ViMoE:设计视觉专家混合的实证研究
抽象的
混合专家 (MoE) 模型体现了分治的概念,是一种很有前途的提高模型容量的方法,在多个领域展现出优异的可扩展性。 在本文中,我们将 MoE 结构集成到经典的视觉 Transformer (ViT) 中,命名为 ViMoE,并通过对图像分类的全面研究探索将 MoE 应用于视觉的潜力。 然而,我们观察到性能对 MoE 层的配置很敏感,这使得在没有精心设计的情况下难以获得最佳结果。 根本原因是不合适的 MoE 层会导致不可靠的路由,并阻碍专家有效地获取有用的知识。 为了解决这个问题,我们引入了共享专家来学习和捕获共同信息,作为构建稳定 ViMoE 的有效方法。 此外,我们展示了如何分析专家路由行为,揭示哪些 MoE 层能够专门处理特定信息,哪些层不能。 这为保留关键层并去除冗余提供了指导,从而使 ViMoE 更高效,而不会牺牲准确性。 我们希望这项工作能为视觉 MoE 模型的设计提供新的见解,并为未来的研究提供有价值的经验指导。
1简介

通用人工智能正在不断发展,朝着更大、更强大的模型发展 (Achiam et al., 2023; Reid et al., 2024; Yang et al., 2024; Dubey et al., 2024). 然而,更大的模型需要大量的计算资源用于训练和部署,而平衡性能和效率仍然是一个关键问题,尤其是在资源受限的环境中。 一种很有前景的方法是使用神经网络中的专家混合 (MoE) (Jacobs 等人,1991;Eigen 等人,2013) 层,它将模型大小与推理效率分离。 MoE 体现了 分治 原则,其中特征嵌入通过门控机制路由到选定的专家,使每个专家能够专门处理数据的一部分。 因此,每个输入只由一小部分参数处理,而传统的密集模型则对每个输入激活所有参数。 这种方法在自然语言处理 (NLP) 中越来越受欢迎,因为它能够在保持计算成本适度的情况下实现参数扩展 (Jiang 等人,2024;Dai 等人,2024)。
本文重点探讨了 MoE 在视觉模型中的简单应用。 我们将经典的视觉 Transformer (ViT) (Dosovitskiy,2020) 转换为稀疏的 MoE 结构,命名为 ViMoE。 我们对 ViT 的修改遵循 (Riquelme 等人,2021),其中每个块中的前馈网络 (FFN) 被替换为多个专家,同时保持每个专家的结构相同。 为简单起见,我们选择在图像级别而不是符号级别 (Daxberger 等人,2023;Liu 等人,2024) 选择专家。 通过对图像分类的全面研究,我们探索了以稳定且高效的方式配置 MoE 的策略,同时也从不同的角度观察到与专家路由相关的几个有趣现象。
在设计 ViMoE 时,一个重要的考虑因素是确定要包含多少个 MoE 层以及将它们放置在何处。 一种常见的方法是将它们插入最后一个 ViT 块 (Wu 等人,2022;Liu 等人,2024) 中,这些块接收最大的梯度幅度。 或者,另一种更直接的方法是在所有块中添加 MoE 层,而无需仔细设计。 我们采用了一种穷举的方式来扫描层数,以确定哪种配置可以为 ViMoE 提供最佳精度。 有趣的是,增加 MoE 层的数量并不总是会导致更好的性能;相反,在超过一定数量的层之后,会出现下降趋势。 我们将其归因于以下事实:不合适的 MoE 层,特别是在浅层 ViT 块中,不仅不能做出贡献,还会使优化变得复杂。 虽然扫描和观察可以揭示最佳性能点和最合适的 MoE 层数,但这种方法总是很费力。 受 Xue 等人(2022 年);Dai 等人(2024 年) 的启发,我们引入了一个共享专家,它从整个数据集中吸收知识,从而减轻了单个专家学习中的不足和路由机制的负担。 共享专家为 ViMoE 带来了更强的稳定性,因为它防止了在 MoE 层数过多时观察到的精度下降。 这消除了不断试错以寻找最佳点的必要性,从而促进了一个更加简化的设计过程。
以上是根据扫描结果得出的推论,但我们希望进一步探索启发式方法。 基于稳定的 ViMoE,我们试图深入研究 MoE 层内的路由行为,以揭示每个专家关注的内容。 由于我们的路由策略,我们可以观察到每个类别的数据是如何分布在专家之间的。 对于更深层的 ViT 块中的 MoE 层,门控网络有效地将同一类别的样本分配给同一个专家,每个专家专门处理不同的数据。 然而,在浅层块中,门控网络难以始终如一地将同一类别的图像路由到同一个专家,或者有效地引导专家专门处理不同的类别。 这表明专家没有学习到高度判别性的知识;相反,他们最终实施了非常相似的功能,不加区分地从所有类别中提取共同特征 (Riquelme 等人,2021)。 这些结果突出了哪些层真正起到了 分而治之 的作用,哪些层没有起到作用,这与通过层扫描观察到的精度趋势相对应。
