FireRedTTS:面向工业级生成语音应用的基础文本转语音框架
摘要
本文提出了 FireRedTTS,一个基础文本转语音框架,以满足个性化和多样化生成语音应用不断增长的需求。 该框架包含三个部分:数据处理、基础系统和下游应用。 首先,我们全面介绍了我们的数据处理流程,该流程将海量的原始音频转化为一个大规模高质量的 TTS 数据集,该数据集包含丰富的标注和广泛的内容、说话风格和音色覆盖。 然后,我们提出了一种基于语言模型的基础 TTS 系统。 语音信号通过语义感知语音分词器压缩成离散的语义符元,并且可以通过语言模型从提示文本和音频中生成。 然后,提出了一种两阶段波形生成器来将其解码为高保真波形。 我们展示了该系统的两个应用:用于配音的语音克隆和用于聊天机器人的类人语音生成。 实验结果证明了 FireRedTTS 强大的上下文学习能力,它可以稳定地合成与提示文本和音频一致的高质量语音。 对于配音,FireRedTTS 可以以零样本的方式克隆目标声音,以适应 UGC 场景,并通过 1 小时的录音进行少样本微调,以适应 PUGC 场景中的工作室级表现力声音角色。 此外,FireRedTTS 通过指令调优实现了可控的类人语音生成,以休闲风格、副语言行为和情感,更好地服务于语音聊天机器人。 我们的演示可在 https://fireredteam.github.io/demos/firered_tts 中获取。
1 引言
文本转语音合成 (TTS) 在智能交互 [1, 2] 中发挥着至关重要的作用,例如虚拟助手、聊天机器人和 AI 内容创作,例如视频配音 [3, 4]。 随着这些 AI 产品的开发和普及,TTS 面临着新的挑战:提供个性化和多样化的语音生成,以更好地满足用户对 AI 产品的不同要求。
这项要求需要一个强大的模型来理解语音并生成任意语音。 近年来,大型语言模型 (LLM) 的成功[5, 6, 7] 表明了它们在序列建模方面的强大能力,暗示了它们在语音应用中的潜力。 利用海量语音数据训练的大型语言模型在语音生成方面表现出令人印象深刻的性能,例如 VALL-E [8]、TorToiSe [9]、BASE-TTS [10]、Seed-TTS [11]、CosyVoice [12] 等。 它们可以通过零样本上下文学习[13] 生成富有表现力和多样性的语音。 受其启发,我们提出了一种基于语言模型的基石 TTS 框架,FireRedTTS,以更好地支持行业级生成语音应用。
所提出的框架包含三个部分:数据处理、基石系统和下游应用。 首先,我们展示了一个完整且有效的数据处理流程,从海量的原始音频数据中通过五个步骤创建高质量的大规模 TTS 数据集:语音增强、语音分割、说话人聚类、转录和数据过滤。 然后,我们使用此数据集来训练所提出的基于语言模型的基石 TTS 系统。 在此系统中,我们提出了一种语义感知语音分词器,用于将长语音序列压缩成具有足够语义信息的离散语音分词。 这些分词可以从文本到语音语言模型生成,并通过两阶段分词到波形生成器重建成音频,即首先通过 Mel 解码器将语义分词转换为 Mel 谱图,然后通过超分辨率神经声码器以 48 kHz 的高采样率生成音频。
我们介绍了所提出系统的两个下游应用:用于配音的语音克隆和用于聊天机器人的类人语音生成。 与传统的 TTS 方法[14, 15] 相比,我们使用更少的训练数据实现了工作室级语音合成,例如,针对非工作室用户生成内容 (UGC) 场景的零样本语音克隆和针对专业用户生成内容 (PUGC) 场景的 1 小时的少样本说话人自适应,使视频配音可定制。 此外,我们通过指令微调实现了类人语音生成,使聊天机器人能够以休闲风格、多种情绪和丰富的副语言行为说话。
我们工作的贡献总结如下:
-
•
我们提出了一个完整且详细的数据处理流程,将原始的、嘈杂的音频数据集锻造成一个干净的 TTS 数据集,该数据集具有丰富的标注,并涵盖了基石 TTS 训练所需的丰富内容、说话风格和音色。
-
•
我们提出了一种基于语言模型的基石 TTS 系统。 特别是,我们提出了一种语义感知分词器,以有效地将语音信号转换为离散语义符元,这些符元可以通过文本到语音语言模型从提示文本和音频中生成。 此外,提出了两阶段的符元到波形生成方法,以实现高保真音频合成。
-
•
我们介绍了 FireRedTTS 的两个应用:配音的语音克隆和聊天机器人的类人语音生成,展示了 FireRedTTS 在下游语音应用中的潜力。
