CDM:一种可靠的公式识别评估公平准确度量
摘要
由于数学表达式的复杂结构和多样化的符号,公式识别面临着重大挑战。 尽管公式识别模型不断取得进展,但这些模型采用的评估指标(如 BLEU 和编辑距离)仍然存在显著的局限性。 它们忽略了这样一个事实,即同一个公式具有多种表示形式,并且对训练数据的分布高度敏感,从而导致公式识别评估中的不公平性。 为此,我们提出了一种字符检测匹配 (CDM) 度量,通过设计一种图像级而非 LaTeX 级的度量得分来确保评估客观性。 具体来说,CDM 将模型预测的 LaTeX 和真实 LaTeX 公式渲染成图像格式的公式,然后采用视觉特征提取和定位技术进行精确的字符级匹配,并结合空间位置信息。 与仅依赖于基于文本的字符匹配的先前 BLEU 和编辑距离度量相比,这种空间感知和字符匹配方法提供了更准确和公平的评估。 在实验中,我们使用 CDM、BLEU 和 ExpRate 度量评估了各种公式识别模型。 他们的结果表明,CDM 更符合人类评估标准,并通过消除由不同公式表示形式引起的差异,在不同模型之间提供了更公平的比较。
1 引言
数学公式识别在文档分析中至关重要,因为它直接影响内容的科学严谨性和准确性。 与标准光学字符识别 (OCR) 不同,公式识别面临着独特的挑战。 公式通常包含多级符号、下标、分数和其他复杂结构,要求模型理解空间和结构关系,而不仅仅是线性、顺序文本。 此外,公式表现出表示多样性,这意味着同一个公式可以用多种有效的方式表达。
近年来,公式识别领域取得了重大进展 (Deng 等人,2017;Zhang 等人,2020;Yuan 等人,2022;Blecher,2022;Paruchuri,2023) 主要由深度学习驱动。 深度学习模型,尤其是那些利用 Transformer 架构和大型预训练策略的模型,在特定场景中表现出优异的性能。 值得注意的是,像 Mathpix 这样的商业公式识别软件以及最近提出的 UniMERNet Wang 等人 (2024) 模型在各种现实世界环境中取得了令人印象深刻的结果。 尽管取得了这些进展,但现有的公式识别评估指标存在着明显的缺陷。 常用的指标,如 BLEU 和编辑距离,主要依赖于基于文本的字符匹配,这带来了以下几个限制:
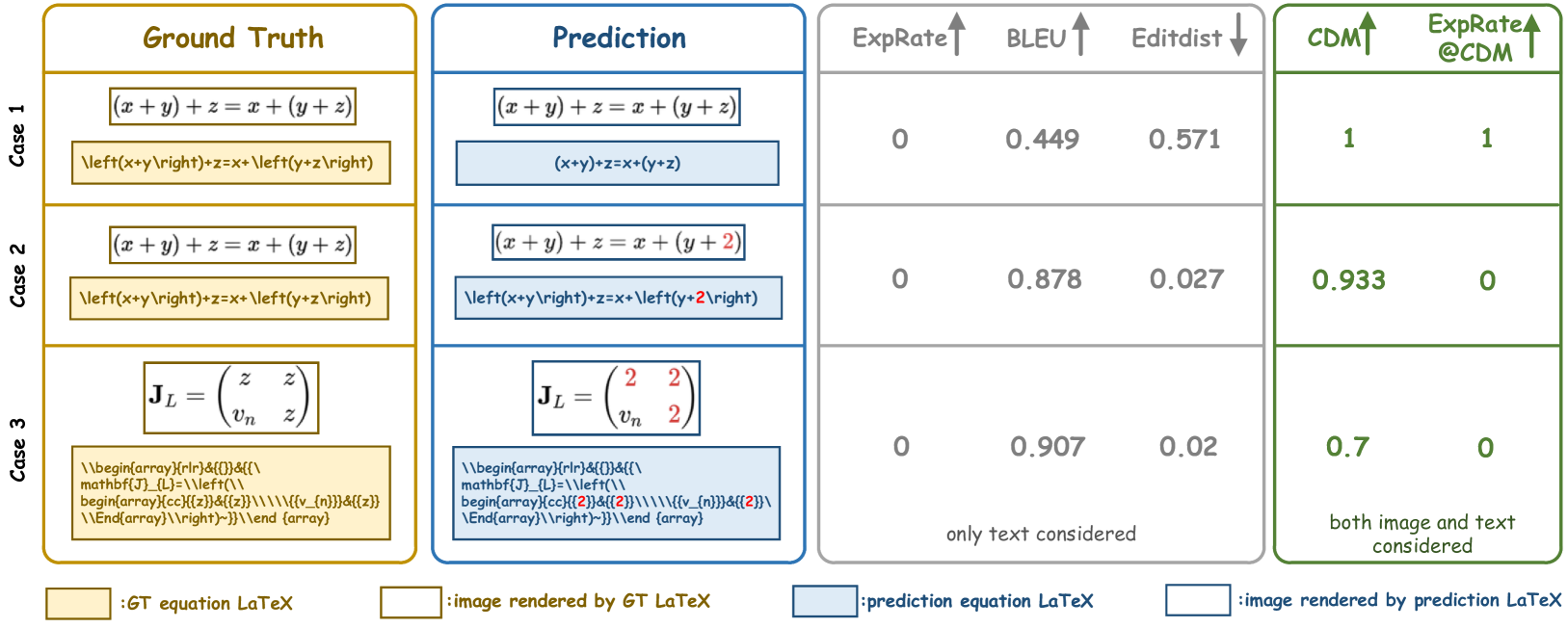
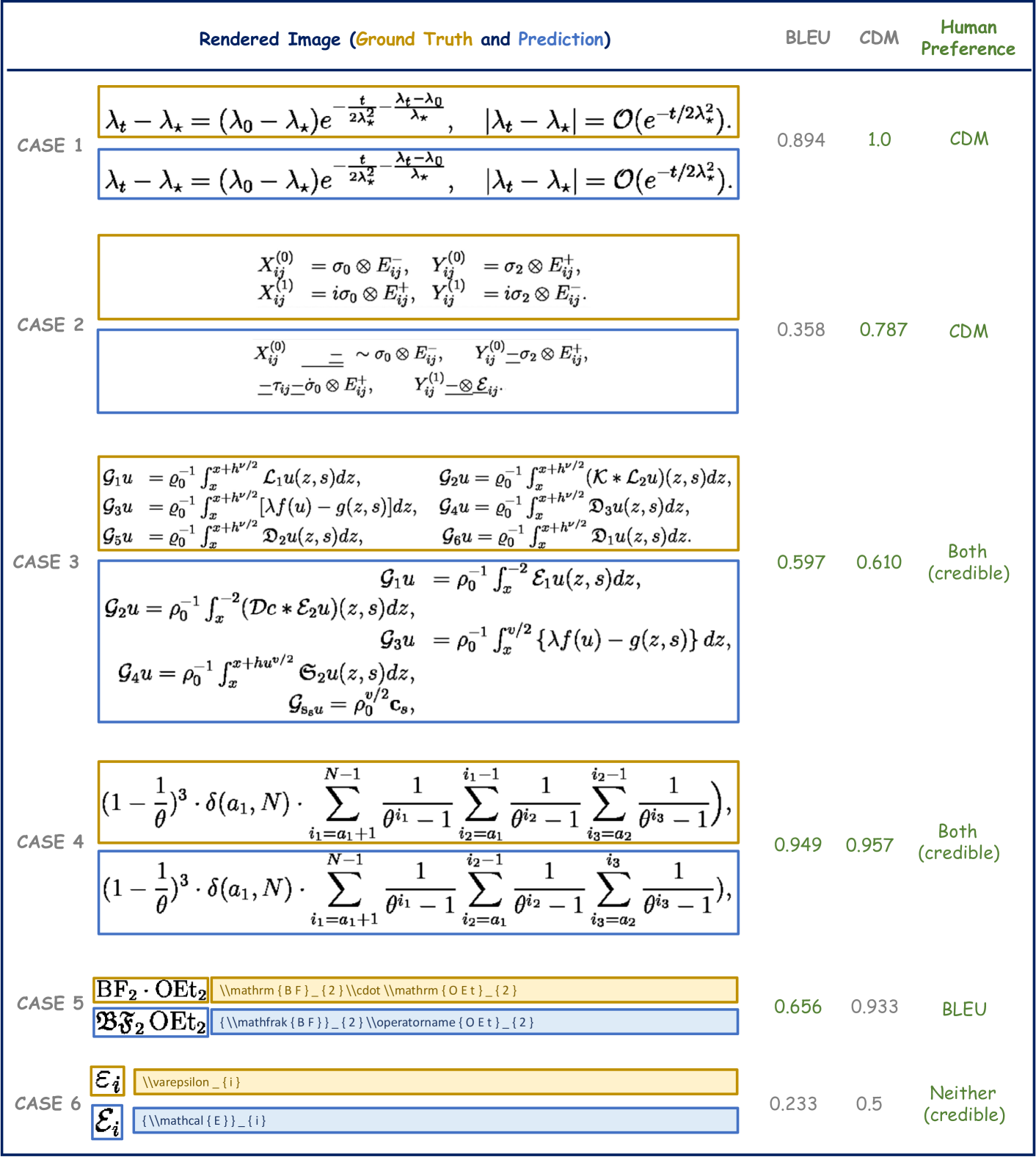
(1) 指标可靠性低。 BLEU 和编辑距离对于评估文本级别相似性的质量是可靠的。 但是,公式表示的多样性使得这些文本级别评估指标不足以精确地反映公式识别质量。 例如,如图 1(情况 1)所示,模型的预测可能生成与真实公式相同的图像。 然而,由于公式表达方式的多样性,使用 ExpRate Deng 等人(2017)、BLEU Papineni 等人(2002) 和 Edit Distance Levenshtein 等人(1966) 获得的评估结果可能有些误导。
(2) 不公平的模型比较。 当前指标可能受到训练和测试数据分布的影响。 如果模型的训练数据分布与测试数据有显著差异,则会对评估指标产生不利影响。 如图 1(情况 1 和情况 2)所示,模型可能产生正确的预测,但由于与真实值的表示差异而得分很低,而错误的预测如果其表示与测试数据分布更一致,则可能得分更高。
(3) 缺乏直观的评分。 BLEU 分数和人类感知之间可能存在很大差异。 例如,在图 1(情况 3)中,模型的预测包含许多错误,但 BLEU 分数高达 0.907,这与人类判断不符。
为了解决这些问题,我们提出了一种新的公式识别评估指标:字符检测匹配 (CDM)。 提出的 CDM 将公式识别评估视为一项基于图像的物体检测任务,通过将预测的 LaTeX 和真实 LaTeX 公式转换为图像格式的公式,并将每个字符视为一个独立的目标。 这种方法克服了公式多样化表示带来的挑战,与人类主观评价标准更一致。 CDM 具有以下优势: 1) 准确性和可靠性。 通过在图像空间中计算指标,CDM 消除了由相同公式的不同有效表示引起的问题,直接反映了识别准确性,并与人类直觉感知更一致。 2) 公平性。 CDM 消除了训练和评估任务之间对一致数据分布的高度依赖,从而能够根据模型的真实识别能力进行公平的比较。 我们的贡献可以概括如下:
-
•
我们对现有的公式识别评估方法进行了详细分析,突出了 ExpRate 和 BLEU 指标的问题和不可靠性。
-
•
我们引入了一种新的评估指标 CDM,该指标通过对预测公式和真实公式的渲染图像进行视觉字符匹配来评估公式识别质量,提供了一种直观且公平的评估标准。
-
•
我们通过对各种主流模型和数据集进行广泛的实验验证了 CDM 的有效性,证明了它在评估公式识别性能方面优于 BLEU 等传统指标。
2 相关工作
2.1 公式识别算法
最初,研究人员采用特定的语法规则来表示公式的空间结构,包括图语法 Lavirotte and Pottier (1998)、关系语法 MacLean and Labahn (2013) 和概率语法 Awal, Mouchere, and Viard-Gaudin (2014); Álvaro, Sánchez, and Benedí (2016)。 此外,CROHME 竞赛 Mouchere et al. (2013, 2014); Mouchère et al. (2016); Mahdavi et al. (2019) 通过整合深度学习算法,推动了手写公式识别的发展。 主要贡献包括具有粗到细注意力的神经编码器-解码器模型 Deng et al. (2017)、树结构解码器 Zhang et al. (2020) 以及整合了弱监督计数模块的计数感知网络 Li et al. (2022)。 ABM 网络 Bian et al. (2022) 采用互蒸馏和注意力聚合模块,而基于 Transformer 的解码器 Zhao et al. (2021) 简化了模型架构。 语法感知网络 (SAN) Yuan et al. (2022) 将识别建模为树遍历过程,显著提高了复杂表达式的准确性。 总体而言,这些模型采用 ExpRate 来评估公式。
