蒸馏神经网络中的知识
提高几乎所有机器学习算法性能的一种非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测求平均。 不幸的是,使用一个完整的集成模型进行预测很笨重,并且可能在计算上过于昂贵,以致无法部署到大量用户,尤其是在单个模型是大型神经网络的情况下。 Caruana 和他的合作者表明,可以将一组集成模型的知识压缩到一个更易于部署的单一模型中,我们将使用另一种压缩技术进一步开发此方法。 我们在 MNIST 上取得了一些令人惊讶的结果,并且表明通过将一组集成模型中的知识提取为单个模型,可以显着改善在商业系统中大量使用的声学模型。 我们还引入一种由一个或多个完整模型以及许多专家模型组成的新型集成方式,这些专家模型学习区分完整模型所混淆的细粒度分类。 与专家的混合不同,这些专家模型可以快速并行地进行训练。
1 简介
许多昆虫的幼虫形式针对从环境中提取能量和养分进行了优化,而成虫形式则完全不同,其针对旅行和繁殖等不同的需求进行优化。 在大规模机器学习中,我们通常在训练阶段和部署阶段使用非常相似的模型,尽管它们有非常不同的要求:对于语音和对象识别之类的任务,训练必须从非常大且高度冗余的数据集中提取结构,但并不需要实时操作,并且可能需要使用巨量计算。 但是,部署到大量用户对延迟和计算资源有更严格的要求。 与昆虫的类比表明,如果笨重的模型可以更轻松地从数据中提取结构,我们应该愿意训练非常笨重的模型。 笨重的模型可以是单独训练的模型的集成,也可以是使用非常强大的正则化器(例如 dropout )训练的单个非常大的模型。 一旦训练好笨重模型,我们就可以使用另一种训练,我们称之为“蒸馏”,将知识从笨重模型转移到更适合部署的小型模型中。 Rich Caruana 及其合作者已经率先采用了这种策略。 在他们的重要论文中,他们令人信服地证明,大型模型集成所获得的知识可以转移到单个小型模型中。
一个可能阻止了对该非常有前景的方法进行更多研究的概念性障碍是,我们倾向于使用已学习的参数值来识别经过训练的模型中的知识,这使我们很难看到如何更改模型的形式,但要保持同样的知识。 将知识摆脱任何特定实例的一种更抽象的看法是,它是一种从输入向量到输出向量的学习映射。 对于学会区分大量类别的笨重模型,正常的训练目标是使正确答案的平均对数概率最大化,但是学习的副作用是训练后的模型将概率分配给所有不正确的答案答案,即使这些概率很小,也有一些比其他概率大得多。 错误答案的相对概率告诉我们很多有关笨重模型如何泛化的趋势。 例如,宝马车的图像被误认为是垃圾车的机会很小,但是与误认为是胡萝卜相比,这种错误的可能性仍然高很多倍。
通常认为,用于训练的目标函数应尽可能接近用户的真实目标。 尽管如此,当实际目标是很好地推广到新数据时,通常会训练模型以优化训练数据的性能。 显然,训练模型以更好地进行概括会更好,但是这需要有关正确的概括方法的信息,而该信息通常是不可用的。 但是,当我们将知识从大型模型提炼成小型模型时,我们可以训练小型模型以与大型模型相同的方式进行概括。 如果繁琐的模型能够很好地推广,例如,因为它是不同模型的大型整体的平均值,那么经过训练以相同方式进行归纳的小型模型通常比在模型中经过训练的小型模型在测试数据上的表现要好得多。在与用于训练合奏相同的训练集上的常规方法。
将笨重模型的泛化能力转换为小型模型的一种明显方法是,将笨重模型产生的类别概率用作训练小型模型的“软目标”。 在此转移阶段,我们可以使用相同的训练集或单独的“转移”集。 当笨重模型是大量简单模型的集成时,我们可以使用其单个预测分布的算术或几何平均值作为软目标。 当软目标具有较高的熵时,与硬目标相比,它们在每个训练样本中提供的信息要多得多,并且训练样本之间的梯度差异较小,因此与原始的笨重模型相比,使用小模型可以用少得多的数据训练并使用更高的学习率。
对于诸如 MNIST 之类的任务,其笨重模型几乎总是以很高的置信度产生正确的答案,学习到的功能的许多信息都驻留在软目标中很小概率的比率中。 例如,2 的一个版本可能被赋予 10−6 的概率为 3,10−9 为7,而对于其他版本,可能是相反的情况。 这是有价值的信息,它定义了数据的丰富相似性结构(即 它说哪个 2 看上去像 3 一样,哪个看上去像 7 一样),但是由于概率非常接近零,因此在转移阶段对交叉熵成本函数的影响很小。 Caruana 和他的合作者通过使用 logits(最终 softmax 的输入)而不是 softmax 产生的概率作为学习小型模型的目标来克服这个问题,并且他们最小化笨重模型和小模型产生的 logit 的均方差。 我们更通用的解决方案称为“蒸馏”,是提高最终 softmax 的温度,直到笨重模型产生一组合适的软目标为止。 然后,当训练小型模型以匹配这些软目标时,我们将使用相同的高温。 稍后我们将演示,匹配笨重模型的 logits 实际上是蒸馏的一种特殊情况。
