本被打包成长度为 4096 的块,以加速训练,并使用 64 的全局批次大小。 我们还屏蔽训练中的所有用户消息(即提示和 Python 解释器返回的消息)。 使用 8xA100 80G GPU 进行训练大约需要 10-15 小时。 第三轮结束时的检查点用于 Gemma,第二轮结束时的检查点用于 Mistral,作为 RLHF 的起点。 这是因为这些模型的表现明显优于最后一轮的模型,并且非常接近下一轮的模型。 还包括关于 SFT 纪元的消融研究。
数据标注。
对于每个提示,我们首先通过检查最终答案将响应划分为获胜集 和失败集 。 在实践中,我们观察到该模型可以记住最终答案并输出它,即使推理路径本身不正确。 为了缓解这个问题,我们包含一些启发式过滤过程。 首先,我们删除了获胜集中的所有轨迹,其中倒数第二轮返回的消息表明代码存在一些错误,但模型只是忽略了它并预测了真实答案。 然后,如果获胜集 和失败集 中的响应长度超过 2048 个符元,我们就会删除它们。 最后,我们从 中随机采样一条轨迹,从 中随机采样一条轨迹,以构建一对或将它们添加到 KTO 算法的训练集中。 对于每次迭代,我们通常会获得 15K-20K 个样本,因为一些提示可能没有正确答案。 我们注意到,可以利用 AI 反馈,例如 Gemini (Team 等人,2023) 或 GPT4 (OpenAI,2023) 来逐步进一步验证轨迹的正确性,或构建一个 PRM (Lightman 等人,2023;Wang 等人,2023a) 来对轨迹进行排序,这些都留待以后的工作。
M-DPO 和 M-KTO 的实现。
为了实现 M-DPO,我们只需将所有用户轮次符元的标签设置为 -100,并在后续的损失计算中屏蔽对数概率。 我们最多对模型进行 1 个 epoch 的训练,并在迭代训练的第一轮中调整学习率,调整范围为 {2e-7, 4e-7, 7e-7, 1e-6}。 最终,学习率为 4e-7 用于 Gemma-1.1 模型,2e-7 用于 Gemma-2 模型和 Mistral 模型。 全局批次大小为 32,预热步数为 40。 我们每 50 个训练步使用分割提示集评估模型,最佳模型通常在 150 步到 600 步之间获得,这是预期的,因为 SFT 的提示和 RLHF 的提示是重叠的。 这在之前关于制作通用聊天机器人的 RLHF 的工作 (Lin 等人,2023) 中也有观察到。 进一步探索提示缩放也留待以后的工作。 M-KTO 的超参数与 M-DPO 大致相同。 我们还设置 遵循原始 KTO 论文 (Ethayarajh 等人,2024)。 本文中的 RLHF 实验使用 8xA100 80G GPU 运行,其中还使用一台具有 8xA100 40G GPU 的机器进行数据收集和模型评估。 使用此设置,本文的主要实验可以在 24-48 小时内重现。 由于篇幅限制,我们将其他一些实现细节留待附录 B 中介绍。
3.2 主要结果
我们在零样本设置下评估模型,并在表 1 中报告主要结果。
基线。
现有文献主要关注合成数据生成,并通过对收集到的数据的监督微调来训练模型使用外部工具。 我们使用 Toshniwal 等人 (2024) 的结果作为基线,因为我们使用相同 SFT 数据集,所以结果大体上是可以比较的。 对于 CoT 基线,我们使用来自 Luo 等人 (2023) 的 Wizardmath 模型。 我们还将奖励排名微调 (RAFT) 作为基线 (Dong 等人, 2023),它在文献中也被称为拒绝采样微调 (Touvron 等人, 2023)。 RAFT 首先为每个提示收集 N 条轨迹,过滤低质量数据(通过奖励函数),并对选定的轨迹进行微调。 另一个基线是单轮在线迭代 DPO 和 KTO (Rafailov 等人, 2023; Ethayarajh 等人, 2024),它忽略了问题结构(即外部消息),并将轨迹视为一个整体。 在实现中,这意味着我们不会屏蔽用户回合,外部消息的符元也会对损失做出贡献。
| Base Model | Method | with Tool | GSM8K | MATH | AVG |
|---|---|---|---|---|---|
| WizardMath-7B | SFT for CoT | ✗ | 54.9 | 10.7 | 32.8 |
| WizardMath-13B | SFT for CoT | ✗ | 63.9 | 14.0 | 39.0 |
| WizardMath-70B | SFT for CoT | ✗ | 81.6 | 22.7 | 52.2 |
| CodeLLaMA-2-7B | SFT | ✓ | 75.9 | 43.6 | 59.8 |
| CodeLLaMA-2-13B | SFT | ✓ | 78.8 | 45.5 | 62.2 |
| CodeLLaMA-2-34B | SFT | ✓ | 80.7 | 48.3 | 64.5 |
| LLaMA-2-70B | SFT | ✓ | 84.7 | 46.3 | 65.5 |
| CodeLLaMA-2-70B | SFT | ✓ | 84.6 | 50.7 | 67.7 |
| Gemma-1.1-it-7B | SFT† | ✓ | 77.5 | 46.1 | 61.8 |
| Gemma-1.1-it-7B | RAFT | ✓ | 79.2 | 47.3 | 63.3 |
| Gemma-1.1-it-7B | Iterative Single-turn DPO | ✓ | 81.7 | 48.9 | 65.3 |
| Gemma-1.1-it-7B | Iterative Single-turn KTO | ✓ | 80.6 | 49.0 | 64.8 |
| Gemma-1.1-it-7B | Iterative M-DPO + fixed reference | ✓ | 79.9 | 48.0 | 64.0 |
| Gemma-1.1-it-7B | M-DPO Iteration 1 | ✓ | 81.5 | 49.1 | 65.3 |
| Gemma-1.1-it-7B | M-DPO Iteration 2 | ✓ | 82.5 | 49.7 | 66.1 |
| Gemma-1.1-it-7B | M-DPO Iteration 3 | ✓ | 83.9 6.4 | 51.2 5.1 | 67.6 5.8 |
| Gemma-1.1-it-7B | Iterative M-KTO | ✓ | 82.1 4.6 | 49.5 3.4 | 65.8 4.0 |
| CodeGemma-1.1-it-7B | SFT† | ✓ | 77.3 | 46.4 | 61.9 |
| CodeGemma-1.1-it-7B | RAFT | ✓ | 78.8 | 48.4 | 63.6 |
| CodeGemma-1.1-it-7B | Iterative Single-turn DPO | ✓ | 79.1 | 48.9 | 64.0 |
| CodeGemma-1.1-it-7B | Iterative Single-turn KTO | ✓ | 80.2 | 48.6 | 64.4 |
| CodeGemma-1.1-it-7B | Iterative M-DPO | ✓ | 81.5 4.2 | 50.1 3.7 | 65.8 4.0 |
| CodeGemma-1.1-it-7B | Iterative M-KTO | ✓ | 81.6 4.3 | 49.6 3.2 | 65.6 3.8 |
