WildVis: 开源可视化工具,用于分析海量真实聊天记录
摘要
真实对话数据的日益普及为研究人员提供了激动人心的机会,让他们可以研究用户与聊天机器人的互动。 然而,海量数据使得手动检查单个对话变得不切实际。 为了克服这一挑战,我们引入了 WildVis,这是一个交互式工具,可以实现快速、灵活的大规模对话分析。 WildVis 基于一系列标准,在文本和嵌入空间中提供搜索和可视化功能。 为了管理百万级数据集,我们实现了优化,包括搜索索引构建、嵌入预计算和压缩以及缓存,以确保在数秒内实现响应式用户交互。 我们通过三个案例研究展示了 WildVis 的实用性:促进聊天机器人滥用研究,可视化和比较跨数据集的主题分布,以及刻画特定于用户的对话模式。 WildVis 是开源的,并且设计为可扩展的,支持额外的数据集以及自定义的搜索和可视化功能。
WildVis: 开源可视化工具,用于分析海量真实聊天记录
Yuntian Deng1∗, Wenting Zhao2, Jack Hessel3, Xiang Ren4, Claire Cardie2, Yejin Choi5∗ 1University of Waterloo 2Cornell University 3Samaya AI 4University of Southern California 5University of Washington yuntian@uwaterloo.ca, wzhao@cs.cornell.edu, jmhessel@gmail.com xiangren@usc.edu, cardie@cs.cornell.edu, yejin@cs.washington.edu
1 引言
尽管数亿用户与 ChatGPT 等聊天机器人进行互动 (Malik, 2023),但对话记录在很大程度上对开放式研究来说是透明的,限制了我们对用户行为和系统性能的理解。 最近,WildChat (Zhao et al., 2024) 和 LMSYS-Chat-1M (Zheng et al., 2024) 等项目发布了数百万个真实的用户-聊天机器人互动,为研究互动动态提供了丰富的机会。 然而,这些数据集的规模和复杂性对有效分析提出了重大挑战。
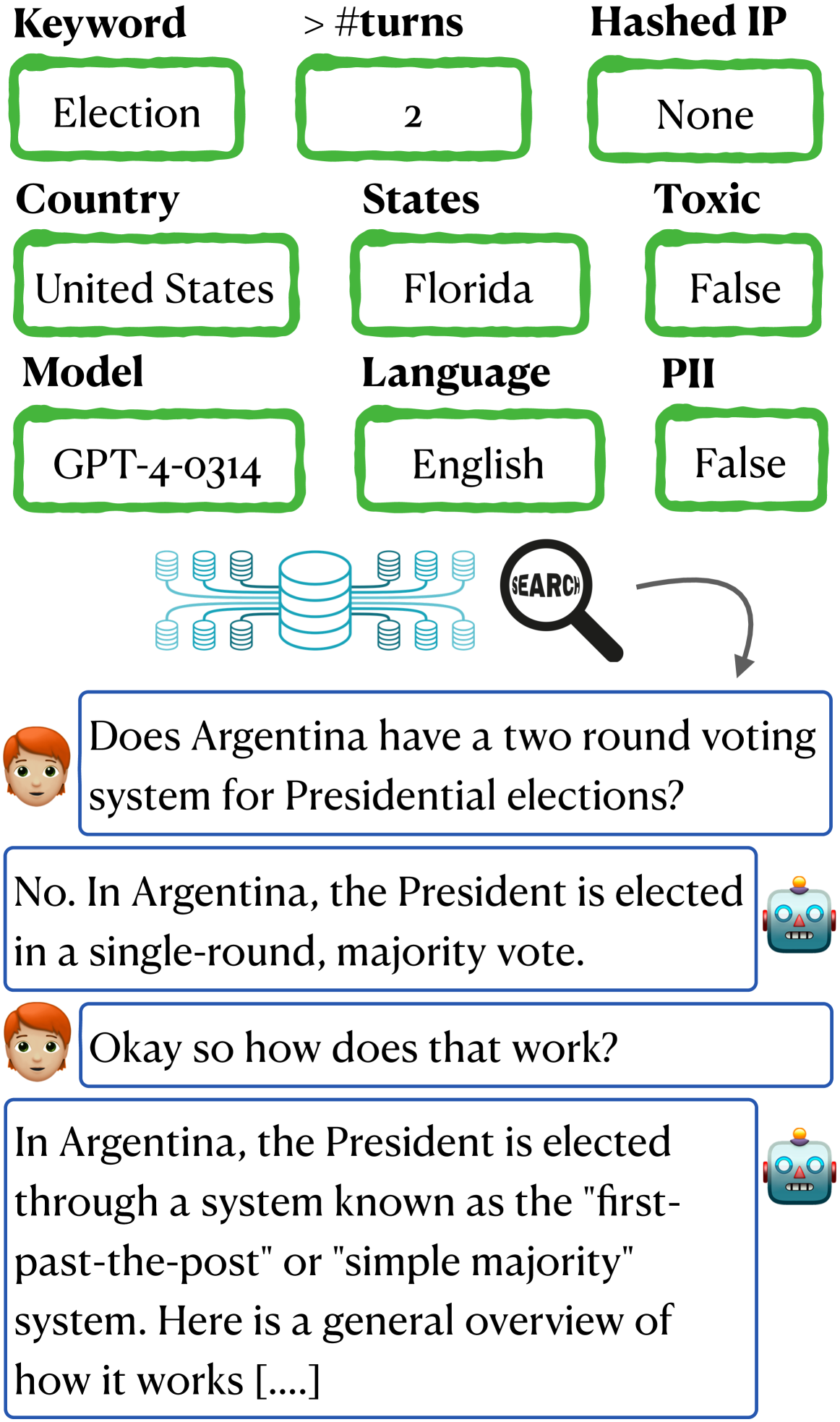
为了帮助研究人员在这些庞大的聊天数据集内发现模式和异常,我们引入了WildVis,这是一种用于探索百万级聊天记录的交互式工具。 WildVis 使研究人员能够根据特定标准查找对话,了解主题分布,并探索语义上类似的对话,同时保持效率。 图 1 说明了使用WildVis进行示例搜索,应用了诸如关键词“Election”、超过两轮的对话以及来自佛罗里达州用户的聊天记录等标准。
WildVis 包含两个主要组件:一个精确的、基于组合过滤器的检索系统,允许用户使用十个预定义过滤器(例如关键词、地理位置、IP 地址等)来细化他们的搜索。 第二个组件是基于嵌入的可视化模块,它将对话表示为二维平面上的点,类似的对话彼此靠近。 这两个组件都设计为可以扩展到数百万次对话。 该工具的预发布版本支持对一百万次 WildChat 对话进行基于过滤器的检索,仅在 2024 年 7 月和 8 月就被 962 个独特的 IP 地址访问了超过 18,000 次。 本文描述的最新版本扩展了对 WildChat 和 LMSYS-Chat-1M 两个组件的支持。
