ELECTRA:预训练文本编码器作为区分器而不是生成器
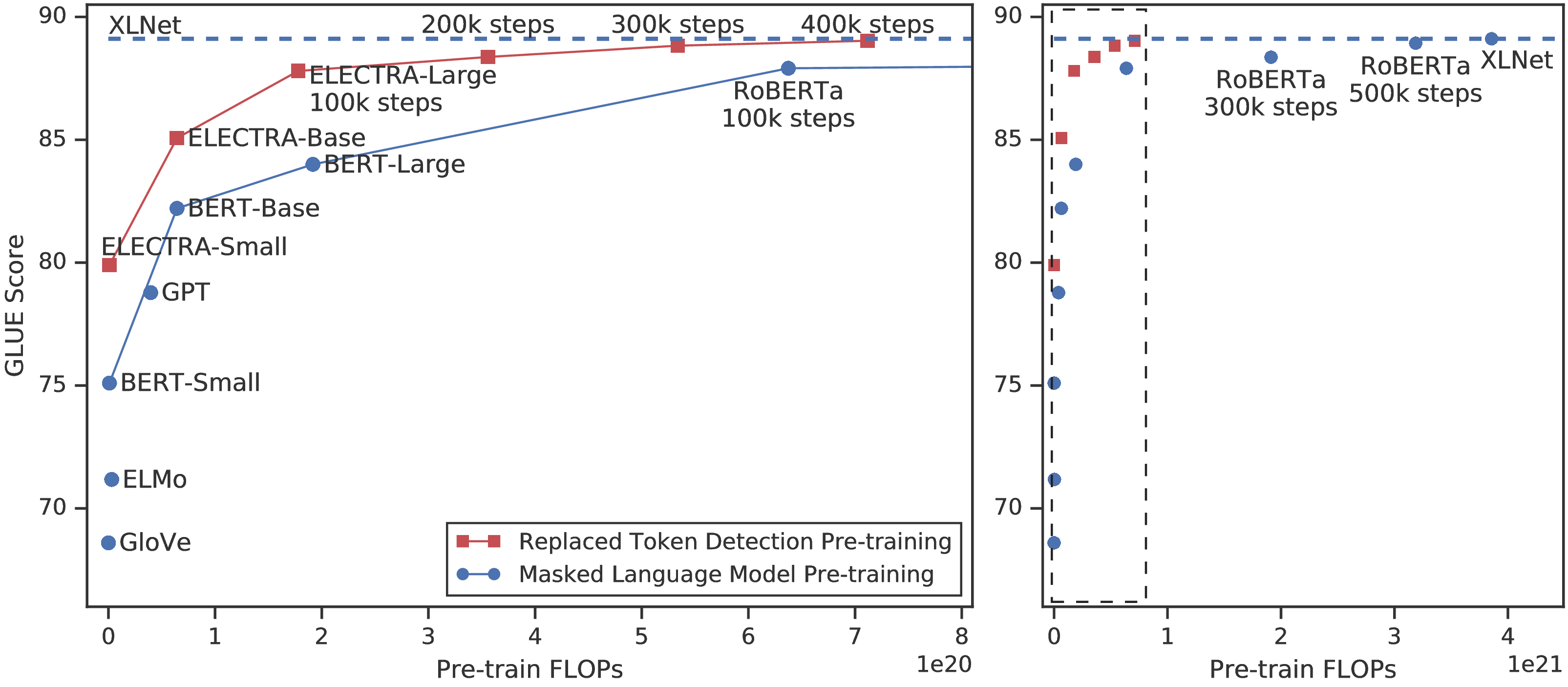
屏蔽语言模型(MLM)预训练方法如 BERT 通过将某些词符替换为[MASK]破坏输入,然后训练模型来重建原始词符。 尽管它们在迁移到下游 NLP 任务时会产生良好的结果,但它们通常需要大量计算才能有效。 作为另外一种方法,我们提出一种更有效的样本预训练任务,称为替换词符检测。 我们的方法不是屏蔽输入,而是通过使用从小的生成器网络采样的样本替换一些词符来破坏输入。 然后,我们训练一个区分模型预测破坏的输入中的每个词符是否被生成器样本替换,而不是训练一个预测破坏的词符的原始身份的模型。 全面的实验表明,这个新的预训练任务比 MLM 更有效,因为该任务是在所有 输入词符而不是仅被屏蔽的一小部分上定义的。 结果,在相同的模型大小、数据和计算条件下,我们的方法学习到的上下文表示明显优于 BERT 学习的上下文表示。 小模型的收益尤为明显;例如,在 GLUE 自然语言理解基准上,我们在一个 GPU 上训练 4 天的模型优于 GPT(使用 30 倍的计算能力训练)。 我们的方法在规模上也行之有效,在使用少于 1/4 的计算量时,其性能与 RoBERTa 和 XLNet 相当,而在使用相同量的计算量时性能优于它们。
1 简介
当前关于语言的最先进的表示学习方法可以看作是学习降噪自动编码器(Vincent 等人,2008)。 它们选择无标签输入序列的一小部分(通常为 15%),屏蔽这些词符(例如 BERT Devlin 等人,2019),或者 attention 这些词符(例如 XLNet Yang 等人,2019),然后训练网络恢复原始输入。 尽管由于学习双向表示而比常规语言模型预训练更有效,但这些屏蔽语言模型(MLM)方法产生大量的计算成本,因为网络仅从每个样本的 15% 词符中学习。
作为另外一种方法,我们提出替换词符检测 的预训练任务,模型学习将实际输入词符与可能是合成生成的词符区分开。 我们的方法不是屏蔽,而是通过使用样本替换一些词符来破坏输入,这些样本通常是小型屏蔽语言模型的输出。 这种破坏过程解决 BERT 中的不匹配问题(尽管在 XLNet 中不是),BERT 在预训练期间看到人工的 [MASK] 词符,但在下游任务上进行微调时却看不到。 然后,我们将网络作为区分器进行预训练,预测每个词符是原始词符还是替换词符。 相反,MLM 将网络训练为生成器,预测破坏的词符的原始身份。 我们的判别任务的主要优势在于,该模型从所有 输入词符中学习,而不是从屏蔽的子集中学习,从而提高计算效率。 尽管我们的方法让人想起训练 GAN 的判别器,但我们的方法并不具有对抗性,区别在于因为将 GAN 应用于文本的困难,产生损坏词符的生成器以极大似然性训练 (Caccia 等人, 2018)。
我们将我们的方法称为 ELECTRA 1 ,以“有效地学习一个编码器以准确分类词符替换”。与先前的工作一样,我们将其应用于可以在下游任务上进行微调的预训练 Transformer 文本编码器(Vaswani 等人,2017)。 通过一系列的消融,我们表明,从所有输入位置学习会使 ELECTRA 的训练速度比 BERT 快得多。 我们还显示,经过充分训练,ELECTRA 在下游任务上可以达到更高的准确性。
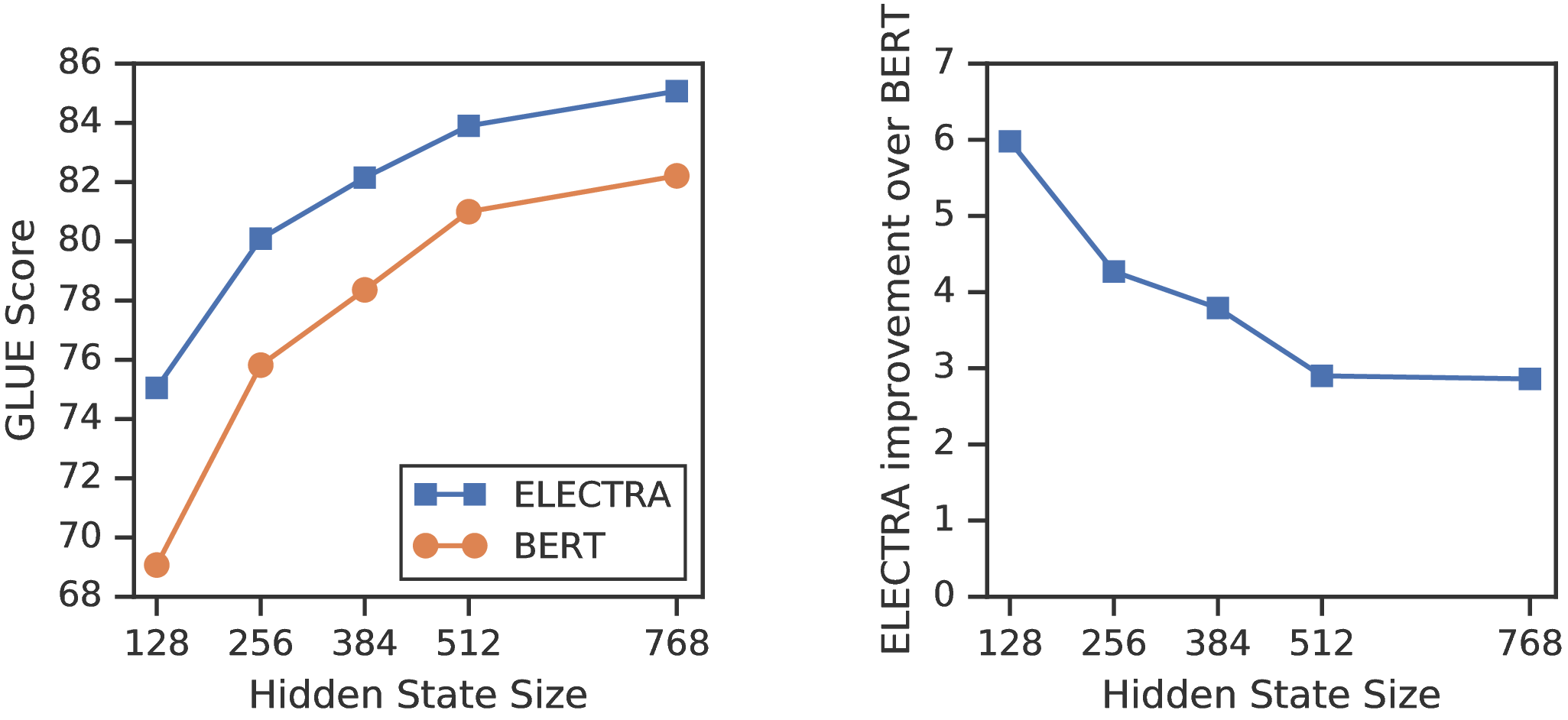
当前大多数预训练方法都需要大量计算才能有效,这引起人们对其成本和可用性的担忧。 由于具有更多计算能力的预训练几乎总是可以带来更好的下游精度,因此我们认为,计算效率应该和下游认为的绝对性能一样是预训练方法的重要考虑因素。 从这个角度出发,我们训练各种大小的ELECTRA模型,并评估其下游性能与计算需求。 特别是,我们在 GLUE 自然语言理解基准(Wang 等人,2019)和 SQuAD 问题回答基准(Rajpurkar 等人,2016)上进行实验。 在相同的模型大小、数据和计算条件下,ELECTRA 的性能明显优于 BERT 和 XLNet 等基于 MLM 的方法(请参见图 1)。 例如,我们建立一个 ELECTRA-Small 模型,该模型可以在 1 个 GPU 上在 4 天内训练完成。