AlpacaFarm:从人类反馈中学习的各种方法的模拟框架
摘要
由于 ChatGPT 等大型语言模型(LLM)能够很好地遵循用户指令,因此得到了广泛应用。 这些 LLM 的开发涉及到一个复杂但又鲜为人知的工作流程,需要通过人工反馈进行培训。 复制和理解这一指令遵循过程面临三大挑战:数据收集成本高昂、缺乏值得信赖的评估,以及缺乏参考方法的实施。 我们通过 AlpacaFarm 来应对这些挑战,该模拟器能够以较低的成本从反馈中进行学习研究和开发。 首先,我们设计了 LLM 提示来模拟人类的反馈,其成本比众包工低 45 倍,并且与人类的反馈具有很高的一致性。 其次,我们提出了一种自动评估方法,并根据真实世界交互中获得的人类指令对其进行了验证。 第三,我们为从成对反馈中学习的几种方法(PPO、最佳、专家迭代等)提供了参考实现。 最后,作为对 AlpacaFarm 的端到端验证,我们在 10k 对真实人类反馈上对 11 个模型进行了训练和评估,结果表明,在 AlpacaFarm 中训练的模型的排名与在人类数据上训练的模型的排名相吻合。 作为对 AlpacaFarm 研究成果的展示,我们发现使用奖励模型的方法比监督微调的方法有很大改进,我们的参考 PPO 实现比 Davinci003 的胜率提高了 10%。 我们在 https://github.com/tatsu-lab/alpaca_farm 发布 AlpacaFarm 的所有组件。
1导言
大型语言模型(LLMs)(Bommasani21,;Brown20,;OpenAI23,)在遵循多样化和开放式指令方面展示了前所未有的能力(Ouyang22,;Askell21,;Longpre23,)。 这些成就往往归功于利用人工反馈对预训练 LLM 进行的微调,但由于 LLM 供应商缺乏有关训练方法的公开信息,人们对这一过程仍然知之甚少。 例如,最近有人发现,在 OpenAI 模型的指导系列中,只有 Davinci003 模型使用了强化学习(RL)和 PPO 算法 OpenAI*a ,这让一些人质疑 RL 在训练过程中的重要性。 要了解和改进这些方法,需要对训练过程进行公开透明的复制,但由于从人类反馈中学习的方法成本高、复杂性大,这仍然具有挑战性。
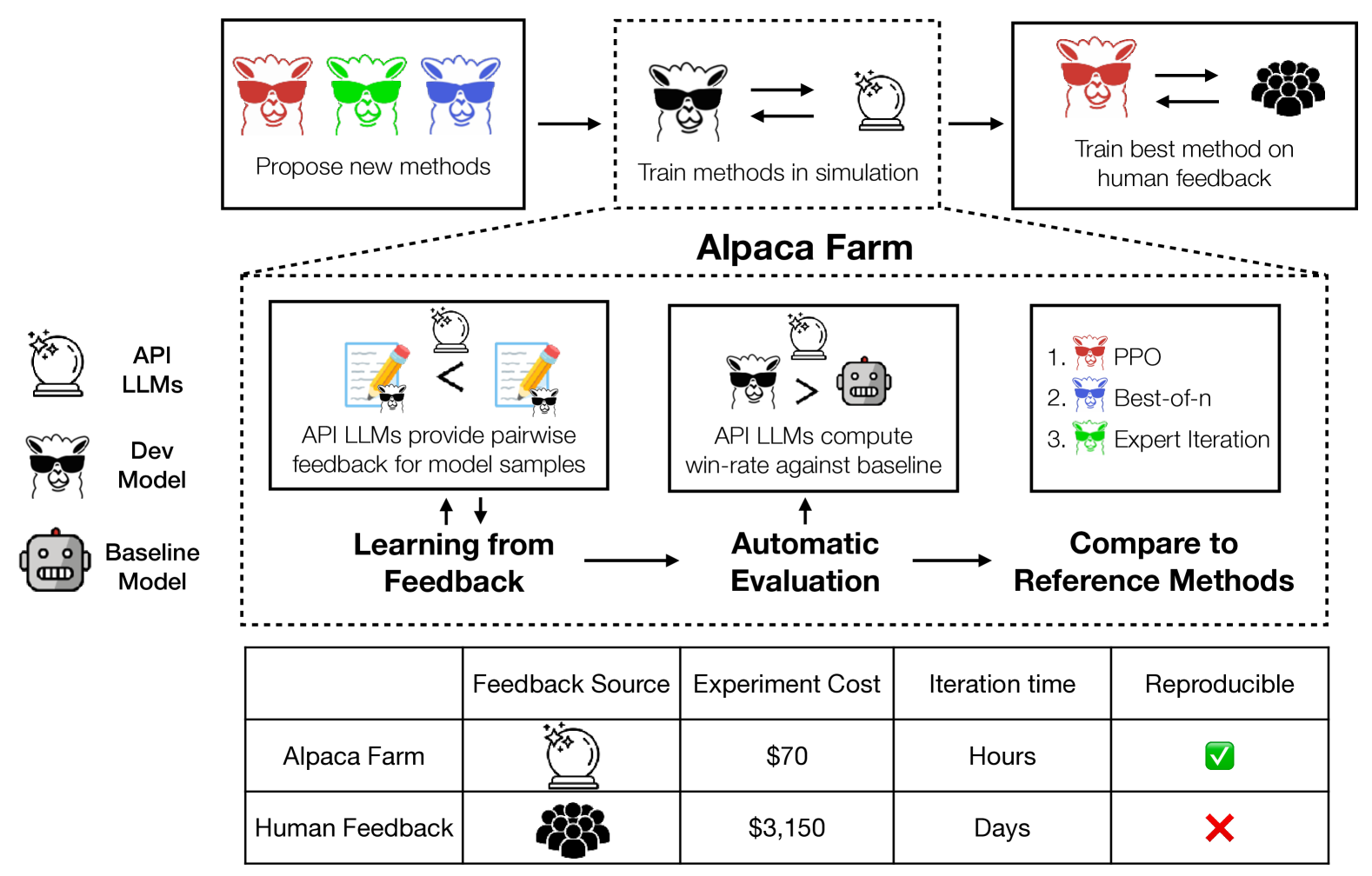
我们的目标是促进研究和开发从人类反馈中学习的教学模式和方法。 我们发现了三个主要挑战:数据标注成本高昂、模型开发缺乏自动评估以及现有方法缺乏有效实现。 为了应对这三个挑战,我们引入了 AlpacaFarm(图 1),它是一个仿真沙箱,能以低成本进行实验。 利用 AlpacaFarm,研究人员可以在模拟中快速迭代方法开发,并将这些见解用于构建具有实际人类反馈的高性能系统。
对于数据注释成本的第一个挑战,AlpacaFarm 使用速度更快、成本更低的 API LLM 来模拟人类标注员。 为了收集模拟反馈数据,我们为 API LLMs(如 GPT-4)设计了提示语,使我们能够以比众包工便宜 45 倍的成本模拟人类配对比较,并调整这些提示语,以忠实地捕捉人类标注者的许多方面,如他们的质量判断、标注者之间的差异性和文体偏好。
对于自动评估的第二个挑战,我们设计了一个自动评估协议,试图量化系统在简单但真实的人类指令上的性能。 由于人工评估的成本和不可复制性、缺乏真实的人机交互数据以及自然人指令的多样性,改进对开放式指令的评估一直是一项挑战。 为了解决这个问题,我们使用用户交互中的指令(Alpaca Demo (Taori23,))作为简单但真实的人类交互的参考,并证明我们可以结合现有的公共评估数据集来模仿这种评估。 根据我们的评估数据对系统排名进行的定量评估显示,系统排名与羊驼演示指令的排名高度相关。
针对缺少参考实现的第三个挑战,我们实现并测试了几种流行的学习算法,包括 PPO (Schulman17, ), 专家迭代 (Anthony17, ), Quark Lu22*b , 并发布了参考实现。 我们的研究表明,在我们研究的方法中,使用代理奖励模型的 PPO 是训练时间最有效的方法,它将指令微调 LLaMA 7B 模型对抗 Davinci003 的胜率从 44% 提高到 55%。 相比之下,在较简单任务上验证过的其他基线算法就显得不足了,这也凸显了在真实指令跟随环境中测试这些算法的重要性。
作为对 AlpacaFarm 的端到端评估,我们将在 AlpacaFarm 中训练和评估的 11 种方法与在实际人类反馈中训练和评估的相同方法进行了比较。 我们的研究表明,在 AlpacaFarm 上开发的方法排名与在实际人类数据上训练获得的方法排名非常吻合(Spearman 相关性为 0.98),而且 AlpacaFarm 中的最佳方法在人类反馈的帮助下获得了巨大的收益。 最后,我们发现 AlpacaFarm 可以复制人类反馈的定性行为,如奖励模型的过度优化,这表明 AlpacaFarm 是研究人员快速研究和开发从人类反馈中学习方法的有效途径。
2背景与问题陈述
首先,我们将介绍我们所研究的指令遵循任务和基于成对比较的人类反馈设置。 在这一背景下,我们正式确定了开发低成本模拟器的目标,用于研究指令遵循和从人类反馈中学习。
2.1学会听从指令
在任务 Ouyang22 ; Bai22*a ; Wang22*b ; Longpre23 之后的指令中,我们会看到用户指令 (例如:"说说羊驼吧")。"告诉我一些关于羊驼的事情")、我们的目标是开发一个模型,以生成高质量的回复
虽然有大量方法可以通过学习人类反馈来直接优化 (请参阅 Section 6),但由于 learning from pairwise feedback (LPF) 在最近的指令遵循 LLM 中发挥了核心作用,因此我们在本工作中将重点放在 learning from pairwise feedback (LPF) 的设置上。 这一过程的起点是在指令遵循样例 上进行微调的模型,我们表示为 。 LPF 过程包括从 中提取成对样本,询问人类每对样本中哪个样本更好,并从成对反馈中学习。 由于所有方法都以 SFT 为起点,我们使用 来简化符号。
成对反馈学习(LPF)。
更正式地说,我们将成对反馈数据集定义为 . 在此符号中,人工注释器对两个候选回答进行评分 的指令 。 这些二元评级 假设是根据其未观察到的奖励 生成的,表示(可能是随机的)比较更好的响应 、where .
