有一种从少数标记示例中进行学习并充分利用大量非标记数据的模式是先进行无监督预训练,然后用有监督微调。 虽然这种模式与大多数以前的计算机视觉半监督学习方法相反以与任务无关的 方式使用未标记的数据,但是我们表明它在 ImageNet 上的半监督学习非常有效。 我们方法的关键要素是在预训练和微调过程中使用大型(深度和广度)网络。 我们发现,标签越少,这种方法(与任务无关的无标记数据的使用)从更大的网络中受益越多。 在微调之后,通过第二次使用未标记的示例,但以特定于任务的方式,大型网络可以进一步改进并将其蒸馏为一个很小的网络,而几乎不会降低分类准确性。 我们提出的半监督学习算法可以总结为三个步骤:使用 SimCLRv2(SimCLR [1]) 的修改版)对一个大型 ResNet 模型进行无监督预训练,在少量的有标记示例上进行 有监督的微调,使用无标记示例蒸馏 改进和迁移与任务相关的知识。 使用 ResNet-50,这个过程仅使用 1% 的标签(每各类别 ≤ 13 个有标签图像)即可达到 73.9% 的 ImageNet top-1 精度,与之前的最先进结果相比,标签效率得到 10× 提高。 使用 10% 的标签,使用我们的方法训练的 ResNet-50 可以达到 77.5% 的 top-1 准确率,优于使用所有标签训练的标准监督模型。 2
1 简介
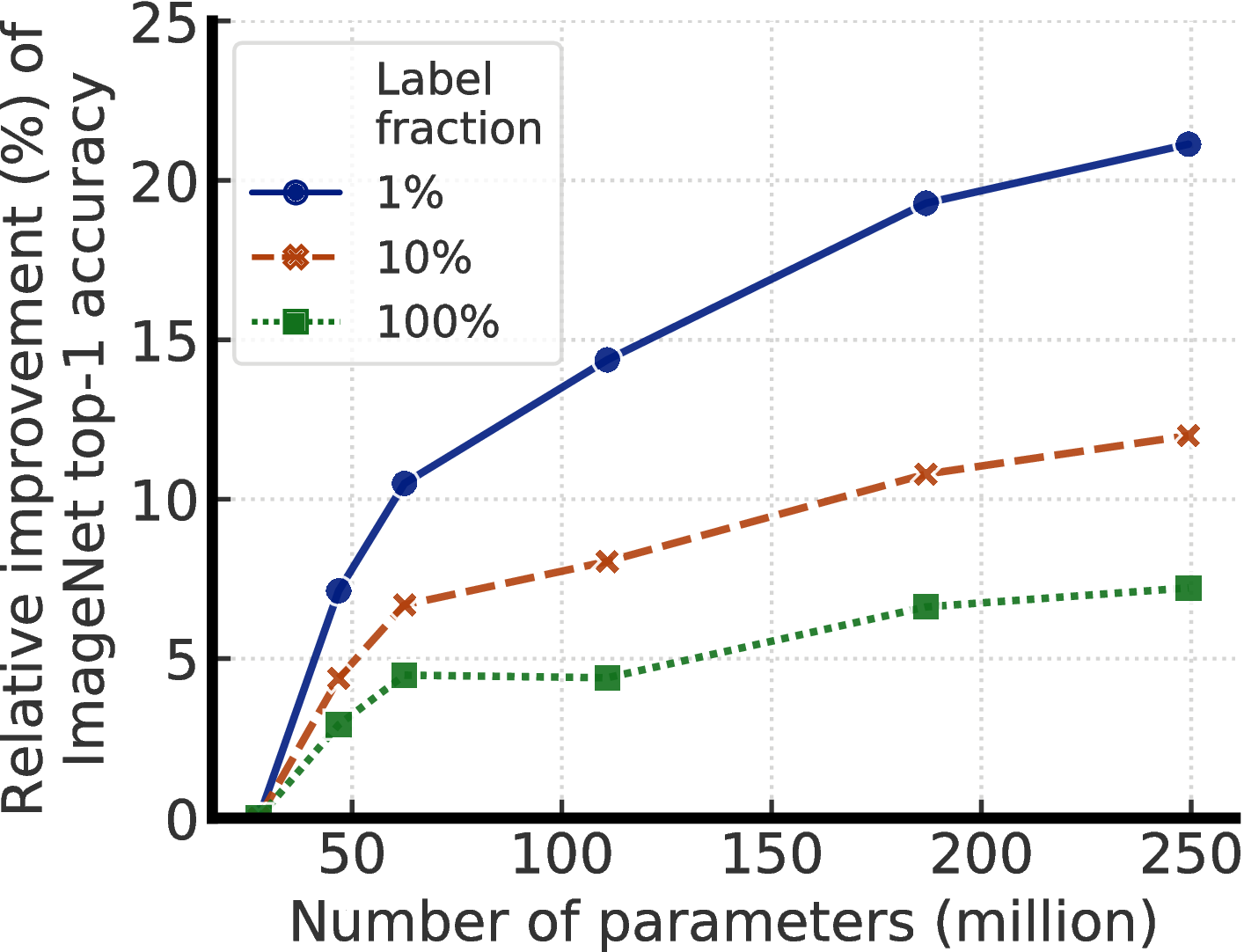

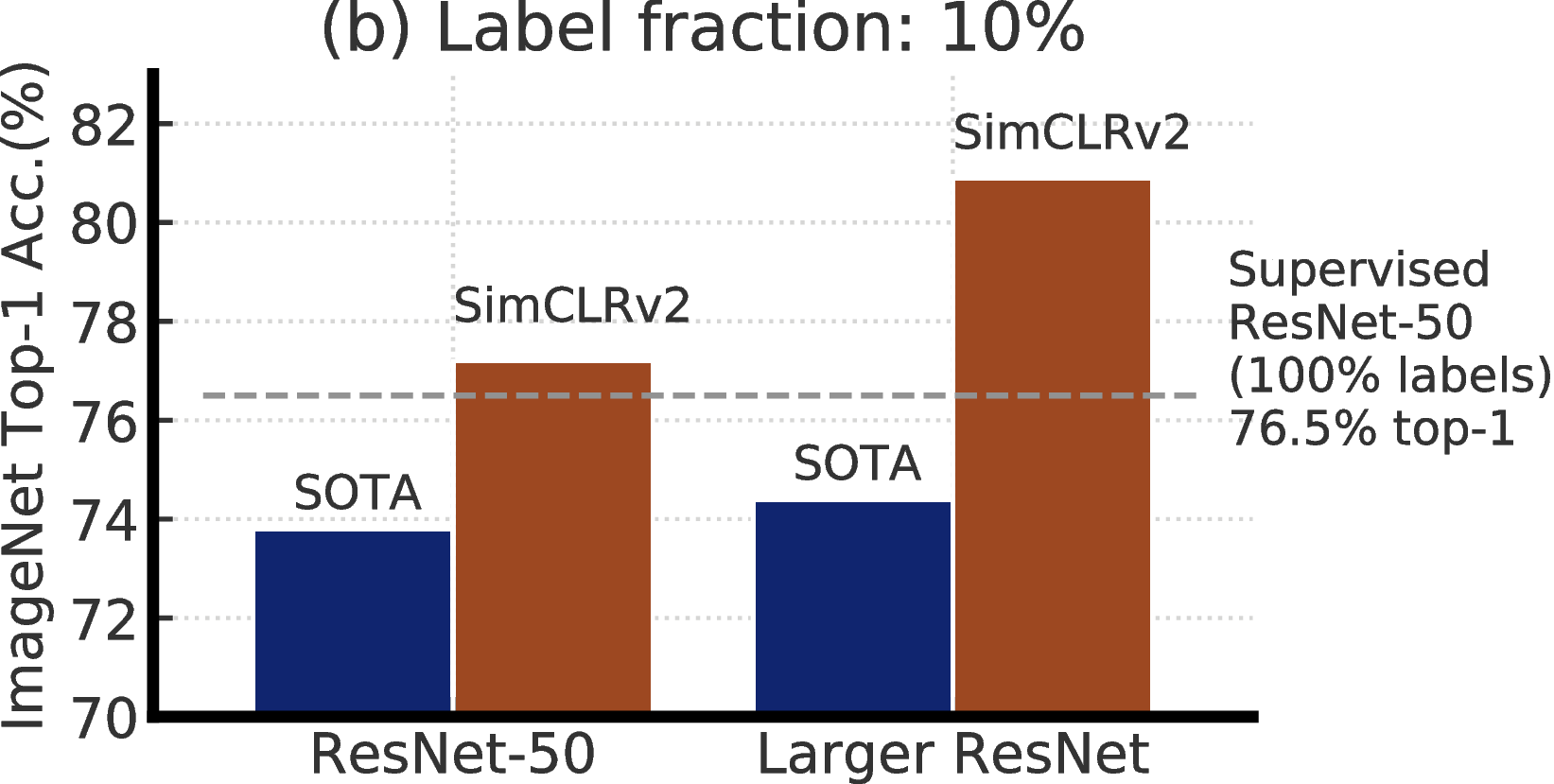
在仅从少量标记示例学习的同时充分利用大量未标记数据是机器学习中一个长期存在的问题。 有一种半监督学习方法首先进行无监督或自我监督的预训练,然后进行有监督的微调 [3, 4]。 这种方法在预训练期间以与任务无关的 方式利用未标记的数据,因为仅在微调期间使用有监督的标记。 尽管它在计算机视觉中很少受到关注,但是这种方法已在自然语言处理中占主导地位,在自然语言处理中,人们首先在未标记的文本(例如 Wikipedia)上训练大型语言模型,然后在少量有标记的示例中对模型进行微调 [5–10]。 在计算机视觉中很常见的另一种方法是在监督学习过程中直接利用未标记的数据,作为一种正则化的形式。 这种方法以特定任务 的方式使用未标记数据,鼓励不同模型 [11, 12, 2] 或不同数据增强[13-15] 下未标记数据的类别标签预测一致性。
基于视觉表示的自我监督学习的最新进展 [16–20, 1],本文首先在 ImageNet [21] 上对 “无监督预训练、有监督微调”模式进行彻底的研究。 在自我监督的预训练过程中,使用图像时不使用类别标签(以与任务无关的方式),因此不能直接针对特定的分类任务来调整表示形式。 通过与任务无关的未标记数据的使用,我们发现网络规模非常重要:使用大型(深层和宽层)神经网络进行自我监督的预训练和微调可大大提高准确性。 除网络规模外,我们还为对比表示学习提供一些重要的设计选择,这些选择有益于监督微调和半监督学习。
在对卷积网络进行预训练和微调之后,我们发现其特定任务的预测可以得到进一步改善,并提炼成更小的网络。 到这个阶段,我们第二次使用未标记的数据来鼓励学生网络模仿教师网络的标签预测。 因此,我们使用未标记数据方法的蒸馏 [22, 23] 阶段类似在自我训练 [24, 12] 中使用的伪标记 [11],但没有太多额外的复杂性。
总之,我们提出的半监督学习框架包括三个步骤,如图3所示:(1)无监督或自我监督的预训练,(2)有监督的微调,以及(3)使用未标记数据的蒸馏。 我们开发一个最近提出的对比学习框架 SimCLR [1] 的改进版本,用于 ResNet 结构 [25] 的无监督预训练。 我们将此框架称为 SimCLRv2。 我们在 ImageNet ILSVRC-2012 [21] 上评估该方法的有效性,其中只有 1% 和 10% 的标记图像可用。 我们的主要发现和贡献可以总结如下:
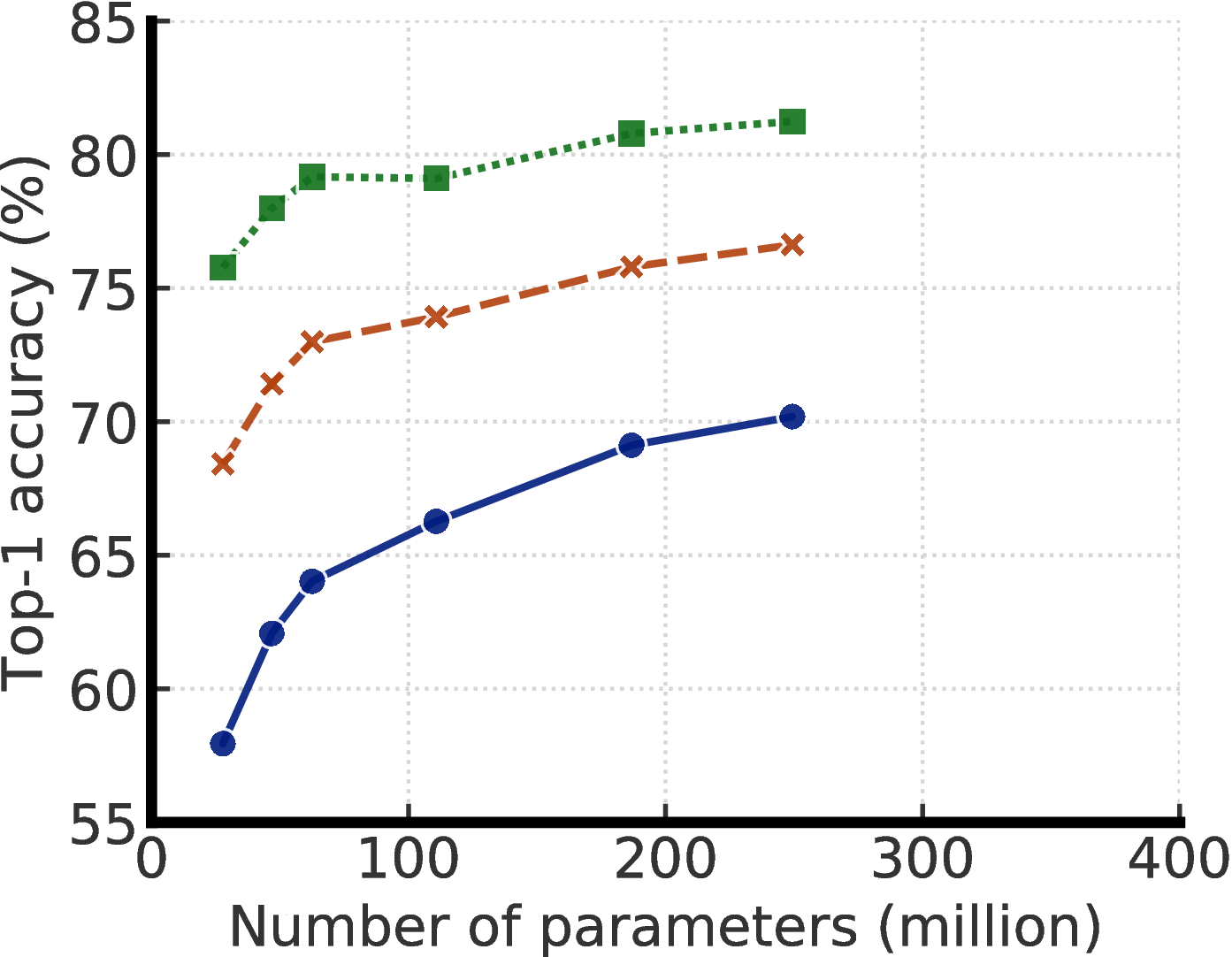
- 我们的实验结果表明,对于半监督学习(通过与任务无关的未标记数据的使用),标签越少,就越有可能受益于更大的模型(图1)。 更大的自我监督模型的标签效率更高,当只在几个标签的示例上进行微调时表现明显更好,尽管它们有更大的能力去潜在地过拟合。
- 我们表明,尽管大型模型对于学习通用(视觉)表示很重要,但是当涉及到特定的目标任务时,可能不需要额外的能力。 因此,通过将未标记数据使用到特定任务中,可以进一步提高模型的预测性能,并将其转移到较小的网络中。
- 我们进一步表明非线性变换的重要性(即 投影头),它在半监督学习 SimCLR 中卷积层之后使用。 从投影头的中间层 进行微调时,一个更深的投影头不仅可以改善线性评估测得的表示质量,还可以改善半监督性能。
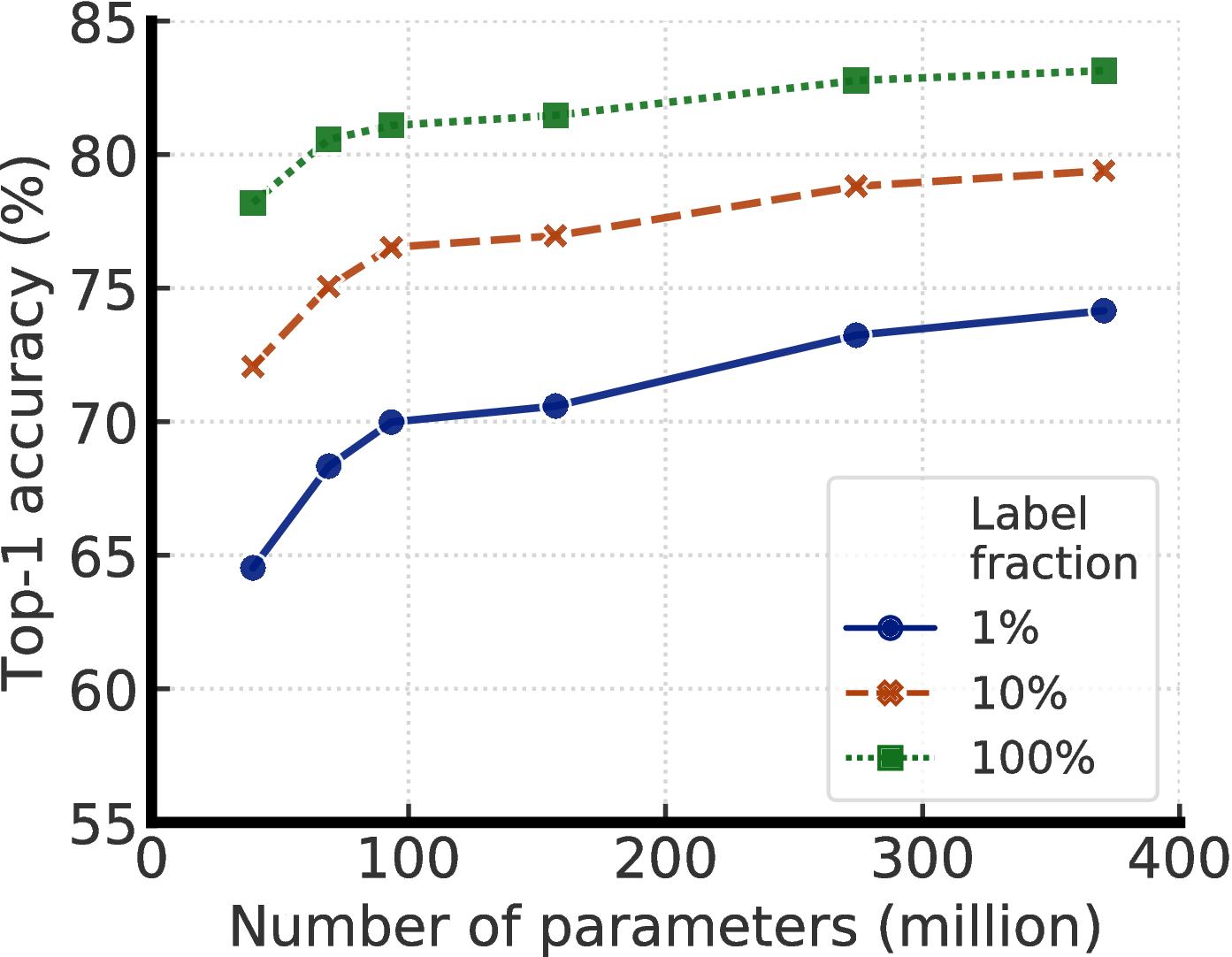
我们结合这些发现,在 ImageNet 上实现半监督学习的最先进结果,如图2所示。 在线性评估协议下,SimCLRv2 的 top-1 准确率达到 79.8%,比之前最先进结果 [1] 相对提高 4.3%。 如果仅在 1%/10% 的标记示例上进行微调,并使用未标记的示例将其蒸馏至相同的结构,则可以达到 76.6%/80.9% 的 top-1 准确率,比之前的最先进结果相对提高 21.6%/8.7%。 通过蒸馏,这些改进也可以转移到较小的 ResNet-50 网络中,使用 1%/10% 的标签达到 73.9%/77.5% 的 top-1 准确率。 相比之下,在所有标签图像进行训练的标准监督 ResNet-50 取得 76.6% 的 top-1 准确率。
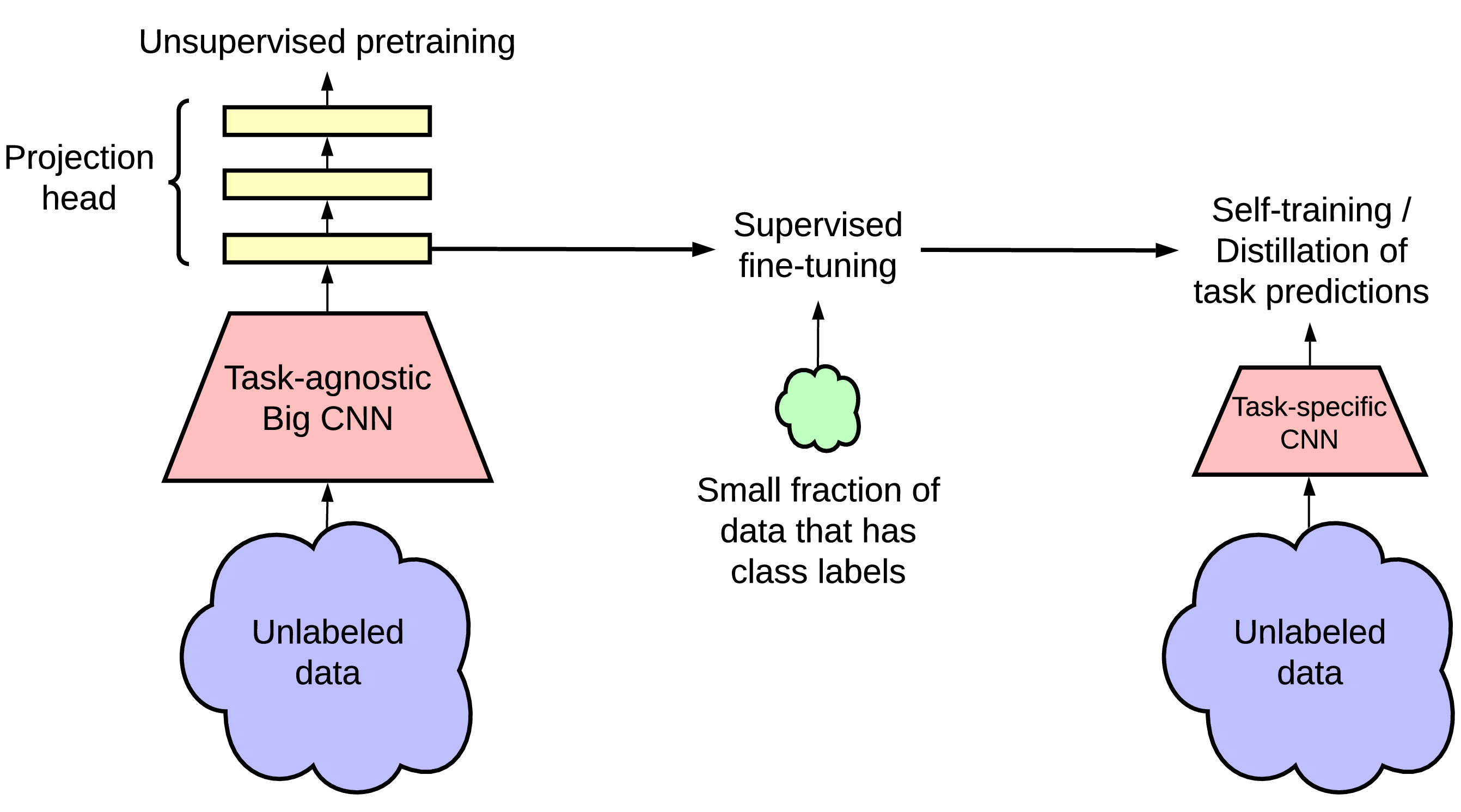
2 方法
受到最近从无标签数据学习成功的启发 [19, 20, 1, 11, 24, 12],我们提出的半监督学习框架以与任务无关的方式和针对特定任务的方式利用未标记的数据。 第一次使用未标记的数据时,它以与任务无关的方式,用于通过无监督的预训练来学习通用(视觉)表示、。 然后通过监督的微调使通用表示适合于特定任务。 第二次使用未标记的数据,它以特定于任务的方式用于进一步改善预测性能并获得紧凑模型。 在这个阶段,我们使用经过微调的教师网络中的推定标签在未标签数据上训练学生网络。 我们的方法可以概括为三个主要步骤:预训练、微调 和蒸馏。 图3中说明了该过程。 我们将在下面详细介绍每个特定的组成部分。