| Mistral-7B-v0.3 | SFT† | ✓ | 77.8 | 42.7 | 60.3 |
| Mistral-7B-v0.3 | RAFT | ✓ | 79.8 | 43.7 | 61.8 |
| Mistral-7B-v0.3 | Iterative Single-turn DPO | ✓ | 79.8 | 45.1 | 62.5 |
| Mistral-7B-v0.3 | Iterative Single-turn KTO | ✓ | 81.3 | 46.3 | 63.8 |
| Mistral-7B-v0.3 | Iterative M-DPO | ✓ | 82.3 4.5 | 47.5 4.8 | 64.9 4.7 |
| Mistral-7B-v0.3 | Iterative M-KTO | ✓ | 81.7 3.9 | 46.7 4.0 | 64.2 4.0 |
| Gemma-2-it-9B | SFT† | ✓ | 84.1 | 51.0 | 67.6 |
| Gemma-2-it-9B | RAFT | ✓ | 84.2 | 52.6 | 68.4 |
| Gemma-2-it-9B | Iterative Single-turn DPO | ✓ | 85.2 | 53.1 | 69.2 |
| Gemma-2-it-9B | Iterative Single-turn KTO | ✓ | 85.4 | 52.9 | 69.2 |
| Gemma-2-it-9B | Iterative M-DPO | ✓ | 86.3 2.2 | 54.5 3.5 | 70.4 2.9 |
| Gemma-2-it-9B | Iterative M-KTO | ✓ | 86.1 2.0 | 54.5 3.5 | 70.3 2.8 |
从表 1 中的前两部分,我们首先观察到,集成工具的 LLM 在仅使用 SFT 的情况下,明显优于它们的 CoT 对应模型,这证明了利用外部工具的优势。 在随后的讨论中,我们将重点放在集成工具的 LLM 范围内的比较。
迭代 M-DPO 和 M-KTO 显着提高了 SFT 模型。
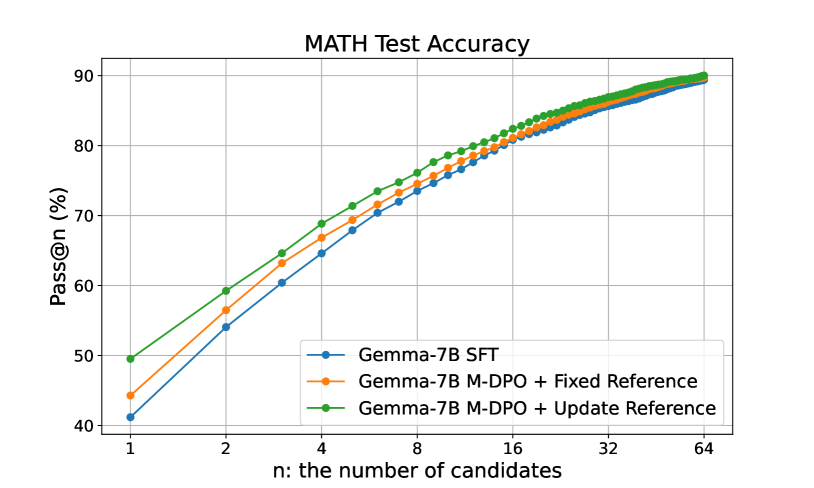
我们观察到,对于所有四个基础模型,在使用 M-DPO 或 M-KTO 进行迭代训练后,生成的模型在 GSM8K 和 MATH 上都以相当大的优势优于其起始 SFT 检查点。 尤其是在使用 M-DPO 时,对齐的 Gemma-1.1-it-7B 模型在 GSM8K 和 MATH 上分别实现了 83.9% 和 51.2% 的准确率,与开源的 Open-MathInstruct 微调的 CodeLLaMA-2-70B 相当(在 GSM8K 上略差,但在 MATH 上也略好)。 此外,对齐的 Gemma-2-it-9B 模型在 GSM8K 和 MATH 上分别实现了 86.3% 和 54.5% 的准确率,超过了所有使用 Open-MathInstruct 在 7B 到 70B 范围内训练的开源模型。 总体而言,我们的框架可以稳固地进一步增强集成工具的模型在监督微调基础上的能力。
迭代 M-DPO 和 M-KTO 超越了现有的 RLHF 基线。
我们还观察到,迭代 M-DPO 和 M-KTO 超越了其他现有的 RLHF 基线。 首先,它们在所有四个基础模型中始终如一地且显著优于 RAFT 算法,该算法在文献中被认为是一个稳健且具有竞争力的基线 (Dong 等人,2023;Yuan 等人,2023a)。 这是因为 RAFT 算法仅利用通过模仿正确轨迹的正信号,而基于 DPO 和基于 KTO 的算法进一步利用了来自那些不正确轨迹的负信号。 我们注意到,我们管道中的 SFT 阶段也可以被视为 RAFT 的应用,这个想法可以追溯到专家迭代 (Anthony 等人,2017)。 因此,我们的结果应被解释为,在 SFT 的第一阶段之上,具有负信号的算法更具样本效率。 此外,虽然在线迭代单轮 DPO (KTO) (Xiong et al., ; Xu et al., 2023) 也提升了性能,但总体上不如多轮版本。 这表明学习预测代码解释器返回的非策略外部消息通常会对推理能力的提升产生负面影响。 从本质上讲,这对应于这样一个事实,即在推导出 KL 正则化优化问题的最优性条件时,我们不允许优化外部消息。 同时,我们展示了一个我们在图 3 中遇到的代表性例子,其中 LLM 生成的代码结构不良,导致异常和冗长的外部消息。 强迫 LLM 学习预测这些消息会严重损害模型的推理能力。

迭代训练和参考更新导致更好的性能。
我们使用 Gemma-1.1-it-7B 和 M-DPO 作为代表性例子,观察到模型从在线迭代训练中获益,其中 GSM8K 的测试精度从 77.5% (SFT) 提高到 81.5% (iter 1) 到 82.5% (iter2) 到 83.9% (iter3),而 MATH 的测试精度从 46.1% (SFT) 提高到 49.1% (iter 1) 到 49.7% (iter2) 到 51.2% (iter3)。 这与我们的理论见解一致,即迭代训练允许模型探索底层空间并逐步学习最优策略。 此外,我们观察到,如果我们将参考模型固定为 SFT 策略,最终的模型性能比我们在每次迭代中将参考模型更新为当前模型的情况要差得多。 我们怀疑这是因为这种版本的算法本质上优化了非正则化奖励,而数学推理任务中的奖励比一般聊天任务中的奖励更准确,从而导致了更好的领域内性能。 我们将关于 KL 正则化影响的更详细的消融研究推迟到下一节。

偏好学习仅在 n 相对较小时提高 pass@n。
我们在图 4 中根据候选轨迹数 n 绘制了 pass@n 准确率。 为了评估 pass@n,对于每个问题,我们独立采样 n 个轨迹,如果存在至少有一个具有正确最终答案的轨迹,则认为该问题已解决。 我们观察到,偏好学习仅在 n 相对较小时提高了 pass@n。 特别地,当 时,所有模型在 GSM8K 和 MATH 上的表现都类似。 换句话说,迭代式 M-DPO 不会注入新知识,而是通过提高前 n 个响应的质量来引出模型在预训练和 SFT 阶段获得的知识。 该观察结果与 Shao 等人 (2024) 的观察结果一致,该研究针对 CoT 数学推理任务研究了基于 DRL 的 GRPO 方法。 因此,偏好学习的成功建立在经过良好训练的 SFT 模型的基础之上。 我们预计,使用更多高质量的 SFT 数据可以进一步提高最终模型的性能。
3.3 消融研究和讨论
我们在本小节中进行消融研究,以便更全面地了解所提出的算法。
一定程度的 KL 正则化可以平衡每次迭代的改进和探索效率。
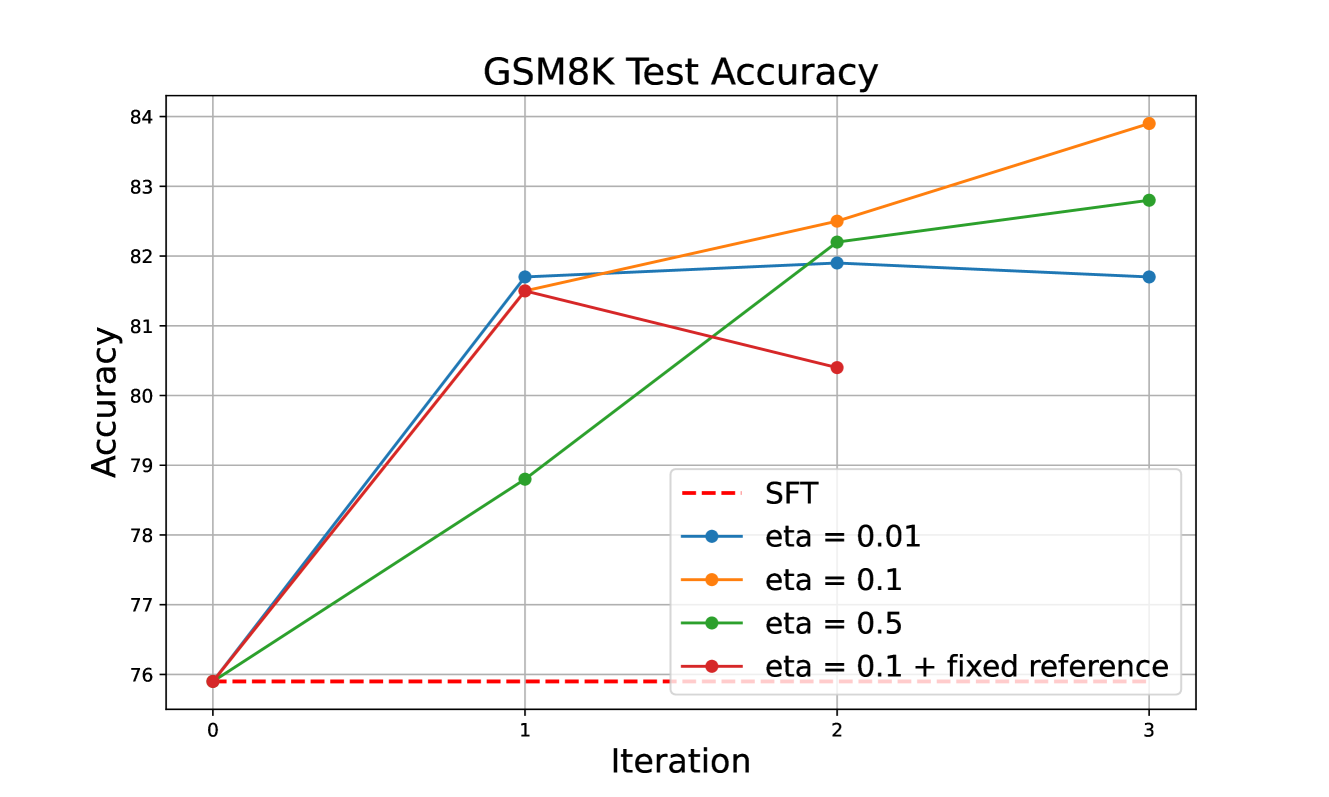
(迭代式) DPO 的有效性受参考模型和 KL 系数的选择的影响很大。 Tunstall 等人 (2023) 在针对通用聊天机器人应用程序的离线 DPO 上进行的先前研究表明,较低的 KL 系数,特别是 0.01,可以通过允许生成的模型远离 SFT 模型 来获得更好的性能。 同时,对于在线迭代训练,Xiong 等人; Dong 等人 (2024) 采用 的固定参考模型,并在训练迭代过程中实现持续改进。 在我们的消融研究中,我们考虑了两种不同的选择:(1)使用固定的参考模型 ;(2)在每一轮中将参考模型更新到上一轮的模型。 此外,我们搜索了 KL 系数 。 结果总结在表 2 中。 首先,我们注意到,如果我们在每次迭代中更新参考模型,最终模型将以较大优势胜过使用固定参考模型 的模型。 本质上,这种动态方法优化了非正则化的奖励,而使用固定参考模型 的方法旨在最大化 KL 正则化的奖励。 这可以被视为生成多样性和奖励优化之间的权衡。 我们怀疑这种性能差异是因为对于推理任务,正确的推理路径高度集中在生成空间的一个小子集上,在这种情况下,多样性并不重要。