本文介绍了 WildVis 的设计与实现,探讨了在保持秒级延迟的情况下扩展到百万级数据集的策略。 我们还展示了几个用例:促进聊天机器人滥用研究 (Brigham et al., 2024; Mireshghallah et al., 2024),可视化和比较 WildChat 和 LMSYS-Chat-1M 之间的主题分布,以及描述用户特定的对话模式。 例如,WildVis 揭示了不同的主题集群,例如 WildChat 中的 Midjourney 提示生成和 LMSYS-Chat-1M 中的化学相关对话。 此外,我们观察到 WildChat 与 LMSYS-Chat-1M 相比,通常表现出更具创意的写作风格。 作为一个开源项目,WildVis 在 github.com/da03/WildVisualizer 上以 MIT 许可证发布,可以在 wildvisualizer.com 上访问一个工作演示。
2 用户界面
WildVis 包含两个主要页面——一个基于过滤器的搜索页面和一个嵌入可视化页面——以及一个对话详细信息页面。 这些页面旨在为用户提供对单个对话的整体概览和详细见解。
2.1 基于过滤器的搜索页面
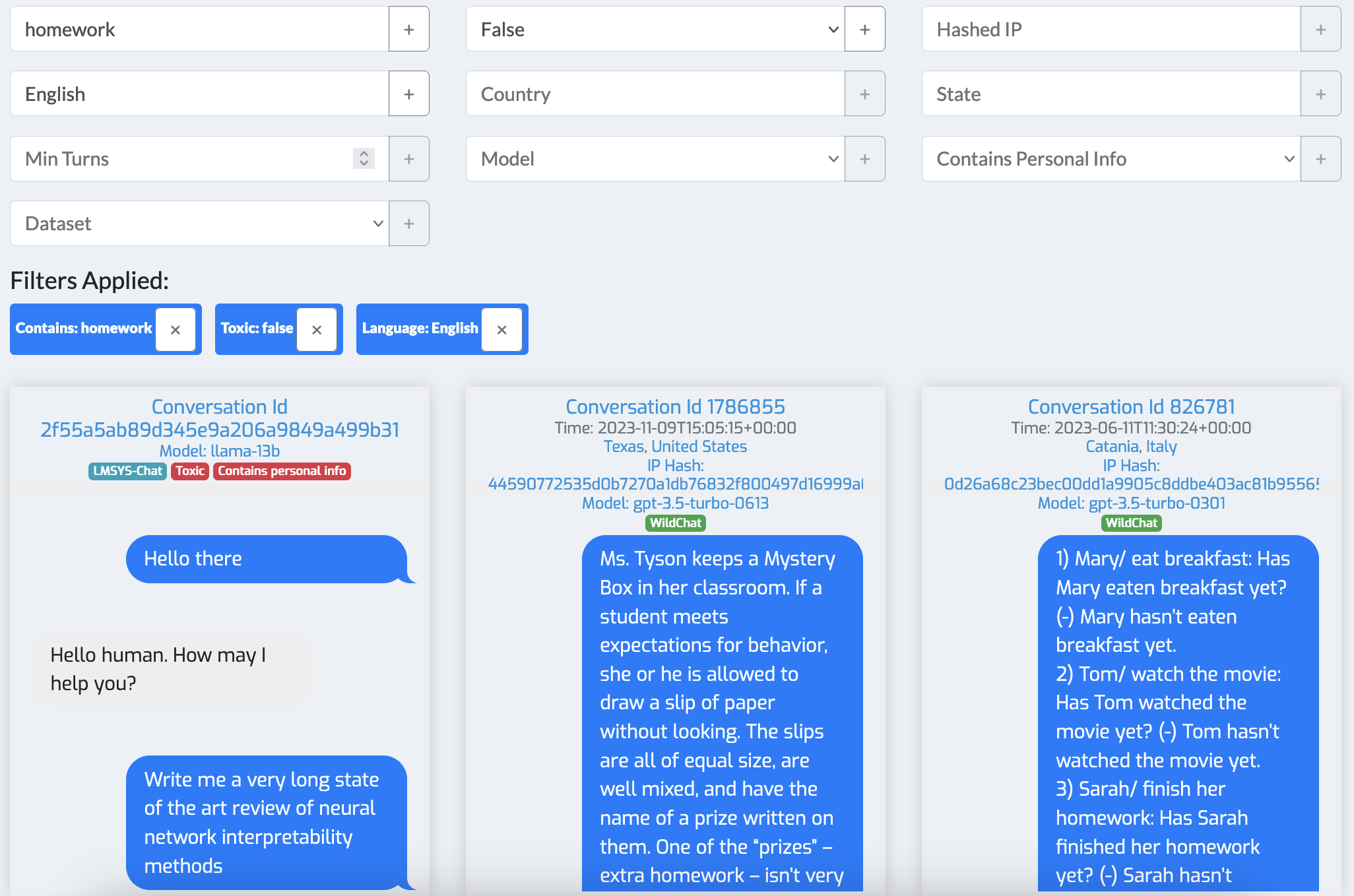
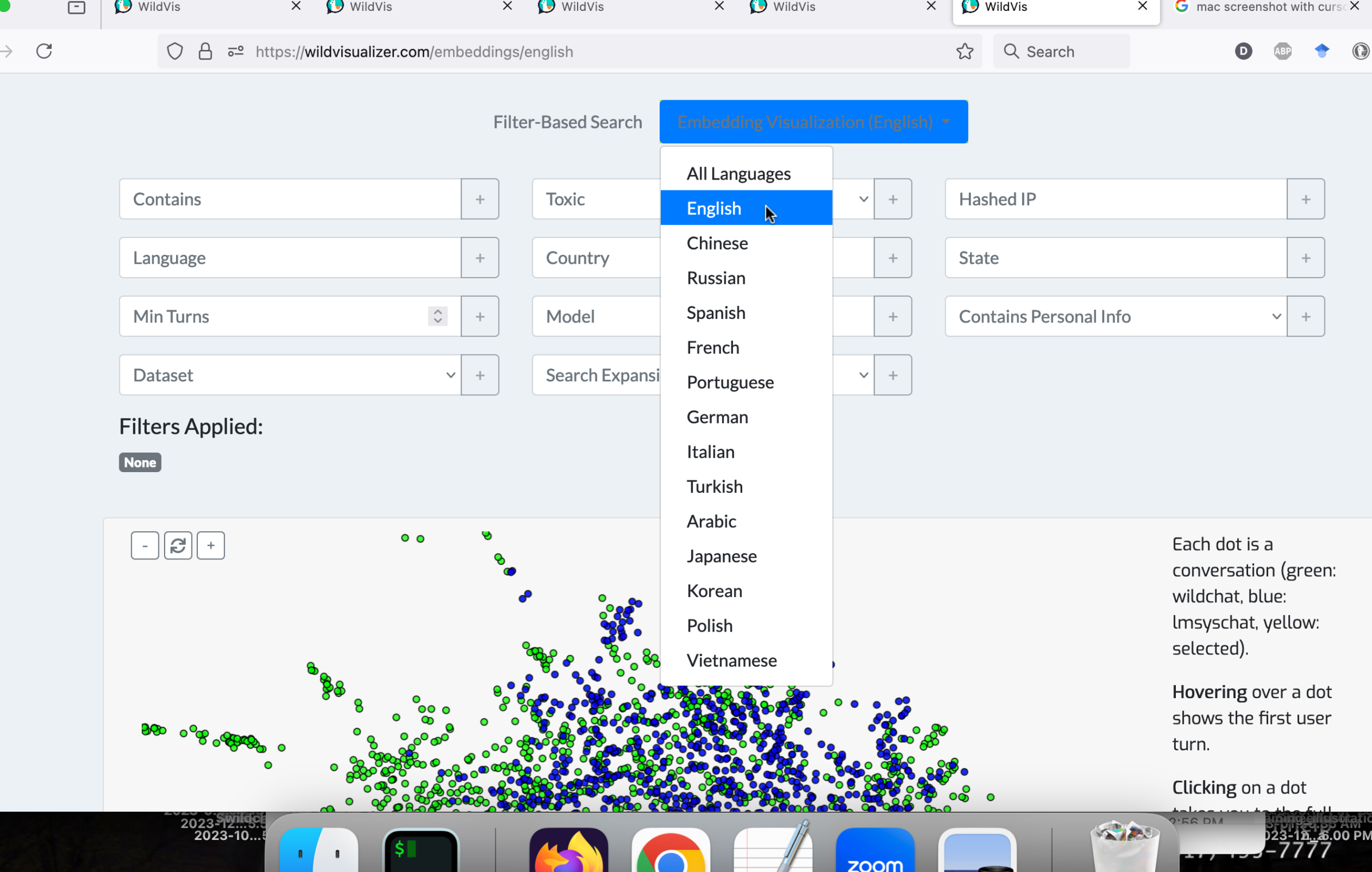
基于过滤器的搜索页面 (图 2) 允许用户根据一组标准筛选数据集。 用户可以输入关键词来检索相关的对话,或者使用特定标准缩小搜索范围。 总共提供了十个预定义的过滤器,包括:
-
•
哈希 IP 地址:通过哈希 IP 地址筛选对话,以分析来自同一用户的交互。 5 55IP 地址被哈希以保护用户隐私,同时仍然允许分析与同一用户相关的交互。
-
•
地理数据:根据推断的州和国家进行筛选,以洞悉对话模式的区域差异。
-
•
语言:将结果限制在特定语言的对话中。
-
•
毒性:包含或排除被标记为有毒的对话。
-
•
编辑状态:包含或排除包含已编辑的个人身份信息 (PII) 的对话。
-
•
最小轮数:关注具有指定最小轮数的对话。
-
•
模型类型:根据所用底层语言模型选择对话,例如 GPT-3.5 或 GPT-4。
搜索结果以分页表格格式显示,确保轻松浏览大型数据集。 活动过滤器在结果上方醒目显示,可以通过单击每个过滤器旁边的“”图标来移除。
每个结果条目显示关键元数据,包括对话 ID、时间戳、地理位置、哈希 IP 地址和模型类型。 用户可以通过多种方式与这些结果进行交互。 点击对话 ID 会跳转到该对话的详细视图。 此外,所有元数据字段(例如哈希的 IP 地址)都是可点击的,使用户能够根据特定属性快速搜索。 例如,点击哈希的 IP 地址会显示与该 IP 关联的所有对话的列表,方便进行用户特定的分析。
2.2 嵌入可视化页面
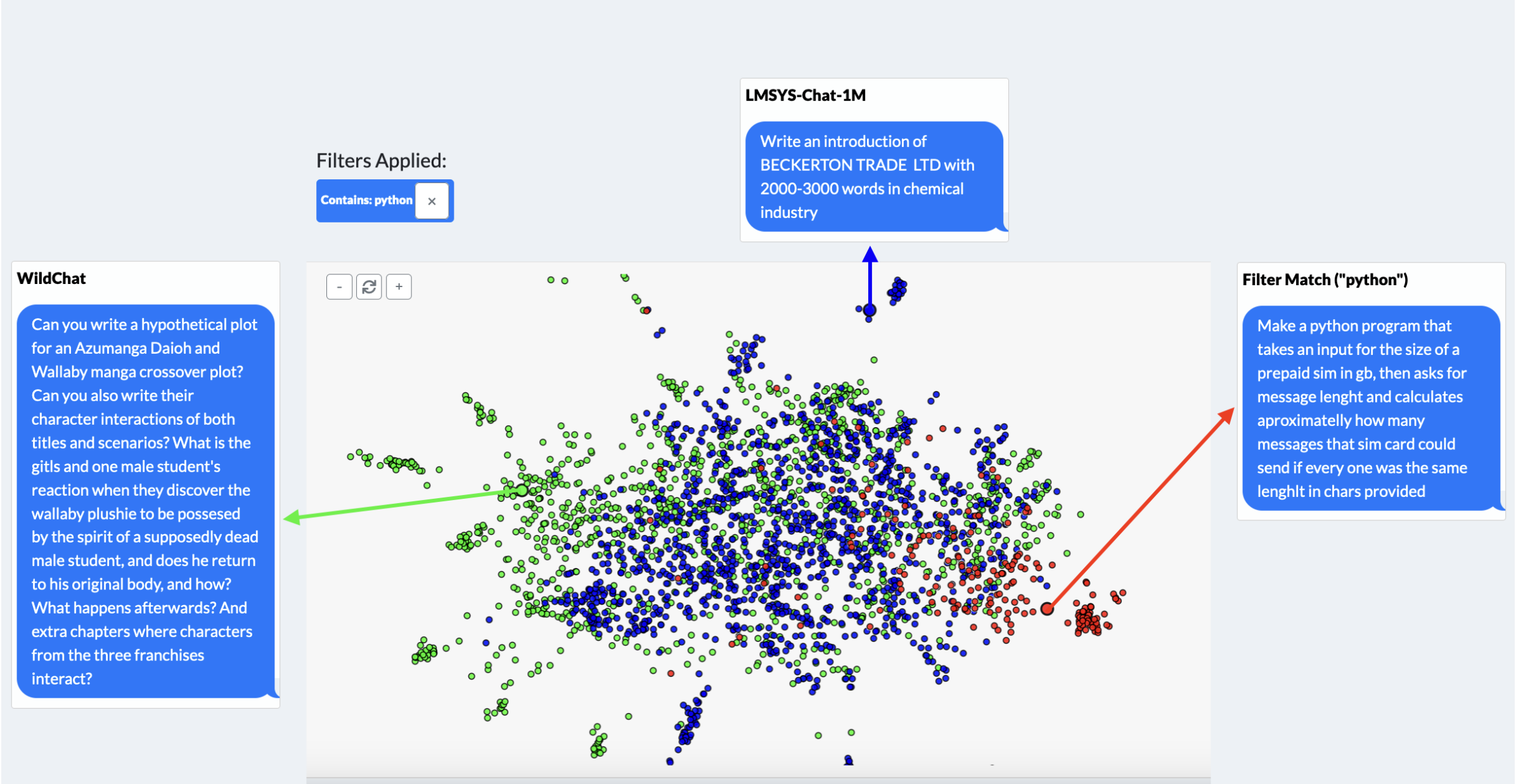
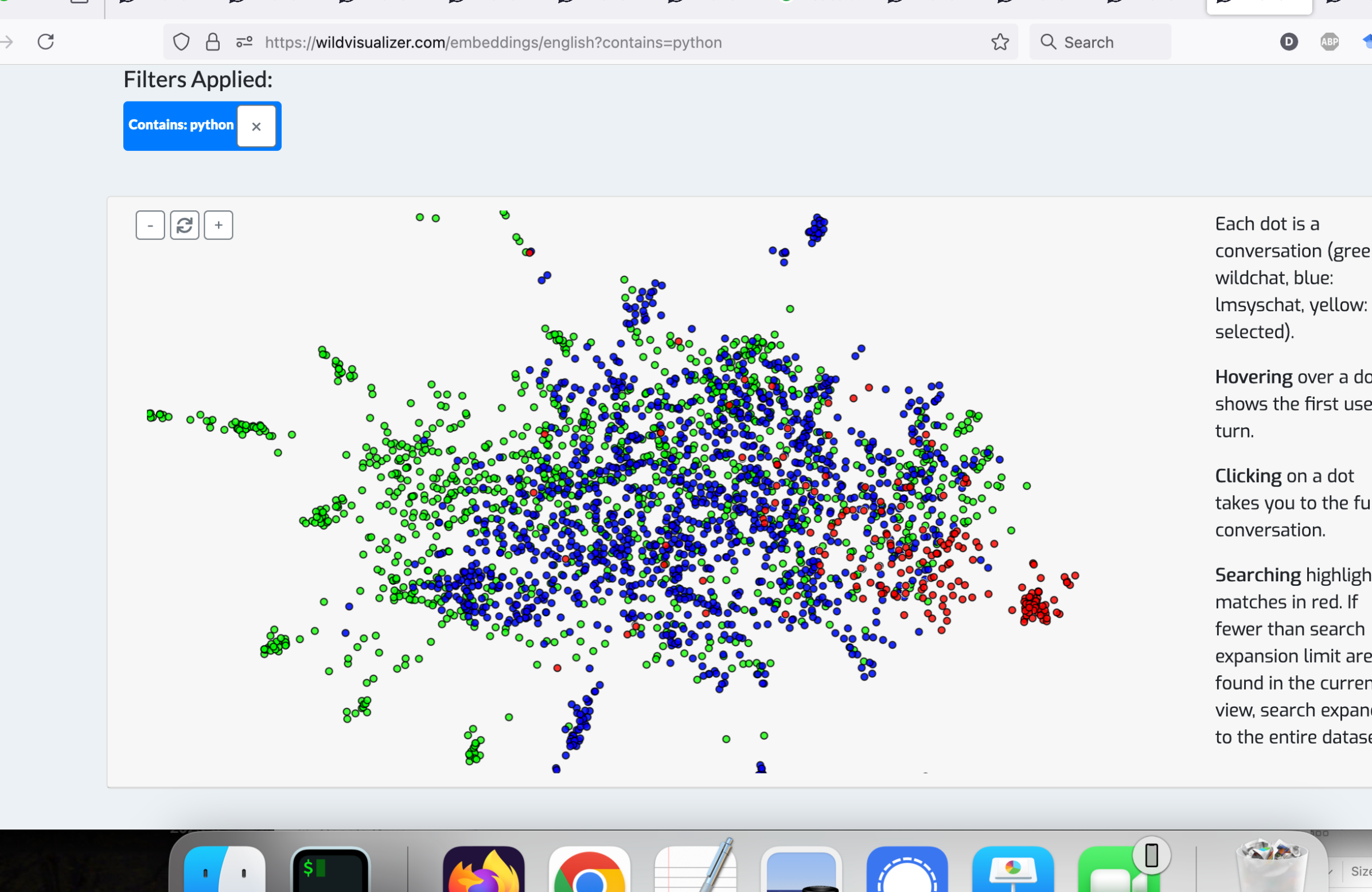
除了传统的搜索功能外,WildVis 还提供了一个嵌入可视化页面(图 3),允许用户根据语义相似性探索对话。 对话以二维平面上的点表示,相似的对话放置得更近。
基本可视化
基于过滤器的突出显示
与基于过滤器的搜索页面类似,用户可以应用过滤器来突出显示二维地图上的特定对话,匹配的对话将以红色标记。 此功能有助于用户找到他们感兴趣的对话,例如识别与特定用户相关的主题。
对话嵌入
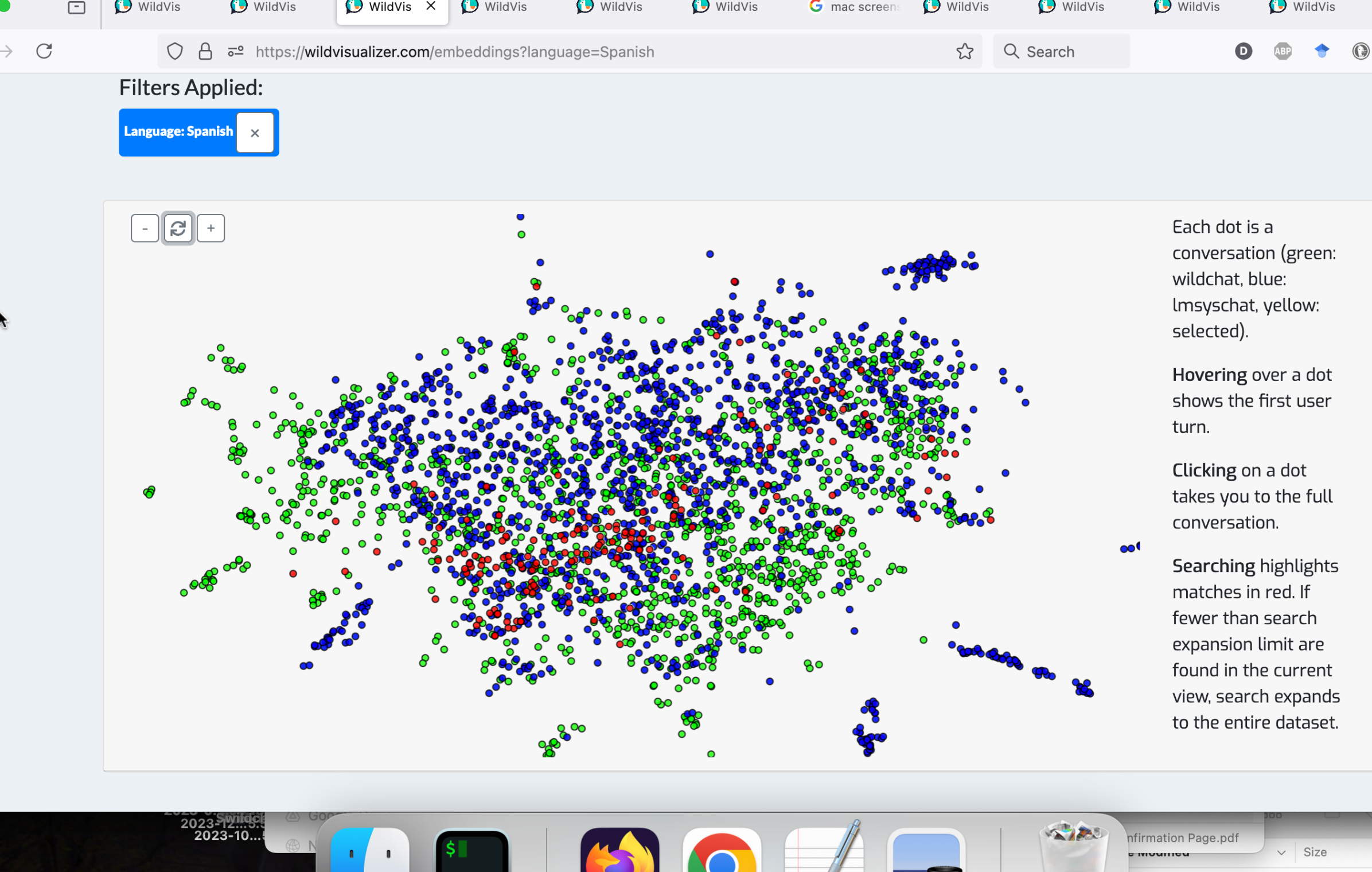
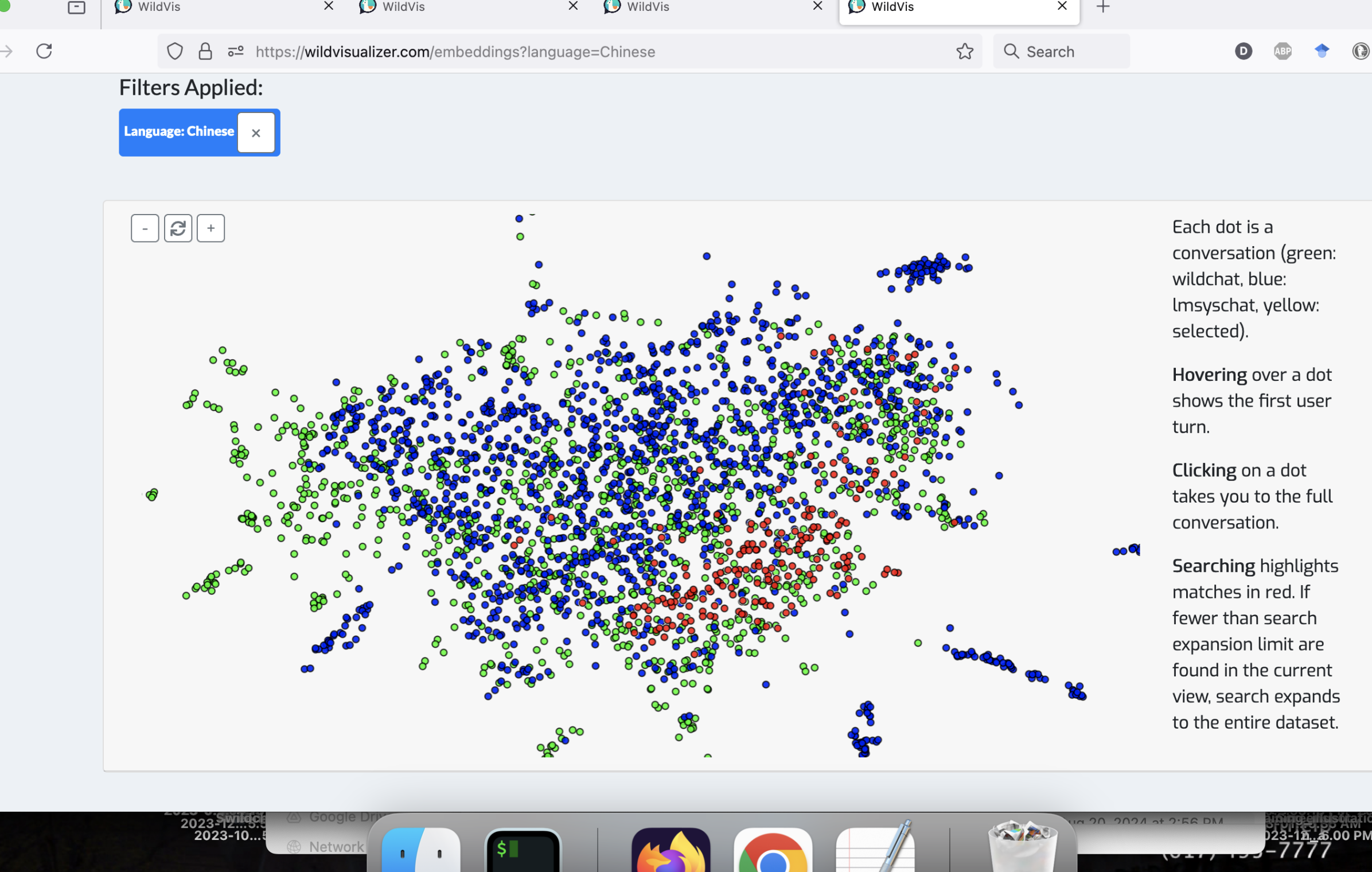
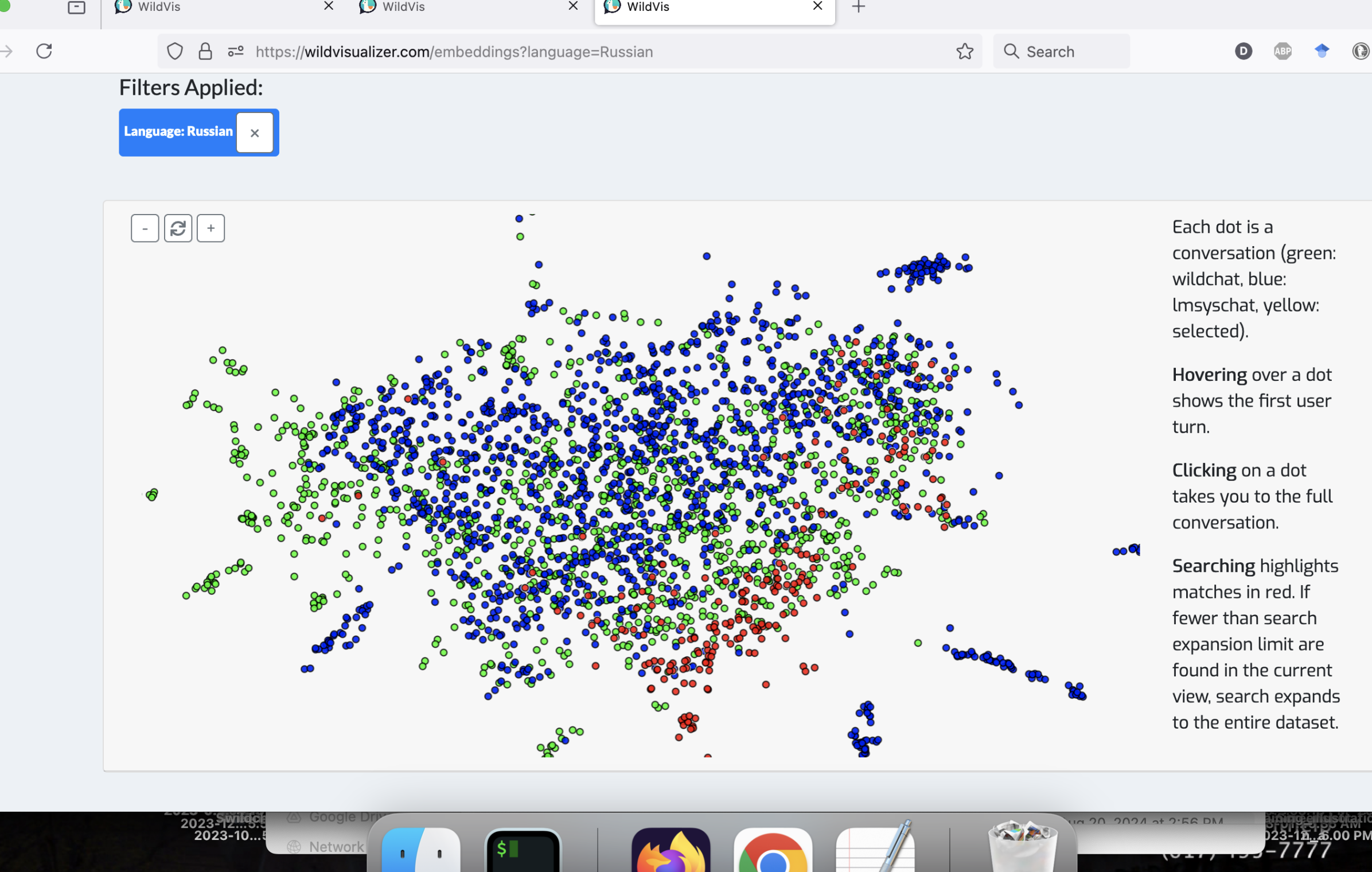