使用 SimCLRv2 进行自我监督的预训练。 为了有效地利用未标记的图像学习一般的视觉表示,我们采用并改进 SimCLR [1],一种最近提出的基于对比学习的方法。 SimCLR 通过潜在空间中的对比损失最大化同一数据示例不同增强视图之间的一致性 [26] 来学习表示。 更具体地,给定一个随机采样的图像,每个图像 xi 使用 random crop、color distortion 和 Gaussian blur 增强,创建同一个示例的两个不同视图 x2k−1 和 x2k。 这两个图像通过编码器网络 f(⋅) (ResNet [25])编码生成表示 h2k−1 和 h2k−1。 这两个表示然后使用非线性变换网络 g(⋅) (MLP 投影头)再次变换,得到 z2k−1 和 z2k 用于对比损失。 对于一个批次的增强示例,一对正示例 i,j(从同一张图片中增强)之间的对比损失如下所示:
 | (1) |
其中 sim(⋅,⋅) 是两个向量之间的余弦相似度,τ 是温度标量。
在这项工作中,我们提出 SimCLRv2,它在三个主要方面对 SimCLR [1] 进行了改进。 以下我们总结了Imagenet ILSVRC-2012 [21]上的更改及其准确性的提高。
- 为了充分利用通用预训练的能力,我们探索更大的 ResNet 模型。 SimCLR [1] 和其它先前的工作 [27, 20] 的最大模型是 ResNet-50 (4×),与它们不同,我们训练更深但宽度要小的模型。 我们训练的最大模型是 152 层 ResNet [25],具有 3× 更宽的通道和选择性内核(SK)[28],一种逐通道关注机制,可提高网络的参数效率。 通过将模型从 ResNet-50 扩展到 ResNet-152 (3×+SK),在微调时,我们的 top-1 准确率在 1% 的有标签的示例上相对提高 29%。
- 我们还增加非线性网络 g(⋅) 的能力(即 投影头),使之更深 3。此外,没有像 SimCLR [1] 一样,在进行预训练之后完全扔掉 g(⋅) ,我们从中间层进行微调(稍后详细介绍)。 这个很小的变化对于线性评估和微调都产生了重大改进,仅需几个标记示例即可。 与具有 2 层投影头的 SimCLR 相比,通过使用 3 层投影头并从第一层投影头进行微调,在微调时,它的 top-1 准确率在 1% 的有标签的示例上相对提高14%。(请参见图E.1)。
- 受 [29] 的启发,我们还结合 MoCo [20] 中的存储机制,指定一个存储网络(具有稳定权重的移动平均值),其输出将被缓存为负样本。 由于我们的训练是基于大批次进行的,里面已经提供许多对比鲜明的负面示例,因此对于线性评估以及对 1% 的标记示例进行微调时,此更改可提高 〜 1%(请参阅附录D)。
微调。 微调是一种使任务无关的预训练网络适应特定任务的常用方法。 在 SimCLR [1] 中,MLP 投影头 g(⋅) 在预训练后完全丢弃,在微调期间仅使用 ResNet 编码器 f(⋅) 。 我们提出在微调过程中将 MLP 投影头的一部分合并到基本编码器中,而不是将其全部丢掉。 这等效于从投影头的 中间层 进行微调,而不是像 SimCLR 中那样对投影头的输入层进行微调。
我们详细说明一个三层投影头,即 g(hi) = W(3)(σ(W(2)σ(W(1)hi)) ,其中 σ 是 ReLU 非线性,为简洁起见,在此我们忽略偏置项。 对应微调,SimCLR 使用 f task(xi) =Wtaskf(xi) 计算预定义类别的 logits,其中 Wtask 是添加的与任务有关的线性层权重(为描述简便,同样忽略偏置项)。 这相当于从投影头的输入层进行微调。 为了从投影头的第一层进行微调,我们用一个新的编码器函数 ftask(xi) = Wtaskσ(W(1)f(xi)),这是一个 ResNet,然后是完全连接的层。
通过未标记的示例进行自我训练/知识蒸馏。 为了进一步改善目标任务的网络,此处我们直接将未标记的数据用于目标任务。 受 [23, 11, 22, 24, 12] 的启发,我们使用经过微调的网络作为老师来生成标签以训练学生网络。 具体来说,在不使用实际标记的情况下,我们将以下蒸馏损失降至最低:
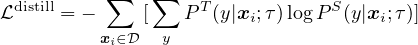 | (2) |
其中 P(y|xi) = exp(f task(xi)[y] / τ) / ∑ y′exp(f task(xi)[y′] / τ),τ 是一个标量温度参数。 生成 PT(y|xi) 的教师网络在蒸馏过程中是固定的;只有生成 PS(y|xi) 的学生网络接受训练。 尽管我们在这项工作中只使用未标记的示例进行蒸馏,但当标记的示例数量很大时,也可以使用加权组合将蒸馏损失与真实的标记示例进行合并
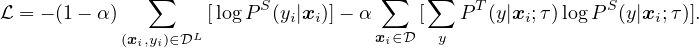 | (3) |
可以使用具有相同模型结构(自我蒸馏)的学生来执行此过程,这可以进一步提高特定任务的性能,也可以使用较小的模型结构来获得紧凑的模型。
3 实证研究
3.1 设置和实现细节
遵循 [30, 19, 1] 中的半监督学习设置,我们在 ImageNet ILSVRC-2012 [21] 上评估提出的方法。 虽然所有 ∼128 万张图像都可用,但只有随机子采样的 1%(12811)或 10%(128116)图像与标签相关联。4 和以前的工作一样,我们还报告在所有有标签的固定表示上训练线性分类器时的性能 [31, 16, 17, 1] 以直接评估 SimCLRv2 的表示。 我们始终使用 LARS 优化器[32](动量为 0.9)进行预训练、微调和蒸馏。
对于预训练,类似于 [1],我们在 128 个 Cloud TPU 上训练模型,批次大小为 4096,全局批归一化 [33],总计 800 个周期。 学习率在前 5% 的周期内线性增加,最高达到 6.4(= 0.1 × sqrt(BatchSize)),然后以余弦衰减。 使用 1e−4 的权重衰减。 我们在 ResNet 编码器的顶部使用三层 MLP 投影头。 根据 [20],内存缓冲区设置为 64K,指数移动平均值(EMA)衰减设置为 0.999。 我们使用与 SimCLR [1]相同的一组简单增强,即随机裁剪、颜色失真和高斯模糊。
