-
大规模预训练语言模型在 GLUE 和 SuperGLUE 等语言理解基准上显示出令人印象深刻的结果,比其它预训练方法如分布式表示(GloVe)和纯监督方法有显着改善。 我们引入双重意图和实体 Transformer(DIET)架构,并研究不同的预训练表示对两种常见的对话语言理解任务意图和实体预测的有效性。 DIET 在复杂的多领域 NLU 数据集上超过最先进结果,并在其它更简单的数据集上取得类似的高性能。 出乎意料的是,我们显示出使用大型预训练模型来完成此任务并没有明显的好处,实际上 DIET 甚至在没有任何预训练嵌入的纯监督设置下也可以改进当前的先进结果。 我们性能最好的模型优于微调的 BERT,训练速度快大约六倍。
1 简介
数据驱动对话建模的两种常见方法是端到端和模块化系统。 模块化方法如基于 POMDP 的对话策略(Williams 和 Young,2007)和 Hybrid Code Networks(Williams 等人,2017)使用独立的自然语言理解(NLU)和生成(NLG)系统。 对话策略接收 NLU 系统的输出,在 NLG 系统生成相应的响应之前选择下一个系统操作。 在端到端方法中,用户输入直接输入到对话策略中预测下一个系统语句。 最近,这两种方法已在 Fusion Networks 中结合使用(Mehri 等人,2019)。
在对话系统的上下文中,自然语言理解通常指两个子任务:意图分类和实体识别。
Goo 等人 认为,分别对这些子任务建模可能会导致错误传播,因此只用一个多任务结构应该有益于两个任务之间相互增强。
最近的工作表明,经过预先训练的大型语言模型在具有挑战性的语言理解基准方面产生最佳性能(参见2节)。 但是,这类模型的预训练和微调的计算成本都相当可观(Strubell 等人,2019)。
对话系统不仅由研究人员开发,而且由全球成千上万的软件开发人员开发。 仅 Facebook 的 Messenger 平台就支持数十万个第三方对话助手(Johnson,2018)。 对于这些应用程序,希望可以对模型进行快速训练和迭代以适合典型的软件开发工作流程。 此外,由于许多这些助手中都使用英语以外的其它语言,因此重要的是要了解无需 大规模的训练能达到什么样的性能。
在本文中,我们提出 DIET(Dual Intent and Entity Transformer),这是一种用于意图分类和实体识别的新型多任务体系结构。 一个关键的特性是能够以即插即用的方式合入语言模型的预训练单词嵌入,并将它们与单词和字符级 n-gram 稀疏特征结合起来。 我们的实验表明,即使没有预训练的嵌入,仅使用单词和字符级 n-gram 稀疏特征,DIET 仍可以改善复杂 NLU 数据集上的当前最先进结果。 此外,添加经过语言模型预训练的单词和句子嵌入,可进一步提高所有任务的整体准确性。 我们性能最好的模型明显优于微调的 BERT,训练速度快六倍。 可在 https://github.com/RasaHQ/DIET-paper 在线获得用于重现这些实验的文档化代码。
2 相关工作
2.1 密集表示的迁移学习
在 GLUE(Wang 等人,2018)和 SuperGLUE(Wang 等人,2019)等语言理解基准上表现优异的模型(Liu 等人,2019a;Zhang 等人,2019)得益于使用大型预训练语言模型的单词和句子的密集表示,如 ELMo(Peters等人,2018)、BERT(Devlin 等人,2018)、GPT(Radford,2018)等。 由于这些嵌入是在大规模自然语言文本语料库上进行训练的,因此它们可以很好地泛化到各个任务,并且可以作为输入特征迁移移到其它语言理解任务上,无论是否进行微调(Peters 等人,2018 ;Sun 等人,2019a;Lee 和 Hsiang,2019;Adhikari 等人,2019;Klein 和 Nabi,2019)。 不同的微调策略被提出来实现跨任务的有效迁移学习(Howard 和 Ruder,2018; Sun 等人,2019b)。 然而, Peters 等人 (2019)表明,对 BERT 这样的大型预训练语言模型进行微调可能并非对每个下游任务都是最佳的。 而且,这些大规模语言模型速度慢、训练成本高,因此对于现实世界中的对话 AI 应用而言并不理想(Henderson 等人,2019b)。 为了获得更紧凑的模型, Henderson 等人 (2019b)在 Reddit 的大型会话语料库上对单词和句子级别的编码器进行预训练(Henderson 等人,2019a)。 当将结果句子级别的密集表示(无需微调)迁移到意图分类的下游任务时,其性能要好于 BERT 和 ELMo 的嵌入。 我们将进一步针对联合意图分类和实体识别的任务研究这个行为。 我们还研究使用稀疏表示(如单词级 one-hot 编码和字符级 n-grams)以及从大型预训练语言模型中迁移过来的密集表示的影响。
