DriveDreamer4D:世界模型是 4D 驾驶场景表示的有效数据机
摘要
闭环模拟对于推动端到端自动驾驶系统的进步至关重要。 当今的传感器模拟方法,例如 NeRF 和 3DGS,主要依赖于与训练数据分布密切相关的条件,这些条件主要局限于前向驾驶场景。 因此,这些方法在渲染复杂动作(例如,变道、加速、减速)时面临局限性。 自动驾驶世界模型的最新进展表明,它有可能生成各种驾驶视频。 然而,这些方法仍然局限于 2D 视频生成,本质上缺乏捕获动态驾驶环境复杂性的时空一致性。 在本文中,我们介绍了 DriveDreamer4D,它利用世界模型先验来增强 4D 驾驶场景表示。 具体来说,我们利用世界模型作为数据机,根据真实世界的驾驶数据合成新的轨迹视频。 值得注意的是,我们明确利用结构化条件来控制前景和背景元素的时空一致性,因此生成的数据严格遵循交通限制。 据我们所知,DriveDreamer4D 是第一个利用视频生成模型来改进驾驶场景中 4D 重建的模型。 实验结果表明,DriveDreamer4D 在新的轨迹视图下显着提高了生成质量,与 PVG、Gaussian 和 Deformable-GS 相比,FID 相对提高了 24.5%、39.0% 和 10.5%。 此外,DriveDreamer4D 显着增强了驾驶代理的时空一致性,这已通过全面的用户研究和 NTA-IoU 指标的相对增长 20.3%、42.0% 和 13.7% 进行了验证。
![[Uncaptioned image]](x1.png)
1 引言
端到端规划 [24, 25, 28],它直接将传感器输入映射到控制信号,是自动驾驶中最关键和最有希望的任务之一。 但是,目前的开环评估不足以准确评估端到端规划算法,突出了对增强评估方法的迫切需求 [36, 75]。 一个引人注目的解决方案 在于现实场景中的闭环评估,这需要从任意指定的视角检索传感器数据。 这需要构建一个能够重建复杂、动态驾驶环境的 4D 驾驶场景表示。
驾驶环境中的闭环仿真主要依赖于场景重建技术,例如神经辐射场 (NeRF) [41, 66, 68, 16] 和 3D 高斯 splatting (3DGS) [30, 65, 26, 10],这些技术本质上受到输入数据密度的限制。 具体来说,这些方法仅在与训练数据分布密切相关的条件下(主要是正向驾驶场景)才能有效地渲染场景,并且在复杂操作期间难以准确执行(参见图 1)。 为了减轻这些限制,SGD [73] 和 GGS [18] 等方法利用生成模型来扩展训练视角的范围。 但是,这些方法主要补充稀疏图像数据或静态背景元素,不足以模拟动态、交互式驾驶场景的复杂性。 最近,自动驾驶世界模型 [57, 76, 58, 23, 59, 14] 的进步引入了生成多样化、命令对齐的视频视角的能力,为自动驾驶的闭环仿真带来了新的希望。 然而,这些模型仍然局限于 2D 视频,缺乏准确模拟复杂驾驶场景所必需的时空一致性。
在本文中,我们介绍了 DriveDreamer4D,它通过整合来自自动驾驶世界模型的先验知识来改进 4D 驾驶场景表示。 我们的方法利用自动驾驶世界模型 [57, 76] 作为生成引擎,合成新的轨迹视频数据,使真实世界驾驶数据集变得更密集,从而增强训练。 值得注意的是,我们提出了新的轨迹生成模块 (NTGM) 来生成多样化的结构化交通状况,并且 DriveDreamer4D 将这些条件应用于独立调节复杂驾驶环境中前景和背景元素的运动动力学。 这些条件经过与车辆操作同步的视图投影,确保合成数据严格遵守 4D 驾驶场景的时空约束。 据我们所知,DriveDreamer4D 是第一个利用视频生成模型来提高自动驾驶中 4D 场景重建质量的框架,它为包括换道、加速和减速在内的场景提供了丰富多样的视角数据。 如图 1 所示,实验结果表明,DriveDreamer4D 显着提高了新颖轨迹视角的生成保真度,与 PVG [8]、高斯 [26] 和 Deformable-GS [69] 相比,在 FID 上取得了 24.5%、39.0% 和 10.5% 的相对改进。 此外,DriveDreamer4D 加强了前景和背景元素之间的时空一致性,在 NTA-IoU 指标方面分别提高了 20.3%、42.0% 和 13.7%。 此外,一项全面的用户研究证实,与三个基线相比,DriveDreamer4D 的平均胜率超过 80%。
