研究用于基于语音语言模型的语音生成的神经音频编解码器
抽象的
神经音频编解码器符元是基于语音语言模型 (SLM) 的语音生成的基石。 但是,对于编解码器系统如何影响 SLM 的语音生成性能,目前还没有系统性的理解。 在这项工作中,我们研究了 SLM 框架中用于语音生成的编解码器符元,为有效的编解码器设计提供见解。 我们在相同的训练数据集和损失函数上重新训练现有的高性能神经编解码器模型,以在统一的环境中比较它们的性能。 我们将编解码器符元集成到两个 SLM 系统中:基于掩码的并行语音生成系统和基于自回归 (AR) 加非自回归 (NAR) 模型的系统。 我们的研究结果表明,编解码器系统中更好的语音重建并不一定能保证 SLM 中语音生成的改进。 高质量的编解码器解码器对于 SLM 中自然语音的生成至关重要,而语音的清晰度则更多地取决于量化机制。
Index Terms— 神经音频编解码器,语音语言模型,语音生成,符元,编解码器研究
1简介
大型语言模型的出现和成功,例如 GPT 系列工作 [1, 2],激发了语音生成领域内语音语言模型 (SLM) 的研究 [3, 4, 5, 6]。 与其以样本级方式合成语音 [7] 或通过估计连续特征(如梅尔谱)来合成语音,SLM 直接预测离散的语音符元。 然后,这些预测的符元被预先训练的解码器模块用来重建波形。 通过在语言模型框架中对离散的语音符元进行建模,我们可以利用大型语言模型的进步来增强语音生成任务。 使用离散符元的另一个优点是它有利于构建多模态模型。 这些来自各种模态(如语音、文本、视频等)的符元,可以无缝地集成和以统一的方式处理。
离散语音表示符元主要源于两条研究路线:自监督学习 [8, 9, 10],产生语义符元,以及神经音频编解码系统 [11, 12, 13],产生编解码符元。 最初,语义符元被 SLM 基语音生成所采用 [14]。 虽然它们能产生可理解的语音,但它们无法捕捉到像说话人身份这样的始终如一的声学特征。 相反,基于残差矢量量化 (RVQ) 的神经音频编解码系统,生成保留丰富声学信息的层次化编解码符元。 这些编解码符元随后被采用,单独 [4] 或与 SLM 的语义符元一起 [3, 5] 生成语音。
神经音频编解码系统最初是为通信目的而设计的,而压缩率和重建质量是主要的评估指标。 基于 VQ-VAE [15] 并引入 RVQ 模块,SoundStream [11] 作为开创性的神经音频编解码模型。 它包含三个基本模块:编码器、基于 RVQ 的量化器和解码器。 这些组件使用重建损失和对抗性损失进行联合训练。 随后,一系列神经音频编解码模型被提出 [12, 13, 16],扩展了 SoundStream。 Encodec [12] 在量化单元上加入了 LSTM 层和一个小型 Transformer 语言模型,以进一步降低带宽。 Vocos [16] 在解码阶段预测了短时傅里叶变换 (STFT) 系数而不是波形,这表明了对 Encodec 的改进。 DAC [13] 提出了对 Encodec 的两项主要改进。 首先,它通过将潜在向量的维度缩减到一个较小的值以进行量化来解决码本崩溃问题。 其次,DAC 用蛇形激活函数 [17] 替换了 ReLU 激活函数,这为重建语音和音乐等周期性信号提供了好处。 最近,研究人员在设计低比特率编解码系统 [18, 19, 20, 21, 22, 23]方面投入了大量精力,这些系统可以与语音语言模型集成,以实现更高效的效率。 对现有神经编解码模型和音频语言模型的全面综述可以在 [24, 25] 中找到。
虽然神经编解码器设计的最初目标是实现高压缩率和优异的信号级重建质量,但编解码器如何影响基于 SLM 的语音生成尚不清楚。 在这项工作中,我们调查了已建立的编解码系统在 SLM 框架内用于零样本语音生成的有效性。 我们的目标是确定为 SLM 量身定制的编解码系统设计关键组件。 关于编解码系统,我们选择了三种高性能模型:Encodec [12]、Vocos [16] 和 DAC [13]。 为了确保公平比较,我们使用相同的数据集和损失函数重新训练这些模型及其变体。 我们考虑了两个基于 SLM 的零样本语音生成模型。 首先,我们采用基于掩码的并行语音生成模型,该模型最初在 SoundStorm 工作 [5] 中提出。 我们在原始设计的基础上,通过整合掩码跨度和无分类器引导 (CFG) 技术等增强功能 [26, 27]。 其次,我们探索了 VALL-E 工作 [4] 中介绍的 AR + NAR 模型。 我们系统地评估了编解码系统的语音重建质量和语音生成系统的语音生成质量。 这项工作的主要贡献包括:
-
•
我们利用大规模语音数据重新训练高性能编解码模型,以便进行统一比较。
-
•
我们将这些编解码器集成到两个流行的基于 SLM 的语音生成系统中进行调查。
-
•
彻底的评估和分析为基于 SLM 的语音生成提供了有效的编解码器设计信息。