2 ELECTRA-Small 在 GLUE 上比同等级的 BERT-small 模型高出 5 个点,甚至胜过大的多的 GPT 模型(Radford 等人,2018)。 我们的方法在大的模型上也有效,我们训练一个 ELECTRA-Large 模型,与 RoBERTa(Liu 等人,2019)和 XLNet(Yang 等人,2019)性能相当,尽管参数较少且使用 1/4 的计算训练。 在 GLUE上 训练 ELECTRA-Large 会进一步产生更强的模型,该模型优于 ALBERT(Lan 等人,2019),并为 SQuAD 2.0 设置新的最先进结果。 总之,我们的结果表明,对应语言表示学习,区分真实数据与负样本的区分任务比现有的生成方法具有更高的计算效率和参数效率。
2 方法
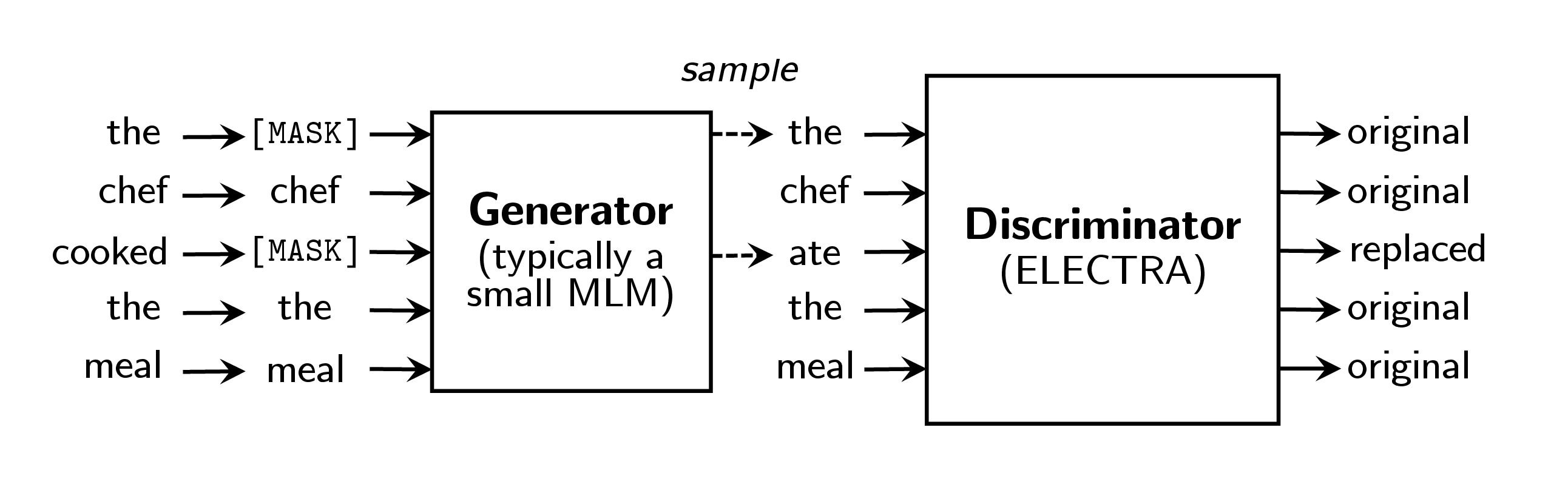
我们首先描述替换词符检测预训练任务;参见图 2 中的概述。 我们在 3.2 节中建议并评估该方法的一些模型改进。
我们的方法训练两个神经网络,一个生成器 G 和一个区分器D。每个神经网络主要由一个编码器组成(例如一个 Transformer 网络),将一个输入词符序列 x = [ x1,...,xn] 映射成一个上下文相关的向量表示序列 h(x) = [ h1,...,hn]。 对于给定位置 t,(在我们的情况下,仅是 xt = [MASK] 的位置),生成器使用 softmax 层输出特定词符 xt 的概率:
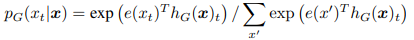
其中 e 表示词符嵌入。 对于给定位置 t,区分器使用一个sigmoid 输出层预测词符 xt 是否为“真的”,即它来自数据而不是生成器的分布:
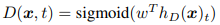
训练生成器以执行屏蔽语言模型(MLM)。 给定一个输入 x= [ x1,x2,...,xn],MLM 首先随机选择一个位置的集合(1 到 n 之间的整数)来屏蔽 m= [ m1,...,mk]。3 选择到的位置用 [MASK] 词符替换:我们将这个表示为 xmasked = replace(x,m,[MASK])。 然后,生成器学习预测被屏蔽词符的原始身份。 区分器训练将数据中的词符与已被生成器替换的词符区分开。 更具体地说,我们通过用生成器输出替换被掩盖的词符来创建损坏的样本 xcorrupt,并训练区分器预测 xcorrupt 中哪些词符与原始输入 x 一致。 形式上模型输入的依据是
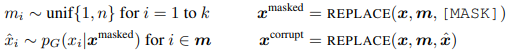
损失函数是

尽管与 GAN 的训练目标相似,但仍存在一些关键差异。 首先,如果生成器碰巧生成正确的词符,则该词符被视为“真实”而不是“伪造”;我们发现这种方式可以适度改善下游任务的结果。 更重要的是,对生成器的训练是用极大似然性,而不是通过对抗性训练来欺骗区分器。 对抗生成器具有挑战性,因为不可能通过生成器的采样进行反向传播。 尽管我们通过使用强化学习来训练生成器(请参见附录F)来尝试解决该问题,但其效果不如最大似然训练。 最后,我们没有像典型的 GAN 那样为生成器提供噪声向量作为输入。
我们将综合损失降至最低
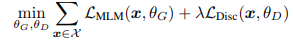
在原始文本的大型语料库 X 上。 我们用一个样本来估算损失的预期值。 我们不会通过生成器向后传播区分器损失(实际上,由于采样步骤而无法做到)。 经过预训练后,我们扔掉生成器,并对下游任务上的区分器进行微调。
3 实验
3.1 实验设置
