Sentence-BERT:使用 Siamese BERT 网络的句子嵌入
-
BERT(Devlin 等人,2018)和 RoBERTa(Liu 等人,2019)在句子对回归任务如语义文本相似性(STS)上建立了新的最先进性能。 但是,它要求将两个句子都输入网络,这会导致大量的计算开销:在 10,000 个句子的集合中查找最相似的句子对需 BERT 要进行大约 5,000 万次推理计算(约 65 小时)。 BERT 的构造使其不适合语义相似性搜索以及诸如聚类之类的无监督任务。
在本论文中,我们提出对预训练 BERT 网络的一种修改 Sentence-BERT (SBERT),它使用 siamese 和 triplet 网络结构来推导出语义上有意义的句子嵌入,这些句子嵌入可以使用余弦相似性进行比较。 这样可以将查找最相似句子对的工作量从 BERT/RoBERTa 的 65 小时减少到 SBERT 的大约 5 秒,同时保持 BERT 的准确性。
我们在常见的 STS 任务和迁移学习任务上评估 SBERT 和 SRoBERTa,其性能优于其它最先进的句子嵌入方法。 1
1 简介
在本论文中,我们介绍 Sentence-BERT(SBERT),它是使用 siamese 和 triplet 网络对 BERT 网络的一种修改,它能够得出语义上有意义的句子嵌入2 。 这使 BERT 可以用于某些新任务,而这些新任务迄今为止不适用于 BERT。 这些任务包括大规模的语义相似度比较、聚类以及通过语义搜索进行信息检索。
BERT为 各种句子分类和句子对回归任务建立了最先进的性能。 BERT 使用 cross-encoder:两个句子传递到 transformer 网络,并预测目标值。 但是,由于可能的组合太多,这种方式不适用于各种句子对回归任务。 在 n = 10000 的集合中找到句子相似度最高的句子对,需要 BERT n ⋅ (n − 1)∕2 = 49995000 次推理计算。 在一个现代 V100 GPU 上,这大约需要 65 个小时。 类似的,在 Quora 的 4000 多万个存在的问题中查找哪一个新问题是最相似的,可以用 BERT 进行配对比较,然而,回答一个问题需要 50 多个小时。
解决聚类和语义搜索的常用方法是将每个句子映射到向量空间,以使语义相似的句子接近。 研究人员已开始将单个句子输入 BERT,并得出固定大小的句子嵌入。 最常用的方法是对 BERT 输出层(称为 BERT 嵌入)求平均,或使用第一个词符([CLS]词符)的输出。 就像我们将要展示的那样,这种通用做法产生的句子嵌入效果很差,通常比平均 GloVe 嵌入(Pennington 等人,2014)效果要差。
为了缓解此问题,我们开发了 SBERT。 Siamese 网络结构使得可以导出输入句子的固定大小向量。 使用类似余弦相似度或 Manhatten/Euclidean 距离的相似度度量,可以找到语义上相似的句子。 这些相似性度量可以在现代硬件上非常高效地执行,从而允许 SBERT 用于语义相似性搜索以及聚类。 在 1 万个句子集合中寻找最相似的句子对的复杂度从 BERT 的 65 小时降低到计算 1 万个句子的嵌入(SBERT 的计算时间 ˜5 秒)和计算余弦相似度(˜0.01 秒)。 通过使用优化的索引结构,找到最相似的 Quora 问题可以从 50 小时减少到几毫秒(Johnson 等人,2017)。
我们在 NLI 数据上对 SBERT 进行微调,其创建的句子嵌入方法明显优于其他最先进的句子嵌入方法,如 InferSent(Conneau 等人,2017)和 Universal Sentence Encoder(Cer 等人,2018)。 在七个语义文本相似性(STS)任务上,SBERT 与 InferSent 相比提高了 11.7 分,与 Universal Sentence Encoder 相比提高了 5.5 分。 在 SentEval(Conneau 和 Kiela,2018)(一种用于句子嵌入的评估工具包)上,我们分别获得了 2.1 和 2.6 点的提高。
SBERT 可以适应特定任务。 它在观点相似性挑战数据集(Misra 等人,2016)和维基百科文章句子区分的三元组数据集上(Dor 等人,2018)建立了新的最先进性能。
本文的结构如下:第 3 节介绍 SBERT,第 4 节评估常见的 STS 任务和观点相似度挑战(AFS)语料库(Misra 等人,2016)。 第 5 节在 SentEval 上评估 SBERT。 在第 6 节,我们进行细分研究,以测试 SBERT 的一些设计。 在第 7 节中,我们比较 SBERT 句子嵌入的计算效率与其它最先进的句子嵌入方法。
2 相关工作
我们首先介绍 BERT,然后讨论最先进的句子嵌入方法。
BERT(Devlin 等人,2018)是一个预训练的 transformer 网络(Vaswani 等人,2017),为各种 NLP 任务设置了新的最先进结果,包括问题问题回答、句子分类和句子对回归。 用于句子对回归的 BERT 的输入包含两个句子,两个句子之间用特殊的 [SEP] 词符分隔。 它应用 12 层(base-模型)或 24 层(large-模型)上的 multi-head attention,并将输出传递给简单的回归函数以得出最终标签。 使用这个方式,BERT 在语义文本相似度(STS)基准(Cer 等人,2017)上建立了新的最先进性能。 RoBERTa(Liu 等人,2019)表明,通过对预训练过程进行少量修改,可以进一步提高 BERT 的性能。 我们还测试了 XLNet(Yang 等人,2019),但通常导致比 BERT 更糟糕的结果。
