-
BERT 之类的通用预训练语句编码器对于现实世界中的对话 AI 应用而言并不理想;它们在计算上繁重、缓慢且训练成本很高。 我们提出 ConveRT(基于 Transformer 的对话表示),一种用于满足以下所有要求的对话任务的预训练框架:高效、便宜并且训练迅速。 我们使用基于检索的响应选择任务进行预训练,在双编码器中有效利用量化和子词级参数化构建轻量级的内存和能源高效模型。 我们表明 ConveRT 在广泛建立的响应选择任务中实现最先进的性能。 我们还演示扩展对话历史记录并用作上下文会进一步提高性能。 最后,我们表明我们提出的编码器的预训练表示形式可以迁移到意图分类任务,在三个不同的数据集上产生很好的结果。 ConveRT 的训练速度远快于标准句子编码器或以前最先进的双编码器。 凭借其减小的尺寸和卓越的性能,我们相信该模型有望为会话式 AI 应用提供更广泛的可移植性和可伸缩性。
1 简介
对话系统或对话代理,已在许多应用中得到使用。 它们帮助用户完成定义明确的任务,例如查找和预订餐厅、酒店和航班(Hemphill 等人,1990; Williams,2012; El Asri 等人,2017),并进一步用于旅游信息(Budzianowski 等人,2018)、语言学习(Raux 等人,2003 ;Chen 等人,2017)、娱乐(Fraser 等人,2018)和医疗保健(Laranjo 等人,2018;Fadhil 和 Schiavo,2019)。 它们还是智能虚拟助手(例如 Siri、Alexa、Cortana 和 Google Assistant)的关键组件。
数据驱动的面向任务的对话系统需要特定于领域的标记数据:意图标注、显式对话状态和提及的实体(Williams,2014; Wen 等人,2017,a;Ramadan 等人,2018;Liu 等人,2018; Zhao 等人,2019b)。 这使得此类系统的扩展和维护非常具有挑战性。 预训练模型(尤其是 Devlin 等人,2019;Liu 等人,2019)之上的迁移学习提供一种途径减少训练具有泛化能力的模型所需的标注数据量。
利用基于语言模型(LM)的学习目标进行预训练的模型在 NLP 研究社区中已经很普遍。 对于对话系统,响应选择 为学习可以封装对话信息的表示形式提供更合适的预训练任务。 可以使用大量未标记的自然会话 数据对此类模型进行预训练(Henderson 等人,2019b;Mehri 等人,2019)。 响应选择也直接适用于基于检索的对话系统,这是一种流行而优雅的框架对话方法(Wu 等人,2017;Weston 等人,2018;Mazaré 等人,2018;Gunasekara 等人,2019;Henderson 等人,2019b)。1
响应选择是根据对话历史记录选择最合适响应 的任务(Wang 等人,2013;Al-Rfou 等人,2016;Yang 等人,2018;Du 和 Black,2018;Chaudhuri 等人,2018)。 这个任务对于基于检索的对话系统至关重要,通常在联合语义空间中对 context 和大量响应进行编码,然后通过将查询表示与每个候选响应的编码进行匹配来检索最相关的响应。 关键思想是:1) 利用大型未标记的会话数据集(例如 Reddit 会话)来预训练 关于通用响应选择任务的神经模型;然后 2) 使用要少得多的特定于任务的数据微调 模型(可能具有附加的网络层)。
对响应选择进行预训练的双编码器架构在对话社区中变得越来越流行(Cer 等人,2018;Humeau 等人,2020; Henderson 等人,2019b)。 在最近的工作中, Henderson 等人 (2019a)表明,将标准的基于LM的预训练体系结构应用于对话任务(如响应检索)时,无法匹配双编码器的性能。
可扩展性和可移植性。 预训练模型的一个基本问题是它们的参数众多(请参阅后面的表2):对于训练和运行而言,它们通常在计算上非常昂贵(Liu 等人,2019)。 如此高的内存占用量和计算要求阻碍快速部署以及它们的广泛可移植性、可伸缩性和面向研究的探索。 最近已经认识到需要使预训练模型更紧凑,其工作重点是建立更有效的预训练和微调协议(Tang 等人,2019;Sanh 等人,2019)。 相关的方法有蒸馏(Sanh 等人,2019)、量化训练(Zafrir 等人,2019),权重修剪(Michel 等人,2019)或权重共享(Lan 等人,2019)。 但是,到目前为止,主要重点是优化基于 LM 的模型如 BERT。
ConveRT。 这项工作为对话引入更紧凑的 预训练响应选择模型。 ConveRT 的大小仅为 59MB,远远小于以前的最先进双编码器(444MB)。 如表2所示,它还比其它流行的句子编码器更紧凑。 通过将词嵌入 8 比特量化和量化训练,子词级参数化和修剪的自我注意相结合,可以实现大小和训练加速的显着降低。 此外,轻巧的设计使我们能够保留其他参数,以提高双编码器体系结构的表现力;这导致对会话 表示 的学习得到改善,可以将其转移到其他对话任务中(Casanueva 等人,2020; Bunk 等人,2020年)。
