深度预训练 transformer 的使用已在许多应用中取得显着进展(Devlin 等人,2019)。 对于在序列之间进行成对比较,将给定输入与相应标签相匹配的任务,常见的两种方法是:Cross-encoder 对两个句子一起 self-attention,而 Bi-encoder 分别编码句子对中的两个句子。 前者通常表现更好,但对于实际使用而言却太慢了。 在这项工作中,我们开发了一种新的 transformer 结构 Poly-encoder,该结构学习全局而不是词符级别的 self-attention 特征。 我们对这三种方法进行了详细的比较,包括哪些预训练和微调策略最有效。 我们展示了我们的模型在四个任务上达到了最先进的结果; Poly-encoder 比 Cross-encoder 更快,比 Bi-encoder 更准;并且通过在与下游任务类似的大型数据集上预训练可以获得最佳结果。
1 简介
最近,通过使用深度预训练的语言模型然后进行微调,各种语言理解任务的最先进基准取得了重大改进(Devlin 等人,2019)。 在这项工作中,我们探讨对这一方法的改进,用于需要多句子打分的一类任务:给定一个输入上下文,对一组候选标签进行打分,这种场景在检索和对话等任务中很常见。 必须通过两个轴来衡量此类任务的性能:预测质量和预测速度,因为对许多候选标签进行评分可能会过慢。
目前最先进的技术集中在使用 BERT 模型进行预训练(Devlin 等人,2019),这些模型采用了一般主题的大型文本语料库:维基百科和多伦多图书语料库(Zhu 等人,2015)。 通常在上面建有两类微调架构:Bi-encoder 和 Cross-encoder。 Cross-encoder(Wolf 等人,2019;Vig 和 Ramea,2019)对给定的输入和候选标签进行完全(交叉)的自注意力,往往比其对应的 Bi-encoder(Mazaré 等人,2018;Dinan 等人,2019)具有更高的准确率,后者分别对输入和候选标签执行自注意力,并在最后将它们结合起来进行最终表示。 由于表示是分开的,Bi-encoder 能够缓存编码好的候选标签,并对每个输入重新使用这些表示,从而缩短预测时间。 Cross-encoder 必须为每个输入和标签重新计算编码;结果,它们在预测的时侯非常慢。
在这项工作中,我们提供了新颖的贡献,质量和速度比目前最先进的结果都有所提高。 我们引入 Poly-encoder,这是一种带有额外学习 attention 机制的架构,它表示更多的全局特征,从中可以进行 self-attention,从而性能比 Bi-encoder 有所提升,速度比 Cross-Encoder 更有所提高。 为了预训练我们的架构,我们表明选择更类似于我们下游任务的丰富数据,同样比 BERT 预训练带来更显著的收益。 在所有不同的结构选择和我们尝试的下游任务中都是如此。
我们在对话和信息检索(IR)领域的四个现有数据集上进行实验,除了分析现有方法的各种设置的最佳效果外,我们还对新方法进行了比较,其中预训练策略基于Reddit(Mazaré 等人,2018)和 Wikipedia/Toronto Books(即 BERT)进行比较。 我们使用最好的架构和预训练策略,在所有四个数据集上获得了新的最先进水平,并提供可实时使用的实用实现。 我们的代码和模型将以开源形式发布。
2 相关工作
给定输入上下文为候选标签评分的任务是机器学习中的经典问题。 尽管多类分类是一种特殊情况,但更一般的任务是将候选对象作为结构化对象而不是离散的类别;在这项工作中,我们认为输入和候选标签是文本序列。
有一类广泛的模型,它们将输入和候选标签分别映射到一个共同的特征空间,其中通常使用点积、余弦或(参数化的)非线性来测量它们的相似性。 我们将这些模型称为 Bi-encoder。 这样的方法包括向量空间模型(Salton 等人,1975)、LSI(Deerwester 等人,1990)、有监督的嵌入(Bai 等人,2009; Wu 等人,2018)和经典的 siamese 网络(Bromley 等人,1994)。 对于在这项工作中的下一个语句预测任务,我们考虑了几种神经网络 Bi-encoder 方法,具体是 Memory Networks(Zhang 等人,2018a)和 Transformer Memory networks(Dinan 等人,2019)以及 LSTM(Lowe 等人,2015)和 CNN(Kadlec 等人,2015),它们对输入和候选标签分别编码。 Bi-encoder 方法的主要优点是它们能够缓存大量、固定的候选集的表示。 由于候选集的编码与输入无关,因此 Bi-encoder 在预测的时候非常高效。
研究人员还研究了我们称为 Cross-encoders 的一类更丰富的模型,这些模型不对输入标签和候选标签之间的相似性评分函数做出任何假设。 取而代之的是,输入和候选连接在一起作为非线性函数的新输入,根据所需的任何依赖关系对它们的匹配进行评分。 这已经通过基于 CNN 的序列匹配网络架构(Wu 等人,2017)、深度匹配网络(Yang 等人,2018)、门控自注意力(Zhang 等人,2018b)以及最近的 transformers (Wolf 等人,2019;Vig 和 Ramea,2019;Urbanek 等人,2019)进行了探索。 对于后者,将两个文本序列连接起来会在每一层应用 self-attention。 由于候选标签中的每个单词都可以关注输入上下文中的每个单词,因此这会在输入上下文和候选单词之间产生丰富的交互作用,反之亦然。 Urbanek 等人 (2019)使用预训练的 BERT 模型并对 Bi-encoder 和 Cross-encoder 进行微调,在对话和动作任务上进行了明确比较,发现 Cross-encoder 的性能更好。 但是,性能提升的代价是计算量巨大。 Cross-encoder 表示的计算速度要慢得多,从而使某些应用不可行。
3 任务
我们考虑对话句子选择和 IR 文章搜索的任务。 前者是一项经过广泛研究的任务,最近在两个比赛中出现:Neurips ConvAI2 比赛(Dinan 等人,2020)和 DSTC7 挑战赛,Track 1(Yoshino 等人,2019;Jonathan K. Kummerfeld 和 Lasecki,2018;Chulaka Gunasekara 和 Lasecki,2019)。 我们在这两个任务上进行比较,此外我们还在流行的 Ubuntu V2 语料库(Lowe 等人,2015)上进行测试。 对于 IR,我们使用 Wikipedia 文章搜索任务 Wu 等人 (2018)。