我们还发现,最强的模型是通过 的中等 KL 系数获得的,优于 0.01 和 0.5。 为了理解这种现象,我们在图 5 中绘制了 GSM8K 在迭代训练过程中的测试准确率。 如我们所见,对于第一次迭代,结果与 Tunstall 等人 (2023) 的发现一致,其中较小的 KL 系数会导致更大的模型改进。 但是,得到的中间模型被进一步用于收集用于后续迭代训练的轨迹。 使用非常低的 KL 系数训练的模型往往会迅速失去多样性,可能降低它们收集用于后续训练的不同轨迹的能力,导致第二和第三次迭代的收益递减。 相比之下,0.5 的较高 KL 系数对得到的模型和参考模型施加了强烈的正则化,并且与 相比,模型改进较少。 总之,对于在线迭代训练,我们需要在每次迭代的改进和探索效率之间取得平衡,以优化整体性能。 我们将看到,这种直觉也扩展到采样策略选择和其他实验技巧的选择。
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | Iterative M-DPO + | 81.7 | 50.1 |
| Gemma-1.1-it-7B | Iterative M-DPO + | 83.9 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO + | 82.8 | 49.7 |
| Gemma-1.1-it-7B | Iterative M-DPO + fixed reference + | 79.9 | 48.0 |
采样策略的影响:数据多样性和覆盖率至关重要。
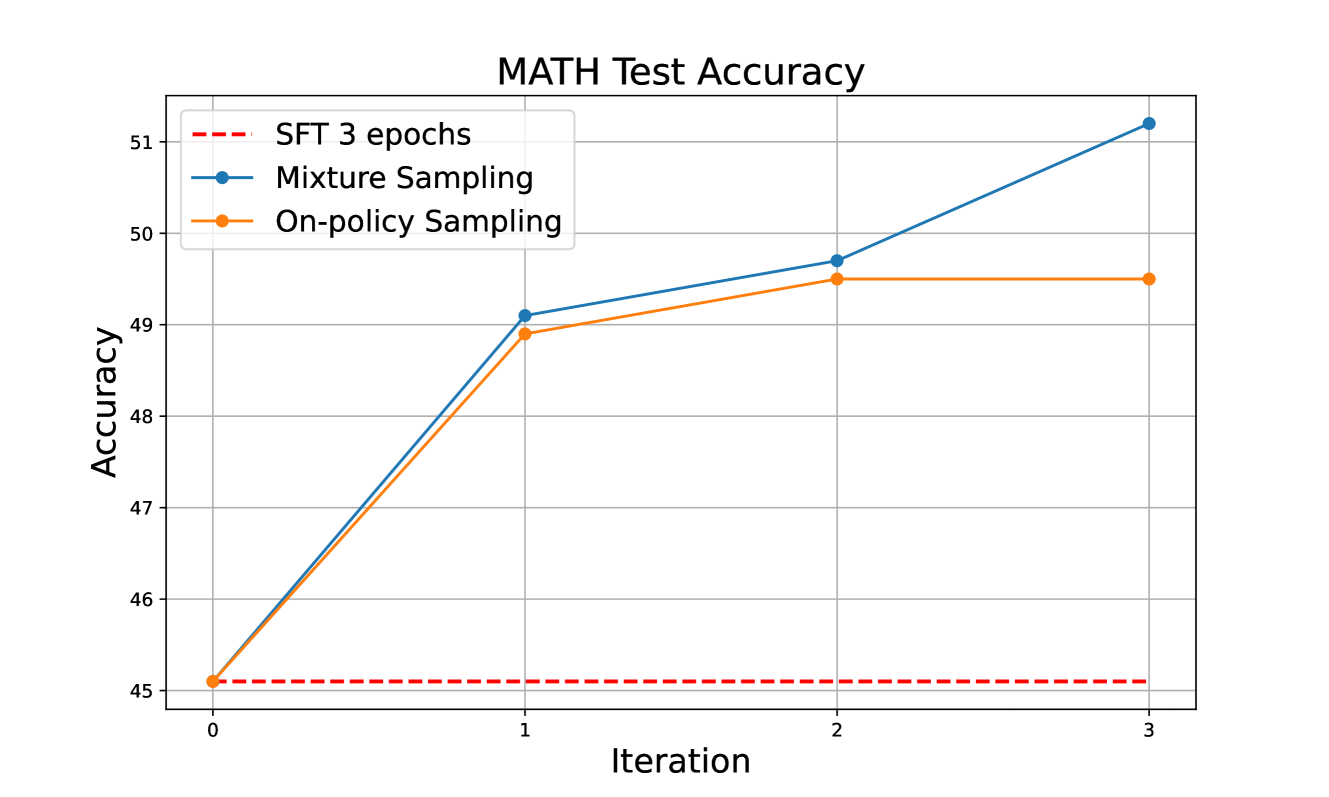
在 Gemma-1.1-it-7B 的迭代训练过程中,我们观察到正确轨迹的百分比稳步上升——从第一次迭代的 47% 上升到最后一次迭代的 76%。 此外,由于我们在每次迭代中更新参考模型,因此生成轨迹的多样性也迅速下降。 然而,由于 DPO/KTO 训练的对比性本质,收集数据的多样性对于 DPO/KTO 训练至关重要。 针对通用聊天机器人的在线迭代 DPO 的先前研究 (Dong 等人,2024) 建议采用具有不同采样温度或训练步骤的模型变体来提高轨迹多样性。 受此启发,我们探索了两种数据收集策略:(1)策略内采样,其中所有轨迹都使用当前策略进行采样;(2)混合采样,其中 20 个轨迹使用当前模型收集,10 个轨迹使用最后一次迭代的模型收集。 我们在表 5 中报告了结果,其中使用混合采样,最终模型性能显著优于仅使用策略内采样的模型。 为了理解这种现象,我们在图 6 中绘制了 MATH 测试精度与迭代次数的关系。 我们观察到策略内采样在第三次迭代中未能提高 MATH 测试精度,而使用混合采样,我们获得了可观的收益。 这再次证明了收集到的响应多样性在迭代训练中的重要性,也与之前的发现一致,即先进的探索策略可以防止多样性崩溃,为迭代偏好学习提供更有意义的信号 (Bai 等人,2022;Touvron 等人,2023;Xiong 等人;Pace 等人,2024;Dong 等人,2024)。 在未来的研究中,探索更先进的探索策略,如蒙特卡洛树搜索 (MCTS),将会很有趣。
在我们的实验中,我们针对每个提示收集了 N 个轨迹,以确保存在正确的和错误的推理路径来构建比较对。 通常,较大的 N 能够更好地覆盖提示集,因为对于一些难题,我们需要采样更多响应才能找到正确的推理路径。 例如,在第 1 次迭代中,当 N=30 时,92.5% 的提示被覆盖,而 N=12 时为 83.0%,N=6 时为 60%。 图 4 说明了 pass@1 与 N 之间的关系。然而,增加 N 也会导致更高的计算成本。 为了了解参数 N 的影响,我们进行了消融研究 ,并在表 3 中总结了结果。 我们观察到,当 N 从 6 增加到 12 时,性能大幅提升,这反映了对需要更多尝试才能找到正确路径的复杂问题的更好覆盖。 相反,从 N=12 到 N=30,测试精度仅略有提升,这表明在最佳 N 采样中增加 N 的增量效益迅速减弱。
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=30 | 83.9 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=12 | 83.5 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=6 | 82.0 | 49.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=30 + On-policy sampling | 83.1 | 49.5 |
最佳模型是通过使用超过 1 个 epoch 微调的起点获得的。
Tunstall 等人(2023) 发现,如果 SFT 模型训练超过一个 epoch,随后的 DPO 训练会导致性能下降,在指令遵循能力和一般聊天机器人的基准测试方面训练时间更长。 换句话说,SFT 训练 epoch 和 DPO 训练步骤之间存在权衡。 此外,最佳模型是在他们实践中通过 SFT 训练一个 epoch 获得的。 我们还对 SFT 时期影响进行了消融研究,并将结果总结在表 4 中。 在所有测试场景中,后续的迭代 M-DPO 训练与 SFT 模型相比,带来了显著的模型改进。 同时,我们还观察到 SFT 和 RLHF 训练之间类似的权衡,因为随着 SFT 时期增加,RLHF 阶段的收益会减少。 然而,在我们的案例中,最强的模型是在 SFT 三个时期后通过迭代 M-DPO 微调得到的,这与离线 DPO 训练 (Tunstall 等人,2023) 或仅用一个 SFT 时期的迭代 DPO 用于一般聊天机器人 (Dong 等人,2024) 不同。
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 1 epoch | 75.1 | 41.1 |
| Gemma-1.1-it-7B | SFT 1 epoch + Iterative M-DPO | 80.6 5.5 | 46.7 5.6 |
| Gemma-1.1-it-7B | SFT 2 epoch | 75.3 | 44.0 |
| Gemma-1.1-it-7B | SFT 2 epoch + Iterative M-DPO | 82.4 7.1 | 49.8 5.8 |
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | SFT 3 epoch + Iterative M-DPO | 83.9 6.4 | 51.2 5.1 |
当 SFT 模型严重欠拟合时,NLL 损失会有所帮助。
