Jason Wei1,2 Kai Zou3 1Protago Labs Research, Tysons Corner, Virginia, USA 2Department of Computer Science, Dartmouth College 3Department of Mathematics and Statistics, Georgetown University jason.20@dartmouth.edu kz56@georgetown.edu
摘 要
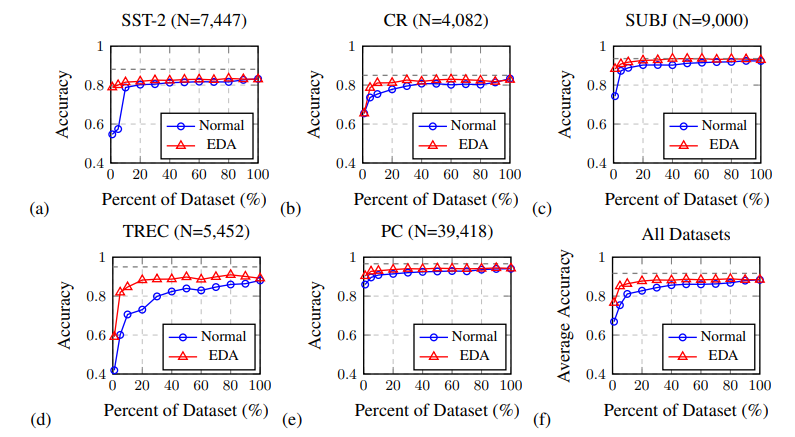
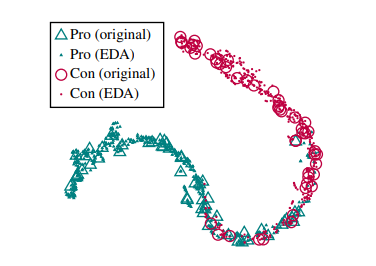
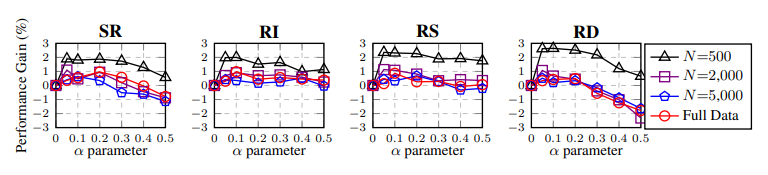
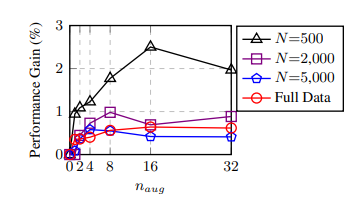
我们提出 EDA:easy data augmentation 简单数据增强技术,以提高文本分类任务的性能。EDA由四个简单但功能强大的操作组成:同义词替换,随机插入,随机交换和随机删除。在五个文本分类任务上,我们表明EDA可以提高卷积神经网络和循环神经网络的性能。EDA 对较小的数据集显示出特别强的结果;平均而言,在五个数据集中,用 EDA 仅以训练集的 50% 进行训练,其准确性与使用所有可用数据的正常训练相同。我们还进行了广泛的消融研究,并建议实际使用的参数。
Marzieh Fadaee, Arianna Bisazza, and ChristofMonz. 2017. Data augmentation for low-resourceneural machine translation. In Proceedings of the55th Annual Meeting of theAssociation for Computational Linguistics (Volume2: Short Papers), pages 567–573. Association forComputational Linguistics.
Murthy Ganapathibhotla and Bing Liu. 2008.Mining opinions in comparative sentences. InProceedings of the 22Nd International Conferenceon Computational Linguistics - Volume 1, COLING’08, pages 241–248, Stroudsburg, PA, USA.Association for Computational Linguistics.
Minqing Hu and Bing Liu. 2004. Mining andsummarizing customer reviews. In Proceedings ofthe Tenth ACM SIGKDD International Conferenceon Knowledge Discovery and Data Mining, KDD’04, pages 168–177, New York, NY, USA. ACM.