2 神经音频编解码系统
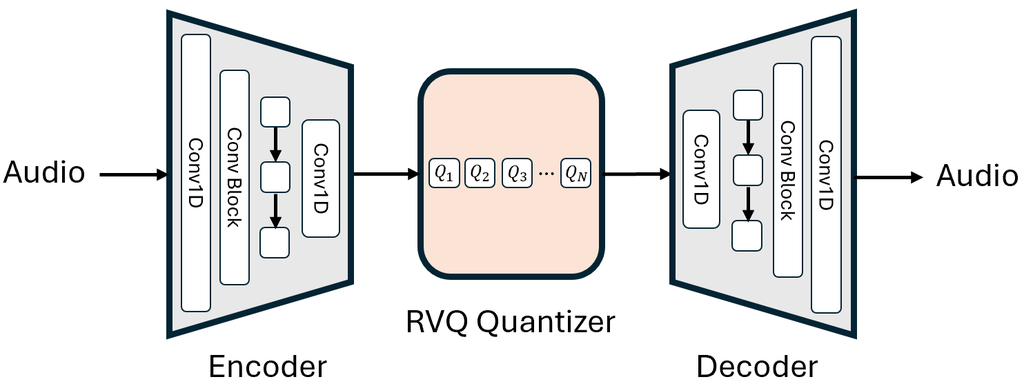
神经音频编解码器可以将音频压缩成离散表示形式,供语音生成模型使用。 图 1 展示了一个神经音频编解码器的系统架构。 它包含一个将波形降采样到更低采样率(例如 50Hz)的编码器、一个将潜在特征离散化的残差向量量化 (RVQ) 模块,以及一个从离散符元重建音频的解码器。 在接下来的部分中,我们将探讨 Encodec [12]、Vocos [16] 和 DAC [13] 的设计选择。 我们将编解码器影响语音生成的两个方面归类为:i) 向量量化 (VQ) 方案,它会影响符元的分布并间接影响语音建模的复杂度;ii) 解码器方案,它会影响生成的音频质量。
2.1编码器
为了量化,Encodec [12] 使用了类似于 SoundStream [11] 的残差向量量化 (RVQ)。 第 个量化器 的输出表示为 其中 是连续的潜在向量。 每一层上的 VQ 操作都是为了找到在欧氏距离上最接近残差嵌入的码本向量。 在训练过程中,码本向量使用指数移动平均 (EMA)[15] 进行更新。 为了缓解码本崩溃问题,Encodec 还采用了一种“重启”技术,用从批次中采样的候选向量替换未使用的码本向量。 Encodec 利用了一个全卷积解码器 SEANet[28],与 SoundStream[11] 相同,它使用转置卷积将量化特征上采样成波形。 添加了两个小的 LSTM 层来改进序列建模。
2.2沃科斯
Vocos [16] 是一种基于 GAN 的 Vocoder,经过训练可以生成 STFT 系数。 它可以作为解码器集成到任何神经编解码框架中 [16],方法是通过从冻结的预训练编码器和量化器进行训练,或者通过端到端的方式从头开始构建。 Vocos 预测 STFT 系数(对数尺度频谱幅度和相位值),而不是原始波形,并且通过逆傅立叶变换实现波形上采样 [16]。 该系统已证明可以生成比原始 Encodec [16] 质量更高的音频,并用于语音生成系统 VALL-E 2 [29]。
2.3DAC
Descript-audio-codec (DAC) [13] 是一个最近的编解码系统,它在 Encodec 上具有几个 VQ 改进。 DAC 通过在非常低维的潜在空间中量化来缓解码本坍塌。 其更新的 RVQ 是: 其中 Proj_In 是从原始潜在空间(1024 维)到低维量化潜在空间(8 或 32 维)的线性投影。 它还将 VQ 查找距离从欧几里得距离更改为余弦相似度,以确保稳定性。 DAC 使用显式 MSE 码本损失函数,而不是 EMA 更新方案来学习投影函数。 此损失可以表示为 ,其中 和 分别表示查找的向量和量化的向量。
与 Encodec 中的解码器相比,DAC 用 Snake 激活代替了 ReLU 激活,这被证明有利于周期性信号重建质量 [17]。
3 使用编解码器令牌进行语音生成
对于语音生成任务,我们选择了两种类型的基于 SLM 的系统。 第一个是基于掩码的并行语音生成模型 [5],以预言语义令牌为条件。 第二个是基于 AR + NAR 模型的文本到语音系统 [4]。 两种系统都预测目标语音的编解码器符元,然后通过预训练的编解码器解码器重建最终的波形。
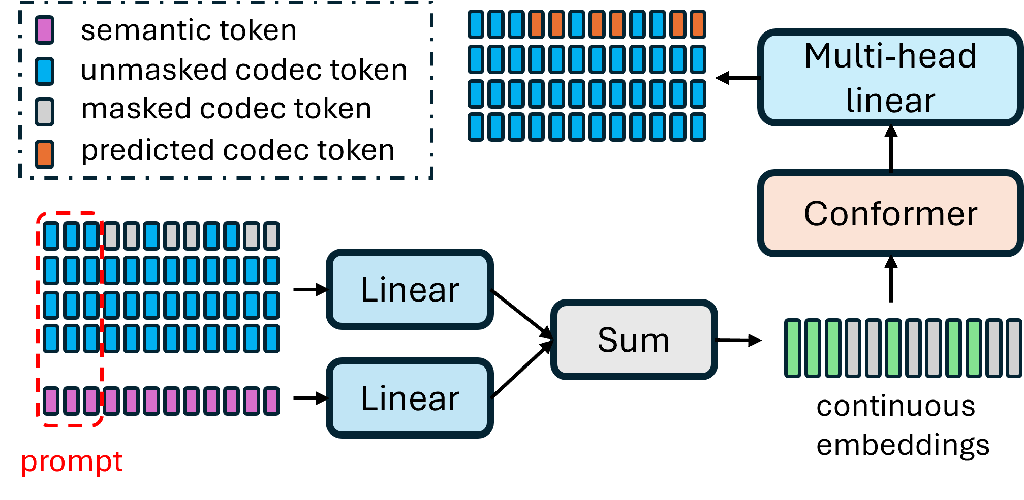
3.1 基于掩码的并行语音生成
基于掩码的并行语音生成是在 [5] 中提出的,它受到图像生成领域中的 maskGIT 的启发 [30]。 与基于 AR 的方法不同,基于掩码的并行语音生成以批处理的方式为整个语音样本生成编解码器符元,并根据置信度评分迭代多个轮次。 图 2 说明了基于掩码的并行语音生成的模型架构。 主干采用基于双向自注意力的 Conformer,它使用编解码器符元和语义符元的加权嵌入来预测掩码编解码器符元。 由于基于 RVQ 的编解码器符元的层次结构,基于掩码的并行生成逐层进行,只有当当前层的所有符元都已估计后,才能推进到下一层。
我们采用了基于跨度的掩码策略 [26],其中应用了一系列分块掩码(块大小在我们的情况下设置为 5),而不是在每次迭代中单独掩码每个符元。 为了进一步提高生成的语音质量,我们集成了基于退火的 CFG 机制,如同一项工作 [26] 中所提出的。 在训练期间,模型以一定的概率有条件地和无条件地进行训练。 在推理期间,生成的信号从预测的条件概率和无条件概率的线性组合中采样,其比例由掩码率控制。 这种机制逐渐将生成过程从仅仅由语义符元引导转向结合上下文填充。 最终,预测的编解码器符元使用编解码器系统的解码器模块转换为语音波形。
请注意,在本实验中,我们只关注研究跨不同编解码器系统的基于掩码的并行生成框架。 我们通过使用预言语义符元作为输入来实现这一点,而无需像[5]中那样进行文本到语义符元映射。
3.2 使用 AR 和 NAR 模型进行语音生成