人们提出了许多算法来学习 。 有些算法(如 RLHF Christiano17*b;Ouyang22)学习一个替代奖励函数作为学习信号,有些算法则更直接地在 上运行。 关于不同学习算法的讨论,我们将推迟到 节 3.4。
配对评估。
2.2问题陈述
羊驼农场的目标是提供三个关键组成部分,以便快速研究和开发以下教学模式:低成本成对反馈生成器、用于方法开发的自动评估以及用于比较和修改的参考实施。 有了这三个组成部分,研究人员就能开发出新的模拟方法,并将这些见解应用于根据实际人类反馈构建高性能系统。
对于成对反馈、我们用人类偏好判断来替代 ,并模拟偏好 using API LLMs. 我们的目标是构建一个 ,它既能降低成本,又能忠实地捕捉人类偏好反馈的不同方面,如质量判断、注释者之间的一致率和文体偏好。
在评估方面,我们使用成对偏好模拟器对系统输出进行评估,并确定了反映人类与 LLM 自然交互的评估数据集。 我们的评估目标是确保系统在新的评估数据集上的排名与人类排名以及根据 Alpaca Demo 的实际使用情况得出的指令排名密切吻合。
作为参考方法,我们开发并评估了六种 LPF 方法。 我们的目标是提供简单可行的实施方案,在模拟数据和人类反馈数据方面都有实质性的改进。 这将使研究人员能够在复杂的教学环境中,以竞争基线为基础并与之进行比较。
AlpacaFarm 将这三个组成部分结合到一个模拟框架中,用于从配对反馈中学习。 我们通过端到端的工作流程对整个系统进行评估,即在模拟中开发方法,并将洞察力转移到现实世界中。
3建造 AlpacaFarm
在本节中,我们将详细介绍如何构建羊驼农场。 在 节 4中,我们将通过比较 LPF 工作流程与人工反馈和评估来验证我们的设计选择。
3.1指令遵循数据
在定义如何模拟成对反馈的细节之前,我们必须首先指定一组大型且多样化的指令集 ,我们可以在其上构建 AlpacaFarm 的其余部分。 我们选择使用 Alpaca 数据(Taori23,) 作为起点,因为它的数据量很大(52k 个 样本),而且在此数据上训练的模型具有非同一般的指令遵循能力。
我们采用与 Ouyang22 类似的数据分割比例,将 Alpaca 数据转换为适合从人类反馈方法中学习的分割数据。 我们创建了四个分片(总共 42k),为未来留下 10k:
-
•
监督微调 (SFT) 分割:10K 数据用于微调后续步骤中使用的基本指令跟随 LLM。
-
•
成对偏好 (PREF) 分割:我们将收集成对反馈数据的 10k 条指令。
-
•
无标记分割:20 千条无标记指令,用于 PPO 等算法。
-
•
验证分割:2k 数据用于开发和调优。
3.2设计模拟配对偏好
配备 Alpaca 指令数据后,我们现在描述针对成对偏好的模拟标注工具的设计。 我们的核心提议是通过提示 OpenAI API LLM 设计模拟工具 。 虽然使用 LLM 作为标注工具的代理已变得越来越流行(Chiang23,;Liu23*a,),但将 LLM 用作仿真环境的一部分会带来更多重大挑战。 我们的模拟偏好不仅必须与人类偏好高度一致,还必须捕捉到人类反馈的其他定性方面,如标注者之间和标注者内部的不一致性。 直观地说,成对反馈中的噪声和差异是 LPF 问题所面临挑战的关键部分,我们发现,忽略这些因素会导致模拟工具与真实世界的行为严重背离(节 4.3)。
基本的 GPT-4 提示设计。
首先,我们在设计提示时,会提供适当回答的指南,提供 in-context 示例,并利用批量生成来节约成本。 作为第一条基线,我们使用单个提示来查询 GPT-4(表示为 ),我们发现 与人类标注人员的一致率很高(65%;见 Section 4.3中的结果)。 然而,我们发现 的这个简单基线无法捕获人类标注中的差异性并且可能导致方法开发产生不同质量的结果,尤其是奖励过度优化(4.3 节 )。
模拟人类的差异
为了更全面地模拟人类标注人员,我们修改基本的模拟标注工具设计,以两种方式捕捉标注人员的差异性。 首先,我们通过模拟一组注释者来模拟配对偏好中注释者之间的差异性。 我们通过查询不同的 API LLM,并以不同的格式、批量大小和上下文示例来改变提示,从而设计出不同的标注工具。 最终,我们创建了 13 个模拟标注器,我们将在附录 C中对其进行全面描述。其次,我们通过直接注入随机噪音和翻转模拟偏好 来模拟标注人员内部的差异性。
有了这些成分,我们就得到了一个模拟偏好 ,它符合我们对一致性和可变性的要求。 总体而言,使用模拟偏好标注 1000 个输出结果仅需 6 美元,比人工标注便宜 50 倍。 在 节 4中,我们收集了人类的实际偏好,并定量验证了模拟偏好的一致性和差异性。
3.3设计自动评估
对于在 AlpacaFarm 中开发 LPF 方法的研究人员来说,我们希望通过自动评估为他们提供支持,这样他们就能在可靠地比较各种方法的同时快速进行迭代。 要取代通常的人工评估,有两个挑战。 首先,我们如何量化不同模型输出的质量? 其次,我们可以使用哪些能代表人类互动的指令?
评估规程。
为了量化 LLM 的质量,我们测量了该 LLM 相对于参考模型的胜率,即在相同指令 上, 的输出优于参考模型 的输出的预期次数。 使用模拟胜率的好处在于,它提供了一个易于理解的指标,在单一参考模型的条件下,不同方法之间具有可比性,并且可以重复使用我们为配对反馈建立的例程。 我们使用 节 3.2 中描述的 13 个模拟注释器,不注入额外的噪声(因为添加均匀噪声不会改变模型排名),并将此偏好模拟器称为 。 我们使用 Davinci003 作为参考模型,因为它是一个经过充分研究的系统,与我们微调的模型性能相似。
评估数据。
要进行后续教学,就需要对现实的互动进行多样化的覆盖。 为了建立一个合适的评估协议,我们结合了几个开源评估数据集,并使用与演示指令跟踪 LM(Alpaca Demo (Taori23,))的真实交互作为构建数据组合的指导。 出于对隐私的考虑,我们没有直接发布演示数据,而是选择用它来指导我们如何结合现有的开放评估数据集。
我们的最终评估数据集包含 805 条指令,其中 252 条指令来自自我指导评估集 (Wang22*b,),188 条指令来自开放助手(OASST)评估、129条来自Anthropic发布的有用评价(Bai22*a, ), 80条来自Vicuna评价(Chiang23, ), 156条来自Koala评价(Geng23, ). 在表 1和图 2中,我们展示了评估数据集中的示例指令及其动词词根分布,这显示了评估数据的多样化覆盖范围。 我们发现,如 节 4.4所述,跨数据集汇总对于自动评估匹配真实世界中的交互非常重要。

3.4羊驼农场中的参考方法
最后,羊驼农场为以下指令定义了一系列经过验证的 LPF 方法。 我们将在附录 A中提供更详细的方法说明,并在此提供简要概述。 在接下来的所有 LPF 方法中,我们首先对指令和输出的监督数据执行初始微调步骤。
首先,我们将介绍两个简单的基线,它们直接作用于成对反馈。
-
•
二进制 FeedME。 二进制 FeedME (OpenAI*a,) 在每次成对比较中继续对首选输出进行监督微调。
- •
许多 LPF 方法并不直接处理成对反馈数据,而是首先利用成对反馈对 SFT 基础分类器进行微调,从而构建一个代理奖励模型。 以下 LPF 方法可以最大化该分类器对数定义的连续值奖励。
-
•
最佳抽样。 最佳(或重新排序)(Stiennon20,;Askell21,;Glaese22,;Bakker22,)是一种简单而有效的推理时方法,可得出i.i.d。 并返回代奖励最高的响应。
-
•
专家迭代。 专家迭代 (Anthony17,;Silver17,;Uesato22,) 是 best-of- 的自然训练时间扩展:它首先根据 best-of- 生成新指令,然后根据最佳输出进行微调。
-
•
