ConvLab-2:用于构建、评估和诊断对话系统的开源工具包
-
我们展示 ConvLab-2,这是一个开放源代码工具包,使研究人员能够使用最新模型构建面向任务的对话系统,进行端到端评估并诊断系统的弱点。 作为 ConvLab (Lee et al., 2019b) 的后续产品,ConvLab-2 继承 ConvLab 的框架,但集成更强的对话模型并支持更多数据集。 此外,我们还开发了分析工具和交互式工具来协助研究人员诊断对话系统。 分析工具提供丰富的统计信息,并从模拟对话中总结常见错误,从而有助于错误分析和系统改进。 交互式工具提供一个用户界面,允许开发人员与系统交互并修改每个系统组件的输出来诊断组装好的对话系统。
1 简介

近年来,面向任务的对话系统越来越受到关注,产生了许多数据集 (Henderson et al., 2014; Wen et al., 2017; Budzianowski et al., 2018b; Rastogi et al., 2019) 和各种模型 (Wen et al., 2015; Peng et al., 2017; Lei et al., 2018; Wu et al., 2019; Gao et al., 2019)。 但是,很少有开放源代码工具包完全支持以最新模型组装端到端对话系统、以端到端的方式评估性能,以及定性和定量分析瓶颈。 为弥补这一空白,我们基于我们以前的对话系统平台 ConvLab (Lee et al., 2019b) 开发了 ConvLab-2。 ConvLab-2 继承其前身的框架,并通过集成许多最近提出的最新对话模型对其进行扩展。 此外,还提供两个功能强大的工具,即分析工具和交互式工具,用于深入的错误分析。 ConvLab-2 将成为第九届对话系统技术挑战赛(DSTC9)1 中面向多领域任务导向的对话挑战赛 II 的开发平台。 1https://sites.google.com/dstc.community/dstc9/home。
如图1所示,构建面向任务的对话系统的方法很多,从具有多个组件的流水线方法到完整的端到端模型。 以前的工具包专注于端到端模型 (Miller et al., 2017) 或一个特定的组件如对话策略(POL)(Ultes et al., 2017),而其他为开发人员设计的工具包 (Bocklisch et al., 2017; Papangelis et al., 2020) 没有集成最新模型。 ConvLab (Lee et al., 2019b) 是为所有对话组件提供各种强大模型并允许研究人员快速组装完整对话系统(使用一组方法)的第一个工具包。 ConvLab-2 继承 ConvLab 的灵活框架,并导入最近提出的可实现最好效果的模型。 此外,ConvLab-2 支持多个大型对话数据集,包括 CamRest676 (Wen et al., 2017)、MultiWOZ (Budzianowski et al., 2018b)、DealOrNoDeal (Lewis et al., 2017) 和 CrossWOZ (Zhu et al., 2020)。
为了支持端到端评估,类似于 ConvLab,ConvLab-2 提供用于自动评估的用户模拟器,并集成 Amazon Mechanical Turk 以进行人工评估。 此外,它提供用于诊断对话系统的分析工具和人机交互工具。 研究人员可以使用分析工具进行定量分析。 它提供从用户模拟器和对话系统之间的对话中提取的有用统计信息。 这些信息有助于揭示系统的弱点,并指示进一步改进的方向。 使用交互式工具,研究人员可以通过部署他们的对话系统并通过网页与系统进行对话来进行定性分析。 在对话期间,网页系统中会显示流水线系统中每个组件的中间输出,例如用户对话行为和置信状态。 这样,可以检查系统的性能,并可以手动纠正那些组件的预测错误,这有助于开发人员识别瓶颈组件。 交互式工具还可用于收集实时人机对话和用户反馈,以进一步改善系统。