多上下文建模。 ConveRT 不再使用单个上下文假设 Henderson 等人 (2019b),其中仅使用最近的一个上下文查找相关响应。 我们提出一种多上下文双编码器模型,在响应选择任务中将最近的一个上下文与先前的对话历史结合起来。 多上下文 ConveRT 变体保持紧凑(总计73MB),同时在一系列已建立的响应选择任务上提供更高的性能。 我们报告在 Ubuntu DSTC7(Gunasekara 等人,2019)、AmazonQA(Wan 和 McAuley,2016)和 Reddit 响应选择(Henderson 等人,2019a)等基准测试中取得明显的进步,无论是单上下文还是多上下文场景。 此外,我们证明该模型学习到的句子编码可以转移到其他对话任务,在三个评估集上达到很强的意图分类性能。 预训练的双编码器模型(单上下文和多上下文模型)都作为 TensorFlow Hub 模块共享在 github.com/PolyAI-LDN/polyai-models。2
2 方法
在 Reddit 数据上预训练。 在本文全文中,我们假设使用英语。 将对话学习任务简化为响应选择,我们可以将目标对话任务与通用领域的对话数据如 Reddit 相关联(Al-Rfou 等人,2016)。 这使我们可以从 Reddit 上预训练的通用领域响应选择模型开始,微调特定于任务的响应选择模型的参数。 类似于 Henderson 等人 (2019b),由于以下原因,我们选择 Reddit 进行预训练:1)其自然的会话结构;和2) 无法比拟的规模,因为 Reddit 数据的公开存储库包含 727M 个 (input, response) 对。3
2.1 更紧凑的响应选择模型
我们提出 ConveRT — Conversational Representations from Transformers — 一种紧凑的双编码器预训练架构,利用子词表示、Transformer 风格的网络以及模型量化,如图1所示。 ConveRT 满足以下所有要求:高效、便宜并且训练迅速。
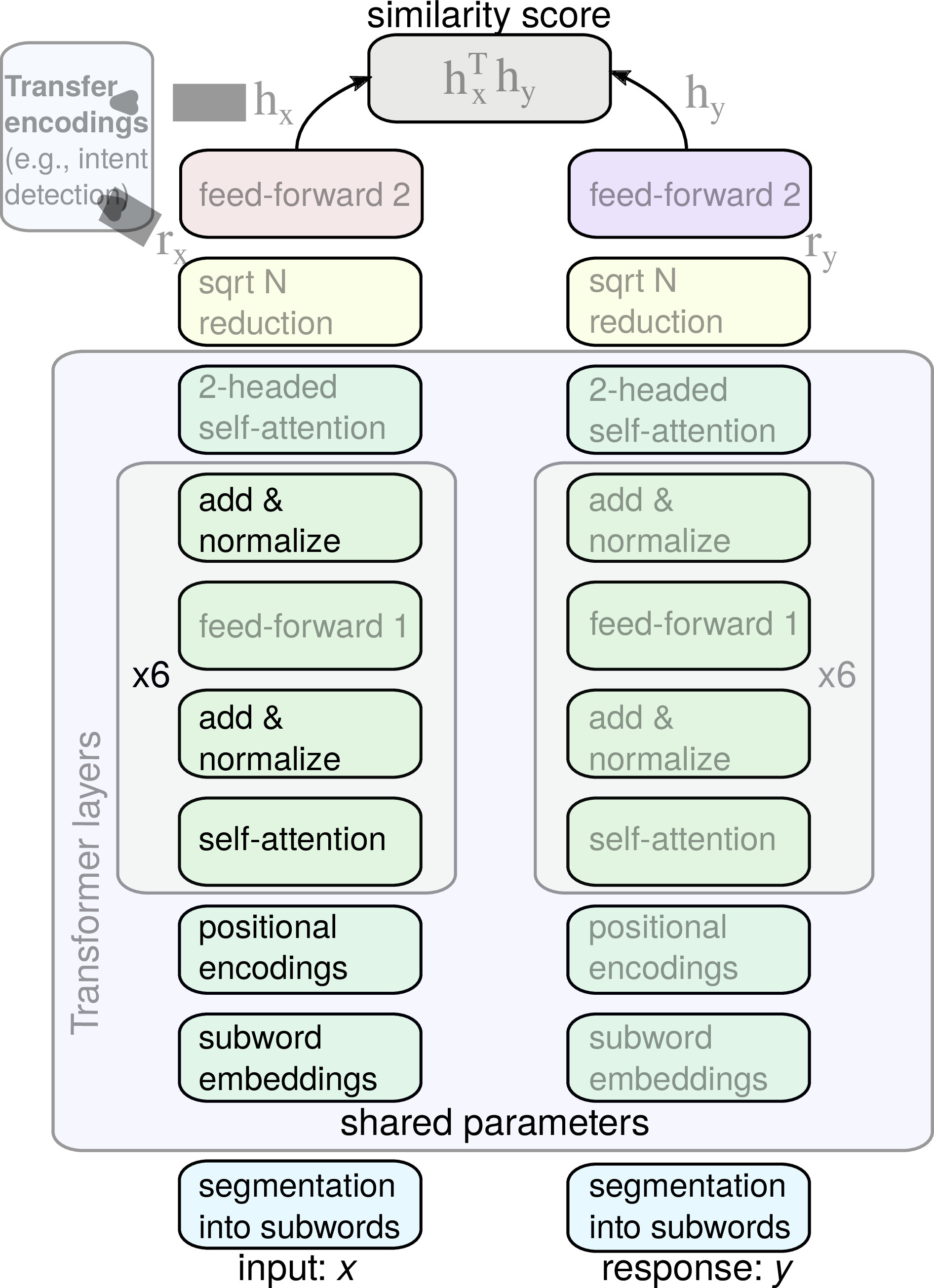
输入和响应表示。 在训练之前,我们获得输入端和响应端共享的子词 V 的词汇表:我们从 Reddit 中随机采样并小写 10M 个句子,然后迭代地运行任何子词标记化算法。4 最终词汇 V 包含 31,476 个子单词标记。 在训练和推理过程中,如果遇到 OOV 字符,则将其视为子词符,使用哈希函数计算其 ID,并将其分配给为 OOV 保留的 1,000 个其它“存储桶”之一。 因此,我们为 V 中的 31,476 个子词以及其它 1,000 个与 OOV 相关的存储桶保留参数(即嵌入)。 在训练和推理时,在对 UTF8 标点和单词边界进行最初的单词级词符化之后,输入的文本 x 在简单的从左到右的贪婪前缀匹配之后被分解为子单词(Vaswani 等人,2018年)。 在训练期间,我们以完全相同的方式词符化所有响应 y。
输入和响应编码器网络。 然后,子词嵌入在输入端和响应端都经历一系列转换。 转换基于标准的 Transformer 架构(Vaswani 等人,2017)。 在进行自我关注网络之前,我们向子词嵌入输入添加位置编码。 先前的工作(例如 BERT 和相关模型)(尤其是 Devlin 等人,2019; Lan 等人,2019)学习固定数量的位置编码,序列中每个位置对应一个位置编码,从而允许模型表示固定数量的位置。 不同的是,我们学校两个不同大小的位置编码矩阵 — 维度为 [47, 512] 的 M1 和 维度为 [11, 512] 的 M2。 位置 i 处的嵌入添加:Mi mod471 + Mi mod112。5
接下来的几层与原始的 Transformer 体系结构密切相关,但有一些明显的不同。 首先,我们将六层中的最大相对注意力(Shaw 等人,2018)设置为以下各个值:[3, 5, 48, 48, 48, 48]。6 这也有助于将体系结构推广到长序列和远距离的依存关系:在后面的层对较大的模式进行建模之前,必须先将较早的层在短语级别上组合含义。 我们在整个网络中使用单头注意力。7
在进入 softmax 之前,我们在注意力分数上添加一个偏置,该偏置仅取决于相对位置:αij →αij + Bn−i+j,其中 B 是学习的偏置向量。 这有助于模型理解相对位置,但比计算完整的相对位置编码要有效得多(Shaw 等人,2018)。 同样,它也有助于模型推广到更长的序列。
六个 Transformer 网络模块使用 64 维的投影来计算注意力权重、一个 2,048 维的内核(图1中的 feed-forward 1)和 512 维的嵌入。 请注意,所有Transformer层都使用在输入端和响应端之间完全共享的参数。 与通用句子编码器(use)(Cer 等人,2018)一样,我们使用 N 的平方根归约法将嵌入序列转换为固定维的向量。 两个自我关注头分别计算加权总和的权重,并由序列长度的平方根缩放。8 归约层的输出,图1 中标记为 rx 和 ry 是 1,024 维向量,它们被馈送到两个(即它们不共享参数)前馈网络。
换句话说,向量 rx 和 ry 经过一系列 Nf l-维前馈隐藏层(Nf = 3; l = 1,024),具有丢弃连接、层归一化和正交初始化。 这些网络和整个架构中使用的激活函数是快速的 GeLU 近似值(Hendrycks 和 Gimpel,2016):GeLU(x) = xσ(1.702x)。 最后一层是线性的,并将文本映射到最终的 L2 标准化的 512 维表示中:hx 用于输入文本,而 hy 表示相应的响应文本(图1)。