2.2 联合意图分类和命名实体识别
近年来,人们研究了许多方法,用于多任务设置中的训练意图分类和命名实体识别(NER)。 Zhang 和 Wang(2016)提出一种由双向门控循环单元(BiGRU)组成的联合体系结构。 每个时间步骤的隐藏状态用于实体标记,最后一个时间步骤的隐藏状态用于意图分类。 Liu 和 Lane(2016); Varghese 等人 (2020)和 Goo 等人 (2018)提出一种基于注意力的双向长期短期记忆(BiLSTM),用于联合意图分类和 NER。 Haihong 等人 (2019)在每个意图和实体关注单元的上方引入一个共同关注网络,用于每个任务之间的相互信息共享。 Chen 等人 (2019)提出联合 BERT,在 BERT 之上并以端到端的方式训练。 他们将第一个特殊标记 [CLS] 的隐藏状态用于意图分类。 实体标签使用其它词符的最终隐藏状态预测。 一种分层的自下而上的体系结构由 Vanzo 等人 (2019)提出,用 BiLSTM 单元组成捕获语义框架的较浅表示(Baker 等人,1998)。 他们从以自下而上的方式堆叠的各个层学到的表示形式来预测对话行为、意图和实体标签。 在这项工作中,我们的 DIET 采用类似的基于 transformer 的多任务设置,并且还进行消融研究以观察其与单任务设置相比的有效性。
3 DIET体系结构
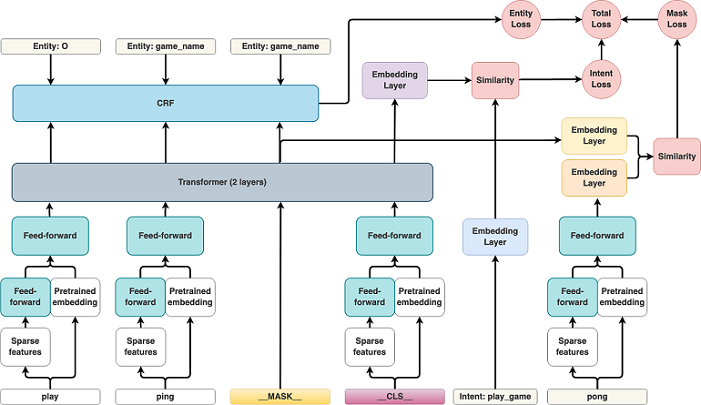
图1是我们架构的示意图。 DIET由几个关键部分组成。
特征 输入句子被视为词符序列,根据特征管道的不同,词符可以是单词或子词。 遵循 Devlin 等人,2018,我们在每个句子的末尾添加一个特殊的分类标记 __CLS__。 每个输入词符都具有我们所谓的稀疏特征和/或密集特征。 稀疏特征是词符级 one-hot 编码和字符级 n-gram ( n ≤ 5) multi-hot 编码。 字符 n-gram 包含许多冗余信息,因此为避免过拟合,我们对这些稀疏特征应用 dropout。 密集特征可以是任何预先训练的词嵌入:ConveRT(Henderson 等人,2019b)、BERT(Devlin 等人,2018)或 GloVe(Pennington 等人,2014)。 由于 ConveRT 还被训练为句子编码器,因此在使用 ConveRT 时,我们将 __CLS__ 词符的初始嵌入设置为从 ConveRT 获得的输入句子的句子编码。1 这在单个单词嵌入信息基础上添加了完整句子的额外上下文信息。 对于开箱即用的预训练 BERT 我们将其设置为 BERT [CLS] 词符对应的输出嵌入,对于GloVe 将其设置为一个句子中词符嵌入的平均值。 稀疏特征将通过所有连接步骤中具有共享权重的完全连接的层传递,以匹配稠密特征的尺寸。 全连接层的输出与来自预训练模型的密集特征连接在一起。
Transformer 为了对整个句子中的上下文进行编码,我们使用了两层 transformer(Vaswani 等人,2017 ),并注意相对位置(Shaw 等人,2018)。 Transformer 体系结构要求其输入与 transformer 层的尺寸相同。 因此,连接起来的特征在所有序列步骤中均传递给具有相同权重的另一个完全连接的层,以匹配 transformer 层的尺寸,在我们的实验中为 256。
命名实体识别 命名体标签序列 yentity 通过在 transformer 输出序列 a 之上的条件随机场 (CRF) 标记层(Lafferty 等人, 2001)预测。
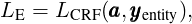 | (1) |
其中 LCRF(.) 表示 CRF 的对数似然可能性(Lampleet 等人,2016)。
