https://en.navinfo.com/
†miao.fan@ieee.org
基于自动驾驶车辆局部生成的多个矢量化瓦片的生成式神经网络高清地图构建 † †thanks: 本研究得到了国家自然科学基金 (批准号: U22A20104) 的资助。 如需详细了解我们的最新研究成果,请访问通讯作者的网站:https://godfanmiao.github.io/homepage-en/.
摘要
高清(HD)地图是自动驾驶系统的重要组成部分,因为它可以提供关于驾驶场景的精确环境信息。 最近关于矢量化地图生成的工作可以通过使用机载传感器进行一次旅行,在运行时仅生成自我车辆周围的本地地图元素,从而留下了如何构建投影在世界坐标系中的全球高清地图的难题在高质量标准下。 为了解决这个问题,我们提出了一种端到端的生成式神经网络 GNMap,它可以通过自动驾驶车辆通过多次行驶局部生成的多个矢量化瓦片来自动构建 HD 地图。 它利用了一个多层、基于注意力的自动编码器作为共享网络,其参数从两个不同的任务(即分别为预训练和微调)中学习,以确保生成地图的完整性和元素类别。 对一个真实数据集进行了大量的定性评估,实验结果表明 GNMap 可以超越 SOTA 方法,F1 分数提高了 以上,在少量人工修改的情况下达到了工业应用水平。 我们已经将其部署在 Navinfo Co., Ltd.,它成为自动构建自动驾驶系统 HD 地图的必不可少的软件。
关键词:
HD 地图 自动驾驶 矢量化瓦片 多次行驶1 引言
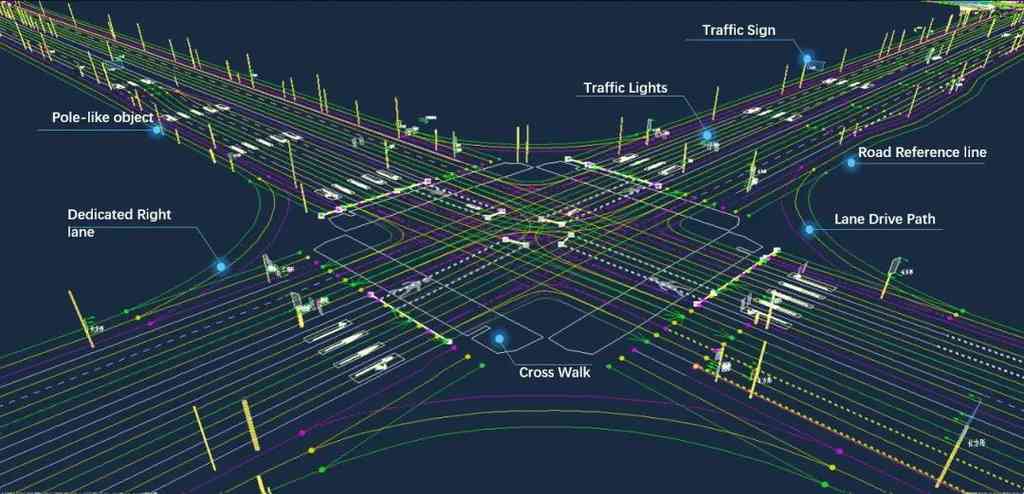
高清(HD)地图 [7] 在自动驾驶 [4, 11] 中起着至关重要的作用。 如图 1 所示,它提供了关于道路拓扑和交通规则的高精度矢量化元素(包括人行横道、车道分隔线、道路边界等),这些元素对于自动驾驶车辆的导航至关重要。 矢量化地图元素在几何上被离散化为折线或多边形,并传统上由基于 SLAM 的方法 [20, 17] 脱机生成,这些方法严重依赖于人工标注,面临着可扩展性和最新问题。
为了解决这些问题,最近的研究 [9, 10, 14, 18, 6, 12] 专注于开发用于矢量化地图构建的在线方法。 这些方法旨在设计车载模型,这些模型能够在运行时使用车载传感器(如激光雷达 [16] 和相机)学习生成自车周围的局部元素。 基于学习的方法越来越受到关注,因为它们在一定程度上可以减轻人工工作量。 然而,即使是其中最先进的方法 [10, 6] 也只能在一次巡航中生成 自车周围的地图元素,这给如何在世界坐标系下构建高质量的全局高清地图带来了难题。
作为解决该难题的首次尝试,我们在本文中提出了 GNMap。 它是一个端到端的生成式神经网络,它以车辆生成的多个巡航的矢量化瓦片作为输入,并自动生成以世界坐标为输出的全局化高清地图。 具体来说,GNMap 采用多层和基于注意力的自动编码器作为共享网络,其参数分别从两个不同的任务(即预训练和微调)中学习。 在预训练阶段,共享自动编码器负责完成掩蔽的矢量化瓦片。 预训练的参数被进一步利用作为微调的初始权重,微调旨在将地图元素的每个像素分配到正确的类别。 通过这种方式,我们既保证了生成地图的完整性,又保证了元素类别的正确性。