近端策略优化 (PPO)。 PPO (Kakade02,;Schulman17,)是一种流行的强化学习算法,它可以最大化代偿奖励,并受到 KL 惩罚,使参数保持在 SFT 初始化附近。
-
•
Quark. 我们使用 Quark Lu22*b 的顶阙值变体,它按奖励对序列进行分级,并在最佳分级上进行训练,同时添加 KL 和熵正则化。
4验证羊驼农场模拟器
在定义了模拟器和方法之后,我们现在就可以对 AlpacaFarm 进行评估了。 在 节 4.2中,我们分析了模拟 LPF 工作流程和基于人工的 LPF 方法最终排名之间的相关性,这是我们的主要结果。 随后,我们将分析模拟器中的详细设计选择,确定我们的配对反馈是否准确模拟了人类的配对反馈(部分 4.3),以及我们的评估数据排名是否与羊驼演示数据排名一致(部分 4.4)。

4.1实验细节
模型
作为 LPF 方法的基线和起点,我们在 10k SFT 分割上对 LLaMA 7B 进行了微调。 我们将 SFT 10k 作为所有 LPF 方法的起点,并从 SFT 10k 的输出(temp=1.0)中收集 10k 指令 PREF 分割的模拟偏好 和人类偏好 。
然后,对六种参考 LPF 方法中的每一种方法 :
-
•
我们在模拟偏好上训练和调整了,并使用模拟评估器针对 Davinci003 参考文献评估了生成的模型。
-
•
我们根据在模拟中确定的超参数范围对人类的偏好训练了几个模型 ,并将得到的模型 与 Davinci003 中的人类 进行了对比评估。
除了这六种方法外,我们还对现有的标准指令和基础模型进行了评估:GPT-4 (gpt-4-0314)、ChatGPT (gpt-3.5-turbo-0301)、Davinci001 (text-davinci-001)、LLaMA 7B (Touvron23, ) 和 Alpaca 7B (Taori23, ). Alpaca 7B 是一个 LLaMA 7B 模型,在所有数据分片(表示为 SFT 52k)的串联上进行了微调。 对于这些模型,我们同时测量模拟胜率 和人类胜率 。
在推理时,对于除 best-of- 以外的所有系统,我们都以 temp=0.7 进行采样,并将标记数上限设置为 300。 对于最佳采样,我们发现较高的温度有助于促进输出多样性,因此我们使用 temp=1.0 对来自 SFT 10k 的样本进行了重排。 我们将在附录 B中提供所有方法的更详尽的实验细节和超参数。
人类标注
我们通过向人群工作者展示给定指令 的两个潜在输出 或 来收集参考人类注释,并要求他们选择索引 其首选输出。 注释员是从亚马逊 Mechanical Turk 网站上通过 25 个问题的资格测试招募的。 在最初的 34 位注释者中,我们选出了与作者注释一致率高于 70% 的 16 位注释者。 我们向注释者支付的时薪中位数为 21 美元,因此注释 PREF 拆分模型的一次性成本为 3000 美元,而在 805 条评估指令上评估单个模型的经常性成本为 242 美元。 更多详情,包括我们提供的注释接口,请参见附录 D。
4.2羊驼农场的端到端验证
现在我们来分析模拟排名和人类数据排名之间的相关性。 图 3显示了 AlpacaFarm 方法的胜率(x 轴)和基于人工的管道的胜率(y 轴)。 我们看到,这些排名的斯皮尔曼相关性为 0.98,这表明 AlpacaFarm 忠实地捕捉到了不同 LPF 方法之间的排名。 这使研究人员能够在低成本的 AlpacaFarm 环境中开发模型,并将这些见解用于训练真实世界中人类互动的模型。
仔细观察这些结果,我们会发现两个等级不匹配的问题。 第一项比较是 SFT10k 与 SFT52k,其中人类注释者更倾向于 SFT10k(44.3% vs 40.7%),而模拟器的偏好正好相反(36.7% vs 39.2%,表 2)。 另一个不匹配现象是 ChatGPT 与 PPO 的对比,与模拟器(46.8% 对 61.4%)不同,人类注释者更喜欢 PPO(55.1% 对 52.9%)。 在这两种情况下,这些都不是重大错误,因为我们并不指望 SFT52k 比 SFT10k 差多少,也不指望 7B LLaMA 模型大大优于 ChatGPT。
4.3验证成对偏好组件
在证明了 AlpacaFarm 在方法排名的端到端验证方面取得成功之后,我们现在来仔细研究一下我们的配对偏好,结果表明它们与人类注释者具有很高的一致性,并且复制了模型训练的重要定性特征。 有关其他详细信息,请参见 附录 C 。

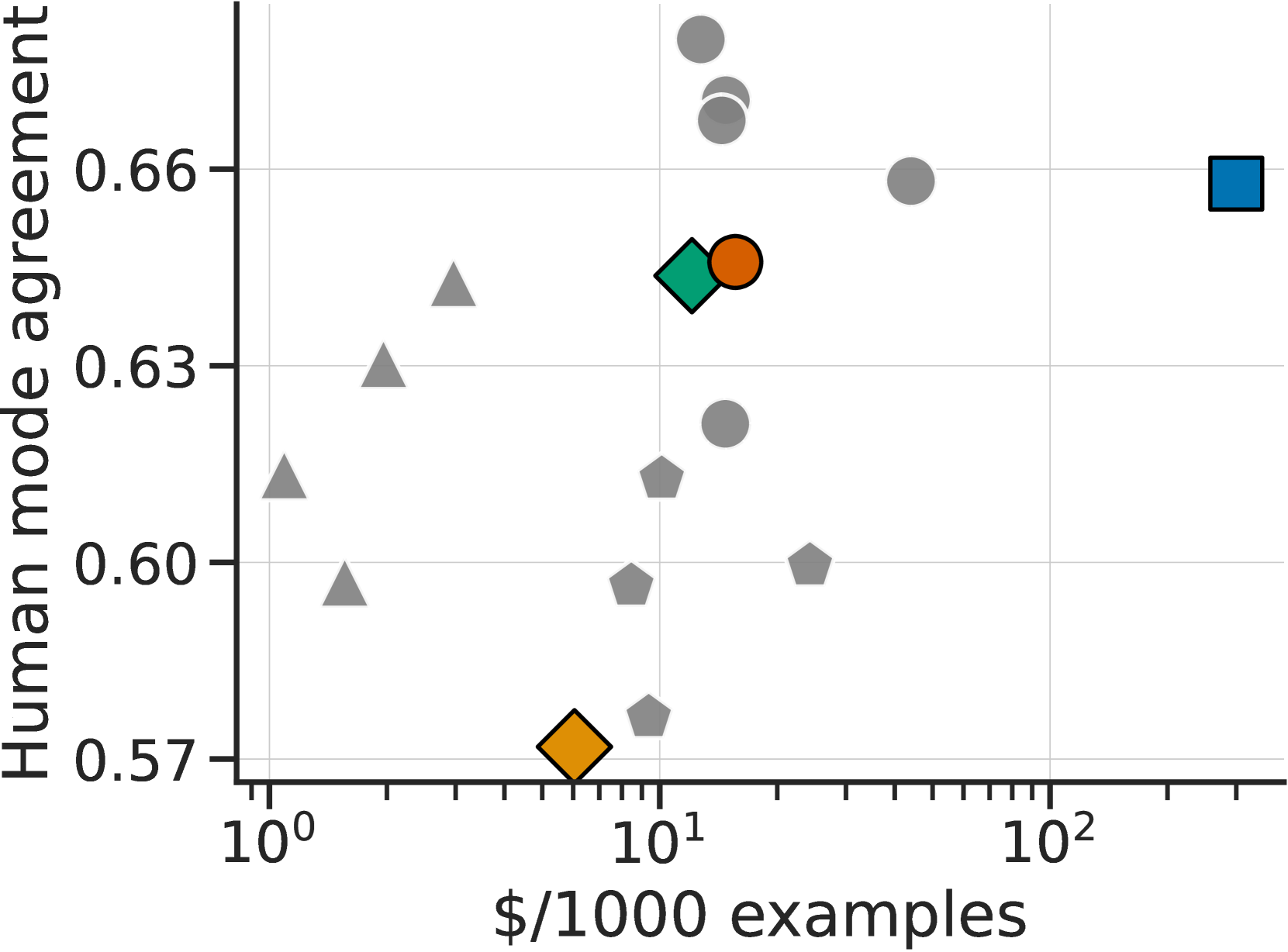

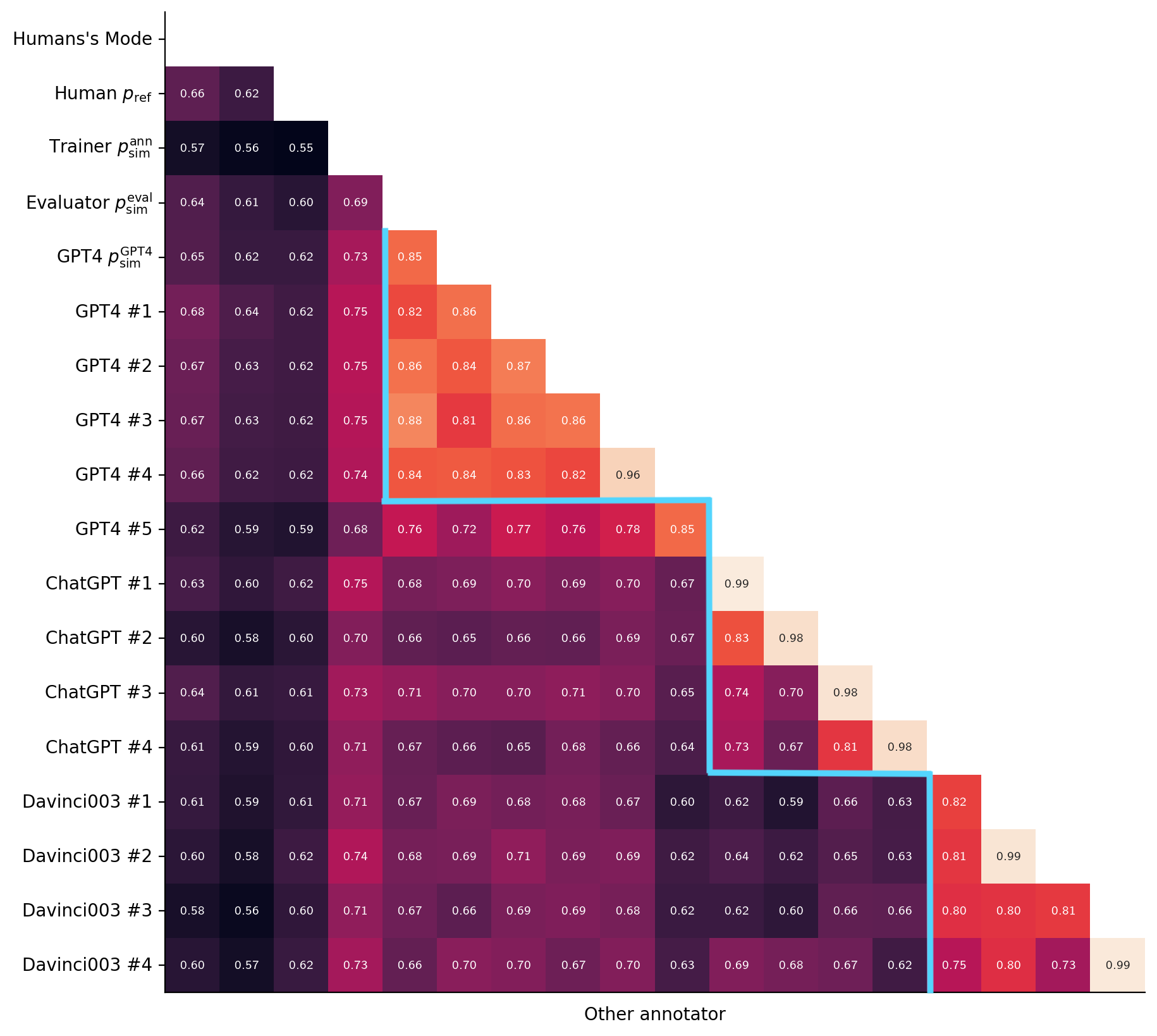
模拟注释者与人类一致
我们首先计算模拟注释器与 3 位人类注释器多数票之间的一致程度,并将其与一位未参与注释的人类注释器的一致程度进行比较,如 图 4所示。 我们发现,我们的评估器 (绿色)与人类多数票的一致率为 65%,与人类保持的一致率 66%(蓝色)相似。 同时,的价格更便宜(每 1000 个示例 300 $12 美元)。 由于标签翻转噪声,训练时间注释器 (黄色)的一致性较低,但这并不意味着 对人类注释的忠实度较低、因为这种噪声是无偏的,而且两个注释器(、)代表的基本偏好函数是相同的。
图 4还显示,我们发现了一些比 表现更好的单个提示,其中一个 GPT-4 提示的一致性达到了 68%。 虽然这种高度的一致性令人印象深刻,但我们并没有在 AlpacaFarm 中直接使用单一提示,因为单一提示无法复制对模拟器来说非常重要的标注者之间的差异性。 相反,我们需要对不同的注释者进行随机化处理,并注入额外的噪声,以匹配人类数据的分布特征和学习动态。
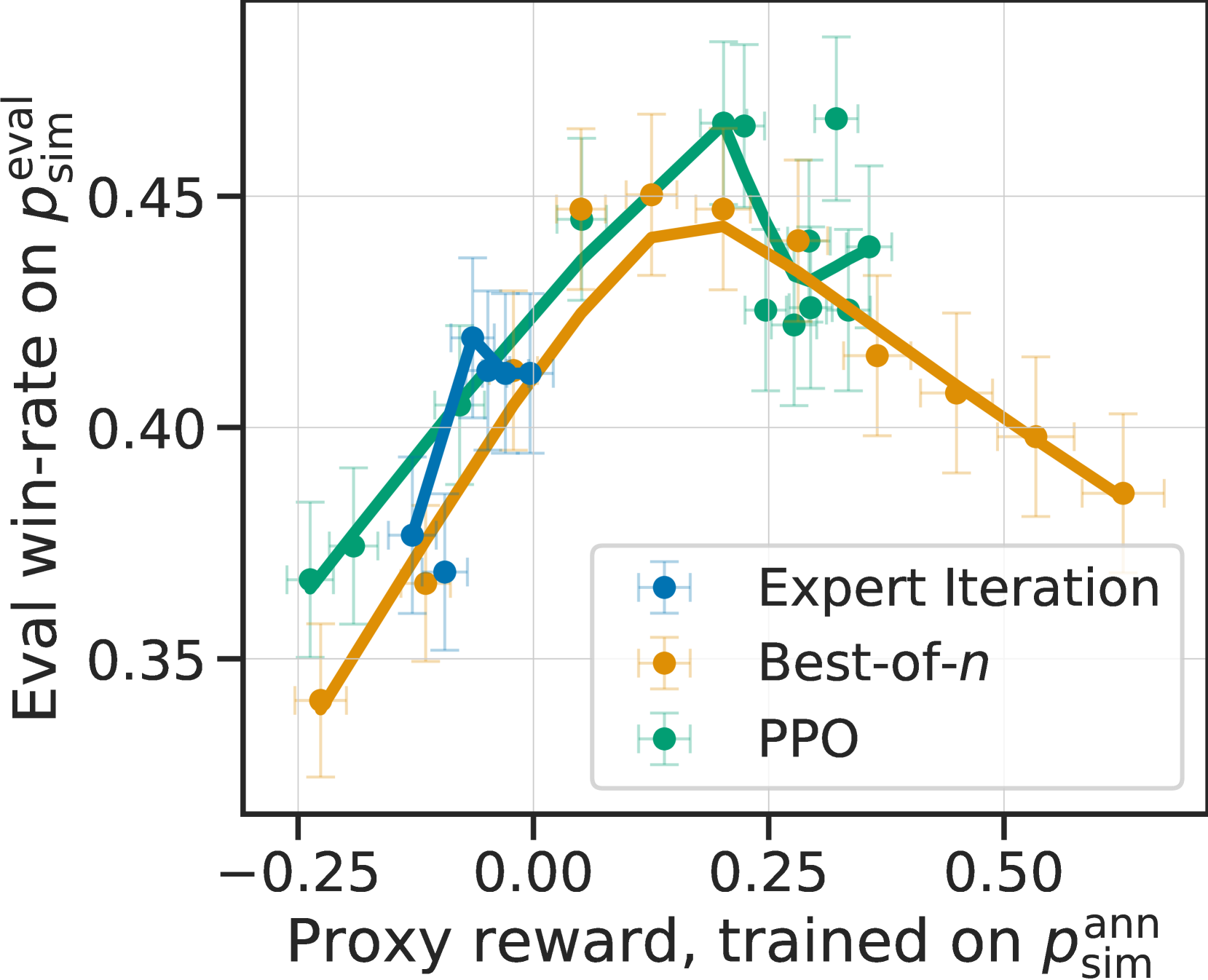
模拟注释器复制了过度优化。
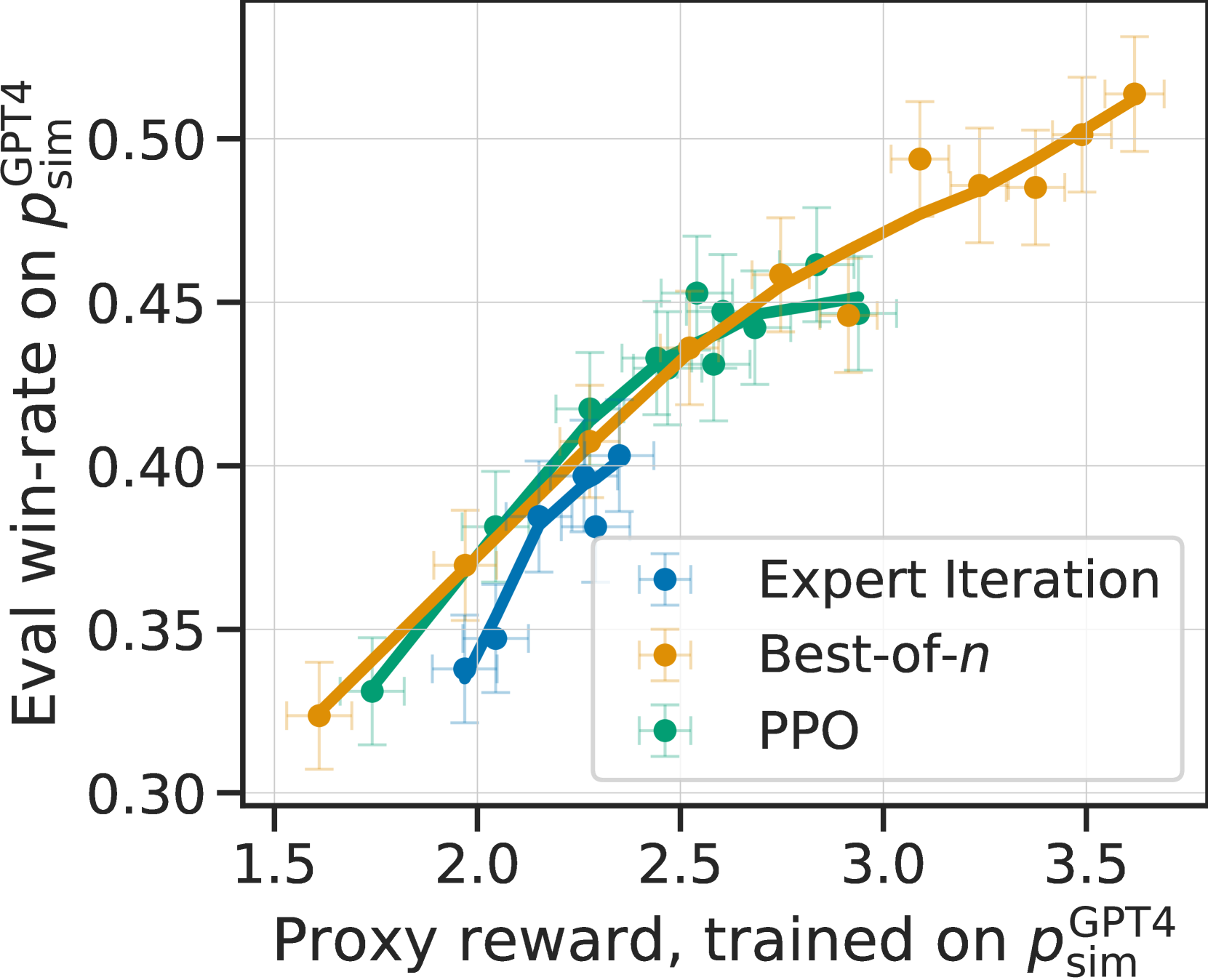
我们现在要说明的是,在模拟注释器()中模拟注释器的可变性对于捕捉 LPF 模型训练的重要定性特征是必要的。 为此,我们比较了在和使用单一 GPT-4 提示下训练的三个表现最好的模型的行为,后者具有更高的人类一致性,但注释者的变异性很小。
图 5(c)显示了这些模型在 (左)、(中)配对反馈时的学习动态、和 (右),随着最佳和专家迭代的 PPO 迭代次数和重排样本数的增加。 对于人类和羊驼农场的偏好而言,更有效地优化代用奖励(x 轴)的模型会提高胜率(y 轴),直到出现奖励过度优化、胜率下降的情况。 与此相反,简单的 GPT-4 反馈没有显示出过度优化,这导致了一个错误的结论,即 LPF 方法可以优化的时间比实际情况要长得多。 例如,图 5(c)右侧显示 best-of- 比 PPO 好得多,这与人类数据的结果大相径庭。
先前的工作Gao22 指出,过度优化是代理奖励模型对真实奖励不完全估计的结果。我们假设,在人类注释者身上看到的强烈过度优化部分是由于他们注释的(内部和内部)可变性,这降低了奖励模型的质量。 为了验证这一假设,我们通过计算 3 次随机抽签中被排除在外的注释对多数票的平均误差,测量了三位注释者各自的方差。 的方差为 0.26,的方差为 0.43,AlpacaFarm 的方差接近人类的 0.35;相比之下,GPT-4 注释者的方差要低得多,仅为 0.1。 最后,在 节 E.1中,我们对 AlpacaFarm 的设计进行了更精细的消减,发现增加的标签噪声为诱导过度优化提供了大部分益处。 附录 C包含对注释者偏差和差异性的进一步分析。
4.4验证评估方案
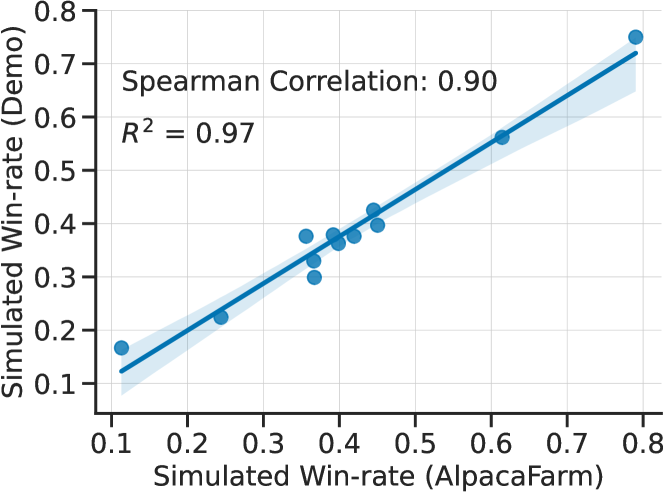