ConvAI2 任务基于 Persona-Chat 数据集(Zhang 等人,2018a),它涉及一对说话人之间的对话。 每个说话人都有一个角色,也就是几句描述自己要模仿的角色,如 "我喜欢浪漫的电影",并被指示去了解对方。 然后,模型应该根据对话历史和角色的台词来决定自己选择的回应。 作为比赛中的一项自动指标,对于每个响应,模型都必须从 20 种选择中选择正确标注的语句,其余 19 种是从评估集中随机选择的其他语句。 但是请注意,在最终系统中,可能是从超过 100k 语句的整个训练集中进行检索,但是由于速度原因,在通用评估设置中避免这种情况。 使用针对此任务进行了微调的预训练 Transformer,该任务中 23名 参与者中表现最好的参赛人员在测试集上达到了 80.7% 的准确性(Wolf 等人,2019)。
DSTC7 挑战(Track 1)由从 Ubuntu 聊天日志中提取的对话组成,其中一个伙伴从另一伙伴那里获得与 Ubuntu 相关的各种问题的技术支持。 在这项任务中表现最好的参赛者(Track 1 有 20 名参赛者)达到了 64.5% 的 R@1(Chen 和 Wang,2019)。 Ubuntu V2 是类似但较大的流行语料库,它是在竞赛之前创建的(Lowe 等人,2015);我们也会报告此数据集的结果,因为有许多已报告的结果。
最后,我们对 Wikipedia 文章搜索进行评估(Wu 等人,2018)。 使用英语维基百科的 2016-12-21 转储(〜5M 文章),任务从文章中给出一个句子作为搜索查询,找到它来自的文章。 评估使用检索指标对 10,000 条其他文章和真实文章(减去句子)进行排名。 这模仿类似 Web 搜索的场景,在该场景中,人们希望搜索最相关的文章(Web文档)。 报道得最好的方法是 learning-to-rank 嵌入模型 StarSpace,它优于 fastText、SVM和其他基准。
我们在表 1 中总结了所有四个数据集及其统计信息。
4 方法
在本节中,我们描述了我们探索的各种模型和方法。
4.1 Transformer 和预训练策略
Transformer 我们在4.2、4.3 和 4.4 节分别介绍的 Bi-、Cross- 和 Poly-encoder 基于大型预训练 transformer 模型,具有与 BERT-base (Devlin 等人,2019)相同的架构和大小,有 12 层、12 个 attention head 和 隐藏层大小为 768。 除了考虑 BERT 的预训练权重外,我们还探索自己的预训练方案。 具体来说,我们使用与 BERT 基本相同的架构从头开始再训练两个 transformer。 一种使用与 BERT 相似的训练设置,对从 Wikipedia 和 Toronto Books Corpus 提取的 1.5 亿个 [INPUT, LABEL] 样本进行训练,另一种针对从 在线平台Reddit(Mazaré 等人,2018)中提取的 1.74 亿个[INPUT, LABEL] 样本进行训练,它是一个更适合对话的数据集。 执行前者是为了验证重现类似 BERT 的设置是否能提供与先前报告的结果相同的结果,而后者则是测试对与下游任务更相似的数据进行预训练是否有帮助。 为了训练这两种新设置,我们使用 XLM(Lample 和 Conneau,2019)。
输入表示 我们的预训练输入是输入和标签 [INPUT, LABEL] 的连接,两者都用特殊的标记 [S] 包围,遵循 Lample 和 Conneau(2019)。 在 Reddit 上进行预训练时,输入是上下文,标签是下一个语句。 在 Wikipedia 和 Toronto Books 上进行预训练时,如 Devlin 等人 (2019),输入为一个句子,标签为文本中的下一个句子。 每个输入词符都表示为三个嵌入的总和:词符嵌入、位置(在序列中)嵌入和段嵌入。 输入词符的段为 0,标签词符的段为 1。
预训练过程 我们的预训练策略使用掩蔽语言模型(MLM)任务进行训练完全相同于 Devlin 等人 (2019)。 在 Wikipedia 和 Toronto Books 上的预训练中,我们添加了与 BERT 训练相同的下一句预测任务。 在 Reddit 上的预训练中,我们添加了下一个话语预测任务,该任务与前一个略有不同,因为一个话语可以由多个句子组成。 在训练期间,候选语句有 50% 的时间是实际的下一个句子/话语,有 50% 的时间是从数据集中随机抽取的句子/话语。 我们在 MLM 任务和下一个句子/下一个话语预测任务的批次之间交替进行。 与 Lample 和 Conneau (2019) 一样,我们使用 Adam 优化器,学习率为 2e-4、β1 = 0.9、β2 = 0.98、没有 L2 权重衰减、学习率线性线性、学习率的平方根倒数衰减。 我们在所有层上使用 0.1 的丢弃率,每个批次由长度相似的 [INPUT, LABEL] 32000 个词符组成。 我们在 32 个 GPU 上训练模型 14 天。
微调 在进行预训练后,可以针对所选的多句选择任务进行微调,在本例中为第 3 节中的四个任务。 我们考虑微调 transformer 的三种结构:Bi-encoder、Cross-encoder 和新提出的 Poly-encoder。
4.2 Bi-encoder
在 Bi-encoder,输入上下文和候选标签都被编码为向量:

我们考虑三种通过 red(⋅) 将输出规约为一个向量表示的方法:选择 transformer 的第一个输出(对应于特殊标记 [S]),计算所有输出的平均值或前 m ≤ N 个输出的平均值。 我们在附录的表 7 中对它们进行比较。 我们在实验中使用 transformer 的第一个输出,因为它的输出会稍好一些。
评分 候选 candi 的得分由点积给出 s(ctxt,candi) = yctxt ⋅ ycandi。 对网络进行训练以使交叉熵损失最小化,其中 logit 为 yctxt ⋅ ycand1,...,yctxt ⋅ ycandn, cand1 是从训练集中选择正确的标签和其他标签是从训练集中随机选择的。 类似于 Mazaré 等人 (2018),在训练期间,我们将批次中的其他标签视为负标签。 这样可以更快地进行训练,因为我们可以重复使用为每个候选计算的嵌入,并且还可以使用更大的批次;例如,在我们对 ConvAI2 的实验中,我们能够使用 512 个元素的批次。
推理速度 在对已知候选对象进行检索的设置中,Bi-encoder 允许对系统所有可能候选对象的嵌入进行预计算。 计算上下文嵌入 yctxt 后,剩下的唯一操作是 yctxt 与每个候选嵌入的点积,在一个现代 GPU 上可以扩展到数百万个候选,使用 FAISS 之类的 nearest-neighbor 库可能扩展到数十亿个候选者(Johnson 等人,2019)。
4.3 Cross-encoder
Cross-encoder 允许输入上下文和候选标签之间进行丰富的交互,因为它们被联合编码以获得最终表示。 与预训练中的过程类似,上下文和候选被特殊标记 [S] 包围,并连接到一个向量中,该向量使用一个 transformer 进行编码。 我们将 transformer 的第一个输出视为上下文候选的嵌入:
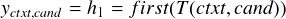
评分 为了给一个候选打分,线性层 W 被应用到嵌入yctxt,cand,将其从向量还原为标量。
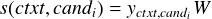
与 Bi-encoder 所做的类似,这个网络训练为最小化交叉熵,其中 logits 为 s(ctxt,cand1),...,s(ctxt,candn),cand1 是正确的标签,其他的为从训练集中采集的负样本。 与 Bi-encoder 中不同的是,我们不能将该批次的其他标签回收为负值,所以我们使用训练集中提供的外部负值。 Cross-encoder 比 Bi-encoder 使用更多的内存,从而使批次大小小得多。
推理速度 不幸的是,Cross-encoder 不允许对候选嵌入进行预计算。 在推理时,每个候选都必须与输入上下文连接起来,并且必须经过整个模型的前向传递。 因此,该方法无法扩展到大量候选对象。 我们将在 5.4 部分中进一步讨论该瓶颈。
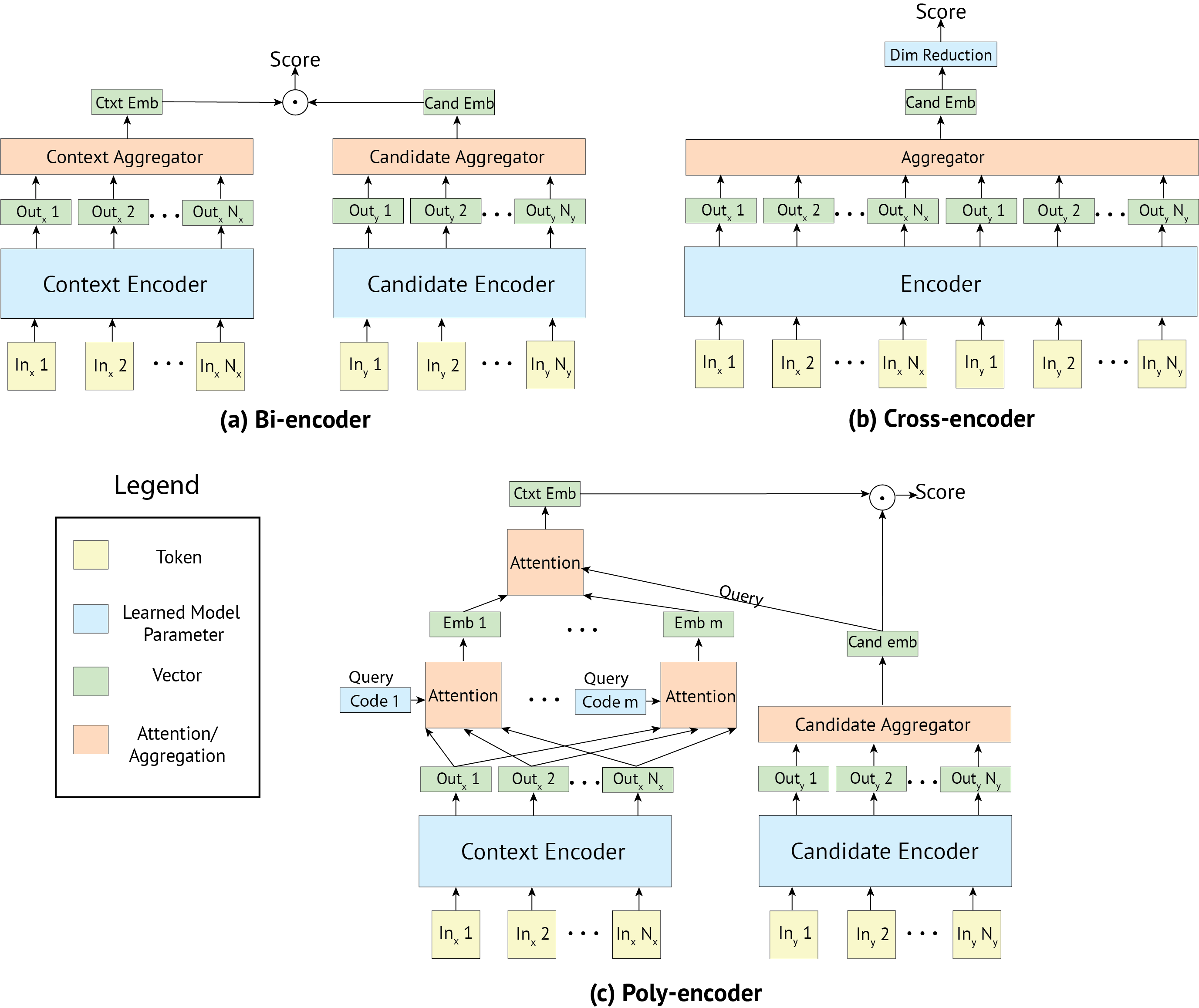
4.4 Poly-encoder
Poly-encoder 架构旨在从 Bi-encoder 和 Cross-encoder 中获得两全其美的效果。 一个给定的候选标签如 Bi-encoder 一样由一个向量表示,可以缓存候选标签以获得快速的推理时间,而输入上下文与候选标签如 Cross-encoder 一样联合编码,可以提取更多的信息。
Poly-encoder 像 Bi-encoder 一样为上下文和标签使用两个单独的 transformer,并且将候选标签编码为单个向量 ycandi。 因此,Poly-encoder 方法可以使用预先计算的编码响应缓存来实现。 然后,输入上下文以 m 个向量 (yctxt1..yctxtm) 而不是 Bi-encoder 中的一个向量表示,通常比候选标签长很多, 而 m 将影响推理的速度。 为了获得这些表示输入的 m 个全局特征,我们学习 m 个上下文码 (c1,...,cm),其中 ci 通过关注上一层的所有输出提取表示 yctxti。 也就是说,我们使用以下方法获得 yctxti:
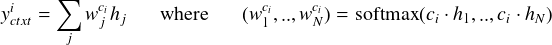
最后,根据我们的 m 个全局上下文特征,我们使用 ycandi 做为查询:
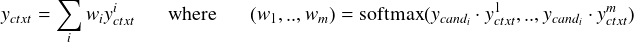
5 实验
我们执行各种实验以测试我们的模型架构和针对四个任务的训练策略。 对于度量,我们测量 Recall@k ,其中每个测试样本都有 C 个可能的候选标签供选择,缩写为 R@k/C,以及平均排序倒数(MRR)。
5.1 Bi-encoder 和 Cross-encoder
我们首先研究微调 Bi-encoder 和 Cross-encoder 结构,初始化的权重使用 Devlin 等人 (2019),并研究其它超参数的选择(我们在 5.3 节中探索了我们自己的预训练方案)。 对于 Bi-encoder,我们可以通过将其它批次的内容视为负训练样本来使用,从而避免重新计算其嵌入。 在 8 个 Nvidia Volta v100 GPU 上使用半精度运算(即 float16 运算),我们可以在 ConvAI2 上每个批次可以达到 512 个样本。 表 2 显示,在这种设置下,我们用更大的批次大小,即更多的负样本来获得更高的性能,其中 511 个负样本可以获得最好的结果。 对于其它任务,我们将批次大小保持为 256,因为这些数据集中的较长序列使用更多内存。 Cross-encoder 的计算量更大,因为(context, candidate) 对的嵌入每次都必须重新计算。 因此,我们将其批次大小限制为 16,并从训练集中提供负随机样本。 对于 DSTC7 和 Ubuntu V2,我们选择15个此类负样本;对于ConvAI2,数据集提供 19 个负样本。
以上结果是基于第一个输出的 Bi-encoder 聚合报告的。 相反,选择所有输出的平均值非常相似,但略差一点(83.1,5 次运行的平均值)。 我们还尝试添加进一步的非线性而不是两个表示形式的内积,但是无法在较简单的体系结构上获得改进的结果(结果未显示)。
我们尝试了两个优化器:重量衰减为 0.01 的 Adam(Kingma 和 Ba,2015)的(如(Devlin 等人的建议,2019))和 没有权重衰减的 Adamax(Kingma 和 Ba,2015);根据验证集的性能,在使用 BERT 权重时,我们选择用 Adam 进行微调。 学习率初始化为 5e-5,Bi-encoder 预热 100 次迭代,Cros-encoder 预热 1000 次迭代。 在每半个周期,在验证集上评估的损失达到平稳状态后,学习率下降 0.4 倍。 在表 3 中,我们显示了使用具有衰减的 Adam 优化器对(Devlin 等人,2019)提供的权重的各个层进行微调时的验证集性能。 除了词嵌入之外,对整个网络进行微调非常重要。
通过上述设置,我们在数据集上对 Bi-encoder 和 Cross-encoder 进行微调,并将结果报告在表 4中。 在前三个任务中,当我们从 BERT 权重进行微调时,我们的 Bi-encoder 和 Cross-encoder 的性能优于文献中现有的最佳方法。 例如,Bi-encoder 在 ConvAI2 上达到 81.7%R@1,在 DSTC7 上达到 66.8%R@1,Cross-encoder 在 ConvAI2 上达到 84.8%R@1,在 DSTC7 上达到 67.4%R@1。 总之,Cross-encoder(包括我们的 Bi-encoder) 在三个对话任务上均胜过以前的所有方法(符合预期)。 我们没有报告 Wikipedia IR 的 BERT 微调结果,因为我们不能保证测试集不属于该数据集的预训练集。 此外,Cross-encoder 还是太慢了,无法评估具有 10k 个候选对象的任务。
| 数据集 | ConvAI2 | DSTC 7 | Ubuntu V2 | Wikipedia IR | |||
| split | 测试 | 测试 | 测试 | 测试 | |||
| metric | R@1/20 | R@1/100 | MRR | R@1/10 | MRR | R@1/10001 | |
| (Wolf et al., 2019) | 80.7 | ||||||
| (Gu et al., 2018) | - | 60.8 | 69.1 | - | - | - | |
| (Chen & Wang, 2019) | - | 64.5 | 73.5 | - | - | - | |
| (Yoon et al., 2018) | - | - | - | 65.2 | - | - | |
| (Dong & Huang, 2018) | - | - | - | 75.9 | 84.8 | - | |