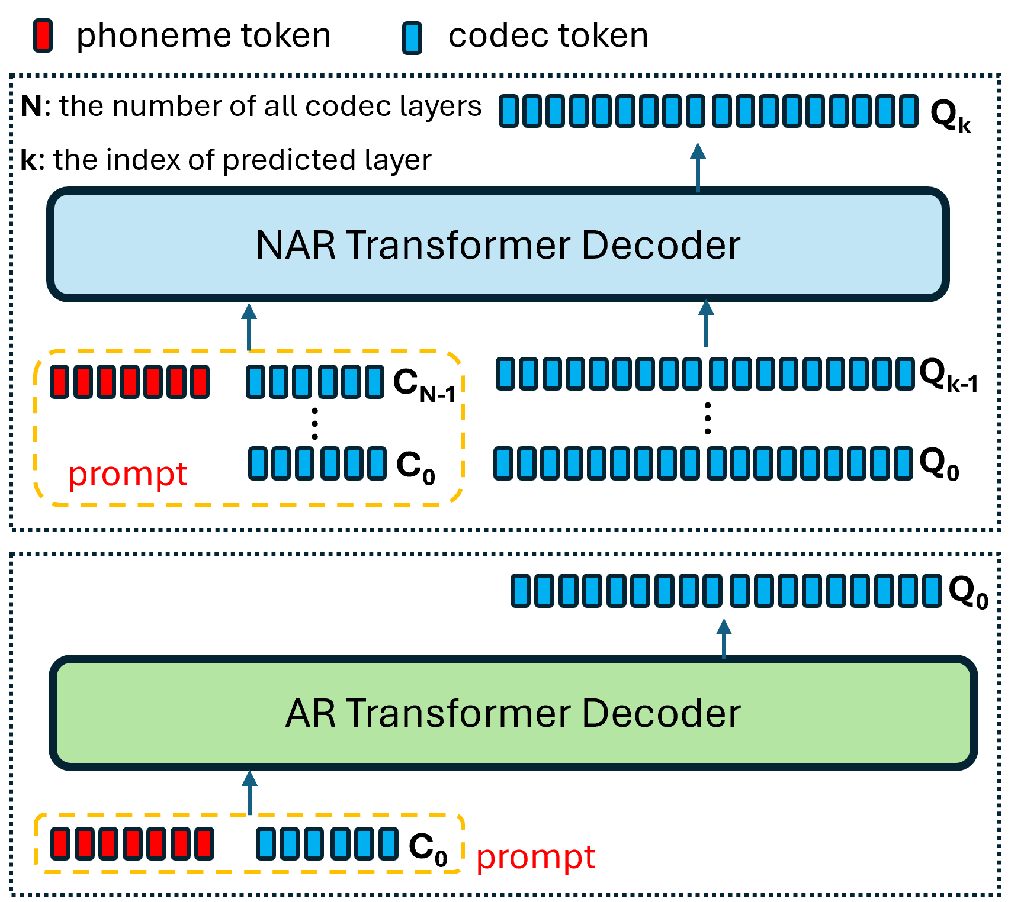
我们实验过的另一种基于 SLM 的语音生成系统采用 AR 和 NAR 模型,如 VALL-E 工作[4]中所提议的那样。 图 3 说明了该方法的模型架构。 整个系统涉及两个生成阶段。 首先,AR 模型以从文本中推导出的音素序列和来自第一量化层的提示编解码器符元作为输入,以 AR 方式预测目标语音的第一层编解码器符元。 随后,NAR 模型以并行的方式,根据所有已预测的编解码器符元层与所有量化层的音素序列和提示编解码器符元相结合,逐层预测其余的编解码器符元。 AR 和 NAR 模型都使用相同的 Transformer 模型架构。 但是,AR 模型以因果方式运行,而 NAR 模型以并行方式运行。
4 实验
4.1 编解码器重建实验
4.1.1 模型配置
我们评估了 Encodec [12]、Vocos(带有 Encodec 特性)[16] 和 DAC [13] 的官方 24kHz 预训练模型。 我们也评估了这些复制的编解码器模型。 由于官方的 Encodec 没有提供训练代码,我们根据 Encodec 复制了一个具有编码器和解码器架构的基线编解码器。 对于量化器,我们使用了一个没有重启技术的 EMA 量化模块。 在获得基线编解码器系统后,我们训练了一个 Vocos 解码器,其编码器和量化器被冻结。 我们使用其官方代码库111https://github.com/descriptinc/descript-audio-codec复制了 DAC。 然后,我们训练了一个 Vocos 解码器,用于复制的 DAC,其编码器和量化器被冻结。
我们使用 54,000 小时的 Librilight-Large 数据集[31]重新训练了所有编解码器模型。 表1 显示了官方预训练模型与我们复制模型的比较。 我们使用 16kHz 的采样率训练了我们的模型,以与我们的训练集保持一致。 我们还为训练复制模型使用了固定比特率。
| Model name | Quantization | Sampling | Token | Bitrate |
| method | rate (kHz) | rate (Hz) | (kbps) | |
| Encodec-official | EMA w/ restart | 24 | 75 | 1.5-24 |
| Vocos-official | - | 24 | 75 | 1.5-12 |
| DAC-official | Projection | 24 | 75 | 0.75-24 |
| [1pt/2pt][0pt/1pt] Baseline-16kHz | EMA | 16 | 50 | 4 |
| Baseline-Vocos-16kHz | - | 16 | 50 | 4 |
| DAC-16kHz | Projection | 16 | 50 | 4 |
| DAC-Vocos-16kHz | - | 16 | 50 | 4 |
4.1.2 训练细节
对于鉴别器,我们使用了 Encodec[12] 中的多尺度 STFT (MS-STFT) 鉴别器和 HiFi-GAN[32] 中的多周期鉴别器 (MPD) 的组合。 我们对所有复制的编解码器使用了相同的鉴别器实现。 对于损失公式,我们遵循了[13] 中的有效配置,并使用重建损失、对抗损失和承诺损失的组合。
每个复制的模型都在 8 个 V100 GPU 上训练了 200k 步。 我们使用了 1 秒的片段长度,每个 GPU 的批次大小为 22。 我们使用了 AdamW 优化器,学习率为 1e-4,,,以及具有 的指数学习率衰减。
4.1.3 评估指标
我们使用了 Librispeech-test-clean [33] 的短片段作为测试集,其持续时间范围为 4 秒到 10 秒。 为了评估编解码器的语音质量,我们使用了感知语音质量评估 (PESQ) [34],短期客观可懂度 (STOI) [35],虚拟语音质量客观听者 (ViSQOL) [36],梅尔倒谱失真 (MCD) [37] 作为指标。 我们还使用 WavLM-TDNN 模型 [38] 测量了原始语音和重建语音之间的说话人相似度 (SIM)。 对于字错误率 (WER) 评估,我们使用了市场领先的 ASR API 来获取转录文本并使用真实转录文本计算字错误率。
4.1.4 结果
如表 2 所示,对于官方模型,我们观察到官方 DAC 模型在大多数指标中表现最佳。 我们还观察到,使用 Vocos-official 解码器来改进 Encodec 的编解码器质量。 我们复制的模型共享类似的趋势,其中复制的 DAC-16kHz 模型的表现优于基线编解码器。 此外,添加 Vocos 可以改善音质的某些方面,特别是我们发现这可以获得更好的说话人相似度和 ViSQOL 分数,以及更低的字错误率。 我们观察到,我们复制的模型在评估指标方面通常优于官方模型。 这种优越性可能源于我们的训练集和测试集都在有声读物领域内,确保了与官方模型相比,训练测试分布之间的更好对齐,官方模型在训练中包含了像 Common Voice [39] 这样的众包数据。