为了将每段对话表示为二维空间中的一个点,我们使用 OpenAI 的 text-embedding-3-small 模型嵌入每段对话的第一个用户轮次。 7 77我们选择仅嵌入第一个用户轮次,因为初步实验表明嵌入整个对话会导致不太直观的聚类。 然后,我们训练了一个参数化的 UMAP 模型 (Sainburg et al., 2021; McInnes et al., 2020) 将这些嵌入投影到二维空间。 8 88我们选择参数化UMAP而不是t-SNE (van der Maaten and Hinton, 2008) 来实现在线降维,这将在 第 3.2节中讨论。 由于最初的实验表明,在所有嵌入上训练单个 UMAP 模型会导致一些聚类由语言差异驱动(参见 图 9, 附录 B),为了创建更多语义上更有意义的聚类,我们还为每种语言训练了单独的参数化 UMAP 模型。 用户可以轻松地在不同的语言及其相应的 UMAP 投影之间切换( 图 7, 附录 C)。
嵌入可视化、过滤、突出显示和交互式预览的组合使用户能够浏览大量对话数据,发现可能隐藏的洞察力和联系。 例如,用户可以轻松地识别异常值和聚类。
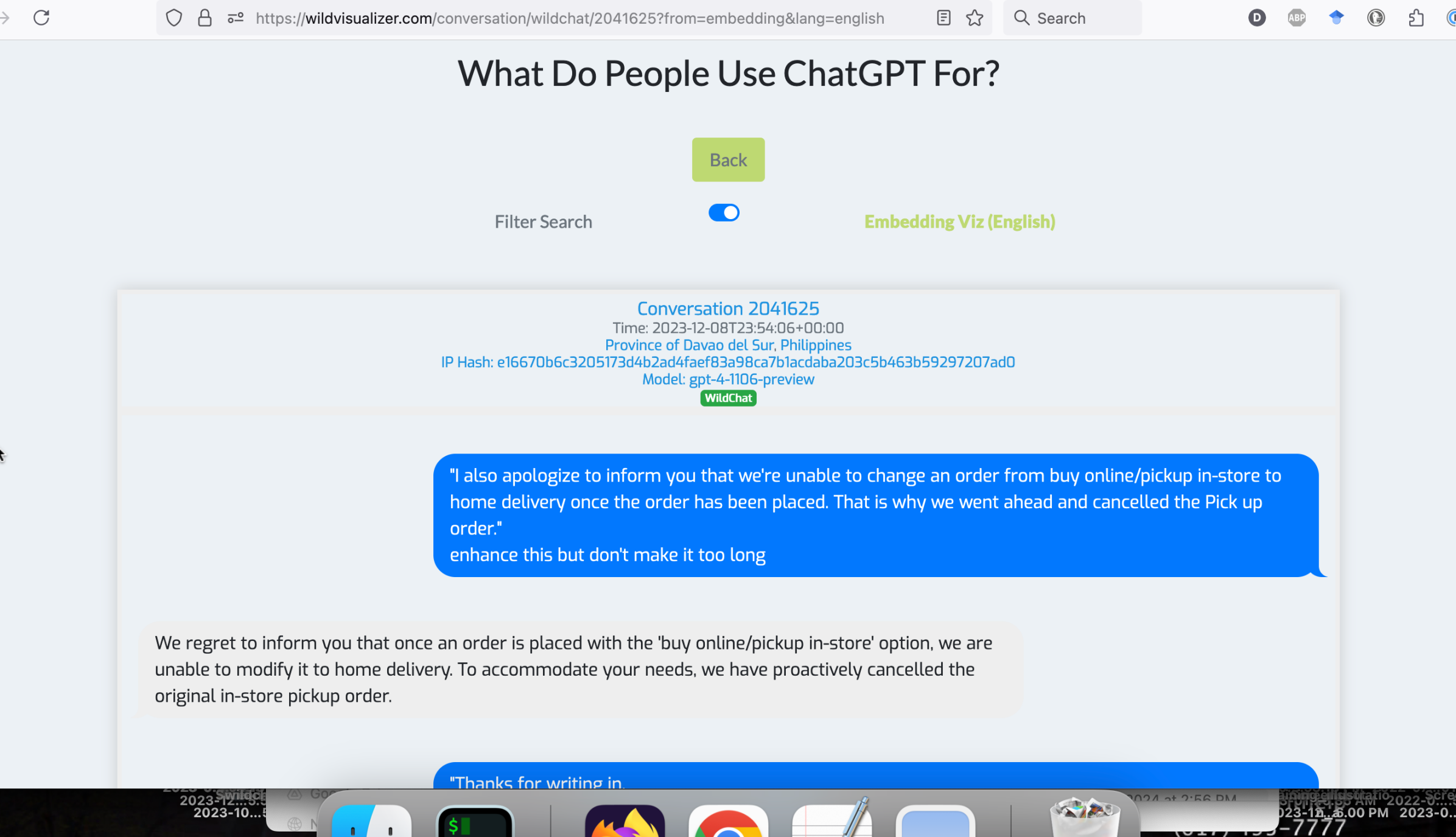
2.3 对话详细信息页面
3 系统实现
WildVis 旨在高效地处理大规模对话数据集。
3.1 系统架构
WildVis 在客户端-服务器架构上运行,其中服务器处理数据处理、搜索和对话嵌入,而客户端提供用于数据探索的界面。 高层系统架构如图图4所示。
用户与前端 Web 界面交互,该界面将他们的查询传达给后端服务器。 后端服务器使用 Flask999https://flask.palletsprojects.com/ 构建,它处理这些查询并为 Elasticsearch101010https://www.elastic.co/elasticsearch 引擎构建搜索请求。 Elasticsearch 以其可扩展的搜索功能而闻名,它检索相关的对话,然后将这些对话发送回前端以进行渲染。 前端使用 HTML、CSS 和 JavaScript 开发 11 1111前端建立在 MiniConf (Rush and Strobelt, 2020) 之上。 ,使用 Deck.gl121212https://deck.gl/ 渲染大规模的交互式嵌入可视化。
3.2 可扩展性和优化
为了管理大量数据并确保用户顺利交互,WildVis 使用了几种优化策略。
搜索
对于搜索功能,使用 Elasticsearch 为每个数据集构建一个索引,其中包含所有元数据,允许后端有效地检索相关的对话。 为了减少在大量匹配结果查询时的负载,我们采用了两种策略:分页,每次检索一页结果,每页最多 30 个对话;以及将检索到的匹配结果限制为每次搜索最多 10,000 个对话。
嵌入可视化 - 前端
在浏览器中渲染大量对话嵌入对于计算来说非常密集,尤其是在移动设备上,并且可能导致重叠点带来的视觉混乱。 为了缓解这些问题,我们使用 Deck.gl 来高效地渲染大量点。 此外,我们将可视化范围限制在每个数据集的 1,500 个对话的子集,确保渲染流畅和可视化清晰。
嵌入可视化 - 后端
在后端,计算大量对话的嵌入可能会导致显著的延迟。 为了解决这个问题,我们预先计算了用于可视化的对话子集的二维坐标。 然后使用 gzip 压缩这些预先计算的结果并存储在文件中,该文件在用户首次访问嵌入可视化页面时发送给用户。 压缩文件的大小约为 1 MB,并且只需要下载一次。
虽然我们只显示了对话的子集,但用户可能仍然需要搜索整个数据集。 为了支持这一点,我们将嵌入可视化与 Elasticsearch 引擎集成在一起。 当用户提交查询时,我们首先在显示的对话子集中搜索(针对该子集建立索引)。 如果在子集中找到了足够的匹配结果(默认阈值为 100,可调整至 1,000),我们只需将它们突出显示,而不进一步扩展搜索。 但是,如果匹配结果不足,我们将使用 Elasticsearch 扩展到整个数据集的搜索,检索相关的对话(最多达到阈值数量),并将它们嵌入并投影到二维坐标中,然后再将它们发送到前端进行可视化。 为了加快此过程,我们将所有计算的坐标缓存在 SQLite 数据库中。 由于需要动态计算缓存中不存在的对话的坐标,我们选择了参数化的UMAP而不是t-SNE,因为t-SNE不学习投影函数,而参数化的UMAP允许将新的对话快速投影到低维空间。