2 数据处理流程
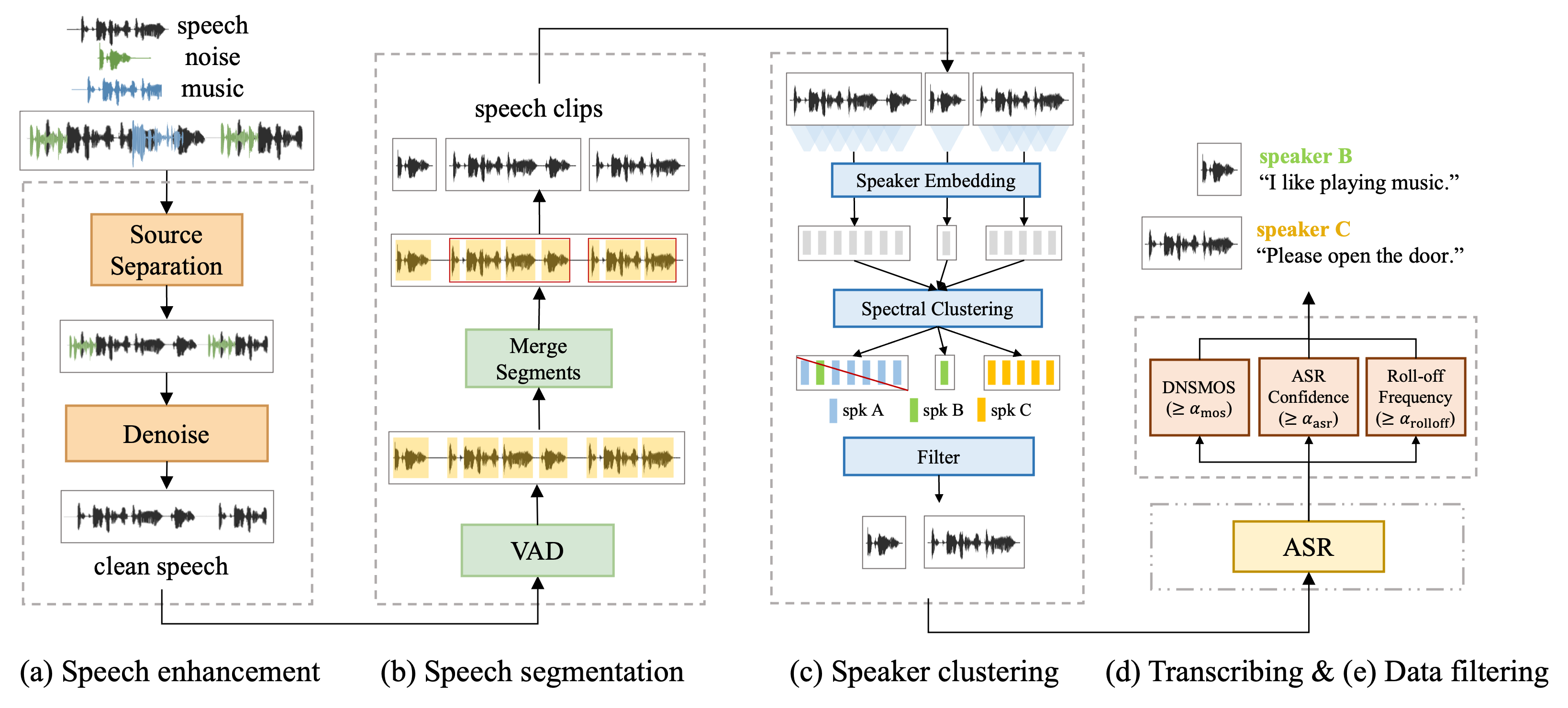
如图 1 所示,我们提出了一种数据处理流程,用于从海量的野外语音数据中创建大规模 TTS 数据集。 该流程包括五个步骤:语音增强、语音分割、说话人聚类、转录和数据过滤,将在本节中详细阐述。
语音增强:首先,语音增强消除音频中的非语音成分,例如背景音乐和噪声,以提供清晰的语音音频。 该模块由两个模型组成:一个用于消除背景音乐的音乐源分离模型 [16] 和一个用于语音降噪的语音增强模型 [17]。
语音分割:然后,我们执行语音分割,将长的语音音频切割成 2 秒到 20 秒的短片段,以适应 TTS 训练。 我们训练了一个基于帧的 TDNN 语音活动检测 (VAD) 模型 [18],以从梅尔谱图中准确地检测语音片段,帧移为 25ms。 我们将间隔静默时间小于 1 秒的相邻片段合并,并将片段边界扩展 0.3 秒,以避免在吸气和尾音中出现切断。
说话人聚类:由于缺乏说话人信息,我们在所有语音片段的说话人嵌入 [19] 上执行谱聚类。 具体来说,我们进行 K 均值聚类,并迭代地合并余弦相似度高于 0.8 的聚类。 最后,每个片段的块都与说话人质心和相应的说话人 ID 相关联。 具有多个 ID 的片段将被标记为多说话人片段,并从数据集中删除。 此外,我们注意到,与相应的说话人质心距离过远的片段通常意味着较低的语音质量或说话人混合,这也将被过滤掉。
转录: 我们采用基于双通道的端到端 ASR 模型 [20] 来转录语音片段。 批处理转录器束搜索用于推理,以有效地转录海量数据。
数据过滤: 最后,我们在完成长链语音预处理后,执行数据过滤以删除所有不合格的语音片段。 过滤从三个方面进行:
-
•
语音质量:我们使用 DNSMOS [21] 估计整体语音质量,并且只保留 DNSMOS P.835 OVRL 分数 [22] 高于 3.3 的语音片段。
-
•
采样率:我们的目标是创建一个高采样率的语音数据集。 因此,我们过滤掉以高采样率格式保存的低采样率(例如 8 kHz)音频。 我们计算滚降频率,其下方的能量占总能量的 99.5%。 然后,只有滚降频率高于 7 kHz 的语音片段保留在数据集中。
-
•
转录置信度:我们丢弃 ASR 置信度分数低于 0.8 的语音片段,以减轻转录错误对 TTS 训练的影响。
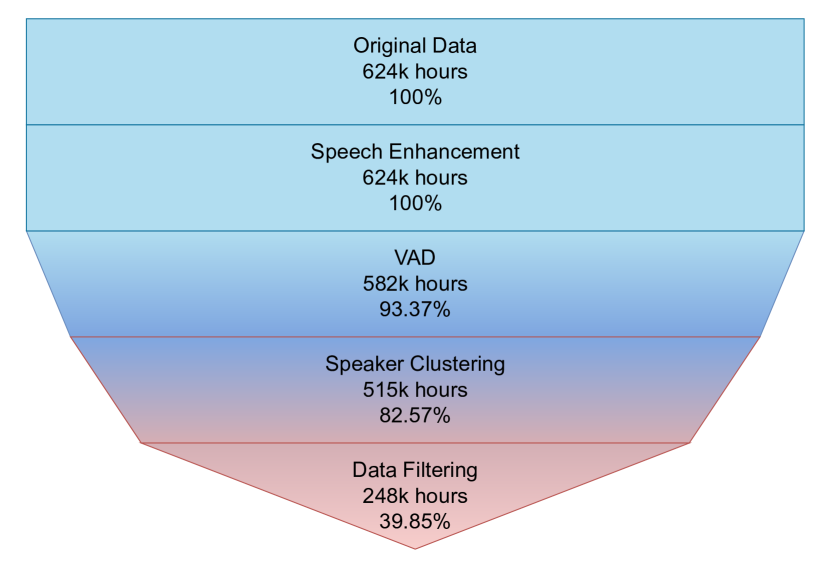
最后,我们通过提议的管道从 624,000 小时的未标记音频中收集了大约 248,000 小时的标记语音数据。 图 2 中显示的漏斗图详细分析了在每个步骤中过滤了多少数据。 在这项工作中,我们使用一个包含 150,000 小时(中文 110,000 小时,英文 40,000 小时)的子集用于模型训练。
3 基础 TTS 系统
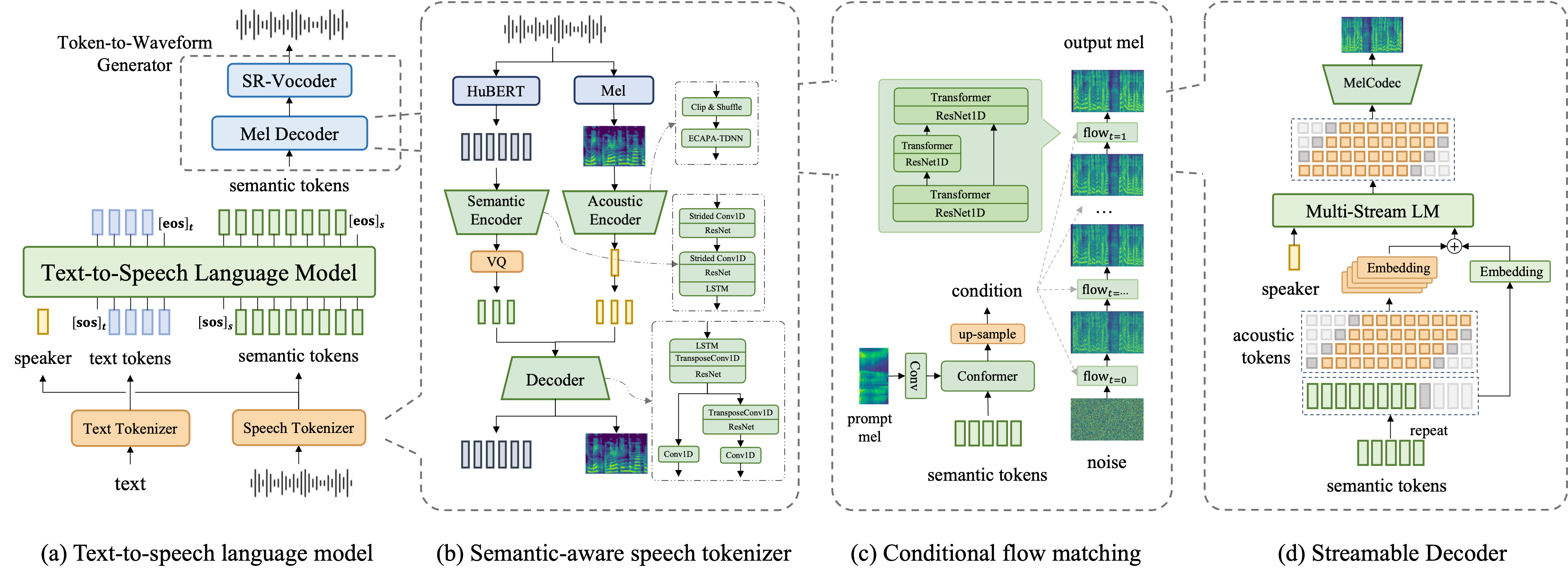
如图 3 所示,我们提出了一种基于语言模型的基础 TTS 系统。 该系统由三个模块组成:语音标记器、文本到语音语言模型和标记到波形生成器。
3.1 语义感知语音标记器
如图 3(b) 所示,语义感知语音标记器 (SAST) 旨在将语音信号压缩成离散标记以进行 TTS 建模。 它由语义编码器、声学编码器和解码器组成。
语义编码器:该模块旨在将语音信号转换为语义标记序列。 它首先利用预训练的自监督学习 (SSL) 模型 HuBERT [23] 将语音信号转换为语义嵌入序列。 然后,使用 ResNet 架构构建的语义编码器被用来进一步处理和降采样序列以生成编码序列。 最后,我们遵循 [24] 将该序列量化为离散序列,帧移为 40 毫秒,码本为 16,384 个码字。
声学编码器:同时,我们采用基于 ECAPA-TDNN 的声学编码器,如 [25] 所述,从语音信号中推导出语句级别的全局嵌入。 这捕获了重要的时不变特征,包括说话人身份、说话风格和声学环境。 该嵌入可用于在零样本 TTS 场景中模拟目标声音。 为了确保内容信息不会泄漏到该嵌入中,我们对梅尔谱图应用了简单的预处理策略“剪切和混洗”,以去除短时变异信息。 该过程首先选择构成总语句持续时间 25% 到 75% 的一段,然后将其划分为 1 秒的切片。 这些切片随后以随机顺序重新排列,以通过声学编码器获得全局嵌入。