我们根据通用语言理解评估(GLUE)基准(Wang 等人,2019)和斯坦福问答(SquAD)数据集(Rajpurkar 等人,2016)进行评估。 GLUE包含各种任务,包括文本蕴涵(RTE 和 MNLI)、问题答案蕴涵(QNLI)、释义(MRPC)、问题释义(QQP)、文本相似性(STS)、情感(SST)和语言可接受性(CoLA) 。 有关GLUE任务的更多详细信息,请参见附录C。 我们的评估指标包括STS的Spearman相关性,CoLA的Matthews相关性以及其他GLUE任务的准确性。我们通常会报告所有任务的平均分数。 对于SQuAD,我们评估版本1.1(在模型中选择回答问题的文本的跨度)和版本2.0(在模型中选择无法回答的问题)的版本。 我们使用精确匹配(EM)和F1分数的标准评估指标。 对于大多数实验,我们对与BERT相同的数据进行预训练,该数据由来自 Wikipedia 和 BooksCorpus 的 3.3B 个词符组成(Zhu 等人,2015)。 但是,对于我们的大型模型,我们使用 XLNet(Yang 等人,2019)所使用的数据进行预训练,它包含 ClueWeb(Callan 等人,2009)、CommonCrawl 和 Gigaword(Parker 等人,2011)将 BERT 的数据集扩展到 33B 个词符。 尽管我们认为将来将我们的方法应用于多语言数据会很有趣,但是所有的预训练和评估都基于英语数据。
我们的模型架构和大多数超参数与BERT相同。 为了在GLUE上进行微调,我们在ELECTRA的顶部添加了简单的线性分类器。 对于SQuAD,我们在ELECTRA的基础上添加了XLNet的问题解答模块,该模块比BERT更为复杂,因为它联合而不是独立地预测开始位置和结束位置,并且为SQuAD 2.0添加了“可回答性”分类器。 我们的一些评估数据集很小,这意味着微调模型的准确性可能会因随机种子而有很大差异。 因此,我们为每个结果报告来自相同的预训练检查点的10次微调运行的中值。 除非另有说明,结果都是基于开发集的。 有关更多训练详细信息和超参数值,请参见附录。
3.2 模型扩展
我们通过提出和评估模型的几个扩展来改进我们的方法。 除非另有说明,否则这些实验使用与BERT-Base相同的模型大小和训练数据。
权重共享 我们提出通过在生成器和区分器之间共享权重来提高预训练的效率。 如果发生器和区分器的大小相同,则可以共享 transformer 的所有权重。 但是,我们发现用一个小型生成器会更有效,在这种情况下,我们仅共享生成器和区分器的嵌入(词符和位置嵌入)。 在这种情况下,我们使用嵌入作为区分器的隐藏状态。4 生成器的“输入”和“输出”词符嵌入始终像 BERT 一样捆绑在一起。
当生成器与区分器的大小相同时,我们比较权重共享策略。 我们以50万步训练这些模型。 没有权重共享的 GLUE 得分为 83.6,共享词符嵌入的得分为 84.3,所有权重共享的得分为 84.4。 我们假设 ELECTRA 受益于共享词符嵌入,因为屏蔽语言模型在学习这些表示上特别有效:区分器仅更新输入中存在的词符或由生成器采样的词符,而生成器在词汇表上的 softmax 密集地更新所有词符嵌入。 另一方面,共享所有编码器权重几乎没有改善,同时带来要求发生器和区分器具有相同大小的重大缺点。 基于这些发现,本文将共享嵌入用于进一步的实验。
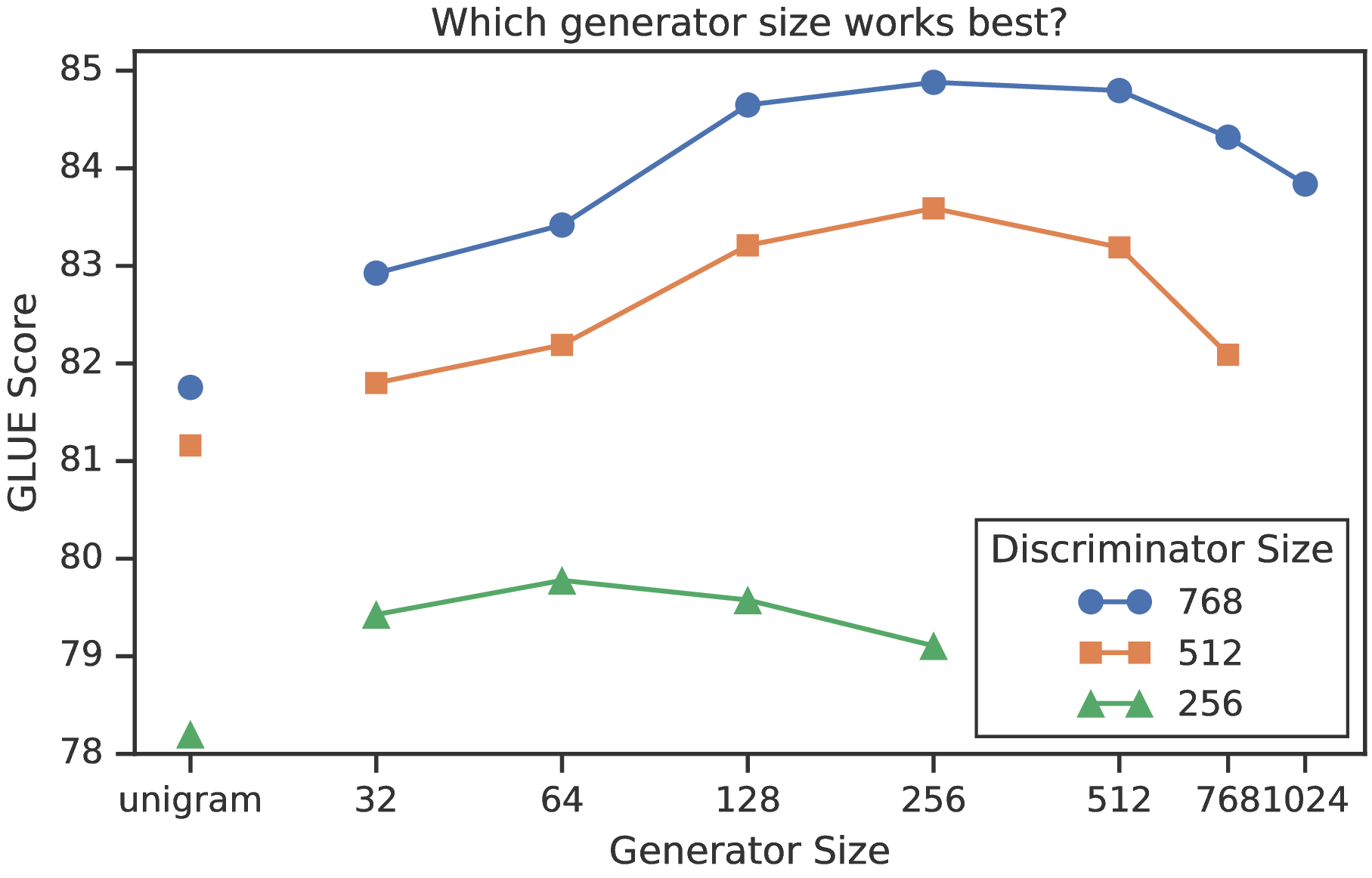
较小的生成器 如果生成器和区分器的大小相同,则训练 ELECTRA 每步所需的计算量约为仅使用屏蔽语言建模的训练量的两倍。 我们建议使用较小的生成器来减少此因素。 具体来说,我们通过减小网络层大小并使其他超参数保持恒定来使模型更小。 我们还探索使用极其简单的“unigram”生成器,根据训练语料中的词符频率采样。 图 3 的左侧显示大小不同的生成器和区分器的 GLUE 得分。 所有模型都经过 500k 步的训练,这使得较小的生成器在计算方面处于劣势,因为它们每个训练步需要更少的计算。 但是,我们发现发生器的大小为区分器的 1/4-1/2 时型效果最佳。 我们推测,生成器太强大可能会给区分器带来太挑战性的任务,从而阻止其有效学习。 特别是,区分器可能必须使用其许多参数来模拟生成器,而不是实际的数据分布。 对于给定区分器的大小,本文的进一步实验将使用找到的最佳发生器的大小。
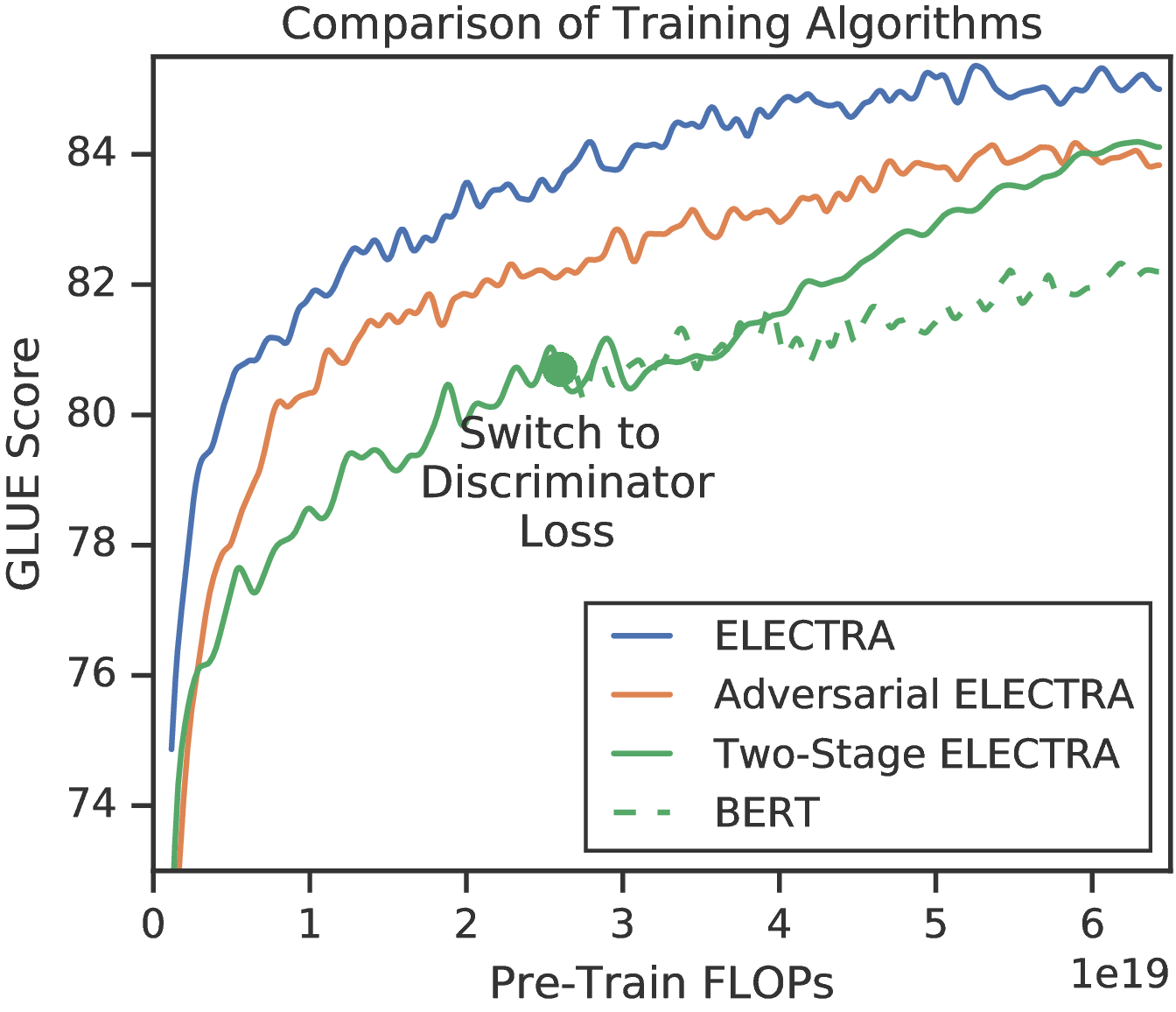
训练算法 最后,我们探索 ELECTRA 的其他训练算法,尽管这些最终并没有改善结果。 我们提出的训练目标联合训练生成器和区分器。 我们使用以下两个阶段的训练过程进行试验:
- 1.