| Codec models | PESQ | STOI | VISQOL | MCD() | SIM | WER () |
| Encodec-official | 3.12 | 0.94 | 4.37 | 2.60 | 0.89 | 1.31 |
| Vocos-official | 3.57 | 0.95 | 4.41 | 2.50 | 0.90 | 1.31 |
| DAC-official | 3.77 | 0.95 | 4.36 | 2.34 | 0.90 | 1.27 |
| [1pt/2pt][0pt/1pt] Baseline-16kHz | 3.63 | 0.95 | 4.44 | 2.32 | 0.90 | 1.29 |
| Baseline-Vocos-16kHz | 3.62 | 0.95 | 4.47 | 2.58 | 0.92 | 1.20 |
| DAC-16kHz | 3.99 | 0.97 | 4.53 | 1.95 | 0.94 | 1.12 |
| DAC-Vocos-16kHz | 3.98 | 0.97 | 4.54 | 2.00 | 0.95 | 1.06 |
4.2 基于掩码的并行生成实验
| ID | Codecs | Token rate | Continuation generation | Cross-speaker generation | |||||||
| SIM-O | NISQA | WER (%) | SIM-O | NISQA | WER (%) | CMOS | SMOS | ||||
| GT | GroundTruth | - | 0.67 | 3.87 | 0.96 | 0.70 | 3.87 | 0.96 | 0.29 | 4.75 | |
| [1pt/2pt][0pt/1pt] S1 | Encodec-official | 75 | 0.50 | 3.17 | 1.54 | 0.55 | 3.31 | 1.79 | -0.79 | 4.29 | |
| S2 | Baseline-16kHz | 50 | 0.59 | 3.33 | 1.27 | 0.58 | 3.52 | 1.85 | -0.38 | 4.69 | |
| S3 | Baseline-Vocos-16kHz | 50 | 0.61 | 3.47 | 1.22 | 0.58 | 3.76 | 1.86 | -0.31 | 4.52 | |
| S4 | DAC-16kHz | 50 | 0.54 | 3.80 | 1.37 | 0.58 | 3.99 | 1.78 | -0.09 | 4.43 | |
| S5 | DAC-Vocos-16kHz | 50 | 0.54 | 3.74 | 1.28 | 0.59 | 3.97 | 1.79 | 0.00 | 4.57 | |
4.2.1 数据集
我们使用 54,000 小时的 Librilight-Large 数据集 [31] 训练了基于掩码的并行语音生成模型。 每个训练样本的数据被分成最多 30 秒的片段。 为了推断,我们使用了 LibriSpeech-test-clean [33] 数据集的短分割。
4.2.2 模型配置
对于语义符号提取,我们使用了 Hubert-base 模型 [9]。 语义和重新训练的编解码器符号以每秒 50 个符号的速率生成,而官方的 Encodec 符号以每秒 75 个符号的速率生成。 为了对齐官方 Encodec 符号和语义符号之间的时间,我们将语义符号的嵌入向上采样,以匹配官方 Encodec 符号的速率。 该模型具有 12 层 Conformer,每层具有 16 个注意力头,1024 维的嵌入,4096 维的 FFN,卷积核大小为 5,以及旋转位置嵌入,类似于 [5]。 在解码过程中,我们对第一个编解码器层应用了 5 次迭代。 对于退火 CFG 配置,我们将初始和最终的引导系数分别设置为 0 和 2。 对于其余的 RVQ 层,我们使用贪婪解码,没有迭代。 总体而言,需要 12 次前向传递来预测所有 8 个 RVQ 层的符元。
该模型使用 Adam 优化器进行训练,批次大小为 32。 我们采用线性衰减学习率调度器,预热步骤为 10k 步,峰值学习率为 1e-4。 使用官方 Encodec 符元训练的模型使用了 10 个 epoch,而其他编解码器符元使用了 5 个 epoch。
4.2.3 结果
