Tele-LLMs:面向电信的专业大型语言模型系列
摘要。
大型语言模型(LLMs)的出现对各个领域产生了重大影响,从自然语言处理到医药和金融等领域。 然而,尽管其迅速普及,LLMs 在电信领域的应用仍然有限,通常依赖于缺乏领域特定专业知识的通用模型。 这种专业知识的缺乏导致性能下降,特别是在处理电信领域的专业术语及其相关数学表示时。 本文首先通过创建和传播 Tele-Data(一个从相关来源整理的综合电信材料数据集)和 Tele-Eval(一个针对该领域的大规模问答数据集)来解决这一差距。 通过大量实验,我们探索了将 LLMs 适应电信领域的最佳训练技术,从检查不同电信方面的专业知识划分到采用参数高效技术。 我们还研究了不同大小的模型在适应过程中的表现,并分析了其训练数据对这种表现的影响。 利用这些发现,我们开发并开源了 Tele-LLMs111The Hugging Face links to both the datasets and Tele-LLMs can be found at https://github.com/Ali-maatouk/Tele-LLMs,第一个专门针对电信的语言模型系列,参数规模从 1B 到 8B 不等。 我们的评估表明,这些模型在 Tele-Eval 上优于它们的通用模型,同时保留了它们之前获得的能力,从而避免了灾难性遗忘现象。
1. 引言

大型语言模型 (LLMs) 最近在自然语言处理领域取得了重大突破。 自 2022 年以来,这些深度学习系统迅速普及,科技巨头、研究机构和开源社区发布了许多模型 (OpenAI, 2024; et al., 2023, 2024)。 LLMs 在海量文本语料库上进行训练,在理解上下文、生成类似人类的文本以及执行跨不同领域的推理任务方面展现出前所未有的能力 (Radford et al., 2019)。 这些能力引起了研究人员和行业专业人士的兴趣,他们希望采用这些能力并探索其在广泛领域的潜在应用。
电信和网络领域的研究人员也不例外,他们旨在利用 LLM 的潜力来完成该领域内的各种任务。 这些应用包括面向工程师的聊天机器人 (Kotaru, 2023)、网络文档分析 (Bariah et al., 2023b)、网络建模和开发 (Maatouk et al., 2024) 以及无线系统设计 (Du et al., 2023; Xu et al., 2024)。 正在探索的可能获得 LLM 支持的任务列表仍在不断增长 (Bariah et al., 2023a),新研究正在迅速出现,以评估这些模型在电信环境中的局限性和效用。
到目前为止,LLM 在电信领域的应用主要涉及提示 (Du et al., 2023; Maatouk et al., 2024)、上下文学习 (Kotaru, 2023) 和特定于任务的微调 (Zhou et al., 2024; Bariah et al., 2023b),这些应用使用的是 OpenAI 的 GPT 等专有 LLM (OpenAI, 2024) 或 Meta 的 LLaMA 系列等本地开源通用 LLM (et al., 2024)。 然而,专有 LLM 会引发隐私问题,因为它们需要与 LLM 所有者共享提示和相关数据。 此外,它们的可操作性和适应性有限,因为用户无法访问模型权重。 此外,尽管通用开源 LLM 具有适应性,但它们在电信领域缺乏专业性,因为它们涵盖了来自医药、历史和法律等不同领域的知识。 这种缺乏专业性阻碍了它们的性能;事实上,人们已经认识到,在特定领域中,从提示到特定于任务的微调,当使用特定领域 LLM 而不是通用 LLM 时,LLM 应用的性能会更好 (Gururangan et al., 2020)。
鉴于上述情况,在许多领域,人们一直在努力创建专门的开源 LLM,以推动 LLM 应用在这些领域中的性能极限,例如医药 (Labrak et al., 2024)、法律 (Colombo et al., 2024) 和金融 (Xie et al., 2023)。 然而,迄今为止,电信文献中还没有特定领域的开源模型。 这是由于电信领域的特殊性,包括标准和学术著作等异构材料,对复杂方程的严重依赖,数据集中的格式不一致,以及迄今为止公司使用 LLM 进行工作的封闭源代码性质 (Kotaru, 2023; Holm, 2021)。 鉴于 LLM 在电信中的预期作用,这代表了该领域的一个重大差距。
拟议工作。 这项工作旨在通过引入第一个专门用于电信领域的 LLM 系列来解决上述差距。 我们的贡献不仅限于开源模型;我们开源了实现这种专业化所需的框架的每一个步骤。 我们还通过广泛的实验,对如何将大型语言模型(LLM)适应电信领域的过程提供了关键见解。 这包括要使用的技术以及不同大型语言模型在适应过程中表现出的不同行为,这些行为基于它们的大小和整体趋势。
首先,我们利用基于大型语言模型的过滤方法,对 arXiv 论文、标准、维基百科文章和网络内容进行筛选,以识别相关来源,从而构建了一个全面的电信资料集,称为 Tele-Data。 我们报告了基于人工标注数据的过滤方法的精确度和召回率,并强调了其高召回率。 然后,使用正则表达式和针对电信领域特点量身定制的基于大型语言模型的过滤技术对收集到的材料进行广泛的清理。 具体而言,我们的流程解决了标准文档中的格式差异,并将所有类型文档中的方程材料统一为 LaTeX 格式。 为了量化结果材料的干净程度,我们提出了一种基于交叉熵的方法,并证明了经过此过程后材料明显更干净。
其次,利用 Tele-Data,我们使用基于大型语言模型的框架创建了一个包含 75 万个问答对 (QnA) 的评估数据集,称为 Tele-Eval。 该数据集是电信领域第一个大型开放式问答数据集。 它还包括对每个问题所生成材料的具体参考,使用户能够从他们感兴趣的材料中选择问题,并促进检索增强生成框架 (Lewis 等人,2021)。 为了确保大型语言模型生成问题的相关性和质量,我们应用严格的正则表达式和基于大型语言模型的过滤,以排除局部兴趣的问题,例如模拟结果或本地定义的内容。
第三,我们研究了使用参数高效微调 (PEFT) 技术将电信知识注入这些模型的可行性,证明这种注入反而需要完整的微调 (FFT) 范式。 基于此,我们进行实验以确定最大化模型性能所需的训练次数,并确定在此适应过程中出现过拟合的点。 在整个探索过程中,我们还研究了不同大小的模型在适应过程中的行为方式,并调查了这种适应的训练动态如何根据原始模型的训练数据而变化。 此外,我们评估了将这种适应分解为训练多个专注于电信不同方面的专门模型(而不是一个总体组合模型)的有效性。 我们的发现表明,由于这些方面之间发生的迁移学习,后一种方法更优。
最后,我们的实验最终将一系列从 10 亿到 80 亿个参数的 LLM 适应到电信领域并开源。 我们这一系列 LLM 是基于 Tinyllama-1.1B、Phi-1.5、Gemma-2B 和 LLama-3-8B 的,包括基础模型及其针对聊天机器人应用的指令微调版本。 我们通过定量分析(使用一组提出的指标)和定性评估,将这些模型与其原始版本进行比较,对它们进行评估。 结果突出了它们在电信领域的优势,在 Tele-Eval 上平均提高了 25%。 此外,我们的研究结果表明,较小的适应模型可以在 Tele-Eval 上与较大的通用模型相媲美。 评估还表明,这些模型保留了它们最初的功能,有效地避免了灾难性遗忘现象。 图 1 提供了整个适应管道。
2. 领域适应
2.1. 背景
LLM 使用涵盖各种领域的语料库进行训练,这些语料库包括医学、历史等等,使用的是下一个符元预测目标。 在这种情况下,符元指的是一个子词,它代表文本中最基本的单元。 此训练过程使 LLM 能够适应这些数据集中符元的分布,并对它们之间的统计关系建立理解。 因此,LLM 对其所训练的多个领域形成了全面的理解。