- 仅以 ℒMLM 训练生成器 n 步。
- 2.
- 用生成器的权重初始化区分器的权重。 然后用 ℒDisc 进行 n 步训练区分器,保持发生器的权重冻结。
注意,此过程中的权重初始化要求生成器和区分器具有相同的大小。 我们发现,如果没有进行权重初始化,则区分器有时将无法学习多数类之外的所有知识,这可能是因为生成器的起步时间远早于区分器。 另一方面,联合训练自然为区分器提供课程,生成器开始比较弱,但在整个训练过程中变得更好。 我们还探索如何像 GAN 中那样对抗训练生成器,使用强化学习来适应来自生成器的离散采样操作。 有关详细信息,请参见附录F。
结果显示在图3的右侧。 在两阶段训练中,从生成目标切换到区分目标后,下游任务性能显着提高,但最终并未超过联合训练。 尽管仍然优于BERT,但我们发现对抗训练的效果不如最大似然训练。 进一步的分析表明,差距是由对抗训练中的两个问题引起的。 首先,对抗性生成器在屏蔽语言模型时就比较差;在屏蔽语言模型中,它的准确性为 58%,而经过 MLE 训练的模型则为 65%。 我们认为,较差的准确性主要是由于在生成文本的较大动作空间中工作时,强化学习的样本效率很差。 其次,经过对抗训练的生成器会产生低熵的输出分布,其中大部分概率质量都位于单个词符上,这意味着生成器样本中的多样性并不多。 在以前的工作中,GAN 在文本中都发现了这两个问题(Caccia 等人,2018)。
3.3 小模型
这项工作的目标是提高预训练的效率,我们开发了一个可以在单个GPU上快速进行训练的小型模型。 从 BERT-Base 超参数开始,我们缩短序列长度(从512到128)、减小批次大小(从256减少到128),减小模型隐藏维度大小(从768减少到256),并使用更小的词符嵌入(从768到128)。 为了提供公平的比较,我们还使用相同的超参数训练了BERT-Small模型。 我们训练BERT-Small进行150万步,因此它使用与ELECTRA-Small相同的训练FLOP,后者训练了100万步。5 除了BERT,我们与两种基于语言建模的资源消耗较少的预训练方法进行比较:ELMo(Peters等人,2018)和GPT(Radford等人,2018)。 6 我们还显示了与BERT-Base相当的基本尺寸的ELECTRA模型的结果。
结果显示在表1中。 有关其他结果,请参见附录D,包括使用更多计算能力训练的更强大的小型和基础尺寸模型。 ELECTRA-Small具有出色的性能,与其他使用大量计算和参数的方法相比,其GLUE得分更高。 例如,与同类的BERT-Small模型相比,它的得分高出5分,甚至超过了更大的GPT模型。 对ELECTRA-Small的培训主要是针对收敛性,而经过培训的模型即使花费更少的时间(仅6个小时)仍然可以实现合理的性能。 从较大的预训练变压器中提取的小型模型也可以获得良好的GLUE分数(Sun等人,2019b; Jiao等人,2019),这些模型首先需要花费大量计算来预训练较大的教师模型。 结果还证明了中等大小的ELECTRA的强度。我们的基本尺寸ELECTRA模型大大优于BERT-Base,甚至优于BERT-Large(获得84.0 GLUE得分)。 我们希望ELECTRA能够以较少的计算量获得出色的结果,从而拓宽在NLP中开发和应用预训练模型的可访问性。
| 模型 | 训练/推断FLOP | 加速 | 参数 | 训练时间+硬件 | GLUE |
| ELMo | 3.3e18 / 2.6e10 | 19x / 1.2x | 96M | 14d on 3 GTX 1080 GPUs | 71.2 |
| GPT | 4.0e19 / 3.0e10 | 1.6x / 0.97x | 117M | 25d on 8 P6000 GPUs | 78.8 |
| BERT-Small | 1.4e18 / 3.7e9 | 45x / 8x | 14M | 4d on 1 V100 GPU | 75.1 |
| BERT-Base | 6.4e19 / 2.9e10 | 1x / 1x | 110M | 4d on 16 TPUv3s | 82.2 |
| ELECTRA-Small | 1.4e18 / 3.7e9 | 45x / 8x | 14M | 4d on 1 V100 GPU | 79.9 |
| 50% trained | 7.1e17 / 3.7e9 | 90x / 8x | 14M | 2d on 1 V100 GPU | 79.0 |
| 25% trained | 3.6e17 / 3.7e9 | 181x / 8x | 14M | 1d on 1 V100 GPU | 77.7 |
| 12.5% trained | 1.8e17 / 3.7e9 | 361x / 8x | 14M | 12h on 1 V100 GPU | 76.0 |
| 6.25% trained | 8.9e16 / 3.7e9 | 722x / 8x | 14M | 6h on 1 V100 GPU | 74.1 |
| ELECTRA-Base | 6.4e19 / 2.9e10 | 1x / 1x | 110M | 4d on 16 TPUv3s | 85.1 |
3.4 大模型
我们训练大型的ELECTRA模型,以在当前最先进的预训练变压器的大规模规模下测量替换的令牌检测预训练任务的有效性。 我们的ELECTRA-Large模型的尺寸与BERT-Large相同,但是训练时间更长。 特别是,我们训练了一个模型,用于400k步长(ELECTRA-400K;大约是RoBERTa的预训练计算的1/4),而模型则用于1.75M步长(ELECTRA-1.75M;与RoBERTa相似的计算)。 我们使用批次大小2048和XLNet预训练数据。 我们注意到,尽管XLNet数据类似于用于训练RoBERTa的数据,但是比较并不完全直接。 作为基准,我们使用与ELECTRA-400K相同的超参数和训练时间来训练自己的BERT-Large模型。
表2中显示了GLUE开发集上的结果。 ELECTRA-400K的性能与RoBERTa和XLNet相当。 但是,与训练RoBERTa和XLNet一样,训练ELECTRA-400K所花费的计算不到1/4,这表明ELECTRA的采样效率获得了大幅度提高。 训练ELECTRA更长的时间(ELECTRA-1.75M)可以得到一个模型,该模型在大多数GLUE任务中均胜过它们,同时仍需要较少的预训练计算量。 令人惊讶的是,我们的基准BERT模型得分明显低于RoBERTa-100K,这表明我们的模型可能会受益于更多的超参数调整或使用RoBERTa训练数据。 ELECTRA的收益在GLUE测试集上保持不变(请参见表3),尽管由于模型采用了其他技巧,这些比较之间的差异较小(请参见附录B t1) >)。
| 模型 | Train FLOPs | 参数 | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE | Avg. |
| BERT | 1.9e20(0.27倍) | 335M | 60.6 | 93.2 | 88.0 | 90.0 | 91.3 | 86.6 | 92.3 | 70.4 | 84.0 |
RoBERTa-100K | 6.4e20(0.90x) | 356M | 66.1 | 95.6 | 91.4 | 92.2 | 92.0 | 89.3 | 94.0 | 82.7 | 87.9 |
RoBERTa-500K | 3.2e21(4.5倍) | 356M | 68.0 | 96.4 | 90.9 | 92.1 | 92.2 | 90.2 | 94.7 | 86.6 | 88.9 |
XLNet | 3.9e21(5.4倍) | 360M | 69.0 | 97.0 | 90.8 | 92.2 | 92.3 | 90.8 | 94.9 | 85.9 | 89.1 |
| BERT (ours) | 7.1e20(1倍) | 335M | 67.0 | 95.9 | 89.1 | 91.2 | 91.5 | 89.6 | 93.5 | 79.5 | 87.2 |
ELECTRA-400K | 7.1e20(1倍) | 335M | 69.3 | 96.0 | 90.6 | 92.1 | 92.4 | 90.5 | 94.5 | 86.8 | 89.0 |
ELECTRA-1.75M | 3.1e21(4.4倍) | 335M | 69.1 | 96.9 | 90.8 | 92.6 | 92.4 | 90.9 | 95.0 | 88.0 | 89.5 |
| 模型 | Train FLOPs | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE | WNLI | Avg.* | Score |
| BERT | 1.9e20(0.06倍) | 60.5 | 94.9 | 85.4 | 86.5 | 89.3 | 86.7 | 92.7 | 70.1 | 65.1 | 79.8 | 80.5 |
RoBERTa | 3.2e21(1.02倍) | 67.8 | 96.7 | 89.8 | 91.9 | 90.2 | 90.8 | 95.4 | 88.2 | 89.0 | 88.1 | 88.1 |
ALBERT | 3.1e22(10倍) | 69.1 | 97.1 | 91.2 | 92.0 | 90.5 | 91.3 | – | 89.2 | 91.8 | 89.0 | – |
XLNet | 3.9e21(1.26倍) | 70.2 | 97.1 | 90.5 | 92.6 | 90.4 | 90.9 | – | 88.5 | 92.5 | 89.1 | – |
| ELECTRA | 3.1e21(1倍) | 71.7 | 97.1 | 90.7 | 92.5 | 90.8 | 91.3 | 95.8 | 89.8 | 92.5 | 89.5 | 89.4 |
|
模型 | Train FLOPs | 参数 | SQuAD 1.1 dev | SQuAD 2.0 dev | SQuAD 2.0 test
| |||
| EM | F1 | EM | F1 | EM | F1 | ||
| BERT-Base | 6.4e19 (0.09x) | 110M | 80.8 | 88.5 | – | – | – | – |
BERT | 1.9e20 (0.27x) | 335M | 84.1 | 90.9 | 79.0 | 81.8 | 80.0 | 83.0 |
SpanBERT | 7.1e20 (1x) | 335M | 88.8 | 94.6 | 85.7 | 88.7 | 85.7 | 88.7 |