BERT 网络结构的一大缺点是没有计算独立的句子嵌入,这使得很难从 BERT 导出句子嵌入。 为了避免这种局限性,研究人员向 BERT 传递单个句子,然后通过平均输出(类似于平均单词嵌入)或使用特殊的 CLS 词符的输出来推导固定大小的向量(例如: May 等人 (2019); Zhang 等人 (2019); Qiao 等人 (2019))。 流行的 bert-as-a-service-repository 3 也提供这两个选项。 据我们所知,到目前为止,这些方法是否能得到有用的句子嵌入,尚无评估。
句子嵌入是一个经过广泛研究的领域,提供了数十种建议的方法。 Skip-Thought(Kiros et al。,2015)训练编码器-解码器体系结构以预测周围的句子。 InferSent(Conneau 等人,2017)使用斯坦福自然语言推理数据集(Bowman 等人,2015)和多体裁 NLI 数据集(Williams 等人,2018)的标签数据来训练一个具有最大池化输出的 siamese BiLSTM 网络。 Conneau 人表明,InferSent 始终优于 SkipThought 等无监督方法。 Universal Sentence Encoder(Cer 等人,2018)训练 transformer 网络并通过 SNLI 训练来增强无监督学习。 Hill 等人 (2016)表明,训练句子嵌入的任务会显着影响其质量。 先前的工作(Conneau 等人,2017;Cer 等人,2018)发现 SNLI 数据集适用于训练句子嵌入。 Yang 等人 (2018)介绍了一种使用 siamese DAN 和 siamese transformer 网络训练 Reddit 对话的方法,该方法在 STS 基准数据集上产生了良好的结果。
Humeau 等人 (2019)解决了 BERT cross-encoder 的运行时开销,并提出了一种方法(poly-encoders)用 attention 来计算 m 个上下文向量和预先计算好的嵌入之间的分值。 这个想法适用于在较大的集合中找到得分最高的句子。 但是,poly-encoders 的缺点是,分数函数不对称,并且对于像聚类这样的场景计算开销太大,需要 O(n2) 次得分计算。
先前的神经网络语句嵌入方法从随机初始化开始训练。 在本论文中,我们使用经过预训练的 BERT 和 RoBERTa 网络,并且仅对其进行微调以产生有用的句子嵌入。 这大大减少所需的训练时间:SBERT 可以在不到 20 分钟的时间内进行调整,同时比同类的句子嵌入方法产生更好的结果。
3 模型
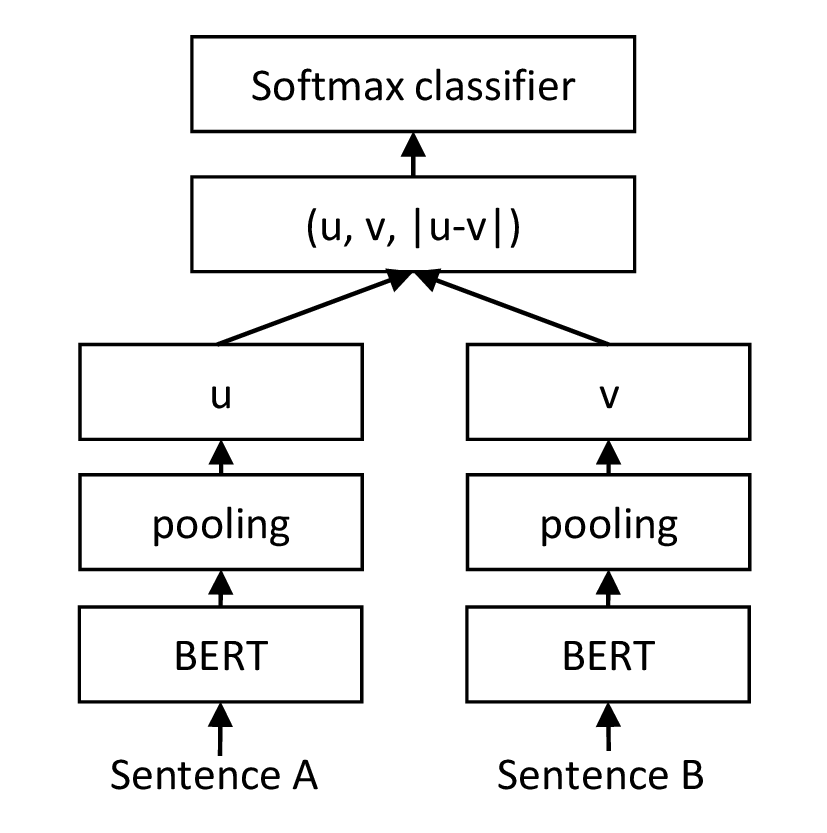
SBERT 添加一个池化操作到 BERT/RoBERTa 的输出中,以得出固定大小的句子嵌入。 我们尝试了三种池化策略:使用 CLS 词符的输出,计算所有输出向量的均值(MEAN-策略)以及计算输出向量的 max-over-time (MAX -策略)。 默认配置为 MEAN。
为了微调 BERT/RoBERTa,我们创建 siamese 和 triplet 网络(Schroff 等人,2015)来更新权重,以使生成的句子嵌入在语义上有意义,并且可以比较余弦相似。
网络结构取决于可用的训练数据。 我们尝试以下结构和目标函数。
分类目标函数。 我们连接句子嵌入 u、v 和差值 |u −v| 并与可训练的权重 Wt ∈ℝ3n×k 相乘:
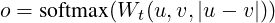
其中 n 是句子嵌入的维数,k 是标签数。 我们优化交叉熵损失。 图 1 描述了这种结构。
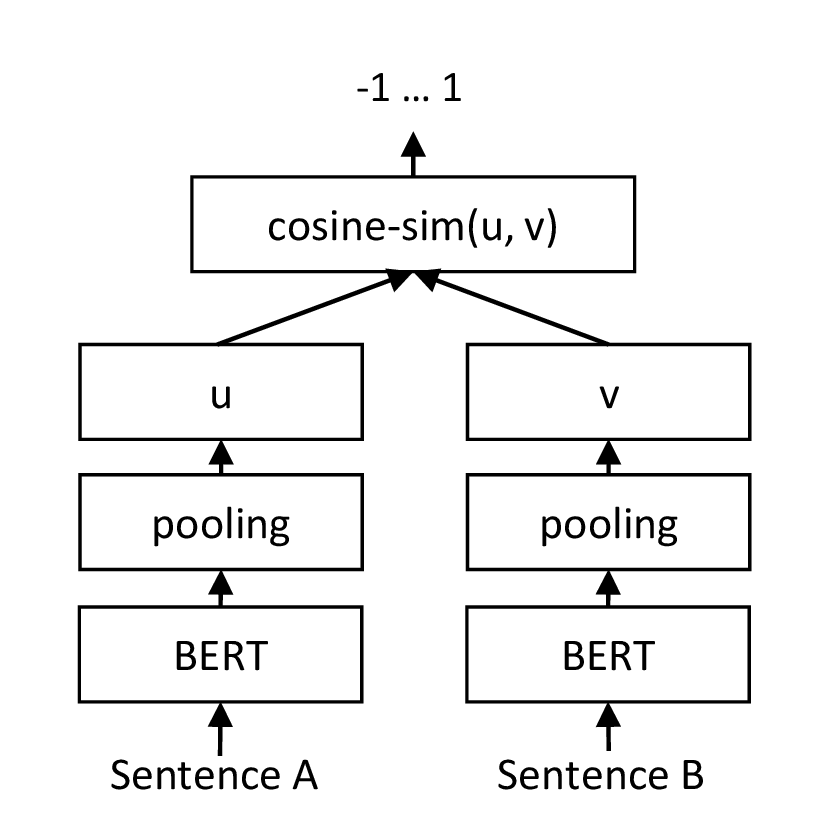
回归目标函数。 计算两个句子嵌入 u 和 v 之间的余弦相似度(图2)。 我们使用均方误差损失作为目标函数。
Triplet 目标函数。 给定一个主句 a,一个正句 p 和一个负句 n,triplet 损失会调整网络使得 a 和 p 小于 a 和 n 之间的距离。在数学上,我们最小化以下损失函数:
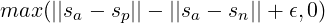
sx 为 a/n/p 的句子嵌入,||⋅|| 为距离度量和边距 ε。 边距 ε 确保 sp 与 sa 的距离至少比 sn 更接近 ε。 作为度量,我们使用欧几里得距离,并在实验中设置 ε = 1。
| 模型 | STS12 | STS13 | STS14 | STS15 | STS16 | STSb | SICK-R | 平均 |
| Avg. GloVe embeddings | 55.14 | 70.66 | 59.73 | 68.25 | 63.66 | 58.02 | 53.76 | 61.32 |
| Avg. BERT embeddings | 38.78 | 57.98 | 57.98 | 63.15 | 61.06 | 46.35 | 58.40 | 54.81 |
| BERT CLS-vector | 20.16 | 30.01 | 20.09 | 36.88 | 38.08 | 16.50 | 42.63 | 29.19 |
| InferSent - Glove | 52.86 | 66.75 | 62.15 | 72.77 | 66.87 | 68.03 | 65.65 | 65.01 |