3.3 性能评估
为了评估我们系统的效率,我们生成了十个随机的基于关键词的搜索查询,并使用我们的工具测量了每个查询的执行时间。 在基于过滤器的搜索页面上,每个查询平均需要0.47秒 (s)。 相比之下,使用HuggingFace Datasets库的基于for循环的朴素方法需要1148.89秒 (s)。 对于嵌入可视化,使用相同的方法进行测量,每个查询平均需要0.43秒 (s)。
4 用例
本节介绍了几个用例,展示了WildVis的潜力。 值得注意的是,WildVis主要用于探索性数据分析,而不是用于最终的定量分析。
数据
WildVis目前支持两个数据集:WildChat (Zhao et al., 2024) 和 LMSYS-Chat-1M (Zheng et al., 2024)。 这些数据集通过构建Elasticsearch索引并将随机选择的对话子集的二维坐标预先计算用于嵌入可视化,从而集成到系统中。
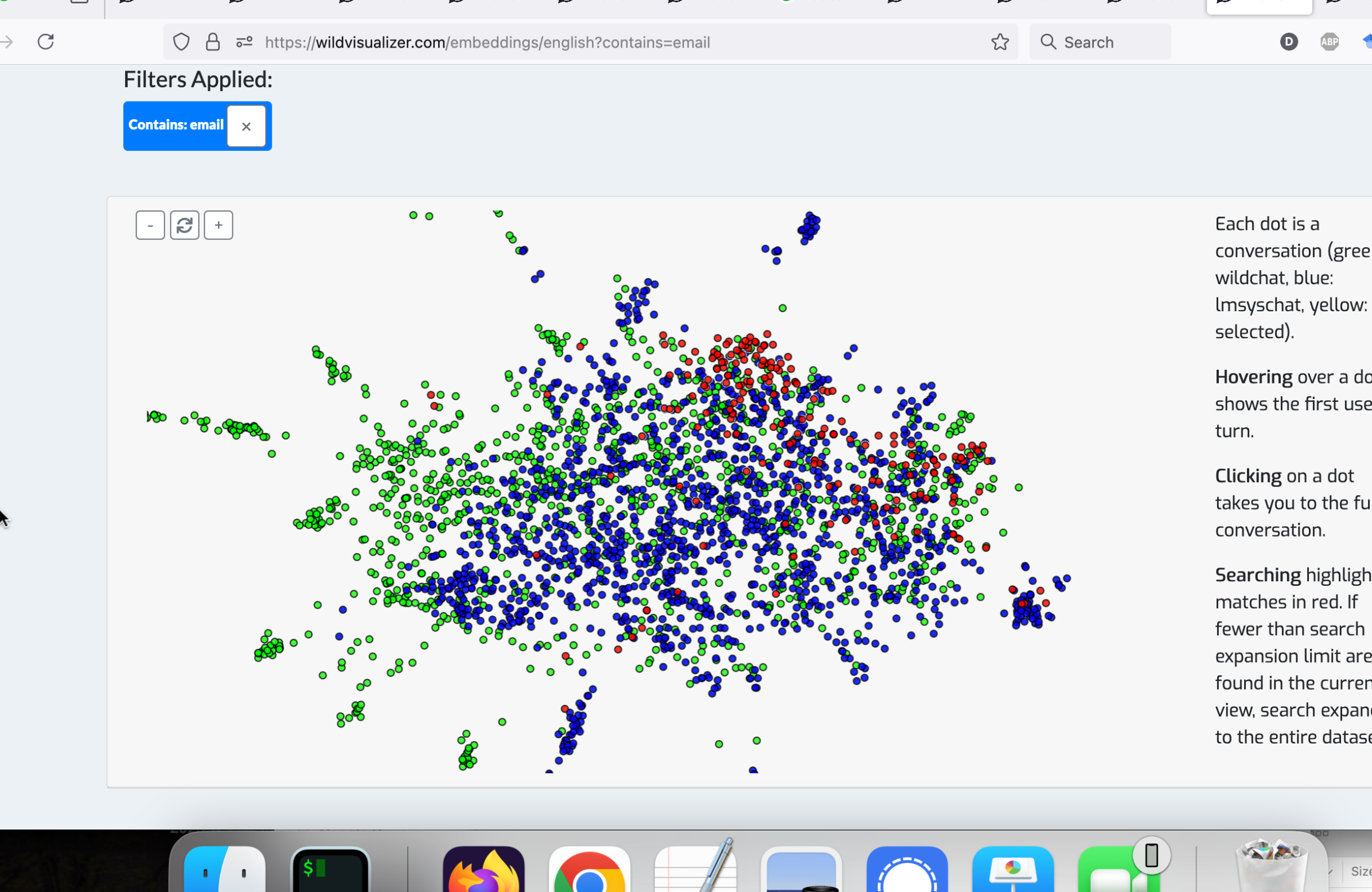
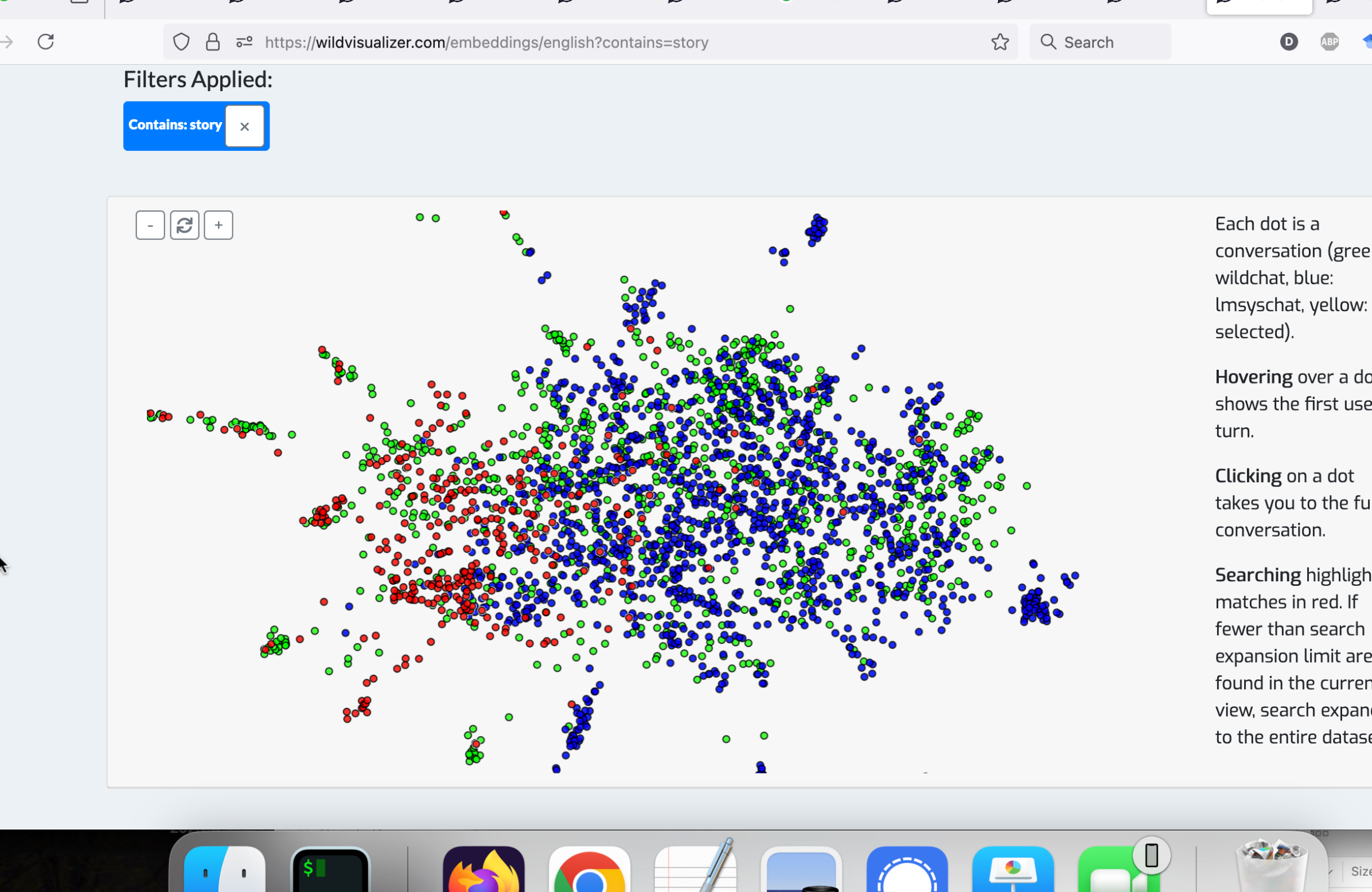
4.1 促进聊天机器人滥用研究
WildVis 的一个应用是在促进对聊天机器人滥用的研究。 我们在这里表明 WildVis 能够重现现有的关于聊天机器人滥用的研究,并发现新的滥用案例。
重现关于记者滥用的研究
在这个用例中,我们复制了 Brigham 等人 (2024) 的研究结果,该研究识别了记者滥用 WildChat 背后的聊天机器人来为他们的工作改写现有文章的实例。 为了找到研究中提到的特定实例,我们使用以下引文来自原始研究:
从这篇文章的信息中写一篇新文章,不要让它明显地表明你从他们那里获取信息,但在非常敏感的信息中给他们署名。
为了找到这段对话,我们在搜索页面的“包含”字段中输入短语 you are taking information from them 并执行搜索。 15 1515此案例可以在 https://wildvisualizer.com/?contains=you%20are%20taking%20information%20from%20them 找到。 搜索结果返回单个匹配项,与原始论文中提到的案例一致。 通过点击哈希后的 IP 地址,我们可以查看来自该用户的全部对话,识别出原始研究中分析的所有 15 次对话 (Brigham 等人,2024)。
重复用户自我披露研究
另一个例子是,我们复制了 Mireshghallah 等人 (2024) 关于用户自我披露行为研究的发现。 我们搜索该论文中的一个关键词:我邀请了我的父亲。 16 1616 该案例可在 https://wildvisualizer.com/?contains=I%20have%20invited%20my%20father 找到。 搜索再次返回单个匹配项,使我们能够找到研究中讨论的对话。
发现额外的滥用案例
WildVis 还便于发现额外的滥用案例。 例如,通过搜索包含个人身份信息 (PII) 和“签证官” 171717https://wildvisualizer.com/?contains=Visa%20Officer&redacted=true 两个词语的对话,我们识别出来自同一 IP 地址的多个条目。 基于此 IP 地址的进一步筛选表明,该用户似乎与一家移民服务公司有关联,并披露了敏感的客户信息。 181818https://wildvisualizer.com/?hashed_ip=048b169ad0d18f2436572717f649bdeddac793967fb63ca6632a2f5dca14e4b8