如 (Çağatay Yıldız 等人,2024) 所示,如果想要将 LLM 专用于特定领域,则在该领域专门化 LLM 对任何后续的上下文学习或特定于任务的微调都有利。 这是因为目标领域中符元的概率分布可能与 LLM 内化的其他领域的符元概率分布有很大差异。 通过适应这种分布,LLM 的知识变得更加针对领域,从而为后续使用阶段的迁移学习创造条件。
领域适应的主要方法是持续预训练。 该方法涉及在特定领域的语料库上进一步训练 LLM,使其能够将参数适应到感兴趣的领域 (Gururangan 等人,2020)。 持续预训练已成为 LLM 领域适应的标准,这一点在它在医学等各个领域的应用中得到了证明 (Labrak 等人,2024),法律 (Colombo 等人,2024) 和金融 (Xie 等人,2023)。 下面,我们将探讨持续预训练的细节,重点关注它在电信领域的应用。
备注 1。
将预训练的 LLM 适应到特定领域通常比从头开始在特定领域数据上训练 LLM 更可取。 这种方法利用从其他领域学习的能力(例如,英语能力,编码)并将它们转移到新领域,减少了学习基本技能所需的广泛数据和时间。
2.2. 持续预训练
鉴于当前 LLM 训练数据集的规模(例如,LLama-3 的 15T 个符元 (等人,2024)),我们可以合理地假设文献中可用的语言模型已在所有可用的公共来源数据上进行过训练。 因此,这些模型可能已经遇到过大多数公开可用的与电信相关的数据。 然而,持续预训练的目标是通过将模型重新暴露于这些数据来使 LLM 的知识适应这个特定领域。 具体来说,考虑一个在符元 的语料库上训练的 LLM,这些符元来自分布 。 该 LLM 在整个语料库 上进行训练,以最小化从该语料库中抽取的符元 的交叉熵损失函数:
| (1) |
其中 是上下文长度, 等于 , 是 LLM 的参数, 是参数的总数。 另一方面,让我们考虑一组与电信相关的数据 。 从 中抽取的符元 的样本源于不同的分布,表示为 。 持续预训练涉及将 LLM 初始化为其现有参数,表示为 ,并进一步减少交叉熵损失,这次使用从 中抽取的标记样本 :
| (2) |
通过这样做,模型参数会更接近新分布,使 LLM 能够更好地校准到特定于电信的数据。
2.3. 灾难性遗忘
理想情况下,人们希望这种领域适应不会产生任何损失。 但是,通常会产生损失。 通过将重点从训练数据集 的一般标记分布 转移到新的分布 ,模型有可能会忘记先前获得的知识。 这种风险取决于模型的大小、特定领域数据集的大小以及 与 的差异程度 (Luo et al., 2024)。 解决这个问题至关重要;否则,最终可能会得到一个精通电信知识的 LLM,但在过程中失去推理能力、编码能力和一般的英语理解能力。 在本文后面,特别是在第 7 节中,我们将详细说明如何在我们的持续预训练框架中解决这个问题。 考虑到这一点,我们框架中的下一步涉及整理一个全面的电信语料库,我们将其称为 Tele-Data。
3. 远程数据
| Items | Size | Tokens | |
|---|---|---|---|
| Arxiv | 90k | 4 GBs | 1.08B |
| Standards | 2.8k | 334 MBs | 86.45M |
| Wikipedia | 19.5k | 123 MBs | 26.44M |
| Web | 740k | 6.8 GBs | 1.55B |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Arxiv | 0.666 | 0.956 | 0.785 |
| Wikipedia | 0.632 | 0.897 | 0.741 |
| Webpages | 0.455 | 1 | 0.625 |
我们收集的电信资料包含四个主要来源: (1) 来自 arXiv 的科学论文,(2) 3GPP 标准,(3) 与电信相关的维基百科文章,以及 (4) 从 Common Crawl 转储中提取的与电信相关的网站。 这些来源的多样性确保了对电信知识的广泛覆盖,并且对于从一个来源中涵盖的电信的一个方面到另一个方面的专业知识转移至关重要,如第 8.1 节中所示。 我们数据集的详细组成如表 1 所示,其中使用 LLama-3 分词器提供令牌计数作为示例。
3.1. Arxiv
整理。 关于电信的最大公开访问研究来源之一包括作者提交到 arXiv 存储库的预印本。 截至 2024 年 3 月,计算机科学和电气工程类别的合并 arXiv 快照包含大约 610k 篇论文。 但是,考虑到这些类别之间存在重叠,并且包括超出电信主题的主题 ,有针对性的过滤对于识别相关材料是必要的。 为此,我们使用基于语言模型的过滤方法。 具体来说,我们利用 Mixtral 8x-7B-Instruct222https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1 模型,为其提供每篇论文的摘要,以确定它是否与电信和网络领域相关。 该模型被提示333All the prompts utilized in our framework are reported in Appendix C 提供关于论文是否相关的“是”或“否”答案。 然后,我们利用“是”和“否”令牌的 logits 来分类一篇论文是否与电信相关。
为了评估我们的过滤过程的质量,我们随机抽取了 500 篇 arXiv 论文,并对其进行手动标注以确定其与电信和网络领域的关联性。 为了确保相关和不相关示例之间的平衡,我们在计算机科学和电气工程类别中抽取了相同数量的样本,因为后者更有可能包含电信材料,而前者更有可能包含不相关的论文。 然后我们评估了过滤过程的精确度和召回率。 如表 2 所示,该过程展示了高召回率和中等精确度。 高召回率尤其重要,因为它表明我们的过滤过程几乎捕获了所有相关的电信材料。 中等精确度可以归因于相关领域论文的纳入。 例如,一些研究云计算主题的论文被纳入。 由于这些额外的领域与电信并不正交,因此它们可以提供可转移的知识,从而增强语言模型对电信领域的适应性。 总之,这证明了我们的过滤过程的有效性。
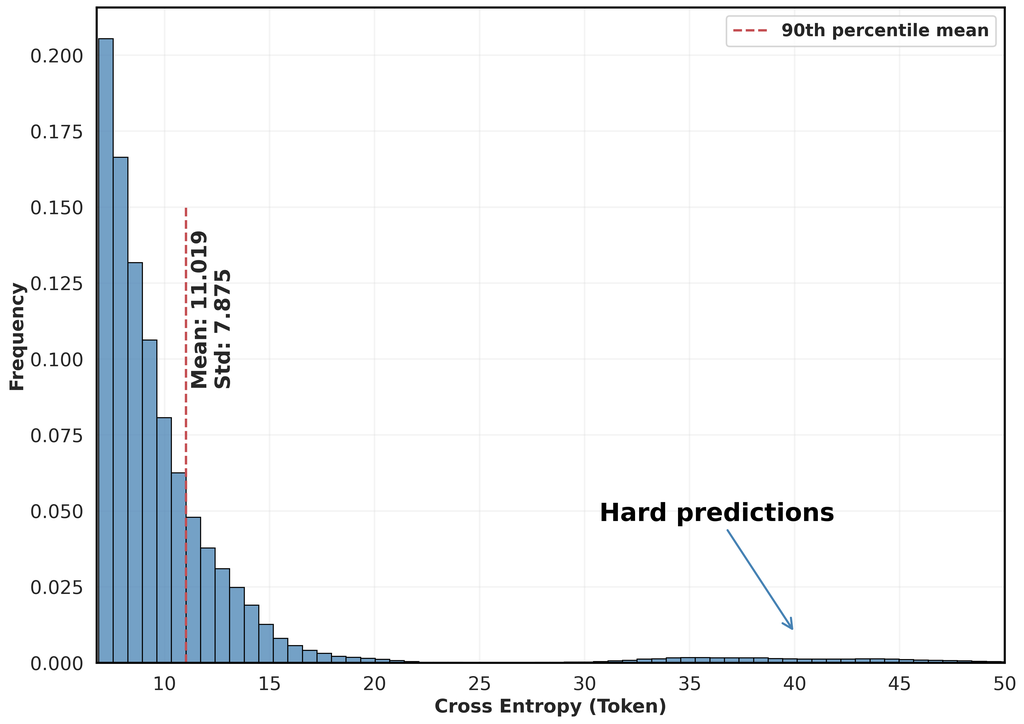
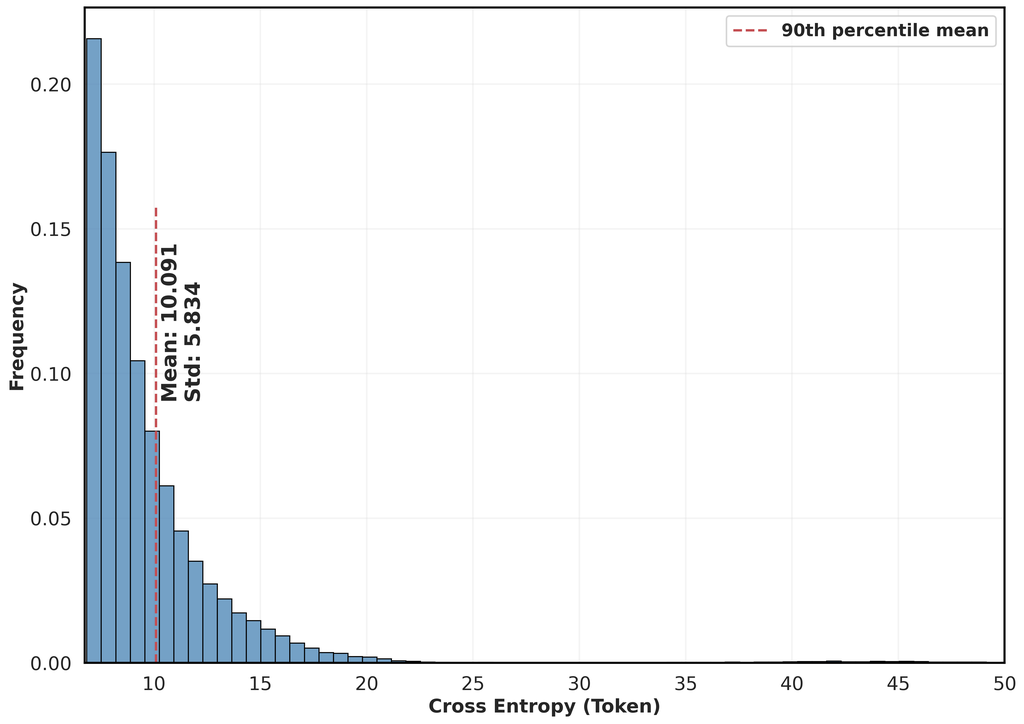
清理。 在整理之后,我们对论文实施了全面的清理过程,包括:(1)删除注释,(2)扁平化 LaTeX 源代码,(3)用标准 LaTeX 命令替换用户定义的宏,(4)消除 LaTeX 本地命令,以及(5)标准化引用格式并删除标记更改。 我们还删除了图形和表格,以专注于内联文本和等式。 关于此过程的详细信息在附录 A 中提供。 为了评估我们的清理过程的有效性,我们随机选择了 500 篇 arXiv 论文,并推导出了一种基于交叉熵的方法来评估清洁度,如下所述。 令 和 分别表示来自原始数据集和清理数据集的 个符元的不重叠块,其中 和 是块的总数。 接下来,让我们使用 GPT-2 (Radford et al., 2019) 定义原始数据或清理数据中任何块中任何符元索引 的交叉熵损失,如下所示
| (3) |
选择 GPT-2 是因为它主要是在网络内容上训练的,不包括 arXiv 科研论文。 因此,交叉熵在这里充当一个代理,用于衡量文本与一般在线内容的相似程度,而不是更复杂的 arXiv 论文,从而提供数据集清洁程度的指示。 考虑到这一点,我们将 设置为 1024,与 GPT-2 的训练数据 (Radford 等人,2019) 一致,并将原始数据集和清理数据集的交叉熵损失的总集合定义为
| (4) |