解码器:在解码器中,全局嵌入被复制并与量化序列相加以形成解码器输入。 然后它通过具有转置卷积层的 ResNet 块进行处理,以进行上采样,从而重建 SSL 特征和声学特征。
SAST 使用以下损失函数进行训练:
| (1) |
其中 是权重系数。 是 VQ 损失,即量化前后的嵌入之间的 L2 损失 [26]。 是 SSL 特征与重建特征之间的 L2 损失,而 是真实梅尔谱图与重建梅尔谱图之间的 L2 损失。 在这项工作中,我们采用 ,并以 6400 秒的大批量大小训练模型,迭代 300k 次。
3.2 文本到语音语言模型
受 LLM 成功启发,我们将 TTS 形式化为使用仅解码器的自回归 Transformer 的下一个符元预测任务。 如图 3 (a) 所示,我们的目标是从提示文本和音频中预测语义符元。 文本通过基于 BPE 的文本分词器 [27] 编码为符元序列。 提示音频通过 SAST 的声学编码器嵌入到话语级嵌入中。 在训练过程中,我们从目标音频中提取语音符元和说话人嵌入,并分别将它们和文本嵌入,然后将它们连接在一起作为 GPT 类仅解码器 Transformer 的输入。 [28]。 在推理过程中,我们可以通过上下文学习自动回归地生成语义符元,即给出提示文本和来自提示音频的说话人嵌入。 在这项工作中,我们训练了一个 30 层仅解码器 Transformer (400M),其特征维度为 1024。
3.3 符元到波形的生成
这项工作旨在合成多种语音音频,包括采样率为 48 kHz 的高保真样本。 但是,我们的训练数据集主要包含低采样率 ( 24 kHz) 音频,不能直接用于训练高采样率波形生成器。 为了解决这个限制,我们提出了一种新颖的两阶段符元到波形生成器。 第一阶段包括训练一个 Mel 解码器,将语义符元转换为从低采样率 (16 kHz) 音频中提取的 Mel 谱图。 随后,我们使用超分辨率神经声码器 [29] 从 Mel 谱图中生成高采样率 (48 kHz) 音频。 这种方法使系统能够有效地利用整个训练数据集。 对于符元到 Mel 的生成过程,我们引入了两个解码器:基于流匹配的解码器和可流式解码器。
3.3.1 流匹配
为了提高生成梅尔语谱图的质量,我们采用流匹配结构 [30, 31, 12],该结构从噪声到语谱图分布学习去噪过程。 在推理时,它可以迭代地将高斯噪声转换为高质量的梅尔语谱图,以语义符元作为输入条件。
具体来说,流匹配学习从标准高斯分布中抽取的噪声样本 开始,到语谱图样本 的时间条件转换 。 此转换受常微分方程 (ODE) 控制:
| (2) |
时间条件向量场 可以选择为最优传输路径:
| (3) |
| (4) |
其中 是一个小的常数。 由 参数化的神经网络估计向量场。 如图 3(c) 所示,语义符元首先由 Conformer 编码,然后上采样以匹配梅尔语谱图的长度。 编码后的特征(表示为条件 ),连同样本 和时间步长 ,被馈送到基于 U-Net 的估计器以进行向量场预测。
| (5) |
由于语义符元包含有限的音色信息,我们建议在 Conformer 中的每个自注意力层之后引入一个交叉注意力层,以从参考音频的梅尔语谱图中提取音色,即与目标音频相同的说话者的另一个音频。
训练目标定义为:
| (6) |
此外,为了更好地生成梅尔语谱图,我们应用了无分类器引导 (CFG [32]) 技术。 在训练中,我们以 20% 的概率随机删除一个批次中的条件。 在推理时,向量场通过条件预测和无条件预测来估计:
| (7) |
其中 为 0.7。
3.3.2 可流式传输解码器
流匹配在梅尔谱图生成中展现出令人印象深刻的生成质量,但一直受到缓慢迭代推理的困扰,这使得其实现流式生成变得具有挑战性。 为了避免这个问题,我们提出了一种可流式解码器,它结合了梅尔编解码器和多流语言模型。
如图 3(d)所示,我们首先遵循 [33] 训练一个基于 CNN 的基于 GAN 的梅尔编解码器,以学习多流离散表示,即每个帧包含多个符元以保留足够的声学细节。 具体来说,具有 10 毫秒帧移的梅尔谱图被压缩成具有 20 毫秒帧移的四流离散序列,由四个分别具有 16,384 个码字的码本构成。 该序列可以通过梅尔编解码器解码器重建,并通过具有“延迟模式”的多流 LM [34] 从语义符元预测。