XLNet-Base | 6.6e19(0.09x) | 1.17亿 | 81.3 | – | 78.5 | – | – | – |
XLNet | 3.9e21 (5.4x) | 360M | 89.7 | 95.1 | 87.9 | 90.6 | 87.9 | 90.7 |
RoBERTa-100K | 6.4e20 (0.90x) | 356M | – | 94.0 | – | 87.7 | – | – |
RoBERTa-500K | 3.2e21 (4.5x) | 356M | 88.9 | 94.6 | 86.5 | 89.4 | 86.8 | 89.8 |
ALBERT | 3.1e22 (44x) | 235M | 89.3 | 94.8 | 87.4 | 90.2 | 88.1 | 90.9 |
| BERT (ours) | 7.1e20 (1x) | 335M | 88.0 | 93.7 | 84.7 | 87.5 | – | – |
ELECTRA-Base | 6.4e19 (0.09x) | 110M | 84.5 | 90.8 | 80.5 | 83.3 | – | – |
ELECTRA-400K | 7.1e20 (1x) | 335M | 88.7 | 94.2 | 86.9 | 89.6 | – | – |
ELECTRA-1.75M | 3.1e21 (4.4x) | 335M | 89.7 | 94.9 | 88.0 | 90.6 | 88.7 | 91.4 |
SQuAD上的结果显示在表4中。 与GLUE结果一致,在给定相同计算资源的情况下,ELECTRA的得分要比基于掩码语言建模的方法更好。 例如,ELECTRA-400K优于RoBERTa-100k和我们的BERT基线,后者使用相似数量的预训练计算。 尽管使用的计算量不到1/4,但ELECTRA-400K的性能也与RoBERTa-500K相当。 毫不奇怪,培训ELECTRA更长的时间可以进一步改善结果:ELECTRA-1.75M的得分比SQuAD 2.0基准测试中的先前模型高。 ELECTRA-Base也会产生出色的结果,得分大大优于BERT-Base和XLNet-Base,并且根据大多数指标甚至超过BERT-Large。 ELECTRA在SQuAD 2.0上的性能通常优于1.1。 也许替换的令牌检测(模型会将模型中的真实令牌与真实的假货区别开来)特别适用于SQuAD 2.0的可回答性分类,在该模型中,模型必须将可回答的问题与假的无法回答的问题区分开。
3.5 效率分析
我们建议,将训练目标放在一小部分标记上会使掩盖语言建模效率低下。 但是,事实并非如此。 毕竟,该模型尽管只预测了少量的被屏蔽的令牌,但仍然收到了大量的输入令牌。 为了更好地了解ELECTRA的收益来自何处,我们比较了一系列其他的预训练目标,这些目标被设计为BERT和ELECTRA之间的一系列“垫脚石”。
- ELECTRA 15%:此模型与ELECTRA相同,区别在于标识符损失仅来自被输入掩盖的15%的令牌。 换句话说,区分器损失 ℒDisc 中的和来自于 i ∈ m 而不是从 1 到 n。7
- 替换 MLM:此目标与屏蔽语言建模相同,除了用[MASK]代替被屏蔽的词符外,它们还被生成器模型中的词符代替。 这个目标测试了ELECTRA在解决预训练期间将模型暴露于[MASK]令牌而不是进行微调时的差异的程度。
- 所有词符MLM:就像在替换 MLM 中一样,用生成器样本替换屏蔽的词符。 此外,该模型可以预测输入中所有令牌的身份,而不仅仅是被掩盖的令牌。 我们发现使用显式复制机制训练该模型的结果得到了改进,该机制使用S形曲面为每个令牌输出复制概率D。 模型的输出分布将D权重放在输入令牌上,再加上1 -D乘以MLM softmax的输出。 该模型实质上是BERT和ELECTRA的组合。 请注意,如果没有生成器替换,该模型将简单地学习从词汇表中对[MASK]词符进行预测,并复制其他词符的输入。
结果显示在表5中。 首先,我们发现,对所有输入令牌(而不只是一个子集)进行定义损失,ELECTRA将从中受益匪浅:ELECTRA 15%的性能要比ELECTRA差得多。 其次,我们发现[MASK]令牌的训练前微调失配会稍微影响BERT性能,因为Replace MLM的性能略好于BERT。 我们注意到BERT(包括我们的实现)已经包含了一种技巧,以帮助改善训练前/微调的差异:被屏蔽的令牌在10%的时间内被替换为随机令牌,并在10%的时间内保持不变。 但是,我们的结果表明,这些简单的启发式方法不足以完全解决问题。 最后,我们发现全令牌MLM(一种生成模型,可对所有令牌而不是子集进行预测)弥合了BERT和ELECTRA之间的大部分鸿沟。 总体而言,这些结果表明,ELECTRA的大量改进可以归因于所有令牌的学习,而较小的归因于减轻了训练前的微调失配。
| 模型 | ELECTRA | All-Tokens MLM | Replace MLM | ELECTRA 15% | BERT |
| GLUE score | 85.0 | 84.3 | 82.4 | 82.4 | 82.2 |
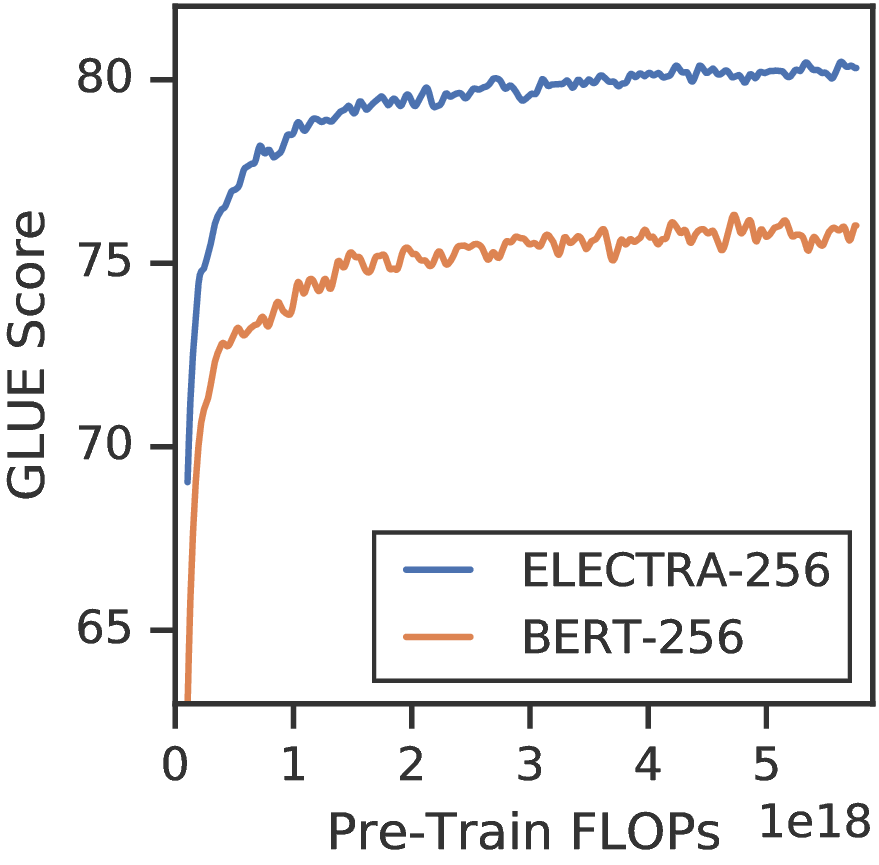
ELECTRA比全令牌MLM的改进表明,ELECTRA的收益不仅来自更快的培训。 我们通过将BERT与ELECTRA比较各种模型尺寸来进一步研究(参见图4,左)。 我们发现,随着模型的变小,ELECTRA的收益会变大。 对小型模型进行全面训练以使其收敛(请参见图4,右图),表明充分训练后,ELECTRA比BERT可获得更高的下游精度。 我们推测,ELECTRA比BERT具有更高的参数效率,因为它不必对每个位置上可能的令牌的全部分布建模,但是我们认为需要进行更多分析才能完全说明ELECTRA的参数效率。
4 相关工作
NLP 的自我监督预训练 自我监督学习已用于学习单词表示(Collobert 等人,2011; Pennington 等人,2014)和最近的单词上下文 表示法,其目标是语言建模(Dai&Le,2015;Peters 等人,2018;Howard & Ruder, 2018)。 BERT(Devlin 等人,2019)在屏蔽语言模型任务中预训练了一个大型 Transformer(Vaswani 等人,2017)。 BERT有许多扩展。 例如,MASS(Song等人,2019)和UniLM(Dong等人,2019)通过添加自回归生成训练目标将BERT扩展到生成任务。 ERNIE(Sun等人,2019a)和SpanBERT(Joshi等人,2019)遮盖了令牌的连续序列以改善跨度表示。 这个想法可能是ELECTRA的补充;我们认为让ELECTRA的生成器自动回归并添加“替换范围检测”任务会很有趣。 XLNet(Yang等人,2019)不是掩盖输入令牌,而是掩盖注意力权重,从而以随机顺序自动回归生成输入序列。 但是,这种方法的效率与BERT相同,因为XLNet仅以这种方式生成15%的输入令牌。 像ELECTRA一样,XLNet可以通过不需要[MASK]令牌来缓解BERT的训练前微调差异,尽管这尚不完全清楚,因为XLNet在训练前使用了两个“注意流”,但只有一个微调。 最近,诸如TinyBERT(Jiao等人,2019)和MobileBERT(Sun等人,2019b)之类的模型表明BERT可以有效地简化为较小的模型。 相比之下,我们更多地关注预训练速度而不是推理速度,因此我们从头开始训练ELECTRA-Small。
生成对抗网络 GAN(Goodfellow等,2014)可有效生成高质量的合成数据。 Radford 等人,2016 建议在下游任务中使用 GAN 的区分器,这与我们的方法类似。 GAN 已应用于文本数据(Yu 等人,2017;Zhang 等人,2017),尽管最新先进结果仍落后于标准最大似然训练(Caccia 等人,2018;Tevet 等人,2018)。 虽然我们不使用对抗性学习,但我们的生成器特别让人想起 MaskGAN(Fedus 等人,2018),它可以训练生成器填充从输入中删除的词符。
对比学习广泛地,对比学习方法将观察到的数据点与虚拟否定样本区分开。 它们已应用于多种形式,包括文本(Smith&Eisner,2005),图像(Chopra等,2005)和视频(Wang&Gupta ,2015; Sermanet等人,2017)数据。 常见的方法是学习相关数据点相似的嵌入空间(Saunshi等人,2019)或将真实数据点排列在负样本上的模型(Collobert等人,2011 ; Bordes等人,2013)。 ELECTRA特别与噪声对比估计(NCE)有关(Gutmann&Hyvärinen,2010),该方法还训练了一个二进制分类器来区分真实数据点和虚假数据点。
Word2Vec(Mikolov等人,2013)是NLP最早的预训练方法之一,它使用对比学习。 实际上,ELECTRA可以看作是带有负采样的连续词袋(CBOW)的大规模扩展版本。 CBOW还会在给定周围环境的情况下预测输入令牌,并且负采样将学习任务重新定义为关于输入令牌是否来自数据或提案分布的二进制分类任务。 但是,CBOW使用矢量袋编码器,而不是变压器,而是从unigram令牌频率导出的简单建议分布,而不是有学习能力的生成器。
5 结论
我们提出替换词符检测,一种用于语言表示学习的新的自我监督任务。 关键思想是训练文本编码器,以区分输入词符与由小型生成器网络产生的高质量负样本。 与屏蔽语言模型相比,我们的预训练目标具有更高的计算效率,并且可以在下游任务上实现更好的性能。 即使使用相对较少的计算量,它也能很好地工作,我们希望这将使研究人员和从业人员更容易访问开发和应用经过预训练的文本编码器,而对计算资源的访问较少。 我们还希望未来在NLP预训练方面的更多工作将考虑效率和绝对性能,并按照我们的工作报告计算使用情况和参数计数以及评估指标。
致谢
我们感谢Allen Nie,Prajit Ramachandran,CIFAR LMB会议和蒙特利尔大学的听众以及匿名审阅者的深思熟虑的意见和建议。 感谢Matt Peters回答关于ELMo的问题,Alec Radford回答关于GPT的问题,Naman Goyal和Myle Ott回答关于RoBERTa的问题,Dai Zihang回答关于XLNet的问题,Lan Zhenzhong回答关于ALBERT的问题以及Chen Dan和Mandar Joshi的回答关于SpanBERT。 Kevin获得Google博士奖学金的支持。
参考