此外,我们构建了一个真实世界数据集,以进行离线定性评估。 数据中的每个实例都属于一个向量化的瓦片,该瓦片主要由三种地图元素组成,即人行横道、车道分隔线和道路边界。 此外,每个瓦片都由自动驾驶汽车在多个行程中穿过,每个行程都包含一个街景。 消融研究表明,为了获得最佳性能,在 GNMap 上进行预训练至关重要。 丰富的评估实验结果也表明,它可以比 SOTA 方法高出 5% 以上的 F1 分数。 到目前为止,GNMap 已经部署到 Navinfo Co., Ltd. 用于工业用途,作为自动构建中国大陆自动驾驶高清地图的必不可少的软件。
2 相关工作
2.1 基于 SLAM 的方法(离线)
高清地图通常是在环境的 LiDAR 点云上手动标注的。 这些点云是从配备 GPS [8] 和 IMU [3] 的勘测车辆的 LiDAR 扫描中收集的。 为了将 LiDAR 扫描融合成一个准确且一致的点云,SLAM 方法 [20, 17] 通常使用,它们通常采用以下解耦管道。 ICP [1] 和 NDT [2] 等成对对齐算法首先用于匹配两个相邻时间戳之间的 LiDAR 数据。 为了构建全局一致的地图,通过 GTSAM [5] 估计自车准确的姿态至关重要。 尽管进一步设计了几种机器学习方法 [13] 来从融合的 LiDAR 点云中提取静态地图元素,如人行横道、车道分隔线和道路边界,但由于需要及时更新以适应自动驾驶,因此维护可扩展的高清地图仍然很费力和昂贵。
2.2 基于学习的方法(在线)
为了摆脱离线人工的努力,基于学习的高清地图构建引起了越来越多的兴趣。 这些方法 [9, 10, 14, 18, 6, 12] 提出在运行时基于车载摄像头捕获的环绕视图图像构建局部地图。 特别地,HDMapNet [9] 首先生成语义地图,然后在后处理中对像素级语义分割结果进行分组。 VectorMapNet [12] 采用了一个两阶段的从粗到细框架,并利用自回归解码器来顺序预测点,导致推理时间过长以及排列的模糊性。 为了缓解这个问题,BeMapNet [14] 采用了一个统一的分段贝塞尔曲线来描述地图元素的几何形状。 InstaGraM [18] 提出了一种新颖的图模型,用于地图元素的矢量化折线,该模型将几何、语义和实例级信息建模为图表示。 MapTR [10] 使用固定数量的点来表示一个地图元素,而不管其形状的复杂程度。 PivotNet [6] 通过集合预测框架中的基于枢轴的表示对地图元素进行建模。 然而,即使是其中最先进的方法也仅仅能够通过一次巡回产生 车辆周围的地图元素,这留下了一个难题,即如何构建一个在世界坐标系下投影的全局 HD 地图。
3 模型
3.1 问题公式化
GNMap 的目标是从多个车辆生成的瓦片中生成世界坐标系下的全局 HD 地图。 车辆生成的瓦片由 RGB 图像表示,我们使用 表示图像集作为输入。 如公式 1 所示,GNMap 被公式化为 ,它学习融合图像 并生成全局 HD 地图作为输出,表示为 :
| (1) |
其中 表示 GNMap 需要探索的最佳参数集。
3.2 共享自编码器
为了实现 ,我们设计了一个自编码器,它被结构化到两个部分:一个神经编码器 和一个神经解码器 。 编码器和解码器之间的关系由公式 2 和公式 3 所示:
| (2) |
和
| (3) |
其中 以 作为输入,通过编码器的参数 生成中间特征表示 ,而 以中间特征 作为输入,通过解码器的参数 生成输出 。 和 都属于 :
| (4) |
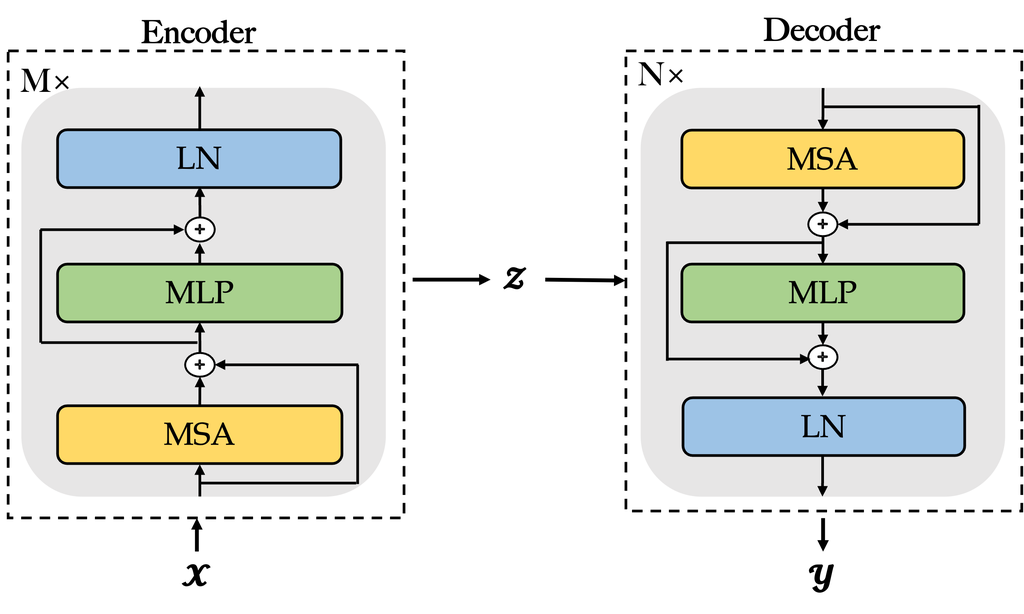
如图 2 所示,编码器 和解码器 都是多层网络,主要由多头自注意力函数组成。 我们将在接下来的段落中详细阐述它们。
编码器:
解码器:
3.3 预训练阶段