声学 LM 将语义序列和声学序列与“前瞻模式”相结合。 具体来说,我们将首先通过重复嵌入和上采样语义序列,使其与声学序列对齐,然后添加延迟,即 ,其中 是第 个声学嵌入, 是第 个语义嵌入, 是前瞻帧的数量。 这种方法能够实现同步流式处理:一旦我们从 TTS 语言模型接收语义符元,我们就会开始同步流式生成声学符元和相应的波形。
流式。
3.3.3 超分辨率声码器
为了训练超分辨率声码器,我们使用了一个精心挑选的原始训练语料库子集,包含 294 小时的高采样率音频。 从这些文件中,我们通过将音频下采样到 16 kHz,提取具有 10 毫秒帧移的梅尔谱图。 这个改进后的数据集用于训练一个基于 BigVGAN-V2 的神经声码器 [35]。 声码器将梅尔谱图上采样 480 倍,有效地将其转换为具有 48 kHz 采样率的高保真波形。 这种两阶段方法能够生成高质量、高采样率音频,同时有效地利用了主要以低采样率为主的训练数据。
4 下游 TTS 应用
基础系统在大型语音语料库上训练,以捕捉不同的说话人身份和说话风格。 这种全面的训练使系统能够适应各种场景。 因此,在实际应用中,我们可以利用这个基础系统来完成下游任务,而对数据的需求量很小。 在这项工作中,我们重点介绍了两个关键应用,它们展示了该系统的多功能性和效率:用于配音的语音克隆和用于聊天机器人的类人语音生成。
4.1 用于配音的语音克隆
语音克隆技术已在视频编辑和内容创作的配音中得到广泛应用,能够合成目标声音中带有自定义文本的语音音频。 在现实世界中的应用中,基于语音克隆的配音主要服务于两种截然不同的场景:用户生成内容 (UGC) 场景和专业用户生成内容 (PUGC) 场景。
UGC 场景通常呈现数据有限的场景,需要使用仅几秒钟或几分钟的低质量(非工作室)录音作为参考来合成目标声音。 在这些情况下,我们使用从提示音频中提取的说话人嵌入来实现零样本(或单样本)文本到语音 (TTS),从而利用上下文学习。 这种方法的有效性取决于获得准确表示目标声音的全局嵌入。 然而,在实践中,用户通常上传的低质量、嘈杂的录音经常会干扰精确说话人嵌入的提取,从而降低语音克隆性能。 为了缓解这个问题,我们使用“提示处理”,即对提示音频进行语音增强,以获得干净的参考音频。 此关键步骤提高了说话人嵌入的质量,从而提高了 UGC 场景中语音克隆的整体性能。
PUGC 场景通常提供由专业配音演员演绎的具有独特声音的录音室级音频数据。 这些数据中固有的高度表现力为建模带来了重大挑战。 为了解决这个问题,我们建议通过监督微调将我们的基础模型适应目标声音。 这种方法使我们能够利用预训练基础模型的泛化能力,快速捕捉专业语音录音中丰富细微的特征,从而用更少的目标数据实现高质量的合成。

4.2 面向聊天机器人的类人语音生成
聊天机器人的激增,对自然和类人语音生成产生了迫切需求,以实现沉浸式人机交互。 尽管我们的基础系统已经能够合成具有任意说话风格的自然语音,但它在类人语音生成中仍然缺乏细粒度的可控性,特别是在传达情绪和副语言行为方面。 为了解决这一限制,我们提出了一种基于指令调优的方法,利用一个专门的 50 小时数据集,该数据集富含情绪和副语言内容。
如图 4 所示,我们通过修改提示序列将情绪和副语言行为引入 LM。 最初,我们从一个包含四个不同类别(中性、快乐、悲伤和愤怒)的专用嵌入层中推导出情绪嵌入。 然后将此情绪嵌入插入提示序列中。 值得注意的是,在训练阶段,我们从同一个说话者的单独音频样本中提取说话者嵌入。 这种刻意的方法旨在将说话者和情绪表示分离。
副语言行为通过两种不同的模式融入文本序列:符元插入和嵌入注入。 对于基于声学事件的行为,例如停顿、延长、重复、笑声和呼吸声,我们将预先设计的符元直接插入原始文本序列中。 相反,对于重叠的副语言标签,例如“边笑边说”或“强调”,我们引入了专门的副语言行为嵌入层,使这些标签能够与特定词语相关联。 这种方法使我们能够实现可控的副语言行为合成。 在目前的实现中,我们已成功地整合了 13 种副语言行为,如表 1 所示。 这套全面的行为使人类般的语音合成系统能够模仿在自然的人类对话中观察到的复杂语音模式。
|
|
|
|||
| Char repetition | UTF8gbsn我 UTF8gbsn我 | token insertion | |||