表 3 展示了评估结果。 在延续生成中,我们使用了来自同一话语的前 3 秒语音作为提示。 对于跨说话人生成,我们使用了来自不同话语的 3 秒语音作为提示。 我们用于延续生成的评估指标包括 SIM-O [40]、NISQA 分数 [41] 和 WER。 此外,对于跨说话人生成,我们还纳入了 CMOS(比较平均选项分数)和 SMOS(相似度平均选项分数)来评估人类对生成语音的语音自然度和说话人相似度的感知。 CMOS 和 SMOS 的测试程序遵循与 [4] 中描述的相同协议,每次测试有 10 名参与者,每个条件随机选择 10 个样本。
总体而言,使用重新训练的编解码器符元生成的语音在大多数评估指标中都优于官方 Encodec 符元。 生成语音的 WER 结果在所有编解码器符元中都相似,这可能是因为我们使用了先验语义符元作为条件。 从 NISQA 分数,我们观察到以下趋势:i)在基线编解码器模型中,Vocos 解码优于基于波形的解码;ii)DAC 解码表现出与 Vocos 解码相似的性能,两者都超过了基线解码。 此外,跨说话人生成中的 CMOS 分数与 NISQA 分数呈强相关性。 这些结果表明,将蛇形激活函数用于波形解码对语音自然度的影响与预测 STFT 系数的影响相似。 对比基线-Vocos-16kHz 和 DAC-Vocos-16kHz,我们观察到 DAC 的量化带来了更好的语音自然度。
在 SIM-O 结果方面,对比基线-16kHz 和 DAC-16kHz 时,在延续生成和跨说话人生成之间存在轻微差异。 然而,考虑到所有 SIM-O 分数都落在一个狭窄的范围内,这种差异可以忽略不计。 SMOS 分数表明,基线-16kHz 具有最佳的说话人相似度性能,其次是 DAC-Vocos-16kHz。
4.3 AR + NAR 生成模型实验
| ID | Codecs | Token rate | Continuation generation | Cross-speaker generation | |||||||
| SIM-O | NISQA | WER (%) | SIM-O | NISQA | WER (%) | CMOS | SMOS | ||||
| GT | GroundTruth | - | 0.67 | 3.87 | 0.96 | 0.70 | 3.87 | 0.96 | 0.61 | 4.77 | |
| AR model sampling temperature: 1.0 | |||||||||||
| [1pt/2pt][0pt/1pt] S1 | Encodec-official | 75 | 0.43 | 3.21 | 4.73 | 0.47 | 3.25 | 3.53 | -1.03 | 4.15 | |
| S2 | Baseline-16kHz | 50 | 0.46 | 3.35 | 10.20 | 0.48 | 3.32 | 11.25 | -0.73 | 4.39 | |
| S3 | Baseline-Vocos-16kHz | 50 | 0.46 | 3.52 | 10.10 | 0.48 | 3.53 | 11.31 | -0.70 | 4.37 | |
| S4 | DAC-16kHz | 50 | 0.48 | 3.78 | 4.97 | 0.49 | 3.72 | 3.31 | 0.01 | 4.33 | |
| S5 | DAC-Vocos-16kHz | 50 | 0.48 | 3.76 | 4.95 | 0.49 | 3.72 | 3.28 | 0.00 | 4.33 | |
| AR model sampling temperature: 0.9 | |||||||||||
| [1pt/2pt][0pt/1pt] S1a | Encodec-official | 75 | 0.44 | 3.23 | 3.88 | 0.47 | 3.22 | 3.38 | - | - | |
| S2a | Baseline-16kHz | 50 | 0.46 | 3.35 | 6.94 | 0.48 | 3.31 | 8.52 | - | - | |
| S3a | Baseline-Vocos-16kHz | 50 | 0.47 | 3.52 | 6.97 | 0.49 | 3.52 | 8.63 | - | - | |
| S4a | DAC-16kHz | 50 | 0.48 | 3.76 | 3.08 | 0.49 | 3.75 | 3.03 | - | - | |
| S5a | DAC-Vocos-16kHz | 50 | 0.48 | 3.74 | 3.09 | 0.50 | 3.73 | 2.91 | - | - | |
| AR model sampling temperature: 0.8 | |||||||||||
| [1pt/2pt][0pt/1pt] S1b | Encodec-official | 75 | 0.42 | 3.23 | 4.59 | 0.45 | 3.16 | 9.80 | - | - | |