意图分类 Transformer 输出的 __CLS__ 词符 aCLS 和意图标签 yintent 被嵌入到一个语义向量空间中 hCLS = E(aCLS), hintent = E(yintent),其中 h∈ IR20。 我们使用点积损失(Wu 等人,2017;Henderson 等人,2019c;Vlasov 等人;2019)最大化与目标标签 y+intent 的相似性 S+I = hTCLSh+intent 并最小化与负样本 y−intent S−I = hTCLS h−intent 的相似性。
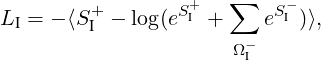 | (2) |
其中求和是在一组负样本 ΩI− 上进行,平均值 ⟨.⟩ 在所有样本中进行。
在推论时,点积相似性用于在所有可能的意图标签上排序。
屏蔽 受屏蔽语言模型任务的启发(Taylor,1953;Devlin 等人,2018年),我们添加一个额外的训练目标来预测随机屏蔽的输入词符。 我们在序列中随机选择输入词符的 15%。 对于选定的词符,在70%的情况下我们将输入替换为特殊屏蔽词符 __MASK__ 对应的向量,在 10% 情况下我们用随机词符的向量替换输入,并在其余的 20% 情况下保留原始输入。 每个选定词符 ytoken 的 transformer 输出 aMASK 通过点积损失进行馈送(Wu 等人,2017; Henderson 等人,2019c;Vlasov 等人,2019),与意图损失类似。
 | (3) |
其中 S+M = hTMASKh+token 是与目标标签 y+token 的相似性,S−M = hTMASKh−token 是与负样本 y−token 的相似性,hMASK = E(aMASK) 以及 htoken = E(ytoken ) 是相应的嵌入向量 h ∈ IR20;求和在所有的负样 Ω−M 上进行,去平均 ⟨. ⟩ 在所有样本上进行。
我们假设添加一个以重建屏蔽输入的训练目应该可以作为一个正则化器,帮助模型从文本中学习更多一般特征,而不仅要从分类中获得区分性(Yoshihashi 等人,2018) 。
总损失 我们通过使总损失 Ltotal 最小化以多任务方式训练模型。
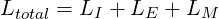 | (4) |
这个结构可以配置,随时关闭上述总和中的任何一种损失。
批次 我们使用平衡批次策略(Vlasov 等人,2019)来减轻类别不平衡(Japkowicz 和 Stephen,2002),因为某些意图可能比其它意图更为频繁。 我们还在整个训练期间增加批次大小,作为正则化的另一个来源(Smith 等人,2017)。
4 实验评估
在本节中,我们首先描述实验中使用的数据集,然后描述实验设置,然后进行消融研究以了解体系结构每个组件的有效性。
4.1 数据集
我们使用三个数据集进行评估:NLU-Benchmark、ATIS 和 SNIPS。 我们的实验重点是 NLU-Benchmark 数据集,因为它是这三个中最具挑战性的。 ATIS 和 SNIPS 测试集精度的最先进水平已经接近 100%,请参见表5。
NLU-Benchmark 数据集 NLU-Benchmark 数据集(Liu 等人,2019b),可在线访问2 ,带有场景、动作和实体的标注。 例如,“schedule a call with Lisa on Monday morning” 标注为场景 calendar、动作 set_event、实体 [event_name: a call with Lisa] 和 [date: Monday morning]。 将场景和动作标签进行连接得到意图标签(例如 calendar_set_event)。 该数据集有 25,716 个语句,涵盖多个家庭助理任务,例如播放音乐或日历查询、聊天、以及向机器人发出的命令。 我们将数据分为 10 份。 每一份都有自己的训练集和测试集,分别有 9960 和 1076 个个语句。3 总共存在 64 个意图和 54 种实体类型。
ATIS ATIS(Hemphill 等人,1990)是 NLU 领域中经过充分研究的数据集。 它由预订机票的人的录音经过标注转录。 我们使用与 Chen 等人 (2019)一样分划分,最初由 Goo 等人 (2018)提出,可在线访问 4。 训练、开发和测试集分别包含 4,478、500 和 893 个语句。 训练数据集包含 21 个意图和 79 个实体。