| Word repetition | UTF8gbsn就是 UTF8gbsn就是 | token insertion | |||
| Elongation | UTF8gbsn就是 | token insertion | |||
| Hissing | token insertion | ||||
| Dental click | token insertion | ||||
| Breath | token insertion | ||||
| Laugh | token insertion | ||||
| Speak with a laugh | UTF8gbsn真是笑^UTF8gbsn死^UTF8gbsn我^UTF8gbsn了^ | embedding injection | |||
| Emphasis | UTF8gbsn你真@UTF8gbsn棒@ | embedding injection | |||
| Filled pause | UTF8gbsn嗯P | embedding injection | |||
| Confirmation | UTF8gbsn啊C | embedding injection | |||
| Realization | UTF8gbsn哦R | embedding injection | |||
| Surprise | UTF8gbsn哦S | embedding injection |
5 结果
5.1 基础模型评估
5.1.1 一致性评估
预计所提出的基础系统将通过上下文学习合成语音,以提示文本的音调和说话风格呈现提示文本的内容。 因此,为了衡量合成语音和提示之间的一致性,我们进行了一致性 MOS(CoMOS)测试。 我们创建了一个包含 94 个汉语
如表 2 所示,我们比较了三组音频:真实音频、CosyVoice [12] 生成的合成音频和 FireRedTTS 生成的合成音频。 首先,真实音频获得了 4.53 的最高 CoMOS 分数。 CosyVoice 是一种基于 LM 的高质量大规模 TTS 系统,在超过 100,000 小时的数据上训练,表现出较高的合成质量,其 CoMOS 分数为 4.15。 但是,与真实音频相比,仍然存在明显的差距。 相反,FireRedTTS 在使用提出的数据处理管道获得的更多高质量数据上进行训练,并使用具有 4 亿个参数的更大 LM,以更高的 CoMOS 分数 4.32 实现了更好的性能。 在某些情况下,它甚至超越了地面实况音频。 这些结果强调了所提出的基础系统的有效性。
| System | CoMOS() |
|---|---|
| GroundTruth | 4.53 |
| CosyVoice | 4.15 |
| FireRedTTS | 4.32 |
5.1.2 稳定性评估
接下来,我们通过检测从用于产品发布测试的具有挑战性的测试集中合成的 2000 个话语中的发音错误来评估 FireRedTTS 的稳定性。 具体来说,我们选择了 200 个 DNSMOS 分数在 2.5 到 3.5 之间的音频提示。 对于每个音频提示,我们生成六个中文话语、三个英文话语和一个代码切换(中英混合)话语。 专业的聆听者被用来检测合成音频中的发音问题,提供比基于 ASR 的评估方法更准确的评估。
表 3 显示了 CosyVoice 和 FireRedTTS 在三种情况下(总体、替换、“插入和删除”)的句子级错误率。 结果表明,我们的系统比 CosyVoice 表现出更好的总体性能,但在英语和代码切换话语中仍然存在明显的稳定性问题。 尤其是在英语中,大多数发音错误归因于插入和删除。 这种性能差异主要归因于当前训练集的组成,其中英语和代码切换数据所占比例相对较小,这些样本的多样性也不足。 解决训练数据中的这些局限性将是我们未来工作的重要重点,以提高系统在各种语言环境中的鲁棒性。
| System | Overall(%) | Sub(%) | #Ins.&Del.(%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ZH | EN | MIX | ZH | EN | MIX | ZH | EN | MIX | |
| CosyVoice | 5.68 | 12.17 | 29.50 | 3.76 | 6.67 | 25.00 | 1.92 | 5.50 | 4.50 |