在文档信息提取 Xia et al. (2024a, b) 中,Donut Kim et al. (2022) 直接将输入文档转换为结构化输出,而无需使用传统的 OCR 工具。 Texify Paruchuri (2023) 和 UniMERNet Wang et al. (2024) 是使用 Donut (Kim et al., 2022) 设计的,利用了更多样化的数据集和数据增强操作。 Nougat (Blecher et al., 2023) 被设计为将 PDF 文档从截图转换为 Markdown 格式,使文档内容(例如 表格和公式)更容易编辑。 这些方法使用 BLEU 和编辑距离度量来评估公式。
2.2 公式识别评估指标
BLEU最初是为机器翻译任务而提出的,它使用生成的文本和参考文本之间的 N 元语法(N 个词的序列)来匹配标准文本和机器翻译文本。 它应用一个简洁惩罚因子来生成最终的 BLEU 分数 Papineni et al. (2002):
| (1) |
其中 BP 是简洁惩罚因子, 是 N 元语法匹配结果, 范围从 1 到 4。
编辑距离 也是一种常用的度量标准,用于评估生成文本和参考文本之间的相似性。 它测量将一个文本转换为另一个文本所需的插入、删除或替换次数,编辑距离越小,相似度越高 Levenshtein et al. (1966)。
ExpRate 指的是在所有样本中,文本完全匹配的样本所占的比例。 与 BLEU 和编辑距离相比,ExpRate 在评估中更粗略,也更严格 Li et al. (2022)。
以上三种指标可以有效地评估真实值和参考值之间的文本差异,使其适合需要严格匹配的任务。 特别是 BLEU 和编辑距离,与 ExpRate 相比,它们提供了更精细的文本识别能力评估,使其广泛应用于文档识别等广泛的文本识别任务中 Blecher et al. (2023); Huang et al. (2024)。 这些指标也应用于公式识别,大多数开源模型,如 Pix2Tex Blecher (2022) 和 Texify,采用它们进行评估和比较。
除了基于文本的指标之外,图像编辑距离也被用来衡量预测公式的准确性 Wang and Liu (2021)。 图像处理指标,如 MSE(均方误差)和 SSIM Wang et al. (2004) 也已被考虑。 结构化图表定向表示指标 (SCRM) Xia et al. (2023) 旨在全面评估结构化三元组表示所代表的信息。 然而,这些指标更适合于自然图像。 对于公式图像等文档图像,即使是轻微的字符错位也会导致明显的惩罚,使这些指标不太适合公式识别。
3 当前指标的局限性
尽管 ExpRate、BLEU 和编辑距离被广泛用于公式评估任务,但它们在准确反映公式识别性能方面存在显着局限性,尤其是在训练和测试数据分布之间存在领域差距的情况下。 主要原因是单个公式可以有多种有效的 LaTeX 表示,导致地面实况 (GT) LaTeX 不唯一,从而为公式评估引入了固有缺陷。
如 图 1 的案例 1 所示,公式 对应于 GT 标注 "\left(x+y\right)+z=x+\left(y+z\right)"。 当模型的预测为 "(x+y)+z=x+(y+z)" 时,该预测是正确的,因为渲染后的公式图像与 GT 图像匹配,尽管 LaTeX 语法不同。 从理论上讲,ExpRate/BLEU/编辑距离结果应为 1/1/0,表示正确实例。 但是,在实践中,ExpRate 为 0,BLEU 为 0.449,编辑距离为 0.571,未能准确评估公式的质量。
上述问题使得客观评估不同公式识别模型的性能极具挑战性。 例如,如 图 1 的案例 2 所示, 一个字符 "z" 被误识别为 "2"。 预测不正确,ExpRate、BLEU 和编辑距离指标反映了这种错误。 然而,与模型预测正确的案例 1 相比,案例 2 中错误预测的 BLEU 和编辑距离指标优于案例 1 中正确预测的指标。
一种 LaTeX 正则化方法将 LaTeX 代码抽象成树形结构并标准化元素,从而解决了 LaTeX 语法多样性问题 Deng 等人(2017)。 Pix2tex (Blecher, 2022)、Texify (Paruchuri, 2023) 和 UniMERNet (Wang 等人,2024) 在评估之前将这种正则化方法用作预处理步骤,这可以解决部分语法不一致问题。 例如,"x^b_a"、"x^{b}_{a}" 和 "x_{a}^{b}" 都编译为 。 直接计算 BLEU 分数无法正确评估模型的预测质量。 正则化代码将这些统一为一致的格式,例如始终添加花括号并将上标放在下标之前,这有助于后续指标计算的公平性。 但是,正则化并不能解决所有 LaTeX 语法多样性问题。 一些符号有多种表示形式,例如 "\leq" 和 "\le" 都表示 。 由于 LaTeX 符号库庞大,并且扩展包提供了许多额外的符号(例如,amsmath,amssymb),因此穷举列出这些表示形式具有挑战性。
总体而言,虽然正则化缓解了一些问题,但它并不能完全解决当前指标在评估公式识别性能方面固有的局限性。 这突出了对更健壮、更全面的评估指标的需求,该指标能够准确地反映公式识别在不同表示形式中的质量。
4 字符检测匹配