| S2b | Baseline-16kHz | 50 | 0.46 | 3.35 | 5.39 | 0.48 | 3.23 | 8.40 | - | - | |
| S3b | Baseline-Vocos-16kHz | 50 | 0.47 | 3.54 | 5.30 | 0.48 | 3.46 | 8.55 | - | - | |
| S4b | DAC-16kHz | 50 | 0.48 | 3.74 | 3.16 | 0.49 | 3.69 | 3.82 | - | - | |
| S5b | DAC-Vocos-16kHz | 50 | 0.49 | 3.73 | 3.17 | 0.49 | 3.68 | 3.89 | - | - | |
4.3.1 数据集
我们使用 54k 小时的 Librilight-Large 数据集 [31] 训练了 AR 和 NAR 模型。 对于 AR 模型,数据被分成 10 到 20 秒的样本,而对于 NAR 模型,我们使用了最多 30 秒的样本。 音素数据来自 ASR 模型和 [4] 中介绍的音素对齐工具,帧大小为 30ms,并删除了连续的音素重复。 对于推理,我们还使用了 LibriSpeech-test-clean [33] 数据集的短分割。
4.3.2 模型配置
我们为 AR 和 NAR 模型采用了与 VALL-E 工作 [4] 中描述的相同 Transformer 架构。 该架构包含 12 层,每层包含 16 个注意力头。 嵌入维度为 1024,前馈层维度为 4096。
所有模型都在 16 个 GPU 上以 6k 编解码器符元批次大小训练了 800k 步,除了使用 Encodec 符元的 NAR 模型,该模型训练了 560k 步。 使用 AdamW 优化器,AR 和 NAR 模型经过优化,采用线性衰减学习率调度器、32k 预热步和 5e-4 的峰值率。
4.3.3 结果
我们在表 4 中展示了评估结果。 对于继续和跨说话者生成,我们在 AR 模型推理期间尝试了三种不同的温度设置。 值得注意的是,不同的温度对于不同的系统产生了最佳结果。对于每种温度设置,DAC-16kHz 和 DAC-Vocos-16kHz 在所有评估指标上都表现出同样出色的性能。 从表 4 中一个意想不到的观察结果是,Baseline-16kHz 和 Baseline-Vocos-16kHz 表现出明显更差的 WER 性能,相比于其他编解码器设置,尽管它们在表 2 中重建的 WER 相似。
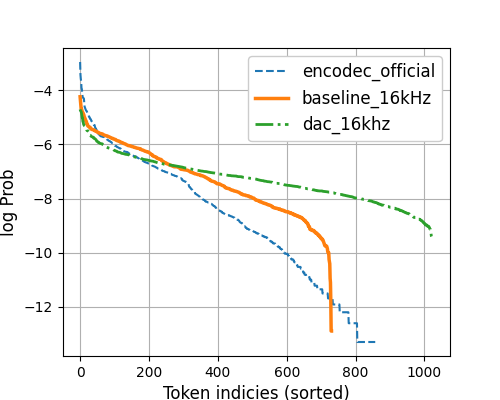
为了调查这个问题,我们使用 LibriSpeech-test-clean 分析了第一层编解码器符元利用率的对数分布,如图 4 所示。 Baseline-16kHz 曲线在大约 700 处急剧下降,表明三个编解码器系统中代码利用率最低(Encodec-official 和 DAC-16kHz 分别使用 850 和 1024 个代码)。 这种低代码利用率可能是导致 WER 性能差的原因。 我们推断,这种低代码利用率与底层的 VQ 方案有关:我们的基线模型使用标准 EMA 更新,而其他模型则应用了技术来提高码本利用率。 在 AR 模型推理期间使用较低的温度显著提高了 Baseline-16kHz 的 WER 性能。 较低温度导致的更尖锐的采样分布可以减轻幻觉问题,尤其是在使用代码数量远小于 AR 模型分类层中类别数量的情况下。 但是,我们发现采样温度必须在一个特定的范围内;过小的值可能会使 WER 恶化。
我们报告了 AR 模型采样温度为 1.0 时的主观评价结果。 来自基于掩码的并行语音生成实验的相同 10 名参与者被邀请参加此测试,遵循相同的协议。 结果表明,CMOS 分数与 NISQA 分数之间存在正相关性,而 SMOS 分数则落在一个狭窄的范围内,其中 Baseline-16kHz 实现了最高得分。
5 结论
我们探索了各种用于 SLM 驱动的语音生成任务的神经编解码器系统。 我们的研究包括训练我们自己的基线编解码器系统,以及基于现有高性能编解码器系统(包括 Encodec、Vocos 和 DAC)的变体。 我们将这些编解码器系统中的编解码器符元集成到两种类型的基于 SLM 的语音生成系统中:基于掩码的并行语音生成系统和基于 AR + NAR 模型的文本到语音生成系统。 我们的实验结果表明,DAC 模型在基于 SLM 的语音生成方面总体表现出色。 Vocos 作为一个竞争性的声码器,展现出与 DAC 解码器相似的性能。 有趣的是,我们观察到语音重建质量与生成的语音的自然度高度相关,但这种相关性在说话人相似性和语音清晰度方面并不成立。
参考文献
- [1] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, et al., “Language models are few-shot learners,” in arXiv: 2005.14165, 2020.