SNIPS 此数据集是从 Snips 个人语音助手收集的(Coucke 等人,2018)。 它包含 13,784 个训练和 700 个测试样本。 为了公平比较,我们使用与 Chen 等人 (2019)和 Goo 等人 (2018)一样的数据划分。 训练集中分 700 个样本用作开发集。 数据可以在线访问 4。 SNIPS 数据集包含 7 个意图和 39 个实体。
4.2 实验设置
我们的模型用 Tensorflow 实现(Abadi 等人,2016)。 我们使用 NLU-Benchmark 数据集的第一小份来选择超参数。 为此,我们从训练集中随机抽取 250 个语句作为开发集。 我们在一台具有 4 个 CPU,15 GB 内存和一台 NVIDIA Tesla K80 的计算机上训练 200 多个周期的模型。 我们使用 Adam(Kingma 和 Ba,2014)进行优化,初始学习率为 0.001。 批次大小从 64 增加到 128(Smith 等人,2017)。 在 NLU-Benchmark 数据集的第一个小份上训练我们的模型大约需要一个小时。 在推断的时候,我们需要大约 80 毫秒来处理一条语句。
4.3 在 NLU-Benchmark 数据集上的实验
NLU-Benchmark 数据集包含 10 个小份,每个小份具有单独的训练和测试集。 为了获得该模型在该数据集上的整体性能,我们采用 Vanzo 等人 (2019)的方法:分别训练 10 个模型,每个小份一次,将平均值作为最终得分。 Micro-averaged precision、召回率和 F1 得分用作指标。 意图标签的 True positives、false positives 和 false negatives 的计算方式与其它任何多类分类任务一样。 如果预测范围和正确范围之间重叠,并且其标签匹配,则该实体被视为 true positive。
| 意图 | 实体 | ||
| F1 | 87.55±0.63 | 84.74±1.18 | |
HERMIT | R | 87.70±0.64 | 82.04±2.12 |
| P | 87.41±0.63 | 87.65±0.98 | |
sparse + | F1 | 90.18±0.53 | 86.04±1.01 |
ConveRT† | R | 90.18±0.53 | 86.13±0.99 |
| P | 90.18±0.53 | 85.95±1.42 |
表1显示我们在 NLU-Benchmark 数据集上表现最好的模型的结果。 我们性能最好的模型使用稀疏特征,即词符级别的 one-hot 编码和字符 n-gram 的 multi-hot 编码(n ≤ 5)。 这些稀疏特征与 ConveRT 的密集嵌入相结合(Henderson 等人,2019b)。 我们性能最好的模型没有使用屏蔽损失(在第3节描述,在表中由†表示)。 我们在意图方面的表现优于 HERMIT,绝对值超过 2%。 我们的实体 F1 微观平均得分(86.04%)也高于 HERMIT(84.74%)。 HERMIT 报告的实体精度值相似,但是,我们的召回率要高得多(86.13% 相比 82.04%)。
4.4 NLU-Benchmark 数据集上的消融研究
我们使用 NLU-Benchmark 数据集来评估模型体系结构的不同组成部分,因为它涵盖多个领域并且在三个数据集中拥有最多的意图和实体。
联合训练的重要性 为了评估意图分类和命名实体识别这两个任务是否受益于联合优化,我们针对每个任务分别训练了模型。 表2列出使用 DIET 仅训练单个任务的结果。 结果表明,与实体识别一起训练时,意图分类的性能略有下降(90.90% vs 90.18%)。 应该注意的是,意图分类单任务训练的最佳性能配置对应于使用没有 transformer 层5 的 ConveRT 嵌入。 但是,当单独训练实体时,实体的 micro-averaged F1 分数从 86.04 %下降到 82.57%。 检查 NLU-Benchmark 数据集,这可能是由于特定意图与特定实体的存在之间的强相关性。 例如,几乎所有属于 play_game 意图的语句都有一个名为 game_name 的实体。 同样,实体 game_name 仅与意图 play_game 一起出现。 我们认为,这一结果进一步表明拥有像 DIET 这样的模块化和可配置架构的重要性,以便处理这两项任务之间的性能折衷。