本工作的主要贡献如下: (1) 我们提出了 DriveDreamer4D,这是第一个利用世界模型先验来推动自动驾驶中 4D 场景重建的框架。 (2) 提出了 NTGM,用于自动生成各种结构化条件,使 DriveDreamer4D 能够生成具有复杂动作的新颖轨迹视频。 通过显式地整合结构化条件,DriveDreamer4D 确保了前景和背景元素之间的时空一致性。 (3) 我们进行了全面的实验,以验证 DriveDreamer4D 显着提高了新颖轨迹视角下的生成质量,以及驾驶场景元素的时空一致性。
2 相关工作
2.1 驾驶场景表示
NeRF 和 3DGS 已成为 3D 场景表示的领先方法。 NeRF 模型 [41, 2, 3, 42] 使用多层感知器 (MLP) 网络来模拟连续体积场景,从而实现具有卓越渲染质量的非常详细的场景重建。 最近,3DGS [30, 72] 通过在 3D 空间中定义一组各向异性高斯函数,利用自适应密度控制,从稀疏点云输入中实现高质量渲染,引入了一种创新方法。 一些研究将 NeRF [68, 66, 27, 39, 48, 54, 16] 或 3DGS [65, 77, 8, 73, 26, 10] 扩展到自动驾驶场景。 鉴于驾驶环境的动态性,在建模 4D 驾驶场景表示方面也付出了巨大的努力。 一些方法将时间编码为额外的输入,以参数化 4D 场景 [1, 11, 35, 38, 44, 52, 26],而其他方法将场景表示为移动物体模型与静态背景模型的组合 [68, 33, 43, 55, 61, 63]。 尽管取得了这些进步,但基于 NeRF 和 3DGS 的方法面临着与输入数据密度相关的限制。 这些技术只有在传感器数据与训练数据分布高度匹配的情况下才能有效地渲染场景,而这通常局限于正向行驶场景。
2.2 世界模型
世界模型模块根据行为者提出的想象行动序列预测可能的未来世界状态 [34, 78]。 一些方法,例如 [58, 64, 74, 15, 17, 4, 20, 40, 21, 5, 32, 70, 22, 62],通过由自由文本动作控制的视频生成来模拟环境。 Sora [6]处于这一演变的最前沿,它利用先进的生成技术来生成尊重物理基本规律的复杂视觉序列。 这种深入理解和模拟环境的能力不仅提高了视频生成的质量,而且对现实世界中的驾驶场景也有着重大影响。 自动驾驶世界模型 [57, 76, 59, 23, 14, 67] 采用预测方法来解释驾驶环境,从而生成逼真的驾驶场景,并从视频数据中学习关键的驾驶要素和策略。 尽管这些模型成功地生成了以复杂驾驶动作为条件的各种驾驶视频数据,但它们仍然局限于 2D 输出,并且缺乏准确捕捉动态驾驶环境复杂性的时空一致性。
2.3 用于 3D 表示的扩散先验
从有限的观察结果构建全面的 3D 场景需要生成先验,特别是对于看不见的区域。 早期研究将文本到图像扩散模型的知识 [49, 45, 50, 47] 提炼成一个 3D 表示模型。 具体而言,分数蒸馏采样 (SDS) [46, 37, 60] 被用于从文本提示合成 3D 对象。 此外,为了增强 3D 一致性,一些方法扩展了多视角扩散模型 [51, 13] 和视频扩散模型 [4, 56, 9] 到 3D 场景生成。 为了将扩散先验扩展到用于 3D 重建的复杂、动态、大规模的驾驶场景,SGD [73]、GGS [18] 和 MagicDrive3D [12] 等方法采用生成模型来扩展训练视角的范围。 然而,这些方法主要解决稀疏图像数据或静态背景元素的问题,缺乏完全捕捉 4D 驾驶环境固有复杂性的能力。
3 方法
在本节中,我们首先阐述 4D 驾驶场景表示和驾驶视频生成的世界模型的预备知识。 然后,我们介绍了 DriveDreamer4D 的详细信息,它利用来自驾驶世界模型的先验信息来增强 4D 驾驶场景表示。
3.1 预备知识
3.1.1 4D 驾驶场景表示
4DGS 模型使用 3DGS 集合和时间域模块来模拟驾驶场景。 每个 3DGS [30] 由其中心位置 、不透明度 、协方差 和通过球谐函数控制的视点相关 RGB 颜色 参数化。 为了稳定性,每个协方差矩阵 通过以下方式分解:
| (1) |
其中缩放矩阵 和旋转矩阵 是可学习参数,分别用缩放 和四元数 表示。 单个 3D 高斯的所有可训练参数统称为 。 时间域 以 和时间步长 作为输入,输出每个高斯相对于规范空间的偏移量 。 然后通过以下公式计算 4D 高斯 :
| (2) |