由于 LaTeX 表达式多样性,基于文本的字符匹配方法对于公式识别评估不可靠。 CDM 的基本思想是比较 LaTeX 文本生成的渲染图像。 如果从预测的 LaTeX 源代码生成的图像与从真实 LaTeX 源代码生成的图像匹配,则认为该公式完全正确。 然而,直接比较原始公式和预测公式的像素值并不是理想的。 预测中的任何错误、多余或缺失的字符都会导致后续字符匹配错误。 此外,两个相似的公式可能具有不同的布局,一个可能是单行公式,而另一个可能是由于换行符造成的多行公式。 因此,需要一个更强大的算法来计算预测结果与真实图像之间的匹配程度。
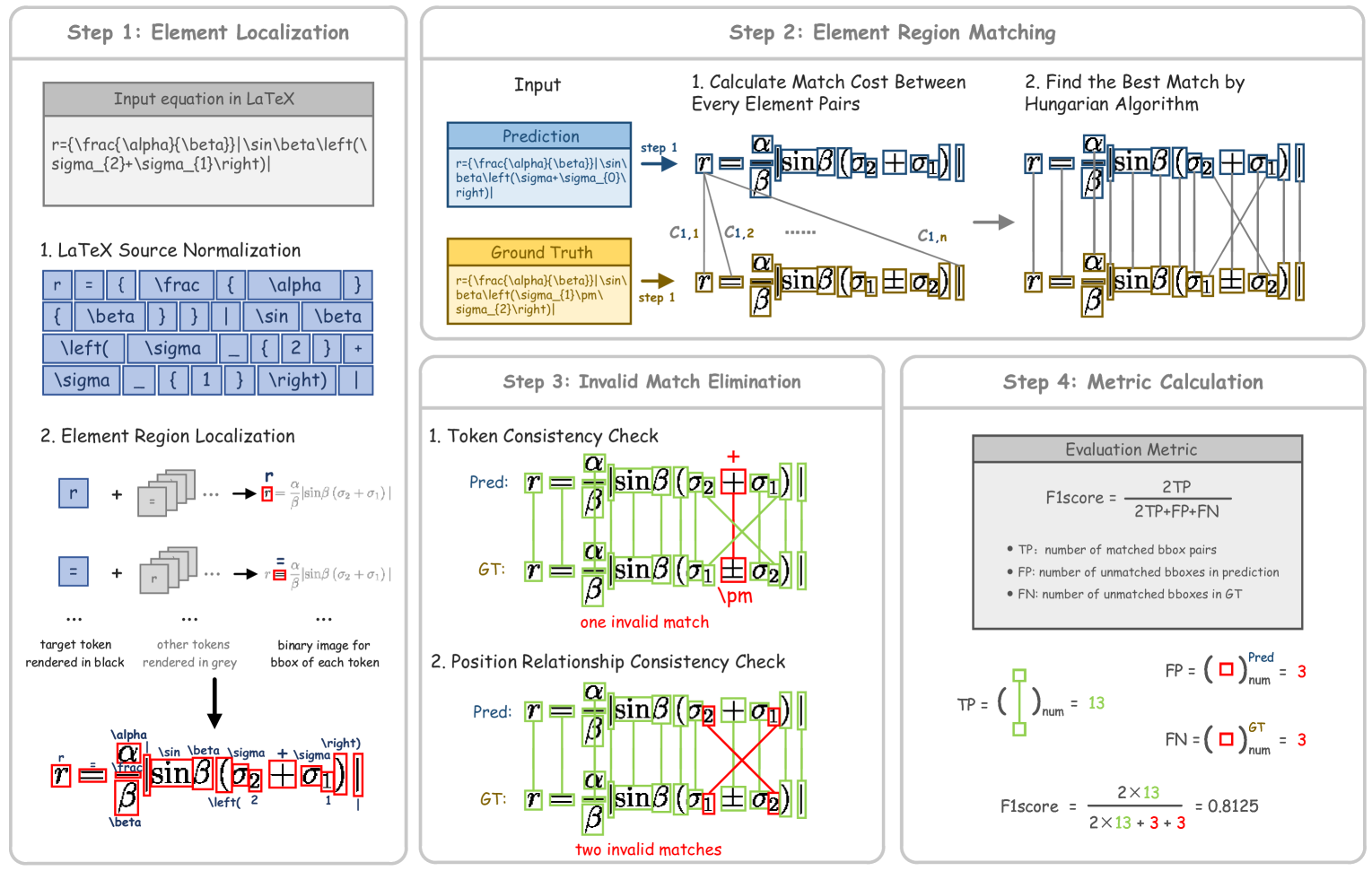
为此,我们提出了一种度量方法,该方法将二分匹配步骤融入图像中的元素级匹配,从而提供更直观的评估。 如 图 2 所示,该算法包含以下四个阶段。
4.1 元素定位
首先,提取渲染图像中每个单独元素的边界框(bboxes),然后进行后续步骤。
LaTeX 源代码规范化。 将真实公式和预测公式的 LaTeX 源代码规范化,将其分解为单个符元,例如 "2", "a", "A", "\alpha", "\sin"。 将复合元素分解为单个字符,例如,"\frac ab" 被分解为 "\frac {a} {b}"。
元素区域定位。 基于规范化的 LaTex 源代码,以颜色渲染每个符元。 为了定位元素 ,使用 "\black{e}" 渲染它,同时使用 "\gray{}" 渲染其他元素。 通过对完全渲染的公式进行二值化以提取每个元素的边界框,重复此过程,直到所有元素都被准确地定位。
4.2 元素区域匹配
在此阶段,双向匹配方法将预测的元素与相应的真实元素配对。 基于元素定位,每个公式会获得两个集合:一个是真实独立元素的集合 ,另一个是预测独立元素的集合 。 每个集合中的独立元素数量分别为 和 ,其中 为较小集合中的元素数量。
为了衡量 和 之间的相似度,我们通过识别每个预测元素对应的真实元素来匹配两个集合中的元素。 我们使用双向匹配匈牙利算法 Kuhn (1955),如DETR Carion et al. (2020) 中所述,来找到一个排列 ,使总匹配成本最小化:
| (2) |
| (3) |
其中,匹配成本 定义为三个成分的加权和,具体介绍如下:
-
•
符元匹配成本 :此成分衡量两个边界框对应的符元是否相同。 如果相同,则成本为 0;如果不同,则成本为 1。 对于呈现相同但不同的符元,例如 "("、"\left(" 和 "\big(",成本为 0.05,可以表述如下:
(4) 其中, 表示差异但呈现相同的符元。
-
•
位置邻近成本 :此成分使用两个边界框坐标的 L1 范数来衡量两个边界框位置的邻近度,可以表述如下:
(5) 其中, 和 为边界框坐标的维度。
-
•
顺序相似度成本 :此成分衡量原始 LaTeX 源码(阅读顺序的近似值)中符元顺序的相似度。 顺序被归一化到 [0, 1] 范围内,L1 范数可以计算如下:
(6) 此计算类似于 ,其中 。
总体而言,权重 用于平衡三个成分的贡献。 通过采用这种综合匹配策略,我们确保了对预测元素和真实元素之间对应关系的更准确和稳健的评估,从而提高了公式识别质量的整体评估。
4.3 无效匹配消除
使用匈牙利匹配算法将预测结果的各个元素与真实元素配对后,我们需要验证这些配对并消除无效匹配。 此过程涉及两个步骤:
符元一致性检查。 检查每个匹配对中的元素在字符方面是否一致。 如果它们不一致,则丢弃匹配。
位置关系一致性检查。 数学公式中元素的相对位置至关重要。 例如,在表达式 和 中,二分匹配可能会将 2 与 2 配对,将 3 与 3 配对,但它们的含义和视觉表示完全不同。 因此,我们需要检查匹配对中位置关系的一致性。 我们将匹配对中的每个元素视为一个边界框,并分析它们的相对位置。 具体来说,我们假设真实元素和预测元素之间存在仿射变换:
| (7) |
其中 是仿射变换矩阵。 为了识别不一致的匹配对,我们检测不符合这种变换关系的配对。 为此,我们采用 RANSAC 算法 Fischler and Bolles (1981)。 RANSAC 可以在存在噪声的情况下确定最佳变换矩阵 。 鉴于公式在渲染过程中通常水平排列,我们将变换矩阵中的旋转角度固定为 0,仅考虑平移和缩放。 这种方法不仅提高了 RANSAC 算法的收敛速度,还提高了最终的匹配精度。
为了解决公式中换行带来的影响,我们执行多轮 RANSAC 迭代,以确保尽可能多的匹配对符合变换关系。 在多次迭代之后,仍然不符合变换关系的匹配对被认为是错误的,并被消除。
以上两个步骤有效地消除了无效的匹配对,确保了更准确的最终匹配结果。
4.4 指标计算
我们使用 F1-Score 作为评估 CDM(字符检测指标)的默认指标,定义为:
| (8) |
其中 表示真阳性, 表示假阳性, 表示假阴性。
为了进一步评估公式识别的准确性,我们引入 指标,定义为:
| (9) |
其中 是一个指示函数,如果 则等于 1,否则等于 0, 是公式的总数。 该指标表示模型预测结果完全匹配的公式的比例。 从本质上讲, 充当专门用于公式识别的 ExpRate 指标的精确版本。
5 实验
5.1 模型和数据
我们通过使用主观印象和客观指标评估几个主流公式识别模型来验证 CDM 指标。 这些模型包括开源 UniMERNet Wang 等人 (2024)、Texify (Paruchuri, 2023)、Pix2tex (Blecher, 2022) 和 商业 Mathpix API,所有这些模型都在 UniMER-Test 数据集上进行了测试。 此外,我们还评估了文档级模型,例如开源 Nougat Blecher 等人 (2023) 和 商业 GPT-4o GPT-4o (2024)。 魏等人(2023) 和 StrucTexTv3 Lyu 等人(2024) 被排除在外,因为它们目前不可用。