用于训练小型模型的转移集可以完全由未标记的数据组成,或者我们可以使用原始的训练集。 我们发现使用原始训练集效果很好,特别是如果我们在目标函数中添加一个小的项式,从而鼓励小模型既预测真实目标又匹配笨重模型提供的软目标。 通常,小型模型无法完全匹配软目标,且朝正确答案的方向出错会很有帮助。
2 蒸馏
神经网络通常通过使用“softmax”输出层来产生类别概率,该输出层通过比较为每个类别与其它类别计算的 zi,将 zi 转换为概率 qi。
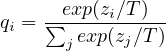 | (1) |
其中 T 是通常设置为 1 的温度。 对 T 使用较高的值会在类别上产生较软的概率分布。
在最简单的蒸馏形式中,通过在转移集上训练将知识转移到蒸馏模型,转移集中的每一个样本使用笨重模型以温度较高的 softmax 生成的软目标分布。 训练蒸馏模型时使用相同的高温,但是训练后使用的温度为 1。
当转移集中所有或部分正确标签已知时,可以通过训练蒸馏模型生成正确标签来显著改进这个方法。 一种方法是使用正确的标签来修改软目标,但是我们发现更好的方法是简单地使用两个不同目标函数的加权平均值。 第一个目标函数是与软目标的交叉熵,并且这个交叉熵计算使用的蒸馏模型的 softmax 温度与从笨重模型中生成软目标温度相同。 第二个目标函数是与正确标签的交叉熵。 它使用与蒸馏模型中 softmax 中完全相同的 logit 进行计算,但温度为 1。 我们发现最好的结果通常是通过在第二目标函数上使用相当低的权重来获得的。 由于软目标产生的梯度大小按 1∕T2 缩放,因此在同时使用硬目标和软目标时需要将软目标产生的梯度乘以 T2。 这样可以确保在使用元参数实验时如果更改蒸馏所用的温度,硬目标和软目标的相对贡献将大致保持不变。
2.1 匹配 logits 是蒸馏的一种特殊情况
转移集中每个样本对于蒸馏模型的每个 logit zi 贡献一个交叉熵梯度 dC∕dzi。 如果笨重模型的 logit vi 产生软目标概率 pi,转移训练在温度 T 下进行,则该梯度由下式给出:
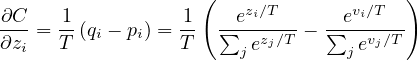 | (2) |
如果温度比 logits 的幅度高,我们可以近似得出:
 | (3) |
如果我们现在假设 logit 已经以 0 为平均值对于每个训练样本单独进行过归一化,即 ∑jzj = ∑jvj = 0,那么等式 3 简化为:
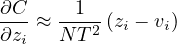 | (4) |
所以在高温限制下,蒸馏等同于最小化 1∕2(zi −vi)2,只要 logits 为每个转移样本进行平均值为 0 的归一化。 在较低的温度下,蒸馏对比平均值负得多的 logits 的匹配要关注少得多。 这是潜在的优势,因为这些 logit 几乎完全不受用于训练笨拙模型的成本函数的约束,因此它们可能非常嘈杂。 另一方面,非常负的 logit 可能会传达笨重模型获取的有关知识的有用信息。 这些影响中的哪个占主导地位是一个经验问题。 我们显示出,当蒸馏模型太小而无法捕获笨重模型中的所有知识时,中间温度效果最佳,这强烈表明忽略较大的负 logits 可以有所帮助。
3 MNIST 上的初步实验
为了了解蒸馏的效果如何,我们在所有 60,000 个训练样本中训练了一个大型神经网络,该网络具有两个包含 1200 个 ReLU 隐藏单元的隐藏层。 网络使用 dropout 和权重约束对进行了严格的正则化,如[5] 所述。 Dropout 可以看作是训练一个共享权重的指数级大模型集成的一种方式。 另外,输入图像在任何方向上最多抖动两个像素。 该网络得到 67 个测试错误,而一个较小的网络(具有 800 个 ReLU 隐藏单元的两个隐藏层,没有进行正则化)则得到 146 个错误。 但如果仅通过增加在 20 的温度下匹配大网络产生的软目标的额外任务来规范小网络,它的测试误差达到 74。 这表明软目标可以将大量知识转移到蒸馏模型中,包括有关如何泛化从翻译的训练数据中学到的知识,即使转移集不包含任何翻译也是如此。