最近的工作 Pang 等人 (2024) 引入了迭代 RPO,专门用于增强解决数学问题的思维链 (CoT) 能力。 该方法的一个关键特征是包含一个用于首选响应的附加负对数似然 (NLL) 损失。 添加 NLL 损失的主要直觉是原始 DPO 算法 (Rafailov 等人,2023) 倾向于降低首选响应的可能性,这被认为会损害推理能力 (Wang 等人,2024)。 受其结果的启发,我们探索了这个想法在我们设置中的适用性。 我们通过将 NLL 损失添加到迭代 M-DPO 训练中进行消融研究,并观察到如表 5 所示的性能下降。 我们观察到,即使我们使用混合采样来增加收集数据的多样性,如果添加额外的 NLL 损失,最佳模型将在第二次迭代中获得。 通过时间加权指数移动平均来平滑训练记录,我们观察到,在第三次迭代训练的第 200 步,当添加 NLL 损失时,所选响应和拒绝响应的对数概率分别为 (-126, -222),而没有 NLL 损失的情况下,对数概率分别为 (-166, -350)。 这与 Pang 等人 (2024) 的结果一致,其中,通过添加 NLL 损失,选定响应和拒绝响应的对数概率都会增加。 这些证据表明,NLL 损失进一步导致模型分布崩溃,最终损害在线迭代学习的整体性能。 最后,我们注意到,附加的 NLL 损失可以看作是悲观原则的实现 (Liu 等人,2024b)。 这也解释了它在域内表现不佳的原因,尽管它可能有助于稳定训练,但这需要更深入的研究。
然而,我们设置和 Pang 等人 (2024) 之间的一个明显区别在于,我们是否首先使用域内数据对初始化的 SFT 模型进行微调。 为了进一步了解这种现象,我们将 Gemma-1.1-it-7B 微调仅 100 步(这样模型就知道利用 Python 代码来解决问题)作为偏好学习的起始检查点,并使用此模型对 NLL 损失进行消融研究。 我们观察到,当 SFT 模型严重欠拟合时,添加 NLL 损失实际上会提高性能。 这种情况反映了 Pang 等人 (2024) 的发现,他们使用了通用的 LLaMA2-70B-chat 模型 (Touvron 等人,2023),而没有首先在域内数据上进行微调。 我们的观察结果与先前在开发通用聊天机器人方面的研究一致 (Lin 等人,2023),该研究表明,如果没有预先进行 SFT,RLHF 的效果较差。
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | SFT 3 epoch + Iterative M-DPO | 83.9 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with NLL loss | 81.7 2.2 | 49.5 1.7 |
| Gemma-1.1-it-7B | SFT 100 steps | 50.8 | 23.7 |
| Gemma-1.1-it-7B | + M-DPO Iteration 1 | 57.8 | 27.9 |
| Gemma-1.1-it-7B | + M-DPO and NLL loss Iteration 1 | 61.0 3.2 | 30.1 2.2 |
策略内采样和小学习率减轻了首选响应中的概率下降。
在文献中,直接偏好优化 (DPO) 算法通常被报道会通过降低首选响应的可能性来降低推理能力 (Yuan 等人,2024; Hong 等人,2024; Meng 等人,2024)。 在我们的初步实验中,我们也观察到类似的现象,其中,使用较大的学习率 (1e-6),模型的推理能力在经过几个训练步骤后就会崩溃,从而无法收敛到良好的推理性能。 相反,我们发现,在我们在线迭代训练框架中使用按策略采样,再加上较小的学习率(2e-7 或 4e-7),DPO 算法增强了模型的推理能力。 为了解释我们的观察结果,我们首先可以写下 DPO 的梯度,如下所示:
其中 是隐式奖励,为了简单起见,我们使用单轮奖励。 在实践中,被拒绝响应的概率通常会下降,并且当 时,它们的梯度会迅速占主导地位,优化变得为取消学习被拒绝的响应。 在这种情况下,所选响应的概率无法增加。 此现象在 Guo 等人 (2024a) 的博客中也有讨论。 当我们采用按策略采样时,它会导致被拒绝响应和所选响应在初始阶段的概率相对较大,从而确保两种梯度都保持有效。 此外,较小的学习率可以防止模型偏离太多,从而保持两种梯度的有效性。 我们还注意到,对于 KTO 算法,首选响应和被拒绝响应不会成对出现。 我们怀疑首选响应的概率之所以会增加,是因为被拒绝响应的梯度不会在每个数据小批次中都占主导地位。 对直接偏好学习算法的训练动态有更全面的了解,在很大程度上仍然是一个开放性的问题,我们将对这种现象的更详细研究留待以后进行。
4 结论、限制和未来的研究方向
我们证明了偏好学习作为监督微调的替代学习范式,可以进一步提高工具集成推理 LLM 的性能,超越迭代最佳-n 微调。 我们介绍了一种在线迭代多轮直接偏好优化算法,并通过跨各种基本模型的大量实验验证了它的有效性。 我们的结果表明,pass@1 指标在 SFT 策略方面有了实质性改进,这从 GSM8K (Cobbe 等人,2021a) 和 MATH (Hendrycks 等人,2021) 等标准基准上的性能提升可以看出。 此外,我们还进行了各种消融研究,以表明获得最佳性能需要在每次迭代的改进和探索之间取得平衡,这可以通过适度的 KL 正则化水平和战略性探索选择来实现。
本文没有探索几种潜在的方向来进一步提高模型性能。 目前,我们的实验只使用最终结果检查作为偏好信号,因此我们无法有效地比较以正确或错误答案结束的轨迹。 虽然我们的算法是为轨迹级偏好学习而设计的,但 Bradley-Terry 模型中的奖励信号可以适应逐步级别。 特别是,我们可以利用 AI 反馈来逐步验证轨迹,或训练一个过程监督奖励模型(Lightman 等人,2023)来提供学习信号。 此外,随着更细粒度的奖励信号,也可以采用更高级的启发式探索策略,如西-N 采样,这被证明在构建通用聊天机器人(Pace 等人,2024;Dong 等人,2024;Xu 等人,2023;Hoang Tran,2024)和蒙特卡罗树搜索 (MCTS) (Xie 等人,2024b)方面有效。 此外,还可以利用一些成熟的技巧,如自适应边距和长度正则化来进行 DPO 训练(Hong 等人,2024;Meng 等人,2024)。 这些技术已被证明对聊天任务的域内性能提升有效。 我们预计,这些更细粒度的偏好信号和算法设计可以大大提高模型的性能。
最后,虽然直接偏好学习算法在具有代码解释器的数学推理任务中显示出有希望的收益,但它不直接适用于具有更复杂和随机外部环境或对抗动态对手的通用智能体学习。 特别是,它需要构建一个价值网络,以在优化目标中包含自适应边距,并考虑外部环境的随机性。 我们将这种更复杂的算法的研究留待将来工作。 除了本文提出的框架之外,还可以探索比 BT 模型更一般的偏好结构(Munos 等人,2023;Ye 等人,2024)。 我们希望本文的见解能激发这方面进一步的研究,将偏好学习的效用扩展到一般的结构化聊天任务之外。
*
参考文献
- qwe (2024) Qwen2 technical report. 2024.
- Agarwal et al. (2023) A. Agarwal, Y. Jin, and T. Zhang. VOL: Towards optimal regret in model-free rl with nonlinear function approximation. In The Thirty Sixth Annual Conference on Learning Theory, pages 987–1063. PMLR, 2023.