遵循 [71],采用可微分高斯 Splatting 渲染器将 4D 高斯 投影到相机坐标系中,从而生成协方差矩阵 ,其中 是透视投影的雅可比矩阵, 是变换矩阵。 每个像素的颜色通过 有序点使用 混合计算:
| (3) |
其中 是由 定义的透射率, 表示每个点的颜色, 由评估具有协方差 的二维高斯与学习的每个点的不透明度 相乘得到。 可训练参数 可以通过 RGB 损失、深度损失和 SSIM 损失的组合来优化:
| (4) | ||||
其中 和 分别表示渲染的图像和真实图像。 和 分别表示渲染的深度和真实 LiDAR 深度图。 指的是结构相似度指数测度操作, 是损失权重。
3.1.2 可控驾驶视频生成的世界模型
世界模型模块根据想象的动作序列 [34] 预测可能的未来世界状态。 自动驾驶世界模型 [57, 76, 59, 14] 通常基于扩散模型,利用结构化的驾驶信息或动作控制来指导未来视频预测。 在训练期间,这些模型首先使用变分编码器 将视频 编码到一个低维潜在空间 中。 在向潜在空间添加噪声 后,扩散模型学习降噪过程。 此扩散过程通过以下方式优化:
| (5) |
其中 是参数化的降噪网络, 表示时间步长,代表每个阶段添加或移除的噪声级别。 此外,为了提高生成数据的可控性,条件特征 (例如,参考图像、速度、转向角、场景布局、相机姿态和文本信息)可以被引入到逆扩散过程中,以确保生成的输出符合输入控制信号。 在推理期间,世界模型可以根据参考图像来控制输出场景的风格,同时根据其他输入动作预测未来的世界状态。
3.2DriveDreamer4D
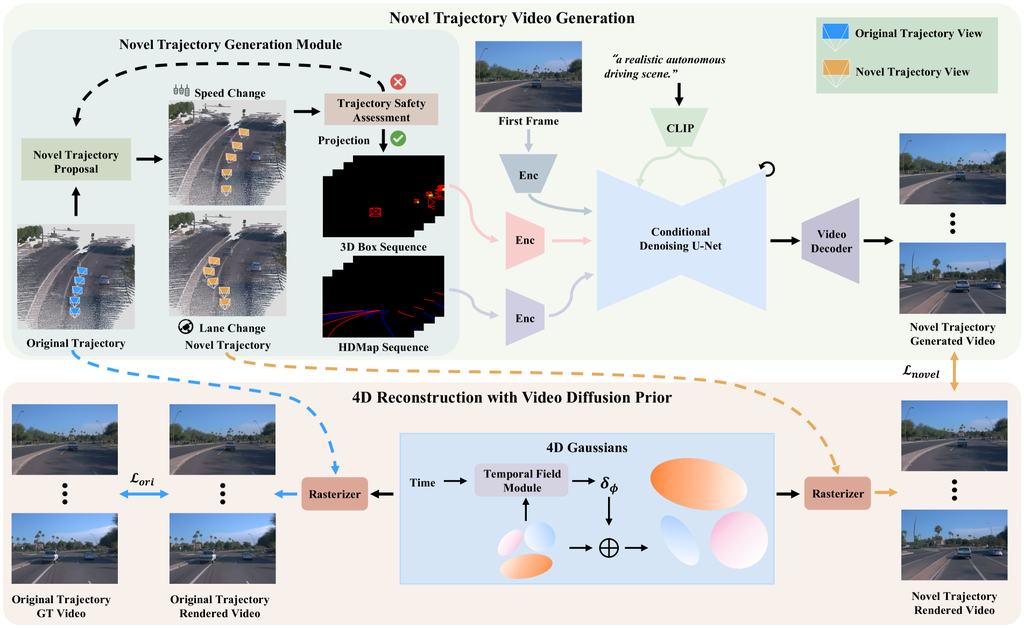
DriveDreamer4D 的整体流程如图 2 所示。 在上半部分,提出了新轨迹生成模块 (NTGM),用于调整原始轨迹动作,例如转向角和速度,以生成新的轨迹。 这些新轨迹为提取结构化信息(如 3D 框和 HDMap 细节)提供了新的视角。 随后,可控视频扩散模型从这些更新的视角合成视频,并结合与修改后的轨迹相关的特定先验信息。 在下半部分,将原始轨迹视频和新轨迹视频集成在一起,以优化 4DGS 模型。 在接下来的部分,我们将深入探讨新轨迹视频生成的相关细节,然后介绍带有视频扩散先验的 4D 重建。
3.2.1 新轨迹视频生成
如前所述,传统的 4DGS 方法在渲染复杂动作方面存在局限性,这主要是由于训练数据以简单的驾驶场景为主。 为了克服这一问题,DriveDreamer4D 利用世界模型先验信息生成多种视角数据,从而增强 4D 场景表示。 为此,我们提出了 NTGM,该模块旨在创建新的轨迹,作为世界模型的输入,从而实现复杂动作数据的自动生成。 NTGM 包含两个主要组成部分:(1) 新轨迹建议,(2) 轨迹安全评估。 在新轨迹建议阶段,可以采用 文本到轨迹 [76] 自动生成多种复杂轨迹。 此外,可以根据特定需求定制设计轨迹,以便根据精确的需求进行定制的数据生成。 定制设计轨迹建议(例如,变道)和轨迹安全评估的概述如图 1 所示。 在特定的驾驶场景中,世界坐标系中的原始轨迹可以很容易地获得为 ,其中 表示帧数, 表示第 帧的自我车辆位置。 为了提出新轨迹,原始轨迹 被转换为第一帧的自我车辆坐标系,表示为 并计算为:
| (6) |
其中 表示从第一帧的自我车辆坐标系到世界坐标系的变换矩阵, 表示串联运算。 在自我车辆坐标系中,车辆的航向与正 轴对齐, 轴指向车辆左侧, 轴垂直向上,垂直于车辆平面。 因此,车辆速度和方向的变化可以通过调整 轴和 轴上的值来分别表示。 对新生成的轨迹点进行最终的安全评估,包括验证车辆轨迹 是否保持在可行驶区域 内,并确保与行人或其他车辆 不发生碰撞。
| (7) |
其中 是不同智能体之间的最小距离。 一旦生成符合交通法规的新轨迹,道路结构和 3D 边界框就可以从新轨迹的角度投影到相机视图上,从而生成相对于更新轨迹的结构化信息。 这种结构化信息以及初始帧和文本被输入到一个世界模型 [76] 中,以生成遵循新轨迹的视频。
3.2.2 4D 重建与视频扩散先验
基于视频扩散先验,我们可以生成具有不同轨迹的新视频,从而增强不同基线 [8, 26, 69] 的 4D 重建能力。 具体来说, 为了用视频扩散先验训练 4DGS,必须构建一个混合数据集 ,该数据集将原始轨迹数据集 与新轨迹数据集 相结合。 这些数据集之间的平衡可以通过超参数 进行调整,使我们能够控制 4DGS 场景重建性能,包括原始轨迹和新轨迹。 此关系被公式化为 。 用于优化使用生成数据的 4DGS 的损失函数 与 [8, 26] 类似,定义如下:
| (8) | ||||
其中 表示对应于新轨迹的生成图像,如第 3.2.1 节所述,而 表示通过可微 splatting [71] 在新轨迹下渲染的图像。 值得注意的是,与 [8, 26] 不同的是,在使用生成数据集 时,深度图没有用作 4DGS 优化的约束。 限制源于 LiDAR 点云数据仅针对原始轨迹收集。 当将这些 LiDAR 点投影到新轨迹时,它无法为新视角生成完整的深度图,因为在新轨迹中可见的东西可能在原始视图中被遮挡。 因此,加入此类深度图并不能促进 4DGS 模型的优化。 第 4.3 节中描述了更多细节。 混合训练的总体损失函数定义如下:
| (9) |
| Method | Lane Change | Acceleration | Deceleration | Average | ||||
| NTA-IoU | NTL-IoU | NTA-IoU | NTL-IoU | NTA-IoU | NTL-IoU | NTA-IoU | NTL-IoU | |
| PVG [8] | 0.256 | 50.70 | 0.396 | 53.08 | 0.394 | 53.65 | 0.349 | 52.48 |
| DriveDreamer4D with PVG | 0.428 | 53.00 | 0.411 | 53.10 | 0.421 | 53.78 | 0.420 | 53.29 |
| Gaussian [26] | 0.175 | 49.05 | 0.434 | 51.93 | 0.384 | 52.14 | 0.331 | 51.04 |
| DriveDreamer4D with Gaussian | 0.491 | 53.36 | 0.474 | 52.60 | 0.445 | 52.57 | 0.470 | 52.84 |
| Deformable-GS [69] | 0.240 | 51.62 | 0.346 | 52.17 | 0.377 | 53.21 | 0.321 | 52.33 |
| DriveDreamer4D with Deformable-GS | 0.322 | 52.90 | 0.370 | 52.50 | 0.404 | 53.79 | 0.365 | 53.06 |
4 实验
在本节中,我们首先概述实验设置,详细说明数据集、实现细节和评估指标。 然后,我们提供定量和定性证据,证明所提出的 DriveDreamer4D 显着提高了新轨迹视点生成质量,并改善了前景和背景组件的时空一致性。
4.1 实验设置
数据集. 我们使用 Waymo 数据集 [53] 进行实验,该数据集以其全面的现实世界驾驶日志而闻名。 然而,大多数日志捕获的场景具有相对简单的动态,缺乏对密集、复杂的车辆交互场景的关注。 为了解决这一差距,我们专门选择了八个以高度动态交互为特征的场景,这些场景具有众多车辆,这些车辆具有不同的相对位置和错综复杂的驾驶轨迹。 每个选定的片段包含大约 40 帧,片段 ID 在补充材料中详细说明。
实现细节. 为了证明 DriveDreamer4D 的通用性和稳健性,我们在我们的管道中加入了各种 4DGS 基线,包括可变形 GS [69]、高斯 [26] 和 PVG [8]。 为了公平比较,LiDAR 监督被引入到可变形 GS 中。 在训练期间,场景被分割成多个片段,每个片段包含 40 帧,与生成模型的输出长度对齐。 我们只使用前向摄像头数据,并将所有方法的解析度标准化为 。 我们的模型使用 Adam 优化器 [31] 训练了 50,000 次迭代,遵循用于 3D 高斯散点图的学习率计划。 训练策略和超参数与每个基线的原始设置一致,每个模型都训练了 50,000 次迭代。
指标. 传统的 3D 重建任务通常使用 PSNR 和 SSIM 指标进行评估,其验证集与训练数据分布非常匹配(即,从视频序列中均匀采样帧以进行验证,其余用于训练)。 然而,在闭环驾驶模拟中,重点转移到评估模型在全新轨迹下的渲染性能,其中相应的传感器数据不可用,这使得 PSNR 和 SSIM 等指标不适用于评估。 因此,我们提出了新轨迹代理 IoU (NTA-IoU) 和新轨迹车道 IoU (NTL-IoU),它们评估了新轨迹视角下前景和背景交通组件的时空一致性。
| Method | FID |
| PVG | 105.29 |