- [2] OpenAI, “GPT-4 technical report,” in arXiv: 2303.08774, 2024.
- [3] Z. Borsos, Raphael Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, et al., “AudioLM: a language modeling approach to audio generation,” in arXiv: 2209.03143, 2023.
- [4] C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, et al., “Neural codec language models are zero-shot text to speech synthesizers,” in arXiv: 2301.02111, 2023.
- [5] Z. Borsos, M. Sharifi, D. Vincent, E. Kharitonov, N. Zeghidour, and M. Tagliasacchi, “Soundstorm: Efficient parallel audio generation,” in arXiv: 2305.09636, 2023.
- [6] P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, et al., “Audiopalm: A large language model that can speak and listen,” in arXiv: 2306.12925, 2023.
- [7] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “Wavenet: A generative model for raw audio,” in arXiv: 1609.03499, 2016.
- [8] A. Baevski, S. Schneider, and M. Auli, “vq-wav2vec: Self-supervisedlearning of discrete speech representations,” in International Conferenceon Learning Representations (ICLR), 2020.
- [9] W. Hsu, B. Bolte, Y. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learningby masked prediction of hidden units,” in arXiv:2106.07447, 2021.
- [10] Y. Chung, Y. Zhang, W. Han, C. Chiu, J. Qin, R. Pang, and Y. Wu, “w2v-bert: Combining contrastive learning and masked language modelingfor self-supervised speech pre-training,” in IEEE Automatic SpeechRecognition and Understanding Workshop, ASRU, 2021.
- [11] N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,” in arXiv:2107.03312, 2021.
- [12] A. Défossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” in arXiv:2210.13438, 2022.
- [13] R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,” in Advances in Neural Information Processing Systems, NeurIPS, 2023.
- [14] K. Lakhotia, E. Kharitonov, W.-N. Hsu, Y. Adi, A. Polyak, et al., “On generative spoken language modeling from raw audio,” Transactions of the Association forComputational Linguistics, vol. 9, pp. 1336–1354, 2021.
