加法就是你需要的
用于节能语言模型
摘要
大型神经网络在浮点张量乘法上花费了最多的计算量。 在这项工作中,我们发现浮点乘法器可以通过一个整数加法器以高精度进行近似。 我们提出了线性复杂度乘法 (-Mul) 算法,该算法使用整数加法运算来近似浮点数乘法。 新算法的计算资源成本远低于 8 位浮点乘法,但精度更高。 与 8 位浮点乘法相比,该方法精度更高,但消耗的位级计算量明显更少。 由于浮点数乘法所需的能量比整数加法运算高得多,因此在张量处理硬件中应用 -Mul 操作可以潜在地通过逐元素浮点张量乘法减少 95% 的能量成本,以及 80% 的点积能量成本。 我们计算了 -Mul 的理论误差期望,并在各种文本、视觉和符号任务上对算法进行了评估,包括自然语言理解、结构推理、数学和常识问答。 我们的数值分析实验与理论误差估计一致,这表明 4 位尾数的 -Mul 精度与 float8_e4m3 乘法相当,而 3 位尾数的 -Mul 精度优于 float8_e5m2。 在流行基准上的评估结果表明,将 -Mul 直接应用于注意力机制几乎是无损的。 我们进一步表明,在 Transformer 模型中用 3 位尾数 -Mul 替换所有浮点乘法,在微调和推理中都实现了与使用 float8_e4m3 作为累积精度相同的精度。
1 引言
现代人工智能 (AI) 系统是重要的能源消耗者。 由于神经网络推理需要大规模计算,因此基于此类模型的 AI 应用正在消耗大量的电力资源。 据报道,ChatGPT 服务在 2023 年初的平均电力消耗为每天 564 兆瓦时,相当于美国 18,000 个家庭的每日总用电量111https://www.eia.gov/tools/faqs/faq.php?id=97。 据估计,在最坏情况下,谷歌的 AI 服务可能消耗与爱尔兰相当的电力(每年 29.3 TWh)(de Vries, 2023)。
减少神经网络所需的计算量是降低大型 AI 模型能源消耗和推理速度的关键。 神经网络,特别是大型语言模型 (LLM) (Radford et al., 2019; Brown, 2020; Achiam et al., 2023; Touvron et al., 2023; Team et al., 2023),包含大量参与逐元素和矩阵乘法运算的浮点参数。 在基于 Transformer (Vaswani, 2017) 的 LLM 中,注意力机制是限制计算效率的主要瓶颈。 给定一个 个符元的输入上下文,标准注意力机制计算的复杂度为 ,涉及乘以高维张量。 除了注意力机制之外,还有大量的逐元素乘法和线性变换计算。 在这项工作中,我们提出了线性复杂度乘法 (-Mul) 算法,该算法使用整数加法运算近似浮点乘法。 该算法可以集成到现有模型的各个级别,例如替换注意力机制中的乘法或替换所有矩阵和逐元素乘法。
提出的 -Mul 方法将显著降低模型训练和推理的能源消耗。 在现代计算硬件中,浮点数之间的乘法消耗的能量明显高于加法运算 (Horowitz, 2014)。 具体来说,两个 32 位浮点数 (fp32) 的乘法消耗的能量是两个 fp32 数相加的四倍,是两个 32 位整数 (int32) 相加的 37 倍。 表 1 显示了各种操作的粗略能量成本。 在 PyTorch (Paszke et al., 2019) 中,用于累积张量乘法结果的默认精度设置为 fp32。 虽然没有考虑 I/O 和控制操作,但用 int32 加法近似 fp32 乘法仅消耗 的能量。 当累积精度降低到 fp16 时,整数加法消耗的能量大约是浮点乘法所需的能量的 。
| Operation | Integer | Floating Point | ||
|---|---|---|---|---|
| 8-bit | 32-bit | 16-bit | 32-bit | |
| Addition | 0.03 pJ | 0.1 pJ | 0.4 pJ | 0.9 pJ |
| Multiplication | 0.2 pJ | 3.1 pJ | 1.1 pJ | 3.7 pJ |