最后,我们结合现有的开源评估数据集,对我们的评估数据进行了测试。 虽然我们注意到该数据集具有多样性(见 图 2),但尚不清楚该数据集是否评估了现实世界中人类使用的任何类型的性能。 为了解决这个问题,我们根据在 Alpaca Demo (Taori23,)上记录的一组真实用户交互来测量方法级相关性。 我们手动查看了这些互动,找出了 200 条不包含任何个人身份信息、有毒或不安全问题的指令,以及直接指向聊天机器人的指令(例如 "你是由谁开发的?) 演示的使用条款不允许我们公开发布这些数据,但我们使用这些数据来评估所提出的评估集。
我们使用与 图 3中显示的相同的 11 个系统,在模拟中训练 LPF 方法,并使用 对其进行评估。 图 6将演示说明中的模拟胜率与羊驼农场评估数据中的模拟胜率进行对比。 这两个胜率具有很强的相关性(),表明羊驼农场的评估数据可以作为评估简单演示互动方法的替代数据。
5AlpacaFarm 基准测试参考方法
| 方法 | 模拟胜率 (%) | 人类胜率 (%) |
|---|---|---|
| GPT-4 | ||
| ChatGPT | ||
| PPO | ||
| Best-of- | ||
| Expert Iteration | ||
| SFT 52k (Alpaca 7B) | ||
| SFT 10k | ||
| Binary FeedME | ||
| Quark | - | |
| Binary Reward Conditioning | - | |
| Davinci001 | ||
| LLaMA 7B |
现在我们来研究参考方法在羊驼农场中的表现。 表 2包含主要评估结果的详细信息(在图 3中以图表形式展示)。 在本节的其余部分,我们将讨论我们从这些结果中得出的结论,证明我们通过人工反馈得出的结论本可以通过羊驼农场以更低的成本获得。
5.1比较 LPF 方法
监督微调非常有效。
表 2显示,SFT 步骤非常有效,提高了大部分胜率。 SFT 使基本 LLaMA 模型的模拟器胜率从 上升到 ,人类胜率从 上升到 。 然而,我们观察到,从 SFT 10k 到 SFT 52k 几乎没有增益。
PPO 在 LPF 排行榜上名列前茅。
在我们研究的 LPF 方法中,PPO 在模拟器()和人类反馈数据()中的表现都是最好的。 值得注意的是,我们的人类注释者认为,在单轮指令跟随中,根据人类反馈训练的 PPO 的胜率为,优于 ChatGPT。
最佳简单且具有竞争力。
除 PPO 外,最佳采样优于所有 LPF 方法。 最佳采样的出色性能表明奖励模型捕捉到了有用的学习信号,有助于我们理解训练时间 LPF 方法如何从奖励模型中获益。
Expert Iteration 和 Quark 落后。
尽管专家迭代以最佳输出进行训练,但在模拟和人工反馈工作流程中,专家迭代仍落后于最佳,胜率差距为 3-6%。 这一结果表明,从最佳采样中获得改进并不简单,这也说明了为什么像 PPO 这样更复杂的学习算法可能会有用。
对于 Quark,我们观察到,虽然样本的奖励在训练过程中有所提高,但这并没有使模型的性能优于基线 SFT 10k。 有关调整的详细信息,请参见附录 B。
直接从成对反馈中学习的方法效果不佳。
我们观察到,二元奖励调节和二元 FeedME 并未比 SFT 10k 基线有所改善。 这一结果表明,学习代理奖励模型可能是 LPF 的一个重要组成部分。
计算成本
虽然我们的主要关注点是 LPF 方法的胜率,但我们也测量了每种参考方法的计算成本,发现在一台 8A100 机器上,大多数方法的训练过程一般需要 小时。 最大的计算成本涉及对最佳和专家迭代的大量样本进行解码(详见节 E.2)。
5.2模型输出分析
通过 AlpacaFarm 的模拟反馈和人工反馈,PPO 和最佳重新排名都显示出了显著的提高。 虽然胜率的变化是显而易见的,但模型的哪些变化导致了这些改进却不那么清楚--这些改进是由事实或推理方面的改进驱动的,还是由风格上的差异驱动的? 现在,我们将重点分析这些系统的产出,以了解哪些因素有助于提高它们的胜率。
| 指导:人们最常见的五种压力原因是什么? | |
|---|---|
|
SFT 10k:造成人们压力的五个最常见原因是工作、金钱、人际关系、健康和家庭。 |
PPO:造成人们压力的五个最常见原因是1. 工作压力:无论是由于紧迫的期限、过高的期望值,还是难以承受的工作量,工作压力都可能成为压力的主要来源。 2. 金钱问题:从入不敷出到债台高筑,财务问题都可能成为压力的重要来源。 3. 不健康的生活方式:不良的饮食习惯、缺乏锻炼和睡眠不足都会导致压力过大。 4. 家庭不幸福:人际关系问题、与家庭成员的冲突以及其他家庭问题都可能成为压力的主要来源。 5. 不确定性:对未来、健康问题或其他未知因素的过度担忧和焦虑是造成压力的主要原因。 |
5.3 使用 AlpacaFarm 直接训练模型,供人类使用
AlpacaFarm 的主要目标是提供一个模拟器来开发方法,然后在部署之前根据人类反馈进行训练。 一个自然而然的问题是,是否可以使用 AlpacaFarm 来训练模拟偏好模型,使其直接在人类评估中表现出色,而无需重新训练人类偏好。 我们的研究表明,一旦成对反馈模拟器被修改为最大限度地提高一致性,而不是匹配人类注释者的可变性,AlpacaFarm 就可以重新用于实现这一目标。
为了说明这一点,我们将在 AlpacaFarm 中训练的最佳 PPO 模型(步骤 40)与在单一低方差 GPT-4 注释器 中训练的匹配 PPO 模型(步骤 )进行比较。 然后,我们根据人类偏好评价来衡量它们的胜率。 结果显示在 Table 4 中。
| 方法 | 人类胜率 (%) |
|---|---|
| 55% | |
| 51% | |
| 50% | |
| SFT 10k | 44% |
| 43% |
我们发现,在 AlpacaFarm 中训练的 的胜率仅为 43%,而在 GPT-4 数据中训练的 的胜率为 50%。 为了说明这些结果,初始 SFT 模型的胜率为 44%,的胜率为 55%,而最佳非 PPO 人类方法的胜率为 51%(Best-of-)。 因此,模拟训练可以直接为部署提供良好的模型,不过这种方法与收集真人注释相比,性能差距达 5%。
这些结果表明,在模拟器的设计中,忠实度与性能之间存在权衡:忠实度越高的模拟器,其过度优化的程度越大,客观上训练出的模型也就越差。 标准的 AlpacaFarm 成对评价器最适合用于开发新方法和在模拟器中进行方法选择,因为 图 3 显示,在根据人类偏好对方法进行再训练时,方法的排序保持不变。 不过,对于直接部署在模拟器中训练的模型,单一一致的注释器(如 )可在实际评估中带来显著收益。
6相关工作
指示如下
模拟人类反馈
Constitutional AI Bai22 用AI反馈模拟人类反馈进行模型开发,以提高无害性和帮助性。 另一方面,AlpacaFarm 利用 API LLM 模拟人类反馈,从而使模拟实验能够反映真实人类反馈的实验结果。 由于目标不同,反馈模拟器的构造和使用在两种情况下也有所不同。 例如,AlpacaFarm 的模拟器通过位翻转标签噪声扰乱 LLM 偏好,以模仿人类标注的噪声,而 Constitutional AI 的模拟器不会注入额外的噪声。
我们工作的评估方面与越来越多的模拟人类注释进行评估的工作相关Chiang23 ; Perez22 ; Chiang23 ; Peng23 ; Liu23*b ; Liu23*a . 我们的核心评估和反馈机制使用了相同的基本思想,但我们的工作重点是使用成对反馈进行训练,并进行仔细的验证,而不是单个示例的一致性指标。 AlpacaFarm 表明,LLM 反馈可以捕捉方法层面的相关性以及人类注释的重要定性特征,如过度优化等现象。
从反馈中学习的方法。
