博洛尼亚大学 阿尔玛母校
科学学院
数学专业
深度学习的范畴化
基础研究:
综述
人工智能方向论文
指导老师:
FABIO ZANASI
学生:
FRANCESCO RICCARDO CRESCENZI
2024-2025 学年
献给我最爱的
Benedetta
摘要
英语
机器学习研究前所未有的快速发展带来了令人难以置信的进步,但也带来了严峻的挑战。 目前,该领域缺乏坚实的理论基础,许多重要成果源于临时的设计选择,这些选择在原则上很难证明,其有效性也往往无法解释。 研究债务不断增加,许多论文被发现无法重复。
本论文是对一些试图从范畴角度研究机器学习的最新工作的综述。 范畴论是抽象数学的一个分支,它在数学内外许多领域都找到了成功的应用。 作为数学和科学的通用语言,范畴论可能能够为机器学习领域提供一个统一的结构。 这可以解决上面提到的问题。
在这项工作中,我们主要关注范畴论在深度学习中的应用。 具体来说,我们讨论了使用范畴光学来模拟基于梯度的学习,使用范畴代数和积分变换来连接经典计算机科学和神经网络,使用函子来连接不同抽象层级并保留结构,最后,使用字符串图来提供神经网络架构的详细表示。
意大利人
机器学习领域研究的空前速度带来了非凡的发现,但也带来了未来挑战。 目前,该领域缺乏牢固的理论基础,许多重大发现是基于特定情况的选择,很难用理论来解释,其有效性也难以解释。 同时,研究债务不断增加,许多复制尝试以失败告终。
本论文概述了一些近期尝试从范畴论角度分析机器学习的工作。 范畴论是抽象数学的一个分支,它在数学内外许多领域都找到了成功的应用。 作为数学和科学的通用语言,范畴论可能能够为机器学习领域提供一个统一的结构,这可以解决上面提到的问题。
在这些页面中,我们将主要关注范畴论在深度学习领域的应用。 具体来说,我们将讨论使用范畴光学来模拟基于梯度的学习,使用范畴代数和积分变换来连接经典计算机科学和神经网络,使用函子来连接不同抽象层级并保留结构,最后,使用字符串图来提供神经网络架构的详细表示。
介绍
机器学习研究的零散状态
在过去的七十年里,机器学习从一个好奇的领域发展成为工程学最激动人心的前沿之一。 该领域不断增长的研究量带来了令人难以置信的进步,如今,机器学习模型对许多科学领域 ([HSK+23]) 和社会 ([KM23]) 产生了重大影响。 尽管机器学习取得了无可争议的成功,但该领域在许多层面上也面临着重大挑战。 撇开本文未讨论的伦理和社会问题,还存在重大的科学问题。 首先,机器学习,尤其是深度学习,缺乏强有力的理论基础:目前还没有机器学习的通用数学理论,该领域更像是炼金术而不是科学 ([Gav24b], [Rah17])。 科学家和工程师通过试错来发现和优化模型,没有方向,也没有参照系。 这导致了大量的浪费时间和资源,并明显阻碍了未来的进展。
同时,机器学习社区的不良激励导致了研究过程本身的问题 ([SGW21])。 [OC17] 指出了研究的混乱状态,并将其比作计算机工程中的技术债务,并创造了“研究债务”一词:不良符号、不清楚的解释和未经证实的猜想充斥着机器学习研究领域,使其难以真正产生新的研究。 这些因素,加上错误或缺失的统计分析,也导致了广泛的可重复性问题 ([GCKG22])。 例如,[Raf19] 发现,在他们考虑的 255 篇机器学习论文中,超过一半无法重复。
这些问题在深度学习中尤为突出,深度学习模型通常表现为脆弱的黑盒子:超参数或架构的细微变化会对深度神经网络的性能产生重大影响,而且通常无法主动解释其内部工作原理 ([Gav24b])。 尽管如此,深度学习模型正在大规模部署,几乎没有考虑其缺陷。
范畴论作为科学的 通用语言
用最通用的术语来说,范畴论是处理结构的数学分支。 从代数拓扑开始,范畴论已经发展成为数学中最基础的领域之一。 范畴论可以被看作是数学的通用语言,它将不断扩展的数学领域统一在相同的基本概念下。 许多人将范畴论的兴起比作是对埃尔朗根纲领的扩展,该纲领在十九世纪末统一了几何学,从这个角度来看,范畴可能被看作是数学的跳动心脏。
最近,应用范畴论领域发展起来,其目标是更普遍地将范畴论应用为科学甚至工程的统一语言。 范畴论已在资源理论 ([CFS16])、数据库理论 ([Spi12])、量子力学 ([AC09]) 等领域得到应用。 应用范畴论可以被看作是对组合性的研究,因此它在任何出现组合结构的地方都有用,无论所讨论的对象或现象的性质如何。 这里的组合性被定义为系统和关系的属性,即“可以组合成新的系统或关系” ([FS18])。
组合性是一个应该努力追求的良好特性,因为它提供了对所讨论系统的基本结构的洞察:大型组合系统可以分解成更容易理解的小系统;反过来,小的组合系统可以组装成更大的系统,而无需任何范式转换。 诸如贝叶斯网络和神经网络之类的机器学习模型本质上是模块化的,因此使用范畴论研究它们的组合性是有意义的。 更一般地说,许多作者认为范畴论可以为机器学习提供一个统一的结构,从而可以帮助解决或减轻上述许多问题。 因此,从开创性的论文[FST19]开始,大量的研究已经探索了机器学习和范畴论之间的交集。
一般概述
本论文最初旨在以[SGW21]的风格对机器学习和范畴论之间的交集进行一般性综述。 然而,我们很快意识到该领域在过去几年中发展迅速,以至于我们无法在可用的时间和空间内公正地介绍每个有趣的方法。 因此,我们选择专注于深度学习的范畴方法,并决定围绕四个主要思想来构建本论文,这在相同的章节数中进行了描述。 每章都提供了对一些相关方法的详细描述,然后将这些方法与其他相关工作进行比较,这些工作只是被简要地提及。 章节的简要概述如下。
-
•
第 1 章:基于梯度的学习的参量光学。 基于梯度的学习可以在适当选择的参量光学类别中进行描述和实现。
-
•
第 2 章:从经典计算机科学到神经网络。 范畴论可以构建经典计算机科学和神经网络之间的桥梁,为当前已知的神经网络架构提供见解,并为新型架构的设计提供参考。
-
•
第 3 章:函子学习。 学习范畴之间的函子,而不是仅仅学习对象之间的态射,可以让模型保持结构,从而获得更好的学习结果。
-
•
第 4 章:神经网络的详细表示。 适当的字符串图类可以用来表示神经网络架构,其中包含实现所需的所有细节。
我们强调,这项工作只涵盖了少量可用的研究:例如,我们甚至没有触及庞大且与之相关的范畴概率学习领域,也没有讨论可解释人工智能的范畴方法。 我们甚至没有涵盖所有针对神经网络的范畴方法。 尽管如此,我们相信本论文可以让人们对该领域正在进行的研究有一个有趣的了解。
目标读者和入门读物
这项工作旨在面向那些已经了解范畴论和深度学习基础知识的人。 读者不需要对两者都非常精通,但我们将假设他们已经对神经网络架构、基于梯度的学习、基本的范畴定义以及对称幺半范畴理论有所了解。 不幸的是,我们没有足够的空间提供我们自己的关于这些主题的补充材料,但我们鼓励感兴趣的读者参考 [Gav23] 存储库,了解范畴论的介绍,并参考在线教材 [ZLLS21],了解深度学习的介绍。 [FS18] 是应用范畴论的一个特别好的起点。 我们还建议读者查阅 [Gav24a] 的资料库,其中收集了机器学习和范畴论交叉领域的众多论文,其中一些将在接下来的章节中讨论。
Remark 1.
为了简单起见,我们在处理范畴概念时忽略了任何大小问题。
Chapter 1 Parametric Optics for Gradient-Based Learning
Despite the unquestionable success that gradient-based deep learning has enjoyed in recent years, the field is still both young and poorly understood. As mentioned in the introduction, the lack of theoretical underpinnings means that good performance is highly dependent on ad hoc choices and empirical heuristics leading to brittleness and poorly understood phenomena ([SGW21], [Gav24b]). The ever-growing complexity of deep learning models poses significant challenges both in terms of optimization ([Ell18]) and architectural design ([GLD+24]), and, while there are a number of general purpose deep learning libraries that automatically implement backpropagation and provide tools for designing a wide variety of neural networks, these tools often rely on inelegant machinery difficult to parallelize ([Ell18]). Given the ever-increasing role gradient based learning plays in the sciences, in industry, and in everyday life, solving these issues is of the utmost importance.
Hence, it would be desirable to develop a mathematically structured framework for gradient-based learning able to act as a bridge between low-level automatic differentiation and high level architectural specifications ([Gav24b]). The great number of architectures developed in recent years and the inherently modular structure of deep neural networks call for a model which is general (that is, not dependent on a specific differentiation algorithm or a specific optimizer) and compositional (that is, we should be able to predict the behavior of the entire model if the behavior of each part is known). [CGG+22] and [Gav24b] propose a promising combination of differential categories, parametrization and optics as a full-featured gradient-based framework able to challenge established tools and attack open problems. In this chapter, we illustrate such framework and part of its mathematical foundations.
1.1 Categorical toolkit
Learning neural networks have two important properties: they depend on parameters and information flows through them bidirectionally (forward propagation and back propagation). Any aspiring categorical model of gradient-based learning must take these two aspects into consideration. A number of authors (among which [CGG+22] and [Gav24b]) propose the construction as a categorical model of parameter dependence and various categories of optics as the right categorical abstraction for bidirectionality.
1.1.1 Actegories
Before we can deal with parametric maps, we need to find a way to glue input spaces to parameter spaces, so that such maps have well-defined domains. One common strategy is to provide the category at hand with a monoidal structure. However, monoidal products can only combine elements within the same underlying category. Since (co)parameters are sometimes taken from spaces that are different in nature from the input and output spaces, a more general mathematical tool is needed: namely, actegories (see the survey [CG22] for a thorough treatment of the subject). Actegories are actions of symmetric monoidal categories on other categories. For brevity’s sake, we will only give an incomplete definition (see [CG22] or [Gav24b] for further information).
Definition 2 (Actegory).
Let be a strict symmetric monoidal category. A -actegory is a tuple , where is a category, is a functor, and and are natural isomorphisms enforcing and . The isomorphisms and must also satisfy coherence conditions. If and are identical transformations, we say that the actegory is strict.
Remark 3.
Although the requirement for strictness is somewhat restrictive, we will proceed under the assumption that the actegories we encounter are strict to streamline notation.
We will also be interested in actegories that interact with the monoidal structure of the underlying category.
Definition 4 (Monoidal actegory).
Let be a strict symmetric monoidal category and let be a strict actegory. Suppose has a monoidal structure . Then we say that is monoidal if the underlying functor is monoidal and the underlying natural transformations and are also monoidal.
We may also be interested in studying the interaction between actegorical structures and endofunctors. This interaction can happen owing to a natural transformation known as strength. We will not provide coherence diagrams in the definition below for the sake of brevity, but the interested reader can find more detail in [GLD+24]. The paper also provides a definition of actegorical strong monad, which is a very similar concept.
Definition 5 (Actegorical strong functor).
Let be an -actegory. A strong actegorical endofunctor on is a pair where is an endofunctor and is a natural transformation with components which satisfies a few coherence conditions that we do not list here.
1.1.2 The construction
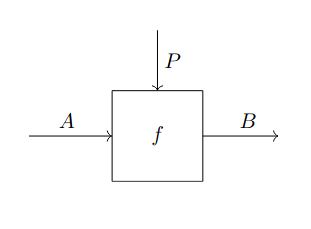
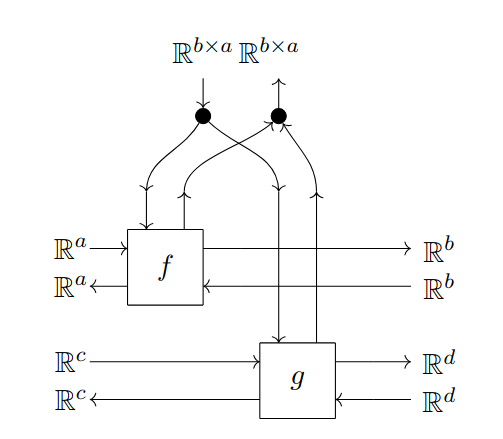
Suppose we have an -actegory . We wish to study maps in which are parametrized using objects of , that is, maps in the form . We are not just interested in the maps by themselves, but also in their compositional structure. Thus, we abstract away the details by defining a new category (first introduced in simplified form by [FST19]). Since we also want to formalize the role of reparametrization, we actually construct as a bicategory, so that a -cell can serve as an input/output space, a -cell can serve as a parametric map, and, finally, a -cell can serve as a reparametrization.
Definition 6 ().
Let be an -actegory. Then, we define as the bicategory whose components are as follows.
-
•
The -cells are the objects of .
-
•
The -cells are pairs , where and .
-
•
The -cells come in the form , where is a morphism in . must also satisfy a naturality condition.
-
•
The -cell composition law is
-
•
The horizontal and vertical -cell composition laws are respectively given by parallel and sequential composition in .
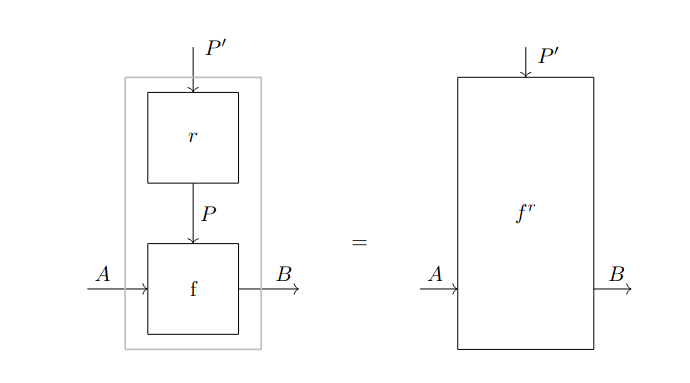
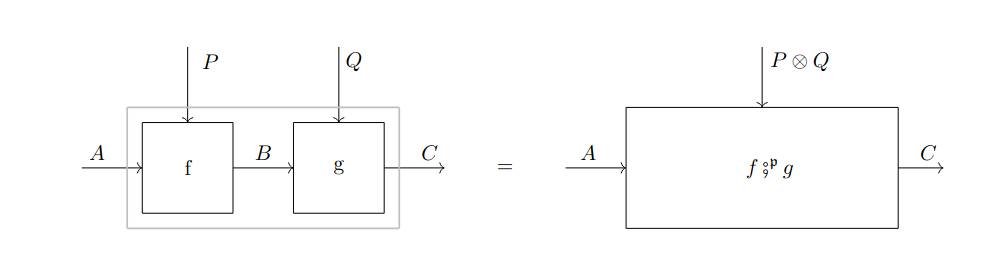
It is quite handy to represent the cells of using the string diagram notation illustrated in Fig. 1.1. The construction has a dual construction whose -cells take the form , where . Cells in can also be represented with appropriate string diagrams. The reader can find a complete definition in [Gav24b].
It is shown in [Gav24b] that is actually a -category if the underlying actegory is strict. Assuming this is the case (as we do in this thesis), we can use a functor to quotient out the -categorical structure and turn into a -category . Here, is the change of enrichment basis functor induced by . This meaningfully recovers the -categorical perspective of [FST19].
Both and can be given a monoidal structure if is a monoidal actegory. This is extremely important because it allows us to compose (co)parametric morphisms both in sequence and in parallel. Once again, more detail can be found in [Gav24b].
Remark 7.
Another way to parametrize morphisms is the coKleisli construction. As noted by [Gav24b], the main difference between and is that the parametrization offered by is global, while the parametrization offered by is local: all morphisms in must take a parameter in , while different morphisms of admit different parameter spaces. Nevertheless, the two constructions are related, and the former can be embedded into the latter.
If we take a parametrized category and we restrict our attention to morphisms parametrized with the monoidal identity , we get back the original category . This is expressed by the following proposition ([Gav24b]).
Proposition 8.
Let be an -actegory. Then, there exists an identity-on-objects pseudofunctor that maps . If is strict, this is a -functor.
1.1.3 Optics
Modelling bidirectional flows of information is not only useful in machine learning, but also in game theory, database theory, and more. As such, categorical tools for bidirectionality have been sought after for a long time: in particular, a great deal of effort has been devoted to the development of lens theory. Lenses have then been generalized into optics (see e.g. [Ril18]) to subsume other tools such as prisms and traversals into a single framework. Finally, there have also been various attempts to generalize optics (see e.g. [CEG+24] for a definition of mixed optics). We will introduce lenses and optics, and focus on the generalization of optics introduced by [Gav24b]: weighted optics.
As stated in [Gav24b], there is no standard definition of lens, and different authors opt for different ad hoc definitions that best suit their purposes. We will borrow the perspective of [CGG+22].
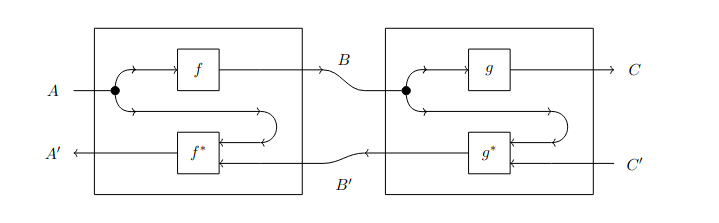
Definition 9 (Lenses).
Let be a Cartesian category. Then, is the category defined by the following data:
-
•
an object of is a pair of objects of ;
-
•
a morphism (or lens) is a pair of morphisms of such that and ; is known as the forward pass of the lens , whereas is known as the backward pass;
-
•
given , the associated identity lens is ;
-
•
the composition of and is
Lenses can be represented using the string diagrams illustrated in Fig. 1.2.
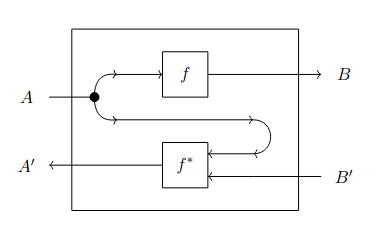
Lenses are a powerful tool, but they cannot be used to model all situations: for instance, lenses cannot be used if we wish to be able to choose not to interact with the environment depending on the input, or if we would like to reuse values computed in the forward pass for further computation in the backward pass.
Optics generalize lenses by weakening the link between forward and backward passes, and by replacing the Cartesian structure of the underlying category with a simpler symmetric monoidal structure. In an optic over , an object acts as an inaccessible residual space transferring information between the upper components and the lower component. We provide the definition given by [Ril18]111[Ril18]also provides a more versatile (but more sophisticated) definition of optics that relies on coends. Under the coend formalism, .