在预训练阶段,共享自动编码器的学习目标是完成掩码向量化图块,并且预训练参数将被进一步用作微调的初始权重。 如图 3 所示,我们将在以下段落中从输入、输出、基本事实和损失函数的角度详细阐述预训练阶段。
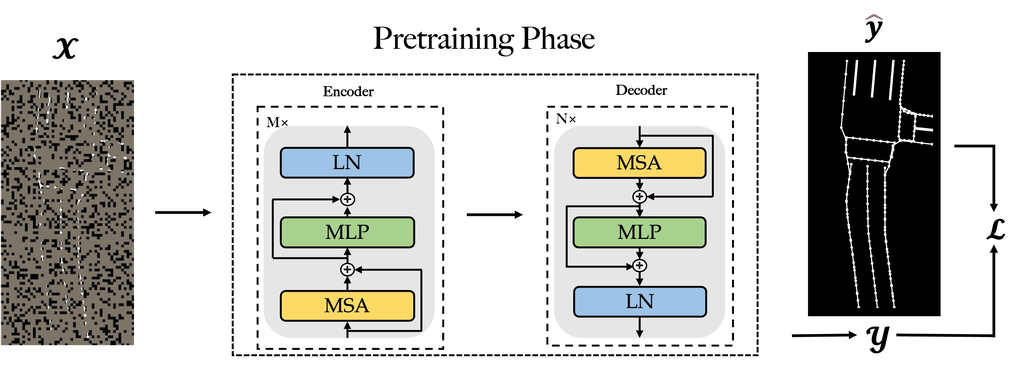
输入:
我们将手动标注的高清地图分割成多个向量化图块。 每个向量化图块都可以转换为一个灰度图像,用 表示,其中 和 分别表示图像的高度和宽度。 在 中,任何元素的像素都设置为 255,而背景的像素设置为 0。 然后将图像分割成形状为 的非重叠块。 因此,可以获得 个补丁(每个 )。 我们对补丁子集进行采样,并屏蔽(即删除)其余的补丁。 我们的策略很简单:在不放回的情况下对随机补丁进行采样,遵循具有高屏蔽率(即已删除补丁的比率)的均匀分布。 通过这种方式,我们创建了一项无法通过从可见邻近补丁推断来轻松解决的任务。
输出:
我们希望通过共享自动编码器获得一个完整的灰度瓦片作为输出,该编码器以被屏蔽的补丁作为输入。 完成的图像由 表示,其中 和 分别表示完成图像的高度和宽度。 每个预测像素 的值,其中 范围从 到 ,因为它是由 softmax 函数缩放的。
真实值:
相应地,真实值图像为未切片图像(即 ),用作输入。 我们用 表示它,因为 的每个像素都设置为 0 或 1,以指示它是否属于背景或矢量化地图元素。
损失函数:
3.4 微调阶段
在微调阶段,共享自动编码器的学习目标变为将生成的图中元素的每个像素分配到正确的类别,利用预训练参数作为初始权重。 如图 4 所示,我们将从输入、输出、真实值和损失函数的角度详细阐述微调阶段。
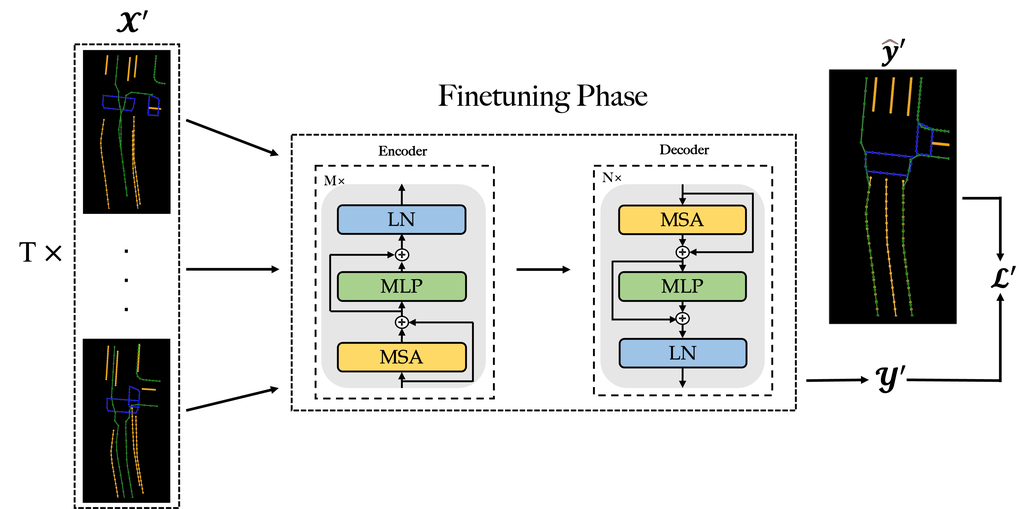
输入:
在这项工作中,一块瓦片被自动驾驶车辆经过 次,每次行驶都包含一个街景。 由安装在测量车辆上的摄像机收集的原始街景通常是 RGB 图像,并且基于学习的方法 [9, 10, 14, 18, 6, 12] 通常将它们转换为矢量化图像,其中每个像素属于一个特定的类别,例如背景、土地分隔线等。 事实上,我们可以在微调阶段开始时获得 张图像。 我们使用一个共享的 CNN 网络从 张图像中提取特征,并将它们连接在一起作为共享自动编码器的输入。
输出:
我们期望在微调阶段获得 GNMap 的融合瓦片作为输出。 生成的图像表示为 ,其中 和 分别表示图像的高度和宽度,而 代表地图元素的种类。 每个预测的像素 由一个 维向量表示,其中每个维度上的值范围为 0.0 到 1.0,表示预测类别的概率,所有这些值的总和为 1.0。
真实值:
相应地,真实图像表示为 。 此外, 中的每个像素由一个 维向量表示,其中只有一个值被设置为 1.0,专门表示该像素属于一个特定的类别,例如背景、人行横道等。
损失函数:
4 实验
4.1 数据集和指标
| Subset | #(Tiles) | #(Map Elements) | Avg. #(Tours)/Tile | #(Street Views) |
| Train | 40,000 | 162,493 | 5.2 | 208,207 |
| Valid | 5,000 | 19,928 | 5.0 | 24,982 |
| Test | 5,000 | 20,061 | 5.1 | 25,564 |