分别。 然后我们重点关注最难的 10% 的符号,以评估两组 和 之间的差异。 为此,让 和 代表它们的第 90 个百分位数。 通过比较图 2 和 3 中 和 的分布,我们观察到在这个百分位数内,清理数据集的平均交叉熵损失及其标准差都低于原始的未清理论文。 这证明了我们数据集的清洁程度有所提高。
3.2. 标准
整理。 标准在电信中起着举足轻重的作用,因为它们确保了来自不同供应商的技术之间的互操作性。 这些标准由 3GPP、IEEE 和 ITU 等公认机构制定和维护。 由于它们的开源性质,我们专注于将 3GPP 文档纳入我们的数据集。 为此,我们使用 3GPP FTP 门户 444https://www.3gpp.org/ftp/ 下载了每个系列中每个标准的最新规范,从而产生了约 2.8k 文档的数据集。
清理。 在整理流程之后,我们通过几个步骤清理和处理标准文件。 我们首先删除不必要的章节,例如相关工作和附录,并消除图形和表格,以便专注于内联文本和方程式,这与我们对 arXiv 论文的方法类似。 一个关键的注意事项是,.doc 文件中的公式以 XML 格式化,与 arXiv 论文中使用的 LaTeX 格式不同。 为了解决这个问题,我们首先将所有 .doc 文件转换为 .docx 格式,然后利用 docx2tex555https://github.com/transpect/docx2tex 将标准转换为 LaTeX 格式。 这种标准化通过确保所有文档类型中的公式一致性来改善训练过程。 最后,我们将用于 arXiv 论文的相同清理管道应用于转换后的标准 LaTeX 文件,以确保整个数据集的一致清洁度和连贯性。
3.3. 维基百科
电信材料的另一个来源是维基百科语料库,特别是与电信领域及其相关技术内容相关的文章。 为了整理此数据集,我们利用维基百科数据集666https://huggingface.co/datasets/wikimedia/wikipedia 的英文子集,其中包含 640 万个样本。 鉴于该数据集的大小,应用基于纯 LLM 的分类在计算上将非常昂贵。 相反,我们采用两步过程:
-
(1)
关键词过滤: 我们定义了一组 100 个与电信相关的关键词,包括电信、基站、Wi-Fi 和 5G 等术语。 包含任何这些关键词的文章将被标记为下一步。 此过程将文章数量从 640 万减少到大约 7 万。
-
(2)
基于 LLM 的内容评估: 在第二步中,我们将基于 LLM 的过滤过程应用于已标记的文章。 特别是,将每篇文章的前 10,000 个字符提供给 Mixtral 8x-7B-Instruct 模型,并提示 LLM 提供关于文章相关性和是否存在与电信相关的技术内容的“是”或“否”答案。 这样做的原因是排除讨论非技术方面,例如电信运营商历史的文章。
通过这两种步骤,我们从维基百科中整理了一个包含 19.5k 篇技术相关电信文章的数据集。 同样,我们通过对 500 篇已标记的文章进行抽样并手动标注来评估我们基于 LLM 的过滤。 然后,我们评估了过滤过程的精确度和召回率。 表 2 中的结果展示了该过程的高召回率,展示了其识别电信中相关技术内容的能力。 另一方面,中等精度源于确定文章所需的适当技术水平的挑战,导致数据集中出现误报。
3.4. 网站
我们考虑的最后一个电信资料来源是 Common Crawl 数据集,它包含来自整个互联网的网络存档。 为了避免原始转储中存在的重复、非英语内容和潜在的亵渎内容,我们利用了经过改进的网络数据集 (Penedo et al., 2023)。 这个经过整理的 Common Crawl 版本包含大约 10 亿行,跨越 2.8 TB 的数据。 为了进一步消除重复,我们从数据集中过滤了维基百科文章。 接下来,为了从这个经过改进的数据集中提取与电信相关的內容,我们使用了与维基百科文章相同的两步过程。 此外,我们还纳入了来自知名电信博客(如 ShareTechNote)的内容,以增强数据集的相关性。 最终的集合包含来自 740k 个网站链接的内容,提供了对网络上可用电信信息的全面表示。
为了评估基于大型语言模型的过滤过程的质量,我们抽取并手动标注了 500 个包含电信关键词的网站。 然后,我们评估了过滤过程的精确率和召回率。 我们观察到完美的召回率,因为包含的网站包括关于电信的专利、技术博客和论坛讨论。 然而,由于难以辨别技术内容,精确率较低。 因此,包含产品技术规格、包含技术细节的 VPN 服务营销网站以及产品评论的网站也被包含在内,导致数据集出现假阳性。
3.5. 数据集格式
Tele-Data 结构化为 JSONL(JSON 行)文件,其中每一行代表一个包含五个不同字段的 JSON 对象:
-
•
ID: 每个数据条目的唯一标识符,将数据类别和数字组合在一起。 例如,“wiki_132” 指的是维基百科数据点的第 132 个条目。
-
•
Category: 一个字符串,指示数据的来源:wiki、standard、arxiv 或 web。
-
•
Content: 包含材料主要文本的字符串。
-
•
Metadata: 一个 JSON 对象,包含与每个特定元素相关的各种信息,其结构根据类别而异。 例如,对于标准,JSON 对象包括 3GPP 系列号、版本和标准文件名,而对于 arXiv 论文,它包含 arXiv ID、标题和摘要。
数据集示例可以在附录 B 中找到。
4. 评估数据集
在准备 Tele-Data 之后,下一步涉及创建评估数据集以测试生成的领域自适应模型的电信知识。 目前,只存在一个这样的数据集:TeleQnA (Maatouk 等人,2023)。 TeleQnA 是一个从标准和研究论文中提取的多项选择题 (MCQ) 数据集,是在人工参与下生成的。 虽然 MCQ 数据集在准确性方面简化了评估,但它仍然有限,因为 LLM 并不是稳健的 MCQ 选择器,因为它们固有的“选择偏差”,这种偏差在几乎所有 LLM 中都普遍存在 (Zheng 等人,2024; Griot 等人,2024)。
鉴于以上情况,为了检验 LLM 的电信能力,我们采取了另一种方法,创建了一个开放式电信问题数据集。 开放式问题评估模型自行阐述以回答有关特定电信概念的问题的能力。 考虑到要涵盖的大量概念以及电信知识的专业性,需要大规模的开放式问题,这使得纯粹的人工方法不可行。
为了克服这一挑战,我们采用了一种基于 LLM 的方法来创建我们的评估数据集,我们将其称为 Tele-Eval。 具体来说,我们从收集的 Tele-Data 中的论文、标准和维基文章中收集资料。 我们关注这些类别,因为它们与 Common Crawl 数据相比相对干净。 然后,我们将材料分割成 20,000 个字符的块。 使用 Mixtral 8x7B-Instruct,我们提示 LLM 以三样本方式为每个片段生成五个问题,提供与 Trivia QA 中类似的示例 (Joshi 等人,2017),但针对电信领域。 生成的问答对随后会经过广泛的基于正则表达式的过滤。 特别是,我们实施过滤器来删除包含诸如“在这种情况下”、“在本文中”、“如文中突出显示”的表达以及对方程、图形、表格和其他本地元素的引用的问题,以及 100 个其他类似的过滤器。 我们的目标是实现尽可能低的保留率,以确保自动生成的数据集具有最高质量。
我们流程中的下一步涉及将 QnA 对馈送到 Mixtral LLM 的另一个实例。 此实例被提示来确定所提供的 QnA 对是否可以在没有访问源材料的情况下被回答(即,消除本地上下文依赖性)。 我们只保留那些同时通过正则表达式过滤和基于 LLM 的过滤的 QnA 对。 结果,保留率达到了 1%,数据集包含 750k 个 QnA 对。 值得注意的是,考虑到这种规模,即使一些问题不能被 LLM 完美地解答,数据集仍然可以有效地作为电信知识的评估器。
备注 2.