| Universal Sentence Encoder | 64.49 | 67.80 | 64.61 | 76.83 | 73.18 | 74.92 | 76.69 | 71.22 |
| SBERT-NLI-base | 70.97 | 76.53 | 73.19 | 79.09 | 74.30 | 77.03 | 72.91 | 74.89 |
| SBERT-NLI-large | 72.27 | 78.46 | 74.90 | 80.99 | 76.25 | 79.23 | 73.75 | 76.55 |
| SRoBERTa-NLI-base | 71.54 | 72.49 | 70.80 | 78.74 | 73.69 | 77.77 | 74.46 | 74.21 |
| SRoBERTa-NLI-large | 74.53 | 77.00 | 73.18 | 81.85 | 76.82 | 79.10 | 74.29 | 76.68 |
3.1 训练细节
我们在SNLI(Bowman 等人,2015)和 Multi-Genre NLI(Williams 等人,2018)数据集上组合训练 SBERT。 SNLI 是一个带有标签contradiction、eintailment 和 neutral 的 570,000 个句子对的集合。 MultiNLI 包含 430,000 个句子对,涵盖一系列口语和书面文字。 我们用一个 3-way softmax-classifier 目标函数微调 SBERT。 我们使用批处理大小为 16 的 Adam 优化器、学习率 2e-5、在 10% 训练数据上线性预热学习率。 我们的默认池化策略是 MEAN。
4 评估 — 语义文本相似性
我们针对常见的语义文本相似性(STS)任务评估 SBERT 的性能。 最先进的方法通常学习(复杂)回归函数,该函数将句子嵌入映射到相似性评分。 但是,这些回归函数是成对运行的,并且由于组合爆炸的原因,如果句子的集合达到一定大小,则这些函数通常无法扩展。 相反,我们总是使用余弦相似度来比较两个句子嵌入之间的相似度。 我们还使用负的 Manhatten 距离和负的 Euclidean 距离作为相似性度量进行了实验,但是所有方法的结果大致相同。
4.1 无监督的 STS
我们在不使用任何 STS 训练数据的情况下评估 SBERT 的 STS 性能。 我们使用 STS 任务 2012 - 2016(Agirre 等人,2012,2013,2014,2015,2016),STS 基准(Cer 等人,2017)以及 SICK-Relatedness 数据集(Marelli 等人,2014)。 这些数据集在句子对的语义相关性上提供介于 0 和 5 之间的标签。 我们在(Reimers 等人,2016)中表明,皮尔逊相关性非常不适合 STS。 相反,我们计算句子嵌入的余弦相似度和标准标签之间的 Spearman rank 相关性。 其它句子嵌入方法的设置相同,通过余弦相似度计算相似度。 结果在表1中描述。
结果表明,直接使用 BERT 的输出会导致性能很差。 平均 BERT 嵌入的平均相关性仅为 54.81,使用 CLS-token 输出的平均相关性仅为29.19。 两者都比计算平均 GloVe 嵌入效果差。
使用所描述的 siamese 网络结构和微调机制可以显着改善相关性,从而大大优于 InferSent 和 Universal Sentence Encoder。 SBERT 的性能比 Universal Sentence Encoder 差的唯一数据集是 SICK-R。 Universal Sentence 编码器在各种数据集上训练,包括新闻、问答页面和讨论论坛,这些数据集似乎更适合 SICK-R 的数据。 相反,SBERT 仅在 Wikipedia(通过BERT)和 NLI 数据上对进行了预训练。
尽管 RoBERTa 能够提高一些监督任务的性能,但我们仅观察到 SBERT 和 SRoBERTa 在生成句子嵌入方面有细微差别。
4.2 有监督的 STS
STS 基准(STSb)(Cer等人,2017)提供了一个流行的数据集,用于评估有监督的 STS 系统。 数据包括来自captions、news 和 forums 三个类别的 8,628 个句子对。 它分为训练集(5,749)、开发集(1,500)和测试集(1,379)。 BERT 通过将两个句子都传递到网络并为输出使用简单的回归方法在此数据集上建立了最先进的性能。
| 模型 | Spearman |
未经 STS 训练
| |
| Avg. GloVe embeddings | 58.02 |
| Avg. BERT embeddings | 46.35 |
| InferSent - GloVe | 68.03 |
| Universal Sentence Encoder | 74.92 |
| SBERT-NLI-base | 77.03 |
| SBERT-NLI-large | 79.23 |
在 STS 基准数据集上训练过 | |
| BERT-STSb-base | 84.30 ± 0.76 |
| SBERT-STSb-base | 84.67 ± 0.19 |
| SRoBERTa-STSb-base | 84.92 ± 0.34 |
| BERT-STSb-large | 85.64 ± 0.81 |