| Ours | 2.09 | 12.00 | 8.50 | 1.00 | 0.50 | 4.50 | 1.09 | 11.50 | 4.00 |
5.1.3 可流式解码
我们通过在第 5.1.1 节中介绍的相同 CoMOS 测试,比较了流匹配解码器与提出的可流式解码器的合成质量。 如表 4 所示,非流式流匹配方法表现出优越的质量,实现了 4.48 的 CoMOS。 尽管如此,可流式解码器成为 FireRedTTS 的可行替代方案,以合成质量略微下降为代价,实现了实时生成能力。 我们注意到,观察到的质量下降部分是由于 Mel 编解码器生成的 Mel 谱图不理想造成的,这将在我们未来的工作中得到改进。
| System | CoMOS() |
|---|---|
| GroundTruth | 4.52 |
| Flow-matching decoder | 4.48 |
| Streamable decoder | 4.41 |
5.2 语音克隆
5.2.1 零样本与少样本
为了评估语音克隆在配音应用中的有效性,我们对 UGC 和 PUGC 场景中的零样本和少样本方法进行了比较分析。 对于 UGC 场景,我们从内部数据集中随机选择 2 位非演播室未见过的说话者(一位男性,一位女性)。 PUGC 场景使用了一种独特的、极具表现力的声音,即悟空,这种声音在我们的大规模训练集中代表性不足。 我们的测试集包含每个说话者 5 个音频提示,每个提示合成 8 个话语。 零样本方法直接通过上下文学习使用基础系统。 相反,少样本方法涉及两种微调策略: (1) 对于 UGC,我们使用 2 分钟的训练数据微调 TTS 语言模型; (2) 对于 PUGC,我们使用更广泛的 1 小时训练集微调 TTS 语言模型和流量匹配解码器。
我们进行了 MOS 测试,并使用预训练的说话人验证模型111https://github.com/modelscope/3D-Speaker计算说话人相似度 (SIM),以从主观和客观两个方面评估这两种方法。 表 5 展示了评估结果。 在 UGC 场景中,由于强大的基础模型,零样本方法已经实现了高质量的合成。 尽管如此,使用 2 分钟的数据进行微调可以进一步略微提高性能,这证明了在数据极其有限的情况下,少样本自适应的有效性。 对于 PUGC 场景,零样本方法在该独特声音的说话人相似性方面表现出次优性能。 少样本方法展示出显著改进,具有更高的 MOS 和 SIM 分数。 此结果突出了少样本微调在工业 PUGC 场景中的有效性。
| Scenario | Approach | MOS | SIM(%)() |
|---|---|---|---|
| UGC | zeroshot | 4.25 | 73.61 |
| fewshot 2min | 4.31 | 73.85 | |
| PUGC | zeroshot | 3.77 | 68.63 |
| fewshot 1h | 4.65 | 78.92 |
5.2.2 提示增强
正如第 4.1 节所述,我们应用语音增强来处理噪声音频提示。 为了评估该方法的有效性,我们进行了相似性 MOS 测试,并计算了使用经过处理或未经处理的音频提示合成的音频的 SIM。 我们随机选择了 40 个未见过的干净音频提示(20 个普通话和 20 个英语),然后按照 [36] 中的方法,在不同的信噪比水平(20 dB、10 dB 和 0 dB)手动添加背景噪声。 然后,我们将增强应用于音频提示,并再次执行合成。
表 6 展示了有无提示增强合成音频的比较。 发现表明,预处理可能会损害具有高信噪比 (SNR) 音频提示的语音克隆。 然而,对于较低 SNR 的音频提示,语音克隆性能会大幅下降。 在这些情况下,语音增强有效地减轻了这种下降。 这些结果表明,在实际应用中,语音增强是一种有效的语音克隆策略,但应有选择地仅应用于低 SNR 音频提示。
| SNR(db) | Similarity MOS | SIM(%) | ||
|---|---|---|---|---|
| w/o process | with process | w/o process | with process | |
| 20 | 3.97 | 3.89 | 50.66 | 49.20 |
| 10 | 3.37 | 3.53 | 41.81 | 43.60 |