输入-响应交互。 然后,通过编码 hx 和 hy 之间的余弦相似度得分 S(x,y) 量化每个响应与给定输入的相关性。 它从 1 开始,到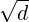 结束,在前 10K 个训练批次中线性增加。 训练的批次位 K 个 (input, response) 对 (x1,y1),…,(xK,yK)。 目标是对每个输入句子 xi,区分真实的相关响应(yi)和不相关的响应(即负样本)yj, j≠i 。 批次大小为 K 的训练目标如下:J=∑ i=1KS(xi,yi)−∑ i=1K log∑ j=1KeS(xi,yj)。
目标是最大化正训练对的分值 (xi,yi) 和最小化输入 xi 与 K′ 个与输入 xi 不相关的负样本之间的分值:为了简单,当前批次中其它的所有 K−1 个样本均用作负样本。
结束,在前 10K 个训练批次中线性增加。 训练的批次位 K 个 (input, response) 对 (x1,y1),…,(xK,yK)。 目标是对每个输入句子 xi,区分真实的相关响应(yi)和不相关的响应(即负样本)yj, j≠i 。 批次大小为 K 的训练目标如下:J=∑ i=1KS(xi,yi)−∑ i=1K log∑ j=1KeS(xi,yj)。
目标是最大化正训练对的分值 (xi,yi) 和最小化输入 xi 与 K′ 个与输入 xi 不相关的负样本之间的分值:为了简单,当前批次中其它的所有 K−1 个样本均用作负样本。
量化。 最近的工作表明,通过应用量化技术(Han 等人,2016)可以使大型语言模型更加紧凑:例如基于 Transformer 的机器翻译系统的量化版本(Bhandare 等人,2019)和 BERT(Shen 等人,2019;Zhao 等人,2019a;Zafrir 等人, 2019)。 在这项工作中,我们专注于在响应选择任务上启用量化感知会话预训练。 我们表明,图1中的双编码器 ConveRT 模型也可以以量化感知的方式进行训练。 并非每个参数都使用标准的 32 位,所有嵌入参数仅使用 8 位表示,其它网络参数仅使用 16 位表示;通过调整混合精度训练方案以量化方式对它们进行训练 Micikevicius 等人 (2018)。 它以 32 位浮点(FP32)精度保留每个变量的卷影副本,但在计算和推理模型中使用 FP16-cast 版本。 但是,若要在数值上稳定图中的某些操作要求 FP32 精度:层归一化、L2 归一化和关注层中的 softmax。
再次,遵循 Micikevicius 等人 (2018),最终损失按 128 缩放,影子 FP32 变量的更新按 1/128 缩放:这使梯度计算可以很好地由 FP16 表示(例如,不会四舍五入到零)。 子词嵌入每个参数使用 8 位存储,并通过训练动态调整量化范围。 它会定期更新,以包含迄今已获悉的所有嵌入值,并在上下范围-范围的10%或0.01-较大的范围内增长。 最后,量化还可以使批处次大小加倍,这也具有增加训练中负面样本数量的有利效果。
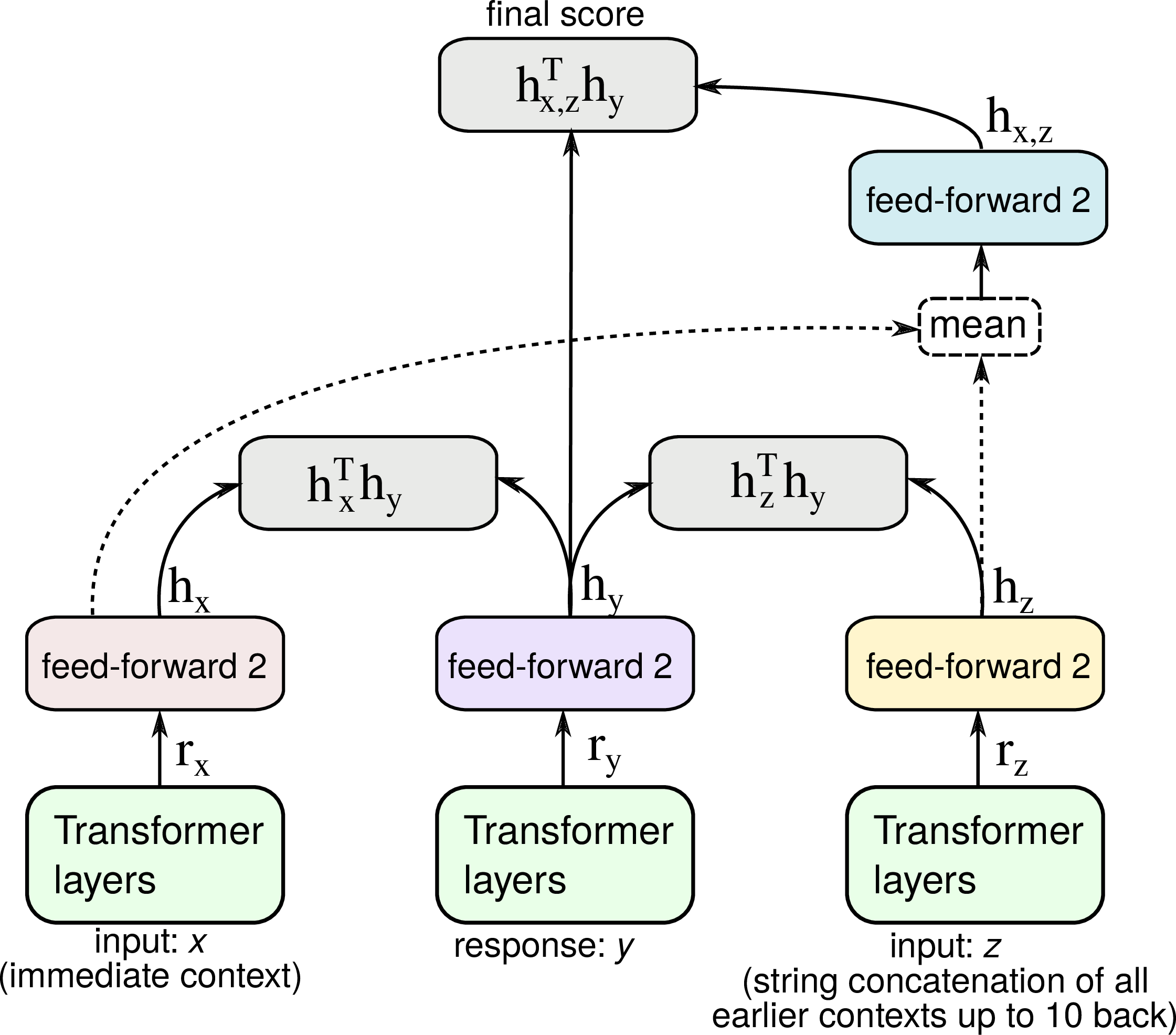
多上下文 ConveRT。 图1描述单上下文双编码器体系结构。 直觉上,单上下文假设限制了对多轮对话的建模,在早期对话历史中可以发现强烈的对话线索,并且有大量工作利用更丰富的对话历史来进行响应选择(Chaudhuri 等人,2018; Zhou等人,2018; Humeau 等人,2020)。 举一个简单的说明性例子:
学生: I’m very interested in representation learning.
老师: Do you have any experience in PyTorch?
学生: Not really.
老师: And what about TensorFlow?
仅在紧接前一个上下文的情况下,选择最后一位老师的回答将非常困难。 但是,考虑到整个会话上下文后,任务将变得更加容易。 因此,我们通过在 Reddit 中使用多达 10 条以前的消息来构建多上下文双编码器模型。 额外的10个上下文从最新到最旧被串联在一起,并被视为网络中的额外特征,如图2所示。 注意,所有上下文表示仍独立于候选响应的表示,因此我们仍然可以进行有效的响应检索和训练。 完整的训练目标是三个子目标的线性组合:1)给定前一个上下文的响应排名(这等同于§2.1),2)仅在给定额外(非上一个)上下文的情况下对排名进行响应,以及3)在给定上一个上下文和其它上下文的平均表示的情况下的排名响应。9
3 实验设置
训练数据和设置。 我们所有的(预)训练均基于源自 3.7B Reddit 评论的大型 Reddit 会话语料库(Henderson 等人,2019a):它包含 727M (input, response) 用于单上下文建模的对 — 保留 654M对用于训练,其余用于测试。 我们将序列截断为 60 个子词,所有子词嵌入和存储桶嵌入的嵌入大小均设置为 512,最终编码 hx, hy, hz 和 hx,z 均为 512 维。 feed forward 2 网络的隐藏层大小设置为 1,024(使用 Nf = 3 个隐藏层)。