4.2 可视化和比较主题
4.3 描述用户特定的模式
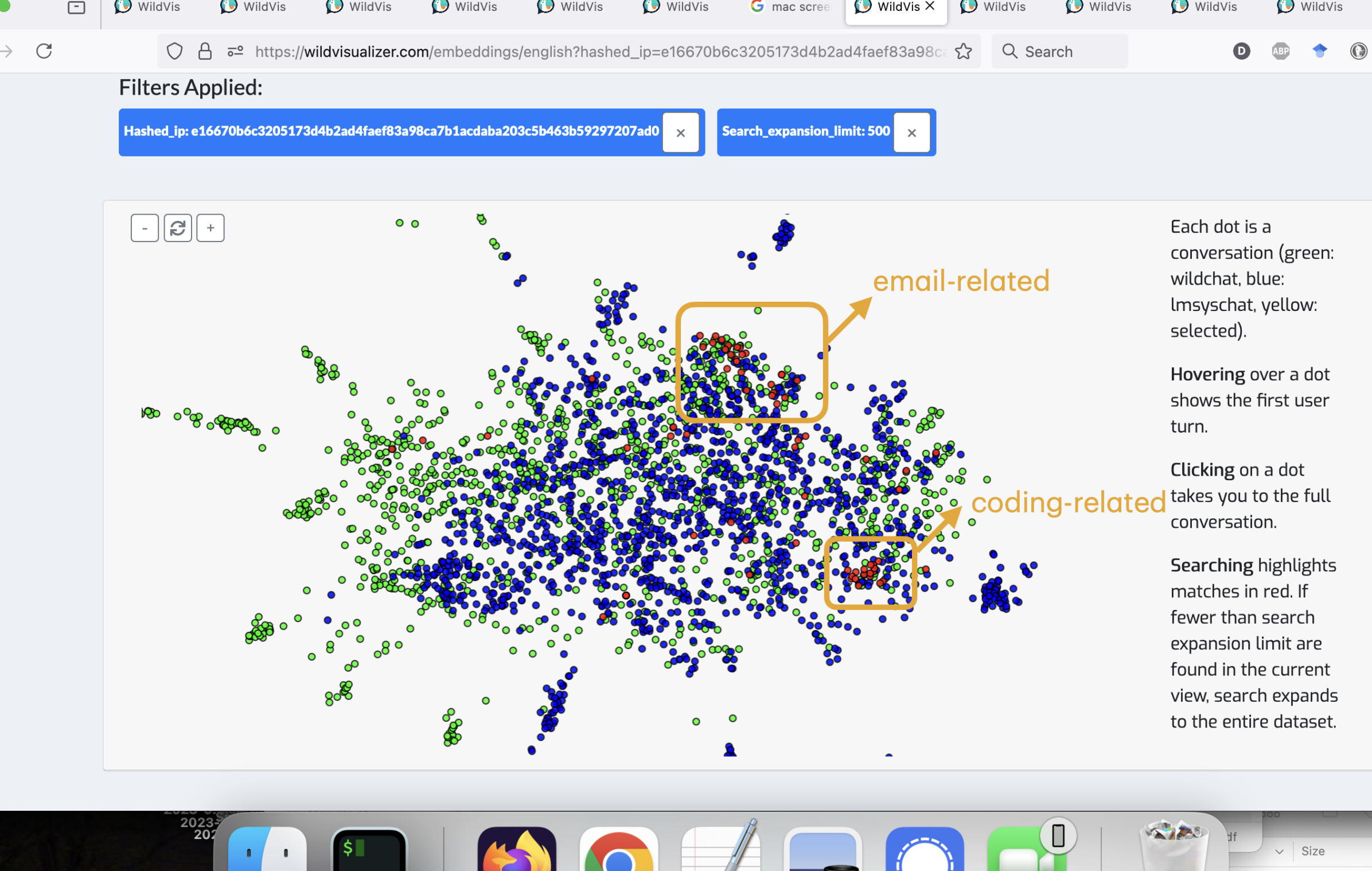
WildVis 也可用于可视化嵌入地图上与特定用户相关的所有对话的主题。 例如,图 12 显示了单个用户的全部对话,揭示了两个主要主题集群:与编码相关的和与电子邮件写作相关的。
5 相关工作
HuggingFace 数据集查看器
HuggingFace 的数据集查看器 (Lhoest 等人,2021)191919https://huggingface.co/docs/dataset-viewer/en/index 为托管在 HuggingFace 上的数据集提供基本搜索功能。 但是,它被设计用于一般的数据集可视化,而不是专门为对话数据集量身定制的。 例如,虽然它提供了有用的统计信息,但在表格格式中导航 JSON 格式的对话可能会很麻烦,并且缺乏探索对话数据的直观可视化。
论文可视化工具
ACM 会士引用可视化工具202020https://mojtabaa4.github.io/acm-citations/ 基于 ACM 会士的贡献声明对其进行嵌入。 虽然其界面与 WildVis 的嵌入可视化页面有很多相似之处,但它关注的是出版物数据,而不是对话数据。 另一项相关工作是 Yen 等人 (2024),它以类似的方式可视化论文,并添加了一个对话组件,允许用户通过提出问题与可视化进行交互。 但是,它主要设计用于学术论文,而不是大型聊天数据集。
用于聊天可视化的浏览器工具
存在一些基于浏览器的聊天可视化工具,例如 ShareGPT212121https://sharegpt.com,它允许用户分享他们的对话。 但是,ShareGPT 缺乏对搜索大型聊天数据集的支持。 同样,像 ShareLM222222https://chromewebstore.google.com/detail/nldoebkdaiidhceaphmipeclmlcbljmh 这样的浏览器扩展允许用户上传和查看他们的对话,而 ChatGPT 历史搜索232323https://chatgpthistorysearch.com/en 为用户的个人对话提供搜索功能。 但是,这些工具并非为探索或分析大型聊天数据集而设计。
大型数据分析工具
像 ConvoKit (Chang 等人,2020) 这样的专业工具为分析对话数据提供了一个框架。 相比之下,WildVis 旨在为交互式探索和可视化聊天数据集提供直观的界面。 这使得 WildVis 对于初步数据探索和假设生成特别有用。 另一个值得注意的工具,WIMBD (Elazar 等人,2024),支持对大型文本语料库的分析和比较,提供诸如搜索包含特定查询的文档和统计计数(如 n 元语法出现次数)的功能。 尽管 WIMBD 可以处理更大的数据集,但 WildVis 提供了额外的功能,例如嵌入可视化,为聊天数据集探索提供了一个更全面的工具包。
6 结论
在本文中,我们介绍了 WildVis,这是一种用于探索大型对话数据集的交互式基于 Web 的工具。 通过将强大的搜索功能与直观的可视化功能相结合,WildVis 使研究人员能够发现模式并从海量用户与聊天机器人交互数据集中获得见解。 该系统的可扩展性优化确保高效处理百万级数据集,同时保持响应迅速且用户友好的体验。
WildVis 通过提供一个专门的平台来可视化和探索聊天数据集,弥合了现有工具的差距,这些数据集本身难以使用通用数据集查看器进行分析。 我们的用例证明了该工具在复制和扩展关于聊天机器人滥用和用户自我披露的现有研究方面的潜力,以及促进基于主题的对话探索。