我们评估了 -Mul 算法在基于 Transformer 的语言模型上的数值精度,这些模型涵盖了广泛的语言和视觉任务。 使用全精度模型权重的实验表明,用 -Mul 替换注意力机制中的标准乘法运算对于基于 Transformer 的 LLM 几乎是无损的。 在自然语言推理任务上,基于 -Mul 的注意力的平均性能损失在常识、结构化推理、语言理解方面为 。 在视觉任务中,基于 -Mul 的注意力在视觉问答、物体幻觉和自由形式的视觉指令任务上获得了 的准确率提升。 实验结果是通过将预训练的 LLM 与标准注意力实现直接调整到新的基于 -Mul 的注意力机制,而无需任何额外的训练获得的。
错误估计和消融研究表明,在无训练设置下,具有 4 位尾数的 -Mul 可以实现与乘以 float8_e4m3 数相同的精度,而具有 3 位尾数的 -Mul 优于 float8_e5m2 乘法。 我们还表明,微调可以弥合 -Mul 与标准乘法之间的性能差距。 对一个模型进行微调,其中注意力机制、线性变换和逐元素乘积中的所有乘法运算都被 3 位尾数 -Mul 替换,结果与使用 float8_e4m3 累加精度的标准模型进行微调的性能相当。
在 AI 效率研究的广阔领域中,我们的方法集中在增强张量算术算法的效率——这是一个与 I/O 和控制优化 (Jouppi 等人,2017;Choquette 等人,2021;Abts 等人,2022) 中的现有努力正交但互补的方向。 2 22 由于没有原生实现,GPU 无法完全利用 -Mul 算法的效率。 我们建议在集成有专门架构设计的设备上训练和托管基于 -Mul 的模型。 专利申请中。 . 我们相信,真正的节能和计算效率高的 AI 计算将来自对 I/O、控制和算术运算的优化进行全面整合。
2 方法
2.1 背景:浮点数和张量
大多数机器学习模型,包括神经网络,使用浮点 (FP) 张量来表示其输入、输出和可训练参数。 典型的选择是 32 位和 16 位 FP 张量 (fp32 和 fp16),由 IEEE 754 标准定义,如图 1 所示。
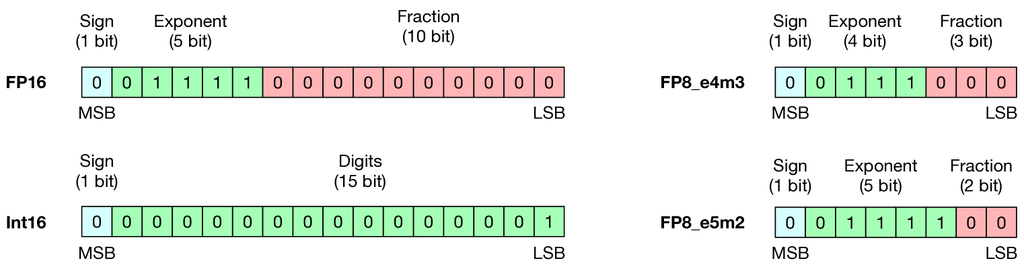
乘法运算通常比加法运算更复杂,FP 运算比整数运算成本更高 (Horowitz, 2014)。 表 1 显示,将两个 fp32 数字相乘消耗的能量比将两个 32 位整数相加高 37 倍。 虽然整数加法的复杂度为 ,其中 是用于表示数字的位数,但 FP 乘法需要 指数加法、 尾数乘法和舍入。 这里 和 代表 FP 数字的指数部分和尾数部分所使用的位数。
现代 LLM 训练和推理涉及张量计算中大量的 FP 计算。 考虑计算两个二维张量的元素大小和点积:
计算 涉及 个 FP 乘法 (Mul)。 如果 和 都是 fp32 张量,则 消耗的能量是将两个相同大小的 int32 矩阵相加的 倍。 同样, 计算 涉及 个 FP Mul 和相同数量的 FP 加法 (Add)。 当 和 是 fp32 张量时,两个数字的每个 Mul-Add 运算消耗 (pJ) 能量。 如果我们用 int32 Add 替换 fp32 Mul,能量成本将变为 (pJ),只有原始成本的 21.7%。 同样,如果推断在 fp16 中进行,用 int16 加法替换 fp16 乘法会导致 % 的节能。
2.2 线性复杂度乘法 (-Mul)
我们提出 -Mul,一种具有 复杂度的 FP 乘法算法,其中 是其 FP 操作数的位大小。 考虑两个 FP 数 ,其指数和小数分别为 和 ,则普通 FP Mul 结果为
加上一个 xor 操作 () 来确定结果的符号。 假设 和 是 位的尾数。 尾数乘法操作是此计算的复杂度瓶颈。 我们删除此操作并引入一种新的乘法算法,该算法以 的计算复杂度处理尾数:
| (1) |
偏移指数 是根据图 3 中所示的观察定义的。 在接下来的部分中,我们将证明 (1) -Mul 操作可以用整数加法器实现,以及 (2) 该算法比 fp8 乘法更准确、更高效。
该算法的实现如图 2 所示,其中我们还添加了用于在 Nvidia GPU 上模拟该过程的内联 PTX 汇编代码。
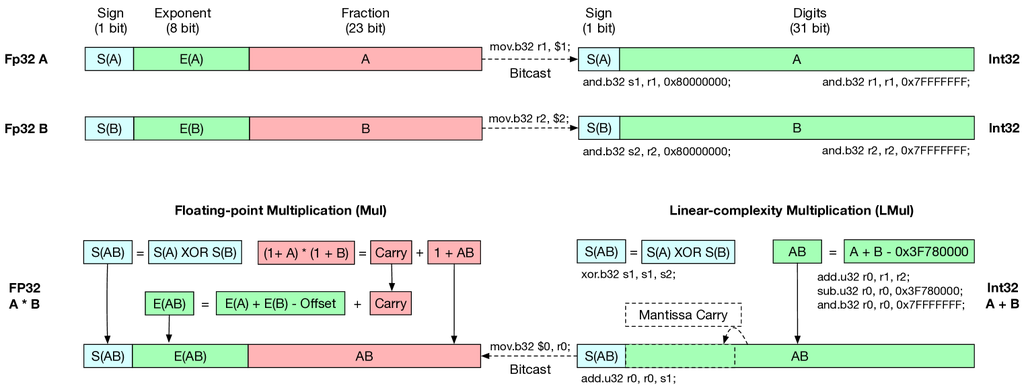
虽然等式 (1) 包含 4 个加法运算,但 FP 数的位格式设计帮助我们使用一个加法器实现 -Mul 算法。 由于 FP 格式隐式地处理 ,我们无需计算 的值。 整数加法运算也会自动将尾数进位发送到指数。 如果尾数和大于 2,则会自动将进位添加到指数。 这与传统 FP 乘法器中的舍入过程不同,在传统 FP 乘法器中,分数会手动舍入到 ,并且进位作为独立的步骤添加到指数。 因此,-Mul 算法通过跳过尾数乘法和舍入运算,比传统的 FP 乘法效率更高。