Definition 10 (Optics).
Let be a symmetric monoidal category (we make the unitors and associators explicit for later use). Then, is the category defined by the following data:
-
•
an object of is a pair of objects of ;
-
•
a morphism (or optic) is a pair of morphisms of such that and , where is known as residual space; such pairs are also quotiented by an equivalence relation that allows for reparametrization of the residual space and effectively makes it inaccessible;
-
•
the identity on is the optic represented by .
Refer to [Ril18] or [Gav24b] for the more information about the composition of optics and the representation of optics with string diagrams.
Lenses come up as a special case of optics ([Ril18]), and optics do solve some of the issues we have with lenses. However, optics are not perfect either: for instance, [Gav24b] points out that optics cannot be used in cases where we ask that the forward pass and backward pass are different kind of maps, as they are both forced to live in the same category. Thus, a further layer of generalization is useful: namely, weighted optics.
1.1.4 Weighted optics
Before we define weighted optics, we need to introduce a new tool to our toolbox: the category of elements of a functor.
Definition 11 (Elements of a functor).
Let be a functor. We define as the category with the following data: (i) the objects of are pairs where and ; (ii) the morphisms in are the morphisms in such that .
[Gav24b] studies -actegories , which are then reparametrized so that the acting category becomes for some weight functor (which is to be specified). The reparametrization takes place thanks to the opposite of the forgetful functor , which maps . Hence, we consider the action
We are finally ready to define weighted optics222Weighted optics also admit a coend definition. Refer to [Gav24b] for more information..
Definition 12 (Weighted ).
If is a weight functor as above and is a -actegory, we define
where is the enrichment base change functor generated by the connected component functor . More explicitly, quotients out the connections provided by reparametrizations.
Definition 13 (Weighted optics).
Suppose is an -actegory, suppose is an -actegory, and suppose is a lax monoidal functor. We define the category of -weighted optics over the product actegory as
The definition is very dense and deserves some explanation. Fist of all, we assume that maps to a set of maps . If that’s the case, a map is a triplet , where is the forward residual, is the backward residual, links the two residuals, is the forward pass, and is the backward pass. The triplets are also quotiented with respect to reparametrization, which makes the residual spaces effectively inaccessible (as it happens in the case of ordinary optics). We can get a clear ”operational” understanding of how a weighted optic works looking at an associated string diagram (see Fig. 1.3): data from flows through the forward map, which computes an output in and a forward residual in . Such forward residual is then converted into a backward residual in by the map , which is provided by the weight functor. Finally, the backward residual is used by , together with input from , in order to compute a value in . A full account of the composition law for weighted optics can be found on [Gav24b]. As stated in [Gav24b], since can be given a monoidal structure, we can also give one such structure as long as the underlying actegories are monoidal and the weight functor is braided monoidal.
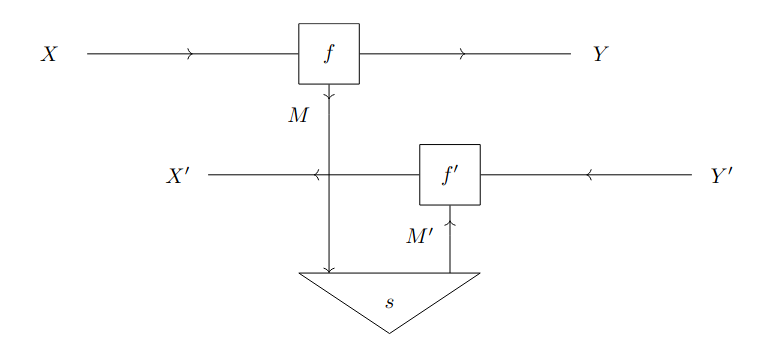
The advantages of weighted optics over ordinary optics are clear: when dealing with weighted optics, we are no longer forced to take reverse maps from the same category as the forward maps. The action on the category of forward spaces is now separated from the action on the category of backward spaces, and the link between the two actions is provided by an external functor. Such modular approach provides a great deal of conceptual clarity and flexibility, more than regular optics or lenses can provide on their own. It is also shown in [Gav24b] that weighted optics are indeed a generalization of optics. In particular, it is shown that the lenses in Def. 9 are the specialized weighted optics obtained when is Cartesian and the actegories are given by the Cartesian product. More generally, [Gav24b] claims that - to the best of the author’s knowledge - all definitions of lenses currently used in the literature are subsumed by the definition of mixed optics (see [CEG+24]), which are themselves a special case of weighted optics. Hence, all lenses are weighted optics.
[Gav24b] goes on to apply the construction onto weighted optics, obtaining parametric weighted optics, which are proposed as a full-featured model for deep learning. The author conjectures that ”weighted optics provide a good denotational and operational semantics for differentiation”. In its full, generality, this is still an unproven conjecture. However, restricting our attention to a special class of lenses with an additive backward passes yields a formal theory of “backpropagation through structure” ([Gav24b]), which will be illustrated in the rest of the chapter, after a short digression on differential categories.
1.1.5 Differential categories
Modelling gradient-based learning obviously requires a setting where differentiation can take place. Although it is tempting to directly employ smooth functions over Euclidean spaces, recent research has shown that there are tangible advantages in working with generalized differential combinators that extend the notion of derivative to polynomial circuits ([WZ22], [WZ21]), manifolds ([PVM+21]), complex spaces ([BQL21]), and so on. Thus, it makes sense to work with an abstract notion of derivative which can then be appropriately implemented depending on the requirements at hand.
One approach to this problem involves the explicit definition of two kinds of differential categories: Cartesian differential categories (first introduced in [BCS06]) and Cartesian reverse differential categories (first introduced by [CCG+19]). The former allow for forward differentiation, while the latter allow for reverse differentiation. We will omit the defining axioms for the sake of brevity, but the reader can find complete definitions in [CCG+19].
Definition 14 (Cartesian differential category).
A Cartesian differential category (CDC) is a Cartesian left-additive category where a differential combinator is defined. Such differential combinator must take a morphism and return a morphism , which is known as the derivative of . The combinator must satisfy a number of axioms.
Definition 15 (Cartesian reverse differential category).
A Cartesian reverse differential category (CRDC) is a Cartesian left-additive category where a reverse differential combinator is defined. Such reverse differential combinator must take a morphism and return a morphism , which is known as the reverse derivative of . The combinator must satisfy a number of axioms.
Example 16.
Consider the category of Euclidean spaces and smooth functions. is a both a CDC and a CRDC. In fact, if is the Jacobian matrix of a smooth morphism ,
and
induce well-defined combinators and . This is only a partial coincidence: as shown in [CCG+19] CRDCs are always CDCs under a canonical choice of differential combinator. The converse, however, is generally false.
As it turns out, forward differentiation tends to be less efficient when dealing with neural networks that come up in practice ([Ell18]), so CDCs are not extremely useful when studying deep learning. CRDCs, on the other hand, have been applied to great success (see e.g. [CGG+22]). As shown in [WZ22], a large supply of CRDCs can be obtained by providing the generators of a finitely presented Cartesian left-additive category with associated reverse derivatives (as long as the choices of reverse derivative are consistent). Moreover, CRDCs have been recently generalized by [Gav24b] to coalgebras associated with copointed endofunctors, which could also increase the number of known CRDCs in the future. The rest of this section is devoted to this generalization.
It is shown in [Gav24b] that there is a particular class of weighted optics which is useful for reverse differentiation, being able to represent both maps (through forward passes) and the associated reverse derivatives (through backward passes). Moreover, such weighted optics can be represented as lenses in the sense of Def 9, which means that their inner workings can be pictured in a simple, intuitive way.
Definition 17 (Additively closed Cartesian left-additive category).
A Cartesian left-additive category is an additively closed Cartesian left-additive category (ACCLAC) if and only if the following are true:
-
•
the subcategory of additive maps has a closed monoidal structure ;
-
•
the embedding is a lax monoidal funtor with respect to the aforementioned structure of and the Cartesian structure of .
Then, we can define the category of lenses with backward passes additive in the second component.
Definition 18.
Let be an ACCLAC with Cartesian structure is and whose subcategory has monoidal structure . Then, we define
As argued in [Gav24b], the symbol is justified because one such optic of type can be concretely represented as a lens with forward pass and backward pass , which is the approach we illustrate in this thesis. Nevertheless, some potential expressivity is lost when passing from weighted optic composition to concrete lens composition. In particular, if we operated with optics, we would be able to implement backpropagation without resorting to gradient checkpointing, which is not possible if we use lenses ([Gav24b]).
The generalization mentioned above is possible because is an endofunctor.
Definition 19.
We defined as the category whose objects are Cartesian left-additive categories and whose morphisms are Cartesian left-additive functors (see e.g.[BCS06]).
Proposition 20.
If , then .
Proof.
The Cartesian structure on is given by and by the initial object . The monoidal structure on each is given by the unit and by the multiplication . ∎
Proposition 21.
is a functor.
Proof.
Given a Cartesian left-additive functor , we can define as the functor that maps and maps , where . It can be shown that is also Cartesian left-additive. ∎
Proposition 22.
has a copointed structure333An endofunctor is copointed if it is endowed with a natural transformation ..
Proof.
It suffices to endow with the natural transformation whose components are the forgetful functors which strip away the backward passes. ∎
Hence, [Gav24b] defines generalized CRDCs as follows.
Definition 23 (Generalized Cartesian reverse differential category).
A generalized Cartesian reverse differential category is a coalgebra for the pointed endofunctor .
Explicitly, a colagebra for is a pair such that and satisfies . The intuition behind such definition is that should map , where is a generalized reverse derivative combinator. [Gav24b] shows that ordinary CRDCs are generalized CRDCs under this definition of .
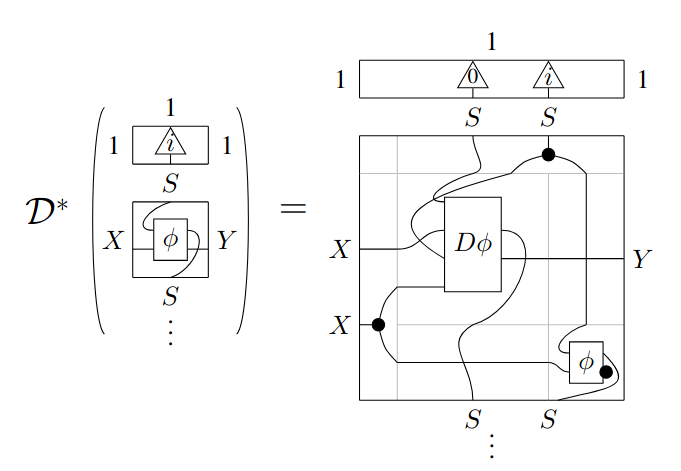
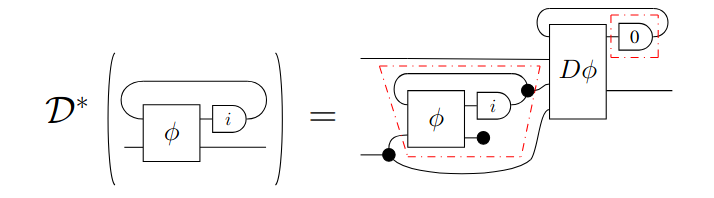
1.1.6 Parametric lenses
We conclude this section discussing the relation between the construction and the endofunctor. [Gav24b] and [GLD+24] show that, under an appropriate definition, actegorical strong functors induce -functors between parametric -categories.
Proposition 24.
Suppose is a strict -actegory and is an actegorical endofunctor with strength . Then, induces a -endofunctor .
Proof.
Define so that:
-
1.
acts like on objects ;
-
2.
for all ;
-
3.
leaves reparametrizations unchanged.
∎
As a consequence, it can be shown that, if is a generalized CRDC, induces a -functor , which takes a parametric map and augments is with its reverse derivative , forming a parametric lens. Parametric lenses behave very similarly to lenses, but we provide a separate stand-alone definition (which we take from [CGG+22]) for the reader’s convenience.
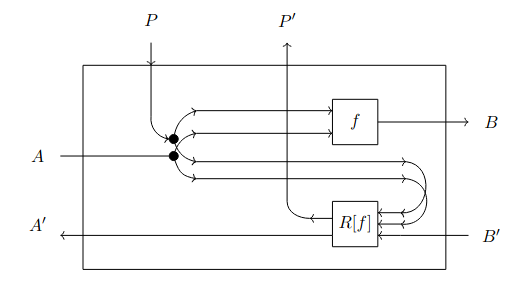
Definition 25 (Parametric lenses).
The category of parametric lenses over a Cartesian category is , where is the action on the lenses generated by the Cartesian structure of :
Refer to Fig. 1.4 to see a string diagram that shows the inner workings of a parametric lens.
1.2 Supervised learning with parametric lenses
In this section, we show how parametric lenses can be used to model supervised gradient-based learning ([CGG+22], [Gav24b], [SGW21]). While lenses are not as general as weighted optics, it is shown in [CGG+22] that they are powerful enough for most purposes and that there is empirical evidence of their applicability and performance. The paper also discusses the use of parametric lenses in modeling unsupervised deep learning and deep dreaming, but we do not have enough space to discuss this topic.
1.2.1 Model, loss, optimizer, learning rate
Supervised gradient-based learning can be modeled using parametric lenses as follows:
-
1.
we can design an architecture as a parametric morphism in for some generalized CRDC ;
-
2.
we can use the functor to endow with its reverse derivative , yielding a lens in ;
-
3.
we can use -categorical machinery of to provide a loss function, a learning rate, and an optimizer, which can be assembled onto to yield a supervised learning lens able to update parameters based on inputs and predictions;
-
4.
we can use copy maps from the Cartesian structure of to create a learning iteration.
The theory of parametric optics and differential categories does not offer explicit insight with respect to architecture design, so we will assume a good architecture has already been designed444We will come back on this in Chpt. 2.. Given an architecture , it can be embedded into as a lens by breaking it up into its basic components (such as linear layers, convolutional layers, etc.), augmenting such components with their reverse derivatives, and the composing the resulting lenses. The backward pass of the composition is the reverse derivative of its forward pass because is a functor555As highlighted by [SGW21], the diagram for the backward pass of the composition of two lenses looks exactly like the diagram describing the chain rule for reverse derivatives, which is what makes a well-defined functor.. Many examples can be found in [CGG+22].
Updating the parameters based on data requires a loss function, an optimizer and a learning rate. Loss functions can be implemented as parametric lenses which take in predictions as input and labels as parameters. The output they produce can be considered the actual loss that needs to be differentiatied. Given a model parametric lens and a loss parametric lens , the composition takes in features as input and takes model parameters and labels as parameters. Then, this information is used to compute the loss associated with the predictions of the model. See Fig. 1.5 (a) for the associated string diagram.
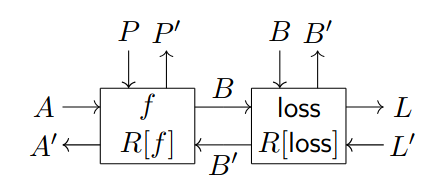
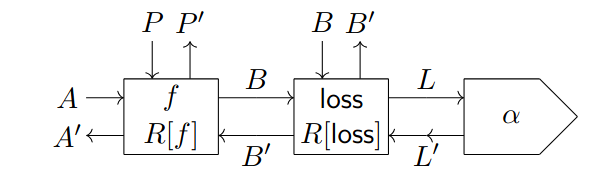
It can be helpful to think about dangling wires in the diagrams as open slots where other components can be plugged. For instance, the diagram of Fig. 1.5 (a) has dangling wires labeled with on its right. We can use a learning rate lens to link these wires and allow forward-propagating information to ”change direction” and go backwards. must have domain equal to and codomain equal to , where is the terminal object of . For instance, if , might just multiply the loss by some , which is what machine learning practitioners would ordinarily call learning rate. Fig. 1.5 (b) shows how a learning rate can be linked to the loss function and the model using post-composition.
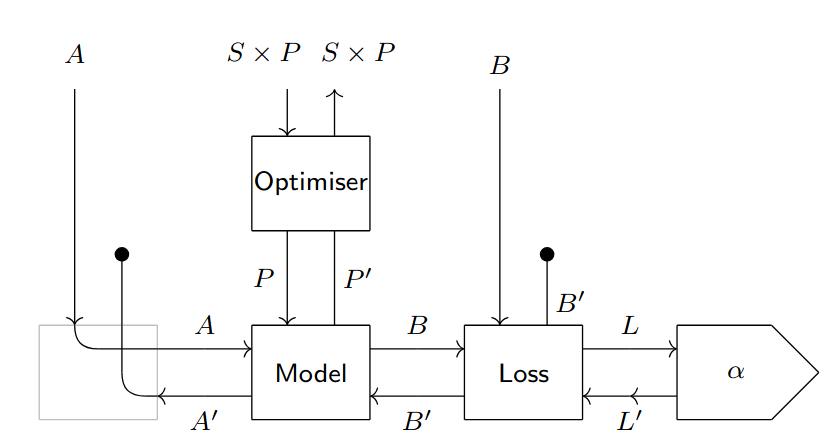
The final element needed for the model in Fig. 1.5 (b) to learn is an optimizer. It is shown in [CGG+22] that optimizers can be represented as reparametrisations in . More specifically, we might see an optimizer as a lens . In gradient descent, for example, and the aforementioned lens is . We can plug such reparametrisation on top of the model, we can redirect the input wires of the model to convert them into parameters, and we can plug useless wires with delete maps taken from the Cartesian structure of . We are then left with a parametric lens with parameter space . This lens is pictured in Fig. 1.5 (c).The diagram shows how the machinery hidden by the can take care of forward propagation, loss computation, backpropagation and parameter updating in a seamless fashion.
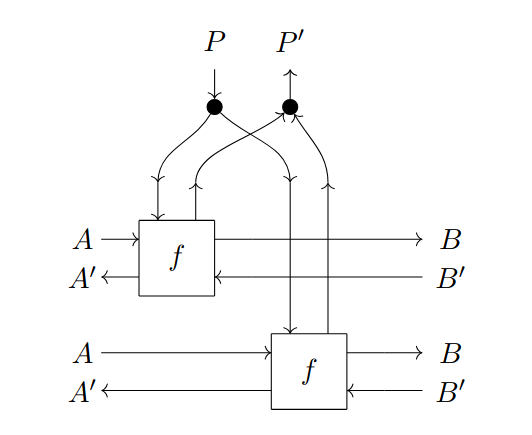
1.2.2 Weight tying, batching, and the learning iteration
Both [CGG+22] and [Gav24b] emphasize the essential role played by weight tying in deep learning. Weight tying can be implemented within the parametric lens framework as a reparametrization that copies a single parameter to many parameter slots (see Fig. 1.6 (a)): given , we can define so that
Copy maps can also be used for batching: batching is implemented by instantiating different copies of our supervised learning lens (comprised of model, loss function, and learning rate) and tying the parameters to a unique value. Then, it suffices to feed the data points to the lenses, and we can optimize across a single parameter (see Fig. 1.6 (b)).