| sparse | dense | mask loss | 意图 | 实体
|
| ✓ | ✗ | ✗ | 87.10±0.75 | 83.88±0.98 |
| ✓ | ✗ | ✓ | 88.19±0.84 | 85.12±0.85 |
| ✗ | GloVe | ✗ | 89.20±0.90 | 84.34±1.03 |
| ✓ | GloVe | ✗ | 89.38±0.71 | 84.89±0.91 |
| ✗ | GloVe | ✓ | 88.78±0.70 | 85.06±0.84 |
| ✓ | GloVe | ✓ | 89.13±0.77 | 86.04±1.09 |
| ✗ | BERT | ✗ | 87.44±0.92 | 84.20±0.91 |
| ✓ | BERT | ✗ | 88.46±0.88 | 85.26±1.01 |
| ✗ | BERT | ✓ | 86.92±1.09 | 83.96±1.33 |
| ✓ | BERT | ✓ | 87.45±0.67 | 84.64±1.31 |
| ✗ | ConveRT | ✗ | 89.76±0.98 | 86.06±1.38 |
| ✓ | ConveRT | ✗ | 90.18±0.53 | 86.04±1.01 |
| ✗ | ConveRT | ✓ | 90.15±0.68 | 85.76±0.80 |
| ✓ | ConveRT | ✓ | 89.47±0.74 | 86.04±1.29 |
不同特征组件和屏蔽的重要性 如第3节所述,不同预训练语言模型的嵌入都可以用作密集特征。 我们训练多种变体来研究每种变体的有效性:仅稀疏特征,即词符级别的 one-hot 编码和字符 n-gram 的 multi-hot 编码(n ≤ 5),以及与 ConveRT、BERT 或 GloVe一起使用的组合。 此外,我们在有和没有屏蔽损失的情况下训练每种组合。 表3中显示的结果显示意图分类和实体识别的 F1 分数,并表明多种观察结果:当使用稀疏特征和屏蔽损失时,没有任何预训练的嵌入,DIET 的性能具有竞争力。 在目标和实体上增加屏蔽损失都会使性能提高绝对值约 1%。 具有 GloVe 嵌入的 DIET 也具有同等的竞争力,并且在与稀疏特征和屏蔽损失结合使用时,在意图和实体上都将得到进一步增强。 有趣的是,使用上下文 BERT 嵌入作为密集特征的效果要比 GloVe 差。 我们假设这是因为 BERT 主要是在各种文本上预训练的,因此在转移到对话任务之前需要微调。 由于 ConveRT 专门针对会话数据进行微调,因此使用 ConveRT 嵌入的 DIET 的性能对此支持了这种说法。 稀疏特征 和 ConveRT 嵌入的结合在意图分类上获得了最佳的 F1 得分,并且在意图分类和实体识别方面都比现有最好结果高出 3% 左右。 与 BERT 和 ConveRT 一起用作密集特征时,增加屏蔽损失似乎会稍微影响性能。
| 意图 | 实体 | ||
Fine-tuned | F1 | 89.67±0.48 | 85.73±0.91 |
BERT | R | 89.67±0.48 | 84.71±1.28 |
| P | 89.67±0.48 | 86.78±1.02 | |
sparse + | F1 | 90.18±0.53 | 86.04±1.01 |
ConveRT† | R | 90.18±0.53 | 86.13±0.99 |
| P | 90.18±0.53 | 85.95±1.42 |
与微调 BERT 比较并遵循 Peters 等人 (2019),我们评估将 BERT 应用到 DIET 的特征流水线中并对整个模型进行微调的有效性。 表4显示使用冻结 ConveRT 嵌入的 DIET 作为密集特征和单词、字符级稀疏特征在实体识别上表现优于微调的 BERT,而在意图分类方面表现持平。 此结果尤为重要,因为在所有 10 个 NLU-Benchmark 数据集上微调的 DIET 中的 BERT 需要 60 个小时,而使用 ConveRT 嵌入和稀疏特征的 DIET 则需要 10 个小时。