- Anthony et al. (2017) T. Anthony, Z. Tian, and D. Barber. Thinking fast and slow with deep learning and tree search. Advances in neural information processing systems, 30, 2017.
- Anthropic (2023) Anthropic. Introducing claude. 2023. URL https://www.anthropic.com/index/introducing-claude.
- Auer et al. (2002) P. Auer, N. Cesa-Bianchi, and P. Fischer. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47:235–256, 2002.
- Azar et al. (2023) M. G. Azar, M. Rowland, B. Piot, D. Guo, D. Calandriello, M. Valko, and R. Munos. A general theoretical paradigm to understand learning from human preferences. arXiv preprint arXiv:2310.12036, 2023.
- Bai et al. (2022) Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- Cai et al. (2020) Q. Cai, Z. Yang, C. Jin, and Z. Wang. Provably efficient exploration in policy optimization. In International Conference on Machine Learning, pages 1283–1294. PMLR, 2020.
- Cen et al. (2024) S. Cen, J. Mei, K. Goshvadi, H. Dai, T. Yang, S. Yang, D. Schuurmans, Y. Chi, and B. Dai. Value-incentivized preference optimization: A unified approach to online and offline rlhf. arXiv preprint arXiv:2405.19320, 2024.
- Chen et al. (2024a) G. Chen, M. Liao, C. Li, and K. Fan. Step-level value preference optimization for mathematical reasoning. arXiv preprint arXiv:2406.10858, 2024a.
- Chen et al. (2022) W. Chen, X. Ma, X. Wang, and W. W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022.
- Chen et al. (2024b) Z. Chen, Y. Deng, H. Yuan, K. Ji, and Q. Gu. Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335, 2024b.
- Choshen et al. (2019) L. Choshen, L. Fox, Z. Aizenbud, and O. Abend. On the weaknesses of reinforcement learning for neural machine translation. arXiv preprint arXiv:1907.01752, 2019.
- Christiano et al. (2017) P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Cobbe et al. (2021a) K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021a.
- Cobbe et al. (2021b) K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021b.
- Coste et al. (2023) T. Coste, U. Anwar, R. Kirk, and D. Krueger. Reward model ensembles help mitigate overoptimization. arXiv preprint arXiv:2310.02743, 2023.
- Dong et al. (2023) H. Dong, W. Xiong, D. Goyal, Y. Zhang, W. Chow, R. Pan, S. Diao, J. Zhang, K. SHUM, and T. Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=m7p5O7zblY.
- Dong et al. (2024) H. Dong, W. Xiong, B. Pang, H. Wang, H. Zhao, Y. Zhou, N. Jiang, D. Sahoo, C. Xiong, and T. Zhang. Rlhf workflow: From reward modeling to online rlhf. arXiv preprint arXiv:2405.07863, 2024.
- Engstrom et al. (2020) L. Engstrom, A. Ilyas, S. Santurkar, D. Tsipras, F. Janoos, L. Rudolph, and A. Madry. Implementation matters in deep policy gradients: A case study on ppo and trpo. arXiv preprint arXiv:2005.12729, 2020.
- Ethayarajh et al. (2024) K. Ethayarajh, W. Xu, N. Muennighoff, D. Jurafsky, and D. Kiela. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306, 2024.
- Gao et al. (2023a) L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig. Pal: Program-aided language models. In International Conference on Machine Learning, pages 10764–10799. PMLR, 2023a.
- Gao et al. (2023b) L. Gao, J. Schulman, and J. Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023b.