2 ConvLab-2
2.1 对话代理
对话中的每个发言人视为一个代理。 ConvLab-2 继承并简化 ConvLab 框架以适应更复杂的对话代理(例如,对一个组件使用多个模型)和更一般的情况(例如,多方对话)。 得益于代理定义的灵活性,研究人员可以构建具有不同类型配置的代理,例如传统的流水线方法(如图1顶部方框的第一层所示)、完全的端到端方法(最后一层)、以及它们之间(其它层)的方法用于实例化相应模型之后。 研究人员还可以自由地定制代理,例如将两个对话系统合并到一个代理中以应对多项任务。 基于将对话系统和用户模拟器都视为代理的统一代理定义,ConvLab-2 支持两个代理之间的对话,并且可以扩展到涉及三个或更多参与方的更一般的方案。
2.2 模型
ConvLab-2 为对话代理中的每个可能组件提供以下模型。 请注意,与 ConvLab 相比,ConvLab-2 中的新集成模型以粗体标记。 研究人员可以通过实现相应组件的接口轻松添加他们的模型。 我们将继续添加最新模型,以反映面向任务的对话的最新进展。
2.2.1 自然语言理解
自然语言理解(NLU)组件用于解析其其它代理的意图,将话语作为输入并输出相应的对话动作。 ConvLab-2 提供三种模型:语义元组分类器(STC)(Mairesse et al., 2009),MILU (Lee et al., 2019b) 和 BERTNLU。 BERT (Devlin et al., 2019) 在许多 NLP 任务中展示出色的表现。 因此,ConvLab-2 提出一个新的 BERTNLU 模型。 BERTNLU 在 BERT 的顶部添加两个 MLP,分别用于意图分类和槽值标记,并微调指定任务上的所有参数。 与其它模型相比,BERTNLU 在 MultiWOZ 上取得最佳表现。
2.2.2 对话状态跟踪
对话状态跟踪(DST)组件更新置信状态,置信状态包含其它代理(例如用户)的约束和要求。 ConvLab-2 提供一个基于规则的跟踪器,以 NLU 解析的对话行为作为输入。
2.2.3 单词级对话状态跟踪
单词级 DST 直接从对话历史中获取置信状态。 ConvLab-2 集成四个模型:MDBT (Ramadan et al., 2018)、SUMBT (Lee et al., 2019a) 和 TRADE(Wu et al., 2019)。 TRADE 使用复制机制从语句中生成置信状态,并在 MultiWOZ 上实现最优的性能。
2.2.4 对话策略
对话策略接收置信状态并输出系统对话行为。 ConvLab-2 提供一个基于规则的策略、一个简单的神经网络策略可以使用模仿学习直接从语料库中学习的,以及强化学习策略 REINFORCE (Williams, 1992)、PPO (Schulman et al., 2017) 和 GDPL (Takanobu et al., 2019)。 GDPL 在 MultiWOZ 上实现最优的性能。
2.2.5 自然语言生成
自然语言生成(NLG)组件将对话动作转换为自然语言句子。 ConvLab-2 提供基于模板的方法和 SC-LSTM (Wen et al., 2015)。
2.2.6 单词级策略
单词级策略根据对话历史和置信状态直接生成自然语言响应(而不是对话行为)。 ConvLab-2 集成三个模型:MDRG (Budzianowski et al., 2018a)、HDSA(Chen et al., 2019) 和 LaRL(Zhao et al., 2019)。 MDRG 是基线模型,由 Budzianowski 等人 (2018b)在 MultiWOZ 上提出,而 HDSA 和 LaRL 在此数据集上取得更好的效果。