4.5 ATIS 和 SNIPS 上的实验
| ATIS | SNIPS | |||
意图 | 实体 | 意图 | 实体
| |
| Joint BERT | 97.90 | 96.10 | 98.60 | 97.00 |
| sparse + ConveRT†∗ | 96.59 | 95.08 | 98.03 | 94.79 |
| sparse + GloVe∗ | 96.31 | 94.99 | 97.50 | 94.84 |
| sparse∗ | 96.61 | 95.37 | 97.71 | 95.10 |
为了将我们的结果与 Chen 等人 (2019)比较,我们使用与以下相同的评估方法 Chen 等人 (2019)和 Goo 等人 (2018)。 他们报告意图分类的准确性和实体识别的 micro-averaged F1 分数。 同样,可以像在其它任何多类分类任务中一样获得意图标签的 true positives、false positives 和 false negatives。 但是,只有当预测范围与正确范围完全匹配并且其标签匹配正确时,实体才算为 true positive,定义比 Vanzo 等人 (2019)更严格。 所有实验在 ATIS 和 SNIPS 上均进行 5 次。 我们将这些运行结果的平均值作为最终数字。
为了解 DIET 超参数的可移植性,我们采用在 NLU-Benchmark 数据集上性能最佳的 DIET 模型配置,并在 ATIS 和 SNIPS 上对其进行评估。 表5中列出 ATIS 和 SNIPS 数据集上的意图分类准确性和命名实体识别 F1 得分。
由于采用了更严格的评估方法,因此我们使用 BILOU 标记模式对数据进行标记(Ramshaw 和 Marcus,1995)。 表5中的 ∗ 指示使用 BILOU 标记模式。
值得注意的是,DIET 仅使用稀疏特征而没有任何预训练的嵌入,即使这样其性能仅比 Joint BERT 模型低 1-2%之内。 利用 NLU-Benchmark 数据集上性能最佳模型的超参数,DIET 在 ATIS 和 SNIPS 上均获得与 Joint BERT 竞争的结果。
5 结论
我们引入 DIET,一种用于意图和实体建模的灵活结构。 我们研究其在多个数据集上的性能,并表明 DIET 在具有挑战性的 NLU-Benchmark 数据集上提高了最先进水平。 此外,我们广泛研究使用来自各种预训练方法嵌入的有效性。 我们发现没有单一的嵌入集总是在不同的数据集上最好,这凸显了模块化结构的重要性。 此外,我们表明,像 GloVe 这样的分布模型中的词嵌入与大规模语言模型中的嵌入效果相当,并且事实上,在不使用任何预训练嵌入的情况下,DIET 仍可以实现类似的性能,在 NLU-Benchmark 上表现出最先进的水平。 最后,我们还表明,在 NLU-Benchmark 上用于 DIET 的最佳预训练嵌入集优于在 DIET 内对 BERT 进行微调的速度,并且训练速度快六倍。
1ConveRT 的句子嵌入是 1024维 的 单词嵌入是 512 维的。 为了克服这个 尺寸不匹配,我们使用一个简单的技巧来平铺单词 嵌入到额外的 512 维并获得 1024 维 词嵌入。 这使得神经体系结构保持不变 对于不同的预训练嵌入。参考文献
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Gregory S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian J. Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Józefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Gordon Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul A. Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda B. Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. CoRR, abs/1603.04467.