为了对 HD 地图生成方法进行离线评估,我们构建了一个真实世界数据集,其中包含自动驾驶汽车通过多个行程生成的街景和矢量化瓦片。 我们将数据集随机分成三个子集。 如表 1 所示,它们分别用于模型训练(缩写为 Train)、超参数调整(缩写为 有效), 以及性能测试(简称 测试)。 每个子集由许多独立的单元组成,每个单元都由自动驾驶汽车经过多次 巡回。 对于每次巡回,都会收集 街景,并通过车载模型在线同时生成矢量化单元。 沿袭以往工作,我们主要关注三种地图元素,包括人行横道(简称 为 ped. ),车道分隔线(简称 为 div. ),以及道路边界(简称 为 bou. )。
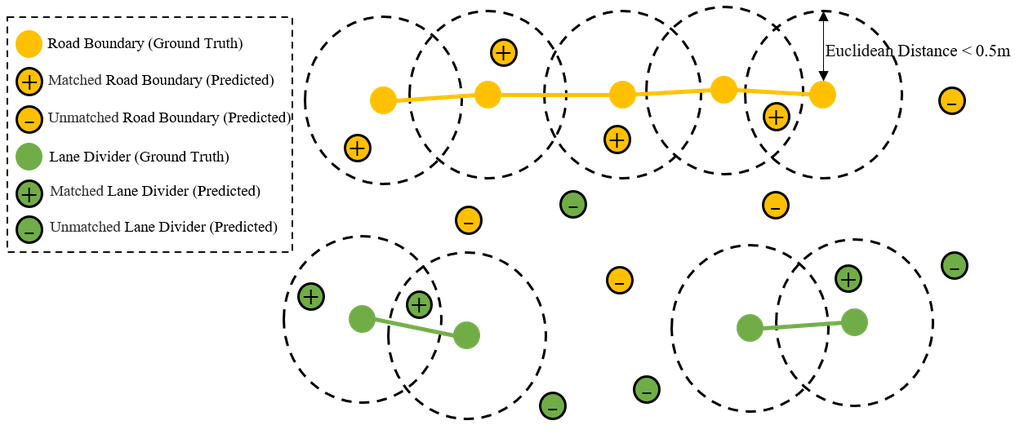
4.2 比较细节
| Method | mAP APped. APdiv. APbou. | mAR ARped. ARdiv. ARbou. | F1 |
| HDMapNet [9] | 45.3 42.8 47.9 45.1 | 44.1 41.3 47.5 43.6 | 44.7 |
| VectorMapNet [12] | 62.9 60.4 65.3 63.1 | 61.5 59.2 61.8 63.4 | 62.2 |
| InstaGraM [18] | 53.6 51.9 54.2 54.8 | 62.4 59.8 62.3 65.1 | 57.7 |
| BeMapNet [14] | 62.3 60.5 61.6 64.9 | 66.1 62.8 70.3 65.1 | 64.1 |
| MapTR [10] | 64.5 62.8 65.2 65.5 | 73.2 71.3 73.4 74.9 | 68.6 |
| PivotNet [6] | 64.8 63.1 66.5 64.8 | 72.4 70.3 72.8 74.1 | 68.4 |
| GMM [15] | 63.4 61.4 64.7 64.0 | 63.2 59.8 67.6 62.3 | 63.3 |
| GNMap (Ours) | 72.5 70.5 74.8 72.3 | 75.6 75.4 78.1 73.3 | 74.0 |
我们主要将 GNMap 与两组方法进行比较。 一组包含车载模型(包括 HDMapNet [9]、VectorMapNet [12]、InstaGraM [18]、BeMapNet [14]、MapTR [10] 和 PivotNet [6]),它们从现场摄像机捕获的实时街景中在线推断矢量化瓦片。 另一组代表融合车载瓦片构建全局 HD 地图的方法(即 GMM [15] 和我们的 GNMap)。 表 2 报告了这两组方法用于 HD 地图构建的实验结果。 所有方法均通过表 1 所示的真实世界数据集进行测试,并通过第 4.1 节中提到的指标进行衡量。 根据我们的结果,MapTR 和 PivotNet 在仅进行一次巡游的情况下,在线地图学习方面取得了相当的性能。 我们的 GNMap 在 F1 分数上优于 GMM。 即使与现有的在线地图学习 SOTA 方法相比,GNMap 也实现了超过 的更高 F1,展示了 HD 地图构建方面的先进性能。
4.3 消融研究
我们在表 3 中报告了消融实验,以验证采用预训练阶段的有效性以及使用不同车载模型的鲁棒性。 我们选择 MapTR [10] 和 PivotNet [6] 作为 SOTA 的一次巡游车载模型,为 GMM [15] 和我们的 GNMap 生成矢量化瓦片。 实验结果表明,无论车载模型如何,GNMap 都始终优于 GMM。 此外,预训练的 GNMap 可以提供至少 比那些没有预训练的模型更高的 F1 分数。