2.2.7 用户策略
用户策略是用户模拟器的核心。 它采用预设的用户目标,系统对话充当输入并输出用户对话行为。 ConvLab-2 提供 agenda-based 模型 (Schatzmann et al., 2007) 和基于神经网络的模型,包括 HUS 及其变体(Gür et al., 2018)。 为执行端到端仿真,研究人员可以为用户策略配备 NLU 和 NLG 组件,以组装完整的用户仿真器。
2.2.8 端到端模型
完整的端到端对话模型接收对话历史并直接以自然语言生成响应。 ConvLab-2 将 Sequicity (Lei et al., 2018) 扩展到多领域场景:当模型感知到当前领域已切换时,它将重置置信区间,记录当前领域的信息。 ConvLab-2 还集成 DAMD (Zhang et al., 2019),可在 MultiWOZ 上获得最新的最优结果。 对于 DealOrNoDeal 数据集,我们提供 ROLLOUTS RL 策略,由 Lewis et al. (2017)提出。
2.3 数据集
与 ConvLab 相比,ConvLab-2 可以更方便地集成新数据集。 对于每个数据集,ConvLab-2 提供一个可由所有模型使用的统一数据加载器,从而将数据处理与模型定义分开。 目前,ConvLab-2 支持四个面向任务的对话数据集,包括 CamRest676 (Wen et al., 2017)、MultiWOZ(Eric et al., 2019)、DealOrNoDeal (Lewis et al., 2017) 和 CrossWOZ(Zhu et al., 2020)。
2.3.1 CamRest676
CamRest676 (Wen et al., 2017) 是一个 Wizard-of-Oz 数据集,由 restaurant 领域的 676 个对话组成。 ConvLab-2 提供 agenda-based 用户模拟器以及用于在 CamRest676 数据集上构建传统流水线对话系统的完整模型集。
2.3.2 MultiWOZ
MultiWOZ (Budzianowski et al., 2018b) 是大规模的多领域 Wizard-of-Oz 数据集。 它包含 10438 个对话,包含系统对话行为和置信状态。 然而,缺少用户对话行为,并且置信状态注释和对话语句富含噪声。 为解决这些问题,Convlab (Lee et al., 2019b) 使用启发式方法自动注释用户对话。 Eric et al. (2019)进一步重新注释置信状态和语句,生成 MultiWOZ 2.1 数据集。
2.3.3 DealOrNoDeal
DealOrNoDeal (Lewis et al., 2017) 是有关多项目讨价还价任务的人与人谈判的数据集。 它包含基于 2,236 个独立场景的 5,805 个对话。 在此数据集上,ConvLab-2 实现 ROLLOUTS RL (Lewis et al., 2017) 和 LaRL (Zhao et al., 2019) 模型。
2.3.4 CrossWOZ
CrossWOZ (Zhu et al., 2020) 是最近提出的第一个大规模的中文多域 Wizard-of-Oz 数据集。 它包含跨越 5 个领域的 6,012 个对话。 除了对话行为和置信状态外,还提供指示用户目标完成的用户状态注释。 ConvLab-2 提供基于规则的用户模拟器以及用于在 CrossWOZ 数据集上构建流水线系统的完整模型集。
总体结果: |
成功率:60.8%;inform F1:44.5% |
最令人困惑的用户对话行为: |
Request-Hotel-Post-? |