- Gou et al. (2023a) Z. Gou, Z. Shao, Y. Gong, Y. Shen, Y. Yang, N. Duan, and W. Chen. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738, 2023a.
- Gou et al. (2023b) Z. Gou, Z. Shao, Y. Gong, Y. Yang, M. Huang, N. Duan, W. Chen, et al. Tora: A tool-integrated reasoning agent for mathematical problem solving. arXiv preprint arXiv:2309.17452, 2023b.
- Gui et al. (2024) L. Gui, C. Gârbacea, and V. Veitch. Bonbon alignment for large language models and the sweetness of best-of-n sampling. arXiv preprint arXiv:2406.00832, 2024.
- Gulcehre et al. (2023) C. Gulcehre, T. L. Paine, S. Srinivasan, K. Konyushkova, L. Weerts, A. Sharma, A. Siddhant, A. Ahern, M. Wang, C. Gu, et al. Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998, 2023.
- Guo et al. (2024a) S. Guo, W. Xiong, and C. Wang. "alignment guidebook. Notion Blog, 2024a.
- Guo et al. (2024b) S. Guo, B. Zhang, T. Liu, T. Liu, M. Khalman, F. Llinares, A. Rame, T. Mesnard, Y. Zhao, B. Piot, et al. Direct language model alignment from online ai feedback. arXiv preprint arXiv:2402.04792, 2024b.
- Hendrycks et al. (2021) D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Hoang Tran (2024) B. H. Hoang Tran, Chris Glaze. Snorkel-mistral-pairrm-dpo. https://huggingface.co/snorkelai/Snorkel-Mistral-PairRM-DPO, 2024. URL https://huggingface.co/snorkelai/Snorkel-Mistral-PairRM-DPO.
- Hong et al. (2024) J. Hong, N. Lee, and J. Thorne. Orpo: Monolithic preference optimization without reference model. arXiv preprint arXiv:2403.07691, 2(4):5, 2024.
- Jiang et al. (2023) A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Jiao et al. (2024) F. Jiao, C. Qin, Z. Liu, N. F. Chen, and S. Joty. Learning planning-based reasoning by trajectories collection and process reward synthesizing. arXiv preprint arXiv:2402.00658, 2024.
- Lai et al. (2024) X. Lai, Z. Tian, Y. Chen, S. Yang, X. Peng, and J. Jia. Step-dpo: Step-wise preference optimization for long-chain reasoning of llms. arXiv preprint arXiv:2406.18629, 2024.
- Lightman et al. (2023) H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- Lin et al. (2023) Y. Lin, L. Tan, H. Lin, Z. Zheng, R. Pi, J. Zhang, S. Diao, H. Wang, H. Zhao, Y. Yao, et al. Speciality vs generality: An empirical study on catastrophic forgetting in fine-tuning foundation models. arXiv preprint arXiv:2309.06256, 2023.
- Liu and Yao (2024) H. Liu and A. C.-C. Yao. Augmenting math word problems via iterative question composing. arXiv preprint arXiv:2401.09003, 2024.
- Liu et al. (2023a) Q. Liu, P. Netrapalli, C. Szepesvari, and C. Jin. Optimistic mle: A generic model-based algorithm for partially observable sequential decision making. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, pages 363–376, 2023a.
- Liu et al. (2023b) T. Liu, Y. Zhao, R. Joshi, M. Khalman, M. Saleh, P. J. Liu, and J. Liu. Statistical rejection sampling improves preference optimization. arXiv preprint arXiv:2309.06657, 2023b.
- Liu et al. (2024a) T. Liu, Z. Qin, J. Wu, J. Shen, M. Khalman, R. Joshi, Y. Zhao, M. Saleh, S. Baumgartner, J. Liu, et al. Lipo: Listwise preference optimization through learning-to-rank. arXiv preprint arXiv:2402.01878, 2024a.
- Liu et al. (2024b) Z. Liu, M. Lu, S. Zhang, B. Liu, H. Guo, Y. Yang, J. Blanchet, and Z. Wang. Provably mitigating overoptimization in rlhf: Your sft loss is implicitly an adversarial regularizer. arXiv preprint arXiv:2405.16436, 2024b.
- Lu et al. (2024) Z. Lu, A. Zhou, K. Wang, H. Ren, W. Shi, J. Pan, and M. Zhan. Step-controlled dpo: Leveraging stepwise error for enhanced mathematical reasoning. arXiv preprint arXiv:2407.00782, 2024.
- Luo et al. (2023) H. Luo, Q. Sun, C. Xu, P. Zhao, J. Lou, C. Tao, X. Geng, Q. Lin, S. Chen, and D. Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Meng et al. (2024) Y. Meng, M. Xia, and D. Chen. Simpo: Simple preference optimization with a reference-free reward. arXiv preprint arXiv:2405.14734, 2024.
- Meta (2024) Meta. Introducing meta llama 3: The most capable openly available llm to date. Meta AI Blog, 2024. https://ai.meta.com/blog/meta-llama-3/.
- Mishra et al. (2022) S. Mishra, M. Finlayson, P. Lu, L. Tang, S. Welleck, C. Baral, T. Rajpurohit, O. Tafjord, A. Sabharwal, P. Clark, et al. Lila: A unified benchmark for mathematical reasoning. arXiv preprint arXiv:2210.17517, 2022.
- Mitra et al. (2024) A. Mitra, H. Khanpour, C. Rosset, and A. Awadallah. Orca-math: Unlocking the potential of slms in grade school math. arXiv preprint arXiv:2402.14830, 2024.
- Munos et al. (2023) R. Munos, M. Valko, D. Calandriello, M. G. Azar, M. Rowland, Z. D. Guo, Y. Tang, M. Geist, T. Mesnard, A. Michi, et al. Nash learning from human feedback. arXiv preprint arXiv:2312.00886, 2023.
- Nemirovskij and Yudin (1983) A. S. Nemirovskij and D. B. Yudin. Problem complexity and method efficiency in optimization. 1983.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Ouyang et al. (2022) L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Pace et al. (2024) A. Pace, J. Mallinson, E. Malmi, S. Krause, and A. Severyn. West-of-n: Synthetic preference generation for improved reward modeling. arXiv preprint arXiv:2401.12086, 2024.
- Pang et al. (2024) R. Y. Pang, W. Yuan, K. Cho, H. He, S. Sukhbaatar, and J. Weston. Iterative reasoning preference optimization. arXiv preprint arXiv:2404.19733, 2024.
- Pi et al. (2024) R. Pi, T. Han, W. Xiong, J. Zhang, R. Liu, R. Pan, and T. Zhang. Strengthening multimodal large language model with bootstrapped preference optimization. arXiv preprint arXiv:2403.08730, 2024.
- Rafailov et al. (2023) R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Rafailov et al. (2024) R. Rafailov, J. Hejna, R. Park, and C. Finn. From r to q*: Your language model is secretly a q-function. arXiv preprint arXiv:2404.12358, 2024.
- Richemond et al. (2024) P. H. Richemond, Y. Tang, D. Guo, D. Calandriello, M. G. Azar, R. Rafailov, B. A. Pires, E. Tarassov, L. Spangher, W. Ellsworth, et al. Offline regularised reinforcement learning for large language models alignment. arXiv preprint arXiv:2405.19107, 2024.
- Rosset et al. (2024) C. Rosset, C.-A. Cheng, A. Mitra, M. Santacroce, A. Awadallah, and T. Xie. Direct nash optimization: Teaching language models to self-improve with general preferences. arXiv preprint arXiv:2404.03715, 2024.
- Schulman et al. (2017) J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shani et al. (2024) L. Shani, A. Rosenberg, A. Cassel, O. Lang, D. Calandriello, A. Zipori, H. Noga, O. Keller, B. Piot, I. Szpektor, et al. Multi-turn reinforcement learning from preference human feedback. arXiv preprint arXiv:2405.14655, 2024.