| SBERT-STSb-large | 84.45 ± 0.43 |
| SRoBERTa-STSb-large | 85.02 ± 0.76 |
在 NLI 数据 + STS 基准数据集上训练过
| |
| BERT-NLI-STSb-base | 88.33 ± 0.19 |
| SBERT-NLI-STSb-base | 85.35 ± 0.17 |
| SRoBERTa-NLI-STSb-base | 84.79 ± 0.38 |
| BERT-NLI-STSb-large | 88.77 ± 0.46 |
| SBERT-NLI-STSb-large | 86.10 ± 0.13 |
| SRoBERTa-NLI-STSb-large | 86.15 ± 0.35 |
我们使用训练集通过回归目标函数对 SBERT 进行微调。 在预测时,我们计算句子嵌入之间的余弦相似度。 所有系统都接受 10个 随机种子训练以考虑到差异(Reimers 和 Gurevych,2018)。
结果在表2中描述。 我们尝试了两种设置:仅针对 STSb 进行训练,并且首先针对 NLI 进行训练,然后针对 STSb 进行训练。 我们观察到,后面的策略导致略微提高了 1-2 个点。 这种两步法对 BERT cross-encoder 产生了特别大的影响,使性能提高了 3-4 个点。 我们没有观察到 BERT 和 RoBERTa 之间的显着差异。
4.3 观点相似性
我们在 Argument Facet Similarity (AFS) 语料库上评估 SBERT Misra 人 (2016)。 AFS 语料库从社交媒体对话中标注了 6,000 个观点语句对,涉及三个有争议的主题:gun control、gay marriage 和 death penalty。 数据以从 0(“不同主题”)到 5(“完全等同”)的尺度进行标注。 AFS 语料库中的相似性概念与 SemEval 的 STS 数据集中的相似性概念完全不同。 STS数据通常是描述性的,而 AFS 数据是对话中的观点摘要。 要被认为是相似的,论点不仅必须提出相似的主张,而且必须提供相似的推理。 此外,AFS 中句子之间的词汇间隔更大。 因此,简单的无监督方法以及最新的 STS 系统在此数据集上表现不佳(Reimers 等人,2019)。
我们在两种情况下在此数据集上评估 SBERT:1)如 Misra 等人所提出的,我们使用 10-fold 交叉验证对 SBERT 进行评估。 此评估设置的缺点在于,尚不清楚方法在多大程度上适用于不同主题。 因此,2)我们在跨主题设置中评估 SBERT。 用两个主题供训练,用剩下的主题评估这个方法。 我们对所有三个主题重复此操作,并对结果取平均值。
使用回归目标函数对SBERT进行了微调。 基于句子嵌入,使用余弦相似度计算相似度分数。 我们还提供了Pearson相关性r,以使结果与Misra等人的结果相当。 但是,我们证明了(Reimers等,2016)皮尔森相关性存在一些严重的缺陷,在比较STS系统时应避免使用。 结果在表3中描述。
tf-idf、平均 GloVe 嵌入或 InferSent 等无监督方法在这个数据集上的表现相当糟糕,得分很低。 在 10-fold 交叉验证设置中训练 SBERT 可以给出几乎与 BERT 相当的性能。
但是,在跨主题评估中,我们发现SBERT的性能下降了约7点Spearman相关性。 要被认为是相似的,论据应涉及相同的主张并提供相同的理由。 BERT 能够利用注意力直接对两个句子进行比较(如逐词比较),而 SBERT 则必须将未见过的主题中的个别句子映射到一个向量空间中,使具有相似主张和理由的论点接近。 这是一项更具挑战性的任务,要与 BERT 保持同等水平,似乎不只需要训练两个主题。
| 模型 | r | ρ |
无监督方法
| ||
| tf-idf | 46.77 | 42.95 |
| Avg. GloVe embeddings | 32.40 | 34.00 |
| InferSent - GloVe | 27.08 | 26.63 |
10-fold 交叉验证
| ||
| SVR(Misra et al., 2016) | 63.33 | - |
| BERT-AFS-base | 77.20 | 74.84 |
| SBERT-AFS-base | 76.57 | 74.13 |
| BERT-AFS-large | 78.68 | 76.38 |
| SBERT-AFS-large | 77.85 | 75.93 |
Cross-Topic Evaluation
| ||
| BERT-AFS-base | 58.49 | 57.23 |
| SBERT-AFS-base | 52.34 | 50.65 |
| BERT-AFS-large | 62.02 | 60.34 |
| SBERT-AFS-large | 53.82 | 53.10 |
4.4 维基百科节选区分
Dor 等人 (2018)使用Wikipedia创建主题细粒度的训练,开发和测试集,用于句子嵌入方法。 维基百科的文章被分为不同的节选,分别着重于特定的方面。 Dor 等人假设同一节选中的句子在主题上比不同部分中的句子更接近。 他们以此创建了一个大型的弱标签句子 triplet 数据集:anchor 和正样本来自同一章节 而负样本来自同一篇文章的不同章节。 例如,来自 Alice Arnold 的文章:Anchor: Arnold joined the BBC Radio Drama Company in 1988.,正样本: Arnold gained media attention in May 2012.,负样本:Balding and Arnold are keen amateur golfers.