| (Wu et al., 2018) | - | - | - | - | - | 56.8 | |
| 预训练的 BERT 权重,来自(Devlin 等人, 2019) - Toronto Books + Wikipedia | |||||||
| Bi-encoder | 81.7 ± 0.2 | 66.8 ± 0.7 | 74.6 ± 0.5 | 80.6 ± 0.4 | 88.0 ± 0.3 | - | |
| Poly-encoder 16 | 83.2 ± 0.1 | 67.8 ± 0.3 | 75.1 ± 0.2 | 81.2 ± 0.2 | 88.3 ± 0.1 | - | |
| Poly-encoder 64 | 83.7 ± 0.2 | 67.0 ± 0.9 | 74.7 ± 0.6 | 81.3 ± 0.2 | 88.4 ± 0.1 | - | |
| Poly-encoder 360 | 83.7 ± 0.2 | 68.9 ± 0.4 | 76.2 ± 0.2 | 80.9 ± 0.0 | 88.1 ± 0.1 | - | |
| Cross-encoder | 84.8 ± 0.3 | 67.4 ± 0.7 | 75.6 ± 0.4 | 82.8 ± 0.3 | 89.4 ± 0.2 | - | |
| 经过我们在 Toronto Books + Wikipedia 上预训练 | |||||||
| Bi-encoder | 82.0 ± 0.1 | 64.5 ± 0.5 | 72.6 ± 0.4 | 80.8 ± 0.5 | 88.2 ± 0.4 | - | |
| Poly-encoder 16 | 82.7 ± 0.1 | 65.3 ± 0.9 | 73.2 ± 0.7 | 83.4 ± 0.2 | 89.9 ± 0.1 | - | |
| Poly-encoder 64 | 83.3 ± 0.1 | 65.8 ± 0.7 | 73.5 ± 0.5 | 83.4 ± 0.1 | 89.9 ± 0.0 | - | |
| Poly-encoder 360 | 83.8 ± 0.1 | 65.8 ± 0.7 | 73.6 ± 0.6 | 83.7 ± 0.0 | 90.1 ± 0.0 | - | |
| Cross-encoder | 84.9 ± 0.3 | 65.3 ± 1.0 | 73.8 ± 0.6 | 83.1 ± 0.7 | 89.7 ± 0.5 | - | |
| 经过我们在 Reddit 上预训练 | |||||||
| Bi-encoder | 84.8 ± 0.1 | 70.9 ± 0.5 | 78.1 ± 0.3 | 83.6 ± 0.7 | 90.1 ± 0.4 | 71.0 | |
| Poly-encoder 16 | 86.3 ± 0.3 | 71.6 ± 0.6 | 78.4 ± 0.4 | 86.0 ± 0.1 | 91.5 ± 0.1 | 71.5 | |
| Poly-encoder 64 | 86.5 ± 0.2 | 71.2 ± 0.8 | 78.2 ± 0.7 | 85.9 ± 0.1 | 91.5 ± 0.1 | 71.3 | |
| Poly-encoder 360 | 86.8 ± 0.1 | 71.4 ± 1.0 | 78.3 ± 0.7 | 85.9 ± 0.1 | 91.5 ± 0.0 | 71.8 | |
| Cross-encoder | 87.9 ± 0.2 | 71.7 ± 0.3 | 79.0 ± 0.2 | 86.5 ± 0.1 | 91.9 ± 0.0 | - | |
5.2 Poly-encoder
我们使用与 Bi-encoder 实验相同的批次大小和优化器选择来训练 Poly-encoder。 表 4 报告了各种 m 个上下文向量值的结果。
在所有任务上,Poly-encoder 的性能均优于 Bi-encoder,通常更多上下文码会带来更大的改进。 因此,我们的建议是在计算时间允许的范围内使用尽可能大的上下文代码大小(请参见 5.4 节)。 在 DS TC7上,采用 BERT 预训练的 Poly-encoder 结构,通过 360 个中间上下文码,R1 达到 68.9%;这实际上比 Cross-encoder 结果(67.4%)更好,并且明显优于我们的 Bi-encoder 结果(66.8%)。 在 Ubuntu V2 和 ConvAI2 上也发现了类似的结论,尽管在后者中,Cross-encoder 给出了稍微好点结果。
我们注意到,自从报告了我们的结果以来, Li 等人 (2019)对 ConvAI2 进行了一项人类评估研究,该研究中,我们的 Poly-encoder 架构在基于生成和检索的模型(包括竞赛的获胜者)方面均优于其他所有模型。
5.3 特定领域的预训练
我们在所有四个任务上微调了 Reddit 预训练的 transformer;我们还对与 BERT 相同的数据集进行了预训练的 transformer 进行了微调,特别是 Toronto Books + Wikipedia。 使用预先训练的权重时,我们使用 Adamax 优化器并优化 transformer 的所有层,包括嵌入层。 由于我们不使用权重衰减,因此最后一层的权重比 BERT 的最后一层的权重大得多;为避免 Poly-encoder 中关注层的饱和,我们重新缩放了最后一个线性层,以使其输出的标准偏差与 BERT 的输出相匹配,这是我们取得良好结果所必需的。 我们在表 4 中报告了使用我们预先训练的权重进行微调的结果。 我们展示在 Reddit 上进行预训练比之前 BERT 测试结果给出更先进的性能,这是在所有三个对话任务和所有三个架构的都观察到的发现。
我们自己在 Toronto Books + Wikipedia 上预训练 transformer 并微调得到的结果和原来的 BERT 权重得到的结果非常相似,说明用于预训练模型的数据集而不是我们训练中的一些其它细节影响了最终的结果。 事实上,由于这两种设置用相似大小的数据集进行预训练,我们可以得出结论,选择与感兴趣的下游任务(如对话)相似的预训练任务(如对话)是对这些性能提升的一个可能的解释,这与之前的结果一致,表明用相似的任务进行多任务处理比用不相似的任务进行多任务处理更有用(Caruana,1997)。
5.4 推理速度
Poly-encoder 结构的重要动机是要获得比 Bi-encoder 更好的结果,同时还要以合理的速度运行。 尽管 Cross-encoder 通常会产生很强的结果,但它的速度实在是太慢了。 我们进行速度实验,以确定从 Poly-encoder 获得改进性能的权衡。 具体来说,我们预测 ConvAI2 验证集中的 100 个对话样本的下一个语句,其中模型评分 C 个候选标签(这里是从训练集中选择的)。 我们在 CPU 和 GPU 上执行这些实验。 CPU 计算在 80 核 Intel Xeon 处理器 CPU E5-2698 上运行。 GPU 计算使用 cuda 10.0 和 cudnn 7.4 在单个 Nvidia Quadro GP100 上运行。