- 34%: Request-Hospital-Post-? |
- 32%: Request-Attraction-Post-? |
Request-Hotel-Addr-? |
-29%:Request-Attraction-Addr-? |
-28%:Request-Restaurant-Addr-? |
Request-Hotel-Phone-? |
- 26%: Request-Restaurant-Phone-? |
- 26%: Request-Attraction-Phone-? |
无效的系统对话行为: |
- 31%: Inform-Hotel-Parking |
- 28%: Inform-Hotel-Internet |
冗余系统对话行为: |
- 34%: Inform-Hotel-Stars |
缺少系统对话行为: |
- 25%: Inform-Hotel-Phone |
最令人困惑的系统对话行为: |
Recommend-Hotel-Parking-yes |
- 21%: Recommend-Hotel-Parking-none |
- 18%: Inform-Hotel-Parking-none |
Inform-Hotel-Parking-yes |
- 17%: Inform-Hotel-Parking-none |
Inform-Hotel-Stars-4 |
- 16%: Inform-Hotel-Internet-none |
用户对话导致循环的行为: |
- 53% Request-Hotel-Phone-? |
- 21% Request-Hotel-Post-? |
- 14% Request-Hotel-Addr-? |
2.4 分析工具
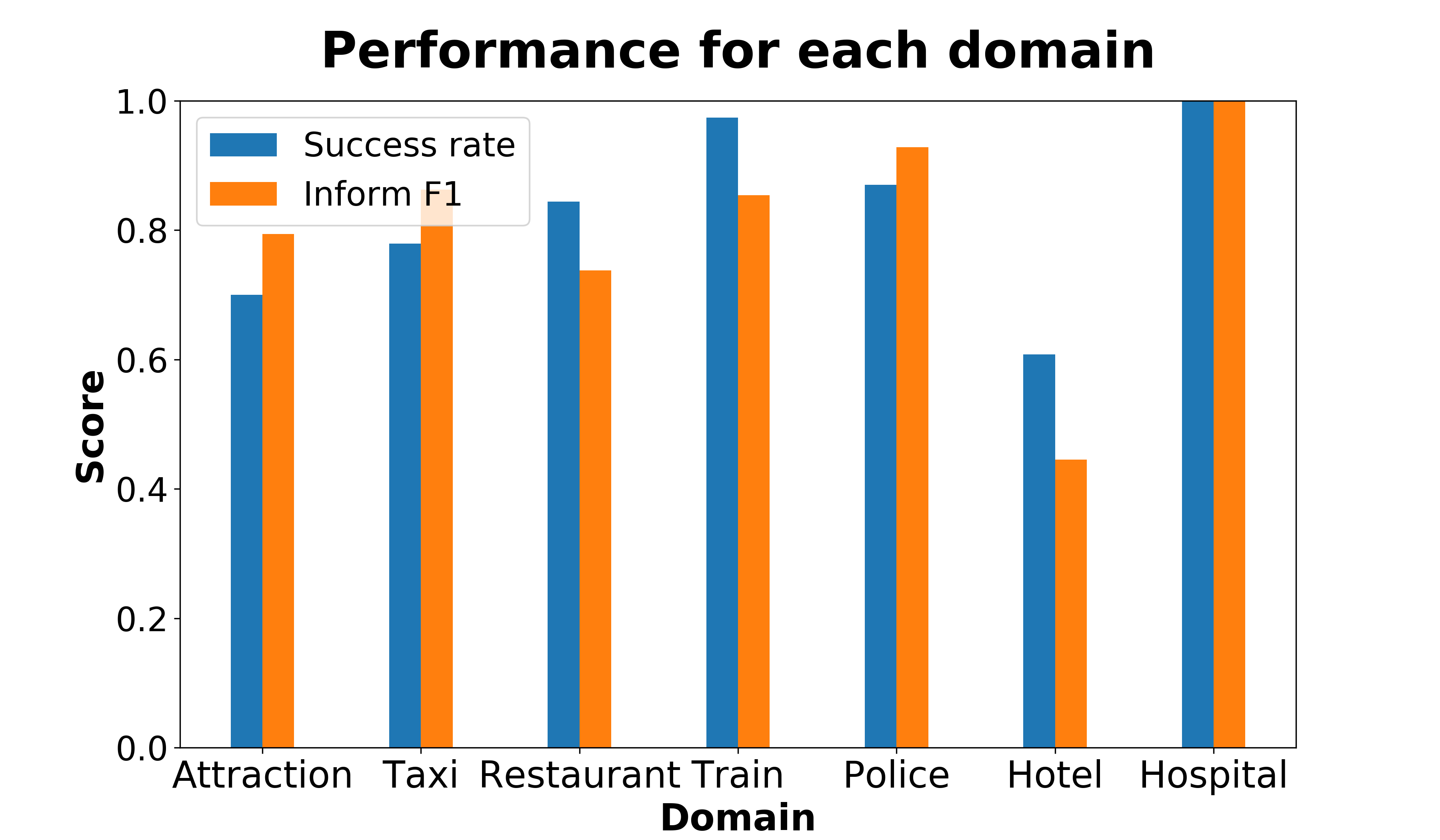
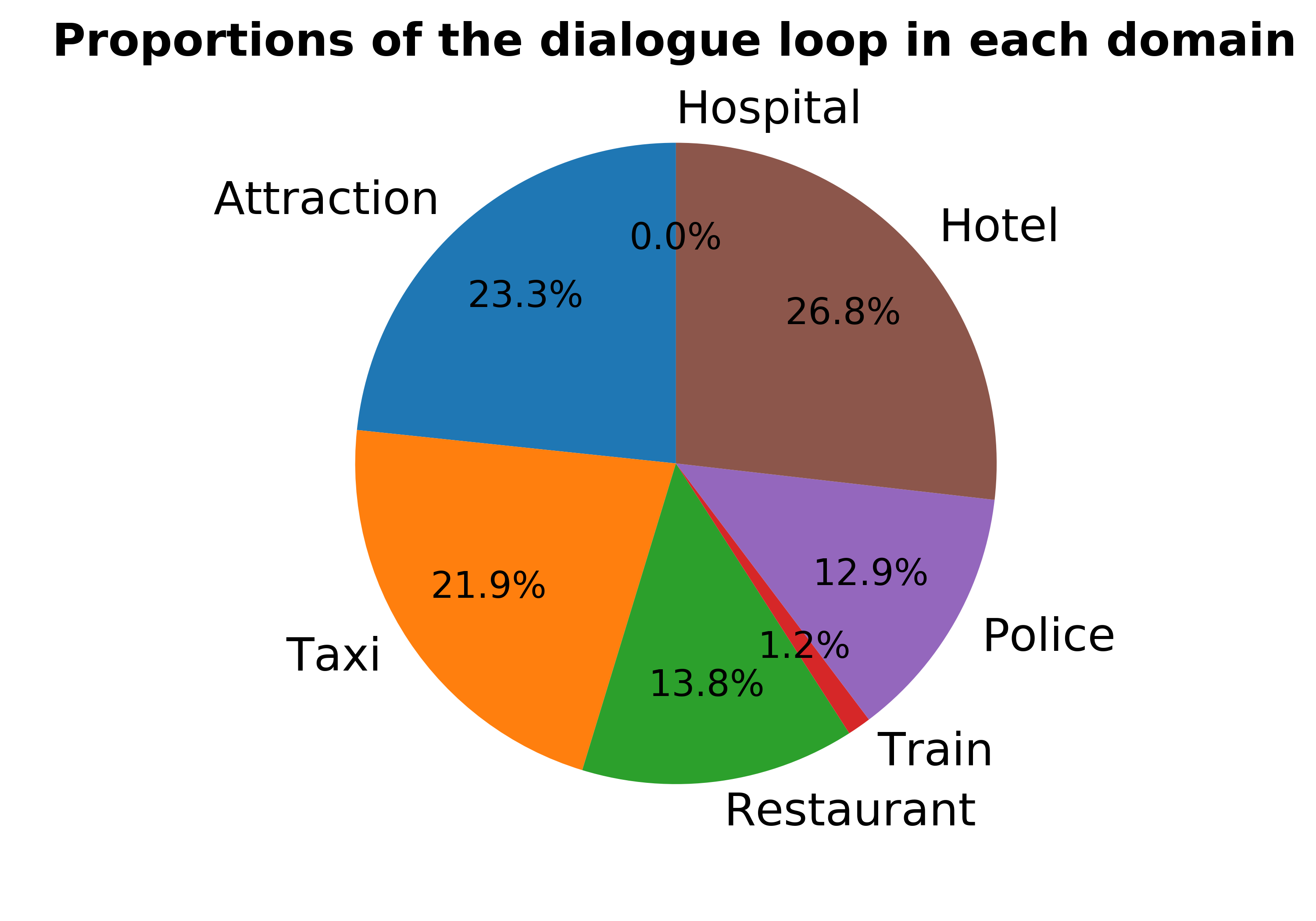
为定量评估对话系统,ConvLab-2 提供一种分析工具,可以使用指定的用户模拟器执行端到端评估,并生成包含丰富的模拟对话统计信息的 HTML 报告。 测试报告中使用图表来更好地演示。 第3节中演示系统的部分结果显示在图2和表1中。
当前,该报告包含每个任务领域的以下信息:
- 整体表现指标,例如成功率、inform F1、平均轮数等。
- NLU 组件的常见错误,例如用户对话行为的混淆矩阵。 对于表1中的示例,Hotel 领域中对邮政编码的 34% 请求被误解为 Hospital 领域的请求。
- 对话策略所预测的频繁的无效、冗余和丢失的系统对话行为。
- NLG 组件从系统对话行为生成的使用户模拟器感到困惑的响应。 对于表1中的示例,很难通知用户酒店有免费停车位。
- 对话循环的原因。 对话循环是用户不断重复同一请求直到达到最大轮数的情况。 此结果显示系统难以处理的请求。
分析工具还支持与同一用户模拟器进行交互的不同对话系统之间的比较。 以上统计和比较结果可以极大地促进错误分析和系统改进。
2.5 交互式工具
ConvLab-2 提供一种交互式工具,使研究人员可以通过图形用户界面与对话系统进行对话,并修改中间结果以纠正系统错误。
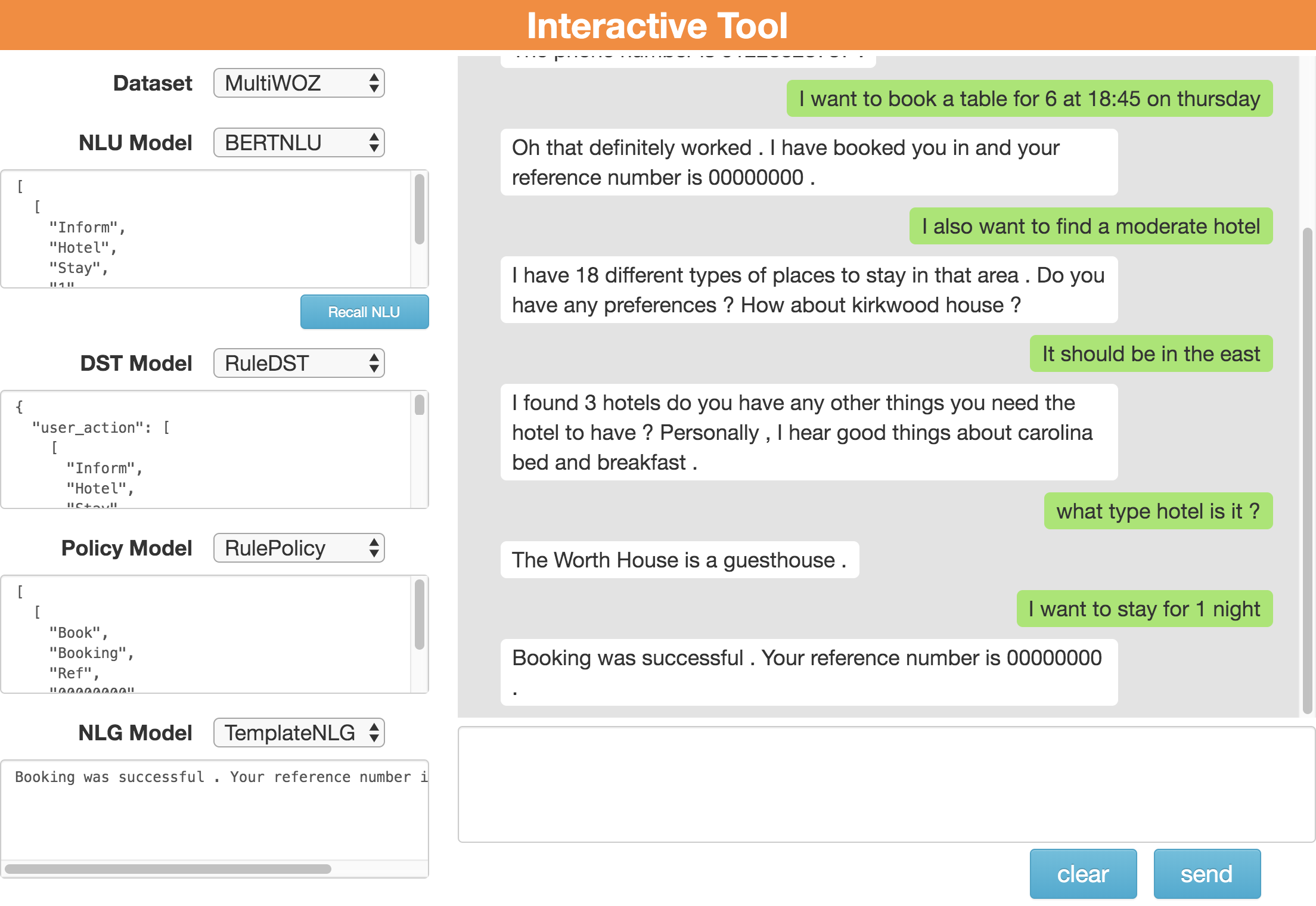
如图3所示,研究人员可以通过选择每个组件的数据集和模型来定制其对话系统。 然后,他们可以通过用户界面与系统进行交互。 在对话过程中,每个组件的输出都以JSON格式的字符串显示在左侧,包括NLU解析的用户对话行为,DST跟踪的置信状态,策略选择的系统对话行为以及最终NLG生成的系统响应。 通过显示对话历史和组件输出,研究人员可以很好地了解他们的系统如何工作。