对于微调,默认情况下,我们从投影头的第一层微调 1%/10% 的标记示例,但使用 100% 标签时从投影头的输入微调。 我们使用全局批归一化,移除权重衰减、学习率预热,使用更小的学习率 0.16(= 0.005 × sqrt(BatchSize)) 于标准的 ResNets [25], 0.064 (= 0.002 × sqrt(BatchSize)) 用于更大的 ResNets 变体(宽度乘以 1 倍以上并带有 SK [28])。 使用的批次大小为 1024。 类似于 [1],我们使用 1% 的标签微调 60 个周期,使用 10% 以及完整的 ImageNet 标签微调 30 个周期。
对于蒸馏,除非另有说明,否则我们仅使用未标记的示例。 我们考虑两种类型的蒸馏:学生与教师具有相同模型结构的自我蒸馏(不包括投影头),以及学生是一个较小网络的从大到小的蒸馏。 我们使用与预训练相同的学习率调整、权重衰减、批次大小训练模型 400 个周期。 在微调和蒸馏过程中,仅应用训练图像的随机裁剪和水平翻转。
3.2 更大的模型更具标签效率
| 深度 | 宽度 | SK | Param (M) | F-T (1%) | F-T (10%) | F-T (100%) | Linear eval | Supervised |
|
50 |
1 × | False | 24 | 57.9 | 68.4 | 76.3 | 71.7 | 76.6 |
| True | 35 | 64.5 | 72.1 | 78.7 | 74.6 | 78.5 | ||
|
2 × | False | 94 | 66.3 | 73.9 | 79.1 | 75.6 | 77.8 | |
| True | 140 | 70.6 | 77.0 | 81.3 | 77.7 | 79.3 | ||
|
101 |
1 × | False | 43 | 62.1 | 71.4 | 78.2 | 73.6 | 78.0 |
| True | 65 | 68.3 | 75.1 | 80.6 | 76.3 | 79.6 | ||
|
2 × | False | 170 | 69.1 | 75.8 | 80.7 | 77.0 | 78.9 | |
| True | 257 | 73.2 | 78.8 | 82.4 | 79.0 | 80.1 | ||
|
152 |
1 × | False | 58 | 64.0 | 73.0 | 79.3 | 74.5 | 78.3 |
| True | 89 | 70.0 | 76.5 | 81.3 | 77.2 | 79.9 | ||
|
2 × | False | 233 | 70.2 | 76.6 | 81.1 | 77.4 | 79.1 | |
| True | 354 | 74.2 | 79.4 | 82.9 | 79.4 | 80.4 | ||
| 152 | 3 × | True | 795 | 74.9 | 80.1 | 83.1 | 79.8 | 80.5 |
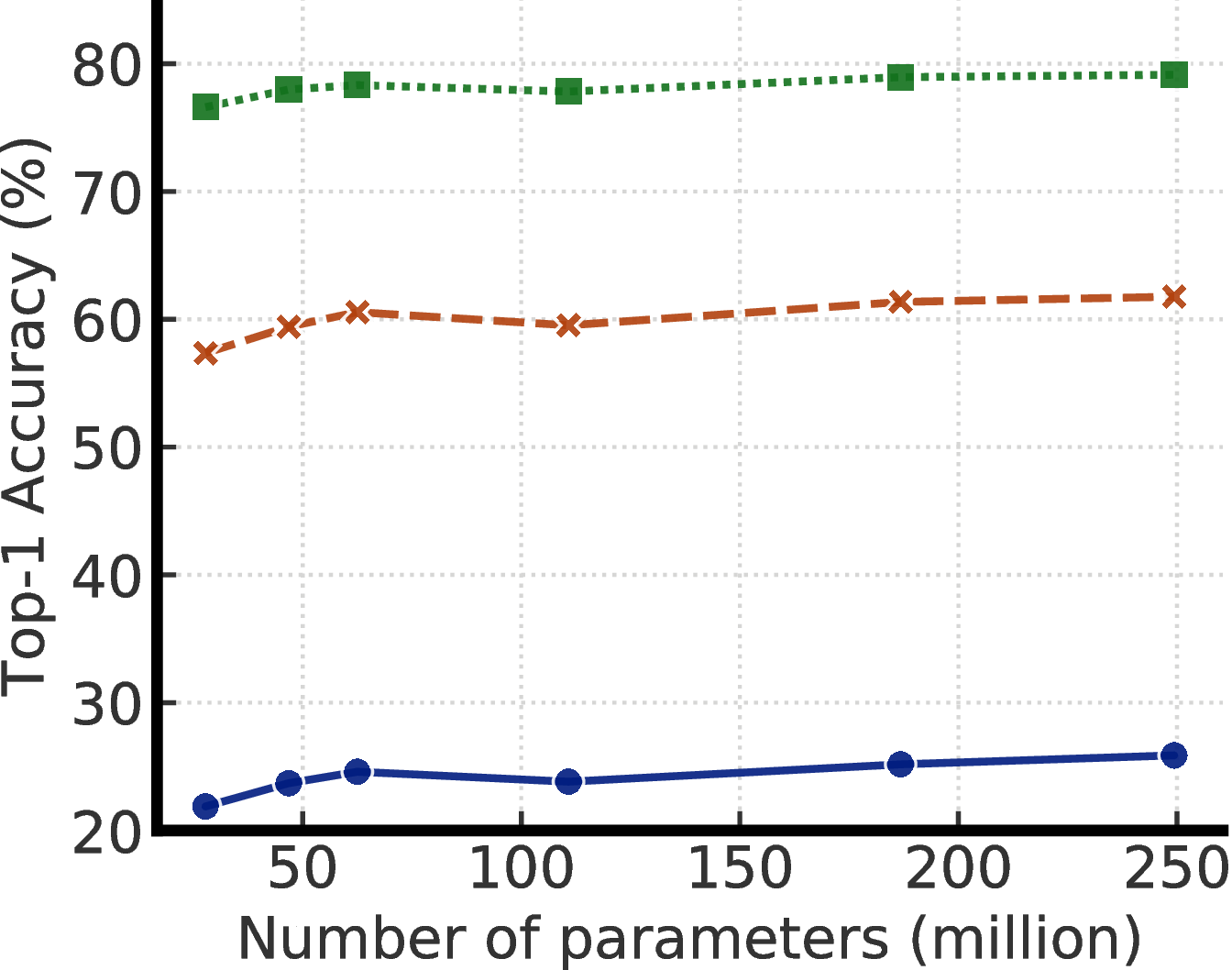
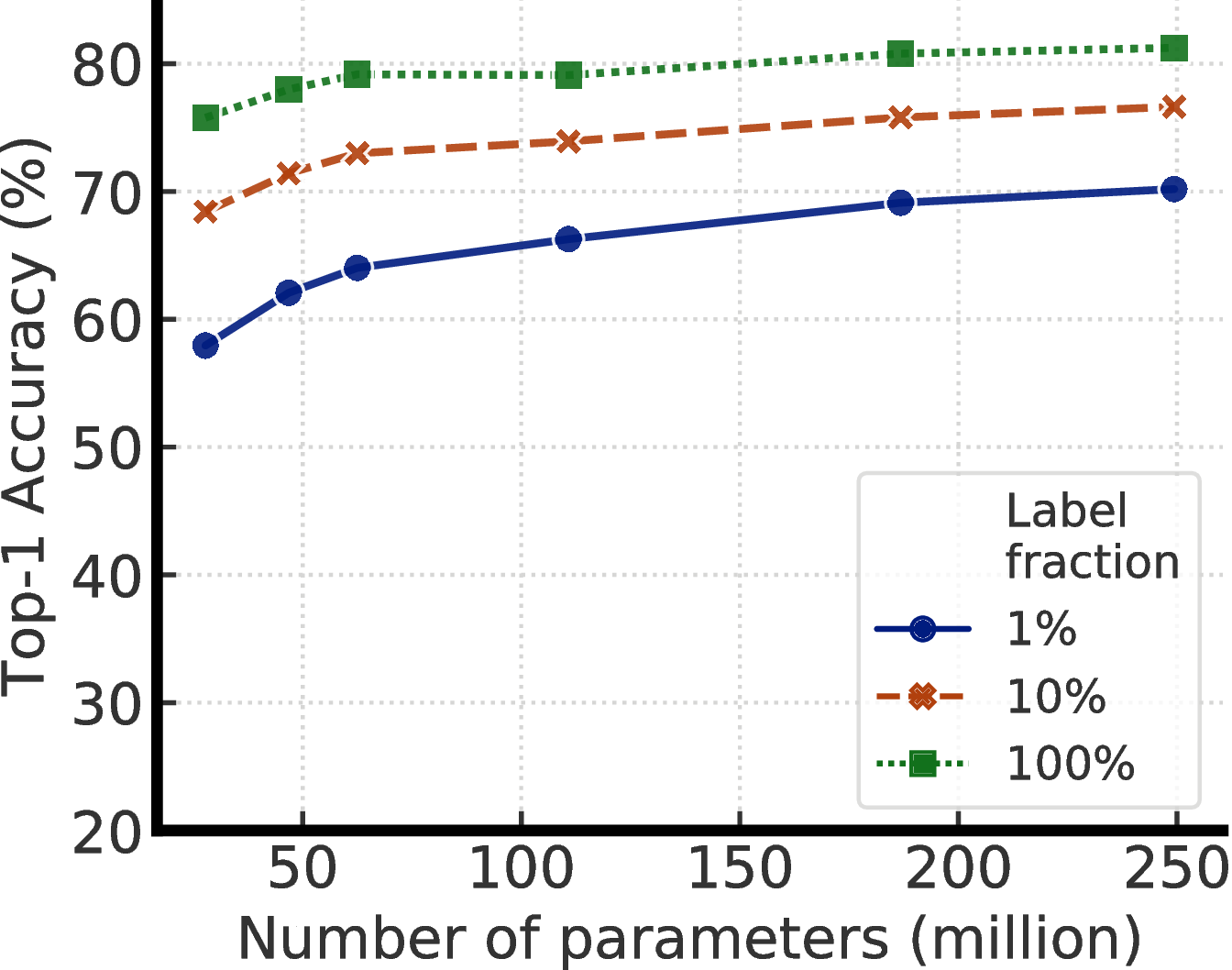
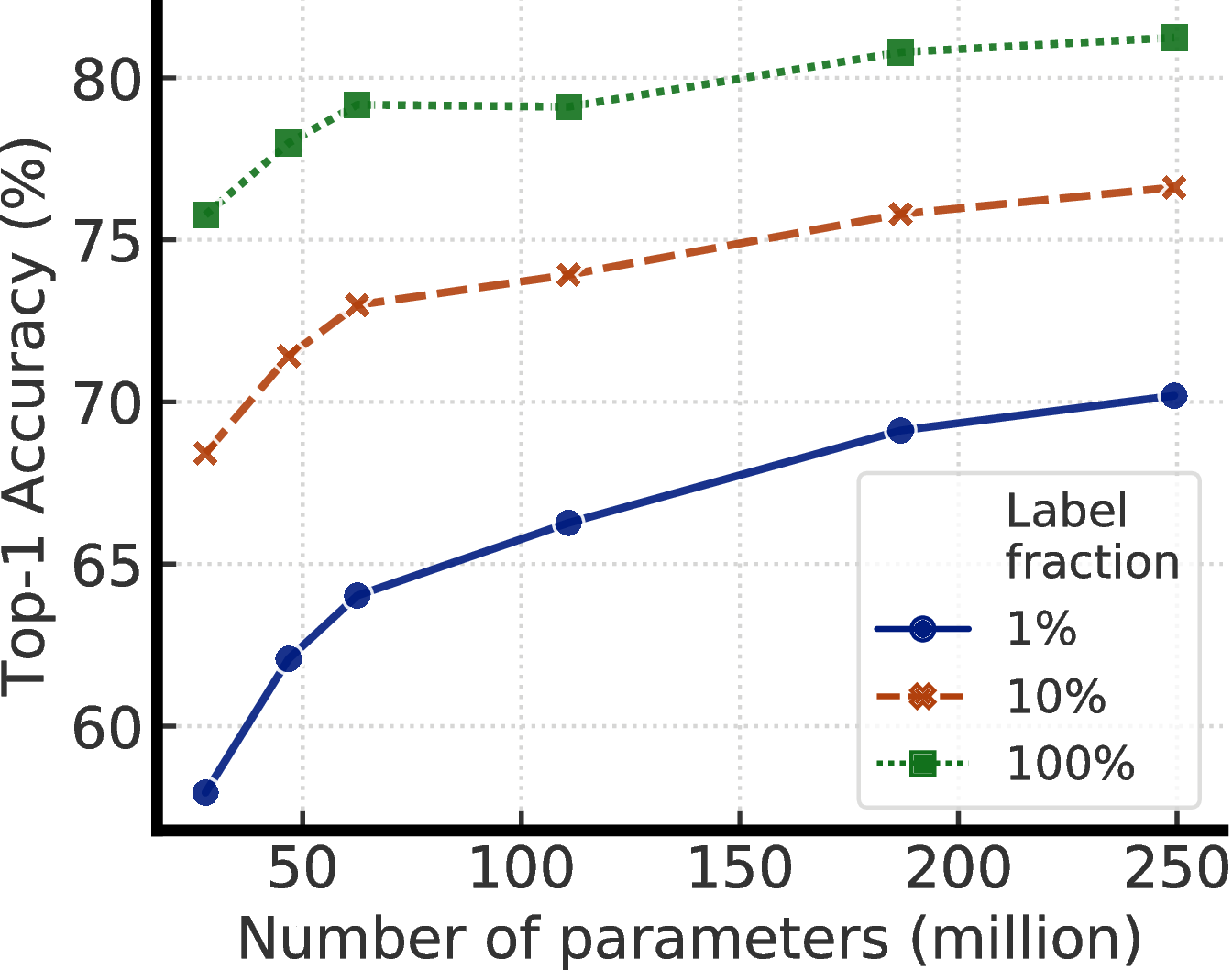
为了研究大模型的有效性,我们通过改变宽度和深度以及是否使用选择性核(SK)[28]来训练ResNet模型。5每当使用SK时,我们还使用ResNet-D[36]的变体ResNet。 最小的模型是标准的ResNet-50,最大的模型是ResNet-152(3 × + SK)。
表1比较了不同模型大小和评估协议(包括微调和线性评估)下的自我监督学习和监督学习。 我们可以看到,增加宽度和深度以及使用SK都可以改善性能。 这些体系结构操作对标准监督学习的影响相对有限(最小和最大模型的差异为4%),但对于自我监督的模型,线性评估的准确度相差8%,而对微调的精确度相差17%。 1%的标签图像。 我们还注意到,尽管参数大小几乎增加了一倍,但ResNet-152(3 × + SK)仅比ResNet-152(2 × + SK)好一点。这表明宽度的好处可能已经停滞了。
图4显示了模型尺寸和标签比率变化时的性能。 这些结果表明,对于监督和半监督学习来说,更大的模型都更具有标签效率,但对于半监督学习来说,收益似乎更大(更多讨论见附录 A)。 此外,值得指出的是,尽管更大的模型更好,但某些模型(例如使用SK的模型)比其他模型(附录B)具有更高的参数效率,这表明寻找更好的架构是有帮助的。
3.3 更大/更深的投影头可改善表示学习


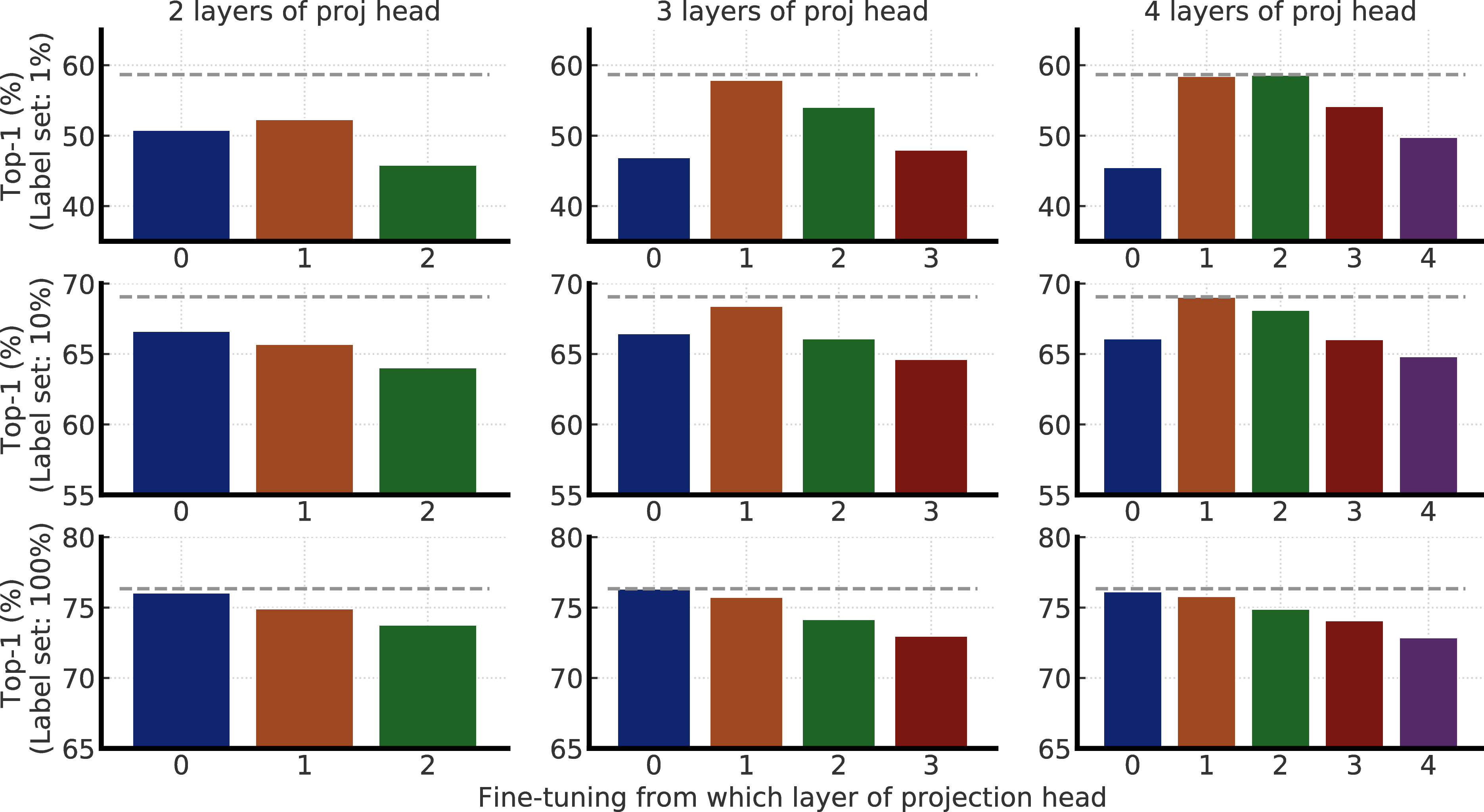
为了研究投影头进行微调的效果,我们使用SimCLRv2对带有不同数量的投影头层(从2到4个全连接层)进行预训练ResNet-50,并检查从投影头不同层进行微调时的性能。 我们发现,在预训练期间从投影头的最佳层进行微调时,最好使用更深的投影头(图5a),并且该最佳层通常是投影头的第一层,而不是投影头的第一层。输入(第0 th层),尤其是在较少标记的示例上进行微调时(图5b)。
还值得注意的是,当使用更大的ResNet时,具有更深的投影头所带来的改进会更小(请参见附录E)。 在我们的实验中,较宽的ResNet也具有较宽的投影头,这是因为宽度乘数同时应用于这两者。 因此,当投影头已经相当宽时,增加投影头的深度可能具有有限的效果。
当更改体系结构时,微调模型的准确性与线性评估的准确性相关(请参见附录C)。 尽管我们使用投影头的输入进行线性分类,但发现从投影头的最佳中间层进行微调时的相关性比从投影头输入进行微调时的相关性更高。
3.4 使用无标签数据进行蒸馏可改善半监督学习
蒸馏通常涉及鼓励学生与老师相匹配的蒸馏损失和标签上的普通监督交叉熵损失(等式3)。 在表2中,我们证明了在进行蒸馏损失训练时使用未标记示例的重要性。 此外,当标记分数较小时,仅使用蒸馏损失(方程2)几乎可以平衡蒸馏和标记损失(方程3)。 为简单起见,等式 2 是我们所有其他实验的默认设置。
|
方法 | 标签比率 | |
| 1% | 10% | |
| 仅标签 | 12.3 | 52.0 |
| 标签+蒸馏损失(在标签上) | 23.6 | 66.2 |
| 标记+蒸馏损失(标记+未标记组) | 69.0 | 75.1 |
| 蒸馏损失(带标签和无标签集;默认) | 68.9 | 74.3 |
