: 迈向语境忠实的 LLM
摘要
检索增强生成 (RAG) 是一种将外部语境信息与大型语言模型 (LLM) 集成的范式,旨在提高事实准确性和相关性,已成为生成式 AI 中的关键领域。 RAG 应用程序中使用的 LLM 需要忠实且完整地理解提供的语境和用户的问题,避免幻觉,处理无法回答、反事实或其他低质量和不相关的语境,执行复杂的多跳推理并生成可靠的引文。 在本文中,我们介绍了 ,一个小型 LLM,它经过指令调优,重点关注语境化的生成和幻觉最小化。 我们还提出了 ContextualBench,一个新的评估框架,它汇集了多个流行且多样化的 RAG 基准,例如 HotpotQA 和 TriviaQA,并具有一致的 RAG 设置,以确保模型评估的可重复性和一致性。 实验结果表明,我们的 -9B 模型优于领先的基线,例如 Command-R+ (104B) 和 GPT-4o,在 ContextualBench 中 7 个基准中的 3 个取得了最先进的结果,参数明显减少。 该模型还表现出对语境信息变化的弹性,并在相关语境被移除时表现得当。 此外,该模型在一般指令遵循任务和函数调用能力方面保持着有竞争力的性能。
1 介绍
检索增强生成 (RAG) 近年来已成为生成式 AI [53, 54] 中最突出的研究领域之一,这是由基础大型语言模型 (LLM) [4, 39, 29, 30, 40, 9, 14, 2] 的最新进展推动的。 RAG 框架非常适合解决依赖于知识的问题或疑问,其中提供了外部语境信息,并且生成的答案应以 基于事实 的语境线索为基础。 在实践中,RAG 设置的设计使生成器 LLM 与知识检索器协同工作。 检索器 [26, 46, 5, 21] 的任务是从文档数据库(可能是整个互联网)中检索与给定查询相关的段落。 LLM 与用户交互,为检索器制定查询以收集知识,最后回答用户的问题。 为了检索最准确的上下文信息,检索器通常依赖于嵌入模型 [28, 26, 5, 21],并且可以选择使用重新排序器来获取经过细化的上下文文档列表 [24]。 最近的研究还导致了更复杂的 RAG 框架的开发 [1, 13, 22, 47, 16, 45],这些框架涉及多个推理步骤来提高答案的可靠性。
在这项工作中,我们专注于 RAG 框架中的生成器 LLM 组件。 传统的为聊天训练的通用 LLM 在直接应用于 RAG 框架时经常会遇到困难。 这可以归因于几个潜在因素,包括:
-
•
从检索器获得的上下文中的知识可能与用于 LLM 的训练数据相冲突。
-
•
LLM 没有经过训练来处理检索器中的冲突或冗余事实。
-
•
在检索到的知识不足的情况下,LLM 会恢复到根据其训练数据回答问题。
-
•
它也可能无法在代理环境 [50] 中提供足够的引文或调用适当的功能和参数来检索适当的上下文,在该环境中,模型可以使用提供的功能或工具来执行任务。
最近的尝试集中在训练专门针对 RAG 框架进行调整的 LLM,例如 Command-R(+) [36] 和 RAG-2.0 [37]。 这些针对 RAG 的 LLM 不仅作为生成最新和真实 AI 响应的基础,而且还能在不同的领域快速采用,避免增加模型容量、上下文长度或对可能专有的数据进行 LLM 微调的需要。
在这项工作中,我们介绍了 1 11该模型将通过 API 提供,并在稍后完全开源。 ,一个 90 亿参数的语言模型,在训练中重点关注针对 RAG 和相关代理任务的可靠、精确和忠实的上下文生成能力。 除了上下文任务之外,还接受过培训,可以在常规任务中充当有竞争力的人工智能助手[12, 7]。 我们在数据合成和培训程序方面开发了一个全面的方案来培训基础 LLM ,使其熟悉并适应各种现实生活中的 RAG 使用案例。 这包括精确的事实知识提取、区分相关内容和分散注意力的上下文、引用适当的来源和答案、在多个上下文中产生复杂的多跳推理、遵循一致的格式,以及避免对无法回答的查询产生幻觉。 还具备函数调用和代理能力,使其能够主动从外部工具中搜索知识,并进行类似于Self-RAG [1]、ReAct [50] 和类似的 [22, 51, 20, 34]。