当蒸馏网络的两个隐藏层中的每个具有 300 或更多的单元时,所有高于 8 的温度都给出了相当相似的结果。 但是,当彻底地减少到每层 30 个单元时,温度在 2.5 到 4 之间的效果明显好于较高或较低的温度。
然后,我们尝试从传输集中省略数字 3 的所有样本。 因此,从蒸馏模型的角度来看,3 是一个从未见过的神秘数字。 尽管如此,蒸馏模型仅产生 206 个测试错误,其中 133 个出现在测试集中的 1010 三上。 大多数错误是由以下事实造成的:对类别 3 的学习偏差过低。 如果此偏差增加 3.5(可优化测试集的整体性能),则蒸馏模型将产生 109 个错误,其中 14 个错误出现在 3 上。 因此,在正确的偏置下,尽管训练期间从未见过 3,但经过蒸馏的模型仍能获得 98.6% 的数字 3 的测试正确率。 如果传输集仅包含训练集中的 7 和 8,则蒸馏模型会产生 47.3% 的测试错误,但是当将 7 和 8 的偏差减少 7.6 以优化测试性能时,这会下降达到 13.2% 的测试错误。
4 语音识别实验
在本节中,我们将研究用于自动语音识别(ASR)的深度神经网络(DNN)声学模型集成的效果。 我们表明,本文提出的蒸馏策略达到了将一组模型蒸馏到单个模型中的预期效果,该模型比直接从相同训练数据中学习的相同大小的模型要好得多。
当前,最先进的 ASR 系统使用 DNN 将从波形导出的特征的(短)时间上下文映射到隐马尔可夫模型(HMM)离散状态的概率分布。 更具体地说,DNN 每次都会在三音素状态簇上产生概率分布,然后解码器找到一个 HMM 状态的路径,使用高概率状态和产生在该语言模型下可能出现的转录之间最好的折衷。
尽管有可能(并且很希望)通过边缘化所有可能的路径来考虑解码器(以及语言模型)的方式来训练DNN,但是训练DNN执行帧通过(局部)最小化每个帧的分类,通过最小化网络的预测与通过强制对齐与每次观察的地面真实状态序列给出的标签之间的交叉熵:
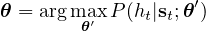
其中 θ 是我们的声学模型 P 的参数,该模型将声学时序特征 t, st 映射为 HMM “正确”状态 ht 的一个概率 P(ht|st;θ′) ,HMM “正确”状态使用正确的单词序列强制对齐确定。 该模型使用分布式随机梯度下降方法进行训练。
我们使用的结构具有 8 个隐藏层,每个隐藏层包含 2560 个 ReLU,最后是一个带有 14,000 个标签(HMM 目标 ht)的 softmax 层。 输入是 26 帧 40 个 Mel-scaled filterbank coefficient,每帧提前 10ms,我们预测第 21st 帧的 HMM 状态。 参数总数约为85M。 这是 Android 语音搜索所使用的稍显过时的声学模型,应被视为非常牢固的基准。 我们使用大约 2000 个小时的英语口语数据训练 DNN 声学模型,产生大约 700M 的训练样本。 这个系统在我们的开发集上实现 58.9% 的帧准确率和 10.9% 的词错误率(WER)。
4.1 结果
我们训练了 10个 单独的模型来预测 P(ht|st;θ),使用与基线完全相同的结构和训练过程。 使用不同的初始参数值对模型进行随机初始化,我们发现这会在训练后的模型中产生足够的多样性,以使集成的平均预测明显优于单个模型。 我们探索通过改变每个模型看到的数据集来增加模型的多样性,但是我们发现这不会显着改变我们的结果,因此我们选择了更简单的方法。 对于蒸馏,我们尝试的温度有 [1,2,5,10],硬目标交叉熵的相对权重为 0.5,其中粗体 2 表示表 1 的最佳值。
表 1 显示,确实,我们的蒸馏方法能够比仅使用硬标签训练单个模型从训练集中提取更多有用的信息。 通过使用 10 个模型的集成实现的帧分类准确性的提高中,有 80% 以上被转移到了蒸馏模型中,这与我们在 MNIST 的初步实验中观察到的改进相似。 由于目标函数的不匹配,该集成对最终目标 WER(在 23K 词的测试集上)的改进较小,但同样,集成对 WER 的改进也转移到了蒸馏模型中。
| System | 测试帧准确率 | WER |
| Baseline | 58.9% | 10.9% |
| 10xEnsemble | 61.1% | 10.7% |
| Distilled Single model | 60.8% | 10.7% |
最近,我们已经意识到有相关的工作通过匹配已经训练好的较大模型的类别概率来学习一个小型声学模型。 但是,他们使用大型的未标记数据集在温度为 1 下进行蒸馏,并且它们最佳的蒸馏模型只会将小型模型的错误率降低大模型和小模型都用硬标签训练差距的 28%。