| 0 | 2.62 | 3.01 | 28.81 | 35.15 |
5.3 类人语音生成
为了验证 FireRedTTS 在类人语音生成中的有效性,我们通过指令调优评估其合成情绪语音和语用行为的能力。
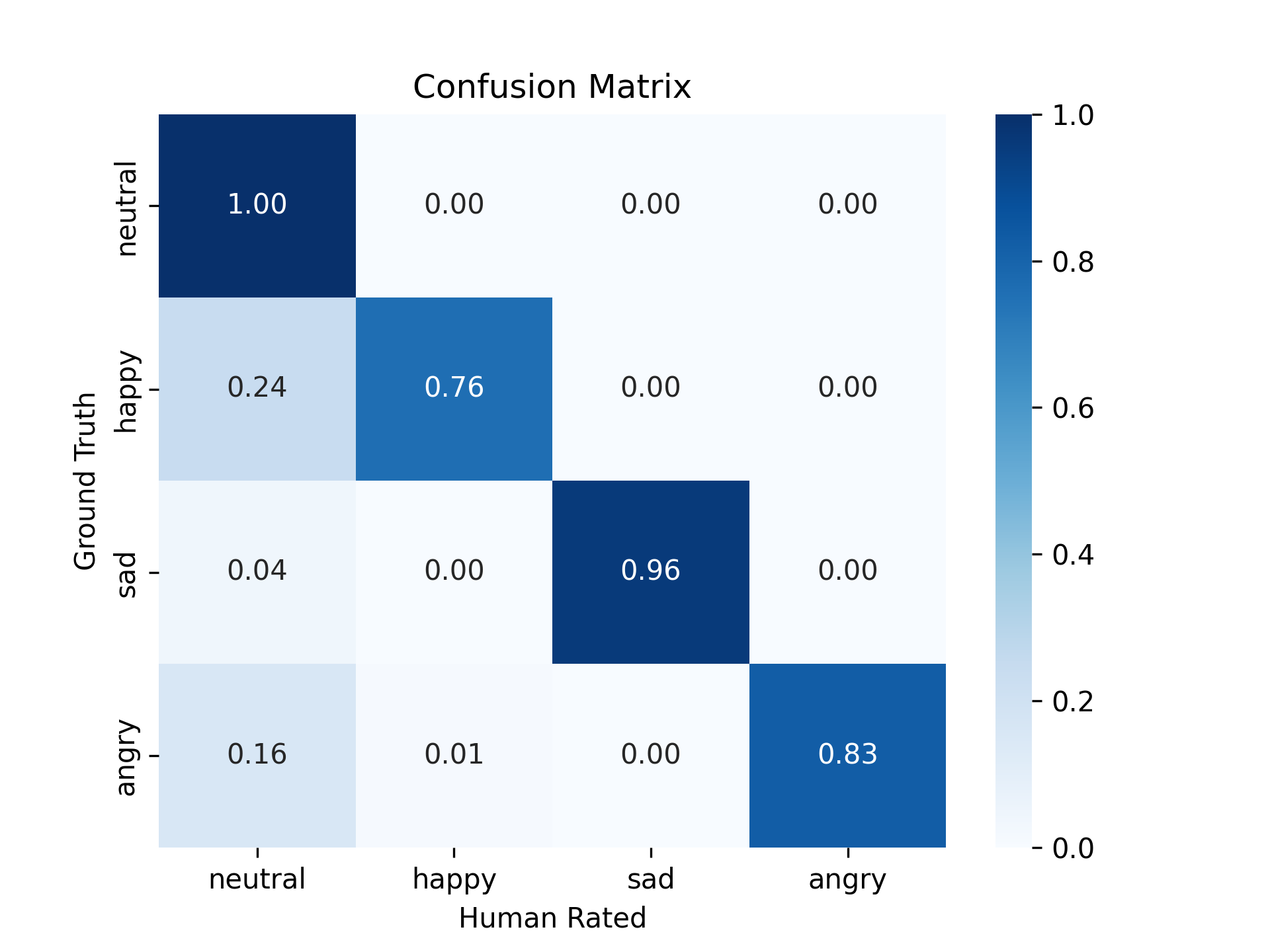
首先,我们评估情绪语音合成的控制精度。 我们构建了一个包含 100 个中文话语的单说话人测试集,每个话语都分配了一个情绪,分别是“中性”、“高兴”、“悲伤”或“愤怒”。 要求听众将合成的音频归类为一种情绪类型。 正如图 5 中的混淆矩阵所示,大多数音频样本成功地传达了预期的情绪。 只有很少一部分样本,其特点是情绪强度较低,被错误地归类为中性。 这一结果表明,微调后的 FireRedTTS 能够可控地合成情绪语音。
此外,为了研究指令调优的影响,我们通过使用情绪识别模型222https://modelscope.cn/models/iic/emotion2vec_base_finetuned计算分类精度来衡量预训练和微调后的 LLM 的情绪可控性。 如表 7 所示,与预训练模型相比,指令调优显著提高了模型合成目标情绪语音的能力。 这一发现进一步强调了指令调优将 FireRedTTS 变成情绪可控 TTS 系统的有效性。
最后,我们进行了一个偏好测试,以评估副语言行为对合成语音的影响。 如表 8 所示,副语言行为的加入显著提高了合成语音的类人度,呈现出 45% 的更高偏好。 这一结果强调了副语言行为在为语音聊天机器人生成自然、类人语音中的关键作用。
| Model | Neutral | Happy | Sad | Angry |
|---|---|---|---|---|
| pre-trained | 50% | 45% | 76% | 87% |
| fine-tuned | 97% | 97% | 100% | 98% |
| w/o | no difference | w/ |
| 26% | 29% | 45% |
6 结论与未来工作
本工作介绍了 FireRedTTS,一个新颖的基础文本到语音框架。 该系统包含三个关键组件:数据处理、基础系统和下游应用。 最初,我们开发了一个全面的数据处理管道,将 624k 小时的原始音频转换为 248k 小时的高质量、大规模 TTS 数据集,涵盖了广泛的内容、说话风格和音色。 随后,我们提出了一种基于语言模型的基础 TTS 系统,该系统从语音中提取离散的语义符元用于文本到语音建模,并通过两阶段的符元到波形的生成器生成高保真音频。 我们展示了 FireRedTTS 的两个下游应用:配音的语音克隆和面向聊天机器人的类人语音生成。 通过主观和客观评估,我们确定了 FireRedTTS 在生成高质量语音方面的强大能力,该语音具有预期的内容、说话风格和音色,与提示文本和音频保持一致。 语音克隆实验突出了 FireRedTTS 在通过零样本和少样本方法为 UGC 和 PUGC 场景配音方面的巨大潜力。 此外,我们展示了 FireRedTTS 在通过指令调优以可控的方式合成具有副语言行为的情感语音方面的熟练程度,验证了其在为聊天机器人生成类人语音方面的有效性。
参考文献
- [1] Haohan Guo, Shaofei Zhang, Frank K Soong, Lei He, and Lei Xie. Conversational end-to-end TTS for voice agents. In Proc. SLT, pages 403–409. IEEE, 2021.
- [2] Paweł Budzianowski, Taras Sereda, Tomasz Cichy, and Ivan Vulić. Pheme: Efficient and conversational speech generation. arXiv preprint arXiv:2401.02839, 2024.
- [3] Chenxu Hu, Qiao Tian, Tingle Li, Wang Yuping, Yuxuan Wang, and Hang Zhao. Neural dubber: Dubbing for videos according to scripts. Proc. NeurIPS, 34, 2021.