[CGG+22] introduces a possible representation for the whole learning iteration of a supervised learning model as a single map. The paper suggests extracting the backward pass of the lens in Fig. 1.5 (d) and reframing it as a parametric map with parameters . Since this is an endomap, it can be composed times with itself to obtain a map, which is proposed as a model of the learning iteration. While this approach requires breaking lenses apart, it is markedly simple.
1.2.3 Empirical evidence
Empirical evidence for the effectiveness of the parametric lens framework discussed in this section can be found in [CGG+22], where the authors implement a Python library for gradient-based learning rooted in these ideas. They use the library to develop a MNIST classifier, obtaining comparable accuracy to models developed using traditional tools. The Python implementation of components of learning as parametric lenses is elegant and mathematically principled, as it mirrors an abstract categorical structure. It is also insightful because it highlights possible generalizations, which manifest as simple modifications of existing lenses.
This kind of success story foreshadows a future where popular machine learning libraries also follow elegant principled paradigms informed by category theory. Quoting [CGG+22] directly, “[the] proposed algebraic structures naturally guide programming practice”.
1.3 Future directions and related work
The parametric optic framework discussed in this chapter is very promising, but there is still a lot of work that needs to be done for it to reach its full potential. For instance, [Gav24b] conjectures that weighted optics can be used in its full generality to model differentiation in cases which are not covered by lenses. For instance, lenses cannot model automatic differentiation algorithms that do not use gradient checkpointing, while weighted optics are conjectured to be able to do so. [Gav24b] suggests investigating locally graded categories as potential replacements for actegories, and also suggests investigating the applications of parametric optics to meta-learning, that is deep learning where the optimizers themselves are learned. Moreover, [CGG+22] conjectures that some of the axioms of CRDC may be used to model higher order optimization algorithms. Finally, as suggested by [CGG+22], future work might allow the parametric optic framework to encompass non-gradient based optimizers such as the ones used in probabilistic learning. See [SGW21] for more on this topic.
We conclude this chapter by discussing three other directions of machine learning research that are closely related to the framework of parametric optics.
1.3.1 Learners
One of the first compositional approaches to training neural networks in the literature can be found in the seminal paper [FST19], which spurred a lot of research in the field, including what is presented in [Gav24b] and [CGG+22]. The authors introduce a category of learners, objects which are meant to represent neural network components and behave similarly to parametric lenses.
Definition 26 (Category of learners).
Let and be sets. A learner is a tuple where is a set, and , , and are functions. is known as parameter space, as implement function, as update function, and as request function. Two learners and compose forming , where
Learners quotiented by an appropriate reparametrization relationship666As argued in [FST19], learners could be studied from a bicategorical point of view, where reparametrizations would just be -cells. We could then use a connected component projection to compress into a -category , as it is done for when defining weighted optics. form a category .
A learner represents an instance of supervised learning: the implement function takes a parameter and implements a function and the update function updates the parameters using a data from a dataset. The request function is necessary to implement backpropagation when optimizing a composition of learners. Suppose we select a learning rate and an error function such that is invertible for all . It is argued in [FST19] that we can define a functor which takes a parametric map and yields an associated learner that implements gradient descent.
We do not have the space to talk about learners at length, but we wish to draw a short comparison between parametric weighted optics (and, in particular, parametric lenses) and the approach of [FST19], given the relevant position held by the latter in machine learning literature. The similarities between learner-based learning and lens-based learning are evident: every learner looks like a parametric lens, where passes information forward, passes information backwards and is the parameter space. Moreover, the role of is very similar to the role played by in optic-based learning. Such similarities were even discussed in the original paper [FST19] and have been researched at length: it has been proved in [FJ19] that learners can be functorially embedded in a special category of symmetric lenses (as opposed to the lenses of Def. 9, which are asymmetric).
Despite the similarities, there is one fundamental difference between the lens-based approach and the learner-based approach: each learner carries its own optimizer, whereas optimization of lenses is usually carried out separately. Moreover, if we compare parametric weighted optics with learners, the latter clearly win in versatility, generality, and (at least from our point of view) conceptual clarity. It is argued in [SGW21] and [CGG+22] that the parametric lens framework largely subsumes the learner approach. More information regarding the comparison can also be found in [Gav24b].
1.3.2 Exotic differential categories
We have presented the parametric weighted optic approach of [Gav24b] and [CGG+22] within the context of neural networks for the sake of simplicity, but the framework has been developed with generality in mind and applies to a much wider range of situations. For instance, we can easily replace with any other CRDC , yielding a full-feature compositional framework for gradient-based learning over .
Switching to a different CRDC is useful because different differential categories can lead to different learning outcomes, both in terms of accuracy of the model and in terms of computational costs ([WZ22]). For instance, is argued in [WZ22] that polynomial circuits can be used to define and train intrinsically discrete machine learning models. Even ‘radical’environments such as Boolean circuits - where scalars reside in - seem to be conductive to machine learning under the right choice of architecture and optimizer ([WZ21]). Using such exotic differential categories could be of great advantage because they might be able to better reflect the intrinsic computational limits of computer arithmetic, leading to more efficient learning ([WZ22]).
1.3.3 Functional reverse-mode automatic differentiation
Finally, we wish to highlight the similarities between the formal theory of differential categories illustrated here and the work in [Ell18]. The paper describes the Haskell implementation of a purely functional automatic differentiation library, which is able to handle both forward mode and reverse mode automatic differentiation without resorting to the mutable computational graphs used by most current day libraries.
Among the main insights of [Ell18], it is stated that derivatives should not be treated as simple vectors, but as linear maps, or multilinear maps in the case of uncurried higher-order derivatives. Moreover, the author shows that differentiation can be made compositional by working on pairs , which behaved very similarly to lenses. As noted by [SGW21], however, [CGG+22] and other lens-theoretical perspectives do not subsume the work in [Ell18] because of the latter’s programming focus. See [SGW21] for more information regarding this comparison.
Chapter 2 From Classical Computer Science to Neural Networks
Classical computer science focuses on discovering algorithms, that is ordered sequences of steps which operate in precisely set, idealized conditions and have strong guarantees of correctness due to their exact mathematical formulations. Neural networks, on the other hand, are able to work in messy, real-world conditions, but offer very so few guarantees of correctness that their performance is often described as unreasonably good. Moreover, whereas algorithms generalize very well (most software engineers will only need a few dozen algorithms in their entire career), neural networks are often completely helpless when pitted against out of distribution inputs. Hence, algorithms and neural networks can be seen as complementary opposites ([VB21], [VBB+22]).
Recent attempts going under the label of neural algorithmic reasoning (see [VB21] for a very short introduction to the subject) have tried to get the best of both worlds by training neural networks to execute algorithms (see e.g [IKP+22]). The CLRS benchmark (introduced by [VBB+22]) uses graphs to represent the computations associated with a few classical algorithms from the famous CLRS introductory textbook ([CLRS22]) so that graph neural networks (GNNs) can be trained to learn these algorithms. The benchmark has spurred a large amount of research in this direction, with very promising results.
More generally, linking machine learning to classical computer science might unlock interesting advances. For example, recovering neural networks as parametric versions of known algorithms might help classify existing architectures in a conceptually clear manner, and it might even help discover new neural network architectures by taking inspiration from well-researched classical notions. In this chapter, we illustrate two lines of inquiry which use category theory to build such a bridge: categorical deep learning and an interesting categorical approach to algorithmic alignment. Before treating such topics, we go on a short categorical tangent regarding (co)algebras and integral transforms.
2.1 Categorical toolkit
2.1.1 (Co)algebras
Categorical algebras and coalgebras are a formalization of the principles of induction and coinduction. Induction and coinduction are fundamental to computer science because they allow us to give precise definitions for many data structures and to formalize recursive and corecursive algorithms on such structures. We will touch on (co)algebras very briefly but we refer interested readers to [JR97] and [Wis08] for further detail.
Definition 27 ((Co)algebra over an endofunctor).
Let be an endofunctor. An algebra over is a pair where and . A coalgebra is a pair where and . In both cases is known as carrier set and as structure map.
(Co)algebras can also be defined on monads: the only difference between (co)algebras over an endofunctor and (co)algebras over a monad is that the latter also need to be compatible with the monad structure, that is, they have satisfy various coherence conditions (see [GLD+24]). (Co)algebras over the same functor can be given a categorical structure by using the following notion of homomorphism.
Definition 28 (Homomorphisms of (co)algebras over an endofunctor).
Let and be algebras over the same endofunctor . An algebra homomorphism is a map such that the diagram in Fig. 2.1 (a) is commutative.
Now suppose and are coalgebras. A homomorphism between them is a map such that the diagram in Fig. 2.1 (b) is commutative.
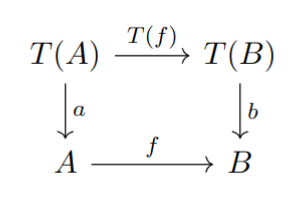
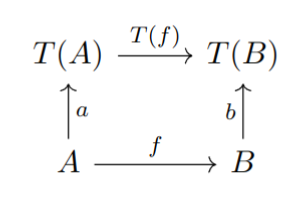
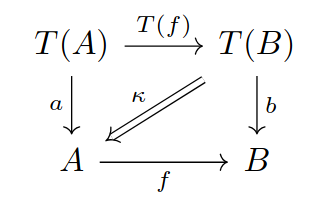
The main intuition behind the notions of algebra and coalgebra is the following: the underlying functor defines a signature for the (co)algebraic structure; the structure of an algebra is a constructor that takes data from and uses it to build data from , whereas the structure of a coalgebra observes data from and produces an observation in the form of data from ; (co)algebra homomorphism are arrows that preserve the underlying structure. Consider the following clarifying examples from [GLD+24].
Remark 29.
In the examples below we use polynomial and exponential expressions to define endofunctors over . In this context, is the argument of the functor, is the Cartesian product, is the disjoint union, is the pairing induced by , is the pairing induced by , and is the set of functions . The operator is assumed to take precedence over the operator. Similarly, the exponential operator is assumed to take precedence over the operator.
Example 30 (Lists).
Let be a set. Consider the endofunctor . If is the set of -labeled lists, is an algebra over . Here, is the map which takes the unique object of and returns the empty list, while is the map which takes an element and a list of elements of and returns the concatenated list . The algebra describes lists in inductively as objects formed by concatenating elements of to other lists in . The base case is the empty list.
Example 31 (Mealy machines).
Now consider two sets and of possible inputs and outputs, respectively. Consider the endofunctor . Define as the set of Mealy machines with inputs and outputs in and , respectively. Now we can consider the coalgebra , where is the map that takes a Mealy machine and yields a function which in turn, given , returns the output of at and a new machine . This is a coinductive description of Mealy machines.
Remark 32.
Notice how the description we have given of Mealy machines does not mention internal states at all. This is a recurring aspect of coinductive descriptions: as argued in [JR97], coinduction is best interpreted as a process where an observer tracks the behavior of an object from the outside, with no access to its internal state. This is very useful in machine learning because the internal state of a learning model is often difficult to interpret.
The link between (co)algebras and (co)induction does not stop at the definition level. The example below shows that an algebra homomorphism can model a recursive fold procedure. A similar corecursive unfold procedure can be defined by using a coalgebra homomorphism (see [GLD+24] for further detail).
Example 33 (List folds).
Consider the algebra of lists from Ex. 30, and consider a second algebra over the same functor. A homomorphism from the former into the latter must satisfy
Hence, is necessarily a fold over a list with recursive components and . Incidentally, this proves that is unique, making an initial object in the category of algebras over the polynomial endofunctor .
The notion of (co)algebra over a functor can be generalized to the sphere of -categories, defining the notion of (co)algebra over a -endofunctor. The basic concepts stay the same but the commutativity of the diagrams definining (co)algebra homomorphisms is relaxed into lax-commutativity. A square diagram of -cells is lax-commutative if there exists a -cell that carries the top-right composition of the diagram onto its left-bottom composition, as in Fig. 2.1 (c). Once again, we refer to [GLD+24] for further information.
2.1.2 Integral transform
Remark 34.
In accordance with the notation of [DV22] and [DvGPV24], we use to represent the set of functions, where and are sets.
Suppose is a commutative semiring. An integral transform is a transformation that carries a function in to a function in following a precise chain of steps. Integral transforms111The label integral transform refers to the fact that similar ideas can be used to write categorical definitions for familiar analytical integral transforms ([Wil10]). A similar construct is also used in physics ([EPWJ80]). have been introduced by [DV22] to provide a single formalism able to describe both dynamic programming and GNNs. Integral transforms can be encoded as polynomial spans.
Definition 35 (Polynomial span).
A polynomial span is a triplet of morphisms in (that is, the category of finite sets and functions). is known as input, as process, as ouput. is known as input set, as argument set, as message set, as ouput set. We also ask that the fibers of have total orderings222Neither we nor [DV22] use this requirement but, as stated in the original paper, the requirement is useful to support functions with non-commuting arguments.. The polynomial span can be graphically represented as the diagram in Fig. 2.2 (a).
Definition 36 (Integral transform).
Let be a commutative semiring. Let be a polynomial span. The associated integral transform is the triplet , where:
-
1.
is the pullback mapping ;
-
2.
is the argument pushforward mapping
-
3.
is the message pushforward mapping
The integral transform can be represented by the diagram in Fig. 2.2 (b).
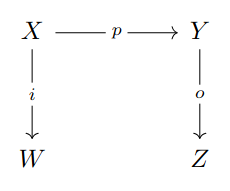
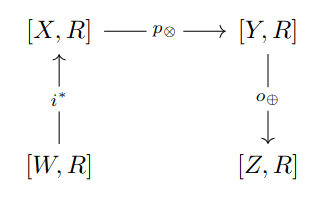
Remark 37.
Whereas defining is quite straight-forward, defining and is more difficult because the arrows and point in the wrong direction, which implies that the underlying functions must be inverted before considering the associated pullbacks. However, inverting non-invertible functions yields functions into the powersets of the original domains. Moreover, if we want to preserve the multiplicity of arguments and messages, we have to construct inverses that go into the sets of multisets over the original domains. Hence why we need and to aggregate results over such multisets. The significance of these steps will be clarified later on in this chapter.
2.2 Categorical deep learning
The optic-based framework we presented in the last chapter provides a structured general-purpose compositional framework for gradient-based learning, but its great versatility has a price: optics are unable to guide the architectural design of our models. It has been shown times and times again that a better architecture makes as much of a difference in machine learning as an algorithm with a better asymptotic cost does in classical computer science. Therefore, finding a principled mathematical framework able to guide such architectural choices is of paramount importance. In this section, we discuss a categorical approach to this problem known as categorical deep learning (CDL). To understand the origin and motivations behind this approach, we also briefly touch upon its main precursor: geometric deep learning (GDL).
2.2.1 From GDL to CDL
GDL (see e.g. [BBCV21]) is one of the most significant approaches to the problem of architecture design. Not unlike the Erlangen Programme, discussed in the introduction, GDL taxonomizes architectures based on the notion of symmetry. In particular, GDL considers architectures that implement equivariance constraints with respect to group actions.
Definition 38 (Group action equivariance and invariance).
Let be a group and let and be -actions. A function is equivariant with respect to the aforementioned actions if for all and for all . We say that is invariant if is the trivial action on , and thus for all and .
The GDL framework is very general and is powerful enough to derive many fundamental neural network architectures in a principled fashion. For instance, GDL recovers convolutional neural networks from equivariance with respect to translations (actions of translation groups) and recovers graph neural networks from equivariance with respect to permutations (actions of permutation groups). However, GDL has also its limitations: first and foremost, many interesting transformations are not invertible and cannot even be approximated by group actions ([GLD+24]). Hence, a generalization of GDL able to work outside group theory is desirable. Since category theory can be seen as a generalization of the Erlangen Programme, it makes sense to generalize the geometric approach using category theory: [GLD+24] achieves this by replacing the group-theoretical notion of equivariant map with the categorical notion of (co)algebra homomorphism. The authors call their approach CDL.
Remark 39.
At the moment, to the best of our knowledge, [GLD+24] is the only publicly available paper that discusses the ideas of CDL.
The main insight of CDL is that group actions can be represented as algebras over group action monads, and that maps that are equivariant with respect to these actions are homomorphisms between these algebras. Hence, GDL can be generalized by taking into consideration (co)algebras over other monads and endofunctors. According to [GLD+24], this yields a ”theory of all architectures”. The field is too young to know whether this prophecy will actually be fulfilled, but the results obtained by [GLD+24] already look very promising.
The following proposition and the subsequent example show how exactly CDL subsumes GDL.
Proposition 40.
Let be a group. The endofunctor can be given a monad structure using the natural transformations , with components , and , with components . The monad can serve as a signature for -actions. The actions themselves can be recovered by considering algebras for the monad, and, given two actions and , an associated equivariant map is a monad algebra homomorphism.
Proof.
It suffices to compare the equations that define group actions and group action invariance with the commutative diagrams in Fig. 2.1. ∎
Example 41 (Linear equivariant layer).
Consider a carrier set , which can be seen as a pair of pixels. Consider the translation action of on , which can be seen as swapping the pixels. We want to find a linear map which is equivariant with respect to the action. Imposing the equivariance constraints as equations on the entries of the matricial representation of the map, we can prove that is equivariant if and only if is symmetric ([GLD+24]).
2.2.2 (Co)inductive definitions for RNNs
As seen in Ex. 41, the formalism of CDL subsumes the formalism of GDL, but the difference between the two is not a simple matter of notation: CDL offers a fresh new perspective and builds a novel bridge between classical computer science and machine learning. The most significant piece of novel contribution delineated in [GLD+24] is the use of (co)algebras and (co)algebra homomorphisms over parametric categories to (co)inductively define recurrent neural networks (RNNs) and recursive neural networks (TreeRNNs). (Co)algebras are used to define cells, whereas the associated homomorphisms provide the weight-sharing mechanics used to unroll them. Let us build on Ex. 30 and Ex. 33, as is done in [GLD+24].
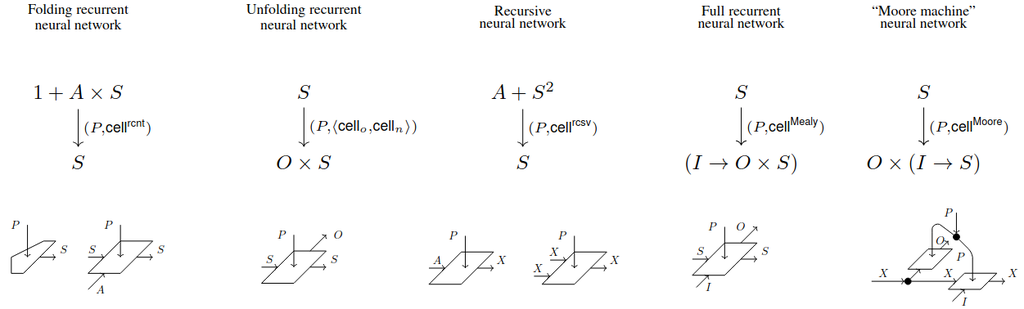
Example 42 (Folding recurrent neural network cell).