此外,我们旨在通过对 MoE 行为的观察,告知更加周到和高效的 ViMoE 设计。 我们提出的一个尝试是根据路由分布估计必要的 MoE 层数,然后将其与每层设置的专家数量结合起来,以近似所需的专家组合。 这种见解使我们能够通过移除可能冗余的 MoE 层来简化结构,从而实现更有效的 ViMoE。 结果,我们基于 ViT-S/14 的 ViMoE 在 ImageNet-1K (Deng 等人,2009) 微调方面比 DINOv2 (Oquab 等人,2023) 提高了 1.1%。 激活参数不到三分之一,ViMoE 甚至超过了一些先进的 ViT-B/16 模型 (Touvron 等人,2021;Bao 等人,2021;Zhou 等人,2021;Zhang 等人,2022;Xinlei 等人,2021;He 等人,2022)。
总之,我们相信随着 MoE 在视觉任务中得到更广泛的应用,本研究中提出的观察结果、证据和分析值得了解。 我们希望我们的见解和经验将有助于推动这一前沿领域的发展。
2 ViMoE
2.1 预备知识
专家混合 (MoE) (Jacobs 等人,1991;Jordan & Jacobs,1994) 是一种很有前景的方法,它允许在不增加计算开销的情况下扩展参数数量。 对于基于 Transformer 的 MoE 模型,其架构主要由两个关键组件组成: (1) 稀疏 MoE 层: 一个 MoE 层包含 个专家(表示为 ),每个专家充当一个独立的神经网络 (Shazeer 等人,2017)。 (2) 门控网络: 该组件负责将输入符元 路由到最合适的 top- 个专家 (Cao 等人,2023)。 门控网络由一个可学习的线性层组成,定义为 ,其中 是门控参数, 是 softmax 函数。 令 表示 top- 个索引的集合,则该层的输出计算为从所选专家输出的线性组合,并根据相应的门控值加权,
| (1) |
负载均衡损失。 为了鼓励专家之间的负载均衡,我们在每个 MoE 层中加入了一个可微的负载均衡损失 (Lepikhin 等人,2020;Zoph 等人,2022),促使输入符元在专家之间更平衡地分布。 对于包含 个符元的批次 ,辅助损失计算为向量 和 之间的缩放点积,
| (2) |
其中 是损失系数, 表示路由到专家 的符元分数,以及 是分配给专家 的路由概率分数,
| (3) |
| (4) |
MoE Transformer。 将 MoE 应用于 Transformer 模型的一种广泛使用的方法是,用 MoE 层替换标准(非 MoE)Transformer 块中的一些前馈神经网络(FFN)(Fedus et al., 2022)。 具体来说,在 MoE 层中,专家保留与原始 FFN 相同的结构。 门控函数接收来自先前自注意力层的输出,并将符元表示路由到不同的专家。
2.2 图像分类设置
架构。 我们引入了一个 ViMoE 框架来促进我们对 MoE 在图像分类应用中的研究。 我们选择 Vision Transformer (ViT) (Dosovitskiy, 2020) 主干,并将 ViT 块中的 FFN 替换为 MoE 层。 我们考虑继承自监督预训练权重,而不是从头开始训练 (Riquelme et al., 2021),这降低了训练成本,同时也受益于高级特征表示。 由于 MoE 层中的专家与 FFN 具有相同的结构,因此我们简单地复制 FFN 的预训练权重到每个专家以进行初始化。
路由策略。 最近的大规模稀疏 MoE 模型 (Achiam et al., 2023; Jiang et al., 2024; Dai et al., 2024; Yang et al., 2024) 通常采用基于符元的路由策略,其中门控机制将每个符元分配给选定的专家。 然而,值得考虑这种策略对于图像分类中的 MoE 是否必要,其中模型更多地关注图像的整体特征以预测图像的单个类别。 我们建议路由策略应与视觉任务的特定需求相一致。 在图像级别进行路由(i.e.,为每个完整图像选择专家) (Daxberger et al., 2023; Liu et al., 2024) 更简单,更适合图像分类的目标。 在实践中,我们使用 [CLS] 符元来表示图像 作为门控网络的输入,因为它封装了来自所有图像符元的信息,并用于分类预测。 此外,除非另有说明,我们默认只选择前 1 个路由专家来简化架构。 因此,与基于符元的路由相比,这种策略减少了每个图像激活的专家数量。
共享专家。 不同专家分配的输入符元之间通常存在一些常识或共享信息。 因此,采用传统的路由策略,多个专家可能会在其各自的参数中获得重叠的知识。 通过设计共享专家 (Xue 等人,2022;Dai 等人,2024) 来专注于捕获和整合公共信息,其他路由专家可以专门学习独特的知识,从而形成一个更参数有效的模型,该模型包含更多数量的专业专家。 因此,我们将共享专家 引入 ViMoE 以便从所有数据中学习公共知识。 在我们的实现中,我们将共享专家的数量设置为 1,结构与其他专家相同。 共享专家的输出将添加到选定路由专家的输出中,从而使公式 1 可以重写为,
| (5) |
3 设计 ViMoE 中的经验观察结果
3.1 用于便捷设计的稳定策略
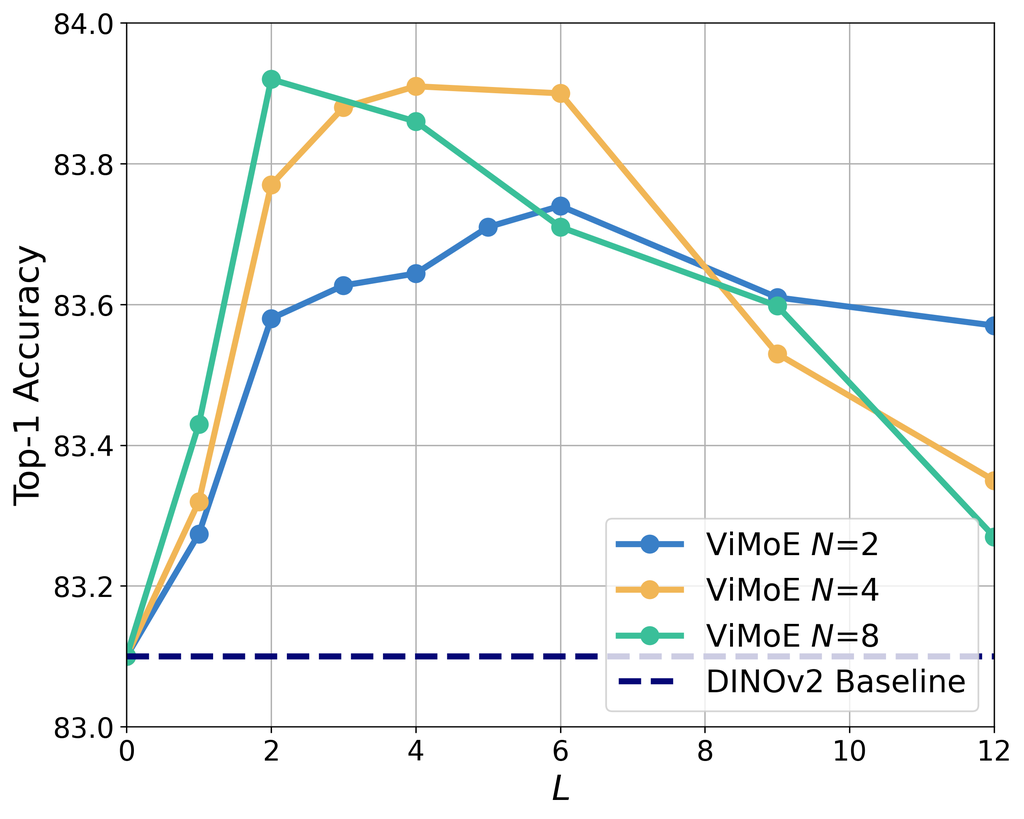