带有未标记示例的蒸馏以两种方式改进微调的模型,如图6所示:(1)当学生模型的结构比教师模型小时,它通过转移任务来提高模型效率(2)即使学生模型与教师模型具有相同的体系结构(不包括ResNet编码器之后的投影头),自蒸馏仍然可以有意义地提高半监督学习性能。 为了获得较小的ResNet的最佳性能,在将大型模型蒸馏为较小的模型之前先对其进行自我蒸馏。
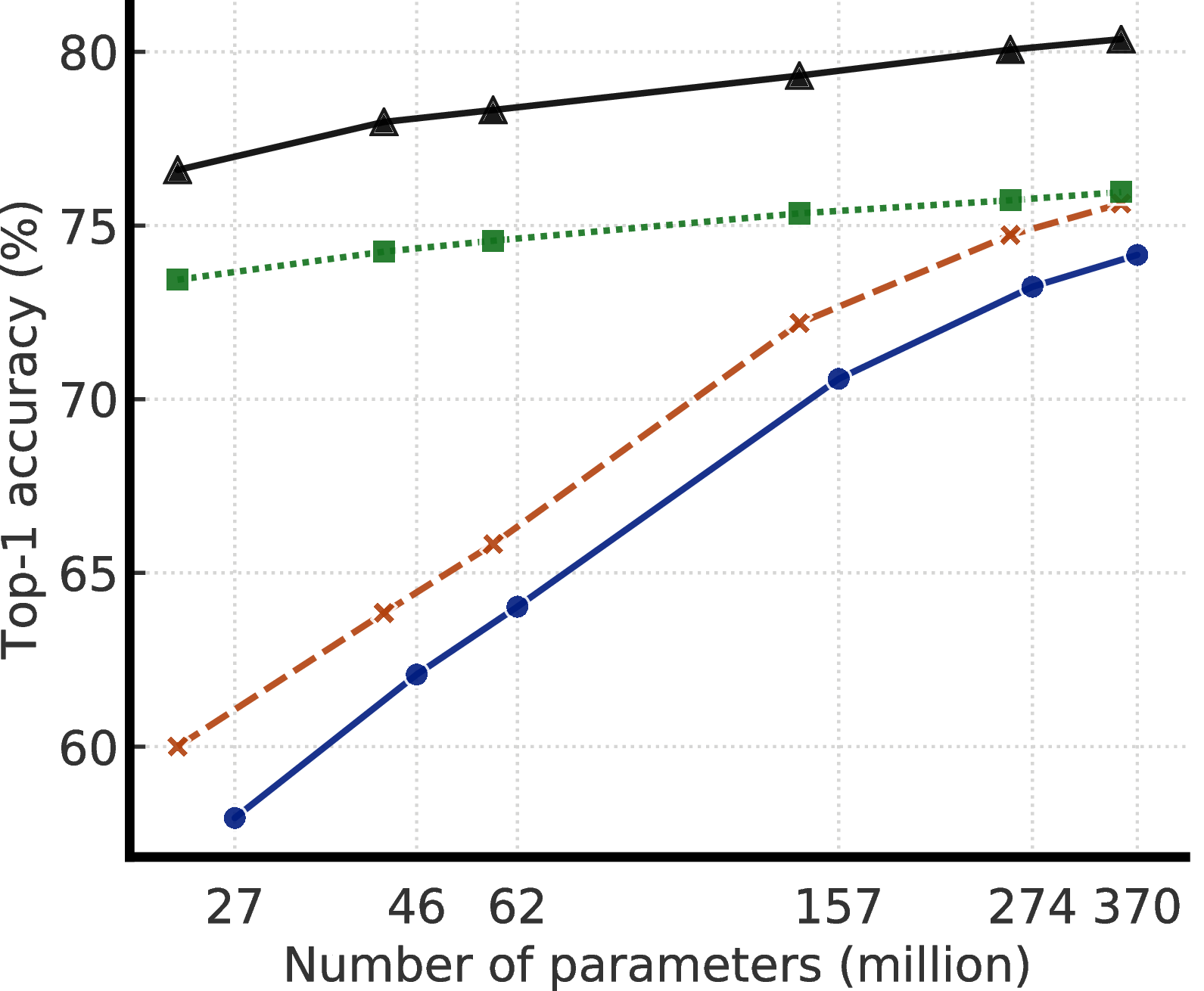
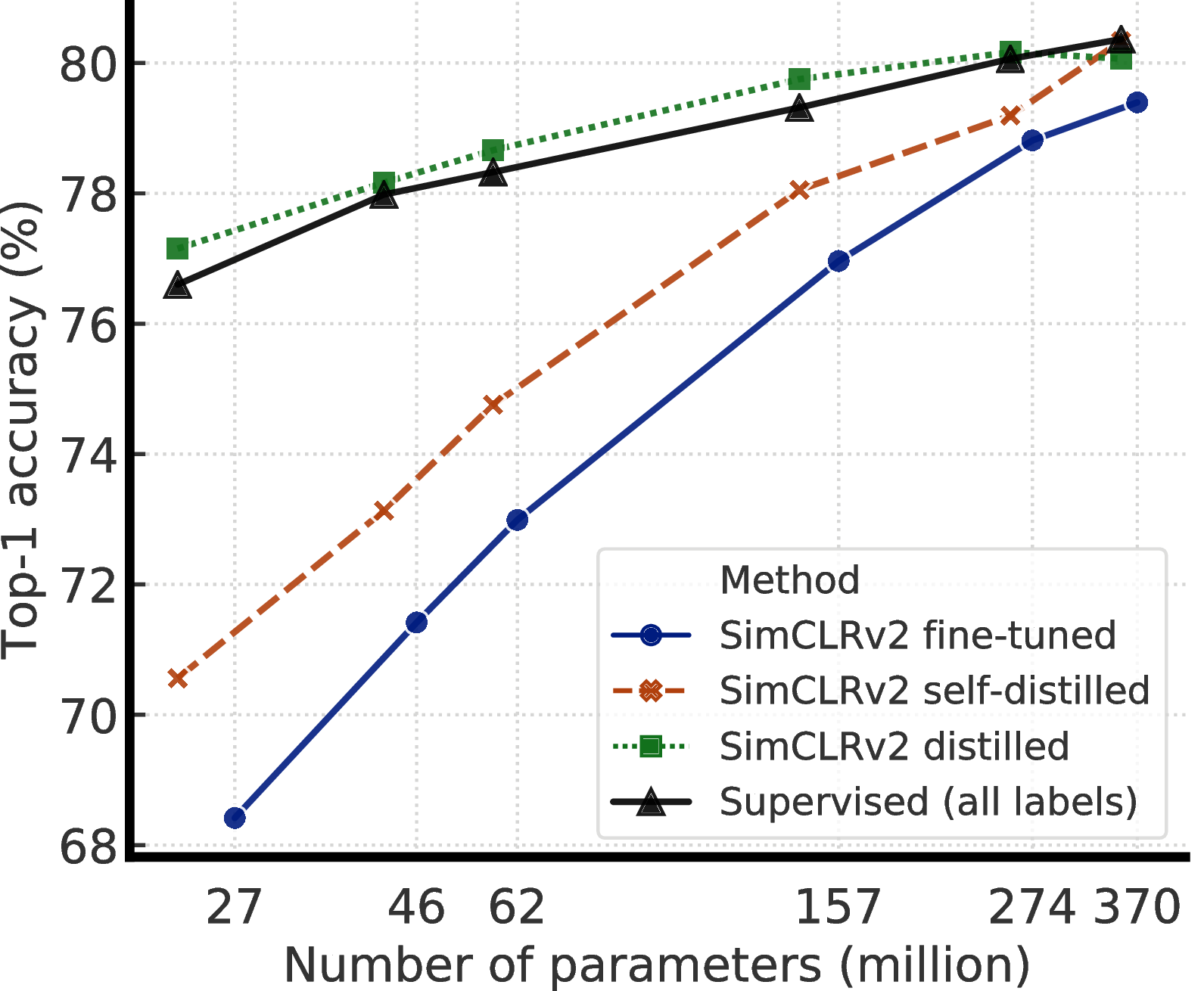
|
方法 |
Architecture | Top-1 | Top-5
| ||
| 标签比率 | 标签比率 | ||||
| 1% | 10% | 1% | 10% | ||
| 有监督的基线模型 [30] | ResNet-50 | 25.4 | 56.4 | 48.4 | 80.4 |
| 以特定于任务的方式使用未标记数据的方法: | |||||
| Pseudo-label [11, 30] | ResNet-50 | - | - | 51.6 | 82.4 |
| VAT+Entropy Min. [37, 38, 30] | ResNet-50 | - | - | 47.0 | 83.4 |
| UDA(带有RandAug) [ 14 ] | ResNet-50 | - | 68.8 | - | 88.5 |
| FixMatch(带有RandAug) [ 15 ] | ResNet-50 | - | 71.5 | - | 89.1 |
| S4L(Rot + VAT +熵最小值)[ 30 ] | ResNet-50(4 × ) | - | 73.2 | - | 91.2 |
| MPL(带有RandAug) [ 2 ] | ResNet-50 | - | 73.8 | - | - |
| 以与任务无关的方式使用未标记数据的方法: | |||||
| BigBiGAN [ 39 ] | RevNet-50( 4 × ) | - | - | 55.2 | 78.8 |
| PIRL [ 40 ] | ResNet-50 | - | - | 57.2 | 83.8 |
| CPC v2 [ 19 ] | ResNet-161( ∗ ) | 52.7 | 73.1 | 77.9 | 91.2 |
| SimCLR [ 1 ] | ResNet-50 | 48.3 | 65.6 | 75.5 | 87.8 |
| SimCLR [ 1 ] | ResNet-50( 4 × ) | 63.0 | 74.4 | 85.8 | 92.6 |
| 两种方式都使用未标记数据的方法: | |||||
| 蒸馏SimCLRv2(我们的) | ResNet-50 | 73.9 | 77.5 | 91.5 | 93.4 |
| 蒸馏SimCLRv2(我们的) | ResNet-50( 2 × + SK) | 75.9 | 80.2 | 93.0 | 95.0 |
| SimCLRv2 自蒸馏(我们的) | ResNet-152( 3 × + SK) | 76.6 | 80.9 | 93.4 | 95.5 |
在表3中,我们将最好的模型与ImageNet上现有的最新半监督学习方法进行了比较。 对于小型和大型的ResNet变体,我们的方法都大大改善了以前的结果。
4 相关工作
与任务无关的未标记数据的使用。 无监督或自监督的预训练,然后在少数有标记的示例上进行有监督的微调,在自然语言处理中得到了广泛的应用 [6, 5, 7–9],但最近才在计算机视觉中显示出有希望的成果 [19, 20, 1]。 我们的工作建立在近来视觉表示的对比学习之上 [41, 16–19, 42, 40, 20, 43, 44, 1],它是自监督学习的一个子领域。 这些基于对比学习的方法以区分方式而不是通用方式学习表示 [3, 45, 46, 39, 47]。 自监督学习还有其它一些基于人工预设任务的方法 [48, 31, 49, 50, 27]。 我们还注意到同时进行的一项关于推进不使用负样本的自监督预训练的工作[51],我们在附录G中进行了对比。我们的工作还扩展了 "无监督预训练,有监督微调 "模型,使用无标签数据将其与(自)蒸馏 [23,22,11] 结合起来。
特定于任务的未标记数据的使用。 除了表示学习范式,还有大量的半监督学习方法,我们建议读者参考 [52–54] 进行经典方法的调查。 在这里,我们仅审查与我们的方法密切相关的方法(尤其是在计算机视觉范围内)。 一类高度相关的方法基于伪标记 [11, 15] 或自训练 [12, 24]。 这些方法与我们的方法之间的主要区别在于,我们的初始/教师模型是使用SimCLRv2(具有无监督的预训练和监督的微调)进行训练的,而学生模型也可以小于初始/教师模型。 此外,我们使用温度缩放代替基于置信度的阈值,并且我们不使用强增强来训练学生。 另一类方法基于标签一致性正则化 [55–58, 14, 13, 59, 15],其中未标记的示例直接用作正则器以鼓励任务预测的一致性。 尽管在SimCLRv2预训练中,我们在不同放大视图下最大化了同一图像表示的一致性/一致性,但是在我们的对比损失中没有 使用有监督标签,这是与标签一致性损失的关键区别。
5 讨论
在这项工作中,我们分三个步骤介绍了一种用于半监督ImageNet分类的简单框架:无监督的预训练,监督的微调以及使用未标记的数据进行蒸馏。 尽管类似的方法在NLP中很常见,但我们证明了这种方法也可以成为计算机视觉中半监督学习的令人惊讶的强大基准,在很大程度上领先于最新技术。
我们观察到,较大的模型可以用更少的标记示例产生更大的改进。 大型模型的有效性已在监督学习[60 – 63]上进行了证明,并在一些示例[64]上微调了监督模型,以及在语言[9,65,10,66]上的无监督学习。 但是,仍然可以感到惊讶的是,较大的模型(可以很容易地用几个带有标签的示例进行过度拟合)可以更好地推广。 通过与任务无关的未标记数据的使用,我们推测更大的模型可以学习更多的一般特征,这增加了学习与任务相关的特征的机会。 但是,需要做进一步的工作才能更好地了解这种现象。 除了模型大小,我们还认为提高参数效率的重要性是改进的另一个重要方面。