我们使用 ρ = 0.9 的 ADADELTA 进行训练(Zeiler,2012) ,批次大小为 512,学习速度为 1.0,退火后的余弦衰减为 0.001。 使用 10−5 的 L2 正则化,将子词嵌入梯度限制为 1.0,标签平滑应用 0.2。10
我们在 Reddit 上用 12 个 GPU 节点对模型进行预训练,每个节点有一个 Tesla K80,历时18小时;通常这足以达到收敛。 在 Google Cloud Platform 上,总的训练费用约为 $85。 与 BERT、GPT-2、XLNet 和 RoBERTa (Strubell 等人,2019)等常见的预训练 NLP 模型相比,这种预训练方案便宜且效率高出几个数量级。
基线。 我们报告响应选择任务的结果,并与标准基准集进行比较(Henderson 等人,2019a)。 首先,我们比较一个基于 tf-idf 查询-响应评分的简单关键字匹配基准(Manning 等人,2008年),然后使用一个公开的代表性的神经编码器将输入和响应嵌入向量空间中,取决于各种预训练目标:(1)Universal Sentence Encoder 的较大变体(Cer 等人,2018)(use-large);(2)BERT 的较大变体(Devlin等人,2019)(bert-large)。 我们还将比较两种最新的双编码器体系结构:(3) use-qa 是 USE(large) 模型的双重问答编码器版本(Chidambaram 等人,2019)。11(4) polyai-dual 是性能最好的双编码器模型 Henderson 等人 (2019b)在 Reddit 响应选择上进行了预训练。 对于基准模型 1-3,我们将结果报告为 map 响应选择变体(Henderson 等人,2019a):它表现出比基于简单相似度的变体更好的性能,该变体直接根据响应与上下文向量的余弦相似度对响应进行排名。 map学习将响应向量(线性)映射到输入向量空间。
响应选择:评估任务。 我们报告了Reddit测试集(Henderson等人,2019a)上具有单上下文和多上下文ConveRT变体的响应选择性能。 对于多上下文ConveRT,在评估中使用(立即和先前)上下文的平均表示。 这些模型直接应用于Reddit测试数据,无需任何进一步的微调。 我们还评估了其他两个在不同领域中众所周知的响应选择问题。 (1) amazonQA (Wan 和 McAuley,2016)是一个电子商务数据集,其中以问答对的形式包含有关亚马逊产品的信息:3.6M 个(单上下文)QA 对,300K 个 QA 对保留用于测试。 (2) dstc7-ubuntu 基于 Ubuntu v2 语料库(Lowe 等人,2017):它包含高度技术性领域(即 Ubuntu 技术支持)超过 1M 的对话。 dstc7-ubuntu 使用 100K 对话进行训练,使用 10K 进行验证,并使用 5K 对话进行测试(Gunasekara 等人,2019)。
对于 dstc 7- ubuntu 我们微调 60K 个训练步骤:12 个 GPU 大约需要 2 小时。 学习速率始于0.1,然后在训练过程中使用余弦衰减将其退火至0.0001。 我们使用的批次大小为 256,在嵌入和自我关注层之后,则使用 0.2 的丢弃率。 我们对amazon QA使用相同的微调机制。 对于 dstc7-ubuntu,额外的上下文以数字字符串 0–9 开头,以帮助模型识别其位置。 我们还将发布经过微调的模型。
我们使用受IR启发的标准评估方法Recall @ k进行评估,该方法用于基于检索的对话的先前工作中(Chaudhuri等人,2018; Henderson等人,2019b; Gunasekara等人,2019)。 给定输入的一组 N 个响应,其中只有一个响应是相关的,它指示相关的响应是否出现在排名最高的 k 个候选对象中。 我们将此度量表示为 RN@k,并设置 N = 100;k = 1: R100@1。
意图分类:任务,数据,设置。 预训练语句编码器由于在其学习的表示基础上针对下游任务的训练模型的成功而特别受欢迎,与从头开始的训练相比,极大地改善了结果,尤其是在低数据条件下(请参见表 1)。 因此,我们还探讨 ConveRT 编码在意图分类任务中对迁移学习的有用性:该模型必须将用户的话语分类为几种预定义类别之一,即意图(例如,在 e-banking 中意图可能是 card lost 或 replace card)。 我们使用来自三个不同领域的三个内部意图分类数据集(请参见表1),并使用80/10/10拆分方式将其分为训练集,开发集和测试集。
我们在输入侧使用预先训练的 ConveRT 编码 rx(参见图1)作为意图分类模型的输入。 我们还在输入端尝试后面的 hx 编码,但是使用 rx 观察到更强的结果。 我们在 rx 的顶部训练一个带有丢弃的 2 层前馈网络。 使用批次大小为 32 的 SGD,在对验证集没有改善后 5 个周期后停止。 通过网格搜索选择层大小、丢弃率和学习率。 我们再次与其他两个标准句子编码器进行比较: use-large 和 bert-large。 对于 ConveRT 和 use-large 我们保持编码器固定,并在句子编码之上训练分类器层。 对于 bert-large,我们在 CLS 词符的顶部进行训练,并对其所有参数进行微调。
4 结果与讨论