| Method | mAP APped. APdiv. APbou. | mAR ARped. ARdiv. ARbou. | F1 |
| GMM (MapTR) | 62.5 61.8 63.2 62.5 | 66.5 65.4 67.3 66.9 | 64.5 |
| GNMap (MapTR) w/o Pre. | 64.2 64.3 63.6 64.8 | 67.3 66.3 67.4 68.3 | 65.7 |
| GNMap (MapTR) w/ Pre. | 72.7 70.8 74.8 72.5 | 75.6 73.3 78.1 75.4 | 74.1 |
| GMM (PivotNet) | 61.7 60.9 61.5 62.7 | 65.6 64.7 66.6 65.4 | 63.6 |
| GNMap (PivotNet) w/o Pre. | 63.8 62.8 63.7 64.9 | 66.5 65.2 66.3 67.9 | 65.1 |
| GNMap (PivotNet) w/ Pre. | 72.6 72.8 73.1 71.9 | 75.5 74.2 77.3 75.1 | 74.0 |
5 结论
本文介绍了 GNMap 作为一种用于 HD 地图构建的端到端生成框架,它有别于最近在利用自动驾驶汽车上的机载传感器(如激光雷达和摄像头)本地生成矢量化瓦片方面的研究。 GNMap 是一项重要的后续研究,因为它首次尝试融合多个车辆产生的瓦片,以在世界坐标系下自动构建全球化的 HD 地图。 具体来说,它采用了一个纯粹由多头自注意力组成的多层自动编码器作为共享网络,其中参数分别从两个不同的任务(即预训练和微调)中学习,以确保地图生成完整性和元素类别正确性。 消融研究表明,为了在工业应用中取得最佳性能,对 GNMap 进行预训练至关重要。 并且在真实世界数据集上的大量评估的实验结果表明,GNMap 的 F1 分数可以超过最先进的 SOTA 方法。 到目前为止,它已经部署在四维图新公司,作为自动构建中国大陆自动驾驶 HD 地图的必不可少的软件。
参考文献
- [1] Besl, P., McKay, N.D.: A method for registration of 3d shapes. IEEE Transactions on Pattern Analysis and Machine Intelligence 14(2), 239–256 (1992)
- [2] Biber, P., Straßer, W.: The normal distributions transform: A new approach to laser scan matching. Proceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems 3, 2743–2748 vol.3 (2003)
- [3] Borodacz, K., Szczepański, C., Popowski, S.: Review and selection of commercially available imu for a short time inertial navigation. Aircraft Engineering and Aerospace Technology (2021)