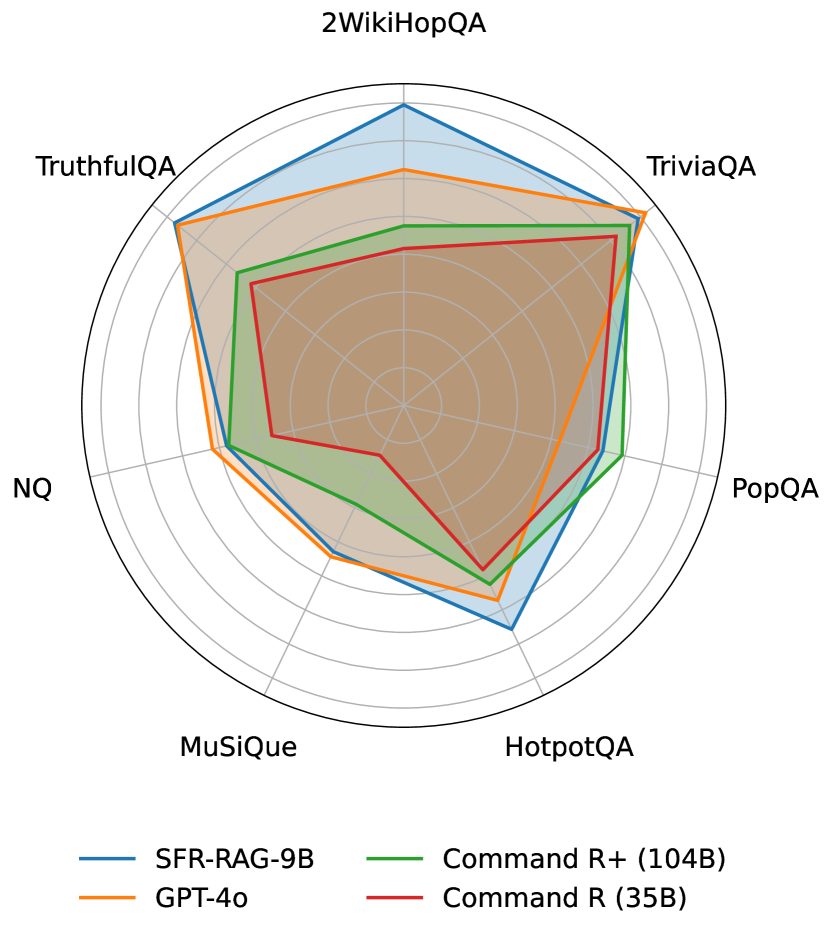
用于衡量 LLM 情境理解质量进展的既定评估标准有限。 值得注意的是,Command-R(+) [36] 和 RAG-2.0 [37] 根据非重叠指标评估了他们提出的模型[49, 23] 由于设置不一致或未公开,这导致不同研究之间的结果对齐和比较变得困难。 为了可靠地评估我们的模型以及其他众所周知的基线,在这项工作中,我们还引入了 ContextualBench 222https://huggingface.co/datasets/Salesforce/ContextualBench,这是许多流行的 RAG 和上下文基准的汇编,例如 HotpotQA 和 TriviaQA [49,15,25,23,13,42,18],标准化评估设置,从而获得一致且可重复的评估结果。 在实验中,我们表明 -9B 模型是一个全面且高性能的模型,在 ContextualBench 的七个基准测试中的三个中实现了最先进的性能;请参阅图1以预览我们的结果。 -9B 在 ContextualBench 中的所有任务上均优于 GPT-4o [30] 或具有竞争力。 尽管参数减少了 10 倍,但它在各种任务上的性能也优于强大的上下文模型,例如 Command-R+ [36]。 与可比较的基线相比,我们的模型也被证明能够适应上下文中的事实变更和不可回答性测试。 最后,尽管我们的训练重点是 RAG 和上下文应用程序,但我们的模型作为常规指令调整的 LLM 仍然具有竞争力,在 MMLU 或 GSM8K 等标准基准测试中具有强大且可比的性能[12,7,6],以及函数调用能力[48]。
2
在本节中,我们将提供更多关于 的见解。 首先,我们介绍一种新颖的聊天模板,其中包含两个具有特定功能的新聊天角色(部分 2.1)。 然后,我们简要讨论(Section 2.2)的训练过程。
2.1 聊天模板
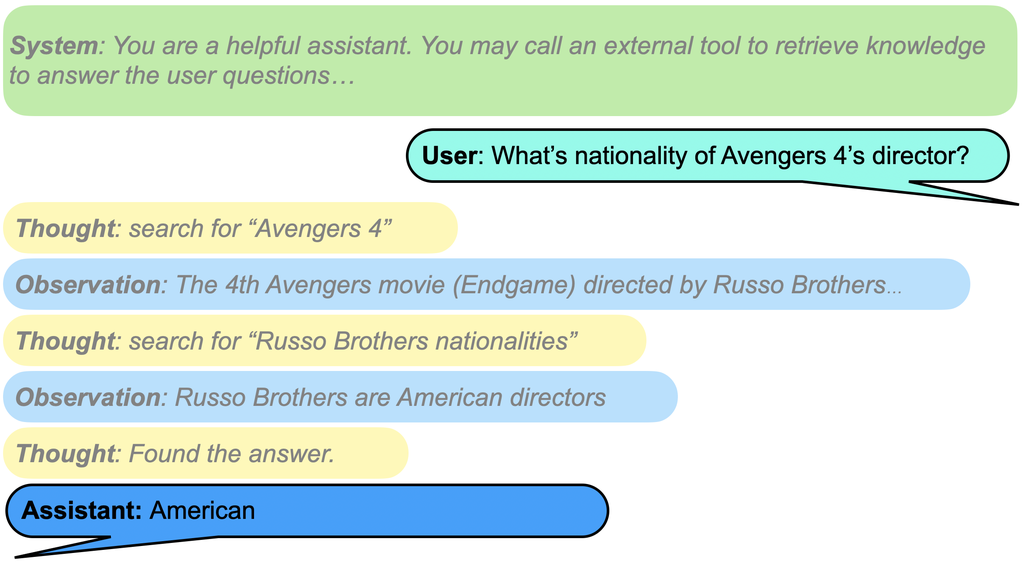
大多数指令调整后的语言模型通常包含一个聊天模板,该模板允许三种对话角色:(i) 系统 角色,通常在开始时指定一次,用于定义 AI 助手的一般特征,以及有关如何响应用户输入的一般指令;(ii) 用户 角色指定用户消息所在的位置;(iii) 助手 轮次是模型根据 系统 轮次提供的指南对用户查询进行响应的位置。
然而,随着越来越多的复杂应用程序(可能包含多步)检索或函数调用被使用,这些角色可能不得不处理越来越复杂和混乱的数据格式。 例如,在检索任务中,外部上下文信息可以注入到 系统 或 用户 轮次中,甚至可以构成 助手 轮次的一部分,如果上下文是在模型的函数调用后检索到的 [36, 50]。 这可能会导致混乱,并分散用户在 用户 轮次中查询的实际指令或问题的注意力。 换句话说,在这些任务中,还没有普遍接受的存储上下文信息的位置。 在另一个代理函数调用任务的示例中,助手 轮次必须生成使用特定工具语法的响应,并期望在 [50] 之后收到函数调用的结果。 这使得微调过程变得棘手,因为函数的结果是 助手 轮次的一部分,通常包含答案线索,需要从损失中屏蔽以防止记忆 [40]。 此外,对于某些应用程序,从业人员可能更愿意隐藏模型的推理或模型调用的中间操作,而只向用户显示对用户友好的响应。 将所有数据处理步骤都包含在 助手 轮次中可能会阻碍这些用例。 由于模型可能无法在像 ReAct [50] 这样的推理策略中始终如一地生成特定的关键词,因此可靠性也是一个问题。 3 33ReAct 在 助手 轮次中使用任意字面短语,如“思考:”、“结果:”和“最终答案:”,分别解析推理、工具输出和答案,而 LLM 可能并不总是遵守这些短语。 此外,角色、功能和权限的模糊性可能会导致模型无法遵守 系统 提示,并屈服于通过 用户 轮次或工具输出 [44] 注入的越狱。