| 嵌入 | 网络 | 总 | 之后的大小 | |
| 参数 | 参数 | 尺寸 | 量化 | |
| USE (Cer et al., 2018) | 256 M | 2 M | 1033 MB | 261 MB * |
| BERT-BASE(Devlin et al., 2019) | 23 M | 86 M | 438 MB | 196 MB */ 110 MB ** |
| BERT-LARGE(Devlin et al., 2019) | 31 M | 304 M | 1341 MB | 639 MB */ 336 MB ** |
| GPT-2(Radford et al., 2019) | 80 M | 1462 M | 6168 MB | 3004 MB * |
| POLYAI-DUAL(Henderson et al., 2019b) | 104 M | 7 M | 444 MB | 118 MB |
| ConveRT(这项工作) | 16 M | 13 M | 116 MB | 59 MB |
模型大小、训练时间、成本。 表2列出了先前工作的编码器及其模型大小,以及量化后的估计模型大小。 报告的数字表示通过子词级参数化和ConveRT量化获得的收益。 除了降低训练成本外,ConveRT 还减少了内存占用并加快了训练速度。 我们仅对所有模型进行 18 个小时的预训练(在 12 个 16GB T4 GPU上),而模型压缩技术 DistilBERT(Sanh 等人,2019)(它报告原始 BERT 减小 ≈ 40% ) 在 8 个 16GB V100 GPU 上训练 90 个小时,像 RoBERTa 这样的大型模型则需要在 1024 个 32 GB V100 GPU 上进行整整一天的训练。 实现的尺寸减小和快速训练还可以加快开发速度和进行深入的消融研究(请参见表4的后面部分),并且使用量化还可以提高每秒实例数的训练效率。
| Model Configuration |
|
| ConveRT | 68.2 |
| A: Multi-headed attention (8 64-dim heads) | 68.5 |
| B: No relative position bias | 67.8 |
| C: Without gradually increasing max attention span | 67.7 |
| D: Only 1 OOV bucket | 68.0 |
| E: 1-headed (instead of 2-headed) reduction | 67.7 |
| F: No skip connections in feed forward 2 | 67.8 |
| D + E + F | 66.7 |
| B + C + D + E + F | 66.6 |
| R100@1 | MRR |
|
| Best DSTC7 System | 64.5 | 73.5 |
| GPT * | 48.9 | 59.5 |
| BERT * | 53.0 | 63.2 |
| Bi-encoder (Humeau et al., 2020) | 70.9 | 78.1 |
| ConveRT(单上下文) | 38.2 | 49.2 |
| ConveRT(多上下文) | 71.2 | 78.8 |
Reddit上的响应选择。 结果总结在表3中。 即使单上下文 ConveRT 都能在任务中达到最佳性能,比以前的最佳报道分数大有提高 Henderson 等人 (2019b)。 它也大大优于所有其它不是直接在响应选择任务上而是在标准 LM 任务上直接训练的模型。 但是,最强的基准是两种双重编码器架构(即use-large use-qa 和polyai-dual);这说明在对响应选择进行建模时,明确区分输入/上下文和响应的重要性。
表3还显示了利用其他上下文的重要性(请参见图2)。 多上下文ConveRT在最新的Reddit响应选择得分上达到了71.8%,我们在其他报告的响应选择任务中也观察到了类似的好处。 我们还注意到1)仅使用对即时上下文和响应之间的交互进行建模的子网的结果(即 hxT hy 交互),以及2)用空字符串人为地替换串联的额外上下文 z。 分别为 65.7% 和 65.6%。 这表明当没有为目标任务提供额外上下文时,多上下文 ConveRT 也适用于单上下文方案。
消融研究。 高效的训练还使我们能够执行各种诊断性实验和消融。 我们在表4中报告单上下文 ConveRT 各种变体的结果。 它们表明用多头注意力代替单头注意力会导致稍有改善,但这是以较慢的训练为代价的(因此也要花费更多)。 使用1个而不是1,000个OOV存储桶只会导致性能略有下降。 最重要的是,消融研究表明,最终性能实际上来自应用各种组件和技术设计选择(例如跳过连接、2头减小,相对位置偏差等)的协同效应。 虽然一次只删除一个组件只会产生适度的性能损失,但结果表明,随着我们删除更多组件这些损失加起来了,而不同的组件的确有助于最终得分。12
其他响应选择任务。 结果就 amazonQA 表3中提供了任务。 我们看到与Reddit评估类似的趋势。 经过微调的 ConveRT 取得新的最先进水平,最强的基准再次是双编码器网络。 对完全相同的数据进行预训练的微调 polyai-dual 无法匹配 ConveRT 的性能。13