我们数据集的一个重要方面是,每个生成的 QnA 对都包含了其所基于的特定电信材料的 ID。 这允许用户从他们感兴趣的材料中选择问题,并促进检索增强生成框架 (Lewis 等人,2021)。 例如,如果有人对某个特定主题(例如,信源和信道编码)感兴趣,他们可以识别电信数据集中相关的内容,获取其 ID,然后使用与这些 ID 链接的 Tele-Eval 部分。
以下是一些数据集示例,以说明数据的样式和格式:
陈述: 在什么情况下,UE 应该在 Contact 标头字段中插入公共 GRUU 值?
答案: 如果在 P-Called-Party-ID 标头字段中与公共用户身份关联的公共 GRUU 值已被保存,并且 UE 不表示 P-Asserted-Identity 的隐私,则 UE 应该在 Contact 标头字段中插入公共 GRUU 值。
ID: 标准_1309
陈述: 在量子信道的情况下,无辅助容量和纠缠辅助容量之间有什么区别?
回答: 无辅助容量是指在没有使用纠缠的情况下,通过量子信道传输经典或量子信息的最高速率,而纠缠辅助容量是指在使用纠缠的情况下,通过量子信道传输经典或量子信息的最高速率。
ID: arxiv_36721
5. 评估指标
持续预训练后,一项关键挑战是有效地评估由此产生的领域自适应模型。 如前文所述,Tele-Eval 由开放式问答对组成。 与 MCQ 数据集相比,评估开放式响应更为复杂。 例如,传统的评估指标,如 ROUGE (Lin, 2004) 和 BLEU (Papineni et al., 2002),通常用于摘要和翻译任务,衡量模型输出与参考答案之间的词语重叠。 然而,当模型使用替代的措辞或词汇来表达与参考答案相同的含义时,这些指标无法捕捉到响应的语义相似性和正确性。 当评估模型生成的方程式时,这种挑战尤为突出,因为这在电信领域经常需要,因为这些指标难以捕捉到这种细微差别。 为了解决这个问题,我们采用了三个评估指标:答案困惑度、SemScore (Aynetdinov and Akbik, 2024) 和 LLM-Eval (Zheng et al., 2023)。 在第 7 节中,我们将展示每个评估指标的优缺点,并得出结论,LLM-Eval 是电信领域最强大的比较工具。 下面,我们将详细介绍这些指标。
5.1. 答案困惑度
我们将答案困惑度定义为模型相对于真实答案的困惑度,以问题为条件。 具体来说,让我们考虑 Tele-Eval 的 个样本,其中 表示第 i 个对的问题和真实答案的串联。 假设在索引 处,真实答案开始。 考虑到这一点,我们将答案困惑度定义为:
| (5) |
其中 是第 i 个配对中的符元数量,而 代表模型权重。 此指标可以看作是模型在给定问题的情况下对答案的惊讶程度。 直观地,一个精通电信的模型应该对答案的惊讶程度较低(因此,困惑度较低),相比于一个非专业模型。
5.2. 语义评分
我们用来评估模型输出相对于基本事实答案的正确性的另一个指标是语义相似度。 这是通过利用句子转换模型 (Reimers and Gurevych, 2020) 来实现的,例如来自 Sentence Transformers 家族的 all-mpnet-base 模型。 777https://sbert.net/docs/sentence_transformer/pretrained_models.html 这些仅编码器的 BERT 模型使用对比损失进行训练,将一对序列编码到高维空间中,使得相似配对的嵌入之间的余弦相似度很高(更接近 1),而对于不相似的配对则较低(更接近 -1)。 这些仅编码器的 BERT 模型使用对比损失进行训练,将序列对编码到高维空间中,使得相似对的嵌入之间的余弦相似度较高(接近 1),而不同序列对的嵌入之间的余弦相似度较低(更接近 1)。至-1)。 考虑到这一点,我们将 SemScore (Aynetdinov 和 Akbik,2024) 定义为
| (6) |
其中 指的是 BERT 嵌入模型,而 和 分别指的是基本事实答案和模型的输出。 因此,此指标使我们能够判断模型的输出与正确答案的匹配程度。
5.3. LLM 评估
我们框架中的最后一个指标是使用一个 LLM 作为评判,来评估模型输出与真实答案的正确性 (Zheng et al., 2023)。 鉴于 LLM 在训练中积累了丰富的知识,我们可以利用它们作为助手来评估模型输出的质量和准确性。 之前的研究表明,基于 LLM 的评判者可以在各种评估任务中有效地匹配受控和众包的人类偏好 (Zheng et al., 2023)。 通过这种方法,在评估 Tele-Eval 中任何问题的模型输出时,我们会提示 Mixtral 8x-7B-Instruct 将模型输出与真实答案进行比较,并提供关于其正确性的“是”或“否”答案。 我们将 LLM-Eval 指标定义为这些布尔响应的平均得分,使得
| (7) |
其中 是模型对 Tele-Eval 中问题 的答案, 是已评估输出的总数,而 是指示函数。
6. 初始实验
准备好了训练和评估数据集后,下一步就是训练我们的模型。 然而,在继续之前,需要解决关于训练技术和参数的几个关键问题,为训练过程奠定基础。 虽然可以从之前研究中得到关于训练参数(如学习率和批次大小)的一般性指导原则 (Labrak et al., 2024; Colombo et al., 2024; Xie et al., 2023),但电信知识的特性(如方程式的普遍存在)带来了特殊的挑战。 需要回答的关键问题包括是否需要进行全参数微调,或者参数高效微调方法是否足以,以及确定有效地将 LLM 适应电信领域所需的训练轮数。 我们将在本节中解决这些问题,同时指出我们的结果可以作为将其他模型适应电信领域的指南,而不仅仅是本文中讨论的模型。
6.1. 训练设置
对于这些实验,我们考虑了两个模型:Gemma-2B 和 LLaMA-3-8B。 在这些研究中,我们将 Tele-Data 数据集的 20% 作为训练数据,其中 10% 作为验证集。 为了解决等式 (2),我们将批次大小设置为 4M 个符元(序列长度为 8192 个符元),并使用 AdamW 优化器,权重衰减为 0.1,保持 Hugging Face 的默认参数不变。 最大梯度范数设置为 。 学习率根据余弦学习率计划下降,降至最大学习率的 10%,并应用一个历元的 10% 的线性预热 (Gupta 等人,2023)。 LLaMA 的最大学习率设置为 1e-5,Gemma 的最大学习率设置为 2e-5。 这些值与这些 LLM 的预训练阶段保持一致 (等人,2024;团队,2024)。 为了提高效率,我们在混合精度训练的同时,采用样本打包和块注意力技术来避免交叉污染 (Krell 等人,2022)。
6.2. PEFT 与 FFT
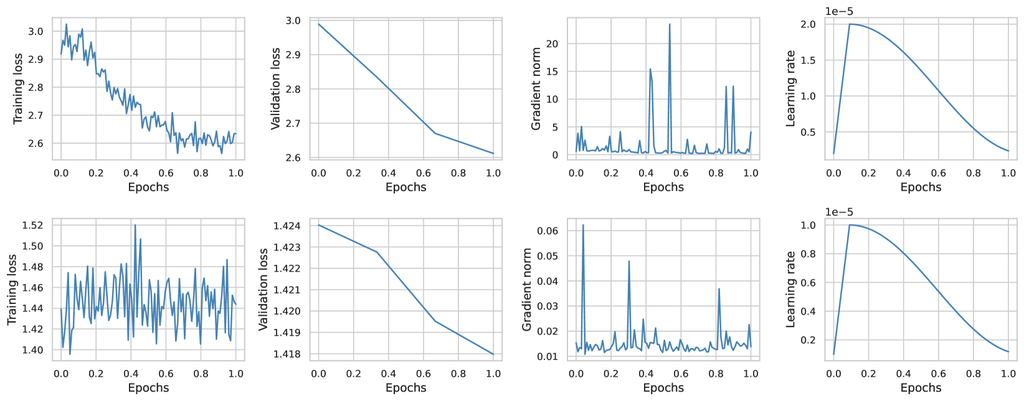
PEFT 技术旨在通过仅训练最小数量的参数来减少域适应过程中的计算成本和内存需求,而 FFT 方法则更新模型的所有参数。 在这些技术中,LoRa (Hu 等人,2022) 作为一种突出的 PEFT 方法而脱颖而出。 它在预训练模型的现有权重中添加了小的、可训练的低秩矩阵。 为了调查像 LoRa 这样的 PEFT 方法是否足以将语言模型适应到电信领域,我们使用 Gemma-2B 和 LLaMA-3-8B 模型对 LoRa 和 FFT 进行了比较研究。 对于我们的 LoRa 实现,我们将 LoRa 等级固定为 r=64,将 Lora alpha 设置为 32,并将 LoRa 丢弃率设置为 0.1。
图 4 中报告的结果表明,对于较小的模型,LoRa 可以最初注入电信知识,但由于其容量有限,很快就会饱和。 相反,对于 LLaMA-3-8B 模型,它对电信的了解更多,LoRa 方法的梯度范数保持极低。 这阻碍了参数更新,导致训练损失几乎没有变化,并限制了 LoRa 注入额外知识的能力。 这些发现表明,尽管 LoRa 的计算效率很高,但它可能不足以将模型适应到电信领域。 因此,在接下来的部分中,我们将依靠完整的参数微调来进行所有训练。