我们在表 5 中显示每种结构每个示例的平均时间。 当只有 1000 个候选标签可供模型考虑时,Bi-encoder 和 Poly-encoder 结构之间的时间差异非常小。 在考虑 10 万个候选对象(更实际的设置)时,差异更加明显,因为我们发现 Poly-encoder 变体的速度降低了 5-6 倍。 不过,这两种模型仍然是可圈可点的。 但是,Cross-encoder 比 Bi-encoder 和 Poly-encoder 要慢 2 个数量级,因此对于实时推理是难以应付的,例如与对话客户端进行交互或从大量文档中检索。 因此,考虑到其理想的性能和速度的折衷,Poly-encoder 是首选方法。
另外,我们在附录表 6 中报告了训练时间。 Poly-encoder 还具有比 Cross-encoder 快 3-4 倍的训练优势(训练时间类似于 Bi-encoder)。
6 结论
在本文中,我们提出候选标签选择任务中深度双向 transformer 的新架构和预训练策略。 我们引入 Poly-encoder方法,提供一种使用候选标签关注上下文上的机制,同时保持预计算每个候选标签表示的能力,这允许在生产环境中进行快速的实时推理,使准确性和速度之间的平衡得到改善。 我们对 Bi-encoder、Poly-encoder 和 Cross-encoder 的权衡取舍进行了实验分析,结果表明 Poly-encoder 比 Bi-encoder 更准确,但比 Cross-encoder 要快得多,Cross-encoder 对于实时使用是不切实际的。 关于这些结构的训练,我们表明与下游任务更紧密相关的预训练策略带来了很大的改进。 特别是,在 Reddit 上进行从头开始的预训练使我们能够胜过使用 BERT 获得的结果,该结果适用于我们试验的所有三个模型结构和所有三个对话数据集。 但是,这项工作中介绍的方法并不仅限于对话,而是可以用于对一组候选标签评分的任何任务,我们也针对信息检索任务展现了该方法。
参考
Bing Bai, Jason Weston, David Grangier, Ronan Collobert, Kunihiko Sadamasa, Yanjun Qi, Olivier Chapelle, and Kilian Weinberger. Supervised semantic indexing. In Proceedings of the 18th ACM conference on Information and knowledge management, pp. 187{196. ACM, 2009.
Jane Bromley, Isabelle Guyon, Yann LeCun, Eduard Säckinger, and Roopak Shah. Signature verification using a” siamese” time delay neural network. In Advances in neural information processing systems, pp. 737{744, 1994.
Rich Caruana. Multitask learning. Machine learning, 28(1):41{75, 1997.
Qian Chen and Wen Wang. Sequential attention-based network for noetic end-to-end response selection. CoRR, abs/1901.02609, 2019. URL http://arxiv.org/abs/1901.02609.
Lazaros Polymenakos Chulaka Gunasekara, Jonathan K. Kummerfeld and Walter S. Lasecki. Dstc7 task 1: Noetic end-to-end response selection. In 7th Edition of the Dialog System Technology Challenges at AAAI 2019, January 2019. URL http://workshop.colips.org/dstc7/papers/dstc7_task1_final_report.pdf.
Scott Deerwester, Susan T Dumais, George W Furnas, Thomas K Landauer, and Richard Harshman. Indexing by latent semantic analysis. Journal of the American society for information science, 41(6):391{407, 1990.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171{4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/ v1/N19-1423.
Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli, and Jason Weston. Wizard of Wikipedia: Knowledge-powered conversational agents. In Proceedings of the International Conference on Learning Representations (ICLR), 2019.
Emily Dinan, Varvara Logacheva, Valentin Malykh, Alexander Miller, Kurt Shuster, Jack Urbanek, Douwe Kiela, Arthur Szlam, Iulian Serban, Ryan Lowe, Shrimai Prabhumoye, Alan W. Black, Alexander Rudnicky, Jason Williams, Joelle Pineau, Mikhail Burtsev, and Jason Weston. The second conversational intelligence challenge (convai2). In Sergio Escalera and Ralf Herbrich (eds.), The NeurIPS ’18 Competition, pp. 187{208, Cham, 2020. Springer International Publishing. ISBN 978-3-030-29135-8.