为了克服这些复杂性,我们在对话模板中引入了两个可选的角色(轮次):思考 和 观察。 如 图 2 所示,观察 角色用于存放从外部来源获取的任何上下文信息,这些信息可以是检索用例中的检索文档,也可以是代理工具使用场景中的函数调用结果。 同时,思考 角色的设计是为了让模型说出任何内部推理,或使用工具语法来调用某些函数调用。 此更改带来的好处是多方面的。 首先,它允许在训练期间轻松地进行掩码。 具体来说,系统、用户 和 观察 轮次可能无法训练,因为它们是模型生成响应的输入信息。 另一方面,与 助理 类似,思考 轮次应包含在微调损失中,以训练模型生成这种“想法”。 其次,角色的分离和澄清有助于执行指令层次结构 [44],通过确保 LLM 尊重 系统 提示并拒绝遵循在 用户 和 观察 轮次中注入的恶意指令,从而使 LLM 更安全。 第三,额外的角色简化了构建可靠和安全的 RAG 和代理应用程序的过程,使开发人员能够显示或隐藏内部数据处理步骤,并避免不得不从 助理 输出中解析自定义关键词。
2.2 SFR-RAG 微调过程
的最重要的目标之一是充分利用和完全理解现实世界 RAG 场景中提供的任何上下文信息。 此特性包含许多功能,其中包括 (i) 从任意长的上下文中提取相关信息,(ii) 识别缺乏相关信息并避免幻觉生成,(iii) 识别上下文段落中可能存在的冲突信息,以及 (iv) 对来自预训练过程的令人分心、违反直觉的信息或内容具有弹性。 我们使用模仿现实世界检索问答应用程序的大量指令遵循数据,通过标准的监督微调和偏好学习 [40, 9, 31] 对 SFR-RAG 进行微调。
3 评估
3.1 上下文评估套件 - ContextualBench
已经有几种评估协议可用,用于衡量 LLM 和 RAG 系统在不同领域和复杂度下的上下文理解性能 [15, 23, 25, 49, 13, 42, 6, 18]。 但是,先前研究 [36, 37, 1, 50] 报告了非重叠指标、数据集和不一致设置的结果,尤其是在向 LLM 提供哪些上下文内容和模型超参数方面。 这给直接比较不同研究结果带来了挑战。
为了提供更好的共同基础,我们提出了 ContextualBench,它主要是一个包含 7 个流行的上下文问答任务的集合,包括 HotpotQA、TriviaQA、TruthfulQA、PopQA、2WikiHopQA、Musique 和自然问题 (NQ) [15, 23, 25, 49, 13, 42, 18]。 有几个关键贡献使 ContextualBench 成为一个全面的上下文 LLM 基准测试框架:
-
•
ContextualBench 中的指标是在相同指令下评估的,上下文内容始终被指定。 上下文内容包括每个基准的原始上下文文档(如果提供),否则它们将从一个更大的维基百科数据库中检索,并使用选择的嵌入模型。
-
•
由于使用生成的输出中各种详细程度来评估助手型 LLM 并非易事,ContextualBench 提供了多种评分方法来解释与基本事实相比的答案变化。 这些评分方法是 (i) 生成的答案与基本事实的完全匹配 (EM),(ii) 易匹配 (EasyM) 检查基本事实是否在生成的答案中,以及 (iii) F1 分数,并留有进一步添加的空间。 附录提供了所有这些指标的完整结果。
-
•
ContextualBench 提供了 RAG 场景中常见的多种设置,其中包括是否使用一致的嵌入模型检索前 k 个片段,或将所有可用的上下文文档直接提供给 LLM(无需检索)。
ContextualBench 中的各种指标和任务能够对上下文 LLM 进行全面和具体的评估。 通过平等地权衡每个任务和指标,ContextualBench 允许直接比较模型的总体性能。 另一方面,根据从业人员的用例和领域规范,某些指标或数据集可能会被优先考虑,从而能够快速识别最佳的任务特定模型。
数据集特定设置。