为了保持各种学习方法的注释成本不变,我们在这项工作中只关注从成对反馈中学习的方法。 然而,除羊驼农场探索的方法外,文献中还有其他方法可以纳入其他反馈来源,例如自然语言 Weston16 ; Li16*f ; Hancock19 ;Shi22 ; Saunders22 ; Chen23 ; Scheurer23 ; Madaan23 , 数字评级 OpenAI*a ; Lee23 , 或执行跟踪 Chen23 . 我们认为,将 AlpacaFarm 扩展到这些环境中是未来令人兴奋的工作。
我们的研究中包含了一组可优化代偿奖励的 RL 算法,但这组算法并不全面。 应用于 NLP 的 RL 研究由来已久 Wu16 ; Sokolov16 ; Kiegeland21 ; Paulus17 ; Nguyen17 ; Lam18 ;Kreutzer18;Ramamurthy22;Snell22,我们希望未来在这方面的工作能从 AlpacaFarm 中的想法和工具中获益。
7局限性和未来方向
GPT4 与人类反馈的区别。
我们的沙盒假设 LLM 可以模拟人类的反馈。 第 4节表明,从 LLM 注释符合人类偏好模式并复制其许多特征的意义上讲,这一假设是成立的。 不过,我们也注意到,没有一种基于 LLM 的注释器能捕捉到人类注释的异质性,因此必须在 AlpacaFarm 中训练的方法的模拟偏好排名中注入大量噪声,才能与根据真实人类反馈训练的方法相匹配。
此外,我们还发现,在使用模拟反馈进行训练时,适合学习算法的超参数可能不同于人类反馈。 例如,由于代偿奖励模型的数值规模发生变化,适合 RLHF 的 KL 正则化系数范围也不同。 这表明,目前的 AlpacaFarm 模拟器并不总能帮助调整超参数以提高人类评估的性能。
最后,我们要指出的是,我们的偏好模拟器是针对我们招募的人群工作者进行验证的,并因此模拟了他们的偏好变化。 将见解转移到其他更一致的人群工作者库的最佳提示可能涉及较低的噪音水平或较小的提示组合。
目前实验的局限性。
由于资源限制(包括计算和人工标注),我们没有对A节中研究的方法进行广泛的超参数调整。 对于每种方法,我们都进行了至少 3 次调整运行,附录 B 详细介绍了我们的调整过程。 如果进行更细致的调整,PPO 与专家迭代和夸克等替代方法之间的比较可能会发生变化。
此外,我们还利用特定规模的模型和数据集进行了实验。 随着模型或数据集的扩大,定性研究结果可能会发生变化。
我们的研究重点是比较从成对反馈中学习的方法。 我们不研究其他形式的反馈,如数字评分或自然语言。 我们也没有研究从成对反馈中学习的质量-数量权衡。 我们将在今后的工作中对此进行阐述。
未来发展方向。
我们的研究表明,AlpacaFarm 大大降低了研究和开发配对反馈学习方法的成本和迭代时间。 羊驼农场为构建其他有用的人工智能研究模拟器提供了蓝图,这些研究需要人类的监督,我们认为这是一个令人兴奋的机会,可以扩展这种模拟方法,以支持其他领域的数据以及从其他形式的人类反馈中学习的方法。
致谢和资金披露
我们感谢斯坦福大学基础模型研究中心(CRFM)、斯坦福 HAI 和 Stability AI 提供的计算支持。 数据收集工作得到了陈天桥与克里希研究所和开放慈善基金的支持。 XL 由斯坦福大学研究生奖学金资助。 RT 得到了国家自然科学基金 GRFP 的资助,资助号为 No. DGE 1656518。 YD 由骑士-轩尼诗奖学金支持。
参考资料
- [1] Gati Aher, Rosa I Arriaga, and Adam Tauman Kalai. Using large language models to simulate multiple humans. arXiv preprint arXiv:2208.10264, 2022.
- [2] Thomas Anthony, Zheng Tian, and David Barber. Thinking fast and slow with deep learning and tree search. Advances in neural information processing systems, 30, 2017.
- [3] Lisa P Argyle, Ethan C Busby, Nancy Fulda, Joshua Gubler, Christopher Rytting, and David Wingate. Out of one, many: Using language models to simulate human samples. arXiv preprint arXiv:2209.06899, 2022.
- [4] Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q Tran, Dara Bahri, Jianmo Ni, et al. Ext5: Towards extreme multi-task scaling for transfer learning. arXiv preprint arXiv:2111.10952, 2021.
- [5] Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplan. A general language assistant as a laboratory for alignment, 2021.
- [6] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, Ben Mann, and Jared Kaplan. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022.
- [7] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- [8] Michiel Bakker, Martin Chadwick, Hannah Sheahan, Michael Tessler, Lucy Campbell-Gillingham, Jan Balaguer, Nat McAleese, Amelia Glaese, John Aslanides, Matt Botvinick, et al. Fine-tuning language models to find agreement among humans with diverse preferences. Advances in Neural Information Processing Systems, 35:38176–38189, 2022.
- [9] R. Bommasani et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- [10] Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- [11] Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- [12] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot learners. In Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [13] Angelica Chen, Jérémy Scheurer, Tomasz Korbak, Jon Ander Campos, Jun Shern Chan, Samuel R Bowman, Kyunghyun Cho, and Ethan Perez. Improving code generation by training with natural language feedback. arXiv preprint arXiv:2303.16749, 2023.