我们使用 Dor 等人的数据集。我们使用 Triplet 目标,在约 180 万个训练 triplets 上训练 SBERT 一个周期,在 222,957 个测试 triplets 上对其进行评估。 测试 triplets 来自一组独立的 Wikipedia 文章。 作为评估指标,我们使用准确性:正样本是否比负样本更靠近 anchor?
结果显示在表4中。 Dor 等人对具有 triplet 损失的 BiLSTM 结构进行了微调,以导出该数据集的句子嵌入。 如表所示,SBERT 明显优于 Dor 等人的 BiLSTM 方法。
| 模型 | 准确性 |
| mean-vectors | 0.65 |
| skip-thoughts-CS | 0.62 |
| Dor et al. | 0.74 |
| SBERT-WikiSec-base | 0.8042 |
| SBERT-WikiSec-large | 0.8078 |
| SRoBERTa-WikiSec-base | 0.7945 |
| SRoBERTa-WikiSec-large | 0.7973 |
5 评估 — SentEval
| 模型 | MR | CR | SUBJ | MPQA | SST | TREC | MRPC | 平均 |
| Avg. GloVe embeddings | 77.25 | 78.30 | 91.17 | 87.85 | 80.18 | 83.0 | 72.87 | 81.52 |
| Avg. fast-text embeddings | 77.96 | 79.23 | 91.68 | 87.81 | 82.15 | 83.6 | 74.49 | 82.42 |
| Avg. BERT embeddings | 78.66 | 86.25 | 94.37 | 88.66 | 84.40 | 92.8 | 69.45 | 84.94 |
| BERT CLS-vector | 78.68 | 84.85 | 94.21 | 88.23 | 84.13 | 91.4 | 71.13 | 84.66 |
| InferSent - GloVe | 81.57 | 86.54 | 92.50 | 90.38 | 84.18 | 88.2 | 75.77 | 85.59 |
| Universal Sentence Encoder | 80.09 | 85.19 | 93.98 | 86.70 | 86.38 | 93.2 | 70.14 | 85.10 |
| SBERT-NLI-base | 83.64 | 89.43 | 94.39 | 89.86 | 88.96 | 89.6 | 76.00 | 87.41 |
| SBERT-NLI-large | 84.88 | 90.07 | 94.52 | 90.33 | 90.66 | 87.4 | 75.94 | 87.69 |
SentEval(Conneau和Kiela,2018)是一种流行的工具包,用于评估句子嵌入的质量。 句子嵌入用作逻辑回归分类器的功能。 逻辑回归分类器在各种任务以 10-fold 交叉验证方法训练,然后计算测试集的预测准确性。
SBERT 句子嵌入的目的不用于其它任务的迁移学习。 在这里,我们认为对 BERT 进行微调,如 Devlin 等人 (2018)处理新任务是更合适的方法,因为它会更新BERT网络的所有层。 但是,SentEval仍然可以使我们对各种任务的句子嵌入质量产生印象。
在以下七个 SentEval 迁移任务上,我们将 SBERT 句子嵌入与其它句子嵌入方法进行了比较:
- MR:电影评论片段的情感预测,以五分为标准(Pang 和 Lee,2005)。
- CR:客户产品评论的情感预测(Hu 和 Liu,2004)。
- SUBJ:根据电影评论和情节摘要对句子进行主观性预测(Pang 和 Lee,2004)。
- MPQA:新闻专线的短语级别观点极性分类(Wiebe 等人,2005)。
- SST:带有二元标签的斯坦福情感树库(Socher 等人,2013)。
- TREC:来自 TREC 的细粒度问题类型分类(Li 和 Roth,2002)。
- MRPC:来自并行新闻来源的 Microsoft Research Paraphrase 语料库(Dolan 等人,2004)。
结果可在表5中找到。 SBERT能够在7个任务中的5个中获得最佳性能。 与InferSent以及Universal Sentence编码器相比,平均性能提高了大约2个百分点。 即使迁移学习不是SBERT的目的,它在此任务上也优于其他最新的句子嵌入方法。
看起来 SBERT 的句子嵌入可以很好地捕获情感信息:与 InferSent 和 Universal Sentence Encoder 相比,我们观察到 SentEval 的所有情感任务(MR、CR 和 SST)都得到了很大的改进。
TREC数据集是唯一一个SBERT明显比Universal Sentence Encoder差的数据集。 Universal Sentence Encoder已针对问题回答数据进行了预训练,这似乎对TREC数据集的问题类型分类任务很有帮助。