Consider the endofunctor from Ex. 30. Consider the Cartesian action of on itself and associate the following actegorical strength to the functor: and . Now that the functor is actegorical strong, we can use Prop. 24 to construct an endofunctor . Consider an algebra for this functor. Via the isomorphism , we deduce that , where and . We can interpret and as folding recurrent neural network cells: provides the initial state based on its parameter and takes in the old state, a parameter, and an input, which are then used to return a new state (Fig. 2.3 (a)).
Example 43 (Unrolling of a folding recurrent neural network).
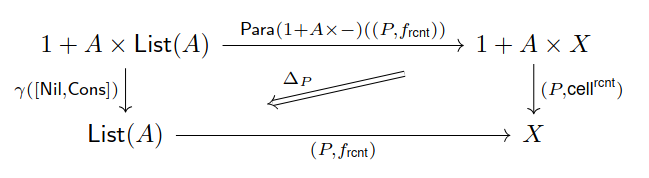
Use Prop. 8 to embed the list algebra from Ex. 30 as an algebra over the endofunctor define in Def. 42. Now consider an algebra homomorphism . Since we are working with algebras over a -endofunctor, we also need to specify a -cell that makes the homomorphism diagram (Fig. 2.1 (c)) lax-commutative. Using the weight-tying reparametrization yields the lax commutative diagram in Fig. 2.4, which uniquely identifies as the fold function which takes a list of inputs in and unrolls a folding recurrent neural network that reads such inputs. The weight-tying reparametrization makes sure that each cell of the unrolled network uses the same parameters (see Fig. 2.3 (b) for a graphical representation).
The construction in Ex. 42 and Ex. 43 constitutes a precise mathematical link between the classical data structure of lists and the machine learning construct of folding RNNs. Similarly, [GLD+24] recovers recursive neural networks (TreeRNNs) by building upon classical binary trees and, even more interestingly, complete RNNs are recovered from the coalgebra of Ex. 31, which reveals an interesting link between RNNs and Mealy machines. This begs the question: if Mealy machines generalize to recurrent neural networks, what do Moore machines generalize to? It is argued in the paper that they generalize to a variant of RNN where different cells (which share the same weights) are used for state update and output production. Hopefully, more work in this direction will lead to new neural network architectures inspired from other classical concepts. Fig. 2.5 shows various kinds of neural network cells and the endofunctors used in their (co)algebraic definitions.
Remark 44 (CDL and optic-based learning).
In all the examples discussed above, the (co)algebra homomorphisms in question return parametric maps , which we can interpret as untrained neural networks. We can feed these maps into the functor associated with a generalized Cartesian reverse differential category333The examples illustrated in this section have been developed in , but we see no reason why they couldn’t be specialized to an appropriate CRDC. to augment them with their reverse derivative. The framework of parametric lenses described in Sec. 1.2 can then be used to train these networks. CDL and optic-based learning are thus compatible and even complementary.
2.3 Algorithmic alignment: GNNs and dynamic programming
One of them main tenets of neural algorithmic reasoning is algorithmic alignment ([XLZ+19]), that is, the presence of structural similarities between the subroutines of a particular algorithm and the architecture of the neural network selected to learn such algorithm. Since [XLZ+19] has shown that dynamic programming algorithms align very well with message passing GNNs, and since dynamic programming encompasses a wide variety of techniques used in various domains, these GNNs are at the forefront of neural algorithmic reasoning research ([DV22]). However, the exact link between GNNs and dynamic programming has yet to be fully formalized. In this section we present the work of [DV22], which attempts to derive such a formalization, and the work in [DvGPV24], which studies conditions under which message passing GNNs are invariant with respect to various form of asynchrony444While much of the work described in [DvGPV24] does not fall under the umbrella of applied category theory, we still mention it because on its close link with the work of [DV22] and with the idea of algorithmic alignment. Hopefully, future work will explore the intersection between this work and category theory., which is argued to improve algorithmic alignment in some cases.
2.3.1 Integral transforms for GNNs and dynamic programming
The main link between dynamic programming and GNNs is that dynamic programming itself can be interpreted from a graph-theoretical point of view. Dynamic programming breaks up problems into subproblems recursively until trivial base cases are reached. We can thus consider the graph with nodes corresponding to subproblems and edges corresponding to the relationships ‘ is a subproblem of ’. Then, the solutions of the subproblems are recursively recombined to solve the original problem. This dynamic is very similar to message passing: the simpler cases are solved first, and their solutions are passed as messages along the edges so that they can be used to solve more complex cases. More precisely, we can implement a dynamic programming algorithm as a GNN on this subproblem graph, where the feature vector associated with a node at the -th message passing iteration represents the state of the solution of the subproblem at the -th iteration of the algorithm ([XLZ+19]). Despite this striking resemblance, rigorously formulating the link between the architecture of GNN and the structure an associated dynamic programming algorithm is not easy, the main obstacle being the difference in data type handled by the two mathematical processes: dynamic programming usually deals with tropical objects such as the semiring , while GNNs usually deal with linear algebra over ([DV22]).
[DV22] proposes the formalism of integral transforms as the common structure behind both message passing GNNs and dynamic programming. While a full formal proof is not given, the idea is illustrated by showing that both the Bellman-Ford algorithm and a message passing GNN can be expressed with the help of integral transforms. The difference in data type is overcome by using the weakest common hypothesis: that the data and associated operations form a semiring.
Bellman-Ford algorithm
The Bellman-Ford (BF) algorithm is one of the most popular dynamic programming algorithms and is used to find the shortest paths between a single starting node and every other node in a weighted graph . Since we can see every node of the graph as a subproblem, and since we can see the associated edges as subproblem relationships, the BF algorithm is a very good candidate for a GNN implementation. The algorithm operates within the tropical min-plus semiring , and the data can be provided as a tuple of three functions into . Here, stores the current best distances of the nodes, stores the weights of the nodes, and stores the weights of the edges. is initialized as the function that maps the initial node to and every other node to . The values of are updated at each step of the algorithm according to the following formula, where represent the one-hop neighborhood of a node :
[DV22] propose the integral transform encoded by the polynomial span in Fig. 2.6 (a) as the supporting structure of the BF algorithm. The functions , , and are defined as follows:
-
1.
acts as the identity on the first , it maps the edges of the first to their sources, and it acts as the identity on the second pair;
-
2.
just collapses the two copies of ;
-
3.
acts as the target function on the and as the identity on .
It is argued in the paper that the whole integral transform acts as step of the algorithm, carrying the data in to the updated function . Let’s examine each step: the input pullback extracts the distances of the sources of every edge; the argument pushforward computes the lengths of the one-hop extensions of the known shortest paths (the weight of each node is treated as the weight of a self-edge in this case); finally, the message pushforward selects the shortest paths to each node among the ones studied by the argument pushforward. Hence, the simple polynomial span in Fig. 2.6 (a) successfully encode the whole BP algorithm without any information loss or ad hoc choice.
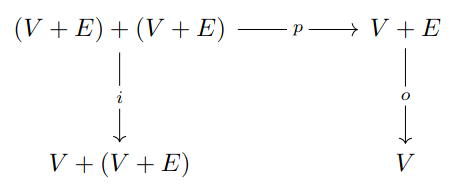
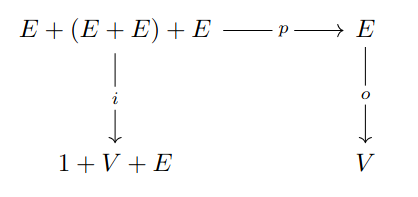
Message passing neural network
Consider the message passing GNN architecture described by the following equations ([GSR+17]):
where represents the time step, and and are learned differentiable functions.[DV22] argues that this GNN layer can be implemented as the integral transform associated with the polynomial span of Fig. 2.6 (b), with an extra MLP. Here,
-
1.
sends the first to , acts as the source function on the second , acts and target function on the third , and acts as the identity on the fourth ;
-
2.
collapses four ’s into one;
-
3.
acts as the target function.
In the associated integral transform, gathers graph features, node features, and edge features; projects such features on the edges, the MLP combines them; finally, sends them to the right target.
Although not a perfect representation of the message passing architecture (due to the extra MLP), the polynomial span in Fig. 2.6 (b) can be used to inform the design of new architectures which are obtained by simple manipulations of the arrows or objects in the diagram. For instance, [DV22] uses the integral transform formalism to investigate possible performance improvements on CLRS benchmark tasks ([VBB+22]). The authors consider messages that reduce over intermediate nodes, and they show that these architectures lead to better average performance on these tasks, which is likely a result of better algorithmic alignment.
2.3.2 Asynchronous algorithmic alignment
The customary assumption behind the message passing GNN architecture requires that all messages are generated, sent, and received at the same time. We call this kind of GNN synchronous. [DvGPV24] derives conditions under which synchronous GNNs are invariant under a hypothetical asynchronous execution. This is relevant because, as stated in the paper, in many dynamic programming tasks modeled by graphs, only small parts of the aforementioned graphs are changed at each step. A synchronously executed GNN that is trained on these tasks must learn the identity function many times over, which leads to brittleness and wasted computational resources. On the other hand, an asynchronously executed GNN would be more aligned with these algorithms and thus achieve a better performance. The work in [DvGPV24] aims to reproduce these performance improvements on synchronous GNNs by imposing asynchrony invariance constraints.
The authors of [DvGPV24] revise the model explored in [DV22] so that it includes a message function that generates messages based on gathered arguments (see Fig. 2.7 (a) for the update diagram). Moreover, the authors argue that it is best to consider GNNs where every graph component that has a persistent state is elevated to the status of node, whereas transient computations are carried out along edges. The resulting GNN can be described by the diagram in Fig. 2.7 (b), where is the transit function that updates the persistent state of each node, and is the function that computes the arguments needed to generate the next messages.
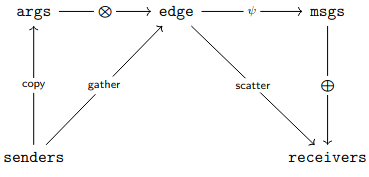
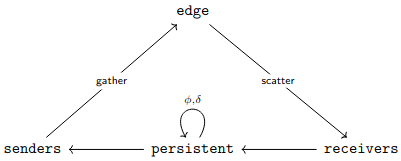
It is argued in [DvGPV24] that invariance under asynchrony can be modeled by giving both arguments and messages monoidal structures. For instance, let be the message monoid and let be the argument monoid. Then, if is the set of persistent states, state update and argument generation can be modeled as a function which maps . Invariance under asynchronous message aggregation is obtained by defining as a monoidal action of on . However, [DvGPV24] shows that this is meaningful if and only if the argument generation function is compatible with the unitality and associativity equations of the action. This can only happen if is a -cocycle.
Definition 45 (-cocycle).
A map is a -cocycle if and only if the following are satisfied:
-
1.
for all ;
-
2.
for all .
Proposition 46.
The state update function described above is asynchronous with respect to message passing if and only if it is a -cocycle.
[DvGPV24] also proves the following.
Proposition 47.
Under the hypotheses described above, a single-input message function supports asynchronous invocation if and only if is a homomorphism of monoids.
We will not describe the whole formalism of [DvGPV24], but we will show (without proof) its implications on GNN architecture design.
Example 48.
Consider the message passing GNN architecture:
where is a message aggregator. The authors of [DvGPV24] derive conditions under which this architecture is invariant under asynchronies in message aggregation, node update, and argument generation: the GNN is trivially invariant under asynchronous message aggregation if messages are given a commutative monoidal structure; invariance under asynchronies in node updates is obtained by selecting an update function which satisfies the associative law for all and for all ; finally, invariance under argument generation is obtained if satisfies the -cocycle equations (Def. 45). These conditions are all satisfied if is commutative, and .
2.4 Future directions and related work
In this section we provide a brief introduction to the theory of differentiable causal computations and the theory of sheaf neural networks. These two lines of work are adjacent to the main theme of this chapter - relating classical computer science to modern machine learning - and they highlight possible directions for future research into categorical deep learning and the application of integral transforms to neural networks.
2.4.1 Differentiable causal computations
A trained RNN can be seen as a casual function according to the following definition ([SK19]).
Definition 49 (Causal function).
Let and be sets. A function is causal if and only if, for all sequences and for all , if for all , then for all .
[SK19] studies the differential properties of causal computations, offering valuable insight into the formal properties of RNNs. The paper focuses on sequences of functions which represent computations executed in discrete time , where, at each tick of the clock, takes an input and the current state , and uses this data to compute an output and a new state . In symbols, . Such sequences are given a nice compositional structure using the formalism of double categories.
Definition 50 (Category of tiles).
Let be a Cartesian category. Define as the double category with the following data:
-
1.
there is only one -cell, which we represent with the symbol;
-
2.
the horizontal and vertical -cells are the objects of ;
-
3.
a -cell (tile) with horizontal source , horizontal target , vertical source , and vertical target is a morphism which we represent with the symbol .
It is handy to also represent -cells as the tile string diagrams in Fig. 2.8 (a). The horizontal and vertical composition laws for -cells are consistent with the tile diagrams. Refer to [SK19] for more information.
Definition 51 (Category of stateful morphism sequences).
Let be a Cartesian category. Define as the category with the following data:
-
1.
the objects of are sequences of objects of ;
-
2.
the morphisms are pairs , where is a sequence of tiles in such that , for some sequence of states, and selects an initial state.
The morphisms of are known as stateful morphisms sequences and are represented using string diagrams as in Fig. 2.8 (b).
Stateful morphisms sequences can be easily truncated and unrolled as one would expect, and it is proved in [SK19] that there is a bijection between stateful morphism sequences in and causal functions (here is the constant sequence of objects ). More generally, given any , we can restrict our attention to constant sequences and stateful sequences of morphisms in the form , where is a tile in . This yields a subcategory whose morphisms can be thought of as Mealy machines that take in an input and produce an output based on an internal state which is updated after every computation. The new state is fed back to the machine after the computation, so that a new computation can take place. This is represented by the diagram in Fig. 2.8 (b).
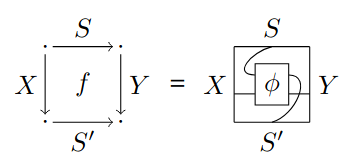
The authors of [SK19] go on to define a delayed trace operator, which provides a rigorous formalization for feedback loops such as the one in Fig. 2.9 (a). As stated in the paper, the delayed trace operator is closely related to the more popular trace operator ([JSV96]) and shares many of the same properties. Finally, the authors of [SK19] show how both and can be given the structure of a CDC (Def. 14), as long as is itself a CDC. This differential structure is conceptually clear, rigorously defined, and compatible with the dealyed trace operator. We do not have space to describe the details of these definitions, but we report the relevant string diagrams in Fig. 2.9 (b),(c).
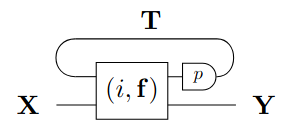
The work in [SK19] provides a theoretical foundation for the technique of backpropagation through time (BPTT), which consists in computing the gradient of the -th unrolling of an RNN in place of the gradient of the RNN at discrete time . Despite the alleged ad hoc nature of BPTT, [SK19] proves that the technique does not just “involve differentiation” but is an actual “form of differentiation” that can be reasoned about in the formalism of CDCs. Nevertheless, as stated in the paper, the differential operator of does not compute explicit gradients, and deriving the latter from the former would be computationally infeasible when there are millions of parameters.
It is interesting to compare the approach of [SK19] with the framework of categorical deep learning: both CDL and the work in [SK19] synthetically describe RNN architectures, but, while CDL focuses on weight sharing mechanics and the (co)inductive nature of the definition, [SK19] focuses on the differential properties of these architectures. However, neither categorical framework deals with the problems that come up when computing gradients of unrolled RNNs, such as the presence of vanishing or exploding gradients (see e.g. [Han18]).
2.4.2 Sheaf neural networks
The theory of sheaf neural networks ([HG20], [BDGC+22], [Zag24]), or SNNs, is informed by both topology and category theory, and aims to improve the GNN architecture by endowing graphs with cellular sheaf structures. In particular, SNNs are designed to solve two main issues that are encountered when training GNNs: oversmoothing, which is the tendency of deep GNNs to spread information too far in the graph to be able to effectively classify nodes, and the poor performance characteristic of GNNs when applied on heterophilic input graphs, i.e., input graphs where the nodes features are diverse in structure and attributes.
Definition 52 (Cellular sheaf).
A cellular sheaf associated with a graph consists of the following data:
-
1.
a vector space for every node ;
-
2.
a vector space for every edge ;
-
3.
a linear map for each incident node-edge pair .
The vector spaces associated to nodes and edges are known as stalks. The linear maps associated to incident node-edge pairs are known as restriction maps. The direct sum of all node stalks is known as space of -cochains, and the direct sum of all edge stalks is known as space of -cochains.
As stated in [Zag24], the node stalks assigned by serve as spaces for node features, while the restriction maps allow the data that resides on adjacent nodes to interact on edge stalks. Given a cellular sheaf , we can define a coboundary map which measures the amount ‘disagreement’555There is a close link between SNNs and the theory of opinion dynamics. See [Zag24] for further information. between nodes. The coboundary map can then be used to define a sheaf Laplacian which can be used to propagate information in the graph ([HG20]).
Definition 53 (Coboundary map).
Let be a cellular sheaf on a directed graph . The coboundary map associated with is the linear map that maps for each edge .
Definition 54 (Sheaf Laplacian).
Let be a cellular sheaf on a directed graph and let be the associated coboundary map. The sheaf Laplaciant associated with is the linear map . The normalized sheaf Laplacian associated with the sheaf is the linear map , where is the diagonal of .
Remark 55.
The coboundary map and the sheaf Laplacian associated with a cellular sheaf are generalizations of the more commonly known incidence matrix and Laplacian associated to a graph (see e.g. [WJL+22]).
There are many kinds of SNN architectures ([HG20], [BDGC+22], [Zag24]). Due to space constraints, we only give a short description of the first one to appear in the literature: the Hansen-Gebhart SNN proposed by [HG20], as described by [Zag24].
Definition 56 (Sheaf neural network).
Suppose is a directed graph and is a cellular sheaf on it. Suppose the stalks of are all equal to , where is the dimension of each feature vector and is the number of channels. Then, is isomorphic to , where is the number of nodes, and its elements can be represented as matrices . The sheaf neural network proposed by [HG20] uses the following transition function to update this features:
where is a non-linearity, refers to identity matrices, is the normalized sheaf Laplacian, is the Kronecker product, and, finally, and are weight matrices.