致谢
这项工作得到了 ONR 资助 N00014-24-1-2207、NSF 资助 DMS-2134012 和 NSERC 发现资助的支持。 我们还要感谢 Bing Yan、Pengyu Nie 和 Jiawei Zhou 的宝贵反馈。
参考文献
- Brigham et al. (2024) Natalie Grace Brigham, Chongjiu Gao, Tadayoshi Kohno, Franziska Roesner, and Niloofar Mireshghallah. 2024. Breaking news: Case studies of generative ai’s use in journalism. Preprint, arXiv:2406.13706.
- Chang et al. (2020) Jonathan P. Chang, Caleb Chiam, Liye Fu, Andrew Wang, Justine Zhang, and Cristian Danescu-Niculescu-Mizil. 2020. ConvoKit: A toolkit for the analysis of conversations. In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 57–60, 1st virtual meeting. Association for Computational Linguistics.
- Elazar et al. (2024) Yanai Elazar, Akshita Bhagia, Ian Helgi Magnusson, Abhilasha Ravichander, Dustin Schwenk, Alane Suhr, Evan Pete Walsh, Dirk Groeneveld, Luca Soldaini, Sameer Singh, Hannaneh Hajishirzi, Noah A. Smith, and Jesse Dodge. 2024. What’s in my big data? In The Twelfth International Conference on Learning Representations.
- Lhoest et al. (2021) Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario Šaško, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger, Clément Delangue, Théo Matussière, Lysandre Debut, Stas Bekman, Pierric Cistac, Thibault Goehringer, Victor Mustar, François Lagunas, Alexander Rush, and Thomas Wolf. 2021. Datasets: A community library for natural language processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 175–184, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Malik (2023) Aisha Malik. 2023. OpenAI’s ChatGPT now has 100 million weekly active users. Accessed: 2024-08-04.