Antoine Bordes, Nicolas Usunier, Alberto García-Durán, Jason Weston, and Oksana Yakhnenko. Translating embeddings for modeling multi-relational data. In NeurIPS, 2013.
Avishek Joey Bose, Huan Ling, and Yanshuai Cao. Adversarial contrastive estimation. In ACL, 2018.
Massimo Caccia, Lucas Caccia, William Fedus, Hugo Larochelle, Joelle Pineau, and Laurent Charlin. Language GANs falling short. arXiv preprint arXiv:1811.02549, 2018.
Jamie Callan, Mark Hoy, Changkuk Yoo, and Le Zhao. Clueweb09 data set, 2009. URL https://lemurproject.org/clueweb09.php/.
Daniel M. Cer, Mona T. Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. Semeval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In SemEval@ACL, 2017.
Sumit Chopra, Raia Hadsell, and Yann LeCun. Learning a similarity metric discriminatively, with application to face verification. CVPR, 2005.
Kevin Clark, Minh-Thang Luong, Urvashi Khandelwal, Christopher D. Manning, and Quoc V. Le. BAM! Born-again multi-task networks for natural language understanding. In ACL, 2019.
Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel P. Kuksa. Natural language processing (almost) from scratch. JMLR, 2011.
Andrew M Dai and Quoc V Le. Semi-supervised sequence learning. In NeurIPS, 2015.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT, 2019.
William B. Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. In IWP@IJCNLP, 2005.
Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. Unified language model pre-training for natural language understanding and generation. In NeurIPS, 2019.
William Fedus, Ian J. Goodfellow, and Andrew M. Dai. MaskGAN: Better text generation via filling in the _______. In ICLR, 2018.
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and William B. Dolan. The third pascal recognizing textual entailment challenge. In ACL-PASCAL@ACL, 2007.
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, 2014.
Michael Gutmann and Aapo Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In AISTATS, 2010.
Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. In ACL, 2018.
Shankar Iyer, Nikhil Dandekar, and Kornél Csernai. First Quora dataset release: Question pairs, 2017. URL https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs.
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. arXiv preprint arXiv:1909.10351, 2019.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. SpanBERT: Improving pre-training by representing and predicting spans. arXiv preprint arXiv:1907.10529, 2019.
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
Tomas Mikolov, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. In ICLR Workshop Papers, 2013.
Robert Parker, David Graff, Junbo Kong, Ke Chen, and Kazuaki Maeda. English gigaword, fifth edition. Technical report, Linguistic Data Consortium, Philadelphia, 2011.
Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In EMNLP, 2014.
Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In NAACL-HLT, 2018.
Jason Phang, Thibault Févry, and Samuel R Bowman. Sentence encoders on STILTs: Supplementary training on intermediate labeled-data tasks. arXiv preprint arXiv:1811.01088, 2018.
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. https://blog.openai.com/language-unsupervised, 2018.
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy S. Liang. Squad: 100, 000+ questions for machine comprehension of text. In EMNLP, 2016.
Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora, Mikhail Khodak, and Hrishikesh Khandeparkar. A theoretical analysis of contrastive unsupervised representation learning. In ICML, 2019.
Pierre Sermanet, Corey Lynch, Yevgen Chebotar, Jasmine Hsu, Eric Jang, Stefan Schaal, and Sergey Levine. Time-contrastive networks: Self-supervised learning from video. ICRA, 2017.
Noah A. Smith and Jason Eisner. Contrastive estimation: Training log-linear models on unlabeled data. In ACL, 2005.
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In EMNLP, 2013.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MASS: Masked sequence to sequence pre-training for language generation. In ICML, 2019.
Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, and Hua Wu. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223, 2019a.
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. MobileBERT: Task-agnostic compression of bert for resource limited devices, 2019b. URL https://openreview.net/forum?id=SJxjVaNKwB.
Guy Tevet, Gavriel Habib, Vered Shwartz, and Jonathan Berant. Evaluating text gans as language models. In NAACL-HLT, 2018.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. In ICML, 2008.
Alex Wang, Amapreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In ICLR, 2019.