- [14] Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? arXiv preprint arXiv:2305.01937, 2023.
- [15] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- [16] Linxi Fan, Yuke Zhu, Jiren Zhu, Zihua Liu, Orien Zeng, Anchit Gupta, Joan Creus-Costa, Silvio Savarese, and Li Fei-Fei. Surreal: Open-source reinforcement learning framework and robot manipulation benchmark. In Conference on Robot Learning, pages 767–782. PMLR, 2018.
- [17] C Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax–a differentiable physics engine for large scale rigid body simulation. arXiv preprint arXiv:2106.13281, 2021.
- [18] Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. arXiv preprint arXiv:2210.10760, 2022.
- [19] Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, and Dawn Song. Koala: A dialogue model for academic research, March 2023.
- [20] Amelia Glaese, Nat McAleese, Maja Trębacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, et al. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375, 2022.
- [21] Braden Hancock, Antoine Bordes, Pierre-Emmanuel Mazare, and Jason Weston. Learning from dialogue after deployment: Feed yourself, chatbot! arXiv preprint arXiv:1901.05415, 2019.
- [22] Arthur Juliani, Vincent-Pierre Berges, Ervin Teng, Andrew Cohen, Jonathan Harper, Chris Elion, Chris Goy, Yuan Gao, Hunter Henry, Marwan Mattar, et al. Unity: A general platform for intelligent agents. arXiv preprint arXiv:1809.02627, 2018.
- [23] S. Kakade, Y. W. Teh, and S. Roweis. An alternate objective function for Markovian fields. In International Conference on Machine Learning (ICML), 2002.
- [24] Saketh Reddy Karra, Son Nguyen, and Theja Tulabandhula. Ai personification: Estimating the personality of language models. arXiv preprint arXiv:2204.12000, 2022.
- [25] N. S. Keskar, B. McCann, L. R. Varshney, C. Xiong, and R. Socher. CTRL: A Conditional Transformer Language Model for Controllable Generation. arXiv preprint arXiv:1909.05858, 2019.
- [26] Samuel Kiegeland and Julia Kreutzer. Revisiting the weaknesses of reinforcement learning for neural machine translation. arXiv preprint arXiv:2106.08942, 2021.
- [27] Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. Pretraining language models with human preferences. arXiv preprint arXiv:2302.08582, 2023.
- [28] Julia Kreutzer, Shahram Khadivi, Evgeny Matusov, and Stefan Riezler. Can neural machine translation be improved with user feedback? arXiv preprint arXiv:1804.05958, 2018.
- [29] Tsz Kin Lam, Julia Kreutzer, and Stefan Riezler. A reinforcement learning approach to interactive-predictive neural machine translation. arXiv preprint arXiv:1805.01553, 2018.
- [30] Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback. arXiv preprint arXiv:2302.12192, 2023.
- [31] Jiwei Li, Alexander H Miller, Sumit Chopra, Marc’Aurelio Ranzato, and Jason Weston. Dialogue learning with human-in-the-loop. arXiv preprint arXiv:1611.09823, 2016.
- [32] H Liu, C Sferrazza, and P Abbeel. Chain of hindsight aligns language models with feedback. arXiv preprint arXiv:2302.02676, 2023.
- [33] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- [34] Yang Liu, Dan Iter, Xu Yichong, Wang Shuohang, Xu Ruochen, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignmentg. arXiv preprint arXiv:2303.16634, 2023.
- [35] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688, 2023.
- [36] X. Lu, S. Welleck, J. Hessel, L. Jiang, L. Qin, P. West, P. Ammanabrolu, and Y. Choi. Quark: Controllable text generation with reinforced unlearning. In Advances in Neural Information Processing Systems, 2022.
- [37] Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, and Yejin Choi. Quark: Controllable text generation with reinforced unlearning. Advances in neural information processing systems, 35:27591–27609, 2022.
- [38] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023.
- [39] Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. Cross-task generalization via natural language crowdsourcing instructions. arXiv preprint arXiv:2104.08773, 2021.
- [40] Khanh Nguyen, Hal Daumé III, and Jordan Boyd-Graber. Reinforcement learning for bandit neural machine translation with simulated human feedback. arXiv preprint arXiv:1707.07402, 2017.
- [41] OpenAI. Introducing chatgpt.
- [42] OpenAI. Model index for researchers.
- [43] OpenAI. Gpt-4 technical report, 2023.
- [44] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback, 2022.
- [45] Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442, 2023.
- [46] Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Social simulacra: Creating populated prototypes for social computing systems. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, pages 1–18, 2022.
- [47] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
- [48] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- [49] Ethan Perez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, et al. Discovering language model behaviors with model-written evaluations. arXiv preprint arXiv:2212.09251, 2022.
- [50] Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, and Yejin Choi. Is reinforcement learning (not) for natural language processing?: Benchmarks, baselines, and building blocks for natural language policy optimization. arXiv preprint arXiv:2210.01241, 2022.
- [51] Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207, 2021.
- [52] William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. Self-critiquing models for assisting human evaluators. arXiv preprint arXiv:2206.05802, 2022.
- [53] Jérémy Scheurer, Jon Ander Campos, Tomasz Korbak, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, and Ethan Perez. Training language models with language feedback at scale. arXiv preprint arXiv:2303.16755, 2023.
- [54] John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015.
- [55] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017.
- [56] Weiyan Shi, Emily Dinan, Kurt Shuster, Jason Weston, and Jing Xu. When life gives you lemons, make cherryade: Converting feedback from bad responses into good labels. arXiv preprint arXiv:2210.15893, 2022.
- [57] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L., M. Lai, A. Bolton, et al. Mastering the game of go without human knowledge. Nature, 550(7676):354–359, 2017.
- [58] Charlie Snell, Ilya Kostrikov, Yi Su, Mengjiao Yang, and Sergey Levine. Offline rl for natural language generation with implicit language q learning. arXiv preprint arXiv:2206.11871, 2022.
- [59] Artem Sokolov, Stefan Riezler, and Tanguy Urvoy. Bandit structured prediction for learning from partial feedback in statistical machine translation. arXiv preprint arXiv:1601.04468, 2016.
- [60] Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback, 2020.
- [61] Colin Summers, Kendall Lowrey, Aravind Rajeswaran, Siddhartha Srinivasa, and Emanuel Todorov. Lyceum: An efficient and scalable ecosystem for robot learning. In Learning for Dynamics and Control, pages 793–803. PMLR, 2020.
- [62] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpaca: A strong, replicable instruction-following modely, March 2023.
- [63] Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018.
- [64] Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012.
- [65] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [66] Adaku Uchendu, Zeyu Ma, Thai Le, Rui Zhang, and Dongwon Lee. Turingbench: A benchmark environment for turing test in the age of neural text generation. arXiv preprint arXiv:2109.13296, 2021.
- [67] Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback, 2022.
- [68] Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, 2022.
- [69] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- [70] J. E. Weston. Dialog-based language learning. In Advances in Neural Information Processing Systems (NeurIPS), pages 829–837, 2016.
- [71] Y. Wu, M. Schuster, Z. Chen, Q. V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016.
附录 AAlpacaFarm 中 LPF 方法参考
我们将对 AlpacaFarm 中的方法以及我们所做的定制修改进行更详尽的说明。 有关超参数调整、实验细节和进一步消融的更多信息,请参见附录 B。
我们的方法可分为两类,取决于它们是否在学习过程中采用了代理奖励模型。
A.1直接从配对反馈中学习的方法
二元 FeedME。
FeedME 是 OpenAI [42] 提出的一种方法,它将人类反馈与对模型生成的监督微调相结合,人类标注人员评分为 7/7。 我们将这一方法应用到成对反馈环境中,并将这一基线称为二元 FeedME。 这种方法通过监督学习根据每个偏好对中所选的响应来微调 SFT 模型。
二元奖励调节
A.2优化代理奖励函数的方法
现在,我们要介绍的方法是,首先利用成对反馈数据建立一个代理奖励模型,从而将反馈纳入其中。 首先,我们介绍一下训练代理奖励模型的步骤。
要训练一个参数化的代理变量 ,可以最大化布拉德利-特里模型 [10] 下偏好值 的对数似然。
| (1) |
代奖励模型训练完成后,训练和推理算法都可以根据奖励模型而不是查询配对反馈进行优化。 虽然这是一种强大的方法,但我们也会看到,它也可能导致过度优化 [18],即模型学会利用奖励模型,而不是获得高额真实奖励。 现在我们介绍 4 种利用代用奖励模型的方法。
最佳采样。
专家迭代。
近端策略优化
Quark.