平均 BERT 嵌入或使用 BERT 网络的 CLS-词符输出对各种 STS 任务(表1)均取得了不好的结果,比平均 GloVe 嵌入要差。 但是,对于 SentEval,平均 BERT 嵌入和 BERT CLS-词符输出可实现不错的结果(表5),优于平均 GloVe 嵌入。 其原因是不同的设置。 对于STS任务,我们使用余弦相似度来估计句子嵌入之间的相似度。 余弦相似度平等地对待所有维度。 相反,SentEval使逻辑回归分类器适合句子嵌入。 这允许某些尺寸可以对分类结果产生较高或较低的影响。
我们得出的结论是,BERT 返回语句嵌入的平均 BERT 嵌入/CLS-词符输出无法与余弦相似度或与 Manhatten/Euclidean 距离一起使用。 对于迁移学习,与 InferSent 或 Universal Sentence Encoder相比,它们产生的结果稍差。 然而,在NLI数据集上使用所描述的微调设置与 siamese 网络结构,可以产生句子嵌入,实现 SentEval 工具包新的最先进结果。
6 细分研究
我们已经证明了SBERT句子嵌入质量的强大经验结果。 在本节中,我们将对 SBERT 的各个方面进行细分研究,以便更好地了解它们的相对重要性。
我们评估了不同的池化策略(MEAN、MAX 和 CLS)。 对于分类目标函数,我们评估不同的连接方法。 对于每种可能的配置,我们用10个不同的随机种子训练SBERT并平均性能。
目标函数(分类与回归)取决于标注的数据集。 对于分类目标函数,我们基于SNLI和Multi-NLI数据集训练SBERT。 对于回归目标函数,我们在STS基准数据集的训练集上进行训练。 性能是根据 STS 基准数据的开发集来衡量的。 结果显示在表6中。
| NLI | STSb | |
Pooling Strategy
| ||
| MEAN | 80.78 | 87.44 |
| MAX | 79.07 | 69.92 |
| CLS | 79.80 | 86.62 |
Concatenation
| ||
| (u,v) | 66.04 | - |
| (|u − v|) | 69.78 | - |
| (u ∗ v) | 70.54 | - |
| (|u − v|,u ∗ v) | 78.37 | - |
| (u,v,u ∗ v) | 77.44 | - |
| (u,v,|u − v|) | 80.78 | - |
| (u,v,|u − v|,u ∗ v) | 80.44 | - |
当使用分类目标函数对 NLI 数据进行训练时,池化策略的影响较小。 连接模式的影响要大得多。 InferSent(Conneau 等人,2017)和 Universal Sentence Encoder(Cer 等人,2018)都使用(u,v,|u −v|,u ∗v) 作为 softmax 分类器的输入。 但是,在我们的结构中,添加 u ∗v 会降低性能。
最重要的部分是元素逐项相减 |u −v|。 请注意,连接模式仅与训练 softmax 分类器有关。 推断时,在预测 STS 基准数据集的相似性时,只有句子嵌入 u 和 v 与余弦相似度结合使用。 元素的逐项差值度量两个句子嵌入的维度之间的距离,从而确保相似的对更接近,而相似的对则更远。
当用回归目标函数训练时,我们观察到池化策略具有很大的影响。 在那里,MAX 策略的效果明显低于 MEAN 和 CLS-词符策略。 这与(Conneau 等人,2017)相反,他们发现使用MAX 代替 MEAN 对于 InferSent 的 BiLSTM 层有益。
7 计算效率
句子嵌入可能需要计算数百万个句子,因此需要较高的计算速度。 在本节中,我们将 SBERT 与平均 GloVe 嵌入、InferSent(Conneau 等人,2017)和 Universal Sentence Encoder (Cer 等人,2018)进行比较。
为了进行比较,我们使用 STS 基准测试中的语句(Cer 等人,2017)。 我们使用 Python 字典查找和 NumPy 的简单 for 循环来计算平均 GloVe 嵌入。 InferSent 4 基于PyTorch。 对于Universal Sentence Encoder,我们使用基于 TensorFlow 的 TensorFlow Hub 版本5 。 SBERT 基于 PyTorch。 为了改进句子嵌入的计算,我们实施了一种智能的批处理策略:将具有相似长度的句子组合在一起,并且仅填充至 mini-batch 中最长的元素。 这大大减少了填充词符的计算开销。
性能是在配备Intel i7-5820K CPU @ 3.30GHz、Nvidia Tesla V100 GPU、CUDA 9.2 和 cuDNN 的服务器上测得的。 结果在表7中描述。
在CPU上,InferSent 比 SBERT 快 65%。 这是由于更简单的网络体系结构。 InferSent 使用单个 BiLSTM 层,而 BERT 使用 12个 堆叠的 transformer 层。 但是,transformer 网络的优点是 GPU 的计算效率。 在那里,具有智能批处理功能的 SBERT 比 InferSent 快 9%,比 Universal Sentence Encoder 快 55%。 智能批处理可将 CPU 的速度提高 89%,将 GPU 的速度提高 48%。 平均 GloVe 嵌入显然在很大程度上是计算句子嵌入的最快方法。