Remark 57.
The values of , , , and the restriction maps are all hyperparameters. Choosing allows the SNN layer described above to change the number of features from to .
As observed by [BDGC+22], the SNN architecture proposed by [HG20] can be seen as a discretization of the differential equation
which is known as sheaf diffusion equation and is analogous to the heat diffusion equation used in graph convolutional networks ([BDGC+22]). Studying the time limit of the sheaf diffusion equation yields important results about the diffusion of information through the graph after repeated application of the transformation in Def. 56. In particular, [BDGC+22] argues that, in the time limit, node feature tend to values that ‘agree’on the edges. Hence, “sheaf diffusion can be seen a synchronization process over the graph”. [BDGC+22] goes on to study the discriminative power of different classes of cellular sheaves and proposes strategies to learn the restriction maps themselves. [Zag24] extends the work of [BDGC+22] by analyzing non-linear sheaf Laplacians and the associated sheaf diffusion process.
It is important to notice that SNNs can be considered a strict generalization of GNNs since the latter are nothing but instances of the former where the sheaf structure is trivial ([BDGC+22]). Thus, although we are not aware of any work applying SNNs to neural algorithmic reasoning, given the success enjoyed by GNNs in this area of research, we hypothesize that SNNs are be even more effective at executing algorithms. To the best of our knowledge, no one has ever explicitly described SNN architectures using integral transforms either. However, a passing remark in [DvGPV24] hints that the message passing dynamic of GNNs is very similar to sheaf diffusion and thus such a generalization should be all but impossible. Hopefully, future research will shed light on these conjectures.
Chapter 3 Functor Learning
All categorical machine learning frameworks examined in the previous chapters represent machine learning models, both trained and untrained, as morphisms in some category. Morphisms capture the core idea of compositionality and are thus a very good choice in many contexts; nevertheless, there are also cases where a simple morphism is unable to interface with the structure that one might want preserved. For instance, different datasets might be linked using morphisms in an appropriate category (see e.g. [Spi12], [Gav19]) or sets containing machine learning data could be given a categorical structure, where elements are objects and morphisms capture relations between such objects (see e.g. [Lam99]). In these and other cases, learning functors instead of morphisms is advantageous as it allows us to preserve the aforementioned structure during the learning process. In this chapter we examine various approaches that testify to the usefulness of this insight: we will see how functors can be used to separate different layers of abstraction in the machine learning process ([Gav19]), to embed data in vector spaces ([SY21], [CSC10],[Lew19]), to carry out unsupervised translation ([SY21]), and to impose equivariance constraints and pool data effectively ([CLLS24]). As we will illustrate, functors can be learned by gradient descent, just like morphisms, as long as we have appropriate parametrizations ([Gav19]) or specialized objective functions ([SY21], [CLLS24]).
3.1 Using functors to separate layers of abstraction
The author of [Gav19] takes inspiration from the field of categorical data migration ([Spi12]) to create a categorical framework for deep learning that separates the development of a machine learning model into a number of key steps. The different steps concern different levels of abstraction and are linked by functors.
3.1.1 Schemas, architectures, models, and concepts
The first step in the learning pipeline proposed by [Gav19] is to write down the bare-bones structure of the model in question. This can be done by using a directed multigraph , where nodes represent data and edges represent neural networks interacting with such data. Constraints can be added at this level in the form of a set of equations that identify parallel paths (see e.g. Fig. 3.1).
Definition 58 (Model schema).
The schema of a model represented by a multigraph is the freely generated category .
The schema of a model does not contain any data nor does it do any computation, but it encodes the bare-bones structure of such model. If is the path congruence relation induced by the equations in , we can take the module to impose the constraints represented by . Depending on the context, the word schema will refer either to or to . As we will discuss later, each equation in can be associated with a specific loss function and these losses can be used to teach models to abide by .
Given a schema , we can choose an architecture for the model, that is, we can assign to each node a Euclidean space and to each morphism a parametric map. This procedure yields an untrained neural network.
Definition 59 (Model architecture).
maps objects to Euclidean spaces. These might be interpreted as the spaces data will live in, but it is wiser to put data outside the machinery and in the simpler category, as this allows for better compartmentalisation. Thus, [Gav19] also defines an embedding functor, which agrees with on objects but exists independently of it.
Definition 60 (Model embedding).
Let be a model schema and let be a chosen architecture. An embedding for such schema is a functor which agrees with on objects111The reason why the domain is the discretized schema instead of the original schema is clarified in Rem. 63..
Now that we have a model, we must find a way to assign specific values to the parameters, so that the model can be optimized by gradient descent. Consider the function , which takes the parameter space out of a parametric map in . We can use it to define the function
where is the set of generating morphisms of the free category on the multigraph . The function takes and architecture and returns the parameter space. Given , we can define the notion of parameter specification function.
Definition 61 (Parameter specification function).
Let be a model schema and let be a chosen architecture. A parameter specification function is a function which maps a pair - comprised of an architecture and some - to a functor . The functor takes the model schema and returns its implementation according to , partially applying to each , so that we obtain an actual smooth map.
The functor takes a schema and implements it replacing nodes with Euclidean spaces and arrows with appropriate smooth functions. Although we need to choose an architecture and specific values for its parameter in order to define , the latter directly acts on the schema and does not pass through the architecture. See Fig. 3.2 for a srting diagram that depicts the relationship between and .
Now, if we hope to train the model we have defined, we will need a dataset. [Gav19] suggests that a dataset should be represented as a subfunctor of the model embedding functor.
Definition 62 (Dataset).
Let be a model embedding. Then, a dataset is a subfunctor which maps every object of the discretized free category to a finite subset .
Remark 63.
The reason why [Gav19] defines and on discretized categories is because it often happens in practical machine learning that the available data is not paired. In these cases, it would be meaningless to provide an action on morphisms because they would end up being incomplete maps.
Given a node of , we have associated to a Euclidean space and a dataset . A dataset may be considered a collection of instances of something more specific than just vectors; for instance, if we have a finite dataset of pictures of horses, we are clearly interested in the concept of horse, that is in the set of all possible pictures of horses, which is much larger than our dataset but still much smaller than the vector space used to host such pictures. It makes thus sense to define another set representing such concept: this set will satisfy the inclusion relations . Moreover, since concepts are assumed to be complete, we can extend to a functor.
Definition 64 (Concept functor).
Given a schema , an embedding and a dataset , a concept associated with this information is a functor such that, if is the inclusion functor, .
As [Gav19] states, is an idealization, but it is a useful idealization as it represent the goal of the optimization process: given a dataset , we wish to learn the concept functor . More concretely, we want to train a model which is as close of an approximation of as possible222Notice that and have different domains and codomains. The difference of codomains is not an issue: we can just forget the differential structure of the codomain of , which yields a functor with image in (see Fig. 3.2). The difference of domains, on the other hand, is by design as can only approximate the constraints imposed by . This is not an issue in practice as we are only interested in the performance of the image of the trained model .. Total achievement of such goal is clearly impossible as, even in the simplest of cases (such as linear regression on synthetic linearly generated data), finite arithmetics and the finite nature of the learning iteration prevent us from obtaining a perfect copy of the generating function. Nevertheless, it is often possible to design an optimization process which makes the model converge towards the ideal goal.
Now that we know what the optimization goal is, we can define tasks. The task formalism brings together what has been defined in this section in an integrated fashion.
Definition 65 (Task).
Let be a directed multigraph, let be a congruence relation on and let be a dataset. Then, we call the triple a task.
Once we are assigned a machine learning task , we have to choose an architecture, an embedding and a concept compatible with the given multigraph, equations and dataset. Then, we specify a random initial parameter with an appropriate parameter specification function. Now we can choose an optimizer, but we must be careful to design an appropriate loss function. The loss function should incorporate both an architecture specific loss and a path equivalence loss. The former penalizes wrong predictions while the latter penalizes violations of the constraints embodied by .
Definition 66 (Path equivalence loss).
Let be a task. Let be an associated model. Then, if in , we define the path equivalence loss associated with , and as
Definition 67 (Total loss).
Let be a task. Let be an associated architecture, let be an associated model, and let be an architecture specific loss. Suppose is a non-negative hyperparameter. Then, we define the total loss associated with the task, the architecture, the model, and the hyperparameter as
| (3.1) |
We can now proceed as usual, computing the loss on the dataset for a number of epochs and updating the parameter each time.
It is important to notice that, while the learning iteration employed by [Gav19] is nothing new, the functor approach is actually novel, in that the usual optimization process is used to explore a functor space instead of a simple morphism space. This point of view offers two main advantages: on one hand, it separates different layers of abstraction are separated, which provides much needed conceptual clarity; on the other hand, it offers an explicit treatment of constraints, which are often only described implicitly and hidden away in the architecture of the model or in the loss function.
3.1.2 Datasets influence the semantics of tasks
[Gav19] centers its investigation around the powerful cycleGAN architecture ([ZPIE17]), which is described using an appropriate task consisting of the cycleGAN schema (see Fig. 3.1), the cycle consistency equations, and a cycleGAN dataset, that is, a dataset with two sets and containing data which is essentially isomorphic, such as pictures of horses and zebras. This description is particularly insightful because it can be used to prove a very important point: the choice of dataset influences the semantics of the learned task in non-trivial ways. In other words, changing the dataset functor can result in semantically different tasks even if the same schema and equations are retained.
For instance, combining the cycleGAN schema with the cycleGAN equations and a cycleGAN dataset yields a task whose semantics can be described as learn maps that turn horses into zebras and vice versa. Now consider replacing the cycleGAN dataset with a new dataset consisting of two sets and , where contains pictures depicting two elements and together, and contains separate images of and . The resulting task has very different semantics: learn how to separate from . [Gav19] follows this paradigm and shows how the CelebA dataset can be used to train a neural network able to remove glasses from pictures of faces, and one able to insert them.
This example is especially relevant to the present discussion because it shows how important the categorical structure of can be to machine learning. We can interpret pairs (face, glasses) as elements of the Cartesian product of the set of faces and the set of glasses. On the other hand, the set of pictures of faces with glasses can instead be considered another categorical product of the aforementioned sets. Since categorical products are unique, we know that there must be a unique isomorphism between the two products. The task at hand can thus be interpreted as find the canonical isomorphism. [Gav19] labels this task as product task.
3.2 Categorical representation learning
We now discuss frameworks where the categorical structure of data is not only used to integrate data distributed among different sets (as in [Gav19]) but also to model relationships within the data. Functorially preserving and exploiting this structure can lead to marked improvements in effectiveness and efficiency of the models in question because the structure of data is often closely linked with its semantics (see e.g. [SY21]), especially in the field of natural language processing, or NLP (see e.g. [CSC10], [Lew19]).
The field of categorical representation learning ([CSC10], [Lew19], [SY21]) aims to learn vectorial representations endowed with a categorical structure mirroring the one of the original data, so that models trained on these representations can use the structure efficiently. This is often a symbol-to-vector transformation, which poses conceptual and computational challenges (see e.g. [CSC10]). We will examine two examples of categorical representation learning: the approach of [SY21], which uses the obtained representations to carry out (partially) unsupervised translation, and the approaches of [CSC10] and [Lew19], which develop a compositional distributional model of meaning for NLP.
3.2.1 Unsupervised functorial translation
We now illustrate the approach of [SY21] showing how it is applied to the same example described in the original paper: unsupervised translation of the names of chemical elements from English to Chinese. The authors are tasked with converting between two identical chemical compound datasets, one labeled in English and the other in Chinese. Both datasets can be given a categorical structure by considering elements as objects and chemical bonds as morphisms. Suppose and are the resulting categories. The authors of [SY21] leverage the shared structure by training a model to learn a translation functor . To this aim, they functorially embed these categories into the vector space category defined below, which contains representations as objects.
Definition 68 (Vector space category).
Let . Let be the category whose objects are the vectors in and such that, for all ,
Composition is ordinary matrix multiplication and the identity on is .
The embedding of into is a functor which maps each object to a vector and each morphism to a matrix . The actual mapping can be learned with a neural network consisting of two separate embedding layers: one mapping objects to vectors and one mapping relations to matrices. The authors of [SY21] train the embedding layers using co-occurrence statistics and negative sampling to make sure that the embedded morphisms actually represent the same relations as the original morphisms. Here, the authors of [SY21] take on a distributional point of view, positing that co-occurrence must encode such relations. In the authors’ words, “co-occurrence does not happen for no reason”. The training strategy used in the paper is the following: given two embedded words and , model the probability of co-occurrence as , where the logit is defined as
Here, is non-linear and represents concatenation (or more sophisticated forms of aggregation) over all morphisms in . Taking on a probabilistic perspective allows us to represent non-strict relations, which is often necessary in machine learning. From this point of view, the likelihood of is proportional to the degree of alignment between and are closely aligned. The latter can be computed as , and the non-linearity reads out these measurements into a single value. Now, the actual co-occurrence probability of two objects can be approximated directly from the dataset. Given a negative sampling distribution on objects unrelated to , we can implement the negative sampling objective
The embedding network can then be trained by maximizing this objective function. The embedding of into can be defined and trained in the same way.
Remark 69.
Strictly speaking, morphisms in category should have a specific domain and a specific codomain but, in the case of the vector space category of Def. 68, a single matrix can be in many hom-sets of . This is mirrored by and , where morphisms correspond to classes of chemical bond and the same morphism can link different objects. From this point of view, morphisms in , in , and in behave more similarly to relations on sets than to morphisms in categories. Although this line of thinking does not strictly adhere to the definition of category, it helps our intuition and greatly reduces the size of the model. We will see a possible formal solution to this problem later on in this section, when we discuss the approach of [CSC10] and [Lew19].
The procedure described above can be been applied to both and to obtain meaningful vectorial representations of both datasets. An English to Chinese translation functor can be similarly embedded as an functor by precomposition with the embedding and postcomposition with the inverse of the embedding. Such functor must equate chemical bonds of the same kind, for example, if is a covalent bond so is . It is argued in [SY21] that this functor can be represented by a matrix so that and . This representation is only meaningful if (i) for all , (ii) for all , and (iii) for all . This is not true for all choices of but, if we choose every to be a unit vector, and if we constrain to be orthogonal, (ii) and (iii) are trivially satisfied. Requirement (i), on the other hand, can be learned by minimizing the following structure loss:
As the authors of [SY21] remark, this loss is universal, in the sense that it does not depend on any specific object, but acts on the morphisms themselves. While this approach is very elegant and does indeed return a functor, it might not produce the functor we expect because is not unique if the happen to be singular. Thus, it is better to integrate the structure loss with a second alignment loss that introduces some supervision to the unsupervised translation task. For instance, if the value of is known for a set for objects, we can define
Then, the total loss can be written as a weighted sum
| (3.2) |
where is a hyperparameter that regulates the relative importance of the two losses.
Remark 70.
It is interesting to compare the total loss in Eq. 3.2 to the one in Eq. 3.1. In both cases, the total loss is obtained as a linear combination of a model specific loss and a second more abstract loss. Both abstract losses enforce equality between morphisms but the abstract loss in Eq. 3.2 does not enforce functoriality because is already a functor by definition in the framework of [Gav19]. This highlights the main difference between the approach of [Gav19] and the approach of [SY21]: the latter requires functoriality to be learned from the structure of data, while the former takes functoriality as a given.
According to [SY21], the categorical approach described above can also be strengthened by endowing the categories , , and with monoidal products that make combining objects into higher-level structures possible. In particular, the monoidal structure of can be given as
where is the Kronecker tensor product and is a learned operator that sends the products back into the original spaces. This monoidal structure can then be used to mine categorical structure on multiple levels: for instance, in the running example of unsupervised translation of chemicals, it can be used to derive vectorial representations for functional groups or even whole compounds. If the data has a non-obvious high-level structure, [SY21] suggests a bootstrap approach where different possible links are randomly tested and the stronger ones are selected.
It is shown in [SY21] that the categorical representation learning framework described in the paper and the associated functor learning architecture for unsupervised translation can be successfully implemented. Benchmark tests against traditional sequence-to-sequence models show that the functorial paradigm leads to marked improvements in efficiency of learning. In particular, the authors compare the functorial model described in the paper with a GRU cell model of similar performance, noting that the former needs 17 times more parameters than the latter to learn to translate element names with a similar accuracy. The authors also compare their approach with the multi-head attention mechanism of [VSP+17], arguing that the matrices are essentially equivalent to the products , where is a query matrix and is a key matrix. Keeping united emphasizes the important role of functoriality and provides intuition concerning the nature of the vectorial representations of objects: in fact, it makes sense to interpret each as a metric that distorts the space and makes two vectors and closer if and only if there is a high likelihood that .
3.2.2 Compositional distributional model for NLP
There are two general approaches to natural language processing (NLP): the compositional (also known as distributional) approach and the contextual approach. The former aims to exploit the symbolic structure of grammar to understand text, while the latter posits that many aspects of text can be understood from distributional properties of the words ([AACFM22]). While compositionality has been very popular with theoreticians due to its elegance and its abstract structure, contextuality has been successfully applied by practitioners, yielding remarkably effective NLP models that learn the meaning of words and utterances by embedding them in vector spaces based on contextual information. The fact that both compositionality and contextuality are successful in their domains hints that the two approaches should be seen as complementary and that it would be desirable to integrate them both in a single compositional distributional framework333Cognitive science faces a similar challenge in integrating the competing connectionists and symbolic models of the human mind. This is the central theme of [SL06], whose approach inspired [CP07] (discussed in this section). The important role of language in cognition suggests that advances in the development of a compositional distributional model of language may yield advances in cognitive science and vice versa. (see e.g. [AACFM22], [Mar19]).
There have been numerous attempts to develop such a framework in the last few decades. For instance, [CP07] proposes to represent both text and the structural roles of its constituents as vectors, which can then be combined using sums and tensor products. We will focus on the approach of [CSC10], whose authors take inspiration from the ideas in [CP07] and propose a framework that uses the language of compact closed categories to unite symbolic grammar rules with concrete representation vectors. Grammar is represented as a pregroup category, whereas vectorial representations are learned on vector spaces which are then organized within , the category of finite dimensional real vector spaces444We work under the same assumption as [CSC10], namely, that each vector space in is endowed with a scalar product .. We start by defining pregroup categories.
Definition 71 (Pregroup).
A pregroup is a monoidal poset category where each object has a left adjoint and a right adjoint . The adjoints must be such that the following are true:
where is the monoidal unit of .
The use of pregroups to model grammatical structures dates back to [Lam99]. The key idea is that we can define a grammar category as the free pregroup generated by an initial set of basic grammatical roles. Then, we can represent various parts of speech using basic objects, their adjoints, and their monoidal products. The poset structure of the pregroup serves as a system of reduction rules which can be used to prove if a sentence is grammatical. Consider the following example (taken from [Lew19]).