扫描 MoE 层的数量。 在设计 ViMoE 时,一个重要的考虑因素是确定要包含多少个 MoE 层以及在哪里将它们放置在 ViT 块中。 这里,我们首先探索没有共享专家的稀疏 MoE,以简化起见。 最直接的方法是在每个 ViT 块中放置 MoE 层,或者选择最后一个块,在这些块中梯度幅度最大。 为了探索合理的配置并寻求指导性见解,我们扫描了 MoE 层的数量,并评估了图像分类的准确性。 我们的实验基于 DINOv2 (Oquab 等人,2023) 预训练的 ViT-S/14 (Dosovitskiy,2020),修改为 ViMoE 并在 ImageNet-1K (Deng 等人,2009) 上微调了 个 epoch(更多实现细节在第 4.1 节中提供)。 从图 2 中可以看出,无论专家的数量如何,无论是 、 还是 ,准确性都始终呈现出先增加后减少的趋势,随着 的增加,这种趋势变得更加明显。 这种现象在 Daxberger 等人 (2023) 中也提到了。 我们假设在浅层 ViT 块中过早地引入多个专家会导致优化困难,并且由于信息有限,门控网络难以实现精确的路由(图 5 中对此进行了更详细的分析)。 这表明 ViMoE 设计中可能存在 不稳定性。 在没有仔细考虑的情况下,简单地将 MoE 层添加到所有 ViT 块中可能不会带来最佳结果。 需要对 的不同值进行扫描,以确定最合适的层数,这不可避免地会增加设计成本。
共享专家用于稳定 ViMoE。 如前所述,共享专家从所有数据中学习和整合知识,使其在捕获共同信息方面更加有效。 我们认为这种结构在减轻门控决策的挑战以及稀疏结构中个体专家学习的局限性方面是有效的。 因此,我们尝试将共享专家整合到 ViMoE 中,以减轻训练 MoE 层时的潜在不稳定性。 图 3 展示了使用和不使用共享专家模型之间的比较。 通过整合共享专家,ViMoE 可以实现稳定的结果,无需进行详尽的搜索来确定最佳层数 。 即使是在所有 ViT 块中添加 MoE 层的简单方法也能获得良好的准确性,避免了由于不合适的 MoE 配置导致的性能下降。 此外,通过引入共享专家,ViMoE 的准确性提高了 0.4%(84.3% vs. 83.9%),与 DINOv2 基线相比提高了 1.2%。


收敛优势。 以 和 为例,图 4 展示了使用和不使用共享专家的训练曲线,以及用于参考的 DINOv2 基线。 显然,仅仅添加稀疏的 MoE 层会导致早期训练阶段的收敛速度变慢,最终的性能与基线几乎没有区别,这支持了这样一种假设,即不合适的 MoE 设置甚至可能阻碍优化。 相反,当引入共享专家时,训练变得更加稳定,收敛速度更快,准确性显着提高。 值得一提的是,通过引入共享专家,MoE 层总共包含 9 个专家(1 个共享专家和 8 个路由专家),前向传递激活共享专家和一个选定的路由专家。 为了确保更公平的比较,我们通过从 9 个路由专家中选择前 2 个专家进行了消融研究。 一方面,从 9 个专家中选择 2 个可以被视为比从 8 个专家中选择 1 个更密集的设置,这部分缓解了过于稀疏带来的负面影响。 另一方面,即使使用相同数量的专家和激活专家,共享专家仍然展现出收敛速度更快和准确性更高的优势。
3.2 基于稳定性的高效探索
在构建稳定的 ViMoE 后,我们进一步分析图 3 并观察到性能平台的存在。 有趣的是,每个 的转折点不同。对于 、 和 ,准确率在 、 和 分别已经超过 84.2%。 超过这些层数,增加更多 MoE 并没有观察到显著的改进。 我们试图解释这些现象并提出设计更有效的 ViMoE 的策略。
路由热图。 以 为例,我们在图 5 中绘制了几个 MoE 层的路由热图。 这些热图说明了不同专家中类别样本的分布,帮助我们观察专家是否能够捕获不同的信息。 可以观察到,对于浅层 ViT 块中的 MoE 层(e.g。、),门控网络难以始终如一地将同一类别的图像路由到同一专家,或者有效地区分每个专家应该关注的类别。 这表明专家未能学习高度判别性的知识;相反,他们很可能执行相似的功能,不加区别地提取共同特征。 然后,我们重点关注准确率平台发生在 处的层,对应于 。 很明显,在最后两个 MoE 层中,门控网络可以有效地将适当的专家分配给每个类别,并且多个专家可以专门处理相应的数据。 因此,我们得出结论,深层是 MoE 真正实现其 分而治之 目标的地方,不同的专家专门处理特定于类别的内容。 这一观察结果验证了将 MoE 层放置在最后几个 ViT 块中的经验方法 (Wu et al., 2022; Liu et al., 2024) 是一种合理的策略。 相反,MoE 难以在浅层 ViT 块中展示其优势,因为使用多个专家似乎对于捕获基本的视觉特征来说是不必要的。 稀疏结构反而会引入优化困难,使原始密集 FFN 结构成为更简单、更合适的选择。

路由度。 另一个有趣的观察结果是,所需的 MoE 层数 会随着专家数量 的变化而变化。 我们认为这与路由度有关,路由度表示可能的专家组合数量,可以简单地定义为 。 由于我们将门控选择固定为 top- (即.,),我们得到 用于 , 用于 ,以及 用于 。 这意味着大约 32 到 64 个路由组合足以有效地划分和处理数据。 较少的组合可能会影响性能,而更多的组合不会带来进一步的显著收益。 从另一个角度看,如果我们将门控网络将专家分配给数据视为聚类过程,路由度本质上反映了从数据集中形成的聚类数量。 然后,每个专家组合可以专门学习其对应聚类的样本,帮助模型达到最佳效果。 我们的结果验证了端到端训练可以有效地实现这种聚类效果,而无需额外的聚类策略来为门控机制提供先验信息 (Liu et al., 2024)。