除了细粒度的系统输出外,交互式工具还支持中间输出修改。 当某个组件出错并且对话无法继续时,研究人员可以通过将该原始输出替换为正确的内容,来更正该组件的JSON输出以重定向对话。 当研究人员调试特定组件时,此功能很有用。
考虑到跨平台的兼容性,交互式工具被部署为可通过Web浏览器访问的Web服务。 要使用自定义模型,研究人员必须编辑配置文件,该文件定义每个组件的所有可用模型。 研究人员还可以轻松地将自己的模型添加到配置文件中。
3 演示
本节演示如何使用 ConvLab-2 构建、评估和诊断在 MultiWOZ 数据集上开发的传统流水线对话系统。
2# Create models for each component
3# Parameters are omitted for simplicity
4sys_nlu = BERTNLU(...)
5sys_dst = RuleDST(...)
6sys_policy = RulePolicy(...)
7sys_nlg = TemplateNLG(...)
8# Assemble a pipeline system named "sys"
9sys_agent = PipelineAgent(sys_nlu, sys_dst, sys_policy, sys_nlg, name="sys")
10# Build a user simulator similarly but without DST
11user_nlu = BERTNLU(...)
12user_policy = RulePolicy(...)
13user_nlg = TemplateNLG(...)
14user_agent = PipelineAgent(user_nlu, None, user_policy, user_nlg, name="user")
15# Create an evaluator and a conversation environment
16evaluator = MultiWozEvaluator()
17sess = BiSession(sys_agent, user_agent, evaluator)
18# Start simulation
19sess.init_session()
20sys_utt = ""
21while True:
22 sys_utt, user_utt, sess_over, reward = sess.next_turn(sys_utt)
23 if sess_over:
24 break
25print(sess.evaluator.task_success())
26print(sess.evaluator.inform_F1())
27# Use the analysis tool to generate a test report
28analyzer = Analyzer(user_agent, dataset="MultiWOZ")
29analyzer.comprehensive_analyze(sys_agent, total_dialog=1000)
30# Compare multiple systems
31sys_agent2 = PipelineAgent(MILU(...), sys_dst, sys_policy, sys_nlg, name="sys")
32analyzer.compare_models(agent_list=[sys_agent, sys_agent2], model_name=["bertnlu", "milu"], total_dialog=1000)