| DriveDreamer4D with PVG | 79.54 |
| Gaussian | 124.90 |
| DriveDreamer4D with Gaussian | 76.24 |
| Deformable-GS | 92.34 |
| DriveDreamer4D with Deformable-GS | 82.67 |
对于 NTA-IoU,我们使用 YOLO11 [29] 来识别从新轨迹视图渲染的图像中的车辆,生成 2D 边界框。 同时,几何变换被应用于原始的 3D 边界框,将它们投影到新的视点以生成相应的 2D 边界框。 对于每个投影的 2D 框,我们然后识别最接近的检测器生成的 2D 框并计算它们的交并比 (IoU)。 为了确保准确匹配,引入了距离阈值 :当最近检测到的框 与正确投影的框 之间的中心到中心距离 超过此阈值时,它们的 NTA-IoU 被分配为零值:
| (10) |
对于 NTL-IoU,我们使用 TwinLiteNet [7] 从渲染图像中提取 2D 车道。 地面实况车道也投影到 2D 图像平面。 然后我们计算渲染车道和地面实况车道 和 之间的平均交并比 (mIoU):
| (11) |

此外,在车道变更场景中,我们观察到相对定位中的不准确,以及飞点和鬼影等伪影的频繁出现,这些都明显降低了图像质量。 为了评估这一点,我们使用 FID 指标 [19],它量化了渲染的新轨迹图像与原始轨迹图像之间的特征分布差异。 该指标有效地反映了视觉质量,并且对飞点和鬼影等伪影特别敏感,为这些复杂场景中的图像保真度提供了一个可靠的度量。 最后,我们进行了一项用户研究来评估生成质量。 具体来说,我们比较了每个基线方法与其在三个不同的新轨迹上的 DriveDreamer4D 增强版本的视觉结果。 评估标准侧重于整体视频质量,特别关注前景物体,例如车辆。 对于每项比较,参与者被要求选择他们认为最有利的选项。 补充材料中提供了更多详细信息。

4.2 与不同的 4DGS 基线比较
定量结果。 如表 1 所示,将 DriveDreamer4D 与不同的 4DGS 算法集成,在各种复杂的操作(例如,车道变更、加速和减速)中始终提供优越的 NTA-IoU 和 NTL-IoU 分数,显着优于基线方法。 具体来说,使用 DriveDreamer4D,三个基线(PVG [8], Gaussian [26], Deformable-GS [69])的平均 NTL-IoU 分数分别提高了 1.5%、3.5% 和 1.4%,这突出了 DriveDreamer4D 能够显着提高背景车道的时空一致性。 此外,在复杂的驾驶场景中渲染动态前景代理带来了巨大的挑战。 然而,DriveDreamer4D 促进了这些基线的平均 NTA-IoU 相对提高了 20.3%、42.0% 和 13.7%,从而显着提高了驾驶场景 4D 渲染中前景代理的时空一致性。
除了验证渲染的新轨迹视图的时空一致性外,我们还利用 FID 度量来评估新轨迹下的渲染质量。 鉴于加速和减速场景会产生与真实数据分布相似的渲染视图,这限制了 FID 在算法之间的判别能力,我们的 FID 比较专门针对车道变更场景。 实验结果(如表 2 所示)表明,我们的方法在很大程度上优于基线方法(PVG [8], Gaussian [26], Deformable-GS [69]),FID 相对提高了 24.5%、39.0% 和 10.5%。 这些结果突出了 DriveDreamer4D 在增强新轨迹视角生成质量方面的能力。
最后,我们进行了一项用户研究,以评估不同方法在新轨迹上的渲染质量,重点关注前景代理。 对于每种方法,我们在 Waymo 数据集中的八个场景中生成了三种新轨迹视图——车道变更、加速和减速。 然后要求参与者在每次比较中选择他们认为最具视觉吸引力的渲染结果。 如表 3 所示,从这项研究中得出的 DriveDreamer4D 胜率表明,用户对我们方法的渲染结果有显著的偏好。
| Counterpart Method | DriveDreamer4D Win Rate | |||
| Lane Change | Acceleration | Deceleration | Average | |
| PVG [8] | 100.0% | 85.7% | 79.4% | 88.6% |
| Gaussian [26] | 100.0% | 96.9% | 90.6% | 95.8% |