6.3. 一次还是多次迭代?
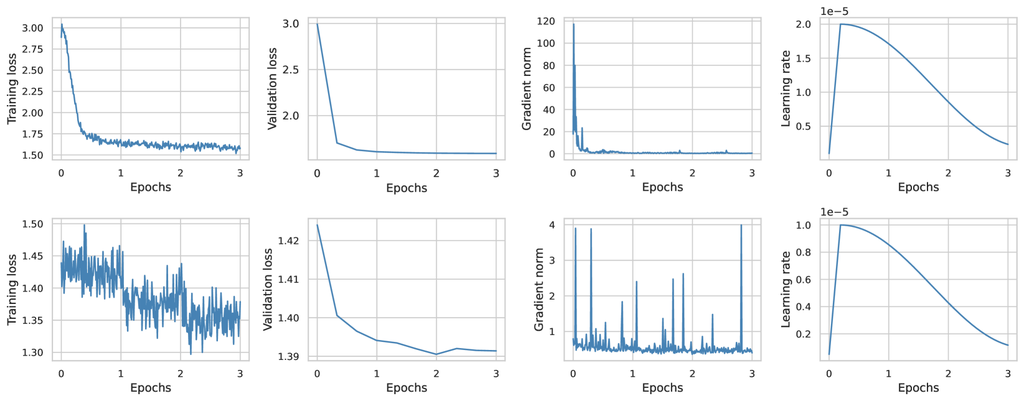
在将 LLM 适应目标领域时,我们以电信为例,一个关键问题是确定模型训练的最有效持续时间。 单个迭代足以适应模型,还是多次暴露于数据,并在每个迭代中进行随机排序会产生更好的结果? 为了解决这个问题,我们使用两种不同模型规模进行了实验:Gemma-2B 和 LLama-3-8B。 正如我们将要展示的,这种区别源于这些模型由于其不同规模而产生的不同行为。 结果在图 5 中报告,并在下面讨论。
杰玛-2B. 如图 5 所示,Gemma-2B 的训练损失表现出一致的行为,在约两个迭代后下降并趋于平稳。 在验证损失中也观察到类似的模式,它在两个迭代后也趋于稳定。 此外,梯度范数接近 0,表明训练正在达到收敛。 值得注意的是,对于较小的模型,在三个迭代的训练之后,没有过度拟合的迹象,因为验证损失和训练损失在类似的水平上趋于平稳。 这表明该模型已经对电信数据有了全面的理解,进一步的训练只会对这种理解进行微调,而不会显著增加或减少现有的电信知识。
LLama-3-8B. 通过研究图 5 的底部图,可以做出的第一个观察是,训练损失以大约 1.42 的交叉熵开始。 这表明该模型在电信方面已经相当了解。 这并不奇怪,原因有两个:首先,该模型在 15T 个符元上进行了训练,因此它可能遇到了各种与电信相关的资料;其次,模型中大量的参数使它能够保留这些信息。 不管怎样,持续预训练有助于进一步巩固这些知识。
通过进一步检查训练损失,可以观察到一个有趣的现象:在每个 epoch 的末尾,训练损失都会出现明显的下降。 这表明模型正在记忆训练数据集中的模式,并在每个 epoch 后遇到这些模式时,对下一个符元的预测变得更加自信。 这些模式具有一些可泛化的成分,这从验证损失在前两个 epoch 的下降中可以看出。 但是,超过两个 epoch 后,这种记忆就会成为问题,因为学习到的模式变得更加特定于训练数据,而对验证数据的可迁移性较差,从而导致过拟合。 我们假设两个 epoch 代表一个最佳点:第一个 epoch 用于预热模型并吸收电信知识,而第二个 epoch 在余弦衰减的帮助下,以非常低的学习率塑造这些知识,使模型能够在损失景观中进行最终调整。 基于以上内容,我们在下一节中使用两个 epoch 来创建 Tele-LLMs 系列。
备注 3。
我们在其他模型(例如 Mistral-7B)中观察到类似的训练损失行为。 随着参数数量的增加,模型变得更加具有表现力,并且能够更好地捕获训练数据中的复杂关系,从而导致这种行为。 我们没有报告这些结果,因为它们与图 5 底部图中显示的结果相似。
7. 远程 LLM

| Tele-Eval | General Knowledge | |||||
|---|---|---|---|---|---|---|
| Ans-PPL | SemScore | LLM-Eval | MMLU | HellaSWAG | GSM8K | |
| Tinyllama-1.1B | 230.44 | 0.5952 | 8.26 | 0.2501 | 0.4670 | 0.0258 |
| Tinyllama-1.1B-Tele | 9.06 | 0.6093 | 11.37 | 0.2519 | 0.4663 | 0.0212 |
| Gemma-2B | 13.31 | 0.5998 | 13.59 | 0.3289 | 0.5275 | 0.0576 |
| Gemma-2B-Tele | 11.73 | 0.6302 | 17.07 | 0.3497 | 0.5304 | 0.0622 |
| LLama-3-8B | 9.17 | 0.6358 | 24.60 | 0.6209 | 0.6009 | 0.144 |
| LLama-3-8B-Tele | 8.49 | 0.6482 | 29.60 | 0.6157 | 0.6068 | 0.2441 |
在完成初始实验后,我们继续对 LLMs 进行全面训练,以创建适应电信的模型系列,从以下三个模型开始:Tinyllama-1.1B-Tele、Gemma-2B-Tele 和 LLaMA-3-8B-Tele。 我们选择这些基础模型是基于多方面的考虑,包括它们在 Hugging Face 开放式 LLM 排行榜上的表现以及对它们许可证的考量。 我们还考虑了发布公司的多样性,以减轻这些许可证变化带来的潜在风险。
训练设置 . 我们保留了第 6.1 节中描述的设置,Tinyllama-1.1B 遵循与 Gemma-2B 相同的方法。 值得注意的是,Tinyllama-1.1B 使用了 2048 的序列长度,这与它的初始预训练规范 (et al., 2023) 相一致。 对于整个系列的训练数据集,我们使用了完整的 Tele-Data 数据集进行两个 epoch 的训练,并用从 SlimPajama 获取的 5% 的常规通用数据进行增强 888https://huggingface.co/datasets/cerebras/SlimPajama-627B. 这种增强旨在通过将通用数据重新引入模型来缓解灾难性遗忘现象,帮助它保留在初始预训练阶段获得的关键技能。 这些模型的训练是在 8 个 NVIDIA A6000 GPU 的集群上进行的,总共消耗了 2500 个 GPU 小时。
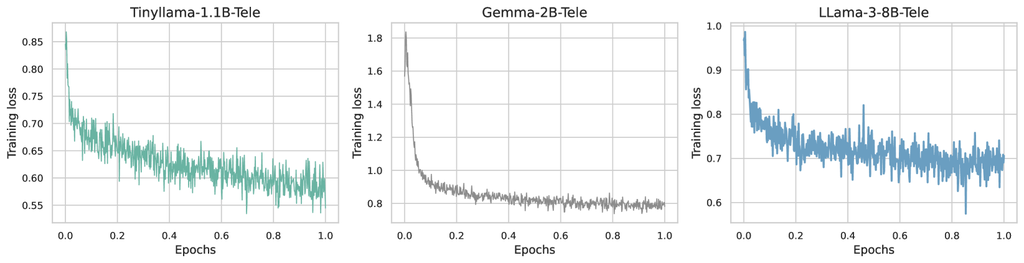
损失趋势 . 如图 6 所示,这三个模型的结果与我们上一节训练实验中报告的结果一致。 具体来说,Tinyllama-1.1B 和 Gemma-2B 展示了较小模型典型的稳定训练损失行为,而 LLaMA-3-8B 在每个 epoch 都显示出较大模型特有的急剧损失下降。 另一方面,由于其较短的上下文长度,Tinyllama-1.1B 的训练损失起点低于 Gemma-2B,突出了在 8k 个符元序列中捕获长距离依赖关系的挑战。
评估设置 . 我们使用第 5 节中讨论的三个指标来评估 Tele-Eval 上的 LLM ,根据附录 C 中提供的提示,通过贪婪解码 100 个新标记来生成模型答案。为了评估我们的培训对其他 LLM 能力的影响,我们根据三个额外的基准评估我们的模型:MMLU (Hendrycks 等人,2021) 用于一般世界知识,HellaSWAG (Zellers 等人, 2019) 用于常识理解,GSM-8K (Cobbe 等人, 2021) 用于数学推理能力。 所有评估,包括 Tele-Eval 和额外的基准测试,都在零样本设置中进行。
定量评估 . 如表 3 所示,适应后的电信 LLM 在 Tele-Eval 上的所有指标上都优于其对应模型。 对于一般知识任务,这些模型表现出与原始模型相比稳定的性能,在大多数任务中都有轻微的变化——无论是改进还是退化。 值得注意的是,GSM-8K 有所改进,LLama-3-8B-Tele 的准确率提高了 10%。 这种改进归因于 Tele-Data 中发现的方程式,使适应后的模型在数学推理方面变得更强大。
比较 LLM 在 Tele-Eval 上三个指标的性能揭示了一些见解:首先,Ans-PPL 在较大的模型中表现出最小的相对差异。 这是因为较大的模型,凭借其更高的熟练程度,对真实答案中使用的术语不那么感到意外。 因此,在该指标中,电信知识的改进变得不那么明显,并且更加稀释。 另一个观察结果是,使用 Ans-PPL 指标跨不同模型缺乏可比性,如 Tinyllama-1.1B-Tele 和 Gemma-2B-Tele 之间的性能比较所证明。 模型在回答问题时遵循某些格式的倾向会使该指标产生偏差,导致性能好或差。 由于其倾向的异质性,这使得 Ans-PPL 更适合比较同一家族内的模型,而不是跨不同家族的模型。