-Mul 结果的构造可以使用以下等式表示,其中所有位级计算都作为无符号整数之间的运算执行。
| (2) |
我们进一步使用 -Mul 实现注意力机制。 在 Transformer 模型中,注意力机制的计算成本很高,因为它需要 复杂度来处理输入上下文 。 我们发现 -Mul 可以用最小的性能损失替换复杂的张量乘法,而无需额外的训练。 在这项工作中,我们实施了一种更有效的注意力机制,如下所示,
| (3) |
其中 代表矩阵乘法运算,其中所有常规 FP 乘法都在 -Mul 中实现。 通过这样做,所有 FP 乘法都被替换为整数加法,这消耗了明显更少的计算资源。
2.3 精度和成本分析
在本节中,我们将展示 -Mul 比 fp8_e4m3 乘法更精确,但比 fp_e5m2 使用更少的计算资源。 为了简洁起见,在 Mul 和 -Mul 的误差分析和复杂度估计中,我们不考虑四舍五入到最近偶数模式。
2.3.1 精度估计
精度分析的目标是找到-Mul 算法的精度,相当于将一个浮点数的比例四舍五入到多少位,例如,fp8 具有 2 位或 3 位尾数 (e5m2 或 e4m3)。 考虑正浮点数 和 ,如果我们显式地突出显示四舍五入后要保留的 位,它们可以写成以下格式:
其中 是 的前 k 位, 是 k 位四舍五入后将被忽略的剩余位的数值。 是通过保留尾数的前 k 位对 进行四舍五入后的值。 考虑 和 在其全精度下具有 位尾数。 例如,Float16 数字具有 10 位尾数,而 BFloat16 包含 7 位。 的误差及其期望值是
| (4) |
与 位尾数 FP 乘法相比, 位尾数 -Mul 的误差是
| (5) |
使用上面的等式,我们可以计算 位 -Mul 与 FP 乘法之间的精度差距的期望值:
当 均匀分布时,我们可以计算以下期望值,
通过估计 和 并进一步推断 和 ,我们发现 -Mul 比具有均匀分布操作数的 fp8_e5m2 更准确。 但是,权重分布在预训练的 LLM 中通常是有偏差的。 基于五个流行的 LLM 的组合权重分布,我们发现 -Mul 在实践中可以实现比具有 5 位尾数操作数的 fp8_e4m3 更高的精度。 我们通过附录 A 中详细的估计误差来支持这两个说法。
2.3.2 门复杂度估计
在本节中,我们对 -Mul 和 fp8 乘法所需的闸级计算量进行了粗略估计。 两个 fpn_eimj 数的乘法需要以下计算:符号预测、带偏移的指数加法、 位尾数乘法和指数舍入。 尾数乘法包括 个 AND 操作、 个半加器和 个全加器。 指数舍入需要 个半加器。 在常规电路设计中,全加器包含 2 个 AND、2 个 XOR 和 1 个 OR。 每个 XOR 具有 4 个 NAND 门。 因此,全加器消耗 11 个闸级计算,而半加器(没有进位)消耗 5 个闸级计算(1 个 AND 和 1 个 XOR)。
综上所述,fp8 Mul 所需的闸级计算总量可以估计为
| (6) |
-Mul 消耗 个 XOR 用于符号预测、 个半加器和 个全加器。 16 位和 8 位 -Mul 所需的总闸门数量可以估计如下:
| (7) |
-Mul 具有 fp8_e4m3 和 fp8_e5m2 操作数的复杂度相似,因为指数偏移通常由 8 位无符号整数加法器实现。 据估计,fp16 -Mul 所需的闸门数量少于 fp8 乘法,而 fp8 -Mul 的效率明显更高。
总结误差和复杂度分析,-Mul 比 fp8 乘法更有效且更准确。
3 实验
为了证明理论精度估计,并了解基于 -Mul 的 LLM 在实际任务中的表现,我们在使用不同基于 Transformer 的大型语言模型的各种基准上进行了实验。 我们评估了 Llama-3.1-8b-Instruct (Dubey 等人,2024)、mistral-7b-v0.3-Instruct (Jiang 等人,2023)、Gemma2-2b-It (Team 等人,2024) 和 Llava-v1.5-7b (Liu 等人,2024) 模型,发现所提出的方法可以在微调或无训练设置下替换 Transformer 层中的不同模块。 在本节中,我们首先介绍用于评估的基准和任务,然后比较 -Mul 算法的数值误差与 fp8 参数模型的数值误差。 我们还报告了不同精度设置下 LLM 的基准测试结果。
3.1 任务