- Shao et al. (2022) Z. Shao, F. Huang, and M. Huang. Chaining simultaneous thoughts for numerical reasoning. arXiv preprint arXiv:2211.16482, 2022.
- Shao et al. (2024) Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. Li, Y. Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Singh et al. (2023) A. Singh, J. D. Co-Reyes, R. Agarwal, A. Anand, P. Patil, P. J. Liu, J. Harrison, J. Lee, K. Xu, A. Parisi, et al. Beyond human data: Scaling self-training for problem-solving with language models. arXiv preprint arXiv:2312.06585, 2023.
- Sutton and Barto (2018) R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- Swamy et al. (2024) G. Swamy, C. Dann, R. Kidambi, Z. S. Wu, and A. Agarwal. A minimaximalist approach to reinforcement learning from human feedback. arXiv preprint arXiv:2401.04056, 2024.
- Tajwar et al. (2024) F. Tajwar, A. Singh, A. Sharma, R. Rafailov, J. Schneider, T. Xie, S. Ermon, C. Finn, and A. Kumar. Preference fine-tuning of llms should leverage suboptimal, on-policy data. arXiv preprint arXiv:2404.14367, 2024.
- Tang et al. (2024) Y. Tang, Z. D. Guo, Z. Zheng, D. Calandriello, R. Munos, M. Rowland, P. H. Richemond, M. Valko, B. Á. Pires, and B. Piot. Generalized preference optimization: A unified approach to offline alignment. arXiv preprint arXiv:2402.05749, 2024.
- Team (2024) C. Team. Codegemma: Open code models based on gemma. arXiv preprint arXiv:2406.11409, 2024.
- Team et al. (2023) G. Team, R. Anil, S. Borgeaud, Y. Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Team et al. (2024) G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivière, M. S. Kale, J. Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Tong et al. (2024) Y. Tong, X. Zhang, R. Wang, R. Wu, and J. He. Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving. 2024.
- Toshniwal et al. (2024) S. Toshniwal, I. Moshkov, S. Narenthiran, D. Gitman, F. Jia, and I. Gitman. Openmathinstruct-1: A 1.8 million math instruction tuning dataset. arXiv preprint arXiv:2402.10176, 2024.
- Touvron et al. (2023) H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Tunstall et al. (2023) L. Tunstall, E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y. Belkada, S. Huang, L. von Werra, C. Fourrier, N. Habib, et al. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944, 2023.
- Uesato et al. (2022) J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- Wang et al. (2023a) P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y. Li, D. Chen, Y. Wu, and Z. Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. CoRR, abs/2312.08935, 2023a.
- Wang et al. (2024) X. Wang, Z. Wang, J. Liu, Y. Chen, L. Yuan, H. Peng, and H. Ji. Mint: Multi-turn interactive evaluation for tool-augmented llms with language feedback. In Proc. The Twelfth International Conference on Learning Representations (ICLR2024), 2024.
- Wang et al. (2023b) Y. Wang, Q. Liu, and C. Jin. Is rlhf more difficult than standard rl? arXiv preprint arXiv:2306.14111, 2023b.
- Wei et al. (2022) J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Williams (1992) R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8:229–256, 1992.
- Williams and Peng (1991) R. J. Williams and J. Peng. Function optimization using connectionist reinforcement learning algorithms. Connection Science, 3(3):241–268, 1991.
- Xie et al. (2022) T. Xie, D. J. Foster, Y. Bai, N. Jiang, and S. M. Kakade. The role of coverage in online reinforcement learning. arXiv preprint arXiv:2210.04157, 2022.
- Xie et al. (2024a) T. Xie, D. J. Foster, A. Krishnamurthy, C. Rosset, A. Awadallah, and A. Rakhlin. Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf. arXiv preprint arXiv:2405.21046, 2024a.
- Xie et al. (2024b) Y. Xie, A. Goyal, W. Zheng, M.-Y. Kan, T. P. Lillicrap, K. Kawaguchi, and M. Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. arXiv preprint arXiv:2405.00451, 2024b.
- (86) W. Xiong, H. Dong, C. Ye, Z. Wang, H. Zhong, H. Ji, N. Jiang, and T. Zhang. Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint. In Forty-first International Conference on Machine Learning.
- Xu et al. (2023) J. Xu, A. Lee, S. Sukhbaatar, and J. Weston. Some things are more cringe than others: Preference optimization with the pairwise cringe loss. arXiv preprint arXiv:2312.16682, 2023.
- Yao et al. (2022) S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Ye et al. (2024) C. Ye, W. Xiong, Y. Zhang, N. Jiang, and T. Zhang. A theoretical analysis of nash learning from human feedback under general kl-regularized preference. arXiv preprint arXiv:2402.07314, 2024.
- Yu et al. (2023) L. Yu, W. Jiang, H. Shi, J. Yu, Z. Liu, Y. Zhang, J. T. Kwok, Z. Li, A. Weller, and W. Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Yuan et al. (2024) L. Yuan, G. Cui, H. Wang, N. Ding, X. Wang, J. Deng, B. Shan, H. Chen, R. Xie, Y. Lin, et al. Advancing llm reasoning generalists with preference trees. arXiv preprint arXiv:2404.02078, 2024.
- Yuan et al. (2023a) Z. Yuan, H. Yuan, C. Li, G. Dong, C. Tan, and C. Zhou. Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825, 2023a.
- Yuan et al. (2023b) Z. Yuan, H. Yuan, C. Tan, W. Wang, S. Huang, and F. Huang. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023b.
- Yue et al. (2023) X. Yue, G. Z. Xingwei Qu, Y. Fu, W. Huang, H. Sun, Y. Su, and W. Chen. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023.
- Yue et al. (2024) X. Yue, T. Zheng, G. Zhang, and W. Chen. Mammoth2: Scaling instructions from the web. arXiv preprint arXiv:2405.03548, 2024.
- Zelikman et al. (2022) E. Zelikman, Y. Wu, J. Mu, and N. Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
- Zhan et al. (2023) W. Zhan, M. Uehara, N. Kallus, J. D. Lee, and W. Sun. Provable offline reinforcement learning with human feedback. arXiv preprint arXiv:2305.14816, 2023.
- Zhang et al. (2024a) B. Zhang, K. Zhou, X. Wei, X. Zhao, J. Sha, S. Wang, and J.-R. Wen. Evaluating and improving tool-augmented computation-intensive math reasoning. Advances in Neural Information Processing Systems, 36, 2024a.
- Zhang et al. (2024b) S. Zhang, D. Yu, H. Sharma, Z. Yang, S. Wang, H. Hassan, and Z. Wang. Self-exploring language models: Active preference elicitation for online alignment. arXiv preprint arXiv:2405.19332, 2024b.
- Zhang (2023) T. Zhang. Mathematical analysis of machine learning algorithms. Cambridge University Press, 2023.
- Zhang et al. (2024c) Y. Zhang, D. Yu, B. Peng, L. Song, Y. Tian, M. Huo, N. Jiang, H. Mi, and D. Yu. Iterative nash policy optimization: Aligning llms with general preferences via no-regret learning. arXiv preprint arXiv:2407.00617, 2024c.
- Zhao et al. (2023) Y. Zhao, R. Joshi, T. Liu, M. Khalman, M. Saleh, and P. J. Liu. Slic-hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425, 2023.
- Zheng et al. (2024) C. Zheng, Z. Wang, H. Ji, M. Huang, and N. Peng. Weak-to-strong extrapolation expedites alignment. arXiv preprint arXiv:2404.16792, 2024.
- Zheng et al. (2021) K. Zheng, J. M. Han, and S. Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics. arXiv preprint arXiv:2109.00110, 2021.
- Zhong et al. (2022) H. Zhong, W. Xiong, S. Zheng, L. Wang, Z. Wang, Z. Yang, and T. Zhang. Gec: A unified framework for interactive decision making in mdp, pomdp, and beyond. arXiv preprint arXiv:2211.01962, 2022.