对于 2WikiHopQA、HotpotQA 和 Musique,每个问题都已提供上下文文档,因此我们直接将它们用作上下文来源。 对于 TriviaQA、TruthfulQA 和 NQ,问题附带各自的维基百科文章或来源 URL。 我们从这些来源抓取了网页内容,并使用 Cohere 嵌入 [35] 从上下文来源中检索前 10 个片段,其中每个片段长 512 个符元。 同时,PopQA 本身没有提供上下文文档,因此我们使用 Self-RAG 检索器 [1] 生成的现成上下文文档。 对于每个任务,如果它们具有完整的金标,我们使用测试集,否则我们使用整个验证集来衡量模型的性能。 这与 Command-R 的报告 [36] 不同,该报告在验证集的 100 个样本子集上对 HotpotQA 进行了评估,并且没有公开有关上下文文档的详细信息。
请注意,ContextualBench 包含流行的现有基准,例如 TriviaQA 和 TruthfulQA,其中评估利用了某些上下文,模型预计会忠实于这些上下文。 也就是说,与传统的闭卷问答设置相反,模型预计只利用在这些上下文中找到的信息,在传统的闭卷问答设置中,LLM 的参数化知识是在不提供上下文的情况下进行评估的。 换句话说,这些上下文的存在可能会导致分数发生显著差异。
3.2 ContextualBench 上的实验结果
| Model | TriviaQA | TruthfulQA | 2WikiHopQA | MuSiQue | NQ | PopQA | HotpotQA | Average |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 81.73 | 76.47 | 62.40 | 44.40 | 51.85 | 42.24 | 57.20 | 59.47 |
| GPT 4 Turbo | 78.34 | 76.13 | 59.90 | 37.10 | 48.23 | 53.82 | 54.20 | 58.25 |
| GPT-4o-mini | 72.55 | 61.02 | 46.60 | 32.10 | 30.75 | 54.75 | 49.80 | 49.65 |
| GPT 3.5 Turbo | 77.43 | 47.00 | 41.20 | 22.60 | 40.40 | 53.39 | 48.10 | 47.16 |
| Command R (35B) | 71.75 | 51.65 | 41.50 | 14.60 | 35.76 | 52.60 | 48.20 | 45.15 |
| Command R+ (104B) | 76.34 | 56.30 | 47.50 | 29.00 | 47.44 | 59.18 | 52.50 | 52.61 |
| gemma-2-9b-it | 77.66 | 59.43 | 49.70 | 30.50 | 37.37 | 53.75 | 52.60 | 51.57 |
| Llama3 8B Instruct | 72.28 | 51.52 | 27.90 | 9.90 | 31.01 | 52.82 | 45.90 | 41.62 |
| Llama3.1 8B Instruct | 71.33 | 59.43 | 17.70 | 9.40 | 44.41 | 59.68 | 46.70 | 44.09 |
| -9B | 79.24 | 77.45 | 79.50 | 42.90 | 48.01 | 53.97 | 65.70 | 63.44 |
表 1 比较了我们的 9B 模型在 ContextualBench 上的表现,与最先进的大模型以及 7 个问答任务中可比模型的表现进行了比较。 PopQA 得分是根据简单匹配来衡量的,而其余得分则是根据精确匹配来衡量的。 如图所示,GPT-4o [30] 预计会在大多数基准测试中取得优异成绩。 然而,鉴于其体积较小,我们的 -9B 模型在性能方面显著优于 Command-R 和 Command-R+ 等强大的开源基线,而后者的参数数量最多是前者的十倍。 值得注意的是,该模型在 TruthfulQA、2WikihopQA 和 HotpotQA 的上下文设置中取得了最先进的水平。 总体而言,该模型还取得了最先进的平均性能,证明了我们模型在许多上下文任务中的强大能力。 值得注意的是,我们的模型在 2WikiHopQA 中表现出色,与 GPT-4o 相比,性能提升了近 25%。 同时,我们的 9B 模型在大多数基准测试中始终优于 Llama-3.1 8B Instruct 和 gemma-2-9b-it。