高效的 ViMoE。 以上结论是通过扫描 MoE 层数得出的。 从另一个角度看,我们可以通过观察每一层的专家分配来近似预测路由度。 如图 5 所示,路由热图提供了哪些 MoE 层起关键作用的证据,可能表明影响结果的必要专家组合。 这些见解指导我们改进结构设计,保留必要的 MoE 层,同时移除不必要的层,从而开发出更有效的 ViMoE。 此外,我们预计这些发现不仅限于 ImageNet-1K 数据集。 在第 4.2 节中,我们进一步探索了将这些见解转移到 CIFAR100 (Wang 等人,2017) 的过程,以验证它们的 普遍性。
在表 2 中,我们展示了各种 ViMoE 配置并比较了它们的参数数量。 尽管稀疏 MoE 层增加了参数总数,但由于我们将门设置为将每个图像路由到前 1 名专家,因此它在不增加激活参数计数或推理负担的情况下实现了更高的准确率。 通过包含共享专家,我们在相对较低的额外成本下进一步提高了准确率。 例如,当 和 时,只需要 2.4M 个额外的激活参数就能将基线的准确率提高 1.1%。 此外,与 的比较突出了我们用于 ViMoE 的结构设计效率,在不牺牲准确率的情况下显著减少了参数数量。
| w/ Shared Expert | Total Param. | Activate Param. | FLOPs | Acc. | ||
| - | 0 | - | 22.0M | 22.0M | 5.53G | 83.1 |
| 2 | 5 | 27.9M | 22.0M | 5.53G | 83.6 | |
| 2 | 5 | ✓ | 33.8M | 27.9M | 7.04G | 84.3 |
| 2 | 12 | ✓ | 50.4M | 36.2M | 9.17G | 84.2 |
| 4 | 3 | 32.7M | 22.0M | 5.53G | 83.9 | |
| 4 | 3 | ✓ | 36.2M | 25.6M | 6.44G | 84.2 |
| 4 | 12 | ✓ | 78.8M | 36.2M | 9.17G | 84.2 |
| 8 | 2 | 38.6M | 22.0M | 5.53G | 83.9 | |
| 8 | 2 | ✓ | 40.9M | 24.4M | 6.13G | 84.2 |
| 8 | 12 | ✓ | 135.5M | 36.2M | 9.17G | 84.3 |
| Method | Arch. | Activate Param. | FLOPs | Acc. |
| DINO | ViT-S/16 | 22.1M | 4.25G | 81.5 |
| BEiT | ViT-S/16 | 22.1M | 4.25G | 81.7 |
| iBOT | ViT-S/16 | 22.1M | 4.25G | 82.3 |
| DINOv2 | ViT-S/14 | 22.0M | 5.53G | 83.1 |
| DINO | ViT-B/16 | 86.6M | 17.58G | 82.8 |
| MoCov3 | ViT-B/16 | 86.6M | 17.58G | 83.2 |
| BEiT | ViT-B/16 | 86.6M | 17.58G | 83.4 |
| MAE | ViT-B/16 | 86.6M | 17.58G | 83.6 |
| iBOT | ViT-B/16 | 86.6M | 17.58G | 84.0 |
| ViMoE | ViT-S/14 | 22.0M | 5.53G | 83.9 |
| ViMoE⋆ | ViT-S/14 | 24.4M | 6.13G | 84.2 |
| Arch. | Activate Param. | FLOPs | Acc. | ||
| Dense | 0 | - | 22.0M | 5.53G | 83.1 |
| Dense | 2 | - | 24.4M | 6.13G | 83.6 |
| Dense | 3 | - | 25.6M | 6.44G | 83.8 |
| Dense | 5 | - | 27.9M | 7.04G | 83.8 |
| Dense | 12 | - | 36.2M | 9.17G | 83.9 |
| Sparse | 2 | 8 | 24.4M | 6.13G | 84.2 |
| Sparse | 3 | 4 | 25.6M | 6.44G | 84.2 |
| Sparse | 5 | 2 | 27.9M | 7.04G | 84.3 |
| Strategy | Avg. # Experts | Activate Param. | Acc. | ||
| Token | 2 | 8 | 16.3 | 38.9M | 84.1 |
| Token | 3 | 4 | 14.4 | 35.5M | 84.2 |