UniMER-Test 数据集。 该数据集包含 23,757 个公式样本,分为简单印刷表达式 (SPE)、复杂印刷表达式 (CPE)、截图表达式 (SCE) 和手写表达式 (HWE)。 我们使用这些类别来进行模型评估。
Tiny-Doc-Math 数据集。 为了评估文档级识别,我们构建了 Tiny-Doc-Math 数据集,该数据集包含 2024 年 6 月之后发表的数学和计算机科学领域的 arXiv 论文,以确保它们不在比较模型的训练数据中。 我们获取 LaTeX 代码和相应的 PDF,使用正则表达式匹配显示的公式,并手动验证它们。 总体而言,该数据集包含 12 个 PDF,共计 196 页和 437 个公式。
该验证集包括公式级和文档级评估:
-
•
公式级: 使用单个渲染的公式图像作为输入,我们评估 Mathpix、Pix2Tex 和 UniMERNet。 这些模型接受裁剪的公式图像作为输入,我们将模型输出与真实值进行比较,以计算相关指标。
-
•
文档级: 使用 PDF 或图像作为输入,我们评估 Nougat、GPT-4o 和 Mathpix,它们可以将整个 PDF 页面转换为 Markdown 格式。 我们使用正则表达式匹配模型输出中显示的公式,并将它们与真实 LaTeX 公式进行比较,以计算相关指标。
5.2 CDM 的可信度评估
渲染成功率
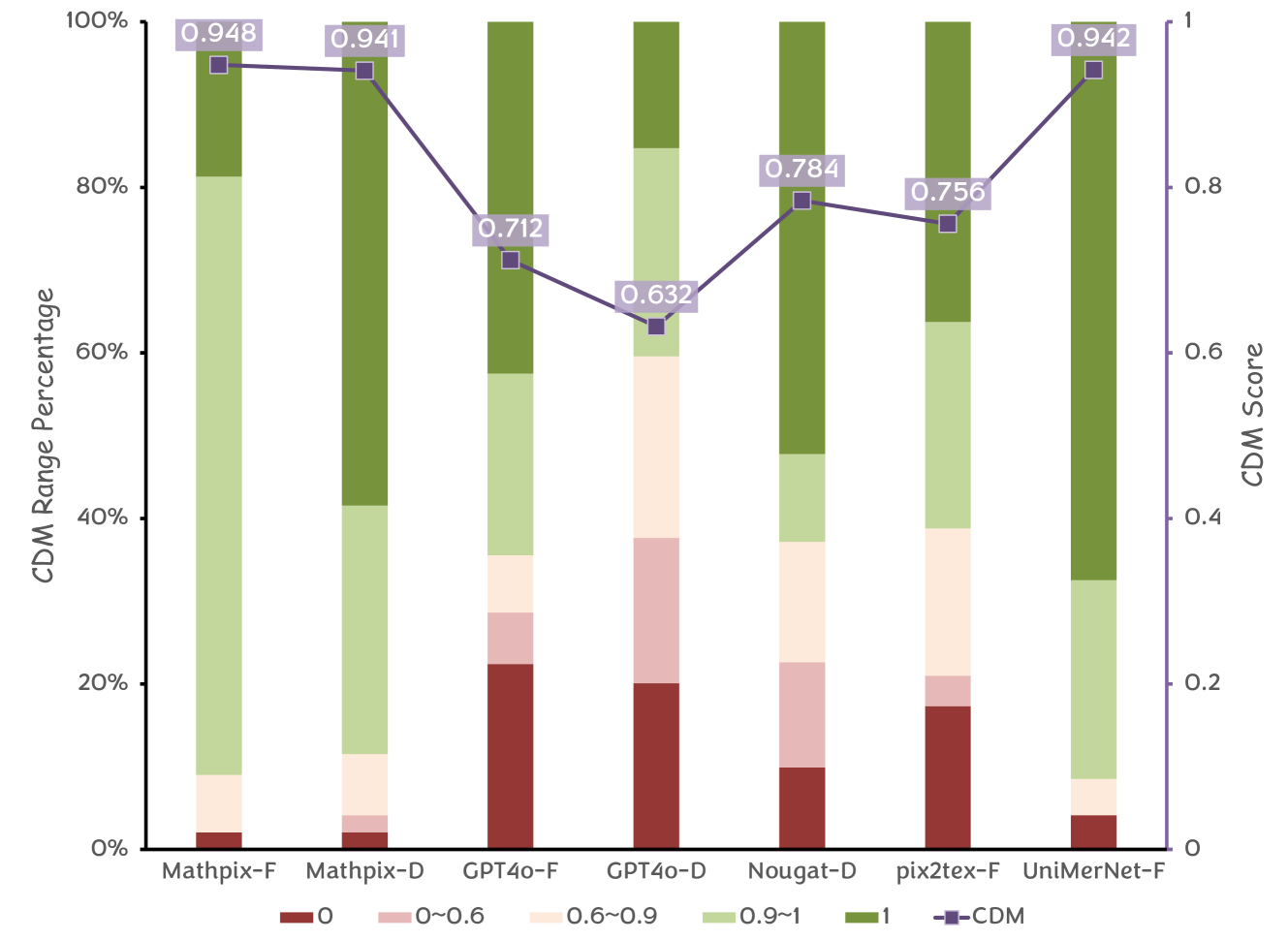
CDM 指标依赖于公式图像的成功渲染。 对于无法渲染图像的模型,我们将其 CDM 分数设置为 0,因为渲染失败表明预测的 LaTeX 代码缺少关键元素。 Pix2tex、Texify、UniMERNet 和 Mathpix 在 UniMER-Test 数据集上的渲染成功率分别为 86.17%、94.97%、97.62% 和 98.95%,这确保了 CDM 指标的适用性和可靠性。
| Model | ExpRate | ExpRate@CDM | BLEU | CDM |
|---|---|---|---|---|
| Pix2tex | 0.1237 | 0.2413 | 0.4080 | 0.570 |
| Texify | 0.2288 | 0.5005 | 0.5890 | 0.759 |
| Mathpix | 0.2610 | 0.4860 | 0.8067 | 0.896 |
| UniMERNet | 0.4799 | 0.8099 | 0.8425 | 0.959 |
| Method | SPE | CPE | HWE | SCE | ||||
|---|---|---|---|---|---|---|---|---|
| BLEU | CDM | BLEU | CDM | BLEU | CDM | BLEU | CDM | |
| Pix2tex Blecher (2022) | 0.8730 | 0.9392 | 0.6550 | 0.4614 | 0.0120 | 0.2131 | 0.0920 | 0.6531 |
| Texify Paruchuri (2023) | 0.9060 | 0.9856 | 0.6900 | 0.7065 | 0.3410 | 0.5341 | 0.4200 | 0.7991 |
| Mathpix | 0.7920 | 0.9664 | 0.8061 | 0.8421 | 0.8060 | 0.9305 | 0.8182 | 0.8156 |
| UniMERNet Wang et al. (2024) | 0.9170 | 0.9955 | 0.9160 | 0.9300 | 0.9210 | 0.9526 | 0.6160 | 0.9513 |
| Image Type | Model | BLEU | CDM | ExpRate@CDM |
|---|---|---|---|---|
| Formula | Pix2tex | 0.4648 | 0.7563 | 0.3592 |
| GPT-4o | 0.6431 | 0.7120 | 0.4210 | |
| UniMERNet | 0.6056 | 0.9422 | 0.6681 | |
| Mathpix | 0.6112 | 0.9480 | 0.1853 | |
| Document | GPT-4o | 0.3148 | 0.6317 | 0.1510 |
| Nougat | 0.5713 | 0.7838 | 0.5171 | |
| Mathpix | 0.5997 | 0.9413 | 0.5789 |
用户偏好评估
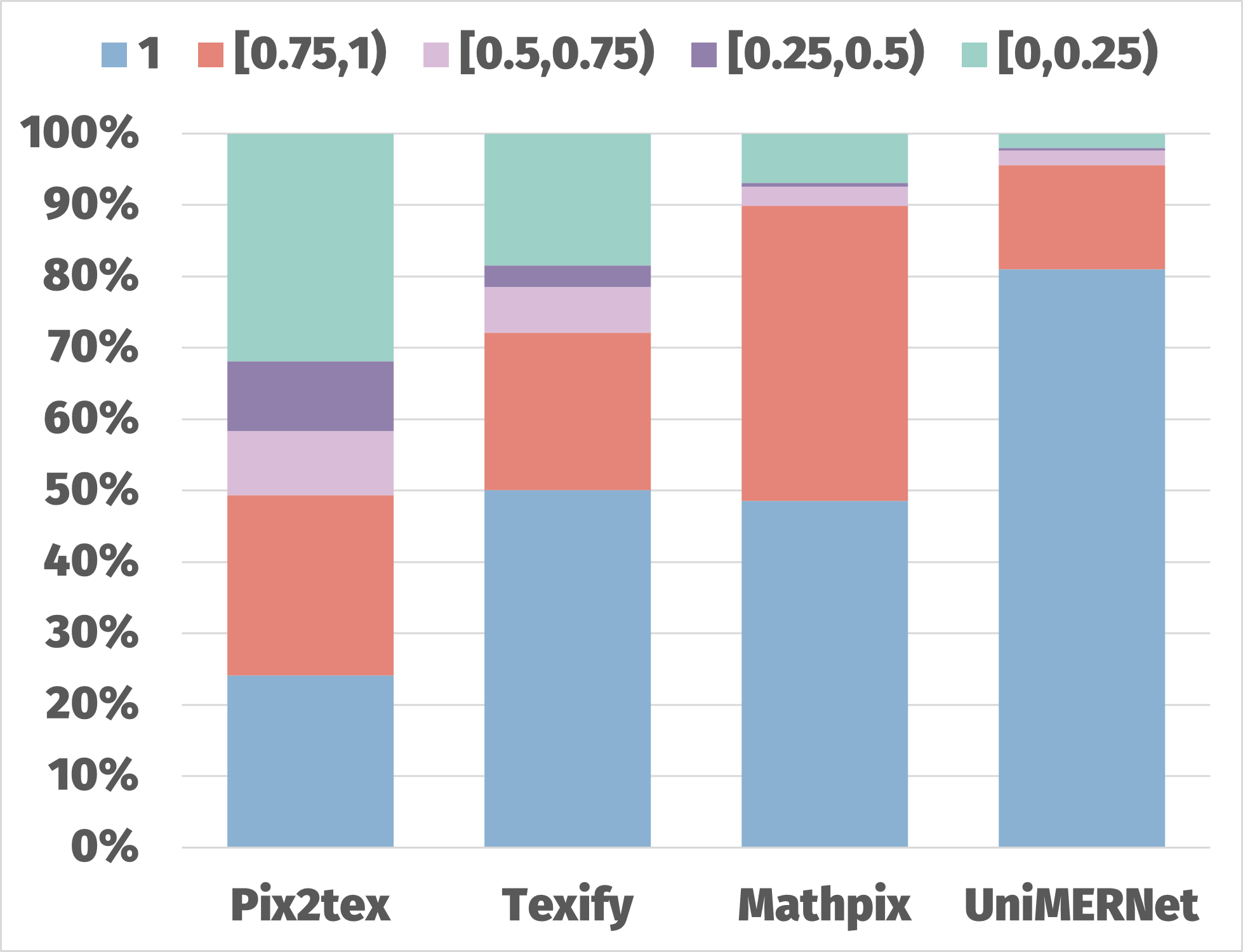
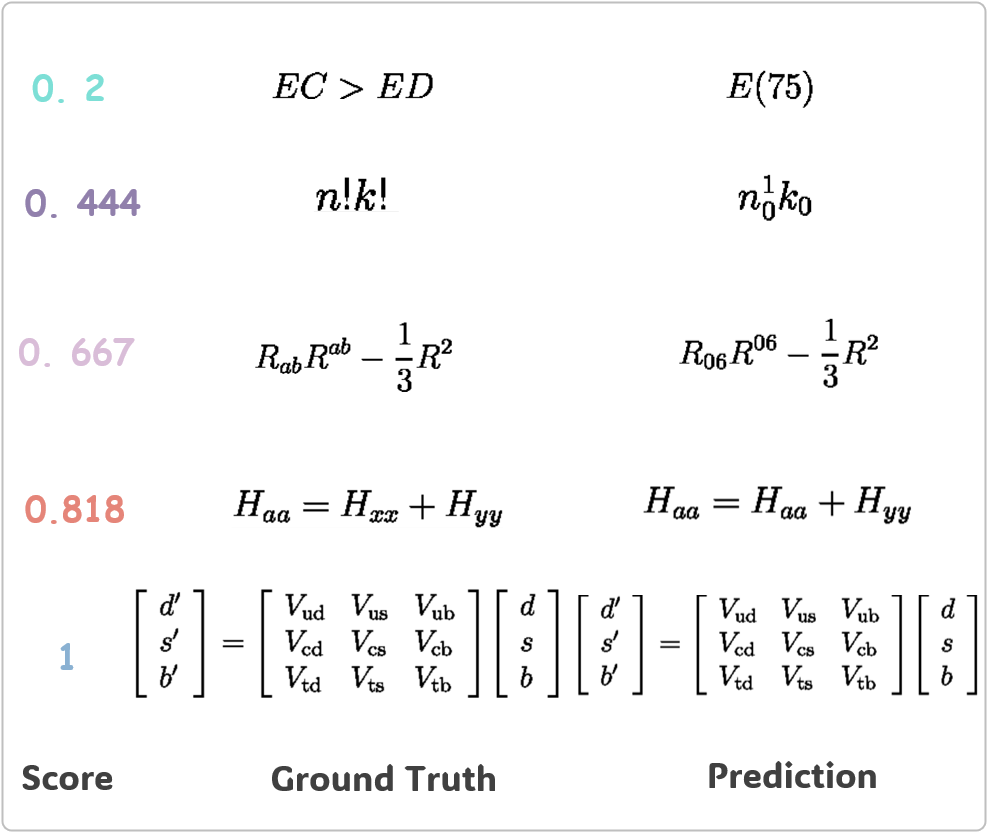
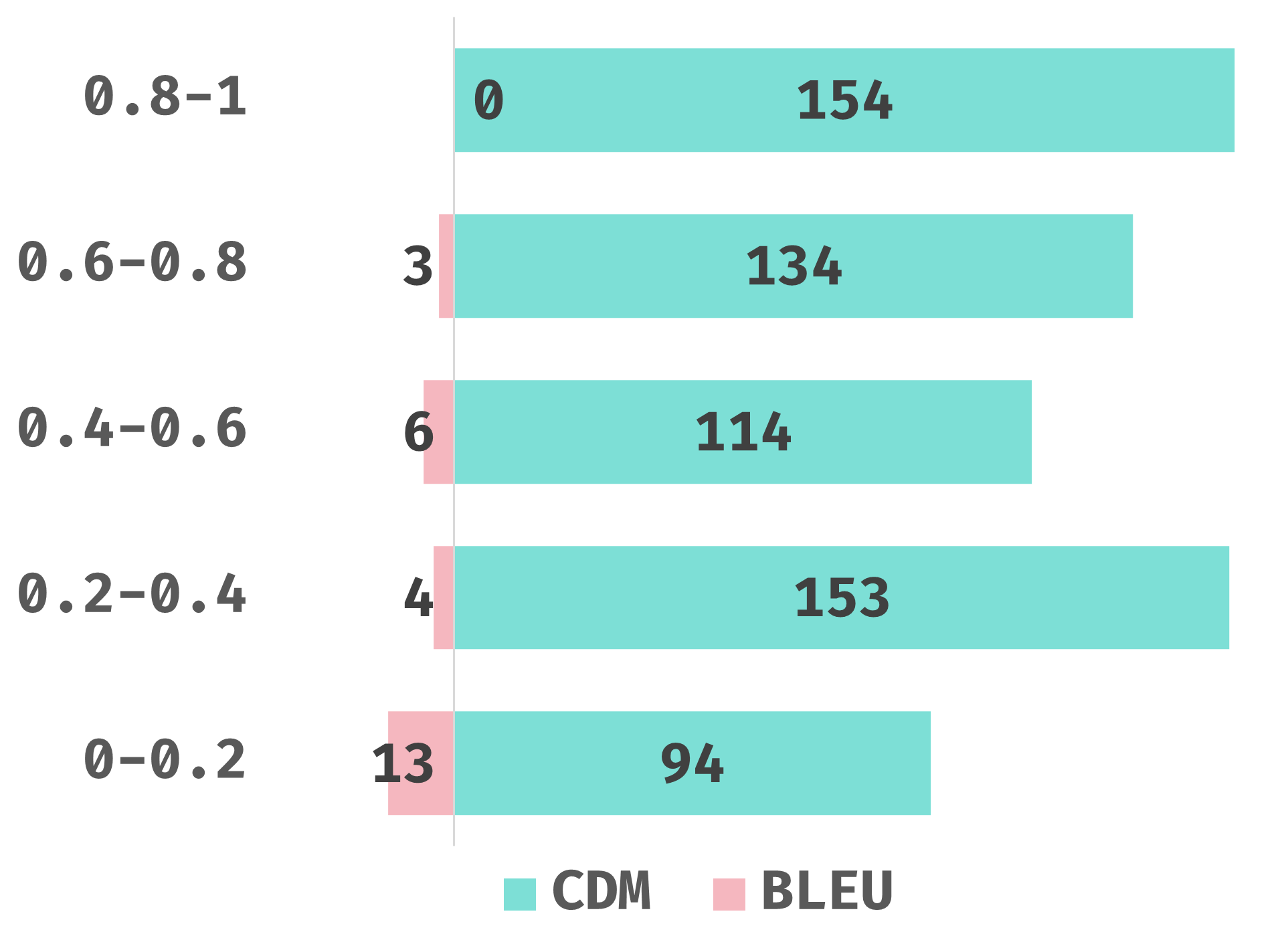
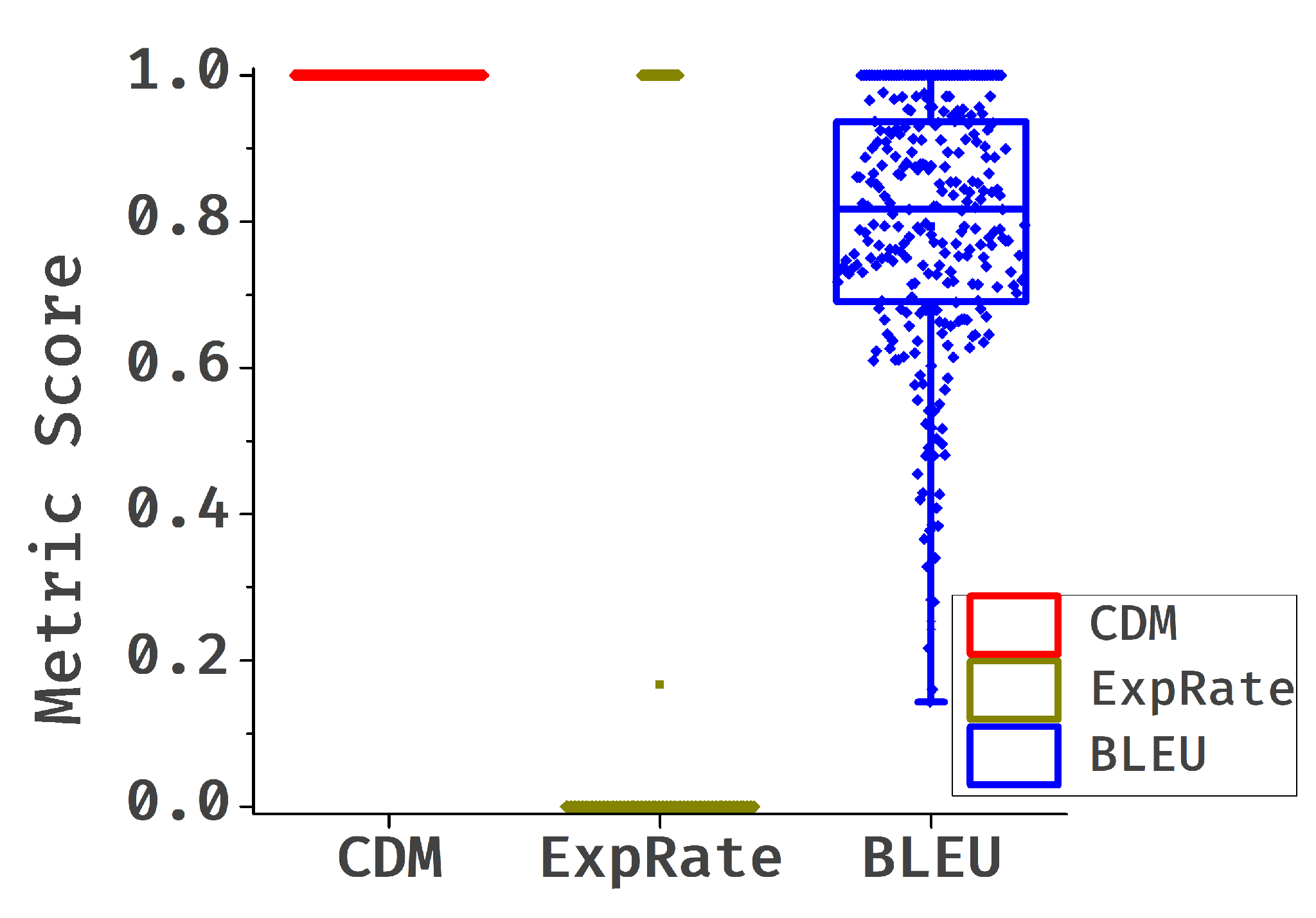
我们分析了 UniMER-Test 数据集上四种模型的 CDM 分数分布。 如 图 3(a) 所示,Mathpix 和 UniMERNet 在 CDM 分数方面表现良好。 我们通过随机从不同分数范围内选择样本,对 Pix2Tex 模型进行了详细分析,以评估预测质量是否与 CDM 分数相对应。 图 3(b) 中的分析表明,CDM 分数有效地反映了公式质量,分数越高表示错误越少。