- [4] Boubakri, A., Gammar, S.M., Brahim, M.B., Filali, F.: High definition map update for autonomous and connected vehicles: A survey. 2022 International Wireless Communications and Mobile Computing (IWCMC) pp. 1148–1153 (2022)
- [5] Dellaert, F., Kaess, M.: Factor Graphs for Robot Perception. Foundations and Trends in Robotics, Vol. 6 (2017)
- [6] Ding, W., Qiao, L., Qiu, X., Zhang, C.: Pivotnet: Vectorized pivot learning for end-to-end hd map construction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3672–3682 (2023)
- [7] Elghazaly, G., Frank, R., Harvey, S., Safko, S.: High-definition maps: Comprehensive survey, challenges, and future perspectives. IEEE Open Journal of Intelligent Transportation Systems 4, 527–550 (2023)
- [8] Kaplan, E.D.: Understanding gps : principles and applications (1996)
- [9] Li, Q., Wang, Y., Wang, Y., Zhao, H.: Hdmapnet: An online hd map construction and evaluation framework. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 4628–4634. IEEE (2022)
- [10] Liao, B., Chen, S., Wang, X., Cheng, T., Zhang, Q., Liu, W., Huang, C.: Maptr: Structured modeling and learning for online vectorized hd map construction. In: The Eleventh International Conference on Learning Representations (2023)
- [11] Liu, R., Wang, J., Zhang, B.: High definition map for automated driving: Overview and analysis. Journal of Navigation (2020)
- [12] Liu, Y., Yuan, T., Wang, Y., Wang, Y., Zhao, H.: Vectormapnet: End-to-end vectorized hd map learning. In: International Conference on Machine Learning. pp. 22352–22369. PMLR (2023)