大型多任务语言理解 (MMLU) (Hendrycks 等人,2020) 包含 57 个多项选择自然语言理解任务,涵盖各种高中和大学科目。 使用 5 个少样本示例,需要评估的 LLM 找到每个问题的最合适答案选项。 该基准侧重于评估与给定主题相关的语言理解和知识能力。
BigBench-Hard (BBH) (Srivastava 等人,2023) 包含一组复杂的符号任务,用于评估语言模型的结构和逻辑推理能力。 在这项工作中,我们选择了一组 17 个多项选择任务来评估 Llama 和 Mistral LLM。 我们在所有 BBH 任务的少样本提示设置下评估语言模型。
常识。 我们整理了一组 5 个问答任务,用于评估 LLM 的常识知识推理能力。 任务集包括 ARC-Challenge (Clark 等人,2018)、CSQA (Saha 等人,2018)、OBQA (Mihaylov 等人,2018)、PIQA (Bisk 等人,2020) 和 SIQA (Sap 等人,2019),涵盖了事实和社会知识的不同方面。
视觉问答。 我们选择了一组基于图像的多项选择问答任务,用于评估视觉语言模型的视觉和语言理解能力。 这些任务包括 VQAv2 (Goyal 等人,2017)、VizWiz (Gurari 等人,2018) 和 TextVQA (Singh 等人,2019),包含不可回答和可回答的问题,以及不同类型的答案。
视觉指令遵循。 我们使用 Llava-bench 任务 (Liu et al., 2024) 测试 Llava-1.5-7b 模型的指令遵循能力,方法是根据图像和相应的指令生成自由格式的响应。 按照官方评估指南,我们使用 GPT4o 评估指令遵循质量,并比较相对性能。
对象幻觉。 我们使用 POPE 基准 (Li et al., 2023) 探索使用较低精度进行推理是否会影响 Llava 模型的真实性,该基准使用一系列关于正负对象的“是/否”问题来提示视觉语言模型。
GSM8k (Cobbe et al., 2021) 包含 8.5k 个人工制作的小学数学问题,测试集包含 1,000 个问题,旨在评估语言模型的算术能力。 我们在 GSM8k 上进行了两种不同设置的实验。 在无训练设置中,我们评估了使用少样本、思维链提示的 LLM (Wei et al., 2022)。 此外,我们在训练集上对 Gemma2-2b-It 模型进行微调,并在零样本设置中评估其性能。
3.2 精度分析
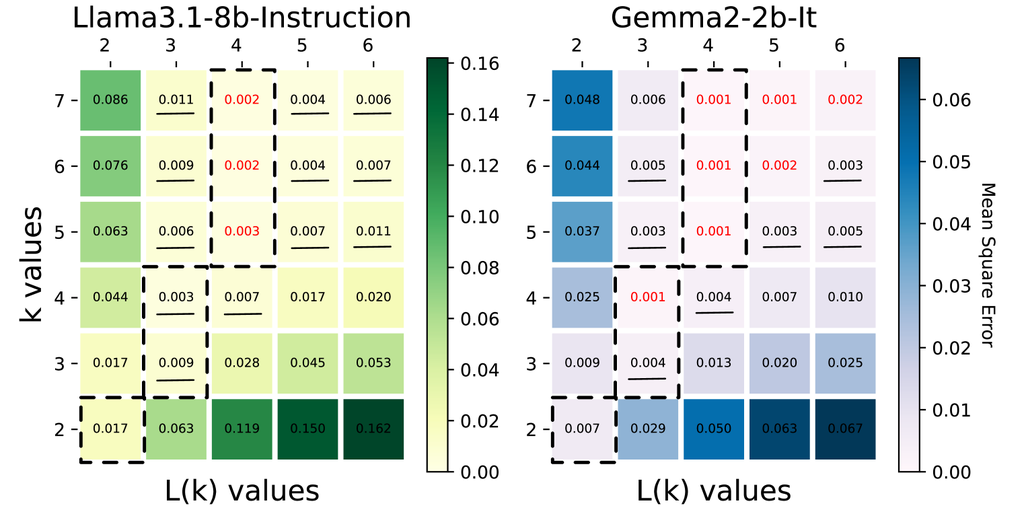
的选择。 我们首先在图 3 中可视化了不同模型在 GSM8k 数据集上使用不同 选择获得的均方误差。 在图中,我们以红色突出显示了导致平均误差低于模型推理中 float8_e4m3 乘法的 配置,并用下划线标出导致误差在 e4m3 和 e5m2 之间的 组合。 在两个模型中,具有 3 位尾数的 -Mul 比 fp8_e5m2 更准确,而具有 4 位尾数的 -Mul 实现了与 fp8_e4m3 相当或更低的误差。
尾数大小。 在 2.3.1 节中,我们论证了 -Mul 的误差期望值可能低于使用 fp8_e4m3 乘法,同时使用比 fp8_e5m2 乘法更少的计算资源。 我们在此通过实验分析证实了我们对 -Mul 算法的理论精度估计的正确性。 Llama 和 Gemma 模型的平均误差如 4 图所示。
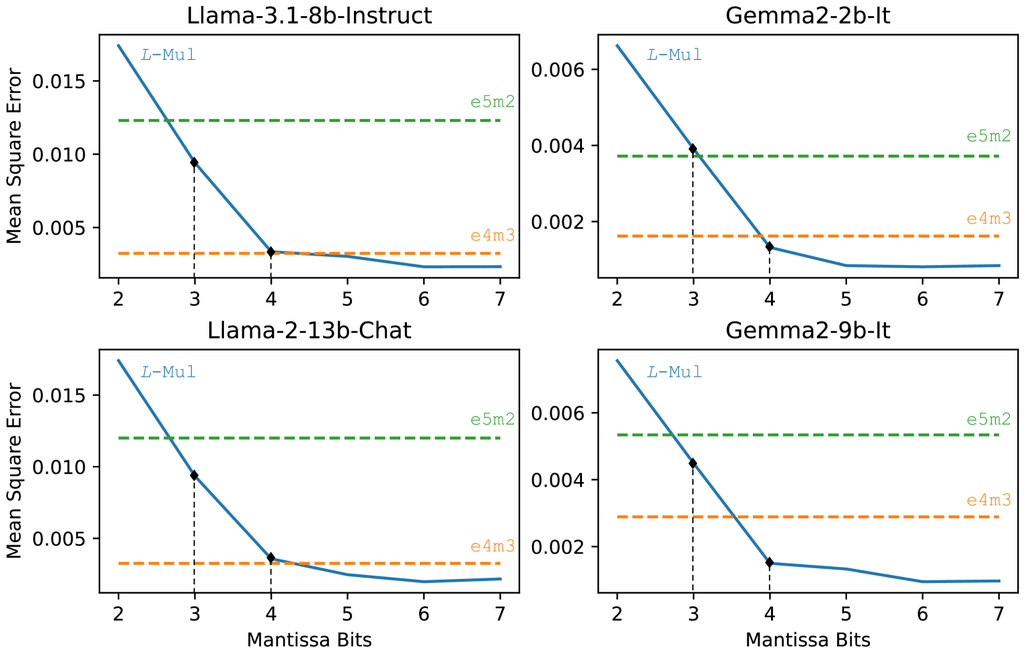
实验表明,在各种规模的 LLM 中,使用 6 位尾数 FP 操作数的 -Mul 算法近似实现了最低的平均误差,显著优于 fp8 格式。 此外,3 位和 4 位尾数 -Mul 实现了与 fp8_e5m2 和 fp8_e4m3 乘法运算分别相当或超过的准确性。
在 IEEE 754 格式(使用 1 位符号和 5 位指数)中,使用 6 位尾数相当于将 fp16 数向下舍入到 fp12。 通过应用等式 (7) 中概述的复杂度估计方法,我们可以计算 12 位 -Mul 运算的门计数,如下所示:
| (8) |
实验结果进一步证实了 -Mul 比 fp8 乘法更有效率且更准确。 尽管我们估计了门计数作为计算复杂度的指标,但实际的能量成本差异大于复杂度差距所暗示的。 根据 Horowitz (2014) 中报告的能耗,fp8 乘法消耗大约 0.25 pJ 到 0.4 pJ 的能量,而 16 位 -Mul 消耗约 0.06 pJ 的能量。