Jianxiong Dong and Jim Huang. Enhance word representation for out-of-vocabulary on ubuntu dialogue corpus. CoRR, abs/1802.02614, 2018. URL http://arxiv.org/abs/1802.02614.
Jia-Chen Gu, Zhen-Hua Ling, Yu-Ping Ruan, and Quan Liu. Building sequential inference models for end-to-end response selection. CoRR, abs/1812.00686, 2018. URL http://arxiv.org/abs/1812.00686.
J. Johnson, M. Douze, and H. Jégou. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, pp. 1{1, 2019. ISSN 2372-2096. doi: 10.1109/TBDATA.2019. 2921572.
Joseph Peper Vignesh Athreya Chulaka Gunasekara Jatin Ganhotra Siva Sankalp Patel Lazaros Polymenakos Jonathan K. Kummerfeld, Sai R. Gouravajhala and Walter S. Lasecki. Analyzing assumptions in conversation disentanglement research through the lens of a new dataset and model. ArXiv e-prints, October 2018. URL https://arxiv.org/pdf/1810.11118.pdf.
Rudolf Kadlec, Martin Schmid, and Jan Kleindienst. Improved deep learning baselines for ubuntu corpus dialogs. CoRR, abs/1510.03753, 2015. URL http://arxiv.org/abs/1510.03753.
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980.
Guillaume Lample and Alexis Conneau. Cross-lingual language model pretraining. Advances in Neural Information Processing Systems (NeurIPS), 2019.
Margaret Li, Jason Weston, and Stephen Roller. Acute-eval: Improved dialogue evaluation with optimized questions and multi-turn comparisons. arXiv preprint arXiv:1909.03087, 2019.
Ryan Lowe, Nissan Pow, Iulian Serban, and Joelle Pineau. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. In SIGDIAL Conference, 2015.
Pierre-Emmanuel Mazaré, Samuel Humeau, Martin Raison, and Antoine Bordes. Training millions of personalized dialogue agents. In EMNLP, 2018.
Gerard Salton, Anita Wong, and Chung-Shu Yang. A vector space model for automatic indexing. Communications of the ACM, 18(11):613{620, 1975.
Jack Urbanek, Angela Fan, Siddharth Karamcheti, Saachi Jain, Samuel Humeau, Emily Dinan, Tim Rocktäschel, Douwe Kiela, Arthur Szlam, and Jason Weston. Learning to speak and act in a fantasy text adventure game. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 673{683, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-1062.
Jesse Vig and Kalai Ramea. Comparison of transfer-learning approaches for response selection in multi-turn conversations. Workshop on DSTC7, 2019.
Thomas Wolf, Victor Sanh, Julien Chaumond, and Clement Delangue. Transfertransfo: A transfer learning approach for neural network based conversational agents. arXiv preprint arXiv:1901.08149, 2019.
Ledell Yu Wu, Adam Fisch, Sumit Chopra, Keith Adams, Antoine Bordes, and Jason Weston. Starspace: Embed all the things! In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
Yu Ping Wu, Wei Chung Wu, Chen Xing, Ming Zhou, and Zhoujun Li. Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots. In ACL, 2017.
Liu Yang, Minghui Qiu, Chen Qu, Jiafeng Guo, Yongfeng Zhang, W Bruce Croft, Jun Huang, and Haiqing Chen. Response ranking with deep matching networks and external knowledge in information-seeking conversation systems. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 245{254. ACM, 2018.
Seunghyun Yoon, Joongbo Shin, and Kyomin Jung. Learning to rank question-answer pairs using hierarchical recurrent encoder with latent topic clustering. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 1575{1584, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/ N18-1142.
Koichiro Yoshino, Chiori Hori, Julien Perez, Luis Fernando D’Haro, Lazaros Polymenakos, R. Chulaka Gunasekara, Walter S. Lasecki, Jonathan K. Kummerfeld, Michel Galley, Chris Brockett, Jianfeng Gao, William B. Dolan, Xiang Gao, Huda AlAmri, Tim K. Marks, Devi Parikh, and Dhruv Batra. Dialog system technology challenge 7. CoRR, abs/1901.03461, 2019.
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pp. 2204{2213, Melbourne, Australia, July 2018a. Association for Computational Linguistics.