SemScore 表现出类似于 Ans-PPL 的模式;一个 LLM 生成具有适当技术术语的连贯响应,即使在提供错误答案的情况下也可能获得高分。 考虑到这一点,并且考虑到 LLM 家族之间异质的响应风格,SemScore 和 Ans-PPL 在突出显示同一 LLM 家族内的显着差异方面更有效。 为了检测细微差异并比较不同 LLM 家族,LLM-Eval 被证明更加稳健。 它不考虑语言差异,而是关注正在评估的底层概念。 使用此指标,我们观察到为电信定制的 LLM 平均相对改进率为 25%。
虽然 LLM-Eval 提供了最准确的评估,但它的缺点是运行时间。 鉴于 注意机制的扩展,其中 是评估的输入提示长度,我们使用 Mixtral-8x-7B 对单个 Nvidia A6000 GPU 上的每个问题进行了大约 50 毫秒的评估。 请注意,鉴于 Tele-Eval 的大小,我们结果的标准偏差可以忽略不计。
备注 4.
值得注意的是,Tele-Eval 专注于高度细粒度的电信概念,这对 LLM 来说是一个重大挑战,这一点从它们在 LLM-Eval 指标上的表现中可以看出。 这种固有的困难是 Tele-Eval 的优势之一;如果问题很容易回答,那么数据集将无法有效地区分通过将模型适应电信领域而获得的优势。
8. 进一步探索
在我们工作的最后阶段,我们研究了各种适应策略和在将 LLM 调整到电信领域时出现的特定动态。 我们特别关注两个关键方面:适应过程中的专业知识划分潜力,以及基于每个模型的特征和训练数据而产生的独特适应动态。 我们还调整了模型以遵循指令,创建类似聊天机器人的模型,用户可以与之交互。 我们表明,这些经过调整的模型在电信方面比其通用指令模型表现出更高的熟练度。
8.1. 专门领域划分
| Tele-Eval | General Knowledge | ||||
|---|---|---|---|---|---|
| Standards | Overall | MMLU | HellaSWAG | GSM8K | |
| Gemma-2B | 8.12 | 13.59 | 0.3289 | 0.5275 | 0.0576 |
| Gemma-2B-Tele | 10.15 | 17.07 | 0.3497 | 0.5304 | 0.0622 |
| Gemma-2B-Standards | 9.58 | 11.18 | 0.3314 | 0.5250 | 0.0432 |
当将 LLM 调整到电信领域时,会出现一个关键问题:我们应该调整一个单一的 LLM 来涵盖整个领域,还是应该调整多个 LLM,每个 LLM 专注于电信的特定方面? 例如,一个 LLM 可以专注于学术材料,而另一个 LLM 可以专注于标准。 为了探索这一点,我们比较了 Gemma-2B 模型的两个版本:一个专门在 Tele-Data 的标准部分上训练的模型,称为 Gemma-2B-Standards,以及 Gemma-2B-Tele。 训练参数与之前报道的 Gemma-2B-Tele 的训练参数一致。 评估基于 Tele-Eval 的全部内容以及与使用 LLM-eval 指标的标准相关的问答,以及通用知识评估数据集,以评估模型能力的保留。 结果如表 4 所示。
如图所示,Gemma-2B-Tele 在与标准相关的问答中优于 Gemma-2B-Standards,同时还展示了更强的通用知识能力。 此外,Gemma-2B-Standards 在整个 Tele-Eval 数据集上的表现比基础模型 Gemma-2B 差。 造成这种情况的原因是,Gemma-2B-Standards 模型仅在标准上进行过训练,因此对这种特定类型的內容更加敏感。 标准往往具有很高的技术性,并且具有独特的符元分布,这与在学术文章和维基百科文章中发现的更广泛的电信知识不同。 这种狭隘的关注使模型处理学术材料的能力不如基础模型,从而导致在 Tele-Eval 上表现不佳。 同时,这种狭隘的关注也会对 LLM 的一般能力产生负面影响。 总而言之,这表明最有效的策略是将 LLM 适应整个电信数据集,从而从跨越这些不同材料的迁移学习中获益,而不是狭隘地关注单个方面。
8.2. 预训练数据影响
也许塑造 LLM 行为最具影响力的因素是它的预训练数据。 此数据通常不公开,因此只能通过与模型的交互来推断其类型。 了解这种行为至关重要,因为在将 LLM 适应电信领域时,基于这种行为会出现特定的趋势。
为了说明这一点,让我们考虑两个模型:Gemma-2B 和 Gemma-2B-it999https://huggingface.co/google/gemma-2b-it . 后者是前者的指令版本,它已在指令遵循数据上进行过后期训练,其中包括问答和摘要等任务。 如表 5 所示,指令模型在 Tele-Eval 上的表现优于其基础模型。 这是因为额外的以指令为中心的训练使 LLM 能够更好地处理问题、遵循指令并利用其内化的知识来有效地回答查询。 这种优势非常显著,以至于 Gemma-2B-it 能够胜过我们适应电信的 LLM,Gemma-2B-Tele。 但是,由于 Gemma-2B-Tele 已被电信知识丰富,我们可以通过使用 Alpaca 这样的数据集应用类似的后期训练指令遵循适应来超越 Gemma-2B-it 的性能。 101010https://huggingface.co/datasets/tatsu-lab/alpaca 并利用之前详细描述的相同训练设置,从而创建了 Gemma-2B-Tele-Alpaca。
| Tele-Eval | |||
|---|---|---|---|
| Original | Tele | Tele-Alpaca | |
| Gemma-2B | 13.59 | 17.07 | 25.31 |
| Gemma-2B-it | 19.84 | 18.05 | 24.83 |
| Phi-1.5 | 14.87 | 13.06 | 18.84 |
上述观察结果的重要性在于,一些基础模型在预训练阶段已经过类似指令的数据训练。 Microsoft Phi-1.5 就是一个例子。 在他们的论文 (et al., 2023) 中,作者指出 Phi-1.5 可以被提示为一个指令模型,因为预训练数据包含了大量的问答格式。 这导致了 Gemma-2B 和 Phi-1.5 之间的明显行为差异,如 Fig. 7 所示。 可以看到,Phi-1.5 更像是一个聊天机器人,遵循提示的指令,而 Gemma-2B 则在不将输入提示视为要遵循的指令的情况下填补句子。
鉴于以上情况,当将本文中描述的训练配方应用于 Phi-1.5 时,Phi-1.5-Tele 在 Tele-Eval 上的性能下降,类似于 Gemma-2B-it 所发生的情况。 但是,通过在 Alpaca 上对 Phi-1.5-Tele 进行后期训练,使用相同的训练设置,性能显着提高,超过了基础模型的性能。 这是因为,这样做,我们将模型重新对齐到其原始行为。 考虑到这一点,在进行适应过程之前,务必注意模型的行为,以便相应地预测其动态。
鉴于上述观察结果和 Phi-1.5 模型的特殊行为,我们只发布了 Phi-1.5 的 Alpaca 微调版本,作为我们 Tele-LLM 系列的一部分。 值得注意的是,其在一般知识数据集上的性能为 MMLU 上的 0.3965、HellaSWAG 上的 0.4680 和 GSM8K 上的 0.1107,相比之下,原始 Phi-1.5 分别为 0.4072、0.4798 和 0.0576。 这表明我们的模型在电信领域表现更好,同时仍然保留了其一般知识,甚至在数学性能方面有所提升。
| Tele-Eval | ||||
|---|---|---|---|---|
| Base | Instruct | Tele | Tele-Instruct | |
| Tinyllama-1.1B | 8.26 | 15.42 | 11.37 | 17.40 |
| Gemma-2B | 13.59 | 19.84 | 17.07 | 27.78 |
| LLama-3-8B | 24.60 | 30.65 | 29.60 | 34.51 |
8.3. 指令微调