尽管大型模型对于预训练和微调非常重要,但是给定特定任务(例如将图像分类为1000个ImageNet类),我们证明了可以使用未标记的示例将与任务无关的学习的通用表示提炼成更专业和紧凑的网络。 为此,我们仅使用老师为未标记示例插入标签,而无需使用噪声,增强,置信度阈值或一致性正则化。 当学生网络与教师具有相同或相似的体系结构时,此过程可以不断提高分类性能。 我们认为,我们的框架可以从更好的方法中受益,这些方法可以利用未标记的数据来改善和转移特定于任务的知识。
6 更广泛的影响
本文描述的发现有可能被利用来提高计算机视觉在任何应用中的准确性,在这些应用中,比训练更大的模型更昂贵或更难以标注附加数据。 一些这样的应用显然对社会有益。 例如,在获取高质量标签需要临床医生仔细注释的医疗应用中,更好的半监督学习方法可能有助于挽救生命。 计算机视觉在农业中的应用可以提高农作物的产量,这可能有助于改善粮食的供应。 但是,我们也认识到,我们的方法可能会成为有害监视系统的组成部分。 此外,整个行业围绕着人类标签服务而建立,而减少对这些服务的需求的技术可能会导致一些目前雇用或签约提供标签的人短期收入损失。
致谢
我们要感谢 David Berthelot、Han Zhang、Lala Li、Xiaohua Zhai、Lucas Beyer 和 Alexander Kolesnikov 对草案提供的有益反馈。 我们也感谢多伦多和其它地方的 Google Research 团队的普遍支持。
参考文献
[1] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
[2] Hieu Pham, Qizhe Xie, Zihang Dai, and Quoc V Le. Meta pseudo labels. arXiv preprint arXiv:2003.10580, 2020.
[3] Geoffrey E Hinton, Simon Osindero, and Yee-Whye Teh. A fast learning algorithm for deep belief nets. Neural computation, 18(7):1527–1554, 2006.
[4] Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy layer-wise training of deep networks. In Advances in neural information processing systems, pages 153–160, 2007.
[5] Andrew M Dai and Quoc V Le. Semi-supervised sequence learning. In Advances in neural information processing systems, pages 3079–3087, 2015.
[6] Ryan Kiros, Yukun Zhu, Russ R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Skip-thought vectors. In Advances in neural information processing systems, pages 3294–3302, 2015.
[7] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
[8] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In Proc. of NAACL, 2018.
[9] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[10] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.
[11] Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks.
[12] Qizhe Xie, Eduard Hovy, Minh-Thang Luong, and Quoc V Le. Self-training with noisy student improves imagenet classification. arXiv preprint arXiv:1911.04252, 2019.
[13] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems, pages 5050–5060, 2019.
[14] Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V Le. Unsupervised data augmentation. arXiv preprint arXiv:1904.12848, 2019.
[15] Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. arXiv preprint arXiv:2001.07685, 2020.
[16] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
[17] Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3733–3742, 2018.
[18] Philip Bachman, R Devon Hjelm, and William Buchwalter. Learning representations by maximizing mutual information across views. In Advances in Neural Information Processing Systems, pages 15509–15519, 2019.
[19] Olivier J Hénaff, Ali Razavi, Carl Doersch, SM Eslami, and Aaron van den Oord. Data-efficient image recognition with contrastive predictive coding. arXiv preprint arXiv:1905.09272, 2019.