3.3 基准测试
在本节中,我们展示了 -Mul 可以替换注意力机制中的张量乘法,而不会损失性能,而使用 fp8 乘法进行相同的操作会降低推理精度。 这表明,我们可以通过将注意力计算的能耗降低 80% 来实现相同的模型推理性能。 此外,我们展示了在 GSM8k 基准测试中,当所有张量乘法运算都被替换为 -Mul 时,完整模型微调的性能。
文本任务。 表格 2 展示了 Llama 和 Mistral 模型在各种自然语言基准测试中的评估结果,包括 MMLU、BBH、ARC-C、CSQA、PIQA、OBQA 和 SIQA。 在这些实验中,注意力层中的矩阵乘法(在 softmax 运算之前和之后)被替换为不同格式的 8 位张量计算或 -Matmul,遵循我们在等式 (3) 中讨论的实现方法。
| Precision | BBH | MMLU | ARC-R | CSQA | OBQA | PIQA | SIQA | Avg. |
|---|---|---|---|---|---|---|---|---|
| Mistral-7b-Instruction-v0.3 | ||||||||
| BFloat16 | 55.85 | 62.20 | 75.94 | 71.42 | 76.20 | 80.74 | 44.83 | 69.83 |
| Float8_e4m3 | 55.16 | 62.18 | 75.39 | 71.25 | 76.00 | 80.47 | 44.63 | 69.55 |
| Float8_e5m2 | 53.20 | 61.75 | 74.91 | 71.25 | 74.40 | 79.76 | 44.52 | 68.97 |
| -Mul | 55.87 | 62.19 | 76.11 | 71.09 | 76.60 | 80.52 | 45.34 | 69.93 |
| Llama-3.1-8B-Instruct | ||||||||
| BFloat16 | 70.79 | 68.86 | 82.51 | 74.53 | 84.20 | 84.00 | 45.96 | 74.24 |
| Float8_e4m3 | 69.91 | 68.16 | 81.66 | 74.28 | 82.20 | 83.51 | 45.34 | 73.40 |
| Float8_e5m2 | 62.94 | 66.61 | 80.12 | 73.30 | 79.40 | 81.07 | 45.39 | 71.86 |
| -Mul | 70.78 | 68.54 | 82.17 | 74.28 | 84.20 | 83.30 | 46.06 | 74.00 |
结果表明,在使用 Mistral 和 Llama 模型的 14 次实验中,有 12 次与 float8-e4m3 张量相比,-Mul 不仅需要更少的计算资源,而且提供了更高的精度。 与 bf16 推理相比,这导致了最小的性能差距。 平均而言,在这两种模型中,bf16 和 -Mul 之间的性能差异仅为 0.07%。 这些发现表明,注意力机制中的矩阵乘法运算可以无缝地用 -Mul 算法替换,而不会造成任何精度损失或需要额外的训练。
GSM8k。 我们使用少样本提示和 -Mul 基于注意力的机制,评估了三种语言模型(Mistral-7b-Instruct-v0.3、Llama3.1-7b-Instruct 和 Gemma2-2b-It)在 GSM8k 数据集上的性能。 这些模型在不同的数值精度格式下进行了测试:bf16、fp8_e4m3、fp8_e5m2 和 -Mul 方法。 结果总结在表格 3 中。
值得注意的是,与 bf16 基线相比,基于 -Mul 的注意力机制略微提高了平均性能。 Mistral-7b-Instruct-v0.3 和 Gemma2-2b-It 均通过 -Mul 表现出更高的准确率,分别达到 52.92% 和 47.01%。 Llama3.1-7b-Instruct 使用 -Mul 的准确率略低于其 bf16 性能,但仍高于 fp8_e4m3 和 fp8_e5m2 。 相反,将注意力计算中的张量舍入为 fp8_e5m2 会导致性能显着下降,尽管它比 -Mul 更复杂。
| Model | Bfloat16 | Float8_e4m3 | Float8_e5m2 | -Mul |