Ashutosh Adhikari, Achyudh Ram, Raphael Tang, and Jimmy Lin. 2019. Docbert: BERT for document classification. CoRR, abs/1904.08398.
Collin F. Baker, Charles J. Fillmore, and John B. Lowe. 1998. The berkeley framenet project. In Proceedings of the 17th International Conference on Computational Linguistics - Volume 1, COLING ’98, pages 86–90, Stroudsburg, PA, USA. Association for Computational Linguistics.
Iñigo Casanueva, Tadas Temčinas, Daniela Gerz, Matthew Henderson, and Ivan Vulić. 2020. Efficient intent detection with dual sentence encoders.
Qian Chen, Zhu Zhuo, and Wen Wang. 2019. BERT for joint intent classification and slot filling. CoRR, abs/1902.10909.
Alice Coucke, Alaa Saade, Adrien Ball, Théodore Bluche, Alexandre Caulier, David Leroy, Clément Doumouro, Thibault Gisselbrecht, Francesco Caltagirone, Thibaut Lavril, Maël Primet, and Joseph Dureau. 2018. Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces. CoRR, abs/1805.10190.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Chih-Wen Goo, Guang Gao, Yun-Kai Hsu, Chih-Li Huo, Tsung-Chieh Chen, Keng-Wei Hsu, and Yun-Nung Chen. 2018. Slot-gated modeling for joint slot filling and intent prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 753–757, New Orleans, Louisiana. Association for Computational Linguistics.
Ee Haihong, Peiqing Niu, Zhongfu Chen, and Meina Song. 2019. A novel bi-directional interrelated model for joint intent detection and slot filling. CoRR, abs/1907.00390.
Charles T. Hemphill, John J. Godfrey, and George R. Doddington. 1990. The ATIS spoken language systems pilot corpus. In Speech and Natural Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, June 24-27,1990.
Matthew Henderson, Pawel Budzianowski, Iñigo Casanueva, Sam Coope, Daniela Gerz, Girish Kumar, Nikola Mrksic, Georgios Spithourakis, Pei-Hao Su, Ivan Vulic, and Tsung-Hsien Wen. 2019a. A repository of conversational datasets. CoRR, abs/1904.06472.
Matthew Henderson, Iñigo Casanueva, Nikola Mrkšić, Pei-Hao Su, Ivan Vulić, et al. 2019b. Convert: Efficient and accurate conversational representations from transformers. arXiv preprint arXiv:1911.03688.
Matthew Henderson, Ivan Vulić, Daniela Gerz, Iñigo Casanueva, Paweł Budzianowski, Sam Coope, Georgios Spithourakis, Tsung-Hsien Wen, Nikola Mrkšić, and Pei-Hao Su. 2019c. Training neural response selection for task-oriented dialogue systems. arXiv preprint arXiv:1906.01543.
Jeremy Howard and Sebastian Ruder. 2018. Fine-tuned language models for text classification. CoRR, abs/1801.06146.
Nathalie Japkowicz and Shaju Stephen. 2002. The class imbalance problem: A systematic study. Intelligent data analysis, 6(5):429–449.
Khari Johnson. 2018. Facebook messenger passes 300,000 bots. venturebeat.com [Online; posted 1-May-2018].
Diederik P. Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. Cite arxiv:1412.6980Comment: Published as a conference paper at the 3rd International Conference for Learning Representations, San Diego, 2015.