[20] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. arXiv preprint arXiv:1911.05722, 2019.
[21] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
[22] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
[23] Cristian Buciluǎ, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 535–541, 2006.
[24] I Zeki Yalniz, Hervé Jégou, Kan Chen, Manohar Paluri, and Dhruv Mahajan. Billion-scale semi-supervised learning for image classification. arXiv preprint arXiv:1905.00546, 2019.
[25] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[26] Suzanna Becker and Geoffrey E Hinton. Self-organizing neural network that discovers surfaces in random-dot stereograms. Nature, 355(6356):161–163, 1992.
[27] Alexander Kolesnikov, Xiaohua Zhai, and Lucas Beyer. Revisiting self-supervised visual representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1920–1929, 2019.
[28] Xiang Li, Wenhai Wang, Xiaolin Hu, and Jian Yang. Selective kernel networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 510–519, 2019.
[29] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
[30] Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. S4l: Self-supervised semi-supervised learning. In The IEEE International Conference on Computer Vision (ICCV), October 2019.
[31] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. In European conference on computer vision, pages 649–666. Springer, 2016.
[32] Yang You, Igor Gitman, and Boris Ginsburg. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888, 2017.
[33] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
[34] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 113–123, 2019.
[35] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
[36] Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 558–567, 2019.
[37] Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in neural information processing systems, pages 529–536, 2005.
[38] Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 41(8):1979–1993, 2018.
[39] Jeff Donahue and Karen Simonyan. Large scale adversarial representation learning. In Advances in Neural Information Processing Systems, pages 10541–10551, 2019.
[40] Ishan Misra and Laurens van der Maaten. Self-supervised learning of pretext-invariant representations. arXiv preprint arXiv:1912.01991, 2019.
[41] Alexey Dosovitskiy, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox. Discriminative unsupervised feature learning with convolutional neural networks. In Advances in neural information processing systems, pages 766–774, 2014.
[42] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. arXiv preprint arXiv:1906.05849, 2019.
[43] Junnan Li, Pan Zhou, Caiming Xiong, Richard Socher, and Steven CH Hoi. Prototypical contrastive learning of unsupervised representations. arXiv preprint arXiv:2005.04966, 2020.
[44] Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola. What makes for good views for contrastive learning. arXiv preprint arXiv:2005.10243, 2020.
[45] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[46] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
[47] Ting Chen, Xiaohua Zhai, Marvin Ritter, Mario Lucic, and Neil Houlsby. Self-supervised gans via auxiliary rotation loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 12154–12163, 2019.