Example 72.
Suppose represents the role of a noun and represents the role of a sentence. Then, an English transitive verb can be represented by the product in the free pregroup generated by and . Thus, the grammatical structure of the sentence “Dragons breathe fire.” is
| (3.3) |
The pregroup axioms show that the structure of “Dragons breathe fire.” can be reduced to the sentence type . This is proof that the sentence is grammatical. More complex patter can be modeled by adding more grammatical types or by combining types in other ways. These kinds of computations have a nice representation in the form of diagrams such as the ones of Fig. 3.3.
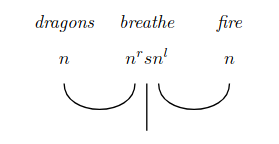
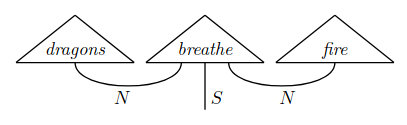
The pregroup grammar framework is useful to analyze the basic structure of language but gives no access to the actual meaning of words and sentences. The compositional distributional model of [CSC10] solves this problem by building a functor . Given a certain pregroup grammar category , for every grammatical type , we can associate a vector space containing vectorial representations of utterances of type . can be defined so that it preserves the pregroup structure of thanks to the following proposition ([CSC10]).
Proposition 73.
Consider the category of finite-dimensional real vector spaces. Suppose is the tensor product of vector spaces. Then, is a monoidal category. For all , define and consider the (co)unit linear maps:
where is a basis for . Then, is a compact closed category.
Now, pregroups have a trivial compact-closed structure as well. Thus, the functor can be defined so that it preserves the shared compact-closed structure just by mapping the poset relatioins of to the appropriate linear maps of . In practice, can be used to take a formal reduction in and implement it in as a series of operations on vectorial representations. The goal of this process is to take vectorial representations of single words in a sentence and obtain the vectorial representation of the meaning of the sentence. The compositional distributional model is thus compositional because it is build around the compositional structure of grammar and distributional because it allows us to encode distributional information in vectorial representations of words and sentences.
Example 74.
The reduction of Eq. 3.3 can be seen as a morphism . The image of this morphism through is a linear map
Remark 75.
Differently from [SY21], [CSC10] does not prescribe a specific method for learning the representations of individual words (some possible strategies are listed in the original paper), but it specifies a strategy to combine existing representations to generate representations of more complex utterances up to the level of whole sentences. It is interesting to notice that both papers suggest using tensor products in order to combine representations of lower-level structures into representations of higher-level structures.
String diagrams such as the ones in Fig. 3.3 can be written down as binary trees thanks to the associativity of the monoidal products of and . [Lew19] proposes to exploit this fact and augment the compositional distributional model of [CSC10] by implementing the (co)unit maps of as one or more recursive neural network (TreeRNN) cells. The paper argues that the use of TreeRNN cells should make the model easier to train and more robust. To our knowledge, such proposal has not yet been implemented, although TreeRNNs have already been applied to NLP many times (see e.g. [ASM19]).
3.3 Equivariant neural networks as functors
Warning 76.
We warn the reader that the paper [CLLS24], whose contents are discussed in this section, has been withdrawn by the authors citing issues with the references. We decided against omitting the paper from this thesis because we think its research direction is intriguing and potentially highly valuable. Hopefully, future research will soon clarify the epistemological status of the ideas hereby discussed.
[CLLS24] presents a categorical framework that describes neural network layers as functors and uses their functorial nature to impose invariance and equivariance constraints. In particular, equivariance constraints are used to effectively transport unary operators from the dataset into a latent embedding layer. It is shown that this enables the creation of models that account for shift and imbalance in covariates when training on pooled medical image datasets. In this section, we describe the framework of [CLLS24] and we draw a short comparison with the work of [PAS24], which also deals with the transport of algebraic structure into embedding layers.
3.3.1 An equivariant classifier to diagnose Alzheimer’s disease
The authors of [CLLS24] consider a data category whose objects are data points and whose morphisms represent differences in covariates. An example considered in the paper is the following: suppose the objects are comprised of brain scans and associated information concerning patient age and other covariates. The goal is to develop a model trained to diagnose Alzheimer’s disease from the scans. An example of morphism in such a data category is , which indicates a difference of years in age: . Notice that this kind of operator is clearly endowed with an algebraic structure as . Since we are dealing with a classification task, the dataset at hand has labels. It is important not to include the labels in the data category, else any classifier model would just read such labels instead of learning to predict them. Use the notation to represent the label associated to .
Now, if we consider another category , we can use a functor to project onto . Learning this functor instead of a simple map between objects is advantageous because the functoriality axioms imply that automatically satisfies equivariance constraints. This is trivial: if , then
| (3.4) |
Invariance with respect to is not much harder to define: it suffices to impose and .
Remark 77.
The authors of [CLLS24] solve the Alzheimer’s disease diagnosis task using a classifier that actively exploits the equivariant nature of functors. The proposed architecture consists of two modules: an invertible functor that embeds the data into a latent space, and a functor that does the actual classification (see Fig. 3.4 for a diagrammatic representation). Here, acts as a latent space and the equivariance of forces the representations in to be robust with respect to covariate shifts and imbalances, so that the actual classification operated by can be more effective at diagnosing the disease. The whole model can be compactly represented as . Although the inverse of does not appear in the formula, its existence is needed to ensure that the latent space accurately represents the data.
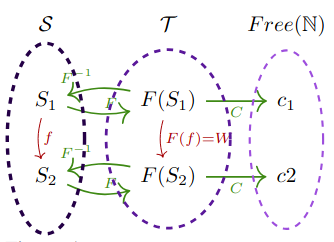
The classifier described above is implemented using similar tools as the ones employed by [SY21]. The latent space can be defined as a vector space category as in Def. 68. The functor is realized as the encoder of an appropriate autoencoder, and the decoder portion of this autoencoder acts as the inverse . The maps can be embedded as matrices as described in the previous section. In particular, [CLLS24] suggests using orthogonal matrices so that the resulting transformations can be efficiently inverted. Finally, can be implemented as a MLP classifier.
Now that the architecture has been specifies in terms of neural networks, the resulting model can be trained using gradient descent and a linear combination of three separate losses: , where , , and are hyperparameters. Here, is a reconstruction loss, which makes sure that is invertible and that its inverse accurately reconstructs the original data; is a prediction loss, which makes sure that accurately predicts the labels of the data; a structure loss, which makes sure that acts as a functor and not just a map. In formulas,
Remark 78.
Notice that the amount of equivariance constraints imposed can vary with no substantial changes to the proposed architecture: it suffices to add or remove terms from . This is in stark contrast with approaches such as [LCRS22], where handling multiple covariates requires a complicate multi-stage model.
The authors of [CLLS24] test the validity of the proposed approach with two interesting experiments: a proof of concept trained on the MNIST dataset, and a working classifier trained on the ADNI brain imaging dataset. The proposed MNIST model implements equivariance with respect to increments, rotations, and zooming. It is shown in the paper that representing the associated morphisms with orthogonal matrices allows such morphisms to be inverted and combined in the latent space. A subsequent application of shows the results of the aforementioned manipulation in human-understandable form. Such results are indeed very promising: the authors are able to combine rotations and scaling successfully, even though the network was only trained to apply them separately (see Fig. 3.5) for an example. The ADNI classifier model also shows promising results which are on par with state-of-the-art models that do not use categorical tools. The comparison takes place according to accuracy of prediction, maximum mean discrepancy, and adversarial validation.
3.3.2 Transporting algebraic structure into embedding spaces
Although stated in terms of equivariance conditions, the work of [CLLS24] can be seen from an algebraic point of view as a framework that allows to transport unary operators from a space of data to an embedding space. This line of thinking has also been explored by [PAS24]. While [PAS24] deos not use category theory, the authors themselves state that their approach could be easily categorified using the language of categorical algebras (Def. 27). The main innovation of [PAS24] is the use of mirrored algebras to fill the gaps between original data and the embeddings.
Consider a pre-trained autoencoder consisting of an encoder and a decoder , where is a data space endowed with an algebraic structure, such as a monoidal product , and where is a latent space. Suppose we want to transport this algebraic structure to through , that is, we want to find a monoidal product over so that acts as a homomorphism. While finding a product that makes and homomorphic might be easy, there is no guarantee that is an actual homomorphism with respect to this choice of algebraic structure. [CLLS24] solves this problem for unary operators by learning appropriate orthogonal matrices, but it is not clear how this approach could be scaled to operators with arities greater than . [PAS24] suggests an alternative approach consisting in learning a bijection between the latent space and a copy of this space. Endow with a product which enjoyes similar properties as (see Fig. 3.6). We will say that is the mirrored algebra of . Now train so that is homomorphism, where is defined by
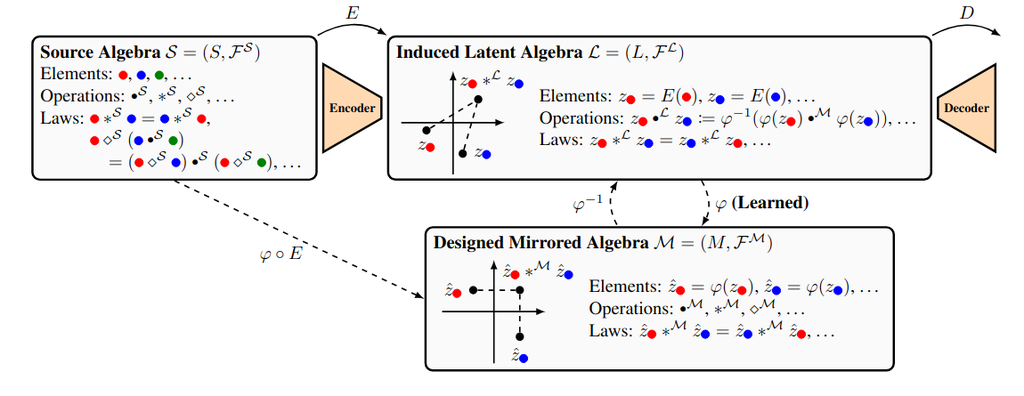
As stated in [PAS24], the bijection can be implemented as an invertible neural network and can be trained using a loss in the form
where the are algebraic expressions sampled from the set of expressions over , the are sampled from , is defined as , is the translation of in terms of the algebraic structure of , and is an appropriate distance function.
We only presented a sketch of the work in [PAS24]: the original paper presents the framework in terms of any general algebraic structure, deals with laws that regulate the interaction of different operations, proves theoretical guarantees, and explores the limitations of the proposed approach. It is shown in the paper that it is not always possible to find a mirrored algebra whose operations satisfy the same laws of the source algebra, which means that it is not always possible to transport this algebraic structure in its entirely. Nevertheless, the authors carry out experiments that prove that there are tangible advantages even in transporting a subset of the algebraic laws. The experiments support the following conjecture: “learned latent space operations will achieve higher performance if they are constructed to satisfy the laws of the underlying source algebra” ([PAS24]).
Chapter 4 Detailed Representations of Neural Networks
One of the main concerns arising from machine learning research is low reproducibility. This is not a simple issue and investigation by many authors (see e.g. [Raf19], [PVLS+21], [GCKG22]) has suggested that many factors might be at play (e.g., bad incentives, unsatisfying experiment design, incorrect evaluation practices, and so on). Source code availability is a recurring theme in these discussions: for instance [GCKG22] observes that “code describes implementation details perfectly and is required for outcome reproducibility for experiments of some complexity”. Similarly, [PVLS+21] describes efforts of the NeurIPS19 conference to improve reproducibility by requiring authors to provide source code. The paper justifies this requirement by speculating that the reproducibility issues affecting machine learning research might be partly caused by a reporting problem within the community, as machine learning papers often do not report all the details needed to reimplement the models they describe. For instance, it is argued that hyperparameters are often missing, together descriptions of entire components of the models at hand and descriptions of the pipeline and external tools employed.
While making code and datasets as available as possible can certainly be considered a good practice, it is argued in [Abb24], [KLLWM24], and [PH22] that over-reliance on code is detrimental to research. In fact, while it is tautologically true that code perfectly describes implementation, code is hardly effective at capturing the essential structure of a machine learning model. Even high-level code (like Python or R code) tends to be excessively verbose and drowns important details in a sea of instructions that have little to do with the theory at play. Hence, the question remains: how should machine learning researches represent their models? This question is extremely relevant in deep learning, where the size and complexity of models is ever increasing. For instance, even the ubiquitous transformer introduced by [VSP+17] is a complex piece of machinery with many components, and it is very challenging to provide a satisfying description.
Many authors describe their models through equations, but this becomes more and more difficult as the size of the models grows. This is especially true especially if complex tensor operations need to be carried out as ordinary tensor notation is not very readable ([XKM23]). Interestingly, the number of equations contained in a paper has been found to be negatively correlated to reproducibility ([Raf19]). An alternative approach that is becoming increasingly common is the use of specially crafted diagrams. For instance, Fig. 4.1 shows the transformer blueprint as provided in the original paper [VSP+17] (the annotations are not from the original authors). Ad hoc diagrams are intuitive but, as argued in [Abb24] and [KLLWM24], they suffer from a lack of systematicity and do not usually have significant mathematical properties. Moreover, important information is often omitted from the diagrams and the reader has to carefully parse the text to (hopefully) find or deduce it. For instance, the diagrams in Fig. 4.1 do not provide any information concerning the size of the matrices , , and , nor is it clear across which dimension the softmax should be computed.
The ad hoc diagrams often employed by machine learning researchers should be compared with the monoidal string diagrams that are almost standardized across applied category theory (see e.g. [BGK+22]). We have already seen many such diagrams in the previous chapters, especially when describing optics (see e.g. Fig. 1.2). On top of being standardized, monoidal string diagrams have precise categorical semantics and can thus be used to write down rigorous mathematical proofs and computations. Given these good properties, it is reasonable to ask whether the systematic use of monoidal string diagrams to represent machine learning models might be helpful. Regrettably monoidal string diagrams are also very inefficient at representing the details of tensor operations. The reader can appreciate this from Fig. 1.5, where dimensionality is all but hidden. This is the price that needs to be paid for generality, as monoidal string diagrams can represent mathematical objects that go well-beyond tensors. Nevertheless, there have been attempts by [Abb23] and by [KLLWM24] to adapt the box-wire notation of monoidal string diagrams so that it can perfectly represent a neural network architecture without leaving out important details. Category theory can then be used to provide rigorous semantics to these diagrams. Hopefully, such diagrams will be able to convey the information that is necessary for implementation and theoretical analysis, leading to improved insight and better reproducibility.
In this chapter, we discuss the two aforementioned categorical diagrammatic approaches and we compare them with other non-categoric and even non-graphical approaches to the problem of representing a neural network. The papers we discuss measure the validity of their approaches against the problem of representing the transformer architecture, which is both well-known and highly non-trivial. We will reproduce some of the diagrams in questions to give an idea of how the approaches compare. Regrettably, we lack the necessary space to fully describe the categorical semantics of the diagrams in question, but the reader can find complete accounts of each approach in the respective papers.
4.1 Neural circuit diagrams
[Abb23] proposes to compensate for the shortcomings of monoidal string diagrams by introducing a novel kind of string diagrams: neural circuits diagrams. neural circuits diagrams are a specialization of a broader class of powerful string diagrams known as functor string diagrams, developed in order to represent objects, morphisms, functors, natural transformations, and products in a single diagram. In this section, we provide a brief description of both classes of diagrams, and we show how neural circuits diagrams can be used to describe the transformer architecture.
4.1.1 Functor string diagrams
Despite their unquestionable usefulness, monoidal string diagrams have are fundamentally limited by their inability to represent functors and natural transformations. [Mar14] and [Nak23] solve this issue by relying on colors and symbols, but this only shifts the problem as their diagrams are unable to effectively represent products ([AZ24]). Functor string diagrams follow a different approach: they represent both objects and functors as wires and both morphisms and natural transformations as boxes111In functor string diagrams, the actual box is often not drawn for the sake of simplicity. In these cases, the box is replaced by a single letter, but we still use the word “box” for lack of better terminology.. These diagrams are built on two fundamental principles, which are already observed in traditional string diagrams. Following these principles ensures that the diagrammatic syntax stays consistent with the underlying categorical structure as it becomes more expressive.
Principle 79 (Vertical section decomposition).
A string diagram can be divided into vertical columns. A single vertical columns must either contain only objects or only morphisms. Object columns and morphism columns must alternate each other.
Principle 80 (Equivalent expression).
Every newly introduced piece of graphical notation must be expressible using the notation already present in a compatible manner.
In accordance with these principles, [Abb23] introduces notation that represents a functors as wires that lie above objects wires and natural transformations as boxes that lie above morphism boxes, as in Fig. 4.2 (a), (b). In standard string diagrams, a wire running through a morphism column is interpreted as an identity morphism. Similarly, in the notation of [Abb23], a wire running where a natural transformation is supposed to be is interpreted as an identical natural transformation. This diagrammatic notation is already effective enough to write a graphical proof of the Yoneda lemma, and can be easily adapted to represent product bifunctors: it suffices to stack two rows (one per category envolved) and to seprate them using a double dashed line, as in Fig. 4.2 (c). Finally, monoidal products can be represented by using a single dashed separation line or no line at all (as in Fig. 4.2 (d)). These pieces of diagrammatic notation are also in perfect compliance with the vertical section decompositionl principle and the equivalent expression principle.