| Token | 5 | 2 | 14.8 | 33.6M | 84.1 |
| Image | 2 | 8 | 4 | 24.4M | 84.2 |
| Image | 3 | 4 | 6 | 25.6M | 84.2 |
| Image | 5 | 2 | 10 | 27.9M | 84.3 |
4 实验
4.1 ImageNet-1K 上的图像分类
实现细节。 所有实验都在 DINOv2 (Oquab et al., 2023) 预训练的 ViT-S/14 (Dosovitskiy, 2020) 上进行,并在 ImageNet-1K (Deng et al., 2009) 上进行了微调,图像分辨率为 ,训练了 个 epoch。 默认情况下,我们使用 AdamW (Sun et al., 2021) 优化器,批次大小为 ,权重衰减为 ,层级学习率衰减为 。 峰值学习率设置为 ,预热时间为 个 epoch。 对于 MoE 层,我们配置了三个不同的专家数量 (、 和 ),选择前 1 名专家,负载均衡损失系数 设置为 。
结果。 ImageNet-1K 基准测试的大多数经验结果已在之前给出。 在这里,我们将 ViMoE 与各种自监督模型(Bao 等人,2021;Zhang 等人,2022;Zhou 等人,2021;Oquab 等人,2023;Xinlei 等人,2021;He 等人,2022) 进行比较。 如表 2 所示,ViMoE 实现了 83.9% 的 top-1 准确率,比 DINOv2 高出 0.8%,而没有增加激活参数。 使用共享专家,准确率进一步提高到 84.2%,比 DINOv2 高出 1.1%。 值得注意的是,我们仅使用 ViT-S/14 实现了这一性能,超越了基于 ViT-B/16 的其他方法,同时激活的参数不到它们的三分之一。
与密集结构的比较。 之前的结果证实了 MoE 结构相对于密集模型的优势。 但是,当我们引入共享专家时,激活参数的数量会增加。 为了确保公平,我们试图通过调整激活参数的数量来修改 DINOv2 基线,同时保持密集架构。 一种可行的方法是通过设置两个专家并选择前 2 个来模拟 MoE,这允许在 ViT 块中添加额外的 FFN。
在表 4 中,我们展示了具有不同层数的密集结构的结果,并将它们与稀疏 MoE 进行比较。 虽然增加参数的数量会提高准确率,但稀疏结构显然更有效,并且具有更高的上限。 例如,在 具有 24.4M 激活参数的情况下,稀疏 MoE 比密集结构高出 0.6%。
4.2 在 CIFAR100 上验证
上述观察和结论基于 ImageNet-1K (Deng et al., 2009)。 为了证明泛化能力,我们在 CIFAR100 (Wang et al., 2017) 上进行了验证,并旨在确定最合适的 ViMoE 配置。
实现细节. 所有模型都在 CIFAR100 上微调了个 epoch,权重衰减为。 峰值学习率设置为 ,预热为 个 epoch,而所有其他设置保持与在 ImageNet-1K 上采用的设置一致。
基线和稳定的 ViMoE。 首先,我们使用 DINOv2 (Oquab 等人,2023) 自监督预训练 ViT-S/14 (Dosovitskiy,2020) 并在 CIFAR100 上对其进行微调作为基线,其 top-1 准确率为 91.3%。 接下来,我们将 ViT 块转换为 ViMoE 框架。 考虑到 CIFAR100 的类别和样本少于 ImageNet-1K,我们在实验中将专家数量设置为 。 基于以往经验,带有共享专家的 ViMoE 往往会产生稳定的结果,使我们在设置 MoE 层数方面有更大的灵活性。 我们选择最直接的方法,即在每个块中添加 MoE 层,即。。。 在此设置下,ViMoE 实现了 91.6% 的 top-1 准确率,超过基线 0.3%。 此外,我们比较了没有共享专家的模型,该模型的准确率仅为 78.4%,远低于基线。 这表明 MoE 不是一个简单的设计,无法保证稳定的收益。 事实上,某些 ViT 块中稀疏结构带来的优化复杂性可能会产生重大负面影响,进一步突出了设计稳定的 ViMoE 的必要性。

从观察中得出的有效结构。 我们观察了 MoE 在稳定 ViMoE 中的行为,并进一步分析了哪些层起着至关重要的作用。 遵循第 3.2 节中概述的方法,我们生成了路由热图,如图 7 所示。 很明显,在最后两层,即即。、和中,门控网络有效地聚集了数据类,允许每个专家专门处理特定的类别。 相反,较浅的层没有表现出明显的专家专业化,表明这些 MoE 层可能不是必需的,并且单个 FFN 可以取代多个稀疏专家的作用。 基于此,我们估计 CIFAR100 的路由度约为 4 到 16。 为了验证这个假设,我们对 配置进行了实验,实现了 91.7% 的准确率。 此设置在保持良好结果的同时,减少了参数并提高了效率。
| w/o Shared Expert | |||||||
| 91.4 | 91.5 | 91.5 | 91.5 | 91.3 | 91.2 | ||
| 91.4 | 91.5 | 91.3 | 90.7 | 89.2 | 78.4 | ||