虽然基础模型至关重要,因为它们包含原始 LLM 的知识,并且最适合用于微调以适应特定的电信应用,但用户通常会将这些模型用作聊天机器人。 因此,在本节中,我们将继续通过指令微调来微调我们的电信适应模型,以使其遵循指令。
训练设置 . 我们保留了第 7 节中的训练设置,并进行了一些小调整。 具体来说,我们将批次大小减少到 128k 个符元,将上下文长度设置为 2048,并将 epoch 次数限制为 1。 在此阶段,我们使用了两个数据集:Alpaca 和 Open-Instruct。 111111https://huggingface.co/datasets/VMware/open-instruct. 这些组合数据集提供了大约 200k 个样本用于训练。
9. 结论
在本文中,我们解决了将大型语言模型 (LLM) 适应电信领域特定用途的挑战。 在我们的努力中,我们创建并发布了 Tele-Data 和 Tele-Eval,这是一套全面的电信训练和评估数据集。 通过广泛的实验,我们确定了将大型语言模型 (LLM) 适应此领域的最佳训练策略。 我们工作的成果是 Tele-LLMs,这是一系列专门为电信领域设计的开源模型,参数范围从 10 亿到 80 亿。 这些模型在 Tele-Eval 上的表现优于通用的模型,同时保留了其更广泛的能力。 除了这些成果,我们的工作还研究了各种适应策略,例如专业领域划分,并探讨了在适应过程中根据所涉及模型出现的动态。 作为未来的方向,我们的工作将旨在利用 Tele-LLMs 并为其增强多模态功能,以理解和推断无线测量和信号。
参考文献
- (1)
- Aynetdinov and Akbik (2024) Ansar Aynetdinov and Alan Akbik. 2024. SemScore: Automated Evaluation of Instruction-Tuned LLMs based on Semantic Textual Similarity. arXiv:2401.17072 [cs.CL] https://arxiv.org/abs/2401.17072
- Bariah et al. (2023a) Lina Bariah, Qiyang Zhao, Hang Zou, Yu Tian, Faouzi Bader, and Merouane Debbah. 2023a. Large Language Models for Telecom: The Next Big Thing? arXiv preprint arXiv:2306.10249 (2023). arXiv:2306.10249 [cs.CL]
- Bariah et al. (2023b) Lina Bariah, Hang Zou, Qiyang Zhao, Belkacem Mouhouche, Faouzi Bader, and Merouane Debbah. 2023b. Understanding Telecom Language Through Large Language Models. arXiv preprint arXiv:2306.07933 (2023). arXiv:2306.07933 [cs.CL]
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems. arXiv:2110.14168 [cs.LG] https://arxiv.org/abs/2110.14168
- Colombo et al. (2024) Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre F. T. Martins, Fabrizio Esposito, Vera Lúcia Raposo, Sofia Morgado, and Michael Desa. 2024. SaulLM-7B: A pioneering Large Language Model for Law. arXiv:2403.03883 [cs.CL] https://arxiv.org/abs/2403.03883
- Du et al. (2023) Yuyang Du, Soung Chang Liew, Kexin Chen, and Yulin Shao. 2023. The Power of Large Language Models for Wireless Communication System Development: A Case Study on FPGA Platforms. arXiv preprint arXiv:2307.07319 (2023). arXiv:2307.07319 [eess.SP]
- et al. (2024) Abhimanyu Dubey et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
- et al. (2023) Suriya Gunasekar et al. 2023. Textbooks Are All You Need. arXiv:2306.11644 [cs.CL] https://arxiv.org/abs/2306.11644
- Griot et al. (2024) Maxime Griot, Jean Vanderdonckt, Demet Yuksel, and Coralie Hemptinne. 2024. Multiple Choice Questions and Large Languages Models: A Case Study with Fictional Medical Data. arXiv:2406.02394 [cs.CL] https://arxiv.org/abs/2406.02394
- Gupta et al. (2023) Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats Leon Richter, Quentin Gregory Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort. 2023. Continual Pre-Training of Large Language Models: How to re-warm your model?. In Workshop on Efficient Systems for Foundation Models @ ICML2023. https://openreview.net/forum?id=pg7PUJe0Tl
- Gururangan et al. (2020) Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 8342–8360. https://doi.org/10.18653/v1/2020.acl-main.740
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Understanding. In International Conference on Learning Representations. https://openreview.net/forum?id=d7KBjmI3GmQ
- Holm (2021) H. Holm. 2021. Bidirectional Encoder Representations from Transformers (BERT) for Question Answering in the Telecom Domain: Adapting a BERT-like language model to the telecom domain using the ELECTRA pre-training approach. (2021).