|---|---|---|---|---|
| Mistral-7b-Instruct-v0.3 | 52.54 | 52.39 | 50.19 | 52.92 |
| Llama3.1-7b-Instruct | 76.12 | 75.44 | 71.80 | 75.63 |
| Gemma2-2b-It | 45.87 | 45.94 | 44.43 | 47.01 |
| Average | 58.17 | 57.92 | 55.47 | 58.52 |
视觉语言任务。 Llava-v1.5-7b 模型在 VQA、物体幻觉和指令跟踪任务上的性能如表 4 所示。 与语言任务的实验类似,注意力计算采用不同的精度/方法进行,而其他线性变换层保持不变。 除了 TextVQA 的准确率差距为 之外,-Mul 和 BFloat16 注意力机制的性能相当。 VQA 任务使用官方评估脚本进行评估,Llava-Bench 结果由 GPT-4o 生成。
| Task | POPE | Llava-Bench | TextVQA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Split | rand. | adv. | pop. | all | comp. | conv. | detail. | all | all |
| BFloat16 | 86.20 | 83.17 | 85.13 | 84.83 | 66.80 | 57.60 | 41.40 | 57.50 | 57.90 |
| -Mul | 86.57 | 83.19 | 85.34 | 85.03 | 64.90 | 58.70 | 43.30 | 57.50 | 57.41 |
| Task | VQAv2 | VizWiz | |||||||
| Split | yes/no | num. | other | all | yes/no | num. | unans. | other | all |
| BFloat16 | 91.88 | 59.04 | 70.56 | 78.03 | 77.19 | 45.24 | 71.75 | 38.19 | 49.31 |
| -Mul | 91.78 | 58.93 | 70.73 | 78.06 | 78.54 | 50.48 | 73.78 | 38.41 | 50.16 |
-Mul 具有更少的位数。 In this section, we explore how -Mul-based attention precision influences the overall model performance using the MMLU benchmark with Mistral and Llama models. 我们使用 -Mul 实现注意力机制,并且只保留操作数张量的前 位。 使用不同精度的 -Mul 注意力机制的结果如表 6 所示。 正如预期的那样,使用具有 4 位尾数的 -Mul 可以实现与 bf16 和 fp8_e4m3 相当或略微更好的性能。 但是,性能会随着图 4 所示的估计误差成比例下降。 当 时,两种模型都显著优于其 fp8_e5m2 对应模型,Llama 模型的性能保持接近 fp8_e4m3。 当 时,Llama 模型的性能与 fp8_e5m2 舍入相当。 这表明使用 Llama 模型,我们可以直接对 fp8 模型执行 -Mul,而不会影响性能。
| Model | e4m3 | e5m2 | |||
|---|---|---|---|---|---|
| Mitral | 62.18 | 61.75 | 62.16 | 62.06 | 61.08 |
| Llama | 68.16 | 66.61 | 68.43 | 68.12 | 66.67 |
| 8bit Acc. | e4m3 | e5m2 | -Mul |
|---|---|---|---|
| GSM8k | 36.09 | 7.96 | 37.91 |
全模型微调。 为了进一步探索 -Mul 算法的影响,我们超越了使用 -Mul 实现注意力层,而是用 fp8_e4m3 -Mul 替换了 Gemma2-2b-It 模型中的所有乘法运算,包括线性变换中的矩阵乘法、逐元素乘法以及注意力层中的乘法。 然后,我们在 GSM8k 语料库的训练集上对更新后的模型进行微调,并在 GSM8k 测试集上使用零样本设置评估微调后的 fp8 和 -Mul 模型。 请注意,本实验中的 -Mul 操作采用具有 3 位尾数 () 的操作数,累积精度为 fp8_e4m3,以探索一种极其高效的设置。