Xiaolong Wang and Abhinav Gupta. Unsupervised learning of visual representations using videos. ICCV, 2015.
Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. Neural network acceptability judgments. arXiv preprint arXiv:1805.12471, 2018.
Adina Williams, Nikita Nangia, and Samuel R. Bowman. A broad-coverage challenge corpus for sentence understanding through inference. In NAACL-HLT, 2018.
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3-–4):229–256, 1992.
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V Le. XLNet: Generalized autoregressive pretraining for language understanding. In NeurIPS, 2019.
Lantao Yu, Weinan Zhang, Jun Wang, and Yingrui Yu. SeqGAN: Sequence generative adversarial nets with policy gradient. In AAAI, 2017.
Yizhe Zhang, Zhe Gan, Kai Fan, Zhi Chen, Ricardo Henao, Dinghan Shen, and Lawrence Carin. Adversarial feature matching for text generation. In ICML, 2017.
Yukun Zhu, Ryan Kiros, Richard S. Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. ICCV, 2015.
A 预训练的详细信息
以下详细信息适用于我们的ELECTRA模型和BERT基线。 我们通常使用与BERT相同的超参数。 我们将λ设置为损失中鉴别目标的权重为50. 8 我们使用动态令牌屏蔽,其屏蔽位置取决于-即时而不是在预处理过程中。 同样,我们没有使用原始BERT论文中提出的下一句预测目标,因为最近的工作表明它不能提高分数(Yang等人,2019; Liu等人。 ,2019)。 对于我们的ELECTRA-Large模型,我们使用较高的掩码百分比(25而不是15),因为我们注意到生成器通过15%的掩码实现了高精度,从而导致替换的令牌很少。 我们从[1e-4、2e-4、3e-4、5e-4]中搜索了基本模型和小型模型的最佳学习率,并从[1、10、20中选择了λ ,50,100]在早期实验中。 否则,除了3.2部分中的实验之外,我们不会进行超参数调整。 表6中列出了完整的超参数集。
| 超参数 | Small | Base | Large |
| Number of layers | 12 | 12 | 24 |
| Hidden Size | 256 | 768 | 1024 |
| FFN inner hidden size | 1024 | 3072 | 4096 |
| Attention heads | 4 | 12 | 16 |
| Attention head size | 64 | 64 | 64 |
| Embedding Size | 128 | 768 | 1024 |
| Generator Size (multiplier for hidden-size, | 1/4 | 1/3 | 1/4 |
| FFN-size, and num-attention-heads) | |||
| Mask percent | 15 | 15 | 25 |
| Learning Rate Decay | Linear | Linear | Linear |
| Warmup steps | 10000 | 10000 | 10000 |
| Learning Rate | 5e-4 | 2e-4 | 2e-4 |
| Adam ε | 1e-6 | 1e-6 | 1e-6 |
| Adam β1 | 0.9 | 0.9 | 0.9 |
| Adam β2 | 0.999 | 0.999 | 0.999 |
| Attention Dropout | 0.1 | 0.1 | 0.1 |
| Dropout | 0.1 | 0.1 | 0.1 |
| Weight Decay | 0.01 | 0.01 | 0.01 |
| Batch Size | 128 | 256 | 2048 |
| Train Steps (BERT/ELECTRA) | 1.45M/1M | 1M/766K | 464K/400K |
B 微调细节
对于大型模型,大部分情况下我们使用的是Clark等人的超参数(2019)。 但是,注意到RoBERTa(Liu等人,2019)使用了更多的训练时期(最多10个而不是3个)后,我们从[10,3]中搜索了最佳训练时期每个任务。 对于SQuAD,我们将训练时期减少到2个,以与BERT和RoBERTa保持一致。 对于基本尺寸的模型,我们从[3e-5、5e-5、1e-4、1.5e-4]中搜索学习率,并从[0.9、0.8、0.7]中搜索分层学习率衰减,但在其他方面则使用与大型模型相同的超参数。 我们发现小型模型受益于较高的学习率,并从[1e-4、2e-4、3e-4、5e-3]中搜索了最佳模型。 除了训练时期的数量外,我们对所有任务使用相同的超参数。 相反,先前对GLUE的研究(例如BERT,XLNet和RoBERTa)分别为每个任务寻找最佳的超参数。 如果执行相同类型的其他超参数搜索,我们希望结果会有所改善。 表7中列出了完整的超参数集。
| 超参数 | GLUE Value |
| 学习率 | 3e-4 for Small, 1e-4 for Base, 5e-5 for Large |
| Adam ε | 1e-6 |
| Adam β 1 | 0.9 |
| Adam β2 | 0.999 |
| Layerwise LR decay | 0.8 for Base/Small, 0.9 for Large |
| Learning rate decay | Linear |
| Warmup fraction | 0.1 |
| Attention Dropout | 0.1 |
| Dropout | 0.1 |
| Weight Decay | 0 |
| Batch Size | 32 |
| Train Epochs | 10 for RTE and STS, 2 for SQuAD, 3 for other tasks |
在执行BERT之后,我们不会在WNLI GLUE任务上显示开发集结果的结果,因为使用标准的微调即分类器方法甚至无法击败多数分类器。 对于GLUE测试集结果,我们应用了许多GLUE排行榜提交者使用的标准技巧,包括RoBERTa(Liu等人,2019),XLNet(Yang等人,2019 < / t1>)和ALBERT(Lan等人,2019)。 特别:
- 对于RTE和STS,我们使用中间任务训练(Phang等人,2018),从在MNLI上进行了微调的ELECTRA检查点开始。 对于RTE,我们发现将其与较低的2e-5的学习率结合起来很有帮助。
- 对于WNLI,我们遵循Liu等人,2019中描述的技巧,在其中我们使用规则提取代词的候选先行词并训练模型以对正确的先行词进行高度评分。 但是,与Liu等人,2019不同的是,评分功能并非基于传销概率。 取而代之的是,我们对ELECTRA的鉴别符进行微调,以便在正确的先行词替换代词时,它会为正确的先行词的标记分配高分。 例如,如果Winograd模式为“奖杯太大,无法放入行李箱”,我们将对鉴别器进行培训,以便在“奖杯无法放入行李箱中,因为奖杯太大”,但“由于箱子太大,所以奖杯无法放入手提箱”中的分数太低而无法“手提箱”。
- 对于每项任务,我们将30种模型中的10种最佳,它们使用不同的随机种子进行微调,但从相同的预训练检查点进行初始化。
尽管这些技巧确实提高了分数,但由于要进行额外的工作,需要大量的计算,并且由于不同的论文采用不同的技巧来实现结果,因此使进行清晰的科学比较变得更加困难。 因此,我们还在表8中报告了ELECTRA-1.75M的结果,唯一的窍门是开发集模型的选择(十个模型中的最好),这是用于报告结果的BERT设置。
对于提交的SQuAD 2.0测试集,我们从相同的预训练检查点微调了20个模型,并提交了具有最佳开发集分数的模型。
C 有关GLUE的详细信息
我们在下面提供有关GLUE基准测试任务的更多详细信息
- CoLA: 语言可接受性语料库(Warstadt等,2018)。 任务是确定给定句子是否语法。 数据集包含有关语言理论的书籍和期刊文章中的8.5k火车示例。
- SST: 斯坦福情感树库(Socher et al。,2013)。 任务是确定句子在情感上是正面还是负面。 数据集包含来自电影评论的67k火车示例。
- MRPC: Microsoft研究释义语料库(Dolan&Brockett,2005)。 任务是预测两个句子在语义上是否相等。 数据集包含来自在线新闻来源的3.7k火车示例。
- STS: 语义文本相似性(Cer et al。,2017)。 任务是预测两个句子的语义相似程度为1-5。 数据集包含从新标题,视频和图像标题以及自然语言推断数据中提取的5.8k火车示例。
- QQP: Quora问题对(Iyer等人,2017)。 任务是确定一对问题在语义上是否等效。 该数据集包含来自社区问答网站Quora的36.4万个火车示例。
- MNLI: 多体自然语言推理(Williams等,2018)。 给定前提句子和假设句子,任务是预测前提是否包含假设,与假设相矛盾或两者都不存在。 数据集包含从10个不同来源中提取的393k火车示例。