| Deformable-GS [69] | 93.8% | 81.2% | 65.6% | 80.2% |
定性结果。 除了定量比较之外,我们还提供了新轨迹视图渲染的定性分析,如图 3 所示,重点关注速度变化场景。 我们的方法显着提高了加速视角下前景车辆和背景元素的位置精度。 具体来说,基线算法结果 (PVG [8], 高斯 [26], 可变形-GS [69]) 显示在第 1、3 和 5 行。 很明显,基线方法在加速下的透视合成方面存在困难,导致自车加速时周围车辆的位置偏移不准确。 相反,通过集成 DriveDreamer4D,4DGS 算法实现了增强的空间一致性和显着改善的渲染质量。 在最后一帧(图 3 的最右边一列)中尤为明显,基线算法会导致前景车辆模糊或消失。 相反,我们的方法显着提高了图像渲染质量,如橙色框所示。 在图 4 中,我们展示了车道变更期间的新轨迹视图合成。 基线算法渲染的图像存在一些问题,例如前景车辆会与相机的运动同步错误地变道,以及一些车辆渲染不完整。 此外,背景充满了斑点和重影。 特别是在最后一帧(图4最右侧列)中,基线算法通常会生成模糊、重叠的前景车辆和天空中的背景斑点,以及模糊的车道标记。 然而,我们的方法显著提高了渲染质量,如橙色框所示。 车辆轮廓更清晰,背景伪影(如斑点和重影)大幅减少。
4.3 消融研究
我们基于 PVG [8] 进行消融研究,以确定组合真实数据和合成数据的最佳混合比例。 如表5所示,我们的结果表明,与仅使用真实数据 () 相比,增加生成数据的比例 () 可显著提高 NTA-IoU 和 FID 指标。 为了平衡 FID 和 NTA-IoU 指标,我们最终选择了。 此外,还进行了一项消融研究,以确定新颖轨迹视图的适当训练损失权重。 表5中的结果表明,在优化 4DGS 算法时,将新颖轨迹视图的损失纳入考虑可有效提高 NTA-IoU 和 FID 指标。 考虑到 FID 和 NTA-IoU 分数之间的平衡, 设置为 1。 最后,如表6所示,实验证实,在优化新颖轨迹视图时,不应包含深度损失,因为由于遮挡,LiDAR 深度图不完整。
| NTA-IoU | FID | |
| 0 | 0.351 | 105.29 |
| 0.2 | 0.413 | 82.37 |
| 0.3 | 0.417 | 80.68 |
| 0.4 | 0.420 | 79.54 |
| 0.5 | 0.425 | 83.19 |
| NTA-IoU | FID | |
| 0 | 0.351 | 105.29 |
| 0.5 | 0.405 | 82.84 |
| 0.7 | 0.411 | 80.61 |
| 1 | 0.420 | 79.54 |
| 1.5 | 0.417 | 82.10 |
| depth loss | NTA-IoU | FID |
| 0.401 | 82.63 | |
| 0.420 | 79.54 |
5 讨论与结论
在本文中,我们提出了 DriveDreamer4D,一个旨在通过利用来自世界模型的先验来推进 4D 驾驶场景表示的新框架。 为了解决当前传感器模拟方法的关键局限性——即它们对正向驾驶训练数据分布的依赖以及无法模拟复杂机动——DriveDreamer4D 利用世界模型生成新的轨迹视频,以补充现实世界的驾驶数据。 通过明确使用结构化条件,我们的框架在前景和背景元素之间保持时空一致性,确保生成的数据严格遵守现实世界交通场景的动态。 我们的实验表明,DriveDreamer4D 在生成各种模拟视角方面取得了优异的质量,在场景组件的渲染保真度和时空一致性方面都有显著提高。 值得注意的是,这些结果突出了 DriveDreamer4D 作为闭环模拟的基础的潜力,这些模拟需要对动态驾驶场景进行高保真重构。
致谢
作者感谢理想汽车有限公司的陈柳、陈雨音、湛昆、贾鹏、湛一飞和刘富,感谢他们对这项工作的富有成效的讨论、相关实现以及贡献的计算资源。
参考文献
- [1] Benjamin Attal, Jia-Bin Huang, Christian Richardt, Michael Zollhoefer, Johannes Kopf, Matthew O’Toole, and Changil Kim. Hyperreel: High-fidelity 6-dof video with ray-conditioned sampling. In CVPR, 2023.