- McInnes et al. (2020) Leland McInnes, John Healy, and James Melville. 2020. Umap: Uniform manifold approximation and projection for dimension reduction. Preprint, arXiv:1802.03426.
- Merrill and Lerman (2024) Jeremy B. Merrill and Rachel Lerman. 2024. What do people really ask chatbots? it’s a lot of sex and homework. The Washington Post. Accessed: 2024-08-27.
- Mireshghallah et al. (2024) Niloofar Mireshghallah, Maria Antoniak, Yash More, Yejin Choi, and Golnoosh Farnadi. 2024. Trust no bot: Discovering personal disclosures in human-llm conversations in the wild. Preprint, arXiv:2407.11438.
- Rush and Strobelt (2020) Alexander M. Rush and Hendrik Strobelt. 2020. Miniconf – a virtual conference framework. Preprint, arXiv:2007.12238.
- Sainburg et al. (2021) Tim Sainburg, Leland McInnes, and Timothy Q Gentner. 2021. Parametric umap embeddings for representation and semi-supervised learning. Preprint, arXiv:2009.12981.
- van der Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of Machine Learning Research, 9(86):2579–2605.
- Yen et al. (2024) Ryan Yen, Yelizaveta Brus, Leyi Yan, Jimmy Lin, and Jian Zhao. 2024. Scholarly exploration via conversations with scholars-papers embedding.
- Zhao et al. (2024) Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. Wildchat: 1m chatGPT interaction logs in the wild. In The Twelfth International Conference on Learning Representations.
- Zheng et al. (2024) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. 2024. LMSYS-chat-1m: A large-scale real-world LLM conversation dataset. In The Twelfth International Conference on Learning Representations.