| 91.5 | 91.3 | 90.8 | 89.9 | 80.9 | 52.9 | ||
| w/ Shared Expert | |||||||
| 91.5 | 91.6 | 91.7 | 91.7 | 91.6 | 91.6 | ||
| 91.6 | 91.7 | 91.7 | 91.7 | 91.7 | 91.6 | ||
| 91.6 | 91.6 | 91.7 | 91.7 | 91.7 | 91.5 | ||
层扫描。 我们通过层扫描进一步验证了结果,如表 5 所示。 当没有使用共享专家时,MoE 层数量的非合理配置会导致明显更低的准确率,这甚至比我们在 ImageNet-1K 中观察到的情况更明显。 我们将其归因于这样一个事实:在数据量较小且类别较少的数据集上,过度稀疏的架构会阻碍每个专家得到充分优化。 这些结果强化了将共享专家纳入以稳定模型收敛的必要性。 此外,对于高效的 ViMoE,当数据集包含较少的类别时,所需的路由度(i.e,专家组合的数量)确实更小。 可以观察到,仅在最深的一两层中加入 MoE 就足以实现相当高的准确率。
讨论 将 CIFAR100 的结果与 ImageNet-1K 的结果进行比较,我们观察到,当类别较少时,所需的专家数量也较少。 这与直觉相符,即让众多专家处理更简单的任务不会带来额外的好处,甚至可能带来弊端。 因此,训练数量较少的专家使其专业化和高效就足够了。
5 相关工作
专家混合 (MoE) (Jacobs 等人,1991) 因其模块化学习和减少数据域间干扰的能力而得到广泛研究 (Lewis 等人,2021;Zhou 等人,2022;Rajbhandari 等人,2022;Gou 等人,2023;Xue 等人,2024;Zhu 等人,2024)。 MoE 使用门控网络来分配哪个专家应该处理每个数据样本。 早期的 MoE 模型是密集激活的,这意味着每个输入都会触发所有专家,虽然功能上可行,但由于将每个输入通过所有专家进行处理所需的资源相当大,因此计算成本很高 (Masoudnia & Ebrahimpour,2014)。 现代主流的 MoE 模型可以看作是动态神经网络的应用 (Han 等人,2021),使用稀疏激活,只选择专家子集来处理每个输入,这大大降低了计算成本,同时保留了模型的表达能力和性能 (Hwang 等人,2023;Hazimeh 等人,2021)。 这种方法在大语言模型中变得越来越重要,因为效率和可扩展性至关重要。 NLP 中一些值得注意的作品,如 Switch Transformers (Fedus 等人,2022)、GShard (Lepikhin 等人,2020) 和 GLaM (Du 等人,2022),已成功应用稀疏 MoE,在处理大规模任务方面取得了重大进展,同时优化了资源使用率。
视觉任务中的 MoE。 近年来,MoE 在 NLP 任务中的高效率促使研究人员探索其在视觉领域的应用。 一些作品,如 V-MoE (Riquelme 等人,2021) 和 M3vit (Fan 等人,2022) 将稀疏 MoE 架构集成到 Vision Transformers 中。 通过将某些密集前馈层替换为稀疏 MoE 层,这些模型在图像分类任务中实现了高效建模,提高了计算效率和性能。 同时,pMoE (Chowdhury 等人,2023) 和 DiT-MoE (Fei 等人,2024) 引入了稀疏条件计算机制。 具体而言,pMoE 使用 CNN 作为专家,动态地为每个专家选择图像块,从而在保持泛化性能的同时降低计算成本。 DiT-MoE 优化了大型扩散 Transformer 模型中与输入相关的稀疏性,提高了图像生成的效率和性能。 此外,AdaMV-MoE (Chen 等人,2023) 和 (Wu 等人,2022) 的工作重点是多任务视觉识别和大型 MoE 视觉 Transformer 的高效训练。
用于视觉的 Transformer。 Transformer 模型最初在自然语言处理方面取得了显著成功,后来被引入计算机视觉,导致了视觉 Transformer (ViT) 的发展 (Dosovitskiy,2020)。 ViT 通过将图像划分为块并将它们视为文本中的词语,引入了图像处理的新方法,允许在整个图像上进行全局特征提取。 与依赖局部感受野的卷积神经网络 (CNN) 不同,ViT 基于 Transformer 的架构可以捕获更广泛的上下文,从而实现了与 CNN 相当或超过 CNN 的性能。 在自监督学习领域,MoCov3 (Xinlei 等人,2021) 将动量对比学习方法扩展到 ViT,成功地从未标记数据中训练出高质量的视觉特征。 受 BERT (Kenton & Toutanova,2019) 的掩码语言建模的启发,BEiT (Bao 等人,2021)、MAE (He 等人,2022) 和 iBOT (Zhou 等人,2021) 等方法通过掩码图像建模对 ViT 进行预训练,以增强模型的泛化能力和表示学习。 DINOv2 (Oquab 等人,2023) 采用基于知识蒸馏的自监督学习方法,利用更大的数据集和更长的训练周期,使其能够以无监督的方式学习鲁棒的视觉特征,进一步推动了自监督 ViT 的发展。