为了验证 CDM 指标与人工评估之间的一致性,我们进行了一项大规模实验。 我们从 Pix2Tex 预测结果中选择了 1008 个 CDM 分数,确保分数分布平衡。 我们设计了一个标注界面,显示一个真实标签和对应的预测 LaTeX 渲染图像。 标注者在 ScoreA、ScoreB、Both(可信)和 Neither(可信)之间进行选择。 ScoreA 和 ScoreB 分别对应 BLEU 和 CDM 分数,但它们的顺序是随机的。
客观稳定性评估
为了评估公式书写风格对 CDM 和 BLEU 指标的影响,我们随机选择了 50 个带有 LaTeX 源代码的公式,并使用 GPT-4 重新编写每个公式五次,生成 250 个额外的公式。 我们手动验证了这些公式,以确保它们渲染的结果与最初的 50 个公式相同。 使用最初的 LaTeX 源代码作为真实值,我们分析了 BLEU 和 CDM 指标的分数分布。 如 图 4(c) 所示,CDM 指标不受风格变化的影响,所有样本的分数均为 1。 相反,BLEU 指标的分数是分散的,使其不适合公式评估。 尽管格式发生了变化,CDM 指标仍然健壮可靠。
5.3 主流模型的评估
我们使用 CDM 和 BLEU 指标对主流模型进行了详细的评估。 请注意,本文中所有 BLEU 指标都已标准化 Deng 等人 (2017); Blecher (2022)。 然而,正如限制部分所述,标准化操作无法解决所有问题,这将在接下来的实验中显而易见。
UniMER-Test 评估
如 表 1 所示,四种模型在 UniMER-Test 数据集上的评估结果表明,根据 BLEU 和 CDM 指标,其质量从低到高依次为:Pix2Tex、Texify、Mathpix 和 UniMERNet。 ExpRate@CDM 清楚地显示了每个模型完全正确预测的比例,表明基于文本字符的 ExpRate 是不可靠的。
从 表 1 中的结果可以看出,BLEU 和 CDM 指标的趋势是一致的。 为了验证使用 BLEU 指标进行模型比较的可靠性,我们进一步在 UniMER-Test 子集上展示了评估结果。 如 表 2 所示,我们观察到两个显著的异常:首先,在 SCE 子集中,比较 Mathpix 和 UniMERNet 模型的质量时,BLEU 和 CDM 指标得出了相反的结论。 对 UniMERNet 论文的详细审查表明,SCE 子集是根据 Mathpix 进行标注,然后手动修正的。 这意味着 SCE 公式的表达风格与 Mathpix 更一致。 因此,尽管 CDM 指标表明 UniMERNet 具有更好的实际模型质量,但 BLEU 指标受表达风格的影响,表明 Mathpix 更优。 其次,对于 Pix2Tex 模型,BLEU 指标在 HWE 和 SCE 子集中非常低,但在 SPE 和 CPE 子集中表现良好。 这种差异产生的原因是,Pix2Tex 训练集包含大量来自 arXiv 的印刷公式,而缺乏 HWE 和 SCE 风格的数据。
这些异常清楚地说明了 BLEU 指标在评估公式识别模型质量方面的局限性。 相反,本文提出的 CDM 指标是公平和直观的。
Tiny-Doc-Math 评估
Tiny-Doc-Math 的评估结果显示在 表 3 中。 对于裁剪的公式输入(公式级别),所有四个模型表现都相当好,CDM 得分都在 0.7 以上。 值得注意的是,当前领先的多模态大型模型 GPT-4o 在四个模型中 BLEU 得分最高,但 CDM 得分最低。 这种差异表明 BLEU 指标可能不可靠,这表明 GPT-4o 的公式识别精度还有提升空间,落后于传统的 SOTA 模型。 此外,虽然 Mathpix 的 CDM 得分最高,但只有 18.53% 的公式完全准确。 手动验证显示许多公式末尾缺少逗号或句号。
当输入是文档级别的截图时,模型会输出整个文档的识别结果(不仅仅是公式)。 评估是通过匹配识别的块公式来进行的。 在这种情况下,可以观察到 GPT-4o 的准确率进一步下降。 相反,Mathpix 和 Nougat 的表现更好,但即使是文档多模态大型模型 Nougat 也只取得了 0.7852 的 CDM 得分。 这表明在文档级别的识别模型方面仍然有很大的提升空间。 Mathpix 仍然是表现最好的,完全正确的公式率为 57.89%。 文档级别识别的准确性对于科学知识问答等高级文档理解任务至关重要,CDM 为选择公式模型提供了极好的标准,并为改进公式识别提供了方向。
6 结论
在本文中,我们介绍了字符检测匹配 (CDM),这是一种用于公式识别的全新评估指标。 CDM通过利用空间字符匹配来解决现有指标的不足,克服了公式表示多样性的问题。 对不同模型和数据集的综合评估表明,CDM在精确反映识别质量方面具有优越性。 CDM提供了一种更公平、更直观的评估方法,突出了当前评估指标的问题,为该领域的未来研究和改进铺平了道路。
参考文献
- Álvaro, Sánchez, and Benedí (2016) Álvaro, F.; Sánchez, J.-A.; and Benedí, J.-M. 2016. An integrated grammar-based approach for mathematical expression recognition. Pattern Recognition, 51: 135–147.
- Awal, Mouchere, and Viard-Gaudin (2014) Awal, A.-M.; Mouchere, H.; and Viard-Gaudin, C. 2014. A global learning approach for an online handwritten mathematical expression recognition system. Pattern Recognition Letters, 35: 68–77.