附录 A 移动设备上的嵌入可视化
图 6 显示了移动设备上嵌入可视化页面的屏幕截图。 由于移动设备不支持悬停交互,我们通过使用点击手势来显示预览来调整界面。 此外,还提供了一个按钮来查看完整的对话,以取代台式机设备上使用的点击操作。
附录 B 语言特定集群
在嵌入可视化页面上将所有对话一起可视化时,会根据语言出现集群,例如 图 9 中的西班牙语、中文和俄语集群。
附录 C 切换嵌入可视化语言
图 7 显示了切换嵌入可视化语言的屏幕截图。 这将仅加载选定语言中的对话子集,并使用相应的训练好的参数化 UMAP 模型来嵌入对话。
附录 D 对话详细信息页面
图 8 显示了对话详情页面的截图,其中所有元数据字段都与对话内容一起显示。 点击任何元数据字段将根据选定的值过滤对话。 根据用户导航到此页面的方式(无论是从基于过滤器的搜索页面还是嵌入可视化页面),过滤操作将把用户重定向回相应的页面。 顶部的切换开关允许用户控制此行为。
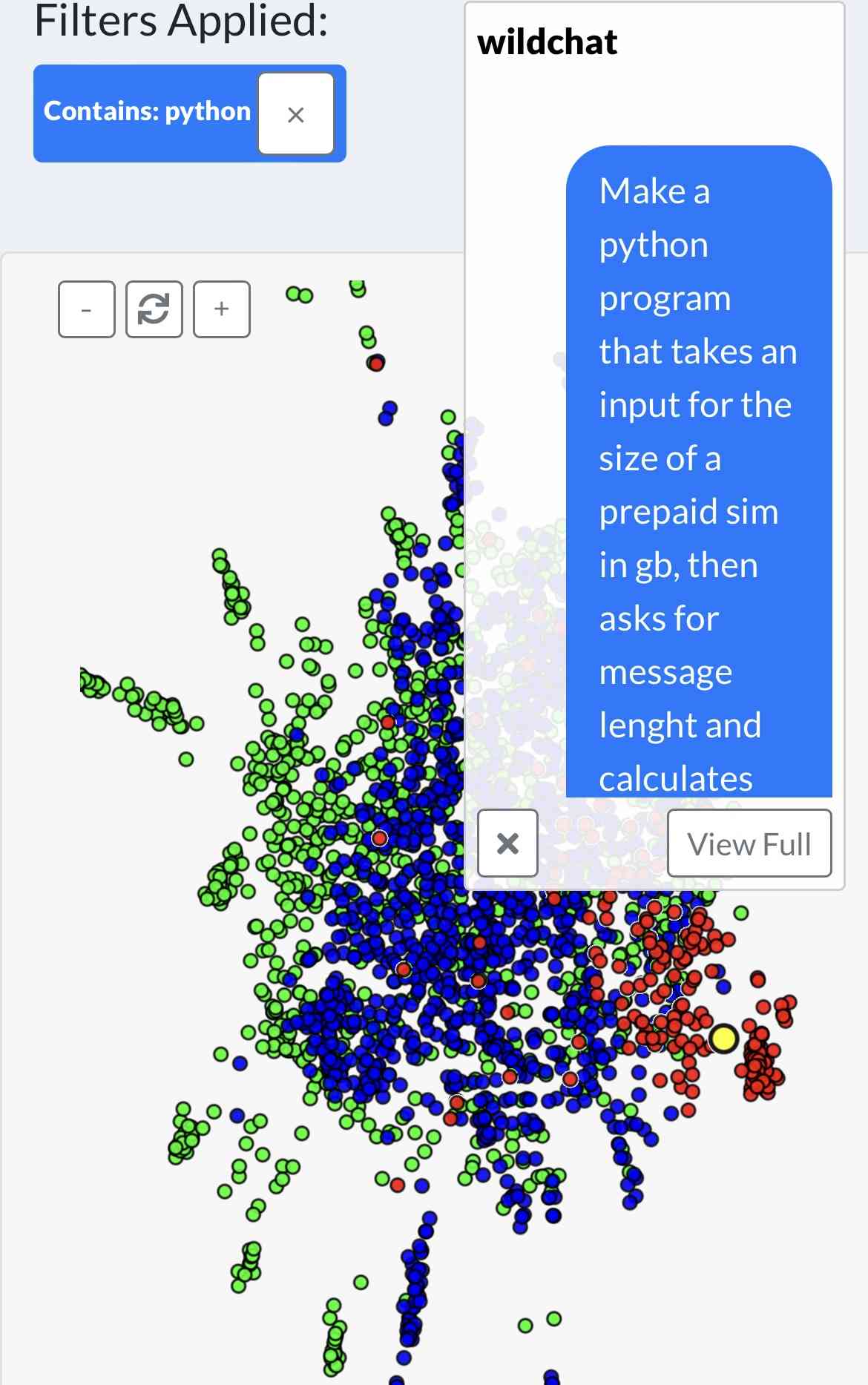
附录 E 可视化和比较主题分布
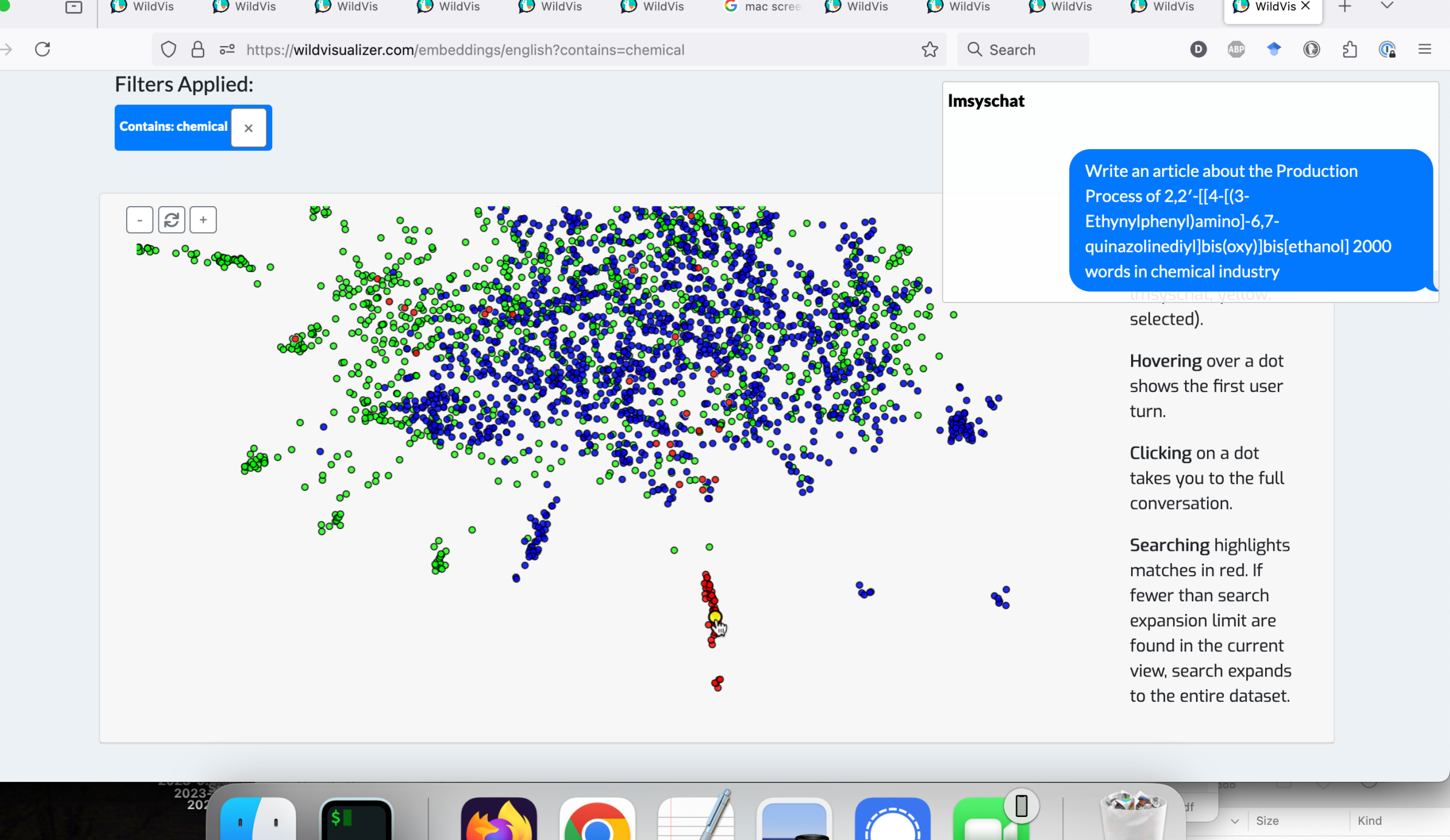
嵌入可视化突出了数据集中独特的异常值集群。 WildChat 数据集中的一个显著集群涉及 Midjourney 提示工程,用户要求聊天机器人为 Midjourney 生成详细的提示,如图 10所示(这种现象也由Merrill 和 Lerman (2024)指出)。 另一个独特的异常值集群包括 LMSYS-Chat-1M 中与化学相关的问答,如图 11所示。 2424 24Yao Fu发现了这种现象,并与作者分享了它。

附录 F 刻画用户特定模式
WildVis 可用于可视化嵌入图上与特定用户相关的所有对话主题。 例如,图 12 显示了来自单个用户的所有对话,揭示了两个主要主题集群:与编码相关和与电子邮件写作相关。