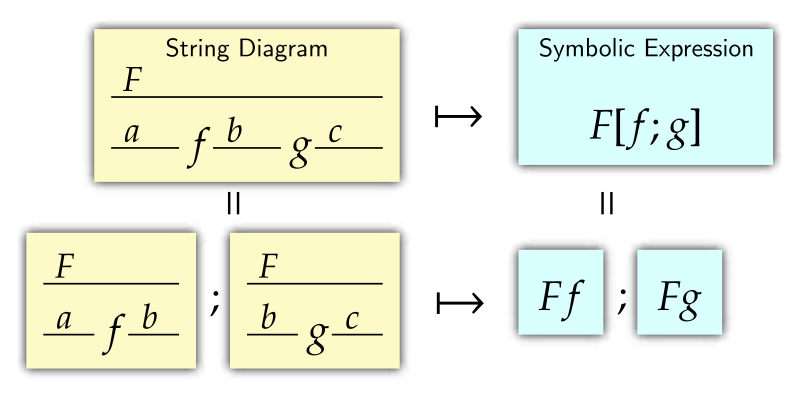

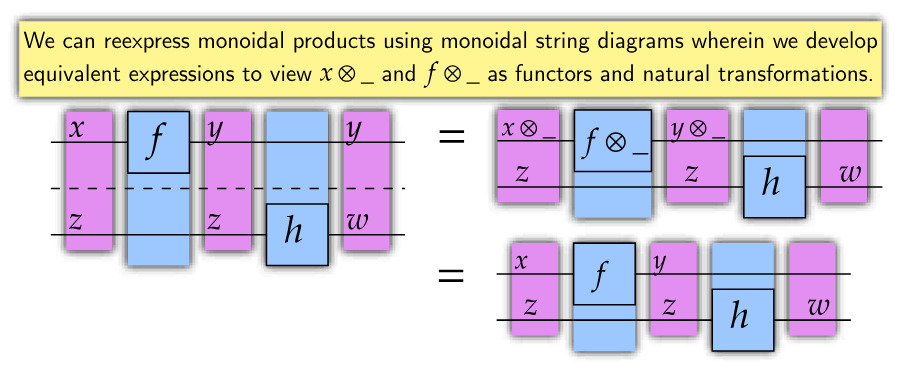
4.1.2 Neural circuit diagrams
Neural circuit diagrams are a specialization of functor string diagrams designed to represent precise schematics for deep neural network architectures. The idea is to capture all information relevant to the implementation and analysis of the aforementioned architecture without using any specific programming framework. In this sense, neural circuits diagrams can be compared to pseudocode. Although neural circuit diagrams can be learned and applied without any reference to category theory (this is the perspective adopted in [Abb24]), the fact that these diagrams are just an instance of the wider class of functor string diagrams is not just a curiosity, but proof that they have rigorous categorical semantics. In other words, every well-formed neural circuit diagrams corresponds to a well-defined neural network, and neural circuit diagrams can be composed intuitively.
Differently from the string diagrams seen in e.g. [Gav24b] or [WZ22], neural circuit diagrams explicitly keep track of dimensionality and indexing. This allows them to represent complex architectures that involve convolutions, residuality, and so on. Crucially, neural string diagrams provide convenient notation to represent broadcasting, which is of fundamental importance in deep learning but is rarely adequately represented by ad-hoc diagrams.
Neural circuit diagrams represent tensor axes as parallel wires and decorate each wire with the associated number of dimensions (see Fig. 4.3 (d)). Indexing is implemented by assigning a specific value to the wire representing the axis in question (see Fig. 4.3 (b)). Finally, broadcasting is represented by running a wire that represents the additional axis over the morphism that is to be broadcasted (see Fig. 4.3 (c)). Mathematically, tensors are constructed as hom-functors over the real line and broadcasting is just the action of these functors on morphisms (Fig. 4.4). This is all representable using functor string diagrams: neural circuit diagrams are just the result of omitting unnecessary detail from the latter. See [Abb24] for more information regarding neural circuit diagrams and see [Abb23] for more information regarding the relationship between neural circuit diagrams and functor string diagrams.
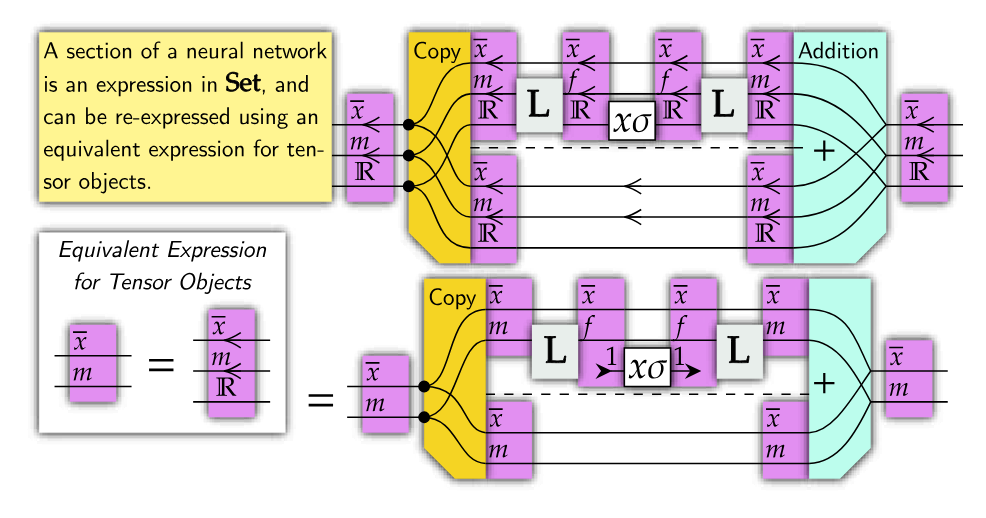
[Abb24] proves the usefulness of neural circuit diagrams by drawing schematics (Fig. 4.5) for the powerful transformer architecture proposed by [VSP+17]. Comparing these schematics with the ones presented in the original paper (Fig. 4.1) shows the wealth of detail that is easily encoded by the former but is completely absent from the latter. Neural circuit diagrams for additional architectures can be found in [Abb24].
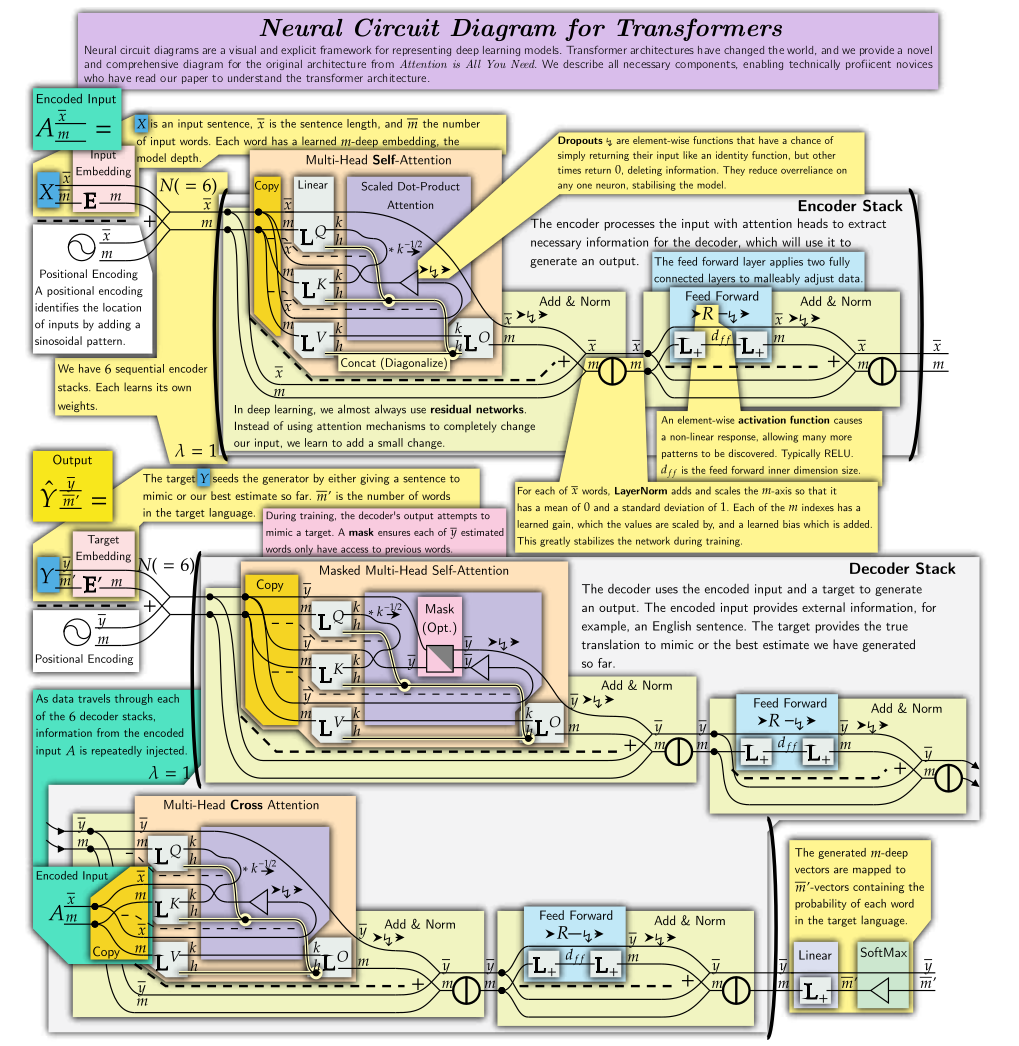
4.2 Diagrams with universal approximators
[KLLWM24] also develops a string-diagrammatic language capable of giving detailed unambiguous descriptions of neural network architectures. It is only natural to compare the approach of [KLLWM24] with the neural circuit diagrams of [Abb23] discussed in the previous section. Despite their unquestionable similarity, the two approaches differ on one key point: while neural circuit diagrams leave little space for abstraction and only allow equational rewrites, [KLLWM24] develops a semantics based on the notion of universal approximator that allows to abstract away details and compare different architectures based on shared abstractions. In this section, we give a brief overview of the approach of [KLLWM24] and we discuss interesting experimental results presented by the paper. We do not discuss the precise categorical semantics of the diagrams introduced [KLLWM24] because we lack the space necessary to do so, but the reader can find a full account of them in the appendices of the original paper.
4.2.1 The diagrammatic approach of [KLLWM24]
Neural circuit diagrams effectively describe neural network architectures, but the aboundance of detail they convey also means that it can be challenging to extract the fundamental structure of an architecture from its complete schematics. [KLLWM24] attacks this problem by drawing different diagrams for different levels of abstraction so that complete schematics (like the ones encoded in neural circuit diagrams) become only the end of a spectrum that begins with a purely abstract black box. The same fundamental grammar underpins all these diagrams, and appropriate rewrites can be used to seamlessly move between layers of abstraction.
Let us begin by discussing the most concrete end of the aforementioned specturm. [KLLWM24] describes computations in the Cartesian category of Euclidean spaces and continuous functions, and follows the basic conventions of Cartesian monoidal string diagrams. A sketch of the language can be found in Fig. 4.6. Unlike neural circuit diagrams, the diagrams of [KLLWM24] represent broadcasting using SIMD boxes (Same Instruction applied to Multiple Data), (Fig. 4.6 (b)), which are also used to represent tensor contractions (Fig. 4.6 (c)). Finally, syntactic sugar is offered to represent reshaping operations (Fig. 4.6 (c)).




The reader can compare Fig. 4.5 against Fig. 4.8 to see how both neural circuit diagrams and the approach of [KLLWM24] can be used to describe the transformer architecture in detail. While both formalisms shine in accuracy of representation, they also both suffer from low readibility: one might ask whether adopting such systems is even worth the trouble given that simpler diagrams such as the one in Fig. 4.1 seem to be better at communicating basic ideas despite their lack of detail. [Abb23] compensates for this by annotating its diagrams and by encapsulating portions of the architectures at hand into dedicated boxes. On the other hand, [KLLWM24] proposes to abstract away detail by replacing portions of the graph representing specific implementations with filled boxes that represent universal approximators with the same inputs and outputs.
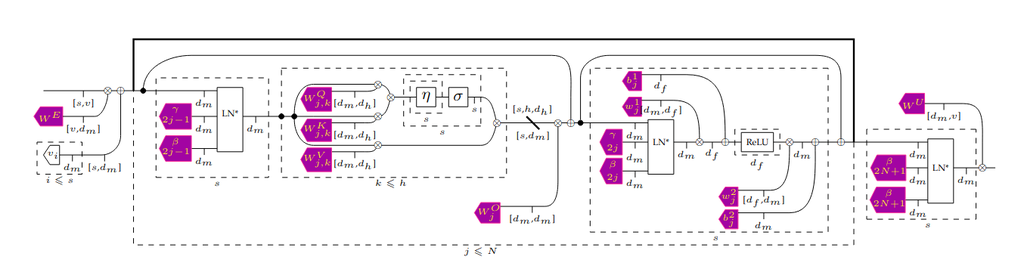
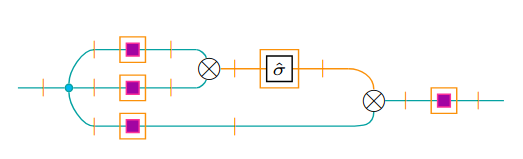
Definition 81 (Universal approximators).
A universal approximator for a class of functions is a neural network architecture able to approximate any element of to any desired precision.
Many well known results concern the existence and characterization of such approximators (see e.g. [Cyb89]). [KLLWM24] uses universal approximators to rigorously represent “typed holes” that need to be filled with an appropriate operator. Replacing detailed structures with these holes allows us to climb the ladder of abstraction. This can be combined with the omission of dimensional information that is not necessary to understrand the architecture at hand, but only to implement it. [KLLWM24] showcases this process in the diagram of Fig. 4.9, which highlights the fundamental structure of the attention mechanism proposed by [VSP+17]. Notice how colors are used to distringuish between dimensions that are fixed as hyperparameters and dimensions that vary with the length of the sequence that is being processed.
4.2.2 Comparing attention mechanisms
The universal approximator abstraction can also be used to compare different architectures. Two architectures that only differ at a point can be considered as descendents of a commmon ancestor architecture, and this common link allows us to compare them. For instance, [KLLWM24] derives all known attention mechanisms as descendents of a prototype “primordial attention”, forming a sort of evolutionary tree of attention (see Fig. 4.10). The process of filling in a universal approximator with a more specialized structure is called by [KLLWM24] an “expressivity reduction”, as it reduces number of architectures represented by the given schematics. Expressivity reductions can be formalized as string diagrammatic rewrites, which implies that the categorical semantics of these diagrams have a central role in the comparative analysis of architectures.
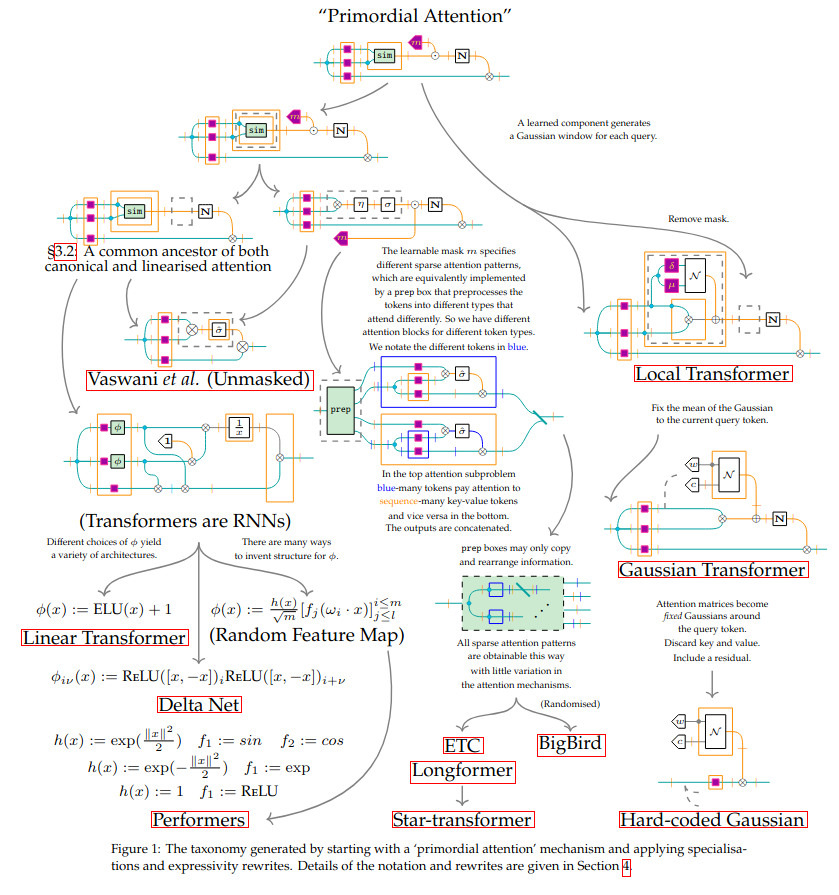
Just like biological taxonomy classifies species based on their evolutionary history, we can use the tree in Fig. 4.10 as a blueprint for the classification of attention mechanisms. This undertaking is analogous to the one of [GLD+24], where recurrent neural network cells are classified based on the classical data structures and automata they are related to. Both taxonomies serve to systematize the scattered panorama of machine learning research, but may also inspire new architectures. The authors of [KLLWM24] pursue this line of thinking and explore a space of possible attention mechanisms freely constructed from five generators (represented as abstract diagrams). This large space is reduced in size by rewriting sections that would lead to overparameterization. This results in a selection of eleven possible attention mechanisms, which the authors of [KLLWM24] go on to test: the mechanisms are embedded in a decoder-only transformer and trained on a Penn-Treebank task. Interestingly, the 11 mechanisms (among which there are known architectures such as the one proposed by [VSP+17]) all perform comparably well, with only one having a slightly better performance than the others. The authors entertain the conjecture that the aforementioned results might be a sign that the choice of attention mechanism matters little, as long as data is exchanged between tokens. While there is no uncontrovertible evidence that this is the case, these experiments prove the usefulness of the approach of [KLLWM24] and, more generally, of the usefulness of string diagrams in machine learning.
4.3 Future directions and related work
The amount of implementational detail conveyed by neural circuit diagrams and the diagrams in [KLLWM24] suggests that it should be possible to find a 1-to-1 correspondence between these diagrams and code. It is even argued in [Abb23] that neural circuit diagrams are expressive enough to be considered a high-level language with explicit memory management. Hopefully, future research will lead to the creations of tools that convert neural circuit diagrams into working models, not unlike the library developed by [CGG+22] that allows programmers to code using parametric lenses. Another interesting direction of research is the application of methods analogous to the ones of [KLLWM24] to the exploration of other classes of architectures.
We conclude the chapter by briefly discussing a few alternative approaches to the problem of unambiguous representation of neural networks. While these approaches are not categorical (yet), we believe there are fruitful comparisons to be drawn between the latter and the categorical approaches discussed in the previous sections. We also believe that these all these methods can be fruitfully integrated on various level, as discussed below.
4.3.1 Tensor networks
The enormous importance of tensors in quantum physics lead to the development of tensor networks (pioneered by [P+71]), in which tensor operations are represented as graphs, where tensors are nodes and modes are represented as edges coming out of the nodes. Given the importance of tensors in deep learning, it makes sense to try to adapt tensor networks to represent neural networks. This is done in [XKM23] and [Tay24]: the two papers introduce similar conventions that endow tensor networks with dedicated notation for non-linear activation functions and copy maps, which are not present in ordinary tensor networks.
The main difference between tensor networks and the string diagrams described in this chapter is that the latter represente data as boxes and processes as wires, whereas the former do the opposite. In tensor network an edge linking two tensors represents a tensor contradction: this choice yields intuitive representations for sophisticated tensor operations such as the Tucker product ([XKM23]) and for various tensor decompositions tecniques ([Tay24]), but it also makes it much more difficult to conceptualize how data moves through a model. For instance, the reader can observe Fig. 4.11 to understand how much more difficult it is to represent copy maps in the notation of [Tay24]. Moreover, while the diagrams of [Abb23] and [KLLWM24] have sophisticated categorical semantics, the notation of [XKM23] and [Tay24] mainly relies on human intuition222We see no reason why the diagrams in [XKM23] and [Tay24] should not be interpreted under the lens of category theory. Refer to [BCJ11] for a categorical approach to tensor networks..