5 训练超大数据集上专家的集成
训练一组模型集成是利用并行计算的一种非常简单的方法,而常见的障碍是集成模型在测试时需要太多计算,这可以通过使用蒸馏解决。 但是,对于集成还有另一个重要的障碍:如果单个模型是大型神经网络并且数据集非常大,则即使易于并行化,训练时所需的计算量也会过多。
在本节中,我们给出一个这样的数据集的示例,并展示学习专家模型(每个模型专注于类别的不同易混淆子集)如何减少学习集成的总计算量。 专注于细粒度区分的专家主要问题是,它们非常容易过度拟合,我们描述如何通过使用软目标来防止这种过拟合。
5.1 JFT 数据集
JFT 是 Google 的内部数据集,具有 1 亿个带有 15,000 个标签的标记好的图像。 当我们完成这项工作时,Google 的 JFT 基准模型是一个深度卷积神经网络,该神经网络已经在大量核上使用异步随机梯度下降训练了大约 6 个月。 它的训练使用两种类型的并行性。 首先,神经网络有许多副本运行在不同的核心集上,并处理来自训练集的不同小批次。 每个副本都会在其当前的小批次上计算平均梯度,然后将此梯度发送到分片参数服务器,该服务器会发回参数的新值。 这些新值反映自上次参数服务器向副本服务器发送参数以来参数服务器收到的所有梯度。 其次,通过将神经元的不同子集放在每个核心上,将每个副本散布在多个核心上。 集成训练是第三种并行性,可以将其封装在其它两种类型中,但前提是要有更多的内核可用。 等待几年来训练一组模型集成不是一个选择,因此我们需要一种更快的方法来改进基线模型。
5.2 专家模型
当类别的数量很多时,将笨重模型作为一个集成模型是有意义的,该模型包含一个对所有数据进行训练的通用模型和许多“专家”模型,其中每个“专家”模型在类别的一个非常容易混淆的子集(例如不同类型的蘑菇)高度丰富的数据样本上训练。 通过将不需要的所有类别合并为一个垃圾箱类别,可以使此类专家的 softmax 变得更小。
为了减少过拟合并分担学习低层特征检测器的工作,每个专家模型都使用通用模型的权重进行初始化。 然后,通过对专家进行训练来稍微修改这些权重,其中一半的样本来自其特殊子集,另一半的样本则来自其余的训练集。 训练后,我们可以通过将垃圾箱类别的 logit 乘以专家类别被过度采样的比例的对数来校正有偏见的训练集。
5.3 将类别分配给专家
为了为专家得出目标类别的分组,我们决定专注于整个网络经常混淆的类别。 即使我们可以计算出混淆矩阵并将其用作查找此类聚类的方法,我们还是选择了一种不需要真正标签即可构建聚类的简单方法。
| JFT 1: Tea party; Easter; Bridal shower; Baby shower; Easter Bunny; ... |
| JFT 2: Bridge; Cable-stayed bridge; Suspension bridge; Viaduct; Chimney; ... |
| JFT 3: Toyota Corolla E100; Opel Signum; Opel Astra; Mazda Familia; ... |
特别是,我们将聚类算法应用于通才模型预测的协方差矩阵,以便使用经常一起预测的一组 Sm 作为我们的专家模型之一 m 的目标。我们将 K-means 算法的在线版本应用于协方差矩阵的列,并获得了合理的聚类(如表 2所示)。 我们尝试的几种聚类算法产生相似的结果。
5.4 通过专家集成进行推理
在研究专家模型被提炼时会发生什么之前,我们想了解包含专家的集成效果如何。 除了专家模型之外,我们总是有一个通才模型,这样我们就可以处理没有专家的类,从而可以决定要使用哪些专家。 给定输入图像 x,我们分两个步骤进行顶级分类:
步骤 1:对于每个测试样本,我们根据通才模型找到 n 个最可能的类别。 将这组类别称为 k。在我们的实验中,我们使用 n = 1。
步骤 2:然后,我们采用所有专家模型 m,它们的易混淆类别的特殊子集 Sm 与k 具有非空交集,并将其称为有效专家集合 Ak(请注意,该集合可能为空)。 然后,我们找到所有类别的完整概率分布 q 来最小化:
 | (5) |
其中 KL 表示 KL 散度,pm 和 pg 分布表示专家模型和通才模型的完整概率分布。 pm 分布是专家 m 所有类别加上垃圾箱类别的分布,因此,从完整的 q分布计算其 KL 散度时我们求和 完整 q 分布分配给 m 垃圾箱中所有类别的概率。