结果在 dstc 7- ubuntu 总结在表5中。首先,它们表明多上下文 ConveRT 模型具有非常好的竞争性能:它胜过官方 DSTC7 挑战赛的最佳评分系统(Gunasekara 等人,2019)。 鉴于多上下文ConveRT依赖简单的上下文串联而没有任何其他关注机制,这是一个令人鼓舞的发现。 我们将研究这种更复杂的模型,以整合其他上下文以供将来的工作。 多上下文 ConveRT 还可以匹配甚至超越另外一个双编码器架构的性能 Humeau 等人 (2020)。 他们的双编码器(即 bi-encoder)基于 BERT 的架构(Humeau 等人,2020):它依赖于 12 个 Transformer 模块,12 个注意力头,隐藏尺寸为 768(而我们使用 512)。 使用该模型进行训练大约要慢 5×,并且预训练目标更加复杂:他们使用标准的 BERT 预训练目标加上下一个语句分类。 而且,他们的模型在 32 个 v100 GPU 上进行了 14 天的训练,这使其价格比 ConveRT 高出 50×。
意图分类。 结果总结在表6中:我们报告了两个最简单的基准。 得分显示 ConveRT 编码 rx 迁移到另一个对话任务时,具有非常好的竞争力。 它们超过 use-large 在所有三个任务中 bert-large 在2/3任务中。 请注意,除了更快的预训练以外,基于 ConveRT 编码的意图分类器的训练速度比基于 bert-large 的训练速度快 40 倍,因为 ConveRT 只训练分类层。 总之,这些初步结果表明,ConveRT作为句子编码器可以在核心响应选择任务之外发挥作用。 基于 ConveRT 的句子表征的有用性最近已经在其它意图分类数据集(Casanueva 等人,2020)、不同的意图分类器(Bunk 等人,2020)和另一个对话任务:turn-based value 提取(Coope 等人,2020;Bunk 等人,2020)上得到证实。 在未来的工作中,我们计划研究迁移的其它可能应用,尤其是对于低数据设置。
5 结论
我们提出 ConveRT,一种新型轻量级对话框神经响应选择模型,它基于 Transformer 的双编码器网络,在一系列响应选择任务和意图分类任务上展示最先进的性能。 除了提供更准确的 对话式预训练模型之外,这项工作还获得更加紧凑 的对话式预训练。 ConveRT 和多上下文 ConveRT 的量化版本分别仅占用 59 MB 和 73 MB,并且 18 个小时的训练成本估计仅为 85 美元。 因为希望这项工作能够激励和指导基于检索的面向任务的对话领域的进一步发展,我们公开发布经过预训练的 ConveRT 模型。
参考文献
Rami Al-Rfou, Marc Pickett, Javier Snaider, Yun-Hsuan Sung, Brian Strope, and Ray Kurzweil. 2016. Conversational contextual cues: The case of personalization and history for response ranking. CoRR, abs/1606.00372.
Aishwarya Bhandare, Vamsi Sripathi, Deepthi Karkada, Vivek Menon, Sun Choi, Kushal Datta, and Vikram Saletore. 2019. Efficient 8-bit quantization of transformer neural machine language translation model. CoRR, abs/1906.00532.
Basma El Amel Boussaha, Nicolas Hernandez, Christine Jacquin, and Emmanuel Morin. 2019. Deep retrieval-based dialogue systems: A short review. CoRR, abs/1907.12878.
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašić. 2018. MultiWOZ - A large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. In Proceedings of EMNLP, pages 5016–5026.
Tanja Bunk, Daksh Varshneya, Vladimir Vlasov, and Alan Nichol. 2020. DIET: Lightweight language understanding for dialogue systems. CoRR, abs/2004.09936.
Iñigo Casanueva, Tadas Temcinas, Daniela Gerz, Matthew Henderson, and Ivan Vulić. 2020. Efficient intent detection with dual sentence encoders. CoRR, abs/2003.04807.