要构建这样的对话系统,我们需要为每个组件实例化一个模型并将它们组装成一个完整的代理。 如上面的代码所示,该系统由 BERTNLU、基于规则的 DST、基于规则的系统策略和基于模板的 NLG 组成。 同样,我们可以构建一个由 BERTNLU、agenda-based 用户策略和基于模板的 NLG 组成的用户模拟器。 由于框架的灵活性,模拟器的 DST 可以为 None,这意味着将解析后的对话直接传递给策略,而无需置信状态。
对于端到端评估,ConvLab-2 提供 BiSession 类,将系统、模拟器和评估器作为输入。 然后,可以使用这个类来模拟对话并计算端到端评估指标。 例如,对于 1000 个模拟对话,系统的任务成功率为 64.2%,inform F1为 67.0%。 除了自动评估之外,ConvLab-2 还可以使用同一系统代理通过 Amazon Mechanical Turk 执行人工评估。
然后,可以使用分析工具进行全面评估。 由于配备用户模拟器,这个工具可以分析和比较多个系统。 一些结果显示在图2和表1中。 我们从 1000 个模拟对话中收集了统计数据,发现
- 演示系统在 Hotel 领域表现最差,但总是在 Hospital 领域完成目标。
- 与其他领域相比,Hotel 领域中的子任务更可能导致对话循环。 Hotel 领域中超过一半的循环是由用户请求电话号码引起的。
- NLU 组件最常见的错误之一是误解用户对话行为的领域。 例如,用户对 Hotel 领域中的邮政编码、地址和电话号码的请求通常会解析成其它领域。
- 在 Hotel 领域,槽值为 Parking 的对话行为比其它对话行为更难被感知。
研究人员可以通过观察细粒度的输出并使用我们提供的交互式工具来挽救失败的对话,从而进一步诊断其系统。 图3中显示一个示例,其中 BERTNLU 首先错误地将领域标识为 Restaurant。 手动将域更正为 Hotel 后,出现 Recall NLU 按钮。 通过单击按钮,对话系统将跳过 NLU 模块并直接使用更正后的 NLU 输出来重新运行此回合。 结合分析工具的观察结果,减轻 NLU 组件的领域混淆问题可以显着提高系统性能。
4 代码和资源
ConvLab-2 在https://github.com/thu-coai/ConvLab-2 上公开可用。 数据集、训练好的模型、教程和演示视频等资源也发布出来了。 我们将跟踪新的数据集和最新模型。 始终欢迎社区的贡献。
5 结论
我们介绍 ConvLab-2,一个用于构建、评估和诊断面向任务的对话系统的开源工具包。 基于 ConvLab (Lee et al., 2019b),ConvLab-2 集成更强的模型、支持更多的数据集,并开发了分析工具和交互式工具以进行全面的端到端评估。 为了演示,我们给出了一个使用 ConvLab-2 在 MultiWOZ 数据集上构建、评估和诊断系统的示例。 我们希望 ConvLab-2 对促进面向任务的对话的研究有帮助。
致谢
这项工作得到了国家自然科学基金委员会项目的共同支持(重点项目 61936010 和常规项目 61876096)和中国国家重点研发计划(批准号: 2018YFC0830200)。 感谢 THUNUS NExT Joint-Lab 的支持。
参考文献
Tom Bocklisch, Joey Faulkner, Nick Pawlowski, and Alan Nichol. 2017. Rasa: Open source language understanding and dialogue management.
Pawel Budzianowski, Iñigo Casanueva, Bo-Hsiang Tseng, and Milica Gasic. 2018a. Towards end-to-end multi-domain dialogue modelling.