8 结论
我们表明,直接用 BERT 将句子映射到一个向量空间相当不适合用常见的相似度量如余弦相似度。 七个 STS 任务的性能低于平均 GloVe 嵌入的性能。
为了克服这一缺点,我们提出了Sentence-BERT(SBERT)。 SBERT以 siamese/triplet 网络结构微调 BERT。 我们在各种常见的基准上评估了质量,在这些基准上,它可以实现比最先进的句子嵌入方法的显著改进。 用 RoBERTa 代替 BERT 在我们的实验中没有产生明显的改善。
SBERT 计算效率高。 在GPU上,它比 InferSent 快 9%,比 Universal Sentence Encoder 快 55%。 SBERT 可用于在计算上无法使用 BERT 建模的任务。 例如,使用分层聚类将 10,000个 句子聚类需要 BERT 大约 65 小时,因为必须计算大约 5000万 个句子组合。 使用 SBERT,我们可以将工作量减少到大约 5 秒。
致谢
这项工作得到了德国研究基金会通过德-以项目合作的支持(DIP, grant DA 1600/1-1 和 grant GU 798/17-1)。 它由德国联邦教育和研究部(BMBF)共同资助,参考代码 03VP02540(ArgumenText)。
参考文献
Eneko Agirre, Carmen Banea, Claire Cardie, Daniel Cer, Mona Diab, Aitor Gonzalez-Agirre, Weiwei Guo, Inigo Lopez-Gazpio, Montse Maritxalar, Rada Mihalcea, German Rigau, Larraitz Uria, and Janyce Wiebe. 2015. SemEval-2015 Task 2: Semantic Textual Similarity, English, Spanish and Pilot on Interpretability. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), pages 252–263, Denver, Colorado. Association for Computational Linguistics.
Eneko Agirre, Carmen Banea, Claire Cardie, Daniel Cer, Mona Diab, Aitor Gonzalez-Agirre, Weiwei Guo, Rada Mihalcea, German Rigau, and Janyce Wiebe. 2014. SemEval-2014 Task 10: Multilingual Semantic Textual Similarity. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 81–91, Dublin, Ireland. Association for Computational Linguistics.
Eneko Agirre, Carmen Banea, Daniel M. Cer, Mona T. Diab, Aitor Gonzalez-Agirre, Rada Mihalcea, German Rigau, and Janyce Wiebe. 2016. SemEval-2016 Task 1: Semantic Textual Similarity, Monolingual and Cross-Lingual Evaluation. In Proceedings of the 10th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2016, San Diego, CA, USA, June 16-17, 2016, pages 497–511.
Eneko Agirre, Daniel Cer, Mona Diab, Aitor Gonzalez-Agirre, and Weiwei Guo. 2013. *SEM 2013 shared task: Semantic Textual Similarity. In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity, pages 32–43, Atlanta, Georgia, USA. Association for Computational Linguistics.
Eneko Agirre, Mona Diab, Daniel Cer, and Aitor Gonzalez-Agirre. 2012. SemEval-2012 Task 6: A Pilot on Semantic Textual Similarity. In Proceedings of the First Joint Conference on Lexical and Computational Semantics - Volume 1: Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation, SemEval ’12, pages 385–393, Stroudsburg, PA, USA. Association for Computational Linguistics.