- QNLI: 质疑自然语言推理;由SQuAD构建(Rajpurkar等,2016)。 任务是预测上下文句子是否包含问题句子的答案。 数据集包含来自Wikipedia的108k火车示例。
- RTE: 识别文本蕴涵(Giampiccolo et al。,2007)。 给定前提句子和假设句子,任务是预测前提是否包含假设。 数据集包含来自一系列年度文本蕴含挑战的2.5k火车示例。
D 关于GLUE的其他结果
我们在表8中的GLUE测试集中报告ELECTRA-Base和ELECTRA-Small的结果。 此外,我们通过在XLNet数据而不是Wikibook上训练基本模型和小型模型的极限,并且持续了更长的时间(4e6训练步骤);这些模型在表中称为ELECTRA-Base ++和ELECTRA-Small ++。 对于ELECTRA-Small ++,我们还将序列长度增加到了512. 否则,超参数与表6中列出的参数相同。 最后,该表包含ELECTRA-1.75M的结果,没有附录B中描述的技巧。 与本文中的开发集结果一致,ELECTRA-Base在平均得分方面优于BERT-Large,而ELECTRA-Small优于GPT。 毫不奇怪,++模型的性能更好。 小模型得分甚至接近TinyBERT(Jiao等人,2019)和MobileBERT(Sun等人,2019b)。 这些模型使用复杂的蒸馏程序向BERT-Base学习。 另一方面,我们的ELECTRA模型是从头开始培训的。 鉴于BERT提取的成功,我们相信通过提取ELECTRA可以构建甚至更强大的小型预训练模型。 ELECTRA对CoLA似乎特别有效。 在CoLA中,目标是将语言上可接受的句子与非语法上的句子区分开,这与ELECTRA识别伪造令牌的预训练任务非常接近,也许可以解释ELECTRA在该任务上的实力。
| 模型 | Train FLOPs | 参数 | CoLA | SST | MRPC | STS | QQP | MNLI | QNLI | RTE | Avg. |
| TinyBERT | 6.4e19 +(45x +) | 1450万 | 51.1 | 93.1 | 82.6 | 83.7 | 89.1 | 84.6 | 90.4 | 70.0 | 80.6 |
MobileBERT | 6.4e19 +(45x +) | 2530万 | 51.1 | 92.6 | 84.5 | 84.8 | 88.3 | 84.3 | 91.6 | 70.4 | 81.0 |
GPT | 4.0e19(29倍) | 1.17亿 | 45.4 | 91.3 | 75.7 | 80.0 | 88.5 | 82.1 | 88.1 | 56.0 | 75.9 |
BERT-Base | 6.4e19(45x) | 110M | 52.1 | 93.5 | 84.8 | 85.8 | 89.2 | 84.6 | 90.5 | 66.4 | 80.9 |
BERT-Large | 1.9e20(135倍) | 335M | 60.5 | 94.9 | 85.4 | 86.5 | 89.3 | 86.7 | 92.7 | 70.1 | 83.3 |
SpanBERT | 7.1e20(507x) | 335M | 64.3 | 94.8 | 87.9 | 89.9 | 89.5 | 87.7 | 94.3 | 79.0 | 85.9 |
| ELECTRA-Small | 1.4e18(1倍) | 1400万 | 54.6 | 89.1 | 83.7 | 80.3 | 88.0 | 79.7 | 87.7 | 60.8 | 78.0 |
ELECTRA-Small ++ | 3.3e19(18倍) | 1400万 | 55.6 | 91.1 | 84.9 | 84.6 | 88.0 | 81.6 | 88.3 | 63.6 | 79.7 |
ELECTRA-Base | 6.4e19(45x) | 110M | 59.7 | 93.4 | 86.7 | 87.7 | 89.1 | 85.8 | 92.7 | 73.1 | 83.5 |
ELECTRA-Base++ | 3.3e20(182x) | 110M | 64.6 | 96.0 | 88.1 | 90.2 | 89.5 | 88.5 | 93.1 | 75.2 | 85.7 |
ELECTRA-1.75M | 3.1e21(2200x) | 330M | 68.1 | 96.7 | 89.2 | 91.7 | 90.4 | 90.7 | 95.5 | 86.1 | 88.6 |
E 计数FLOP
我们选择根据浮点运算(FLOP)来衡量计算使用率,因为它是与特定硬件,低级优化等无关的度量。 但是,值得注意的是,在某些情况下,提取硬件细节是一个缺点,因为以硬件为中心的优化可能是模型设计的关键部分,例如加速ALBERT(Lan等人,2019 )通过捆绑权重而获得,从而减少了TPU工作人员之间的通信开销。 我们使用了TensorFlow的FLOP计数功能9 ,并通过手工计算检查了结果。 我们做出以下假设:
- “运算”是数学运算,而不是机器指令。 例如,exp是一个像add一样的操作,尽管在实践中exp可能会慢一些。 我们认为该假设不会实质改变计算估计,因为对于大多数模型,矩阵乘法主导了计算。 同样,我们将矩阵乘法计数为2 ∗ m ∗ n FLOP,而不是m ∗ n 可能是考虑融合乘法加法运算的一种方法。
- 向后传递与向前传递具有相同数量的FLOP。 这个假设并不完全正确(例如,对于softmax交叉熵损失,后向传递更快),但重要的是,前向/后向传递FLOP对于矩阵乘法实际上是相同的,这无论如何都是大多数计算。
- 我们假设“密集”嵌入查找(即乘以一热向量)。 实际上,稀疏嵌入查找要比固定时间慢得多。在某些硬件加速器上,密集操作实际上比稀疏查找要快。
F 对抗训练
在这里,我们详细介绍了对抗发电机训练的尝试,而不是使用最大可能性。 特别地,我们训练生成器G以最大化鉴别器损耗ℒ Disc。 由于我们的鉴别符与GAN的鉴别符并不完全相同(请参见第2节中的讨论),因此该方法实际上是对抗性对比估计的一个实例(Bose等, 2018),而不是生成对抗训练。 由于来自生成器的离散采样,不可能通过在鉴别器上反向传播来对抗生成器(例如,在针对图像进行训练的GAN中),因此我们改用强化学习。
我们的生成器与大多数文本生成模型不同,因为它是非自动进行的:预测是独立进行的。 换句话说,生成器将采取同时生成所有令牌的单个巨型动作,而不是采取每个动作都会生成令牌的一系列动作,而将动作的概率分解为每个令牌的生成器概率的乘积。 为了处理这个巨大的动作空间,我们做出如下简化假设:区分器的预测 D(xcorrupt,t) 仅取决于词符 xt 和没有替换的词符 { xi : i∉m},即它不依赖于其它生成的词符 {xi : i ∈ m∧ i ≠ t}。 这并不是一个很糟糕的假设,因为替换了相对较少的词符,并且在使用强化学习时大大简化了置信度分配。 用符号表示,我们将这个假设写作 D(xt|xmasked),即给定屏蔽的上下文 xmasked,区分器的预测生成的词符 xt 是否等同于原始的词符 xt。 A useful consequence of this assumption is that the discriminator score for non-replaced tokens (D(xt|xmasked) for t∉m) is independent of pG because we are assuming it does not depend on any replaced token. 因此,在训练G以最大化ℒ Disc时,可以忽略这些标记。 在训练过程中,我们试图找到
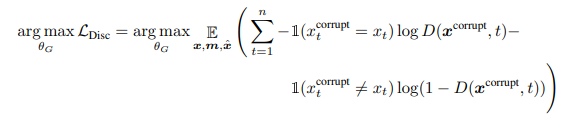
使用简化的假设,我们通过找到
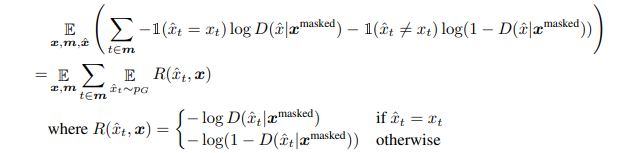
简而言之,简化的假设使我们能够分解各个生成令牌的损失。 我们无法直接找到arg max θ G之所以使用梯度上升,是因为不可能通过x的离散采样进行反向传播。 相反,我们使用策略梯度强化学习(Williams,1992)。 特别是,我们使用REINFORCE渐变
其中b是实现为b(x masked,t)= − logsigmoid(w T h G(x masked )t),其中h G(x masked)是发生器的变压器编码器的输出。 用交叉熵损失训练基线,以匹配相应位置的奖励。 我们用一个样本近似期望值,并学习θG 与梯度上升。 尽管未收到有关哪些生成的令牌正确的明确反馈,但我们发现对抗训练产生了相当准确的生成器(对于256隐藏大小的生成器,经过对抗训练的生成器在蒙版语言建模中达到58%的精度,而相同大小的MLE发电机获得65%)。 但是,使用此生成器并不能比在下游任务上经过MLE训练的生成器有所改善(请参见主文件中图3的右侧)。
G 评估ELECTRA
本节详细介绍了将ELECTRA评估为屏蔽语言模型的一些初步实验。 使用与主要论文略有不同的表示法,给定上下文c,该上下文c由带有一个标记x的被掩盖的文本序列组成,则鉴别符损失可以写为 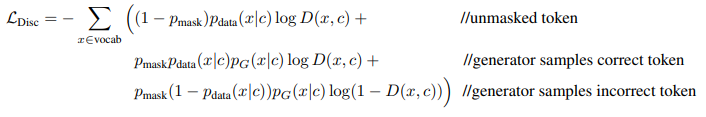
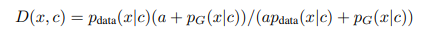
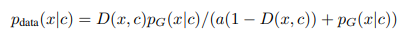
H 阴性结果
我们简要描述了一些在最初的实验中似乎没有希望的想法:
• 我们最初尝试通过策略性地掩盖令牌来提高BERT的效率(例如,更频繁地掩盖我们的稀有令牌,或训练模型以猜测BERT很难预测哪些令牌被掩盖的模型)。 与常规BERT相比,这导致了相当小的加速。
• 考虑到ELECTRA似乎可以从使用较弱的生成器中受益(在一定程度上)(请参阅第3.2节),因此我们探讨了提高生成器输出softmax的温度或禁止生成器采样正确的令牌。 这些结果都没有改善。
• 我们尝试添加句子级别的对比目标。 对于此任务,我们保持20%的输入语句不变,而不是使用生成器对其进行干扰。 然后,我们在模型中添加了一个预测头,用于预测整个输入是否损坏。 令人惊讶的是,这在下游任务上的得分略有下降。