- [2] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In CVPR, 2022.
- [3] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Zip-nerf: Anti-aliased grid-based neural radiance fields. In ICCV, 2023.
- [4] Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023.
- [5] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In CVPR, 2023.
- [6] Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024.
- [7] Quang-Huy Che, Dinh-Phuc Nguyen, Minh-Quan Pham, and Duc-Khai Lam. Twinlitenet: An efficient and lightweight model for driveable area and lane segmentation in self-driving cars. In MAPR, 2023.
- [8] Yurui Chen, Chun Gu, Junzhe Jiang, Xiatian Zhu, and Li Zhang. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering. arXiv preprint arXiv:2311.18561, 2023.
- [9] Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, and Huaping Liu. V3d: Video diffusion models are effective 3d generators. arXiv preprint arXiv:2403.06738, 2024.
- [10] Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, Li Song, and Yue Wang. Omnire: Omni urban scene reconstruction. arXiv preprint arXiv:2408.16760, 2024.
- [11] Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. In CVPR, 2023.
- [12] Ruiyuan Gao, Kai Chen, Zhihao Li, Lanqing Hong, Zhenguo Li, and Qiang Xu. Magicdrive3d: Controllable 3d generation for any-view rendering in street scenes. arXiv preprint arXiv:2405.14475, 2024.
- [13] Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models. arXiv preprint arXiv:2405.10314, 2024.
- [14] Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. arXiv preprint arXiv:2405.17398, 2024.
- [15] Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. Emu video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709, 2023.
- [16] Jianfei Guo, Nianchen Deng, Xinyang Li, Yeqi Bai, Botian Shi, Chiyu Wang, Chenjing Ding, Dongliang Wang, and Yikang Li. Streetsurf: Extending multi-view implicit surface reconstruction to street views. arXiv preprint arXiv:2306.04988, 2023.
- [17] Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Li Fei-Fei, Irfan Essa, Lu Jiang, and José Lezama. Photorealistic video generation with diffusion models. arXiv preprint arXiv:2312.06662, 2023.
- [18] Huasong Han, Kaixuan Zhou, Xiaoxiao Long, Yusen Wang, and Chunxia Xiao. Ggs: Generalizable gaussian splatting for lane switching in autonomous driving. arXiv preprint arXiv:2409.02382, 2024.
- [19] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. NeurIPS, 2017.
- [20] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022.
- [21] Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. NeurIPS, 2022.
- [22] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022.
- [23] Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023.
- [24] Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In ECCV, 2022.
- [25] Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In CVPR, 2023.
- [26] Nan Huang, Xiaobao Wei, Wenzhao Zheng, Pengju An, Ming Lu, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, and Shanghang Zhang. gaussian: Self-supervised street gaussians for autonomous driving. arXiv preprint arXiv:2405.20323, 2024.
- [27] Muhammad Zubair Irshad, Sergey Zakharov, Katherine Liu, Vitor Guizilini, Thomas Kollar, Adrien Gaidon, Zsolt Kira, and Rares Ambrus. Neo 360: Neural fields for sparse view synthesis of outdoor scenes. In ICCV, 2023.
- [28] Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. In ICCV, 2023.
- [29] Glenn Jocher and Jing Qiu. Ultralytics yolo11, 2024.
- [30] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM ToG, 2023.
- [31] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [32] Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, et al. Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125, 2023.
- [33] Abhijit Kundu, Kyle Genova, Xiaoqi Yin, Alireza Fathi, Caroline Pantofaru, Leonidas J Guibas, Andrea Tagliasacchi, Frank Dellaert, and Thomas Funkhouser. Panoptic neural fields: A semantic object-aware neural scene representation. In CVPR, pages 12871–12881, 2022.
- [34] Yann LeCun and Courant. A path towards autonomous machine intelligence version 0.9.2, 2022-06-27. 2022.
- [35] Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. In CVPR, 2021.
- [36] Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? In CVPR, 2024.
- [37] Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In CVPR, 2023.
- [38] Haotong Lin, Sida Peng, Zhen Xu, Yunzhi Yan, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Efficient neural radiance fields for interactive free-viewpoint video. In SIGGRAPH Asia, 2022.
- [39] Fan Lu, Yan Xu, Guang Chen, Hongsheng Li, Kwan-Yee Lin, and Changjun Jiang. Urban radiance field representation with deformable neural mesh primitives. In ICCV, 2023.
- [40] Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation. arXiv preprint arXiv:2401.03048, 2024.
- [41] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 2021.
- [42] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM ToG, 2022.
- [43] Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. Neural scene graphs for dynamic scenes. In CVPR, pages 2856–2865, 2021.
- [44] Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M Seitz. Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields. arXiv preprint arXiv:2106.13228, 2021.
- [45] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023.
- [46] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022.