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Yun-Hsuan Sung, Brian Strope, and Ray Kurzweil. 2018. Universal sentence encoder for English. In Proceedings of EMNLP, pages 169–174.
Debanjan Chaudhuri, Agustinus Kristiadi, Jens Lehmann, and Asja Fischer. 2018. Improving response selection in multi-turn dialogue systems by incorporating domain knowledge. In Proceedings of CoNLL, pages 497–507.
Hongshen Chen, Xiaorui Liu, Dawei Yin, and Jiliang Tang. 2017. A survey on dialogue systems: Recent advances and new frontiers. CoRR, abs/1711.01731.
Muthuraman Chidambaram, Yinfei Yang, Daniel Cer, Steve Yuan, Yun-Hsuan Sung, Brian Strope, and Ray Kurzweil. 2019. Learning cross-lingual sentence representations via a multi-task dual-encoder model. In Proceedings of the 4th Workshop on Representation Learning for NLP, pages 250–259.
Sam Coope, Tyler Farghly, Daniela Gerz, Ivan Vulić, and Matthew Henderson. 2020. Span-ConveRT: Few-shot span extraction for dialog with pretrained conversational representations. In Proceedings of ACL.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pages 4171–4186.
Wenchao Du and Alan Black. 2018. Data augmentation for neural online chats response selection. In Proceedings of the 2nd International Workshop on Search-Oriented Conversational AI, pages 52–58.
Layla El Asri, Hannes Schulz, Shikhar Sharma, Jeremie Zumer, Justin Harris, Emery Fine, Rahul Mehrotra, and Kaheer Suleman. 2017. Frames: A corpus for adding memory to goal-oriented dialogue systems. In Proceedings of SIGDIAL, pages 207–219.
Mihail Eric, Rahul Goel, Shachi Paul, Abhishek Sethi, Sanchit Agarwal, Shuyang Gao, and Dilek Hakkani-Tür. 2019. Multiwoz 2.1: Multi-domain dialogue state corrections and state tracking baselines. CoRR, abs/1907.01669.
Ahmed Fadhil and Gianluca Schiavo. 2019. Designing for health chatbots. CoRR, abs/1902.09022.
Jamie Fraser, Ioannis Papaioannou, and Oliver Lemon. 2018. Spoken conversational AI in video games: Emotional dialogue management increases user engagement. In Proceedings of IVA.
Chulaka Gunasekara, Jonathan K. Kummerfeld, Lazaros Polymenakos, and Walter Lasecki. 2019. DSTC7 task 1: Noetic end-to-end response selection. In Proceedings of the 1st Workshop on NLP for Conversational AI, pages 60–67.
Song Han, Huizi Mao, and William J. Dally. 2016. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding. In Proceedings of ICLR.
Charles T. Hemphill, John J. Godfrey, and George R. Doddington. 1990. The ATIS Spoken Language Systems Pilot Corpus. In Proceedings of the Workshop on Speech and Natural Language, HLT ’90, pages 96–101.
Matthew Henderson, Rami Al-Rfou, Brian Strope, Yun-Hsuan Sung, László Lukács, Ruiqi Guo, Sanjiv Kumar, Balint Miklos, and Ray Kurzweil. 2017. Efficient natural language response suggestion for smart reply. CoRR, abs/1705.00652.
Matthew Henderson, Pawel Budzianowski, Iñigo Casanueva, Sam Coope, Daniela Gerz, Girish Kumar, Nikola Mrkšić, Georgios Spithourakis, Pei-Hao Su, Ivan Vulić, and Tsung-Hsien Wen. 2019a. A repository of conversational datasets. In Proceedings of the 1st Workshop on Natural Language Processing for Conversational AI.
Matthew Henderson, Blaise Thomson, and Jason D. Wiliams. 2014. The Second Dialog State Tracking Challenge. In Proceedings of SIGDIAL, pages 263–272.
Matthew Henderson, Ivan Vulić, Daniela Gerz, Iñigo Casanueva, Paweł Budzianowski, Sam Coope, Georgios Spithourakis, Tsung-Hsien Wen, Nikola Mrkšić, and Pei-Hao Su. 2019b. Training neural response selection for task-oriented dialogue systems. In Proceedings of ACL, pages 5392–5404.
Dan Hendrycks and Kevin Gimpel. 2016. Gaussian error linear units (GELUs). arXiv preprint arXiv:1606.08415.
Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, and Jason Weston. 2020. Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring. In Proceedings of ICLR.
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A Lite BERT for self-supervised learning of language representations. In Proceedings of ICLR.
Liliana Laranjo, Adam G. Dunn, Huong Ly Tong, Ahmet Baki Kocaballi, Jessica Chen, Rabia Bashir, Didi Surian, Blanca Gallego, Farah Magrabi, Annie Y.S. Lau, and Enrico Coiera. 2018. Conversational agents in healthcare: A systematic review. Journal of the American Medical Informatics Association, 25(9):1248–1258.
Bing Liu, Gökhan Tür, Dilek Hakkani-Tür, Pararth Shah, and Larry P. Heck. 2018. Dialogue learning with human teaching and feedback in end-to-end trainable task-oriented dialogue systems. In Proceedings of NAACL-HLT, pages 2060–2069.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692.
Ryan Thomas Lowe, Nissan Pow, Iulian Vlad Serban, Laurent Charlin, Chia-Wei Liu, and Joelle Pineau. 2017. Training end-to-end dialogue systems with the ubuntu dialogue corpus. Dialogue & Discourse, 8(1):31–65.
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. 2008. Introduction to Information Retrieval. Cambridge University Press.
Pierre-Emmanuel Mazaré, Samuel Humeau, Martin Raison, and Antoine Bordes. 2018. Training millions of personalized dialogue agents. In Proceedings of EMNLP, pages 2775–2779.
Shikib Mehri, Evgeniia Razumovskaia, Tiancheng Zhao, and Maxine Eskenazi. 2019. Pretraining methods for dialog context representation learning. In Proceedings of ACL, pages 3836–3845.
Paul Michel, Omer Levy, and Graham Neubig. 2019. Are sixteen heads really better than one? In Proceedings of NeurIPS.