3.3 对无法回答、冲突和反事实上下文的抵御能力
由于大多数 QA 基准测试实际上都是基于现实世界的事实,因此了解 LLM 在上下文 QA 任务中的表现可能模棱两可,因为高得分可能归因于以下两种情况之一:(i)从上下文文档和内容中查找准确事实的能力,或(ii)模型在预训练期间获得的内在参数知识,而像 GPT-4o 这样的大型先进模型通常在这方面具有显著优势。
Ming 等人 [27] 最近提出了 FaithEval,这是一个评估套件,用于衡量 LLM 在上下文事实发生变化的情况下如何保持对上下文的忠实度。 该基准测试在三种场景中评估 LLM:(i)“未知”,其中相关事实被删除,原始问题变得无法回答;(ii)“冲突”,其中提供多个包含冲突或矛盾信息的上下文文档,并且预期模型能够识别这些冲突;以及(iii)“反事实”,其中通过引入虚假的捏造的上下文文档来改变某些常识性事实。 例如,“月球由棉花糖制成。” 被认为是一个 反事实 上下文,并且预期正在评估的 LLM 能够保持对该“事实”的忠实度,如果被提示这样做的话。 遵循 Ming 等人 [27], “未知” 和 “冲突” 任务在 10 个基准 [43, 8, 49, 18, 41, 19, 32, 10, 17, 15] 上取平均值,而 “反事实” 任务则使用 ARC-C 数据集 [6] 进行评估。
| Model | MMLU | GSM8K | Winogrande | TruthfulQA | Hellaswag | ARC-C |
|---|---|---|---|---|---|---|
| Command-R (35B) | 68.20 | 56.63 | 81.53 | 52.32 | 87.00 | 65.53 |
| Llama-3-8b-instruct | 67.07 | 68.69 | 74.51 | 51.65 | 78.55 | 60.75 |
| Llama-3.1-8B-Instruct | 68.22 | 71.04 | 78.06 | 54.58 | 80.47 | 60.92 |
| gemma-2-9b-it | 70.80 | 76.88 | 77.50 | 60.11 | 81.78 | 71.20 |
| -9B | 70.15 | 82.56 | 78.46 | 56.49 | 81.58 | 69.12 |
| Model | Executable | AST | Relevance |
|---|---|---|---|
| GPT 4 Turbo | 86.04 | 90.73 | 62.50 |
| GPT 3.5 Turbo | 81.38 | 75.23 | 87.80 |
| Command R + (104B) | 77.33 | 84.50 | 63.75 |
| xLam 7B | 87.12 | 89.46 | 85.00 |
| Mistral Medium | 73.47 | 84.48 | 88.33 |
| gemma-2-9b-it | 70.50 | 69.69 | 90.00 |
| Meta-Llama-3-8B-Instruct | 65.13 | 61.63 | 26.60 |
| Meta-Llama-3.1-8B-Instruct | 75.17 | 77.56 | 40.00 |
| -9B | 70.88 | 71.69 | 72.50 |