Zhiting Hu, Zichao Yang, Xiaodan Liang, RuslanSalakhutdinov, and Eric P. Xing. 2017. Towardcontrolled generation of text. In ICML.
Kushal Kafle, Mohammed Yousefhussien, andChristopher Kanan. 2017. Data augmentationfor visual question answering. In Proceedingsof the 10th International Conference on NaturalLanguage Generation, pages 198–202. Associationfor Computational Linguistics.
Tom Ko, Vijayaditya Peddinti, Daniel Povey, andSanjeev Khudanpur. 2015. Audio augmentation forspeech recognition. In INTERSPEECH.
SosukeKobayashi. 2018. Contextual augmentation: Dataaugmentation by words with paradigmatic relations.In NAACL-HLT.
Oleksandr Kolomiyets, Steven Bethard, andMarie-Francine Moens. 2011. Model-portabilityexperiments for textual temporal analysis. InProceedings of the 49th Annual Meeting of theAssociation for Computational Linguistics: HumanLanguage Technologies: Short Papers - Volume 2,HLT ’11, pages 271–276, Stroudsburg, PA, USA.Association for Computational Linguistics.
Xin Li and Dan Roth. 2002. Learning questionclassifiers. In Proceedings of the 19th InternationalConference on Computational Linguistics - Volume1, COLING ’02, pages 1–7, Stroudsburg, PA, USA.Association for Computational Linguistics.
JeffreyPennington, Richard Socher, and Christopher D.Manning. 2014. Glove: Global vectors for wordrepresentation. In Empirical Methods in NaturalLanguage Processing (EMNLP), pages 1532–1543.
Matthew E. Peters, Mark Neumann, Mohit Iyyer,Matt Gardner, Christopher Clark, Kenton Lee, andLuke Zettlemoyer. 2018. Deep contextualized wordrepresentations. CoRR, abs/1802.05365.
Rico Sennrich, BarryHaddow, and Alexandra Birch. 2016. Improvingneural machine translation models with monolingualdata. In Proceedings of the 54th Annual Meetingof the Association for Computational Linguistics(Volume 1: Long Papers), pages 86–96. Associationfor Computational Linguistics.
Miikka Silfverberg, Adam Wiemerslage, Ling Liu,andLingshuang Jack Mao. 2017. Data augmentationfor morphological reinflection. In Proceedingsof the CoNLL SIGMORPHON 2017 Shared Task:Universal Morphological Reinflection, pages 90–99.Association for Computational Linguistics.
Richard Socher, Alex Perelygin, Jean Wu, JasonChuang, ChristopherManning, Andrew Ng, and Christopher Potts. 2013.Parsing With Compositional Vector Grammars. InEMNLP.
Christian Szegedy, Wei Liu, Yangqing Jia, PierreSermanet, Scott E. Reed, Dragomir Anguelov,Dumitru Erhan, Vincent Vanhoucke, and AndrewRabinovich. 2014. Going deeper with convolutions.CoRR, abs/1409.4842.
Ziang Xie, Sida I. Wang, Jiwei Li, Daniel Levy,Aiming Nie, Dan Jurafsky, and Andrew Y. Ng.2017. Data noising as smoothing in neural networklanguage models.
Adams Wei Yu, David Dohan, Minh-ThangLuong, Rui Zhao, Kai Chen, Mohammad Norouzi,and Quoc V. Le. 2018. Qanet: Combining localconvolution with global self-attention for readingcomprehension. CoRR, abs/1804.09541.
Xiang Zhang, Junbo Zhao, and Yann LeCun.2015. Character-level convolutional networks fortext classification. In Proceedings of the 28thInternational Conference on Neural InformationProcessing Systems - Volume 1, NIPS’15, pages649–657, Cambridge, MA, USA. MIT Press.