Tassilo Klein and Moin Nabi. 2019. Attention is (not) all you need for commonsense reasoning. CoRR, abs/1905.13497.
John Lafferty, Andrew McCallum, and Fernando CN Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data.
Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural architectures for named entity recognition. CoRR, abs/1603.01360.
Jieh-Sheng Lee and Jieh Hsiang. 2019. Patentbert: Patent classification with fine-tuning a pre-trained BERT model. CoRR, abs/1906.02124.
Bing Liu and Ian Lane. 2016. Attention-based recurrent neural network models for joint intent detection and slot filling. CoRR, abs/1609.01454.
Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. 2019a. Improving multi-task deep neural networks via knowledge distillation for natural language understanding. CoRR, abs/1904.09482.
Xingkun Liu, Arash Eshghi, Pawel Swietojanski, and Verena Rieser. 2019b. Benchmarking natural language understanding services for building conversational agents. CoRR, abs/1903.05566.
Shikib Mehri, Tejas Srinivasan, and Maxine Eskenazi. 2019. Structured fusion networks for dialog. arXiv preprint arXiv:1907.10016.
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543.
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. CoRR, abs/1802.05365.
Matthew E. Peters, Sebastian Ruder, and Noah A. Smith. 2019. To tune or not to tune? adapting pretrained representations to diverse tasks. CoRR, abs/1903.05987.
Alec Radford. 2018. Improving language understanding by generative pre-training.
Lance A. Ramshaw and Mitchell P. Marcus. 1995. Text chunking using transformation-based learning. CoRR, cmp-lg/9505040.
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-attention with relative position representations. arXiv preprint arXiv:1803.02155.
Samuel L Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V Le. 2017. Don’t decay the learning rate, increase the batch size. arXiv preprint arXiv:1711.00489.
Emma Strubell, Ananya Ganesh, and Andrew McCallum. 2019. Energy and policy considerations for deep learning in nlp. arXiv preprint arXiv:1906.02243.
Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. 2019a. Videobert: A joint model for video and language representation learning. CoRR, abs/1904.01766.
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. 2019b. How to fine-tune BERT for text classification? CoRR, abs/1905.05583.
Wilson L Taylor. 1953. “cloze procedure”: A new tool for measuring readability. Journalism Bulletin, 30(4):415–433.
Andrea Vanzo, Emanuele Bastianelli, and Oliver Lemon. 2019. Hierarchical multi-task natural language understanding for cross-domain conversational ai: Hermit nlu. pages 254–263.
Akson Sam Varghese, Saleha Sarang, Vipul Yadav, Bharat Karotra, and Niketa Gandhi. 2020. Bidirectional lstm joint model for intent classification and named entity recognition in natural language understanding. In Intelligent Systems Design and Applications, pages 58–68, Cham. Springer International Publishing.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
Vladimir Vlasov, Johannes EM Mosig, and Alan Nichol. 2019. Dialogue transformers. arXiv preprint arXiv:1910.00486.
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. Superglue: A stickier benchmark for general-purpose language understanding systems. CoRR, abs/1905.00537.
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. CoRR, abs/1804.07461.
Jason D Williams, Kavosh Asadi, and Geoffrey Zweig. 2017. Hybrid code networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning. arXiv preprint arXiv:1702.03274.
Jason D Williams and Steve Young. 2007. Partially observable markov decision processes for spoken dialog systems. Computer Speech & Language, 21(2):393–422.
Ledell Wu, Adam Fisch, Sumit Chopra, Keith Adams, Antoine Bordes, and Jason Weston. 2017. Starspace: Embed all the things! arXiv preprint arXiv:1709.03856.
Ryota Yoshihashi, Wen Shao, Rei Kawakami, Shaodi You, Makoto Iida, and Takeshi Naemura. 2018. Classification-reconstruction learning for open-set recognition. CoRR, abs/1812.04246.
Xiaodong Zhang and Houfeng Wang. 2016. A joint model of intent determination and slot filling for spoken language understanding. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI’16, pages 2993–2999. AAAI Press.
Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. 2019. ERNIE: enhanced language representation with informative entities. CoRR, abs/1905.07129.