[48] Carl Doersch, Abhinav Gupta, and Alexei A Efros. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, pages 1422–1430, 2015.
[49] Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision, pages 69–84. Springer, 2016.
[50] Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728, 2018.
[51] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning, 2020.
[52] Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning. MIT Press, 2006.
[53] Xiaojin Zhu and Andrew B Goldberg. Introduction to semi-supervised learning. Synthesis lectures on artificial intelligence and machine learning, 3(1):1–130, 2009.
[54] Avital Oliver, Augustus Odena, Colin A Raffel, Ekin Dogus Cubuk, and Ian Goodfellow. Realistic evaluation of deep semi-supervised learning algorithms. In Advances in Neural Information Processing Systems, pages 3235–3246, 2018.
[55] Philip Bachman, Ouais Alsharif, and Doina Precup. Learning with pseudo-ensembles. In Advances in neural information processing systems, pages 3365–3373, 2014.
[56] Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. arXiv preprint arXiv:1610.02242, 2016.
[57] Mehdi Sajjadi, Mehran Javanmardi, and Tolga Tasdizen. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In Advances in neural information processing systems, pages 1163–1171, 2016.
[58] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems, pages 1195–1204, 2017.
[59] Vikas Verma, Alex Lamb, Juho Kannala, Yoshua Bengio, and David Lopez-Paz. Interpolation consistency training for semi-supervised learning. arXiv preprint arXiv:1903.03825, 2019.
[60] Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE international conference on computer vision, pages 843–852, 2017.
[61] Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Patwary, Mostofa Ali, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
[62] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[63] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens van der Maaten. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), pages 181–196, 2018.
[64] Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Large scale learning of general visual representations for transfer. arXiv preprint arXiv:1912.11370, 2019.
[65] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
[66] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
[67] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015.
A 更大的模型什么时候提供更多帮助?
图A.1显示了通过在不同数量的带标签的示例下增加模型大小而获得的相对改进。 监督学习和半监督学习(即SimCLRv2)似乎都受益于更大的模型。 当(1)使用正则化技术(例如扩充,标签平滑)或(2)使用未标记的示例对模型进行预训练时,好处更大。 还值得注意的是,这些结果可能反映出“天花板效应”:随着性能越来越接近天花板,改进程度会变小。
(a)有监督
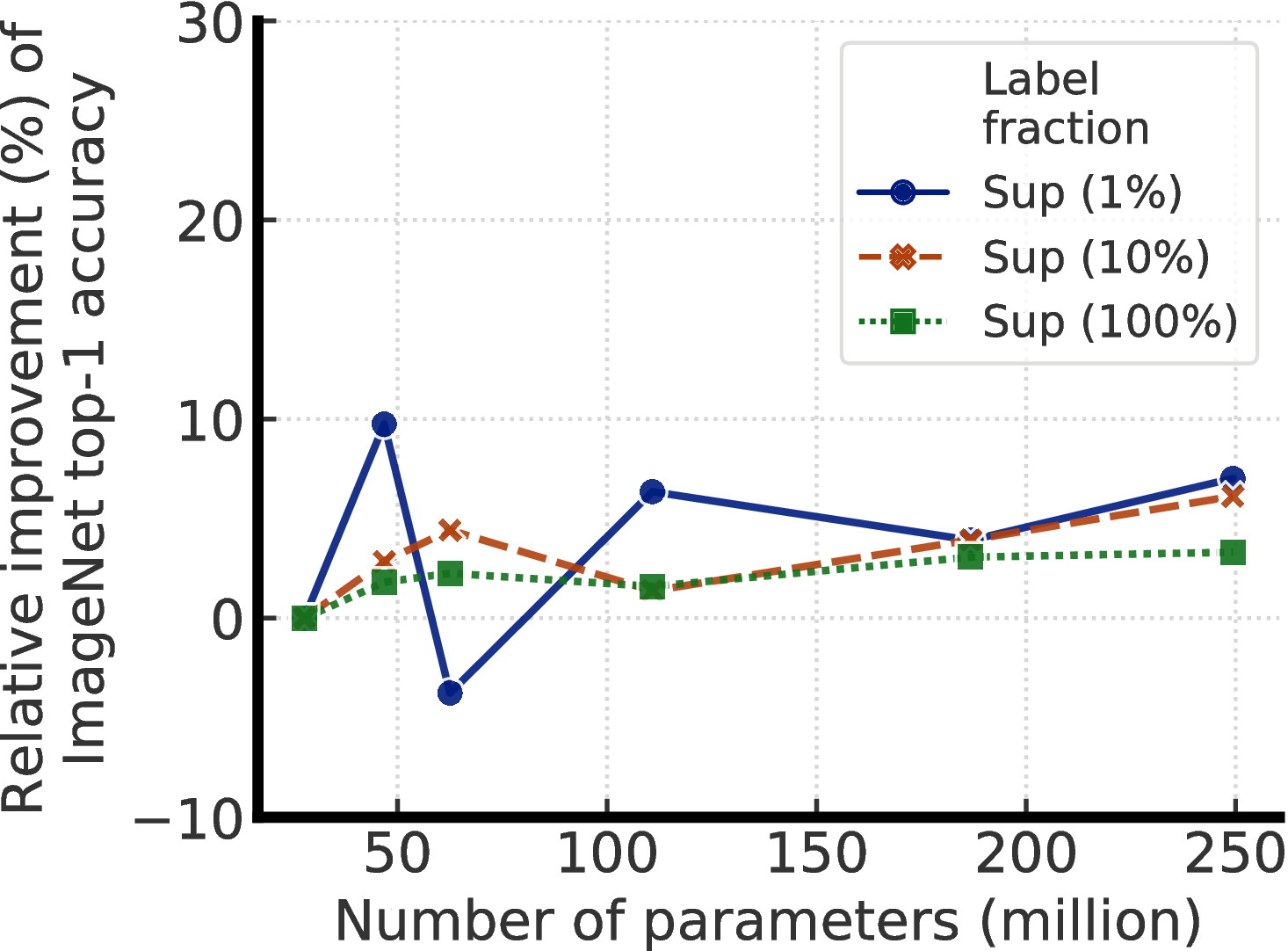
(b)有监督(自动增强 + LS)
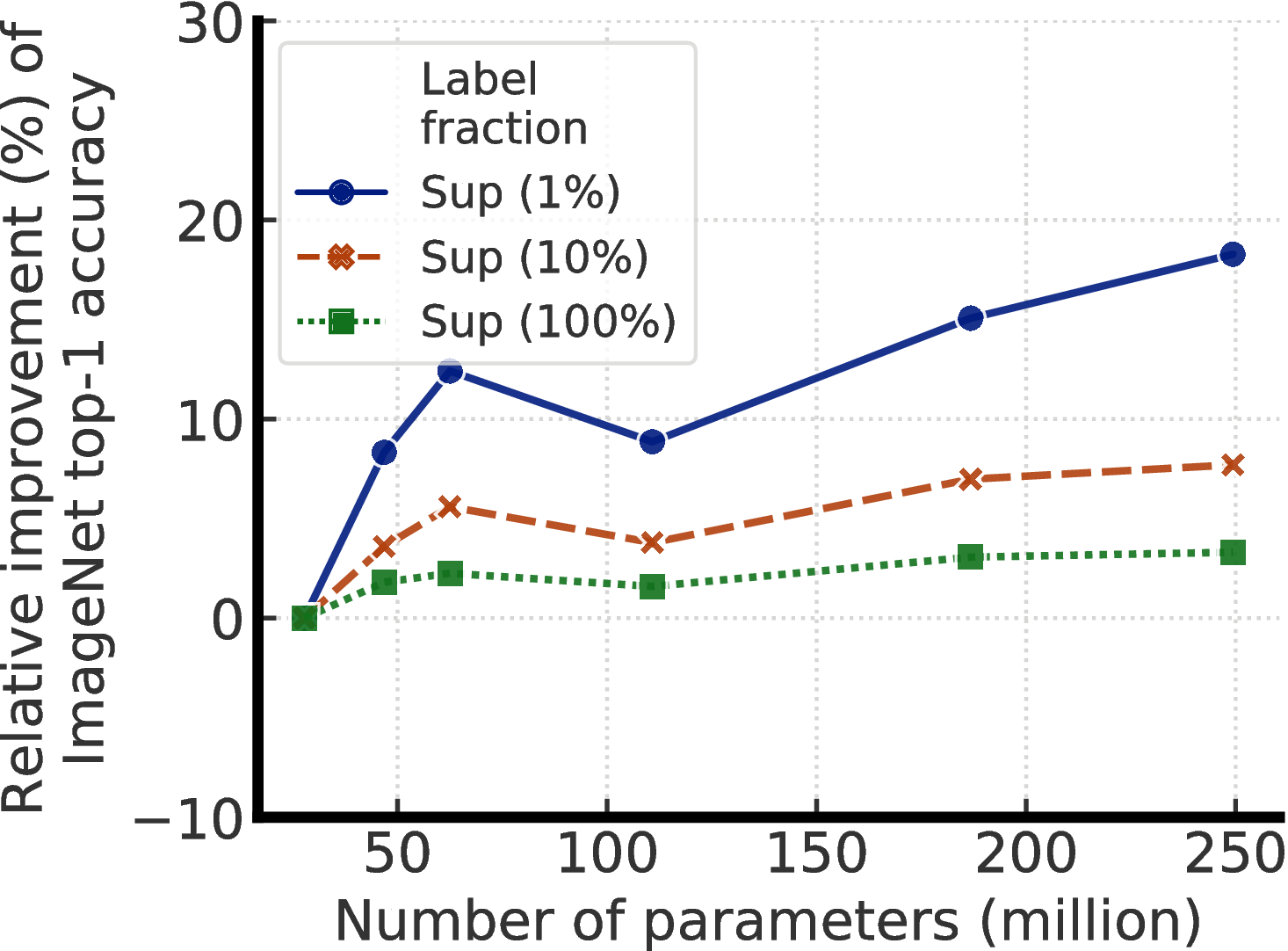
(c)半监督

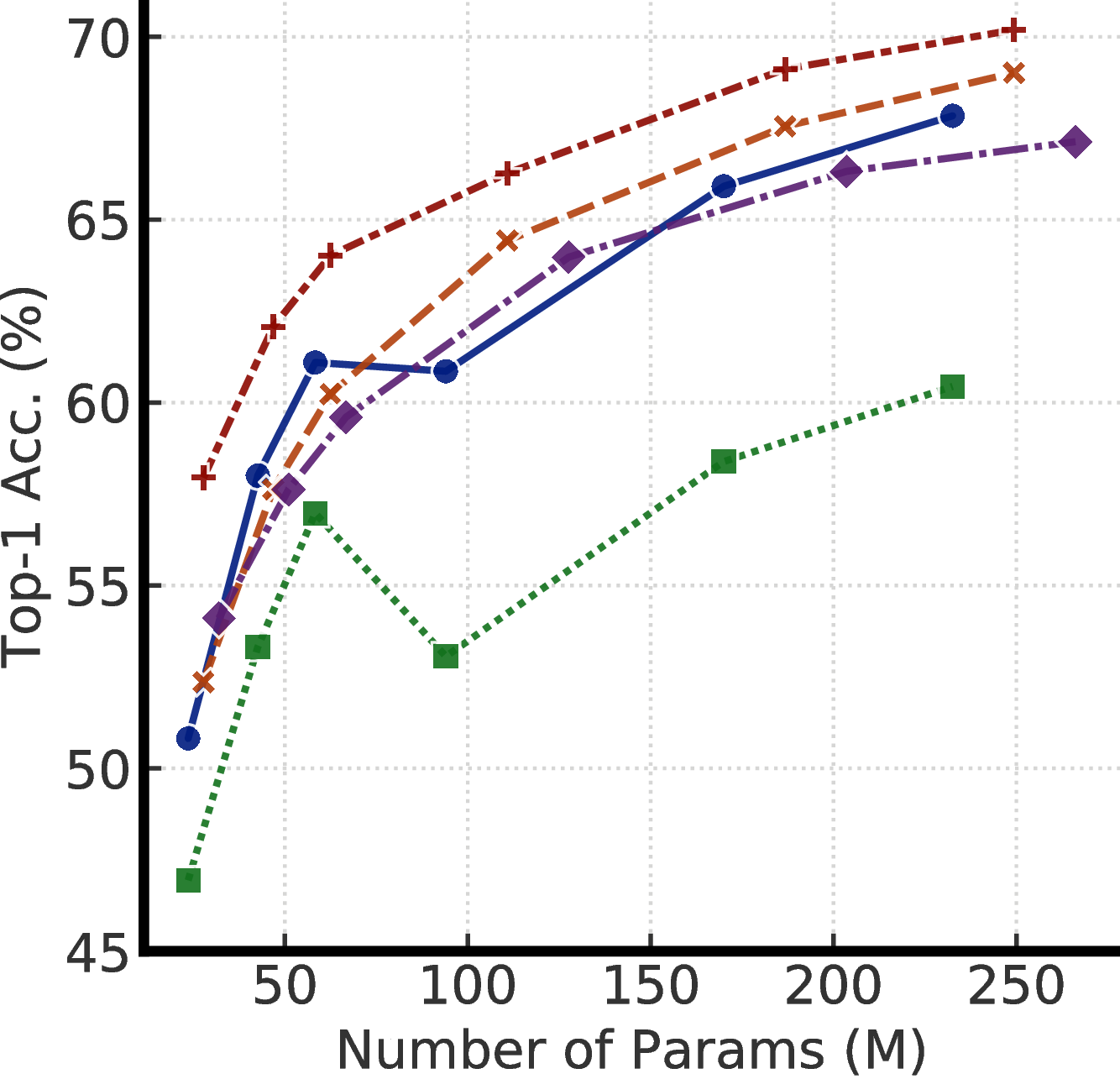
B 参数效率也很重要
图B.1显示了不同大小的微调SimCLRv2模型的top-1精度。 结果表明:(1)较大的模型更好,但是(2)使用SK [28],可以在相同参数数量的情况下获得更好的性能。 值得注意的是,在这项工作中,我们没有对 SK [28] 利用群卷积,我们只使用 3×3 核。 如果使用组卷积,我们期望在参数效率方面进一步改善。
 (a)没有SK的模型 [ 28 ]
(a)没有SK的模型 [ 28 ]
 (b)具有SK [ 28 ]的模型
(b)具有SK [ 28 ]的模型
C 线性评估与微调之间的关系
现有的自监督学习工作 [17, 19, 18, 40, 20, 1] 大多利用线性评价作为评价表示质量的主要指标,而通过微调与半监督学习的相关性并不明确。 在这里,我们进一步研究微调与线性评估的相关性(线性分类器在ResNet输出上而不是在投影头的某些中间层上训练)。 图C.1显示了两种不同的微调策略下的相关性:从投影头的输入进行微调,或从投影头的中间层进行微调。 我们观察到总体上存在线性相关。 从投影头的中间层进行微调时,我们会观察到更强的线性相关性。 另外,我们注意到随着用于微调的标记图像数量的增加,相关的斜率变得更小。

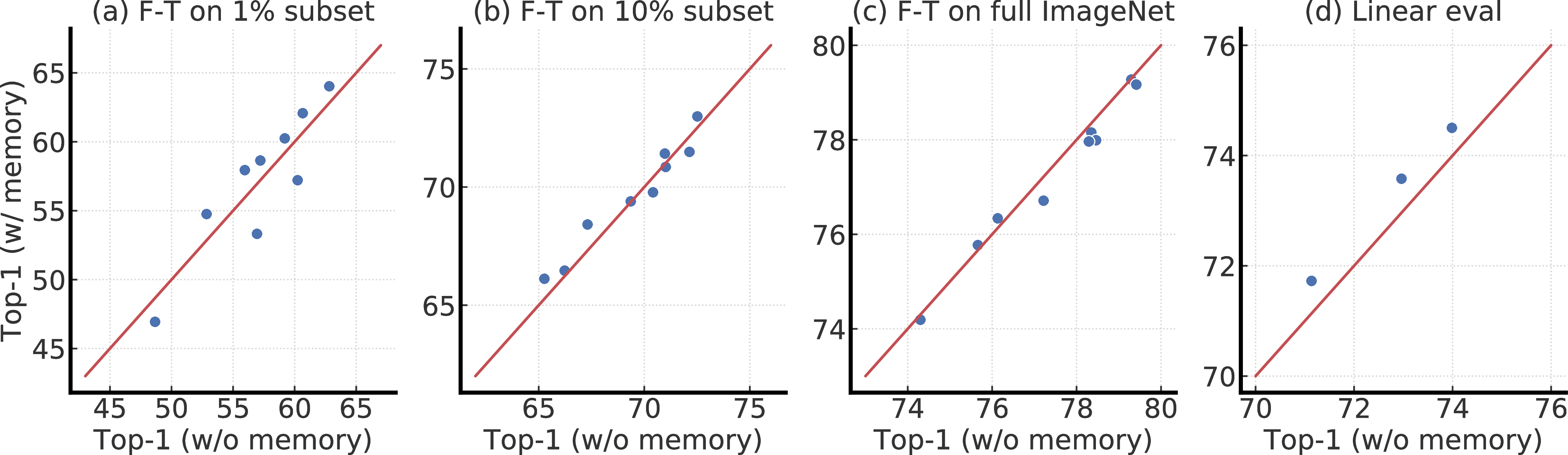