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory F. Diamos, Erich Elsen, David García, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. 2018. Mixed precision training. In Proceedings of ICLR.
Seyed-Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, and Hassan Ghasemzadeh. 2019. Improved knowledge distillation via teacher assistant: Bridging the gap between student and teacher. CoRR, abs/1902.03393.
Nikola Mrkšić, Diarmuid Ó Séaghdha, Blaise Thomson, Milica Gašić, Pei-Hao Su, David Vandyke, Tsung-Hsien Wen, and Steve Young. 2015. Multi-domain dialog state tracking using recurrent neural networks. In Proceedings of ACL, pages 794–799.
Nikola Mrkšić, Ivan Vulić, Diarmuid Ó Séaghdha, Ira Leviant, Roi Reichart, Milica Gašić, Anna Korhonen, and Steve Young. 2017. Semantic specialisation of distributional word vector spaces using monolingual and cross-lingual constraints. Transactions of the ACL, pages 314–325.
Gabriel Pereyra, George Tucker, Jan Chorowski, Lukasz Kaiser, and Geoffrey E. Hinton. 2017. Regularizing neural networks by penalizing confident output distributions. CoRR, abs/1701.06548.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog, 1(8).
Osman Ramadan, Paweł Budzianowski, and Milica Gašić. 2018. Large-scale multi-domain belief tracking with knowledge sharing. In Proceedings of ACL, pages 432–437.
Antoine Raux, Brian Langner, Alan W. Black, and Maxine Eskénazi. 2003. LET’s GO: Improving spoken dialog systems for the elderly and non-natives. In Proceedings of EUROSPEECH.
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. CoRR, abs/1910.01108.
Roy Schwartz, Jesse Dodge, Noah A. Smith, and Oren Etzioni. 2019. Green AI. CoRR, abs/1907.10597.
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-attention with relative position representations. In Proceedings of NAACL-HLT, pages 464–468.
Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W. Mahoney, and Kurt Keutzer. 2019. Q-BERT: Hessian based ultra low precision quantization of BERT. CoRR, abs/1909.05840.
Emma Strubell, Ananya Ganesh, and Andrew McCallum. 2019. Energy and policy considerations for deep learning in NLP. In Proceedings of ACL, pages 3645–3650.
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. 2016. Rethinking the inception architecture for computer vision. In Proceedings of CVPR, pages 2818–2826.
Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, and Jimmy Lin. 2019. Distilling task-specific knowledge from BERT into simple neural networks. CoRR, abs/1903.12136.
Ashish Vaswani, Samy Bengio, Eugene Brevdo, Francois Chollet, Aidan Gomez, Stephan Gouws, Llion Jones, Łukasz Kaiser, Nal Kalchbrenner, Niki Parmar, Ryan Sepassi, Noam Shazeer, and Jakob Uszkoreit. 2018. Tensor2Tensor for neural machine translation. In Proceedings of the 13th Conference of the Association for Machine Translation in the Americas, pages 193–199. Association for Machine Translation in the Americas.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of NeurIPS, pages 6000–6010.
Jesse Vig and Kalai Ramea. 2019. Comparison of transfer-learning approaches for response selection in multi-turn conversations. In Proceedings of DSTC-7.
Vladimir Vlasov, Johannes E. M. Mosig, and Alan Nichol. 2019. Dialogue transformers. CoRR, abs/1910.00486.
Mengting Wan and Julian McAuley. 2016. Modeling ambiguity, subjectivity, and diverging viewpoints in opinion question answering systems. In Proceedings of ICDM, pages 489–498.
Hao Wang, Zhengdong Lu, Hang Li, and Enhong Chen. 2013. A dataset for research on short-text conversations. In Proceedings of EMNLP, pages 935–945.
Tsung-Hsien Wen, Yishu Miao, Phil Blunsom, and Steve J. Young. 2017a. Latent intention dialogue models. In Proceedings of ICML, pages 3732–3741.
Tsung-Hsien Wen, David Vandyke, Nikola Mrkšić, Milica Gašić, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. 2017b. A network-based end-to-end trainable task-oriented dialogue system. In Proceedings of EACL, pages 438–449.
Jason Weston, Emily Dinan, and Alexander Miller. 2018. Retrieve and refine: Improved sequence generation models for dialogue. In Proceedings of the 2018 EMNLP Workshop SCAI: The 2nd International Workshop on Search-Oriented Conversational AI, pages 87–92.
Jason Williams. 2012. A critical analysis of two statistical spoken dialog systems in public use. In Proceedings of SLT.
Jason D. Williams. 2014. Web-style ranking and SLU combination for dialog state tracking. In Proceedings of SIGDIAL, pages 282–291.
Yu Wu, Wei Wu, Chen Xing, Ming Zhou, and Zhoujun Li. 2017. Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots. In Proceedings of ACL, pages 496–505.
Yinfei Yang, Steve Yuan, Daniel Cer, Sheng-Yi Kong, Noah Constant, Petr Pilar, Heming Ge, Yun-hsuan Sung, Brian Strope, and Ray Kurzweil. 2018. Learning semantic textual similarity from conversations. In Proceedings of the 3rd Workshop on Representation Learning for NLP, pages 164–174.
Ofir Zafrir, Guy Boudoukh, Peter Izsak, and Moshe Wasserblat. 2019. Q8BERT: Quantized 8bit BERT. CoRR, abs/1910.06188.
Matthew D. Zeiler. 2012. ADADELTA: an adaptive learning rate method. CoRR, abs/1212.5701.
Sanqiang Zhao, Raghav Gupta, Yang Song, and Denny Zhou. 2019a. Extreme language model compression with optimal subwords and shared projections. CoRR, abs/1909.11687.
Tiancheng Zhao, Kaige Xie, and Maxine Eskénazi. 2019b. Rethinking action spaces for reinforcement learning in end-to-end dialog agents with latent variable models. In Proceedings of NAACL-HLT, pages 1208–1218.
Xiangyang Zhou, Lu Li, Daxiang Dong, Yi Liu, Ying Chen, Wayne Xin Zhao, Dianhai Yu, and Hua Wu. 2018. Multi-turn response selection for chatbots with deep attention matching network. In Proceedings of ACL, pages 1118–1127.