图 3 显示了 FaithEval 套件下不同 LLM 在 3 个任务上的平均非严格匹配准确率得分。 如图所示,其他基线,例如 GPT-4o,在反事实和未知情况下事实发生变化时表现出较高的变化。 尤其是,GPT-4o 在反事实情况下得分较低,可能是因为大型模型可能具有更高的知识惯性和更强的对事实变化的抵抗力。 同时,我们的 -9B 得分始终很高,即使上下文信息被改变。 这表明我们的模型对未见过的上下文信息具有有用的弹性和忠实度。 这也意味着该模型更能适应不断变化的世界。 此外,我们的模型更能识别上下文中的矛盾,以及在呈现的上下文信息违反直觉时抵抗自身的参数化知识。 换句话说,即使上下文与模型预训练的知识相矛盾,该模型仍然对上下文保持更忠实。
3.4 标准基准
我们还在传统的少样本提示基准 [12, 7] 中评估我们的模型,以衡量其参数化知识以及一般指令遵循和推理能力。 使用 Open LLM 排行榜 [3] 中类似的设置,我们采用标准评估工具 [11] 来评估我们在 MMLU(5 个样本)、GSM8K(5 个样本,严格匹配)、Winogrande(5 个样本)、TruthfulQA(0 个样本 MC2)、Hellaswag(10 个样本,归一化准确率)和 ARC-C(25 个样本,归一化准确率)[12, 7, 33, 23, 52, 6] 上的模型。
如表 2所示,尽管我们的模型针对上下文和检索用例进行了优化,但它在世界知识、常识和推理能力方面表现出色。 特别是,我们的 9B 模型在 MMLU、GSM8K、TruthfulQA 以及 ARC-C 中的表现优于参数为 35B 的 Command-R [36]。 同时,它在与 Llama-3.1-Instruct [9] 和 gemma-2-9b-it [38] 的比较中仍然具有竞争力。
我们的模型还使用函数调用进行了训练,重点是支持与外部工具的动态和多跳交互,以检索高质量的上下文信息。 因此,我们将我们的模型与伯克利函数调用任务 [48] 中的某些流行基线进行了比较。 如表 3所示,我们的模型在与 Llama-3-8B-Instruct [9] 等可比基线相比时,表现出色。
4 结论
我们介绍了,一个针对忠实的上下文理解和理解进行了微调的大语言模型,用于检索增强生成应用。 该模型经过训练,可以最大限度地减少幻觉,有效地处理无法回答、反事实或质量低下和不相关的上下文。 它还能够执行复杂的多跳推理,并可靠、准确地生成引用。 我们还引入了 ContextualBench,它是在一致且适当的设置下评估的各种流行 RAG 基准的汇编。 实验表明,我们的 9B 模型优于著名的基线,包括 Command-R+ 和 GPT-4o,并在 ContextualBench 的 7 个基准中的 3 个中取得了最先进的水平。 我们使用 FaithEval 进行的评估也表明,我们的模型对上下文信息的更改具有弹性,并且能够识别无法回答的问题。 最后,与类似大小的基线相比,该模型在一般的指令调整任务和函数调用能力方面保持了竞争性能。
参考文献
- Asai et al. [2023] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- Beeching et al. [2023] Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. Open llm leaderboard. https://huggingface.co/spaces/open-llm-leaderboard-old/open_llm_leaderboard, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Chen et al. [2024] Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation, 2024.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Dua et al. [2019] Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. arXiv preprint arXiv:1903.00161, 2019.