Zhuosheng Zhang, Jiangtong Li, Pengfei Zhu, Hai Zhao, and Gongshen Liu. Modeling multi-turn conversation with deep utterance aggregation. In COLING, 2018b.
Yukun Zhu, Ryan Kiros, Richard S. Zemel, Ruslan R. Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. 2015 IEEE International Conference on Computer Vision (ICCV), pp. 19{27, 2015.
A 训练时间
我们在表6中报告了考虑的3个数据集和4种模型在8 GPU Volta 100上的训练时间。
B Bi-encoder 中的归约层
我们在表 7 中提供了在 Bi-encoder 之上针对不同类型的归约获得的结果。 具体来说,当我们获取 BERT 的第一个输出、前 16个 输出的平均值,前 64 个输出的平均值以及除第一个([S])以外的所有其它结果时,我们在 ConvAI2 验证集上比较 Recall@1/20 。
C 上下文向量的其它选择
我们考虑从底层的 transformer 输出 (hctxt1,...,hctxtN) 获取 Poly-encoder 上下文向量 (yctxt1,...,yctxtm) 的其它几个方法:
- 学习 m 个上下文 code (c1,...,cm),其中 ci 通过关注所有的输出 (hctxt1,...,hctxtN) 提取表示 yctxti。 此方法表示为“ Poly-encoder(Learnt-code)”或“ Poly-encoder(Learnt-m)”,并且是 4.4 节中描述的方法。
- 考虑前 m 个输出(hctxt1,...,hctxtm)。 此方法称为“ Poly-encoder(First m outputs)”或“ Poly-encoder(First-m)”。 注意,当 N < m 时,只考虑 m 个向量。
- 考虑最后 m 个输出。
- 考虑最后 m 个输出与第一个 hctxt1 连接在一起的输出,在 BERT 中,它对应于特殊词符 [S]。
在Convai2和DSTC7的验证集上评估了这四种方法的性能,并在表8中进行了报告。 前两种方法显示在图2中。 我们还为来自表9上Convai2数据集的给定数量的候选者提供推理时间。
| Dataset | ConvAI2 | DSTC 7 | ||
| split | dev | test | dev | test |
| metric | R@1/20 | R@1/20 | R@1/100 | R@1/100 |
| (Wolf 等人,2019) | 82.1 | 80.7 | - | - |
| (Chen 和 Wang,2019) | - | - | 57.3 | 64.5 |
| 1 Attention Code | ||||
| Learnt-codes | 81.9 ± 0.3 | 81.0 ± 0.1 | 56.2 ± 0.1 | 66.9 ± 0.7 |
| First m outputs | 83.2 ± 0.2 | 81.5 ± 0.1 | 56.4 ± 0.3 | 66.8 ± 0.7 |
| Last m outputs | 82.9 ± 0.1 | 81.0 ± 0.1 | 56.1 ± 0.4 | 67.2 ± 1.1 |
| Last m outputs and hctxt1 | - | - | - | - |
| 4 Attention Codes | ||||
| Learnt-codes | 83.8 ± 0.2 | 82.2 ± 0.5 | 56.5 ± 0.5 | 66.8 ± 0.7 |
| First m outputs | 83.4 ± 0.2 | 81.6 ± 0.1 | 56.9 ± 0.5 | 67.2 ± 1.3 |
| Last m outputs | 82.8 ± 0.2 | 81.3 ± 0.4 | 56.0 ± 0.5 | 65.8 ± 0.5 |
| Last m outputs and hctxt1 | 82.9 ± 0.1 | 81.4 ± 0.2 | 55.8 ± 0.3 | 66.1 ± 0.8 |
| 16 Attention Codes | ||||
| Learnt-codes | 84.4 ± 0.1 | 83.2 ± 0.1 | 57.7 ± 0.2 | 67.8 ± 0.3 |
| First m outputs | 85.2 ± 0.1 | 83.9 ± 0.2 | 56.1 ± 1.7 | 66.8 ± 1.1 |
| Last m outputs | 83.9 ± 0.2 | 82.0 ± 0.4 | 56.1 ± 0.3 | 66.2 ± 0.7 |
| Last m outputs and hctxt1 | 83.8 ± 0.3 | 81.7 ± 0.3 | 56.1 ± 0.3 | 66.6 ± 0.2 |
| 64 Attention Codes | ||||
| Learnt-codes | 84.9 ± 0.1 | 83.7 ± 0.2 | 58.3 ± 0.4 | 67.0 ± 0.9 |
| First m outputs | 86.0 ± 0.2 | 84.2 ± 0.2 | 57.7 ± 0.6 | 67.1 ± 0.1 |
| Last m outputs | 84.9 ± 0.3 | 82.9 ± 0.2 | 57.0 ± 0.2 | 66.5 ± 0.5 |
| Last m outputs and hctxt1 | 85.0 ± 0.2 | 83.2 ± 0.2 | 57.3 ± 0.3 | 67.1 ± 0.5 |
| 360 Attention Codes | ||||
| Learnt-codes | 85.3 ± 0.3 | 83.7 ± 0.2 | 57.7 ± 0.3 | 68.9 ± 0.4 |
| First m outputs | 86.3 ± 0.1 | 84.6 ± 0.3 | 58.1 ± 0.4 | 66.8 ± 0.7 |
| Last m outputs | 86.3 ± 0.1 | 84.7 ± 0.3 | 58.0 ± 0.4 | 68.1 ± 0.5 |
| Last m outputs and hctxt1 | 86.2 ± 0.3 | 84.5 ± 0.4 | 58.3 ± 0.4 | 68.0 ± 0.8 |
| CPU | GPU | |||
| Candidates | 1k | 100k | 1k | 100k |
| Bi-encoder | 115 | 160 | 19 | 22 |
| Poly-encoder (First m outputs) 16 | 119 | 551 | 17 | 37 |
| Poly-encoder (First m outputs) 64 | 124 | 570 | 17 | 39 |
| Poly-encoder (First m outputs) 360 | 120 | 619 | 17 | 45 |
| Poly-encoder (Learnt-codes) 16 | 122 | 678 | 18 | 38 |
| Poly-encoder (Learnt-codes) 64 | 126 | 692 | 23 | 46 |
| Poly-encoder (Learnt-codes) 360 | 160 | 837 | 57 | 88 |
| Cross-encoder | 21.7k | 2.2M* | 2.6k | 266k* |
| 数据集 | ConvAI2 | DSTC 7 | Ubuntu V2 | |||||||
| split | dev | test | dev | test | dev | test
| ||||
| metric | R@1/20 | R@1/20 | R@1/100 | R@1/100 | R@10/100 | MRR | R@1/10 | R@1/10 | R@5/10 | MRR |
| Hugging Face |
82.1 |
80.7 |
- |
- |
- |
- |
- |
- |
- |
- |
| (Wolf 等人, 2019 ) | ||||||||||
| ( Chen & Wang , 2019 ) | - | - | 57.3 | 64.5 | 90.2 | 73.5 | - | - | - | - |
| ( Dong & Huang , 2018 ) | - | - | - | - | - | - | - | 75.9 | 97.3 | 84.8 |
| 预训练权重来自(Devlin 等人, 2019) - Toronto Books + Wikipedia | ||||||||||