6 结论
在这项工作中,我们将稀疏混合专家 (MoE) 架构集成到经典的视觉 Transformer (ViT) 中,称为 ViMoE,以探索其在图像分类中的潜在应用。 我们报告了在设计 ViMoE 时遇到的挑战,特别是在没有先验指导的情况下确定 MoE 层的配置,因为不合适的专家安排会对收敛产生负面影响。 为了缓解这个问题,我们引入了共享专家来稳定训练过程,从而简化了设计,无需重复试验来找到最佳配置。 此外,通过观察路由行为和专家之间样本的分布,我们识别了对数据进行分而治之处理至关重要的 MoE 层。 这些见解使我们能够改进 ViMoE 架构,从而实现效率和竞争性能。 我们希望这项工作能为视觉任务的 MoE 模型设计提供新的见解,并为未来的研究提供宝贵的经验指导。
参考文献
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Bao et al. (2021) Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
- Cao et al. (2023) Bing Cao, Yiming Sun, Pengfei Zhu, and Qinghua Hu. Multi-modal gated mixture of local-to-global experts for dynamic image fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 23555–23564, 2023.
- Chen et al. (2023) Tianlong Chen, Xuxi Chen, Xianzhi Du, Abdullah Rashwan, Fan Yang, Huizhong Chen, Zhangyang Wang, and Yeqing Li. Adamv-moe: Adaptive multi-task vision mixture-of-experts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 17346–17357, 2023.
- Chowdhury et al. (2023) Mohammed Nowaz Rabbani Chowdhury, Shuai Zhang, Meng Wang, Sijia Liu, and Pin-Yu Chen. Patch-level routing in mixture-of-experts is provably sample-efficient for convolutional neural networks. In International Conference on Machine Learning, pp. 6074–6114. PMLR, 2023.
- Dai et al. (2024) Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. arXiv preprint arXiv:2401.06066, 2024.
- Daxberger et al. (2023) Erik Daxberger, Floris Weers, Bowen Zhang, Tom Gunter, Ruoming Pang, Marcin Eichner, Michael Emmersberger, Yinfei Yang, Alexander Toshev, and Xianzhi Du. Mobile v-moes: Scaling down vision transformers via sparse mixture-of-experts. arXiv preprint arXiv:2309.04354, 2023.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Dosovitskiy (2020) Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Du et al. (2022) Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al. Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning, pp. 5547–5569. PMLR, 2022.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Eigen et al. (2013) David Eigen, Marc’Aurelio Ranzato, and Ilya Sutskever. Learning factored representations in a deep mixture of experts. arXiv preprint arXiv:1312.4314, 2013.