- [13] Mi, L., Zhao, H., Nash, C., Jin, X., Gao, J., Sun, C., Schmid, C., Shavit, N., Chai, Y., Anguelov, D.: Hdmapgen: A hierarchical graph generative model of high definition maps. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 4225–4234 (2021)
- [14] Qiao, L., Ding, W., Qiu, X., Zhang, C.: End-to-end vectorized hd-map construction with piecewise bezier curve. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13218–13228 (2023)
- [15] Reynolds, D.A., et al.: Gaussian mixture models. Encyclopedia of biometrics 741(659-663) (2009)
- [16] Roriz, R., Cabral, J., Gomes, T.: Automotive lidar technology: A survey. IEEE Transactions on Intelligent Transportation Systems 23, 6282–6297 (2021)
- [17] Shan, T., Englot, B., Meyers, D., Wang, W., Ratti, C., Rus, D.: Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp. 5135–5142 (2020)
- [18] Shin, J., Rameau, F., Jeong, H., Kum, D.: Instagram: Instance-level graph modeling for vectorized hd map learning. arXiv preprint arXiv:2301.04470 (2023)
- [19] Voita, E., Talbot, D., Moiseev, F., Sennrich, R., Titov, I.: Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In: Korhonen, A., Traum, D., Màrquez, L. (eds.) Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 5797–5808. Association for Computational Linguistics, Florence, Italy (Jul 2019)
- [20] Zhang, J., Singh, S.: Loam: Lidar odometry and mapping in real-time. In: Robotics: Science and Systems (2014)