等式 5 没有一个通用的封闭形式的解,虽然当所有的模型为每个类别生成一个概率,这个解是算术或者几何平均值,取决于我们使用 KL(p,q) 还是 KL(q,p))。 我们对 q = softmax(z) 进行参数化(使用T = 1),我们使用梯度下降来优化 logits z 即 等式 5。 请注意,必须针对每个图像执行此优化。
5.5 结果
| System | Conditional Test Accuracy | Test Accuracy | |
| Baseline | 43.1% | 25.0% | |
| + 61 Specialist models | 45.9% | 26.1% | |
从受过训练的基准完全网络开始,专家的训练非常快(JFT 只需几天而不是几周)。 此外,所有专家完全独立地训练。 表 3 显示基准系统以及与专家模型组合的基准系统的测试集绝对准确率。 使用 61 个专家模型,总体测试准确度相对提高了 4.4%。 我们还报告了条件测试的准确率,即仅考虑属于专家类别的样本并将我们的预测限制在该类别的子集上的准确率。
| 专家模型数目 | 测试样本数目 | delta in top1 correct | 准确率相对变化 |
| 0 | 350037 | 0 | 0.0% |
| 1 | 141993 | +1421 | + 3.4% |
| 2 | 67161 | +1572 | + 7.4% |
| 3 | 38801 | +1124 | + 8.8% |
| 4 | 26298 | +835 | + 10.5% |
| 5 | 16474 | +561 | + 11.1% |
| 6 | 10682 | +362 | + 11.3% |
| 7 | 7376 | +232 | + 12.8% |
| 8 | 4703 | +182 | + 13.6% |
| 9 | 4706 | +208 | + 16.6% |
| 10 or more | 9082 | +324 | + 14.1% |
对于我们的 JFT 专家实验,我们训练了 61 个专家模型,每个模型有 300 个类别(加上垃圾箱类别)。 因为专家的类别集和是相交的,所以我们经常有多个专家涵盖一个特定的图像类别。 表 4 显示 JFT 数据集测试集样本的数量、使用专家时 top 1 正确样本数量的变化以及 top 1 准确率的相对百分比改进,根据覆盖类别的专家数目细分。 总的趋势使我们感到鼓舞,当我们有更多的专家覆盖特定的类别时,准确率的提高会更大,因为训练独立的专家模型非常容易并行化。
6 软目标作为正则化器
我们关于使用软目标而不是硬目标的主要主张之一是,许多有用的信息可以在软目标中承载,而这些目标可能无法使用单个硬目标进行编码。 在本节中,我们通过使用少得多的数据来拟合前面所述的基准语音模型的 85M 参数,证明这是非常大的效果。 表 5 显示,只有 3% 的数据(大约 20M 个样本),使用硬目标训练基线模型会导致严重的过拟合(我们确实尽早停止,因为达到 44.5% 后,准确性急剧下降),而使用软目标训练的同一模型能够恢复完整训练集中的几乎所有信息(shy 程度约为 2%)。 更值得注意的是,我们尽早停止不是必须的:具有软目标的系统很容易“收敛”到 57%。 这表明软目标是一种将在所有数据上训练模型发现的规律传达给另一个模型的非常有效的方法。
| 系统和训练集 | 训练集准确率 | 测试集准确率 |
| 基线(训练集的 100%) | 63.4% | 58.9% |
| 基线(训练集的 3%) | 67.3% | 44.5% |
| 软目标(训练集的 3%) | 65.4% | 57.0% |
6.1 使用软目标以防止专家过度拟合
我们在JFT数据集实验中使用的专家将其所有非专家类折叠为一个垃圾箱类。 如果我们允许专家在所有类别上都拥有完整的 softmax,那么与使用早期停止相比,可能有更好的方法来防止它们过拟合。 专家在其特殊类别中高度丰富的数据上训练。 这意味着其有效训练集的大小要小得多,并且有很强的倾向过拟合其特殊的类别。 这个问题不能通过使专家变小很多来解决,因为那样我们将失去对所有非专家类别进行建模而获得的非常有用的传递效果。
我们使用 3% 的语音数据进行的实验强烈表明,如果专家用通才的权重进行初始化,通过使用非专家类别的软目标加上硬目标进行训练,可以使专家保留非专家类别的几乎所有知识。 软目标可以由通才提供。 我们目前正在探索这种方法。
7 与专家混合的关系