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašić. 2018b. MultiWOZ - a large-scale multi-domain wizard-of-Oz dataset for task-oriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5016–5026, Brussels, Belgium. Association for Computational Linguistics.
Wenhu Chen, Jianshu Chen, Pengda Qin, Xifeng Yan, and William Yang Wang. 2019. Semantically conditioned dialog response generation via hierarchical disentangled self-attention. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3696–3709, Florence, Italy. Association for Computational Linguistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Mihail Eric, Rahul Goel, Shachi Paul, Abhishek Sethi, Sanchit Agarwal, Shuyag Gao, and Dilek Hakkani-Tur. 2019. Multiwoz 2.1: Multi-domain dialogue state corrections and state tracking baselines. arXiv preprint arXiv:1907.01669.
Jianfeng Gao, Michel Galley, and Lihong Li. 2019. Neural approaches to conversational ai. Foundations and Trends® in Information Retrieval, 13(2-3):127–298.
Izzeddin Gür, Dilek Hakkani-Tür, Gokhan Tür, and Pararth Shah. 2018. User modeling for task oriented dialogues. In 2018 IEEE Spoken Language Technology Workshop (SLT), pages 900–906. IEEE.
Matthew Henderson, Blaise Thomson, and Jason D. Williams. 2014. The second dialog state tracking challenge. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), pages 263–272, Philadelphia, PA, U.S.A. Association for Computational Linguistics.
Hwaran Lee, Jinsik Lee, and Tae-Yoon Kim. 2019a. SUMBT: Slot-utterance matching for universal and scalable belief tracking. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5478–5483, Florence, Italy. Association for Computational Linguistics.