- Bian et al. (2022) Bian, X.; Qin, B.; Xin, X.; Li, J.; Su, X.; and Wang, Y. 2022. Handwritten mathematical expression recognition via attention aggregation based bi-directional mutual learning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 36, 113–121.
- Blecher (2022) Blecher, L. 2022. pix2tex - LaTeX OCR. https://github.com/lukas-blecher/LaTeX-OCR. Accessed: 2024-2-29.
- Blecher et al. (2023) Blecher, L.; Cucurull, G.; Scialom, T.; and Stojnic, R. 2023. Nougat: Neural optical understanding for academic documents. arXiv.org, 2308.13418.
- Carion et al. (2020) Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV), 213–229. Springer.
- Deng et al. (2017) Deng, Y.; Kanervisto, A.; Ling, J.; and Rush, A. M. 2017. Image-to-markup generation with coarse-to-fine attention. In International Conference on Machine Learning (ICML), 980–989. PMLR.
- Fischler and Bolles (1981) Fischler, M. A.; and Bolles, R. C. 1981. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 24(6): 381–395.
- GPT-4o (2024) GPT-4o. 2024. GPT-4o. https://openai.com/index/hello-gpt-4o/. Accessed: 2024-08-15.
- Huang et al. (2024) Huang, M.; Liu, Y.; Liang, D.; Jin, L.; and Bai, X. 2024. Mini-Monkey: Alleviate the Sawtooth Effect by Multi-Scale Adaptive Cropping. arXiv.org.
- Kim et al. (2022) Kim, G.; Hong, T.; Yim, M.; Nam, J.; Park, J.; Yim, J.; Hwang, W.; Yun, S.; Han, D.; and Park, S. 2022. Ocr-free document understanding transformer. In European Conference on Computer Vision (ECCV), 498–517. Springer.
- Kuhn (1955) Kuhn, H. W. 1955. The Hungarian method for the assignment problem. Naval research logistics quarterly, 2(1-2): 83–97.
- Lavirotte and Pottier (1998) Lavirotte, S.; and Pottier, L. 1998. Mathematical formula recognition using graph grammar. In Lopresti, D. P.; and Zhou, J., eds., Document Recognition V, San Jose, CA, USA, January 24, 1998.
- Levenshtein et al. (1966) Levenshtein, V. I.; et al. 1966. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet physics doklady, volume 10, 707–710. Soviet Union.
- Li et al. (2022) Li, B.; Yuan, Y.; Liang, D.; Liu, X.; Ji, Z.; Bai, J.; Liu, W.; and Bai, X. 2022. When counting meets HMER: counting-aware network for handwritten mathematical expression recognition. In European Conference on Computer Vision (ECCV), 197–214. Springer.
- Lyu et al. (2024) Lyu, P.; Li, Y.; Zhou, H.; Ma, W.; Wan, X.; Xie, Q.; Wu, L.; Zhang, C.; Yao, K.; Ding, E.; et al. 2024. StrucTexTv3: An Efficient Vision-Language Model for Text-rich Image Perception, Comprehension, and Beyond. arXiv.org.
- MacLean and Labahn (2013) MacLean, S.; and Labahn, G. 2013. A new approach for recognizing handwritten mathematics using relational grammars and fuzzy sets. International Journal on Document Analysis and Recognition (IJDAR), 16: 139–163.
- Mahdavi et al. (2019) Mahdavi, M.; Zanibbi, R.; Mouchere, H.; Viard-Gaudin, C.; and Garain, U. 2019. ICDAR 2019 CROHME+ TFD: Competition on recognition of handwritten mathematical expressions and typeset formula detection. In International Conference on Document Analysis and Recognition (ICDAR), 1533–1538. IEEE.
- Mouchere et al. (2014) Mouchere, H.; Viard-Gaudin, C.; Zanibbi, R.; and Garain, U. 2014. ICFHR 2014 competition on recognition of on-line handwritten mathematical expressions (CROHME 2014). In International Conference on Frontiers in Handwriting Recognition (ICFHR), 791–796. IEEE.
- Mouchère et al. (2016) Mouchère, H.; Viard-Gaudin, C.; Zanibbi, R.; and Garain, U. 2016. ICFHR2016 CROHME: Competition on recognition of online handwritten mathematical expressions. In International Conference on Frontiers in Handwriting Recognition (ICFHR), 607–612. IEEE.