使用在数据子集上训练的专家,与使用门控网络计算将每个样本分配给每个专家的概率的专家混合有些相似。 在专家学习处理分配给它们的样本的同时,门控网络正在学习根据该样本的相对判别性能来选择将每个样本分配给哪些专家。 利用专家的判别能力来确定学习的分配要比简单地对输入向量进行聚类并将专家分配给每个聚类要好得多,但这使训练难以并行化:首先,每个专家的加权训练集不断变化这取决于所有其他专家,其次,门控网络需要在同一样本上比较不同专家的性能,以了解如何修改其分配概率。 这些困难意味着,在可能最有利的领域,很少使用专家的混合体:具有庞大数据集的任务包含截然不同的子集。
并行训练多个专家非常容易。 我们首先训练一个通才模型,然后使用混淆矩阵来定义对专家进行训练的子集。 一旦定义了这些子集,就可以完全独立地训练专家。 在测试时,我们可以使用通才模型的预测来确定哪些专家是相关的,并且只需要运行这些专家即可。
8 讨论
我们已经表明,对于将知识从集成模型或大型高度正则化模型转换为较小的蒸馏模型中,蒸馏非常有效。 在 MNIST 上,即使用于训练蒸馏模型的传递集缺少一个或多个类别的所有样本,蒸馏也能很好地工作。 对于 Android 语音搜索所用的一种深层声学模型,我们已经表明,通过训练一组深层神经网络集成实现的几乎所有改进都可以提炼成相同大小的单个神经网络,部署起来容易得多。
对于非常大的神经网络,甚至训练一个完整的集成也是不可行的,但是我们已经表明,通过学习大量的专家网络学习在高度易混淆的群集中区分类别,可以对经过长时间训练的单个非常大的网络的性能进行显着改善。 我们尚未表明我们可以将专家的知识蒸馏回单个大型网络中。
致谢
我们感谢 Yangqing Jia 为 ImageNet 上的模型训练提供的帮助,以及 Ilya Sutskever 和 Yoram Singer 的有益讨论。
参考
[1] C. Buciluǎ, R. Caruana, and A. Niculescu-Mizil. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’06, pages 535–541, New York, NY, USA, 2006. ACM.
[2] J. Dean, G. S. Corrado, R. Monga, K. Chen, M. Devin, Q. V. Le, M. Z. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, and A. Y. Ng. Large scale distributed deep networks. In NIPS, 2012.
[3] T. G. Dietterich. Ensemble methods in machine learning. In Multiple classifier systems, pages 1–15. Springer, 2000.
[4] G. E. Hinton, L. Deng, D. Yu, G. E. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N Sainath, and B. Kingsbury. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal Processing Magazine, IEEE, 29(6):82–97, 2012.
[5] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[6] R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991.
[7] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, pages 1097–1105, 2012.
[8] J. Li, R. Zhao, J. Huang, and Y. Gong. Learning small-size dnn with output-distribution-based criteria. In Proceedings Interspeech 2014, pages 1910–1914, 2014.
[9] N. Srivastava, G.E. Hinton, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929–1958, 2014.