- Dubey et al. [2024] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Dunn et al. [2017] Matthew Dunn, Levent Sagun, Mike Higgins, V Ugur Guney, Volkan Cirik, and Kyunghyun Cho. Searchqa: A new q&a dataset augmented with context from a search engine. arXiv preprint arXiv:1704.05179, 2017.
- Gao et al. [2024] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 07 2024. URL https://zenodo.org/records/12608602.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- Ho et al. [2020] Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. In Donia Scott, Nuria Bel, and Chengqing Zong, editors, Proceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, Barcelona, Spain (Online), December 2020. International Committee on Computational Linguistics. doi: 10.18653/v1/2020.coling-main.580. URL https://aclanthology.org/2020.coling-main.580.
- Jiang et al. [2023] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Joshi et al. [2017] Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551, 2017.
- Ke et al. [2024] Zixuan Ke, Weize Kong, Cheng Li, Mingyang Zhang, Qiaozhu Mei, and Michael Bendersky. Bridging the preference gap between retrievers and llms. arXiv preprint arXiv:2401.06954, 2024.
- Kembhavi et al. [2017] Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, pages 4999–5007, 2017.
- Kwiatkowski et al. [2019] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
- Lai et al. [2017] Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/D17-1082. URL https://aclanthology.org/D17-1082.
- Lee et al. [2024] Myeonghwa Lee, Seonho An, and Min-Soo Kim. Planrag: A plan-then-retrieval augmented generation for generative large language models as decision makers. arXiv preprint arXiv:2406.12430, 2024.
- Li et al. [2023a] Chaofan Li, Zheng Liu, Shitao Xiao, and Yingxia Shao. Making large language models a better foundation for dense retrieval, 2023a.
- Li et al. [2023b] Xingxuan Li, Ruochen Zhao, Yew Ken Chia, Bosheng Ding, Shafiq Joty, Soujanya Poria, and Lidong Bing. Chain-of-knowledge: Grounding large language models via dynamic knowledge adapting over heterogeneous sources. arXiv preprint arXiv:2305.13269, 2023b.
- Lin et al. [2021] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
- Ma et al. [2023] Yubo Ma, Yixin Cao, YongChing Hong, and Aixin Sun. Large language model is not a good few-shot information extractor, but a good reranker for hard samples! arXiv preprint arXiv:2303.08559, 2023.
- Mallen et al. [2022] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. arXiv preprint arXiv:2212.10511, 2022.
- Meng et al. [2024] Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. Sfr-embedding-mistral:enhance text retrieval with transfer learning. Salesforce AI Research Blog, 2024. URL https://blog.salesforceairesearch.com/sfr-embedded-mistral/.
- Ming et al. [2024] Yifei Ming, Senthil Purushwalkam, Shrey Pandit, Zixuan Ke, Xuan-Phi Nguyen, Caiming Xiong, and Shafiq Rayhan Joty. Faitheval: Can your language model stay faithful to context, even if "the moon is made of marshmallows"? 2024.
- Muennighoff et al. [2022] Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. Mteb: Massive text embedding benchmark. arXiv preprint arXiv:2210.07316, 2022. doi: 10.48550/ARXIV.2210.07316. URL https://arxiv.org/abs/2210.07316.
- OpenAI [2023a] OpenAI. Chatgpt (june 2023 version, 2023a.
- OpenAI [2023b] OpenAI. Gpt-4 technical report. arXiv preprint, 2023b.
- Rafailov et al. [2023] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Rajpurkar et al. [2016] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
- Sakaguchi et al. [2021] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- Shi et al. [2023] Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652, 2023.
- Team [2024a] Cohere Team. Introducing embed v3, 2024a. URL https://cohere.com/blog/introducing-embed-v3/.
- Team [2024b] Cohere Team. Command r: Retrieval-augmented generation at production scale, 2024b. URL https://cohere.com/blog/command-r/.
- Team [2024c] Contextual AI Team. Introducing rag 2.0, 2024c. URL https://contextual.ai/introducing-rag2/.
- Team et al. [2024] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Thoppilan et al. [2022] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Trischler et al. [2016] Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. Newsqa: A machine comprehension dataset. arXiv preprint arXiv:1611.09830, 2016.
- Trivedi et al. [2022] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554, 2022.
- Tsatsaronis et al. [2012] George Tsatsaronis, Michael Schroeder, Georgios Paliouras, Yannis Almirantis, Ion Androutsopoulos, Eric Gaussier, Patrick Gallinari, Thierry Artieres, Michael R Alvers, Matthias Zschunke, et al. Bioasq: A challenge on large-scale biomedical semantic indexing and question answering. In 2012 AAAI Fall Symposium Series, 2012.