- Mouchere et al. (2013) Mouchere, H.; Viard-Gaudin, C.; Zanibbi, R.; Garain, U.; Kim, D. H.; and Kim, J. H. 2013. Icdar 2013 crohme: Third international competition on recognition of online handwritten mathematical expressions. In International Conference on Document Analysis and Recognition (ICDAR), 1428–1432. IEEE.
- Papineni et al. (2002) Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 311–318.
- Paruchuri (2023) Paruchuri, V. 2023. Texify. https://github.com/VikParuchuri/texify. Accessed: 2024-2-29.
- Wang et al. (2024) Wang, B.; Gu, Z.; Xu, C.; Zhang, B.; Shi, B.; and He, C. 2024. UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition. arXiv.org.
- Wang et al. (2004) Wang, Z.; Bovik, A. C.; Sheikh, H. R.; and Simoncelli, E. P. 2004. Image quality assessment: from error visibility to structural similarity. IEEE TIP, 13(4): 600–612.
- Wang and Liu (2021) Wang, Z.; and Liu, J.-C. 2021. Translating math formula images to LaTeX sequences using deep neural networks with sequence-level training. International Journal on Document Analysis and Recognition (IJDAR), 24(1): 63–75.
- Wei et al. (2023) Wei, H.; Kong, L.; Chen, J.; Zhao, L.; Ge, Z.; Yang, J.; Sun, J.; Han, C.; and Zhang, X. 2023. Vary: Scaling up the vision vocabulary for large vision-language models. arXiv.org, 2312.06109.
- Xia et al. (2024a) Xia, R.; Mao, S.; Yan, X.; Zhou, H.; Zhang, B.; Peng, H.; Pi, J.; Fu, D.; Wu, W.; Ye, H.; et al. 2024a. DocGenome: An Open Large-scale Scientific Document Benchmark for Training and Testing Multi-modal Large Language Models. arXiv preprint arXiv:2406.11633.
- Xia et al. (2023) Xia, R.; Zhang, B.; Peng, H.; Liao, N.; Ye, P.; Shi, B.; Yan, J.; and Qiao, Y. 2023. Structchart: Perception, structuring, reasoning for visual chart understanding. arXiv preprint arXiv:2309.11268.
- Xia et al. (2024b) Xia, R.; Zhang, B.; Ye, H.; Yan, X.; Liu, Q.; Zhou, H.; Chen, Z.; Dou, M.; Shi, B.; Yan, J.; et al. 2024b. Chartx & chartvlm: A versatile benchmark and foundation model for complicated chart reasoning. arXiv preprint arXiv:2402.12185.
- Yuan et al. (2022) Yuan, Y.; Liu, X.; Dikubab, W.; Liu, H.; Ji, Z.; Wu, Z.; and Bai, X. 2022. Syntax-aware network for handwritten mathematical expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 4553–4562.
- Zhang et al. (2020) Zhang, J.; Du, J.; Yang, Y.; Song, Y.-Z.; Wei, S.; and Dai, L. 2020. A tree-structured decoder for image-to-markup generation. In International Conference on Machine Learning (ICML), 11076–11085. PMLR.
- Zhao et al. (2021) Zhao, W.; Gao, L.; Yan, Z.; Peng, S.; Du, L.; and Zhang, Z. 2021. Handwritten mathematical expression recognition with bidirectionally trained transformer. In International Conference on Document Analysis and Recognition (ICDAR), 570–584. Springer.
附录
附录 A 用户偏好评估分析
为了更直观、更清晰地分析 CDM 的可信度,我们在第 5.2 节的内容基础上,详细考察了用户在不同条件下对 CDM 和 BLEU 指标的偏好。
为了评估 CDM 的可靠性,我们设计了一个如图 5 所示的标注界面。 给定各种样本的地面真实渲染图像和模型预测的渲染图像,要求标注者分配一个合适的评分。 评分 A 和评分 B 分别对应于预测结果的 BLEU 和 CDM 分数,但顺序是随机的,以便用户不知道哪个分数对应哪个指标。 用户根据他们从四个选项中做出的直观判断来做出选择。
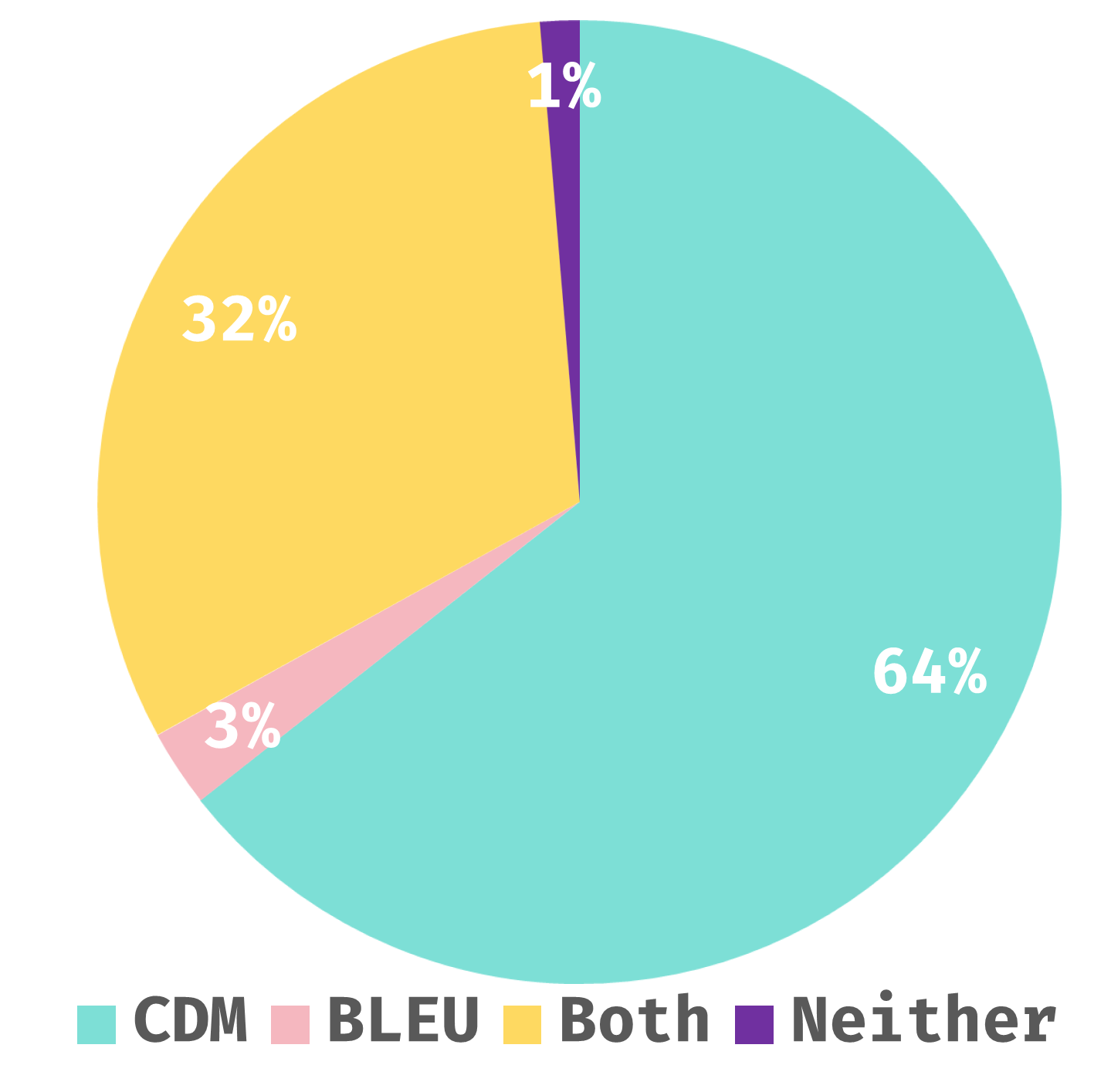
共对 1008 个样本进行了评分,并将结果分为四种场景。 我们对每种场景下用户对 CDM 和 BLEU 指标的偏好进行了详细、清晰的分析,如 图 6所示:
CDM 更好 (64%): 在这种情况下,示例包括案例 1 和案例 2。 在案例 1 中,预测结果 100% 正确,CDM 分数为 1,BLEU 分数为 0。 用户直接选择了 CDM 分数。 在情况 2 中,预测结果大多正确,但 BLEU 分数明显低于预期,导致用户更倾向于 CDM 分数。
两个分数一样好 (32%): 此场景中的示例包括情况 3 和 4,其中 CDM 和 BLEU 分数相对接近,都以准确直观的方式反映了模型预测错误的比例。
BLEU 更好 (3%): 在情况 5 中,由于“BF”的不同符元表示,BLEU 检测到不一致,而 CDM 将 和 视为相同的符元。
两个分数都不好 (1%): 在情况 6 中,尽管两个公式包含不同的符元,"\mathcal{E}" 和 "\varepsilon",但它们呈现出相似的图像( 和 )。 CDM 和 BLEU 在这种情况下都失败了。
CDM 在 96% 的情况下是可靠的。 剩下的 4% 是由于 LaTeX 问题,这将在未来的版本中得到优化,对整体评估的影响很小。
A.1 Latex 渲染和语法错误
CDM 依赖于规范化 LaTeX 源代码和渲染图像。 因此,无法渲染或包含语法错误(无法规范化)的代码将导致计算失败。 例如,表达式 "z = \left( \begin{array}{cc} x \\ y" 由于缺少 "\end{array}",导致渲染失败,是一个失败案例。 对于这些情况,CDM 会分配一个 0 分。 虽然 CDM 无法直接处理它们,但这种方法是合理的,并且与人类感知非常一致。
LaTeX 渲染和语法错误的数量取决于模型预测的质量。 在四个模型中,Pix2tex、Texify、Mathpix 和 UniMERNet,UniMER-Test 上预测结果中的 LaTeX 渲染和语法错误比例分别为 13.83%、5.03%、2.38% 和 1.05%。