- [4] Yan Liu, Li-Fang Wei, Xinyuan Qian, Tian-Hao Zhang, Song-Lu Chen, and Xu-Cheng Yin. M3tts: Multi-modal text-to-speech of multi-scale style control for dubbing. Pattern Recognition Letters, 179:158–164, 2024.
- [5] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [6] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [7] Roberto Gozalo-Brizuela and Eduardo C Garrido-Merchan. Chatgpt is not all you need. a state of the art review of large generative ai models. arXiv preprint arXiv:2301.04655, 2023.
- [8] Ziqiang Zhang, Long Zhou, Chengyi Wang, Sanyuan Chen, Yu Wu, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. CoRR, abs/2303.03926, 2023.
- [9] James Betker. Better speech synthesis through scaling. arXiv preprint arXiv:2305.07243, 2023.
- [10] Mateusz Lajszczak, Guillermo Cámbara, Yang Li, Fatih Beyhan, Arent van Korlaar, Fan Yang, Arnaud Joly, Álvaro Martín-Cortinas, Ammar Abbas, Adam Michalski, et al. Base tts: Lessons from building a billion-parameter text-to-speech model on 100k hours of data. arXiv preprint arXiv:2402.08093, 2024.
- [11] Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, et al. Seed-tts: A family of high-quality versatile speech generation models. arXiv preprint arXiv:2406.02430, 2024.
- [12] Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407, 2024.
- [13] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey on in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- [14] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, R. J. Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, and Yonghui Wu. Natural TTS synthesis by conditioning wavenet on mel spectrogram predictions. CoRR, abs/1712.05884, 2017.
- [15] Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. FastSpeech 2: Fast and high-quality end-to-end text to speech. In Proc. ICLR, 2021.
- [16] Simon Rouard, Francisco Massa, and Alexandre Défossez. Hybrid transformers for music source separation. In Proc. ICASSP, pages 1–5. IEEE, 2023.
- [17] Hendrik Schroter, Alberto N Escalante-B, Tobias Rosenkranz, and Andreas Maier. Deepfilternet: A low complexity speech enhancement framework for full-band audio based on deep filtering. In Proc. ICASSP, pages 7407–7411. IEEE, 2022.
- [18] Ye Bai, Jiangyan Yi, Jianhua Tao, Zhengqi Wen, and Bin Liu. Voice activity detection based on time-delay neural networks. In 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pages 1173–1178. IEEE, 2019.
- [19] Hongji Wang, Chengdong Liang, Shuai Wang, Zhengyang Chen, Binbin Zhang, Xu Xiang, Yanlei Deng, and Yanmin Qian. Wespeaker: A research and production oriented speaker embedding learning toolkit. In Proc. ICASSP, pages 1–5. IEEE, 2023.
- [20] Tara N Sainath, Ruoming Pang, David Rybach, Yanzhang He, Rohit Prabhavalkar, Wei Li, Mirkó Visontai, Qiao Liang, Trevor Strohman, Yonghui Wu, et al. Two-pass end-to-end speech recognition. arXiv preprint arXiv:1908.10992, 2019.
- [21] Chandan KA Reddy, Vishak Gopal, and Ross Cutler. Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In Proc. ICASSP, pages 886–890. IEEE, 2022.
- [22] Jianwei Yu, Hangting Chen, Yanyao Bian, Xiang Li, Yi Luo, Jinchuan Tian, Mengyang Liu, Jiayi Jiang, and Shuai Wang. Autoprep: An automatic preprocessing framework for in-the-wild speech data. In Proc. ICASSP, pages 1136–1140. IEEE, 2024.
- [23] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021.
- [24] Haohan Guo, Fenglong Xie, Dongchao Yang, Hui Lu, Xixin Wu, and Helen Meng. Addressing index collapse of large-codebook speech tokenizer with dual-decoding product-quantized variational auto-encoder. arXiv preprint arXiv:2406.02940, 2024.
- [25] Nauman Dawalatabad, Mirco Ravanelli, François Grondin, Jenthe Thienpondt, Brecht Desplanques, and Hwidong Na. Ecapa-tdnn embeddings for speaker diarization. arXiv preprint arXiv:2104.01466, 2021.
- [26] Aaron van den Oord, Oriol Vinyals, and koray kavukcuoglu. Neural discrete representation learning. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Proc. NeurIPS, volume 30. Curran Associates, Inc., 2017.
- [27] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Proc. ICML, pages 28492–28518. PMLR, 2023.
- [28] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Proc. NeurIPS, 33:1877–1901, 2020.
- [29] Haohe Liu, Ke Chen, Qiao Tian, Wenwu Wang, and Mark D Plumbley. Audiosr: Versatile audio super-resolution at scale. In Proc. ICASSP, pages 1076–1080. IEEE, 2024.
- [30] Shivam Mehta, Ruibo Tu, Jonas Beskow, Éva Székely, and Gustav Eje Henter. Matcha-tts: A fast tts architecture with conditional flow matching. In Proc. ICASSP, pages 11341–11345. IEEE, 2024.
- [31] Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022.
- [32] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- [33] Haohan Guo, Fenglong Xie, Kun Xie, Dongchao Yang, Dake Guo, Xixin Wu, and Helen Meng. Socodec: A semantic-ordered multi-stream speech codec for efficient language model based text-to-speech synthesis. arXiv preprint arXiv:2409.00933, 2024.
- [34] Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. Proc. NeurIPS, 36, 2024.
- [35] Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, and Sungroh Yoon. BigVGAN: A universal neural vocoder with large-scale training. In Proc. ICLR, 2023.
- [36] Harishchandra Dubey, Ashkan Aazami, Vishak Gopal, Babak Naderi, Sebastian Braun, Ross Cutler, Alex Ju, Mehdi Zohourian, Min Tang, Mehrsa Golestaneh, et al. Icassp 2023 deep noise suppression challenge. IEEE Open Journal of Signal Processing, 2024.