Despite their weaknesses, tensor networks can be of great usefulness to deep learning practictioners as they can offer clear insight into tensorization processes. Tensorization is an architecture design patter that aims to reduce the number of parameters of a neural network without compromising its expressivity: this can be done by replacing large matrices with appropriately decomposed low-rank tensors. Owing to the redundance of ordinary fully connected layers (see e.g. [SKS+13]), this strategy leads to remarkable levels of compression ([NPOV15], [XKM23]). The improved efficiency comes at the price of human intuition, as it is much more difficult to think in terms of tensor operations across many modes than in terms of matrix-vector multiplication ([XKM23]). Diagrams can help bridge this gap.
4.3.2 Non-diagrammatic notations
An alternative to diagrammatic notation is the enhancement of algebraic notation. For instance, [CRB21] proposes to give English labels to tensor axes to make it easier to keep track of them. Following this convention, known as named tensor notation, the dot-product self-attention mechanism of [VSP+17] can be represented with the equation (which we lift from [CRB21]):
| (4.1) |
where represents the axes dedicated to query and key features, and represents the axis of sequence tokens. The authors argue that their named tensor notation is an improvement over the popular Einstein notation for sums as axes with English names allow the reader to immediately understand what kind of information they encode; moreover, they claim that named tensor notation limits repetition of indices and thus makes equations cleaner.
Another viable alternative approach is described in [PH22], where it is suggested that neural network architectures should be represented using pseudocode analogous to the one used in algorithm design and analysis (see e.g. [CLRS22]). The authors claim that writing pseudocode distills each architecture down to its fundamental components and removes incidental distractions, all the while preserving the detail necessary for implementation. One disadvantage of using pseudocode is that the structure of the involved tensors and the flow of information are partially obscured, which is detrimental to intuition. More generally, one can argue that pseudocode is readily implementable but hides away mathematics and structure.
4.3.3 A multifaceted approach
In our opinion, the problem of representing neural network architectures is best solved by using a combination of methods. For instance, there is no reason (aside maybe from space concerns that could be mitigated by the use of appendices) why the same architecture cannot be described with a string diagram, a tensor network, named tensor equations, pseudocode, and even code in the same paper. One or more string diagrams might be designed using either of the two approaches described in this chapter; tensor networks and named tensor equations might be employed to clarify the dynamics of complex tensor operations333Since the edges of tensor networks represent axes, we see no reason why they cannot be themselves labelled, effectively integrating the approaches of [XKM23] and [CRB21].; pseudocode could be provided so that practitioners can readily implement the architecture; finally, providing source code might clarify any ambiguity left by these high-level representations.
Conclusions
When discussing applications of category theory outside of pure mathematics, one might ask whether formalizing a concept in categorical terms is really worth the effort. Does a categorical formalization yield any novel insight? Does there exist some aspect of the subject at hand which can be analyzed with category theory more easily or elegantly than without? Experiments confirm that it possible to elegantly model gradient-based learning with parametric lenses; they confirm that thinking in terms of integral transforms leads to better algorithmic alignment; finally, they confirm that functor learning techniques preserve expressivity while reducing the number of parameters. It also appears clear that string diagrams can effectively describe neural network architectures. Hence, in the light of the many categorical approaches discussed in this thesis, we believe that categorical thinking can indeed be productive even in an applied field like deep learning.
Category theory is not the only area of mathematics that has been proposed to attack the open problems of deep learning and machine learning in general. For instance, both topology (see e.g. [HMR21]) and mathematical physics (see e.g. [RYH22]) seem to be good contenders, and linear algebra and probability theory are so foundational to the field that it is hard to imagine that they will not yield important advancements in the future. However, category theory holds a position of high regard in the hierarchy of mathematics because it can be used to build bridges between disparate fields. Thus, while no prediction about the future can be certain, it seems reasonable to expect that, on top of providing important techniques on its own, category theory will be used to build bridges between non-categorical approaches. Hopefully, bringing all these contributions together will lead us to a general theory of deep learning and machine learning at large.
References
- [AACFM22] Enrique Amigó, Alejandro Ariza-Casabona, Victor Fresno, and M Antònia Martí. Information theory–based compositional distributional semantics. Computational Linguistics, 2022.
- [Abb23] Vincent Abbott. Robust Diagrams for Deep Learning Architectures: Applications and Theory. PhD thesis, Honours Thesis, The Australian National University, Canberra, 2023.
- [Abb24] Vincent Abbott. Neural circuit diagrams: Robust diagrams for the communication, implementation, and analysis of deep learning architectures. arXiv preprint arXiv:2402.05424, 2024.
- [AC09] Samson Abramsky and Bob Coecke. Categorical quantum mechanics. Handbook of quantum logic and quantum structures, 2009.
- [ASM19] Mahtab Ahmed, Muhammad Rifayat Samee, and Robert E Mercer. Improving tree-lstm with tree attention. In 2019 IEEE 13th international conference on semantic computing (ICSC), 2019.
- [AZ24] Vincent Abbott and Gioele Zardini. Functor string diagrams: A novel approach to flexible diagrams for applied category theory. arXiv preprint arXiv:2404.00249, 2024.
- [BBCV21] Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv:2104.13478, 2021.
- [BCJ11] Jacob D Biamonte, Stephen R Clark, and Dieter Jaksch. Categorical tensor network states. AIP Advances, 2011.
- [BCS06] Richard F Blute, J Robin B Cockett, and Robert AG Seely. Differential categories. Mathematical structures in computer science, 2006.
- [BDGC+22] Cristian Bodnar, Francesco Di Giovanni, Benjamin Chamberlain, Pietro Lio, and Michael Bronstein. Neural sheaf diffusion: A topological perspective on heterophily and oversmoothing in gnns. Advances in Neural Information Processing Systems, 2022.
- [BGK+22] Filippo Bonchi, Fabio Gadducci, Aleks Kissinger, Pawel Sobocinski, and Fabio Zanasi. String diagram rewrite theory i: Rewriting with frobenius structure. Journal of the ACM (JACM), 2022.
- [BQL21] Joshua Bassey, Lijun Qian, and Xianfang Li. A survey of complex-valued neural networks. arXiv preprint arXiv:2101.12249, 2021.
- [CCG+19] Robin Cockett, Geoffrey Cruttwell, Jonathan Gallagher, Jean-Simon Pacaud Lemay, Benjamin MacAdam, Gordon Plotkin, and Dorette Pronk. Reverse derivative categories. arXiv preprint arXiv:1910.07065, 2019.
- [CEG+24] Bryce Clarke, Derek Elkins, Jeremy Gibbons, Fosco Loregian, Bartosz Milewski, Emily Pillmore, and Mario Román. Profunctor optics, a categorical update. Compositionality, 2024.
- [CFS16] Bob Coecke, Tobias Fritz, and Robert W Spekkens. A mathematical theory of resources. Information and Computation, 2016.
- [CG22] Matteo Capucci and Bruno Gavranović. Actegories for the working amthematician. arXiv preprint arXiv:2203.16351, 2022.
- [CGG+22] Geoffrey SH Cruttwell, Bruno Gavranović, Neil Ghani, Paul Wilson, and Fabio Zanasi. Categorical foundations of gradient-based learning. In European Symposium on Programming, 2022.
- [CLLS24] Sotirios Panagiotis Chytas, Vishnu Suresh Lokhande, Peiran Li, and Vikas Singh. Pooling image datasets with multiple covariate shift and imbalance. arXiv preprint arXiv:2403.02598, 2024.
- [CLRS22] Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, and Clifford Stein. Introduction to algorithms. MIT press, 2022.
- [CP07] Stephen Clark and Stephen Pulman. Combining symbolic and distributional models of meaning. American Association for Artificial Intelli- gence, 2007.
- [CRB21] David Chiang, Alexander M Rush, and Boaz Barak. Named tensor notation. arXiv preprint arXiv:2102.13196, 2021.
- [CSC10] Bob Coecke, Mehrnoosh Sadrzadeh, and Stephen Clark. Mathematical foundations for a compositional distributional model of meaning. arXiv preprint arXiv:1003.4394, 2010.
- [Cyb89] George Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of control, signals and systems, 1989.
- [DV22] Andrew J Dudzik and Petar Veličković. Graph neural networks are dynamic programmers. Advances in neural information processing systems, 2022.
- [DvGPV24] Andrew Joseph Dudzik, Tamara von Glehn, Razvan Pascanu, and Petar Veličković. Asynchronous algorithmic alignment with cocycles. In Learning on Graphs Conference, 2024.
- [Ell18] Conal Elliott. The simple essence of automatic differentiation. Proceedings of the ACM on Programming Languages, 2018.
- [EPWJ80] Michael G Eastwood, Roger Penrose, and Raymond O Wells Jr. Cohomology and massless fields. Communications in mathematical physics, 1980.
- [FJ19] Brendan Fong and Michael Johnson. Lenses and learners. arXiv preprint arXiv:1903.03671, 2019.
- [FS18] Brendan Fong and David I Spivak. Seven sketches in compositionality: An invitation to applied category theory. arXiv preprint arXiv:1803.05316, 2018.
- [FST19] Brendan Fong, David Spivak, and Rémy Tuyéras. Backprop as functor: A compositional perspective on supervised learning. In 2019 34th Annual ACM/IEEE Symposium on Logic in Computer Science (LICS), 2019.
- [Gav19] Bruno Gavranović. Compositional deep learning. arXiv preprint arXiv:1907.08292, 2019.
- [Gav23] Bruno Gavranović. Category theory resources, 2023. https://github.com/bgavran/Category_Theory_Resources.
- [Gav24a] Bruno Gavranović. Category theory (intersection) machine learning, 2024. https://github.com/bgavran/Category_Theory_Machine_Learning.
- [Gav24b] Bruno Gavranović. Fundamental components of deep learning: A category-theoretic approach. arXiv preprint arXiv:2403.13001, 2024.
- [GCKG22] Odd Erik Gundersen, Kevin Coakley, Christine Kirkpatrick, and Yolanda Gil. Sources of irreproducibility in machine learning: A review. arXiv preprint arXiv:2204.07610, 2022.
- [GLD+24] Bruno Gavranović, Paul Lessard, Andrew Joseph Dudzik, Tamara von Glehn, João Guilherme Madeira Araújo, and Petar Veličković. Position: Categorical deep learning is an algebraic theory of all architectures. In Forty-first International Conference on Machine Learning, 2024.
- [GSR+17] Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning, 2017.
- [Han18] Boris Hanin. Which neural net architectures give rise to exploding and vanishing gradients? Advances in neural information processing systems, 2018.
- [HG20] Jakob Hansen and Thomas Gebhart. Sheaf neural networks. arXiv preprint arXiv:2012.06333, 2020.
- [HMR21] Felix Hensel, Michael Moor, and Bastian Rieck. A survey of topological machine learning methods. Frontiers in Artificial Intelligence, 2021.
- [HSK+23] Stefan Hajkowicz, Conrad Sanderson, Sarvnaz Karimi, Alexandra Bratanova, and Claire Naughtin. Artificial intelligence adoption in the physical sciences, natural sciences, life sciences, social sciences and the arts and humanities: A bibliometric analysis of research publications from 1960-2021. Technology in Society, 2023.
- [IKP+22] Borja Ibarz, Vitaly Kurin, George Papamakarios, Kyriacos Nikiforou, Mehdi Bennani, Róbert Csordás, Andrew Joseph Dudzik, Matko Bošnjak, Alex Vitvitskyi, Yulia Rubanova, et al. A generalist neural algorithmic learner. In Learning on graphs conference, 2022.
- [JR97] Bart Jacobs and Jan Rutten. A tutorial on (co) algebras and (co) induction. Bulletin-European Association for Theoretical Computer Science, 1997.
- [JSV96] André Joyal, Ross Street, and Dominic Verity. Traced monoidal categories. In Mathematical proceedings of the cambridge philosophical society, 1996.
- [KLLWM24] Nikhil Khatri, Tuomas Laakkonen, Jonathon Liu, and Vincent Wang-Maścianica. On the anatomy of attention. arXiv preprint arXiv:2407.02423, 2024.
- [KM23] Hisham O Khogali and Samir Mekid. The blended future of automation and ai: Examining some long-term societal and ethical impact features. Technology in Society, 2023.
- [Lam99] Joachim Lambek. Type grammar revisited. In Logical Aspects of Computational Linguistics: Second International Conference, LACL’97 Nancy, France, September 22-24, 1997 Selected Papers 2, 1999.
- [LCRS22] Vishnu Suresh Lokhande, Rudrasis Chakraborty, Sathya N Ravi, and Vikas Singh. Equivariance allows handling multiple nuisance variables when analyzing pooled neuroimaging datasets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- [Lew19] Martha Lewis. Compositionality for recursive neural networks. arXiv preprint arXiv:1901.10723, 2019.
- [Mar14] Daniel Marsden. Category theory using string diagrams. arXiv preprint arXiv:1401.7220, 2014.
- [Mar19] Yoshihiro Maruyama. Compositionality and contextuality: the symbolic and statistical theories of meaning. In Modeling and Using Context: 11th International and Interdisciplinary Conference, CONTEXT 2019, Trento, Italy, November 20–22, 2019, Proceedings 11, 2019.
- [Nak23] Kenji Nakahira. Diagrammatic category theory. arXiv preprint arXiv:2307.08891, 2023.
- [NPOV15] Alexander Novikov, Dmitrii Podoprikhin, Anton Osokin, and Dmitry P Vetrov. Tensorizing neural networks. Advances in neural information processing systems, 2015.
- [OC17] Chris Olah and Shan Carter. Research debt. Distill, 2017. https://distill.pub/2017/research-debt.
- [P+71] Roger Penrose et al. Applications of negative dimensional tensors. Combinatorial mathematics and its applications, 1971.
- [PAS24] Samuel Pfrommer, Brendon G Anderson, and Somayeh Sojoudi. Transport of algebraic structure to latent embeddings. arXiv preprint arXiv:2405.16763, 2024.
- [PH22] Mary Phuong and Marcus Hutter. Formal algorithms for transformers. arXiv preprint arXiv:2207.09238, 2022.
- [PVLS+21] Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program). Journal of machine learning research, 2021.
- [PVM+21] Wei Peng, Tuomas Varanka, Abdelrahman Mostafa, Henglin Shi, and Guoying Zhao. Hyperbolic deep neural networks: A survey. IEEE Transactions on pattern analysis and machine intelligence, 2021.
- [Raf19] Edward Raff. A step toward quantifying independently reproducible machine learning research. Advances in Neural Information Processing Systems, 2019.
- [Rah17] A Rahimi. Machine learning has become alchemy, 2017. https://www.youtube.com/watch?v=x7psGHgatGM.
- [Ril18] Mitchell Riley. Categories of optics. arXiv preprint arXiv:1809.00738, 2018.
- [RYH22] Daniel A Roberts, Sho Yaida, and Boris Hanin. The principles of deep learning theory. Cambridge University Press Cambridge, MA, USA, 2022.
- [SGW21] Dan Shiebler, Bruno Gavranović, and Paul Wilson. Category theory in machine learning. arXiv preprint arXiv:2106.07032, 2021.
- [SK19] David Sprunger and Shin-ya Katsumata. Differentiable causal computations via delayed trace. In 2019 34th Annual ACM/IEEE Symposium on Logic in Computer Science (LICS), 2019.
- [SKS+13] Tara N Sainath, Brian Kingsbury, Vikas Sindhwani, Ebru Arisoy, and Bhuvana Ramabhadran. Low-rank matrix factorization for deep neural network training with high-dimensional output targets. In 2013 IEEE international conference on acoustics, speech and signal processing, 2013.
- [SL06] Paul Smolensky and Géraldine Legendre. The harmonic mind: From neural computation to optimality-theoretic grammar. MIT, 2006.
- [Spi12] David I Spivak. Functorial data migration. Information and Computation, 2012.
- [SY21] Artan Sheshmani and Yi-Zhuang You. Categorical representation learning: morphism is all you need. Machine Learning: Science and Technology, 2021.
- [Tay24] Jordan K Taylor. An introduction to graphical tensor notation for mechanistic interpretability. arXiv preprint arXiv:2402.01790, 2024.
- [VB21] Petar Veličković and Charles Blundell. Neural algorithmic reasoning. Patterns, 2021.
- [VBB+22] Petar Veličković, Adrià Puigdomènech Badia, David Budden, Razvan Pascanu, Andrea Banino, Misha Dashevskiy, Raia Hadsell, and Charles Blundell. The clrs algorithmic reasoning benchmark. In International Conference on Machine Learning, 2022.
- [VSP+17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 2017.
- [Wil10] Simon Willerton. Integral transforms and the pull-push perspective. The n-Category Café, 2010. https://golem.ph.utexas.edu/category/2010/11/integral_transforms_and_pullpu.html.
- [Wis08] Robert Wisbauer. Algebras versus coalgebras. Applied Categorical Structures, 2008.
- [WJL+22] Isaac Ronald Ward, Jack Joyner, Casey Lickfold, Yulan Guo, and Mohammed Bennamoun. A practical tutorial on graph neural networks. ACM Computing Surveys (CSUR), 2022.
- [WZ21] Paul Wilson and Fabio Zanasi. Reverse derivative ascent: A categorical approach to learning boolean circuits. arXiv preprint arXiv:2101.10488, 2021.
- [WZ22] Paul Wilson and Fabio Zanasi. Categories of differentiable polynomial circuits for machine learning. In International Conference on Graph Transformation, 2022.
- [XKM23] Yao Lei Xu, Kriton Konstantinidis, and Danilo P Mandic. Graph tensor networks: An intuitive framework for designing large-scale neural learning systems on multiple domains. arXiv preprint arXiv:2303.13565, 2023.
- [XLZ+19] Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S Du, Ken-ichi Kawarabayashi, and Stefanie Jegelka. What can neural networks reason about? arXiv preprint arXiv:1905.13211, 2019.
- [Zag24] Olga Zaghen. Nonlinear sheaf diffusion in graph neural networks. arXiv preprint arXiv:2403.00337, 2024.
- [ZLLS21] Aston Zhang, Zachary C Lipton, Mu Li, and Alexander J Smola. Dive into deep learning. arXiv preprint arXiv:2106.11342, 2021.
- [ZPIE17] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, 2017.
Acknowledgements
I wish to acknowledge the essential role my advisor Professor F. Zanasi has had in guiding me through the process of writing this thesis. He introduced me to applied category theory, to machine learning, and to the world of academic research in general. I will be forever grateful for it. I also wish to thank my family and my friends, who supported me throughout my academic journey, and without whom I would not have been here writing. To all of you, my most sincere gratitude.