A.2 影响 Token 一致性的渲染类型
CDM 定义字符时不考虑渲染风格。 然而,不同的渲染风格可以产生视觉上不同的结果,这可能会导致不同的 Token 渲染成几乎相同的字符 (Figure 6 案例 6),或者相同的 Token 渲染成不同的字符 (Figure 6 案例 5)。 类似的情况包括 "G" 和 "\mathcal { G }","\mathcal { X }" 和 "\mathfrac { X }",它们的渲染效果分别是 。 这种不一致性可能会混淆 Token 一致性检查,导致模型输出错误。

附录 B 评估 Tiny-Doc-Math 的深入方法
B.1 Tiny-Doc-Math 数据集的构建
评估数据集主要从 2024 年 6 月之后发表的数学和计算机科学领域的 arXiv 论文中构建。 我们手动选择了一批这些论文,并下载了 LaTeX 源代码和相应的 PDF。 使用正则表达式,我们匹配从 LaTeX 源代码中显示的公式。 在单个公式渲染和手动验证之后,Tiny-Doc-Math 验证集构建完成,包含 12 篇论文、196 页和总共 437 个公式。
B.2 公式级评估方法
评估数据集构建完成后,我们从 LaTeX 源代码中提取数学公式。 由于 LaTeX 源代码可能包含来自作者的自定义命令和注释,因此我们应用一系列预处理步骤以确保准确提取。 首先,我们使用正则表达式从 LaTeX 源代码中删除注释(包括 "%"、"\iffalse... \fi" 和 "\begin{comment}...\end{comment}")。 接下来,我们将诸如 "\newcommand{}{}"、"\renewcommand{}{}"、"\DeclareMathOperator{}{}"、"\DeclareMathOperator*{}{}"、"\def\...{}" 和 "\DeclareRobustCommand{}{}" 等命令定义的别名转换为其原始形式,以确保公式渲染成功。 然后,我们删除 "\begin{document}" 之前的內容,以避免匹配不相关的資訊。 预处理后,我们使用一系列正则表达式从 LaTeX 源代码中提取显示的数学公式,如 图 7(a) 所示。 对于每篇论文,匹配的数学公式被写入一个文本文件,每行一个公式。
我们渲染提取的 GT 数学公式以获得公式级别的 GT 图像,然后将其用作 Mathpix、UniMerNet、pix2tex 和 GPT-4o 的输入,以生成相应的预测。 最后,我们在将预测与 GT 匹配后计算 BLEU 和 CDM 等指标。
B.3 文档级评估方法
我们将 PDF 页面转换为图像,并将这些图像用作 Mathpix 和 GPT-4o 的输入,以生成相应的预测,而 Nougat 则将整个 PDF 作为输入。 在获得文档级预测后,我们使用提取算法从预测中提取显示的公式,并将它们与上一节中获得的 GT 公式进行匹配,以计算 BLEU 和 CDM 指标。
由于不同模型输出的语法格式不同,我们使用不同的正则表达式来提取每个模型的公式,如 图 7(b)、(c) 和 (d) 所示。 同样,对于每个 PDF,来自每个模型预测的匹配的数学公式被写入一个文本文件,每行一个公式。
B.4 匹配和指标计算
在获得 GT 和预测的数学公式后,我们逐行匹配 GT 和预测的公式,以计算最终的 CDM 指标。 鉴于显示的公式预测的高精度,我们使用编辑距离作为匹配公式的指标。 为了解决不同模型使用不同的数学分隔符 (e.g., "\begin{equation}...\end{equation}" 与 "\[...\]"),我们在匹配之前删除所有数学分隔符,只关注内容。 标签和标记也从公式中删除。
匹配过程包括两个回合。 在第一轮中,我们为精确匹配设置了较低的编辑距离阈值。 这意味着只有与地面真值公式高度相似的预测才会被匹配。 我们遍历 GT 公式,计算所有预测结果的编辑距离。 只有当最小编辑距离低于阈值时,才将具有最小编辑距离的预测记录为匹配。 否则,我们跳过该行并将 GT 和预测都标记为不匹配。 在第二轮中,我们设置了一个更高的阈值来考虑那些编辑距离可能较大的匹配情况。 我们遍历未匹配的 GT 公式,计算与剩余未匹配的预测公式的编辑距离,并在距离低于阈值时记录匹配项。 如果在头两轮之后仍然有任何预测公式未匹配,我们将它们标记为不正确的或多余的预测,并将它们附加到匹配结果的末尾。
通过实际实现,我们发现将第一轮阈值设置为 0.4,将第二轮阈值设置为 0.8 提供了最合理的匹配。 尽管在渲染结果相同但由于编辑距离过大而无法匹配的极端情况下可能会发生,但这些情况并不常见,并且已手动更正。
在将 GT 和预测公式匹配之后,我们计算 BLEU 和 CDM 等指标。
B.5 结果讨论
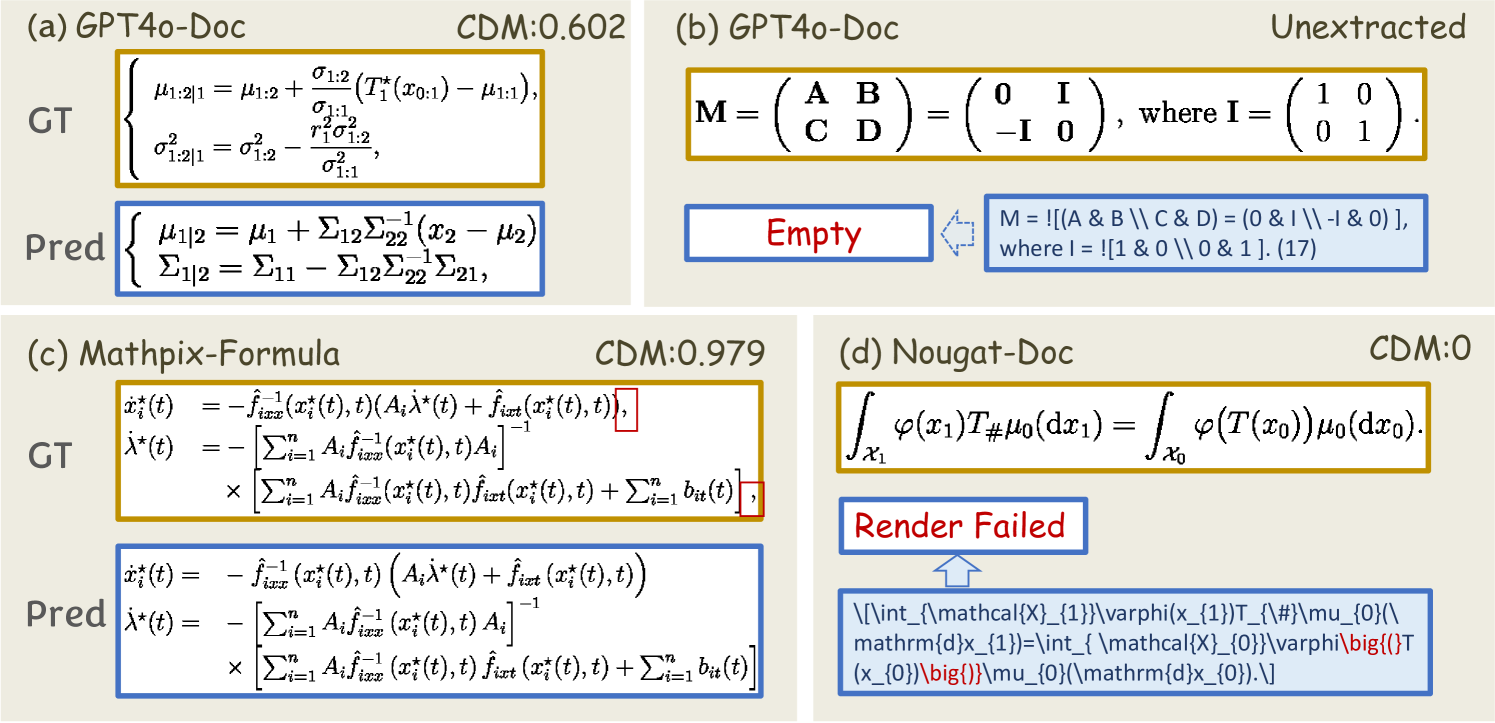
如 图 8 所示,GPT-4o 的文档级预测显示出大量的 CDM 分数介于 0.6 和 0.9 之间,这主要是由于大型模型中的幻觉现象。 例如,如 图 9(a) 所示,GPT-4o 生成了结构相似但内容无关的结果。 此外,如 图 9(b) 所示,GPT-4o 的预测通常缺乏标准化的格式,即,经常生成没有数学分隔符的公式,导致提取和渲染失败,并导致许多 CDM=0 的情况。 对于 Mathpix,尽管文档级和公式级之间的 CDM 很接近,但在公式级的 CDM=1 预测比例明显较低。 这主要是由于 Mathpix 的单个公式预测中缺少逗号,如 图 9(c) 所示。 Nougat 的预测经常包含语法错误,如 图 9(d) 所示,导致渲染失败和 CDM=0 的情况。 此外,Nougat 的预测结果有时会在 PDF 文件的中间留下几页没有预测结果,导致最终输出结果中缺少公式。
附录 C 公式识别的有效数据选择
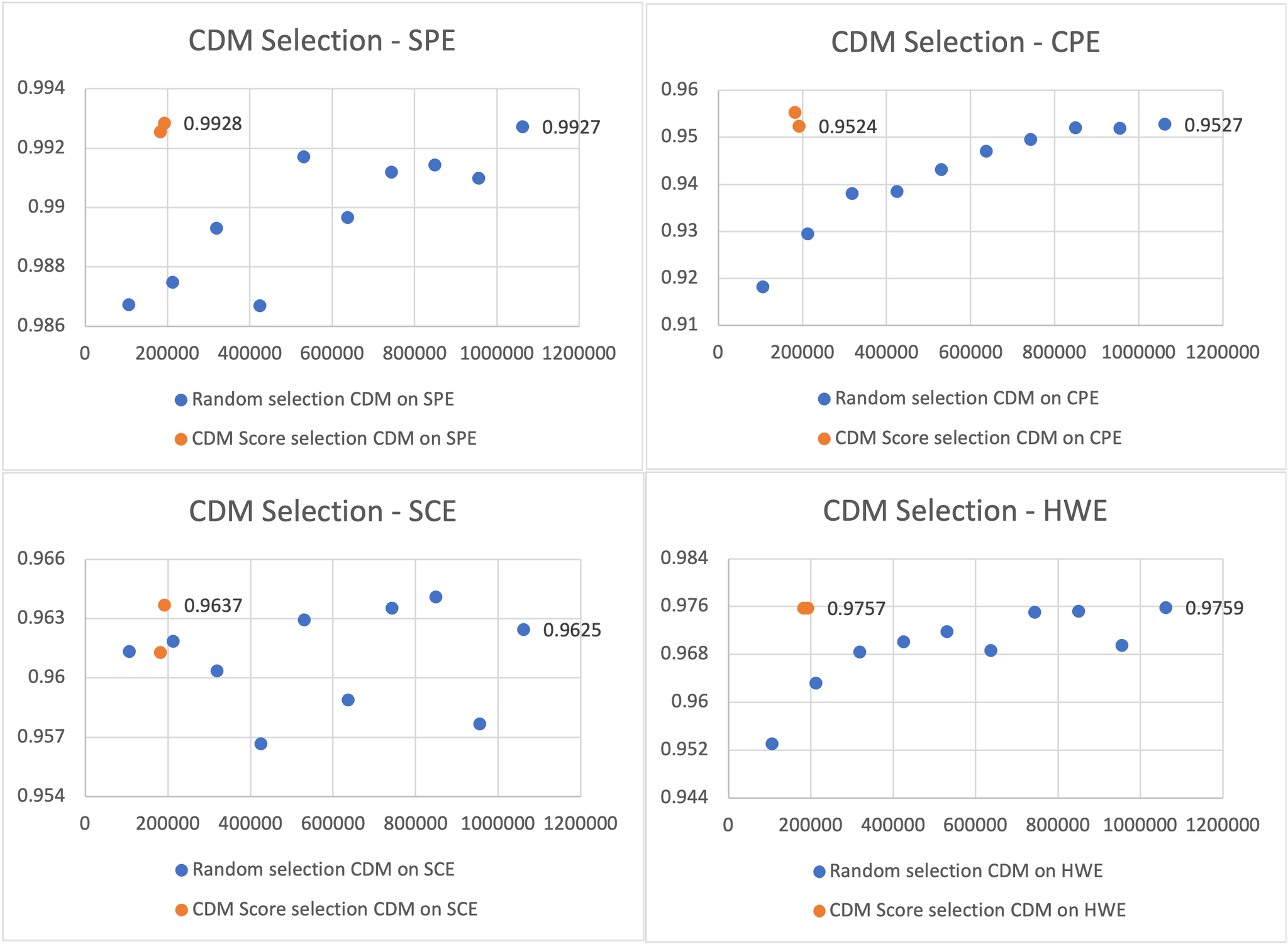
当前的公式识别方法往往忽略了训练过程中样本选择的意义。 我们证明了通过利用 CDM 指标进行训练数据选择,可以实现与使用整个数据集相当的性能,同时仅使用不到 20% 的数据。 我们进行了以下实验:首先,我们将 UniMER-1M 数据集随机分成十个相等的部分。 然后,我们使用 10%、20%、直至 100% 的数据训练模型,并观察模型在不同训练数据量下的性能。 如 图 10 中的蓝色点所示,模型的性能通常会随着训练数据量的增加而提高。 值得注意的是,仅使用 10%(106,179 个样本)的数据,模型就能取得令人满意的性能,准确地预测大多数公式。 这表明,剩余的 90% 的数据在训练目的方面可能很大程度上是冗余的。
为了进一步调查,我们进行了两轮硬案例数据选择。 首先,我们使用在 10% 数据上训练的模型来识别剩余 90% 中具有 CDM 的样本。 我们找到了 76,026 个这样的样本,这不到剩余数据的 8%,表明超过 90% 的公式可以准确预测。 将这些与最初的 10% 随机数据结合起来,我们总共有 182,205 个样本(UniMER-1M 数据集的 17.16%)。 如 图 10 所示,在该组合数据集上训练的模型与在完整数据集上训练的模型性能相当,除了在 SCE 子集上略微表现不佳。
接下来,我们使用此模型从剩余数据中进一步选择硬案例,识别出另外 9,734 个样本,约占剩余数据的 1%。 这使得总数达到 191,939 个样本(整个数据集的 18.08%)。 此模型的性能显示出比上一轮略有提高,在各种子集上取得了与在完整数据集上训练的模型相当或甚至超越的成果。
该实验证明了使用 CDM 进行公式识别硬案例选择的效果。 基于硬案例挖掘的训练可以作为一种提高模型性能的有效方法。 此方法允许通过仅选择必要的样本来扩展训练数据,从而无需使用整个数据集。 未来公式识别数据集可以使用此方法扩展,重点关注最具挑战性的样本,以提高模型的准确性和效率。
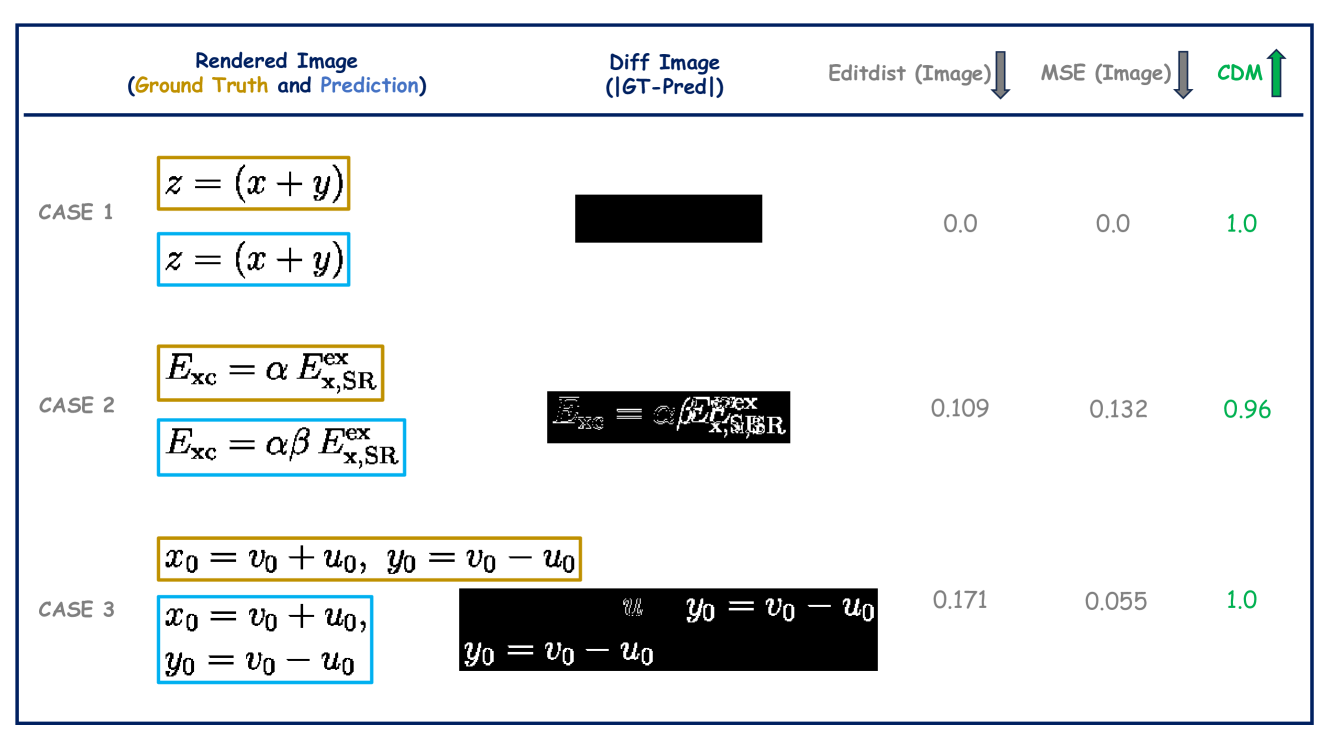
附录 D 基于图像差异的评估方法
之前的工作 王和刘(2021) 提到了使用基于图像的差异方法来评估公式识别结果,但需要对这种方法的局限性进行彻底的分析。 为了进一步评估这些方法的有效性,我们使用图像编辑距离(Editdist)和图像差异的均方误差(MSE)进行了实验。 如图 11所示,案例 1 表明当模型的预测正确且渲染的输出与真实值 (GT) 完全匹配时,EditDist 和 MSE 均为零,表明公式准确。 但是,在案例 2 中,当预测漏掉了字符时,基于图像的差异方法会将所有后续位置标记为不匹配,即使只有一个字符缺失。 案例 3 展示了一个更严重的例子,其中预测的公式内容是正确的,但预测了一个额外的换行符,导致图像差异显著。 在这种情况下,EditDist 和 MSE 均不为零,无法准确反映错误。 这突出了所提出的 CDM 度量的必要性。