D 内存的影响
图D.1显示了有或没有内存(MoCo)[20]训练的SimCLRv2模型的top-1比较。 内存在线性评估和对1%的标签进行微调方面具有适度的优势;改善约为1%。 我们认为内存仅能提供少量改进的原因是我们已经使用了大批量(即4096)。
E 不同模型尺寸下投影头的影响
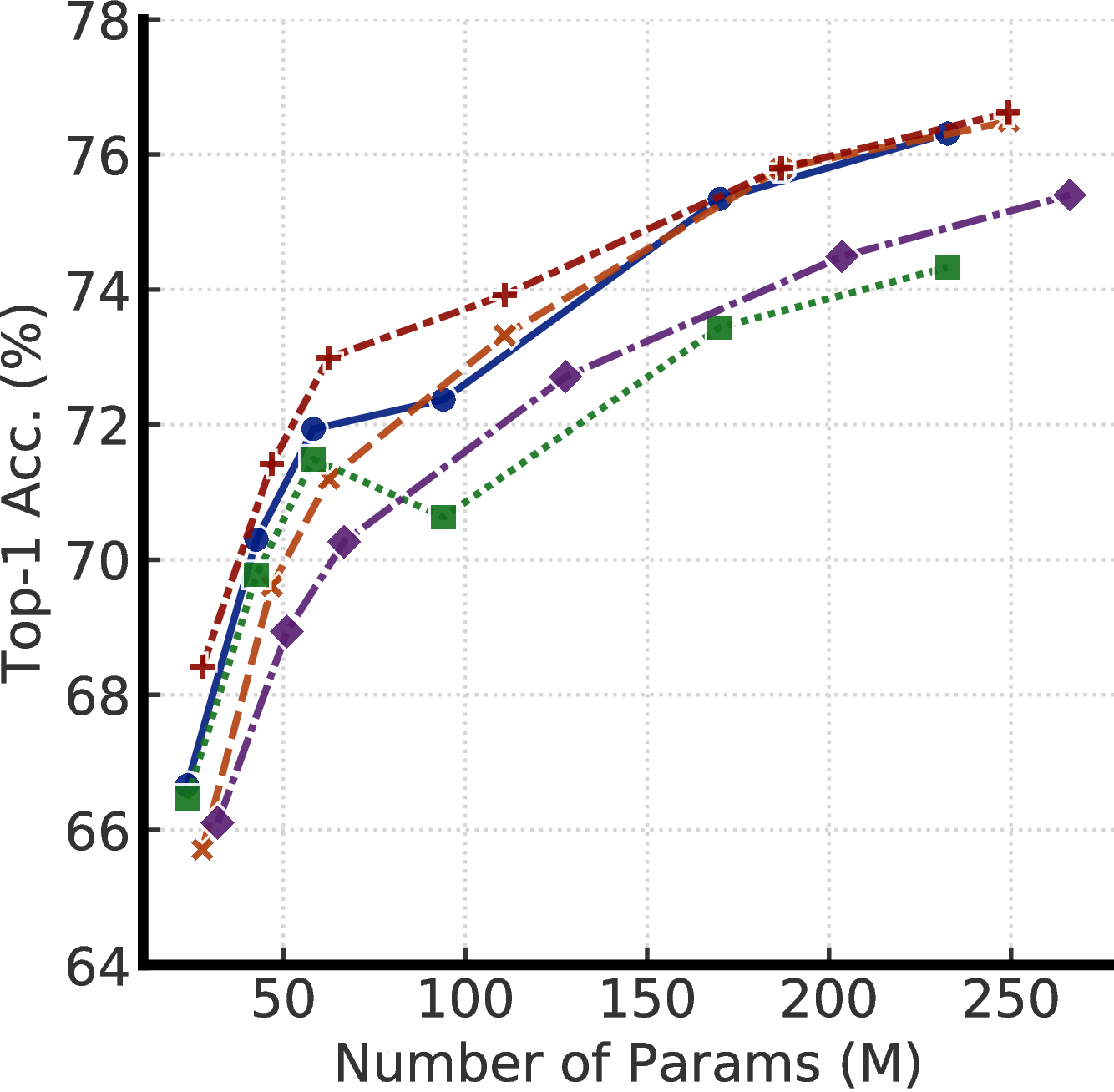

为了了解不同型号投影头设置的影响,图E.1显示了从2层和3层投影头的不同层进行微调的效果。 这些结果证实,仅使用几个标记的示例,使用更深的投影头进行预训练并从中间层进行微调可以改善半监督学习性能。 型号越小,改进越大。
图E.2显示了使用SimCLRv2预训练的ResNet-50的不同投影头设置的微调性能。 正文中的图5是该图结果的汇总。
F 进一步的蒸馏消融
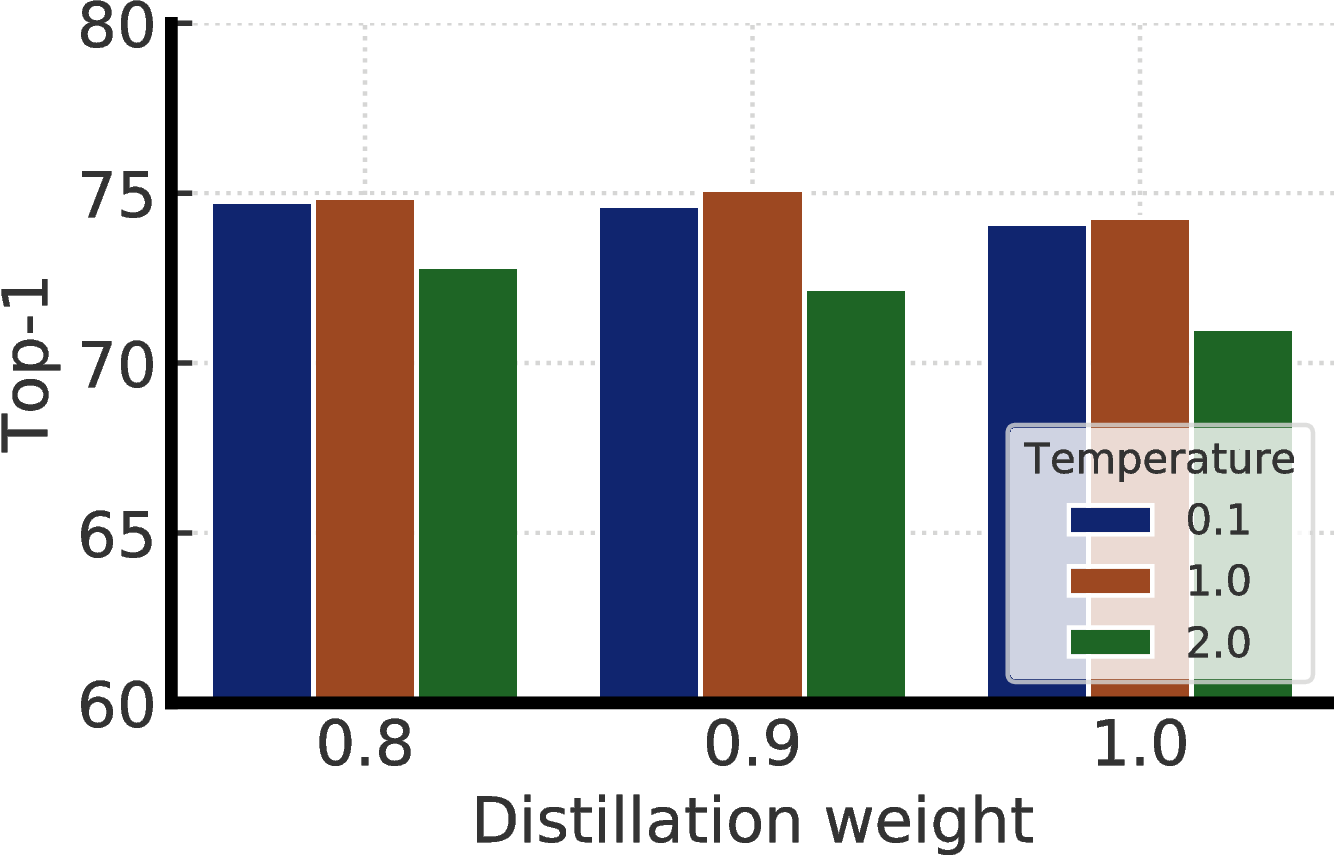
图F.1显示了等式中蒸馏重量(α)的影响。 3和用于蒸馏的温度。 我们看到没有实际标签的蒸馏(即蒸馏重量为1.0)与具有实际标签的蒸馏相当。 此外,温度0.1和1.0相似,但温度2.0则更差。 对于这项工作中的蒸馏实验,默认情况下,当教师为微调模型时,温度为0.1,否则为1.0。

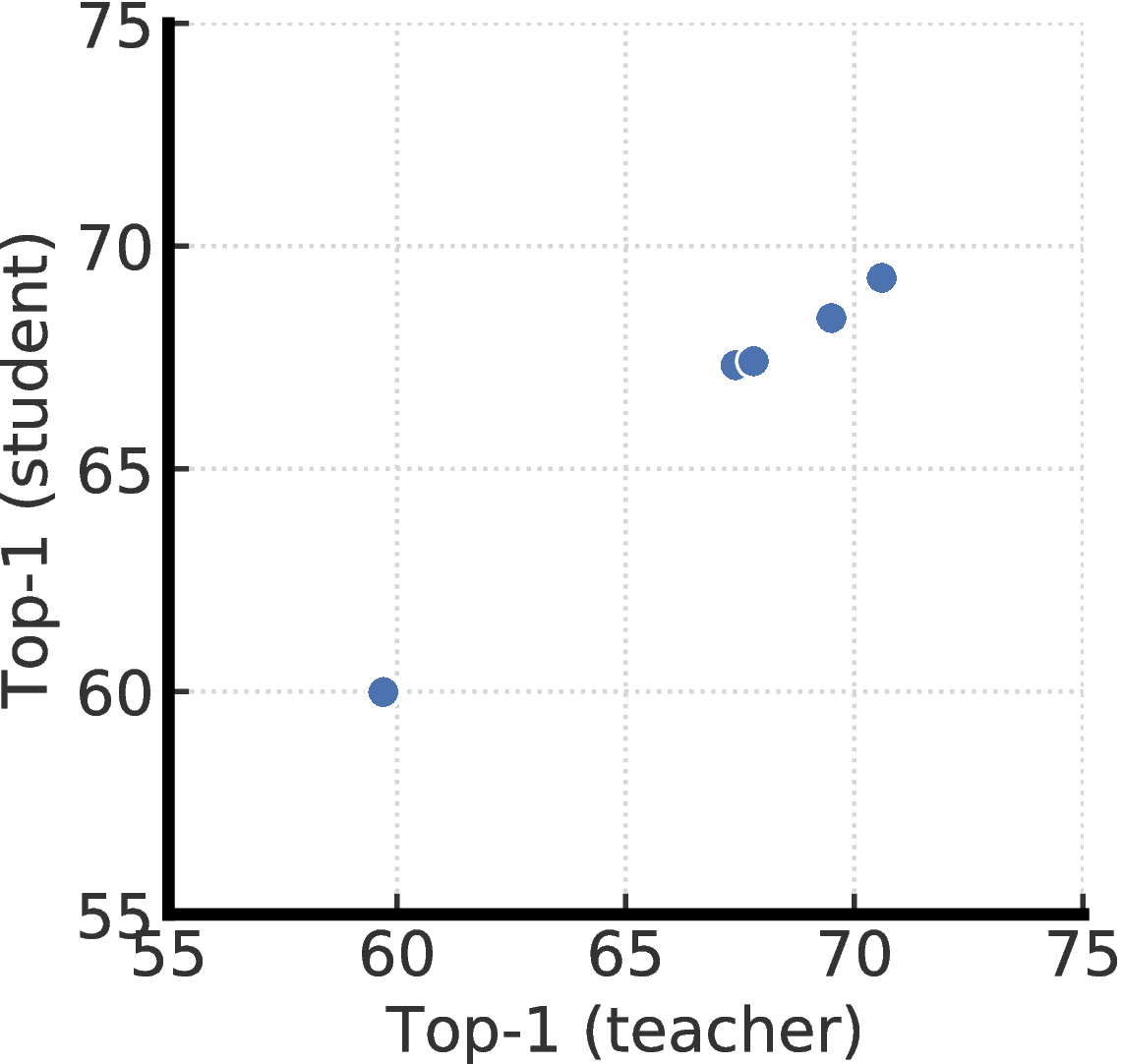
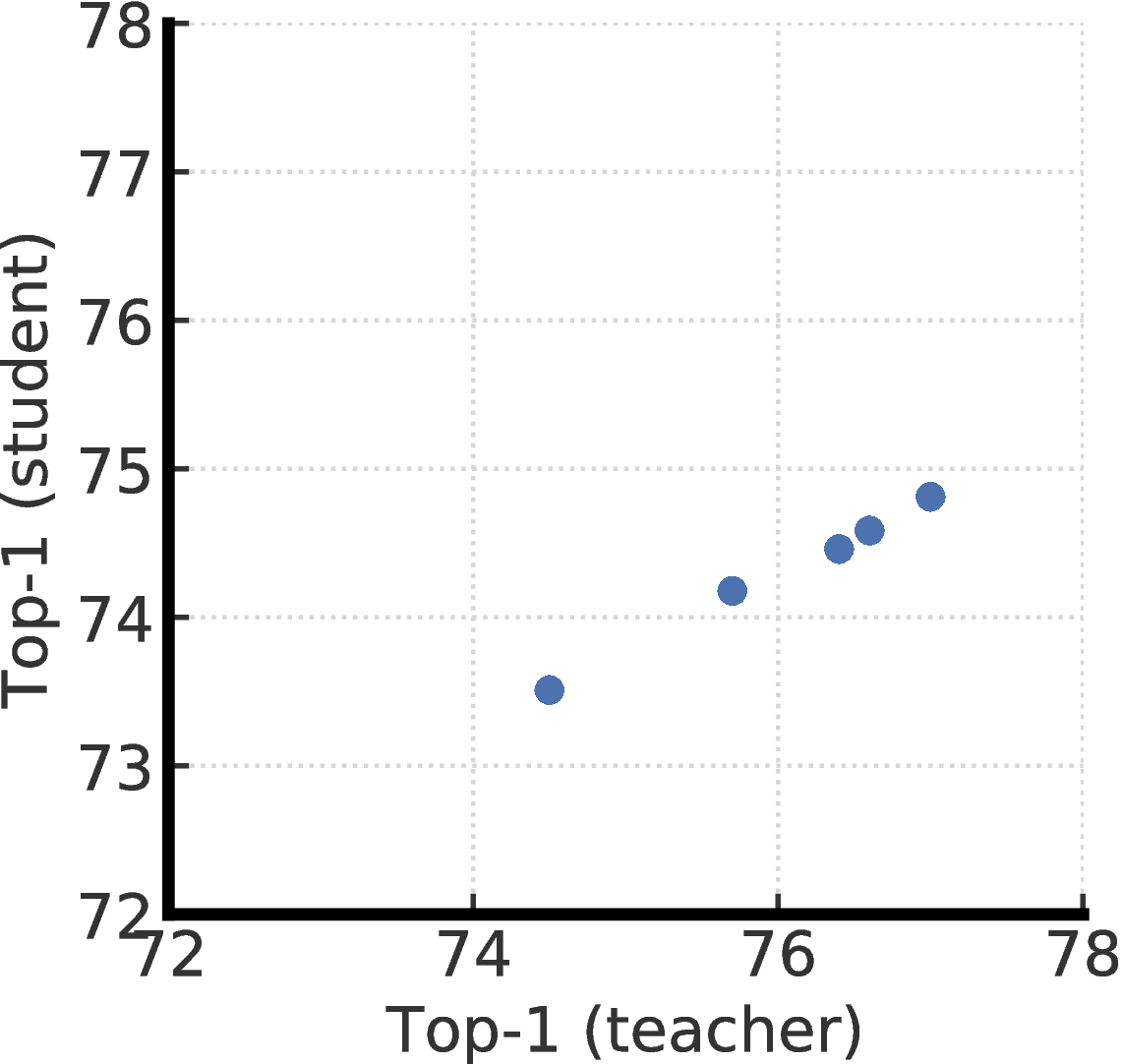
我们将通过使用不同投影头设置进行微调的老师进一步研究蒸馏性能。 更具体地说,我们预训练两个带有两层或三层投影头的ResNet-50(2 × + SK)模型,并从中间层进行微调。 这给我们五个不同的老师,分别对应不同的投影头设置。 毫不奇怪,如图F.2所示,蒸馏性能与微调教师的top-1准确性密切相关。 这表明,更好的微调模型(通过其top-1精度来衡量),无论其投影头的设置如何,都是使用未标记数据将特定于任务的知识传递给学生的更好的老师。
G 其他结果
表G.1显示在 ImageNet 上微调的 SimCLRv2(在不同模型尺寸下)的 top-5 准确率。
| 深度 | 宽度 | SK | 参数(M) | FT(1%) | FT(10%) | F-T(100%) | 线性评估 | 监督下 |
|
50 |
1 × | False | 24 | 82.5 | 89.2 | 93.3 | 90.4 | 93.3 |
| True | 35 | 86.7 | 91.4 | 94.6 | 92.3 | 94.2 | ||
|
2 × | False | 94 | 87.4 | 91.9 | 94.8 | 92.7 | 93.9 | |
| True | 140 | 90.2 | 93.7 | 95.9 | 93.9 | 94.5 | ||
|
101 |
1 × | False | 43 | 85.2 | 90.9 | 94.3 | 91.7 | 93.9 |
| True | 65 | 89.2 | 93.0 | 95.4 | 93.1 | 94.8 | ||
|
2 × | False | 170 | 88.9 | 93.2 | 95.6 | 93.4 | 94.4 | |
| True | 257 | 91.6 | 94.5 | 96.4 | 94.5 | 95.0 | ||
|
152 |
1 × | False | 58 | 86.6 | 91.8 | 94.9 | 92.4 | 94.2 |
| True | 89 | 90.0 | 93.7 | 95.9 | 93.6 | 95.0 | ||
|
2 × | False | 233 | 89.4 | 93.5 | 95.8 | 93.6 | 94.5 | |
| True | 354 | 92.1 | 94.7 | 96.5 | 94.7 | 95.0 | ||
| 152 | 3 × | True | 795 | 92.3 | 95.0 | 96.6 | 94.9 | 95.1 |
在这里,我们还包括了一个同时进行的工作 BYOL [51] 的结果,该工作也显著提高了之前自监督学习的最先进水平 [20,44,1]。 直到BYOL [51]发行前一天,它才出现在arXiv上。 表G.2扩展了我们对半监督学习设置的比较,并包括此并发工作。
|
方法 |
结构 | Top-1 | Top-5
| ||
| 标签比率 | 标签比率 | ||||
| 1% | 10% | 1% | 10% | ||
| 监督基线 [ 30 ] | ResNet-50 | 25.4 | 56.4 | 48.4 | 80.4 |
| 以特定于任务的方式使用未标记数据的方法: | |||||
| Pseudo-label [11, 30] | ResNet-50 | - | - | 51.6 | 82.4 |
| VAT+Entropy Min. [37, 38, 30] | ResNet-50 | - | - | 47.0 | 83.4 |
| Mean teacher [58] | ResNeXt-152 | - | - | - | 90.9 |
| UDA(带有RandAug) [ 14 ] | ResNet-50 | - | 68.8 | - | 88.5 |
| FixMatch(带有RandAug) [ 15 ] | ResNet-50 | - | 71.5 | - | 89.1 |
| S4L(Rot + VAT +熵最小值)[ 30 ] | ResNet-50(4 × ) | - | 73.2 | - | 91.2 |
| MPL(带有RandAug) [ 2 ] | ResNet-50 | - | 73.8 | - | - |
| 以与任务无关的方式使用未标记数据的方法: | |||||
| InstDisc [ 17 ] | ResNet-50 | - | - | 39.2 | 77.4 |
| BigBiGAN [ 39 ] | RevNet-50( 4 × ) | - | - | 55.2 | 78.8 |
| PIRL [ 40 ] | ResNet-50 | - | - | 57.2 | 83.8 |
| CPC v2 [ 19 ] | ResNet-161( ∗ ) | 52.7 | 73.1 | 77.9 | 91.2 |
| SimCLR [ 1 ] | ResNet-50 | 48.3 | 65.6 | 75.5 | 87.8 |
| SimCLR [ 1 ] | ResNet-50( 2 × ) | 58.5 | 71.7 | 83.0 | 91.2 |
| SimCLR [ 1 ] | ResNet-50( 4 × ) | 63.0 | 74.4 | 85.8 | 92.6 |
| BYOL [ 51 ](并行工作) | ResNet-50 | 53.2 | 68.8 | 78.4 | 89.0 |
| BYOL [ 51 ](并行工作) | ResNet-200( 2 × ) | 71.2 | 77.7 | 89.5 | 93.7 |
| 两种方式都使用未标记数据的方法: | |||||
| 蒸馏SimCLRv2(我们的) | ResNet-50 | 73.9 | 77.5 | 91.5 | 93.4 |
| 蒸馏SimCLRv2(我们的) | ResNet-50( 2 × + SK) | 75.9 | 80.2 | 93.0 | 95.0 |
| SimCLRv2 自蒸馏(我们的) | ResNet-152( 3 × + SK) | 76.6 | 80.9 | 93.4 | 95.5 |