Quark 的灵感来源于奖赏条件反射,已被证明对可控生成任务有效。 与二元奖赏条件反射一样,夸克在训练序列中也预设了控制标记。 与二进制奖励调节不同,Quark 根据奖励值将模型样本分成多个组,添加 KL 和熵正则化,并在多轮中重复整个过程。
在初步分析中,我们发现[36]中报告的最高位数变体(即只对最佳奖励组进行训练)比对所有组进行训练的全位数变体表现更好。
附录 B方法实现和超参数详情
B.1 PPO
我们沿用了现有的用于微调语言模型的 PPO 实现,111https://github.com/openai/lm-human-preferences,但也引入了一些修改。 首先,用于语言模型微调的现成 PPO 实现往往会对每个小批量的估计优势进行归一化处理。 我们发现这导致了小批量训练的不稳定性,因此将每个 PPO 步骤所获得的整批推出的优势归一化。 其次,我们从奖励模型初始化价值模型,而不是 SFT 模型,这遵循了最新的文献实践 [44](作者没有发布代码)。 我们的初步实验表明,从奖励初始化比从 SFT 初始化更能最大化代理奖励。
我们对超参数进行了调整,以提高训练的稳定性并缩短收敛时间,从而在计算预算相对紧张的情况下可靠地完成实验。 最后,我们确定每个 PPO 步骤的批量大小为 512,其中包括 2 个梯度步骤的历时,每个梯度步骤的批量为 256 次滚动。 我们使用的峰值学习率为,并在整个训练过程中衰减为 0。 我们采用欧氏规范对梯度进行剪切,阈值为 1。 我们对无标签集进行了 10 次完整的训练,这相当于 390 个 PPO 步骤。 在训练初期,成绩通常会达到峰值(见 图 5(c))。 我们将 和 都设为 1,以进行广义优势估计 [54]。 我们使用的是固定的 KL 正则系数,而不是自适应系数。 我们调整了模拟 PPO 和人类 PPO 的系数值,最终人类 PPO 为 0.02,模拟 PPO 为 0.002。 我们注意到,KL 正则系数的合适值取决于早期停止标准和替代奖励值的规模。
B.2夸克
我们根据自己的需要重新实施了 Quark,并做了一些修改。 首先,夸克的原始配方会在训练过程中积累滚动,并将其存储在一个持续增长的池中。 我们发现,这导致训练过程中的开销增加(因为在生成每批滚动后,池子都会扩大,池中的滚动会根据奖励值重新排序)。 为了在合理的计算预算范围内运行,我们会在生成一批新的滚动信息后丢弃之前的滚动信息。 换句话说,一旦进行滚动,池就会重置。 这一修改使计算成本在整个训练过程中保持不变,因此总体上更具可预测性。 其次,我们发现对更多箱体的滚动进行训练会降低奖励优化的效率,因此我们选择只对得分最高的箱体进行滚动训练(原论文中的最佳量值变量 [37])。 对一项简单的情感任务进行的初步分析表明,通过提高 KL 正则化,可以弥补最佳等值变量在复杂性方面的任何潜在损失。 最后,我们发现在最初的夸克公式中使用的熵罚对处理以下指令没有任何好处。 就流畅性而言,小的熵惩罚项足以导致文本生成质量的大幅下降。
在报告结果的正式运行中,我们使用的 KL 正则系数为 0.05,峰值学习率为 ,并在整个训练过程中衰减为 0。 每个夸克步骤的推出批次大小为 512,每个梯度更新的 2 个历元批次大小为 256。 我们采用欧氏规范对梯度进行剪切,阈值为 1。 我们对无标签集进行了 10 次完整的训练,相当于 390 个夸克步骤。
附录 C 配对偏好模拟
C.1模拟标注工具的详细信息
对于所有模拟标注工具,我们都使用 OpenAI API 生成输出。 下面我们首先讨论所有模拟工具的总体设计选择,然后更详细地讨论我们的标注工具库。 有关我们使用的所有实际提示,请参阅 https://github.com/tatsu-lab/alpaca_farm。
随机顺序。
对于每个标注工具,我们会随机确定要标注的两个输出之间的排序,即随机选择哪个输出是第一个,哪个是第二个。 我们发现随机化非常重要,因为模拟标注工具通常更喜欢第一种输出结果。
有输入和无输入的提示。
GPT4 的批处理。
在添加上下文示例时,提示可能会变得相对较长,从而导致将 GPT-4 作为模拟器使用时的高成本和等待时间。 为了降低成本并提高注释速度,我们通过 GPT-4 一次性提供一批指令-输出对来摊销上下文示例的成本。 对于我们的模拟注释器,我们使用的最大批量大小为 5,但在开发过程中发现,我们可以在上下文窗口中适应最大 20 的批量大小,而不会明显降低性能。 为了在使用批处理时提高性能,我们发现以批处理格式提供一些上下文示例以及对注释的每个组件(指令、输入、输出......)进行索引是非常有用的。
改进 ChatGPT 的解析。
总的来说,我们发现 ChatGPT 作为模拟器要敏感得多,也难用得多。 特别是,我们发现它对提示格式更为敏感,而且经常无法生成可解析的注释,例如,尽管明确指示要选择一种偏好,但它却回答 "两者都不好,这取决于个人偏好"。 我们发现有两种方法可以有效提高 ChatGPT 的可解析度。 首先,我们为 "Neither "和 "Both "等词组添加负偏置,为希望匹配的词组添加正偏置。 我们发现前面提到的标记偏置效果不错,但在使用思维链推理时可能会出现问题。 我们发现有效的第二个窍门是让 ChatGPT 生成一个 JSON 对象,其中包含一个带有简短解释(思维链)的字符串字段和一个布尔字段,表示是否首选第一种输出。
在讨论了模拟注释器的总体设计选择之后,我们将更详细地讨论每个注释器的提示和参数。
羊驼农场的评估注释器 。
为了尽量与人类注释者的偏差和差异相匹配,我们使用了 13 位模拟注释者,他们是在项目的不同阶段培养出来的。 特别是,我们使用了以下变化来源:
-
•
型号 其中五名注释员使用 GPT-4,四名使用 ChatGPT,四名使用 Davinci003。 不同注释者对同一模型的注释差异主要在于提示。
-
•
背景示例 针对相同模型的提示使用了不同数量的语境中的示例。
-
•
提示格式。 对于同一型号,我们使用不同的提示格式。 例如,不同的批量大小和不同的输出格式(JSON 与原始文本)。
-
•
偏好。 GPT4 中的两位注释者被明确提示分别偏好长序列和短序列。
-
•
取样。 对于库中的每位注释者,我们使用的采样温度为 1.0,最高 也是 1.0。 温度高意味着取样会产生变化。
羊驼农场的培训注释员。
我们用于训练的模拟注释器与评估注释器相同,只是我们以 0.25 的概率翻转输出。 为此,我们在 和概率为 0.5 的独立伯努利随机变量之间进行混合。 这意味着我们只需标注一半的输出即可进行训练,这使得的速度更快,成本更低。
GPT4。
对于 GPT4 注释器 ,我们使用了一个批次规模为 5 的提示器,该提示器与我们模拟的注释器库中的一个提示器相对应。 对于 ,我们使用温度 0,即确定性注释。
C.2附加结果
现在,我们为了解我们的成对注释器提供更多结果。

我们的注释器库偏差较小,与人类的差异相匹配。
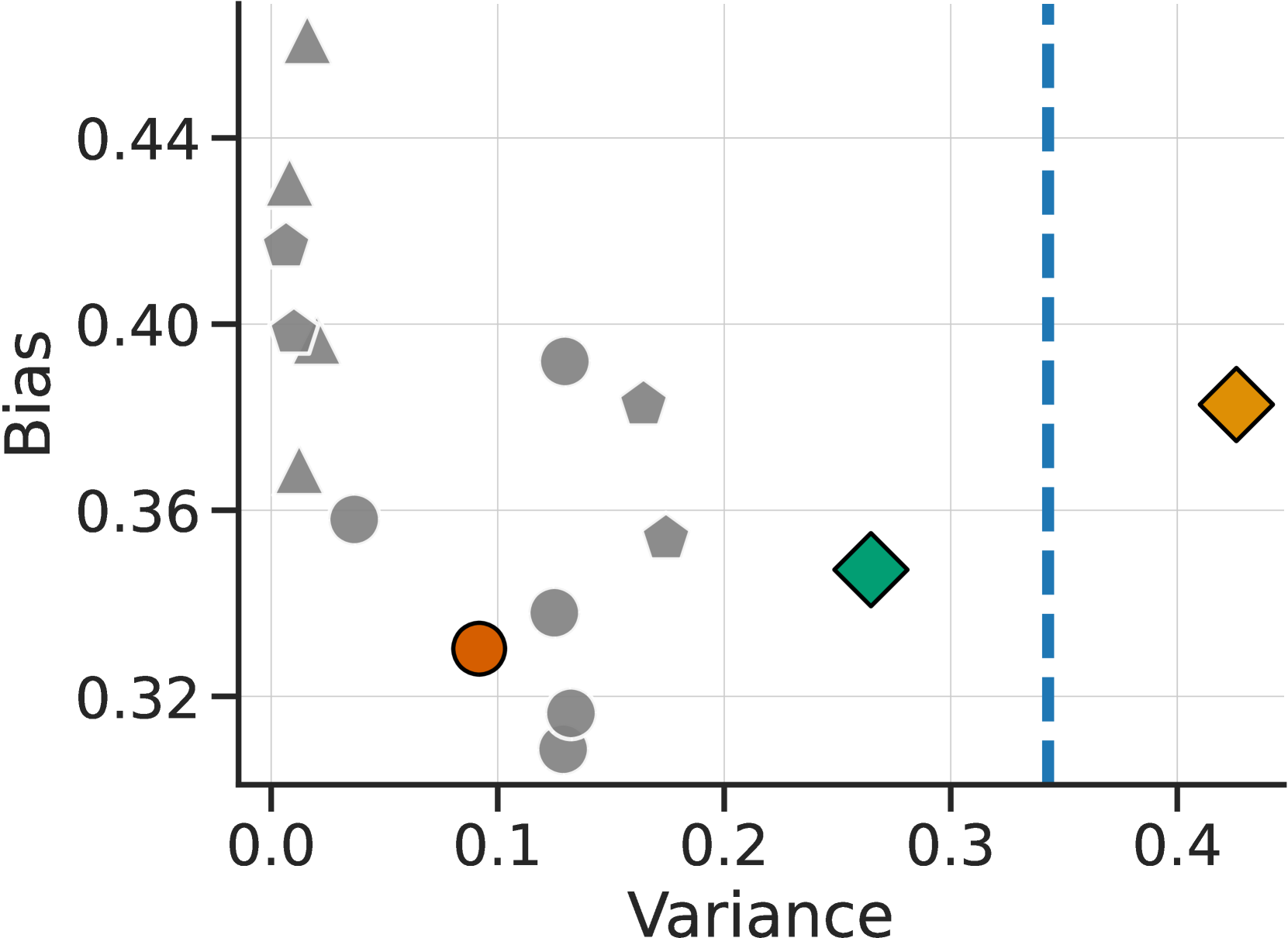
图 7显示了模拟评价器的估计偏差(y 轴)和方差(x 轴)。 我们看到,单个评估者的方差(小于 0.2)小于人类(蓝线,0.34)。 由于缺乏可变性,使用代理奖励进行模拟变得非常容易,并导致模拟器出现不切实际的过度优化特性,如图 5(c)所示。 使用注释者库(绿点)进行评估,并在训练过程中添加噪音(橙色),得出的估计方差明显更接近人类(蓝线 0.35)。 我们假设,这是模拟器表现出与人类类似的过度优化行为的必要条件。 在偏差方面,我们发现用于评估 和训练 的模拟注释器的偏差值都很低(0.38 和 0.35),与我们最好的 GPT-4 注释器之一(0.33)相当。
注释器库中的变量主要来自基础模型。
在图8中,我们显示了我们的注释库中所有注释者与所有其他注释者之间的成对一致性,包括人类多数票(第一列)和单一人类(第二列)。 理想的高方差对应对角线上的低值(注释者与自己意见不一致),低偏差对应第一列中的高值(与人类模式高度一致)。 与 图 7中一样,我们看到我们的注释器库 具有低偏差和高方差。 图 8还显示,注释者之间最大的差异来源于底层模型,GPT4、ChatGPT 和 Davinci003 注释者产生的聚类就说明了这一点。

人类和模拟注释器更喜欢包含列表的较长的输出结果。
一个自然的问题是,模拟注释者和人类注释者是否会对不同类型的输出结果产生偏差,从而导致两种框架中的模型在质量上有所不同。 我们确定了人类强烈偏好的两个文体特征--长度和列表的存在,并分析了模拟注释者是否符合这些偏好。 我们发现,人类在 的情况下更喜欢较长的输出,而我们的模拟注释器在 的情况下更喜欢较长的输出。 同样,在 的情况下,人类更喜欢带列表的输出结果,而我们的模拟注释器在 的情况下更喜欢带列表的输出结果。 这表明,我们模拟的注释者与人类的文体偏好非常吻合,这表明在我们的沙箱中训练的模型正在优化与人类反馈训练的模型相似的偏好,它们很可能会表现出相似的行为。