| Bi-encoder | 83.3 ± 0.2 | 81.7 ± 0.2 | 56.5 ± 0.4 | 66.8 ± 0.7 | 89.0 ± 1.0 | 74.6 ± 0.5 | 80.9 ± 0.6 | 80.6 ± 0.4 | 98.2 ± 0.1 | 88.0 ± 0.3 |
| Poly-encoder (First-m) 16 | 85.2 ± 0.1 | 83.9 ± 0.2 | 56.7 ± 0.2 | 67.0 ± 0.9 | 88.8 ± 0.3 | 74.6 ± 0.6 | 81.7 ± 0.5 | 81.4 ± 0.6 | 98.2 ± 0.1 | 88.5 ± 0.4 |
| Poly-encoder (Learnt-m) 16 | 84.4 ± 0.1 | 83.2 ± 0.1 | 57.7 ± 0.2 | 67.8 ± 0.3 | 88.6 ± 0.2 | 75.1 ± 0.2 | 81.5 ± 0.1 | 81.2 ± 0.2 | 98.2 ± 0.0 | 88.3 ± 0.1 |
| Poly-encoder (First-m) 64 | 86.0 ± 0.2 | 84.2 ± 0.2 | 57.1 ± 0.2 | 66.9 ± 0.7 | 89.1 ± 0.2 | 74.7 ± 0.4 | 82.2 ± 0.6 | 81.9 ± 0.5 | 98.4 ± 0.0 | 88.8 ± 0.3 |
| Poly-encoder (Learnt-m) 64 | 84.9 ± 0.1 | 83.7 ± 0.2 | 58.3 ± 0.4 | 67.0 ± 0.9 | 89.2 ± 0.2 | 74.7 ± 0.6 | 81.8 ± 0.1 | 81.3 ± 0.2 | 98.2 ± 0.1 | 88.4 ± 0.1 |
| Poly-encoder (First-m) 360 | 86.3 ± 0.1 | 84.6 ± 0.3 | 57.8 ± 0.5 | 67.0 ± 0.5 | 89.6 ± 0.9 | 75.0 ± 0.6 | 82.7 ± 0.4 | 82.2 ± 0.6 | 98.4 ± 0.1 | 89.0 ± 0.4 |
| Poly-encoder (Learnt-m) 360 | 85.3 ± 0.3 | 83.7 ± 0.2 | 57.7 ± 0.3 | 68.9 ± 0.4 | 89.9 ± 0.5 | 76.2 ± 0.2 | 81.5 ± 0.1 | 80.9 ± 0.1 | 98.1 ± 0.0 | 88.1 ± 0.1 |
| Cross-encoder | 87.1 ± 0.1 | 84.8 ± 0.3 | 59.4 ± 0.4 | 67.4 ± 0.7 | 90.5 ± 0.3 | 75.6 ± 0.4 | 83.3 ± 0.4 | 82.8 ± 0.3 | 98.4 ± 0.1 | 89.4 ± 0.2 |
| 我们在 Toronto Books + Wikipedia 上预训练 | ||||||||||
| Bi-encoder | 84.6 ± 0.1 | 82.0 ± 0.1 | 54.9 ± 0.5 | 64.5 ± 0.5 | 88.1 ± 0.2 | 72.6 ± 0.4 | 80.9 ± 0.5 | 80.8 ± 0.5 | 98.4 ± 0.1 | 88.2 ± 0.4 |
| Poly-encoder (First-m) 16 | 84.1 ± 0.2 | 81.4 ± 0.2 | 53.9 ± 2.7 | 63.3 ± 2.9 | 87.2 ± 1.5 | 71.6 ± 2.4 | 80.8 ± 0.5 | 80.6 ± 0.4 | 98.4 ± 0.1 | 88.1 ± 0.3 |
| Poly-encoder (Learnt-m) 16 | 85.4 ± 0.2 | 82.7 ± 0.1 | 56.0 ± 0.4 | 65.3 ± 0.9 | 88.2 ± 0.7 | 73.2 ± 0.7 | 84.0 ± 0.1 | 83.4 ± 0.2 | 98.7 ± 0.0 | 89.9 ± 0.1 |
| Poly-encoder (First-m) 64 | 86.1 ± 0.4 | 83.9 ± 0.3 | 55.6 ± 0.9 | 64.3 ± 1.5 | 87.8 ± 0.4 | 72.5 ± 1.0 | 80.9 ± 0.6 | 80.7 ± 0.6 | 98.4 ± 0.0 | 88.2 ± 0.4 |
| Poly-encoder (Learnt-m) 64 | 85.6 ± 0.1 | 83.3 ± 0.1 | 56.2 ± 0.4 | 65.8 ± 0.7 | 88.4 ± 0.3 | 73.5 ± 0.5 | 84.0 ± 0.1 | 83.4 ± 0.1 | 98.7 ± 0.0 | 89.9 ± 0.0 |
| Poly-encoder (First-m) 360 | 86.6 ± 0.3 | 84.4 ± 0.2 | 57.5 ± 0.4 | 66.5 ± 1.2 | 89.0 ± 0.5 | 74.4 ± 0.7 | 81.3 ± 0.6 | 81.1 ± 0.4 | 98.4 ± 0.2 | 88.4 ± 0.3 |
| Poly-encoder (Learnt-m) 360 | 86.1 ± 0.1 | 83.8 ± 0.1 | 56.5 ± 0.8 | 65.8 ± 0.7 | 88.5 ± 0.6 | 73.6 ± 0.6 | 84.2 ± 0.2 | 83.7 ± 0.0 | 98.7 ± 0.1 | 90.1 ± 0.0 |
| Cross-encoder | 87.3 ± 0.5 | 84.9 ± 0.3 | 57.7 ± 0.5 | 65.3 ± 1.0 | 89.7 ± 0.5 | 73.8 ± 0.6 | 83.2 ± 0.8 | 83.1 ± 0.7 | 98.7 ± 0.1 | 89.7 ± 0.5 |
| 我们在 Reddit 上预训练 | ||||||||||
| Bi-encoder | 86.9 ± 0.1 | 84.8 ± 0.1 | 60.1 ± 0.4 | 70.9 ± 0.5 | 90.6 ± 0.3 | 78.1 ± 0.3 | 83.7 ± 0.7 | 83.6 ± 0.7 | 98.8 ± 0.1 | 90.1 ± 0.4 |
| Poly-encoder (First-m) 16 | 89.0 ± 0.1 | 86.4 ± 0.3 | 60.4 ± 0.3 | 70.7 ± 0.7 | 91.0 ± 0.4 | 78.0 ± 0.5 | 84.3 ± 0.3 | 84.3 ± 0.2 | 98.9 ± 0.0 | 90.5 ± 0.1 |
| Poly-encoder (Learnt-m) 16 | 88.6 ± 0.3 | 86.3 ± 0.3 | 61.1 ± 0.4 | 71.6 ± 0.6 | 91.3 ± 0.3 | 78.4 ± 0.4 | 86.1 ± 0.1 | 86.0 ± 0.1 | 99.0 ± 0.1 | 91.5 ± 0.1 |
| Poly-encoder (First-m) 64 | 89.5 ± 0.1 | 87.3 ± 0.2 | 61.0 ± 0.4 | 70.9 ± 0.6 | 91.5 ± 0.5 | 78.0 ± 0.3 | 84.0 ± 0.4 | 83.9 ± 0.4 | 98.8 ± 0.0 | 90.3 ± 0.3 |
| Poly-encoder (Learnt-m) 64 | 89.0 ± 0.1 | 86.5 ± 0.2 | 60.9 ± 0.6 | 71.2 ± 0.8 | 91.3 ± 0.4 | 78.2 ± 0.7 | 86.2 ± 0.1 | 85.9 ± 0.1 | 99.1 ± 0.0 | 91.5 ± 0.1 |
| Poly-encoder (First-m) 360 | 90.0 ± 0.1 | 87.3 ± 0.1 | 61.1 ± 1.9 | 70.9 ± 2.1 | 91.5 ± 0.9 | 77.9 ± 1.6 | 84.8 ± 0.5 | 84.6 ± 0.5 | 98.9 ± 0.1 | 90.7 ± 0.3 |
| Poly-encoder (Learnt-m) 360 | 89.2 ± 0.1 | 86.8 ± 0.1 | 61.2 ± 0.2 | 71.4 ± 1.0 | 91.1 ± 0.3 | 78.3 ± 0.7 | 86.3 ± 0.1 | 85.9 ± 0.1 | 99.1 ± 0.0 | 91.5 ± 0.0 |
| Cross-encoder | 90.3 ± 0.2 | 87.9 ± 0.2 | 63.9 ± 0.3 | 71.7 ± 0.3 | 92.4 ± 0.5 | 79.0 ± 0.2 | 86.7 ± 0.1 | 86.5 ± 0.1 | 99.1 ± 0.0 | 91.9 ± 0.0 |