- Wallace et al. [2024] Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions. arXiv preprint arXiv:2404.13208, 2024.
- Weijia et al. [2023] Shi Weijia, Min Sewon, Yasunaga Michihiro, Seo Minjoon, James Rich, Lewis Mike, and Yih Wen-tau. Replug: Retrieval-augmented black-box language models. ArXiv: 2301.12652, 2023.
- Xiao et al. [2023] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023.
- Xu et al. [2023] Fangyuan Xu, Weijia Shi, and Eunsol Choi. Recomp: Improving retrieval-augmented lms with compression and selective augmentation. arXiv preprint arXiv:2310.04408, 2023.
- Yan et al. [2024] Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Berkeley function calling leaderboard. 2024.
- Yang et al. [2018] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018.
- Yao et al. [2022] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Yu et al. [2024] Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. Rankrag: Unifying context ranking with retrieval-augmented generation in llms. arXiv preprint arXiv:2407.02485, 2024.
- Zellers et al. [2019] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- Zhao et al. [2024] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey. arXiv preprint arXiv:2402.19473, 2024.
- Zhao et al. [2023] Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Xuan Long Do, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, and Shafiq Joty. Retrieving multimodal information for augmented generation: A survey. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4736–4756, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.314. URL https://aclanthology.org/2023.findings-emnlp.314.
附录 A 附录
| Model | HotpotQA | 2WikiHopQA | MuSiQue | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EasyM | EM | F1 | EasyM | EM | F1 | EasyM | EM | F1 | |
| GPT 4 Turbo | 70.90 | 54.20 | 69.00 | 73.00 | 59.90 | 69.60 | 53.10 | 37.10 | 52.70 |
| GPT 4o | 72.70 | 57.2 | 71.40 | 74.70 | 62.40 | 70.90 | 60.20 | 44.40 | 58.60 |
| GPT-4o-mini | 68.70 | 49.80 | 65.50 | 57.70 | 46.60 | 56.50 | 48.30 | 32.10 | 48.90 |
| GPT 3.5 Turbo | 63.10 | 48.10 | 61.80 | 50.50 | 41.20 | 49.70 | 34.90 | 22.60 | 35.90 |
| Command R (35B) | 63.10 | 48.20 | 63.00 | 55.70 | 41.50 | 52.30 | 36.70 | 14.60 | 34.10 |
| Command R + (104B) | 67.30 | 52.50 | 66.60 | 60.80 | 47.50 | 57.30 | 46.30 | 29.00 | 43.60 |
| LLama3 8B Instruct (8B) | 58.80 | 45.90 | 60.00 | 46.50 | 27.90 | 42.20 | 29.30 | 9.90 | 25.30 |
| LLama3.1 8B Instruct (8B) | 64.80 | 46.70 | 62.00 | 51.70 | 17.70 | 38.30 | 38.00 | 9.40 | 29.00 |
| gemma-2-9b-it | 67.20 | 52.60 | 66.10 | 59.60 | 49.70 | 58.10 | 47.00 | 30.50 | 43.50 |
| -9B | 83.60 | 65.70 | 79.90 | 86.20 | 79.50 | 84.60 | 57.40 | 42.90 | 53.50 |
| Model | TriviaQA | TruthfulQA | PopQA | NQ | ||
|---|---|---|---|---|---|---|
| EM | F1 | EM | EasyM | EM | F1 | |
| GPT 4 Turbo | 78.34 | 86.30 | 76.13 | 53.82 | 48.23 | 67.20 |
| GPT 4o | 81.73 | 88.20 | 76.47 | 42.24 | 51.85 | 69.75 |
| GPT-4o-mini | 72.55 | 81.77 | 61.02 | 54.75 | 30.75 | 54.90 |
| GPT 3.5 Turbo | 77.43 | 84.70 | 47.00 | 53.39 | 40.40 | 60.69 |
| Command R (35B) | 71.75 | 79.81 | 51.65 | 52.60 | 35.76 | 55.50 |
| Command R + (104B) | 76.34 | 83.05 | 56.30 | 59.18 | 47.44 | 63.21 |
| LLama3 8B Instruct (8B) | 72.28 | 79.07 | 51.52 | 52.82 | 31.01 | 48.22 |
| LLama3.1 8B Instruct (8B) | 71.33 | 78.33 | 59.43 | 59.68 | 44.41 | 61.60 |
| gemma-2-9b-it | 77.66 | 83.23 | 59.43 | 53.75 | 37.37 | 53.15 |
| -9B | 79.24 | 84.35 | 77.45 | 53.97 | 48.01 | 59.66 |