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 632–642, Lisbon, Portugal. Association for Computational Linguistics.
Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. 2017. SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 1–14, Vancouver, Canada.
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Yun-Hsuan Sung, Brian Strope, and Ray Kurzweil. 2018. Universal Sentence Encoder. arXiv preprint arXiv:1803.11175.
Alexis Conneau and Douwe Kiela. 2018. SentEval: An Evaluation Toolkit for Universal Sentence Representations. arXiv preprint arXiv:1803.05449.
Alexis Conneau, Douwe Kiela, Holger Schwenk, Loïc Barrault, and Antoine Bordes. 2017. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 670–680, Copenhagen, Denmark. Association for Computational Linguistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
Bill Dolan, Chris Quirk, and Chris Brockett. 2004. Unsupervised Construction of Large Paraphrase Corpora: Exploiting Massively Parallel News Sources. In Proceedings of the 20th International Conference on Computational Linguistics, COLING ’04, Stroudsburg, PA, USA. Association for Computational Linguistics.
Liat Ein Dor, Yosi Mass, Alon Halfon, Elad Venezian, Ilya Shnayderman, Ranit Aharonov, and Noam Slonim. 2018. Learning Thematic Similarity Metric from Article Sections Using Triplet Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 49–54, Melbourne, Australia. Association for Computational Linguistics.
Felix Hill, Kyunghyun Cho, and Anna Korhonen. 2016. Learning Distributed Representations of Sentences from Unlabelled Data. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1367–1377, San Diego, California. Association for Computational Linguistics.
Minqing Hu and Bing Liu. 2004. Mining and Summarizing Customer Reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’04, pages 168–177, New York, NY, USA. ACM.
Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, and Jason Weston. 2019. Real-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers. arXiv preprint arXiv:1905.01969, abs/1905.01969.
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2017. Billion-scale similarity search with GPUs. arXiv preprint arXiv:1702.08734.
Ryan Kiros, Yukun Zhu, Ruslan R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Skip-Thought Vectors. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 3294–3302. Curran Associates, Inc.
Xin Li and Dan Roth. 2002. Learning Question Classifiers. In Proceedings of the 19th International Conference on Computational Linguistics - Volume 1, COLING ’02, pages 1–7, Stroudsburg, PA, USA. Association for Computational Linguistics.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
Marco Marelli, Stefano Menini, Marco Baroni, Luisa Bentivogli, Raffaella Bernardi, and Roberto Zamparelli. 2014. A SICK cure for the evaluation of compositional distributional semantic models. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), pages 216–223, Reykjavik, Iceland. European Language Resources Association (ELRA).
Chandler May, Alex Wang, Shikha Bordia, Samuel R. Bowman, and Rachel Rudinger. 2019. On Measuring Social Biases in Sentence Encoders. arXiv preprint arXiv:1903.10561.
Amita Misra, Brian Ecker, and Marilyn A. Walker. 2016. Measuring the Similarity of Sentential Arguments in Dialogue. In Proceedings of the SIGDIAL 2016 Conference, The 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 13-15 September 2016, Los Angeles, CA, USA, pages 276–287.
Bo Pang and Lillian Lee. 2004. A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. In Proceedings of the 42nd Meeting of the Association for Computational Linguistics (ACL’04), Main Volume, pages 271–278, Barcelona, Spain.
Bo Pang and Lillian Lee. 2005. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), pages 115–124, Ann Arbor, Michigan. Association for Computational Linguistics.
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. In Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543.
Yifan Qiao, Chenyan Xiong, Zheng-Hao Liu, and Zhiyuan Liu. 2019. Understanding the Behaviors of BERT in Ranking. arXiv preprint arXiv:1904.07531.
Nils Reimers, Philip Beyer, and Iryna Gurevych. 2016. Task-Oriented Intrinsic Evaluation of Semantic Textual Similarity. In Proceedings of the 26th International Conference on Computational Linguistics (COLING), pages 87–96.
Nils Reimers and Iryna Gurevych. 2018. Why Comparing Single Performance Scores Does Not Allow to Draw Conclusions About Machine Learning Approaches. arXiv preprint arXiv:1803.09578, abs/1803.09578.
Nils Reimers, Benjamin Schiller, Tilman Beck, Johannes Daxenberger, Christian Stab, and Iryna Gurevych. 2019. Classification and Clustering of Arguments with Contextualized Word Embeddings. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 567–578, Florence, Italy. Association for Computational Linguistics.
Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. FaceNet: A Unified Embedding for Face Recognition and Clustering. arXiv preprint arXiv:1503.03832, abs/1503.03832.
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA. Association for Computational Linguistics.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 5998–6008.
Janyce Wiebe, Theresa Wilson, and Claire Cardie. 2005. Annotating Expressions of Opinions and Emotions in Language. Language Resources and Evaluation, 39(2):165–210.
Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics.
Yinfei Yang, Steve Yuan, Daniel Cer, Sheng-Yi Kong, Noah Constant, Petr Pilar, Heming Ge, Yun-hsuan Sung, Brian Strope, and Ray Kurzweil. 2018. Learning Semantic Textual Similarity from Conversations. In Proceedings of The Third Workshop on Representation Learning for NLP, pages 164–174, Melbourne, Australia. Association for Computational Linguistics.
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. 2019. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237, abs/1906.08237.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2019. BERTScore: Evaluating Text Generation with BERT. arXiv preprint arXiv:1904.09675.