- Fan et al. (2022) Zhiwen Fan, Rishov Sarkar, Ziyu Jiang, Tianlong Chen, Kai Zou, Yu Cheng, Cong Hao, Zhangyang Wang, et al. M3vit: Mixture-of-experts vision transformer for efficient multi-task learning with model-accelerator co-design. Advances in Neural Information Processing Systems, 35:28441–28457, 2022.
- Fedus et al. (2022) William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022.
- Fei et al. (2024) Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, and Junshi Huang. Scaling diffusion transformers to 16 billion parameters, 2024.
- Gou et al. (2023) Yunhao Gou, Zhili Liu, Kai Chen, Lanqing Hong, Hang Xu, Aoxue Li, Dit-Yan Yeung, James T Kwok, and Yu Zhang. Mixture of cluster-conditional lora experts for vision-language instruction tuning. arXiv preprint arXiv:2312.12379, 2023.
- Han et al. (2021) Yizeng Han, Gao Huang, Shiji Song, Le Yang, Honghui Wang, and Yulin Wang. Dynamic neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11):7436–7456, 2021.
- Hazimeh et al. (2021) Hussein Hazimeh, Zhe Zhao, Aakanksha Chowdhery, Maheswaran Sathiamoorthy, Yihua Chen, Rahul Mazumder, Lichan Hong, and Ed Chi. Dselect-k: Differentiable selection in the mixture of experts with applications to multi-task learning. Advances in Neural Information Processing Systems, 34:29335–29347, 2021.
- He et al. (2022) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000–16009, 2022.
- Hwang et al. (2023) Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, et al. Tutel: Adaptive mixture-of-experts at scale. Proceedings of Machine Learning and Systems, 5:269–287, 2023.
- Jacobs et al. (1991) Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991.
- Jiang et al. (2024) Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
- Jordan & Jacobs (1994) Michael I Jordan and Robert A Jacobs. Hierarchical mixtures of experts and the em algorithm. Neural computation, 6(2):181–214, 1994.
- Kenton & Toutanova (2019) Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT, volume 1, pp. 2. Minneapolis, Minnesota, 2019.
- Lepikhin et al. (2020) Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668, 2020.
- Lewis et al. (2021) Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. Base layers: Simplifying training of large, sparse models. In International Conference on Machine Learning, pp. 6265–6274. PMLR, 2021.
- Liu et al. (2024) Zhili Liu, Kai Chen, Jianhua Han, Lanqing Hong, Hang Xu, Zhenguo Li, and James T Kwok. Task-customized masked autoencoder via mixture of cluster-conditional experts. arXiv preprint arXiv:2402.05382, 2024.
- Masoudnia & Ebrahimpour (2014) Saeed Masoudnia and Reza Ebrahimpour. Mixture of experts: a literature survey. Artificial Intelligence Review, 42:275–293, 2014.
- Oquab et al. (2023) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Rajbhandari et al. (2022) Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale. In International conference on machine learning, pp. 18332–18346. PMLR, 2022.
- Reid et al. (2024) Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Riquelme et al. (2021) Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mixture of experts. Advances in Neural Information Processing Systems, 34:8583–8595, 2021.
- Shazeer et al. (2017) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- Sun et al. (2021) Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14454–14463, 2021.
- Touvron et al. (2021) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pp. 10347–10357. PMLR, 2021.
- Wang et al. (2017) Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, Cheng Li, Honggang Zhang, Xiaogang Wang, and Xiaoou Tang. Residual attention network for image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3156–3164, 2017.
- Wu et al. (2022) Lemeng Wu, Mengchen Liu, Yinpeng Chen, Dongdong Chen, Xiyang Dai, and Lu Yuan. Residual mixture of experts. arXiv preprint arXiv:2204.09636, 2022.
- Xinlei et al. (2021) Chen Xinlei, Xie Saining, and He Kaiming. An empirical study of training self-supervised visual transformers. arXiv preprint arXiv:2104.02057, 8:7, 2021.
- Xue et al. (2022) Fuzhao Xue, Ziji Shi, Futao Wei, Yuxuan Lou, Yong Liu, and Yang You. Go wider instead of deeper. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 8779–8787, 2022.
- Xue et al. (2024) Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchunshu Zhou, and Yang You. Openmoe: An early effort on open mixture-of-experts language models. arXiv preprint arXiv:2402.01739, 2024.
- Yang et al. (2024) An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024.
- Zhang et al. (2022) Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605, 2022.
- Zhou et al. (2021) Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832, 2021.
- Zhou et al. (2022) Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. Mixture-of-experts with expert choice routing. Advances in Neural Information Processing Systems, 35:7103–7114, 2022.
- Zhu et al. (2024) Tong Zhu, Xiaoye Qu, Daize Dong, Jiacheng Ruan, Jingqi Tong, Conghui He, and Yu Cheng. Llama-moe: Building mixture-of-experts from llama with continual pre-training. arXiv preprint arXiv:2406.16554, 2024.
- Zoph et al. (2022) Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906, 2022.