实验结果表明,经过微调的 fp8_e4m3 -Mul 模型在 fp8 累加精度下,其性能与经过标准微调的 fp8_e4m3 模型相当。 这表明 -Mul 可以在不影响微调模型性能的情况下提高训练效率。 此外,它还揭示了训练 -Mul 原生 LLM 用于准确且节能的模型托管的潜力。
4 相关工作
在保持性能的同时减少神经网络所需的计算量是一个重要问题,它涉及多个研究方向。 典型方法包括神经网络剪枝、量化和改进的张量 I/O 实现。
剪枝。 神经网络剪枝侧重于通过减少层间连接的数量来提高推理效率 (Han et al., 2015a; b; Wang et al., 2020)。 神经网络剪枝方法通常涉及训练。 在识别出重要权重后,对神经网络进行重新训练,以进一步更新所选权重,以用于特定任务。 与模型剪枝不同,我们提出的方法是针对一般任务设计的,不需要特定于任务的重新训练。
优化张量 I/O。 在常规 GPU 上,在 GPU SRAM 和高带宽内存 (HBM) 之间移动张量是时间和能量消耗的主要瓶颈。 减少 Transformer 模型中的 I/O 操作并充分利用 HBM 可以显着提高 AI 训练和推理的效率 (Dao et al., 2022; Dao, ; Kwon et al., 2023)。 我们的方法侧重于优化算术运算,与这个方向正交。
舍入和量化。 标准的神经网络权重以 32 位或 16 位 FP 张量存储。 然而,完整的权重需要大量的 GPU 内存。 为了提高存储效率,权重存储和计算可以在较低的精度下进行,例如使用 16 位、8 位或 4 位 FP 和 Int(fp16、bf16 (Kalamkar 等人,2019)、fp8-e4m3、fp8-e5m2 (Micikevicius 等人,2023)、int8 (Dettmers 等人,2022)、fp4 和 int4 (Dettmers 等人,2024))张量来表示模型权重。 使用低位参数进行推断通常会降低计算精度并影响预训练模型的性能,并且基于整数的量化方法会花费大量时间来处理异常值权重。 与量化方法相比,我们的方法需要更少的计算量,但能获得更高的精度。
5 未来工作
为了充分发挥我们提出的方法的潜力,我们将在硬件级别实现 -Mul 和 -Matmul 内核算法,并开发用于高级模型设计的编程 API。 此外,我们将训练针对 -Mul 原生硬件部署进行优化的文本、符号和多模态生成式 AI 模型。 这将提供高速且节能的 AI 托管解决方案,降低数据中心、机器人和各种边缘计算设备的能耗。
6 结论
在本文中,我们介绍了 -Mul,一种使用整数加法逼近浮点乘法的有效算法。 我们首先证明了该算法相对于其浮点操作数的位大小表现出线性复杂度。 然后我们表明,-Mul 的预期精度超过了 fp8 乘法的精度,同时所需的计算能力明显更少。 为了评估 -Mul 的实际影响,我们使用流行的语言模型在自然语言、视觉和数学基准上对其进行了评估。 我们的实验表明,-Mul 优于 8 位 Transformer,计算量更低,并且在应用于计算密集型注意力层时无需额外训练即可实现无损性能。 基于这些证据,我们认为,可以使用 -Mul 有效地实现语言模型中的张量乘法,从而在保留性能的同时实现节能的模型部署。
参考文献
- Abts et al. (2022) Dennis Abts, Garrin Kimmell, Andrew Ling, John Kim, Matt Boyd, Andrew Bitar, Sahil Parmar, Ibrahim Ahmed, Roberto DiCecco, David Han, et al. A software-defined tensor streaming multiprocessor for large-scale machine learning. In Proceedings of the 49th Annual International Symposium on Computer Architecture, pp. 567–580, 2022.