附录 D人类数据收集详情
资格证书。
我们根据 25 个标注范例对标注员进行了资格认证。 本项目的早期开发阶段曾对 OPT 6B 模型进行过研究,并生成了鉴定示例。 本文的五位学生作者对一组共享的配对偏好进行了注释。 我们从共享的问题集中选出了 25 个大多数作者就正确注释达成一致的问题。 然后,我们将这些问题作为资格测试,选出与作者意见一致度最高的前 16 名注释者。 我们为资格赛向注释员支付的费用与正赛相同。
在注释过程中,我们还将每位注释者的偏好与 GPT-4 的偏好进行比较。 我们发现有一位注释者与 GPT-4 的一致率约为 50%,与其他注释者相比明显偏离。 因此,我们在注释项目期间停止了与该注释者的合作,并删除了他们的注释。
注释准则。
我们在 Figure 10 中显示注释指南,在 Figure 11 中显示注释界面。 在我们的注释过程中,我们发现有些句对仅在标点符号上存在差异或编辑距离极小,如果句对之间的差异微乎其微,我们会指示注释者选择稍好/较差的回复。 因此,在收集到的偏好中,约有 18% 的人选择了稍好的方案。 在 LPF 实验中,我们对偏好进行了二值化处理,并将稍好的选项与普通偏好标签同等对待。 不过,我们将更细粒度的标签作为资源发布,留待今后工作中研究。


附录 E附加结果
E.1模拟注释器的标签噪声消减
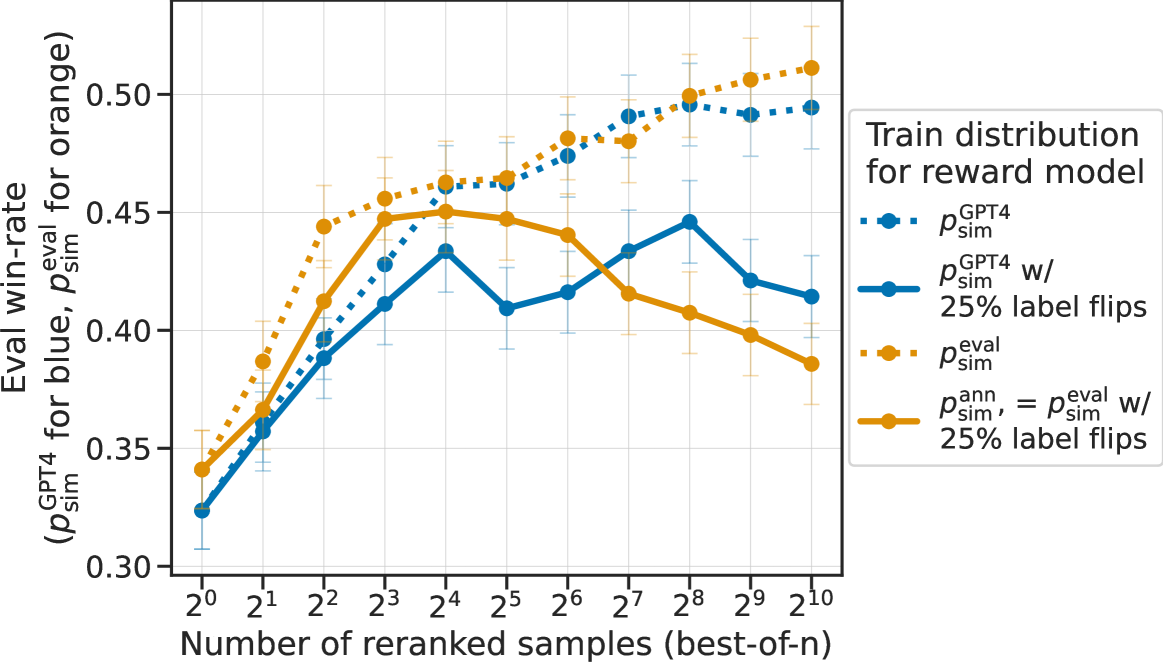
在本节中,我们将删除 中的不同部分,这些部分将沿两个轴线增加可变性:在不同的模拟注释者之间随机化,以及增加标签噪声。 为了消除不同注释者之间的随机性,我们与简单的 GPT-4 提示进行了比较,并添加了标签噪声。 为了消除标签噪声,我们将 与 进行比较,后者没有标签噪声。 我们根据这些偏好分布训练奖励模型,并比较最佳采样的性能。
图 12显示了消融的结果,清楚地表明添加的标签噪声提供了大部分的过度优化效果。 尤其是两个不添加标签噪声的选项,和,随着样本的增加,胜率也在不断提高。 这一结果表明,通过标签噪声对标注者内部的可变性进行建模,可能是理解人类偏好数据学习的一个重要组成部分。
E.2了解计算成本
虽然我们主要关注最终模型的性能,但这些方法的计算成本也是一个重要的考虑因素。 我们提供了在特定实现和计算环境(一台A100 机器)上进行训练的时间估计。 虽然这些时间是我们的实验所特有的,但我们相信,这些见解可能有助于理解从成对反馈中学习的成本。
首先,监督微调和直接适应监督微调的方法(如二进制奖励调节和二进制 FeedME)一般都很快,10k 条指令的微调时间不到一小时。 最佳采样不会产生任何训练成本,但却会耗费大量推理时间。 最佳的最佳约为 16,这(原则上)意味着分批推理的成本增加了 16 倍。
在我们的实验中,专家迭代在对最佳抽样的输出进行训练时效果最佳,而对未标记的拆分进行最佳抽样需要大量计算。 具体来说,在 20k 未标记的分割数据上,这一采样过程大约需要 4 个小时,而随后的微调则不到一个小时。 我们观察到,PPO 的性能在人类数据和仿真中都在 40-80 步后达到峰值,这意味着全机计算时间不到 2 小时。
E.3对模型输出的其他分析
在本节中,我们将对模型输出结果进行定性分析。 在表5中,我们展示了来自 SFT 10k、和的三个输出示例。 如 节 5.2所述,我们发现 LPF 训练后的模型输出往往会变得更长。 在表6和表7中,我们以字符数为单位显示了各种系统的模型输出的平均长度,这定性地说明了这一现象。 虽然较长的回答确实能更好地反映人类的偏好,但我们仍然在输出中看到了幻觉(例如在有关柏林的例题中),而且我们还不清楚我们的 LPF 模型是否在忠实性、知识性等更关键的方面有所改进。
|
您如何看待 ChatGPT? |
|---|
|
SFT 10k:我认为 ChatGPT 是一项很有前途的技术,它有可能彻底改变我们与计算机的交互方式。 它能够快速、准确地生成自然语言文本,可用于多种不同的应用。 我认为这是一项令人兴奋的技术,未来会有越来越多的用途。 |
|
:我认为 ChatGPT 是自然语言处理领域的一个令人着迷的发展。 它是一种人工智能系统,能够生成类似人类的文本,从而可以就各种话题与人类交谈。 它能够从大型数据集中学习,并随着时间的推移不断提高性能,从而使其生成的文本越来越准确和复杂。 我认为,从自然语言处理和机器翻译,到自动客户服务和自然语言处理,它有很多潜在的应用领域。 这是人工智能技术向前迈出的令人难以置信的一步,我期待着看到它在未来有什么新的发展。 |
|
:我认为 ChatGPT 是一项非常酷的技术,它可以根据输入生成自然语言文本。 用户无需编写代码或创建自定义自然语言处理器,即可快速生成文本回复。 它还能很好地理解上下文,并能根据上下文和提示生成文本。 我认为它有很多潜在的应用领域,例如自动客户服务、自然语言处理和文本生成。 我认为技术进步之快令人惊叹,看到人工智能和机器学习所能实现的一切真的很酷。 我非常期待看到 ChatGPT 和其他人工智能技术的未来。 |
|
谁造就了柏林? |
|
SFT 10k: 柏林这座城市是由德国人民创造的。 |
|
:柏林这座城市是由不同的人在历史上共同创造的。 它最早是在 12 世纪作为一个中世纪贸易站而建立的,随后由不同的统治者进行建设。 三十年战争期间,这座城市遭到严重破坏,但霍亨索伦王朝在 17 和 18 世纪对其进行了重建和扩建。 19 世纪,柏林成为德意志帝国的首都,并在市长奥托-冯-俾斯麦的领导下进行了大规模的扩建和现代化改造。 二战后,这座城市还被分为东区和西区,分别由冷战时期的政府统治。 |
|
: 几个世纪以来,柏林这座城市由不同的人建造而成。 该地区已知最早的居民是图巴尔和贾巴尔部落,他们于公元前 2300 年左右到达该地区。 这些部落后来被凯尔特部落取代,他们在公元前 1 世纪建立了柏林城。 公元 1 世纪,罗马人征服了这座城市,并将其更名为 "柏林"。 中世纪晚期,柏林成为神圣罗马帝国的重要城市,由不同的王子和选帝侯统治。 17 世纪,在选帝侯腓特烈-威廉一世(Frederick William I)的统治下,柏林形成了现在的面貌。 18 世纪和 19 世纪,柏林经历了文化和经济的繁荣,1701 年成为普鲁士王国的首都,1871 年成为德意志帝国的首都。 这座城市也是许多历史事件的发生地,包括 1919 年魏玛共和国的成立和 1989 年柏林墙的倒塌。 如今,柏林是一座繁华的城市,人口超过 370 万,是德国第三大城市。 |
|
目前已知存在多少黑洞? |
|
SFT 10k:目前已知存在近 1 亿个黑洞。 |
|
:当时,人们认为宇宙中存在着几百万个黑洞。 随着天文学家通过观测和研究发现越来越多的黑洞,这个数字还在不断增加。 大多数黑洞都位于许多不同星系的中心,被认为是星系中质量最大的恒星耗尽核燃料并在超新星中爆炸时形成的。 由此产生的恒星内核是如此密集,以至于任何东西,甚至是光,都无法逃脱其强大的引力,因此被称为 "黑洞"。 |
|
:在撰写本文时,宇宙中已知的黑洞有 1000 多个。 |
| 模型 | 字符数 |
|---|---|
| GPT-4 | 504.4 |
| ChatGPT | 333.4 |
| Davinci001 | 286.3 |
| SFT 52K | 383.2 |
| SFT 10k | 277.5 |
| LLaMA 7B | 950.5 |
| PPO 200 级 | 495.6 |
| PPO 80 级 | 623.7 |
| PPO 40 级 | 683.1 |
| 最佳-128 | 680.0 |
| 16 佳 | 565.2 |
| 四强 | 478.7 |
| ExpIter-128 | 524.7 |
| ExpIter-16 | 458.3 |
| ExpIter-4 | 422.1 |
| FeedMe | 371.4 |
| 模型 | 字符数 |
|---|---|
| GPT-4 | 504.4 |
| ChatGPT | 333.4 |
| Davinci001 | 286.3 |
| SFT 52K | 383.2 |
| SFT 10k | 277.5 |
| LLaMA 7B | 950.5 |
| PPO 80 级 | 863.4 |
| PPO 20 个步骤 | 637.7 |
| 最佳-128 | 704.7 |
| 16 佳 | 570.5 |
| 四强 | 483.3 |
| ExpIter-128 | 527.5 |
| ExpIter-16 | 458.3 |
| ExpIter-4 | 407.4 |