- Zhong et al. (2024) H. Zhong, G. Feng, W. Xiong, L. Zhao, D. He, J. Bian, and L. Wang. Dpo meets ppo: Reinforced token optimization for rlhf. arXiv preprint arXiv:2404.18922, 2024.
- Zhou et al. (2022) D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
- Zhu et al. (2022) X. Zhu, J. Wang, L. Zhang, Y. Zhang, Y. Huang, R. Gan, J. Zhang, and Y. Yang. Solving math word problems via cooperative reasoning induced language models. arXiv preprint arXiv:2210.16257, 2022.
- Ziebart (2010) B. D. Ziebart. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010.
- Ziegler et al. (2019) D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
附录 A 符号表
| Notation | Description |
|---|---|
| The prompt and the prompt space. | |
| The distribution of initial state (prompt). | |
| The state, action, and observation. | |
| Episode length, e.g., the maximal number of tool calls. | |
| The true observation kernel. | |
| is a trajectory and is the completion part, i.e., we exclude from . | |
| The true utility function associated with the BT model defined in Definition 1. | |
| The true model with observation kernel and utility function | |
| is the sigmoid function. | |
| Preference signal. | |
| The policy, which is parameterized by the LLM. | |
| One arbitrary environment with observation kernel and utility function . | |
| One arbitrary reference policy. | |
| The KL-regularized target ((5)) with environment and reference . | |
| The coefficient of KL penalty, defined in (5). | |
| The optimal -values associated with , defined in (6). | |
| The optimal -values associated with , defined in (7). | |
| The optimal policy associated with , defined in (7). | |
| M-DPO loss, defined in (12). | |
| M-KTO loss, defined in (13). | |
| The abbreviation of , defined in (16). | |
| The optimal policy associated with . | |
| The main and exploration policy at round | |
| Regret over horizon , defined in (17). | |
| Known sets such that and | |
| Assuming . | |
| MLE of and at round , defined in (18) and (19). | |
| Confidences sets of and at round , defined in (21). | |
| Absolute constants. | |
| . | |
| Eluder coefficient from Definition 4. | |
| Generalized Eluder-type condition from Definition 5. | |
| Total variation distance between two distributions. |
附录 B 实现细节
数学问题求解中的工具。
遵循 Gou 等人(2023b);Toshniwal 等人(2024),LLM 代理在解码以 ```python 开头并以 ``` 结尾的 python 代码时,被允许调用 python 解释器。 对于每个步骤 ,为了生成观测 ,我们利用 python 包 IPython,并且逐个运行历史中的所有代码,并将每个代码片段视为一个 Jupyter 单元格。 我们只返回最后一个片段的标准输出或错误消息。 当代码中存在一些错误时,我们只返回错误消息,该消息通常少于 20 个符号,如 Toshniwal 等人(2024) 中所述。 我们注意到一些工作(例如 Shao 等人(2024))也返回了跟踪信息的前 50 个符号和后 50 个符号。
数据生成。
所有模型都在零样本设置中进行评估。 对于所有数据生成过程,我们采用以下约束:(1)对于每个回合,模型最多可以生成 512 个符号;(2)最大步数为 H=6;(3)每个轨迹生成的符号最大数为 2048。 在为在线迭代 M-DPO 收集新数据时,我们将温度设置为 1.0,并在没有 top-K 或 top-p 采样的情况下进行解码。 为了进行评估,采用贪婪解码,以便结果通常与之前的工作 Gou 等人(2023b);Toshniwal 等人(2024) 相 comparable。 为了评估具有 pass@n 率的模型,我们遵循 Toshniwal 等人(2024) 采用 的温度。
Python 实验环境。
我们发现评估会受到 python 环境、精度(尤其是 Gemma-1.1 模型)甚至我们使用的虚拟机的影响。 由于振荡幅度相对于整体改进而言相对较小,因此这不会影响整体趋势和结论。 为了完整起见,我们在此指定一些关键的软件包版本。 我们为所有模型使用 transformers 4.42.4、torch 2.3.0、sympy 1.2、antlr4-python3-runtime 4.11.0、IPython 8.26.0。 我们使用 torch.float 评估模型,并使用 vllm 0.5.0.post1 进行大多数实验,除了 Gemma-2 需要 vllm 0.5.1。 vllm 版本的不一致性是因为我们在执行该项目的 主要实验时,Gemma-2 模型尚未发布。 在整个实验过程中,我们固定了用于评估的 python 环境和机器。 对于 SFT,我们使用开源 axolotl 项目的 0.4.1 版本,对于在线迭代偏好学习和 RAFT,我们使用来自 RLHF 工作流程 (Dong 等人,2024) 的代码库。
RAFT 实现。
数据生成步骤类似于在线迭代 M-DPO 训练,只是我们只保留最终答案正确的轨迹。 对于每个提示,我们最多采样 条轨迹,其中我们搜索 并最终使用 ,因为我们没有看到通过利用更多数据而带来的改进。 我们总共运行该算法三次迭代。 训练参数类似于 SFT 阶段,但我们使用较小的批量大小 32,以便有足够的优化步骤。 对于 Gemma 模型,我们使用 5e-6 的学习率。 对于每个训练阶段,我们根据参数搜索总共训练模型两个时期。 对于 Mistral 模型,我们发现较小的学习率 1e-6 和训练一个时期可以让我们获得更好的性能。
提示模板。
尽管我们观察到提示工程可以进一步提高性能,但我们并没有对提示进行微调。 对于所有实验,我们只是简单地采用了模型的聊天模板,如图 1 所示。
附录 C 省略的理论证明
C.1 命题 1 的证明
命题 1 的证明。
对于一个策略 ,从 开始,我们递归地定义其在模型 和参考策略 上的 值和 值函数,如下所示:
值得注意的是,对于最优策略 , 和 。 在接下来的讨论中,我们只关注模型 ,并使用缩写 和 。
对于任何比较策略 ,它都满足:
对于任何 ,我们可以得到:
在上面的推导中,等式 (a) 来自 和 的定义,以及 和 之间的关系。 等式 (b) 是因为:
| (term I) | |||
其中第二个等式来自关系:
此外,如果 ,我们可以得到:
其中第二个等式利用了 ; 否则,对于所有 ,它都满足:
该命题可以通过迭代使用上述关系来得到,对于 。 ∎
C.2 定理 1 的证明
首先,在假设 和 的前提下,以下引理证明了 和 是有效的置信集。
Lemma 1 (Liu 等人 (2023a) 中的命题 B.1).
存在一个绝对常数 ,使得对于任何 ,以至少 的概率,对于所有 , 和 ,以下成立:
这意味着 和 。
然后,我们提供了一个额外的引理,证明了 MLE 和乐观估计量的样本内误差。
Lemma 2.
存在一个绝对常数 ,使得对于任何 ,以至少 的概率,对于所有 ,我们有:
以及对于所有 ,,我们有:
其中 表示由 和 诱导的轨迹上的概率分布之间的 TV 距离。
引理 2 的证明。
首先,对于 ,我们可以得到,以至少 的概率,存在一个绝对常数 ,使得对于所有 ,
其中第一个不等式来自 Liu 等人 (2023a) 中的命题 B.2,第二个不等式使用了引理 1。 对于 的结果可以类似地建立。
然后,遵循类似的步骤,对于 ,我们可以得到,以至少 的概率,存在一个绝对常数 ,使得对于所有 ,
对于 的结果也可以类似地建立。 ∎
附录 D 技术引理
Lemma 3 (KL正则化优化的解(Zhang (2023)的命题7.16和定理15.3))。
给定一个关于 的损失函数,记为
其中损失函数的最小值是 ,也称为吉布斯分布。
Definition 4 (Eluder系数,Zhang (2023)中的定义17.17)。
给定一个函数类 ,其规避系数 定义为最小的数 ,使得对于任何序列 和 ,
Definition 5 (广义Eluder型条件,Liu 等人(2023a)中的条件3.1)。
存在一个实数 和一个函数 ,使得对于任何 ,转移 和策略 ,我们有