Sungjin Lee, Qi Zhu, Ryuichi Takanobu, Zheng Zhang, Yaoqin Zhang, Xiang Li, Jinchao Li, Baolin Peng, Xiujun Li, Minlie Huang, and Jianfeng Gao. 2019b. ConvLab: Multi-domain end-to-end dialog system platform. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 64–69, Florence, Italy. Association for Computational Linguistics.
Wenqiang Lei, Xisen Jin, Min-Yen Kan, Zhaochun Ren, Xiangnan He, and Dawei Yin. 2018. Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence architectures. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1437–1447, Melbourne, Australia. Association for Computational Linguistics.
Mike Lewis, Denis Yarats, Yann Dauphin, Devi Parikh, and Dhruv Batra. 2017. Deal or no deal? end-to-end learning of negotiation dialogues. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2443–2453, Copenhagen, Denmark. Association for Computational Linguistics.
F. Mairesse, M. Gasic, F. Jurcicek, S. Keizer, B. Thomson, K. Yu, and S. Young. 2009. Spoken language understanding from unaligned data using discriminative classification models. In 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 4749–4752.
Alexander Miller, Will Feng, Dhruv Batra, Antoine Bordes, Adam Fisch, Jiasen Lu, Devi Parikh, and Jason Weston. 2017. ParlAI: A dialog research software platform. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 79–84, Copenhagen, Denmark. Association for Computational Linguistics.
Alexandros Papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, and Gokhan Tur. 2020. Plato dialogue system: A flexible conversational ai research platform.
Baolin Peng, Xiujun Li, Lihong Li, Jianfeng Gao, Asli Celikyilmaz, Sungjin Lee, and Kam-Fai Wong. 2017. Composite task-completion dialogue policy learning via hierarchical deep reinforcement learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2231–2240, Copenhagen, Denmark. Association for Computational Linguistics.
Osman Ramadan, Paweł Budzianowski, and Milica Gašić. 2018. Large-scale multi-domain belief tracking with knowledge sharing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 432–437, Melbourne, Australia. Association for Computational Linguistics.
Abhinav Rastogi, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, and Pranav Khaitan. 2019. Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset. arXiv preprint arXiv:1909.05855.
Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young. 2007. Agenda-based user simulation for bootstrapping a POMDP dialogue system. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers, pages 149–152, Rochester, New York. Association for Computational Linguistics.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
Ryuichi Takanobu, Hanlin Zhu, and Minlie Huang. 2019. Guided dialog policy learning: Reward estimation for multi-domain task-oriented dialog. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 100–110, Hong Kong, China. Association for Computational Linguistics.
Stefan Ultes, Lina M. Rojas-Barahona, Pei-Hao Su, David Vandyke, Dongho Kim, Iñigo Casanueva, Paweł Budzianowski, Nikola Mrkšić, Tsung-Hsien Wen, Milica Gašić, and Steve Young. 2017. PyDial: A multi-domain statistical dialogue system toolkit. In Proceedings of ACL 2017, System Demonstrations, pages 73–78, Vancouver, Canada. Association for Computational Linguistics.
Tsung-Hsien Wen, Milica Gašić, Nikola Mrkšić, Pei-Hao Su, David Vandyke, and Steve Young. 2015. Semantically conditioned LSTM-based natural language generation for spoken dialogue systems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1711–1721, Lisbon, Portugal. Association for Computational Linguistics.
Tsung-Hsien Wen, David Vandyke, Nikola Mrkšić, Milica Gašić, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. 2017. A network-based end-to-end trainable task-oriented dialogue system. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 438–449, Valencia, Spain. Association for Computational Linguistics.
Ronald J. Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3):229–256.
Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher, and Pascale Fung. 2019. Transferable multi-domain state generator for task-oriented dialogue systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 808–819, Florence, Italy. Association for Computational Linguistics.
Yichi Zhang, Zhijian Ou, and Zhou Yu. 2019. Task-Oriented Dialog Systems that Consider Multiple Appropriate Responses under the Same Context. In Proceedings of the AAAI Conference on Artificial Intelligence.
Tiancheng Zhao, Kaige Xie, and Maxine Eskenazi. 2019. Rethinking action spaces for reinforcement learning in end-to-end dialog agents with latent variable models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1208–1218, Minneapolis, Minnesota. Association for Computational Linguistics.
Qi Zhu, Kaili Huang, Zheng Zhang, Xiaoyan Zhu, and Minlie Huang. 2020. CrossWOZ: A large-scale chinese cross-domain task-oriented dialogue dataset. Transactions of the Association for Computational Linguistics.