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp. 7432–7439, 2020.
- Brown (2020) Tom B Brown. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Choquette et al. (2021) Jack Choquette, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. Nvidia a100 tensor core gpu: Performance and innovation. IEEE Micro, 41(2):29–35, 2021.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- (8) Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. In The Twelfth International Conference on Learning Representations.
- Dao et al. (2022) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- de Vries (2023) Alex de Vries. The growing energy footprint of artificial intelligence. Joule, 7(10):2191–2194, 2023.
- Dettmers et al. (2022) Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems, 35:30318–30332, 2022.
- Dettmers et al. (2024) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Goyal et al. (2017) Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6904–6913, 2017.
- Gurari et al. (2018) Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3608–3617, 2018.
- Han et al. (2015a) Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015a.
- Han et al. (2015b) Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network. Advances in neural information processing systems, 28, 2015b.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2020.
- Horowitz (2014) Mark Horowitz. 1.1 computing’s energy problem (and what we can do about it). In 2014 IEEE international solid-state circuits conference digest of technical papers (ISSCC), pp. 10–14. IEEE, 2014.
- Jiang et al. (2023) Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Jouppi et al. (2017) Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th annual international symposium on computer architecture, pp. 1–12, 2017.
- Kalamkar et al. (2019) Dhiraj Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja Vooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, et al. A study of bfloat16 for deep learning training. arXiv preprint arXiv:1905.12322, 2019.
- Kwon et al. (2023) Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pp. 611–626, 2023.
- Li et al. (2023) Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 292–305, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.20. URL https://aclanthology.org/2023.emnlp-main.20.
- Liu et al. (2024) Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26296–26306, 2024.
- Micikevicius et al. (2023) Paulius Micikevicius, Stuart Oberman, Pradeep Dubey, Marius Cornea, Andres Rodriguez, Ian Bratt, Richard Grisenthwaite, Norm Jouppi, Chiachen Chou, Amber Huffman, et al. Ocp 8-bit floating point specification (ofp8). Open Compute Project, 2023.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2381–2391, 2018.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Saha et al. (2018) Amrita Saha, Vardaan Pahuja, Mitesh Khapra, Karthik Sankaranarayanan, and Sarath Chandar. Complex sequential question answering: Towards learning to converse over linked question answer pairs with a knowledge graph. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- Sap et al. (2019) Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473, 2019.
- Singh et al. (2019) Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8317–8326, 2019.
- Srivastava et al. (2023) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research, 2023.
- Team et al. (2023) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Team et al. (2024) Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Vaswani (2017) A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017.
- Wang et al. (2020) Ziheng Wang, Jeremy Wohlwend, and Tao Lei. Structured pruning of large language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6151–6162, 2020.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
附录 A 误差估计
我们使用表 7 中所示的不同 组合来计算误差期望值。 这些值是使用 Mistral、Llama 和 Gemma 模型的实际参数计算的。 对于均匀分布,我们使用第 2.3.1 节中介绍的期望值。 对于实际分布,我们使用五个流行的预训练 LLM 的参数来估计可能操作数的平均值。
| K values | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 0.68 | 0.35 | 0.17 | 0.081 | 0.035 | 0.012 | ||
| Even Distribution | 0.68 | 0.43 | 0.30 | 0.24 | 0.20 | 0.19 | |
| 0.61 | 0.33 | 0.16 | 0.077 | 0.033 | 0.011 | ||
| Real Distribution | 0.16 | 0.18 | 0.18 | 0.12 | 0.15 | 0.14 | |
我们发现,当操作数均匀分布时,-Mul 比 float8_e5m2 乘法更精确。 但是,对于实际模型,-Mul 可以实现比 float8_e4m3 计算更高的精度。