- Hu et al. (2022) Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations. https://openreview.net/forum?id=nZeVKeeFYf9
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Regina Barzilay and Min-Yen Kan (Eds.). Association for Computational Linguistics, Vancouver, Canada, 1601–1611. https://doi.org/10.18653/v1/P17-1147
- Kotaru (2023) Manikanta Kotaru. 2023. Adapting Foundation Models for Information Synthesis of Wireless Communication Specifications. arXiv preprint arXiv:2308.04033 (August 2023). arXiv:2308.04033 [cs.NI]
- Krell et al. (2022) Mario Michael Krell, Matej Kosec, Sergio P. Perez, and Andrew Fitzgibbon. 2022. Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance. arXiv:2107.02027 [cs.CL] https://arxiv.org/abs/2107.02027
- Labrak et al. (2024) Yanis Labrak, Adrien Bazoge, Emmanuel Morin, Pierre-Antoine Gourraud, Mickael Rouvier, and Richard Dufour. 2024. BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains. arXiv:2402.10373 [cs.CL] https://arxiv.org/abs/2402.10373
- Lewis et al. (2021) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL] https://arxiv.org/abs/2005.11401
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013
- Luo et al. (2024) Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2024. An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning. arXiv:2308.08747 [cs.CL] https://arxiv.org/abs/2308.08747
- Maatouk et al. (2023) Ali Maatouk, Fadhel Ayed, Nicola Piovesan, Antonio De Domenico, Merouane Debbah, and Zhi-Quan Luo. 2023. TeleQnA: A Benchmark Dataset to Assess Large Language Models Telecommunications Knowledge. arXiv:2310.15051 [cs.IT] https://arxiv.org/abs/2310.15051
- Maatouk et al. (2024) Ali Maatouk, Nicola Piovesan, Fadhel Ayed, Antonio De Domenico, and Merouane Debbah. 2024. Large Language Models for Telecom: Forthcoming Impact on the Industry. IEEE Communications Magazine (2024), 1–7. https://doi.org/10.1109/MCOM.001.2300473
- OpenAI (2024) OpenAI. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (Philadelphia, Pennsylvania) (ACL ’02). Association for Computational Linguistics, USA, 311–318. https://doi.org/10.3115/1073083.1073135
- Penedo et al. (2023) Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116 (2023). arXiv:2306.01116 https://arxiv.org/abs/2306.01116
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. https://api.semanticscholar.org/CorpusID:160025533
- Reimers and Gurevych (2020) Nils Reimers and Iryna Gurevych. 2020. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics. https://arxiv.org/abs/2004.09813
- Team (2024) Gemma Team. 2024. Gemma: Open Models Based on Gemini Research and Technology. arXiv:2403.08295 [cs.CL] https://arxiv.org/abs/2403.08295
- Xie et al. (2023) Yong Xie, Karan Aggarwal, and Aitzaz Ahmad. 2023. Efficient Continual Pre-training for Building Domain Specific Large Language Models. arXiv:2311.08545 [cs.CL] https://arxiv.org/abs/2311.08545
- Xu et al. (2024) Shengzhe Xu, Christo Kurisummoottil Thomas, Omar Hashash, Nikhil Muralidhar, Walid Saad, and Naren Ramakrishnan. 2024. Large Multi-Modal Models (LMMs) as Universal Foundation Models for AI-Native Wireless Systems. arXiv:2402.01748
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a Machine Really Finish Your Sentence?. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 4791–4800. https://doi.org/10.18653/v1/P19-1472
- Zheng et al. (2024) Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. 2024. Large Language Models Are Not Robust Multiple Choice Selectors. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=shr9PXz7T0
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685 [cs.CL] https://arxiv.org/abs/2306.05685
- Zhou et al. (2024) Hao Zhou, Chengming Hu, Dun Yuan, Ye Yuan, Di Wu, Xue Liu, Zhu Han, and Charlie Zhang. 2024. Generative AI as a Service in 6G Edge-Cloud: Generation Task Offloading by In-context Learning. arXiv:2408.02549 [eess.SY] https://arxiv.org/abs/2408.02549
- Çağatay Yıldız et al. (2024) Çağatay Yıldız, Nishaanth Kanna Ravichandran, Prishruit Punia, Matthias Bethge, and Beyza Ermis. 2024. Investigating Continual Pretraining in Large Language Models: Insights and Implications. arXiv:2402.17400 [cs.CL] https://arxiv.org/abs/2402.17400
附录
附录 A 手稿清理程序
鉴于确保 arXiv 论文干净以进行训练的重要性,我们在这些来源上采用了严格的清理过程。 我们的过程从删除 LaTeX 文件中所有注释开始。 为此,我们利用 Google 的 arXiv LaTeX Cleaner 121212https://github.com/google-research/arxiv-latex-cleaner。
接下来,由于 LaTeX 源代码可以包含多个 LaTeX 文件,因此我们首先统一用于导入这些文件的 LaTeX 命令。 尤其,我们确保导入使用 \input{} 命令。 通过创建映射这些关系的有向图,我们识别出论文的主要 LaTeX 文件。 然后,我们使用 Latexpand Perl 脚本 13 1313我们测试了 fatex (https://ctan.org/pkg/fatex) 和 fap (https://github.com/fchauvel/fap),但使用 latexpand (https://ctan.org/pkg/latexpand) 获得了最佳结果。 来扁平化文档,确保主文件包含所有内容。
在接下来的步骤中,我们通过“去宏化”来解决作者的自定义命令。 为此,我们将所有自定义命令(从 \def{} 和 \DeclareMathOperator{} 到 \newcommand{})统一,然后使用 Python 库 de-macro (https://ctan.org/pkg/de-macro) 将这些宏替换为其原生 LaTeX 等效项。 之后,我们针对删除图形和表格,因为我们的重点是内联文本和方程。 我们还编译了一个包含一百多个 LaTeX 命令和环境的列表,这些命令和环境没有信息量,我们使用正则表达式匹配将其删除。 这确保最终的 LaTeX 文件只包含文本和方程,没有任何 LaTeX 残留。
此外,鉴于引文可以采取的多种形式,以及它们方括号内文本的多种形式,我们统一了所有引文、标签和引用命令。 这种标准化有助于 LLM 在训练期间避免处理异质性。 最后,我们删除了所有 LaTeX 文件的前言,并确保保留了手稿的标题。 这为这些来源提供了一种统一的格式,从而便于下一阶段的 LLM 训练。
附录 B 电信数据样本
我们在下面提供每个类别电信数据的一个示例。 为了缩短字符串的长度,以下插入了 […] 符号。
ID: arxiv_14326
类别: arxiv
内容: 无线通信中的灵活位置 MIMO:基础、挑战和未来方向\n \n 摘要\n \n 灵活位置多输入多输出 (FLP-MIMO),例如流体天线和可移动天线,是未来无线通信中一项很有前景的技术 […]
元数据:
Arxiv_id: 2308.14578
标题: 无线通信中的灵活位置 MIMO:基础、挑战和未来方向
摘要: 灵活位置多输入多输出 (FLP-MIMO),例如 […]
ID: standard_2413
类别: 标准
内容: 第三代合作伙伴计划;\n 技术规范组核心网络和终端;\n 公共陆地移动网络 (PLMN) 之间的互操作\n 支持基于分组的服务与\n 无线局域网 (WLAN) 接入和\n 分组数据网络 (PDN)\n (版本 12)\n 前言\n 本技术规范 (TS) 已产生 […]
元数据:
系列: 29
版本: 12
文件名称: 29161-c00
ID: wiki_5438
类别: 维基百科
内容: 骨干网或核心网是计算机网络的一部分,它互连网络,为不同局域网或子网之间交换信息提供路径。 骨干网可以将各种网络连接在一起 […]
元数据:
标题: 骨干网络
网址: https://en.wikipedia.org/wiki/Backbone%20network
ID: web_71187
类别: 网络
Content:1. 发明领域\n 本发明一般涉及在通信网络中寻址到主机的 数据包的方法,并且特别涉及为移动终端/主机定义地址的方法 [...]
元数据:
网址:http://www.google.com/patents/US6147986
附录 C LLM 提示
为了开发和评估各个领域,我们在整个框架中使用了以下提示。 总之,按照顺序,这些提示用于以下任务:
-
(1)
提示 1: 用于查找与电信和网络领域相关的 arXiv 论文。
-
(2)
提示 2: 用于查找与电信和网络领域相关的网站和维基百科页面。
-
(3)
提示3: 用于生成形成初始远程评估数据集的 QnAs。
-
(4)
提示4: 用于过滤掉本地相关的 QnAs,从而产生过滤后的远程评估数据集。
-
(5)
提示5: 用于指示基础模型根据提供的问题完成答案。
-
(6)
提示6: 用作 LLM 评估的提示。
附录 D 定性示例
以下是展示基本 Gemma-2B 模型和 Gemma-2B-Tele 之间定性差异的示例。 这些示例包括来自 Tele-Eval 的与电信相关的问答(问题)和简单的字符串提示(提示)。