- [47] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- [48] Konstantinos Rematas, Andrew Liu, Pratul P Srinivasan, Jonathan T Barron, Andrea Tagliasacchi, Thomas Funkhouser, and Vittorio Ferrari. Urban radiance fields. In CVPR, 2022.
- [49] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- [50] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS, 2022.
- [51] Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, et al. Zeronvs: Zero-shot 360-degree view synthesis from a single real image. arXiv preprint arXiv:2310.17994, 2023.
- [52] Liangchen Song, Anpei Chen, Zhong Li, Zhang Chen, Lele Chen, Junsong Yuan, Yi Xu, and Andreas Geiger. Nerfplayer: A streamable dynamic scene representation with decomposed neural radiance fields. IEEE Transactions on Visualization and Computer Graphics, 2023.
- [53] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. In CVPR, 2020.
- [54] Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. Block-nerf: Scalable large scene neural view synthesis. In CVPR, 2022.
- [55] Adam Tonderski, Carl Lindström, Georg Hess, William Ljungbergh, Lennart Svensson, and Christoffer Petersson. Neurad: Neural rendering for autonomous driving. In CVPR, 2024.
- [56] Vikram Voleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. Sv3d: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion. arXiv preprint arXiv:2403.12008, 2024.
- [57] Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-driven world models for autonomous driving. arXiv preprint arXiv:2309.09777, 2023.
- [58] Xiaofeng Wang, Zheng Zhu, Guan Huang, Boyuan Wang, Xinze Chen, and Jiwen Lu. Worlddreamer: Towards general world models for video generation via predicting masked tokens. arXiv preprint arXiv:2401.09985, 2024.
- [59] Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. In CVPR, 2024.
- [60] Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P Srinivasan, Dor Verbin, Jonathan T Barron, Ben Poole, et al. Reconfusion: 3d reconstruction with diffusion priors. In CVPR, 2024.
- [61] Zirui Wu, Tianyu Liu, Liyi Luo, Zhide Zhong, Jianteng Chen, Hongmin Xiao, Chao Hou, Haozhe Lou, Yuantao Chen, Runyi Yang, et al. Mars: An instance-aware, modular and realistic simulator for autonomous driving. In ICAI, 2023.
- [62] Jiannan Xiang, Guangyi Liu, Yi Gu, Qiyue Gao, Yuting Ning, Yuheng Zha, Zeyu Feng, Tianhua Tao, Shibo Hao, Yemin Shi, et al. Pandora: Towards general world model with natural language actions and video states. arXiv preprint arXiv:2406.09455, 2024.
- [63] Ziyang Xie, Junge Zhang, Wenye Li, Feihu Zhang, and Li Zhang. S-nerf: Neural radiance fields for street views. arXiv preprint arXiv:2303.00749, 2023.
- [64] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
- [65] Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians for modeling dynamic urban scenes. arXiv preprint arXiv:2401.01339, 2024.
- [66] Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, et al. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision. arXiv preprint arXiv:2311.02077, 2023.
- [67] Xuemeng Yang, Licheng Wen, Yukai Ma, Jianbiao Mei, Xin Li, Tiantian Wei, Wenjie Lei, Daocheng Fu, Pinlong Cai, Min Dou, Botian Shi, Liang He, Yong Liu, and Yu Qiao. Drivearena: A closed-loop generative simulation platform for autonomous driving. arXiv preprint arXiv:2408.00415, 2024.
- [68] Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. Unisim: A neural closed-loop sensor simulator. In CVPR, 2023.
- [69] Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. In CVPR, 2024.
- [70] Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024.
- [71] Wang Yifan, Felice Serena, Shihao Wu, Cengiz Öztireli, and Olga Sorkine-Hornung. Differentiable surface splatting for point-based geometry processing. ACM TOG, 2019.
- [72] Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splatting. In CVPR, 2024.
- [73] Zhongrui Yu, Haoran Wang, Jinze Yang, Hanzhang Wang, Zeke Xie, Yunfeng Cai, Jiale Cao, Zhong Ji, and Mingming Sun. Sgd: Street view synthesis with gaussian splatting and diffusion prior. arXiv preprint arXiv:2403.20079, 2024.
- [74] Yan Zeng, Guoqiang Wei, Jiani Zheng, Jiaxin Zou, Yang Wei, Yuchen Zhang, and Hang Li. Make pixels dance: High-dynamic video generation. arXiv preprint arXiv:2311.10982, 2023.
- [75] Jiang-Tian Zhai, Ze Feng, Jinhao Du, Yongqiang Mao, Jiang-Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jingdong Wang. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes. arXiv preprint arXiv:2305.10430, 2023.
- [76] Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang Wang. Drivedreamer-2: Llm-enhanced world models for diverse driving video generation. arXiv preprint arXiv:2403.06845, 2024.
- [77] Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. In CVPR, pages 21634–21643, 2024.
- [78] Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, et al. Is sora a world simulator? a comprehensive survey on general world models and beyond. arXiv preprint arXiv:2405.03520, 2024.