- [15] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” in Advances in Neural Information Processing Systems, NeurIPS, 2017.
- [16] H. Siuzdak, “Vocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis,” in International Conference on Learning representations, ICLR, 2024.
- [17] Z. Liu, H. Tilman, and U. Masahito, “Neural networks fail to learn periodic functions and how to fix it,” in Advances in Neural Information Processing Systems, NeurIPS, 2020.
- [18] Z. Ju, Y. Wang, K. Shen, X. Tan, D. Xin, et al., “Naturalspeech 3: Zero-shot speech synthesiswith factorized codec and diffusion models,” in arXiv:2403.03100, 2024.
- [19] H. Liu, X. Xu, Y. Yuan, M. Wu, W. Wang, and M. D. Plumbley, “SemantiCodec: An ultra low bitrate semanticaudio codec for general sound,” in arXiv: 2405.00233, 2024.
- [20] Y. Pan, L. Ma, and J. Zhao, “Promptcodec: High-fidelity neural speech codec using disentangled representation learningbased adaptive feature-aware prompt encoders,” in arXiv:2404.02702, 2024.
- [21] Y. Ren, T. Wang, J. Yi, L. Xu, J. Tao, C. Y. Zhang, and J. Zhou, “Fewer-token neural speech codec with time-invariant codes,” in arXiv:2310.00014, 2024.
- [22] S. Ahn, B. J. Woo, M. H. Han, C. Moon, and N. S. Kim, “Hilcodec: High fidelity and lightweight neuralaudio codec,” in arXiv:2405.04752, 2024.
- [23] H. Li, L. Xue, H. Guo, X. Zhu, Y. Lv, et al., “Single-codec: Single-codebook speech codec towards high-performance speech generation,” in arXiv:2406.07422, 2024.
- [24] Haibin Wu, Ho-Lam Chung, Yi-Cheng Lin, Yuan-Kuei Wu, Xuanjun Chen, et al., “Codec-SUPERB: An in-depth analysis of sound codec models,” in arXiv:2402.13071, 2024.
- [25] H. Wu, X. Chen, Y. Lin, K. Chang, H. Chung, et al., “Towards audio language modeling - an overview,” in arXiv:2402.13236, 2024.
- [26] A. Ziv, I. Gat, G. L. Lan, T. Remez1, F. Kreuk1, et al., “Masked audio generation using a single non-autoregressive transformer,” in International conference on learning represenations (ICLR), 2024.
- [27] J. Ho and T. Salimans, “Classifier-free diffusion guidance,” in arXiv:2207.12598, 2024.
- [28] Qitong Wang and Themis Palpanas, “Seanet: A deep learning architecture for data series similarity search,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 12, pp. 12972–12986, 2023.
- [29] Sanyuan Chen, Shujie Liu, Long Zhou, Yanqing Liu, Xu Tan, Jinyu Li, Sheng Zhao, Yao Qian, and Furu Wei, “Vall-e 2: Neural codec language models are human parity zero-shot text to speech synthesizers,” arXiv preprint arXiv:2406.05370, 2024.
- [30] H. Chang, H. Zhang, L. Jiang, C. Liu, and B. Freeman, “Maskgit: Masked generative image transformer,” in The IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2022.
- [31] J. Kahn, M. Rivière, W. Zheng, E. Kharitonov, Q. Xu, P. E. Mazaré, J. Karadayi, V. Liptchinsky, R. Collobert, C. Fuegen, T. Likhomanenko, G. Synnaeve, A. Joulin, A. Mohamed, and E. Dupoux, “Libri-light: A benchmark for asr with limited or no supervision,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 7669–7673, https://github.com/facebookresearch/libri-light.
- [32] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae, “Hifi-gan: generative adversarial networks for efficient and high fidelity speech synthesis,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, NeurIPS, 2020.
- [33] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, “Librispeech: An asr corpus based on public domain audio books,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210.
- [34] A.W. Rix, J.G. Beerends, M.P. Hollier, and A.P. Hekstra, “Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), 2001, vol. 2, pp. 749–752 vol.2.
- [35] Cees H. Taal, Richard C. Hendriks, Richard Heusdens, and Jesper Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, 2010, pp. 4214–4217.
- [36] Michael Chinen, Felicia S. C. Lim, Jan Skoglund, Nikita Gureev, Feargus O’Gorman, and Andrew Hines, “Visqol v3: An open source production ready objective speech and audio metric,” in 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX), 2020, pp. 1–6.
- [37] Robert Kubichek, “Mel-cepstral distance measure for objective speech quality assessment,” in Proceedings of IEEE pacific rim conference on communications computers and signal processing. IEEE, 1993, vol. 1, pp. 125–128.
- [38] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” in arXiv:2110.13900, 2022.
- [39] Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber, “Common voice: A massively-multilingual speech corpus,” arXiv preprint arXiv:1912.06670, 2020.
- [40] M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, et al., “Voicebox: Text-guided multilingual universal speech generation at scale,” in arXiv:2306.15687, 2023.
- [41] G. Mittag, B. Naderi, A. Chehadi, and S. Moller, “Nisqa: A deep cnn-self-attention model for multidimensional speech quality prediction with crowdsourced datasets,” in arXiv:2104.09494, 2021.